
1. Il divario di fiducia
Il momento dell'ispirazione
Hai creato un agente dell'assistenza clienti. Funziona sulla tua macchina. Ma ieri ha detto a un cliente che uno smartwatch non disponibile era disponibile o, peggio ancora, ha inventato una norma sui rimborsi. Come dormi la notte sapendo che il tuo agente è attivo?
Per colmare il divario tra una proof of concept e un agente AI pronto per la produzione, è essenziale un framework di valutazione solido e automatizzato.

Che cosa stiamo valutando esattamente?
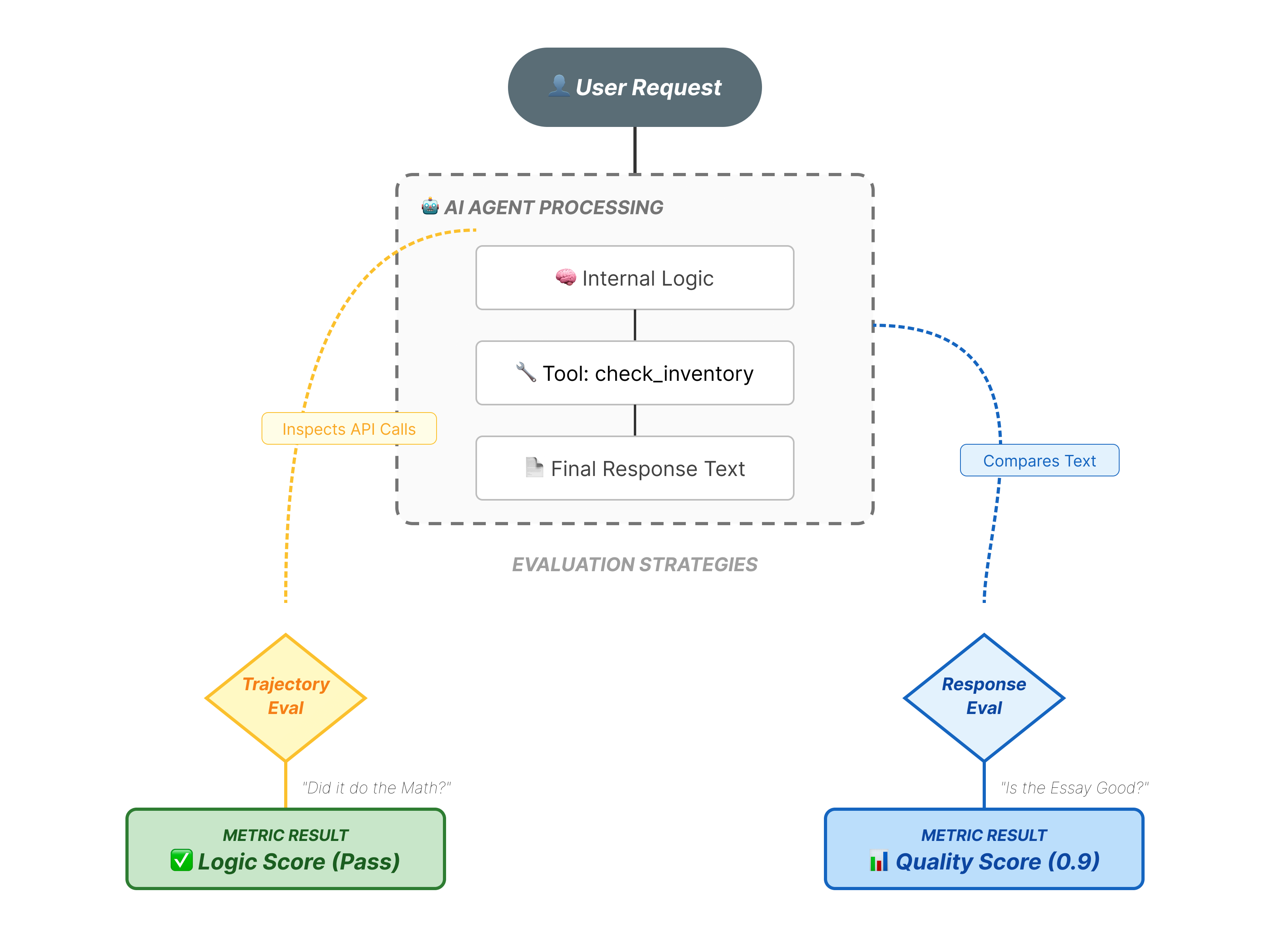
La valutazione degli agenti è più complessa della valutazione LLM standard. Non stai valutando solo il Saggio (Risposta finale), ma anche la Matematica (la logica/gli strumenti utilizzati per arrivare alla risposta).
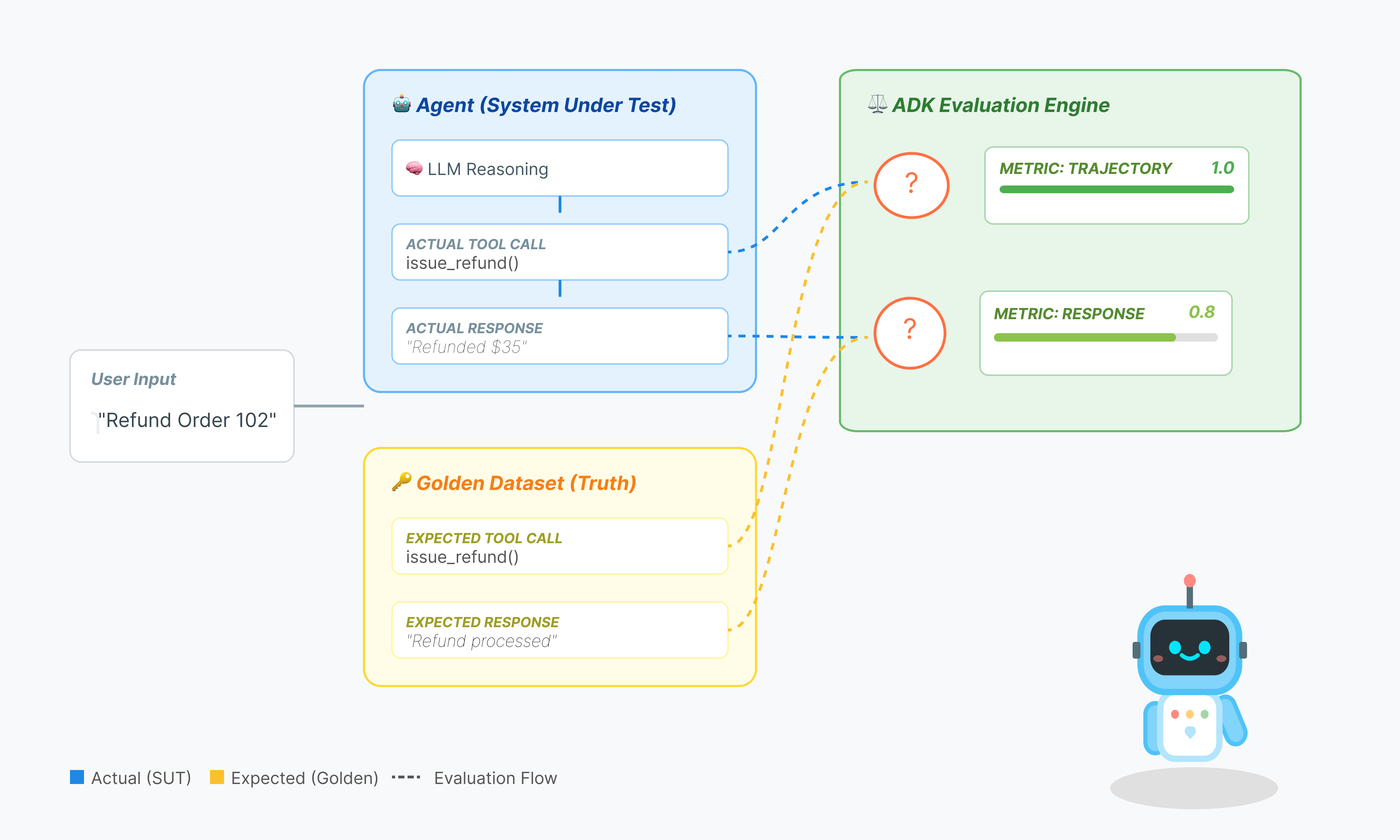
- Traiettoria (la procedura): l'agente ha utilizzato lo strumento giusto al momento giusto? Ha chiamato
check_inventoryprima delleplace_order? - Risposta finale (l'output): la risposta è corretta, educata e basata sui dati?
Il ciclo di vita dello sviluppo
In questo codelab, esamineremo il ciclo di vita professionale dei test degli agenti:
- Ispezione visiva locale (interfaccia utente web ADK): chat e verifica manuale della logica (passaggio 1).
- Test unitari/di regressione (interfaccia a riga di comando ADK): esecuzione di scenari di test specifici in locale per rilevare rapidamente gli errori (passaggi 3 e 4).
- Debug (risoluzione dei problemi): analisi degli errori e correzione della logica del prompt (passaggio 5).
- Integrazione CI/CD (Pytest): automatizzazione dei test nella pipeline di build (passaggio 6).
2. Configura
Per alimentare i nostri agenti AI, abbiamo bisogno di due cose: un progetto Google Cloud per fornire le basi.
Parte 1: abilita l'account di fatturazione
Per eseguire questo codelab, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Parte 2: Open Environment
- 👉 Fai clic su questo link per passare direttamente all'editor di Cloud Shell
- 👉 Se ti viene richiesto di concedere l'autorizzazione in qualsiasi momento della giornata, fai clic su Autorizza per continuare.
- 👉 Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale
 .
.
- 👉💻 Nel terminale, verifica di aver già eseguito l'autenticazione e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list - 👉💻 Clona il progetto di bootstrap da GitHub:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 Esegui lo script di configurazione dalla directory del progetto.
cd ~/adk_eval_starter ./init.sh
Lo script gestirà automaticamente il resto della procedura di configurazione.
- 👉💻 Imposta l'ID progetto necessario:
gcloud config set project $(cat ~/project_id.txt) --quiet
Parte 3: configurazione dell'autorizzazione
- 👉💻 Abilita le API richieste utilizzando il seguente comando. L'operazione potrebbe richiedere alcuni minuti.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 Concedi le autorizzazioni necessarie eseguendo questi comandi nel terminale:
. ~/adk_eval_starter/set_env.sh
Nota che viene creato un file .env per te. Vengono visualizzate le informazioni del progetto.
3. Generazione del Golden Dataset (adk web)
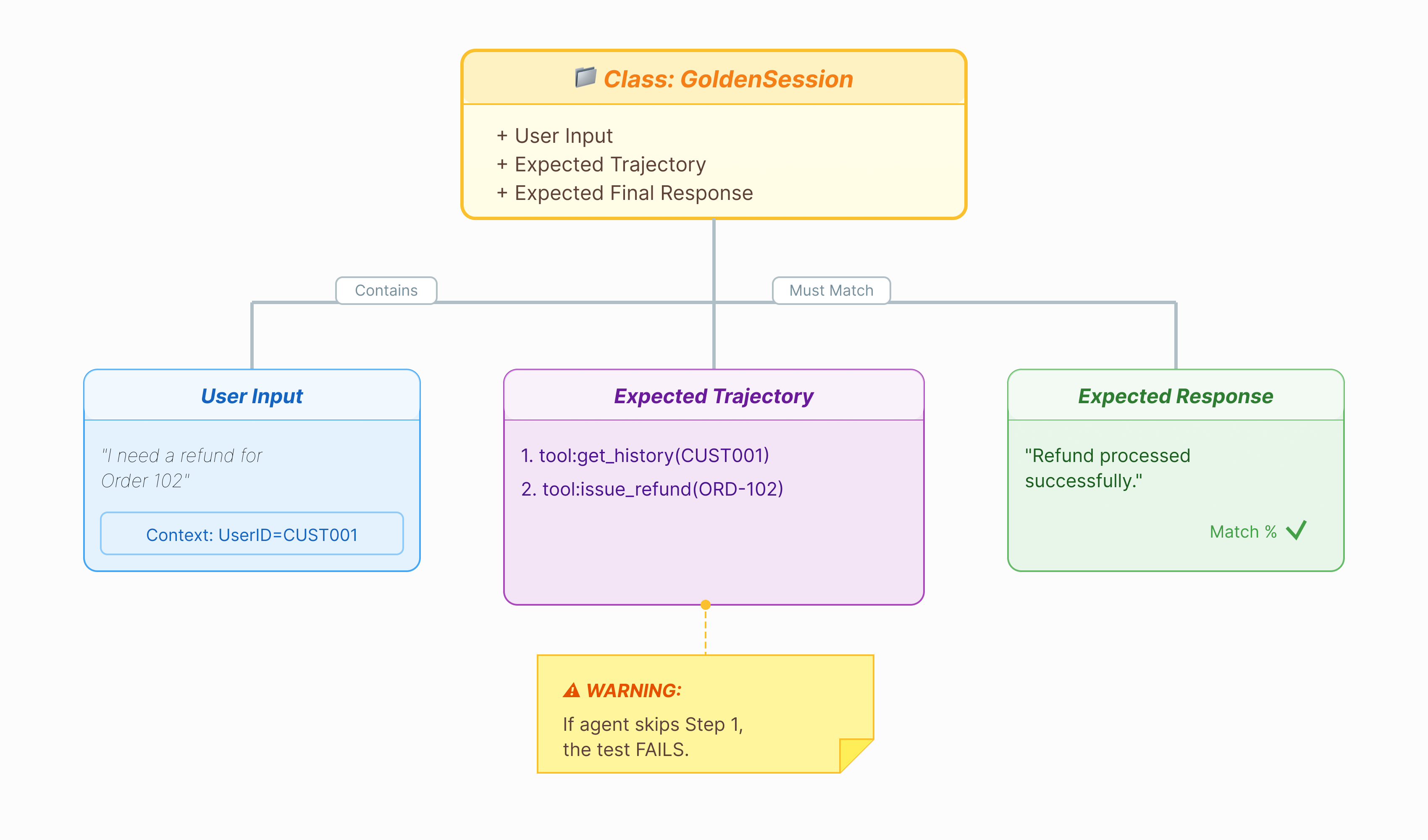
Prima di poter valutare l'agente, abbiamo bisogno di un file di risposte. Nell'ADK, questo set di dati è chiamato Golden Dataset. Questo set di dati contiene interazioni "perfette" che fungono da dati di riferimento per la valutazione.
Che cos'è un set di dati di riferimento?
Un Golden Dataset è un'istantanea del tuo agente che funziona correttamente. Non si tratta solo di un elenco di coppie di domande e risposte. Acquisisce:
- La query dell'utente ("Voglio un rimborso")
- La traiettoria (la sequenza esatta di chiamate agli strumenti:
check_order->verify_eligibility->refund_transaction). - La risposta finale (la risposta di testo "perfetta").
Utilizziamo questo valore per rilevare le regressioni. Se aggiorni il prompt e l'agente smette improvvisamente di verificare l'idoneità prima di rimborsare, il test del Golden Dataset non andrà a buon fine perché la traiettoria non corrisponde più.
Apri l'interfaccia utente web
L'interfaccia utente web dell'ADK offre un modo interattivo per creare questi golden dataset acquisendo interazioni reali con il tuo agente.
- 👉💻 Nel terminale, esegui:
cd ~/adk_eval_starter uv run adk web - 👉💻 Apri l'anteprima della UI web (di solito all'indirizzo
http://127.0.0.1:8000). - 👉 Nell'interfaccia utente della chat, digita
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. Visualizzerai una risposta simile a questa:
Visualizzerai una risposta simile a questa:I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
Acquisizione delle interazioni d'oro
Vai alla scheda Sessioni. Qui puoi visualizzare la cronologia delle conversazioni del tuo agente facendo clic sulla sessione.
- Interagisci con l'agente per creare un flusso di conversazione ideale, ad esempio per controllare la cronologia degli acquisti o richiedere un rimborso.
- Rivedi la conversazione per assicurarti che rappresenti il comportamento previsto.
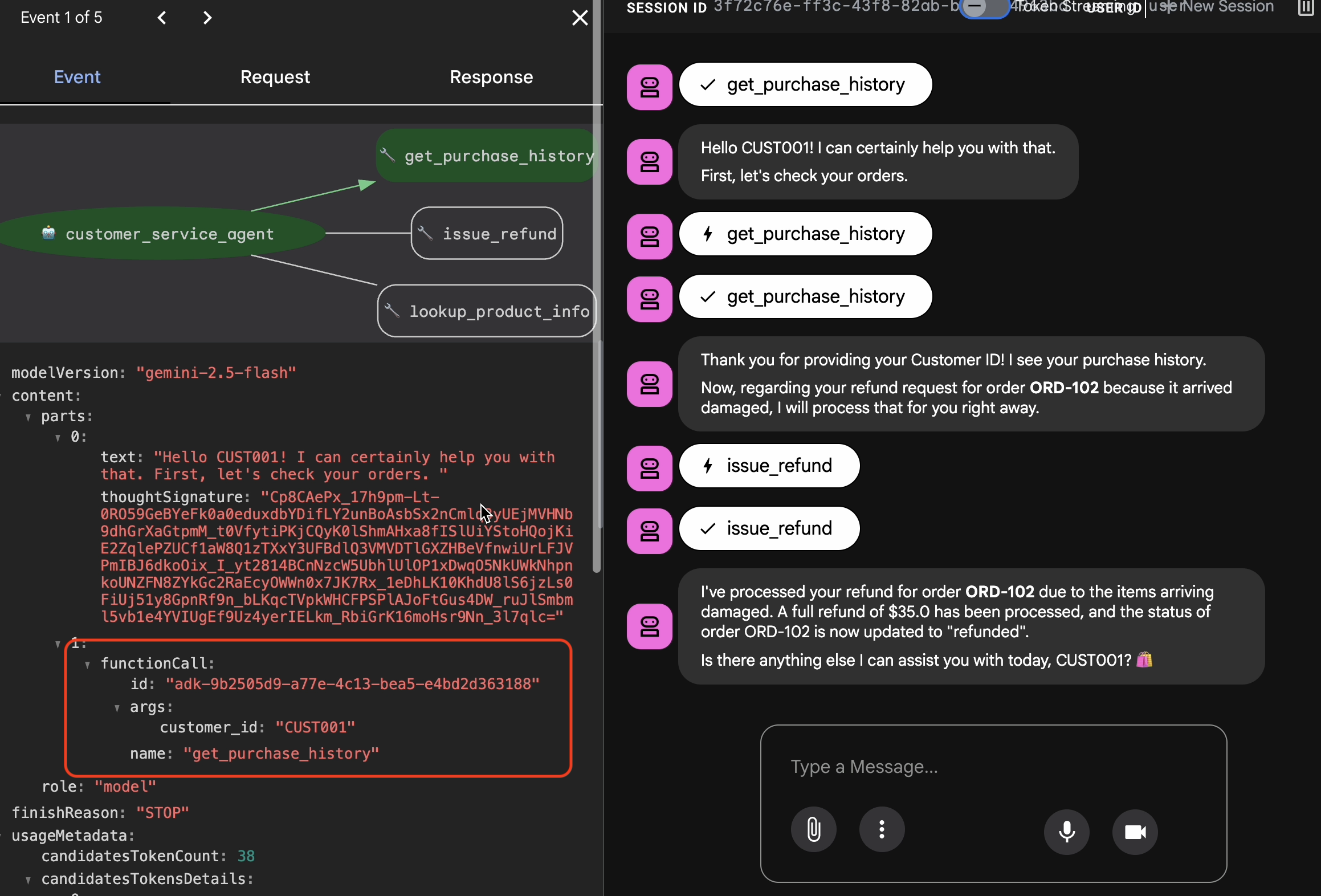
4. Esportare il set di dati principale
Verifica con Trace View
Prima di esportare, devi verificare che l'agente non abbia trovato la risposta giusta per caso. Devi esaminare la logica interna.
- Fai clic sulla scheda Traccia nell'interfaccia utente web.
- Le tracce vengono raggruppate automaticamente in base al messaggio dell'utente. Passa il mouse sopra una riga della traccia per evidenziare il messaggio corrispondente nella chat.
- Esamina le righe blu: indicano gli eventi generati dall'interazione. Fai clic su una riga blu per aprire il pannello di ispezione.
- Controlla le seguenti schede per convalidare la logica:
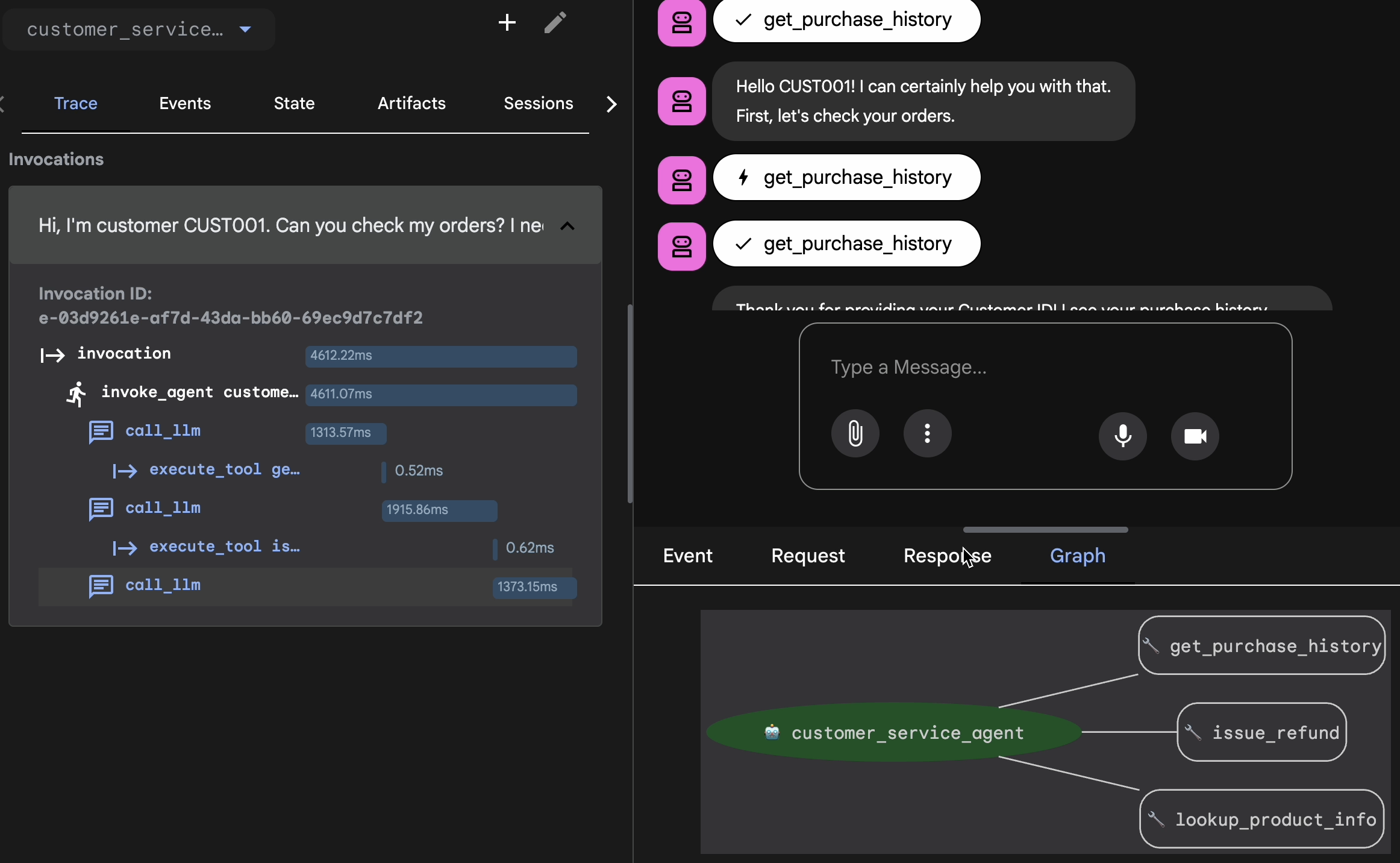
- Grafico: rappresentazione visiva del flusso di logica e delle chiamate agli strumenti. Ha seguito il percorso corretto?
- Richiesta/Risposta: esamina esattamente ciò che è stato inviato al modello e ciò che è stato restituito.
- Verifica: se l'agente ha stimato l'importo del rimborso senza chiamare lo strumento di database, si tratta di un'"allucinazione fortunata".
Aggiungi sessione a EvalSet
Una volta che la conversazione e la traccia ti soddisfano:
- 👉 Fai clic sulla scheda
Eval, poi sul pulsanteCreate Evaluation Sete inserisci il nome della valutazione:evalset1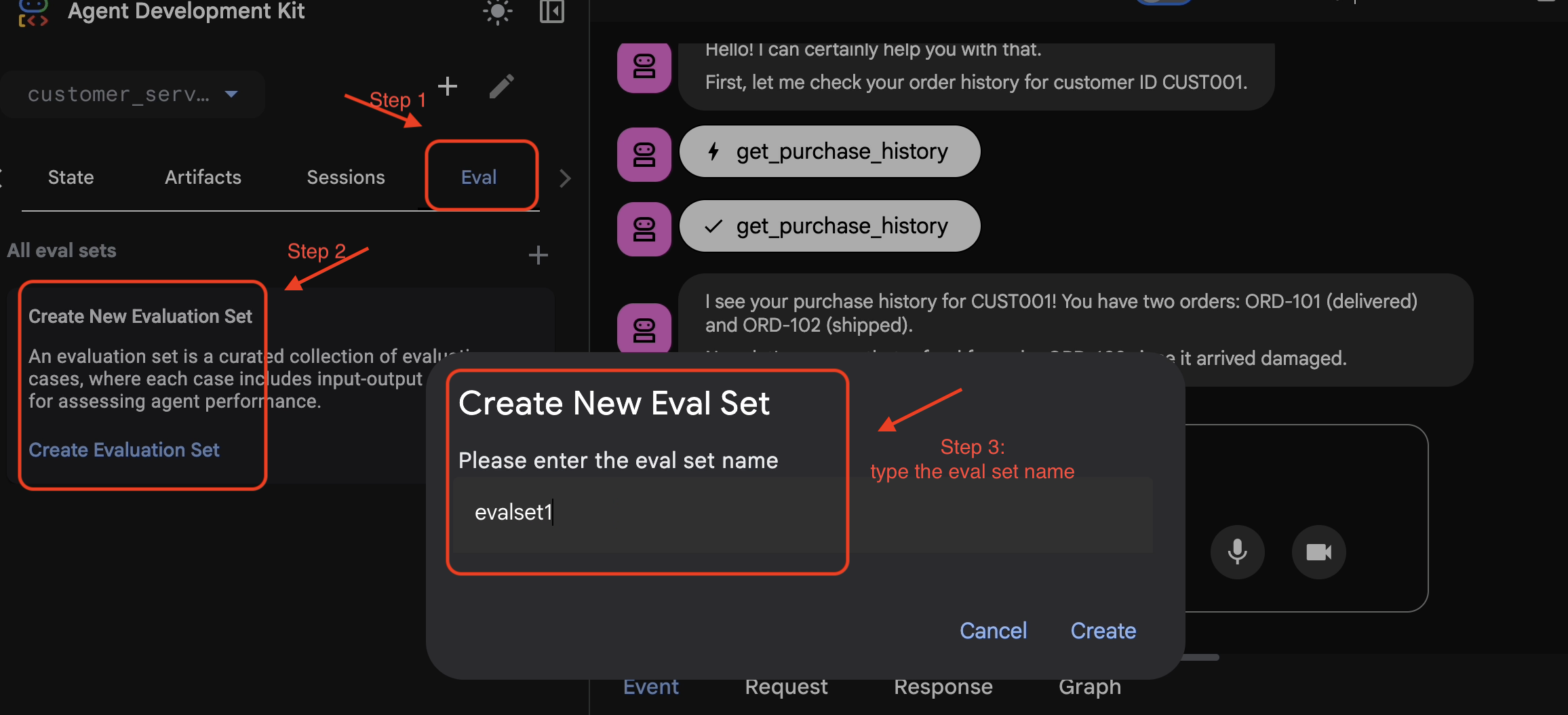
- 👉 In questo evalset, fai clic su
Add current session to evalset1. Nella finestra popup, inserisci il nome della sessione:eval1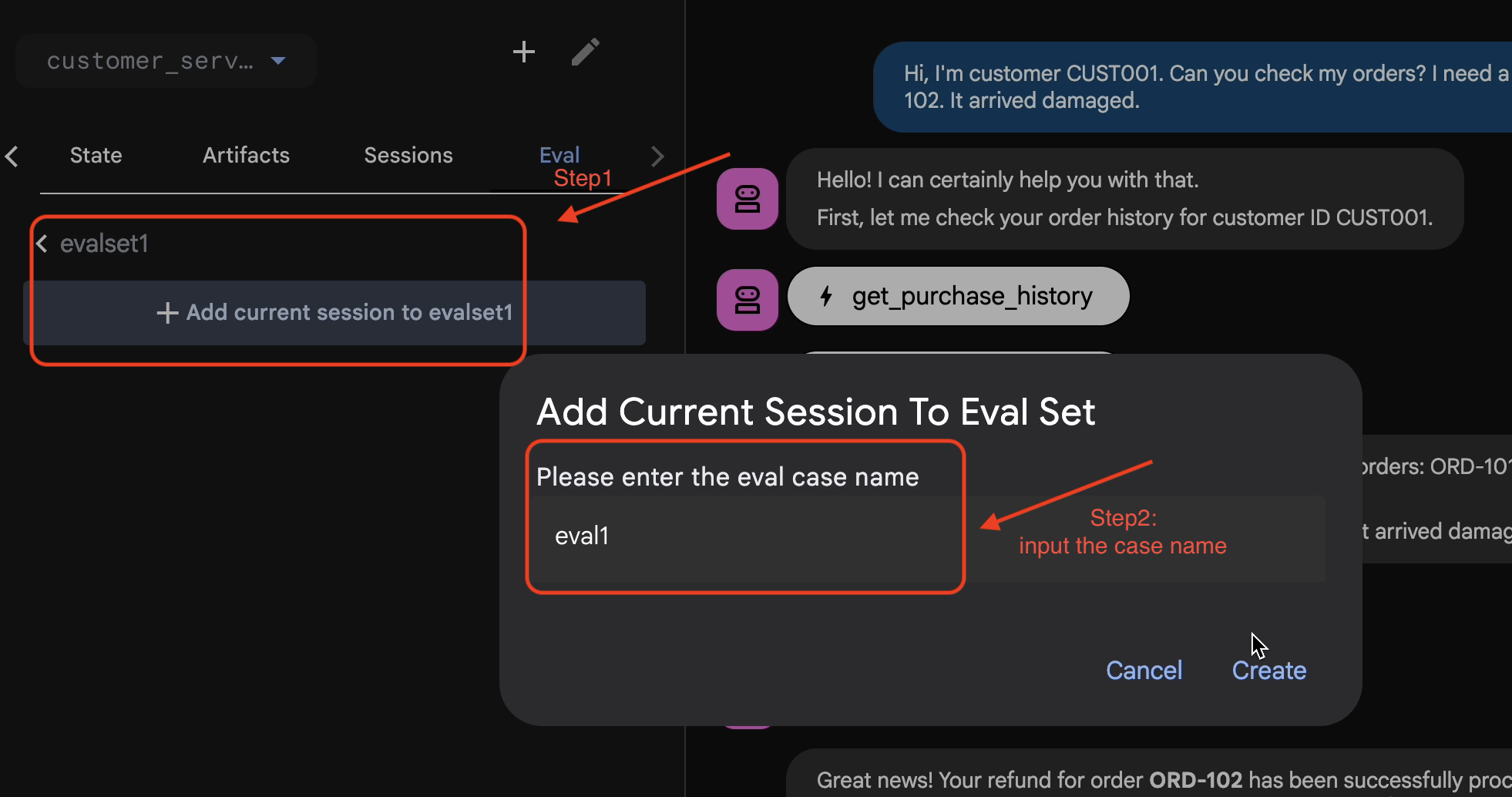
Esegui Eval in ADK Web
- 👉 Nell'interfaccia utente web di ADK, fai clic su
Run Evaluation, nella finestra popup regola le metriche e fai clic suStart:
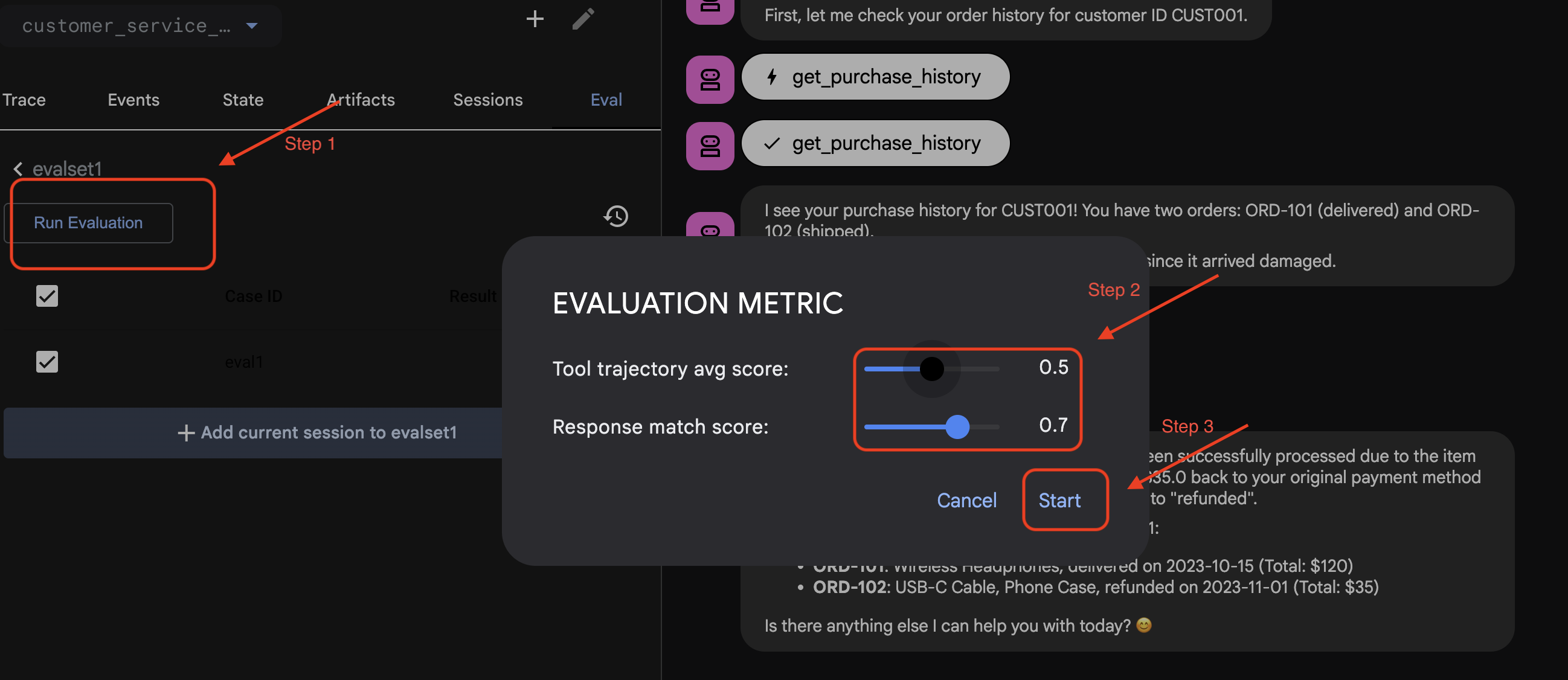
Verifica del set di dati nel repository
Vedrai la conferma che un file del set di dati (ad es. evalset1.evalset.json) è stato salvato nel tuo repository. Questo file contiene la traccia grezza e generata automaticamente della tua conversazione.

5. File di valutazione
Mentre la UI web genera un file .evalset.json complesso, spesso vogliamo creare un file di test più pulito e strutturato per i test automatizzati.
ADK Eval utilizza due componenti principali:
- File di test: possono essere il set di dati di riferimento generato automaticamente (ad es.
customer_service_agent/evalset1.evalset.json) o un insieme selezionato manualmente (ad es.customer_service_agent/eval.test.json). - File di configurazione (ad es.
customer_service_agent/test_config.json): definisci le metriche e le soglie per il superamento.
Configura il file di configurazione del test
- 👉💻 Nel terminale dell'editor di Cloud Shell, inserisci
cloudshell edit customer_service_agent/test_config.json - 👉 Inserisci il seguente codice in
customer_service_agent/test_config.jsonnell'editor.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
Decodifica delle metriche
tool_trajectory_avg_score(The Process) Questo parametro misura se l'agente ha utilizzato correttamente gli strumenti.
- 0,8: richiediamo una corrispondenza dell'80%.
response_match_score(l'output): utilizza ROUGE-1 (sovrapposizione di parole) per confrontare la risposta con il riferimento ideale.
- Vantaggi: veloce, deterministico, senza costi.
- Svantaggi: non funziona se l'agente esprime la stessa idea in modo diverso (ad es. "Rimborsato" anziché "Restituzione del denaro").
Metriche avanzate (per quando hai bisogno di più potenza)
6. Esegui la valutazione per il set di dati di riferimento (valutazione ADK)

Questo passaggio rappresenta il "ciclo interno" di sviluppo. Sei uno sviluppatore che sta apportando modifiche e vuoi verificare rapidamente i risultati.
Esegui il set di dati di riferimento
Eseguiamo il set di dati che hai generato nel passaggio 1. In questo modo, la base di riferimento è solida.
- 👉💻 Nel terminale, esegui:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Cosa c'è di nuovo?
L'ADK ora è:
- Caricamento dell'agente da
customer_service_agentin corso… - Esecuzione delle query di input da
evalset1.evalset.json. - Confrontando la traiettoria e le risposte effettive dell'agente con quelle previste.
- Assegnazione di un punteggio ai risultati in base ai criteri indicati in
test_config.json.
Analizzare i risultati
Guarda l'output del terminale. Vedrai un riepilogo dei test superati e non superati.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Nota: poiché l'hai appena generato dall'agente stesso, dovrebbe superare il test al 100%. Se non riesce, l'agente è non deterministico (casuale).
7. Crea un test personalizzato
Sebbene i set di dati generati automaticamente siano ottimi, a volte è necessario creare manualmente casi limite (ad es. attacchi avversari o gestione di errori specifici). Vediamo in che modo eval.test.json ti consente di definire la "correttezza".
Creiamo una suite di test completa.
Framework di test
Quando scrivi uno scenario di test in ADK, segui questa formula in tre parti:
- La configurazione (
session_input): chi è l'utente? (ad esempiouser_id,state). In questo modo il test viene isolato. - Il prompt (
user_content): qual è il trigger?
Con The Assertions (Expectations):
- Traiettoria (
tool_uses): ha eseguito correttamente i calcoli? (Logica) - Risposta (
final_response): ha dato la risposta giusta? (Qualità) - Intermedio (
intermediate_responses): i subagenti hanno parlato correttamente? (Orchestrazione)
Scrivi la suite di test
- 👉💻 Nel terminale dell'editor di Cloud Shell, inserisci
cloudshell edit customer_service_agent/eval.test.json - 👉 Inserisci il seguente codice nel file
customer_service_agent/eval.test.json.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
Analisi dei tipi di test
Qui abbiamo creato tre tipi distinti di test. Analizziamo cosa valuta ciascuna e perché.
- Test con un solo strumento (
product_info_check)
- Obiettivo: verifica il recupero delle informazioni di base.
- Affermazione chiave: controlliamo
intermediate_data.tool_uses. Affermiamo che viene chiamatolookup_product_info. Affermiamo che l'argomentoproduct_nameè esattamente "cuffie wireless". - Motivo: se il modello allucina un prezzo senza chiamare lo strumento, questo test non riesce. In questo modo, la fondatezza è garantita.
- Test di estrazione del contesto (
purchase_history_check)
- Obiettivo: verificare che l'agente possa estrarre le entità (CUST001) dal prompt dell'utente e trasmetterle allo strumento.
- Asserzione chiave: verifichiamo che
get_purchase_historyvenga chiamato concustomer_id: "CUST001". - Perché: una modalità di errore comune è l'agente che chiama lo strumento corretto, ma con un ID nullo. Ciò garantisce l'accuratezza dei parametri.
- Test di azione/traiettoria (
refund_request)
- Obiettivo: verifica un'operazione di scrittura critica.
- Affermazione chiave: la traiettoria. In uno scenario più complesso, questo elenco conterrebbe più passaggi:
[verify_order, calculate_refund, issue_refund]. L'ADK controlla questo elenco in ordine. - Perché: per le azioni che spostano denaro o modificano i dati, la sequenza è importante quanto il risultato. Non vuoi effettuare il rimborso prima della verifica.
8. Esegui valutazione per test personalizzati ( adk eval)
- 👉💻 Nel terminale, esegui:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Comprendere l'output
Dovresti vedere un risultato PASS come questo:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Ciò significa che l'agente ha utilizzato gli strumenti corretti e ha fornito una risposta sufficientemente simile alle tue aspettative.
9. (Facoltativo: sola lettura) - Risoluzione dei problemi e debug
I test non riusciranno. È il loro lavoro. Ma come si risolvono? Analizziamo gli scenari di errore comuni e come eseguire il debug.
Scenario A: errore "Traiettoria"
L'errore:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
Diagnosi: l'agente ha saltato il passaggio di verifica (lookup_order). Questo è un errore logico.
Come risolvere i problemi:
- Non indovinare: torna alla GUI web dell'ADK (adk web).
- Riproduci: digita nella chat il prompt esatto del test non riuscito.
- Trace: apri la visualizzazione Trace. Guarda la scheda "Grafico".
- Correggere il prompt: in genere, devi aggiornare il prompt di sistema. Modifica: "Sei un agente utile". A: "Sei un agente disponibile. CRITICO: DEVI chiamare lookup_order per verificare i dettagli prima di chiamare issue_refund."
- Adatta il test: se la logica di business è cambiata (ad es. la verifica non è più necessaria), il test è errato. Aggiorna eval.test.json in modo che corrisponda alla nuova realtà.
Scenario B: l'errore "ROUGE"
Errore:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
Diagnosi: l'agente ha fatto la cosa giusta, ma ha usato parole diverse. ROUGE (sovrapposizione di parole) lo ha penalizzato.
Come risolvere il problema:
- È sbagliato? Se il significato è corretto, non modificare il prompt.
- Regola soglia: abbassa la soglia in
test_config.json(ad es. da0.8a0.5). - Esegui l'upgrade della metrica: passa a
final_response_match_v2nella configurazione. Utilizza un modello LLM per leggere entrambe le frasi e valutare se hanno lo stesso significato.
10. CI/CD con Pytest (pytest)
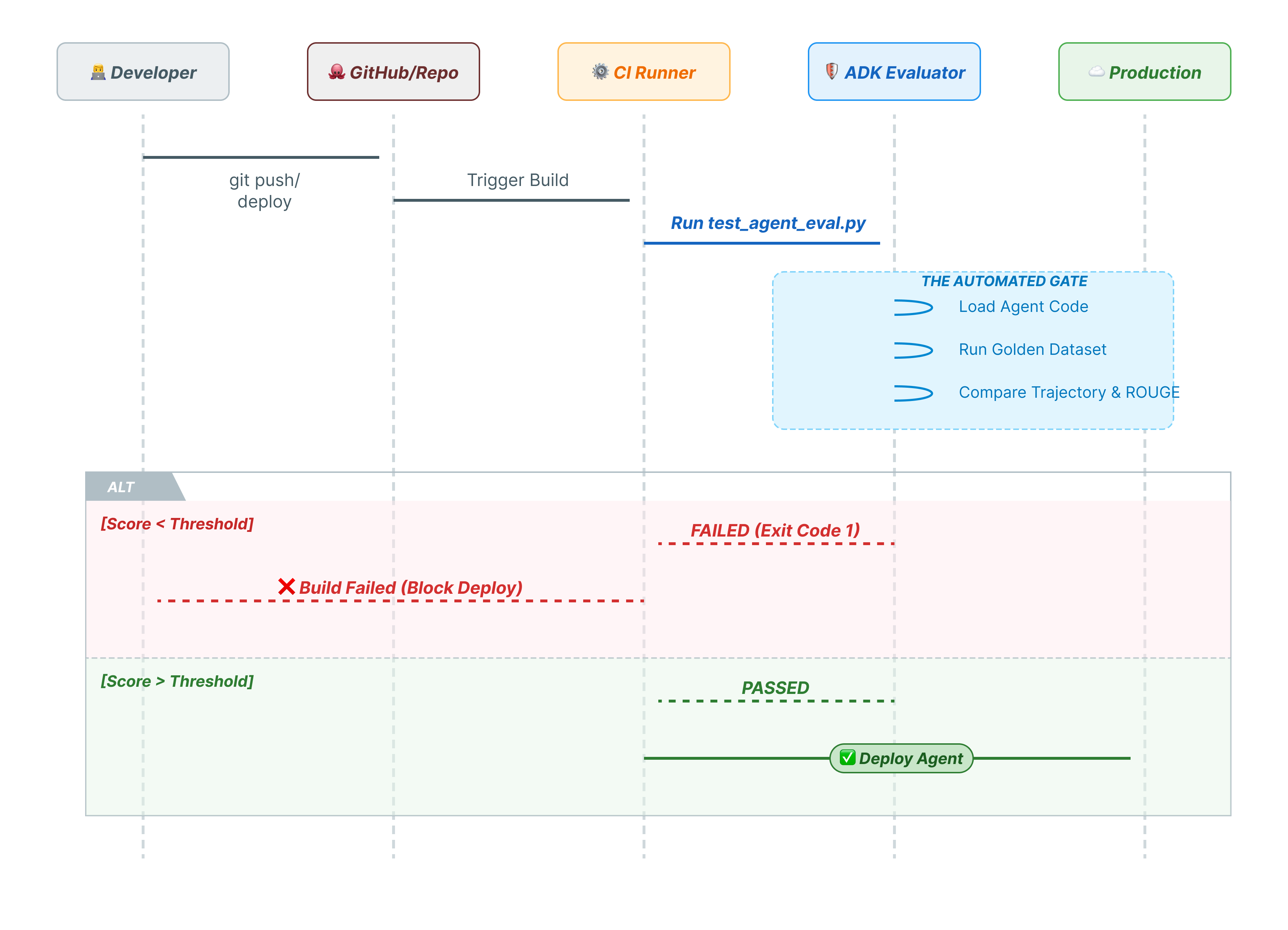
I comandi CLI sono per gli esseri umani. pytest è per le macchine. Per garantire l'affidabilità della produzione, inseriamo le nostre valutazioni in una suite di test Python. In questo modo, la pipeline CI/CD (GitHub Actions, Jenkins) può bloccare un deployment se l'agente subisce un downgrade.
Cosa contiene questo file?
Questo file Python funge da ponte tra il runner CI/CD e il valutatore ADK. Deve:
- Carica l'agente: importa dinamicamente il codice dell'agente.
- Reimposta stato: assicurati che la memoria dell'agente sia pulita in modo che i test non si influenzino a vicenda.
- Esegui valutazione: chiama
AgentEvaluator.evaluate()in modo programmatico. - Assert Success: se il punteggio di valutazione è basso, la build non viene eseguita.
Codice di test di integrazione
- 👉 Apri
customer_service_agent/test_agent_eval.py. Questo script utilizzaAgentEvaluator.evaluateper eseguire i test definiti ineval.test.json. - 👉 Inserisci il seguente codice in
customer_service_agent/test_agent_eval.pynell'editor.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Esegui Pytest
- 👉💻 Nel terminale, esegui:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. Conclusione
Complimenti! Hai valutato correttamente il tuo agente del servizio clienti utilizzando ADK Eval.
Che cosa hai imparato
In questo codelab hai imparato a:
- ✅ Genera un Golden Dataset per stabilire una base di conoscenza per l'agente.
- ✅ Comprendi la configurazione della valutazione per definire i criteri di successo.
- ✅ Esegui valutazioni automatiche per rilevare le regressioni in anticipo.
Se incorpori ADK Eval nel tuo flusso di lavoro di sviluppo, puoi creare agenti con sicurezza, sapendo che qualsiasi cambiamento nel comportamento verrà rilevato dai test automatizzati.
Questo lab fa parte del percorso di apprendimento AI pronta per la produzione con Google Cloud.
- Esplora il curriculum completo per colmare il divario tra prototipo e produzione.
- Condividi i tuoi progressi con l'hashtag
ProductionReadyAI.
Altre letture: