
1. Güven Açığı
İlham Anı
Müşteri hizmetleri temsilcisi oluşturdunuz. Makinenizde çalışır. Ancak dün, stokta olmayan bir akıllı saatin stokta olduğunu bir müşteriye söyledi veya daha da kötüsü, geri ödeme politikası uydurdu. Temsilcinizin canlı olduğunu bilerek geceleri nasıl uyuyorsunuz?
Bir konsept kanıtı ile üretime hazır bir yapay zeka aracısı arasındaki boşluğu kapatmak için güçlü ve otomatikleştirilmiş bir değerlendirme çerçevesi gereklidir.

Aslında neyi değerlendiriyoruz?
Aracı değerlendirmesi, standart LLM değerlendirmesinden daha karmaşıktır. Yalnızca Kompozisyonu (Nihai Yanıt) değil, Matematiği (Sonuca ulaşmak için kullanılan mantık/araçlar) de değerlendiriyorsunuz.

- Yörünge (Süreç): Temsilci, doğru aracı doğru zamanda kullandı mı?
place_orderadlı kişiyi aramadan öncecheck_inventoryadlı kişiyi aradı mı? - Son Yanıt (Çıkış): Yanıt doğru, nazik ve verilere dayalı mı?
Geliştirme Yaşam Döngüsü
Bu codelab'de, aracı testinin profesyonel yaşam döngüsünü inceleyeceğiz:
- Yerel Görsel İnceleme (ADK Web Kullanıcı Arayüzü): Mantığı manuel olarak sohbet ederek doğrulama (1. adım).
- Birim/Regresyon Testi (ADK CLI): Hızlı hataları yakalamak için belirli test senaryolarını yerel olarak çalıştırma (3. ve 4. adım).
- Hata ayıklama (Sorun giderme): Hataları analiz etme ve istem mantığını düzeltme (5. adım).
- CI/CD Entegrasyonu (Pytest): Derleme ardışık düzeninizdeki testleri otomatikleştirme (6. adım).
2. Kur
Yapay zeka aracılarımızı desteklemek için iki şeye ihtiyacımız var: temel işlevleri sağlayacak bir Google Cloud projesi.
Birinci Bölüm: Fatura Hesabını Etkinleştirme
Bu codelab'i çalıştırmak için biraz kredisi olan bir faturalandırma hesabına ihtiyacınız var. Başlamak için bu codelab'in üst kısmındaki banner'da yer alan kredileri kullanın. Zaten bir faturalandırma hesabına bağlıysanız bu adımı atlayabilirsiniz.
2. Bölüm: Açık Ortam
- 👉 Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- 👉 Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
- 👉 Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
- 👉💻 Terminalde, aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını doğrulayın:
gcloud auth list - 👉💻 Bootstrap projesini GitHub'dan kopyalayın:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 Kurulum komut dosyasını proje dizininden çalıştırın.
cd ~/adk_eval_starter ./init.sh
Kurulum işleminin geri kalanı komut dosyası tarafından otomatik olarak gerçekleştirilir.
- 👉💻 Gerekli proje kimliğini ayarlayın:
gcloud config set project $(cat ~/project_id.txt) --quiet
Üçüncü Bölüm: İzinleri ayarlama
- 👉💻 Aşağıdaki komutu kullanarak gerekli API'leri etkinleştirin. Bu işlem birkaç dakika sürebilir.
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 Terminalde aşağıdaki komutları çalıştırarak gerekli izinleri verin:
. ~/adk_eval_starter/set_env.sh
Sizin için bir .env dosyasının oluşturulduğunu fark edin. Bu bölümde proje bilgileriniz gösterilir.
3. Altın veri kümesini oluşturma (adk web)

Temsilciye not verebilmemiz için cevap anahtarı gerekiyor. ADK'da buna Golden Dataset (Altın Veri Kümesi) adı verilir. Bu veri kümesi, değerlendirme için kesin referans görevi gören "mükemmel" etkileşimler içerir.
Altın veri kümesi nedir?
Altın veri kümesi, temsilcinizin doğru şekilde çalıştığı bir anlık görüntüdür. Bu, yalnızca soru-cevap çiftlerinin listesi değildir. Aşağıdaki bilgileri yakalar:
- Kullanıcı Sorgusu ("Geri ödeme istiyorum")
- Yörünge (Araç çağrılarının tam sırası:
check_order->verify_eligibility->refund_transaction). - Nihai Yanıt ("Mükemmel" metin yanıtı).
Gerilemeleri tespit etmek için bu bilgiyi kullanırız. İsteminizde güncelleme yaparsanız ve temsilci, geri ödeme yapmadan önce uygunluğu kontrol etmeyi aniden durdurursa yörünge artık eşleşmediği için Golden Dataset testi başarısız olur.
Web kullanıcı arayüzünü açma
ADK Web Kullanıcı Arayüzü, aracınızla gerçek etkileşimleri yakalayarak bu altın veri kümelerini oluşturmak için etkileşimli bir yöntem sunar.
- 👉💻 Terminalinizde şunu çalıştırın:
cd ~/adk_eval_starter uv run adk web - 👉💻 Web kullanıcı arayüzü önizlemesini açın (genellikle
http://127.0.0.1:8000adresinde). - 👉 Sohbet kullanıcı arayüzünde
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged. Şuna benzer bir yanıt görürsünüz:
Şuna benzer bir yanıt görürsünüz:I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
Değerli etkileşimleri yakalama
Oturumlar sekmesine gidin. Burada, oturumu tıklayarak temsilcinizin görüşme geçmişini görebilirsiniz.
- Satın alma geçmişini kontrol etme veya geri ödeme isteğinde bulunma gibi ideal bir görüşme akışı oluşturmak için temsilcinizle etkileşim kurun.
- Beklenen davranışı yansıttığından emin olmak için görüşmeyi inceleyin.

4. Önemli veri kümesini dışa aktarma
Trace View ile doğrulama
Dışa aktarma yapmadan önce, temsilcinin doğru yanıtı şans eseri almadığını doğrulamanız gerekir. Dahili mantığı incelemeniz gerekir.
- Web kullanıcı arayüzünde İzleme sekmesini tıklayın.
- İzler, kullanıcı mesajına göre otomatik olarak gruplandırılır. Sohbetteki ilgili mesajı vurgulamak için imleci bir izleme satırının üzerine getirin.
- Mavi satırları inceleyin: Bunlar, etkileşimden oluşturulan etkinlikleri gösterir. İnceleme panelini açmak için mavi bir satırı tıklayın.
- Mantığı doğrulamak için aşağıdaki sekmeleri kontrol edin:
- Grafik: Araç çağrılarının ve mantık akışının görsel gösterimi. Doğru yolu mu izledi?
- İstek/Yanıt: Modele tam olarak ne gönderildiğini ve ne yanıt geldiğini inceleyin.
- Doğrulama: Temsilci, veritabanı aracını aramadan geri ödeme tutarını tahmin ettiyse bu "şanslı halüsinasyon" olarak değerlendirilir.

Add Session to EvalSet
Sohbetten ve izlemeden memnun kaldığınızda:
- 👉
Evalsekmesini, ardındanCreate Evaluation Setdüğmesini tıklayın ve değerlendirme adını girin:evalset1
- 👉 Bu değerlendirme setinde
Add current session to evalset1simgesini tıklayın. Pop-up pencerede oturum adını şu şekilde girin:eval1
ADK Web'de değerlendirme çalıştırma
- 👉 ADK Web kullanıcı arayüzünde
Run Evaluationsimgesini tıklayın, pop-up pencerede metrikleri ayarlayın veStartsimgesini tıklayın:

Deponuzdaki Veri Kümesini Doğrulama
Bir veri kümesi dosyasının (ör. evalset1.evalset.json) deponuza kaydedildiğine dair bir onay mesajı görürsünüz. Bu dosyada, görüşmenizin otomatik olarak oluşturulan ham izi yer alır.
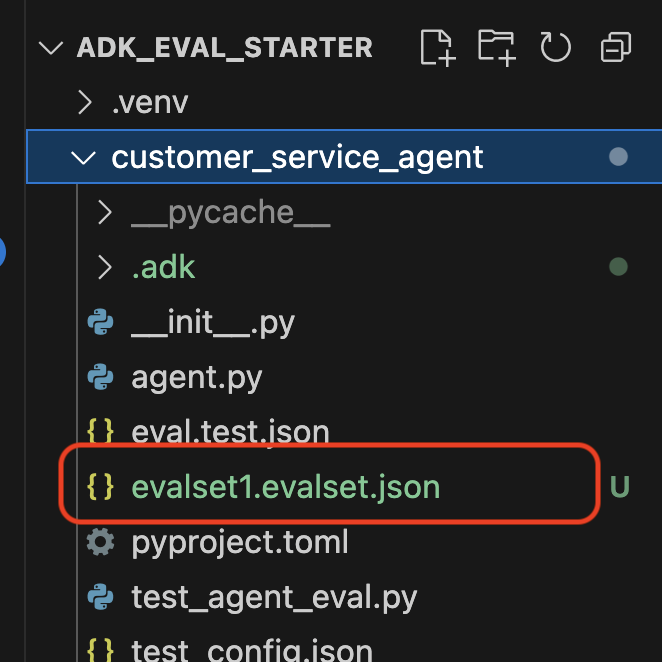
5. The Evaluation Files

Web kullanıcı arayüzü karmaşık bir .evalset.json dosyası oluştururken genellikle otomatik test için daha temiz ve daha yapılandırılmış bir test dosyası oluşturmak isteriz.
ADK Eval iki ana bileşenden oluşur:
- Test Dosyaları: Otomatik olarak oluşturulan Golden Dataset (ör.
customer_service_agent/evalset1.evalset.json) veya manuel olarak seçilen bir küme (ör.customer_service_agent/eval.test.json) olabilir. - Yapılandırma dosyaları (ör.
customer_service_agent/test_config.json): Geçme için metrikleri ve eşikleri tanımlayın.
Test yapılandırma dosyasını ayarlama
- 👉💻 Cloud Shell Düzenleyici terminalinde şunu girin:
cloudshell edit customer_service_agent/test_config.json - 👉 Aşağıdaki kodu düzenleyicinizdeki
customer_service_agent/test_config.jsonbölümüne girin.{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
Metriklerin Kodunu Çözme
tool_trajectory_avg_score(Süreç) Bu metrik, temsilcinin araçları doğru kullanıp kullanmadığını ölçer.
- 0,8: %80 eşleşme istiyoruz.
response_match_score(Çıkış) Bu, yanıtı altın referansla karşılaştırmak için ROUGE-1'i (kelime çakışması) kullanır.
- Avantajları: Hızlı, deterministik, ücretsiz.
- Dezavantajları: Temsilci aynı fikri farklı şekilde ifade ederse (ör. "Geri ödendi" ile "Para iade edildi") başarısız olur.
Gelişmiş Metrikler (daha fazla güce ihtiyacınız olduğunda)
6. Altın Veri Kümesi İçin Değerlendirme Çalıştırma (adk eval)
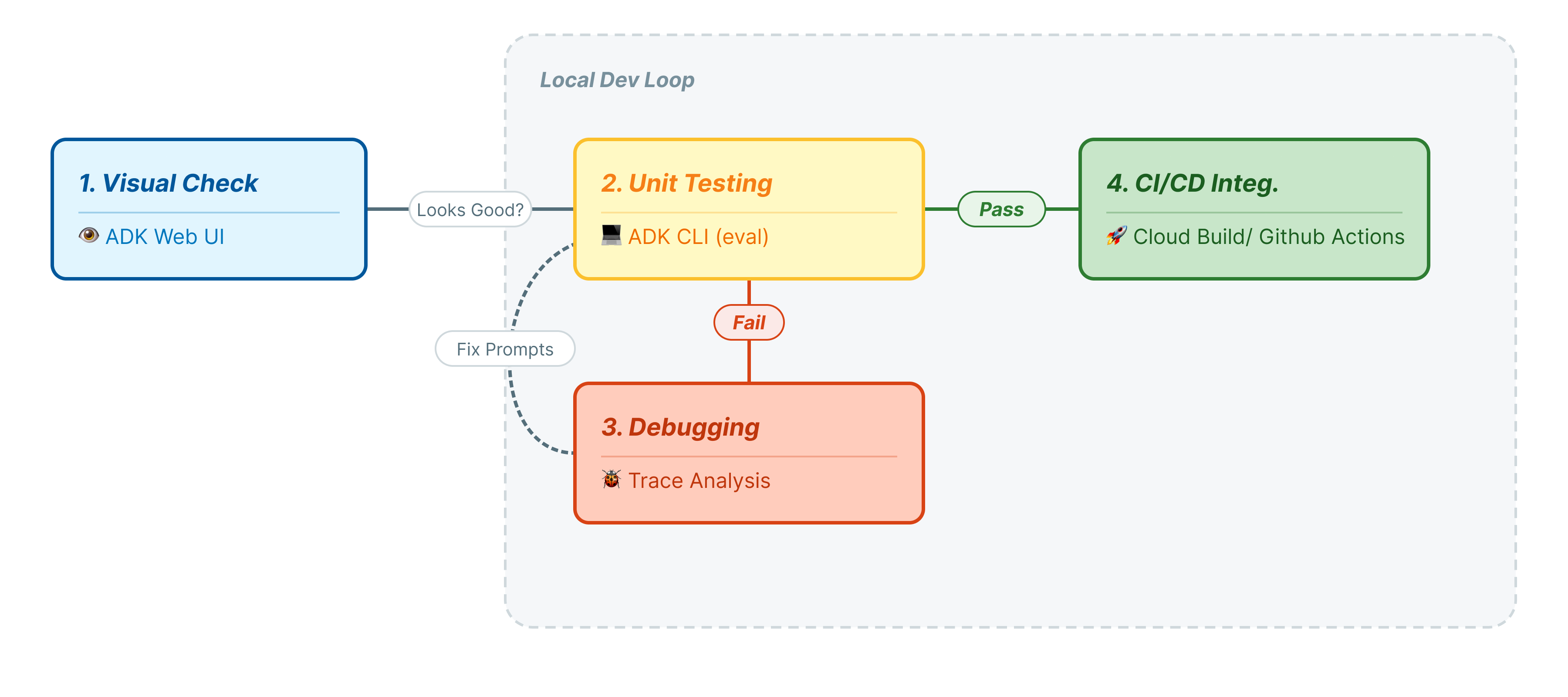
Bu adım, geliştirmenin "İç Döngüsü"nü temsil eder. Değişiklik yapan bir geliştiricisiniz ve sonuçları hızlıca doğrulamak istiyorsunuz.
Altın veri kümesini çalıştırma
1. adımda oluşturduğunuz veri kümesini çalıştıralım. Bu sayede temelinizin sağlam olduğundan emin olabilirsiniz.
- 👉💻 Terminalinizde şunu çalıştırın:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Neler değişiyor?
ADK artık:
- Ajanınız
customer_service_agentüzerinden yükleniyor. evalset1.evalset.jsonkaynağından gelen giriş sorgularını çalıştırma.- Aracının gerçek yörüngesini ve yanıtlarını beklenenlerle karşılaştırma.
- Sonuçları
test_config.json'daki ölçütlere göre puanlama.
Sonuçları analiz etme
Terminal çıkışını izleyin. Geçen ve geçemeyen testlerin özetini görürsünüz.
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Not: Bu yanıtı doğrudan aracıdan oluşturduğunuz için %100 başarılı olması gerekir. Test başarısız olursa temsilciniz deterministik değildir (rastgeledir).
7. Kendi özel testinizi oluşturma
Otomatik olarak oluşturulan veri kümeleri harika olsa da bazen uç durumları (ör. saldırı amaçlı saldırılar veya belirli hata işleme) manuel olarak oluşturmanız gerekir. eval.test.json ile "Doğruluğu" nasıl tanımlayabileceğinize bakalım.
Kapsamlı bir test paketi oluşturalım.
Test Çerçevesi
ADK'da test senaryosu yazarken 3 bölümlü formülü kullanın:
- Kurulum (
session_input): Kullanıcı kimdir? (ör.user_id,state). Bu, testi izole eder. - İstem (
user_content): Tetikleyici nedir?
The Assertions (Expectations) ile:
- Yörünge (
tool_uses): Hesaplamayı doğru yaptı mı? (Mantık) - Yanıt (
final_response): Doğru yanıtı verdi mi? (Kalite) - Orta (
intermediate_responses): Alt aracılar doğru şekilde konuştu mu? (Düzenleme)
Test Paketi'ni yazma
- 👉💻 Cloud Shell Düzenleyici terminalinde şunu girin:
cloudshell edit customer_service_agent/eval.test.json - 👉 Aşağıdaki kodu
customer_service_agent/eval.test.jsondosyasına girin.{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
Test Türlerini İnceleme
Burada üç farklı test türü oluşturduk. Her birinin neyi ve neden değerlendirdiğini inceleyelim.
- Tek Araç Testi (
product_info_check)
- Amaç: Temel bilgilerin alınmasını doğrulayın.
- Önemli Onay:
intermediate_data.tool_useskontrol edilir.lookup_product_infoadlı işlevin çağrıldığını iddia ediyoruz.product_namebağımsız değişkeninin tam olarak "kablosuz kulaklık" olduğunu iddia ediyoruz. - Neden: Model, aracı çağırmadan fiyat uydurursa bu test başarısız olur. Bu, temellendirmeyi sağlar.
- Bağlam Çıkarma Testi (
purchase_history_check)
- Amaç: Aracının, kullanıcı isteminden varlıkları (CUST001) çıkarıp araca iletebildiğini doğrulayın.
- Anahtar Onayı:
get_purchase_historyişlevinincustomer_id: "CUST001"ile çağrıldığını kontrol ederiz. - Neden: Yaygın bir hata modu, aracının doğru aracı boş bir kimlikle çağırmasıdır. Bu, parametrelerin doğruluğunu sağlar.
- İşlem/Yörünge Testi (
refund_request)
- Hedef: Kritik bir yazma işlemini doğrulayın.
- Temel İddia: Yörünge. Daha karmaşık bir senaryoda bu liste birden fazla adım içerir:
[verify_order, calculate_refund, issue_refund]. ADK bu listeyi sırayla kontrol eder. - Nedeni: Para transferi veya veri değişikliği gibi işlemlerde sıra, sonuç kadar önemlidir. Doğrulamadan önce geri ödeme yapmak istemiyorsanız.
8. Özel Testler İçin Değerlendirme Çalıştırma ( adk eval)
- 👉💻 Terminalinizde şunu çalıştırın:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
Çıkışı Anlama
Aşağıdaki gibi bir PASS sonucu görmeniz gerekir:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
Bu, temsilcinizin doğru araçları kullandığı ve beklentilerinize yeterince benzer bir yanıt verdiği anlamına gelir.
9. (İsteğe bağlı: Yalnızca Okuma) - Sorun Giderme ve Hata Ayıklama
Testler başarısız olur. Bu, onların işidir. Peki bu sorunları nasıl düzeltebilirsiniz? Sık karşılaşılan hata senaryolarını ve bunların nasıl ayıklanacağını analiz edelim.
A Senaryosu: "Yörünge" Hatası
Hata:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
Teşhis: Temsilci, doğrulama adımını (lookup_order) atladı. Bu bir mantık hatasıdır.
Sorun giderme:
- Tahmin Etmeyin: ADK Web Kullanıcı Arayüzü'ne (adk web) geri dönün.
- Yeniden üretme: Başarısız olan testteki istemi aynen sohbete yazın.
- Trace: Trace görünümünü açar. "Grafik" sekmesine bakın.
- İstemi düzeltme: Genellikle sistem istemini güncellemeniz gerekir. Değiştir: "Faydalı bir temsilcisin." To: "You are a helpful agent. ÖNEMLİ: issue_refund'u çağırmadan önce ayrıntıları doğrulamak için lookup_order'ı ÇAĞIRMANIZ GEREKİR."
- Testi uyarlama: İşletme mantığı değiştiyse (ör. doğrulama artık gerekli değilse) test yanlıştır. eval.test.json dosyasını yeni gerçekliğe uyacak şekilde güncelleyin.
B Senaryosu: "ROUGE" Hatası
Hata:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
Teşhis: Temsilci doğru şeyi yaptı ancak farklı kelimeler kullandı. ROUGE (kelime çakışması) bu durumu cezalandırdı.
Nasıl düzeltilir?:
- Yanlış mı? Anlam doğruysa istemi değiştirmeyin.
- Eşiği ayarlama:
test_config.jsoniçinde eşiği düşürün (ör.0.8'ten0.5'e). - Metriği yükseltme: Yapılandırmanızda
final_response_match_v2'ye geçin. Bu görevde, her iki cümleyi de okumak ve aynı anlama gelip gelmediklerine karar vermek için bir LLM kullanılır.
10. Pytest ile CI/CD (pytest)
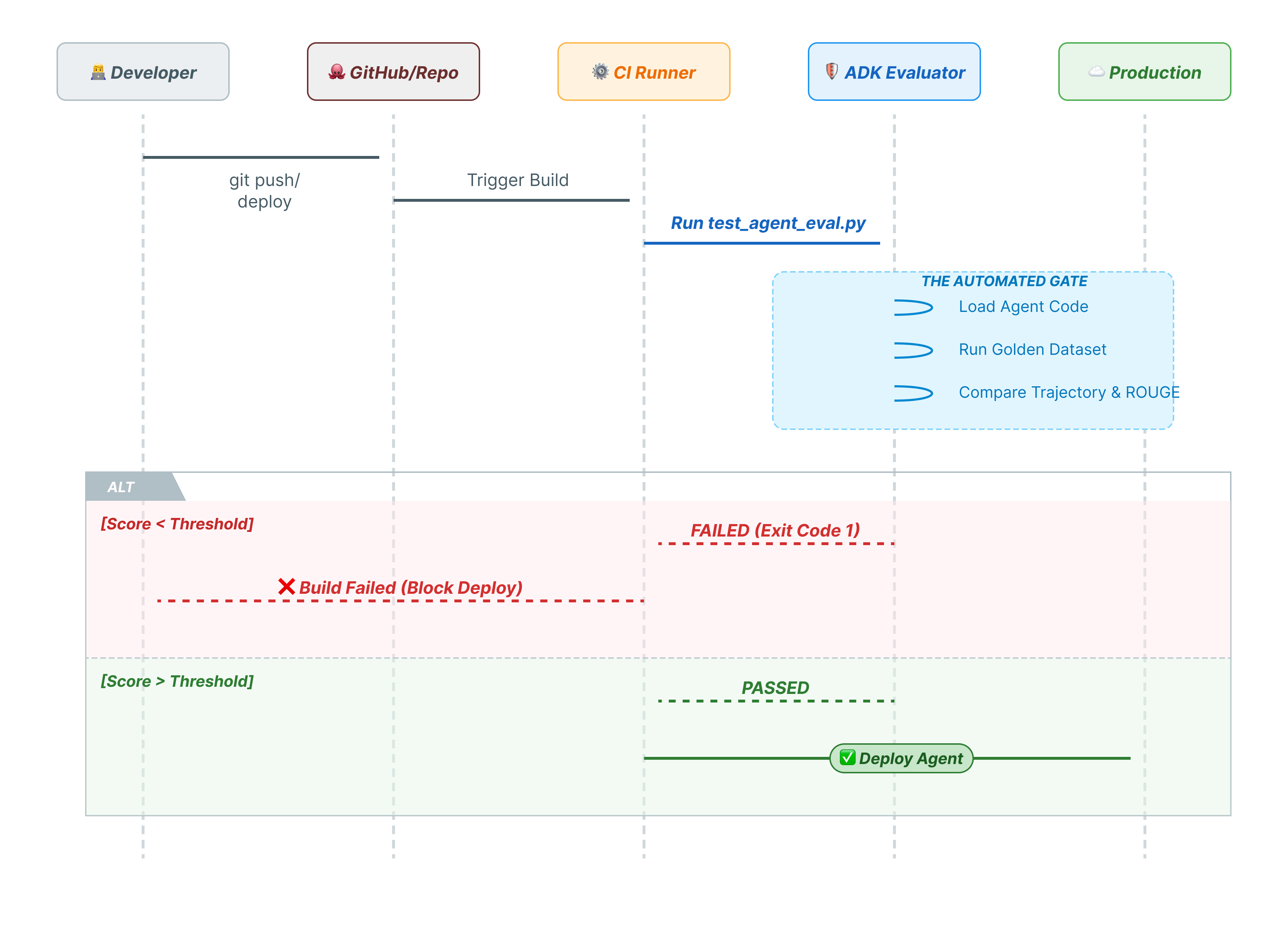
KSA komutları insanlar içindir. pytest makineler içindir. Üretim güvenilirliğini sağlamak için değerlendirmelerimizi bir Python test paketiyle sarmalarız. Bu sayede CI/CD ardışık düzeniniz (GitHub Actions, Jenkins), aracı performansının düşmesi durumunda dağıtımı engelleyebilir.
Bu dosyaya neler dahil edilir?
Bu Python dosyası, CI/CD çalıştırıcınız ile ADK değerlendiricisi arasında köprü görevi görür. Şunları yapması gerekir:
- Aracınızı yükleme: Aracınızın kodunu dinamik olarak içe aktarın.
- Durumu Sıfırla: Testlerin birbirine sızmaması için aracı belleğinin temiz olduğundan emin olun.
- Değerlendirmeyi Çalıştırın:
AgentEvaluator.evaluate()programatik olarak çağrılır. - Başarıyı Onayla: Değerlendirme puanı düşükse derleme başarısız olur.
Entegrasyon Testi Kodu
- 👉
customer_service_agent/test_agent_eval.pyuygulamasını açın. Bu komut dosyası,eval.test.jsoniçinde tanımlanan testleri çalıştırmak içinAgentEvaluator.evaluatekullanır. - 👉 Aşağıdaki kodu düzenleyicinizdeki
customer_service_agent/test_agent_eval.pybölümüne girin.from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
Pytest'i çalıştırma
- 👉💻 Terminalinizde şunu çalıştırın:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. Sonuç
Tebrikler! ADK Eval'i kullanarak müşteri hizmetleri temsilcinizi başarıyla değerlendirdiniz.
Öğrendikleriniz
Bu codelab'de şunları öğrendiniz:
- ✅ Aracınız için kesin referans değer oluşturmak üzere Altın Veri Kümesi oluşturun.
- ✅ Başarı ölçütlerini tanımlamak için Değerlendirme Yapılandırması'nı anlama.
- ✅ Gerilemeleri erken yakalamak için Otomatik Değerlendirmeler Çalıştırın.
ADK Eval'ı geliştirme iş akışınıza dahil ederek, davranışlardaki değişikliklerin otomatik testleriniz tarafından yakalanacağını bilerek güvenle aracı oluşturabilirsiniz.
Bu laboratuvar, Google Cloud ile Üretime Hazır Yapay Zeka öğrenme rotasının bir parçasıdır.
- Prototip aşamasından üretim aşamasına geçiş yapmak için tüm müfredatı inceleyin.
- İlerleme durumunuzu
ProductionReadyAIhashtag'iyle paylaşın.
Daha fazla okuma: