
1. 简介
在此 Codelab 中,您将使用由 Gemini 3.1 Pro 提供支持的 ADK 构建智能体。该智能体将配备来自两个远程(Google 托管)MCP 服务器的工具,以安全地访问 BigQuery 以获取人口统计、定价和销售数据,并访问 Google 地图以进行实际位置分析和验证。
该智能体协调用户与 Google Cloud 服务之间的请求,以解决与虚构的面包店数据集相关的业务问题。
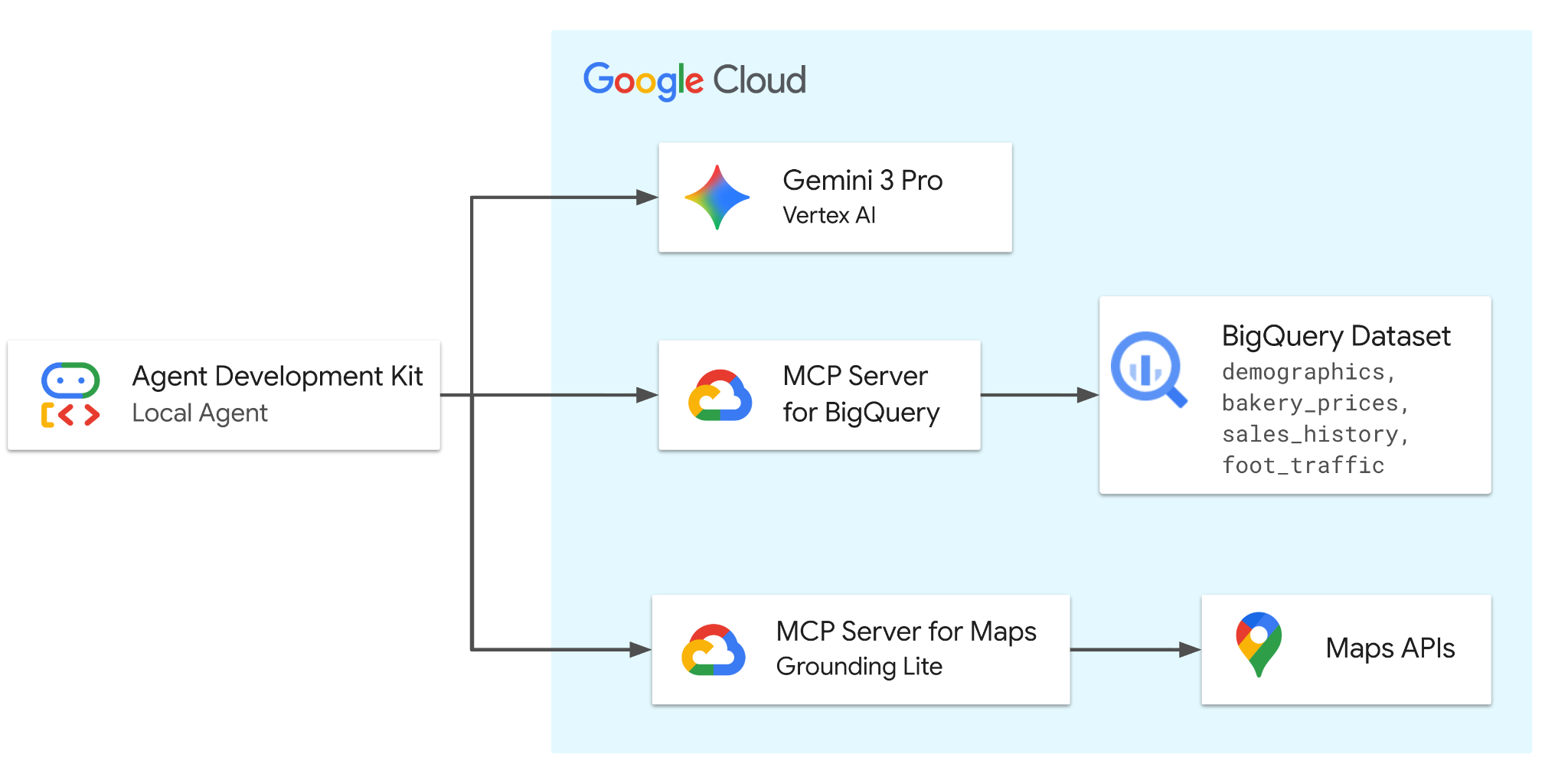
实践内容
- 设置数据: 在 BigQuery 中创建基础面包店数据集。
- 开发智能体: 使用智能体开发套件 (ADK) 构建智能体。
- 集成工具: 通过 MCP 服务器为智能体配备 BigQuery 和 Google 地图功能。
- 分析市场: 与智能体互动,评估市场趋势和饱和度。
所需条件
- 网络浏览器,例如 Chrome
- 启用了结算功能的 Google Cloud 项目或 Gmail 账号。
此 Codelab 适用于各种水平的开发者,包括新手。您将使用 Google Cloud Shell 中的命令行界面和 Python 代码进行 ADK 开发。您无需成为 Python 专家,但对如何阅读代码有基本的了解将有助于您理解相关概念。
2. 准备工作
创建 Google Cloud 项目
- 在 Google Cloud 控制台 的项目选择器页面上, 选择或创建一个 Google Cloud 项目。
- 确保您的云项目已启用结算功能。了解如何 检查项目是否已启用结算功能。
启动 Cloud Shell
Cloud Shell 是在 Google Cloud 中运行的一个命令行环境,其中预加载了必要的工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell :

- 连接到 Cloud Shell 后,运行此命令以验证您在 Cloud Shell 中的身份验证 :
gcloud auth list
- 运行以下命令,确认您的项目已配置为与 gcloud 搭配使用:
gcloud config get project
- 确认项目符合预期,然后运行以下命令来设置项目 ID:
export PROJECT_ID=$(gcloud config get project)
3. 获取代码
克隆代码库
- 将代码库克隆到 Cloud Shell 环境:
git clone https://github.com/google/mcp.git
- 进入演示目录:
cd mcp/examples/launchmybakery
进行身份验证
运行以下命令以使用您的 Google Cloud 账号进行身份验证。这是 ADK 访问 BigQuery 所必需的。
gcloud auth application-default login
按照提示完成身份验证流程。
4. 配置环境和 BigQuery
运行设置脚本
- 运行环境设置脚本。此脚本会启用 BigQuery 和 Google 地图 API,并使用您的项目 ID 和 Google 地图 API 密钥创建
.env文件。
chmod +x setup/setup_env.sh
./setup/setup_env.sh
- 运行 BigQuery 设置脚本。此脚本会自动创建 Cloud Storage 存储分区、上传数据以及预配 BigQuery 数据集和表。
chmod +x ./setup/setup_bigquery.sh
./setup/setup_bigquery.sh
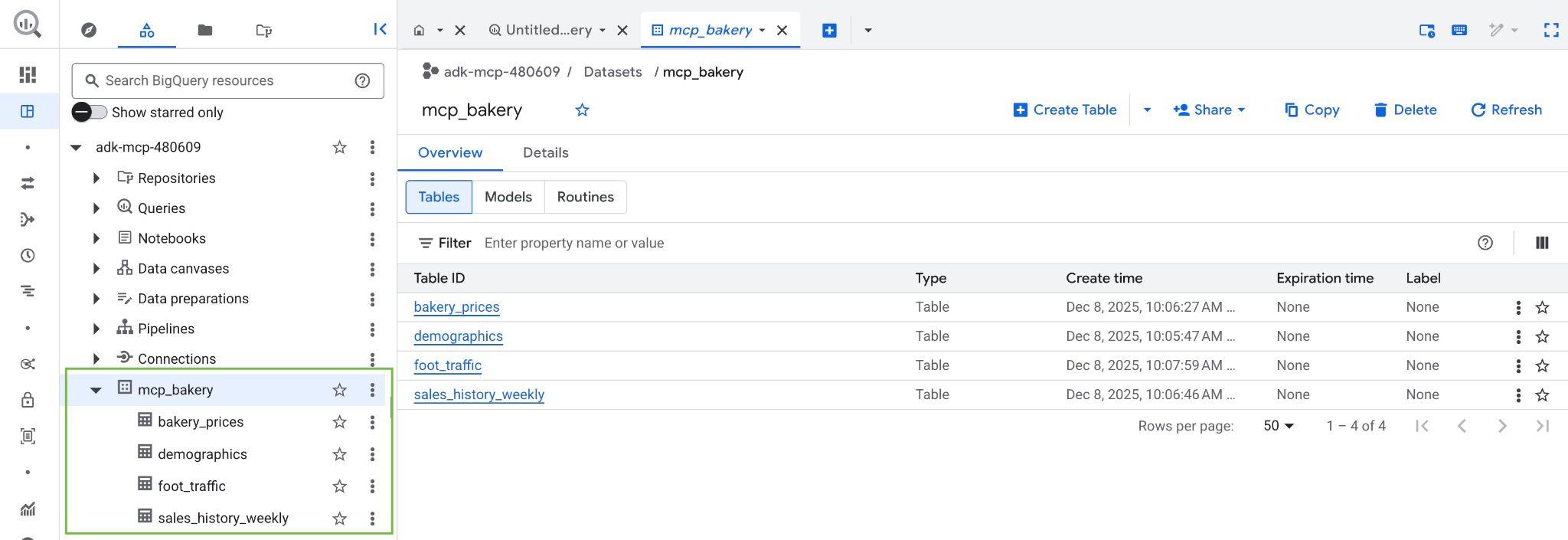
脚本完成后,系统应会创建 mcp_bakery 数据集,并使用以下表填充该数据集:
- demographics - 按邮政编码划分的人口普查数据和人口特征。
- bakery_prices - 各种烘焙食品的竞争对手定价和产品详情。
- sales_history_weekly - 按商店和产品划分的每周销售业绩(数量和收入)。
- foot_traffic - 按邮政编码和一天中的时间划分的估计实体店客流量得分。
- 如需验证数据集和表是否已创建,请访问 Google Cloud 项目中的 BigQuery 控制台 :
5. 安装 ADK
现在基础架构已准备就绪,接下来我们将创建一个虚拟 Python 环境并安装 ADK 所需的软件包。
- 创建虚拟环境:
python3 -m venv .venv
- 激活此虚拟环境:
source .venv/bin/activate
- 安装 ADK:
pip install google-adk==1.28.0
- 进入智能体目录:
cd adk_agent/
6. 检查 ADK 应用
点击 Cloud Shell 中的打开编辑器 按钮,打开 Cloud Shell 编辑器,然后在 mcp/examples/launchmybakery 目录下查看克隆的代码库。

智能体代码已在 adk_agent/ 目录中提供。我们来了解一下解决方案结构:
launchmybakery/
├── data/ # Pre-generated CSV files for BigQuery
├── adk_agent/ # AI Agent Application (ADK)
│ └── mcp_bakery_app/ # App directory
│ ├── agent.py # Agent definition
│ ├── tools.py # Custom tools for the agent
│ └── .env # Project configuration (created by setup script)
├── setup/ # Infrastructure setup scripts
└── cleanup/ # Infrastructure cleanup scripts
mcp_bakery_app 中的关键文件:
agent.py:定义智能体、其工具和模型(Gemini 3.1 Pro 预览版)的核心逻辑。tools.py:包含任何自定义工具定义。.env:包含项目配置和由设置脚本创建的密钥(例如 API 密钥)。
1. MCP 工具集初始化:
现在,在编辑器中打开 adk_agent/mcp_bakery_app/tools.py,了解 MCP 工具集的初始化方式。
为了让智能体能够与 BigQuery 和 Google 地图通信,我们需要配置 Model Context Protocol (MCP) 客户端。
该代码使用 StreamableHTTPConnectionParams 建立与 Google 远程 MCP 服务器的安全连接。
def get_maps_mcp_toolset():
dotenv.load_dotenv()
maps_api_key = os.getenv('MAPS_API_KEY', 'no_api_found')
tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=MAPS_MCP_URL,
headers={
"X-Goog-Api-Key": maps_api_key
}
)
)
print("MCP Toolset configured for Streamable HTTP connection.")
return tools
def get_bigquery_mcp_toolset():
credentials, project_id = google.auth.default(
scopes=["https://www.googleapis.com/auth/bigquery"]
)
credentials.refresh(google.auth.transport.requests.Request())
oauth_token = credentials.token
HEADERS_WITH_OAUTH = {
"Authorization": f"Bearer {oauth_token}",
"x-goog-user-project": project_id
}
tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=BIGQUERY_MCP_URL,
headers=HEADERS_WITH_OAUTH
)
)
print("MCP Toolset configured for Streamable HTTP connection.")
return tools
- Google 地图工具集: 使用您的 API 密钥配置与 Google 地图 MCP 服务器 的连接。
- BigQuery 工具集: 此函数用于配置与 BigQuery MCP 服务器 的连接。它使用 google.auth 自动检索您的 Cloud 凭据,生成 OAuth 载体令牌,并将其注入到 Authorization 标头中。
2. 智能体定义:
现在,在编辑器中打开 adk_agent/mcp_bakery_app/agent.py,了解智能体的定义方式。
LlmAgent 使用 gemini-3.1-pro-preview 模型进行初始化。
maps_toolset = tools.get_maps_mcp_toolset()
bigquery_toolset = tools.get_bigquery_mcp_toolset()
root_agent = LlmAgent(
model='gemini-3.1-pro-preview',
name='root_agent',
instruction=f"""
Help the user answer questions by strategically combining insights from two sources:
1. **BigQuery toolset:** Access demographic (inc. foot traffic index), product pricing, and historical sales data in the mcp_bakery dataset. Do not use any other dataset.
Run all query jobs from project id: {project_id}.
2. **Maps Toolset:** Use this for real-world location analysis, finding competition/places and calculating necessary travel routes.
Include a hyperlink to an interactive map in your response where appropriate.
""",
tools=[maps_toolset, bigquery_toolset]
)
- 系统说明: 智能体将获得特定说明,以结合来自 BigQuery(用于数据)和 Google 地图(用于位置分析)的洞见。
- 工具:
maps_toolset和bigquery_toolset都分配给了智能体,使其能够访问这两项服务的功能。
智能体遵循代码库中定义的说明和工具。您可以随意更改说明,了解其对智能体行为的影响。
7. 与您的智能体聊天!
返回 Cloud Shell 中的终端,然后运行此命令以进入 adk_agent 目录(如果您尚未执行此操作):
cd adk_agent/
运行以下命令以启动 ADK Web 界面。此命令会启动一个轻量级 Web 服务器来托管聊天应用:
adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
服务器启动后,您将在 Cloud Shell 中看到以下内容:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
您可以通过以下两种方式访问 ADK 界面:
方法 1:点击本地链接 点击 Cloud Shell 终端中显示的 http://127.0.0.1:8000 链接。
方法 2:使用网页预览
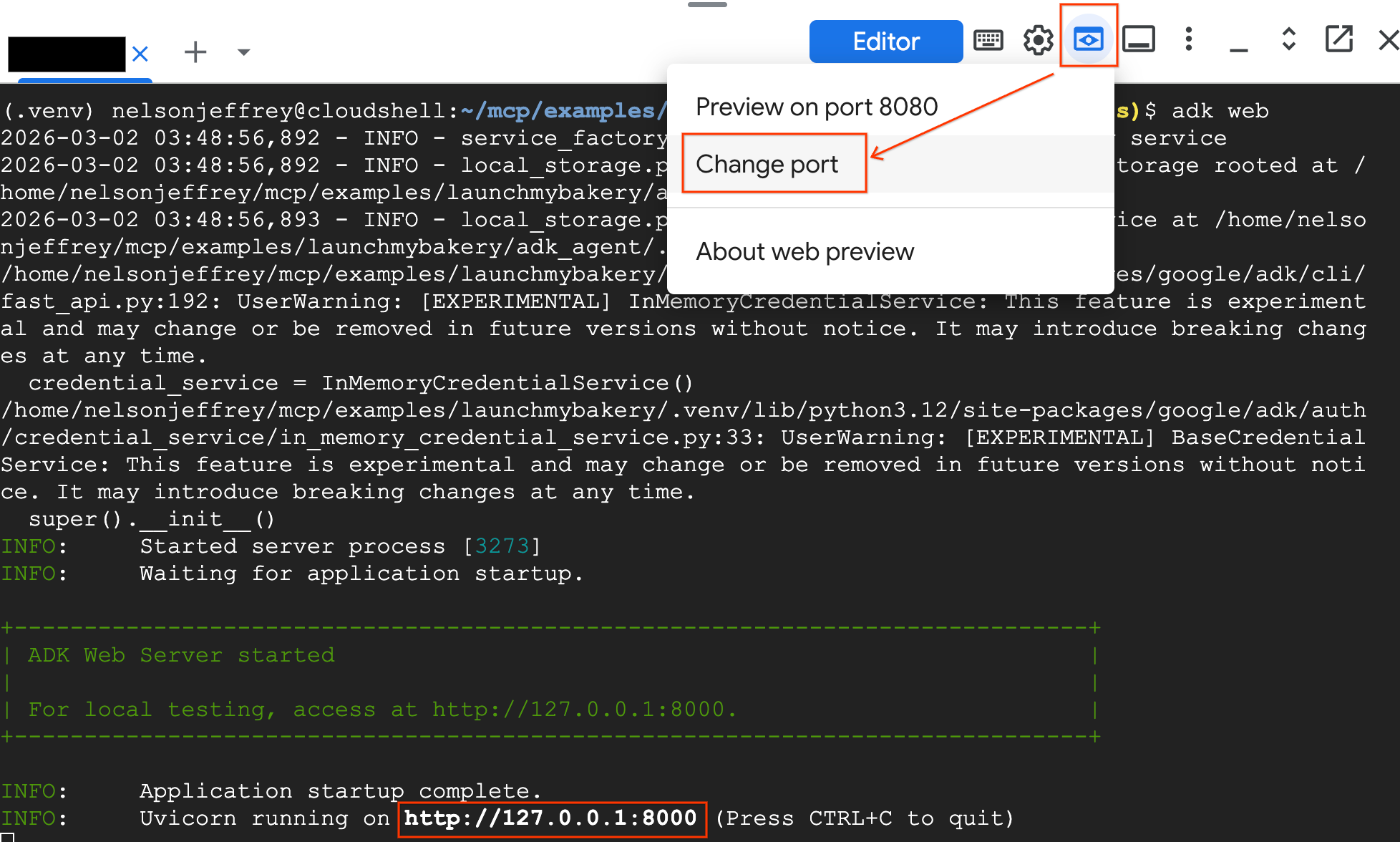
- 点击 Cloud Shell 右上角的网页预览 按钮。
- 选择更改端口 。
- 输入 8000 作为端口号,然后点击更改并预览 。
在 Web 界面中提出以下问题,与智能体互动 。您应该会看到相关工具被调用。
- 查找社区(宏): “我想在洛杉矶开一家面包店。查找上午实体店客流量得分最高的邮政编码。
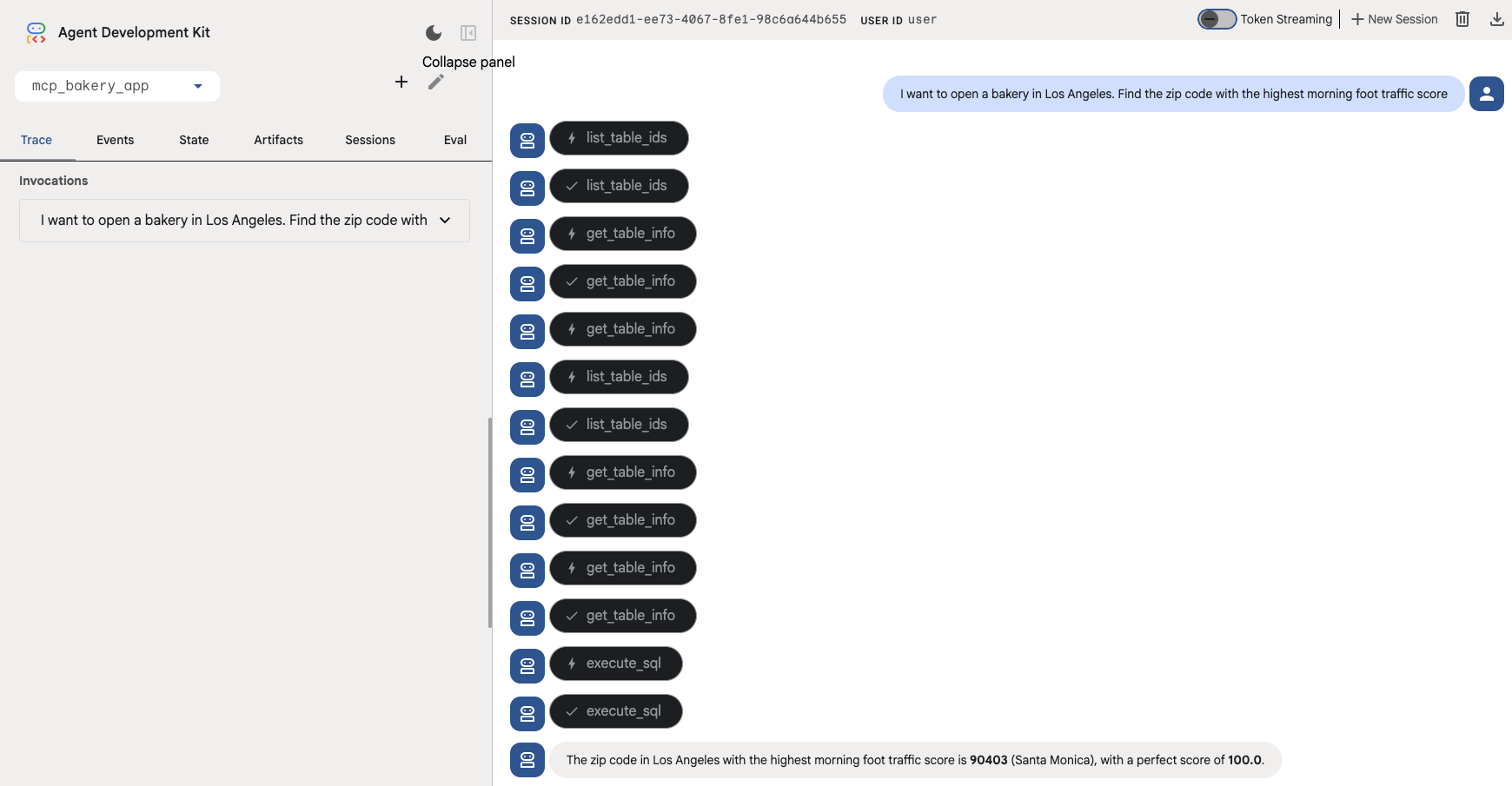
智能体应使用 get_table_info 和 execute_sql 等工具查询 BigQuery 中的 foot_traffic 表。
- 验证位置(微): “您能否在该邮政编码中搜索‘面包店’,看看是否已饱和?”
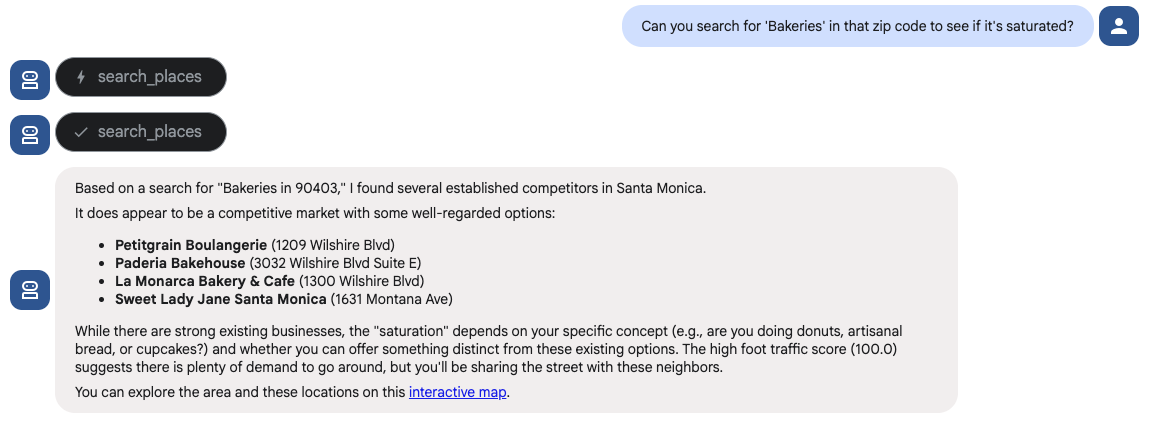
智能体应使用 Google 地图工具集中的 search places 工具来回答此问题。
快来体验一下吧! 查看以下示例问题,了解 ADK 智能体的实际应用:
- “我打算在洛杉矶开设第四家面包店。我需要一个早间活动较多的社区。查找‘上午’实体店客流量得分最高的邮政编码。
- “您能否在该邮政编码中搜索‘面包店’,看看是否已饱和?如果数量过多,请搜索‘特色咖啡’店,以便我将面包店开在附近,吸引客流量。”
- “好的,我想将面包店定位为高端品牌。洛杉矶都会区‘酸面包’的最高价格是多少?”
- “现在,我想要一份 2025 年 12 月的收入预测。查看我的销售历史记录,并从我销售‘酸面包’业绩最好的商店中获取数据。运行 2025 年 12 月的预测,估算我将销售的数量。然后,使用我们找到的略低于高端价格的价格(假设为 18 美元)计算预计总收入”
- “这足以支付我的租金。最后,我们来验证一下物流。找到离拟议区域最近的‘Restaurant Depot’,并确保每日补货的驾车时间不超过 30 分钟。”
测试完智能体后,您可以在 Cloud Shell 终端中按 Ctrl+C 来终止 ADK Web 界面。
8. 清理
为避免系统持续向您的 Google Cloud 账号收取费用,请删除在此 Codelab 中创建的资源。
运行清理脚本。此脚本将删除在设置期间创建的 BigQuery 数据集、Cloud Storage 存储分区和 API 密钥。
chmod +x ../cleanup/cleanup_env.sh
./../cleanup/cleanup_env.sh
9. 恭喜
任务完成!您已使用智能体开发套件 (ADK) 成功构建了地理位置智能体。
通过弥合 BigQuery 中的“企业”数据与 Google 地图 中的实际位置背景信息之间的差距,您创建了一个功能强大的工具,能够进行复杂的业务推理,而这一切都由 Model Context Protocol (MCP) 和 Gemini 提供支持。
您已完成以下任务:
- 基础架构即代码: 您使用 Google Cloud CLI 工具预配了数据堆栈。
- MCP 集成: 您将 AI 智能体连接到两个不同的远程 MCP 服务器(BigQuery 和 Google 地图),而无需编写复杂的 API 封装容器。
- 统一推理: 您构建了一个能够策略性地结合来自两个不同领域的洞见来解决业务问题的智能体。