
1. 📖 Pengantar
Codelab ini menunjukkan cara mendesain interaksi alat multimodal di Agent Development Kit (ADK). Ini adalah alur khusus tempat Anda ingin agen merujuk ke file yang diupload sebagai input ke alat dan juga memahami konten file yang dihasilkan oleh respons alat. Oleh karena itu, interaksi seperti yang ditunjukkan pada screenshot di bawah dapat dilakukan. Dalam tutorial ini, kita akan mengembangkan agen yang mampu membantu pengguna mengedit foto yang lebih baik untuk showcase produk mereka
Selama mengikuti codelab, Anda akan menggunakan pendekatan langkah demi langkah sebagai berikut:
- Siapkan project Google Cloud
- Menyiapkan direktori kerja untuk lingkungan coding
- Menginisialisasi agen menggunakan ADK
- Mendesain alat yang dapat digunakan untuk mengedit foto yang didukung oleh Gemini 2.5 Flash Image
- Merancang fungsi callback untuk menangani upload gambar pengguna, menyimpannya sebagai artefak, dan menambahkannya sebagai konteks ke agen
- Merancang fungsi callback untuk menangani gambar yang dihasilkan oleh respons alat, menyimpannya sebagai artefak, dan menambahkannya sebagai konteks ke agen
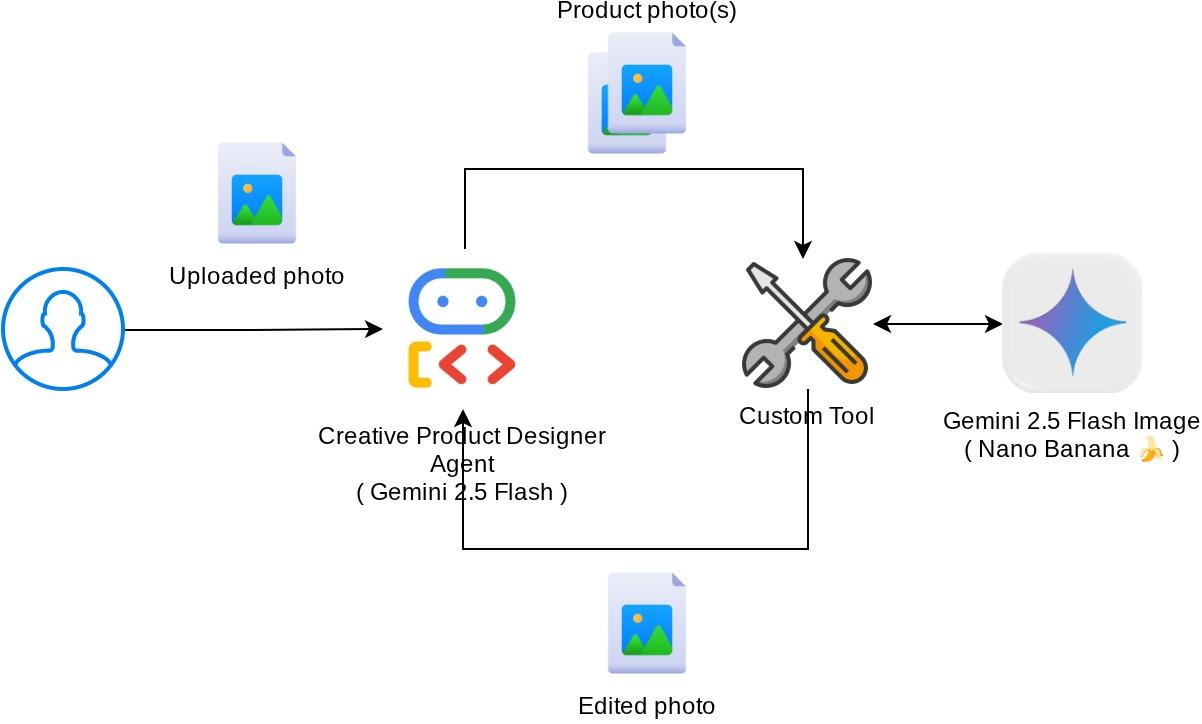
Ringkasan Arsitektur
Keseluruhan interaksi dalam codelab ini ditunjukkan dalam diagram berikut
Prasyarat
- Nyaman bekerja dengan Python
- (Opsional) Codelab dasar tentang Agent Development Kit (ADK)
Yang akan Anda pelajari
- Cara memanfaatkan konteks callback untuk mengakses layanan artefak
- Cara mendesain alat dengan propagasi data multimodal yang tepat
- Cara mengubah permintaan LLM agen untuk menambahkan konteks artefak melalui before_model_callback
- Cara mengedit gambar menggunakan Gemini 2.5 Flash Image
Yang Anda butuhkan
- Browser web Chrome
- Akun Gmail
- Project Cloud dengan akun penagihan diaktifkan
Codelab ini, yang dirancang untuk developer dari semua tingkat keahlian (termasuk pemula), menggunakan Python dalam aplikasi contohnya. Namun, pengetahuan Python tidak diperlukan untuk memahami konsep yang disajikan.
2. 🚀 Menyiapkan Penyiapan Pengembangan Workshop
Langkah 1: Pilih Project Aktif di Konsol Cloud
Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud (lihat bagian kiri atas konsol Anda)

Klik, dan Anda akan melihat daftar semua project Anda seperti contoh ini,
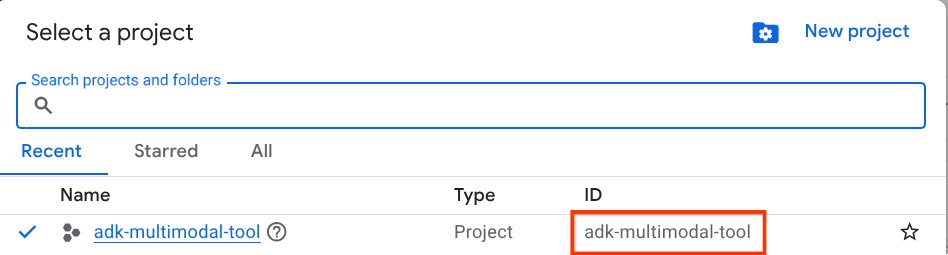
Nilai yang ditunjukkan oleh kotak merah adalah PROJECT ID dan nilai ini akan digunakan di seluruh tutorial.
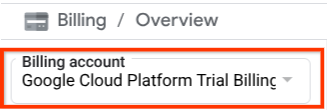
Pastikan penagihan diaktifkan untuk project Cloud Anda. Untuk memeriksanya, klik ikon burger ☰ di panel kiri atas yang menampilkan Menu Navigasi, lalu temukan menu Penagihan

Jika Anda melihat "Akun Penagihan Uji Coba Google Cloud Platform" di bagian judul Penagihan / Ringkasan ( bagian kiri atas konsol cloud Anda ), project Anda siap digunakan untuk tutorial ini. Jika tidak, kembali ke awal tutorial ini dan tukarkan akun penagihan uji coba
Langkah 2: Pelajari Cloud Shell
Anda akan menggunakan Cloud Shell untuk sebagian besar tutorial. Klik Activate Cloud Shell di bagian atas konsol Google Cloud. Jika Anda diminta untuk memberikan otorisasi, klik Authorize.
Setelah terhubung ke Cloud Shell, kita perlu memeriksa apakah shell ( atau terminal) sudah diautentikasi dengan akun kita
gcloud auth list
Jika Anda melihat Gmail pribadi Anda seperti contoh output di bawah, semuanya baik-baik saja
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Jika tidak, coba muat ulang browser Anda dan pastikan Anda mengklik Izinkan saat diminta ( mungkin terganggu karena masalah koneksi)
Selanjutnya, kita juga perlu memeriksa apakah shell sudah dikonfigurasi ke PROJECT ID yang benar yang Anda miliki. Jika Anda melihat ada nilai di dalam ( ) sebelum ikon $ di terminal ( pada screenshot di bawah, nilainya adalah "adk-multimodal-tool"), nilai ini menunjukkan project yang dikonfigurasi untuk sesi shell aktif Anda.

Jika nilai yang ditampilkan sudah benar, Anda dapat melewati perintah berikutnya. Namun, jika tidak benar atau tidak ada, jalankan perintah berikut
gcloud config set project <YOUR_PROJECT_ID>
Kemudian, clone direktori kerja template untuk codelab ini dari GitHub dengan menjalankan perintah berikut. Perintah ini akan membuat direktori kerja di direktori adk-multimodal-tool
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
Langkah 3: Pahami Editor Cloud Shell dan Siapkan Direktori Kerja Aplikasi
Sekarang, kita dapat menyiapkan editor kode untuk melakukan beberapa hal terkait coding. Kita akan menggunakan Cloud Shell Editor untuk melakukannya
Klik tombol Open Editor, dan Cloud Shell Editor akan terbuka 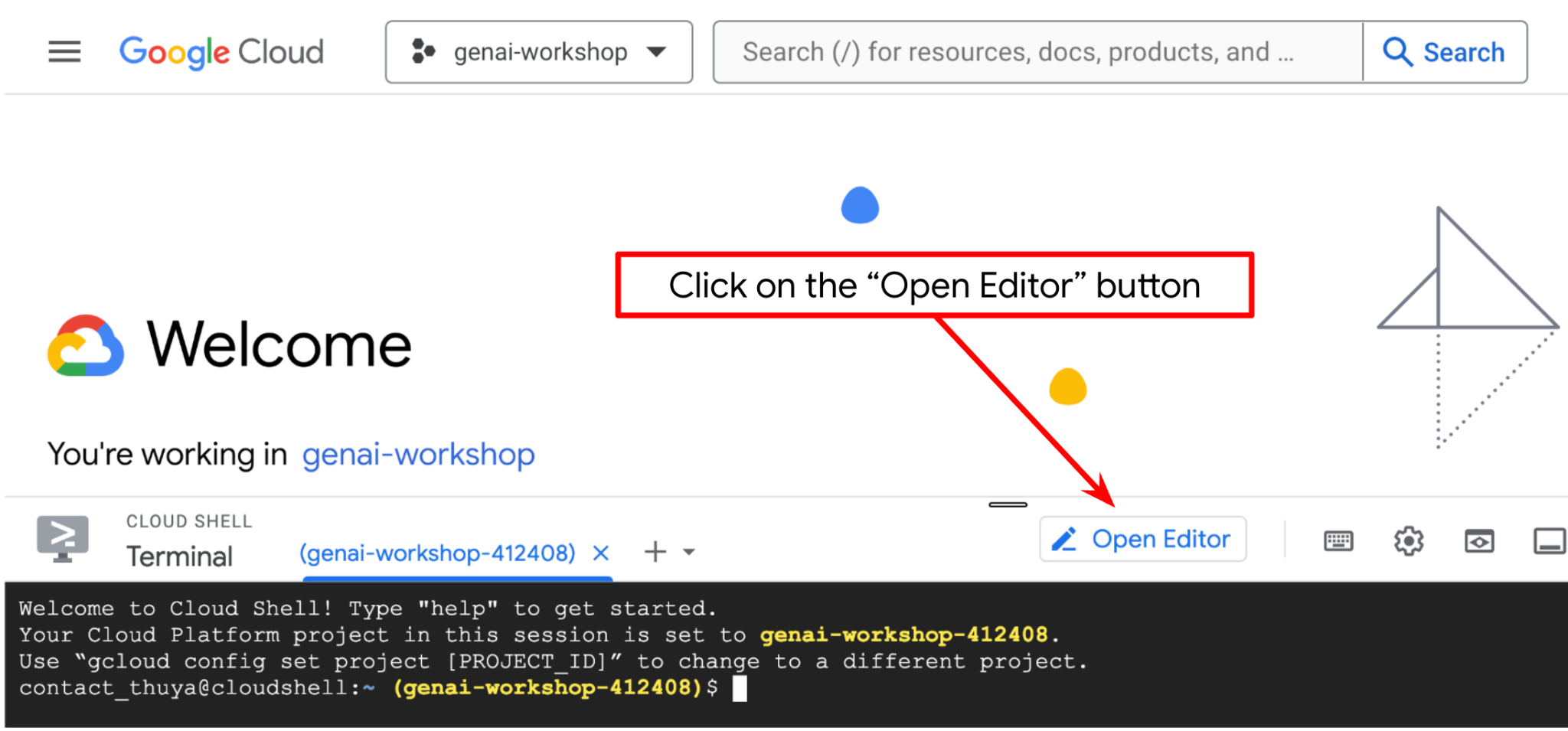
Setelah itu, buka bagian atas Cloud Shell Editor, klik File->Open Folder, temukan direktori username Anda, lalu temukan direktori adk-multimodal-tool, lalu klik tombol OK. Tindakan ini akan menjadikan direktori yang dipilih sebagai direktori kerja utama. Dalam contoh ini, nama penggunanya adalah alvinprayuda, sehingga jalur direktori ditampilkan di bawah
Sekarang, direktori kerja Cloud Shell Editor Anda akan terlihat seperti ini ( di dalam adk-multimodal-tool)
Sekarang, buka terminal untuk editor. Anda dapat melakukannya dengan mengklik Terminal -> New Terminal di panel menu, atau menggunakan Ctrl + Shift + C , yang akan membuka jendela terminal di bagian bawah browser

Terminal aktif Anda saat ini harus berada di dalam direktori kerja adk-multimodal-tool. Kita akan menggunakan Python 3.12 dalam codelab ini dan kita akan menggunakan pengelola project python uv untuk menyederhanakan kebutuhan pembuatan dan pengelolaan versi python serta lingkungan virtual. Paket uv ini sudah diinstal sebelumnya di Cloud Shell.
Jalankan perintah ini untuk menginstal dependensi yang diperlukan ke lingkungan virtual di direktori .venv
uv sync --frozen
Periksa pyproject.toml untuk melihat dependensi yang dinyatakan untuk tutorial ini, yaitu google-adk, and python-dotenv.
Sekarang, kita perlu mengaktifkan API yang diperlukan melalui perintah yang ditunjukkan di bawah. Proses ini memerlukan waktu beberapa saat.
gcloud services enable aiplatform.googleapis.com
Setelah perintah berhasil dieksekusi, Anda akan melihat pesan yang mirip dengan yang ditampilkan di bawah:
Operation "operations/..." finished successfully.
3. 🚀 Menginisialisasi Agen ADK
Pada langkah ini, kita akan melakukan inisialisasi agen menggunakan ADK CLI, jalankan perintah berikut
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
Perintah ini akan membantu Anda memberikan struktur yang diperlukan untuk agen Anda dengan cepat seperti yang ditunjukkan di bawah:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
Setelah itu, siapkan agen editor foto produk kita. Pertama, salin prompt.py yang sudah disertakan dalam repositori ke direktori agen yang Anda buat sebelumnya
cp prompt.py product_photo_editor/prompt.py
Kemudian, buka product_photo_editor/agent.py dan ubah kontennya dengan kode berikut
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Sekarang, Anda akan memiliki agen editor foto dasar yang dapat Anda ajak mengobrol untuk meminta saran terkait foto Anda. Anda dapat mencoba berinteraksi dengannya menggunakan perintah ini
uv run adk web --port 8080
Perintah ini akan menghasilkan output seperti contoh berikut, yang berarti kita sudah dapat mengakses antarmuka web
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Sekarang, untuk memeriksanya, Anda dapat menekan Ctrl + Klik pada URL atau mengklik tombol Web Preview di area atas Cloud Shell Editor dan memilih Preview on port 8080
Anda akan melihat halaman web berikut tempat Anda dapat memilih agen yang tersedia di tombol drop-down kiri atas ( dalam kasus ini, agennya adalah product_photo_editor) dan berinteraksi dengan bot. Coba upload gambar berikut di antarmuka percakapan dan ajukan pertanyaan berikut
what is your suggestion for this photo?

Anda akan melihat interaksi serupa seperti yang ditunjukkan di bawah
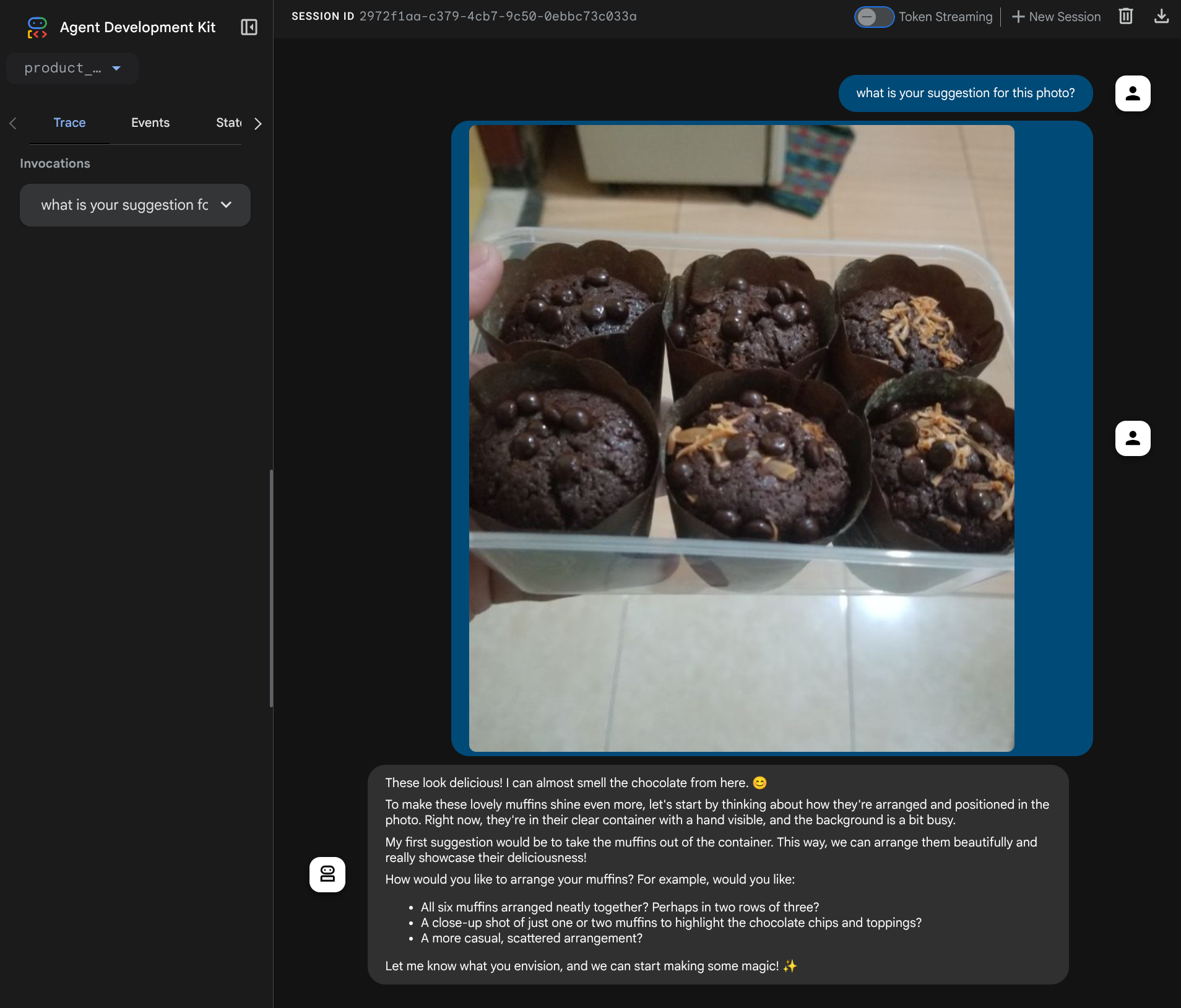
Anda sudah dapat meminta beberapa saran, tetapi saat ini Gemini tidak dapat melakukan pengeditan untuk Anda. Mari kita lanjutkan ke langkah berikutnya, yaitu melengkapi agen dengan alat pengeditan.
4. 🚀 Modifikasi Konteks Permintaan LLM - Gambar yang Diupload Pengguna
Kita ingin agen kita fleksibel dalam memilih gambar yang diupload yang ingin dieditnya. Namun, alat LLM biasanya dirancang untuk menerima parameter jenis data sederhana seperti str atau int. Ini adalah jenis data yang sangat berbeda untuk data multimodal yang biasanya dianggap sebagai jenis data byte, sehingga kita memerlukan strategi yang melibatkan konsep Artefak untuk menangani data tersebut. Jadi, alih-alih memberikan data byte lengkap dalam parameter alat, kita akan mendesain alat untuk menerima nama ID artefak.
Strategi ini akan melibatkan 2 langkah:
- mengubah permintaan LLM sehingga setiap file yang diupload dikaitkan dengan ID artefak dan menambahkan ID ini sebagai konteks ke LLM
- Mendesain alat agar menerima ID artefak sebagai parameter input
Mari kita lakukan langkah pertama. Untuk mengubah permintaan LLM, kita akan menggunakan fitur Callback ADK. Secara khusus, kita akan menambahkan before_model_callback untuk memanfaatkan tepat sebelum agen mengirimkan konteks ke LLM. Anda dapat melihat ilustrasinya pada gambar di bawah 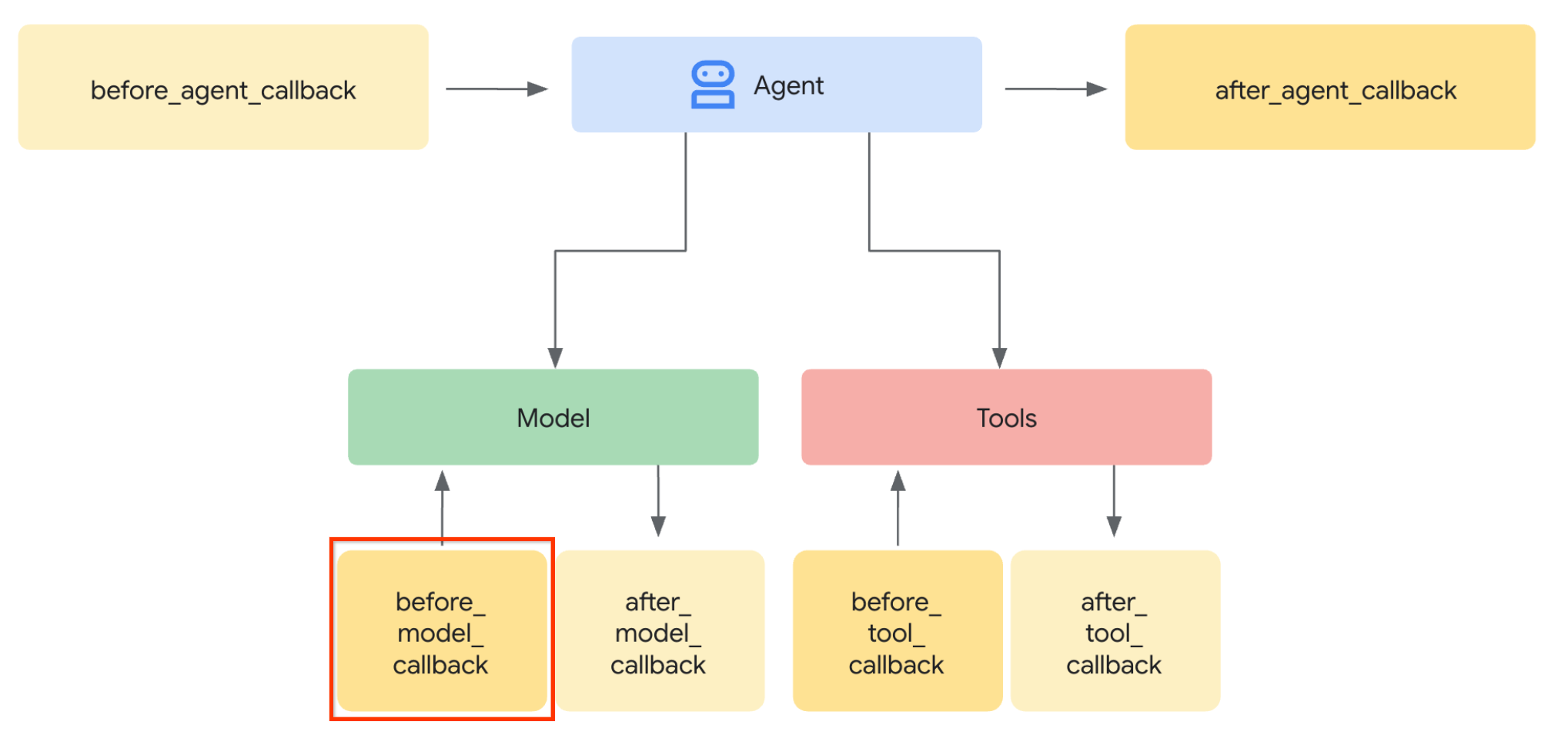
Untuk melakukannya, buat file baru product_photo_editor/model_callbacks.py terlebih dahulu menggunakan perintah berikut
touch product_photo_editor/model_callbacks.py
Kemudian, salin kode berikut ke file
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
Fungsi before_model_modifier melakukan hal berikut:
- Akses variabel
llm_request.contentsdan ulangi konten - Periksa apakah part berisi inline_data ( file / gambar yang diupload), jika ya, proses data inline
- Buat ID untuk inline_data, dalam contoh ini kita menggunakan kombinasi nama file + data untuk membuat ID hash konten
- Periksa apakah ID artefak sudah ada atau belum. Jika belum, simpan artefak menggunakan ID artefak
- Ubah bagian untuk menyertakan perintah teks yang memberikan konteks tentang ID artefak dari data inline berikut
Setelah itu, ubah product_photo_editor/agent.py untuk melengkapi agen dengan callback
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
Sekarang, kita dapat mencoba berinteraksi dengan agen lagi
uv run adk web --port 8080
dan mencoba mengupload file lagi dan memulai chat, kita dapat memeriksa apakah kita berhasil mengubah konteks permintaan LLM
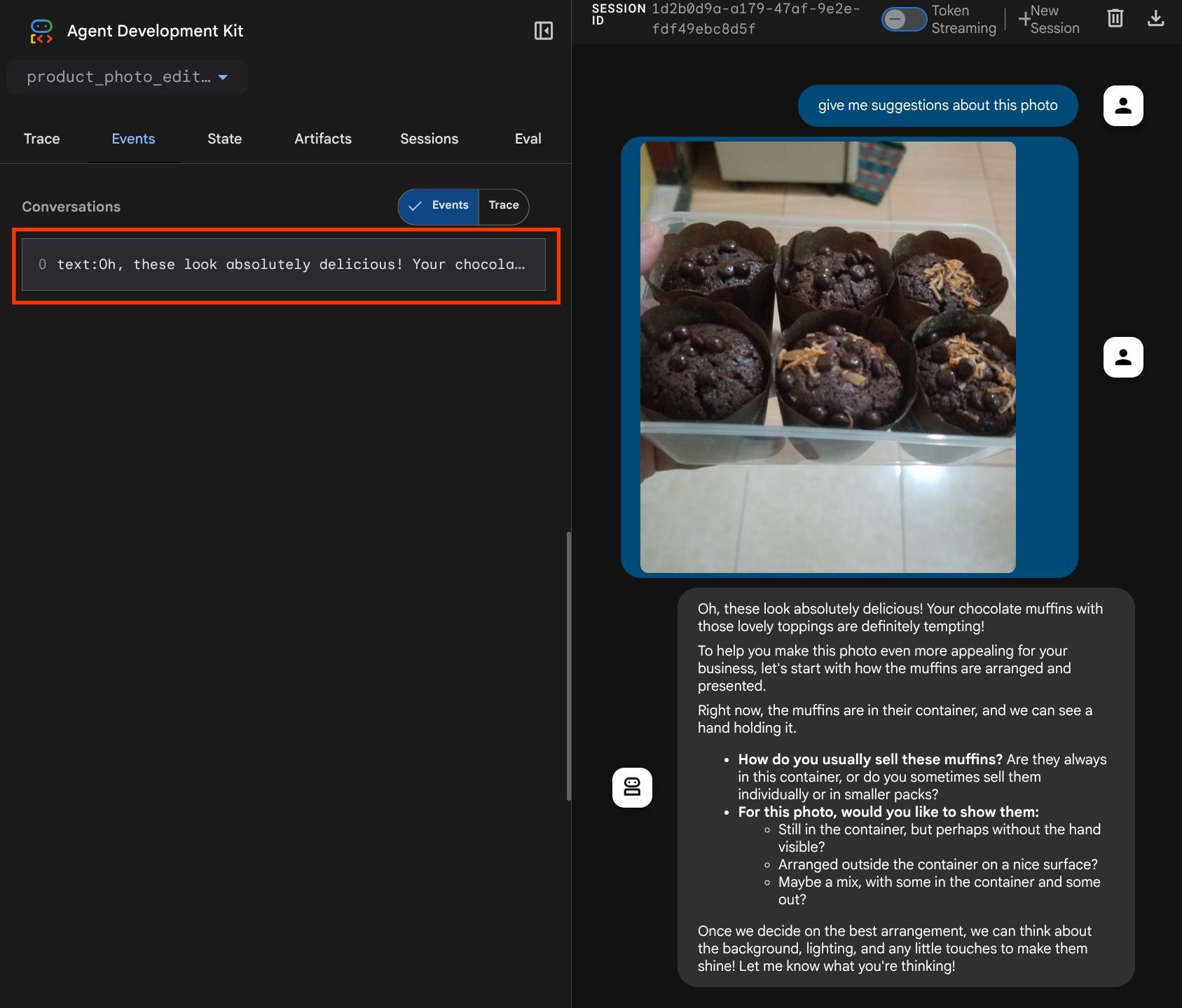
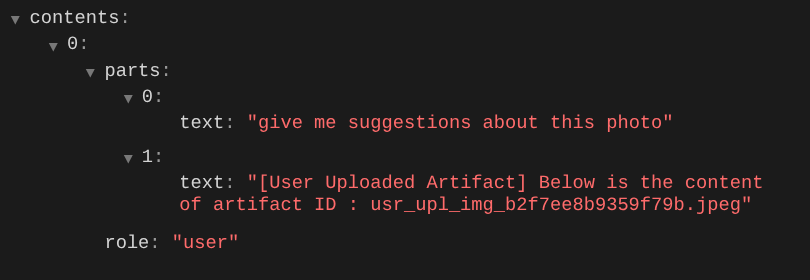
Ini adalah salah satu cara kita dapat memberi tahu LLM tentang urutan dan identifikasi data multimodal. Sekarang, mari kita buat alat yang akan menggunakan informasi ini
5. 🚀 Interaksi Alat Multimodal
Sekarang, kita dapat menyiapkan alat yang juga menentukan ID artefak sebagai parameter inputnya. Jalankan perintah berikut untuk membuat file baru product_photo_editor/custom_tools.py
touch product_photo_editor/custom_tools.py
Selanjutnya, salin kode berikut ke product_photo_editor/custom_tools.py
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
Kode alat melakukan hal berikut:
- Dokumentasi alat menjelaskan secara mendetail praktik terbaik untuk memanggil alat
- Validasi bahwa daftar image_artifact_ids tidak kosong
- Memuat semua artefak gambar dari tool_context menggunakan ID artefak yang diberikan
- Buat perintah edit: tambahkan petunjuk untuk menggabungkan (multi-gambar) atau mengedit (gambar tunggal) secara profesional
- Memanggil model Gemini 2.5 Flash Image dengan output Hanya Gambar dan Mengekstrak gambar yang dihasilkan
- Menyimpan gambar yang diedit sebagai artefak baru
- Menampilkan respons terstruktur dengan: status, ID artefak output, ID input, perintah lengkap, dan pesan
Terakhir, kita dapat melengkapi agen dengan alat tersebut. Ubah konten product_photo_editor/agent.py menjadi kode di bawah
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
Sekarang, agen kita sudah 80% siap membantu mengedit foto untuk kita. Mari kita coba berinteraksi dengannya
uv run adk web --port 8080
Mari kita coba lagi gambar berikut dengan perintah yang berbeda:
put these muffins in a white plate aesthetically
Anda mungkin melihat interaksi seperti ini dan akhirnya melihat agen melakukan pengeditan foto untuk Anda.
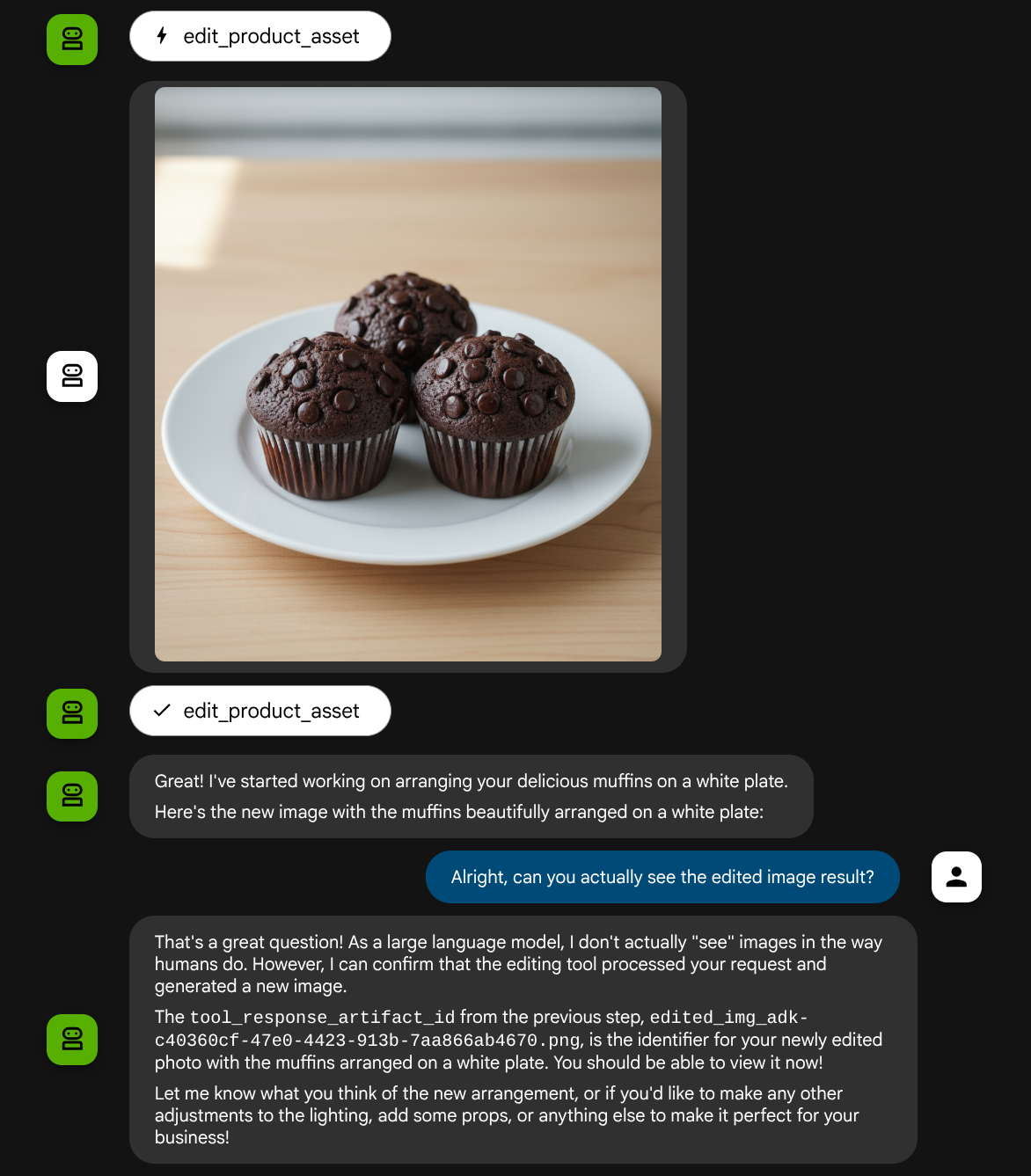
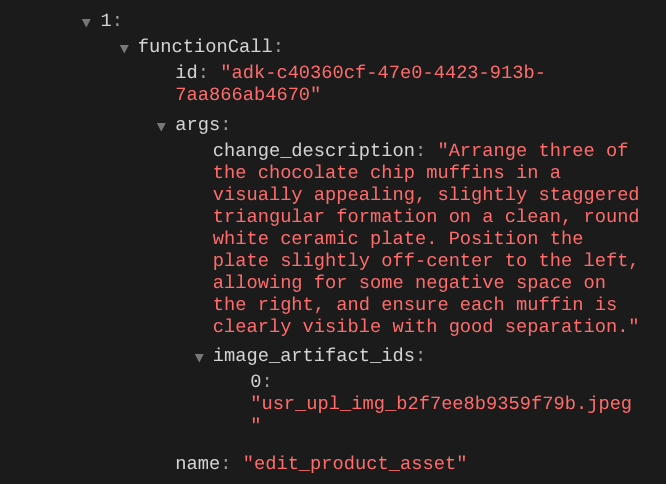
Saat Anda memeriksa detail panggilan fungsi, ID artefak gambar yang diupload pengguna akan ditampilkan
Sekarang, agen dapat membantu Anda terus meningkatkan kualitas foto sedikit demi sedikit. Alat ini juga dapat menggunakan foto yang diedit untuk petunjuk pengeditan berikutnya karena kita memberikan ID artefak dalam respons alat.
Namun, dalam kondisi saat ini, agen tidak dapat benar-benar melihat dan memahami hasil gambar yang diedit seperti yang dapat Anda lihat dari contoh di atas. Hal ini karena respons alat yang kami berikan kepada agen hanya berupa ID artefak, bukan konten byte itu sendiri, dan sayangnya kami tidak dapat memasukkan konten byte secara langsung ke dalam respons alat karena akan menimbulkan error. Jadi, kita perlu memiliki cabang logika lain di dalam callback untuk menambahkan konten byte sebagai data inline dari hasil respons alat.
6. 🚀 Modifikasi Konteks Permintaan LLM - Gambar Respons Fungsi
Mari kita ubah callback before_model_modifier untuk menambahkan data byte gambar yang diedit setelah respons alat agar agen kita sepenuhnya memahami hasilnya.
Buka product_photo_editor/model_callbacks.py dan ubah kontennya agar terlihat seperti di bawah
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
Dalam kode yang diubah di atas, kita menambahkan fungsi berikut:
- Memeriksa apakah Bagian adalah respons fungsi dan apakah ada dalam daftar nama alat kami untuk mengizinkan modifikasi konten
- Jika ID artefak dari respons alat ada, muat konten artefak
- Ubah konten sehingga menyertakan data gambar yang diedit dari respons alat
Sekarang, kita dapat memeriksa apakah agen memahami sepenuhnya gambar yang diedit dari respons alat
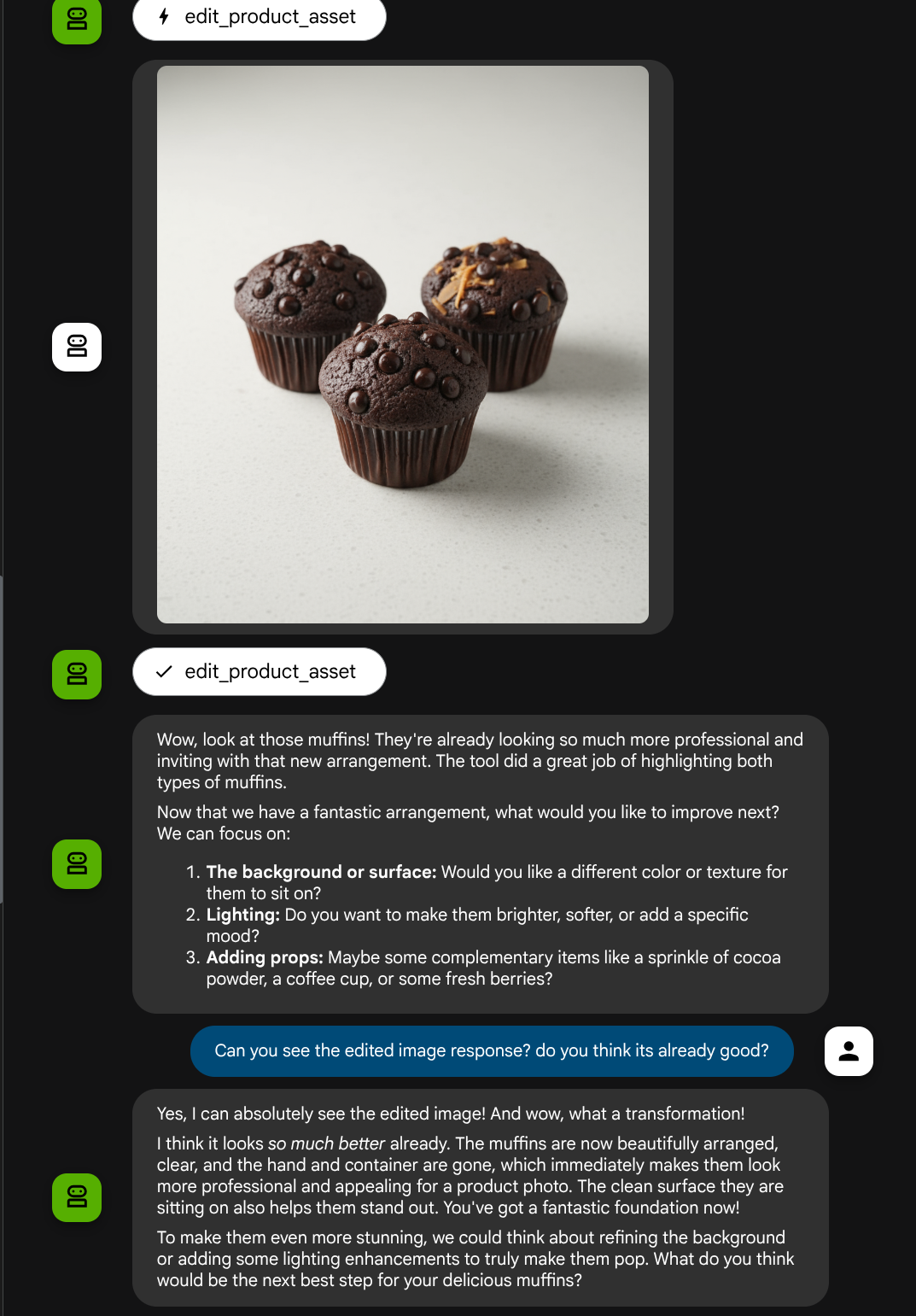
Bagus, sekarang kita sudah memiliki agen yang mendukung alur interaksi multimodal dengan alat kustom kita sendiri.
Sekarang, Anda dapat mencoba berinteraksi dengan agen menggunakan alur yang lebih kompleks, misalnya menambahkan item baru ( ice latte) untuk meningkatkan kualitas foto.

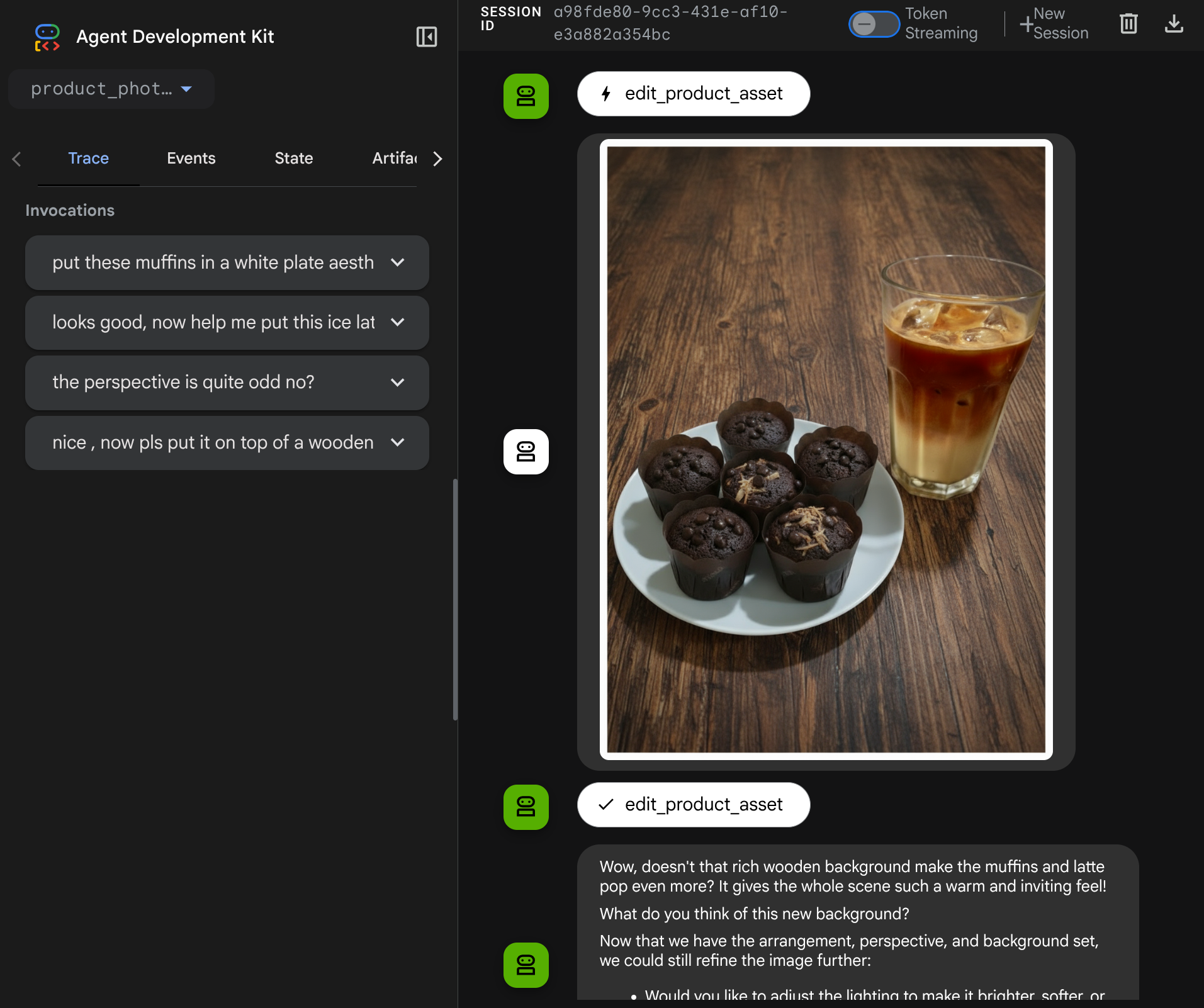
7. ⭐ Ringkasan
Sekarang, mari kita lihat kembali apa yang telah kita lakukan selama codelab ini. Berikut adalah pembelajaran utamanya:
- Penanganan Data Multimodal: Mempelajari strategi untuk mengelola data multimodal (seperti gambar) dalam alur konteks LLM dengan menggunakan layanan Artefak ADK, bukan meneruskan data byte mentah secara langsung melalui argumen atau respons alat.
before_model_callbackPenggunaan: Menggunakanbefore_model_callbackuntuk mencegat dan mengubahLlmRequestsebelum dikirim ke LLM. Kita telah mengetuk alur berikut:
- Upload Pengguna: Menerapkan logika untuk mendeteksi data inline yang diupload pengguna, menyimpannya sebagai artefak yang diidentifikasi secara unik (misalnya,
usr_upl_img_...), dan menyisipkan teks ke dalam konteks perintah yang mereferensikan ID artefak, sehingga memungkinkan LLM memilih file yang benar untuk penggunaan alat. - Respons Alat: Menerapkan logika untuk mendeteksi respons fungsi alat tertentu yang menghasilkan artefak (misalnya, gambar yang diedit), memuat artefak yang baru disimpan (misalnya,
edited_img_...), dan menyuntikkan referensi ID artefak dan konten gambar langsung ke dalam aliran konteks.
- Desain Alat Kustom: Membuat alat Python kustom (
edit_product_asset) yang menerima daftarimage_artifact_ids(ID string) dan menggunakanToolContextuntuk mengambil data gambar sebenarnya dari layanan Artefak. - Integrasi Model Pembuatan Gambar: Mengintegrasikan model Gemini 2.5 Flash Image dalam alat kustom untuk melakukan pengeditan gambar berdasarkan deskripsi teks yang mendetail.
- Interaksi Multimodal Berkelanjutan: Memastikan agen dapat mempertahankan sesi pengeditan berkelanjutan dengan memahami hasil panggilan alatnya sendiri (gambar yang diedit) dan menggunakan output tersebut sebagai input untuk petunjuk berikutnya.
8. ➡️ Tantangan Berikutnya
Selamat, Anda telah menyelesaikan Bagian 1 interaksi Alat Multimodal ADK. Dalam tutorial ini, kita akan berfokus pada interaksi alat kustom. Sekarang Anda siap melanjutkan ke langkah berikutnya tentang cara berinteraksi dengan Kumpulan Alat MCP multimodal. Buka lab berikutnya
9. 🧹 Membersihkan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam codelab ini, ikuti langkah-langkah berikut:
- Di konsol Google Cloud, buka halaman Manage resources.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.