
1. 📖 परिचय
इस कोडलैब में, Agent Development Kit (ADK) में मल्टीमॉडल टूल इंटरैक्शन को डिज़ाइन करने का तरीका बताया गया है. यह एक खास फ़्लो है. इसमें आपको एजेंट से यह उम्मीद होती है कि वह अपलोड की गई फ़ाइल को टूल के इनपुट के तौर पर इस्तेमाल करे. साथ ही, टूल के जवाब के तौर पर जनरेट हुई फ़ाइल के कॉन्टेंट को भी समझे. इसलिए, यहां दिए गए स्क्रीनशॉट में दिखाई गई बातचीत की जा सकती है. इस ट्यूटोरियल में, हम एक ऐसा एजेंट डेवलप करने जा रहे हैं जो उपयोगकर्ता को अपने प्रॉडक्ट को बेहतर तरीके से दिखाने के लिए फ़ोटो में बदलाव करने में मदद कर सके
कोडलैब के ज़रिए, आपको यहां दिया गया तरीका अपनाना होगा:
- Google Cloud प्रोजेक्ट तैयार करना
- कोडिंग एनवायरमेंट के लिए वर्क डायरेक्ट्री सेट अप करना
- ADK का इस्तेमाल करके एजेंट को शुरू करना
- ऐसा टूल डिज़ाइन करें जिसका इस्तेमाल, Gemini 2.5 Flash Image की मदद से फ़ोटो में बदलाव करने के लिए किया जा सके
- उपयोगकर्ता की इमेज अपलोड करने, उसे आर्टफ़ैक्ट के तौर पर सेव करने, और उसे एजेंट के कॉन्टेक्स्ट के तौर पर जोड़ने के लिए, एक कॉलबैक फ़ंक्शन डिज़ाइन करें
- टूल के जवाब से जनरेट हुई इमेज को मैनेज करने के लिए, कॉलबैक फ़ंक्शन डिज़ाइन करो. इसे आर्टफ़ैक्ट के तौर पर सेव करो और एजेंट के कॉन्टेक्स्ट में जोड़ो
आर्किटेक्चर की खास जानकारी
इस कोडलैब में होने वाली पूरी बातचीत को इस डायग्राम में दिखाया गया है
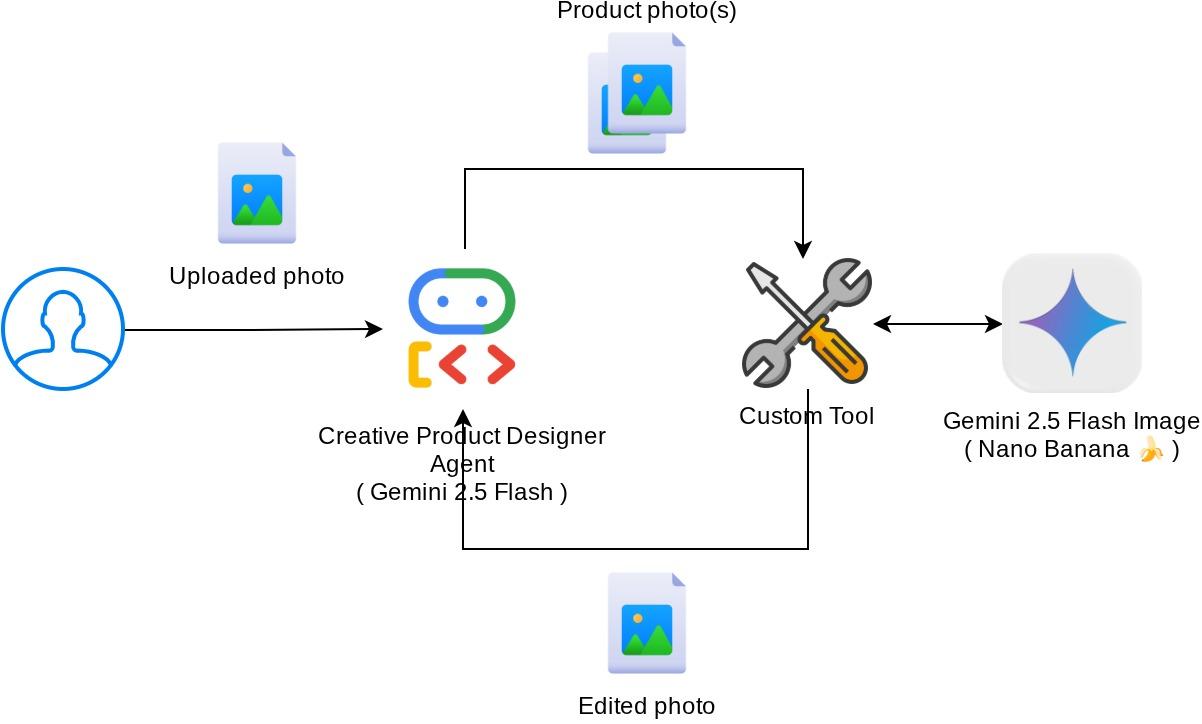
ज़रूरी शर्तें
- Python के साथ काम करने में सहज हों
- (ज़रूरी नहीं) Agent Development Kit (ADK) के बारे में बुनियादी कोडलैब
आपको क्या सीखने को मिलेगा
- आर्टफ़ैक्ट सेवा को ऐक्सेस करने के लिए, कॉलबैक कॉन्टेक्स्ट का इस्तेमाल कैसे करें
- मल्टीमॉडल डेटा को सही तरीके से फैलाने वाले टूल को कैसे डिज़ाइन करें
- before_model_callback के ज़रिए आर्टफ़ैक्ट का कॉन्टेक्स्ट जोड़ने के लिए, एजेंट के एलएलएम अनुरोध में बदलाव करने का तरीका
- Gemini 2.5 Flash Image का इस्तेमाल करके इमेज में बदलाव कैसे करें
आपको इन चीज़ों की ज़रूरत होगी
- Chrome वेब ब्राउज़र
- Gmail खाता
- ऐसा Cloud प्रोजेक्ट जिसमें बिलिंग खाता चालू हो
यह कोडलैब, सभी लेवल के डेवलपर के लिए बनाया गया है. इसमें शुरुआती डेवलपर भी शामिल हैं. इसमें सैंपल ऐप्लिकेशन में Python का इस्तेमाल किया गया है. हालांकि, यहां दिए गए कॉन्सेप्ट को समझने के लिए, Python के बारे में जानकारी होना ज़रूरी नहीं है.
2. 🚀 वर्कशॉप डेवलपमेंट सेटअप तैयार किया जा रहा है
पहला चरण: Cloud Console में चालू प्रोजेक्ट चुनना
Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाकर, Google Cloud प्रोजेक्ट चुनें या बनाएं. (अपनी कंसोल के सबसे ऊपर बाईं ओर मौजूद सेक्शन देखें)

इस पर क्लिक करने से, आपको अपने सभी प्रोजेक्ट की सूची दिखेगी. जैसे, इस उदाहरण में दिखाया गया है,
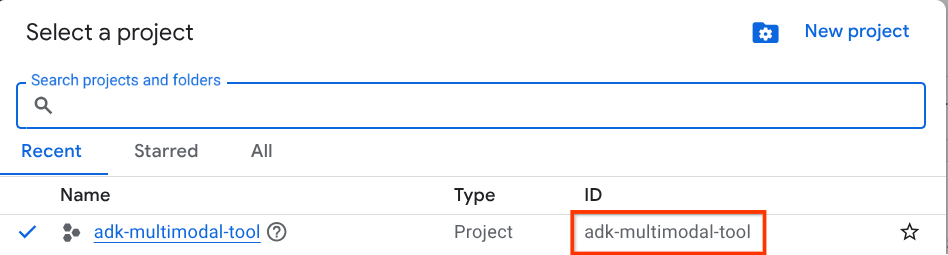
लाल बॉक्स में दिखाई गई वैल्यू, प्रोजेक्ट आईडी है. इस वैल्यू का इस्तेमाल पूरे ट्यूटोरियल में किया जाएगा.
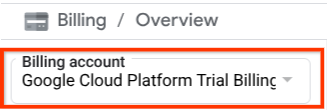
पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. इसे देखने के लिए, सबसे ऊपर बाईं ओर मौजूद बर्गर आइकॉन ☰ पर क्लिक करें. इससे नेविगेशन मेन्यू दिखेगा. इसके बाद, बिलिंग मेन्यू ढूंढें

अगर आपको बिलिंग / खास जानकारी टाइटल ( Cloud Console के सबसे ऊपर बाईं ओर मौजूद सेक्शन ) में, "Google Cloud Platform का ट्रायल बिलिंग खाता" दिखता है, तो इसका मतलब है कि आपका प्रोजेक्ट इस ट्यूटोरियल के लिए तैयार है. अगर ऐसा नहीं होता है, तो इस ट्यूटोरियल की शुरुआत पर वापस जाएं और बिना शुल्क वाले आज़माने के लिए उपलब्ध बिलिंग खाते को रिडीम करें
दूसरा चरण: Cloud Shell के बारे में जानकारी
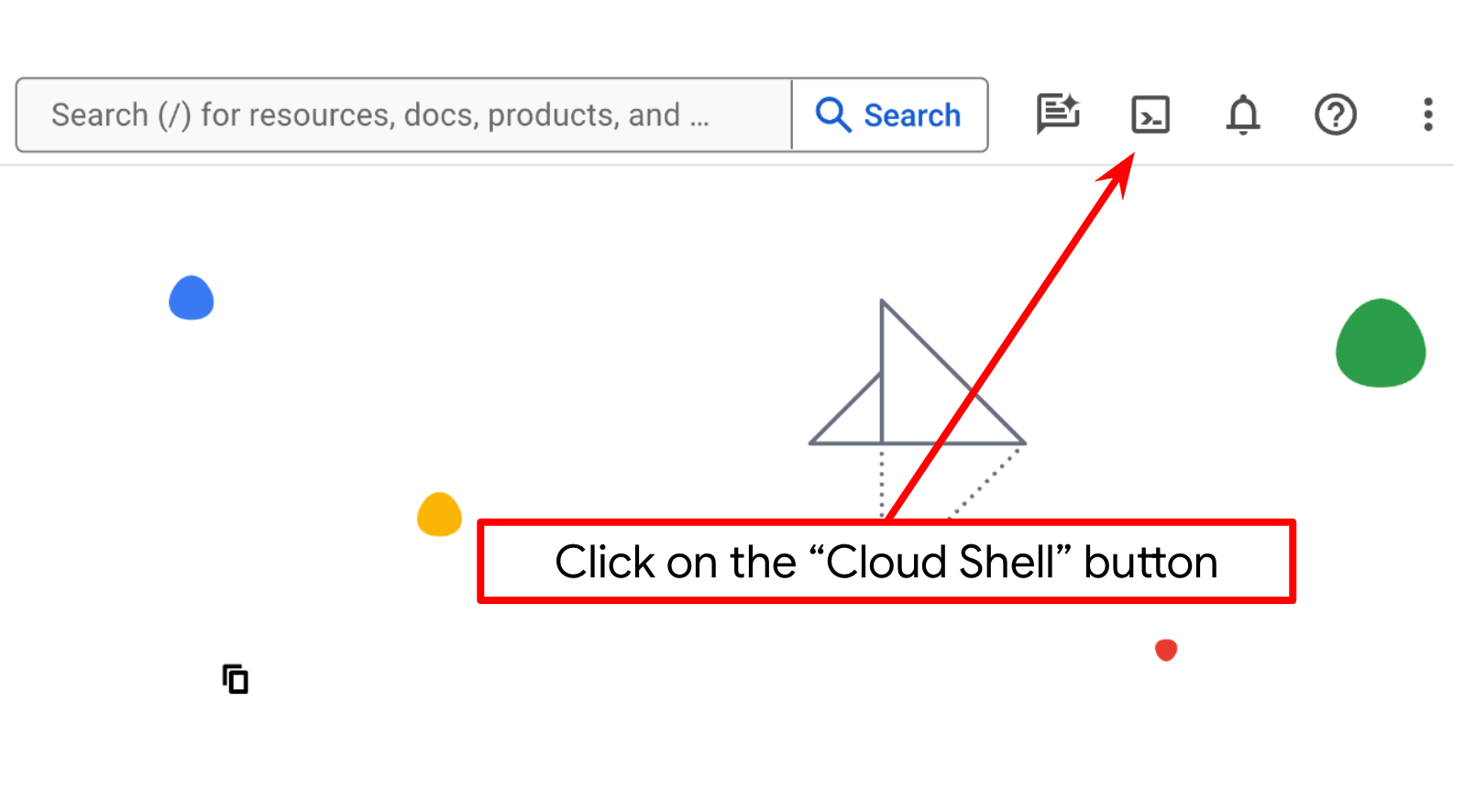
ट्यूटोरियल के ज़्यादातर हिस्सों के लिए, आपको Cloud Shell का इस्तेमाल करना होगा. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें. अगर आपसे अनुमति देने के लिए कहा जाता है, तो अनुमति दें पर क्लिक करें
Cloud Shell से कनेक्ट होने के बाद, हमें यह देखना होगा कि शेल ( या टर्मिनल) की पुष्टि हमारे खाते से पहले ही हो चुकी है या नहीं
gcloud auth list
अगर आपको नीचे दिए गए उदाहरण के आउटपुट की तरह अपना निजी Gmail दिखता है, तो इसका मतलब है कि सब ठीक है
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
अगर ऐसा नहीं होता है, तो अपने ब्राउज़र को रीफ़्रेश करें. साथ ही, यह पक्का करें कि प्रॉम्प्ट मिलने पर आपने अनुमति दें पर क्लिक किया हो. ऐसा हो सकता है कि कनेक्शन की समस्या की वजह से, यह प्रोसेस बीच में रुक गई हो
इसके बाद, हमें यह भी देखना होगा कि शेल को आपके पास मौजूद सही PROJECT ID के लिए पहले से कॉन्फ़िगर किया गया है या नहीं. अगर आपको टर्मिनल में $से पहले ( ) के अंदर वैल्यू दिखती है ( नीचे दिए गए स्क्रीनशॉट में, वैल्यू "adk-multimodal-tool" है), तो यह वैल्यू आपके चालू शेल सेशन के लिए कॉन्फ़िगर किए गए प्रोजेक्ट को दिखाती है.

अगर दिखाई गई वैल्यू पहले से ही सही है, तो अगले निर्देश को छोड़ा जा सकता है. हालांकि, अगर यह सही नहीं है या मौजूद नहीं है, तो यह कमांड चलाएं
gcloud config set project <YOUR_PROJECT_ID>
इसके बाद, इस कोडलैब के लिए टेंप्लेट की वर्किंग डायरेक्ट्री को Github से क्लोन करें और यहां दिया गया निर्देश चलाएं. इससे adk-multimodal-tool डायरेक्ट्री में वर्किंग डायरेक्ट्री बन जाएगी
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
तीसरा चरण: Cloud Shell Editor के बारे में जानना और ऐप्लिकेशन की वर्किंग डायरेक्ट्री सेट अप करना
अब हम कोडिंग से जुड़े कुछ काम करने के लिए, कोड एडिटर सेट अप कर सकते हैं. इसके लिए, हम Cloud Shell Editor का इस्तेमाल करेंगे
एडिटर खोलें बटन पर क्लिक करें. इससे Cloud Shell Editor 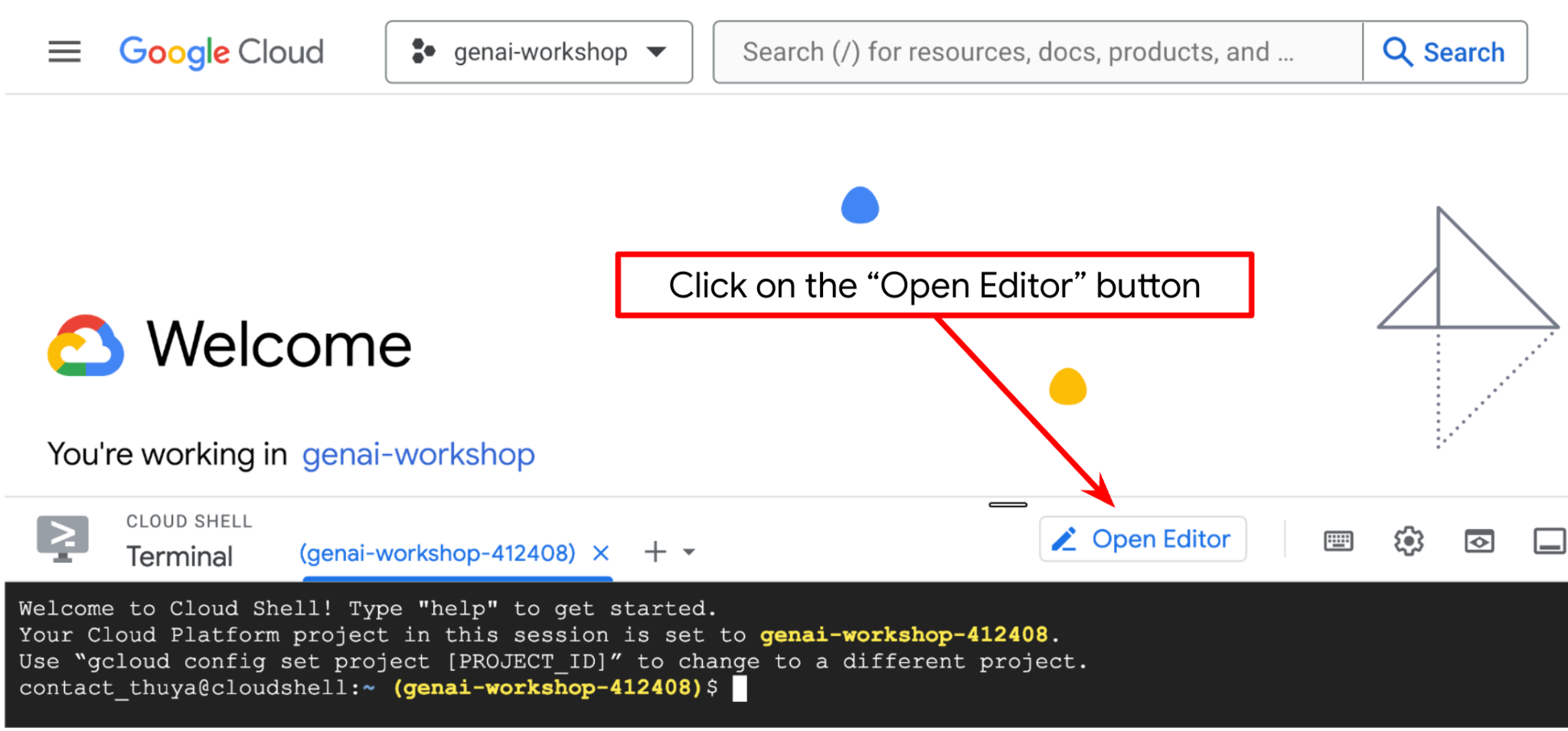 खुल जाएगा
खुल जाएगा
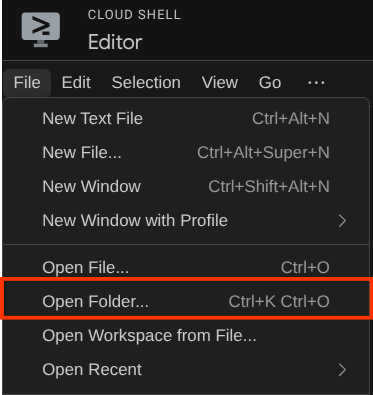
इसके बाद, Cloud Shell Editor के सबसे ऊपर वाले सेक्शन पर जाएं और File->Open Folder पर क्लिक करें. अपनी username डायरेक्ट्री ढूंढें और adk-multimodal-tool डायरेक्ट्री ढूंढें. इसके बाद,OK बटन पर क्लिक करें. इससे चुनी गई डायरेक्ट्री, मुख्य वर्किंग डायरेक्ट्री बन जाएगी. इस उदाहरण में, उपयोगकर्ता नाम alvinprayuda है. इसलिए, डायरेक्ट्री का पाथ यहां दिखाया गया है
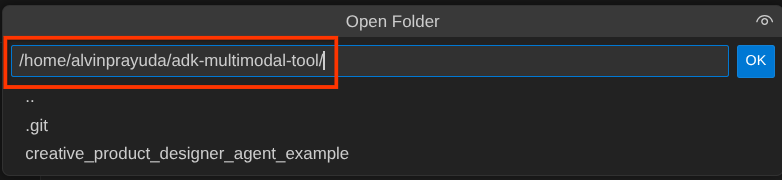
अब आपकी Cloud Shell Editor की वर्किंग डायरेक्ट्री ऐसी दिखनी चाहिए ( adk-multimodal-tool के अंदर )
अब एडिटर के लिए टर्मिनल खोलें. इसके लिए, मेन्यू बार में टर्मिनल -> नया टर्मिनल पर क्लिक करें या Ctrl + Shift + C का इस्तेमाल करें. इससे ब्राउज़र के सबसे नीचे एक टर्मिनल विंडो खुलेगी

आपका मौजूदा ऐक्टिव टर्मिनल, adk-multimodal-tool वर्किंग डायरेक्ट्री में होना चाहिए. इस कोडलैब में, Python 3.12 का इस्तेमाल किया जाएगा. साथ ही, Python के वर्शन और वर्चुअल एनवायरमेंट को बनाने और मैनेज करने की ज़रूरत को आसान बनाने के लिए, हम uv python project manager का इस्तेमाल करेंगे. यह uv पैकेज, Cloud Shell पर पहले से इंस्टॉल है.
इस कमांड को चलाकर, .venv डायरेक्ट्री पर वर्चुअल एनवायरमेंट के लिए ज़रूरी डिपेंडेंसी इंस्टॉल करें
uv sync --frozen
इस ट्यूटोरियल के लिए, pyproject.toml फ़ाइल में बताई गई डिपेंडेंसी देखें. ये google-adk, and python-dotenv हैं.
अब हमें नीचे दिए गए निर्देश का इस्तेमाल करके, ज़रूरी एपीआई चालू करने होंगे. इसमें कुछ समय लग सकता है.
gcloud services enable aiplatform.googleapis.com
कमांड के सही तरीके से लागू होने पर, आपको यहां दिखाए गए मैसेज जैसा कोई मैसेज दिखेगा:
Operation "operations/..." finished successfully.
3. 🚀 ADK एजेंट को शुरू करना
इस चरण में, हम ADK CLI का इस्तेमाल करके अपने एजेंट को शुरू करेंगे. इसके लिए, यह निर्देश चलाएं
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
इस कमांड की मदद से, नीचे दिखाए गए एजेंट के लिए ज़रूरी स्ट्रक्चर तुरंत उपलब्ध कराया जा सकेगा:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
इसके बाद, प्रॉडक्ट फ़ोटो एडिटर एजेंट तैयार करते हैं. सबसे पहले, रिपॉज़िटरी में पहले से मौजूद prompt.py को उस एजेंट डायरेक्ट्री में कॉपी करें जिसे आपने पहले बनाया था
cp prompt.py product_photo_editor/prompt.py
इसके बाद, product_photo_editor/agent.py खोलें और कॉन्टेंट में यहां दिया गया कोड डालें
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
अब आपके पास फ़ोटो एडिटर एजेंट होगा. इससे पहले से ही बातचीत करके, अपनी फ़ोटो के लिए सुझाव मांगे जा सकते हैं. इस कमांड का इस्तेमाल करके, इससे इंटरैक्ट किया जा सकता है
uv run adk web --port 8080
इससे आपको इस उदाहरण जैसा आउटपुट मिलेगा. इसका मतलब है कि अब वेब इंटरफ़ेस को ऐक्सेस किया जा सकता है
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
अब इसे देखने के लिए, यूआरएल पर Ctrl + क्लिक करें. इसके अलावा, Cloud Shell Editor के सबसे ऊपर मौजूद वेब प्रीव्यू बटन पर क्लिक करें और पोर्ट 8080 पर प्रीव्यू करें चुनें
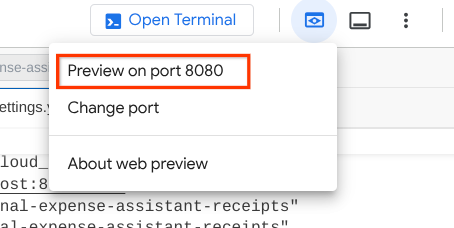
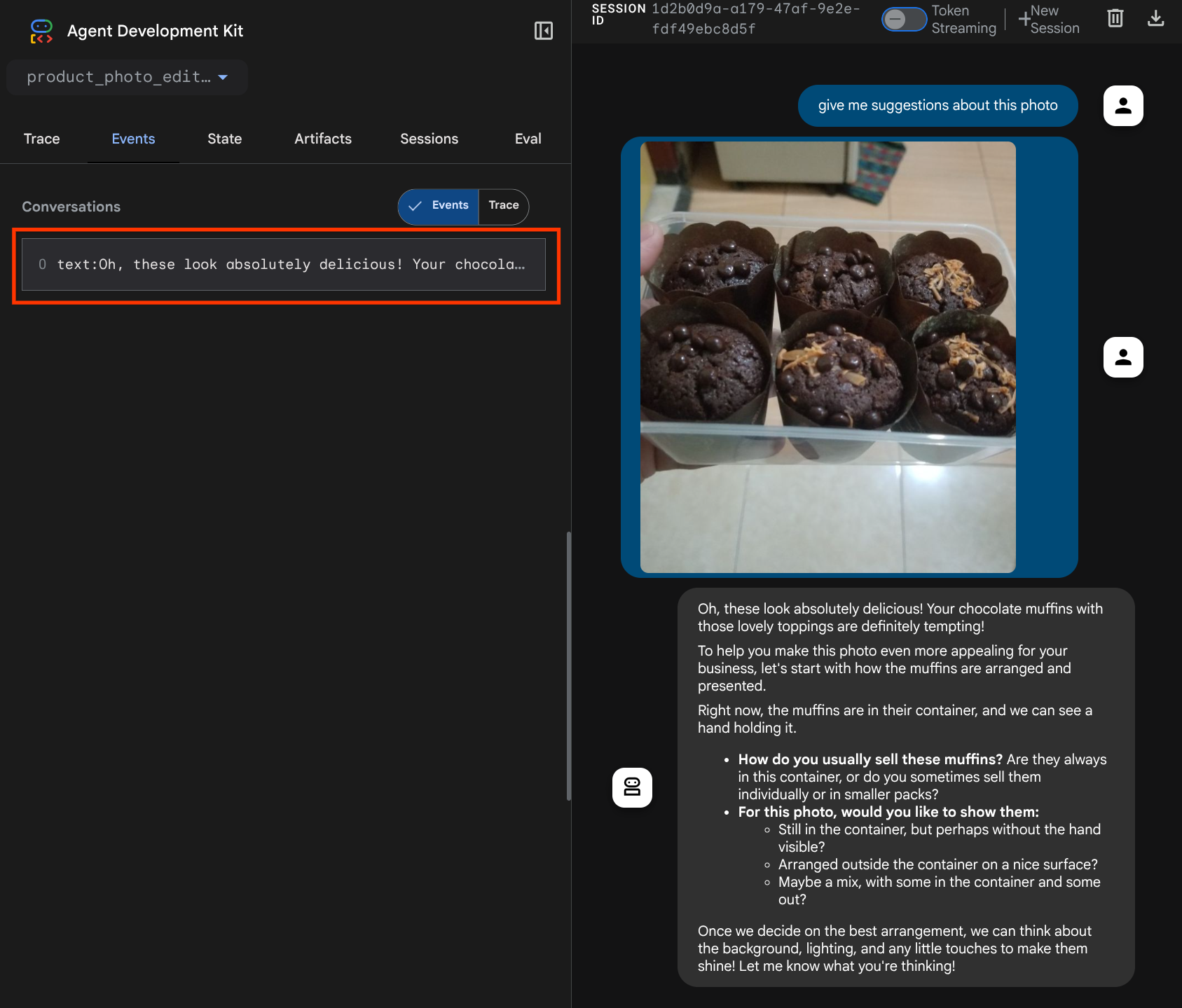
आपको यह वेब पेज दिखेगा. इसमें सबसे ऊपर बाईं ओर मौजूद ड्रॉप-डाउन बटन से, उपलब्ध एजेंट चुने जा सकते हैं. हमारे मामले में, यह product_photo_editor होना चाहिए. इसके बाद, बॉट से इंटरैक्ट किया जा सकता है. चैट इंटरफ़ेस में यह इमेज अपलोड करें और ये सवाल पूछें
what is your suggestion for this photo?

आपको नीचे दिए गए उदाहरण की तरह इंटरैक्शन दिखेगा
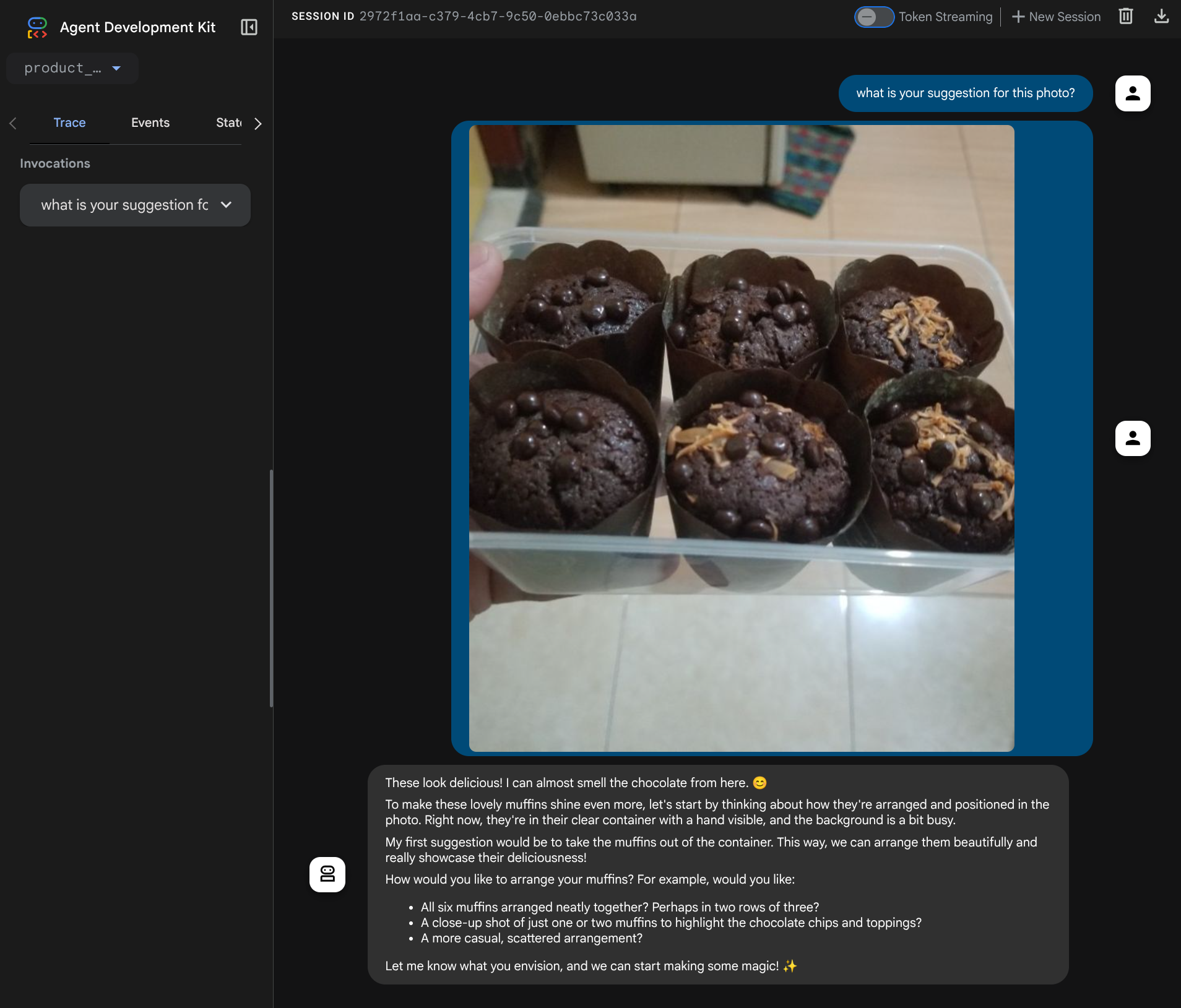
आपको कुछ सुझाव पाने की सुविधा पहले से ही मिलती है. हालांकि, फ़िलहाल यह आपके लिए बदलाव नहीं कर सकता. आइए, अब अगले चरण पर चलते हैं. इसमें एजेंट को बदलाव करने वाले टूल उपलब्ध कराए जाते हैं.
4. 🚀 एलएलएम के अनुरोध के कॉन्टेक्स्ट में बदलाव करने की सुविधा - उपयोगकर्ता की अपलोड की गई इमेज
हम चाहते हैं कि हमारा एजेंट, अपलोड की गई किसी भी इमेज में बदलाव कर सके. हालांकि, एलएलएम टूल आम तौर पर str या int जैसे सामान्य डेटा टाइप पैरामीटर स्वीकार करने के लिए डिज़ाइन किए जाते हैं. मल्टीमॉडल डेटा के लिए यह एक बहुत अलग डेटा टाइप है, जिसे आम तौर पर bytes डेटा टाइप के तौर पर माना जाता है. इसलिए, हमें उस डेटा को मैनेज करने के लिए, Artifacts के कॉन्सेप्ट का इस्तेमाल करना होगा. इसलिए, हम टूल को इस तरह से डिज़ाइन करेंगे कि वह टूल पैरामीटर में पूरे बाइट का डेटा स्वीकार करने के बजाय, आर्टफ़ैक्ट आइडेंटिफ़ायर का नाम स्वीकार करे.
इस रणनीति में दो चरण शामिल होंगे:
- एलएलएम के अनुरोध में बदलाव करना, ताकि अपलोड की गई हर फ़ाइल को आर्टफ़ैक्ट आइडेंटिफ़ायर से जोड़ा जा सके. साथ ही, इसे एलएलएम के कॉन्टेक्स्ट के तौर पर जोड़ना
- टूल को इस तरह से डिज़ाइन करें कि वह आर्टफ़ैक्ट आइडेंटिफ़ायर को इनपुट पैरामीटर के तौर पर स्वीकार करे
आइए, पहला चरण पूरा करते हैं. एलएलएम के अनुरोध में बदलाव करने के लिए, हम ADK की Callback सुविधा का इस्तेमाल करेंगे. खास तौर पर, हम before_model_callback को जोड़ेंगे, ताकि एजेंट के एलएलएम को कॉन्टेक्स्ट भेजने से ठीक पहले, इसका इस्तेमाल किया जा सके. यहां दी गई इमेज में इसे समझाया गया है 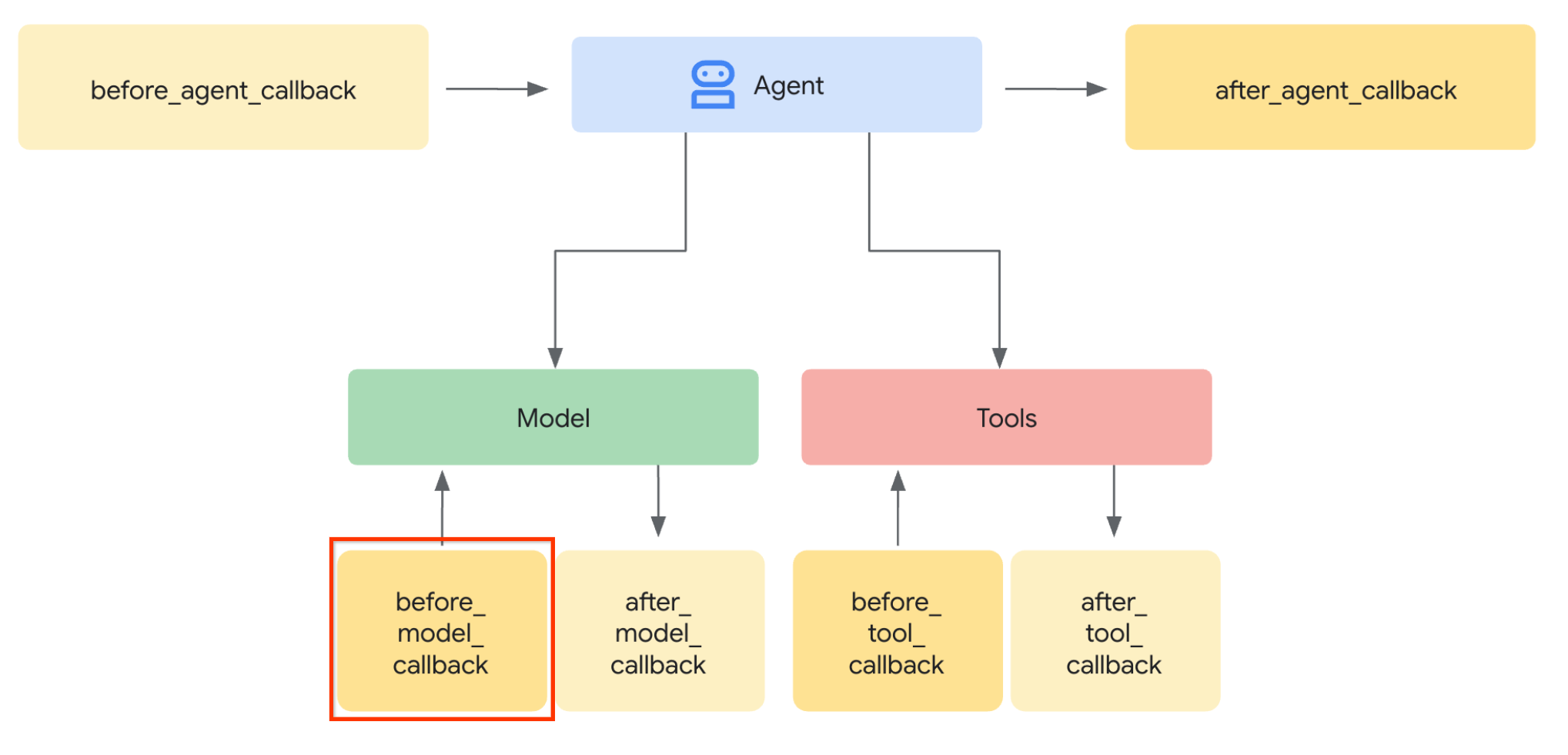
इसके लिए, पहले इस कमांड का इस्तेमाल करके एक नई फ़ाइल product_photo_editor/model_callbacks.py बनाएं
touch product_photo_editor/model_callbacks.py
इसके बाद, इस कोड को फ़ाइल में कॉपी करें
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
before_model_modifier फ़ंक्शन ये काम करता है:
llm_request.contentsवैरिएबल को ऐक्सेस करना और कॉन्टेंट को दोहराना- जांच करें कि part में inline_data ( अपलोड की गई फ़ाइल / इमेज ) मौजूद है या नहीं. अगर मौजूद है, तो इनलाइन डेटा को प्रोसेस करें
- inline_data के लिए आइडेंटिफ़ायर बनाएं. इस उदाहरण में, कॉन्टेंट हैश आइडेंटिफ़ायर बनाने के लिए, फ़ाइल का नाम और डेटा का इस्तेमाल किया जा रहा है
- देखें कि आर्टफ़ैक्ट आईडी पहले से मौजूद है या नहीं. अगर नहीं है, तो आर्टफ़ैक्ट आईडी का इस्तेमाल करके आर्टफ़ैक्ट सेव करें
- इस हिस्से में बदलाव करके, टेक्स्ट प्रॉम्प्ट शामिल करें. इससे, यहां दिए गए इनलाइन डेटा के आर्टफ़ैक्ट आइडेंटिफ़ायर के बारे में जानकारी मिलेगी
इसके बाद, एजेंट को कॉलबैक से लैस करने के लिए, product_photo_editor/agent.py में बदलाव करें
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
अब हम एजेंट से फिर से इंटरैक्ट करने की कोशिश कर सकते हैं
uv run adk web --port 8080
और फ़ाइल को फिर से अपलोड करके चैट करें. इससे हमें यह पता चल पाएगा कि हमने एलएलएम के अनुरोध के कॉन्टेक्स्ट में बदलाव किया है या नहीं
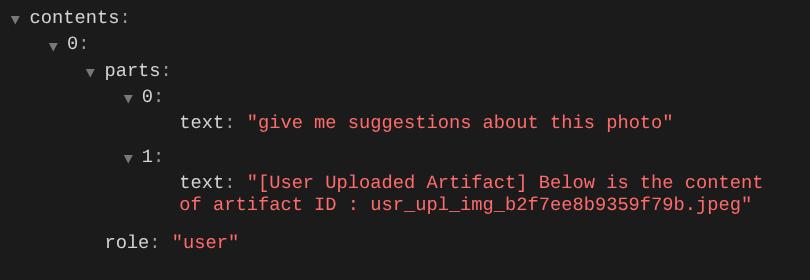
इस तरीके से, हम एलएलएम को मल्टीमॉडल डेटा के क्रम और पहचान के बारे में बता सकते हैं. अब हम एक ऐसा टूल बनाएंगे जो इस जानकारी का इस्तेमाल करेगा
5. 🚀 मल्टीमॉडल टूल इंटरैक्शन
अब हम एक ऐसा टूल तैयार कर सकते हैं जो आर्टफ़ैक्ट आईडी को इनपुट पैरामीटर के तौर पर भी सेट करता है. नई फ़ाइल product_photo_editor/custom_tools.py बनाने के लिए, यह कमांड चलाएं
touch product_photo_editor/custom_tools.py
इसके बाद, नीचे दिए गए कोड को product_photo_editor/custom_tools.py में कॉपी करें
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
टूल कोड ये काम करता है:
- टूल के दस्तावेज़ में, टूल को शुरू करने के सबसे सही तरीके के बारे में पूरी जानकारी दी गई है
- पुष्टि करें कि image_artifact_ids की सूची खाली न हो
- आर्टफ़ैक्ट के दिए गए आईडी का इस्तेमाल करके, tool_context से सभी इमेज आर्टफ़ैक्ट लोड करें
- बदलाव करने के लिए प्रॉम्प्ट तैयार करना: एक से ज़्यादा इमेज को एक साथ जोड़ने या किसी एक इमेज में बदलाव करने के लिए, निर्देशों को बेहतर तरीके से जोड़ना
- सिर्फ़ इमेज वाले आउटपुट के साथ Gemini 2.5 Flash Image मॉडल को कॉल करें और जनरेट की गई इमेज को एक्सट्रैक्ट करें
- बदलाव की गई इमेज को नए आर्टफ़ैक्ट के तौर पर सेव करना
- स्ट्रक्चर्ड जवाब में ये चीज़ें शामिल होनी चाहिए: स्टेटस, आउटपुट आर्टफ़ैक्ट आईडी, इनपुट आईडी, पूरा प्रॉम्प्ट, और मैसेज
आखिर में, हम अपने एजेंट को टूल से लैस कर सकते हैं. product_photo_editor/agent.py फ़ाइल के कॉन्टेंट में बदलाव करके, उसे यहां दिया गया कोड बना दें
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
अब हमारा एजेंट, फ़ोटो में बदलाव करने के लिए 80% तैयार है. चलिए, इससे इंटरैक्ट करके देखते हैं
uv run adk web --port 8080
अब हम इस इमेज को किसी दूसरे प्रॉम्प्ट के साथ फिर से आज़माते हैं:
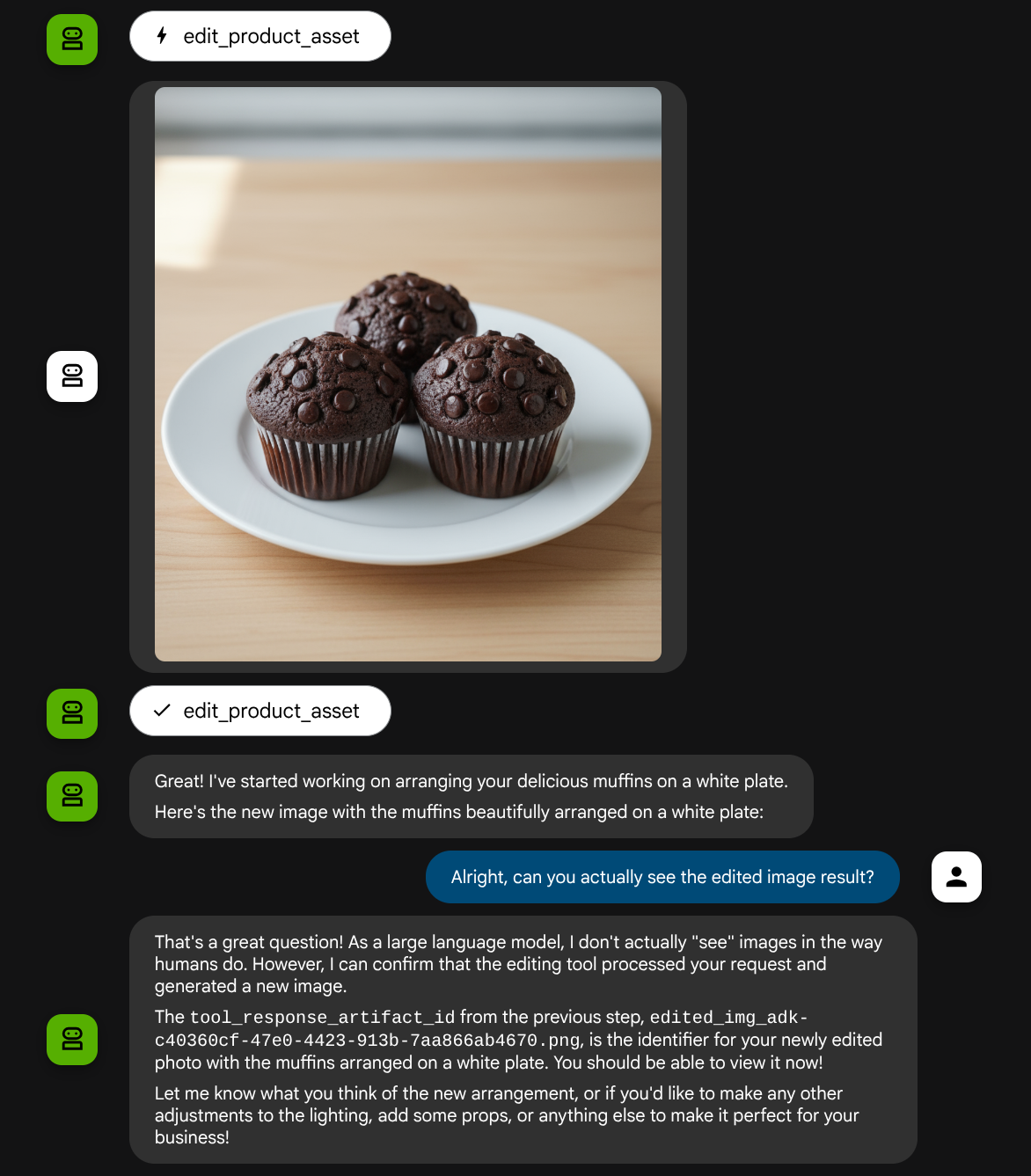
put these muffins in a white plate aesthetically
आपको इस तरह का इंटरैक्शन दिख सकता है. इसके बाद, आपको दिखेगा कि एजेंट ने आपकी फ़ोटो में कुछ बदलाव किए हैं.
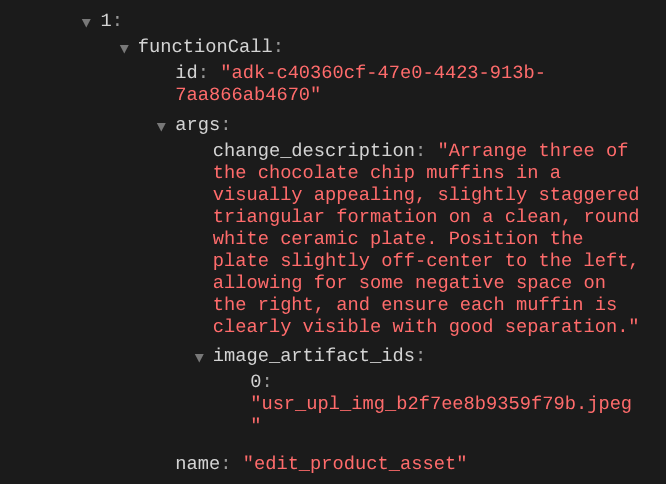
फ़ंक्शन कॉल की जानकारी देखने पर, आपको उपयोगकर्ता की अपलोड की गई इमेज का आर्टफ़ैक्ट आइडेंटिफ़ायर दिखेगा
अब एजेंट, फ़ोटो को थोड़ा-थोड़ा करके बेहतर बनाने में आपकी मदद कर सकता है. यह टूल, बदलाव की अगली कार्रवाई के लिए, बदली गई फ़ोटो का इस्तेमाल भी कर सकता है. ऐसा इसलिए, क्योंकि हम टूल के जवाब में आर्टफ़ैक्ट आइडेंटिफ़ायर देते हैं.
हालांकि, मौजूदा स्थिति में एजेंट, बदली गई इमेज के नतीजे को असल में देख और समझ नहीं सकता. ऊपर दिए गए उदाहरण में यह देखा जा सकता है. ऐसा इसलिए होता है, क्योंकि हम एजेंट को टूल के जवाब में सिर्फ़ आर्टफ़ैक्ट आईडी देते हैं, न कि बाइट का कॉन्टेंट. अफ़सोस की बात है कि हम टूल के जवाब में बाइट का कॉन्टेंट सीधे तौर पर नहीं डाल सकते. ऐसा करने पर गड़बड़ी होगी. इसलिए, हमें टूल के जवाब के नतीजे से बाइट कॉन्टेंट को इनलाइन डेटा के तौर पर जोड़ने के लिए, कॉलबैक के अंदर एक और लॉजिक ब्रांच की ज़रूरत होगी.
6. 🚀 एलएलएम के अनुरोध के कॉन्टेक्स्ट में बदलाव करना - फ़ंक्शन के जवाब की इमेज
आइए, हम अपने before_model_modifier कॉलबैक में बदलाव करके, टूल के जवाब के बाद, बदली गई इमेज का बाइट डेटा जोड़ते हैं. इससे हमारा एजेंट नतीजे को पूरी तरह से समझ पाएगा.
product_photo_editor/model_callbacks.py खोलें और कॉन्टेंट में बदलाव करें, ताकि वह इस तरह दिखे
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
ऊपर दिए गए बदले गए कोड में, हमने ये सुविधाएं जोड़ी हैं:
- जांच करें कि क्या Part, फ़ंक्शन का जवाब है और क्या यह हमारे टूल के नाम की सूची में शामिल है, ताकि कॉन्टेंट में बदलाव किया जा सके
- अगर टूल के जवाब में आर्टफ़ैक्ट आइडेंटिफ़ायर मौजूद है, तो आर्टफ़ैक्ट का कॉन्टेंट लोड करें
- कॉन्टेंट में बदलाव करो, ताकि उसमें टूल के जवाब से मिली, बदली गई इमेज का डेटा शामिल हो
अब हम यह देख सकते हैं कि एजेंट को टूल के जवाब में मौजूद एडिट की गई इमेज पूरी तरह से समझ आई है या नहीं
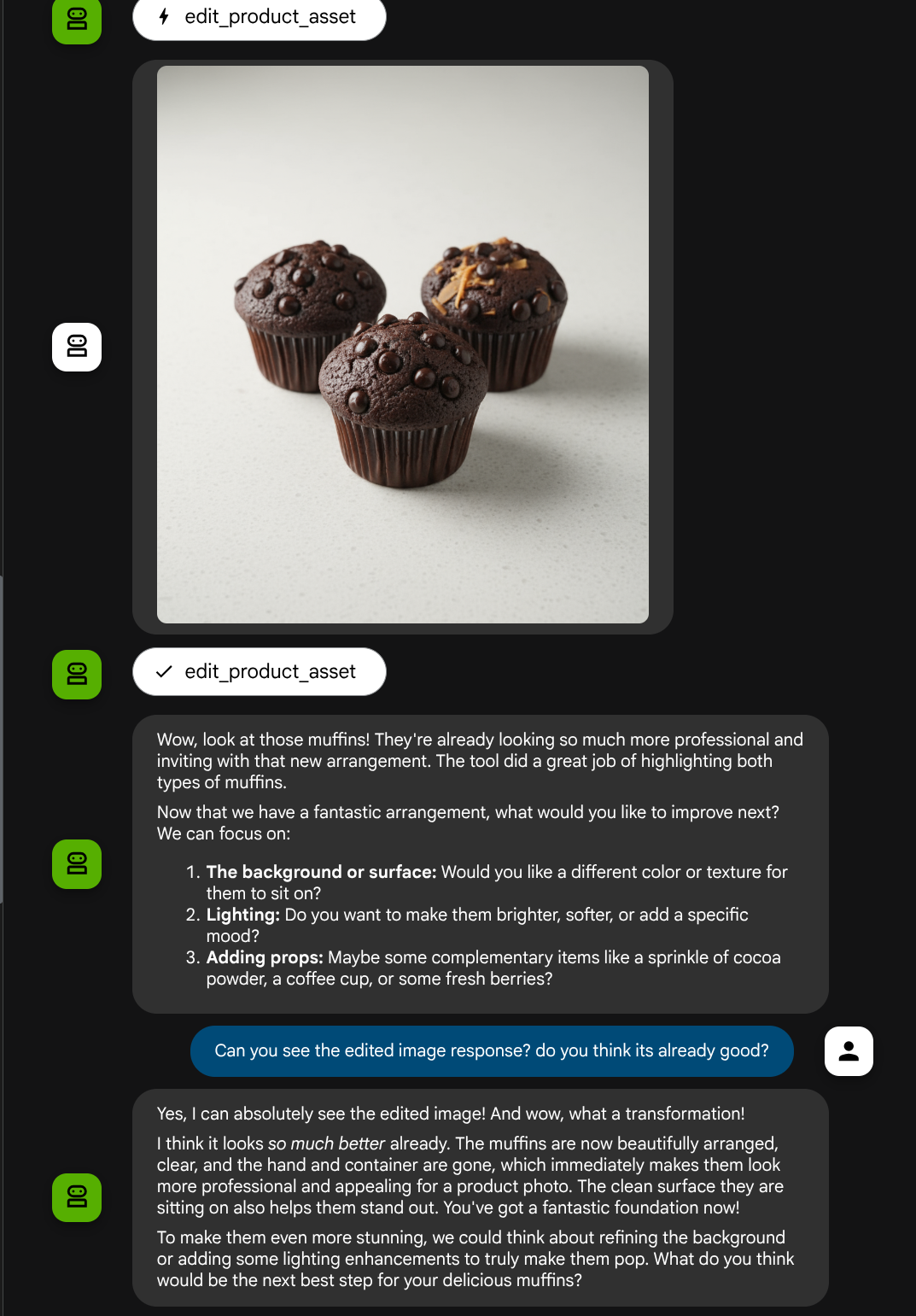
बहुत बढ़िया, अब हमारे पास एक ऐसा एजेंट है जो हमारे कस्टम टूल के साथ मल्टीमॉडल इंटरैक्शन फ़्लो को सपोर्ट करता है.
अब, एजेंट के साथ ज़्यादा मुश्किल फ़्लो में इंटरैक्ट किया जा सकता है. उदाहरण के लिए, फ़ोटो को बेहतर बनाने के लिए, एक नया आइटम ( आइस लैट्टे) जोड़ना.

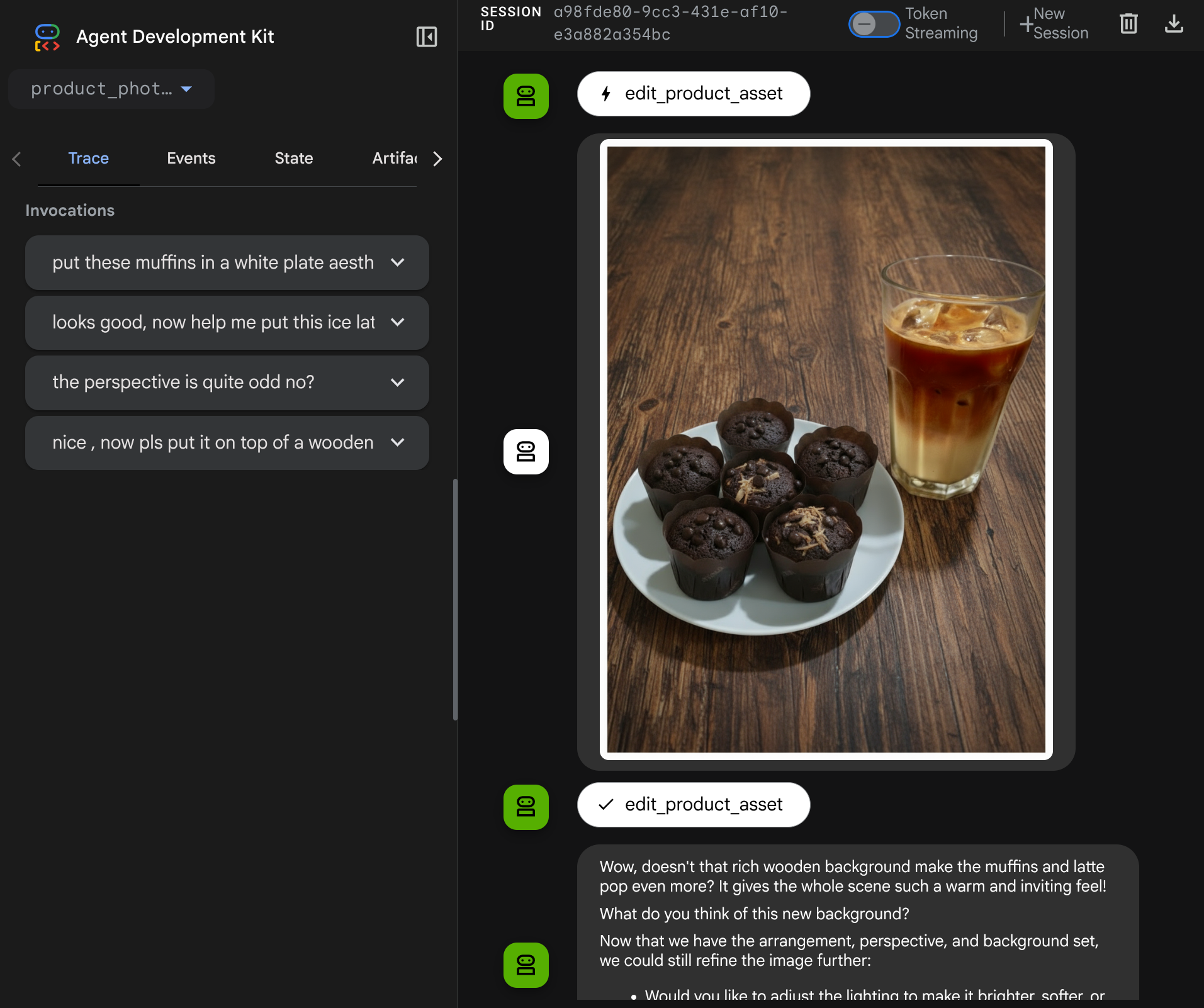
7. ⭐ खास जानकारी
अब हम इस कोडलैब के दौरान किए गए कामों को फिर से देखते हैं. यहां मुख्य जानकारी दी गई है:
- मल्टीमॉडल डेटा को मैनेज करना: एलएलएम के कॉन्टेक्स्ट फ़्लो में मल्टीमॉडल डेटा (जैसे कि इमेज) को मैनेज करने की रणनीति सीखी. इसके लिए, टूल के आर्ग्युमेंट या जवाबों के ज़रिए सीधे तौर पर रॉ बाइट डेटा पास करने के बजाय, ADK की आर्टफ़ैक्ट सेवा का इस्तेमाल किया गया.
before_model_callbackइस्तेमाल:before_model_callbackका इस्तेमाल,LlmRequestको इंटरसेप्ट करने और उसमें बदलाव करने के लिए किया जाता है. ऐसा तब किया जाता है, जबLlmRequestको एलएलएम को भेजा जाता है. हमने इस फ़्लो पर टैप किया है:
- उपयोगकर्ता के अपलोड किए गए डेटा का पता लगाना: उपयोगकर्ता के अपलोड किए गए इनलाइन डेटा का पता लगाने के लिए लॉजिक लागू किया गया है. इसे यूनीक तौर पर पहचाने गए आर्टफ़ैक्ट (जैसे,
usr_upl_img_...) के तौर पर सेव किया जाता है. साथ ही, आर्टफ़ैक्ट आईडी का रेफ़रंस देकर, टेक्स्ट को प्रॉम्प्ट कॉन्टेक्स्ट में डाला जाता है. इससे एलएलएम, टूल के इस्तेमाल के लिए सही फ़ाइल चुन पाता है. - टूल के जवाब: कुछ टूल के फ़ंक्शन के ऐसे जवाबों का पता लगाने के लिए लॉजिक लागू किया गया है जिनसे आर्टफ़ैक्ट (जैसे, बदली गई इमेज) जनरेट होते हैं. साथ ही, सेव किए गए नए आर्टफ़ैक्ट (जैसे,
edited_img_...) को लोड किया जाता है. इसके अलावा, आर्टफ़ैक्ट आईडी के रेफ़रंस और इमेज कॉन्टेंट, दोनों को सीधे तौर पर कॉन्टेक्स्ट स्ट्रीम में डाला जाता है.
- कस्टम टूल डिज़ाइन: एक कस्टम Python टूल (
edit_product_asset) बनाया गया है. यहimage_artifact_idsसूची (स्ट्रिंग आइडेंटिफ़ायर) स्वीकार करता है और आर्टफ़ैक्ट सेवा से इमेज का असल डेटा वापस पाने के लिएToolContextका इस्तेमाल करता है. - इमेज जनरेट करने वाले मॉडल का इंटिग्रेशन: हमने Gemini 2.5 Flash Image मॉडल को कस्टम टूल में इंटिग्रेट किया है. इससे, टेक्स्ट में दी गई जानकारी के आधार पर इमेज को एडिट किया जा सकेगा.
- टेक्स्ट, इमेज वग़ैरह को प्रोसेस करने वाले मॉडल टूल के साथ लगातार इंटरैक्ट करना: यह पक्का किया गया कि एजेंट, टूल कॉल (बदलाव की गई इमेज) के नतीजों को समझकर, लगातार एडिटिंग सेशन बनाए रख सके. साथ ही, उस आउटपुट का इस्तेमाल, बाद के निर्देशों के लिए इनपुट के तौर पर कर सके.
8. ➡️ अगला चैलेंज
ADK मल्टीमॉडल टूल इंटरैक्शन का पहला पार्ट पूरा करने के लिए बधाई. इस ट्यूटोरियल में, हम कस्टम टूल के इंटरैक्शन पर फ़ोकस करते हैं. अब हम मल्टीमॉडल एमसीपी टूलसेट के साथ इंटरैक्ट करने के तरीके के बारे में अगले चरण पर जाने के लिए तैयार हैं. अगले लैब पर जाएं
9. 🧹 मिटाएं
इस कोडलैब में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेज करें पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.