
1. 信任缺口
灵感时刻
您构建了一个客服代理。可在您的设备上运行。但昨天,它却告诉一位客户,某款缺货的智能手表有货,更糟糕的是,它还虚构了一项退款政策。知道代理已上线后,您晚上睡得怎么样?
为了弥合概念验证与可用于生产用途的 AI 智能体之间的鸿沟,强大的自动化评估框架至关重要。

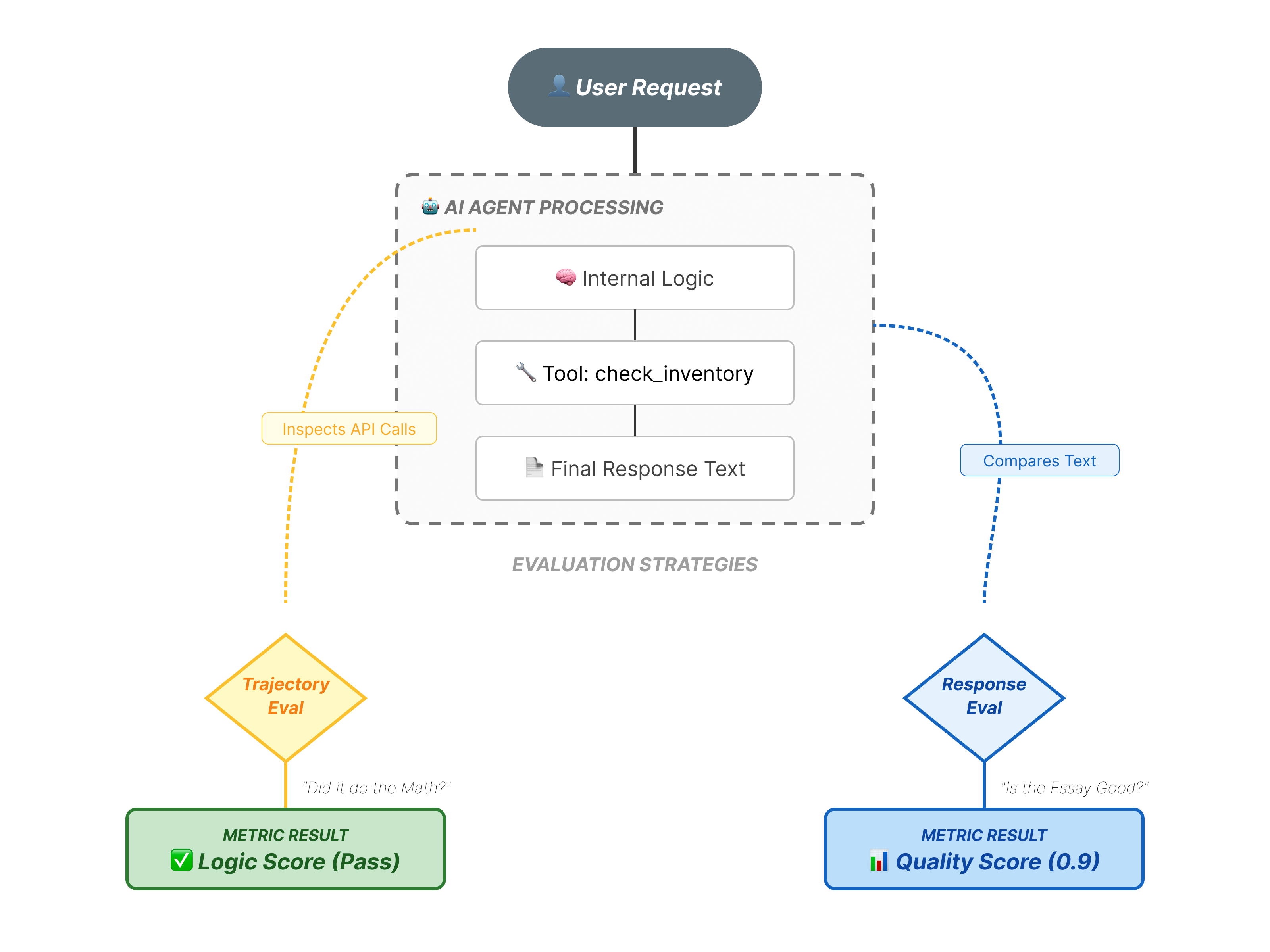
我们实际评估的是什么?
智能体评估比标准 LLM 评估更复杂。您不仅要对作文(最终回答)进行评分,还要对数学(用于得出最终回答的逻辑/工具)进行评分。
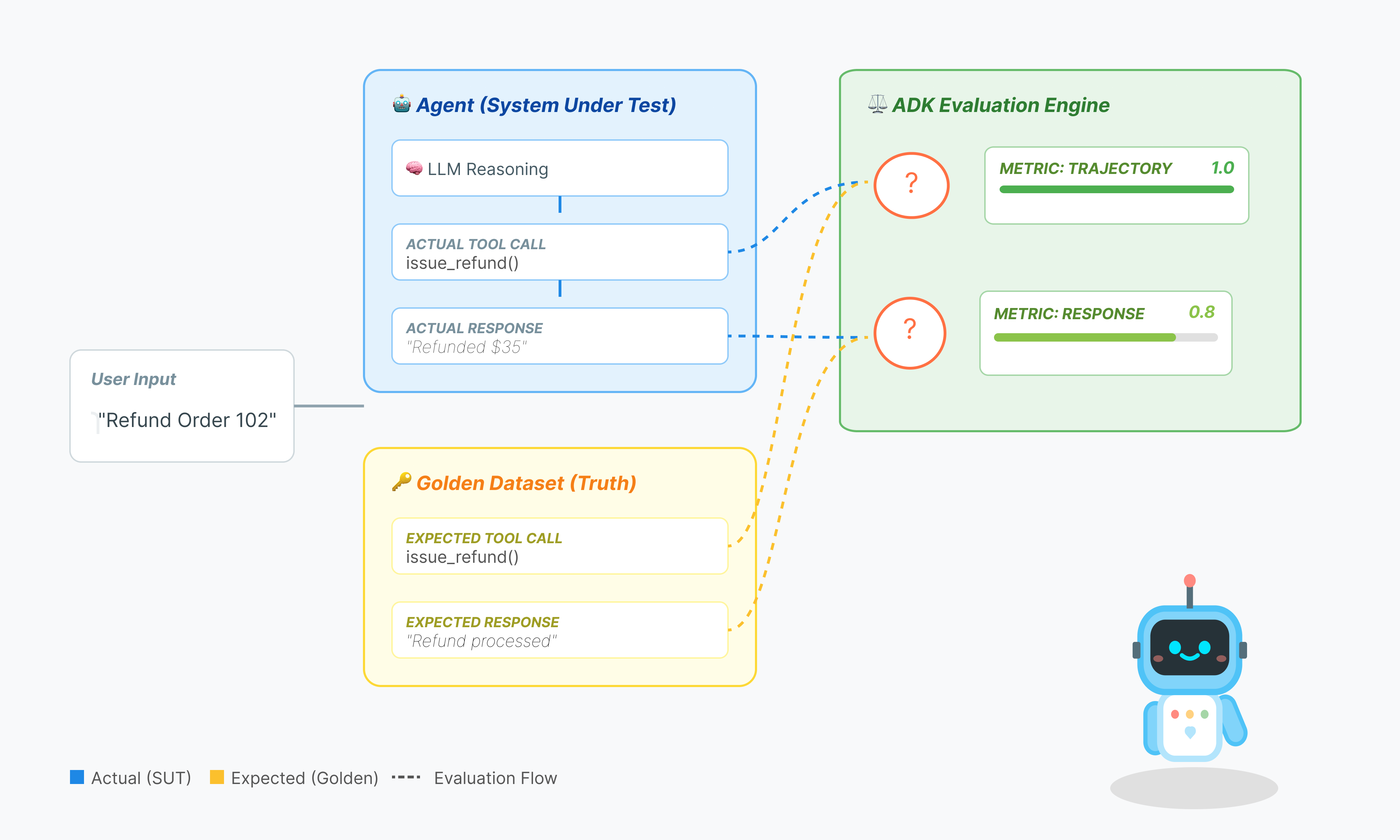
- 轨迹(流程):智能体是否在正确的时间使用了正确的工具?它是否在
place_order之前调用了check_inventory? - 最终回答(输出):回答是否正确、礼貌且基于数据?
开发生命周期
在此 Codelab 中,我们将逐步介绍代理测试的专业生命周期:
- 本地视觉检查 (ADK Web 界面):手动聊天并验证逻辑(第 1 步)。
- 单元/回归测试 (ADK CLI):在本地运行特定测试用例以快速发现错误(第 3 步和第 4 步)。
- 调试(问题排查):分析失败情况并修复提示逻辑(第 5 步)。
- CI/CD 集成 (Pytest):在构建流水线中自动执行测试(第 6 步)。
2. 设置
为了让 AI 代理正常运行,我们需要两样东西:一个 Google Cloud 项目来提供基础。
第 1 部分:启用结算账号
如需运行此 Codelab,您需要拥有一个有一定信用额度的结算账号。使用本 Codelab 顶部横幅中的积分开始学习。如果您已关联结算账号,则可以跳过此步骤。
第二部分:开放环境
- 👉 点击此链接可直接前往 Cloud Shell Editor
- 👉 如果系统在今天任何时间提示您进行授权,请点击授权继续。
- 👉 如果终端未显示在屏幕底部,请打开它:
- 点击查看
- 点击终端
- 👉💻 在终端中,使用以下命令验证您是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list - 👉💻 从 GitHub 克隆引导项目:
git clone https://github.com/cuppibla/adk_eval_starter - 👉💻 从项目目录运行设置脚本。
cd ~/adk_eval_starter ./init.sh
脚本会自动处理其余设置流程。
- 👉💻 设置所需的项目 ID:
gcloud config set project $(cat ~/project_id.txt) --quiet
第三部分:设置权限
- 👉💻 使用以下命令启用所需的 API。这可能需要几分钟的时间。
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ cloudbuild.googleapis.com \ artifactregistry.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 在终端中运行以下命令,授予必要的权限:
. ~/adk_eval_starter/set_env.sh
请注意,系统已为您创建 .env 文件。这会显示您的项目信息。
3. 生成黄金数据集 (adk web)
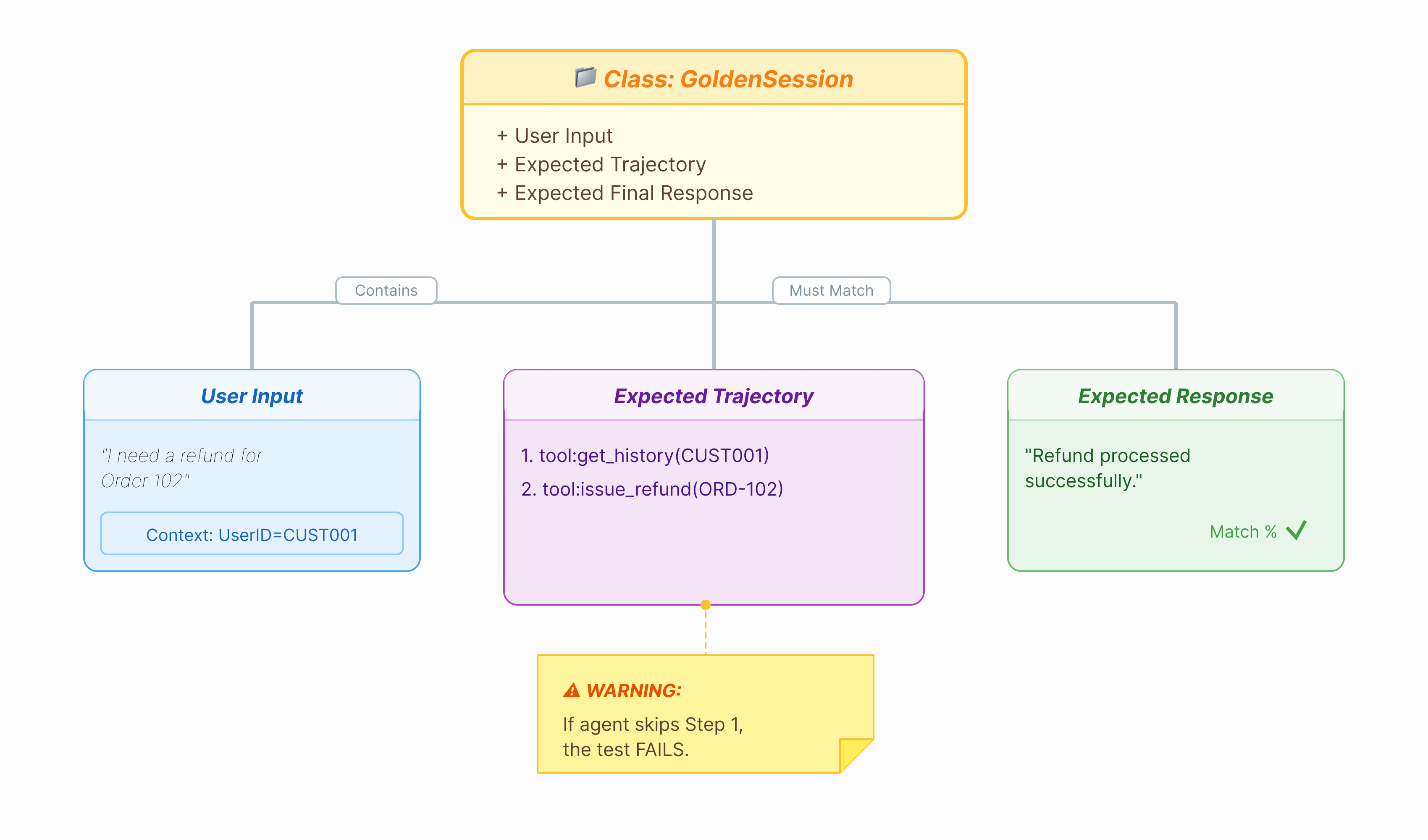
在对代理进行评分之前,我们需要答案密钥。在 ADK 中,我们将其称为黄金数据集。此数据集包含“完美”互动,可作为评估的标准答案。
什么是黄金数据集?
黄金数据集是智能体正确执行操作的快照。它不仅仅是问答对列表。它会捕获以下信息:
- 用户查询(“我想退款”)
- 轨迹(工具调用的确切顺序:
check_order->verify_eligibility->refund_transaction)。 - 最终回答(“完美”的文本回答)。
我们使用此指标来检测回归。如果您更新了提示,但代理突然停止在退款前检查资格,则黄金数据集测试将失败,因为轨迹不再匹配。
打开网页界面
ADK Web 界面提供了一种交互式方式,通过捕获与代理的真实互动来创建这些黄金数据集。
- 👉💻 在终端中,运行:
cd ~/adk_eval_starter uv run adk web - 👉💻 打开网页界面预览版(通常位于
http://127.0.0.1:8000)。 - 👉 在聊天界面中,输入
Hi, I'm customer CUST001. Can you check my orders? I need a refund for order ORD-102. It arrived damaged.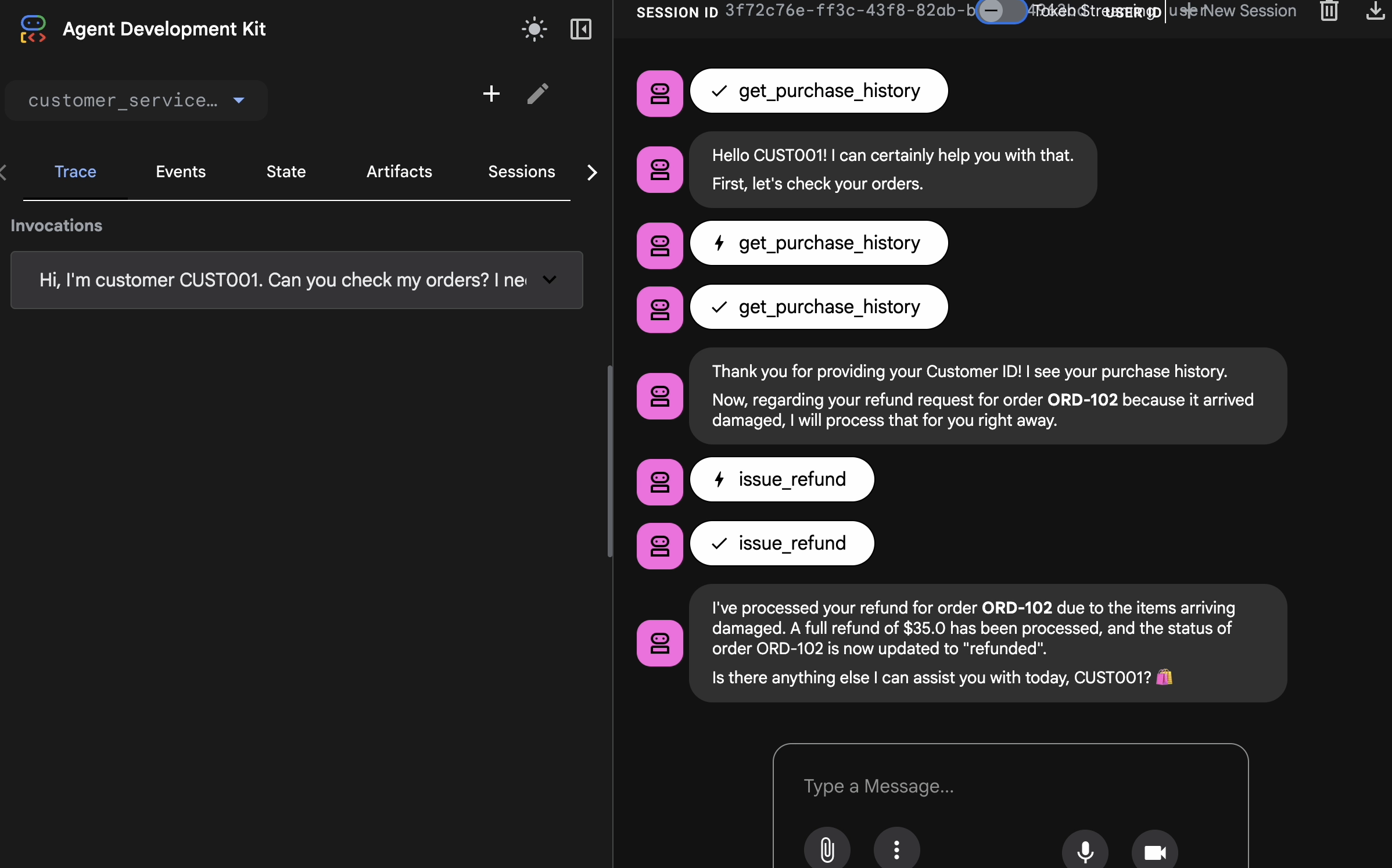 您将看到如下所示的响应:
您将看到如下所示的响应:I've processed your refund for order ORD-102 due to the items arriving damaged. A full refund of $35.0 has been processed, and the status of order ORD-102 is now updated to "refunded". Is there anything else I can assist you with today, CUST001? 🛍️
捕捉黄金互动
前往会话标签页。您可以在此处点击会话,查看代理的对话历史记录。
- 与代理互动,创建理想的对话流程,例如查看交易记录或申请退款。
- 查看对话,确保其代表了预期行为。
4. 导出黄金数据集
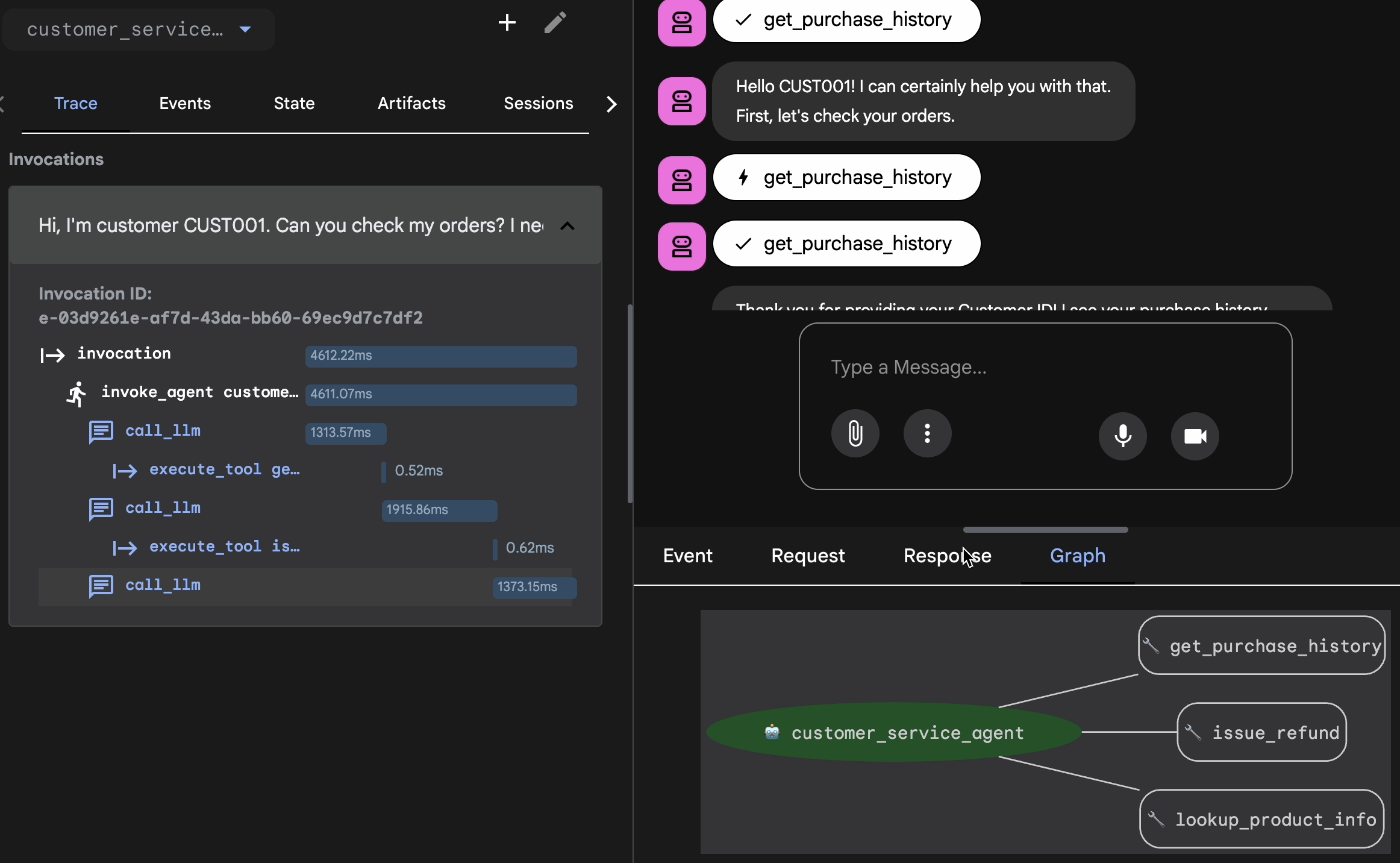
通过轨迹视图进行验证
在导出之前,您必须验证代理是否只是碰巧答对了问题。您需要检查内部逻辑。
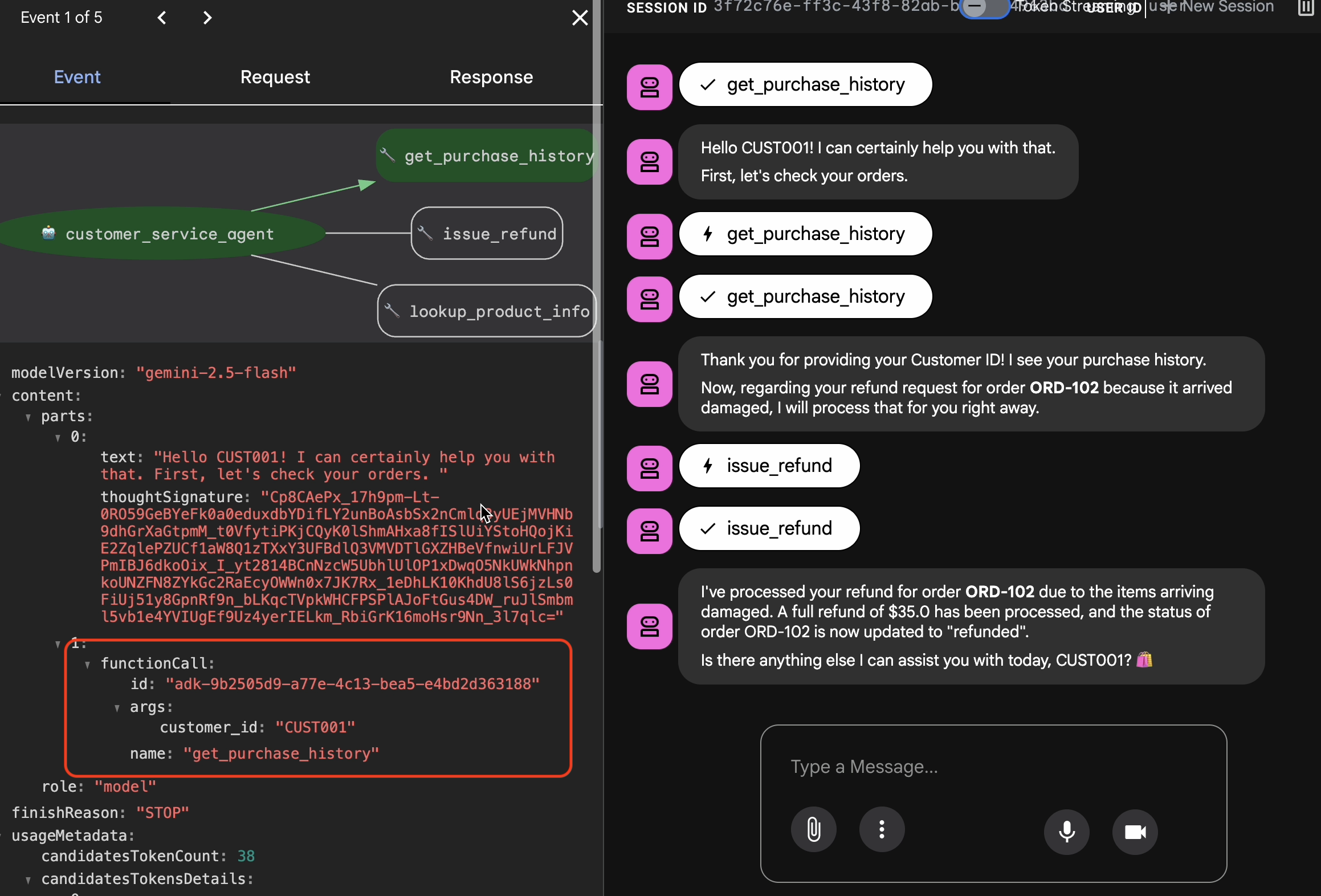
- 在 Web 界面中,点击轨迹标签页。
- 系统会按用户消息自动对轨迹进行分组。将鼠标悬停在轨迹行上,即可突出显示聊天中的相应消息。
- 检查蓝色行:这些行表示由互动生成的事件。点击蓝色行即可打开检查面板。
- 检查以下标签页以验证逻辑:
- 图:工具调用和逻辑流程的直观表示形式。它是否采用了正确的路径?
- 请求/响应:准确查看发送给模型的内容和模型返回的内容。
- 验证:如果智能体在未调用数据库工具的情况下猜对了退款金额,则属于“幸运的幻觉”。
将会话添加到 EvalSet
对对话和轨迹感到满意后:
- 👉 点击
Eval标签页,然后点击Create Evaluation Set按钮,然后输入要使用的评估名称:evalset1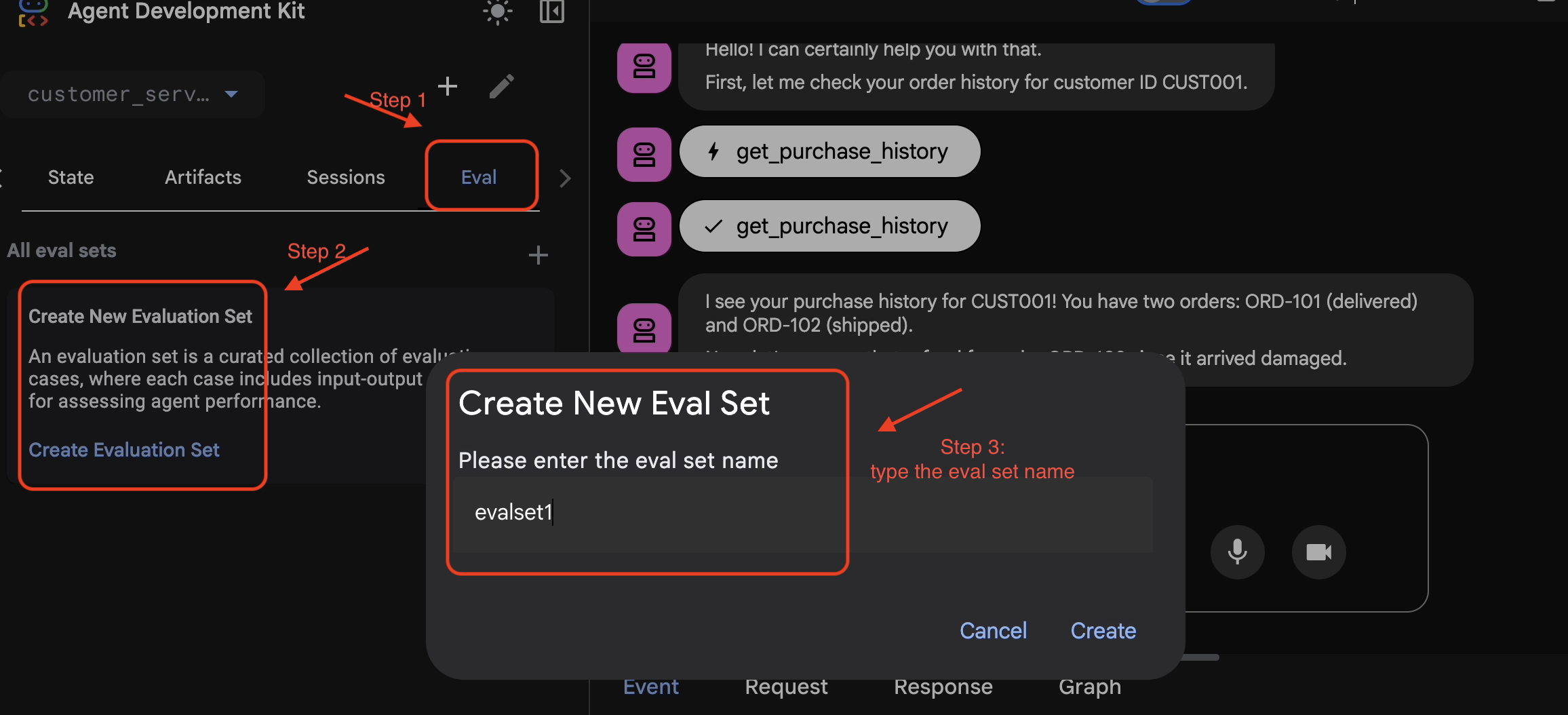
- 👉 在此评估集中,点击
Add current session to evalset1,在弹出式窗口中,输入会话名称:eval1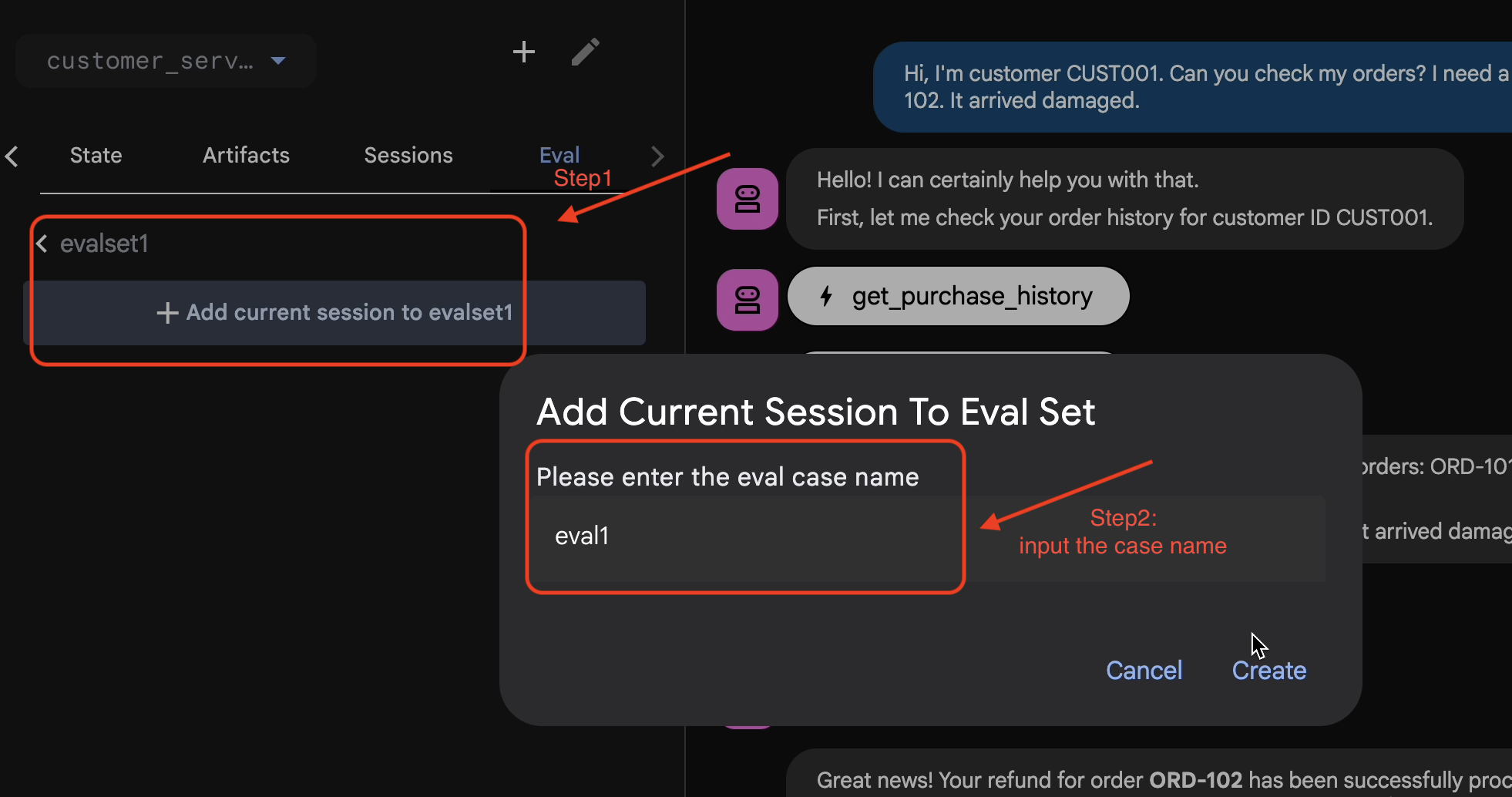
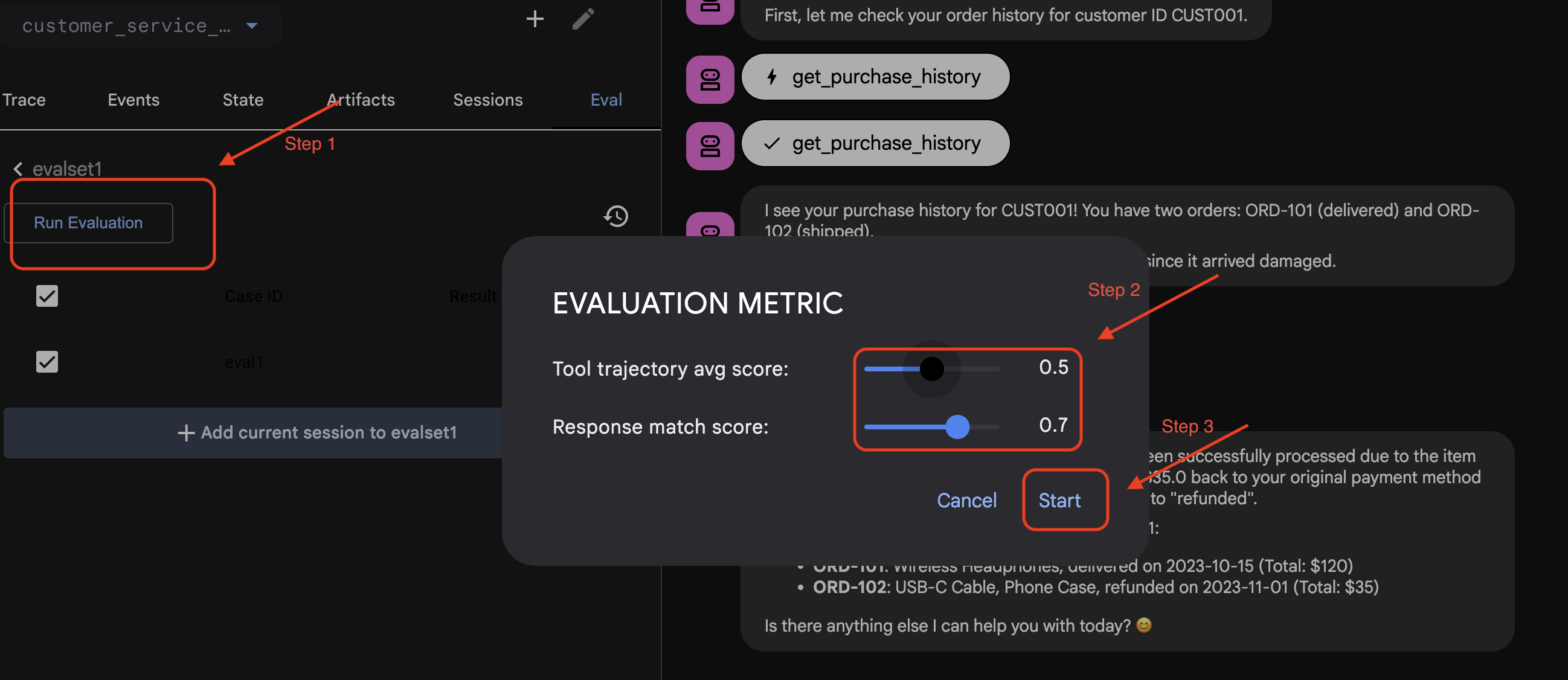
在 ADK Web 中运行评估
- 👉 在 ADK Web 界面中,点击
Run Evaluation,在弹出式窗口中调整指标,然后点击Start:
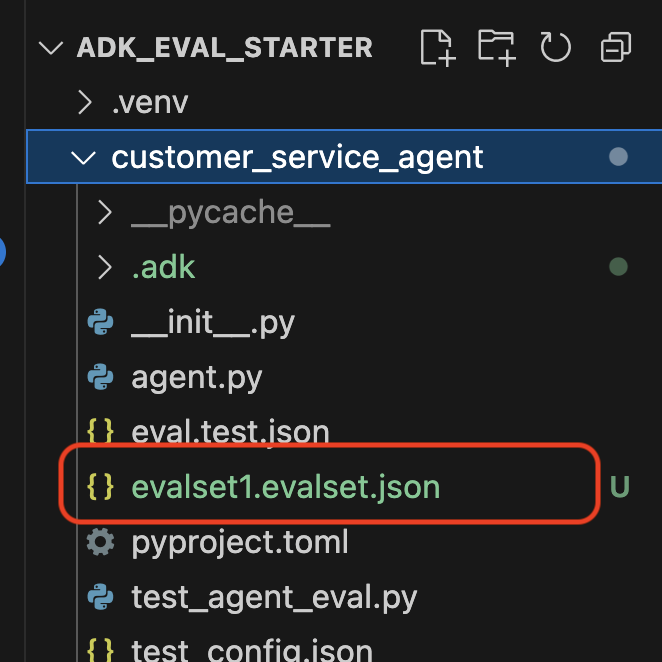
验证代码库中的数据集
您会看到一条确认消息,告知您数据集文件(例如 evalset1.evalset.json)已保存到您的代码库。此文件包含自动生成的原始对话记录。
5. 评估文件
虽然 Web 界面会生成复杂的 .evalset.json 文件,但我们通常希望创建更简洁、更结构化的测试文件以进行自动化测试。
ADK Eval 使用两个主要组件:
- 测试文件:可以是自动生成的黄金数据集(例如
customer_service_agent/evalset1.evalset.json),也可以是手动整理的集合(例如customer_service_agent/eval.test.json)。 - 配置文件(例如
customer_service_agent/test_config.json):定义通过的指标和阈值。
设置测试配置文件
- 👉💻 在 Cloud Shell 编辑器终端中,输入
cloudshell edit customer_service_agent/test_config.json - 👉 在编辑器中将以下代码输入到
customer_service_agent/test_config.json中。{ "criteria": { "tool_trajectory_avg_score": 0.8, "response_match_score": 0.5 } }
解读指标
tool_trajectory_avg_score(流程)此指标用于衡量智能体是否正确使用了工具。
- 0.8:我们要求匹配度达到 80%。
response_match_score(输出)此部分使用 ROUGE-1(字词重叠)将回答与标准参考答案进行比较。
- 优点:速度快、确定性高、免费。
- 缺点:如果代理以不同的方式表达同一想法(例如,“已退款”与“退回款项”),则会失败。
高级指标(当您需要更强大的功能时)
6. 针对黄金数据集运行评估 (adk eval)
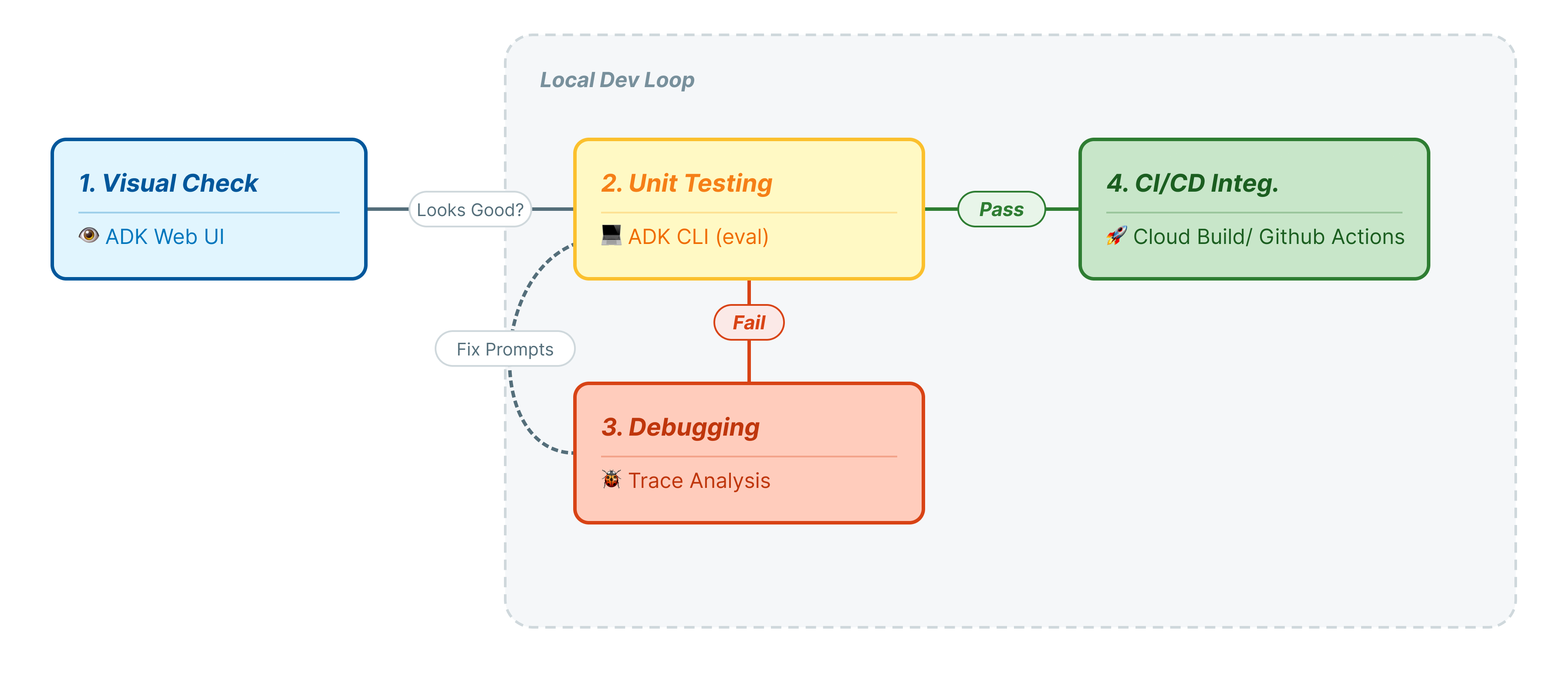
此步骤表示开发的“内部循环”。您是正在进行更改的开发者,并且希望快速验证结果。
运行黄金数据集
我们来运行您在第 1 步中生成的数据集。这样可确保您的基准稳固。
- 👉💻 在终端中,运行:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/evalset1.evalset.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
发生了什么?
ADK 现已:
- 正在从
customer_service_agent加载代理。 - 运行来自
evalset1.evalset.json的输入查询。 - 将智能体的实际轨迹和回答与预期轨迹和回答进行比较。
- 根据
test_config.json中的标准对结果进行评分。
分析结果
观看终端输出。您将看到通过和未通过的测试的摘要。
Eval Run Summary
evalset1:
Tests passed: 1
Tests failed: 0
********************************************************************
Eval Set Id: evalset1
Eval Id: eval1
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5581395348837208, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+==========================+===========================+===========================+=============================+========================+
| 0 | Hi, I'm customer CUST001. | Great news! Your refund | Great news, CUST001! 🎉 | id='adk-051409fe-c230-43f | id='adk-4e9aa570-1cc6-4c3 | Status: PASSED, Score: | Status: PASSED, Score: |
| | Can you check my orders? | for order **ORD-102** has | I've successfully | 4-a7f1- 5747280fd878' | c-aa3e- 91dbe113dd4b' | 1.0 | 0.5581395348837208 |
| | I need a refund for order | been successfully | processed a full refund | args={'customer_id': | args={'customer_id': | | |
| | ORD-102. It arrived | processed due to the item | of $35.0 for your order | 'CUST001'} name='get_purc | 'CUST001'} name='get_purc | | |
| | damaged. | arriving damaged. You | ORD-102 because it | hase_history' | hase_history' | | |
| | | should see a full refund | arrived damaged. The | partial_args=None | partial_args=None | | |
| | | of $35.0 back to your | status of that order has | will_continue=None id= 'a | will_continue=None | | |
| | | original payment method | been updated to | dk-8a194cb8-5a82-47ce-a3a | id='adk- dad1b376-9bcc-48 | | |
| | | shortly. The status of | "refunded." Is there | 7- 3d24551f8c90' | bb-996f-a30f6ef5b70b' | | |
| | | this order has been | anything else I can | args={'reason': | args={'reason': | | |
| | | updated to "refunded". | assist you with today? | 'damaged', 'order_id': | 'damaged', 'order_id': | | |
| | | Here's your updated | | 'ORD-102'} | 'ORD-102'} | | |
| | | purchase history for | | name='issue_refund' | name='issue_refund' | | |
| | | CUST001: * **ORD-101**: | | partial_args=None | partial_args=None | | |
| | | Wireless Headphones, | | will_continue=None | will_continue=None | | |
| | | delivered on 2023-10-15 | | | | | |
| | | (Total: $120) * | | | | | |
| | | **ORD-102**: USB-C Cable, | | | | | |
| | | Phone Case, refunded on | | | | | |
| | | 2023-11-01 (Total: $35) | | | | | |
| | | Is there anything else I | | | | | |
| | | can help you with today? | | | | | |
| | | 😊 | | | | | |
+----+---------------------------+---------------------------+--------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
注意:由于您刚刚通过代理本身生成了此报告,因此它应该会通过 100% 的测试。如果失败,则表示您的代理是非确定性的(随机)。
7. 创建您自己的自定义测试
虽然自动生成的数据集很实用,但有时您需要手动设计极端情况(例如,对抗性攻击或特定的错误处理)。我们来看看 eval.test.json 如何让您定义“正确性”。
我们来构建一个全面的测试套件。
测试框架
在 ADK 中编写测试用例时,请遵循以下三部分公式:
- 设置 (
session_input):用户是谁?(例如,user_id、state)。这样可以隔离测试。 - 提示 (
user_content):触发器是什么?
使用断言(预期):
- 轨迹 (
tool_uses):计算是否正确?(逻辑) - 回答(
final_response):它是否说出了正确答案?(质量) - 中级 (
intermediate_responses):子代理是否正确回答了问题?(编排)
编写测试套件
- 👉💻 在 Cloud Shell 编辑器终端中,输入
cloudshell edit customer_service_agent/eval.test.json - 👉 将以下代码输入到
customer_service_agent/eval.test.json文件中。{ "eval_set_id": "customer_service_eval", "name": "Customer Service Agent Evaluation", "description": "Evaluation suite for the customer service agent covering product info, purchase history, and refunds.", "eval_cases": [ { "eval_id": "product_info_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_1", "state": {} }, "conversation": [ { "invocation_id": "turn_1_product_info", "user_content": { "role": "user", "parts": [ { "text": "Do you have wireless headphones in stock?" } ] }, "final_response": { "role": "model", "parts": [ { "text": "Yes, we have wireless headphones in stock! They are priced at $120.00 and feature noise-canceling with a 20-hour battery life. 🎧" } ] }, "intermediate_data": { "tool_uses": [ { "name": "lookup_product_info", "args": { "product_name": "wireless headphones" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "purchase_history_check", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_2", "state": {} }, "conversation": [ { "invocation_id": "turn_1_purchase_history", "user_content": { "role": "user", "parts": [ { "text": "What did I buy recently? My customer ID is CUST001." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Here's your recent purchase history for Customer ID CUST001:\n\n* **Order ORD-101** (October 15, 2023): Wireless Headphones, Status: delivered, Total: $120\n* **Order ORD-102** (November 1, 2023): USB-C Cable, Phone Case, Status: refunded, Total: $35\n\nLet me know if you have any other questions or need further assistance! 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "get_purchase_history", "args": { "customer_id": "CUST001" } } ], "intermediate_responses": [] } } ] }, { "eval_id": "refund_request", "session_input": { "app_name": "customer_service_agent", "user_id": "eval_user_3", "state": {} }, "conversation": [ { "invocation_id": "turn_1_refund", "user_content": { "role": "user", "parts": [ { "text": "I want a refund for order ORD-102 because it was damaged." } ] }, "final_response": { "role": "model", "parts": [ { "text": "Your refund for order **ORD-102** due to \"damaged\" has been successfully processed! Refund amount: **$35.0**. Your order status has been updated to **refunded**. \nIs there anything else I can help you with today? 🛍️" } ] }, "intermediate_data": { "tool_uses": [ { "name": "issue_refund", "args": { "order_id": "ORD-102", "reason": "damaged" } } ], "intermediate_responses": [] } } ] } ] }
解构测试类型
我们在此处创建了三种不同的测试。下面我们来详细了解一下每种指标的评估对象和原因。
- 单工具测试 (
product_info_check)
- 目标:验证基本信息检索。
- 密钥断言:我们检查
intermediate_data.tool_uses。我们断言会调用lookup_product_info。我们断言实参product_name正好是“无线耳机”。 - 原因:如果模型在不调用工具的情况下虚构价格,此测试将失败。这样可确保接地。
- 上下文提取测试 (
purchase_history_check)
- 目标:验证代理能否从用户提示中提取实体 (CUST001) 并将其传递给工具。
- 密钥断言:我们检查
get_purchase_history是否使用customer_id: "CUST001"调用。 - 原因:一种常见的故障模式是,代理调用了正确的工具,但 ID 为 null。这可确保参数准确无误。
- 动作/轨迹测试 (
refund_request)
- 目标:验证关键写入操作。
- 关键断言:轨迹。在更复杂的场景中,此列表将包含多个步骤:
[verify_order, calculate_refund, issue_refund]。ADK 会按顺序检查此列表。 - 原因:对于涉及资金转移或数据更改的操作,顺序与结果同样重要。您不希望在验证之前退款。
8. 运行自定义测试的评估 ( adk eval)
- 👉💻 在终端中,运行:
cd ~/adk_eval_starter uv run adk eval customer_service_agent customer_service_agent/eval.test.json --config_file_path=customer_service_agent/test_config.json --print_detailed_results
了解输出
您应该会看到类似如下所示的 PASS 结果:
Eval Run Summary
customer_service_eval:
Tests passed: 3
Tests failed: 0
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: purchase_history_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.5473684210526315, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+==========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | What did I buy recently? | Here's your recent | Looks like your recent | id=None | id='adk-8960eb53-2933-459 | Status: PASSED, Score: | Status: PASSED, Score: |
| | My customer ID is | purchase history for | orders include: * | args={'customer_id': | f-b306- 71e3c069e77e' | 1.0 | 0.5473684210526315 |
| | CUST001. | Customer ID CUST001: * | **ORD-101 (2023-10-15):** | 'CUST001'} name='get_purc | args={'customer_id': | | |
| | | **Order ORD-101** | Wireless Headphones for | hase_history' | 'CUST001'} name='get_purc | | |
| | | (October 15, 2023): | $120.00 - Status: | partial_args=None | hase_history' | | |
| | | Wireless Headphones, | Delivered 🎧 * **ORD-102 | will_continue=None | partial_args=None | | |
| | | Status: delivered, Total: | (2023-11-01):** USB-C | | will_continue=None | | |
| | | $120 * **Order | Cable, Phone Case for | | | | |
| | | ORD-102** (November 1, | $35.00 - Status: Refunded | | | | |
| | | 2023): USB-C Cable, Phone | 📱 Is there anything else | | | | |
| | | Case, Status: refunded, | I can help you with | | | | |
| | | Total: $35 Let me know | regarding these orders? | | | | |
| | | if you have any other | | | | | |
| | | questions or need further | | | | | |
| | | assistance! 🛍️ | | | | | |
+----+--------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: product_info_check
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6829268292682927, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+======================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | Do you have wireless | Yes, we have wireless | Yes, we do! 🎧 We have | id=None | id='adk-4571d660-a92b-412 | Status: PASSED, Score: | Status: PASSED, Score: |
| | headphones in stock? | headphones in stock! They | noise-canceling wireless | args={'product_name': | a-a79e- 5c54f8b8af2d' | 1.0 | 0.6829268292682927 |
| | | are priced at $120.00 and | headphones with a 20-hour | 'wireless headphones'} na | args={'product_name': | | |
| | | feature noise-canceling | battery life available | me='lookup_product_info' | 'wireless headphones'} na | | |
| | | with a 20-hour battery | for $120. | partial_args=None | me='lookup_product_info' | | |
| | | life. 🎧 | | will_continue=None | partial_args=None | | |
| | | | | | will_continue=None | | |
+----+----------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
********************************************************************
Eval Set Id: customer_service_eval
Eval Id: refund_request
Overall Eval Status: PASSED
---------------------------------------------------------------------
Metric: tool_trajectory_avg_score, Status: PASSED, Score: 1.0, Threshold: 0.8
---------------------------------------------------------------------
Metric: response_match_score, Status: PASSED, Score: 0.6216216216216216, Threshold: 0.5
---------------------------------------------------------------------
Invocation Details:
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
| | prompt | expected_response | actual_response | expected_tool_calls | actual_tool_calls | tool_trajectory_avg_score | response_match_score |
+====+===========================+===========================+===========================+===========================+===========================+=============================+========================+
| 0 | I want a refund for order | Your refund for order | Your refund for order | id=None args={'order_id': | id='adk-fb8ff1cc- cf87-41 | Status: PASSED, Score: | Status: PASSED, Score: |
| | ORD-102 because it was | **ORD-102** due to | **ORD-102** has been | 'ORD-102', 'reason': | f2-9b11-d4571b14287f' | 1.0 | 0.6216216216216216 |
| | damaged. | "damaged" has been | successfully processed! | 'damaged'} | args={'order_id': | | |
| | | successfully processed! | You should see a full | name='issue_refund' | 'ORD-102', 'reason': | | |
| | | Refund amount: **$35.0**. | refund of $35.0 appear in | partial_args=None | 'damaged'} | | |
| | | Your order status has | your account shortly. We | will_continue=None | name='issue_refund' | | |
| | | been updated to | apologize for the | | partial_args=None | | |
| | | **refunded**. Is there | inconvenience! Is there | | will_continue=None | | |
| | | anything else I can help | anything else I can | | | | |
| | | you with today? 🛍️ | assist you with today? 😊 | | | | |
+----+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+-----------------------------+------------------------+
这意味着,您的代理使用了正确的工具,并提供了与您的预期足够相似的回答。
9. (可选:只读)- 问题排查和调试
测试将会失败。这是他们的工作。但如何修复这些问题呢?下面我们来分析一下常见的失败场景以及如何调试这些场景。
场景 A:“轨迹”失败
错误:
Result: FAILED
Reason: Criteria 'tool_trajectory_avg_score' failed. Score 0.0 < Threshold 1.0
Details:
EXPECTED: tool: lookup_order, then tool: issue_refund
ACTUAL: tool: issue_refund
诊断:代理跳过了验证步骤 (lookup_order)。这是一个逻辑错误。
问题排查方法:
- 不要猜测:返回到 ADK 网页界面 (adk web)。
- 重现:在对话中输入失败测试中的确切提示。
- Trace:打开 Trace 视图。查看“图表”标签页。
- 修复提示:通常,您需要更新系统提示。更改:“你是一名乐于助人的代理。”To: "You are a helpful agent. 重要提示:您必须先调用 lookup_order 来验证详细信息,然后再调用 issue_refund。
- 调整测试:如果业务逻辑发生了变化(例如,不再需要验证),则测试是错误的。更新了 eval.test.json 以适应新情况。
场景 B:“ROUGE”失败
错误:
Result: FAILED
Reason: Criteria 'response_match_score' failed. Score 0.45 < Threshold 0.8
Expected: "The refund has been processed successfully."
Actual: "I've gone ahead and returned the money to your card."
诊断:客服人员的做法正确,但措辞不同。ROUGE(字词重叠)对其进行了惩罚。
解决方法:
- 有错吗?如果含义正确,请勿更改提示。
- 调整阈值:将
test_config.json中的阈值降低(例如,从0.8降至0.5)。 - 升级指标:在配置中切换到
final_response_match_v2。此功能使用 LLM 读取两个句子,并判断它们的含义是否相同。
10. 使用 Pytest (pytest) 实现 CI/CD
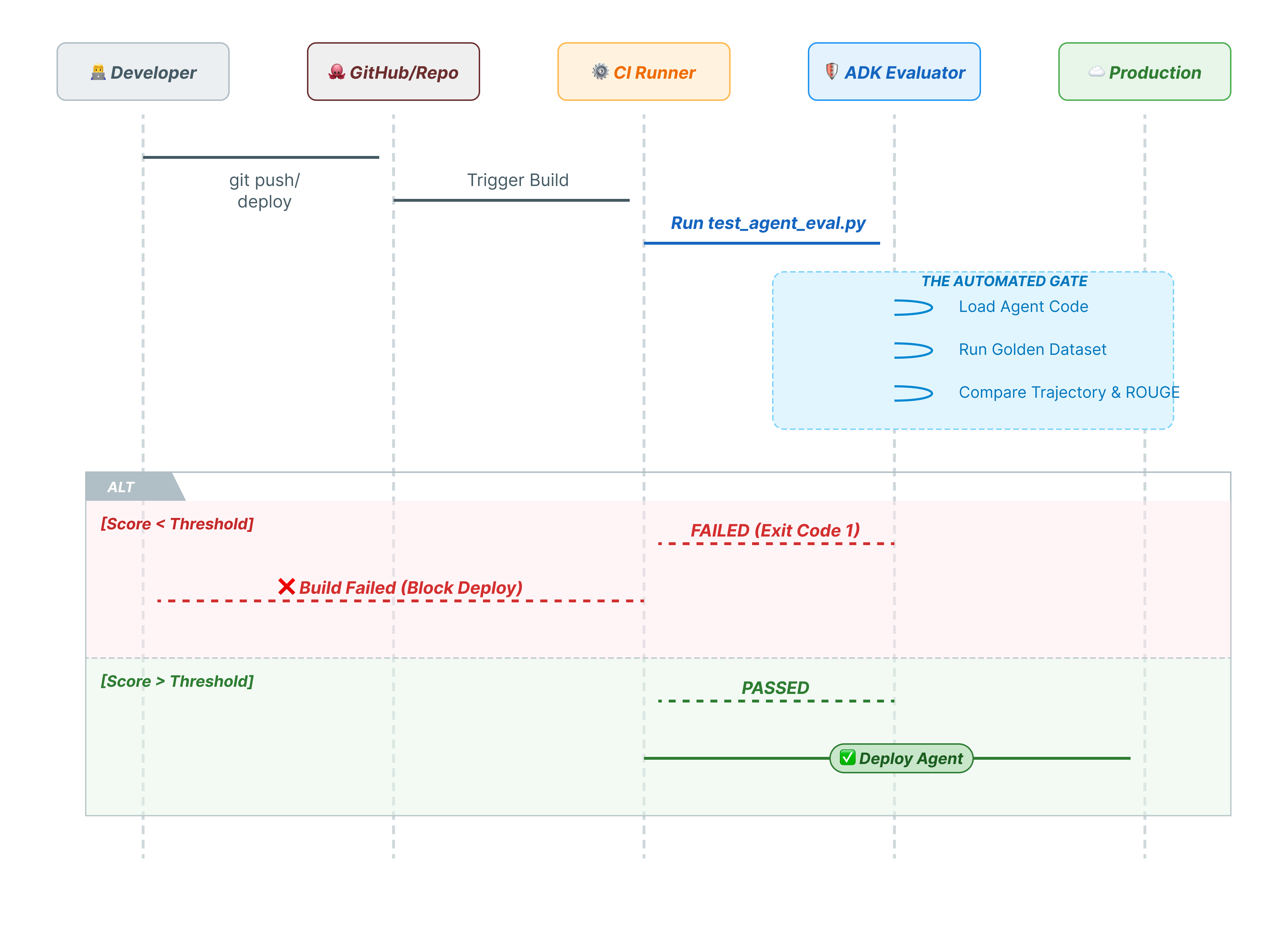
CLI 命令专门供真实用户使用。pytest 适用于机器。为了确保生产可靠性,我们将评估封装在 Python 测试套件中。这样,如果代理性能下降,您的 CI/CD 流水线(GitHub Actions、Jenkins)就可以阻止部署。
此文件中包含哪些内容?
此 Python 文件充当 CI/CD Runner 与 ADK 评估器之间的桥梁。它需要:
- 加载代理:动态导入代理代码。
- 重置状态:确保代理内存干净,以免测试相互泄露。
- 运行评估:以编程方式调用
AgentEvaluator.evaluate()。 - 断言成功:如果评估得分较低,则使构建失败。
集成测试代码
- 👉 打开
customer_service_agent/test_agent_eval.py。此脚本使用AgentEvaluator.evaluate运行eval.test.json中定义的测试。 - 👉 在编辑器中将以下代码输入到
customer_service_agent/test_agent_eval.py中。from google.adk.evaluation.agent_evaluator import AgentEvaluator import pytest import importlib import sys import os @pytest.mark.asyncio async def test_with_single_test_file(): """Test the agent's basic ability via a session file.""" # Load the agent module robustly module_name = "customer_service_agent.agent" try: agent_module = importlib.import_module(module_name) # Reset the mock data to ensure a fresh state for the test if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() except ImportError: # Fallback if running from a different context sys.path.append(os.getcwd()) agent_module = importlib.import_module(module_name) if hasattr(agent_module, 'reset_mock_data'): agent_module.reset_mock_data() # Use absolute path to the eval file to be robust to where pytest is run script_dir = os.path.dirname(os.path.abspath(__file__)) eval_file = os.path.join(script_dir, "eval.test.json") await AgentEvaluator.evaluate( agent_module=module_name, eval_dataset_file_path_or_dir=eval_file, num_runs=1, )
运行 Pytest
- 👉💻 在终端中,运行:
cd ~/adk_eval_starter uv pip install pytest uv run pytest customer_service_agent/test_agent_eval.py``` -- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html =============== 1 passed, 15 warnings in 12.84s =============== ```
11. 总结
恭喜!您已成功使用 ADK Eval 评估了客户服务代理。
学习内容
在本 Codelab 中,你学习了如何:
- ✅ 生成黄金数据集,为代理确定标准答案。
- ✅ 了解评估配置,以定义成功标准。
- ✅ 运行自动化评估,以便尽早发现回归问题。
通过将 ADK Eval 纳入开发工作流,您可以放心地构建智能体,因为您知道任何行为变化都会被自动化测试捕获。
本实验是“利用 Google Cloud 构建可用于生产用途的 AI”学习路线的组成部分。
- 探索完整课程,弥合从原型设计到生产的差距。
- 使用 #
ProductionReadyAI分享您的进度。
更多阅读材料: