
1. 📖 Introducción
En este codelab, se muestra cómo diseñar una interacción de herramientas multimodales en el Kit de desarrollo de agentes (ADK). Este es un flujo específico en el que deseas que el agente consulte el archivo subido como entrada para una herramienta y también comprenda el contenido del archivo que produce la respuesta de la herramienta. Por lo tanto, es posible la interacción que se muestra en la siguiente captura de pantalla. En este instructivo, desarrollaremos un agente capaz de ayudar al usuario a editar una mejor foto para la presentación de su producto.
En el codelab, seguirás un enfoque paso a paso de la siguiente manera:
- Prepara el proyecto de Google Cloud
- Configura el directorio de trabajo para el entorno de codificación
- Inicializa el agente con el ADK
- Diseña una herramienta que se pueda usar para editar fotos con la tecnología de Gemini 2.5 Flash Image
- Diseña una función de devolución de llamada para controlar la carga de imágenes del usuario, guardarla como artefacto y agregarla como contexto al agente.
- Diseña una función de devolución de llamada para controlar la imagen producida por una respuesta de la herramienta, guárdala como artefacto y agrégala como contexto al agente.
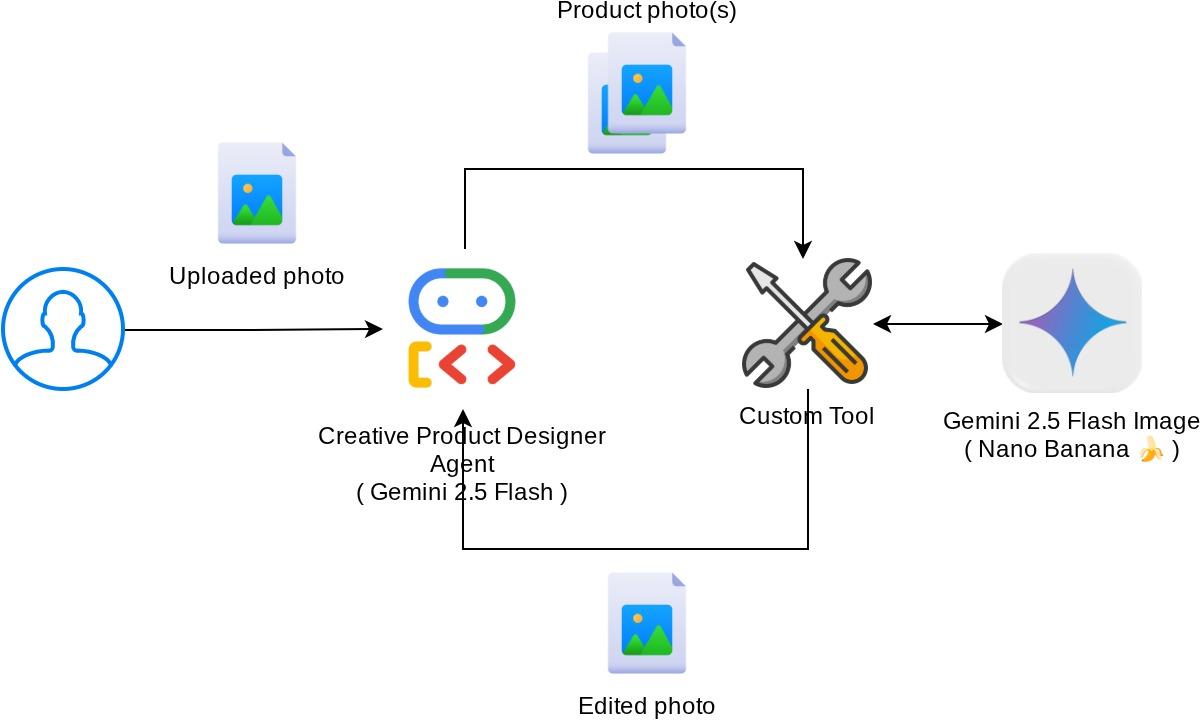
Descripción general de la arquitectura
La interacción general en este codelab se muestra en el siguiente diagrama
Requisitos previos
- Comodidad para trabajar con Python
- (Opcional) Codelabs básicos sobre el Kit de desarrollo de agentes (ADK)
Qué aprenderás
- Cómo utilizar el contexto de devolución de llamada para acceder al servicio de artefactos
- Cómo diseñar una herramienta con la propagación adecuada de datos multimodales
- Cómo modificar la solicitud del LLM del agente para agregar contexto de artefacto a través de before_model_callback
- Cómo editar imágenes con Gemini 2.5 Flash Image
Requisitos
- Navegador web Chrome
- Una cuenta de Gmail
- Un proyecto de Cloud con una cuenta de facturación habilitada
Este codelab, diseñado para desarrolladores de todos los niveles (incluidos los principiantes), usa Python en su aplicación de ejemplo. Sin embargo, no es necesario tener conocimientos de Python para comprender los conceptos presentados.
2. 🚀 Preparación de la configuración del desarrollo del taller
Paso 1: Selecciona el proyecto activo en la consola de Cloud
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud (consulta la sección superior izquierda de la consola).

Haz clic en él y verás una lista de todos tus proyectos, como en este ejemplo:
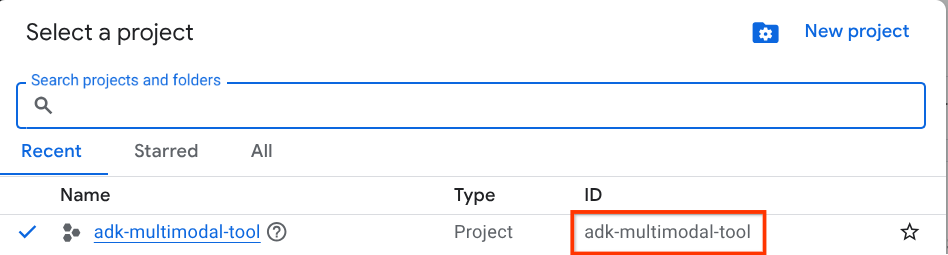
El valor que se indica con el cuadro rojo es el ID DEL PROYECTO, y se usará en todo el instructivo.
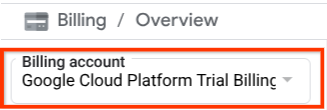
Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Para verificarlo, haz clic en el ícono de hamburguesa ☰ en la barra superior izquierda, que muestra el menú de navegación, y busca el menú Facturación.

Si ves "Cuenta de facturación de la prueba de Google Cloud Platform" debajo del título Facturación / Descripción general ( sección superior izquierda de tu consola de Cloud), tu proyecto está listo para usarse en este instructivo. De lo contrario, vuelve al inicio de este instructivo y canjea la cuenta de facturación de prueba.
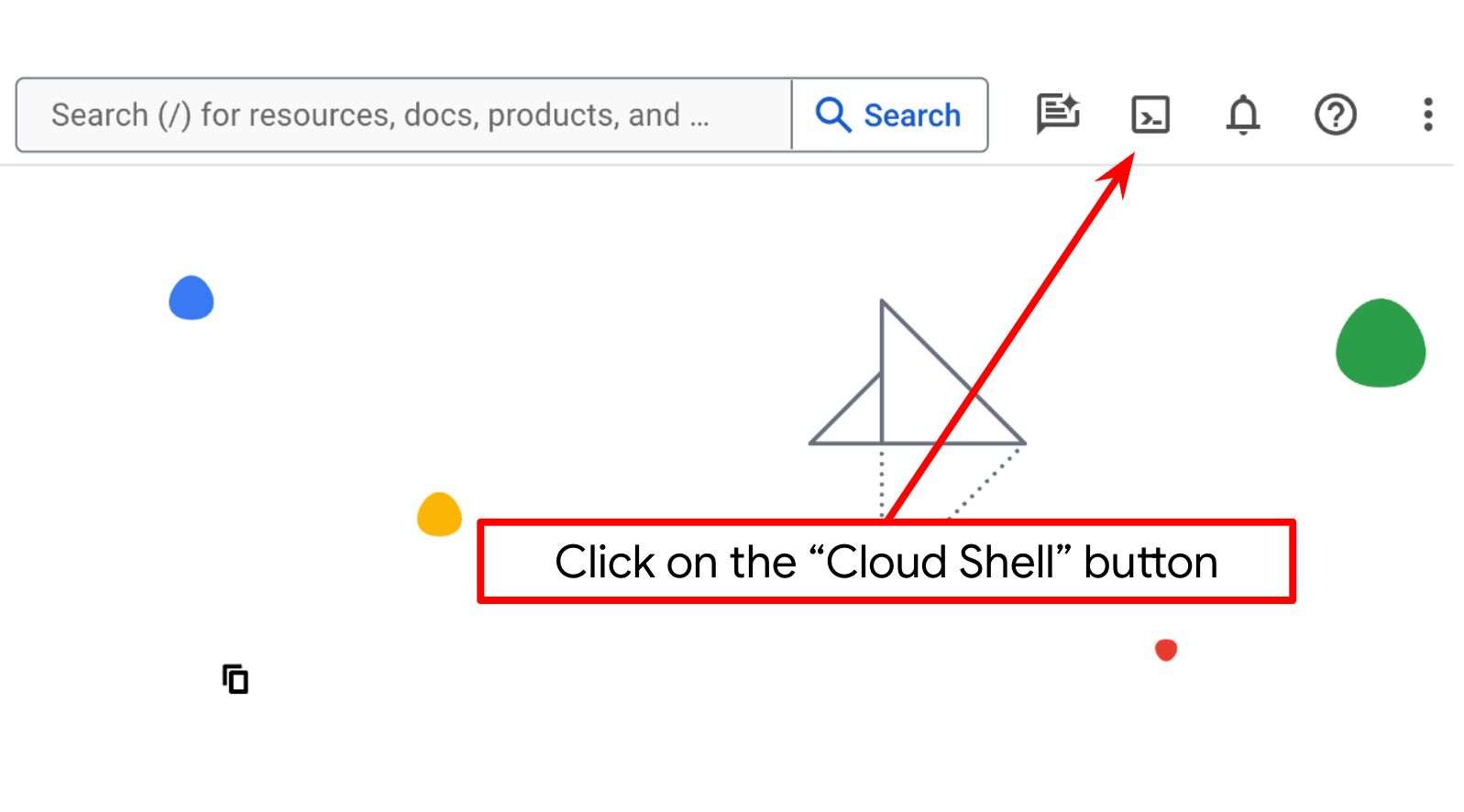
Paso 2: Familiarízate con Cloud Shell
Usarás Cloud Shell durante la mayor parte de los instructivos. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud. Si se te solicita autorización, haz clic en Autorizar.
Una vez que te conectes a Cloud Shell, deberemos verificar si el shell ( o la terminal) ya se autenticó con nuestra cuenta.
gcloud auth list
Si ves tu Gmail personal como en el siguiente ejemplo de resultado, todo está bien.
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Si no es así, intenta actualizar el navegador y asegúrate de hacer clic en Autorizar cuando se te solicite ( es posible que se interrumpa debido a un problema de conexión).
A continuación, también debemos verificar si la shell ya está configurada con el ID DEL PROYECTO correcto que tienes. Si ves que hay un valor dentro de ( ) antes del ícono $ en la terminal ( en la captura de pantalla a continuación, el valor es "adk-multimodal-tool"), este valor muestra el proyecto configurado para tu sesión de shell activa.

Si el valor que se muestra ya es correcto, puedes omitir el siguiente comando. Sin embargo, si no es correcto o falta, ejecuta el siguiente comando:
gcloud config set project <YOUR_PROJECT_ID>
Luego, clona el directorio de trabajo de la plantilla para este codelab desde GitHub. Para ello, ejecuta el siguiente comando. Se creará el directorio de trabajo en el directorio adk-multimodal-tool.
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
Paso 3: Familiarízate con el editor de Cloud Shell y configura el directorio de trabajo de la aplicación
Ahora, podemos configurar nuestro editor de código para hacer algunas cosas de programación. Usaremos el editor de Cloud Shell para esto.
Haz clic en el botón Abrir editor para abrir un editor de Cloud Shell 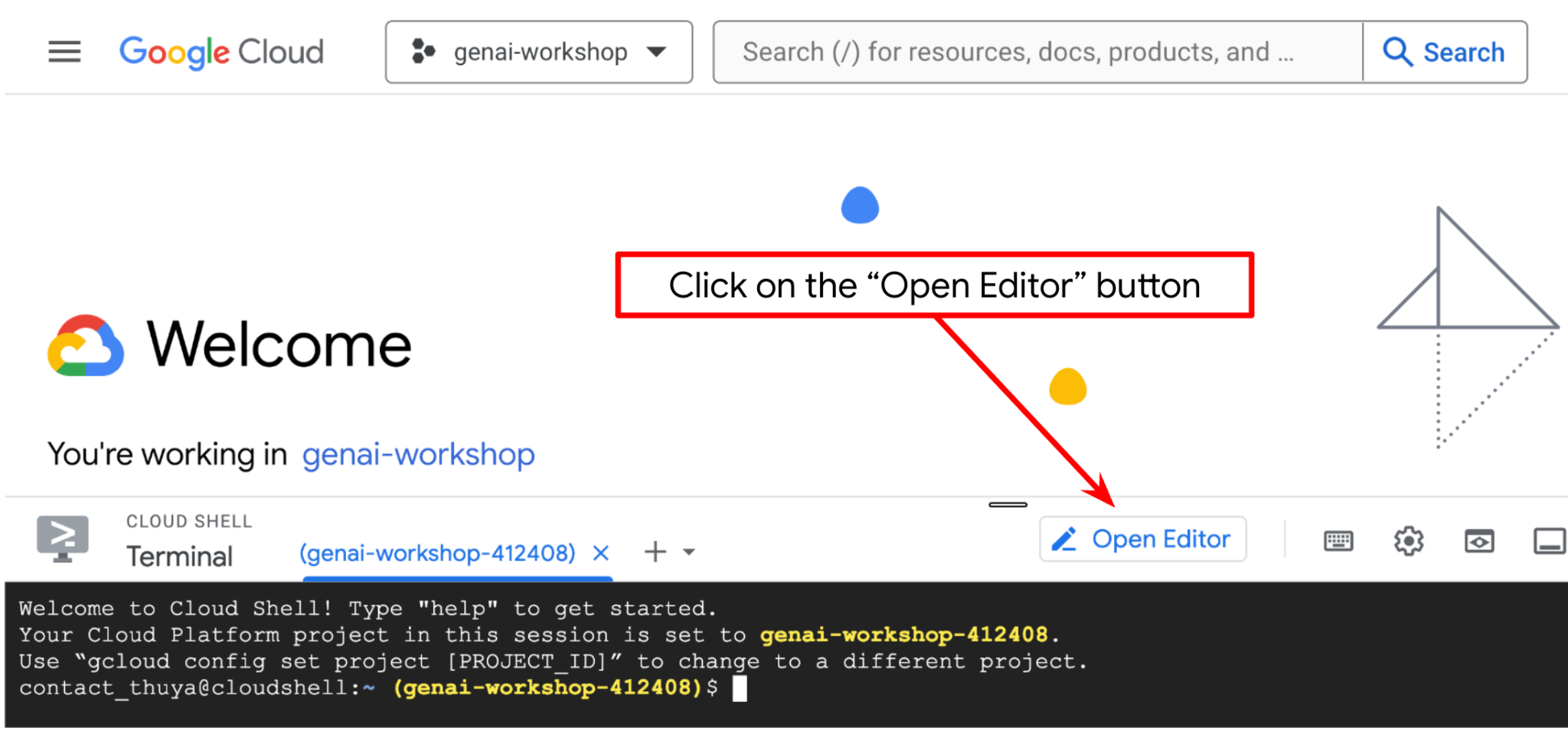 .
.
Después, ve a la sección superior del editor de Cloud Shell y haz clic en File->Open Folder, busca tu directorio de nombre de usuario y el directorio adk-multimodal-tool y, luego, haz clic en el botón Aceptar. Esto convertirá el directorio elegido en el directorio de trabajo principal. En este ejemplo, el nombre de usuario es alvinprayuda, por lo que la ruta de acceso del directorio se muestra a continuación.
Ahora, tu directorio de trabajo del editor de Cloud Shell debería verse de la siguiente manera ( dentro de adk-multimodal-tool):
Ahora, abre la terminal del editor. Para ello, haz clic en Terminal -> New Terminal en la barra de menú o usa Ctrl + Mayúsculas + C. Se abrirá una ventana de terminal en la parte inferior del navegador.

Tu terminal activa actual debe estar dentro del directorio de trabajo adk-multimodal-tool. En este codelab, usaremos Python 3.12 y uv python project manager para simplificar la necesidad de crear y administrar la versión de Python y el entorno virtual. Este paquete uv ya está preinstalado en Cloud Shell.
Ejecuta este comando para instalar las dependencias requeridas en el entorno virtual del directorio .venv.
uv sync --frozen
Consulta el archivo pyproject.toml para ver las dependencias declaradas para este instructivo, que son google-adk, and python-dotenv.
Ahora, deberemos habilitar las APIs requeridas con el siguiente comando. Este proceso podría tardar un poco.
gcloud services enable aiplatform.googleapis.com
Cuando el comando se ejecute correctamente, deberías ver un mensaje similar al que se muestra a continuación:
Operation "operations/..." finished successfully.
3. 🚀 Inicializa el agente del ADK
En este paso, inicializaremos nuestro agente con la CLI del ADK. Para ello, ejecuta el siguiente comando:
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
Este comando te ayudará a proporcionar rápidamente la estructura requerida para tu agente, como se muestra a continuación:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
Después de eso, preparemos nuestro agente editor de fotos de productos. Primero, copia el archivo prompt.py que ya está incluido en el repositorio en el directorio del agente que creaste anteriormente.
cp prompt.py product_photo_editor/prompt.py
Luego, abre product_photo_editor/agent.py y modifica el contenido con el siguiente código:
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Ahora tendrás tu agente editor de fotos básico con el que ya puedes chatear para pedir sugerencias sobre tus fotos. Puedes intentar interactuar con él usando este comando.
uv run adk web --port 8080
Se generará un resultado similar al siguiente ejemplo, lo que significa que ya podemos acceder a la interfaz web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Ahora, para verificarlo, puedes hacer Ctrl + clic en la URL o hacer clic en el botón Vista previa en la Web en la parte superior del editor de Cloud Shell y seleccionar Vista previa en el puerto 8080.
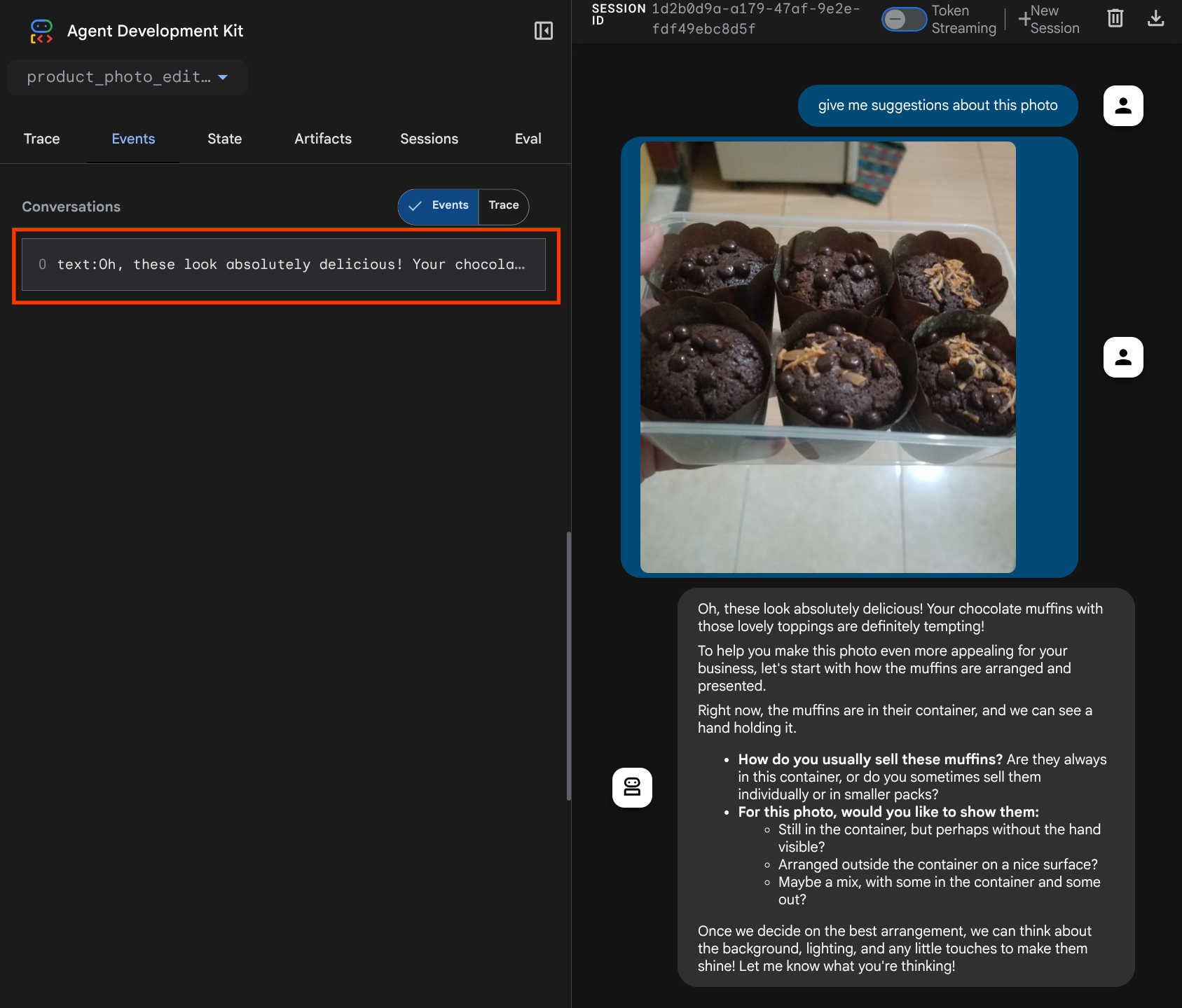
Verás la siguiente página web en la que podrás seleccionar los agentes disponibles en el botón de menú desplegable de la parte superior izquierda ( en nuestro caso, debería ser product_photo_editor) y, luego, interactuar con el bot. Intenta subir la siguiente imagen en la interfaz de chat y haz las siguientes preguntas.
what is your suggestion for this photo?

Verás una interacción similar a la que se muestra a continuación.
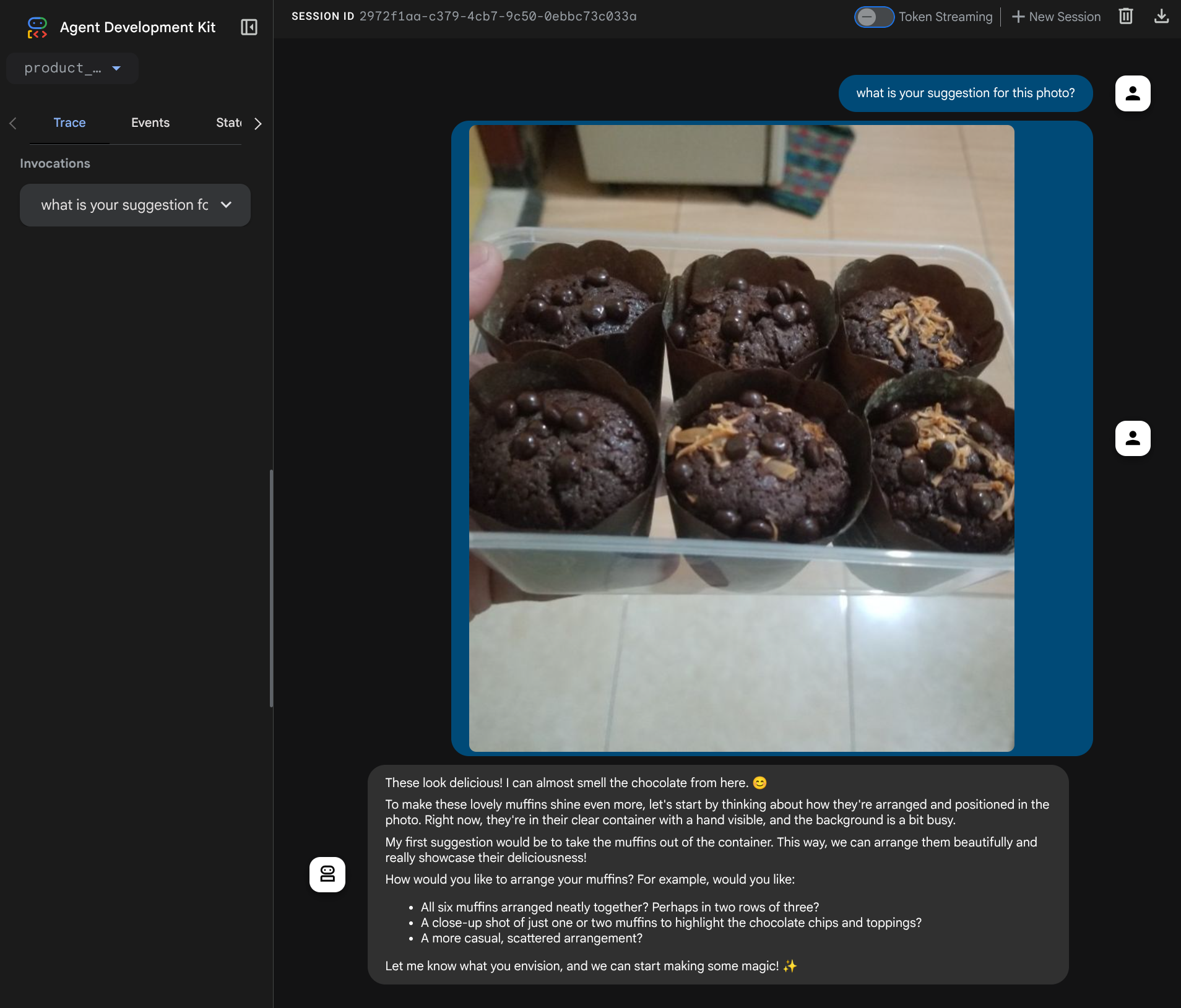
Ya puedes pedir algunas sugerencias, pero, por el momento, no puede realizar la edición por ti. Pasemos al siguiente paso, que consiste en equipar al agente con las herramientas de edición.
4. 🚀 LLM Request Context Modification - User Uploaded Image
Queremos que nuestro agente sea flexible a la hora de seleccionar qué imagen subida desea editar. Sin embargo, las herramientas de LLM suelen diseñarse para aceptar parámetros de tipo de datos simples, como str o int. Este es un tipo de datos muy diferente para los datos multimodales, que suelen percibirse como un tipo de datos bytes, por lo que necesitaremos una estrategia que involucre el concepto de artefactos para controlar esos datos. Por lo tanto, en lugar de proporcionar los datos de bytes completos en el parámetro de herramientas, diseñaremos la herramienta para que acepte el nombre del identificador del artefacto.
Esta estrategia incluirá 2 pasos:
- Modifica la solicitud del LLM para que cada archivo subido se asocie con un identificador de artefacto y agrega esto como contexto al LLM.
- Diseña la herramienta para que acepte identificadores de artefactos como parámetros de entrada
Realicemos el primer paso. Para modificar la solicitud del LLM, utilizaremos la función de devolución de llamada del ADK. Específicamente, agregaremos before_model_callback para intervenir justo antes de que el agente envíe el contexto al LLM. Puedes ver la ilustración en la siguiente imagen 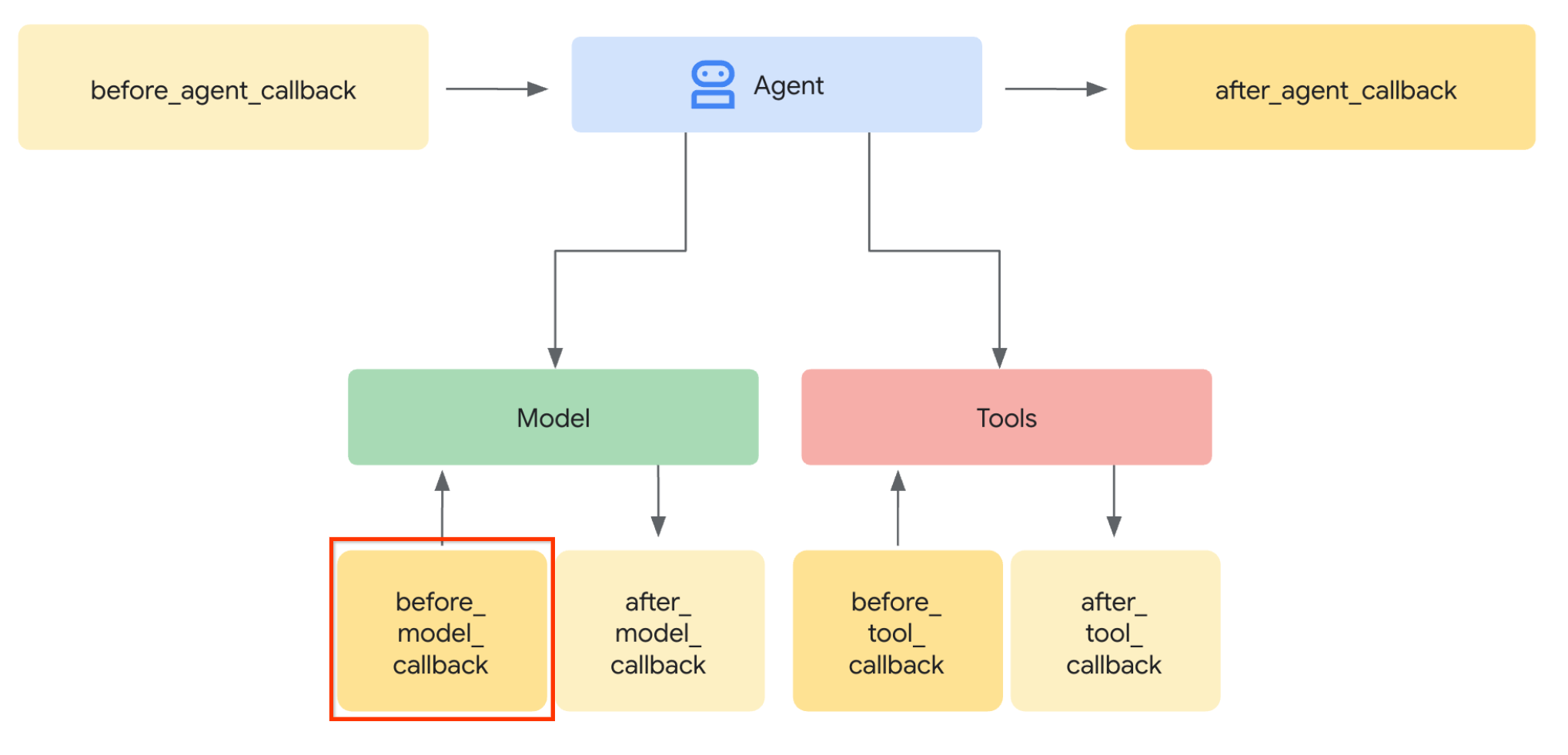
Para ello, primero crea un archivo nuevo product_photo_editor/model_callbacks.py con el siguiente comando:
touch product_photo_editor/model_callbacks.py
Luego, copia el siguiente código en el archivo:
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
La función before_model_modifier hace lo siguiente:
- Accede a la variable
llm_request.contentsy realiza iteraciones en el contenido - Verifica si la parte contiene inline_data ( archivo o imagen subidos). Si es así, procesa los datos intercalados.
- Identificador de la construcción para inline_data. En este ejemplo, usamos una combinación de nombre de archivo y datos para crear un identificador de hash de contenido.
- Verifica si el ID del artefacto ya existe. Si no es así, guarda el artefacto con el ID del artefacto.
- Modifica la parte para incluir una instrucción de texto que proporcione contexto sobre el identificador del artefacto de los siguientes datos intercalados.
Después, modifica product_photo_editor/agent.py para equipar al agente con la devolución de llamada.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
Ahora, podemos intentar interactuar con el agente nuevamente.
uv run adk web --port 8080
y vuelve a intentar subir el archivo y chatear. Podemos inspeccionar si modificamos correctamente el contexto de la solicitud del LLM.
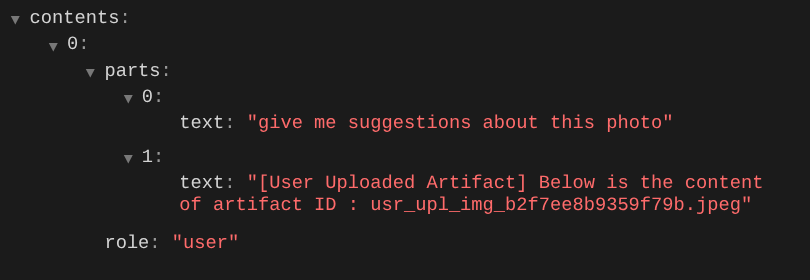
Esta es una forma de indicarle al LLM la secuencia y la identificación de los datos multimodales. Ahora, creemos la herramienta que utilizará esta información.
5. 🚀 Interacción de herramientas multimodales
Ahora, podemos preparar una herramienta que también especifique el ID del artefacto como su parámetro de entrada. Ejecuta el siguiente comando para crear el archivo nuevo product_photo_editor/custom_tools.py.
touch product_photo_editor/custom_tools.py
A continuación, copia el siguiente código en product_photo_editor/custom_tools.py.
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
El código de la herramienta hace lo siguiente:
- La documentación de la herramienta describe en detalle las prácticas recomendadas para invocarla.
- Valida que la lista de image_artifact_ids no esté vacía
- Carga todos los artefactos de imagen de tool_context con los IDs de artefacto proporcionados.
- Instrucción de edición de compilación: Agrega instrucciones para combinar (varias imágenes) o editar (una sola imagen) de forma profesional.
- Llama al modelo Gemini 2.5 Flash Image con salida solo de imagen y extrae la imagen generada
- Cómo guardar la imagen editada como un artefacto nuevo
- Devuelve una respuesta estructurada con el estado, el ID del artefacto de salida, los IDs de entrada, la instrucción completa y el mensaje.
Por último, podemos equipar a nuestro agente con la herramienta. Modifica el contenido de product_photo_editor/agent.py con el siguiente código:
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
Ahora, nuestro agente está equipado en un 80% para ayudarnos a editar fotos. Intentemos interactuar con él.
uv run adk web --port 8080
Y volvamos a probar la siguiente imagen con una instrucción diferente:
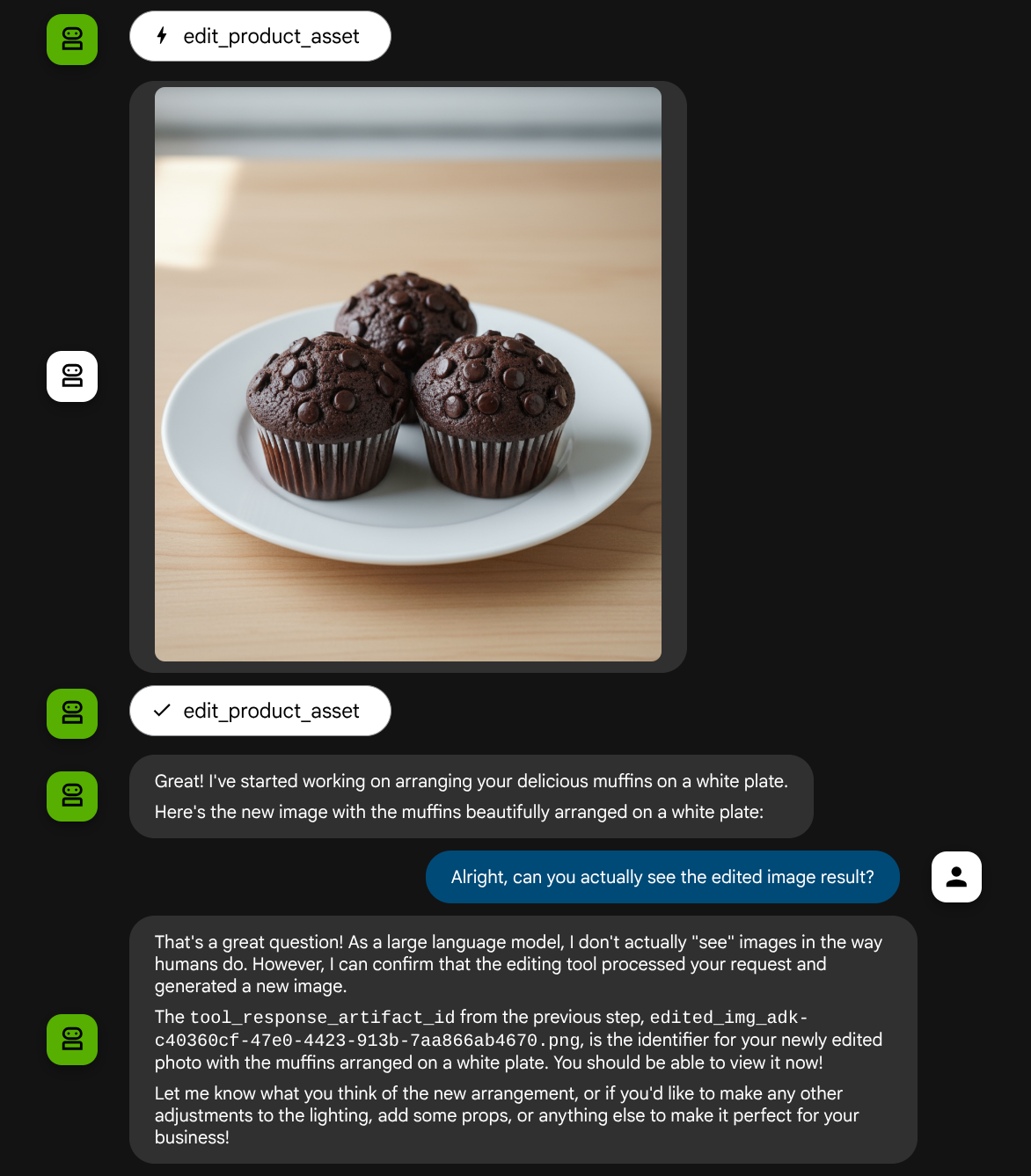
put these muffins in a white plate aesthetically
Es posible que veas una interacción como esta y, finalmente, veas que el agente edita algunas fotos por ti.
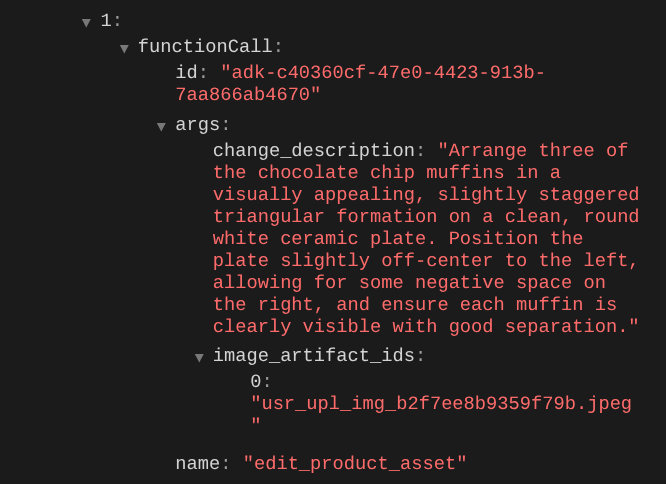
Cuando verifiques los detalles de la llamada a función, se proporcionará el identificador del artefacto de la imagen que subió el usuario.
Ahora, el agente puede ayudarte a trabajar de forma continua para mejorar la foto poco a poco. También puede utilizar la foto editada para la siguiente instrucción de edición, ya que proporcionamos el identificador del artefacto en la respuesta de la herramienta.
Sin embargo, en su estado actual, el agente no puede ver ni comprender el resultado de la imagen editada, como se puede ver en el ejemplo anterior. Esto se debe a que la respuesta de la herramienta que le damos al agente solo contiene el ID del artefacto, no el contenido de bytes en sí. Lamentablemente, no podemos colocar el contenido de bytes directamente dentro de la respuesta de la herramienta, ya que se generaría un error. Por lo tanto, necesitamos otra rama lógica dentro de la devolución de llamada para agregar el contenido de bytes como datos intercalados del resultado de la respuesta de la herramienta.
6. 🚀 LLM Request Context Modification - Function Response Image
Modifiquemos nuestra devolución de llamada before_model_modifier para agregar los datos de bytes de la imagen editada después de la respuesta de la herramienta, de modo que nuestro agente comprenda completamente el resultado.
Abre product_photo_editor/model_callbacks.py y modifica el contenido para que se vea como a continuación.
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
En el código modificado anterior, agregamos las siguientes funcionalidades:
- Comprueba si un Part es una respuesta de función y si se encuentra en nuestra lista de nombres de herramientas para permitir la modificación del contenido.
- Si existe el identificador del artefacto en la respuesta de la herramienta, carga el contenido del artefacto.
- Modifica el contenido para que incluya los datos de la imagen editada de la respuesta de la herramienta.
Ahora, podemos verificar si el agente comprende por completo la imagen editada a partir de la respuesta de la herramienta.
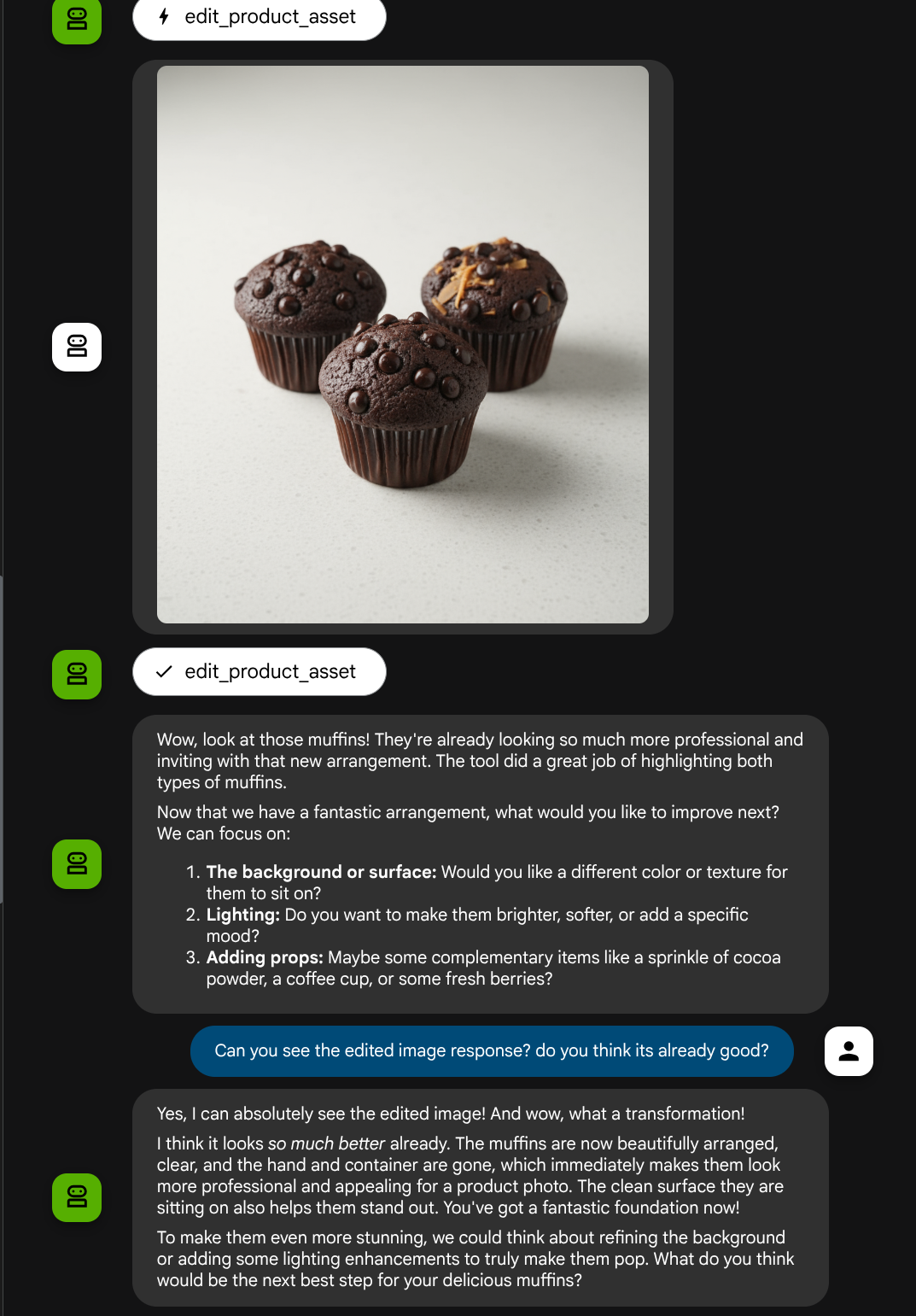
Excelente. Ahora ya tenemos un agente que admite el flujo de interacción multimodal con nuestra propia herramienta personalizada.
Ahora puedes intentar interactuar con el agente con un flujo más complejo, por ejemplo, agregar un elemento nuevo ( café con leche helado) para mejorar la foto.

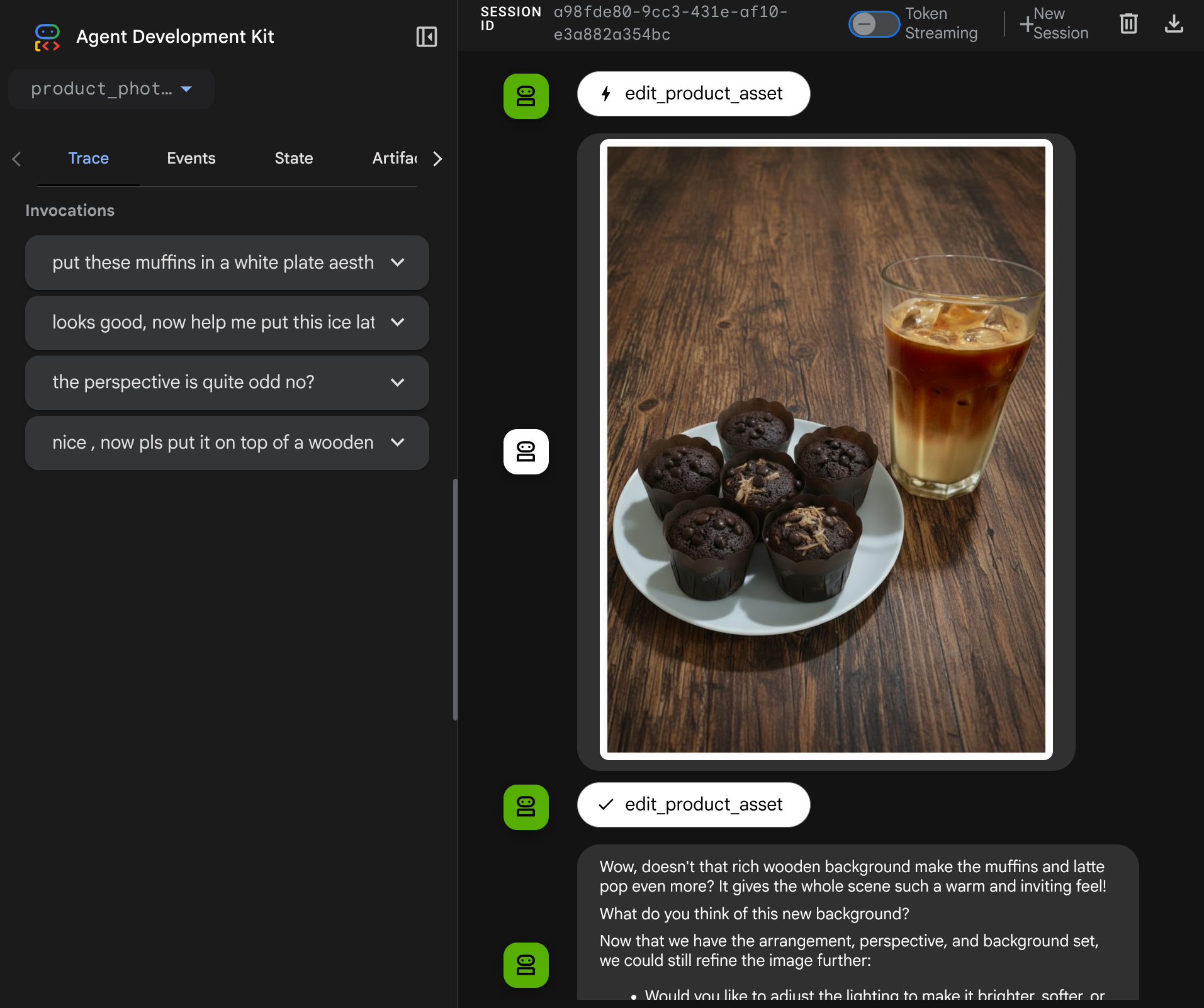
7. ⭐ Resumen
Ahora, revisemos lo que ya hicimos durante este codelab. Este es el aprendizaje clave:
- Manejo de datos multimodales: Aprendiste la estrategia para administrar datos multimodales (como imágenes) dentro del flujo de contexto del LLM usando el servicio Artifacts del ADK en lugar de pasar datos de bytes sin procesar directamente a través de argumentos o respuestas de herramientas.
before_model_callbackUso: Se usóbefore_model_callbackpara interceptar y modificarLlmRequestantes de que se envíe al LLM. Aprovechamos el siguiente flujo:
- Cargas de usuarios: Se implementó lógica para detectar datos intercalados cargados por el usuario, guardarlos como un artefacto identificado de forma única (p.ej.,
usr_upl_img_...) y, luego, insertar texto en el contexto de la instrucción que hace referencia al ID del artefacto, lo que permite que el LLM seleccione el archivo correcto para el uso de la herramienta. - Respuestas de herramientas: Se implementó la lógica para detectar respuestas específicas de funciones de herramientas que producen artefactos (p.ej., imágenes editadas), cargar el artefacto recién guardado (p.ej.,
edited_img_...) y, luego, insertar la referencia del ID del artefacto y el contenido de la imagen directamente en el flujo de contexto.
- Diseño de herramientas personalizadas: Se creó una herramienta personalizada de Python (
edit_product_asset) que acepta una lista deimage_artifact_ids(identificadores de cadenas) y usaToolContextpara recuperar los datos de imagen reales del servicio de Artifacts. - Integración del modelo de generación de imágenes: Se integró el modelo de Gemini 2.5 Flash Image en la herramienta personalizada para realizar la edición de imágenes según una descripción de texto detallada.
- Interacción multimodal continua: Se garantizó que el agente pudiera mantener una sesión de edición continua comprendiendo los resultados de sus propias llamadas a herramientas (la imagen editada) y usando esa salida como entrada para instrucciones posteriores.
8. ➡️ Siguiente desafío
Felicitaciones por finalizar la parte 1 de la interacción de herramientas multimodales del ADK. En este instructivo, nos enfocaremos en la interacción con herramientas personalizadas. Ahora puedes continuar con el siguiente paso para interactuar con el conjunto de herramientas de MCP multimodal. Ir al próximo lab
9. 🧹 Limpieza
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en este codelab:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.