
1. Luka zaufania
Moment inspiracji
Masz agenta obsługi klienta. Działa na Twoim urządzeniu. Wczoraj jednak poinformował klienta, że niedostępny smartwatch jest dostępny, a co gorsza, wymyślił zasady zwrotu środków. Jak Ci się śpi w nocy, gdy wiesz, że Twój agent jest aktywny?
Aby wypełnić lukę między modelem koncepcyjnym a agentem AI przygotowanym do zastosowań produkcyjnych, niezbędne jest solidne i zautomatyzowane środowisko oceny.

Co właściwie oceniamy?
Ocena agenta jest bardziej złożona niż standardowa ocena LLM. Nie oceniasz tylko eseju (odpowiedzi końcowej), ale też matematyki (logiki i narzędzi użytych do uzyskania wyniku).
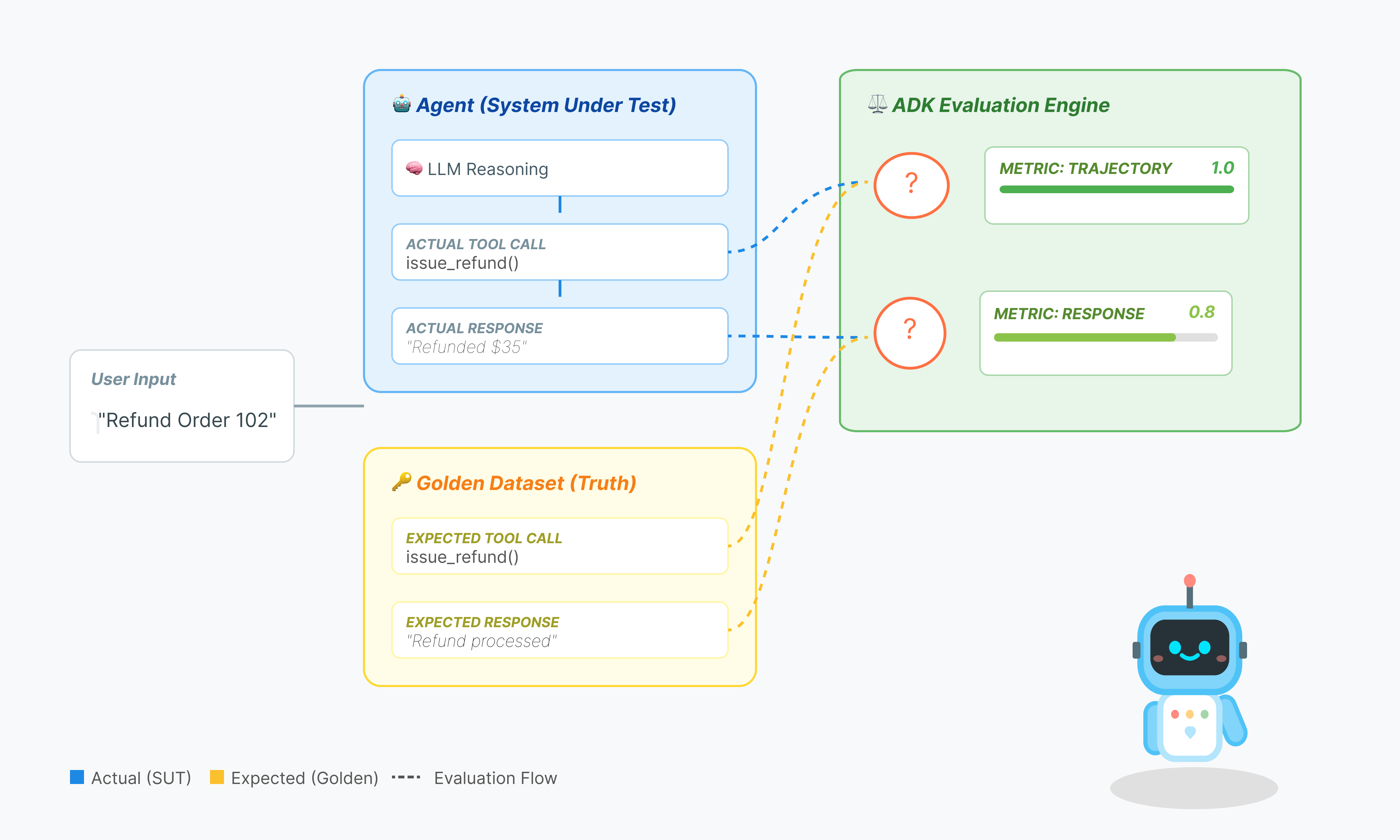
- Trajektoria (proces): czy agent użył odpowiedniego narzędzia we właściwym czasie? Czy połączenie zostało wykonane do
check_inventoryprzedplace_order? - Ostateczna odpowiedź (dane wyjściowe): czy odpowiedź jest poprawna, uprzejma i oparta na danych?
Cykl życia rozwoju
W tym ćwiczeniu z programowania omówimy profesjonalny cykl życia testowania agenta:
- Lokalna kontrola wizualna (interfejs internetowy ADK): ręczne czatowanie i weryfikowanie logiki (krok 1).
- Testy jednostkowe i regresyjne (interfejs ADK CLI): uruchamianie lokalnie konkretnych przypadków testowych w celu wykrycia szybkich błędów (kroki 3 i 4).
- Debugowanie (rozwiązywanie problemów): analiza błędów i korygowanie logiki promptu (krok 5).
- Integracja CI/CD (Pytest): automatyzacja testów w potoku kompilacji (krok 6).
2. Skonfiguruj
Aby obsługiwać agentów AI, potrzebujemy dwóch rzeczy: projektu Google Cloud, który będzie stanowić podstawę.
Część 1. Włączanie konta rozliczeniowego
Aby wykonać to ćwiczenie, musisz mieć konto rozliczeniowe z pewną ilością środków. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Część 2. Środowisko otwarte
- 👉 Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- 👉 Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
- 👉 Jeśli terminal nie pojawia się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
- 👉💻 W terminalu sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list - 👉💻 Sklonuj projekt początkowy z GitHuba:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 Uruchom skrypt konfiguracji z katalogu projektu.
cd ~/adk_eval_starter ./init.sh
Skrypt automatycznie przeprowadzi pozostałą część procesu konfiguracji.
- 👉💻 Ustaw wymagany identyfikator projektu:
gcloud config set project $(cat ~/project_id.txt) --quiet
Część 3. Konfigurowanie uprawnień
- 👉💻 Włącz wymagane interfejsy API za pomocą tego polecenia. Może to potrwać kilka minut.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 Przyznaj niezbędne uprawnienia, uruchamiając w terminalu te polecenia:
. ~/adk_eval_starter/set_env.sh
Zwróć uwagę, że utworzyliśmy dla Ciebie .env. Wyświetlą się informacje o Twoim projekcie.
3. Generowanie złotego zbioru danych (adk web)
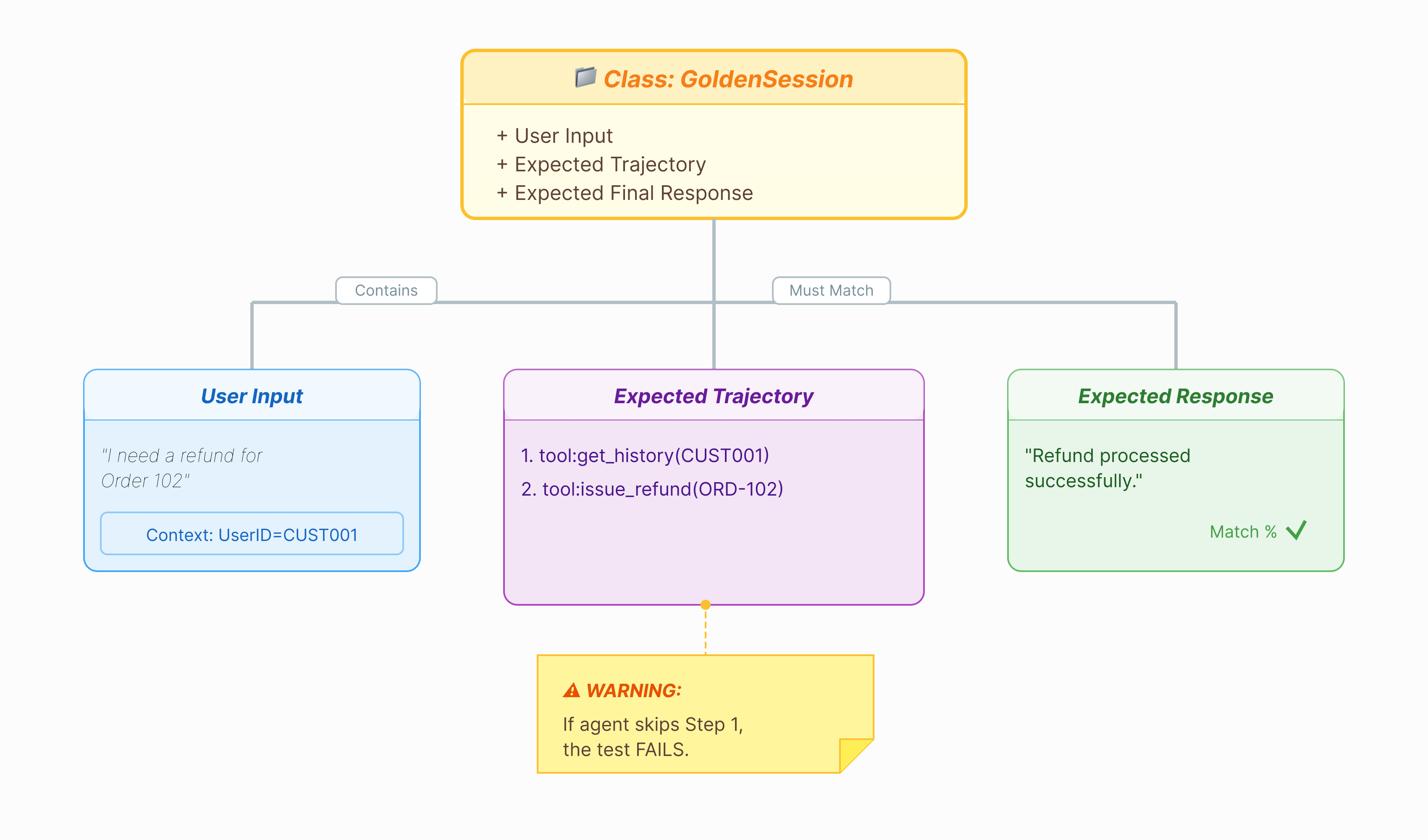
Zanim ocenimy agenta, potrzebujemy klucza odpowiedzi. W ADK nazywamy to zbiorem danych wzorcowych. Ten zbiór danych zawiera „idealne” interakcje, które służą jako dane podstawowe do oceny.
Czym jest zbiór danych wysokiej jakości?
Złoty zbiór danych to zrzut działania agenta, który prawidłowo wykonuje zadanie. To nie tylko lista par pytań i odpowiedzi. Obejmuje on:
- Zapytanie użytkownika („Chcę otrzymać zwrot środków”)
- Ścieżka (dokładna sekwencja wywołań narzędzi:
check_order–>verify_eligibility–>refund_transaction). - Odpowiedź końcowa (idealna odpowiedź tekstowa).
Używamy tej funkcji do wykrywania regresji. Jeśli zaktualizujesz prompt i agent nagle przestanie sprawdzać, czy użytkownik kwalifikuje się do zwrotu środków, test Golden Dataset zakończy się niepowodzeniem, ponieważ ścieżka nie będzie już pasować.
Otwieranie interfejsu internetowego
Interfejs ADK Web UI umożliwia interaktywne tworzenie tych złotych zbiorów danych przez rejestrowanie rzeczywistych interakcji z agentem.
- 👉💻 W terminalu uruchom:
cd ~/adk_eval_starter uv run adk web - 👉💻 Otwórz podgląd interfejsu internetowego (zwykle pod adresem
http://127.0.0.1:8000). - 👉 W interfejsie czatu wpisz
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. Wyświetli się odpowiedź podobna do tej:
Wyświetli się odpowiedź podobna do tej:I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
Rejestrowanie najważniejszych interakcji
Otwórz kartę Sesje. Tutaj możesz wyświetlić historię rozmów agenta, klikając sesję.
- Współpracuj z agentem, aby stworzyć idealny przebieg rozmowy, np. sprawdzić historię zakupów lub poprosić o zwrot środków.
- Sprawdź rozmowę, aby upewnić się, że przebiega zgodnie z oczekiwaniami.
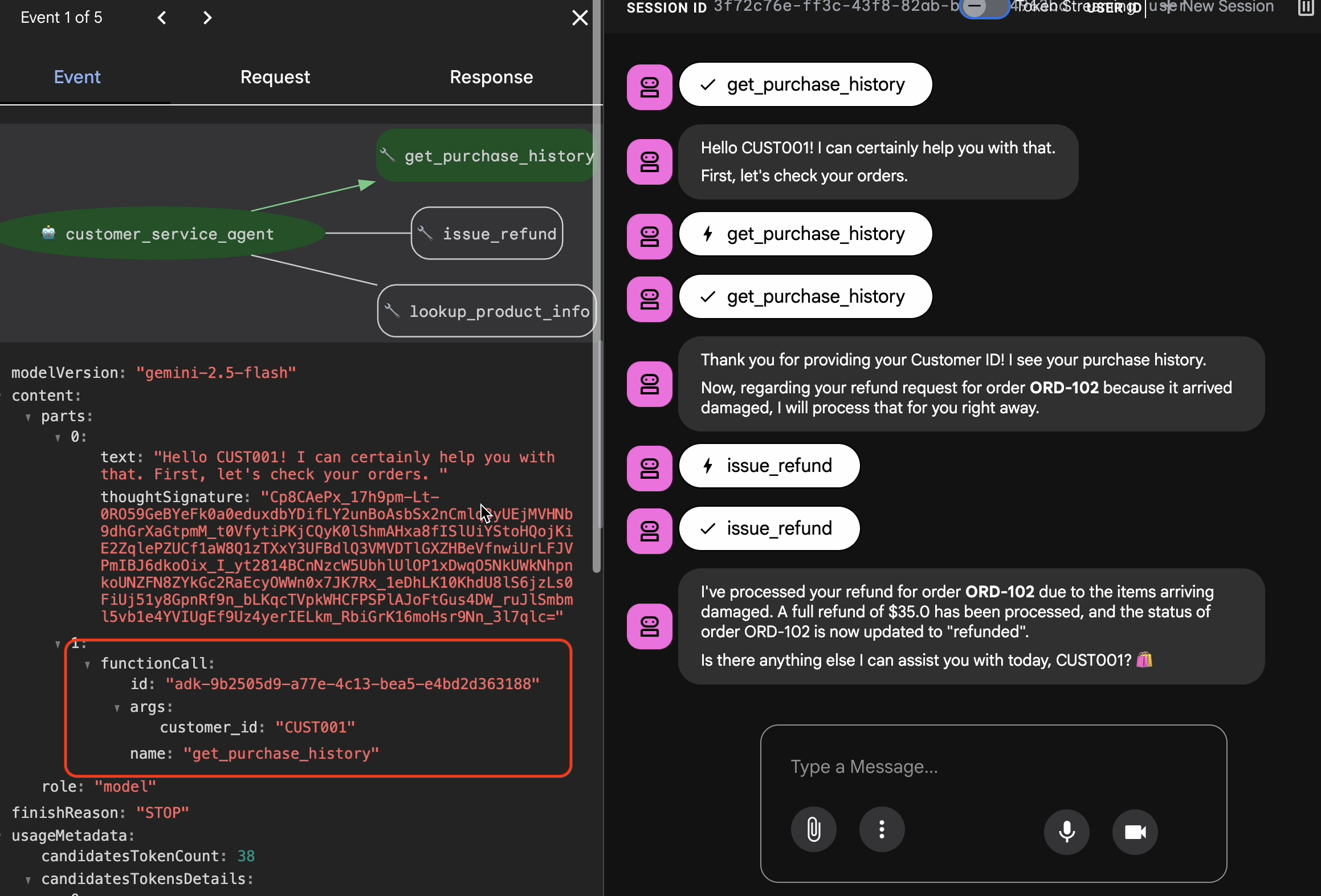
4. Eksportowanie zbioru danych wzorcowych
Weryfikacja za pomocą widoku śledzenia
Zanim wyeksportujesz agenta, musisz sprawdzić, czy nie uzyskał on prawidłowej odpowiedzi przez przypadek. Musisz sprawdzić logikę wewnętrzną.
- W interfejsie internetowym kliknij kartę Ślad.
- Ślady są automatycznie grupowane według wiadomości użytkownika. Najedź kursorem na wiersz śladu, aby wyróżnić odpowiednią wiadomość na czacie.
- Sprawdź niebieskie wiersze: wskazują one zdarzenia wygenerowane w wyniku interakcji. Kliknij niebieski wiersz, aby otworzyć panel sprawdzania.
- Aby sprawdzić logikę, otwórz te karty:
- Wykres: wizualna reprezentacja wywołań narzędzi i logiki. Czy wybrał prawidłową ścieżkę?
- Żądanie/odpowiedź: sprawdź, co dokładnie zostało wysłane do modelu i co zostało zwrócone.
- Weryfikacja: jeśli agent odgadł kwotę zwrotu bez wywoływania narzędzia bazy danych, jest to „szczęśliwa halucynacja”.
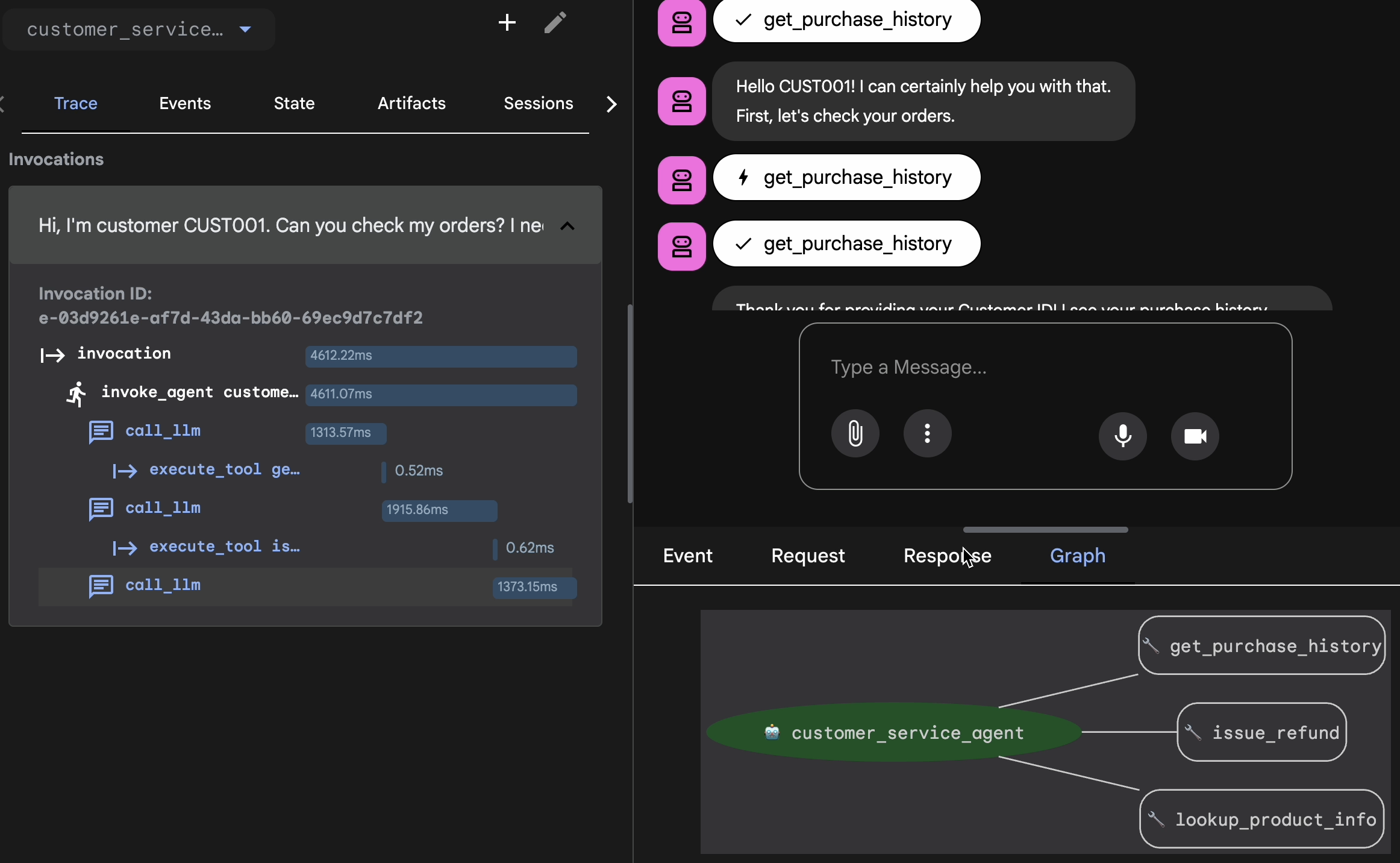
Add Session to EvalSet
Gdy uznasz, że rozmowa i ślad są satysfakcjonujące:
- 👉 Kliknij kartę
Eval, a potem przyciskCreate Evaluation Seti wpisz nazwę oceny:evalset1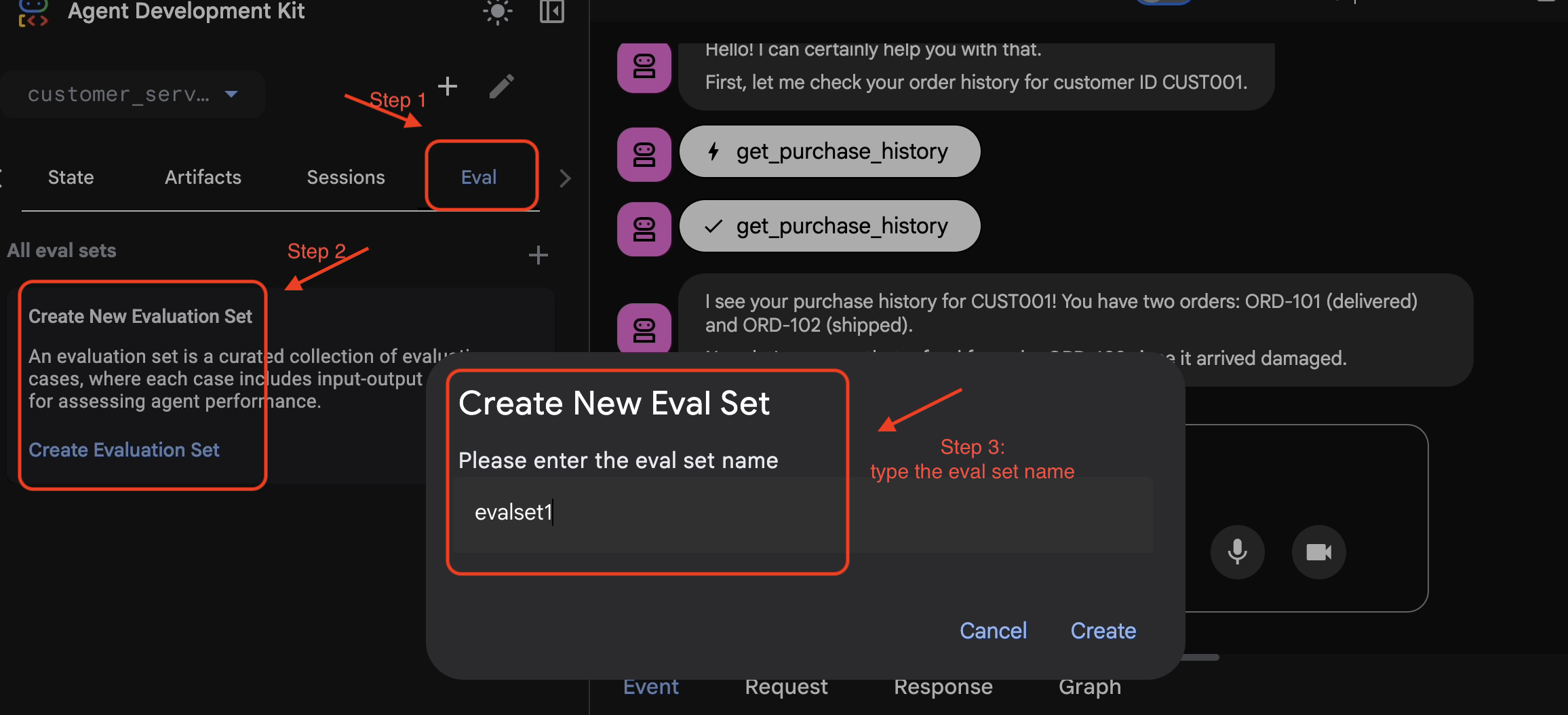
- 👉 W tym zbiorze danych kliknij
Add current session to evalset1. W wyskakującym okienku wpisz nazwę sesji:eval1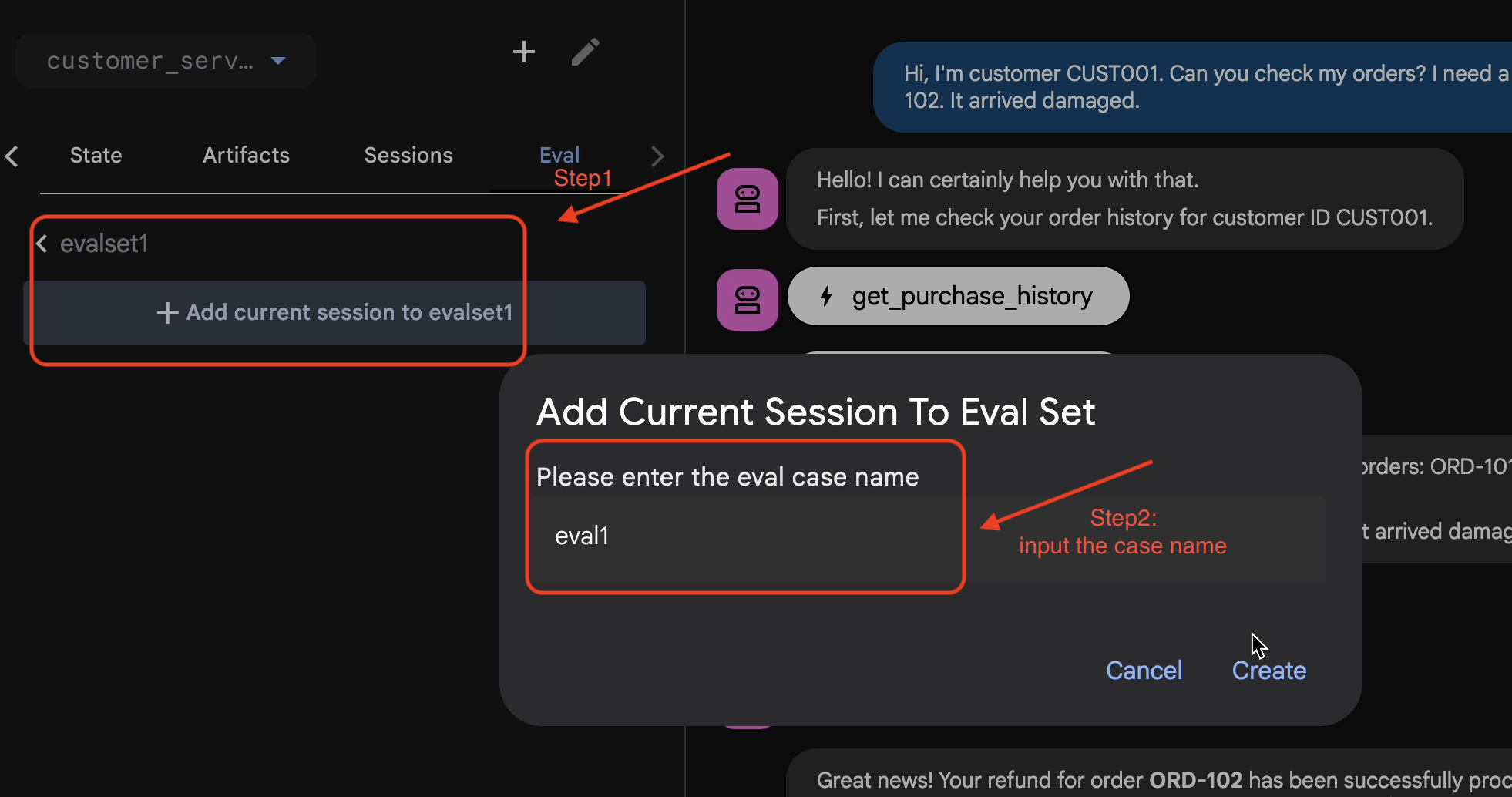
Uruchamianie oceny w pakiecie ADK Web
- 👉 W interfejsie ADK Web UI kliknij
Run Evaluation. W wyskakującym okienku dostosuj dane i kliknijStart:
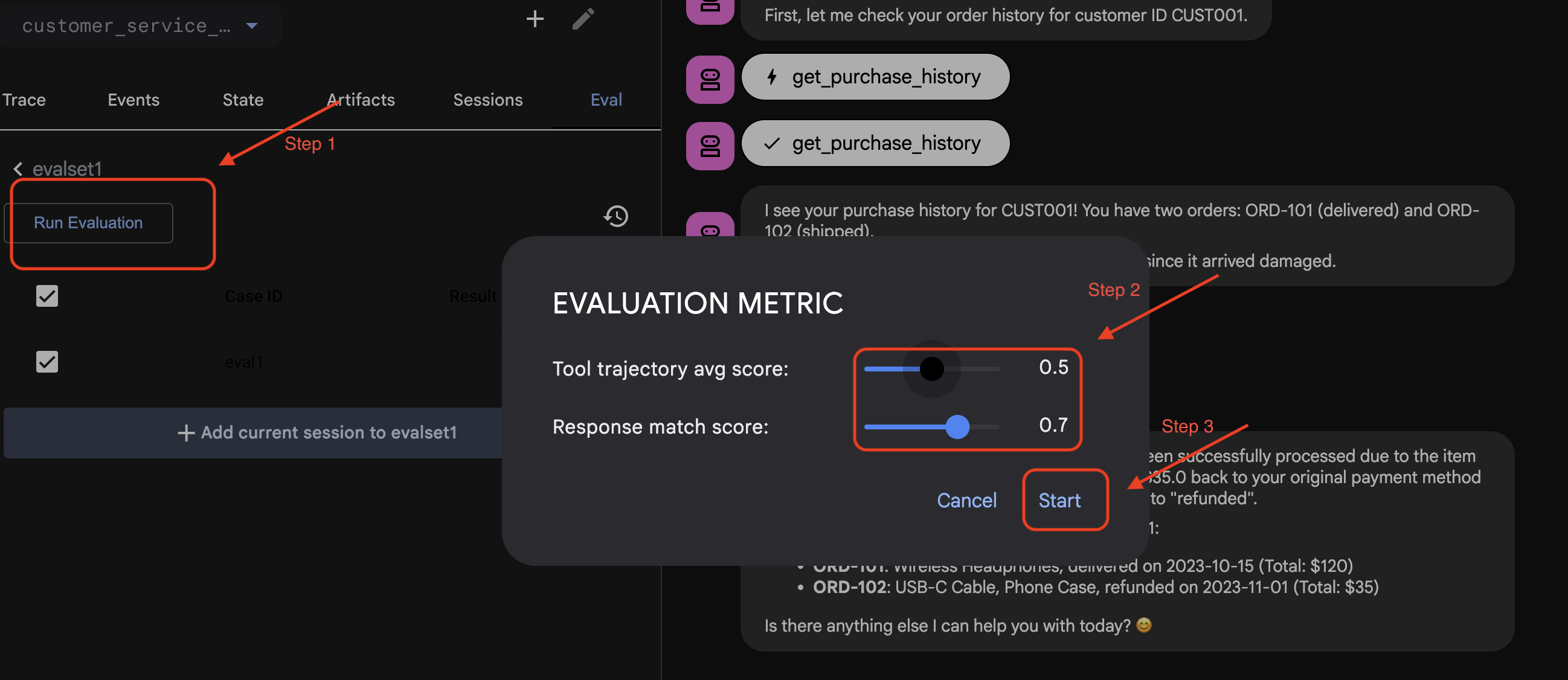
Weryfikowanie zbioru danych w repozytorium
Zobaczysz potwierdzenie, że plik zbioru danych (np. evalset1.evalset.json) został zapisany w repozytorium. Ten plik zawiera nieprzetworzony, wygenerowany automatycznie zapis rozmowy.

5. Pliki oceny
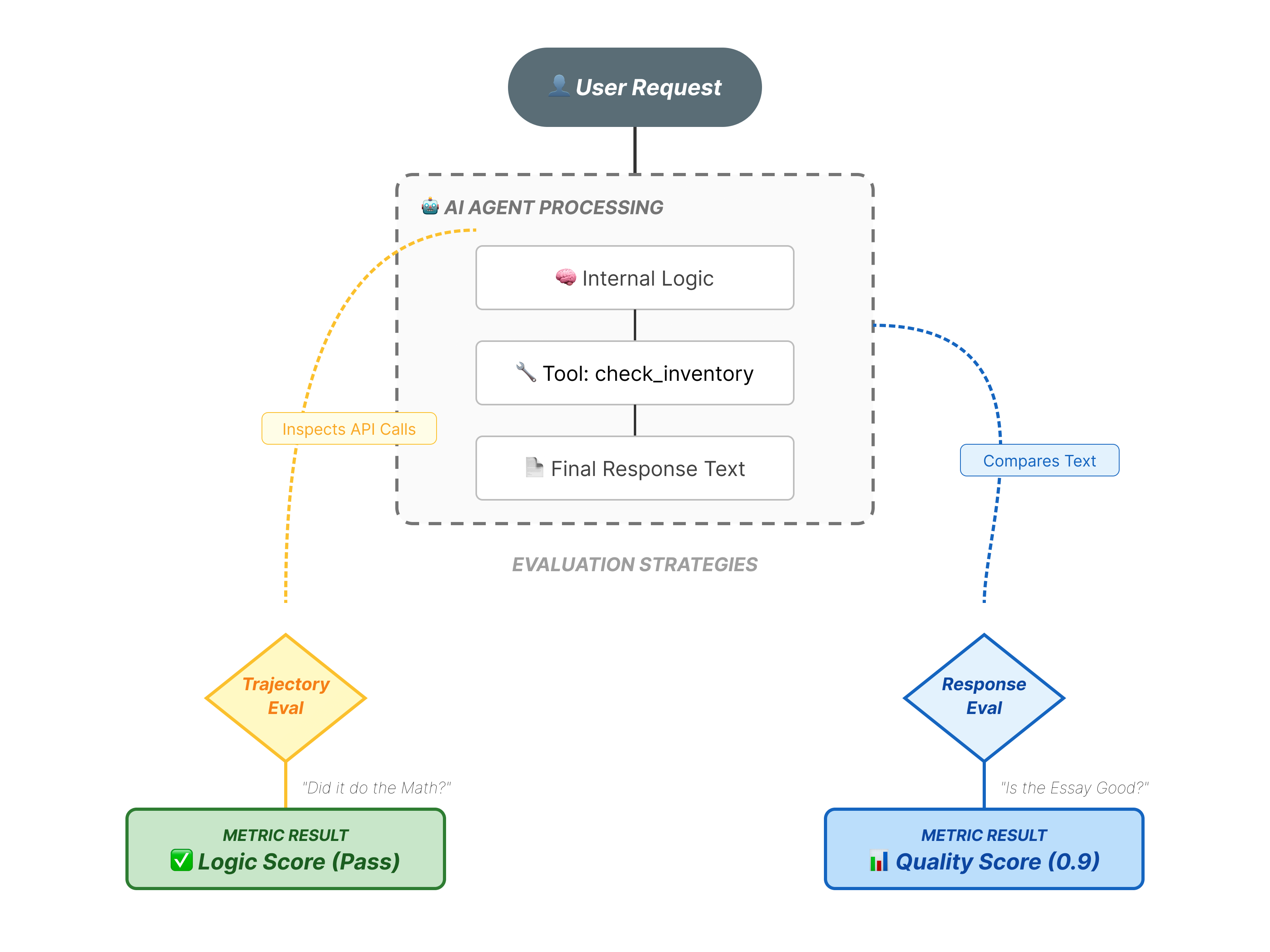
Interfejs internetowy generuje złożony plik .evalset.json, ale często chcemy utworzyć czystszy, bardziej uporządkowany plik testowy do automatycznego testowania.
ADK Eval składa się z 2 głównych komponentów:
- Pliki testowe: może to być automatycznie wygenerowany złoty zbiór danych (np.
customer_service_agent/evalset1.evalset.json) lub ręcznie wyselekcjonowany zbiór (np.customer_service_agent/eval.test.json). - Pliki konfiguracyjne (np.
customer_service_agent/test_config.json): określają dane i progi, które muszą zostać osiągnięte, aby test został zaliczony.
Konfigurowanie pliku konfiguracji testu
- 👉💻 W terminalu edytora Cloud Shell wpisz
cloudshell edit customer_service_agent/test_config.json - 👉 Wpisz ten kod w
customer_service_agent/test_config.jsonw edytorze.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
Interpretacja danych
tool_trajectory_avg_score(The Process) Sprawdza, czy agent prawidłowo używał narzędzi.
- 0,8: wymagamy dopasowania na poziomie 80%.
response_match_score(The Output) Ta funkcja używa ROUGE-1 (nakładanie się słów) do porównania odpowiedzi z odpowiedzią wzorcową.
- Zalety: szybkie, deterministyczne, bezpłatne.
- Wady: nie działa, jeśli agent wyrazi tę samą myśl w inny sposób (np. „Refunded” vs „Money returned”).
Wskaźniki zaawansowane (gdy potrzebujesz większej mocy)
6. Przeprowadzanie oceny zbioru danych wysokiej jakości (adk eval)

Ten krok reprezentuje „wewnętrzną pętlę” procesu programowania. Jesteś deweloperem, który wprowadza zmiany i chce szybko sprawdzić wyniki.
Uruchamianie złotego zbioru danych
uruchommy zbiór danych wygenerowany w kroku 1. Dzięki temu Twój punkt odniesienia będzie solidny.
- 👉💻 W terminalu uruchom:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Co się dzieje?
ADK to teraz:
- Wczytuję agenta z usługi
customer_service_agent. - Wykonywanie zapytań wejściowych z
evalset1.evalset.json. - Porównanie rzeczywistej trajektorii i odpowiedzi agenta z oczekiwanymi.
- ocenianie wyników na podstawie kryteriów podanych w
test_config.json;
Analizowanie wyników
Obserwuj dane wyjściowe terminala. Zobaczysz podsumowanie testów, które zakończyły się powodzeniem i niepowodzeniem.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Uwaga: ponieważ ten tekst został wygenerowany przez agenta, powinien przejść weryfikację w 100%. Jeśli się nie powiedzie, agent jest niedeterministyczny (losowy).
7. Tworzenie własnego testu dostosowanego do potrzeb
Automatycznie generowane zbiory danych są przydatne, ale czasami trzeba ręcznie tworzyć przypadki brzegowe (np. ataki typu adversarial attack lub konkretne sposoby obsługi błędów). Przyjrzyjmy się, jak eval.test.json pozwala zdefiniować „poprawność”.
Utwórzmy kompleksowy zestaw testów.
Platforma testowa
Podczas pisania elementu testowania w pakiecie ADK postępuj zgodnie z tym 3-częściowym wzorem:
- Konfiguracja (
session_input): kim jest użytkownik? (np.user_id,state). W ten sposób odizolujesz test. - Prompt (
user_content): Co jest regułą?
W sekcji The Assertions (Expectations) (Asercje, czyli oczekiwania):
- Trajektoria (
tool_uses): czy obliczenia są prawidłowe? (Logika) - Odpowiedź (
final_response): czy podano prawidłową odpowiedź? (Jakość) - Średnio zaawansowany
intermediate_responses: czy podrzędne klienty rozmawiały prawidłowo? (Orchestration)
Pisanie pakietu testów
- 👉💻 W terminalu edytora Cloud Shell wpisz
cloudshell edit customer_service_agent/eval.test.json - 👉 Wpisz ten kod w pliku
customer_service_agent/eval.test.json.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
Analiza typów testów
Utworzyliśmy tutaj 3 różne typy testów. Przyjrzyjmy się bliżej temu, co i dlaczego jest oceniane.
- Test jednego narzędzia (
product_info_check)
- Cel: weryfikacja podstawowego pobierania informacji.
- Kluczowe stwierdzenie: sprawdzamy
intermediate_data.tool_uses. Twierdzimy, że wywoływana jest funkcjalookup_product_info. Twierdzimy, że argumentproduct_nameto dokładnie „słuchawki bezprzewodowe”. - Uzasadnienie: jeśli model wygeneruje cenę bez wywołania narzędzia, test zakończy się niepowodzeniem. Zapewnia to ugruntowanie.
- Test wyodrębniania kontekstu (
purchase_history_check)
- Cel: sprawdź, czy agent może wyodrębnić encje (CUST001) z promptu użytkownika i przekazać je do narzędzia.
- Key Assertion: sprawdzamy, czy funkcja
get_purchase_historyjest wywoływana z parametremcustomer_id: "CUST001". - Uzasadnienie: częstym trybem awarii jest wywołanie przez agenta prawidłowego narzędzia, ale z identyfikatorem null. Zapewnia to dokładność parametru.
- Test działania/trajektorii (
refund_request)
- Cel: weryfikacja krytycznej operacji zapisu.
- Kluczowe stwierdzenie: trajektoria. W bardziej złożonym scenariuszu ta lista zawierałaby kilka kroków:
[verify_order, calculate_refund, issue_refund]. ADK sprawdza tę listę w podanej kolejności. - Uzasadnienie: w przypadku działań, które wiążą się z przekazywaniem środków lub zmianą danych, kolejność jest równie ważna jak wynik. Nie chcesz zwracać środków przed weryfikacją.
8. Przeprowadzanie oceny testów niestandardowych ( adk eval)
- 👉💻 W terminalu uruchom:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Interpretowanie danych wyjściowych
Powinien pojawić się wynik PASS podobny do tego:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Oznacza to, że agent użył odpowiednich narzędzi i udzielił odpowiedzi wystarczająco podobnej do Twoich oczekiwań.
9. (Opcjonalnie: tylko do odczytu) – rozwiązywanie problemów i debugowanie
Testy zakończą się niepowodzeniem. To ich praca. Jak jednak je naprawić? Przeanalizujmy typowe scenariusze błędów i sposoby ich debugowania.
Scenariusz A: błąd „Trajektoria”
Błąd:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
Diagnoza: agent pominął krok weryfikacji (lookup_order). Jest to błąd logiczny.
Rozwiązywanie problemów:
- Nie zgaduj: wróć do interfejsu ADK Web (adk web).
- Powtórz: wpisz w czacie dokładny prompt z nieudanego testu.
- Trace: otwórz widok Trace. Otwórz kartę „Wykres”.
- Popraw prompta: zwykle musisz zaktualizować prompta systemowego. Zmiana: „Jesteś pomocnym agentem”. Do: „Jesteś pomocnym agentem. WAŻNE: przed wywołaniem funkcji issue_refund MUSISZ wywołać funkcję lookup_order, aby zweryfikować szczegóły.
- Dostosuj test: jeśli logika biznesowa uległa zmianie (np. weryfikacja nie jest już potrzebna), test jest nieprawidłowy. Zaktualizuj plik eval.test.json, aby odzwierciedlał nową rzeczywistość.
Przykład B. Niepowodzenie „ROUGE”
Błąd:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
Diagnoza: pracownik postąpił prawidłowo, ale użył innych słów. ROUGE (pokrywanie się słów) obniżyło wynik.
Rozwiązanie:
- Czy to źle? Jeśli znaczenie jest prawidłowe, nie zmieniaj promptu.
- Dostosuj próg: obniż próg w
test_config.json(np. z0.8na0.5). - Uaktualnij rodzaj danych: w konfiguracji przełącz się na
final_response_match_v2. Model LLM odczytuje oba zdania i ocenia, czy mają one takie samo znaczenie.
10. CI/CD z Pytest (pytest)
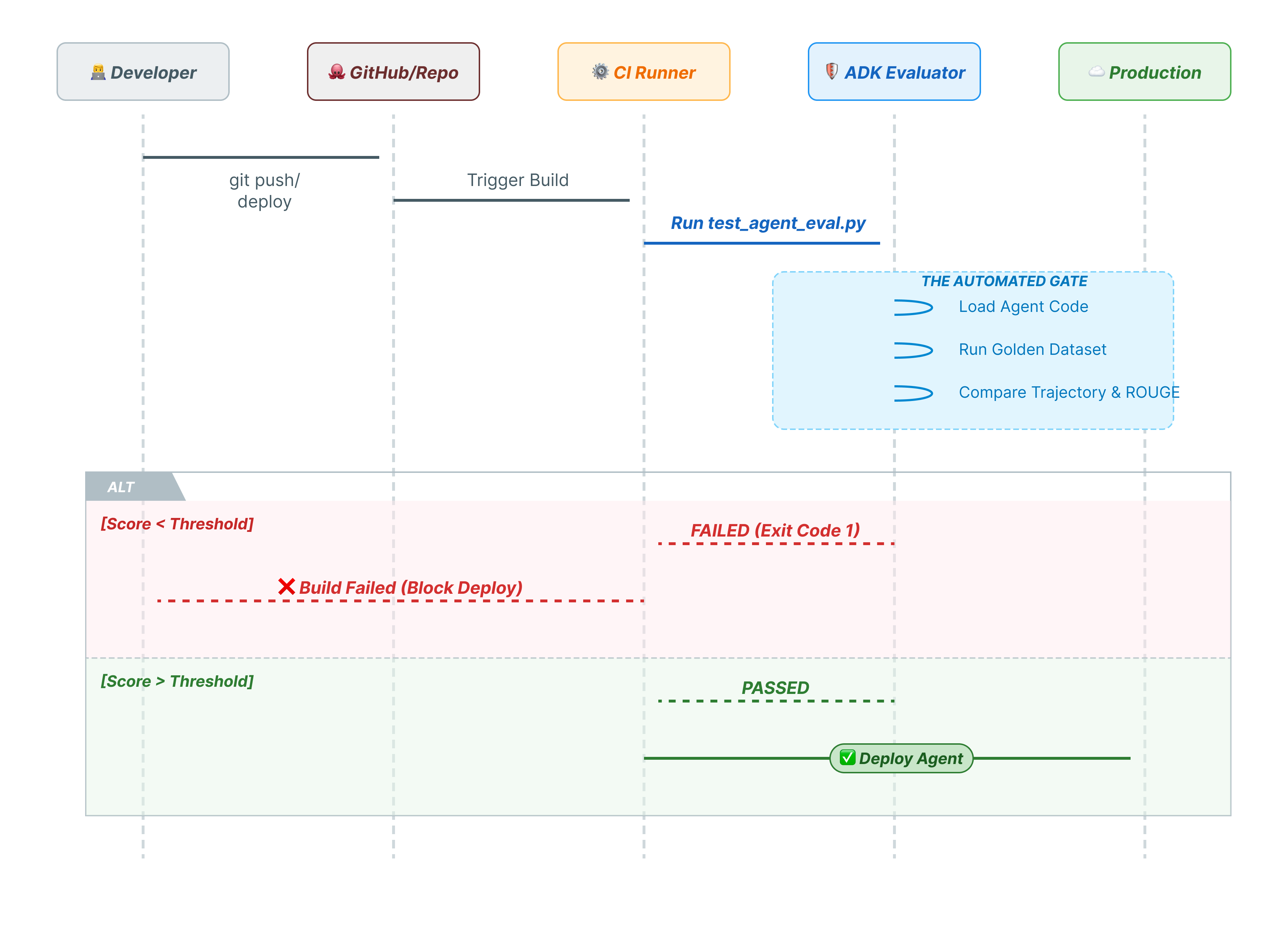
Polecenia interfejsu wiersza poleceń są przeznaczone dla ludzi. pytest jest przeznaczony dla maszyn. Aby zapewnić niezawodność w środowisku produkcyjnym, nasze oceny są przeprowadzane w ramach zestawu testów w języku Python. Umożliwia to potokowi CI/CD (GitHub Actions, Jenkins) blokowanie wdrożenia w przypadku pogorszenia wydajności agenta.
Co zawiera ten plik?
Ten plik Pythona działa jako pomost między narzędziem CI/CD a oceniającym ADK. Musi:
- Załaduj agenta: dynamicznie importuj kod agenta.
- Reset State (Zresetuj stan): upewnij się, że pamięć agenta jest czysta, aby testy nie przenikały do siebie nawzajem.
- Przeprowadź ocenę: wywołaj
AgentEvaluator.evaluate()programowo. - Assert Success (Potwierdź sukces): jeśli wynik oceny jest niski, przerwij kompilację.
Kod testu integracji
- 👉 Otwórz
customer_service_agent/test_agent_eval.py. Ten skrypt używaAgentEvaluator.evaluatedo uruchamiania testów zdefiniowanych weval.test.json. - 👉 Wpisz ten kod w
customer_service_agent/test_agent_eval.pyw edytorze.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Uruchamianie Pytest
- 👉💻 W terminalu uruchom:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. Podsumowanie
Gratulacje! Udało Ci się ocenić agenta obsługi klienta za pomocą ADK Eval.
Czego się dowiedziałeś(-aś)
Z tego laboratorium dowiedziałeś(-aś) się, jak:
- ✅ Wygeneruj złoty zbiór danych, aby ustalić bazę danych dla agenta.
- ✅ Poznaj konfigurację oceny, aby określić kryteria sukcesu.
- ✅ Przeprowadzaj automatyczne oceny, aby wcześnie wykrywać regresje.
Dzięki włączeniu ADK Eval do procesu programowania możesz tworzyć agentów z pewnością, że wszelkie zmiany w ich działaniu zostaną wykryte przez testy automatyczne.
Ten moduł jest częścią ścieżki szkoleniowej Wdrożenie AI w Google Cloud.
- Poznaj pełny program nauczania, aby przejść od prototypu do produkcji.
- Podziel się swoimi postępami, używając hashtagu
ProductionReadyAI.
Więcej materiałów do lektury: