
1. 📖 Einführung
In diesem Codelab wird gezeigt, wie Sie eine multimodale Tool-Interaktion im Agent Development Kit (ADK) entwerfen. In diesem speziellen Ablauf soll der Agent auf die hochgeladene Datei als Eingabe für ein Tool verweisen und auch den Dateiinhalt verstehen, der durch die Tool-Antwort generiert wird. Daher ist eine Interaktion wie im Screenshot unten möglich. In diesem Tutorial entwickeln wir einen Agenten, der dem Nutzer helfen kann, ein besseres Foto für die Produktpräsentation zu bearbeiten.
In diesem Codelab gehen Sie schrittweise so vor:
- Google Cloud-Projekt vorbereiten
- Arbeitsverzeichnis für die Programmierumgebung einrichten
- KI-Agent mit ADK initialisieren
- Ein Tool zum Bearbeiten von Fotos mit Gemini 2.5 Flash Image entwickeln
- Entwerfen Sie eine Callback-Funktion, um das Hochladen von Nutzerbildern zu verarbeiten, speichern Sie sie als Artefakt und fügen Sie sie als Kontext zum Agent hinzu.
- Entwerfen Sie eine Callback-Funktion, um das von einer Tool-Antwort erstellte Bild zu verarbeiten, speichern Sie es als Artefakt und fügen Sie es als Kontext zum Agent hinzu.
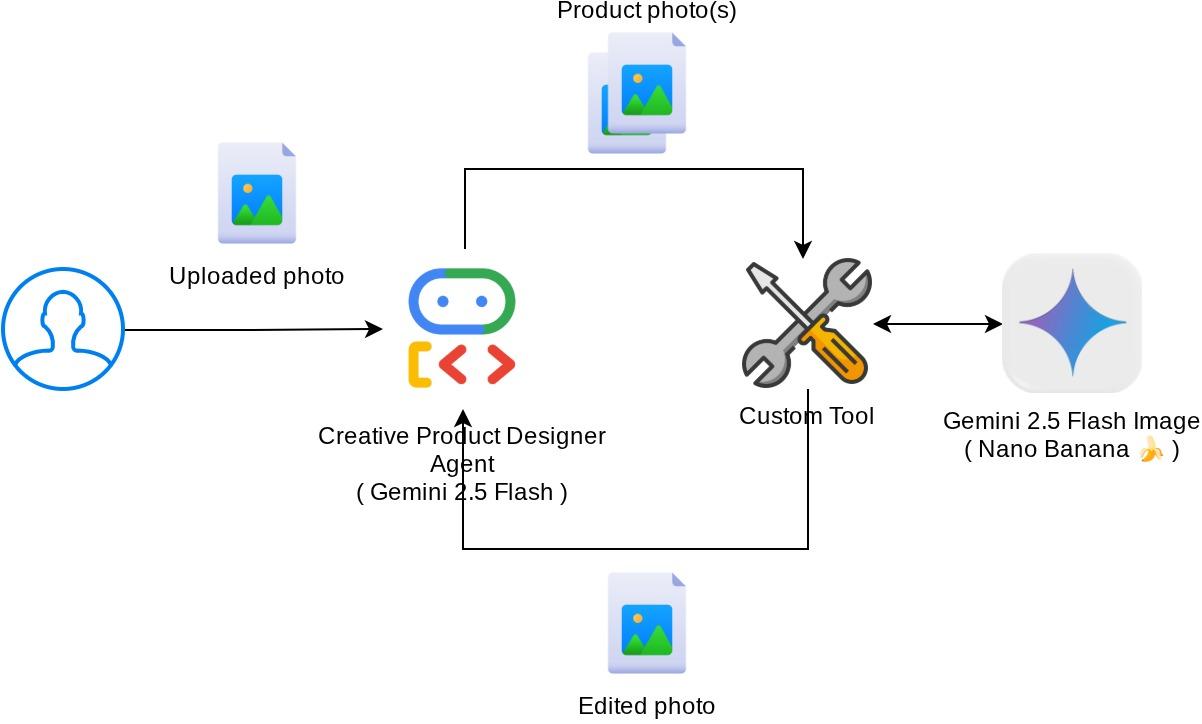
Architekturübersicht
Die gesamte Interaktion in diesem Codelab wird im folgenden Diagramm dargestellt.
Voraussetzungen
- Vertrautheit mit Python
- (Optional) Grundlagen-Codelabs zum Agent Development Kit (ADK)
Lerninhalte
- Callback-Kontext verwenden, um auf den Artifact Service zuzugreifen
- Tool mit korrekter multimodaler Datenweitergabe entwerfen
- So ändern Sie die LLM-Anfrage des KI-Agents, um über „before_model_callback“ Artefaktkontext hinzuzufügen
- Bilder mit Gemini 2.5 Flash Image bearbeiten
Voraussetzungen
- Chrome-Webbrowser
- Ein Gmail-Konto
- Ein Cloud-Projekt mit aktiviertem Abrechnungskonto
In diesem Codelab, das sich an Entwickler*innen aller Erfahrungsstufen (auch Anfänger*innen) richtet, wird Python in der Beispielanwendung verwendet. Python-Kenntnisse sind jedoch nicht erforderlich, um die vorgestellten Konzepte zu verstehen.
2. 🚀 Vorbereitung der Workshop-Entwicklung
Schritt 1: Aktives Projekt in der Cloud Console auswählen
Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines (siehe oben links in der Console).

Klicken Sie darauf, um eine Liste aller Ihrer Projekte aufzurufen, wie in diesem Beispiel:
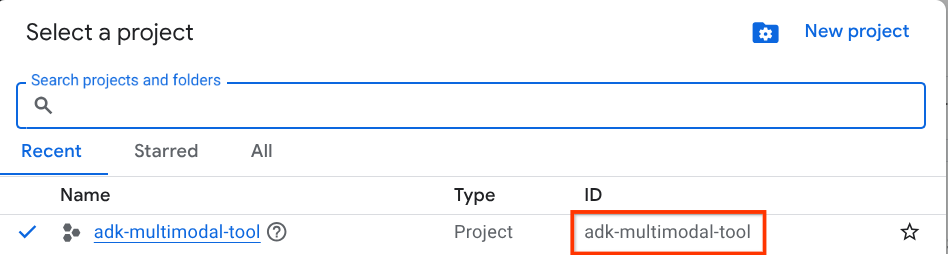
Der Wert, der durch das rote Kästchen angegeben wird, ist die PROJEKT-ID. Dieser Wert wird im gesamten Tutorial verwendet.
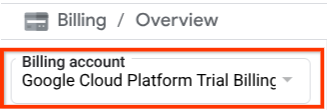
Die Abrechnung für das Cloud-Projekt muss aktiviert sein. Klicken Sie dazu links oben in der Leiste auf das Dreistrich-Menü ☰, um das Navigationsmenü aufzurufen, und suchen Sie nach dem Abrechnungsmenü.

Wenn Sie unter dem Titel Abrechnung / Übersicht ( oben links in der Cloud Console) das Google Cloud Platform-Testabrechnungskonto sehen, kann Ihr Projekt für diese Anleitung verwendet werden. Falls nicht, kehren Sie zum Anfang dieses Tutorials zurück und lösen Sie das Abrechnungskonto für den Testzeitraum ein.
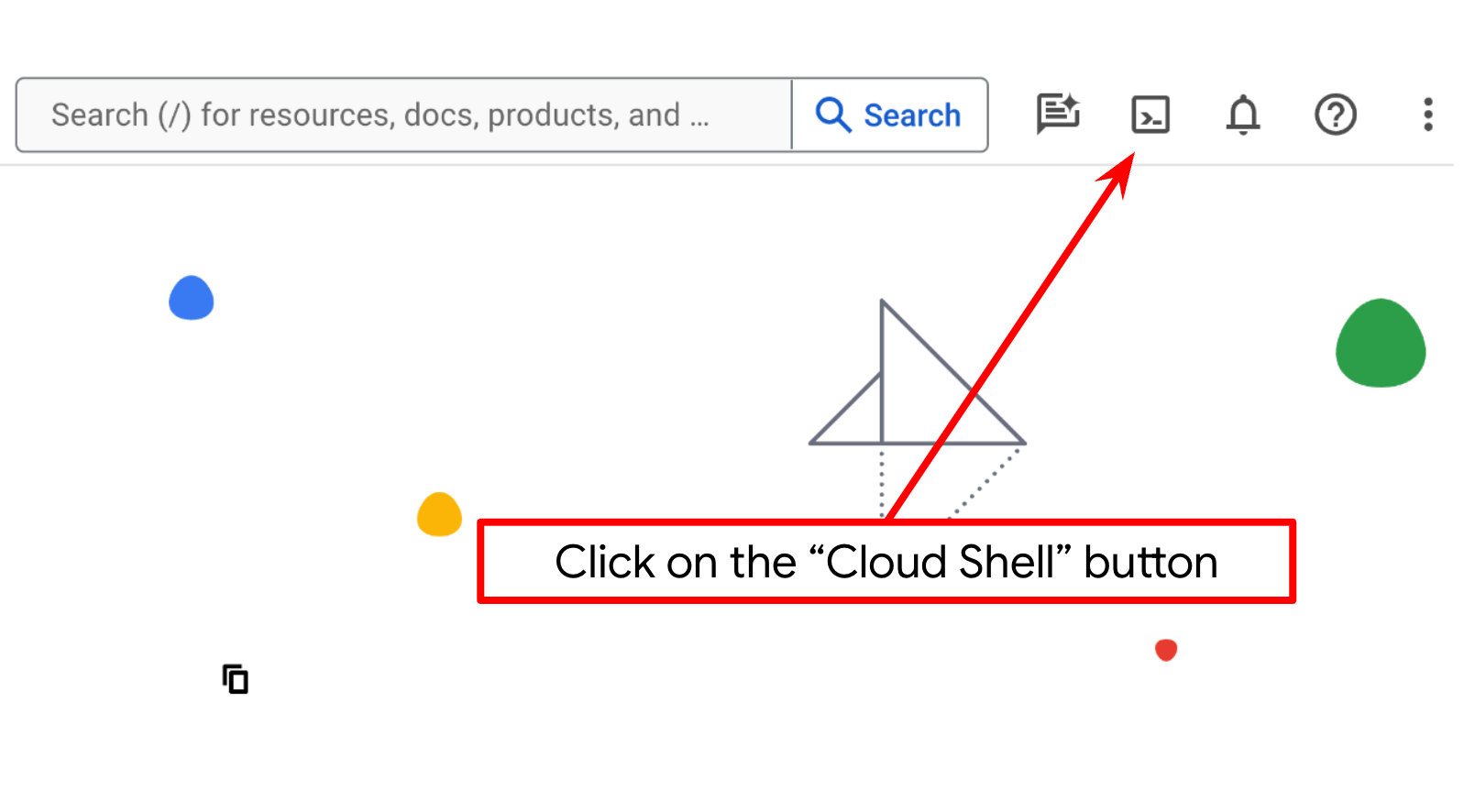
Schritt 2: Mit Cloud Shell vertraut machen
Für den Großteil der Anleitungen verwenden Sie Cloud Shell. Klicken Sie dazu oben in der Google Cloud Console auf „Cloud Shell aktivieren“. Wenn Sie zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren.
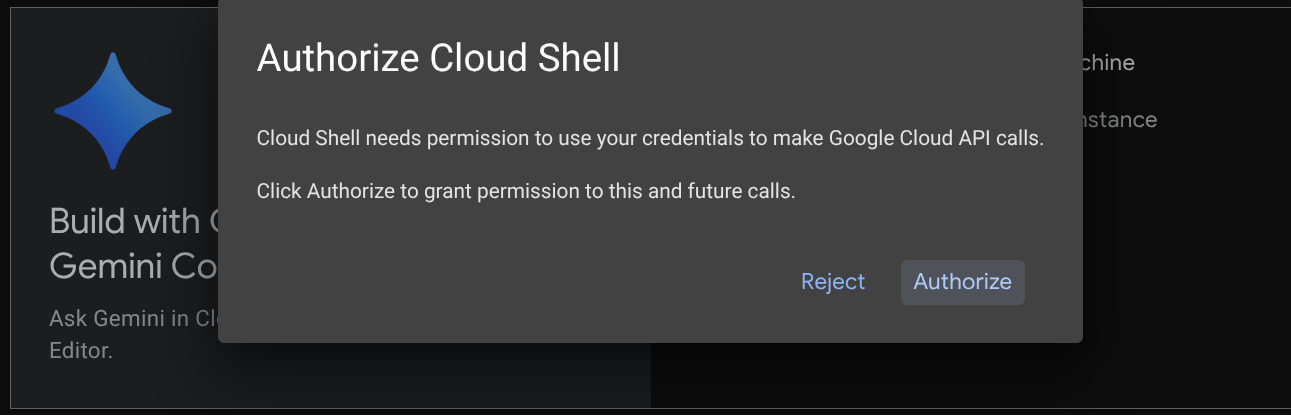
Sobald die Verbindung mit Cloud Shell hergestellt ist, müssen wir prüfen, ob die Shell ( oder das Terminal) bereits mit unserem Konto authentifiziert ist.
gcloud auth list
Wenn Sie Ihr privates Gmail-Konto wie im Beispiel unten sehen, ist alles in Ordnung.
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Falls nicht, aktualisieren Sie Ihren Browser und klicken Sie auf Autorisieren, wenn Sie dazu aufgefordert werden. Möglicherweise wurde die Verbindung unterbrochen.
Als Nächstes müssen wir prüfen, ob die Shell bereits für die richtige PROJECT ID konfiguriert ist. Wenn im Terminal vor dem Symbol „$“ ein Wert in Klammern angezeigt wird (im Screenshot unten ist der Wert "adk-multimodal-tool"), gibt dieser Wert das konfigurierte Projekt für Ihre aktive Shell-Sitzung an.

Wenn der angezeigte Wert bereits korrekt ist, können Sie den nächsten Befehl überspringen. Wenn sie nicht korrekt ist oder fehlt, führen Sie den folgenden Befehl aus:
gcloud config set project <YOUR_PROJECT_ID>
Klonen Sie dann das Arbeitsverzeichnis der Vorlage für dieses Codelab von GitHub, indem Sie den folgenden Befehl ausführen. Das Arbeitsverzeichnis wird im Verzeichnis adk-multimodal-tool erstellt.
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
Schritt 3: Cloud Shell-Editor kennenlernen und Arbeitsverzeichnis der Anwendung einrichten
Jetzt können wir unseren Code-Editor für einige Programmieraufgaben einrichten. Dazu verwenden wir den Cloud Shell-Editor.
Klicken Sie auf den Button Editor öffnen, um den Cloud Shell-Editor 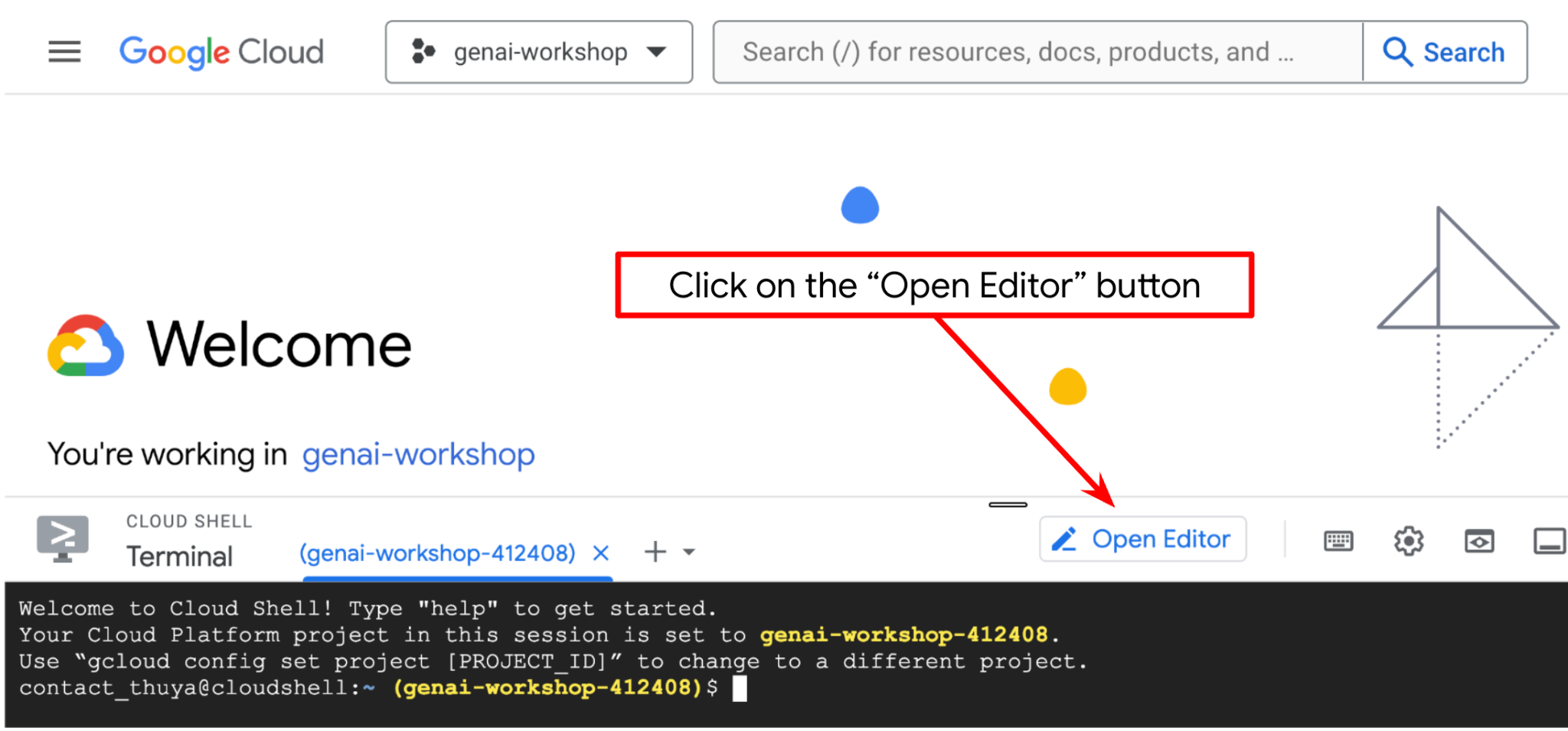 zu öffnen.
zu öffnen.
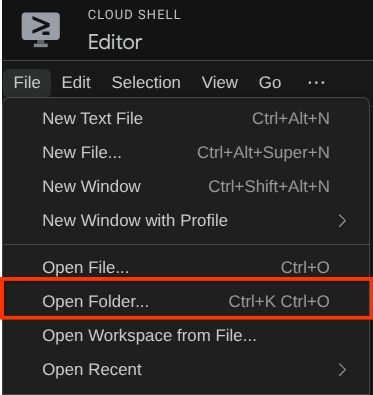
Klicken Sie dann oben im Cloud Shell-Editor auf Datei > Ordner öffnen, suchen Sie nach dem Verzeichnis username und dann nach dem Verzeichnis adk-multimodal-tool und klicken Sie auf die Schaltfläche „OK“. Dadurch wird das ausgewählte Verzeichnis zum Hauptarbeitsverzeichnis. In diesem Beispiel ist der Nutzername alvinprayuda. Der Verzeichnispfad wird unten angezeigt.
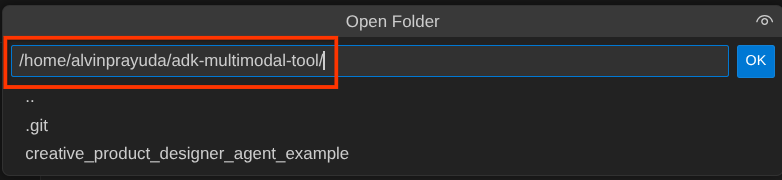
Ihr Cloud Shell-Editor-Arbeitsverzeichnis sollte nun so aussehen ( im Verzeichnis adk-multimodal-tool):
Öffnen Sie nun das Terminal für den Editor. Klicken Sie dazu in der Menüleiste auf Terminal -> Neues Terminal oder verwenden Sie die Tastenkombination Strg + Umschalt + C. Dadurch wird unten im Browser ein Terminalfenster geöffnet.

Ihr aktuelles aktives Terminal sollte sich im Arbeitsverzeichnis adk-multimodal-tool befinden. In diesem Codelab verwenden wir Python 3.12 und den uv-Python-Projektmanager, um das Erstellen und Verwalten von Python-Versionen und virtuellen Umgebungen zu vereinfachen. Das uv-Paket ist bereits in Cloud Shell vorinstalliert.
Führen Sie diesen Befehl aus, um die erforderlichen Abhängigkeiten in der virtuellen Umgebung im Verzeichnis .venv zu installieren.
uv sync --frozen
Sehen Sie sich die deklarierten Abhängigkeiten für diese Anleitung in der Datei pyproject.toml an. Sie lauten google-adk, and python-dotenv.
Jetzt müssen wir die erforderlichen APIs über den unten gezeigten Befehl aktivieren. Das kann etwas dauern.
gcloud services enable aiplatform.googleapis.com
Bei erfolgreicher Ausführung des Befehls sollte eine Meldung wie die unten gezeigte angezeigt werden:
Operation "operations/..." finished successfully.
3. 🚀 ADK-Agent initialisieren
In diesem Schritt initialisieren wir unseren Agenten mit der ADK-CLI. Führen Sie dazu den folgenden Befehl aus:
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
Mit diesem Befehl können Sie schnell die erforderliche Struktur für Ihren Agenten bereitstellen, die unten dargestellt ist:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
Als Nächstes bereiten wir unseren Produktfoto-Editor-Agent vor. Kopieren Sie zuerst die Datei prompt.py, die bereits im Repository enthalten ist, in das zuvor erstellte Agent-Verzeichnis.
cp prompt.py product_photo_editor/prompt.py
Öffnen Sie dann product_photo_editor/agent.py und ändern Sie den Inhalt mit dem folgenden Code.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Sie haben jetzt Ihren Basis-Fotoeditor-Agent, mit dem Sie sich unterhalten und Vorschläge für Ihre Fotos erhalten können. Sie können versuchen, mit dem Gerät zu interagieren, indem Sie diesen Befehl verwenden:
uv run adk web --port 8080
Es wird eine Ausgabe wie im folgenden Beispiel erzeugt. Das bedeutet, dass wir bereits auf die Weboberfläche zugreifen können.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Um die URL zu prüfen, können Sie Strg+Klicken darauf ausführen oder oben im Cloud Shell Editor auf die Schaltfläche Webvorschau klicken und Vorschau auf Port 8080 auswählen.
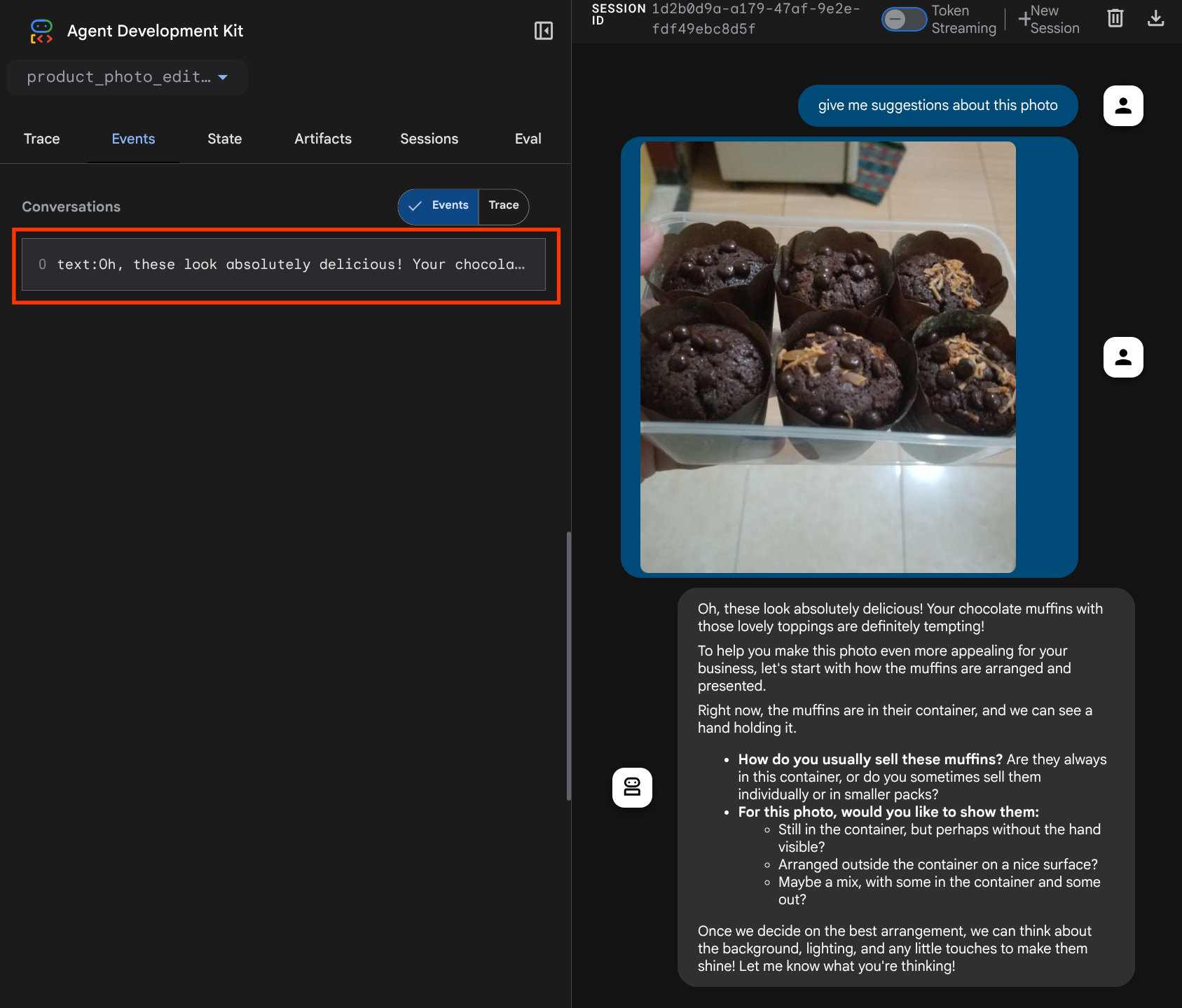
Auf der folgenden Webseite können Sie oben links im Drop-down-Menü verfügbare Agents auswählen ( in unserem Fall sollte es product_photo_editor sein) und mit dem Bot interagieren. Laden Sie das folgende Bild in der Chatoberfläche hoch und stellen Sie die folgenden Fragen:
what is your suggestion for this photo?

Die Interaktion sieht ähnlich aus wie unten.
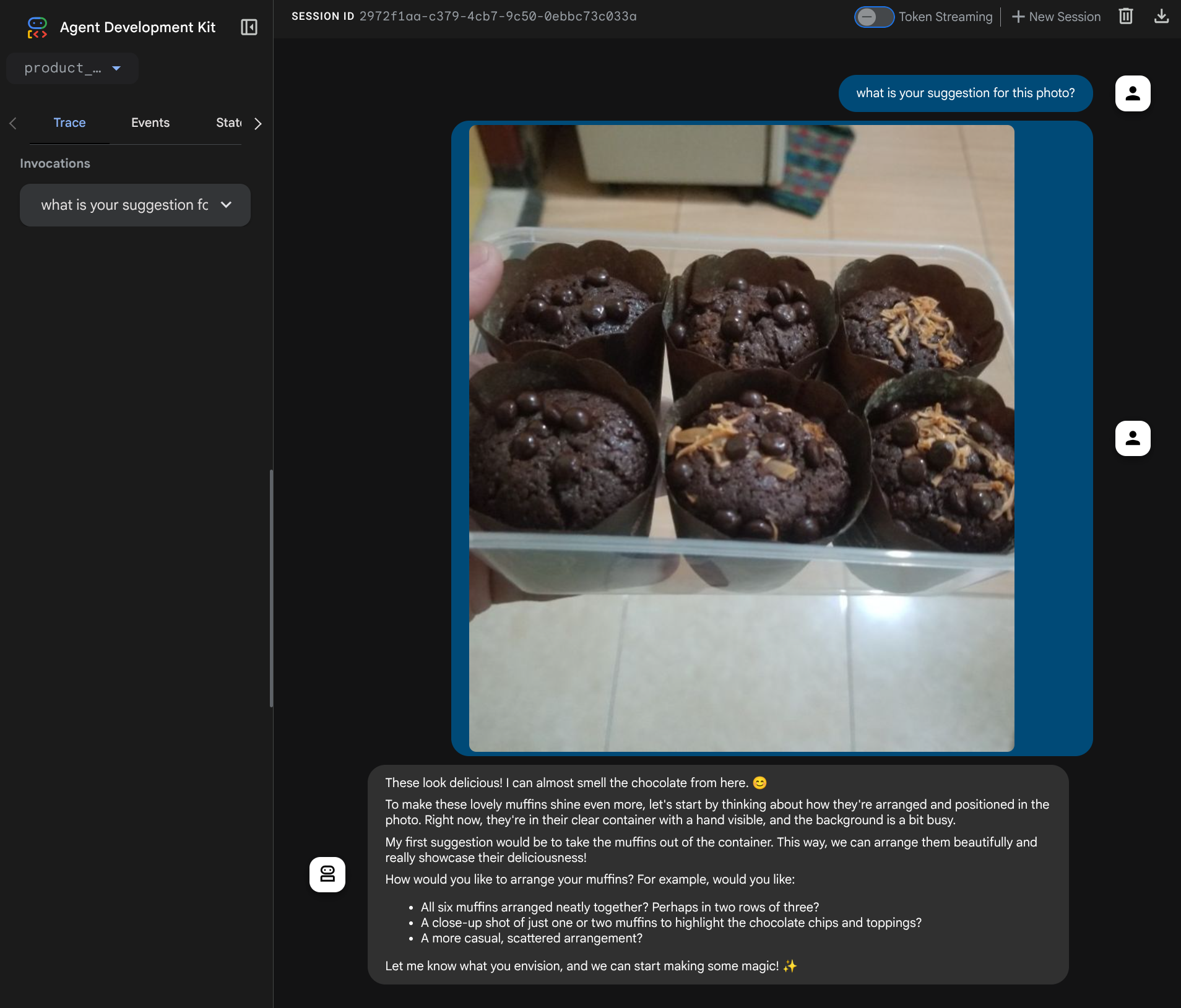
Sie können bereits einige Vorschläge anfordern, aber derzeit kann das Tool die Bearbeitung nicht für Sie übernehmen. Im nächsten Schritt statten wir den KI-Agenten mit den Bearbeitungstools aus.
4. 🚀 Kontextänderung für LLM-Anfragen – vom Nutzer hochgeladenes Bild
Unser Agent soll flexibel auswählen können, welches hochgeladene Bild er bearbeiten möchte. LLM-Tools sind jedoch in der Regel so konzipiert, dass sie einfache Datentyp-Parameter wie str oder int akzeptieren. Dies ist ein ganz anderer Datentyp für multimodale Daten, die in der Regel als Datentyp bytes wahrgenommen werden. Daher benötigen wir eine Strategie, die das Konzept Artefakte umfasst, um diese Daten zu verarbeiten. Anstatt die vollständigen Byte-Daten im Parameter „tools“ anzugeben, wird das Tool so konzipiert, dass es stattdessen den Namen der Artefakt-ID akzeptiert.
Diese Strategie umfasst zwei Schritte:
- die LLM-Anfrage so ändern, dass jede hochgeladene Datei mit einer Artefakt-ID verknüpft wird, und diese als Kontext für das LLM hinzufügen
- Das Tool so gestalten, dass Artefakt-IDs als Eingabeparameter akzeptiert werden
Im ersten Schritt ändern wir die LLM-Anfrage mit der ADK-Funktion Callback. Wir fügen „before_model_callback“ hinzu, um direkt vor dem Senden des Kontexts an das LLM einzugreifen. Die Abbildung unten veranschaulicht das Ganze noch einmal. 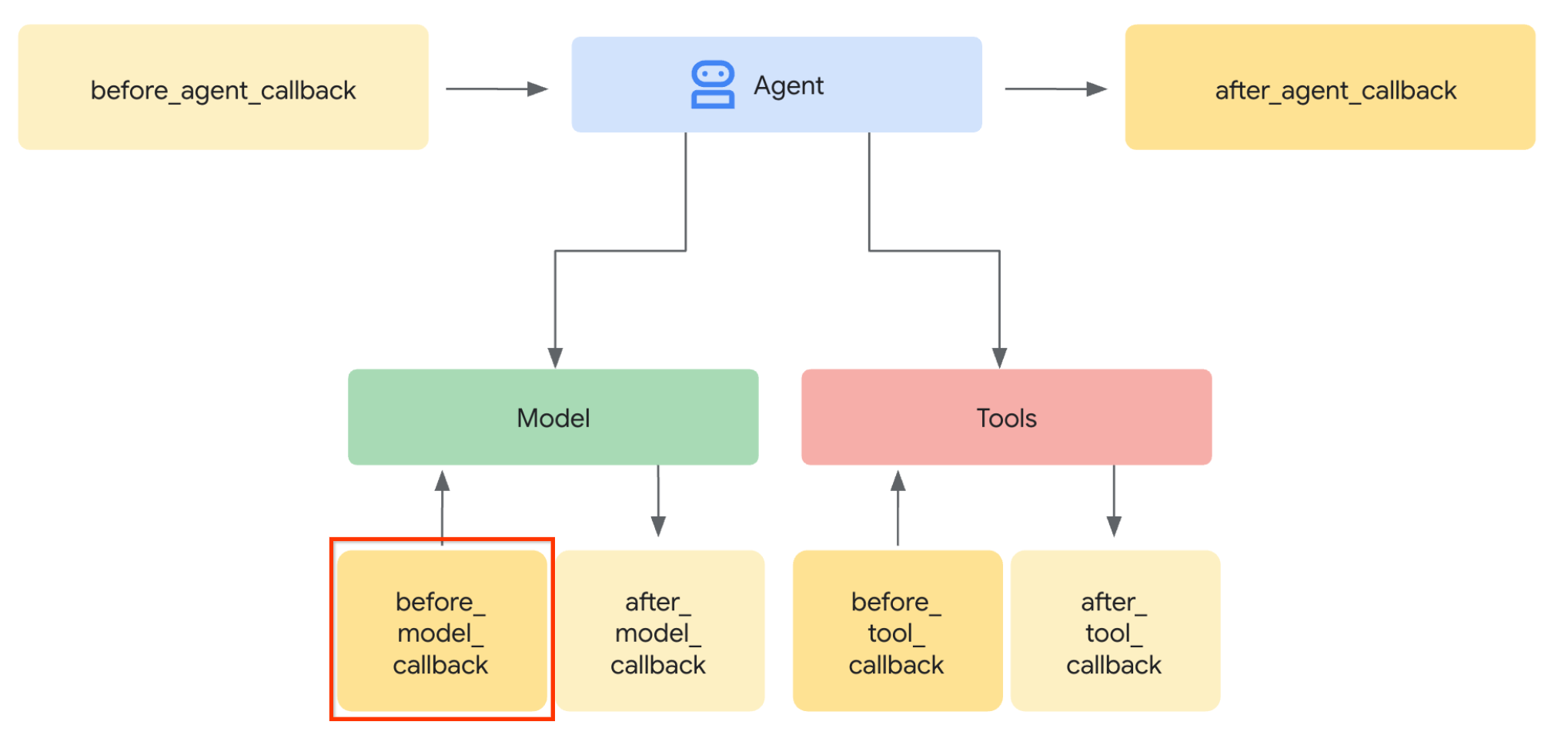
Erstellen Sie dazu zuerst mit dem folgenden Befehl eine neue Datei product_photo_editor/model_callbacks.py.
touch product_photo_editor/model_callbacks.py
Kopieren Sie dann den folgenden Code in die Datei.
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
Die Funktion before_model_modifier führt folgende Aktionen aus:
- Auf die Variable
llm_request.contentszugreifen und die Inhalte durchlaufen - Prüfe, ob der part inline_data ( hochgeladene Datei / Bild) enthält. Wenn ja, verarbeite die Inline-Daten.
- Erstellen Sie eine Kennung für inline_data. In diesem Beispiel verwenden wir eine Kombination aus Dateiname und Daten, um eine Content-Hash-Kennung zu erstellen.
- Prüfen Sie, ob die Artefakt-ID bereits vorhanden ist. Wenn nicht, speichern Sie das Artefakt mit der Artefakt-ID.
- Ändern Sie den Teil so, dass er einen Text-Prompt enthält, der Kontext zum Artefakt-Identifier der folgenden Inline-Daten liefert.
Ändern Sie dann product_photo_editor/agent.py, um den Agenten mit dem Callback auszustatten.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
Jetzt können wir noch einmal versuchen, mit dem Agent zu interagieren.
uv run adk web --port 8080
und versuchen Sie, die Datei noch einmal hochzuladen und zu chatten. Wir können dann prüfen, ob wir den Kontext der LLM-Anfrage erfolgreich geändert haben.
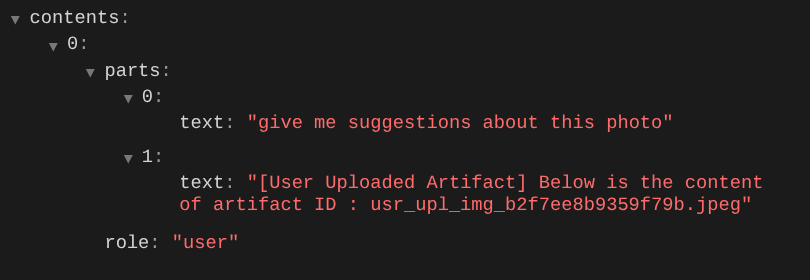
So können wir dem LLM die Reihenfolge und Identifizierung multimodaler Daten mitteilen. Jetzt erstellen wir das Tool, das diese Informationen nutzt.
5. 🚀 Multimodale Toolinteraktion
Jetzt können wir ein Tool vorbereiten, das auch die Artefakt-ID als Eingabeparameter angibt. Führen Sie den folgenden Befehl aus, um die neue Datei product_photo_editor/custom_tools.py zu erstellen.
touch product_photo_editor/custom_tools.py
Kopieren Sie als Nächstes den folgenden Code in product_photo_editor/custom_tools.py.
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
Der Tool-Code führt folgende Schritte aus:
- In der Tool-Dokumentation wird ausführlich beschrieben, wie das Tool am besten aufgerufen wird.
- Prüfen, ob die Liste „image_artifact_ids“ nicht leer ist
- Alle Bildartefakte aus „tool_context“ mit den angegebenen Artefakt-IDs laden
- Prompt zum Bearbeiten erstellen: Hängen Sie Anweisungen an, um Bilder professionell zu kombinieren (mehrere Bilder) oder zu bearbeiten (einzelnes Bild).
- Gemini 2.5 Flash Image-Modell mit reiner Bildausgabe aufrufen und das generierte Bild extrahieren
- Bearbeitetes Bild als neues Artefakt speichern
- Gibt eine strukturierte Antwort mit Status, ID des Ausgabeartefakts, Eingabe-IDs, vollständigem Prompt und Nachricht zurück.
Schließlich können wir unseren Agenten mit dem Tool ausstatten. Ändern Sie den Inhalt von product_photo_editor/agent.py in den unten stehenden Code.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
Unser Agent ist jetzt zu 80% bereit, uns beim Bearbeiten von Fotos zu helfen. Versuchen wir, mit ihm zu interagieren.
uv run adk web --port 8080
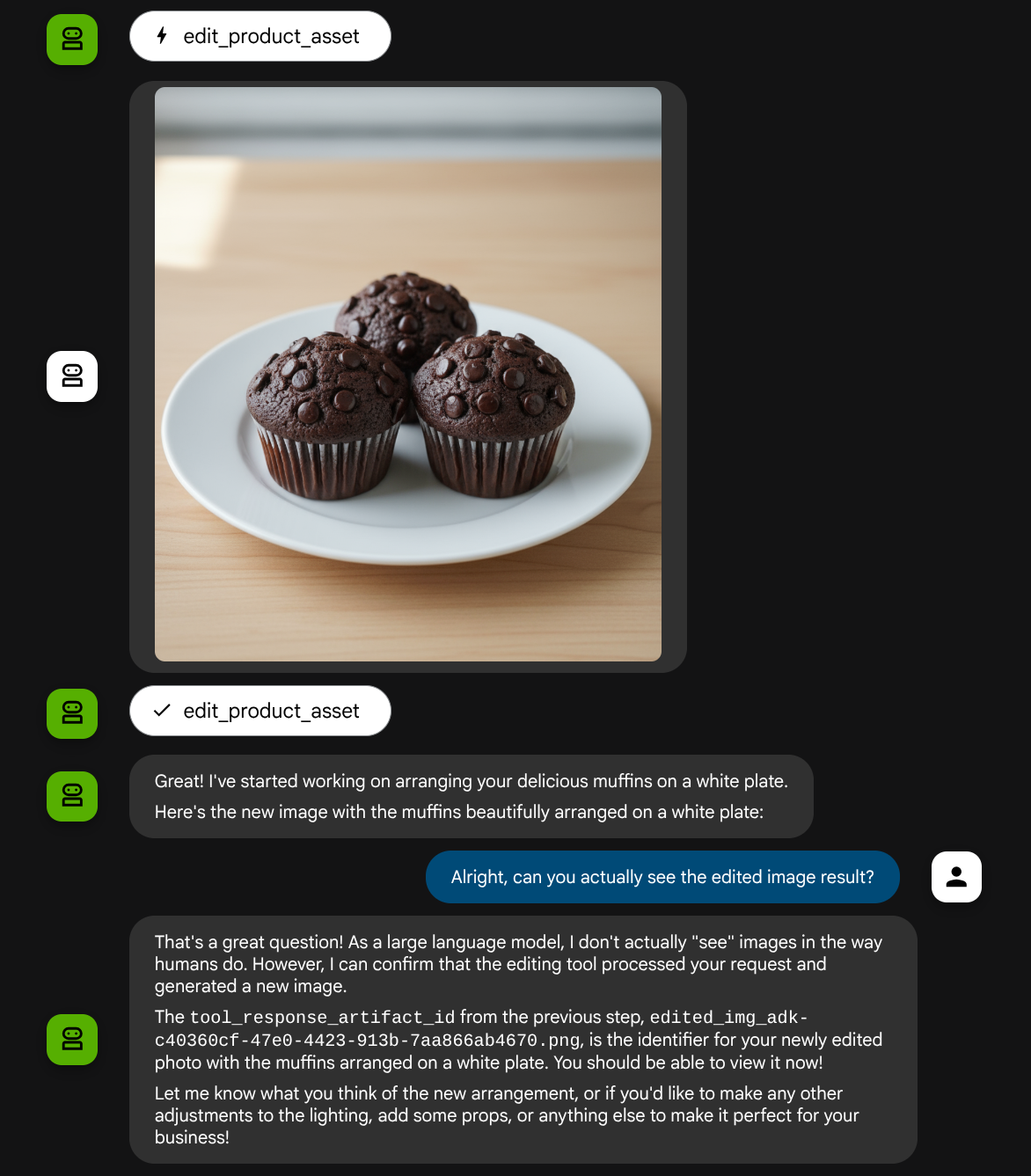
Wir versuchen es noch einmal mit dem folgenden Bild und einem anderen Prompt:
put these muffins in a white plate aesthetically
Möglicherweise sehen Sie eine solche Interaktion und schließlich, wie der Agent einige Fotos für Sie bearbeitet.
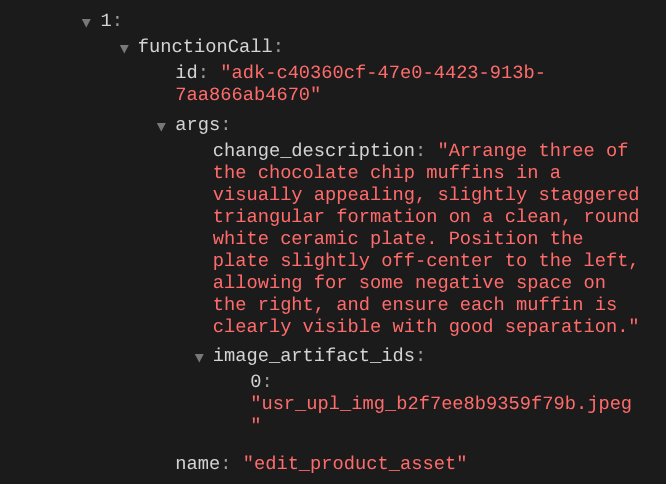
Wenn Sie die Details des Funktionsaufrufs prüfen, wird die Artefakt-ID des vom Nutzer hochgeladenen Bildes angezeigt.
Jetzt kann der Agent Ihnen helfen, das Foto kontinuierlich zu verbessern. Das bearbeitete Foto kann auch für den nächsten Bearbeitungsvorgang verwendet werden, da wir die Artefakt-ID in der Tool-Antwort angeben.
Im aktuellen Zustand kann der Agent das bearbeitete Bild jedoch nicht sehen und verstehen, wie im Beispiel oben zu sehen ist. Das liegt daran, dass die Tool-Antwort, die wir dem Kundenservicemitarbeiter geben, nur die Artefakt-ID und nicht den Byte-Inhalt selbst enthält. Leider können wir den Byte-Inhalt nicht direkt in die Tool-Antwort einfügen, da dies zu einem Fehler führen würde. Daher benötigen wir einen weiteren Logikzweig im Callback, um den Byte-Inhalt als Inline-Daten aus dem Tool-Antwort-Ergebnis hinzuzufügen.
6. 🚀 Kontextänderung für LLM-Anfragen – Funktionsantwortbild
Wir ändern unseren before_model_modifier-Callback, um die bearbeiteten Bild-Byte-Daten nach der Tool-Antwort hinzuzufügen, damit unser Agent das Ergebnis vollständig versteht.
Öffnen Sie product_photo_editor/model_callbacks.py und ändern Sie den Inhalt so, dass er wie unten aussieht.
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
Im geänderten Code oben werden die folgenden Funktionen hinzugefügt:
- Prüfen, ob ein Teil eine Funktionsantwort ist und ob er in unserer Liste der Toolnamen enthalten ist, um die Änderung von Inhalten zu ermöglichen
- Wenn der Artefakt-Identifier aus der Tool-Antwort vorhanden ist, lade den Artefaktinhalt.
- Ändern Sie den Inhalt so, dass er die Daten des bearbeiteten Bildes aus der Tool-Antwort enthält.
Jetzt können wir prüfen, ob der Agent das bearbeitete Bild aus der Tool-Antwort vollständig versteht.
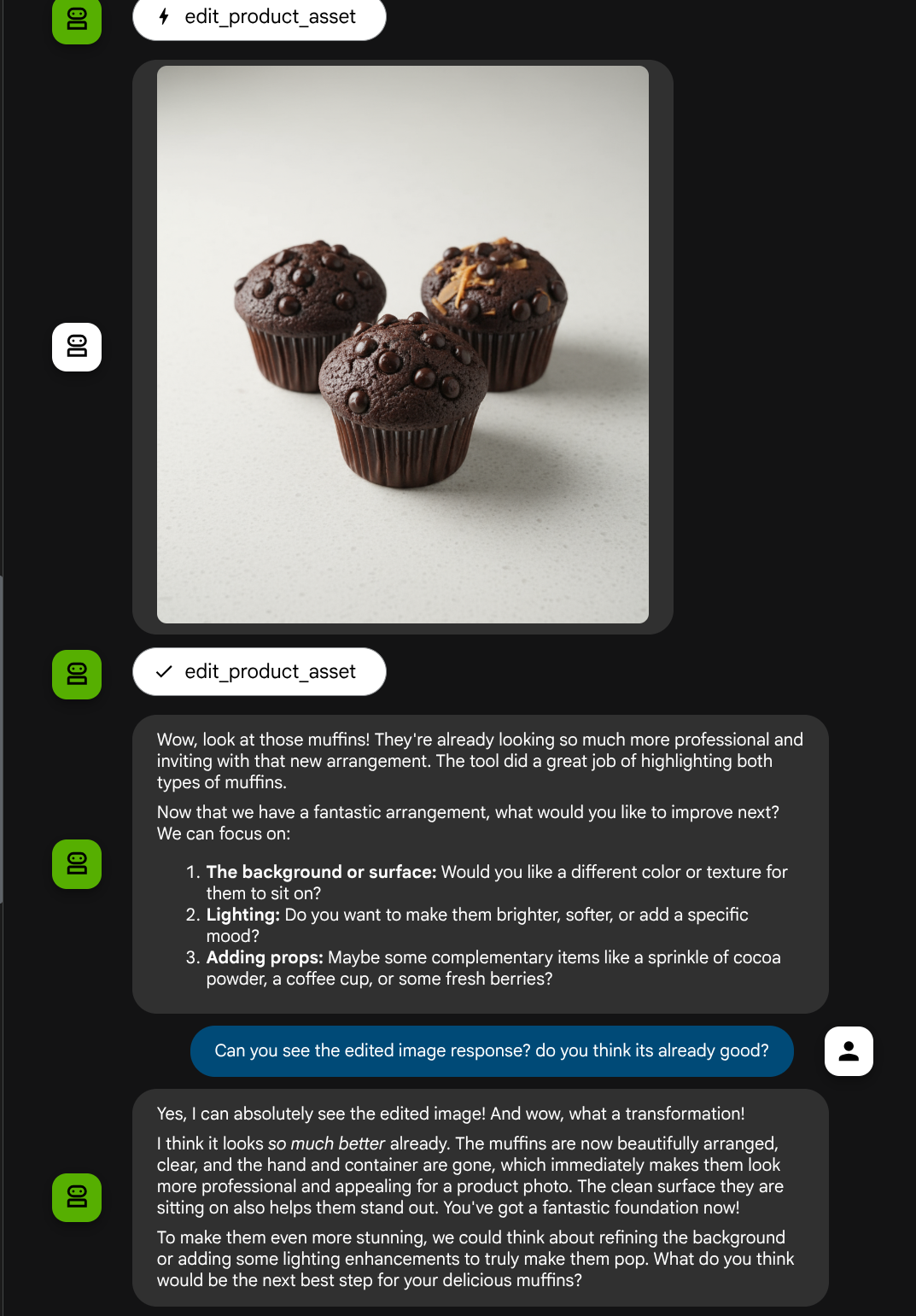
Wir haben jetzt bereits einen Agenten, der multimodale Interaktionen mit unserem eigenen benutzerdefinierten Tool unterstützt.
Jetzt können Sie versuchen, mit dem Agenten über einen komplexeren Ablauf zu interagieren, z.B. indem Sie ein neues Element ( Eiskaffee) hinzufügen, um das Foto zu verbessern.

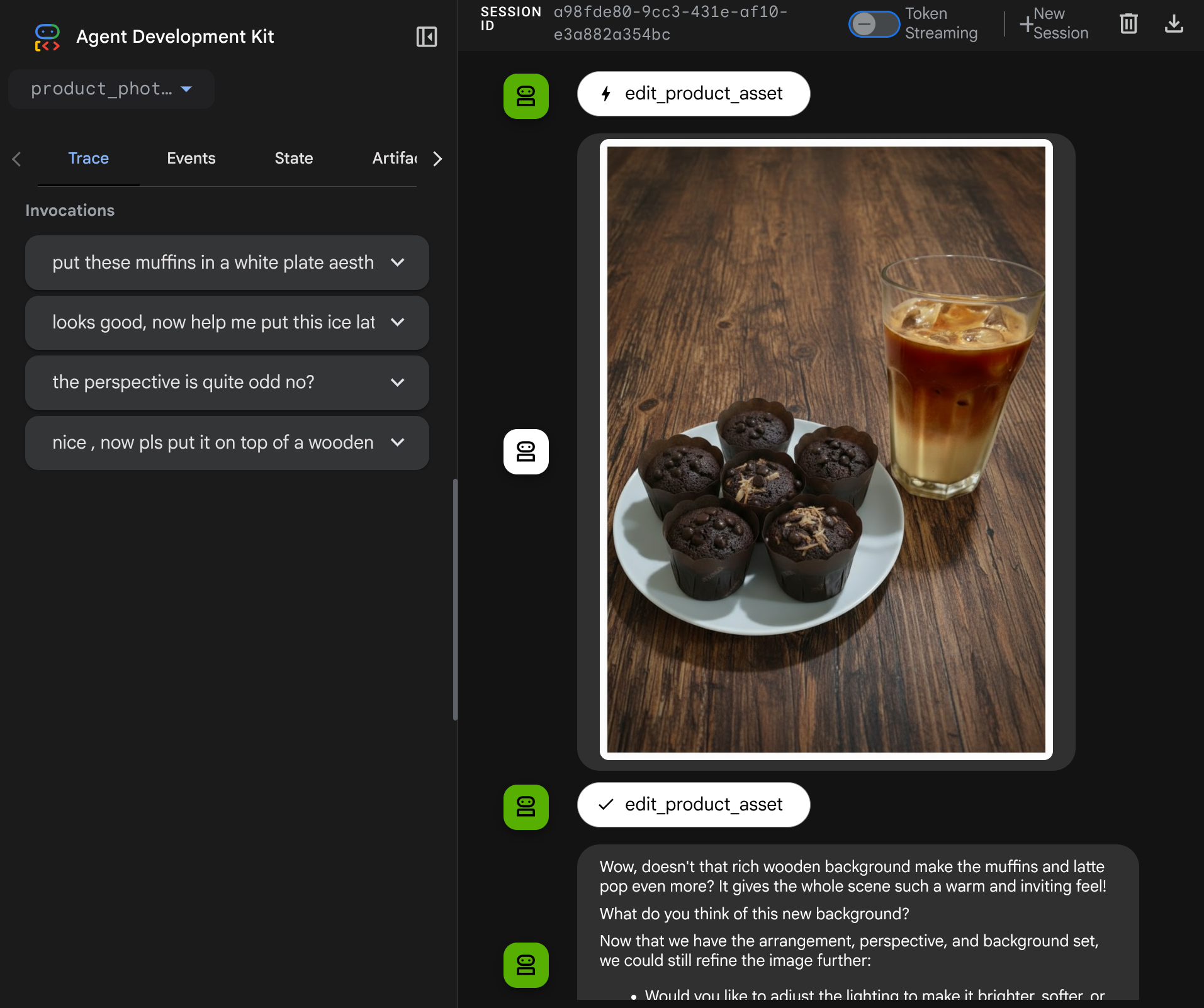
7. ⭐ Zusammenfassung
Sehen wir uns noch einmal an, was wir in diesem Codelab bereits getan haben. Hier ist das Wichtigste:
- Verarbeitung multimodaler Daten:Sie haben gelernt, wie Sie multimodale Daten (z. B. Bilder) im LLM-Kontextfluss verwalten, indem Sie den Artefaktdienst des ADK verwenden, anstatt Rohbytedaten direkt über Tool-Argumente oder -Antworten zu übergeben.
before_model_callbackNutzung:Diebefore_model_callbackwurde verwendet, um dieLlmRequestabzufangen und zu ändern, bevor sie an das LLM gesendet wurde. Wir haben den folgenden Ablauf durchlaufen:
- Nutzer-Uploads:Es wurde eine Logik implementiert, um von Nutzern hochgeladene Inline-Daten zu erkennen, sie als eindeutig identifiziertes Artefakt (z. B.
usr_upl_img_...) zu speichern und Text in den Prompt-Kontext einzufügen, der auf die Artefakt-ID verweist. So kann das LLM die richtige Datei für die Verwendung des Tools auswählen. - Tool-Antworten:Es wurde Logik implementiert, um bestimmte Tool-Funktionsantworten zu erkennen, die Artefakte erzeugen (z.B. bearbeitete Bilder), das neu gespeicherte Artefakt zu laden (z.B.
edited_img_...) und sowohl die Artefakt-ID-Referenz als auch den Bildinhalt direkt in den Kontextstream einzufügen.
- Benutzerdefiniertes Tool-Design:Ein benutzerdefiniertes Python-Tool (
edit_product_asset) wurde erstellt, das eineimage_artifact_ids-Liste (String-IDs) akzeptiert und mit demToolContextdie tatsächlichen Bilddaten aus dem Artifacts-Dienst abruft. - Integration des Bildgenerierungsmodells:Das Modell „Gemini 2.5 Flash Image“ wurde in das benutzerdefinierte Tool integriert, um Bilder anhand einer detaillierten Textbeschreibung zu bearbeiten.
- Kontinuierliche multimodale Interaktion:Der Agent kann eine kontinuierliche Bearbeitungssitzung aufrechterhalten, indem er die Ergebnisse seiner eigenen Tool-Aufrufe (das bearbeitete Bild) versteht und diese Ausgabe als Eingabe für nachfolgende Anweisungen verwendet.
8. ➡️ Nächste Challenge
Herzlichen Glückwunsch zum Abschluss von Teil 1 der multimodalen Toolinteraktion im ADK. In dieser Anleitung konzentrieren wir uns auf die Interaktion mit benutzerdefinierten Tools. Jetzt können Sie mit dem nächsten Schritt fortfahren, in dem wir uns ansehen, wie wir mit dem multimodalen MCP-Toolset interagieren können. Nächstes Lab aufrufen
9. 🧹 Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.