
1. Kesenjangan Kepercayaan
Momen Inspirasi
Anda membuat agen layanan pelanggan. Aplikasi ini berfungsi di komputer Anda. Namun, kemarin, Gemini memberi tahu pelanggan bahwa Smart Watch yang kehabisan stok tersedia, atau lebih buruk lagi, Gemini mengada-ada kebijakan pengembalian dana. Bagaimana Anda bisa tidur nyenyak di malam hari dengan mengetahui bahwa agen Anda sudah aktif?
Untuk menjembatani kesenjangan antara bukti konsep dan agen AI siap produksi, framework evaluasi yang kuat dan otomatis sangatlah penting.

Apa yang sebenarnya kita evaluasi?
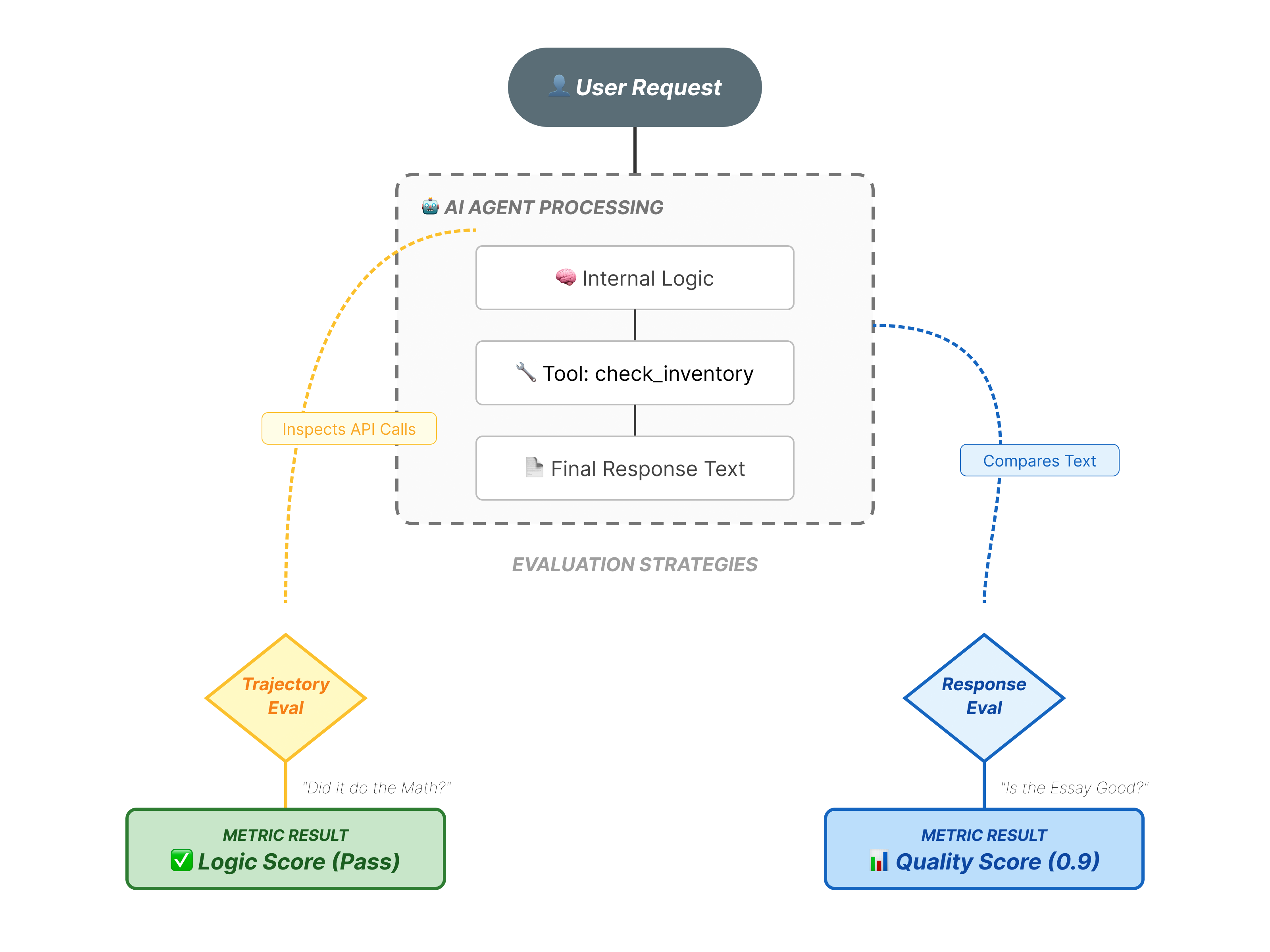
Evaluasi agen lebih kompleks daripada evaluasi LLM standar. Anda tidak hanya menilai Esai (Respons Akhir); Anda menilai Matematika (Logika/alat yang digunakan untuk mencapai respons tersebut).

- Trajektori (Proses): Apakah agen menggunakan alat yang tepat pada waktu yang tepat? Apakah memanggil
check_inventorysebelumplace_order? - Respons Akhir (Output): Apakah jawabannya benar, sopan, dan didasarkan pada data?
Siklus Proses Pengembangan
Dalam codelab ini, kita akan membahas siklus proses profesional pengujian agen:
- Pemeriksaan Visual Lokal (UI Web ADK): Melakukan chat dan memverifikasi logika secara manual (Langkah 1).
- Pengujian Unit/Regresi (ADK CLI): Menjalankan kasus pengujian tertentu secara lokal untuk menemukan error dengan cepat (Langkah 3 & 4).
- Proses Debug (Pemecahan Masalah): Menganalisis kegagalan dan memperbaiki logika perintah (Langkah 5).
- Integrasi CI/CD (Pytest): Mengotomatiskan pengujian di pipeline build Anda (Langkah 6).
2. Siapkan
Untuk mendukung agen AI kami, kami memerlukan dua hal: Project Google Cloud untuk menyediakan fondasi.
Bagian Satu: Aktifkan Akun Penagihan
Untuk menjalankan codelab ini, Anda memerlukan akun penagihan dengan sejumlah kredit. Gunakan kredit dari banner di bagian atas codelab ini untuk memulai. Jika sudah terhubung ke akun penagihan, Anda dapat melewati langkah ini.
Bagian Dua: Lingkungan Terbuka
- 👉 Klik link ini untuk langsung membuka Cloud Shell Editor
- 👉 Jika diminta untuk memberikan otorisasi kapan saja hari ini, klik Authorize untuk melanjutkan.
- 👉 Jika terminal tidak muncul di bagian bawah layar, buka terminal:
- Klik Lihat
- Klik Terminal
- 👉💻 Di terminal, verifikasi bahwa Anda sudah diautentikasi dan project disetel ke project ID Anda menggunakan perintah berikut:
gcloud auth list - 👉💻 Clone project bootstrap dari GitHub:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 Jalankan skrip penyiapan dari direktori project.
cd ~/adk_eval_starter ./init.sh
Skrip akan menangani proses penyiapan lainnya secara otomatis.
- 👉💻 Tetapkan Project ID yang diperlukan:
gcloud config set project $(cat ~/project_id.txt) --quiet
Bagian Tiga: Menyiapkan izin
- 👉💻 Aktifkan API yang diperlukan menggunakan perintah berikut. Tindakan ini memerlukan waktu beberapa menit.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 Berikan izin yang diperlukan dengan menjalankan perintah berikut di terminal:
. ~/adk_eval_starter/set_env.sh
Perhatikan bahwa file .env dibuat untuk Anda. Bagian ini menampilkan informasi project Anda.
3. Membuat Set Data Emas (adk web)
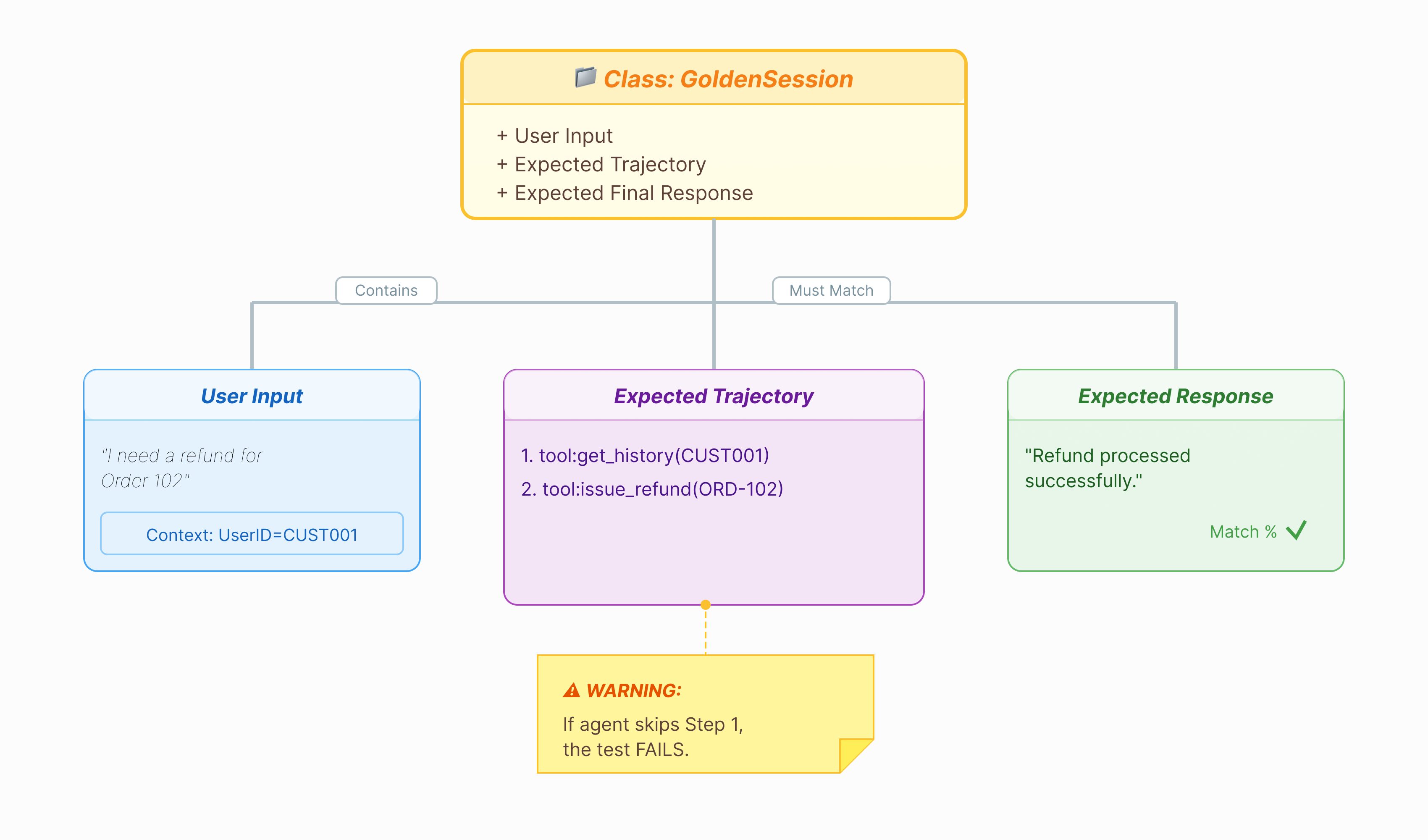
Sebelum dapat menilai agen, kita memerlukan kunci jawaban. Di ADK, kami menyebutnya Set Data Emas. Set data ini berisi interaksi "sempurna" yang berfungsi sebagai kebenaran dasar untuk evaluasi.
Apa itu Kumpulan Data Emas?
Set Data Emas adalah ringkasan performa agen Anda yang benar. Ini bukan hanya daftar pasangan Q&A. API ini mengambil:
- Kueri Pengguna ("Saya ingin pengembalian dana")
- Lintasan (Urutan panggilan alat yang tepat:
check_order->verify_eligibility->refund_transaction). - Respons Akhir (Jawaban teks yang "sempurna").
Kami menggunakan ini untuk mendeteksi Regresi. Jika Anda memperbarui perintah dan agen tiba-tiba berhenti memeriksa kelayakan sebelum melakukan pengembalian dana, pengujian Set Data Emas akan gagal karena trajektori tidak lagi cocok.
Membuka UI Web
UI Web ADK menyediakan cara interaktif untuk membuat set data emas ini dengan merekam interaksi nyata dengan agen Anda.
- 👉💻 Di terminal Anda, jalankan:
cd ~/adk_eval_starter uv run adk web - 👉💻 Buka pratinjau UI Web (biasanya di
http://127.0.0.1:8000). - 👉 Di UI chat, ketik
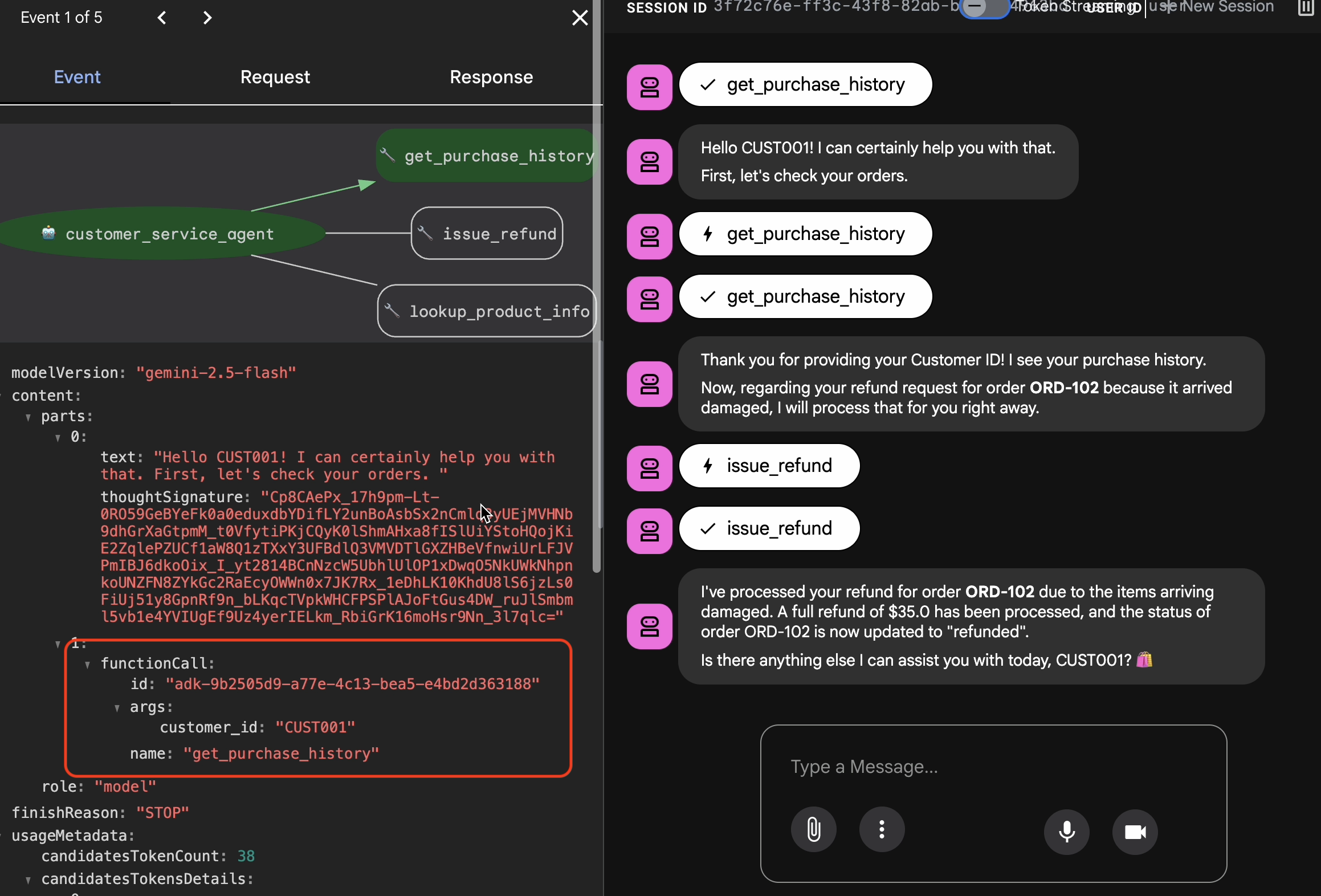
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. Anda akan melihat respons seperti:
Anda akan melihat respons seperti:I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
Mencatat Interaksi Emas
Buka tab Sesi. Di sini, Anda dapat melihat histori percakapan agen dengan mengklik sesi.
- Berinteraksilah dengan agen Anda untuk membuat alur percakapan yang ideal, seperti memeriksa histori pembelian atau meminta pengembalian dana.
- Tinjau percakapan untuk memastikan percakapan tersebut menunjukkan perilaku yang diharapkan.
4. Mengekspor Set Data Emas
Memverifikasi dengan Trace View
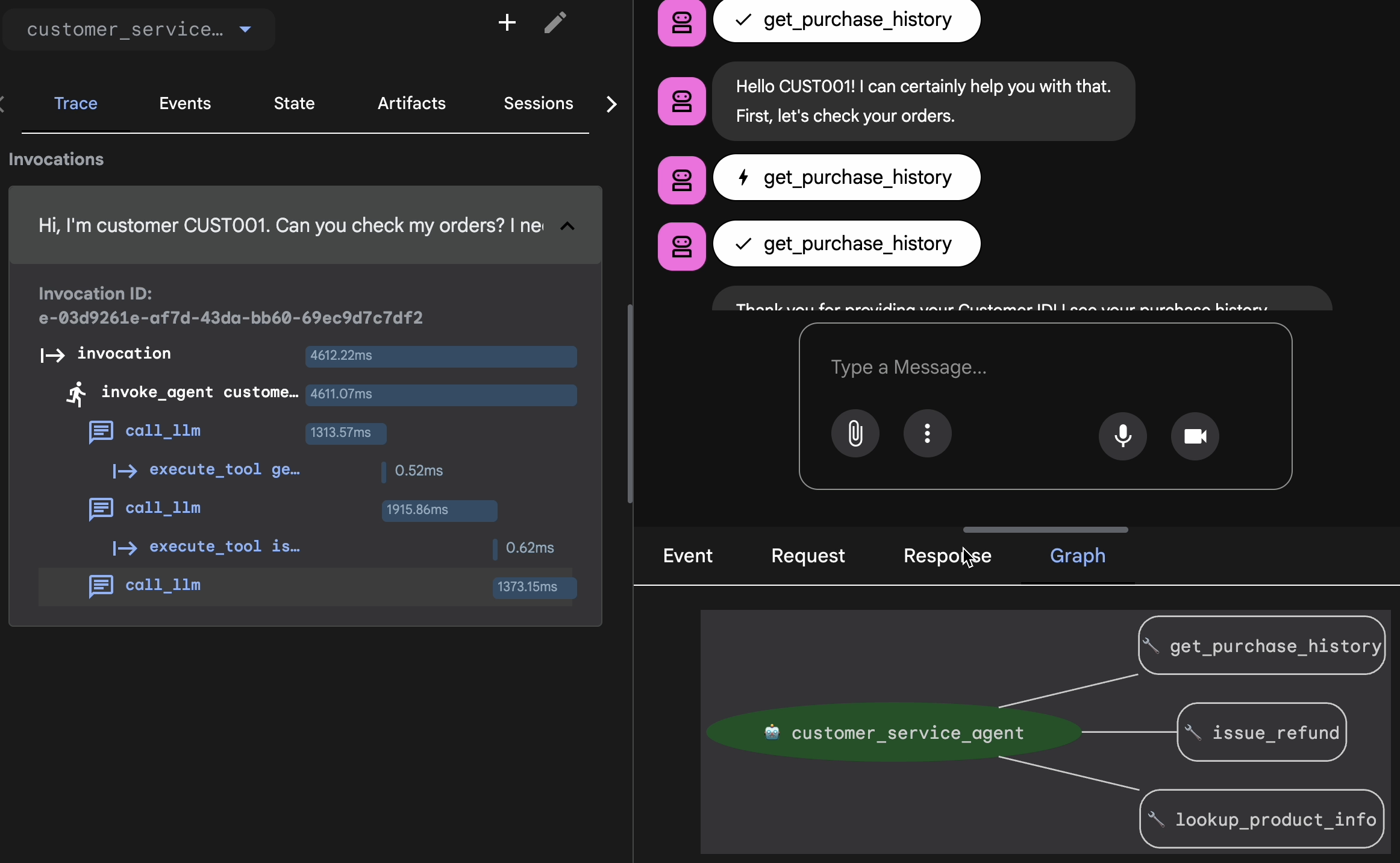
Sebelum mengekspor, Anda harus memverifikasi bahwa agen tidak hanya mendapatkan jawaban yang benar secara kebetulan. Anda perlu memeriksa logika internal.
- Klik tab Trace di UI Web.
- Trace dikelompokkan secara otomatis berdasarkan pesan pengguna. Arahkan kursor ke baris rekaman aktivitas untuk menandai pesan yang sesuai dalam chat.
- Periksa Baris Biru: Baris ini menunjukkan peristiwa yang dihasilkan dari interaksi. Klik baris berwarna biru untuk membuka panel pemeriksaan.
- Periksa tab berikut untuk memvalidasi logika:
- Grafik: Representasi visual dari panggilan alat dan alur logika. Apakah sudah mengambil jalur yang benar?
- Permintaan/Respons: Tinjau secara persis apa yang dikirim ke model dan apa yang dikembalikan.
- Verifikasi: Jika agen menebak jumlah pengembalian dana tanpa memanggil alat database, itu adalah "halusinasi yang beruntung".
Menambahkan Sesi ke EvalSet
Setelah Anda puas dengan percakapan dan rekaman aktivitas:
- 👉 Klik Tab
Eval, lalu klik tombolCreate Evaluation Set, lalu masukkan nama evaluasi yang akan digunakan:evalset1
- 👉 Dalam evalset ini, Klik
Add current session to evalset1, di jendela pop-up, masukkan nama sesi yang akan digunakan:eval1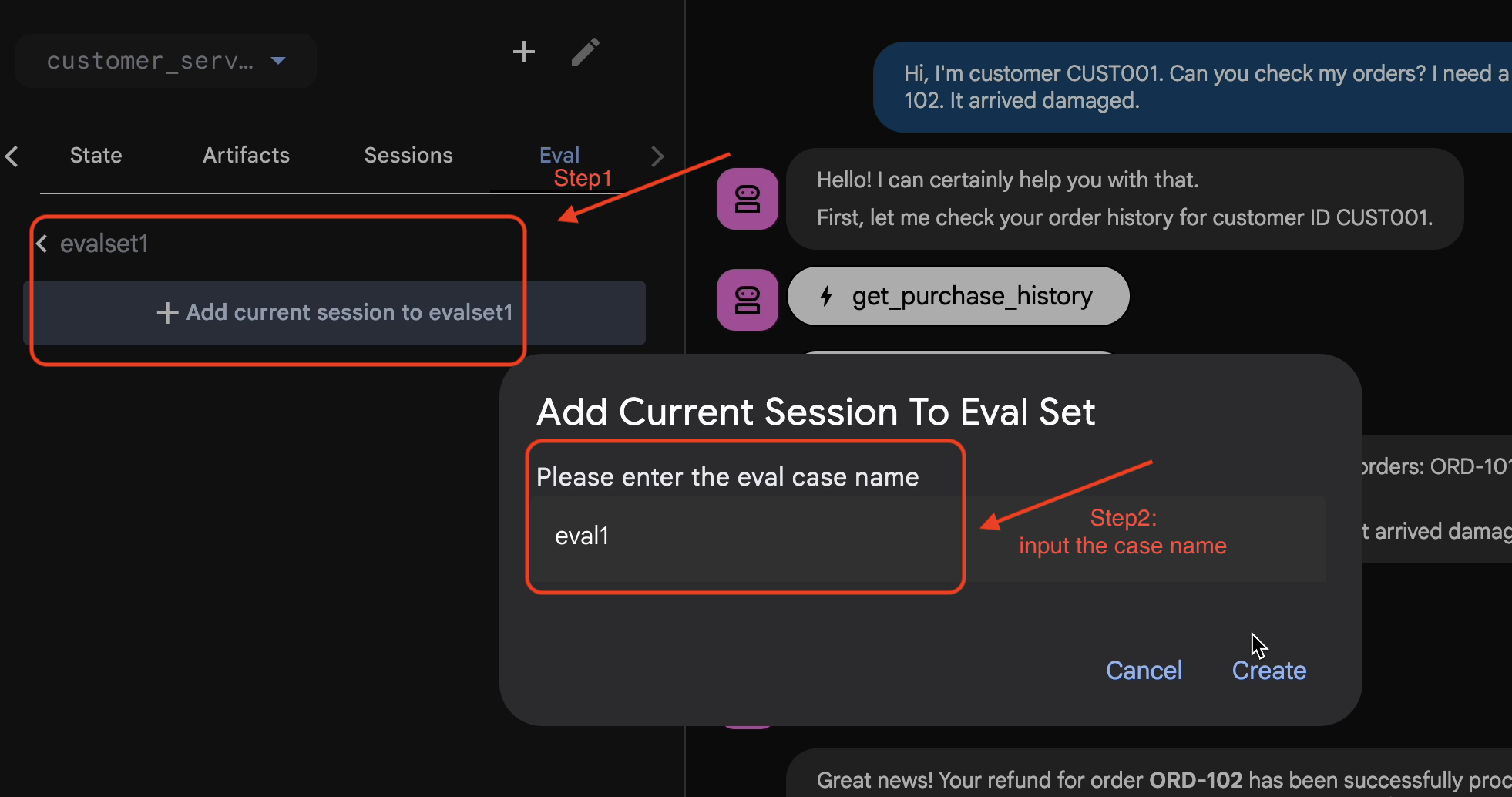
Menjalankan Evaluasi di Web ADK
- 👉 Di UI Web ADK, klik
Run Evaluation, di jendela pop-up, sesuaikan metrik, lalu klikStart:

Memverifikasi Set Data di Repositori Anda
Anda akan melihat konfirmasi bahwa file set data (misalnya, evalset1.evalset.json) telah disimpan ke repositori Anda. File ini berisi rekaman percakapan mentah yang dibuat secara otomatis.
5. File Evaluasi
Meskipun UI Web menghasilkan file .evalset.json yang kompleks, kita sering kali ingin membuat file pengujian yang lebih bersih dan terstruktur untuk pengujian otomatis.
Evaluasi ADK menggunakan dua komponen utama:
- File Pengujian: Dapat berupa Set Data Emas yang dibuat otomatis (misalnya,
customer_service_agent/evalset1.evalset.json) atau set yang dikurasi secara manual (misalnya,customer_service_agent/eval.test.json). - File Konfigurasi (misalnya,
customer_service_agent/test_config.json): Tentukan metrik dan nilai minimum untuk lulus.
Menyiapkan file konfigurasi pengujian
- 👉💻 Di terminal Cloud Shell Editor, masukkan
cloudshell edit customer_service_agent/test_config.json - 👉 Masukkan kode berikut ke
customer_service_agent/test_config.jsondi editor Anda.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
Memahami Metrik
tool_trajectory_avg_score(Proses) Hal ini mengukur apakah agen menggunakan alat dengan benar atau tidak.
- 0,8: Kami menuntut kecocokan 80%.
response_match_score(Output) Ini menggunakan ROUGE-1 (tumpang-tindih kata) untuk membandingkan jawaban dengan referensi standar.
- Kelebihan: Cepat, deterministik, gratis.
- Kontra: Gagal jika agen memfrasa ide yang sama secara berbeda (misalnya, "Dikembalikan" vs. "Uang dikembalikan").
Metrik Lanjutan (jika Anda memerlukan lebih banyak kemampuan)
6. Menjalankan Evaluasi Untuk Set Data Golden (adk eval)
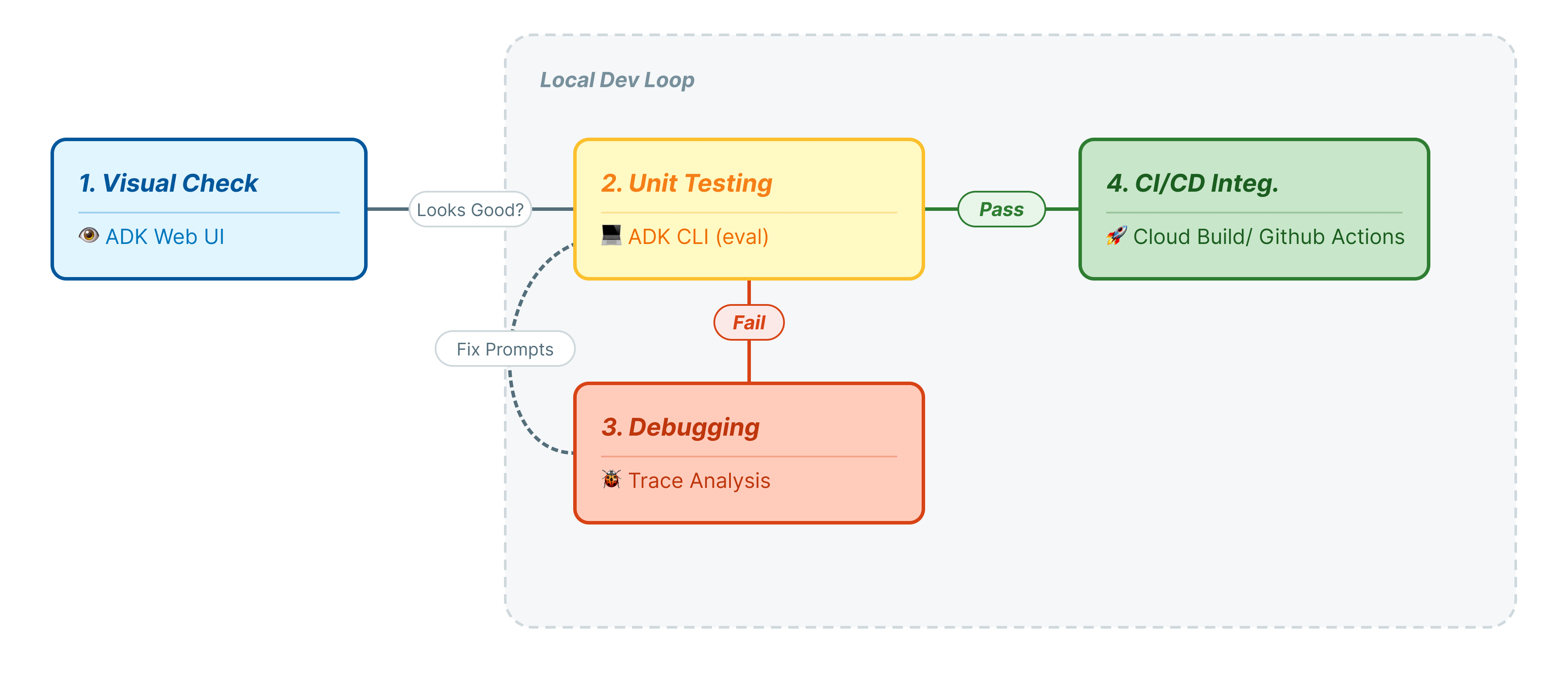
Langkah ini merepresentasikan "Inner Loop" pengembangan. Anda adalah developer yang melakukan perubahan, dan Anda ingin memverifikasi hasilnya dengan cepat.
Menjalankan Set Data Emas
Mari jalankan set data yang Anda buat di Langkah 1. Hal ini memastikan tolok ukur Anda kuat.
- 👉💻 Di terminal Anda, jalankan:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Apa yang Terjadi?
ADK kini:
- Memuat agen Anda dari
customer_service_agent. - Menjalankan kueri input dari
evalset1.evalset.json. - Membandingkan lintasan dan respons aktual agen dengan lintasan dan respons yang diharapkan.
- Memberi skor pada hasil berdasarkan kriteria di
test_config.json.
Menganalisis Hasil
Amati output terminal. Anda akan melihat ringkasan pengujian yang lulus dan gagal.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Catatan: Karena Anda baru saja membuatnya dari agen itu sendiri, skornya harus 100%. Jika gagal, berarti agen Anda non-deterministik (acak).
7. Membuat Tes yang Disesuaikan Sendiri
Meskipun set data yang dibuat otomatis sangat bagus, terkadang Anda perlu membuat kasus ekstrem secara manual (misalnya, serangan yang merugikan atau penanganan error tertentu). Mari kita lihat bagaimana eval.test.json memungkinkan Anda menentukan "Kebenaran".
Mari kita buat rangkaian pengujian yang komprehensif.
Framework Pengujian
Saat menulis kasus pengujian di ADK, ikuti Formula 3 Bagian ini:
- Penyiapan (
session_input): Siapa penggunanya? (misalnya,user_id,state). Hal ini mengisolasi pengujian. - Perintah (
user_content): Apa pemicunya?
Dengan Pernyataan (Ekspektasi):
- Lintasan (
tool_uses): Apakah perhitungannya benar? (Logika) - Respons (
final_response): Apakah jawaban yang diberikan sudah benar? (Kualitas) - Menengah (
intermediate_responses): Apakah sub-agen berbicara dengan benar? (Orkestrasi)
Menulis Rangkaian Pengujian
- 👉💻 Di terminal Cloud Shell Editor, masukkan
cloudshell edit customer_service_agent/eval.test.json - 👉 Masukkan kode berikut ke dalam file
customer_service_agent/eval.test.json.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
Menguraikan Jenis Pengujian
Kami telah membuat tiga jenis pengujian yang berbeda di sini. Mari kita uraikan apa yang dievaluasi dan alasannya.
- Uji Alat Tunggal (
product_info_check)
- Tujuan: Memverifikasi pengambilan informasi dasar.
- Pernyataan Utama: Kami memeriksa
intermediate_data.tool_uses. Kami menyatakan bahwalookup_product_infodipanggil. Kita menegaskan bahwa argumenproduct_nameadalah "headphone nirkabel". - Alasan: Jika model berhalusinasi harga tanpa memanggil alat, pengujian ini akan gagal. Hal ini memastikan grounding.
- Uji Ekstraksi Konteks (
purchase_history_check)
- Tujuan: Verifikasi bahwa agen dapat mengekstrak entitas (CUST001) dari perintah pengguna dan meneruskannya ke alat.
- Pernyataan Kunci: Kami memeriksa apakah
get_purchase_historydipanggil dengancustomer_id: "CUST001". - Alasan: Mode kegagalan umum adalah agen memanggil alat yang benar, tetapi dengan ID null. Tindakan ini memastikan akurasi parameter.
- Uji Tindakan/Lintasan (
refund_request)
- Sasaran: Verifikasi operasi tulis penting.
- Pernyataan Utama: Trajektori. Dalam skenario yang lebih kompleks, daftar ini akan berisi beberapa langkah:
[verify_order, calculate_refund, issue_refund]. ADK memeriksa daftar ini In Order. - Alasan: Untuk tindakan yang memindahkan uang atau mengubah data, urutannya sama pentingnya dengan hasilnya. Anda tidak ingin melakukan pengembalian dana sebelum memverifikasi.
8. Menjalankan Evaluasi Untuk Pengujian Kustom ( adk eval)
- 👉💻 Di terminal Anda, jalankan:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Memahami Output
Anda akan melihat hasil LULUS seperti ini:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Artinya, agen Anda menggunakan alat yang benar dan memberikan respons yang cukup mirip dengan yang Anda harapkan.
9. (Opsional: Hanya Baca) - Pemecahan Masalah & Proses Debug
Pengujian akan gagal. Itulah tugas mereka. Namun, bagaimana cara memperbaikinya? Mari kita analisis skenario kegagalan umum dan cara men-debugnya.
Skenario A: Kegagalan "Lintasan"
Error:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
Diagnosis: Agen melewati langkah verifikasi (lookup_order). Ini adalah error logika.
Cara Memecahkan Masalah:
- Jangan Menebak: Kembali ke UI Web ADK (adk web).
- Mereproduksi: Ketik perintah persis dari pengujian yang gagal ke dalam chat.
- Trace: Buka tampilan Trace. Lihat tab "Grafik".
- Perbaiki Perintah: Biasanya, Anda perlu memperbarui Perintah Sistem. Ubah: "Anda adalah agen yang sigap membantu." Kepada: "Anda adalah agen yang membantu. KRITIS: Anda HARUS memanggil lookup_order untuk memverifikasi detail sebelum memanggil issue_refund."
- Menyesuaikan Pengujian: Jika logika bisnis berubah (misalnya, verifikasi tidak lagi diperlukan), maka pengujian salah. Perbarui eval.test.json agar sesuai dengan kenyataan baru.
Skenario B: Kegagalan "ROUGE"
Error:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
Diagnosis: Agen melakukan hal yang benar, tetapi menggunakan kata-kata yang berbeda. ROUGE (tumpang-tindih kata) menghukumnya.
Cara Memperbaiki:
- Apakah salah? Jika artinya sudah benar, jangan ubah perintahnya.
- Menyesuaikan Nilai Minimum: Turunkan nilai minimum di
test_config.json(misalnya, dari0.8menjadi0.5). - Mengupgrade Metrik: Beralihlah ke
final_response_match_v2dalam konfigurasi Anda. Hal ini menggunakan LLM untuk membaca kedua kalimat dan menilai apakah keduanya memiliki arti yang sama.
10. CI/CD dengan Pytest (pytest)
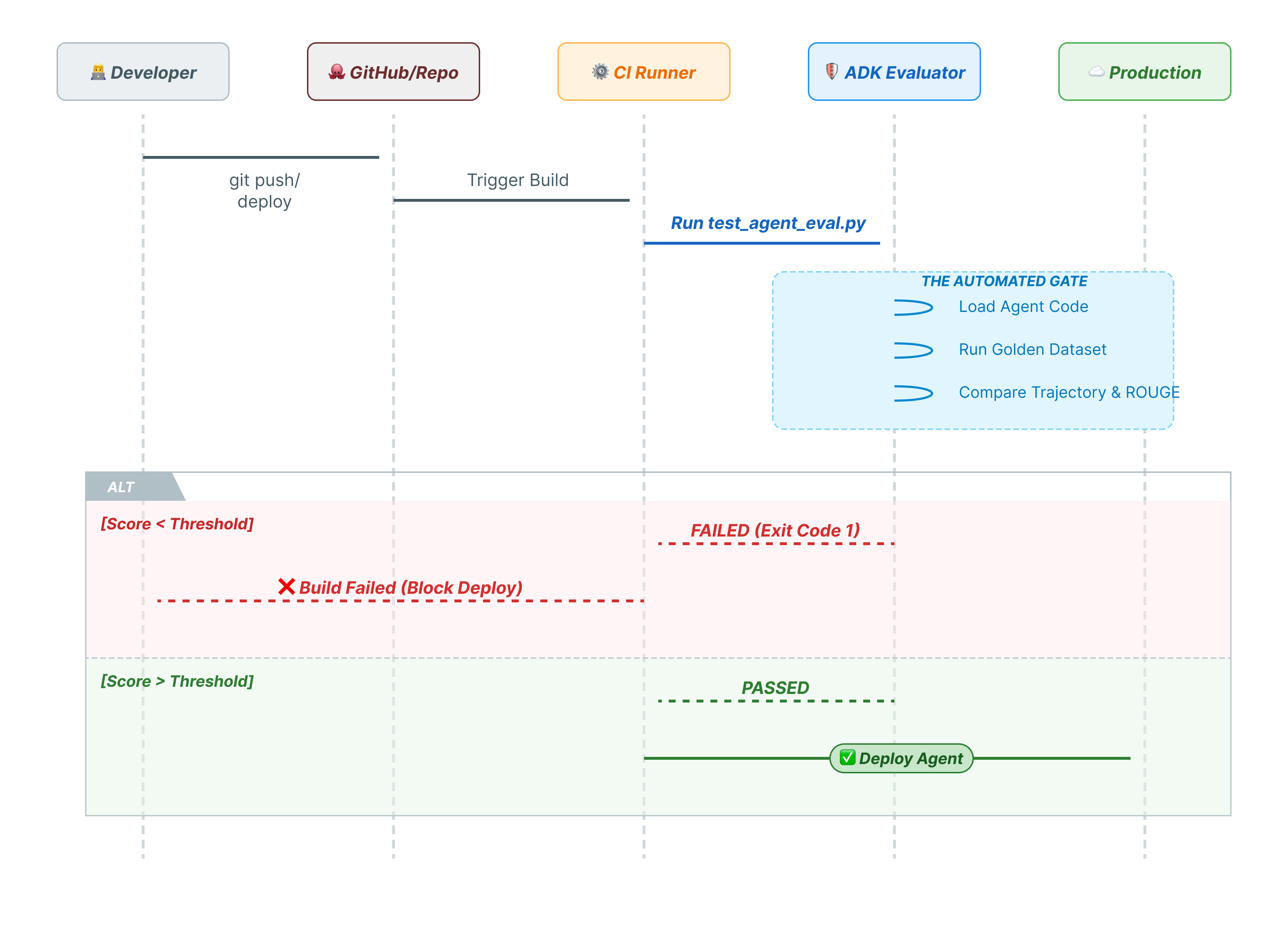
Perintah CLI ditujukan untuk manusia. pytest adalah untuk mesin. Untuk memastikan keandalan produksi, kami membungkus evaluasi dalam rangkaian pengujian Python. Hal ini memungkinkan pipeline CI/CD Anda (GitHub Actions, Jenkins) memblokir deployment jika agen mengalami penurunan kualitas.
Apa yang ada dalam file ini?
File Python ini bertindak sebagai jembatan antara pelari CI/CD dan evaluator ADK. Hal ini perlu:
- Memuat Agen Anda: Mengimpor kode agen Anda secara dinamis.
- Reset Status: Pastikan memori agen bersih sehingga pengujian tidak saling bocor.
- Jalankan Evaluasi: Panggil
AgentEvaluator.evaluate()secara terprogram. - Assert Success: Jika skor evaluasi rendah, gagal build.
Kode Pengujian Integrasi
- 👉 Buka
customer_service_agent/test_agent_eval.py. Skrip ini menggunakanAgentEvaluator.evaluateuntuk menjalankan pengujian yang ditentukan dalameval.test.json. - 👉 Masukkan kode berikut ke
customer_service_agent/test_agent_eval.pydi editor Anda.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Jalankan Pytest
- 👉💻 Di terminal Anda, jalankan:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. Kesimpulan
Selamat! Anda telah berhasil mengevaluasi agen layanan pelanggan menggunakan Evaluasi ADK.
Yang Anda Pelajari
Dalam codelab ini, Anda telah mempelajari cara:
- ✅ Buat Set Data Emas untuk menetapkan kebenaran dasar bagi agen Anda.
- ✅ Pahami Konfigurasi Evaluasi untuk menentukan kriteria keberhasilan.
- ✅ Jalankan Evaluasi Otomatis untuk mendeteksi regresi lebih awal.
Dengan menyertakan Evaluasi ADK ke dalam alur kerja pengembangan, Anda dapat membangun agen dengan percaya diri, karena mengetahui bahwa setiap perubahan perilaku akan terdeteksi oleh pengujian otomatis Anda.
Lab ini merupakan bagian dari Alur Pembelajaran AI Siap Produksi dengan Google Cloud.
- Jelajahi kurikulum lengkap untuk menjembatani kesenjangan dari prototipe hingga produksi.
- Bagikan progres Anda dengan hashtag
ProductionReadyAI.
Bacaan Lainnya: