
1. Разрыв в доверии
Момент вдохновения
Вы создали систему обслуживания клиентов . Она работает на вашем компьютере. Но вчера она сообщила клиенту, что отсутствующие в наличии смарт-часы, или, что еще хуже, выдала ложную информацию о политике возврата средств. Как вы можете спокойно спать по ночам, зная, что ваш агент работает в режиме реального времени?
Для преодоления разрыва между экспериментальной версией и готовым к внедрению в производство ИИ-агентом необходима надежная и автоматизированная система оценки.

Что именно мы оцениваем?
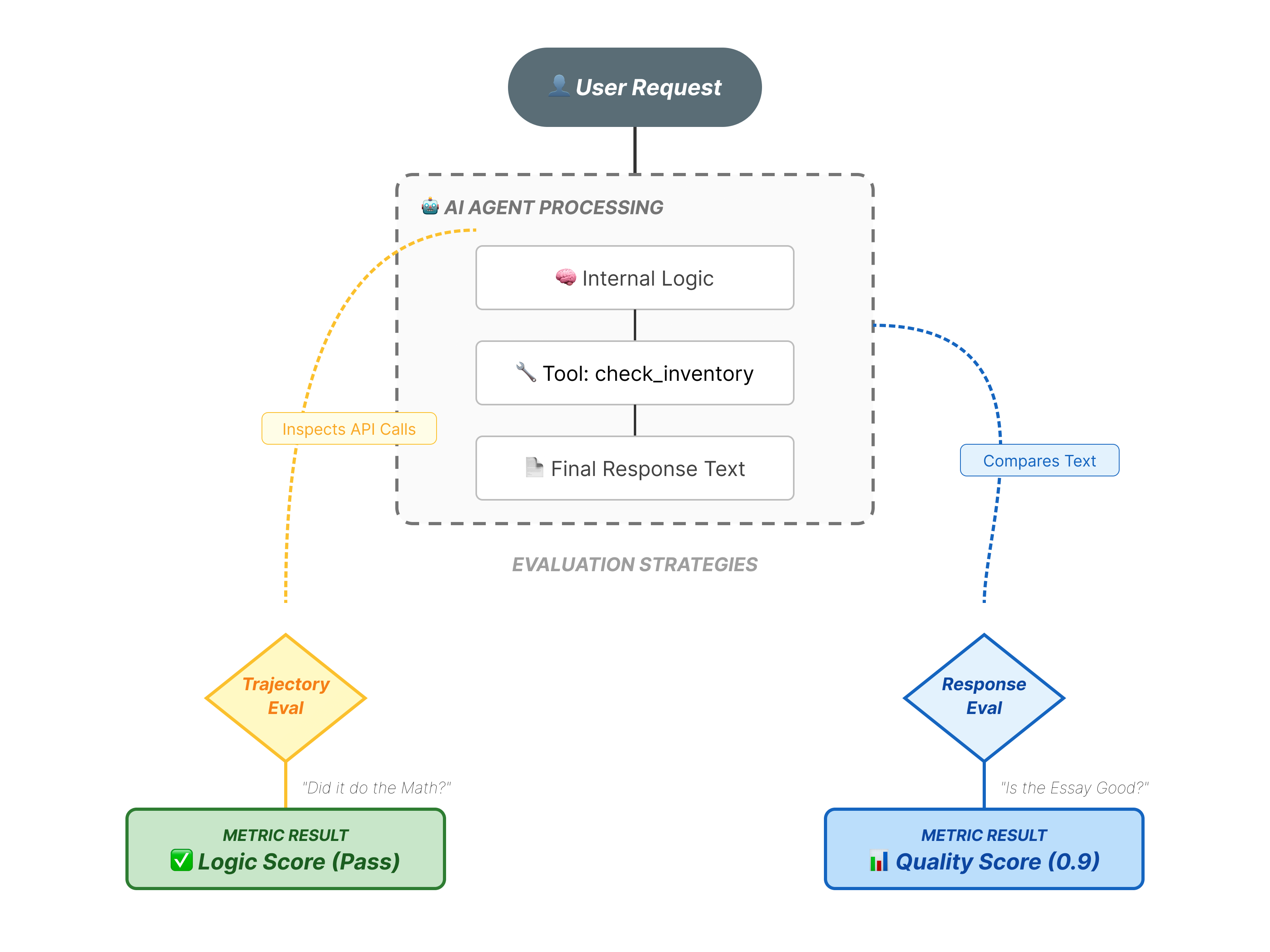
Оценка работы агента сложнее, чем стандартная оценка магистерской программы. Вы оцениваете не только эссе (итоговый ответ), но и математические выкладки (логику/инструменты, использованные для их составления).

- Траектория (процесс): Использовал ли агент правильный инструмент в нужное время? Вызвал ли он
check_inventoryпередplace_order? - Итоговый ответ (результат): Правильный ли ответ, вежливый ли он и основан ли на данных?
Жизненный цикл разработки
В этом практическом занятии мы рассмотрим профессиональный жизненный цикл тестирования агентов:
- Локальная визуальная проверка (веб-интерфейс ADK): ручная проверка и подтверждение логики (Шаг 1).
- Модульное/регрессионное тестирование (ADK CLI): локальное выполнение отдельных тестовых случаев для быстрого выявления ошибок (шаги 3 и 4).
- Отладка (устранение неполадок): анализ сбоев и исправление логики подсказок (Шаг 5).
- Интеграция CI/CD (Pytest): автоматизация тестов в конвейере сборки (Шаг 6).
2. Настройка
Для работы наших агентов искусственного интеллекта нам необходимы две вещи: проект Google Cloud, который обеспечит необходимую основу.
Часть первая: Включение платёжного аккаунта
Для выполнения этого практического задания вам потребуется платежный аккаунт с достаточным балансом. Используйте средства, указанные в баннере вверху страницы, чтобы начать. Если у вас уже есть платежный аккаунт, вы можете пропустить этот шаг.
Часть вторая: Открытая среда
- 👉 Нажмите на эту ссылку, чтобы перейти непосредственно в редактор Cloud Shell.
- 👉 Если сегодня вам будет предложено авторизоваться, нажмите «Авторизовать» , чтобы продолжить.
- 👉 Если терминал не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
- 👉💻 В терминале убедитесь, что вы уже авторизованы и что проект настроен на ваш идентификатор проекта, используя следующую команду:
gcloud auth list - 👉💻 Клонируйте проект Bootstrap с GitHub:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 Запустите скрипт установки из каталога проекта.
cd ~/adk_eval_starter ./init.sh
Скрипт автоматически выполнит остальную часть процесса настройки.
- 👉💻 Укажите необходимый идентификатор проекта:
gcloud config set project $(cat ~/project_id.txt) --quiet
Часть третья: Настройка прав доступа
- 👉💻 Включите необходимые API, используя следующую команду. Это может занять несколько минут.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 Предоставьте необходимые права доступа, выполнив следующие команды в терминале:
. ~/adk_eval_starter/set_env.sh
Обратите внимание, что для вас создан файл .env . В нём отображается информация о вашем проекте.
3. Создание эталонного набора данных (adk web)
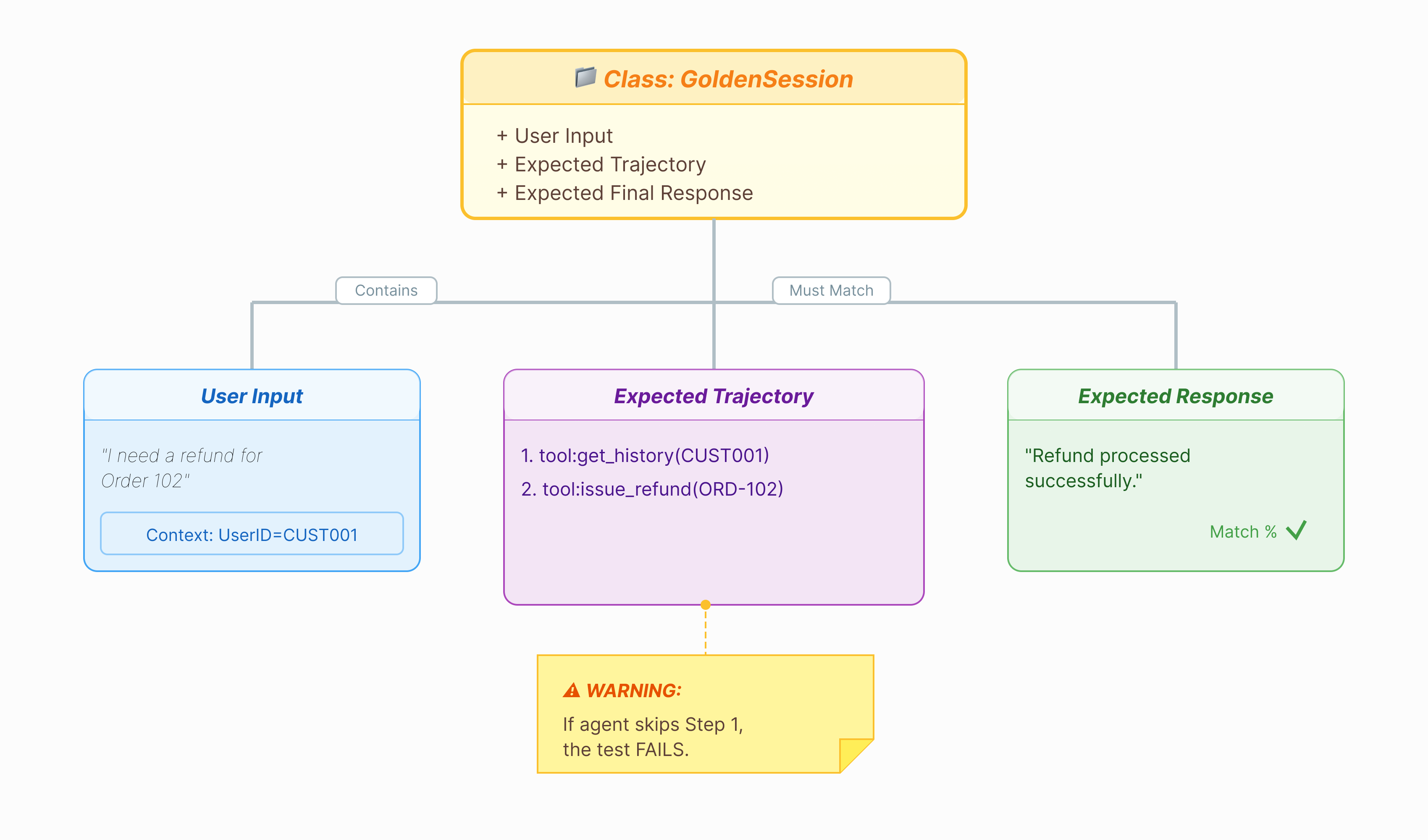
Прежде чем оценивать работу агента, нам нужен ключ к ответам. В ADK мы называем это «золотым набором данных ». Этот набор данных содержит «идеальные» взаимодействия, которые служат эталоном для оценки.
Что такое «золотой набор данных»?
« Золотой набор данных» — это снимок корректной работы вашего агента. Это не просто список пар «вопрос-ответ». Он содержит:
- Запрос пользователя («Я хочу вернуть деньги»)
- Траектория (точная последовательность вызовов инструмента:
check_order->verify_eligibility->refund_transaction). - Окончательный ответ (идеальный текстовый ответ).
Мы используем это для обнаружения регрессий . Если вы обновите запрос, и агент внезапно перестанет проверять соответствие критериям перед возвратом средств, тест с использованием «золотого набора данных» завершится неудачей, поскольку траектория больше не совпадает.
Откройте веб-интерфейс.
Веб-интерфейс ADK предоставляет интерактивный способ создания этих эталонных наборов данных путем фиксации реального взаимодействия с вашим агентом.
- 👉💻 В терминале выполните следующую команду:
cd ~/adk_eval_starter uv run adk web - 👉💻 Откройте предварительный просмотр веб-интерфейса (обычно по адресу
http://127.0.0.1:8000). - 👉 В интерфейсе чата введите
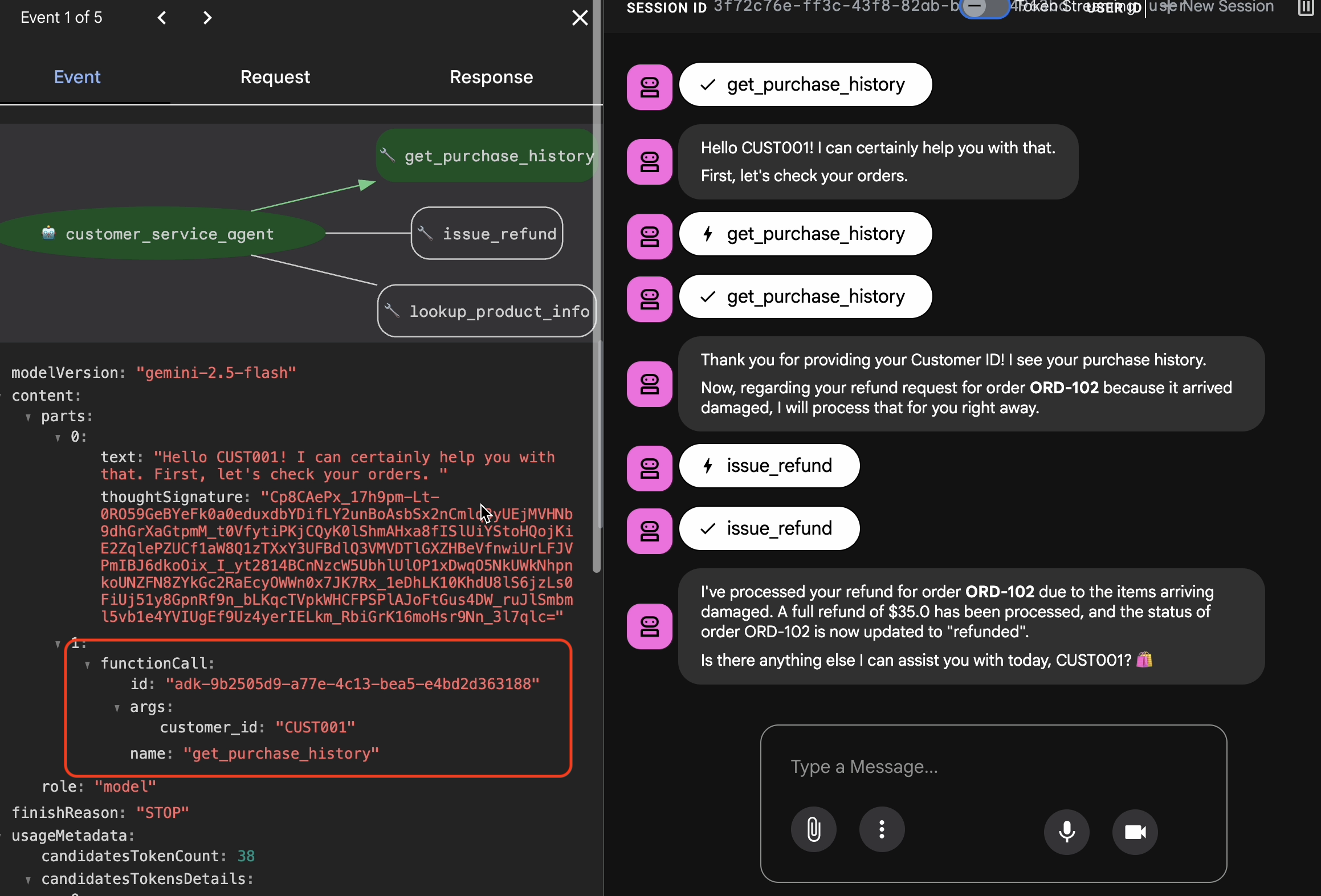
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. Вы увидите ответ примерно такого вида:
Вы увидите ответ примерно такого вида: I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
Запечатлейте золотые моменты взаимодействия
Перейдите на вкладку «Сессии» . Здесь вы можете просмотреть историю разговоров с вашим агентом, перейдя в соответствующую сессию.
- Взаимодействуйте со своим агентом, чтобы выстроить идеальный сценарий разговора, например, проверить историю покупок или запросить возврат средств.
- Проанализируйте разговор, чтобы убедиться, что он соответствует ожидаемому поведению.
4. Экспорт эталонного набора данных.
Проверьте с помощью функции просмотра трассировки.
Перед экспортом необходимо убедиться, что агент не получил правильный ответ случайно. Нужно проверить внутреннюю логику.
- В веб-интерфейсе нажмите вкладку «Трассировка» .
- Трассировки автоматически группируются по сообщениям пользователей. Наведите курсор на строку трассировки, чтобы выделить соответствующее сообщение в чате.
- Просмотрите синие строки : они указывают на события, сгенерированные в результате взаимодействия. Щелкните по синей строке, чтобы открыть панель просмотра.
- Проверьте следующие вкладки, чтобы убедиться в правильности логики:
- График : Визуальное представление вызовов инструментов и логического потока. Выбрался ли процесс по правильному пути?
- Запрос/Ответ : Внимательно проанализируйте, что именно было отправлено модели и что было возвращено.
- Проверка : Если агент угадал сумму возврата, не обращаясь к базе данных, это «удачная галлюцинация».
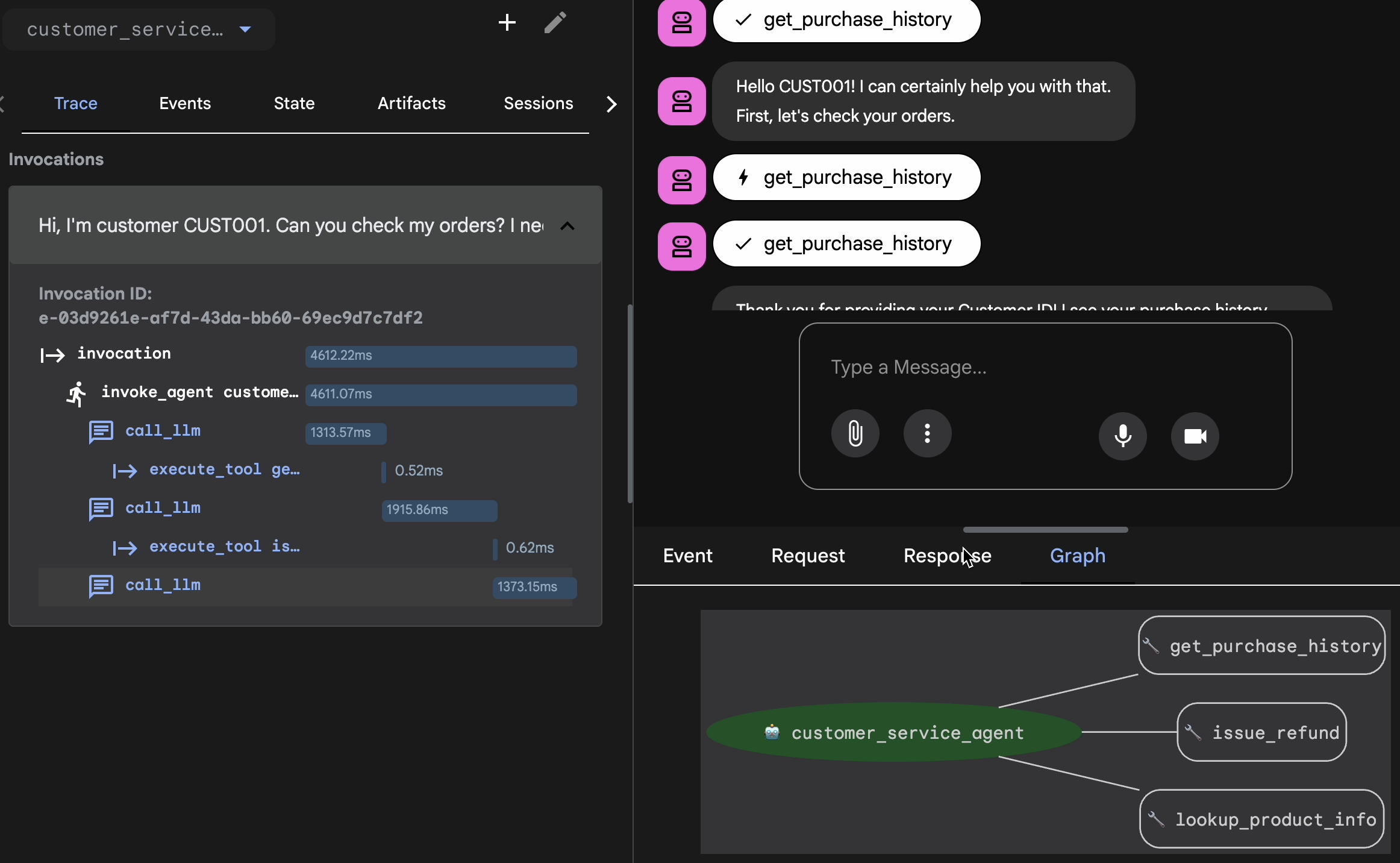
Добавить сессию в EvalSet
Когда вы будете удовлетворены ходом разговора и полученными данными:
- 👉 Перейдите на вкладку
Eval, затем нажмите кнопкуCreate Evaluation Setи введите имя для оценки:evalset1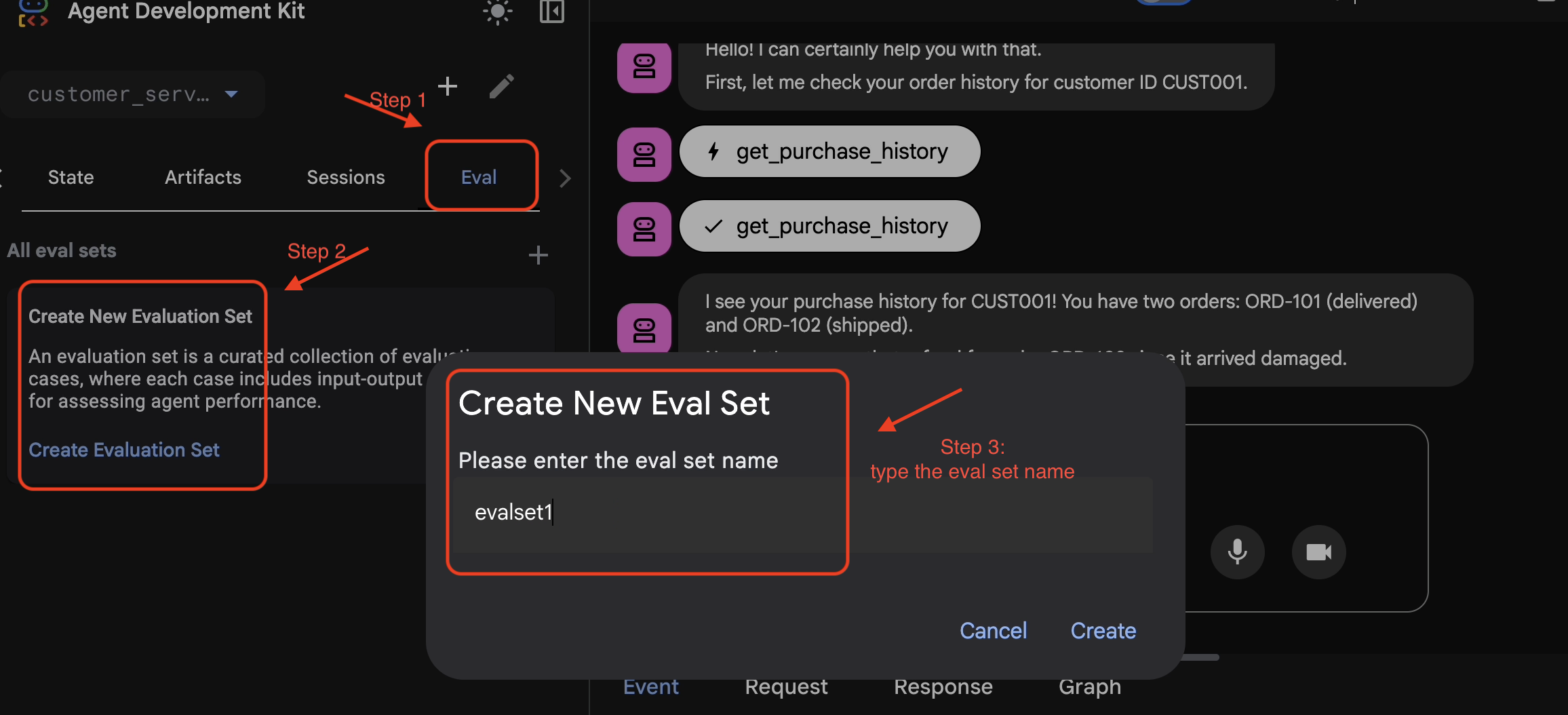
- 👉 В этом наборе оценок нажмите
Add current session to evalset1, во всплывающем окне введите имя сессии:eval1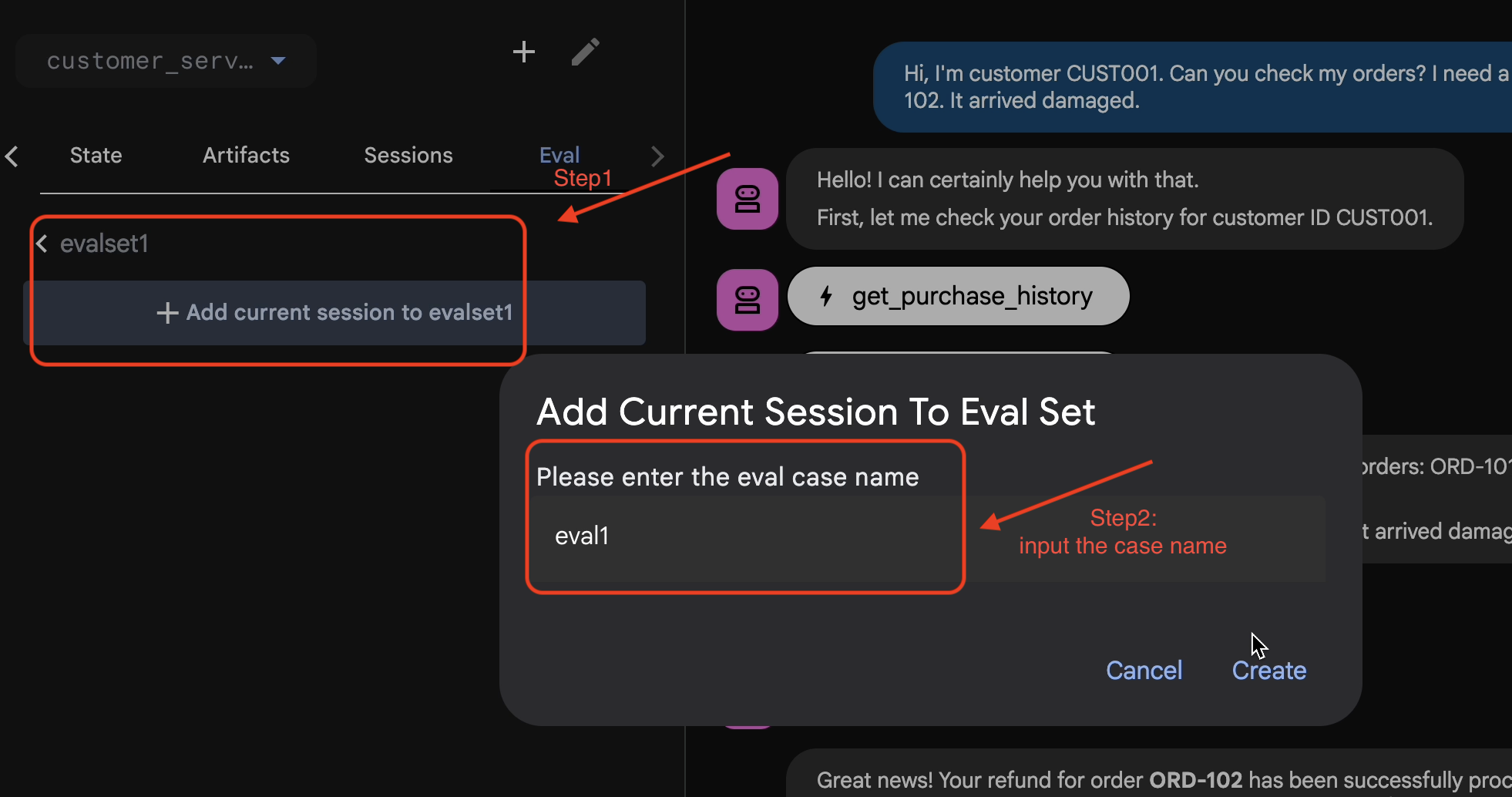
Запуск оценки в ADK Web
- 👉 В веб-интерфейсе ADK нажмите
Run Evaluation, во всплывающем окне настройте метрики и нажмитеStart:
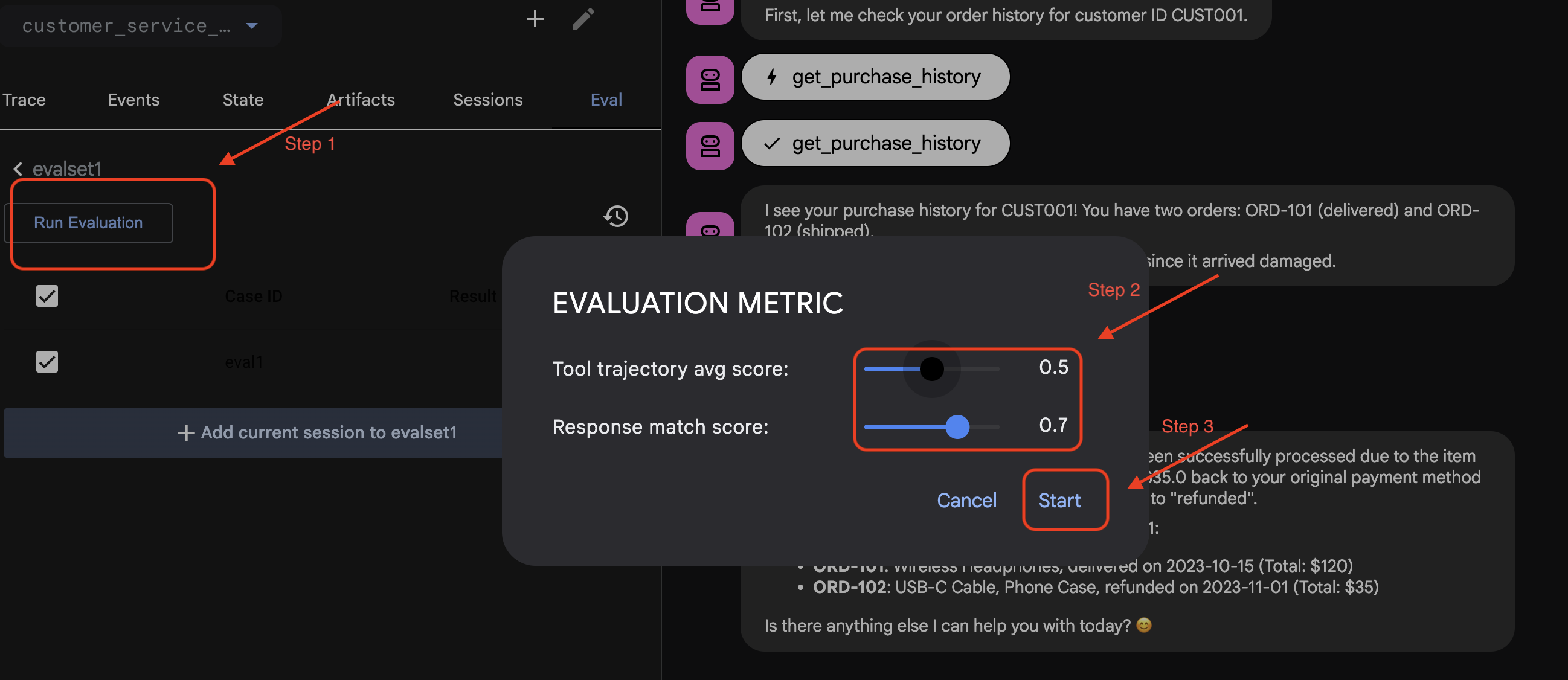
Проверьте набор данных в вашем репозитории.
Вы увидите подтверждение того, что файл набора данных (например, evalset1.evalset.json ) был сохранен в вашем репозитории. Этот файл содержит необработанную, автоматически сгенерированную трассировку вашего разговора.
5. Файлы оценки
В то время как веб-интерфейс генерирует сложный файл .evalset.json , нам часто требуется создать более чистый и структурированный тестовый файл для автоматизированного тестирования.
ADK Eval использует два основных компонента:
- Тестовые файлы : могут представлять собой автоматически сгенерированный эталонный набор данных (например,
customer_service_agent/evalset1.evalset.json) или набор, составленный вручную (например,customer_service_agent/eval.test.json). - Конфигурационные файлы (например,
customer_service_agent/test_config.json): определяют метрики и пороговые значения для успешного прохождения теста.
Настройте файл конфигурации теста.
- 👉💻 В терминале редактора Cloud Shell введите
cloudshell edit customer_service_agent/test_config.json - 👉 Вставьте следующий код в файл
customer_service_agent/test_config.jsonв вашем редакторе.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
Расшифровка метрик
-
tool_trajectory_avg_score(Процесс) Этот параметр измеряет, правильно ли агент использовал инструменты.
- 0,8 : Мы требуем совпадения в 80%.
-
response_match_score(Выходные данные) Эта функция использует ROUGE-1 (перекрытие слов) для сравнения ответа с эталонным значением.
- Плюсы : Быстро, детерминированно, бесплатно.
- Минусы : Не срабатывает, если агент формулирует одну и ту же идею по-разному (например, «Возврат средств» против «Деньги возвращены»).
Расширенные метрики (для случаев, когда требуется большая мощность)
6. Запуск оценки для эталонного набора данных (adk eval)

Этот этап представляет собой «внутренний цикл» разработки. Вы — разработчик, вносящий изменения, и хотите быстро проверить результаты.
Запустите «Золотой набор данных»
Давайте запустим набор данных, который вы сгенерировали на шаге 1. Это обеспечит надежность вашей базовой модели.
- 👉💻 В терминале выполните следующую команду:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Что происходит?
ADK теперь:
- Загрузка вашего агента из
customer_service_agent. - Выполнение входных запросов из
evalset1.evalset.json. - Сравнение фактической траектории движения и действий агента с ожидаемыми.
- Оценка результатов производится на основе критериев, указанных в
test_config.json.
Проанализируйте результаты.
Следите за выводом терминала. Вы увидите сводку пройденных и не пройденных тестов.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Примечание: Поскольку вы сгенерировали это непосредственно от агента, проверка должна пройти на 100%. Если проверка не пройдена, значит, ваш агент является недетерминированным (случайным).
7. Создайте собственный тест.
Хотя автоматически генерируемые наборы данных — это здорово, иногда необходимо вручную создавать граничные случаи (например, атаки злоумышленников или специфическую обработку ошибок). Давайте посмотрим, как eval.test.json позволяет определить "корректность".
Давайте создадим всеобъемлющий набор тестов.
Структура тестирования
При написании тестовых сценариев в ADK следуйте этой формуле из 3 частей:
- Параметр Setup (
session_input) : Кто является пользователем? (например,user_id,state). Это изолирует тест. - Запрос (
user_content) : Что является триггером?
С учетом утверждений (ожиданий) :
- Траектория (
tool_uses) : Правильно ли были произведены вычисления? (Логика) - Ответ (
final_response) : Был ли это правильный ответ? (Качество) - Промежуточный уровень (
intermediate_responses) : Правильно ли говорили суб-агенты? (Оркестрация)
Напишите набор тестов.
- 👉💻 В терминале редактора Cloud Shell введите
cloudshell edit customer_service_agent/eval.test.json - 👉 Вставьте следующий код в файл
customer_service_agent/eval.test.json.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
Разбор типов тестов
Мы создали здесь три различных типа тестов. Давайте разберем, что оценивает каждый из них и почему.
- Тестирование с использованием одного инструмента (
product_info_check)
- Цель : Проверка возможности получения базовой информации.
- Ключевое утверждение : Мы проверяем
intermediate_data.tool_uses. Мы утверждаем, чтоlookup_product_infoвызывается. Мы утверждаем, что аргументproduct_nameв точности равен "wireless headphones". - Почему : Если модель выдает цену, не обращаясь к инструменту, этот тест не проходит. Это обеспечивает корректность результатов.
- Тест на извлечение контекста (
purchase_history_check)
- Цель : Проверить, может ли агент извлекать сущности (CUST001) из запроса пользователя и передавать их инструменту.
- Ключевое утверждение : Мы проверяем, что
get_purchase_historyвызывается сcustomer_id: "CUST001". - Почему : Распространенная ошибка заключается в том, что агент вызывает правильный инструмент, но с нулевым идентификатором. Это обеспечивает точность параметров.
- Тест действия/траектории (
refund_request)
- Цель : Проверить критически важную операцию записи.
- Ключевое утверждение : Траектория. В более сложном сценарии этот список будет содержать несколько шагов:
[verify_order, calculate_refund, issue_refund]. ADK проверяет этот список по порядку . - Почему : В операциях, связанных с перемещением денег или изменением данных, последовательность так же важна, как и результат. Вы же не хотите возвращать деньги, не проверив всё.
8. Запуск оценки пользовательских тестов (adk eval)
- 👉💻 В терминале выполните следующую команду:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Понимание результата
Вы должны увидеть результат «ПРОЙДЕНО» примерно такого вида:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Это означает, что ваш агент использовал правильные инструменты и предоставил ответ, в достаточной степени соответствующий вашим ожиданиям.
9. (Необязательно: Только для чтения) - Поиск и устранение неисправностей
Тесты будут проваливаться. Это их работа. Но как это исправить? Давайте проанализируем распространенные сценарии сбоев и способы их отладки.
Сценарий А: Сбой "траектории"
Ошибка:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
Диагноз : Агент пропустил этап проверки (lookup_order). Это логическая ошибка.
Как устранить неполадки :
- Не гадайте : вернитесь в веб-интерфейс ADK (adk web).
- Воспроизведение : Введите в чат точно ту же подсказку из неудачного теста.
- Трассировка : Откройте окно трассировки. Перейдите на вкладку «График».
- Исправить подсказку : Обычно необходимо обновить системную подсказку. Изменить : «Вы полезный агент» на : «Вы полезный агент. ВАЖНО: Перед вызовом функции issue_refund НЕОБХОДИМО вызвать функцию lookup_order для проверки данных. »
- Адаптируйте тест : если бизнес-логика изменилась (например, проверка больше не требуется), то тест неверен. Обновите файл eval.test.json в соответствии с новыми условиями.
Сценарий Б: Провал "ROUGE"
Ошибка:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
Диагноз : Агент поступил правильно, но использовал другие слова. Система ROUGE (наложение слов) наложила на него штраф.
Как это исправить :
- Это неправильно? Если смысл верен, не меняйте подсказку.
- Настройте пороговое значение : уменьшите пороговое значение в
test_config.json(например, с0.8до0.5). - Улучшите метрику : переключитесь на
final_response_match_v2в вашем файле конфигурации. Эта метрика использует LLM для чтения обоих предложений и определения, означают ли они одно и то же.
10. CI/CD с использованием Pytest (pytest)
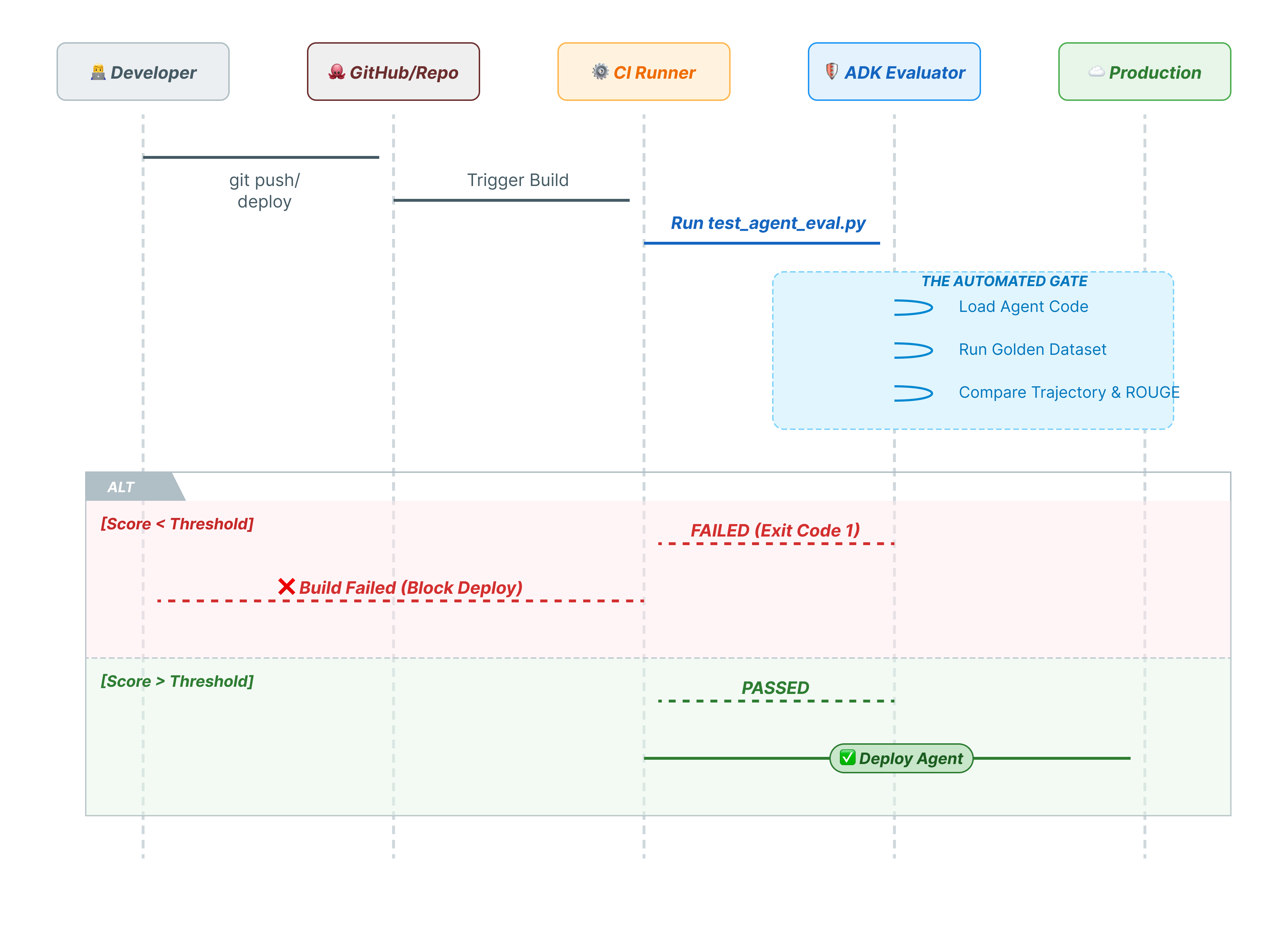
Команды CLI предназначены для людей, pytest — для машин. Для обеспечения надежности в производственной среде мы используем набор тестов на Python для проверки работоспособности. Это позволяет вашему конвейеру CI/CD (GitHub Actions, Jenkins) блокировать развертывание, если агент работает некорректно.
Что содержится в этом файле?
Этот файл Python служит связующим звеном между вашим CI/CD-раннером и оценщиком ADK. Он должен:
- Загрузите своего агента : динамически импортируйте код своего агента.
- Сброс состояния : Убедитесь, что память агента очищена, чтобы тесты не перетекали друг в друга.
- Выполнить оценку : программно вызвать
AgentEvaluator.evaluate(). - Подтверждение успеха : Если оценка низкая, сборка завершается с ошибкой.
Код интеграционного тестирования
- 👉 Откройте файл
customer_service_agent/test_agent_eval.py. Этот скрипт используетAgentEvaluator.evaluateдля запуска тестов, определенных вeval.test.json. - 👉 Вставьте следующий код в файл
customer_service_agent/test_agent_eval.pyв вашем редакторе.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Запустите pytest
- 👉💻 В терминале выполните следующую команду:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. Заключение
Поздравляем! Вы успешно оценили своего сотрудника службы поддержки клиентов с помощью ADK Eval.
Что вы узнали
В этом практическом занятии вы научились:
- ✅ Создайте эталонный набор данных , чтобы установить истинные значения для вашего агента.
- ✅ Разберитесь в настройках оценки , чтобы определить критерии успеха.
- ✅ Запускайте автоматизированные оценки для выявления регрессий на ранней стадии.
Интегрировав ADK Eval в свой рабочий процесс разработки, вы можете создавать агентов с уверенностью, зная, что любые изменения в поведении будут обнаружены вашими автоматизированными тестами.
Данная лабораторная работа является частью учебного курса "Готовый к внедрению ИИ в производство с использованием Google Cloud".
- Изучите полный учебный план , чтобы преодолеть разрыв между прототипом и серийным производством.
- Делитесь своими успехами, используя хэштег
ProductionReadyAI.
Дополнительные материалы для чтения: