
1. A lacuna de confiança
O momento de inspiração
Você criou um agente de atendimento ao cliente. Ele funciona na sua máquina. Mas ontem, ele disse a um cliente que um smartwatch sem estoque estava disponível ou, pior, inventou uma política de reembolso. Como você dorme à noite sabendo que seu agente está ativo?
Para passar da prova de conceito a um agente de IA pronto para produção, é essencial contar com um framework de avaliação robusto e automatizado.

O que estamos avaliando?
A avaliação de agentes é mais complexa do que a avaliação padrão de LLMs. Você não está apenas avaliando o Ensaio (Resposta final), mas também a Matemática (A lógica/ferramentas usadas para chegar lá).

- Trajetória (o processo): o agente usou a ferramenta certa no momento certo? Ele chamou
check_inventoryantes deplace_order? - Resposta final (a saída): a resposta está correta, é educada e baseada nos dados?
O ciclo de vida do desenvolvimento
Neste codelab, vamos explicar o ciclo de vida profissional dos testes de agente:
- Inspeção visual local (interface da Web do ADK): conversar e verificar a lógica manualmente (Etapa 1).
- Teste de unidade/regressão (CLI do ADK): execução de casos de teste específicos localmente para detectar erros rápidos (etapas 3 e 4).
- Depuração (solução de problemas): analisar falhas e corrigir a lógica do comando (etapa 5).
- Integração de CI/CD (Pytest): automatizar testes no pipeline de build (etapa 6).
2. Configurar
Para alimentar nossos agentes de IA, precisamos de duas coisas: um projeto do Google Cloud para fornecer a base.
Parte 1: ativar a conta de faturamento
Para executar este codelab, você precisa de uma conta de faturamento com algum crédito. Use os créditos do banner na parte de cima deste codelab para começar. Se você já estiver conectado a uma conta de faturamento, pule esta etapa.
Parte 2: ambiente aberto
- 👉 Clique neste link para acessar diretamente o editor do Cloud Shell.
- 👉 Se for preciso autorizar em algum momento hoje, clique em Autorizar para continuar.
- 👉 Se o terminal não aparecer na parte de baixo da tela, abra-o:
- Clique em Visualizar.
- Clique em Terminal
 .
.
- 👉💻 No terminal, verifique se você já está autenticado e se o projeto está definido como seu ID do projeto usando o seguinte comando:
gcloud auth list - 👉💻 Clone o projeto de bootstrap do GitHub:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 Execute o script de configuração no diretório do projeto.
cd ~/adk_eval_starter ./init.sh
O script vai processar o restante da configuração automaticamente.
- 👉💻 Defina o ID do projeto necessário:
gcloud config set project $(cat ~/project_id.txt) --quiet
Parte 3: Configurar permissões
- 👉💻 Ative as APIs necessárias usando o comando a seguir. Isso pode levar alguns minutos.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 Conceda as permissões necessárias executando os seguintes comandos no terminal:
. ~/adk_eval_starter/set_env.sh
Um arquivo .env será criado para você. Isso mostra as informações do projeto.
3. Gerar o conjunto de dados de referência (adk web)

Antes de classificar o agente, precisamos de um gabarito. No ADK, chamamos isso de conjunto de dados de ouro. Esse conjunto de dados contém interações "perfeitas" que servem como informações empíricas para avaliação.
O que é um conjunto de dados de ouro?
Um conjunto de dados de ouro é um instantâneo do seu agente com desempenho correto. Não é apenas uma lista de pares de perguntas e respostas. Ela captura:
- A consulta do usuário ("Quero um reembolso")
- A trajetória (a sequência exata de chamadas de ferramentas:
check_order->verify_eligibility->refund_transaction). - A resposta final (a resposta de texto "perfeita").
Usamos isso para detectar regressões. Se você atualizar o comando e o agente parar de verificar a qualificação antes de reembolsar, o teste do conjunto de dados dourado vai falhar porque a trajetória não vai mais corresponder.
Abrir a interface da Web
A interface da Web do ADK oferece uma maneira interativa de criar esses conjuntos de dados de ouro capturando interações reais com seu agente.
- 👉💻 No terminal, execute:
cd ~/adk_eval_starter uv run adk web - 👉💻 Abra a prévia da interface da Web (geralmente em
http://127.0.0.1:8000). - 👉 Na interface do chat, digite
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. Você vai receber uma resposta como esta:
Você vai receber uma resposta como esta:I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
Capturar interações douradas
Acesse a guia Sessões. Aqui você pode conferir o histórico de conversas do seu agente clicando na sessão.
- Interaja com o agente para criar um fluxo de conversa ideal, como verificar o histórico de compras ou pedir um reembolso.
- Revise a conversa para garantir que ela represente o comportamento esperado.

4. Exportar o conjunto de dados de referência
Verificar com a visualização de rastreamento
Antes de exportar, verifique se o agente não acertou a resposta por acaso. Você precisa inspecionar a lógica interna.
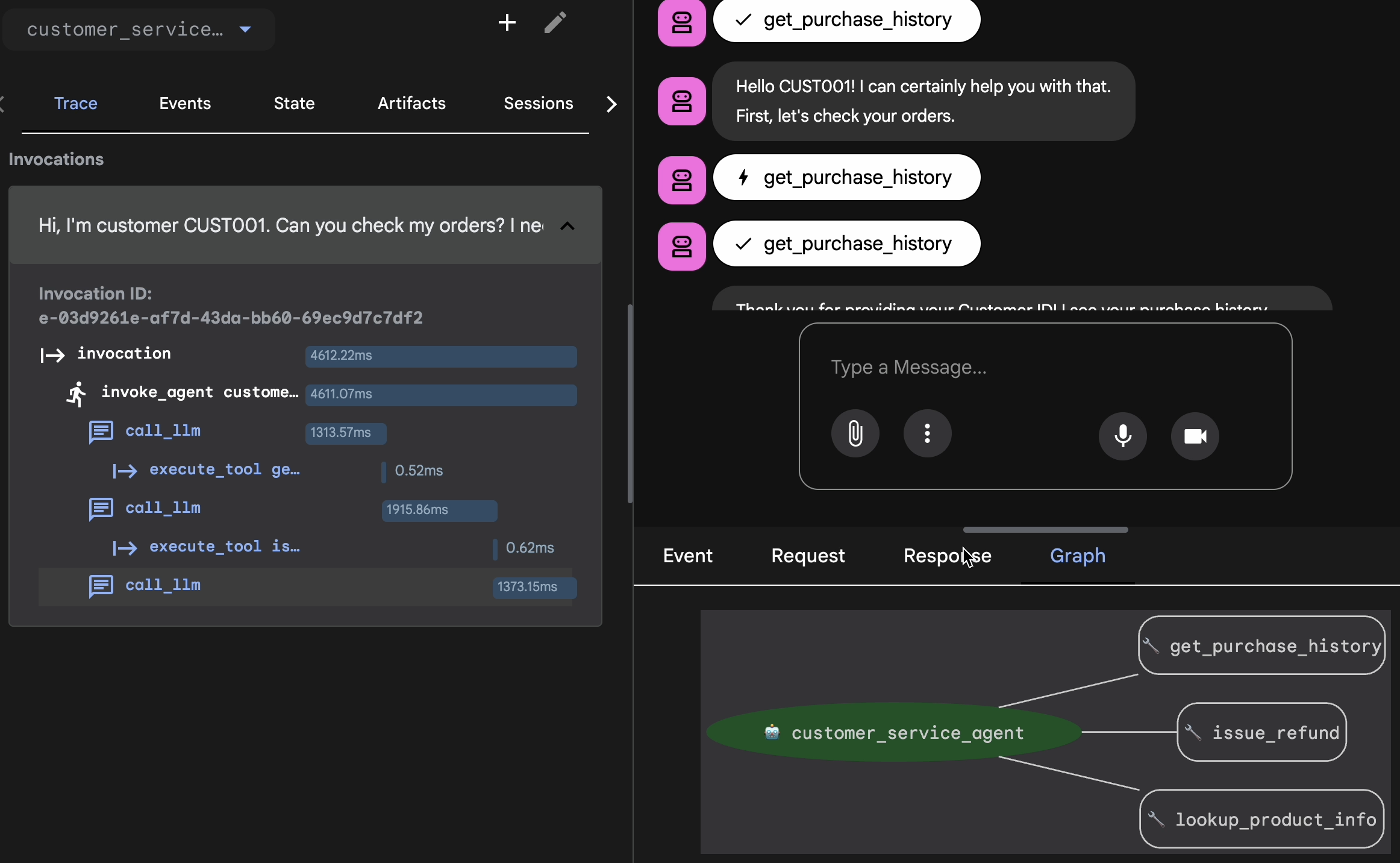
- Clique na guia Trace na interface da Web.
- Os rastreamentos são agrupados automaticamente por mensagem do usuário. Passe o cursor sobre uma linha de rastreamento para destacar a mensagem correspondente no chat.
- Inspecione as linhas azuis: elas indicam eventos gerados pela interação. Clique em uma linha azul para abrir o painel de inspeção.
- Confira as seguintes guias para validar a lógica:
- Gráfico: representação visual das chamadas de função e do fluxo lógico. Ele seguiu o caminho certo?
- Solicitação/resposta: revise exatamente o que foi enviado ao modelo e o que foi retornado.
- Verificação: se o agente adivinhar o valor do reembolso sem chamar a ferramenta de banco de dados, isso é uma "alucinação de sorte".
Adicionar sessão ao EvalSet
Quando você estiver satisfeito com a conversa e o rastreamento:
- 👉 Clique na guia
Evale no botãoCreate Evaluation Set. Em seguida, insira o nome da avaliação como:evalset1
- 👉 Neste conjunto de avaliação, clique em
Add current session to evalset1. Na janela pop-up, insira o nome da sessão:eval1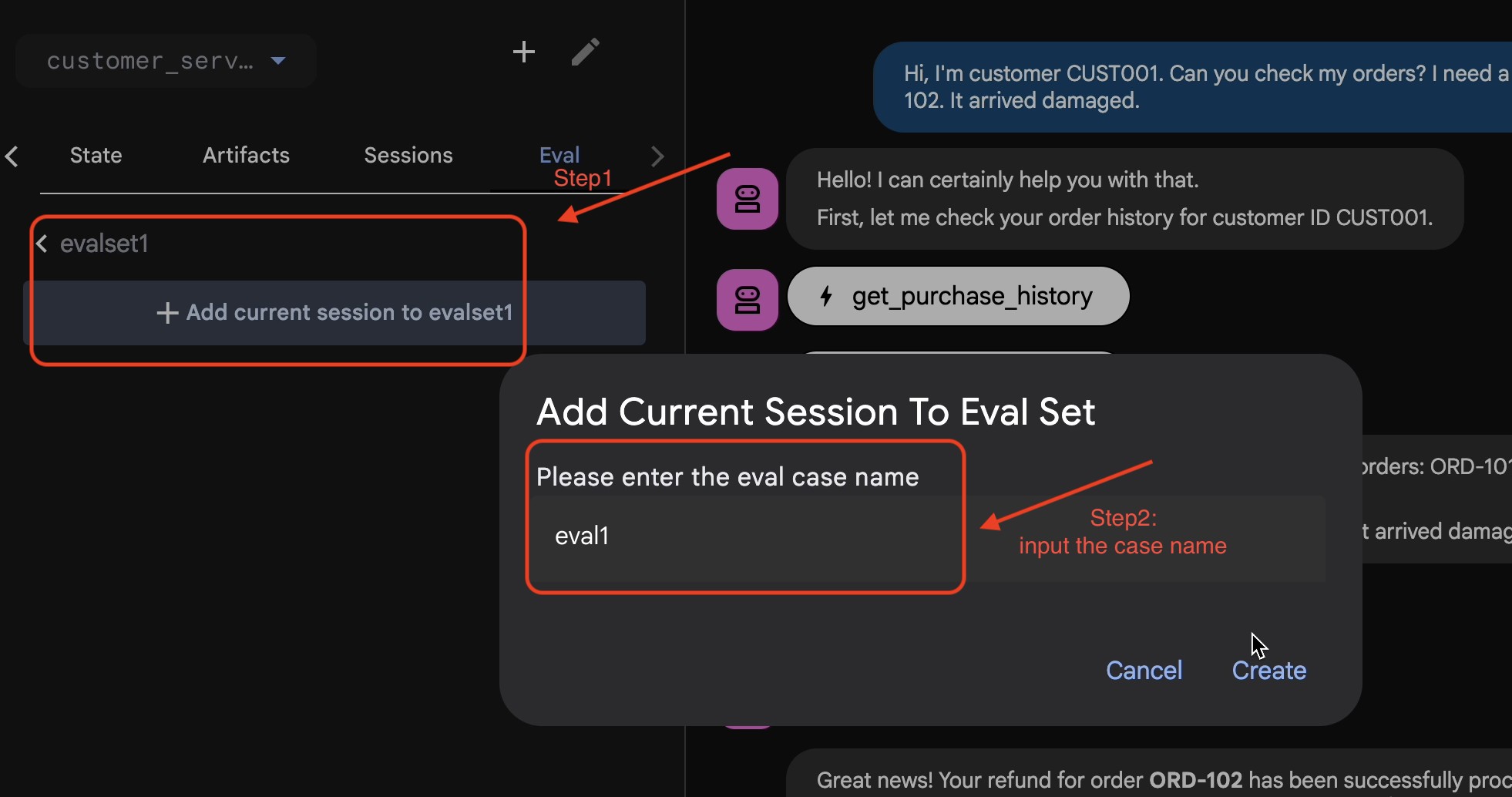
Executar a avaliação na Web do ADK
- 👉 Na interface da Web do ADK, clique em
Run Evaluation. Na janela pop-up, ajuste as métricas e clique emStart:

Verificar o conjunto de dados no repositório
Você vai receber uma confirmação de que um arquivo de conjunto de dados (por exemplo, evalset1.evalset.json) foi salvo no repositório. Esse arquivo contém o rastreamento bruto e gerado automaticamente da sua conversa.
5. Os arquivos de avaliação

Embora a interface da Web gere um arquivo .evalset.json complexo, muitas vezes queremos criar um arquivo de teste mais limpo e estruturado para testes automatizados.
O ADK Eval usa dois componentes principais:
- Arquivos de teste: podem ser o conjunto de dados de referência gerado automaticamente (por exemplo,
customer_service_agent/evalset1.evalset.json) ou um conjunto selecionado manualmente (por exemplo,customer_service_agent/eval.test.json). - Arquivos de configuração (por exemplo,
customer_service_agent/test_config.json): definem as métricas e os limites para aprovação.
Configurar o arquivo de configuração de teste
- 👉💻 No terminal do editor do Cloud Shell, insira
cloudshell edit customer_service_agent/test_config.json - 👉 Insira o seguinte código no
customer_service_agent/test_config.jsondo editor.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
Como decodificar as métricas
tool_trajectory_avg_score(O processo): mede se o agente usou as ferramentas corretamente.
- 0,8: exigimos uma correspondência de 80%.
response_match_score(a saída): usa ROUGE-1 (sobreposição de palavras) para comparar a resposta com a referência de ouro.
- Prós: rápido, determinista e sem custo financeiro.
- Desvantagem: falha se o agente expressar a mesma ideia de maneira diferente (por exemplo, "Reembolsado" x "Dinheiro devolvido").
Métricas avançadas (para quando você precisa de mais poder)
6. Executar avaliação para o conjunto de dados de referência (adk eval)
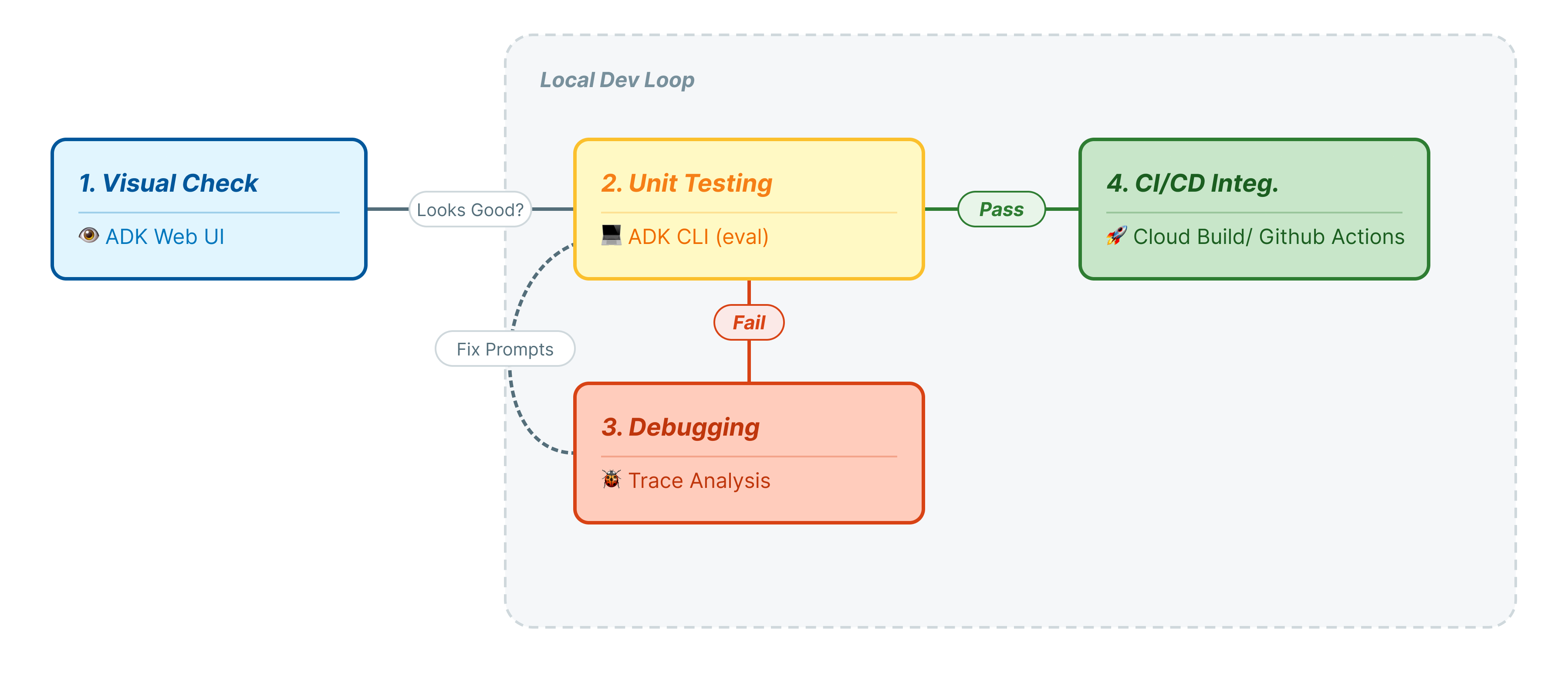
Esta etapa representa o "loop interno" do desenvolvimento. Você é um desenvolvedor fazendo mudanças e quer verificar os resultados rapidamente.
Executar o conjunto de dados de referência
Vamos executar o conjunto de dados gerado na etapa 1. Isso garante que seu valor de referência seja sólido.
- 👉💻 No terminal, execute:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
O que está acontecendo?
O ADK agora é:
- Carregando seu agente de
customer_service_agent. - Executar as consultas de entrada de
evalset1.evalset.json. - Comparar a trajetória e as respostas reais do agente com as esperadas.
- Pontuar os resultados com base nos critérios em
test_config.json.
Analisar os resultados
Confira a saída do terminal. Você vai ver um resumo dos testes aprovados e reprovados.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Observação: como você acabou de gerar isso com o próprio agente, o resultado deve ser 100%. Se ele falhar, seu agente será não determinístico (aleatório).
7. Criar seu próprio teste personalizado
Embora os conjuntos de dados gerados automaticamente sejam ótimos, às vezes é necessário criar manualmente casos extremos (por exemplo, ataques adversários ou tratamento de erros específicos). Vamos ver como o eval.test.json permite definir "Correção".
Vamos criar um conjunto de testes abrangente.
O framework de teste
Ao escrever um caso de teste no ADK, siga esta fórmula de três partes:
- A configuração (
session_input): quem é o usuário? (por exemplo,user_id,state). Isso isola o teste. - O comando (
user_content): qual é o gatilho?
Com As declarações (expectativas):
- Trajetória (
tool_uses): os cálculos estão corretos? (Lógica) - Resposta (
final_response): a resposta estava correta? (Qualidade) - Intermediário (
intermediate_responses): os subagentes conversaram corretamente? (Orquestração)
Criar o conjunto de testes
- 👉💻 No terminal do editor do Cloud Shell, insira
cloudshell edit customer_service_agent/eval.test.json - 👉 Insira o código a seguir no arquivo
customer_service_agent/eval.test.json.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
Desconstruindo os tipos de teste
Criamos três tipos distintos de testes aqui. Vamos detalhar o que cada um avalia e por quê.
- O teste de ferramenta única (
product_info_check)
- Objetivo: verificar a recuperação de informações básicas.
- Declaração principal: verificamos
intermediate_data.tool_uses. Afirmamos quelookup_product_infoé chamado. Afirmamos que o argumentoproduct_nameé exatamente "fones de ouvido sem fio". - Por quê: se o modelo alucinar um preço sem chamar a ferramenta, o teste vai falhar. Isso garante o embasamento.
- Teste de extração de contexto (
purchase_history_check)
- Objetivo: verificar se o agente consegue extrair entidades (CUST001) do comando do usuário e transmiti-las à ferramenta.
- Declaração principal: verificamos se
get_purchase_historyé chamado comcustomer_id: "CUST001". - Motivo: um modo de falha comum é o agente chamar a ferramenta correta, mas com um ID nulo. Isso garante a precisão dos parâmetros.
- O teste de ação/trajetória (
refund_request)
- Objetivo: verificar uma operação de gravação crítica.
- Declaração principal: a trajetória. Em um cenário mais complexo, essa lista teria várias etapas:
[verify_order, calculate_refund, issue_refund]. O ADK verifica essa lista em ordem. - Por quê: para ações que movimentam dinheiro ou mudam dados, a sequência é tão importante quanto o resultado. Não faça isso antes de verificar.
8. Executar avaliação para testes personalizados ( adk eval)
- 👉💻 No terminal, execute:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Como entender a saída
Você vai ver um resultado PASS assim:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Isso significa que o agente usou as ferramentas corretas e deu uma resposta suficientemente semelhante às suas expectativas.
9. (Opcional: somente leitura) - Solução de problemas e depuração
Os testes vão falhar. Esse é o trabalho deles. Mas como corrigir esses problemas? Vamos analisar cenários de falha comuns e como depurá-los.
Cenário A: a falha de "trajetória"
O erro:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
Diagnóstico: o agente pulou a etapa de verificação (lookup_order). Isso é um erro de lógica.
Como resolver problemas:
- Não adivinhe: volte para a interface da Web do ADK (adk web).
- Reproduzir: digite o comando exato do teste com falha no chat.
- Trace: abra a visualização do Trace. Acesse a guia "Gráfico".
- Corrigir o comando: geralmente, é necessário atualizar o comando do sistema. Mudança: "Você é um agente útil". Para: "Você é um agente útil. CRÍTICO: você PRECISA chamar lookup_order para verificar os detalhes antes de chamar issue_refund."
- Adapte o teste: se a lógica de negócios mudou (por exemplo, não é mais necessário verificar), o teste está errado. Atualize eval.test.json para corresponder à nova realidade.
Cenário B: a falha do "ROUGE"
O erro:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
Diagnóstico: o agente fez a coisa certa, mas usou palavras diferentes. ROUGE (sobreposição de palavras) penalizou a resposta.
Como corrigir:
- Está errado? Se o significado estiver correto, não mude o comando.
- Ajustar o limite: diminua o limite em
test_config.json(por exemplo, de0.8para0.5). - Fazer upgrade da métrica: mude para
final_response_match_v2na sua configuração. Isso usa um LLM para ler as duas frases e julgar se elas significam a mesma coisa.
10. CI/CD com Pytest (pytest)
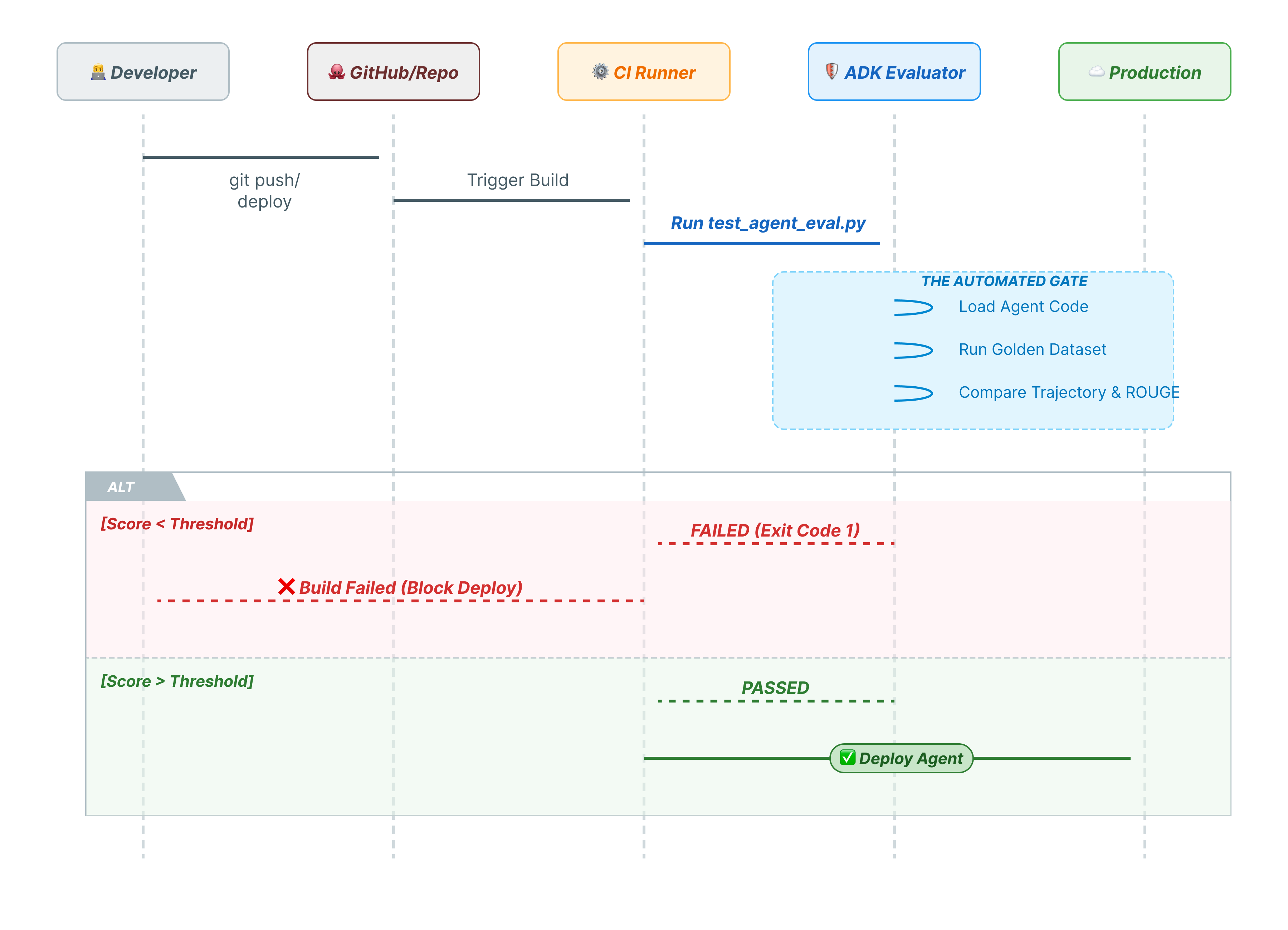
Os comandos da CLI são para humanos. pytest é para máquinas. Para garantir a confiabilidade da produção, incluímos nossas avaliações em um conjunto de testes do Python. Isso permite que seu pipeline de CI/CD (GitHub Actions, Jenkins) bloqueie uma implantação se o agente for degradado.
O que vai nesse arquivo?
Esse arquivo Python atua como ponte entre o executor de CI/CD e o avaliador do ADK. Ele precisa:
- Carregue seu agente: importe dinamicamente o código do agente.
- Redefinir estado: garanta que a memória do agente esteja limpa para que os testes não vazem uns para os outros.
- Executar avaliação: chame
AgentEvaluator.evaluate()de maneira programática. - Assert Success: se a pontuação da avaliação for baixa, a ação vai falhar no build.
O código de teste de integração
- 👉 Abra
customer_service_agent/test_agent_eval.py. Esse script usaAgentEvaluator.evaluatepara executar os testes definidos emeval.test.json. - 👉 Insira o seguinte código no
customer_service_agent/test_agent_eval.pydo editor.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Executar pytest
- 👉💻 No terminal, execute:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. Conclusão
Parabéns! Você avaliou seu agente de atendimento ao cliente usando o ADK Eval.
O que você aprendeu
Neste codelab, você aprendeu a:
- ✅ Gere um conjunto de dados de ouro para estabelecer uma verdade fundamental para seu agente.
- ✅ Entenda a configuração de avaliação para definir critérios de sucesso.
- ✅ Execute avaliações automáticas para detectar regressões antecipadamente.
Ao incorporar o ADK Eval ao seu fluxo de trabalho de desenvolvimento, você pode criar agentes com confiança, sabendo que qualquer mudança de comportamento será detectada pelos seus testes automatizados.
Este laboratório faz parte do programa de aprendizado "IA pronta para produção com o Google Cloud".
- Confira o currículo completo para ir do protótipo à produção.
- Compartilhe seu progresso com a hashtag
ProductionReadyAI.
Mais leituras: