
1. 信頼のギャップ
インスピレーションの瞬間
カスタマー サービス エージェントを構築しました。お使いのパソコンでは動作します。しかし、昨日、在庫切れのスマートウォッチが購入可能であるとお客様に伝えたり、払い戻しポリシーをでっち上げたりする事象が発生しました。エージェントが稼働していることを知って、夜はどのように眠りますか?
概念実証とプロダクション レディな AI エージェントの間のギャップをなくすには、自動化された頑強な評価フレームワークが必要不可欠です。

実際に評価しているのは何ですか?
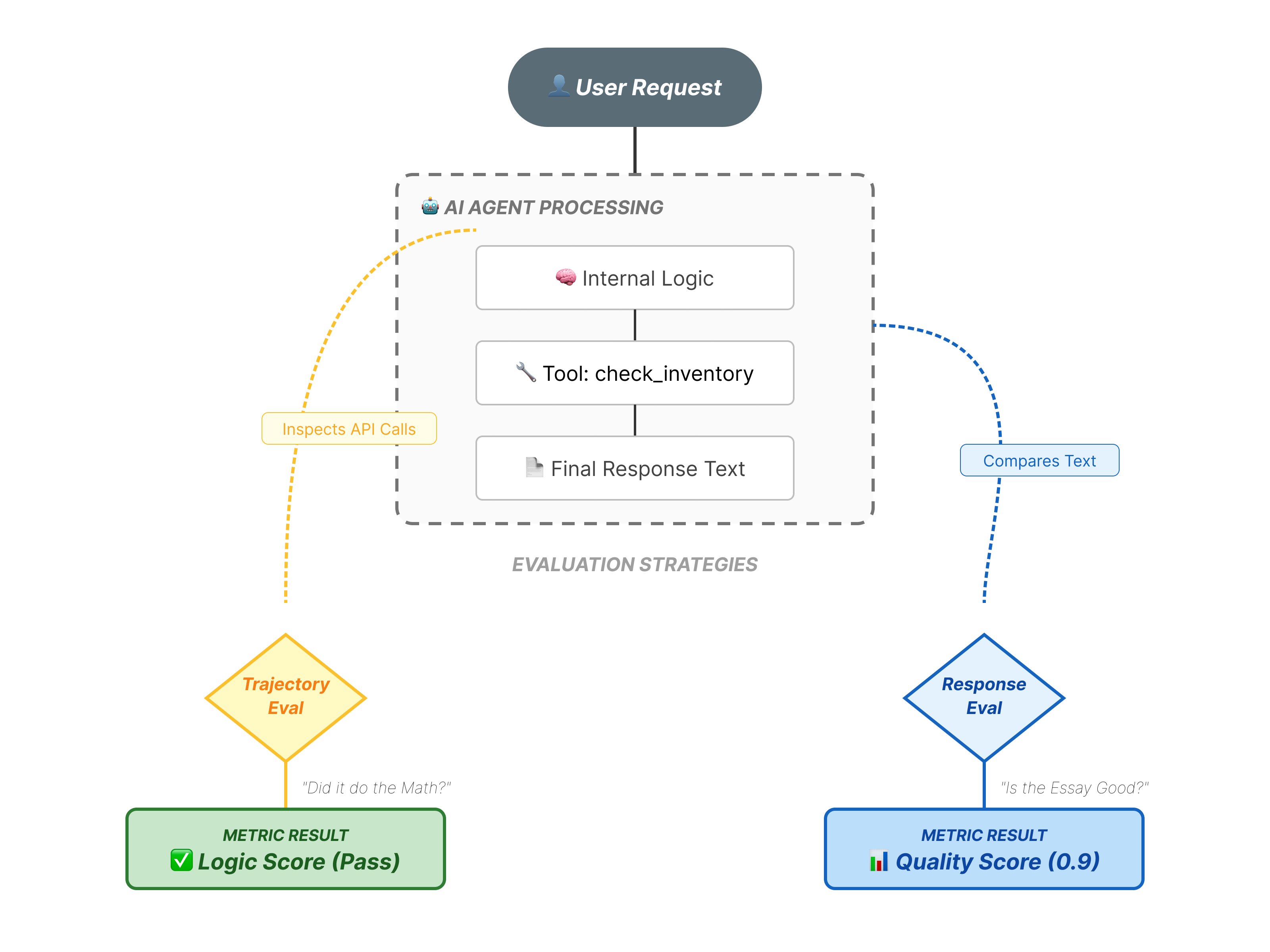
エージェントの評価は、標準の LLM 評価よりも複雑です。エッセイ(最終的な回答)を評価するだけでなく、数学(回答にたどり着くために使用されたロジック/ツール)も評価します。
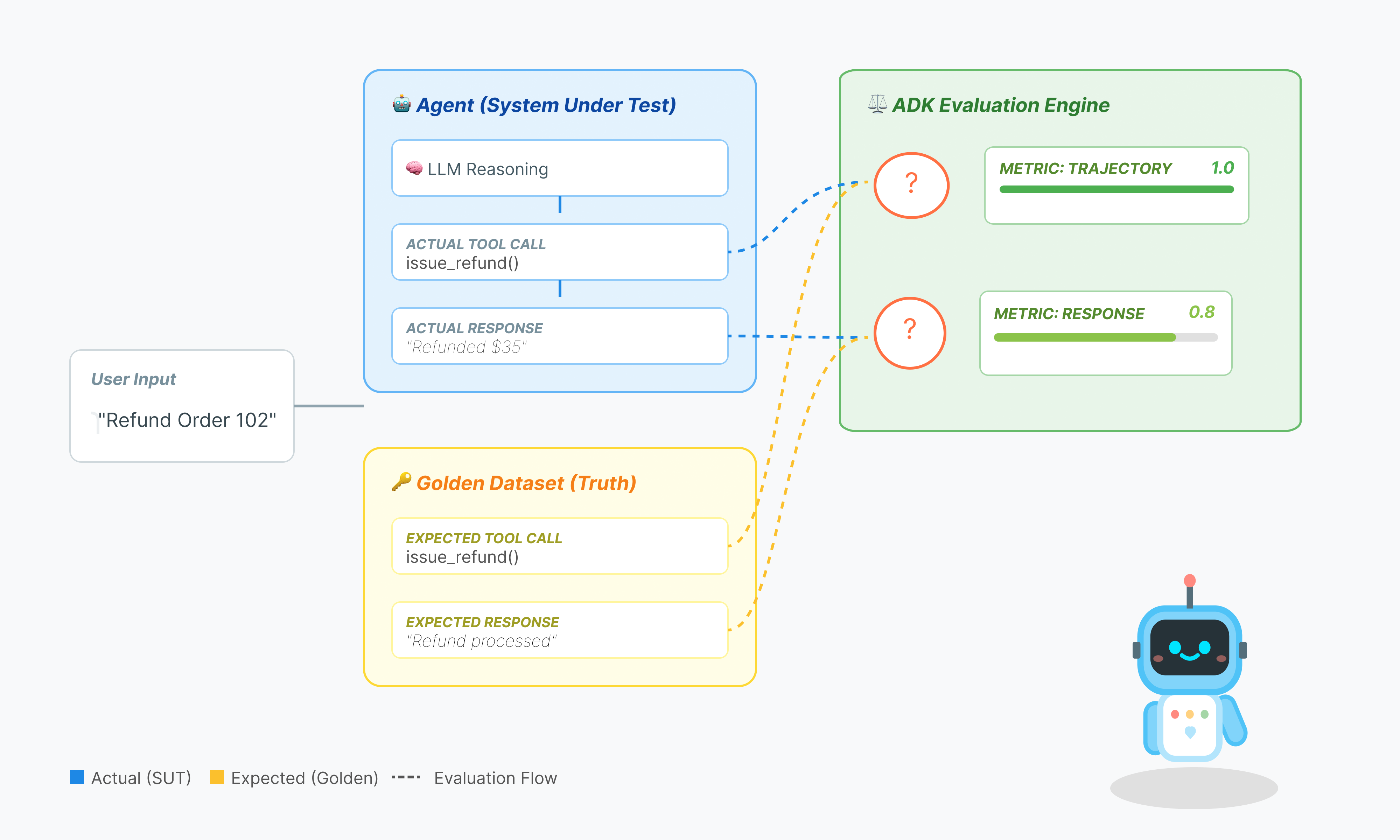
- 軌跡(プロセス): エージェントは適切なタイミングで適切なツールを使用しましたか?
place_orderの前にcheck_inventoryを呼び出しましたか? - 最終的な回答(出力): 回答は正確で、丁寧で、データに基づいているか?
開発ライフサイクル
この Codelab では、エージェント テストのプロフェッショナルなライフサイクルについて説明します。
- ローカル Visual Inspection(ADK ウェブ UI): 手動でチャットしてロジックを確認します(ステップ 1)。
- 単体テスト/回帰テスト(ADK CLI): 特定のテストケースをローカルで実行して、エラーをすばやく検出します(ステップ 3 と 4)。
- デバッグ(トラブルシューティング): エラーを分析し、プロンプト ロジックを修正します(ステップ 5)。
- CI/CD 統合(Pytest): ビルド パイプラインでのテストの自動化(ステップ 6)。
2. セットアップ
AI エージェントを強化するには、基盤となる Google Cloud プロジェクトが必要です。
パート 1: 請求先アカウントを有効にする
この Codelab を実行するには、クレジットが残っている請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して、開始します。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
パート 2: オープン環境
- 👉 このリンクをクリックすると、Cloud Shell エディタに直接移動します。
- 👉 本日、どこかの時点で承認を求められた場合は、[承認] をクリックして続行します。
- 👉 画面下部にターミナルが表示されない場合は、ターミナルを開きます。
- [表示] をクリックします。
- [ターミナル] をクリックします。
- 👉💻 ターミナルで、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list - 👉💻 GitHub からブートストラップ プロジェクトのクローンを作成します。
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 プロジェクト ディレクトリから設定スクリプトを実行します。
cd ~/adk_eval_starter ./init.sh
スクリプトが残りの設定プロセスを自動的に処理します。
- 👉💻 必要なプロジェクト ID を設定します。
gcloud config set project $(cat ~/project_id.txt) --quiet
パート 3: 権限の設定
- 👉💻 次のコマンドを使用して、必要な API を有効にします。これには数分かかることがあります。
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 ターミナルで次のコマンドを実行して、必要な権限を付与します。
. ~/adk_eval_starter/set_env.sh
.env ファイルが作成されていることに注目してください。プロジェクト情報が表示されます。
3. ゴールデン データセットの生成(adk web)
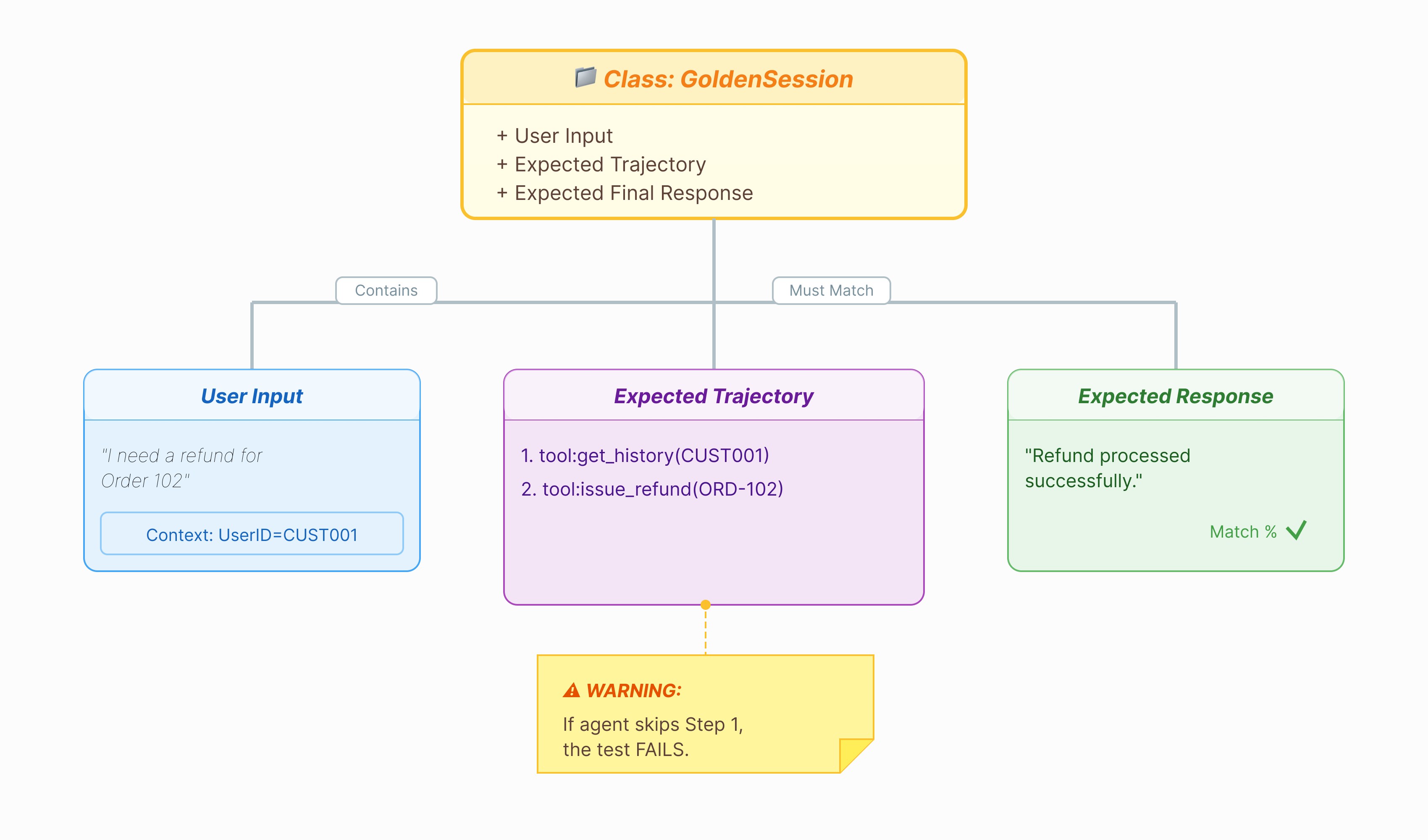
エージェントを評価するには、解答集が必要です。ADK では、これをゴールデン データセットと呼びます。このデータセットには、評価のグラウンド トゥルースとして機能する「完璧な」インタラクションが含まれています。
ゴールデン データセットとは
ゴールデン データセットは、エージェントが正しく動作している状態のスナップショットです。単なる質問と回答のペアのリストではありません。キャプチャされる内容は次のとおりです。
- ユーザーのクエリ(「払い戻しを希望します」)
- 軌跡(ツール呼び出しの正確なシーケンス:
check_order->verify_eligibility->refund_transaction)。 - 最終的な回答(「完璧な」テキスト回答)。
これは、回帰を検出するために使用されます。プロンプトを更新すると、エージェントが突然払い戻し前に資格の確認を停止するため、軌跡が一致しなくなり、ゴールデン データセット テストが失敗します。
ウェブ UI を開く
ADK ウェブ UI は、エージェントとの実際のやり取りをキャプチャして、これらのゴールデン データセットを作成するインタラクティブな方法を提供します。
- 👉💻 ターミナルで以下を実行します。
cd ~/adk_eval_starter uv run adk web - 👉💻 ウェブ UI のプレビューを開きます(通常は
http://127.0.0.1:8000)。 - 👉 チャット UI で、次のように入力します。
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. 次のようなレスポンスが表示されます。
次のようなレスポンスが表示されます。I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
ゴールデン インタラクションをキャプチャする
[セッション] タブに移動します。セッションをクリックすると、エージェントの会話履歴を確認できます。
- エージェントとやり取りして、購入履歴の確認や払い戻しのリクエストなど、理想的な会話フローを作成します。
- 会話を確認して、期待どおりの動作になっていることを確認します。
4. ゴールデン データセットをエクスポートする
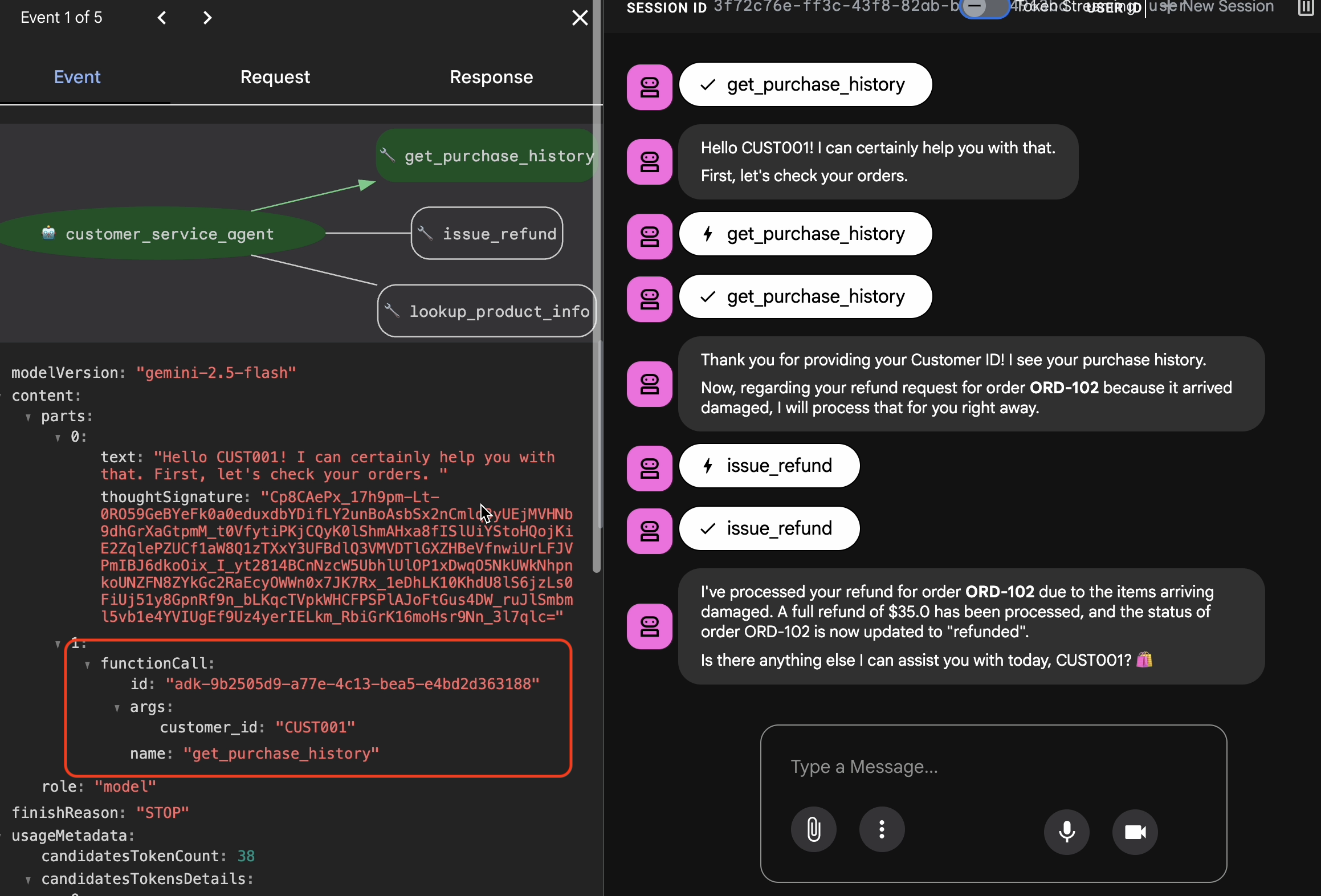
Trace View で確認する
エクスポートする前に、エージェントがたまたま正解したのではないことを確認する必要があります。内部ロジックを検査する必要があります。
- ウェブ UI で [トレース] タブをクリックします。
- トレースはユーザー メッセージごとに自動的にグループ化されます。トレース行にカーソルを合わせると、チャット内の対応するメッセージがハイライト表示されます。
- 青い行を調べる: これらは、インタラクションから生成されたイベントを示します。青い行をクリックして検査パネルを開きます。
- 次のタブをチェックして、ロジックを検証します。
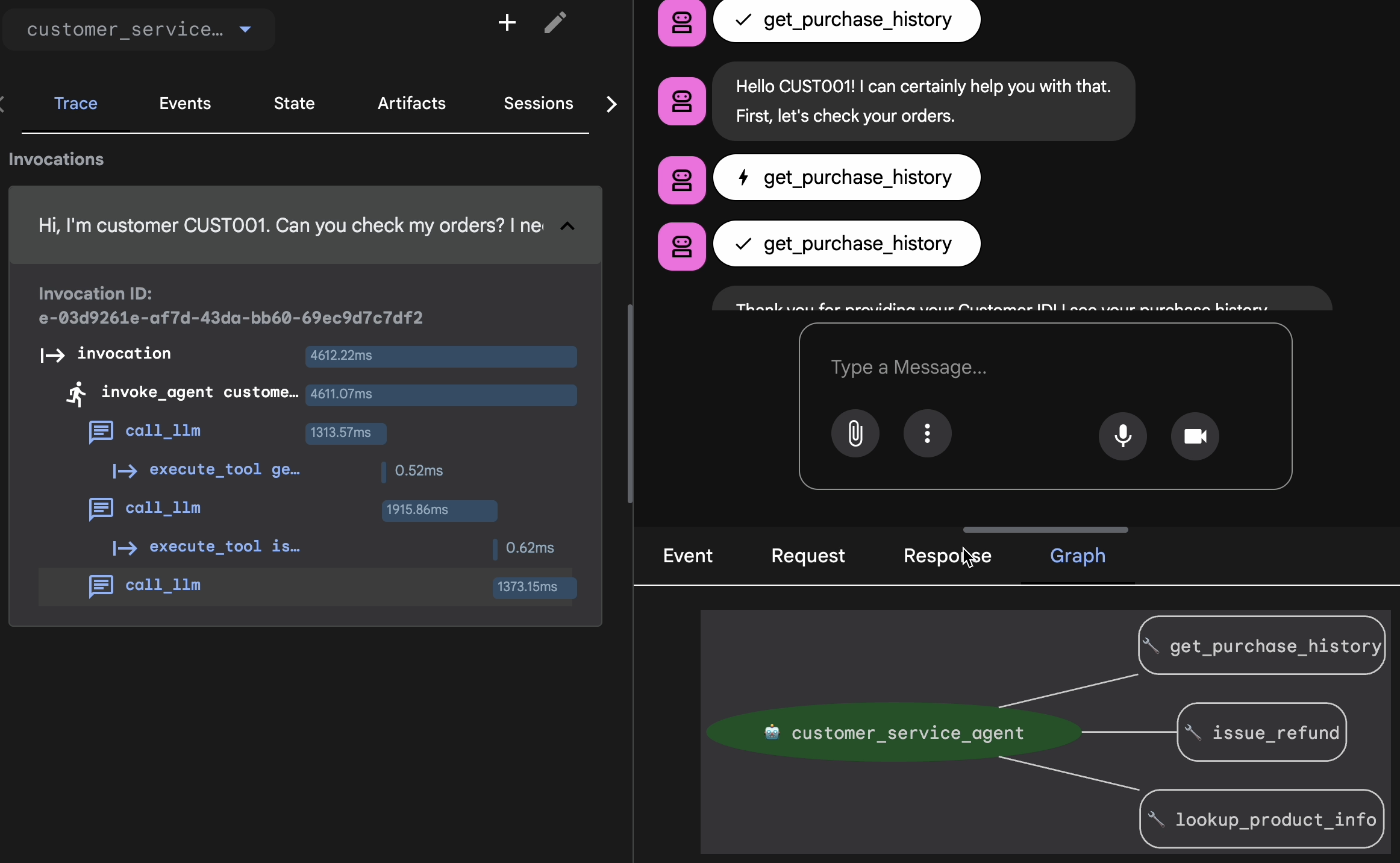
- グラフ: ツール呼び出しとロジックフローの視覚的表現。正しいパスを通ったか
- リクエスト/レスポンス: モデルに送信された内容と、モデルから返された内容を正確に確認します。
- 検証: エージェントがデータベース ツールを使用せずに払い戻し額を推測した場合、それは「ラッキーなハルシネーション」です。
EvalSet にセッションを追加する
会話とトレースに問題がなければ、次の操作を行います。
- 👉 [
Eval] タブをクリックし、[Create Evaluation Set] ボタンをクリックして、評価名に次のように入力します。evalset1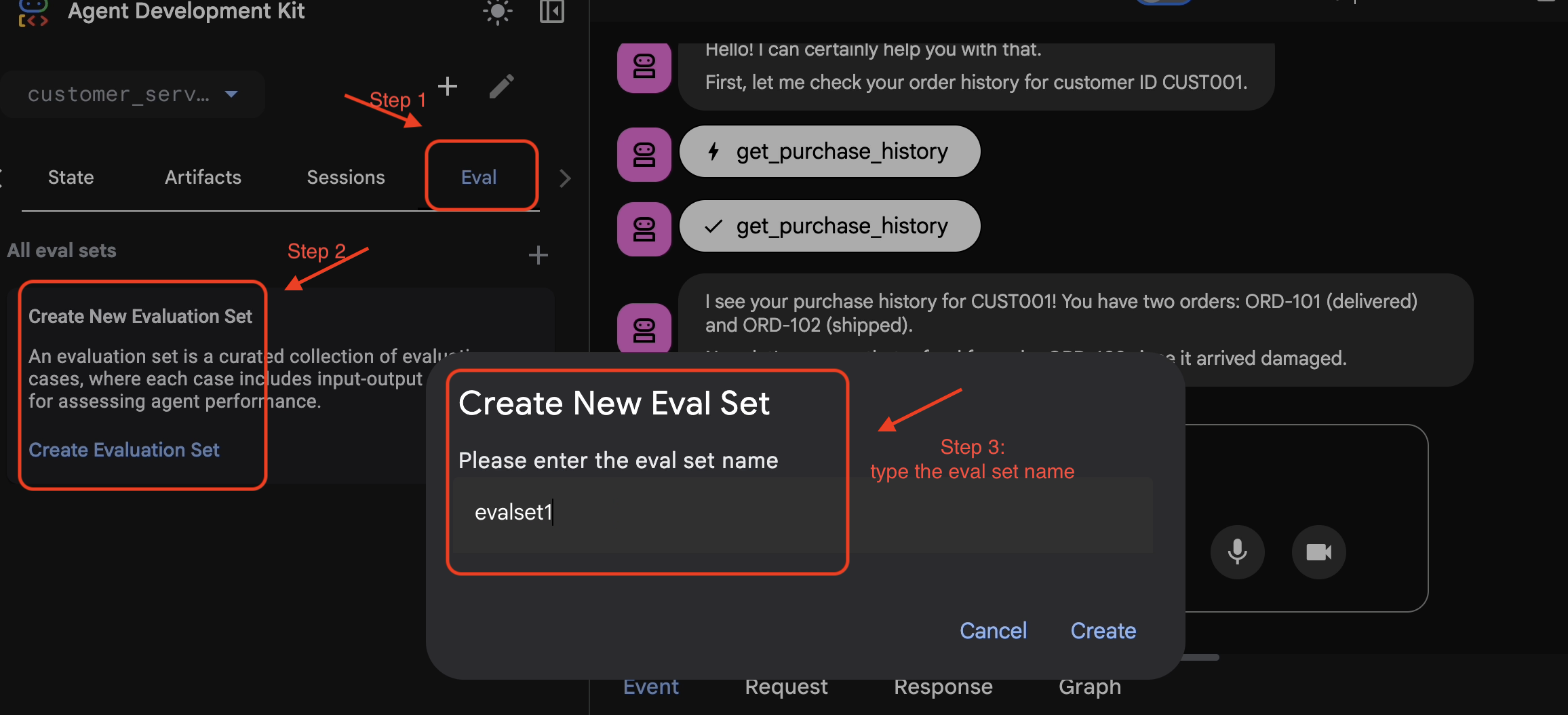
- 👉 この評価セットで、
Add current session to evalset1をクリックし、ポップアップ ウィンドウでセッション名を次のように入力します。eval1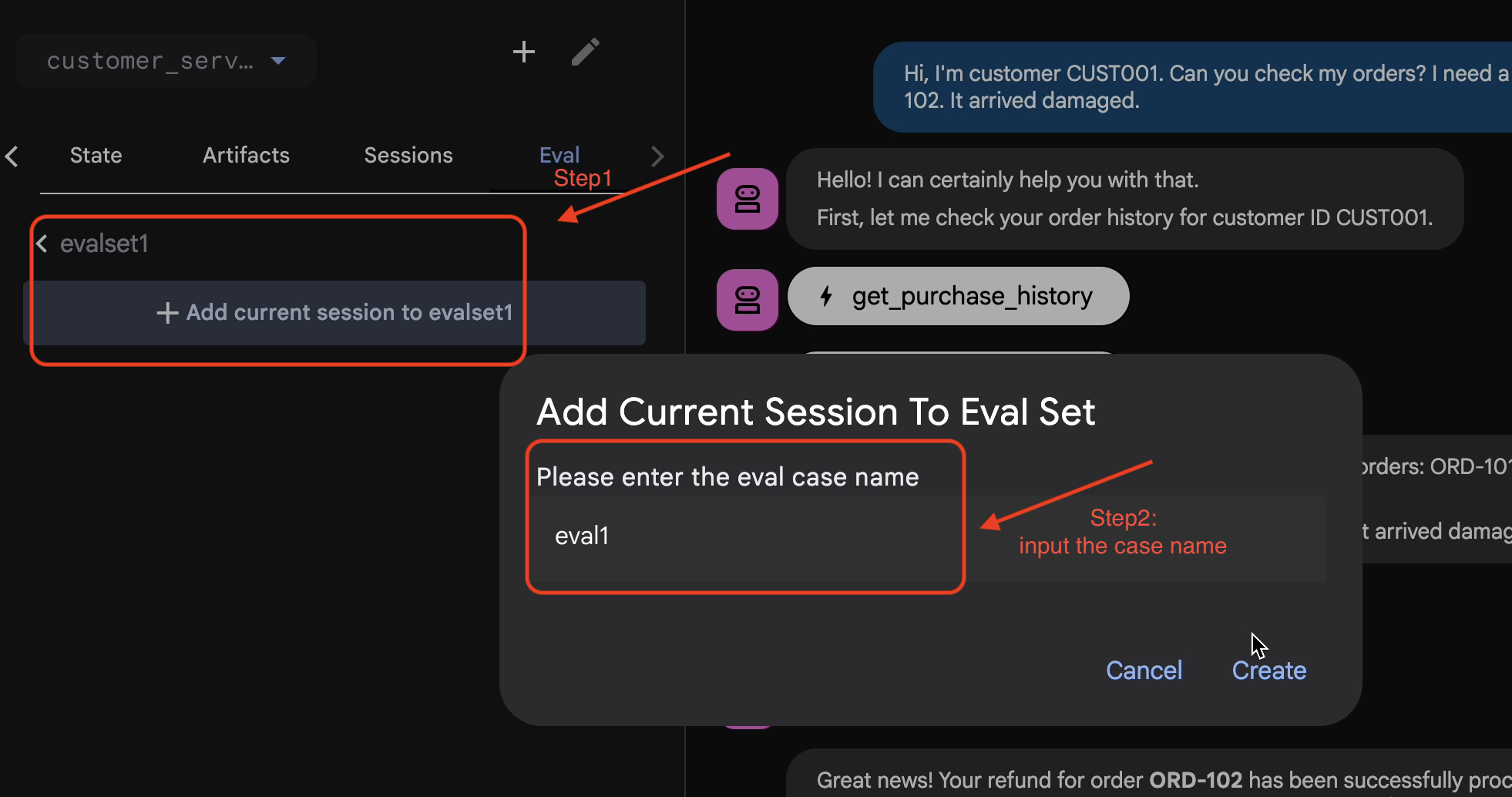
ADK Web で評価を実行する
- 👉 ADK ウェブ UI で
Run Evaluationをクリックし、ポップアップ ウィンドウで指標を調整して、Startをクリックします。
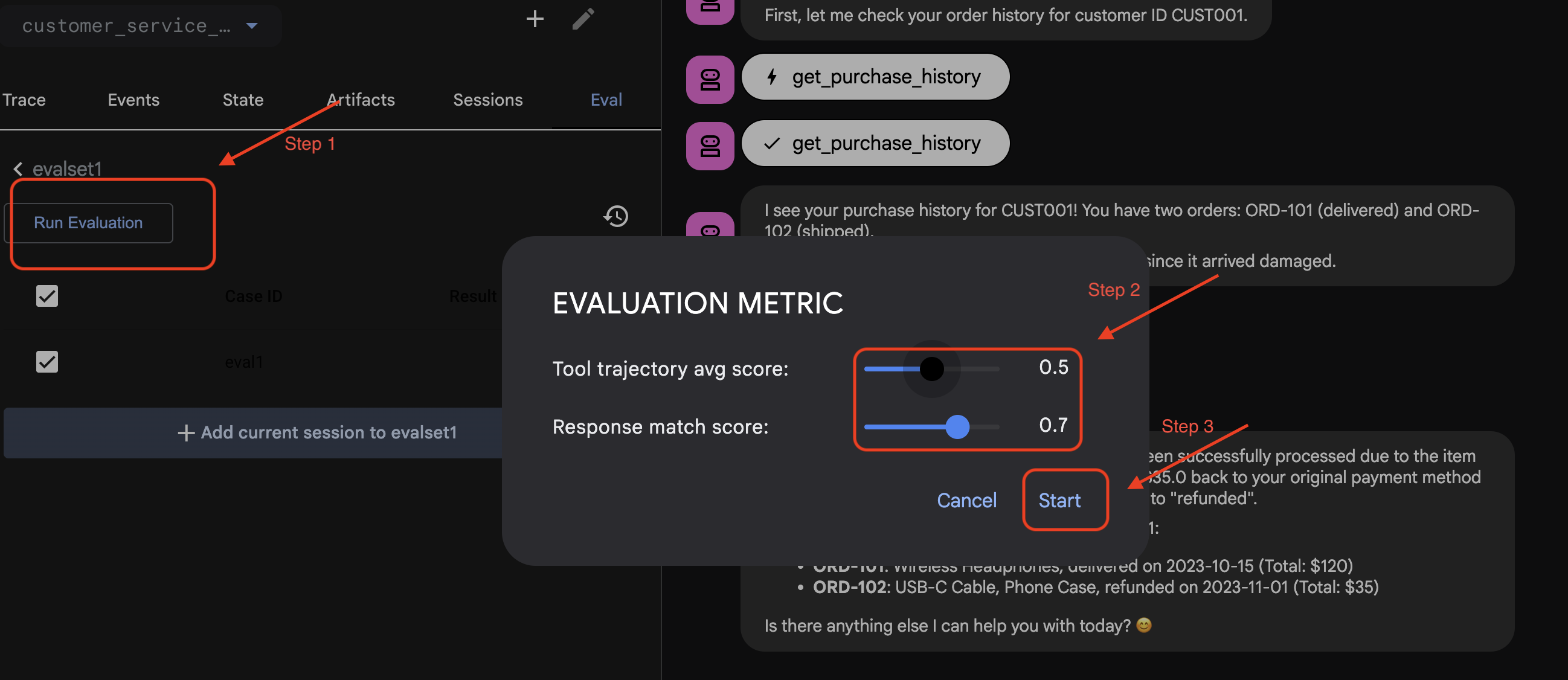
リポジトリ内のデータセットを確認する
データセット ファイル(evalset1.evalset.json など)がリポジトリに保存されたことを示す確認メッセージが表示されます。このファイルには、会話の自動生成された未加工のトレースが含まれています。

5. 評価ファイル
ウェブ UI では複雑な .evalset.json ファイルが生成されますが、自動テスト用に、よりクリーンで構造化されたテストファイルを作成したい場合がよくあります。
ADK Eval は、次の 2 つの主要コンポーネントを使用します。
- テストファイル: 自動生成されたゴールデン データセット(
customer_service_agent/evalset1.evalset.jsonなど)または手動でキュレートされたセット(customer_service_agent/eval.test.jsonなど)にできます。 - 構成ファイル(
customer_service_agent/test_config.jsonなど): 合格するための指標としきい値を定義します。
テスト構成ファイルを設定する
- 👉💻 Cloud Shell エディタのターミナルで、次のように入力します。
cloudshell edit customer_service_agent/test_config.json - 👉 エディタの
customer_service_agent/test_config.jsonに次のコードを入力します。{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
指標の解読
tool_trajectory_avg_score(プロセス): エージェントがツールを正しく使用したかどうかを測定します。
- 0.8: 80% の一致を要求します。
response_match_score(出力): ROUGE-1(単語の重複)を使用して、回答とゴールデン リファレンスを比較します。
- メリット: 高速、決定論的、無料。
- デメリット: エージェントが同じアイデアを異なる表現で言い換えると(「Refunded」と「Money returned」など)、失敗します。
高度な指標(より詳細な分析が必要な場合)
6. ゴールデン データセットの評価を実行する(adk eval)

このステップは、開発の「インナーループ」を表します。変更を行うデベロッパーで、結果をすばやく確認したい。
ゴールデン データセットを実行する
ステップ 1 で生成したデータセットを実行してみましょう。これにより、ベースラインが確実なものになります。
- 👉💻 ターミナルで以下を実行します。
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
最新情報
ADK は次のようになりました。
customer_service_agentからエージェントを読み込んでいます。evalset1.evalset.jsonから入力クエリを実行する。- エージェントの実際の軌跡と回答を、期待される軌跡と回答と比較する。
test_config.jsonの条件に基づいて結果をスコアリングします。
結果を分析する
ターミナル出力を確認します。合格したテストと不合格だったテストの概要が表示されます。
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
注: エージェント自体から生成したばかりであるため、100% 合格するはずです。失敗した場合、エージェントは非決定的(ランダム)です。
7. 独自のカスタマイズされたテストを作成する
自動生成されたデータセットは優れていますが、エッジケース(敵対的攻撃や特定のエラー処理など)を手動で作成する必要がある場合もあります。eval.test.json で「正しさ」を定義する方法を見てみましょう。
包括的なテストスイートを構築しましょう。
テスト フレームワーク
ADK でテストケースを作成する場合は、次の 3 部構成の式に従います。
- セットアップ(
session_input): ユーザーは誰ですか?(例:user_id、state)。これにより、テストが分離されます。 - プロンプト(
user_content): トリガーは何ですか?
アサーション(期待値):
- 軌跡(
tool_uses): 計算は正しく行われたか?(ロジック) - 回答(
final_response): 正解を言いましたか?(品質) - 中級(
intermediate_responses): サブエージェントは正しく会話しましたか?(オーケストレーション)
テストスイートを作成する
- 👉💻 Cloud Shell エディタのターミナルで、次のように入力します。
cloudshell edit customer_service_agent/eval.test.json - 👉 次のコードを
customer_service_agent/eval.test.jsonファイルに入力します。{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
テストタイプの分解
ここでは、3 種類のテストを作成しました。それぞれの評価対象と理由について詳しく見ていきましょう。
- 単一ツールテスト(
product_info_check)
- 目標: 基本的な情報検索を検証します。
- 主なアサーション:
intermediate_data.tool_usesを確認します。lookup_product_infoが呼び出されることをアサートします。引数product_nameが「ワイヤレス ヘッドフォン」であることをアサートします。 - 理由: モデルがツールを呼び出さずに価格を幻覚すると、このテストは失敗します。これにより、グラウンディングが保証されます。
- コンテキスト抽出テスト(
purchase_history_check)
- 目標: エージェントがユーザー プロンプトからエンティティ(CUST001)を抽出し、ツールに渡すことができることを確認します。
- キー アサーション:
get_purchase_historyがcustomer_id: "CUST001"で呼び出されることを確認します。 - 理由: 一般的な障害モードは、エージェントが正しいツールを呼び出しているものの、ID が null であることです。これにより、パラメータの精度が確保されます。
- アクション/軌跡テスト(
refund_request)
- 目標: 重要な書き込みオペレーションを検証します。
- キー アサーション: 軌跡。より複雑なシナリオでは、このリストに複数のステップ(
[verify_order, calculate_refund, issue_refund])が含まれます。ADK はこのリストを順番に確認します。 - 理由: お金の移動やデータの変更を行うアクションでは、結果と同じくらいシーケンスが重要です。確認する前に払い戻しを行うことは避ける必要があります。
8. カスタム テストの評価を実行する(adk eval)
- 👉💻 ターミナルで以下を実行します。
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
出力を理解する
次のような PASS 結果が表示されます。
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
これは、エージェントが正しいツールを使用し、期待どおりの回答を十分に提供したことを意味します。
9. (省略可: 読み取り専用)- トラブルシューティングとデバッグ
テストは失敗します。それが彼らの仕事です。しかし、どのように修正すればよいのでしょうか?一般的な障害シナリオとそのデバッグ方法を分析してみましょう。
シナリオ A: 「軌跡」の失敗
エラー:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
診断: エージェントが確認ステップ(lookup_order)をスキップしました。これはロジックエラーです。
トラブルシューティング方法:
- 推測しない: ADK ウェブ UI(adk web)に戻ります。
- 再現: 失敗したテストのプロンプトをチャットに正確に入力します。
- トレース: トレースビューを開きます。[グラフ] タブを確認します。
- プロンプトを修正する: 通常は、システム プロンプトを更新する必要があります。変更: 「あなたは有能なエージェントです。」To: 「あなたは有能なエージェントです。重要: issue_refund を呼び出す前に、lookup_order を呼び出して詳細を確認する必要があります。」
- テストを適応させる: ビジネス ロジックが変更された場合(検証が不要になったなど)、テストは間違っています。新しい現実に対応するように eval.test.json を更新します。
シナリオ B: 「ROUGE」の失敗
エラー:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
診断: エージェントは正しい対応をしたが、異なる言葉を使用した。ROUGE(単語の重複)によってペナルティが課されました。
修正方法:
- 間違っていますか?意味が正しい場合は、プロンプトを変更しないでください。
- しきい値を調整:
test_config.jsonのしきい値を下げます(例:0.8から0.5)。 - 指標をアップグレードする: 設定で
final_response_match_v2に切り替えます。この場合、LLM は両方の文を読み取り、意味が同じかどうかを判断します。
10. Pytest を使用した CI/CD(pytest)

CLI コマンドは人間が使用することを想定しています。pytest はマシン用です。本番環境の信頼性を確保するため、評価を Python テストスイートでラップします。これにより、エージェントが劣化した場合に CI/CD パイプライン(GitHub Actions、Jenkins)でデプロイをブロックできます。
このファイルの内容
この Python ファイルは、CI/CD ランナーと ADK エバリュエータの橋渡しとして機能します。次のことを行う必要があります。
- エージェントを読み込む: エージェント コードを動的にインポートします。
- 状態をリセット: エージェントのメモリがクリーンであることを確認し、テストが相互にリークしないようにします。
- Run Evaluation:
AgentEvaluator.evaluate()をプログラムで呼び出します。 - Assert Success: 評価スコアが低い場合は、ビルドを失敗させます。
統合テストコード
- 👉
customer_service_agent/test_agent_eval.pyを開きます。このスクリプトは、AgentEvaluator.evaluateを使用してeval.test.jsonで定義されたテストを実行します。 - 👉 エディタの
customer_service_agent/test_agent_eval.pyに次のコードを入力します。from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Pytest を実行する
- 👉💻 ターミナルで以下を実行します。
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. まとめ
おめでとうございます!ADK Eval を使用してカスタマー サービス エージェントを無事評価しました。
学習内容
この Codelab では、以下について学びました。
- ✅ ゴールデン データセットを生成して、エージェントのグラウンド トゥルースを確立します。
- ✅ 評価構成について理解する: 成功基準を定義します。
- ✅ 自動評価を実行して、リグレッションを早期に検出します。
ADK Eval を開発ワークフローに組み込むことで、動作の変更が自動テストで検出されるため、安心してエージェントを構築できます。
このラボは、「Google Cloud でのプロダクション レディな AI の開発」学習プログラムの一部です。
- カリキュラム全体を確認して、プロトタイプから本番環境への移行をスムーズに進めましょう。
- ハッシュタグ
ProductionReadyAIを使用して進捗状況を共有しましょう。
その他の参考資料: