
1. 📖 Introduction
Cet atelier de programmation montre comment concevoir une interaction avec un outil multimodal dans l'Agent Development Kit (ADK). Il s'agit d'un flux spécifique dans lequel vous souhaitez que l'agent se réfère au fichier importé comme entrée d'un outil et comprenne également le contenu du fichier produit par la réponse de l'outil. Il est donc possible d'interagir comme indiqué dans la capture d'écran ci-dessous. Dans ce tutoriel, nous allons développer un agent capable d'aider l'utilisateur à retoucher une photo de son produit pour le mettre en valeur.
Dans cet atelier de programmation, vous allez suivre une approche par étapes :
- Préparer le projet Google Cloud
- Configurer le répertoire de travail pour l'environnement de programmation
- Initialiser l'agent à l'aide d'ADK
- Concevez un outil permettant de retoucher des photos à l'aide de Gemini 2.5 Flash Image.
- Concevez une fonction de rappel pour gérer l'importation d'images par l'utilisateur, enregistrez-la en tant qu'artefact et ajoutez-la en tant que contexte à l'agent.
- Concevez une fonction de rappel pour gérer l'image produite par une réponse d'outil, enregistrez-la en tant qu'artefact et ajoutez-la en tant que contexte à l'agent.
Présentation de l'architecture
L'interaction globale dans cet atelier de programmation est illustrée dans le schéma suivant.
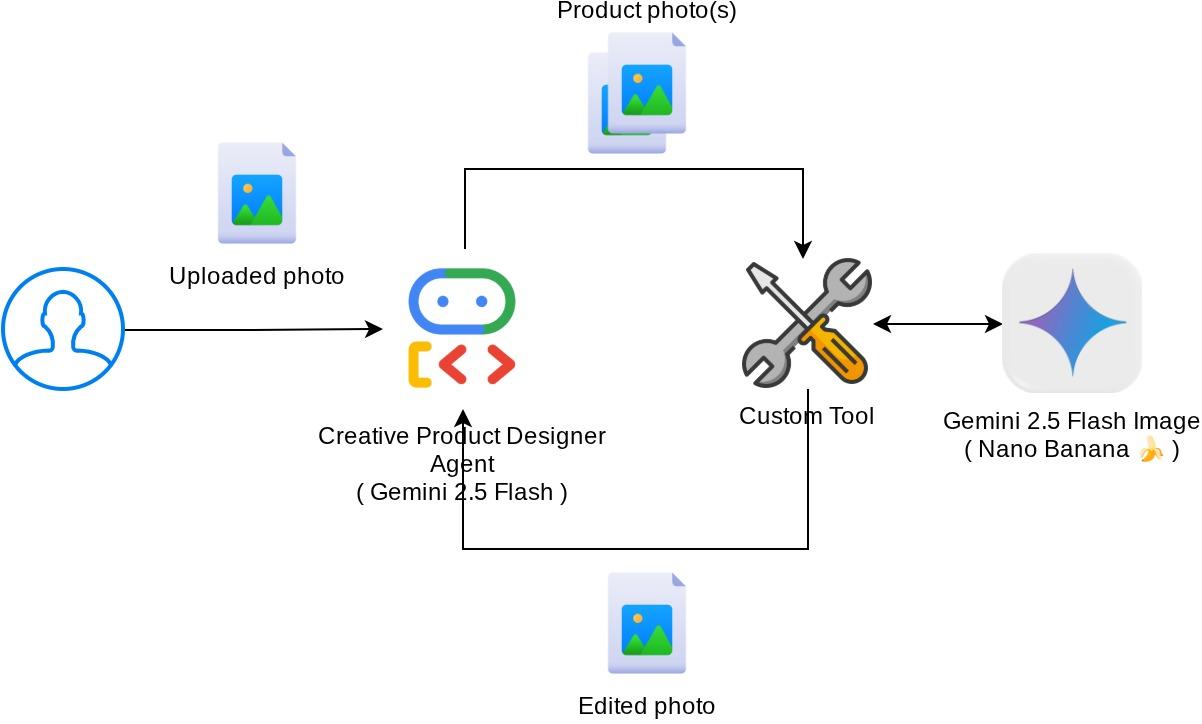
Prérequis
- Vous êtes à l'aise avec Python.
- (Facultatif) Ateliers de programmation de base sur Agent Development Kit (ADK)
Points abordés
- Utiliser le contexte de rappel pour accéder au service d'artefacts
- Concevoir un outil avec une propagation appropriée des données multimodales
- Modifier la requête LLM de l'agent pour ajouter le contexte de l'artefact via before_model_callback
- Modifier une image avec Gemini 2.5 Flash Image
Prérequis
- Navigateur Web Chrome
- Un compte Gmail
- Un projet Cloud pour lequel un compte de facturation est activé
Cet atelier de programmation, conçu pour les développeurs de tous niveaux (y compris les débutants), utilise Python dans son exemple d'application. Toutefois, vous n'avez pas besoin de maîtriser Python pour comprendre les concepts présentés.
2. 🚀 Préparer la configuration de développement de l'atelier
Étape 1 : Sélectionnez le projet actif dans la console Cloud
Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud (voir la section en haut à gauche de la console).

Cliquez dessus pour afficher la liste de tous vos projets, comme dans cet exemple :
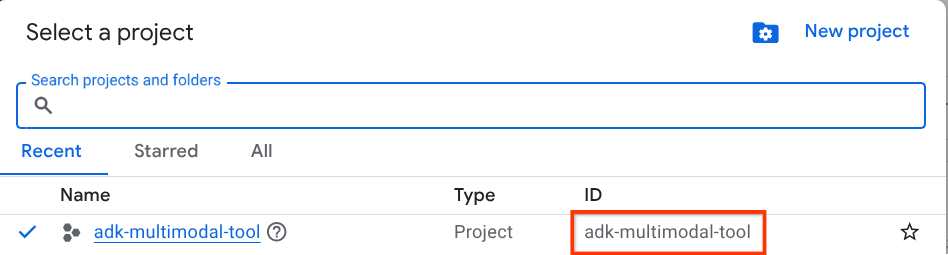
La valeur indiquée par l'encadré rouge correspond à l'ID du projet. Elle sera utilisée tout au long du tutoriel.
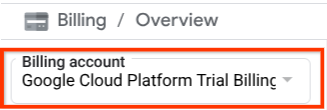
Assurez-vous que la facturation est activée pour votre projet Cloud. Pour vérifier cela, cliquez sur l'icône ☰ en haut à gauche de la barre pour afficher le menu de navigation, puis recherchez le menu "Facturation".

Si vous voyez le compte de facturation de l'essai Google Cloud Platform sous le titre Facturation / Présentation ( en haut à gauche de la console Cloud), votre projet est prêt à être utilisé pour ce tutoriel. Si ce n'est pas le cas, revenez au début de ce tutoriel et utilisez le compte de facturation de l'essai.
Étape 2 : Familiarisez-vous avec Cloud Shell
Vous utiliserez Cloud Shell pour la majeure partie des tutoriels. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud. Si vous êtes invité à autoriser, cliquez sur Autoriser.
Une fois connecté à Cloud Shell, nous devons vérifier si le shell ( ou le terminal) est déjà authentifié avec notre compte.
gcloud auth list
Si votre adresse Gmail personnelle s'affiche comme dans l'exemple ci-dessous, tout est en ordre.
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Si ce n'est pas le cas, essayez d'actualiser votre navigateur et assurez-vous de cliquer sur Autoriser lorsque vous y êtes invité ( la connexion peut être interrompue en raison d'un problème de connexion).
Ensuite, nous devons également vérifier si le shell est déjà configuré avec le bon ID DE PROJET. Si une valeur est indiquée entre parenthèses avant l'icône $ dans le terminal (dans la capture d'écran ci-dessous, la valeur est "adk-multimodal-tool"), cela indique le projet configuré pour votre session de shell active.

Si la valeur affichée est déjà correcte, vous pouvez ignorer la commande suivante. Toutefois, si elle est incorrecte ou manquante, exécutez la commande suivante :
gcloud config set project <YOUR_PROJECT_ID>
Ensuite, clonez le répertoire de travail du modèle pour cet atelier de programmation à partir de GitHub en exécutant la commande suivante. Il créera le répertoire de travail dans le répertoire adk-multimodal-tool.
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
Étape 3 : Familiarisez-vous avec l'éditeur Cloud Shell et configurez le répertoire de travail de l'application
Nous pouvons maintenant configurer notre éditeur de code pour effectuer certaines tâches de codage. Pour cela, nous allons utiliser l'éditeur Cloud Shell.
Cliquez sur le bouton Ouvrir l'éditeur pour ouvrir l'éditeur Cloud Shell 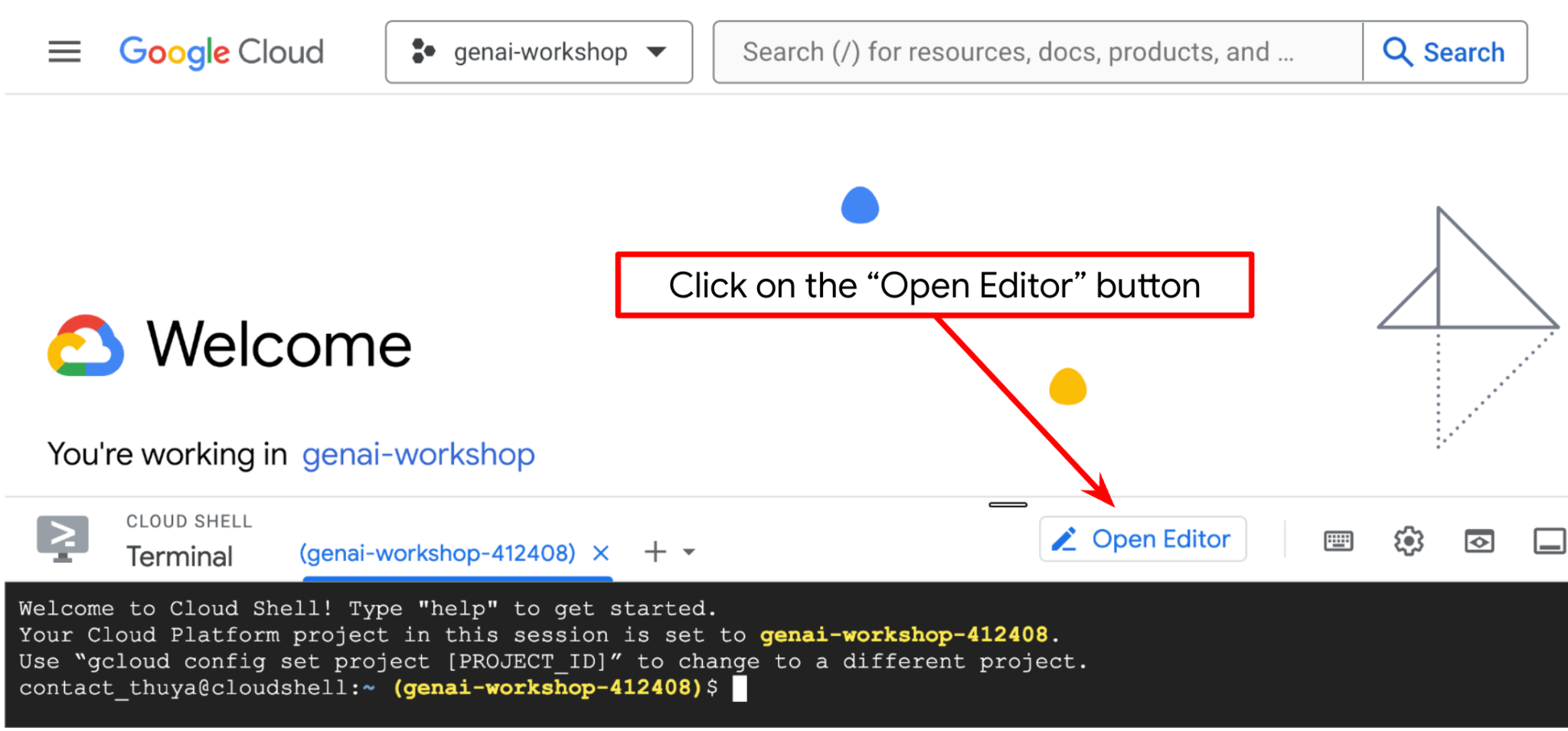 .
.
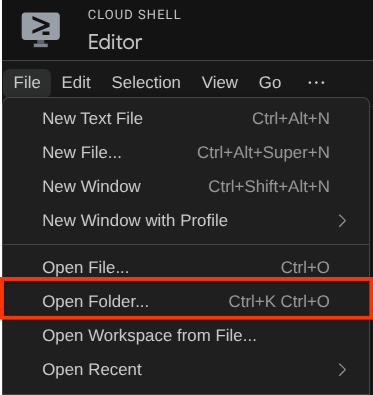
Ensuite, accédez à la section supérieure de l'éditeur Cloud Shell et cliquez sur Fichier > Ouvrir le dossier, recherchez votre répertoire nom d'utilisateur, puis le répertoire adk-multimodal-tool, puis cliquez sur le bouton OK. Le répertoire choisi deviendra le répertoire de travail principal. Dans cet exemple, le nom d'utilisateur est alvinprayuda. Le chemin d'accès au répertoire est donc indiqué ci-dessous.
Votre répertoire de travail de l'éditeur Cloud Shell devrait maintenant ressembler à ceci ( dans adk-multimodal-tool) :
Ouvrez maintenant le terminal pour l'éditeur. Pour ce faire, cliquez sur Terminal > Nouveau terminal dans la barre de menu ou utilisez le raccourci Ctrl+Maj+C. Une fenêtre de terminal s'ouvre en bas du navigateur.

Le terminal actif actuel doit se trouver dans le répertoire de travail adk-multimodal-tool. Dans cet atelier de programmation, nous utiliserons Python 3.12 et le gestionnaire de projets Python uv pour simplifier la création et la gestion de la version Python et de l'environnement virtuel. Le package uv est déjà préinstallé sur Cloud Shell.
Exécutez cette commande pour installer les dépendances requises dans l'environnement virtuel du répertoire .venv.
uv sync --frozen
Consultez le fichier pyproject.toml pour voir les dépendances déclarées pour ce tutoriel, qui sont google-adk, and python-dotenv.
Nous devons maintenant activer les API requises à l'aide de la commande ci-dessous. Cela peut prendre un certain temps.
gcloud services enable aiplatform.googleapis.com
Si la commande s'exécute correctement, un message semblable à celui ci-dessous s'affiche :
Operation "operations/..." finished successfully.
3. 🚀 Initialiser l'agent ADK
Dans cette étape, nous allons initialiser notre agent à l'aide de la CLI ADK. Pour ce faire, exécutez la commande suivante :
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
Cette commande vous aidera à fournir rapidement la structure requise pour votre agent, comme indiqué ci-dessous :
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
Ensuite, préparons notre agent éditeur de photos de produits. Commencez par copier le fichier prompt.py déjà inclus dans le dépôt vers le répertoire de l'agent que vous avez créé précédemment.
cp prompt.py product_photo_editor/prompt.py
Ouvrez ensuite product_photo_editor/agent.py et modifiez le contenu avec le code suivant :
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Vous disposez désormais de votre agent de retouche photo de base, avec lequel vous pouvez déjà discuter pour obtenir des suggestions pour vos photos. Vous pouvez essayer d'interagir avec lui à l'aide de cette commande :
uv run adk web --port 8080
Il générera une sortie semblable à l'exemple suivant, ce qui signifie que nous pouvons déjà accéder à l'interface Web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Pour le vérifier, vous pouvez Ctrl+cliquer sur l'URL ou cliquer sur le bouton Aperçu sur le Web en haut de l'éditeur Cloud Shell, puis sélectionner Prévisualiser sur le port 8080.
La page Web suivante s'affiche. Vous pouvez y sélectionner les agents disponibles dans le menu déroulant en haut à gauche ( dans notre cas, il devrait s'agir de product_photo_editor) et interagir avec le bot. Essayez d'importer l'image suivante dans l'interface de chat et de poser les questions suivantes :
what is your suggestion for this photo?

Vous verrez une interaction semblable à celle ci-dessous.
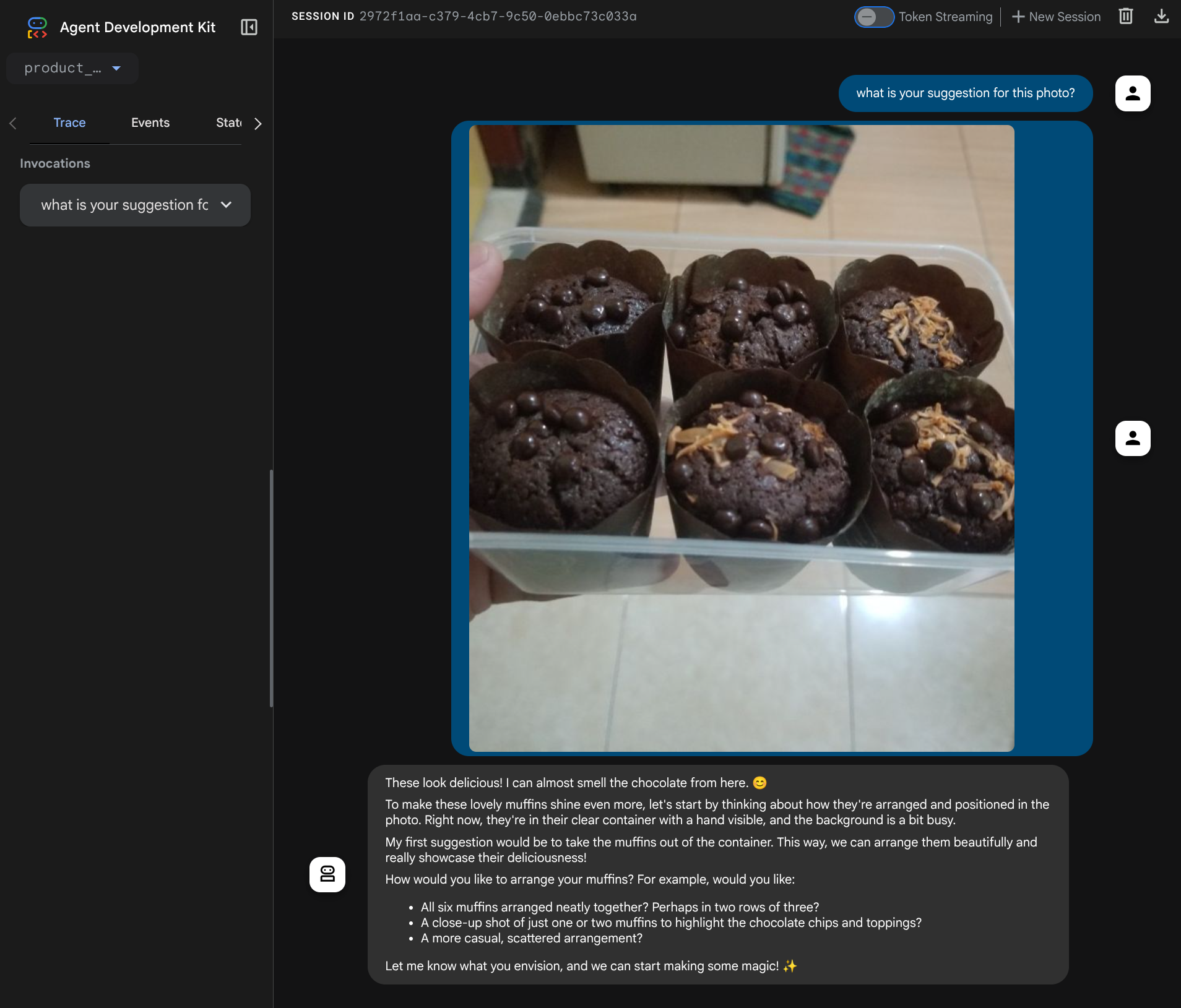
Vous pouvez déjà demander des suggestions, mais le modèle ne peut pas effectuer de modifications pour vous pour le moment. Passons à l'étape suivante, qui consiste à équiper l'agent des outils de modification.
4. 🚀 Modification du contexte de la requête LLM : image importée par l'utilisateur
Nous souhaitons que notre agent puisse choisir de manière flexible l'image importée qu'il souhaite modifier. Cependant, les outils LLM sont généralement conçus pour accepter des paramètres de type de données simples tels que str ou int. Il s'agit d'un type de données très différent pour les données multimodales, qui sont généralement perçues comme un type de données bytes. Nous aurons donc besoin d'une stratégie impliquant le concept d'artefacts pour gérer ces données. Ainsi, au lieu de fournir les données d'octets complets dans le paramètre "tools", nous allons concevoir l'outil pour qu'il accepte le nom de l'identifiant de l'artefact.
Cette stratégie se déroulera en deux étapes :
- modifier la requête LLM afin que chaque fichier importé soit associé à un identifiant d'artefact et ajouter cet identifiant en tant que contexte au LLM ;
- Concevez l'outil pour qu'il accepte les identifiants d'artefacts comme paramètres d'entrée.
Passons à la première étape. Pour modifier la requête LLM, nous allons utiliser la fonctionnalité Callback de l'ADK. Plus précisément, nous allons ajouter before_model_callback pour intervenir juste avant que l'agent n'envoie le contexte au LLM. Vous pouvez voir l'illustration sur l'image ci-dessous 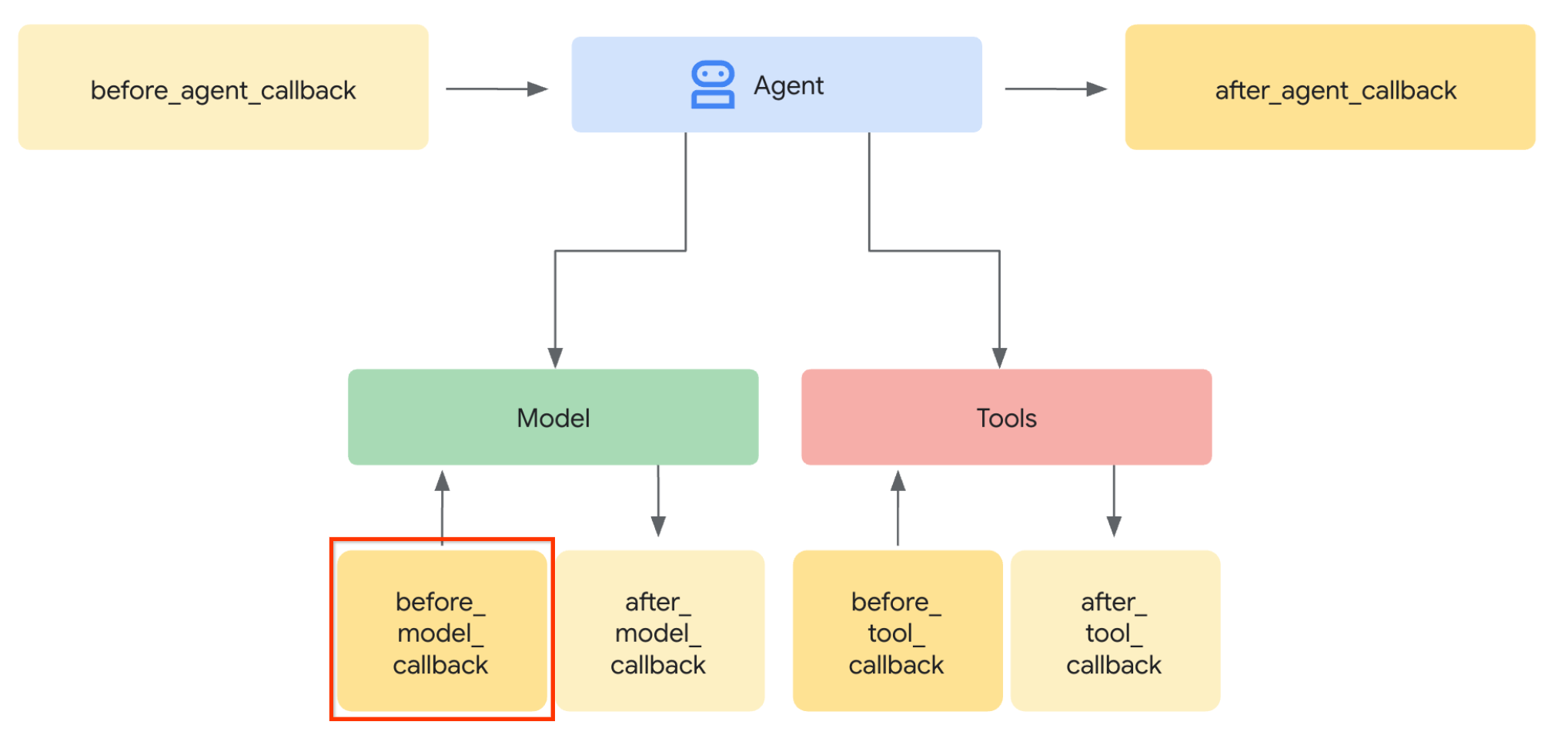
Pour ce faire, commencez par créer un fichier product_photo_editor/model_callbacks.py à l'aide de la commande suivante :
touch product_photo_editor/model_callbacks.py
Ensuite, copiez le code suivant dans le fichier.
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
La fonction before_model_modifier effectue les opérations suivantes :
- Accéder à la variable
llm_request.contentset parcourir le contenu - Vérifiez si la partie contient inline_data ( fichier / image importé). Si c'est le cas, traitez les données intégrées.
- Construisez un identifiant pour inline_data. Dans cet exemple, nous utilisons une combinaison de nom de fichier et de données pour créer un identifiant de hachage de contenu.
- Vérifiez si l'ID d'artefact existe déjà. Si ce n'est pas le cas, enregistrez l'artefact à l'aide de l'ID d'artefact.
- Modifiez la partie pour inclure une invite de texte donnant le contexte de l'identifiant d'artefact des données intégrées suivantes.
Ensuite, modifiez product_photo_editor/agent.py pour équiper l'agent du rappel.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
Nous pouvons maintenant essayer d'interagir à nouveau avec l'agent.
uv run adk web --port 8080
et essayez d'importer à nouveau le fichier et de discuter. Nous pouvons vérifier si nous avons réussi à modifier le contexte de la requête LLM.
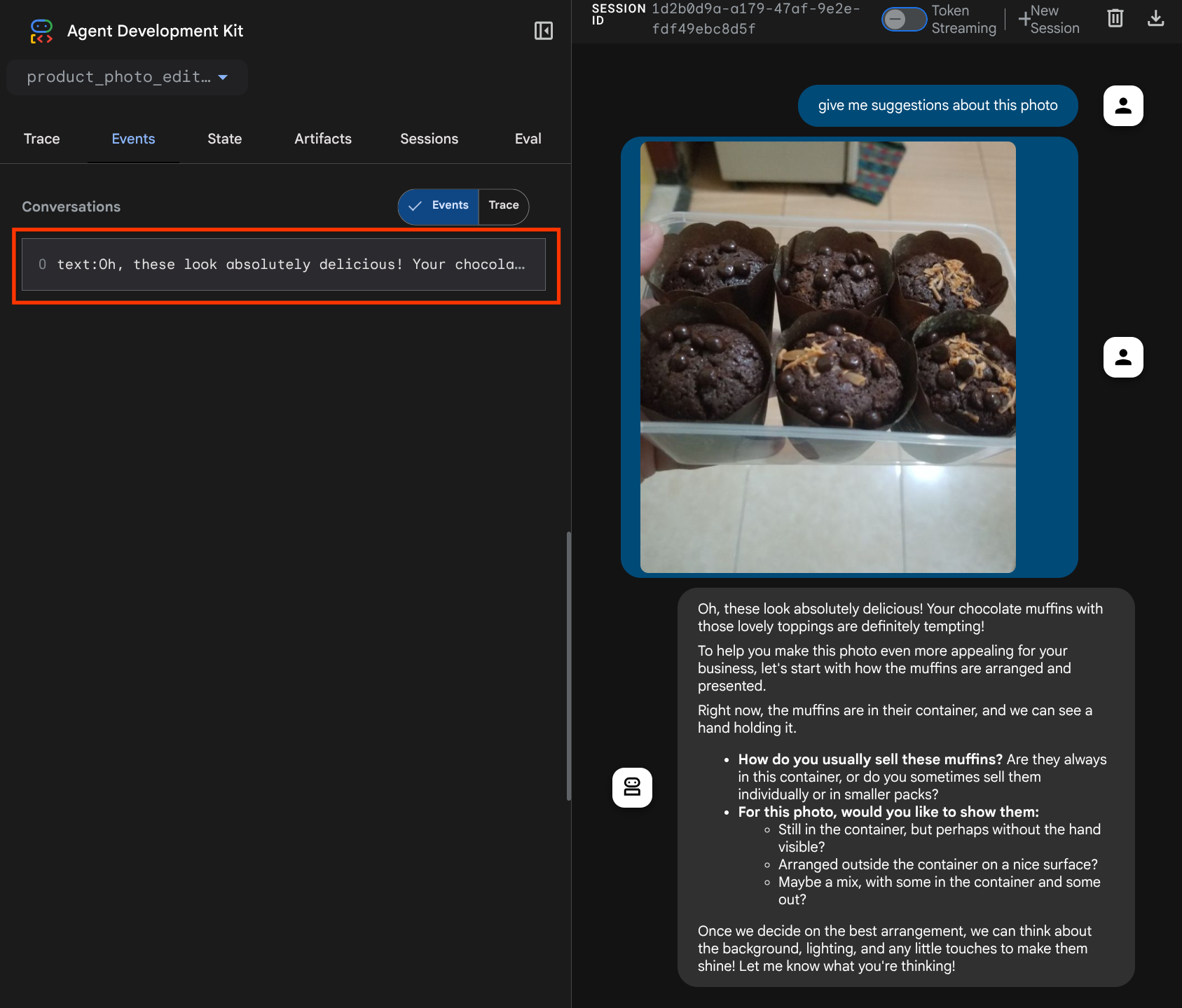
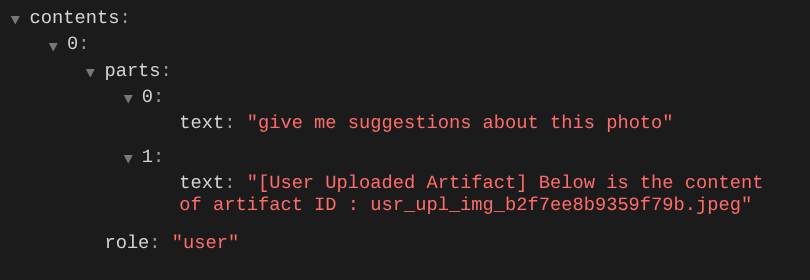
C'est l'une des façons de communiquer au LLM la séquence et l'identification des données multimodales. Nous allons maintenant créer l'outil qui utilisera ces informations.
5. 🚀 Interaction multimodale avec l'outil
Nous pouvons maintenant préparer un outil qui spécifie également l'ID de l'artefact comme paramètre d'entrée. Exécutez la commande suivante pour créer le fichier product_photo_editor/custom_tools.py :
touch product_photo_editor/custom_tools.py
Ensuite, copiez le code suivant dans product_photo_editor/custom_tools.py.
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
Le code de l'outil effectue les opérations suivantes :
- La documentation de l'outil décrit en détail les bonnes pratiques pour l'appeler.
- Valider que la liste image_artifact_ids n'est pas vide
- Charge tous les artefacts d'image à partir de tool_context à l'aide des ID d'artefact fournis.
- Générer un prompt de modification : ajoutez des instructions pour combiner (plusieurs images) ou modifier (une seule image) de manière professionnelle.
- Appeler le modèle Gemini 2.5 Flash Image avec une sortie d'image uniquement et extraire l'image générée
- Enregistrer l'image modifiée en tant que nouvel artefact
- Renvoyer une réponse structurée avec : état, ID de l'artefact de sortie, ID d'entrée, invite complète et message
Enfin, nous pouvons équiper notre agent avec l'outil. Modifiez le contenu de product_photo_editor/agent.py en le remplaçant par le code ci-dessous.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
Notre agent est désormais équipé à 80 % pour nous aider à modifier des photos. Essayons d'interagir avec lui.
uv run adk web --port 8080
Essayons à nouveau l'image suivante avec une autre requête :
put these muffins in a white plate aesthetically
Vous pouvez voir une interaction comme celle-ci et enfin voir l'agent retoucher une photo pour vous.
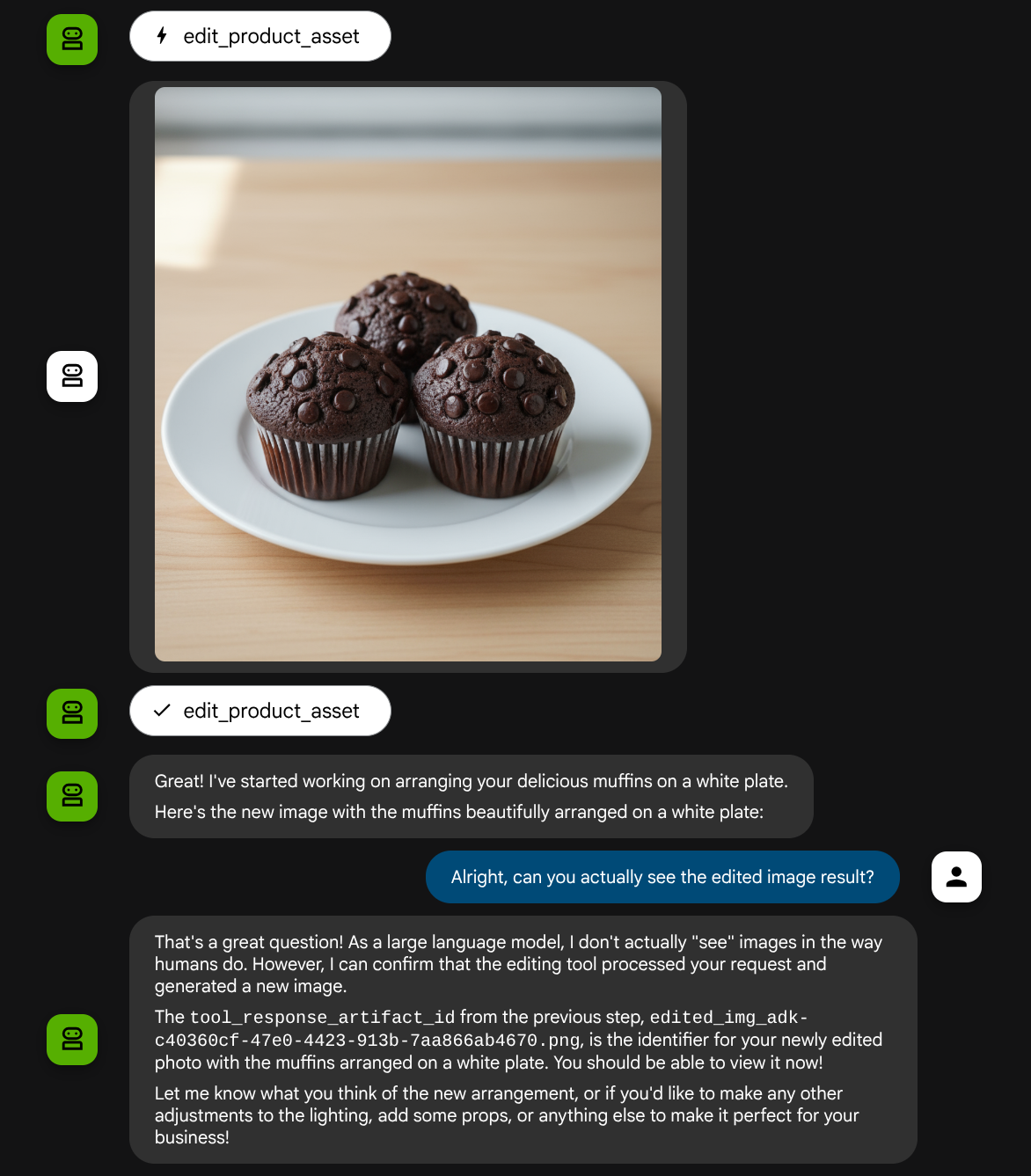
Lorsque vous consultez les détails de l'appel de fonction, l'identifiant de l'artefact de l'image importée par l'utilisateur s'affiche.
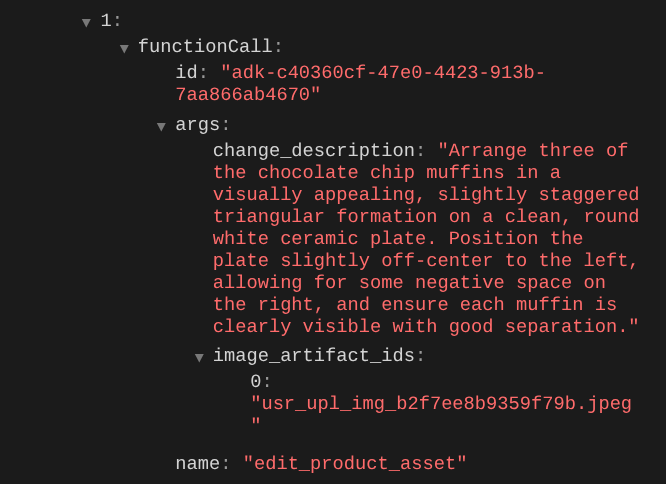
L'agent peut désormais vous aider à améliorer progressivement la photo. Il peut également utiliser la photo modifiée pour la prochaine instruction de modification, car nous fournissons l'identifiant de l'artefact dans la réponse de l'outil.
Toutefois, dans son état actuel, l'agent ne peut pas réellement voir ni comprendre le résultat de l'image modifiée, comme vous pouvez le constater dans l'exemple ci-dessus. En effet, la réponse de l'outil que nous fournissons à l'agent ne contient que l'ID de l'artefact, et non le contenu des octets lui-même. Malheureusement, nous ne pouvons pas insérer directement le contenu des octets dans la réponse de l'outil, car cela générerait une erreur. Nous devons donc avoir une autre branche logique dans le rappel pour ajouter le contenu des octets en tant que données intégrées à partir du résultat de la réponse de l'outil.
6. 🚀 Modification du contexte de la requête LLM : image de réponse de la fonction
Modifions notre rappel before_model_modifier pour ajouter les données d'octets de l'image modifiée après la réponse de l'outil, afin que notre agent comprenne pleinement le résultat.
Ouvrez product_photo_editor/model_callbacks.py et modifiez le contenu pour qu'il ressemble à ce qui suit :
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
Dans le code modifié ci-dessus, nous ajoutons les fonctionnalités suivantes :
- Vérifier si une Part est une réponse de fonction et si elle figure dans notre liste de noms d'outils pour autoriser la modification du contenu
- Si l'identifiant d'artefact de la réponse de l'outil existe, chargez le contenu de l'artefact.
- Modifiez le contenu pour qu'il inclue les données de l'image modifiée à partir de la réponse de l'outil.
Nous pouvons maintenant vérifier si l'agent comprend parfaitement l'image modifiée à partir de la réponse de l'outil.
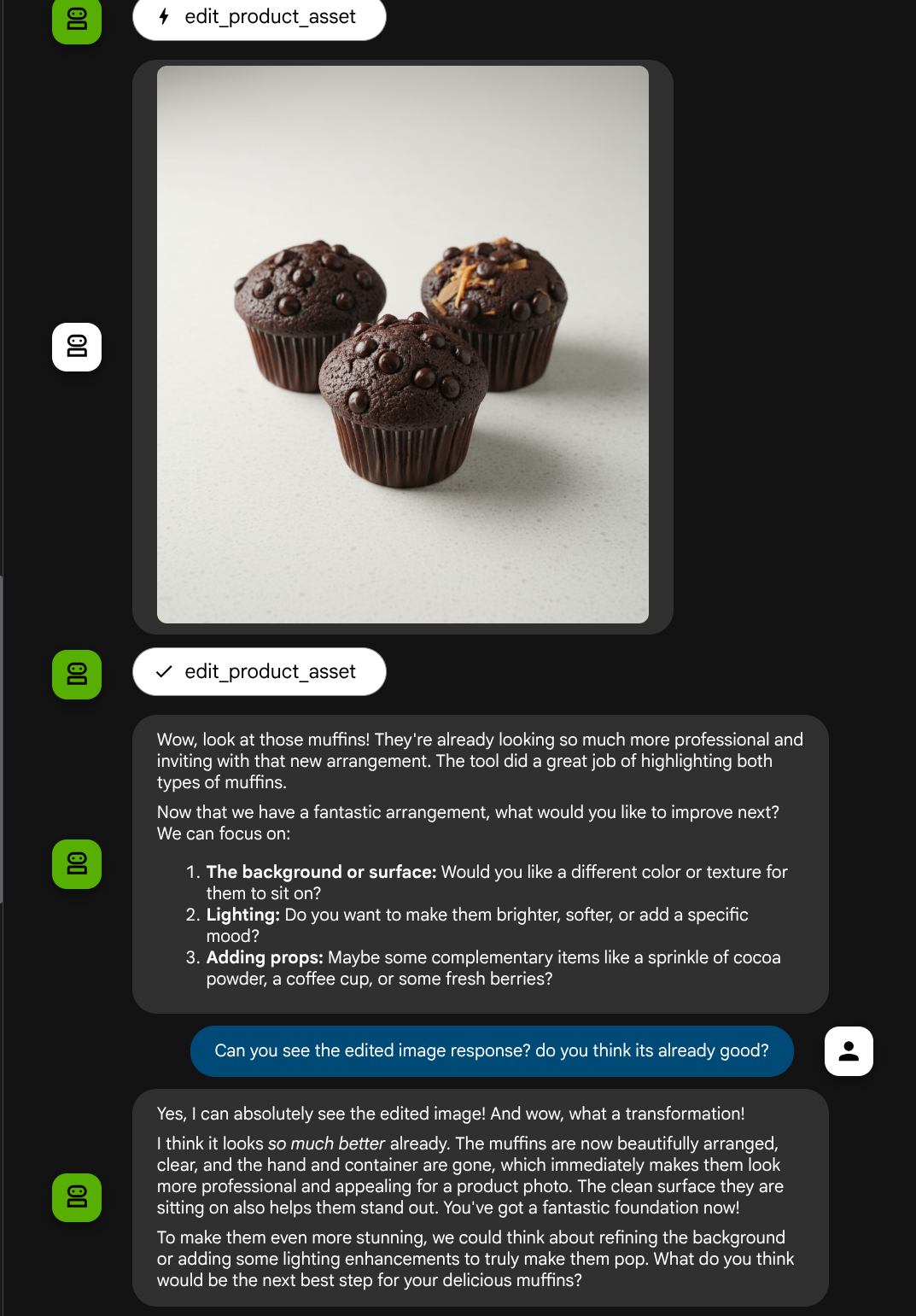
Parfait ! Nous disposons désormais d'un agent qui prend en charge le flux d'interaction multimodale avec notre propre outil personnalisé.
Vous pouvez maintenant essayer d'interagir avec l'agent avec un flux plus complexe, par exemple en ajoutant un nouvel élément ( latte glacé) pour améliorer la photo.

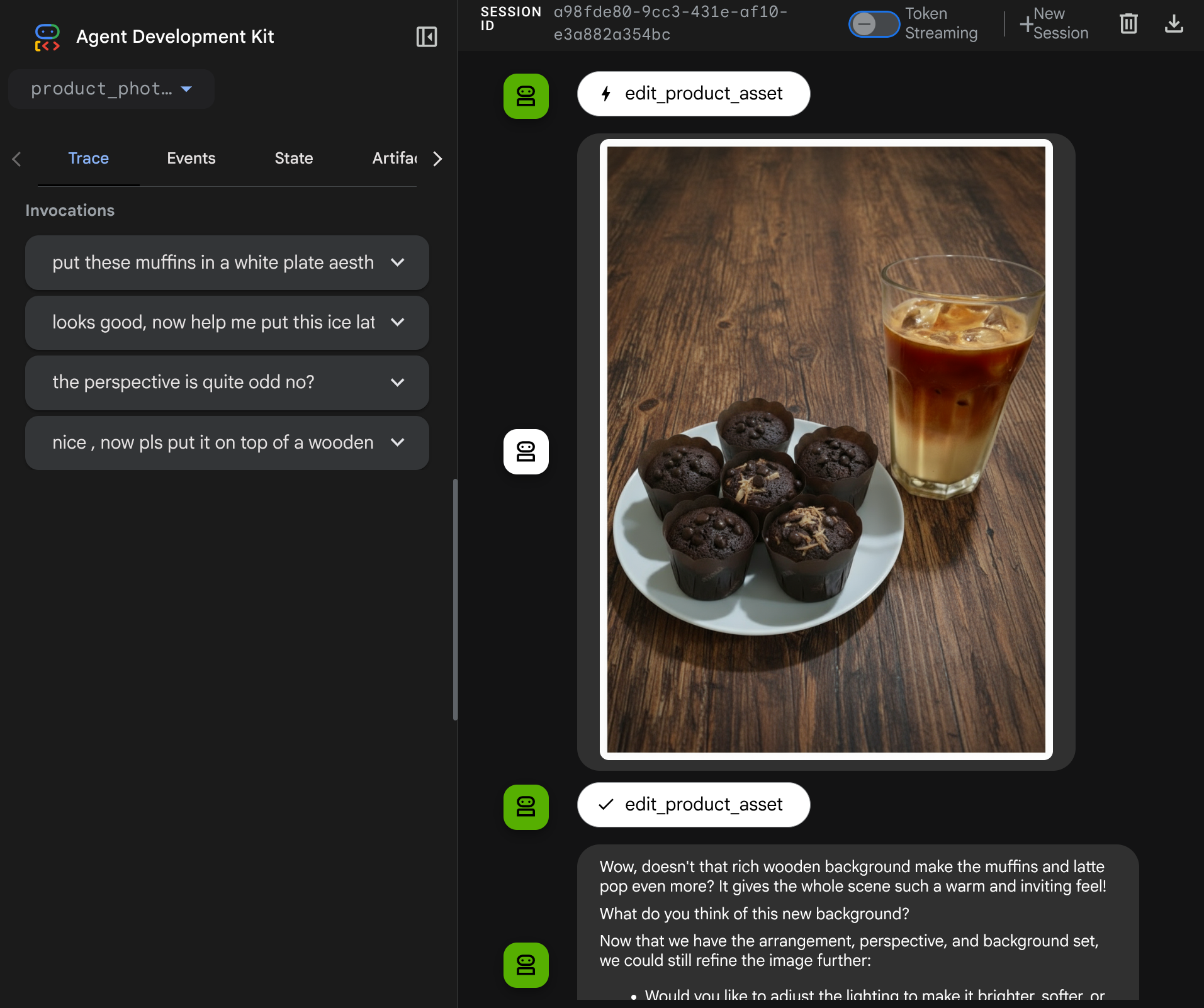
7. ⭐ Résumé
Passons en revue ce que nous avons déjà fait au cours de cet atelier de programmation. Voici le point clé à retenir :
- Gestion des données multimodales : apprentissage de la stratégie de gestion des données multimodales (comme les images) dans le flux de contexte LLM en utilisant le service Artifacts de l'ADK au lieu de transmettre directement les données brutes d'octets via les arguments ou les réponses de l'outil.
before_model_callbackUtilisation : utilisébefore_model_callbackpour intercepter et modifierLlmRequestavant son envoi au LLM. Nous avons appuyé sur le flux suivant :
- Importations par l'utilisateur : nous avons implémenté une logique permettant de détecter les données intégrées importées par l'utilisateur, de les enregistrer en tant qu'artefact identifié de manière unique (par exemple,
usr_upl_img_...) et d'injecter du texte dans le contexte du prompt en faisant référence à l'ID de l'artefact. Cela permet au LLM de sélectionner le fichier approprié pour l'utilisation de l'outil. - Réponses de l'outil : logique implémentée pour détecter les réponses de fonctions d'outil spécifiques qui produisent des artefacts (par exemple, des images modifiées), charger l'artefact nouvellement enregistré (par exemple,
edited_img_...) et injecter à la fois la référence de l'ID de l'artefact et le contenu de l'image directement dans le flux de contexte.
- Conception d'outil personnalisé : création d'un outil Python personnalisé (
edit_product_asset) qui accepte une listeimage_artifact_ids(identifiants de chaîne) et utiliseToolContextpour récupérer les données d'image réelles à partir du service Artifacts. - Intégration du modèle de génération d'images : le modèle Gemini 2.5 Flash Image a été intégré à l'outil personnalisé pour retoucher des images en fonction d'une description textuelle détaillée.
- Interaction multimodale continue : l'agent peut maintenir une session de retouche continue en comprenant les résultats de ses propres appels d'outils (l'image retouchée) et en utilisant cette sortie comme entrée pour les instructions suivantes.
8. ➡️ Défi suivant
Félicitations, vous avez terminé la partie 1 de l'interaction multimodale avec l'outil ADK. Dans ce tutoriel, nous nous concentrons sur l'interaction avec les outils personnalisés. Vous êtes maintenant prêt à passer à l'étape suivante pour découvrir comment interagir avec l'ensemble d'outils MCP multimodal. Accéder à l'atelier suivant
9. 🧹 Nettoyer
Pour éviter que les ressources utilisées dans cet atelier de programmation soient facturées sur votre compte Google Cloud :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.