
1. 신뢰 격차
영감을 받는 순간
고객 서비스 상담사를 구축했습니다. 내 기기에서 작동합니다. 하지만 어제는 재고가 없는 스마트워치를 구매할 수 있다고 고객에게 말하거나 환불 정책을 환각했습니다. 에이전트가 실시간으로 작동하는 것을 알면 밤에 잠이 오나요?
개념 증명 AI 에이전트와 프로덕션 레디 AI 에이전트 간의 격차를 좁히려면 자동화된 강력한 평가 프레임워크가 필수입니다.

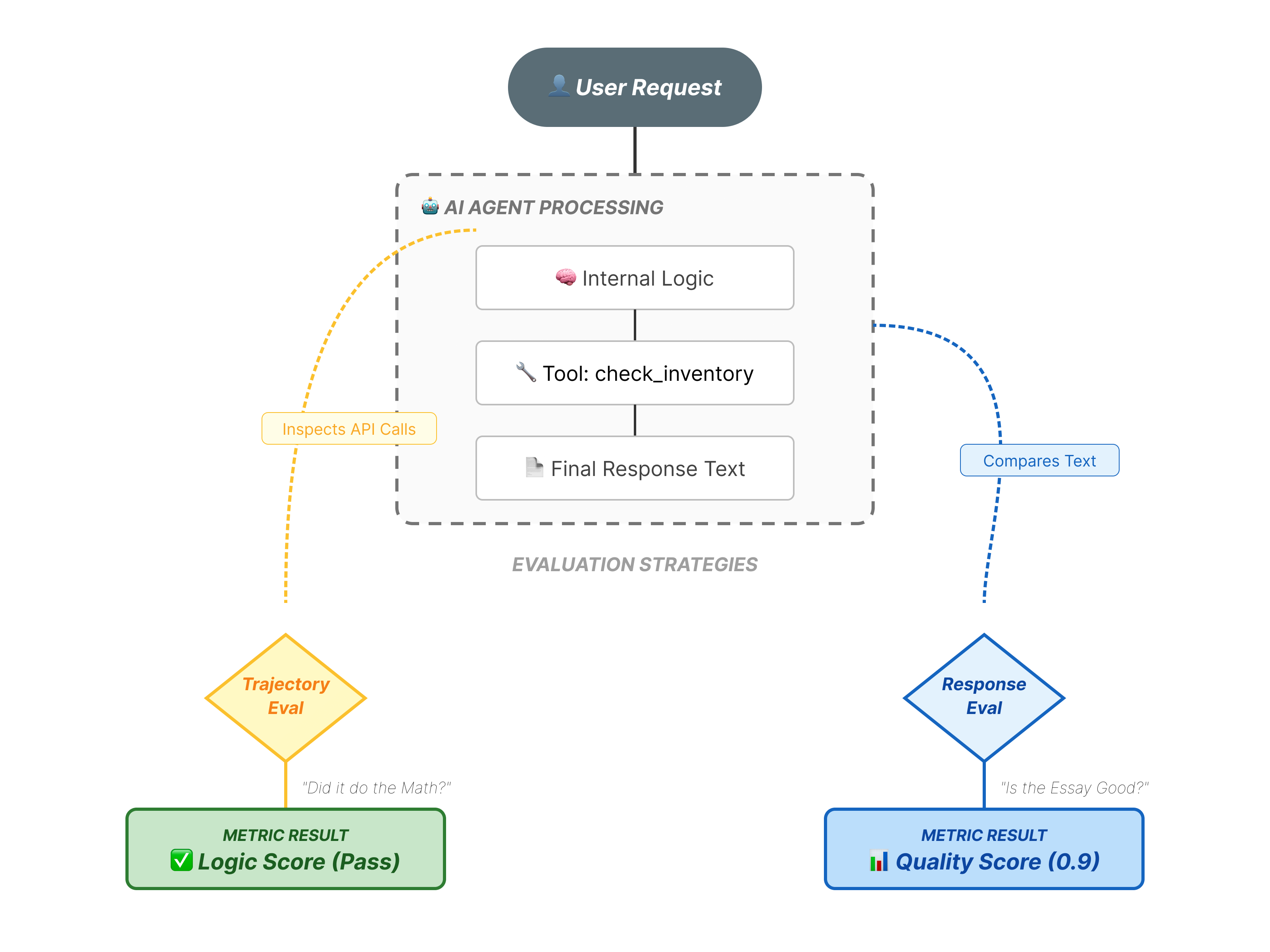
실제로 무엇을 평가하는 것일까요?
에이전트 평가는 표준 LLM 평가보다 복잡합니다. 에세이 (최종 대답)만 평가하는 것이 아니라 수학 (최종 대답을 얻기 위해 사용된 논리/도구)도 평가합니다.
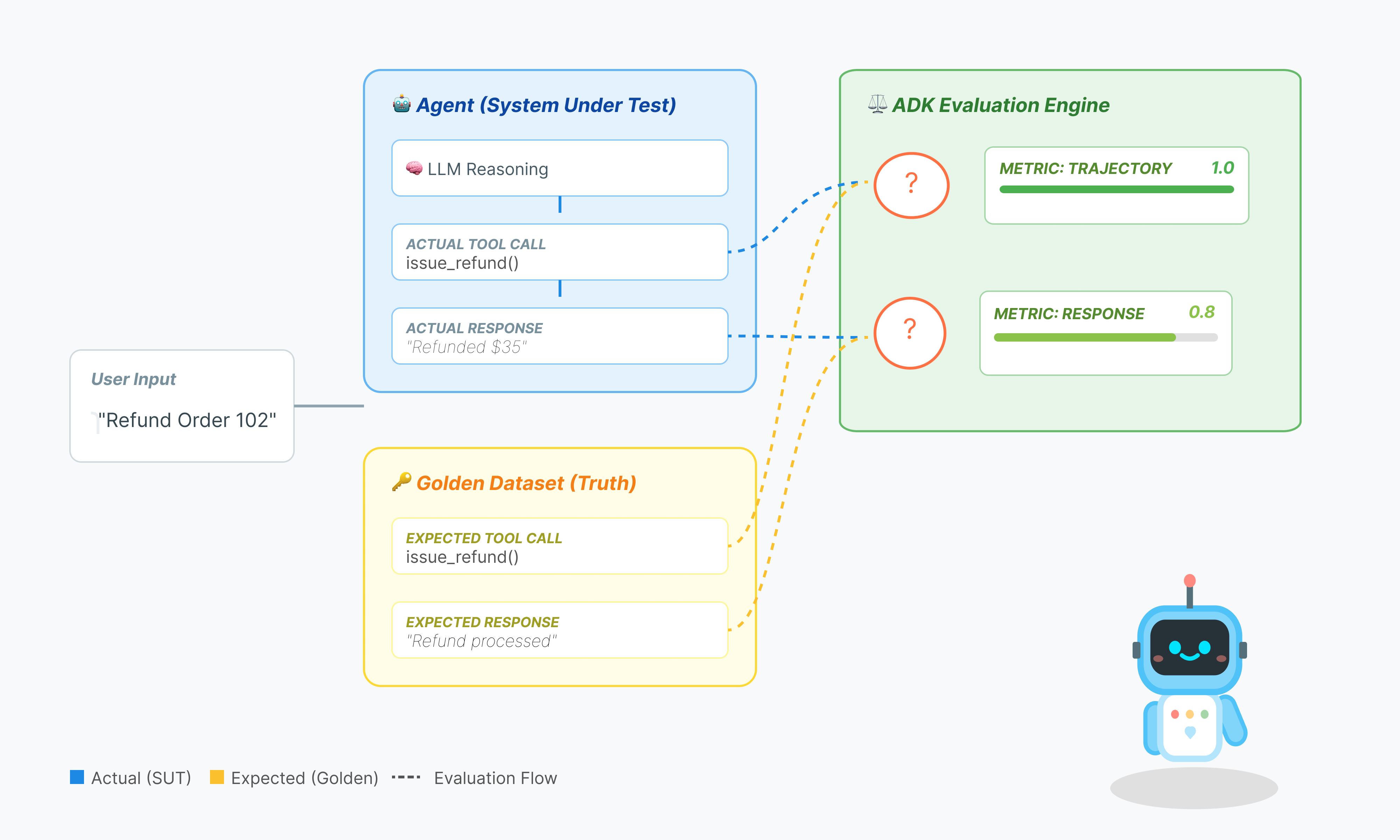
- 궤적 (프로세스): 상담사가 적시에 올바른 도구를 사용했나요?
place_order전에check_inventory를 호출했나요? - 최종 대답 (출력): 대답이 정확하고, 공손하며, 데이터에 기반을 두고 있나요?
개발 수명 주기
이 Codelab에서는 에이전트 테스트의 전문적인 수명 주기를 살펴봅니다.
- 로컬 시각적 검사 (ADK 웹 UI): 수동으로 채팅하고 로직을 확인합니다 (1단계).
- 단위/회귀 테스트 (ADK CLI): 특정 테스트 사례를 로컬에서 실행하여 빠른 오류를 포착합니다 (3단계 및 4단계).
- 디버깅 (문제 해결): 실패를 분석하고 프롬프트 로직을 수정합니다 (5단계).
- CI/CD 통합 (Pytest): 빌드 파이프라인에서 테스트를 자동화합니다 (6단계).
2. 설정
AI 에이전트를 지원하려면 두 가지가 필요합니다. 기반을 제공하는 Google Cloud 프로젝트와
1부: 결제 계정 사용 설정
이 Codelab을 실행하려면 크레딧이 있는 결제 계정이 필요합니다. 이 Codelab 상단의 배너에 있는 크레딧을 사용하여 시작하세요. 이미 결제 계정에 연결되어 있다면 이 단계를 건너뛰어도 됩니다.
2부: 개방형 환경
- 👉 이 링크를 클릭하여 Cloud Shell 편집기로 바로 이동합니다.
- 👉 오늘 언제든지 승인하라는 메시지가 표시되면 승인을 클릭하여 계속합니다.
- 👉 터미널이 화면 하단에 표시되지 않으면 다음을 따라 엽니다.
- 보기를 클릭합니다.
- 터미널을 클릭합니다.
- 👉💻 터미널에서 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list - 👉💻 GitHub에서 부트스트랩 프로젝트를 클론합니다.
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 프로젝트 디렉터리에서 설정 스크립트를 실행합니다.
cd ~/adk_eval_starter ./init.sh
스크립트가 나머지 설정 프로세스를 자동으로 처리합니다.
- 👉💻 필요한 프로젝트 ID를 설정합니다.
gcloud config set project $(cat ~/project_id.txt) --quiet
3부: 권한 설정
- 👉💻 다음 명령어를 사용하여 필요한 API를 사용 설정합니다. 이 과정에 몇 분 정도 소요될 수 있습니다.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 터미널에서 다음 명령어를 실행하여 필요한 권한을 부여합니다.
. ~/adk_eval_starter/set_env.sh
.env 파일이 생성됩니다. 프로젝트 정보가 표시됩니다.
3. 골드 데이터 세트 생성 (adk 웹)
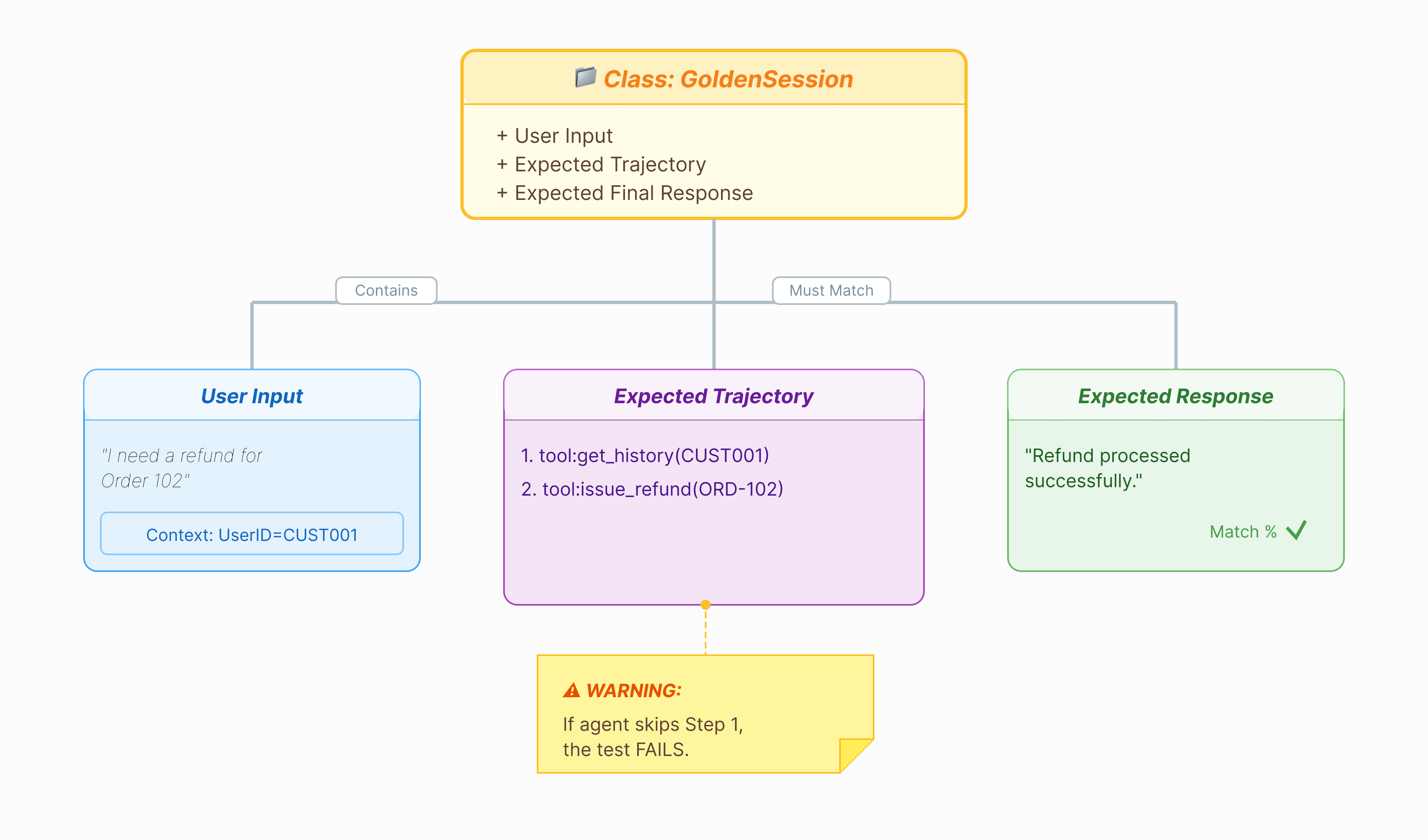
에이전트를 평가하려면 정답이 필요합니다. ADK에서는 이를 골든 데이터 세트라고 합니다. 이 데이터 세트에는 평가의 정답 역할을 하는 '완벽한' 상호작용이 포함되어 있습니다.
골든 데이터 세트란 무엇인가요?
골든 데이터 세트는 에이전트가 올바르게 작동하는 스냅샷입니다. 질문과 답변 쌍의 목록이 아닙니다. 다음과 같은 정보를 캡처합니다.
- 사용자 질문 ('환불을 원합니다')
- 궤적 (도구 호출의 정확한 시퀀스:
check_order->verify_eligibility->refund_transaction) - 최종 대답('완벽한' 텍스트 대답)
이를 사용하여 회귀를 감지합니다. 프롬프트를 업데이트했는데 에이전트가 갑자기 환불 전에 자격 요건 확인을 중단하면 궤적이 더 이상 일치하지 않으므로 골든 데이터 세트 테스트가 실패합니다.
웹 UI 열기
ADK 웹 UI는 에이전트와의 실제 상호작용을 캡처하여 이러한 골든 데이터 세트를 생성하는 대화형 방법을 제공합니다.
- 👉💻 터미널에서 다음을 실행합니다.
cd ~/adk_eval_starter uv run adk web - 👉💻 웹 UI 미리보기를 엽니다 (일반적으로
http://127.0.0.1:8000). - 👉 채팅 UI에 다음을 입력합니다.
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged.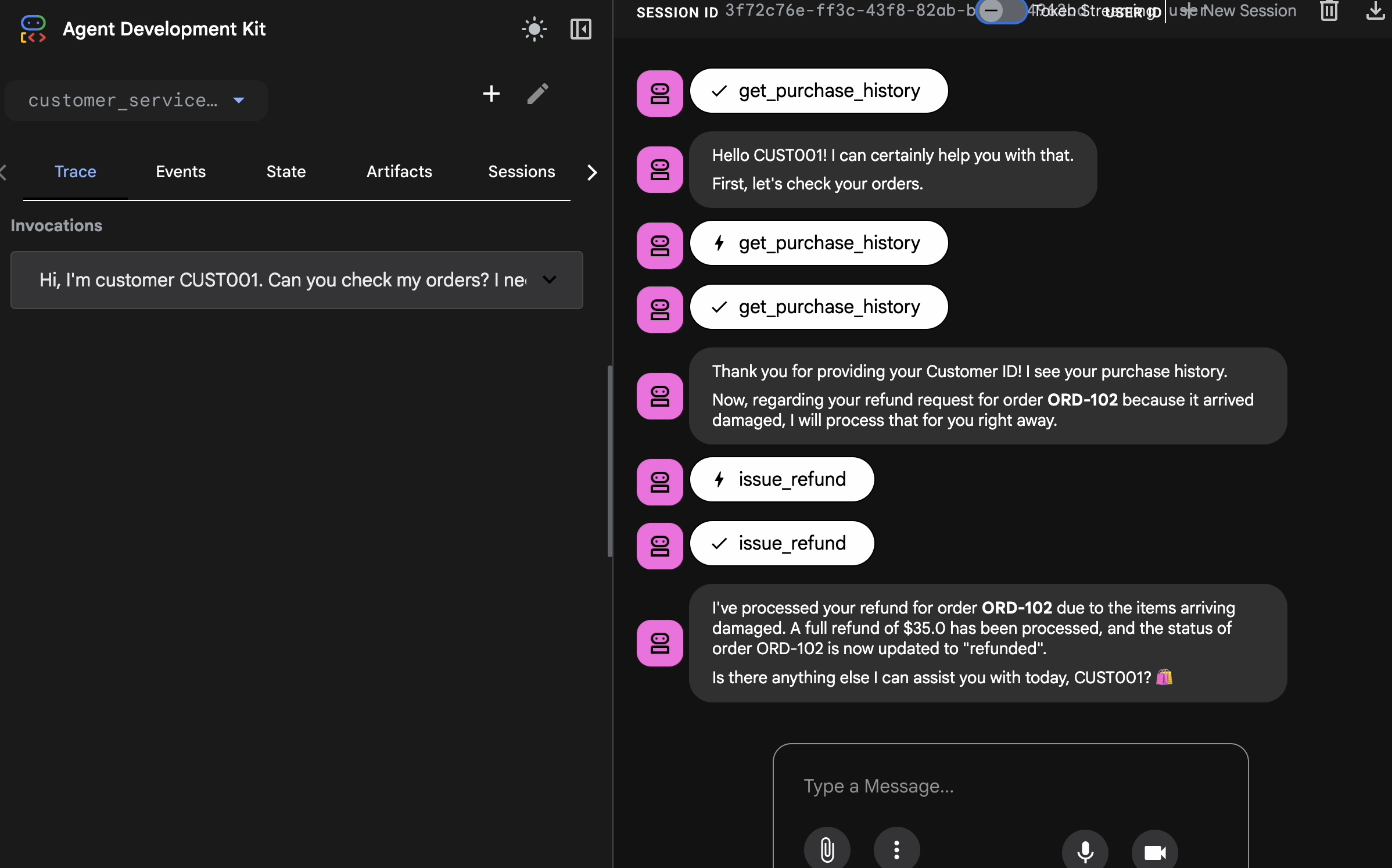 다음과 같은 응답이 표시됩니다.
다음과 같은 응답이 표시됩니다.I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
골든 상호작용 캡처
세션 탭으로 이동합니다. 여기에서 세션을 클릭하여 에이전트의 대화 기록을 확인할 수 있습니다.
- 에이전트와 상호작용하여 구매 내역 확인, 환불 요청 등 이상적인 대화 흐름을 만듭니다.
- 대화를 검토하여 예상되는 동작을 나타내는지 확인합니다.
4. 골드 데이터 세트 내보내기
Trace View로 확인
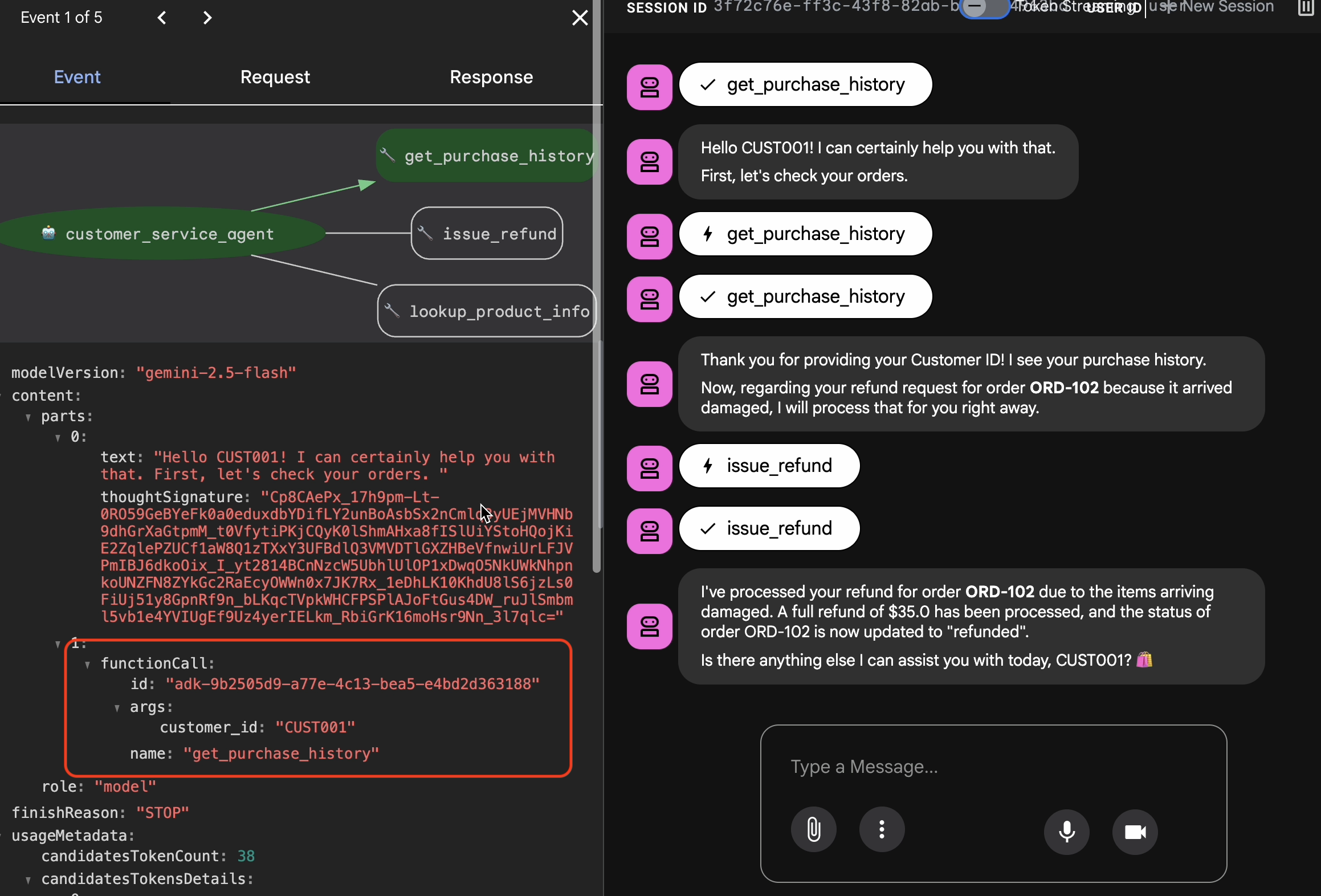
내보내기 전에 상담사가 운 좋게 올바른 답변을 얻은 것이 아닌지 확인해야 합니다. 내부 로직을 검사해야 합니다.
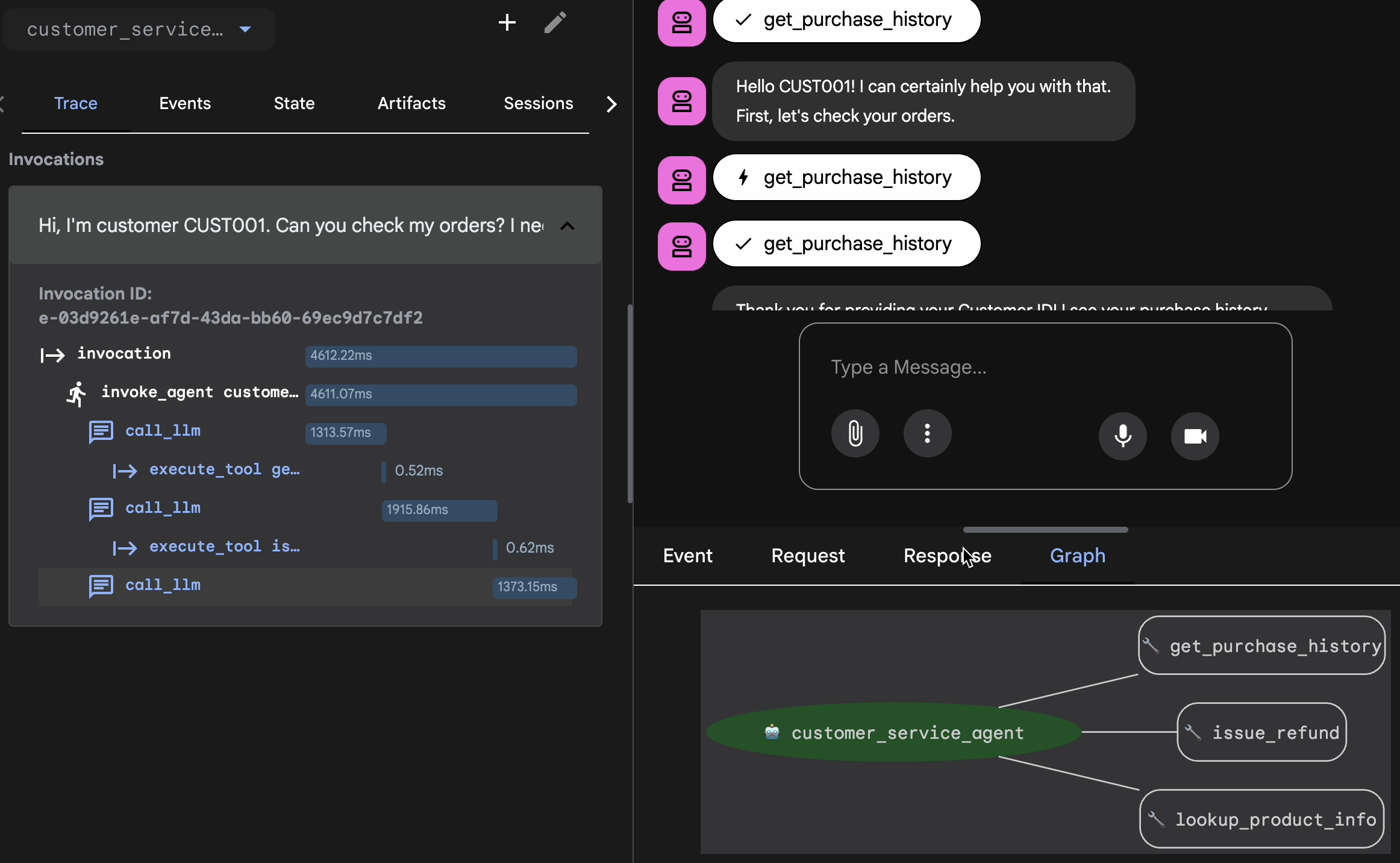
- 웹 UI에서 Trace 탭을 클릭합니다.
- 트레이스는 사용자 메시지별로 자동으로 그룹화됩니다. 추적 행 위로 마우스를 가져가면 채팅에서 해당 메시지가 강조 표시됩니다.
- 파란색 행 검사: 상호작용에서 생성된 이벤트를 나타냅니다. 파란색 행을 클릭하여 검사 패널을 엽니다.
- 다음 탭을 확인하여 로직을 검증합니다.
- 그래프: 도구 호출 및 논리 흐름의 시각적 표현입니다. 올바른 경로를 따랐나요?
- 요청/응답: 모델에 전송된 내용과 모델에서 반환된 내용을 정확하게 검토합니다.
- 인증: 상담사가 데이터베이스 도구를 호출하지 않고 환불 금액을 추측한 경우 '행운의 환각'입니다.
EvalSet에 세션 추가
대화와 트레이스에 만족하면 다음 단계를 따르세요.
- 👉
Eval탭을 클릭한 다음Create Evaluation Set버튼을 클릭하고 평가 이름을 다음과 같이 입력합니다.evalset1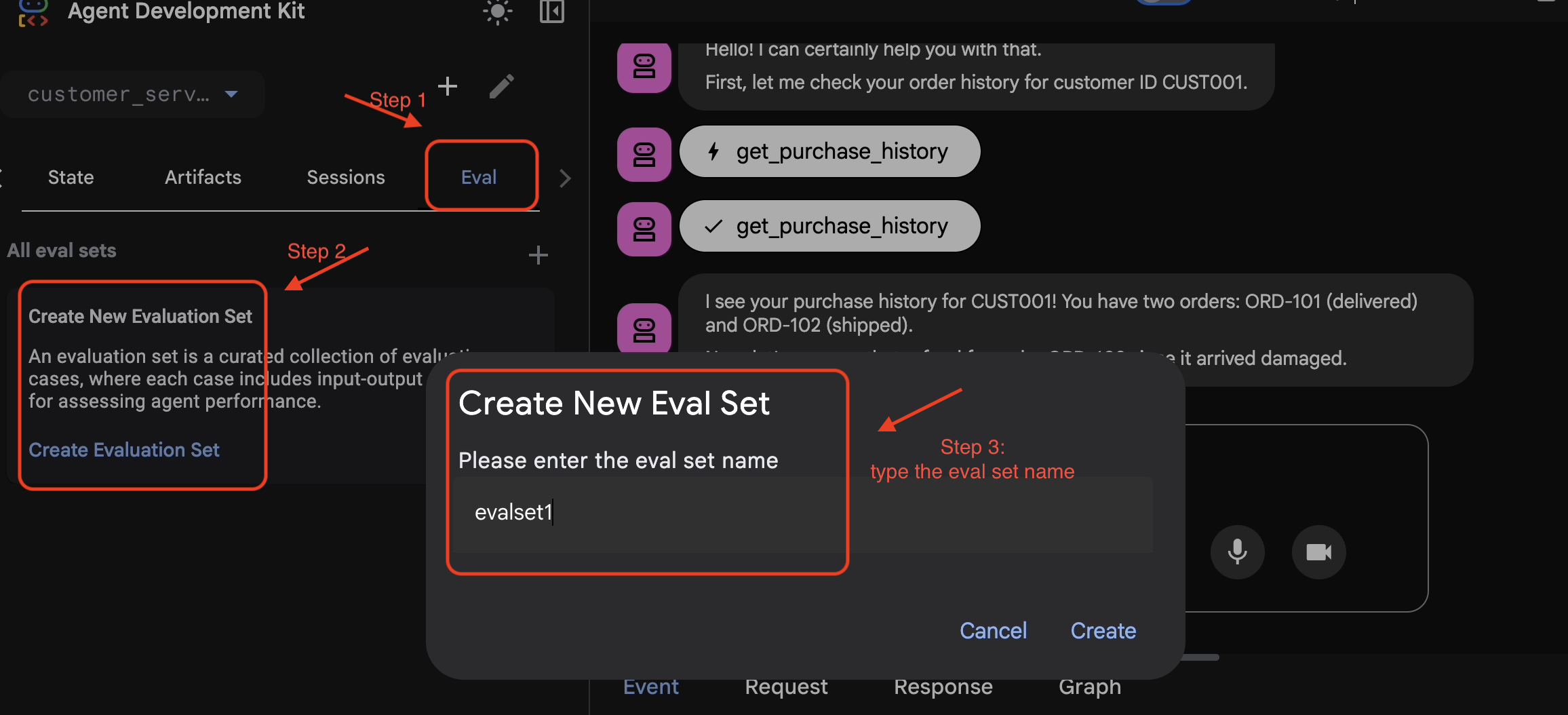
- 👉 이 평가 세트에서
Add current session to evalset1을 클릭하고 팝업 창에 세션 이름을 다음과 같이 입력합니다.eval1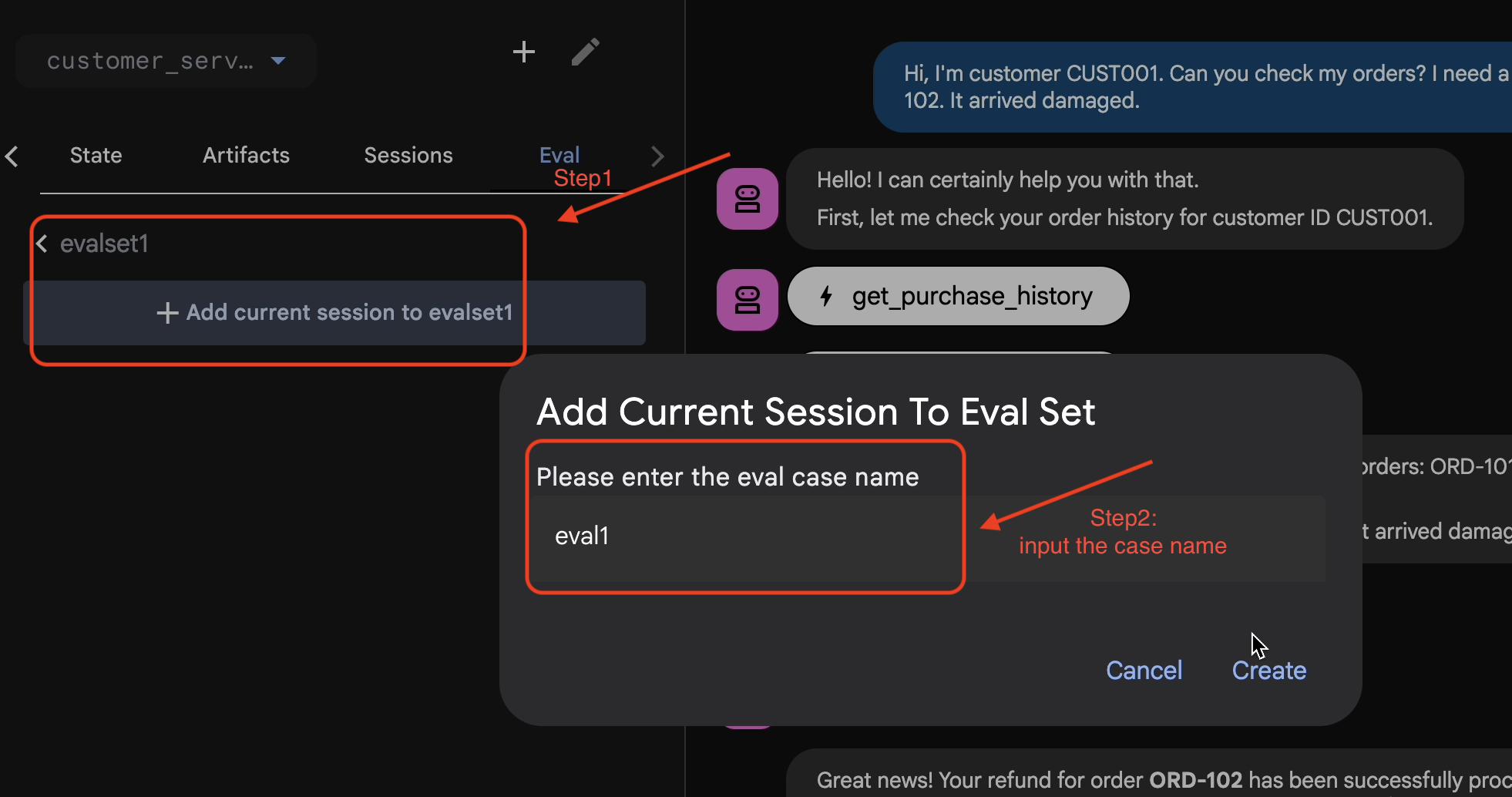
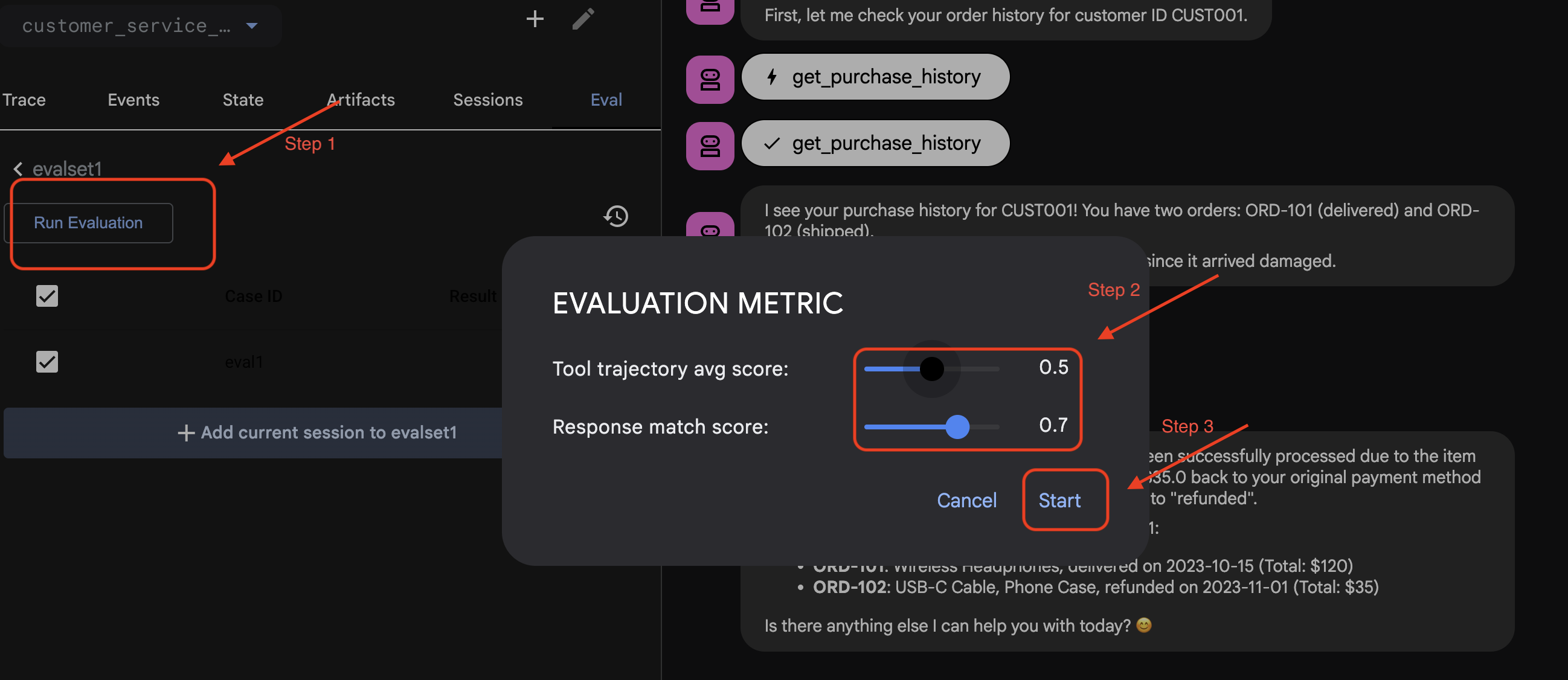
ADK 웹에서 평가 실행
- 👉 ADK 웹 UI에서
Run Evaluation를 클릭하고 팝업 창에서 측정항목을 조정한 다음Start를 클릭합니다.
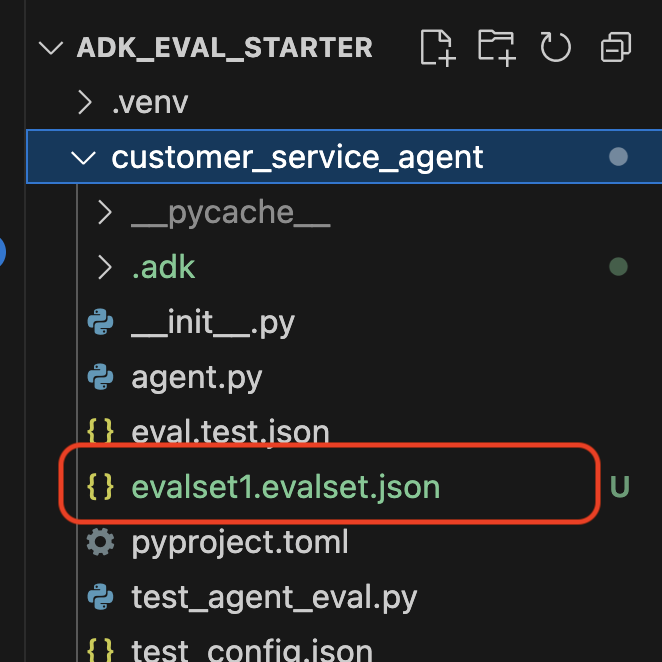
저장소에서 데이터 세트 확인
데이터 세트 파일 (예: evalset1.evalset.json)이 저장소에 저장되었다는 확인 메시지가 표시됩니다. 이 파일에는 대화의 원시 자동 생성 트레이스가 포함되어 있습니다.
5. 평가 파일
웹 UI는 복잡한 .evalset.json 파일을 생성하지만 자동화된 테스트를 위해 더 깔끔하고 구조화된 테스트 파일을 만들고 싶을 때가 많습니다.
ADK Eval은 두 가지 주요 구성요소를 사용합니다.
- 테스트 파일: 자동 생성된 골든 데이터 세트 (예:
customer_service_agent/evalset1.evalset.json) 또는 수동으로 선별된 세트 (예:customer_service_agent/eval.test.json)일 수 있습니다. - 구성 파일 (예:
customer_service_agent/test_config.json): 통과를 위한 측정항목과 기준점을 정의합니다.
테스트 구성 파일 설정
- 👉💻 Cloud Shell 편집기 터미널에서 다음을 입력합니다.
cloudshell edit customer_service_agent/test_config.json - 👉 편집기의
customer_service_agent/test_config.json에 다음 코드를 입력합니다.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
측정항목 디코딩
tool_trajectory_avg_score(프로세스) 상담사가 도구를 올바르게 사용했는지 측정합니다.
- 0.8: 80% 일치를 요구합니다.
response_match_score(출력) ROUGE-1 (단어 중복)을 사용하여 대답을 모범 답안과 비교합니다.
- 장점: 빠르고 결정적이며 무료입니다.
- 단점: 상담사가 동일한 아이디어를 다르게 표현하면 (예: '환불됨'과 '금액이 반환됨') 실패합니다.
고급 측정항목 (더 많은 기능이 필요한 경우)
6. 골드 데이터 세트 평가 실행 (adk eval)
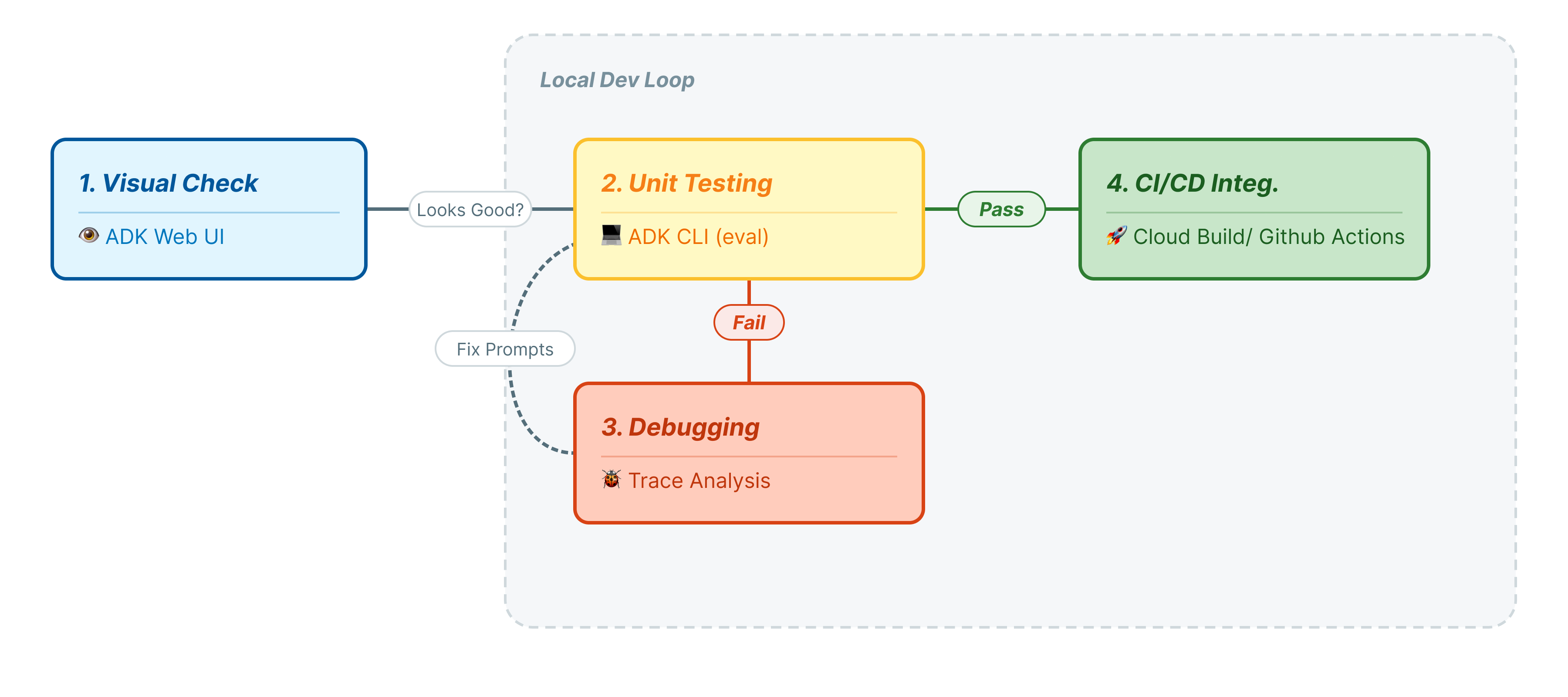
이 단계는 개발의 '내부 루프'를 나타냅니다. 변경사항을 적용하는 개발자로서 결과를 빠르게 확인하고 싶습니다.
골드 데이터 세트 실행
1단계에서 생성한 데이터 세트를 실행해 보겠습니다. 이렇게 하면 기준이 확실해집니다.
- 👉💻 터미널에서 다음을 실행합니다.
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
최근 활동
이제 ADK는 다음을 충족해야 합니다.
customer_service_agent에서 에이전트를 로드하는 중입니다.evalset1.evalset.json에서 입력 쿼리를 실행합니다.- 에이전트의 실제 궤적과 응답을 예상 궤적 및 응답과 비교합니다.
test_config.json의 기준에 따라 결과를 점수화합니다.
결과 분석
터미널 출력을 확인합니다. 통과한 테스트와 실패한 테스트의 요약이 표시됩니다.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
참고: 상담사에서 방금 생성했으므로 100% 통과해야 합니다. 실패하면 에이전트가 비확정적 (무작위)입니다.
7. 맞춤 테스트 만들기
자동 생성 데이터 세트도 유용하지만 때로는 특이 사례 (예: 적대적 공격 또는 특정 오류 처리)를 수동으로 만들어야 할 때도 있습니다. eval.test.json를 사용해 '정확성'을 정의하는 방법을 살펴보겠습니다.
포괄적인 테스트 모음을 만들어 보겠습니다.
테스트 프레임워크
ADK에서 테스트 사례를 작성할 때는 다음 3부분 공식을 따르세요.
- 설정 (
session_input): 사용자는 누구인가요? (예:user_id,state) 이렇게 하면 테스트가 격리됩니다. - 프롬프트 (
user_content): 트리거가 뭐야?
어설션 (기대):
- 궤적 (
tool_uses): 계산이 올바른가요? (로직) - 대답 (
final_response): 올바른 대답을 말했나요? (품질) - 중간 (
intermediate_responses): 하위 에이전트가 올바르게 대화했나요? (조정)
테스트 모음 작성
- 👉💻 Cloud Shell 편집기 터미널에서 다음을 입력합니다.
cloudshell edit customer_service_agent/eval.test.json - 👉 다음 코드를
customer_service_agent/eval.test.json파일에 입력합니다.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
테스트 유형 분석
여기에서는 세 가지 유형의 테스트를 만들었습니다. 각 항목에서 무엇을 평가하고 그 이유는 무엇인지 살펴보겠습니다.
- 단일 도구 테스트 (
product_info_check)
- 목표: 기본 정보 검색을 확인합니다.
- 주요 어설션:
intermediate_data.tool_uses을 확인합니다.lookup_product_info가 호출되었는지 확인합니다.product_name인수가 정확히 '무선 헤드폰'이라고 주장합니다. - 이유: 모델이 도구를 호출하지 않고 가격을 환각하면 이 테스트가 실패합니다. 이렇게 하면 그라운딩이 보장됩니다.
- 컨텍스트 추출 테스트 (
purchase_history_check)
- 목표: 상담사가 사용자 프롬프트에서 엔티티 (CUST001)를 추출하여 도구에 전달할 수 있는지 확인합니다.
- 키 어설션:
get_purchase_history이customer_id: "CUST001"로 호출되는지 확인합니다. - 이유: 일반적인 실패 모드는 에이전트가 올바른 도구를 호출하지만 ID가 null인 경우입니다. 이렇게 하면 파라미터 정확성이 보장됩니다.
- 동작/궤적 테스트 (
refund_request)
- 목표: 중요한 쓰기 작업을 확인합니다.
- 주요 어설션: 궤적 더 복잡한 시나리오에서는 이 목록에 여러 단계가 포함됩니다(
[verify_order, calculate_refund, issue_refund]). ADK는 이 목록을 순서대로 확인합니다. - 이유: 돈을 이동하거나 데이터를 변경하는 작업의 경우 결과만큼 순서가 중요합니다. 확인하기 전에 환불하지 않는 것이 좋습니다.
8. 맞춤 테스트 평가 실행( adk eval)
- 👉💻 터미널에서 다음을 실행합니다.
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
출력 이해하기
다음과 같은 통과 결과가 표시됩니다.
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
이는 에이전트가 올바른 도구를 사용했으며 기대치와 충분히 유사한 대답을 제공했다는 의미입니다.
9. (선택사항: 읽기 전용) - 문제 해결 및 디버깅
테스트가 실패합니다. 그게 그들의 일입니다. 하지만 이러한 문제를 어떻게 해결해야 할까요? 일반적인 실패 시나리오와 디버그 방법을 분석해 보겠습니다.
시나리오 A: '궤적' 실패
오류:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
진단: 상담사가 확인 단계 (lookup_order)를 건너뛰었습니다. 이는 논리 오류입니다.
문제 해결 방법:
- 추측하지 마세요: ADK 웹 UI (adk web)로 돌아갑니다.
- 재현: 실패한 테스트의 정확한 프롬프트를 채팅에 입력합니다.
- Trace: Trace 뷰를 엽니다. '그래프' 탭을 확인합니다.
- 프롬프트 수정: 일반적으로 시스템 프롬프트를 업데이트해야 합니다. 변경: '너는 유용한 상담사야.' To: '너는 유용한 상담사야. 중요: issue_refund를 호출하기 전에 lookup_order를 호출하여 세부정보를 확인해야 합니다(MUST).'
- 테스트 조정: 비즈니스 로직이 변경된 경우 (예: 더 이상 확인이 필요하지 않음) 테스트가 잘못된 것입니다. 새로운 현실에 맞게 eval.test.json을 업데이트합니다.
시나리오 B: 'ROUGE' 실패
오류:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
진단: 상담사가 올바른 조치를 취했지만 다른 단어를 사용했습니다. ROUGE (단어 중복)에서 페널티를 부여했습니다.
해결 방법:
- 잘못된 건가요? 의미가 올바르면 프롬프트를 변경하지 마세요.
- 기준 조정:
test_config.json에서 기준을 낮춥니다 (예:0.8에서0.5로). - 측정항목 업그레이드: 구성에서
final_response_match_v2로 전환합니다. LLM을 사용하여 두 문장을 모두 읽고 의미가 동일한지 판단합니다.
10. Pytest를 사용한 CI/CD
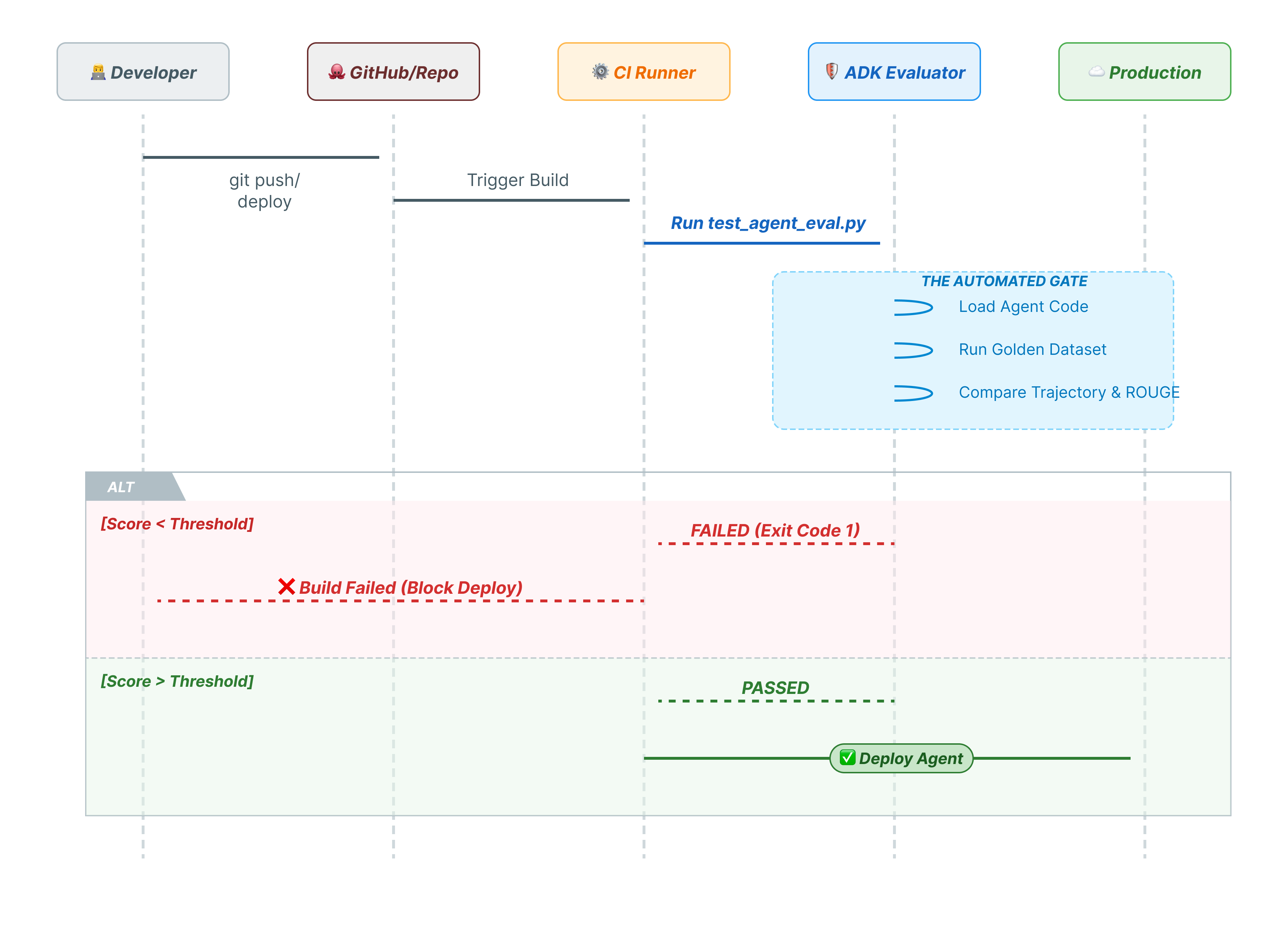
CLI 명령어는 사람을 위한 것입니다. pytest은 머신용입니다. 프로덕션 안정성을 보장하기 위해 평가를 Python 테스트 모음으로 래핑합니다. 이렇게 하면 에이전트가 다운되면 CI/CD 파이프라인 (GitHub Actions, Jenkins)에서 배포를 차단할 수 있습니다.
이 파일에는 무엇이 포함되나요?
이 Python 파일은 CI/CD 러너와 ADK 평가기 간의 브리지 역할을 합니다. 다음과 같은 요건을 충족해야 합니다.
- 에이전트 로드: 에이전트 코드를 동적으로 가져옵니다.
- 상태 재설정: 테스트가 서로 누출되지 않도록 에이전트 메모리가 정리되어 있는지 확인합니다.
- 평가 실행:
AgentEvaluator.evaluate()를 프로그래매틱 방식으로 호출합니다. - 성공 어설션: 평가 점수가 낮으면 빌드를 실패합니다.
통합 테스트 코드
- 👉
customer_service_agent/test_agent_eval.py을 엽니다. 이 스크립트는AgentEvaluator.evaluate를 사용하여eval.test.json에 정의된 테스트를 실행합니다. - 👉 편집기의
customer_service_agent/test_agent_eval.py에 다음 코드를 입력합니다.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Pytest 실행
- 👉💻 터미널에서 다음을 실행합니다.
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. 결론
축하합니다. ADK Eval을 사용하여 고객 서비스 에이전트를 평가했습니다.
학습한 내용
이 Codelab을 통해 학습한 내용은 다음과 같습니다.
- ✅ 골든 데이터 세트 생성을 통해 에이전트의 그라운드 트루스를 설정합니다.
- ✅ 평가 구성 이해를 통해 성공 기준을 정의합니다.
- ✅ 자동 평가 실행을 통해 회귀를 조기에 포착합니다.
개발 워크플로에 ADK Eval을 통합하면 동작의 변경사항이 자동화된 테스트에 포착된다는 것을 알고 있으므로 안심하고 에이전트를 빌드할 수 있습니다.
이 실습은 Google Cloud를 사용한 프로덕션 레디 AI 학습 과정의 일부입니다.
- 전체 커리큘럼을 살펴보고 프로토타입에서 프로덕션으로 전환하세요.
ProductionReadyAI해시태그를 사용하여 진행 상황을 공유하세요.
추가 읽기 자료: