
1. はじめに
この Codelab では、Gemini 3.1 Pro を搭載した ADK を使用してエージェントを構築します。このエージェントには、2 つのリモート(Google がホストする)MCP サーバーのツールが搭載されます。これにより、BigQuery に安全にアクセスして人口統計、価格設定、販売データにアクセスし、Google マップにアクセスして現実世界の場所の分析と検証を行うことができます。
エージェントは、ユーザーと Google Cloud サービス間のリクエストを調整して、架空のパン屋のデータセットに関連するビジネス上の問題を解決します。
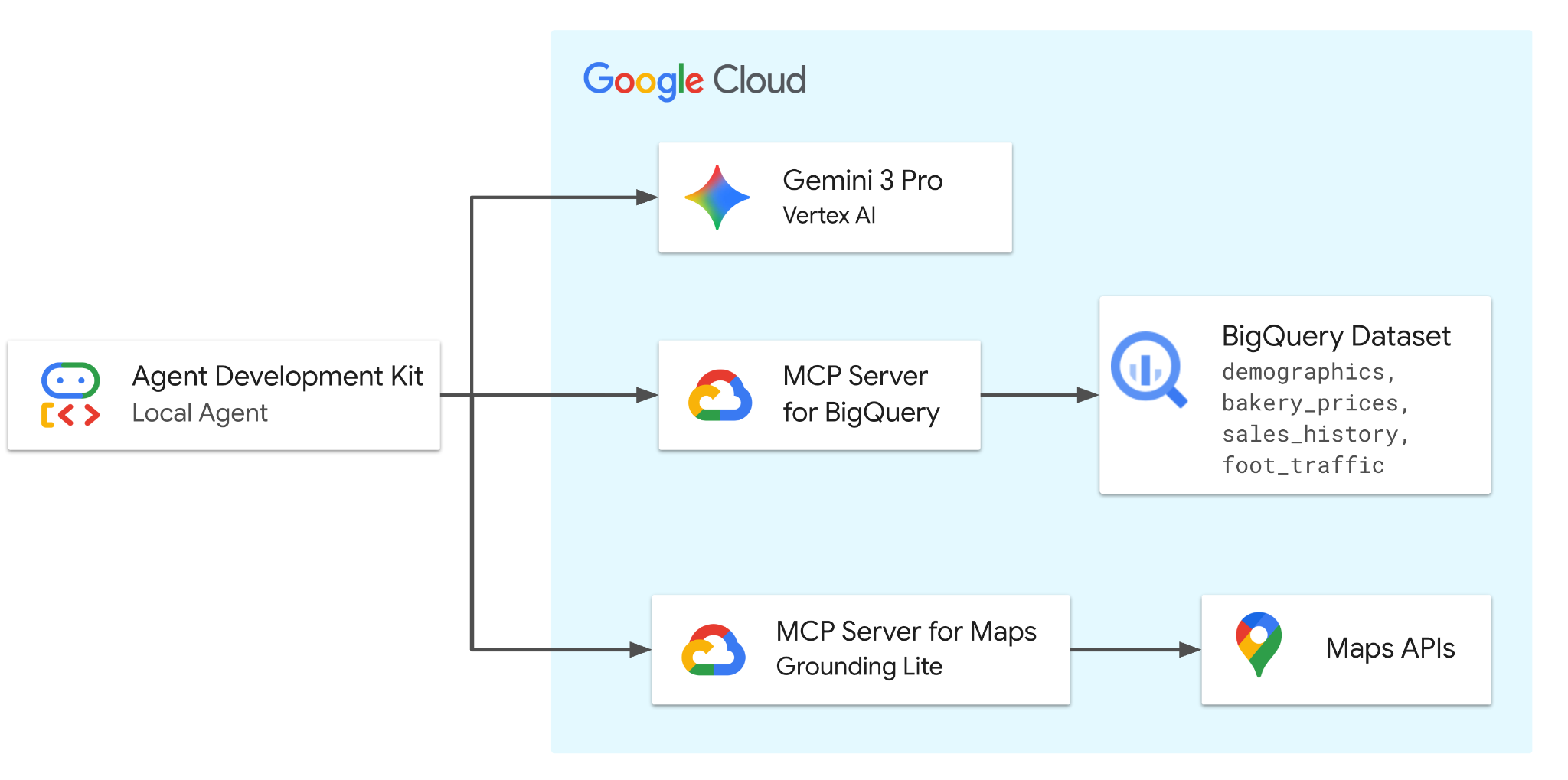
演習内容
- データを設定する: BigQuery でベーカリーの基礎となるデータセットを作成します。
- エージェントを開発する: Agent Development Kit(ADK)を使用してインテリジェント エージェントを構築します。
- ツールを統合する: MCP サーバーを介して、BigQuery と Maps の機能をエージェントに装備します。
- 市場を分析する: エージェントと対話して、市場の動向と飽和度を評価します。
必要なもの
- ウェブブラウザ(Chrome など)
- 課金が有効になっている Google Cloud プロジェクトまたは Gmail アカウント。
この Codelab は、初心者を含むあらゆるレベルのデベロッパーを対象としています。ADK 開発には、Google Cloud Shell のコマンドライン インターフェースと Python コードを使用します。Python の専門家である必要はありませんが、コードの読み取り方法に関する基本的な知識があると、コンセプトを理解するのに役立ちます。
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト選択ページで、クラウド プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。

- Cloud Shell に接続したら、次のコマンドを実行して Cloud Shell で認証を確認します。
gcloud auth list
- 次のコマンドを実行して、プロジェクトが gcloud で使用するように構成されていることを確認します。
gcloud config get project
- プロジェクトが想定どおりであることを確認し、次のコマンドを実行してプロジェクト ID を設定します。
export PROJECT_ID=$(gcloud config get project)
3. コードを取得する
リポジトリのクローンを作成する
- リポジトリのクローンを Cloud Shell 環境に作成します。
git clone https://github.com/google/mcp.git
- デモ ディレクトリに移動します。
cd mcp/examples/launchmybakery
認証
次のコマンドを実行して、Google Cloud アカウントで認証します。これは、ADK が BigQuery にアクセスするために必要です。
gcloud auth application-default login
指示に沿って認証プロセスを完了します。
4. 環境と BigQuery を構成する
設定スクリプトを実行する
- 環境設定スクリプトを実行します。このスクリプトは、BigQuery API と Google Maps API を有効にし、プロジェクト ID と Maps API キーを含む
.envファイルを作成します。
chmod +x setup/setup_env.sh
./setup/setup_env.sh
- BigQuery 設定スクリプトを実行します。このスクリプトは、Cloud Storage バケットの作成、データのアップロード、BigQuery データセットとテーブルのプロビジョニングを自動化します。
chmod +x ./setup/setup_bigquery.sh
./setup/setup_bigquery.sh
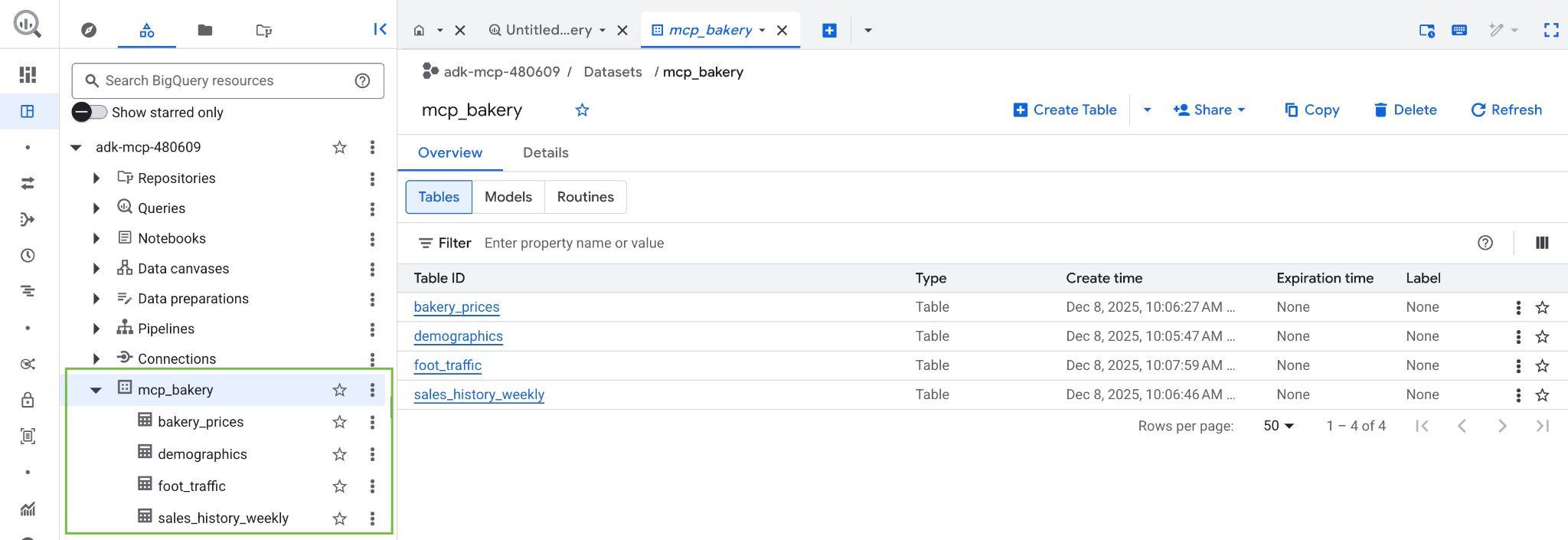
スクリプトが完了すると、mcp_bakery データセットが作成され、次のテーブルが取り込まれます。
- demographics - 郵便番号別の国勢調査データと人口特性。
- bakery_prices - さまざまな焼き菓子の競合他社の価格と商品の詳細。
- sales_history_weekly - 店舗と商品ごとの週ごとの販売実績(数量と収益)。
- foot_traffic - 郵便番号と時間帯別の推定来店数スコア。
- Google Cloud プロジェクトの BigQuery コンソールにアクセスして、データセットとテーブルが作成されていることを確認します。
5. ADK をインストールする
インフラストラクチャの準備が整ったので、仮想 Python 環境を作成し、ADK に必要なパッケージをインストールしましょう。
- 仮想環境を作成します。
python3 -m venv .venv
- 仮想環境をアクティブにします。
source .venv/bin/activate
- ADK をインストールします。
pip install google-adk==1.28.0
- エージェント ディレクトリに移動します。
cd adk_agent/
6. ADK アプリケーションを検査する
Cloud Shell で [エディタを開く] ボタンをクリックして Cloud Shell エディタを開き、mcp/examples/launchmybakery ディレクトリにクローンされたリポジトリを表示します。

エージェント コードは adk_agent/ ディレクトリにすでに用意されています。ソリューションの構造を見てみましょう。
launchmybakery/
├── data/ # Pre-generated CSV files for BigQuery
├── adk_agent/ # AI Agent Application (ADK)
│ └── mcp_bakery_app/ # App directory
│ ├── agent.py # Agent definition
│ ├── tools.py # Custom tools for the agent
│ └── .env # Project configuration (created by setup script)
├── setup/ # Infrastructure setup scripts
└── cleanup/ # Infrastructure cleanup scripts
mcp_bakery_app の重要なファイル:
agent.py: エージェント、そのツール、モデル(Gemini 3.1 Pro プレビュー版)を定義するコアロジック。tools.py: カスタムツールの定義が含まれます。.env: 設定スクリプトによって作成されたプロジェクト構成とシークレット(API キーなど)が含まれています。
1. MCP ツールセットの初期化:
次に、エディタで adk_agent/mcp_bakery_app/tools.py を開き、MCP ツールセットがどのように初期化されるかを確認します。
エージェントが BigQuery と Google マップと通信できるようにするには、Model Context Protocol(MCP)クライアントを構成する必要があります。
このコードは、StreamableHTTPConnectionParams を使用して、Google のリモート MCP サーバーへの安全な接続を確立します。
def get_maps_mcp_toolset():
dotenv.load_dotenv()
maps_api_key = os.getenv('MAPS_API_KEY', 'no_api_found')
tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=MAPS_MCP_URL,
headers={
"X-Goog-Api-Key": maps_api_key
}
)
)
print("MCP Toolset configured for Streamable HTTP connection.")
return tools
def get_bigquery_mcp_toolset():
credentials, project_id = google.auth.default(
scopes=["https://www.googleapis.com/auth/bigquery"]
)
credentials.refresh(google.auth.transport.requests.Request())
oauth_token = credentials.token
HEADERS_WITH_OAUTH = {
"Authorization": f"Bearer {oauth_token}",
"x-goog-user-project": project_id
}
tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=BIGQUERY_MCP_URL,
headers=HEADERS_WITH_OAUTH
)
)
print("MCP Toolset configured for Streamable HTTP connection.")
return tools
- マップ ツールセット: API キーを使用して マップ MCP サーバーへの接続を構成します。
- BigQuery ツールセット: この関数は、BigQuery MCP サーバーへの接続を構成します。google.auth を使用して Cloud 認証情報を自動的に取得し、OAuth ベアラー トークンを生成して、Authorization ヘッダーに挿入します。
2. エージェントの定義:
次に、エディタで adk_agent/mcp_bakery_app/agent.py を開き、エージェントがどのように定義されているかを確認します。
LlmAgent は gemini-3.1-pro-preview モデルで初期化されます。
maps_toolset = tools.get_maps_mcp_toolset()
bigquery_toolset = tools.get_bigquery_mcp_toolset()
root_agent = LlmAgent(
model='gemini-3.1-pro-preview',
name='root_agent',
instruction=f"""
Help the user answer questions by strategically combining insights from two sources:
1. **BigQuery toolset:** Access demographic (inc. foot traffic index), product pricing, and historical sales data in the mcp_bakery dataset. Do not use any other dataset.
Run all query jobs from project id: {project_id}.
2. **Maps Toolset:** Use this for real-world location analysis, finding competition/places and calculating necessary travel routes.
Include a hyperlink to an interactive map in your response where appropriate.
""",
tools=[maps_toolset, bigquery_toolset]
)
- システム指示: エージェントには、BigQuery(データ用)とマップ(位置情報分析用)の両方の分析情報を組み合わせるための具体的な指示が与えられます。
- ツール:
maps_toolsetとbigquery_toolsetの両方がエージェントに割り当てられ、両方のサービスの機能にアクセスできるようになります。
エージェントは、リポジトリで定義された手順とツールに準拠します。指示を変更して、エージェントの動作にどのような影響があるかを確認してみてください。
7. エージェントとチャットしましょう。
Cloud Shell のターミナルに戻り、次のコマンドを実行して adk_agent ディレクトリに移動します(まだ移動していない場合)。
cd adk_agent/
次のコマンドを実行して、ADK ウェブ インターフェースを起動します。このコマンドは、チャット アプリケーションをホストする軽量ウェブサーバーを起動します。
adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
サーバーが起動すると、Cloud Shell に次のように表示されます。
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
ADK UI にアクセスするには、次の 2 つの方法があります。
オプション 1: ローカルリンクをクリックする: Cloud Shell ターミナルに表示される http://127.0.0.1:8000 リンクをクリックします。
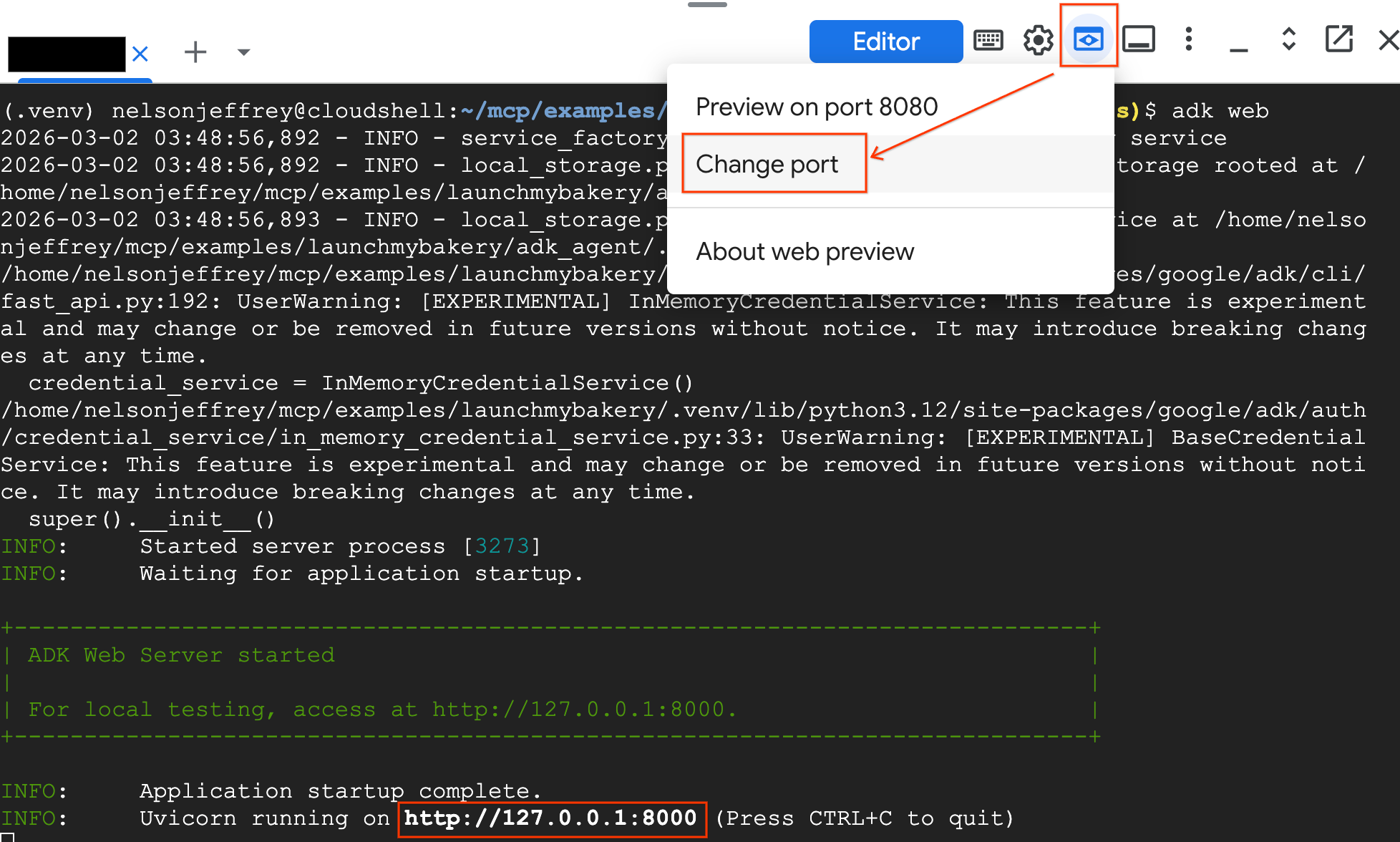
オプション 2: ウェブ プレビューを使用する
- Cloud Shell の右上にある [ウェブでプレビュー] ボタンをクリックします。
- [ポートを変更] を選択します。
- ポート番号に「8000」と入力し、[変更してプレビュー] をクリックします。
ウェブ UI で次の質問をして、エージェントとやり取りします。関連するツールが呼び出されていることがわかります。
- 近隣地域を探す(マクロ): 「ロサンゼルスでパン屋を開業したい。朝の歩行者数が最も多い郵便番号を見つけてください。」
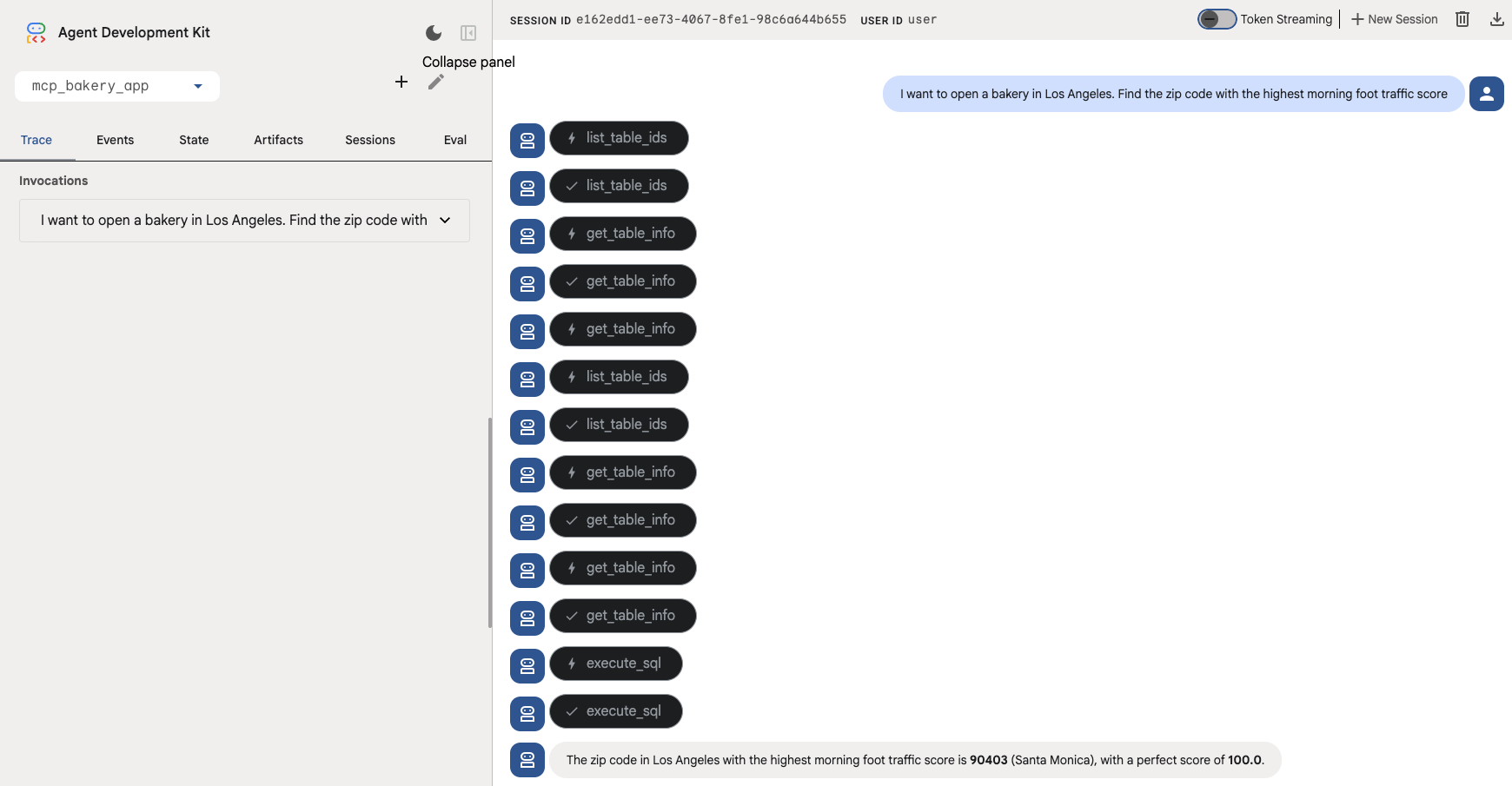
エージェントは、get_table_info や execute_sql などのツールを使用して、BigQuery の foot_traffic テーブルに対してクエリを実行する必要があります。
- 位置情報を検証する(小規模ビジネス): 「その郵便番号で「パン屋」を検索して、飽和状態かどうかを確認できますか?」
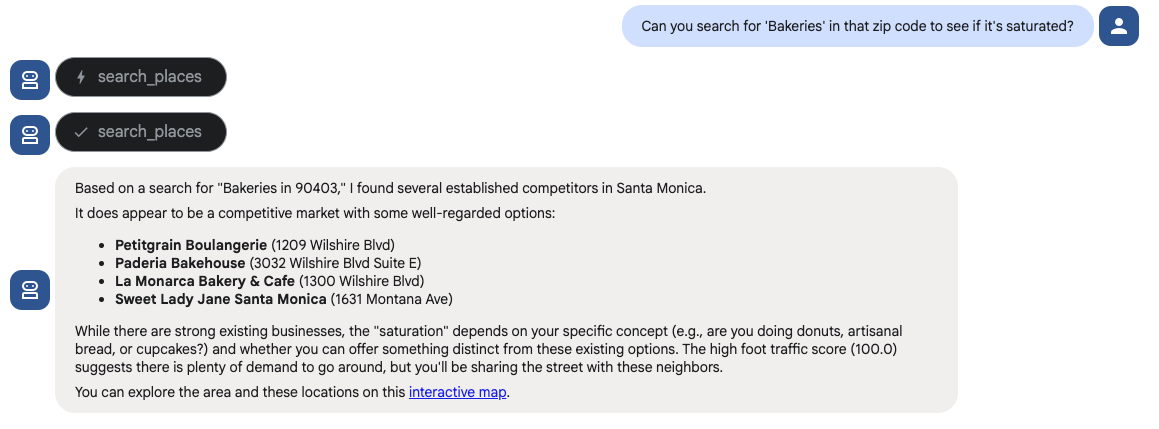
エージェントは、マップ ツールセットの search places ツールを使用して、この質問に回答する必要があります。
ぜひお試しください。ADK エージェントの動作を確認するには、次の質問例をご覧ください。
- 「ロサンゼルスに 4 店舗目のパン屋を開業したいと考えています。早朝から活動している人がいる地域が必要です。「朝」の来店数スコアが最も高い郵便番号を見つけてください。
- 「その郵便番号で「パン屋」を検索して、飽和状態かどうかを確認できますか?数が多すぎる場合は、スペシャルティ コーヒー ショップを探して、その近くに店を構えて通行人を呼び込みます。」
- 「わかりました。このブランドをプレミアム ブランドとして位置付けたいと思います。ロサンゼルス都市圏で「サワードウ ローフ」に課金されている最高価格はいくらですか?
- 「2025 年 12 月の収益予測を教えてください。販売履歴を確認し、最も売れ行きの良い店舗の「サワードウ ローフ」のデータを使用します。2025 年 12 月の予測を実行して、販売数を推定します。次に、プレミアム価格の少し下(ここでは $18 を使用)で予測される合計収益を計算します。」
- 「これで家賃を払える。最後に、ロジスティクスを確認しましょう。提案されたエリアに最も近い「Restaurant Depot」を探し、毎日の補充の所要時間が 30 分以内であることを確認してください。」
エージェントのテストが完了したら、Cloud Shell ターミナルで Ctrl+C を押して ADK ウェブ インターフェースを終了します。
8. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、この Codelab で作成したリソースを削除します。
クリーンアップ スクリプトを実行します。このスクリプトは、設定時に作成された BigQuery データセット、Cloud Storage バケット、API キーを削除します。
chmod +x ../cleanup/cleanup_env.sh
./../cleanup/cleanup_env.sh
9. 完了
ミッション完了!Agent Development Kit(ADK)を使用して位置情報インテリジェンス エージェントを正常に構築しました。
BigQuery のエンタープライズ データと Google マップ の現実世界のロケーション コンテキストのギャップを埋めることで、複雑なビジネス上の推論が可能な強力なツールが作成されました。このツールは、Model Context Protocol(MCP)と Gemini によって実現されています。
達成した内容:
- Infrastructure as Code: Google Cloud CLI ツールを使用してデータスタックをプロビジョニングしました。
- MCP 統合: 複雑な API ラッパーを記述することなく、AI エージェントを 2 つの異なるリモート MCP サーバー(BigQuery と Maps)に接続しました。
- 統合された推論: 2 つの異なるドメインの分析情報を戦略的に組み合わせてビジネス上の問題を解決できる単一のエージェントを構築しました。