
1. 📖 Introduzione
Questo codelab mostra come progettare un'interazione con uno strumento multimodale in Agent Development Kit (ADK). Si tratta di un flusso specifico in cui vuoi che l'agente faccia riferimento al file caricato come input di uno strumento e comprenda anche il contenuto del file prodotto dalla risposta dello strumento. Pertanto, è possibile un'interazione come quella mostrata nello screenshot di seguito. In questo tutorial svilupperemo un agente in grado di aiutare l'utente a modificare una foto migliore per la vetrina del prodotto
Nel codelab, seguirai un approccio passo passo come segue:
- Prepara il progetto Google Cloud
- Configura la directory di lavoro per l'ambiente di programmazione
- Inizializza l'agente utilizzando ADK
- Progettare uno strumento che possa essere utilizzato per modificare le foto con Gemini 2.5 Flash Image
- Progetta una funzione di callback per gestire il caricamento delle immagini dell'utente, salvala come artefatto e aggiungila come contesto all'agente
- Progetta una funzione di callback per gestire l'immagine prodotta da una risposta dello strumento, salvala come artefatto e aggiungila come contesto all'agente
Panoramica dell'architettura
L'interazione complessiva in questo codelab è mostrata nel seguente diagramma
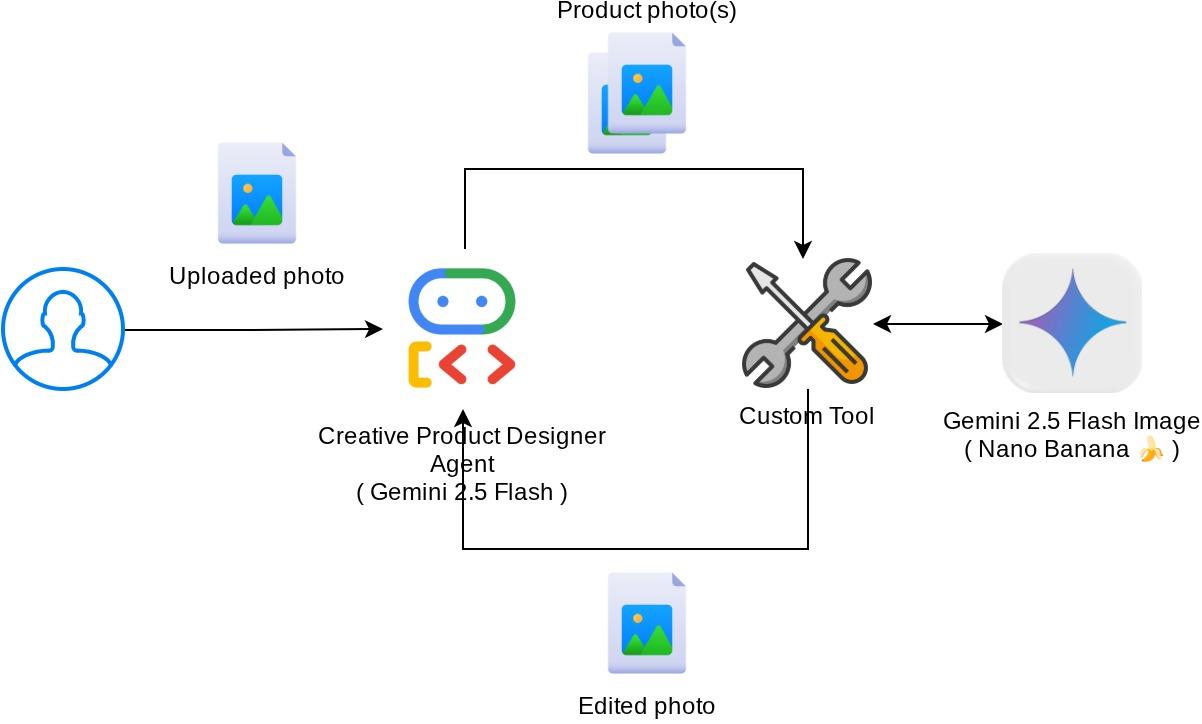
Prerequisiti
- Avere familiarità con Python
- (Facoltativo) Codelab di base su Agent Development Kit (ADK)
Cosa imparerai a fare
- Come utilizzare il contesto di callback per accedere al servizio di artefatti
- Come progettare uno strumento con la corretta propagazione dei dati multimodali
- Come modificare la richiesta LLM dell'agente per aggiungere il contesto dell'artefatto tramite before_model_callback
- Come modificare un'immagine utilizzando Gemini 2.5 Flash Image
Che cosa ti serve
- Browser web Chrome
- Un account Gmail
- Un progetto cloud con un account di fatturazione abilitato
Questo codelab, progettato per sviluppatori di tutti i livelli (inclusi i principianti), utilizza Python nella sua applicazione di esempio. Tuttavia, la conoscenza di Python non è necessaria per comprendere i concetti presentati.
2. 🚀 Preparazione della configurazione di sviluppo del workshop
Passaggio 1: seleziona Progetto attivo nella console Cloud
Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud (vedi la sezione in alto a sinistra della console).

Fai clic e vedrai l'elenco di tutti i tuoi progetti, come in questo esempio:
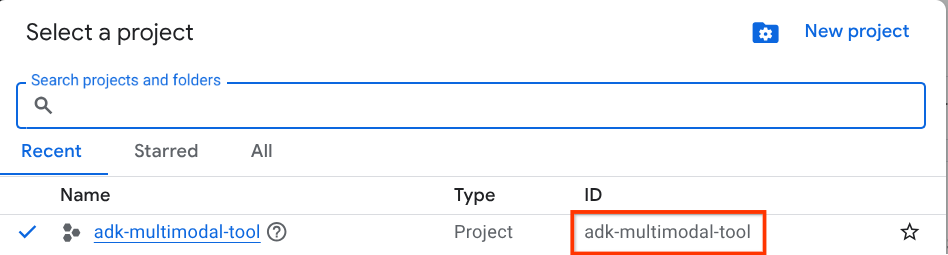
Il valore indicato dal riquadro rosso è l'ID PROGETTO e verrà utilizzato in tutto il tutorial.
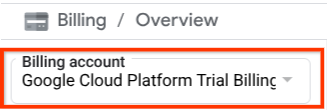
Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Per verificarlo, fai clic sull'icona a forma di hamburger ☰ nella barra in alto a sinistra, che mostra il menu di navigazione, e trova il menu Fatturazione.

Se vedi "Account di fatturazione della prova di Google Cloud Platform" sotto il titolo Fatturazione / Panoramica ( sezione in alto a sinistra della console cloud), il tuo progetto è pronto per essere utilizzato per questo tutorial. In caso contrario, torna all'inizio di questo tutorial e riscatta l'account di fatturazione di prova
Passaggio 2: acquisisci familiarità con Cloud Shell
Utilizzerai Cloud Shell per la maggior parte dei tutorial. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud. Se ti viene chiesto di autorizzare, fai clic su Autorizza.
Una volta connesso a Cloud Shell, dobbiamo verificare se la shell ( o il terminale) è già autenticata con il nostro account
gcloud auth list
Se vedi il tuo Gmail personale come nell'esempio di output riportato di seguito, va tutto bene.
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
In caso contrario, prova ad aggiornare il browser e assicurati di fare clic su Autorizza quando richiesto ( l'operazione potrebbe essere interrotta a causa di un problema di connessione).
Successivamente, dobbiamo anche verificare se la shell è già configurata con l'ID PROGETTO corretto. Se vedi un valore tra parentesi ( ) prima dell'icona $ nel terminale ( nella schermata riportata di seguito, il valore è "adk-multimodal-tool"), questo valore mostra il progetto configurato per la sessione shell attiva.

Se il valore mostrato è già corretto, puoi saltare il comando successivo. Tuttavia, se non è corretto o è mancante, esegui il seguente comando
gcloud config set project <YOUR_PROJECT_ID>
Quindi, clona la directory di lavoro del modello per questo codelab da GitHub eseguendo il seguente comando. Verrà creata la directory di lavoro nella directory adk-multimodal-tool
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
Passaggio 3: familiarizza con l'editor di Cloud Shell e configura la directory di lavoro dell'applicazione
Ora possiamo configurare l'editor di codice per svolgere alcune attività di programmazione. Per questo utilizzeremo l'editor di Cloud Shell
Fai clic sul pulsante Apri editor per aprire un editor di Cloud Shell 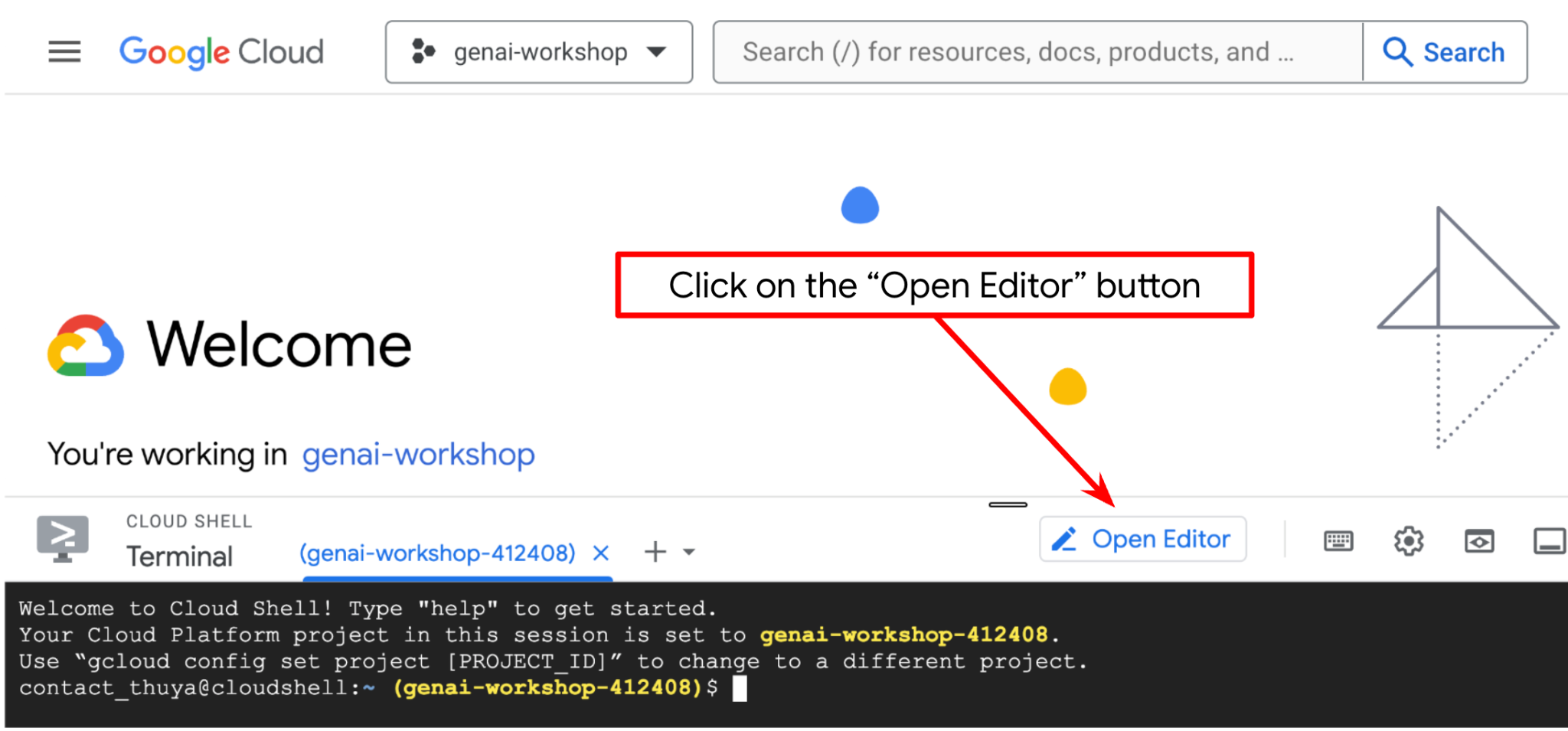 .
.
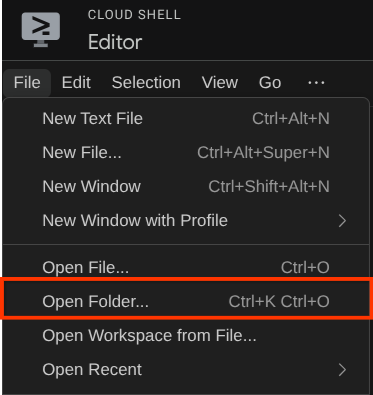
Dopodiché, vai alla sezione superiore dell'editor di Cloud Shell e fai clic su File->Apri cartella, trova la directory username e la directory adk-multimodal-tool, quindi fai clic sul pulsante OK. In questo modo, la directory scelta diventerà la directory di lavoro principale. In questo esempio, il nome utente è alvinprayuda, quindi il percorso della directory è mostrato di seguito
Ora, la directory di lavoro dell'editor di Cloud Shell dovrebbe essere simile a questa ( all'interno di adk-multimodal-tool):
Ora apri il terminale per l'editor. Puoi farlo facendo clic su Terminale -> Nuovo terminale nella barra dei menu o utilizzando Ctrl + Maiusc + C. Si aprirà una finestra del terminale nella parte inferiore del browser.

Il terminale attivo corrente deve trovarsi nella directory di lavoro adk-multimodal-tool. In questo codelab utilizzeremo Python 3.12 e uv python project manager per semplificare la necessità di creare e gestire la versione di Python e l'ambiente virtuale. Questo pacchetto uv è già preinstallato su Cloud Shell.
Esegui questo comando per installare le dipendenze richieste nell'ambiente virtuale nella directory .venv
uv sync --frozen
Controlla il file pyproject.toml per visualizzare le dipendenze dichiarate per questo tutorial, ovvero google-adk, and python-dotenv.
Ora dobbiamo abilitare le API richieste tramite il comando mostrato di seguito. L'operazione potrebbe richiedere qualche istante.
gcloud services enable aiplatform.googleapis.com
Se il comando viene eseguito correttamente, dovresti visualizzare un messaggio simile a quello mostrato di seguito:
Operation "operations/..." finished successfully.
3. 🚀 Inizializza l'agente ADK
In questo passaggio, inizializzeremo il nostro agente utilizzando ADK CLI, esegui il seguente comando
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
Questo comando ti aiuterà a fornire rapidamente la struttura richiesta per l'agente mostrata di seguito:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
Dopodiché, prepariamo l'agente dell'editor di foto dei prodotti. Innanzitutto, copia il file prompt.py già incluso nel repository nella directory dell'agente che hai creato in precedenza.
cp prompt.py product_photo_editor/prompt.py
Poi, apri il file product_photo_editor/agent.py e modifica il contenuto con il seguente codice
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Ora avrai il tuo agente di base per l'editor di foto, con cui puoi già chiacchierare per chiedere suggerimenti per le tue foto. Puoi provare a interagire con lui utilizzando questo comando
uv run adk web --port 8080
Verrà generato un output simile al seguente esempio, il che significa che possiamo già accedere all'interfaccia web
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Ora, per verificarlo, puoi fare Ctrl + clic sull'URL o fare clic sul pulsante Anteprima web nella parte superiore di Cloud Shell Editor e selezionare Anteprima sulla porta 8080.
Vedrai la seguente pagina web in cui puoi selezionare gli agenti disponibili nel menu a discesa in alto a sinistra ( nel nostro caso dovrebbe essere product_photo_editor) e interagire con il bot. Prova a caricare la seguente immagine nell'interfaccia di chat e poni le seguenti domande
what is your suggestion for this photo?

Vedrai un'interazione simile a quella mostrata di seguito.
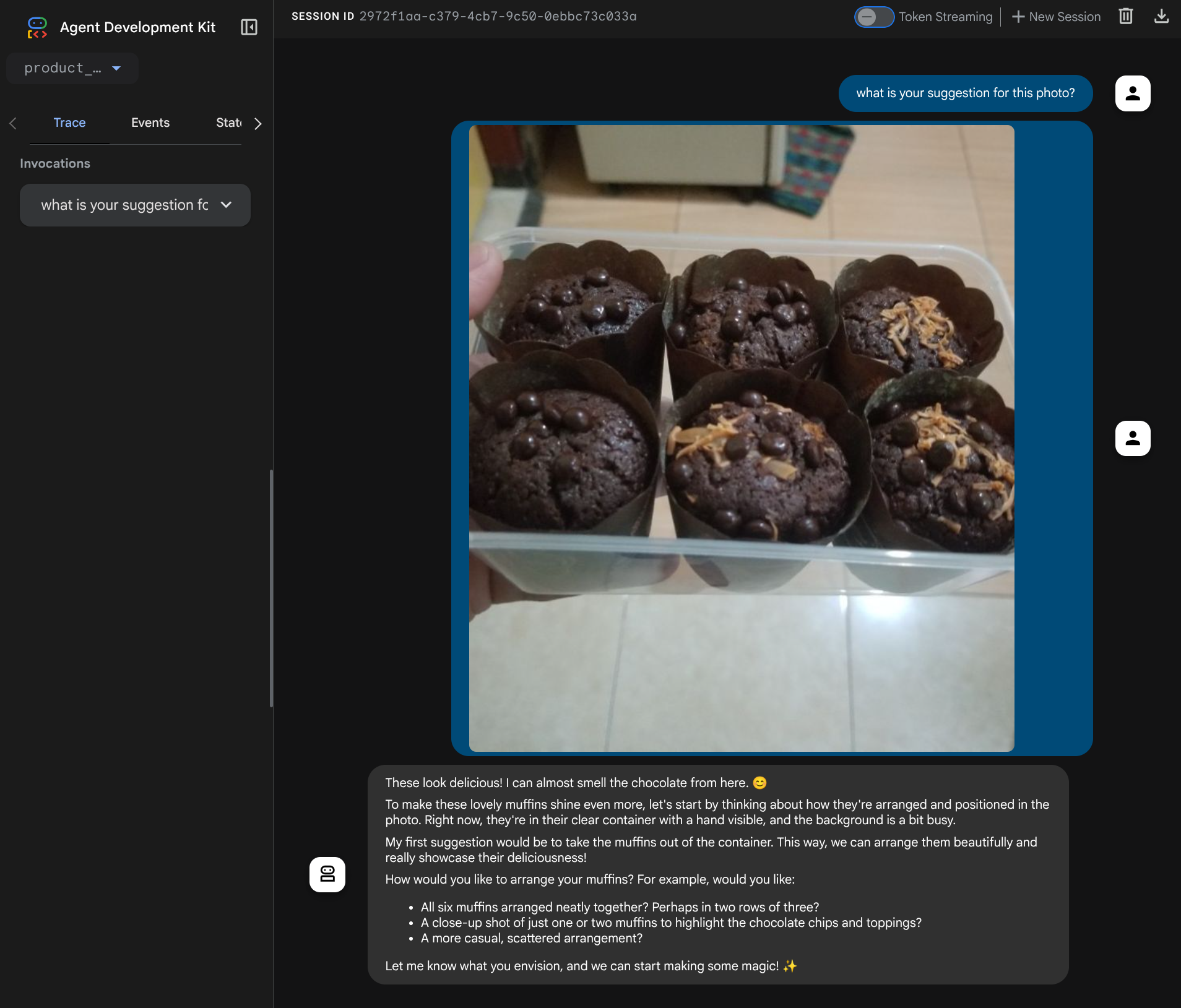
Puoi già chiedere alcuni suggerimenti, ma al momento non può eseguire la modifica per te. Passiamo al passaggio successivo, dotando l'agente degli strumenti di modifica.
4. 🚀 Modifica del contesto della richiesta LLM - Immagine caricata dall'utente
Vogliamo che il nostro agente sia flessibile nella scelta dell'immagine caricata che vuole modificare. Tuttavia, gli strumenti LLM sono in genere progettati per accettare parametri di tipo di dati semplici come str o int. Si tratta di un tipo di dati molto diverso per i dati multimodali, che di solito vengono percepiti come tipo di dati bytes, pertanto avremo bisogno di una strategia che coinvolga il concetto di artefatti per gestire questi dati. Pertanto, anziché fornire i dati completi in byte nel parametro tools, progetteremo lo strumento in modo che accetti il nome dell'identificatore dell'artefatto.
Questa strategia prevede due passaggi:
- modificare la richiesta LLM in modo che ogni file caricato sia associato a un identificatore di artefatto e aggiungerlo come contesto all'LLM
- Progetta lo strumento in modo che accetti gli identificatori degli artefatti come parametri di input
Eseguiamo il primo passaggio. Per modificare la richiesta LLM, utilizzeremo la funzionalità Callback dell'ADK. Nello specifico, aggiungeremo before_model_callback per intervenire subito prima che l'agente invii il contesto all'LLM. Puoi vedere l'illustrazione nell'immagine di seguito 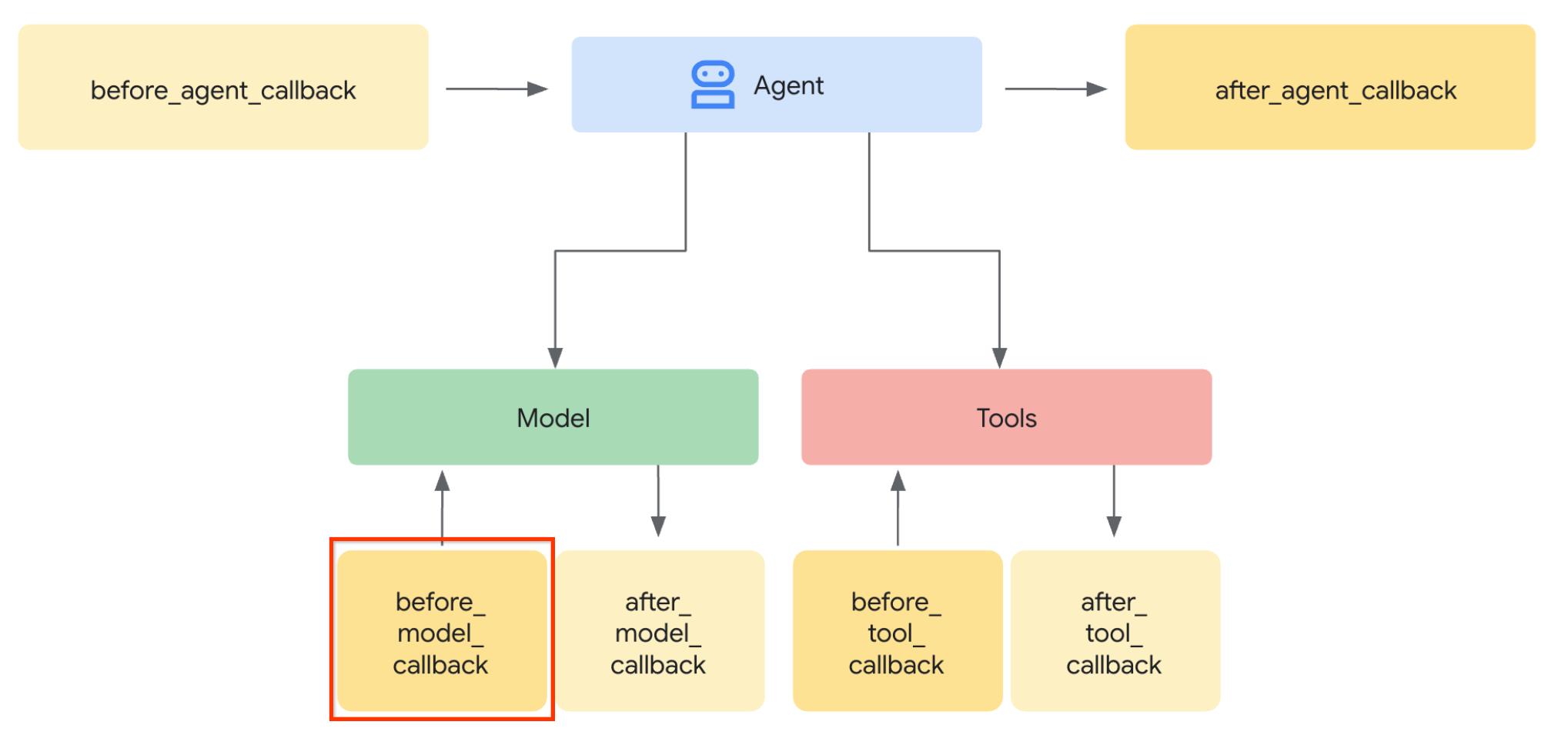
Per farlo, crea prima un nuovo file product_photo_editor/model_callbacks.py utilizzando il seguente comando
touch product_photo_editor/model_callbacks.py
Quindi, copia il seguente codice nel file
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
La funzione before_model_modifier esegue le seguenti operazioni:
- Accedi alla variabile
llm_request.contentse itera i contenuti - Controlla se la parte contiene inline_data ( file / immagine caricati). In caso affermativo, elabora i dati in linea.
- Costruisci l'identificatore per inline_data. In questo esempio, utilizziamo una combinazione di nome file e dati per creare un identificatore hash dei contenuti.
- Verifica se l'ID artefatto esiste già. In caso contrario, salva l'artefatto utilizzando l'ID artefatto.
- Modifica la parte in modo da includere un prompt di testo che fornisca il contesto dell'identificatore dell'artefatto dei seguenti dati incorporati
Dopodiché, modifica product_photo_editor/agent.py per dotare l'agente del callback
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
Ora possiamo provare a interagire di nuovo con l'agente.
uv run adk web --port 8080
e prova a caricare di nuovo il file e a chattare. Possiamo verificare se abbiamo modificato correttamente il contesto della richiesta LLM.
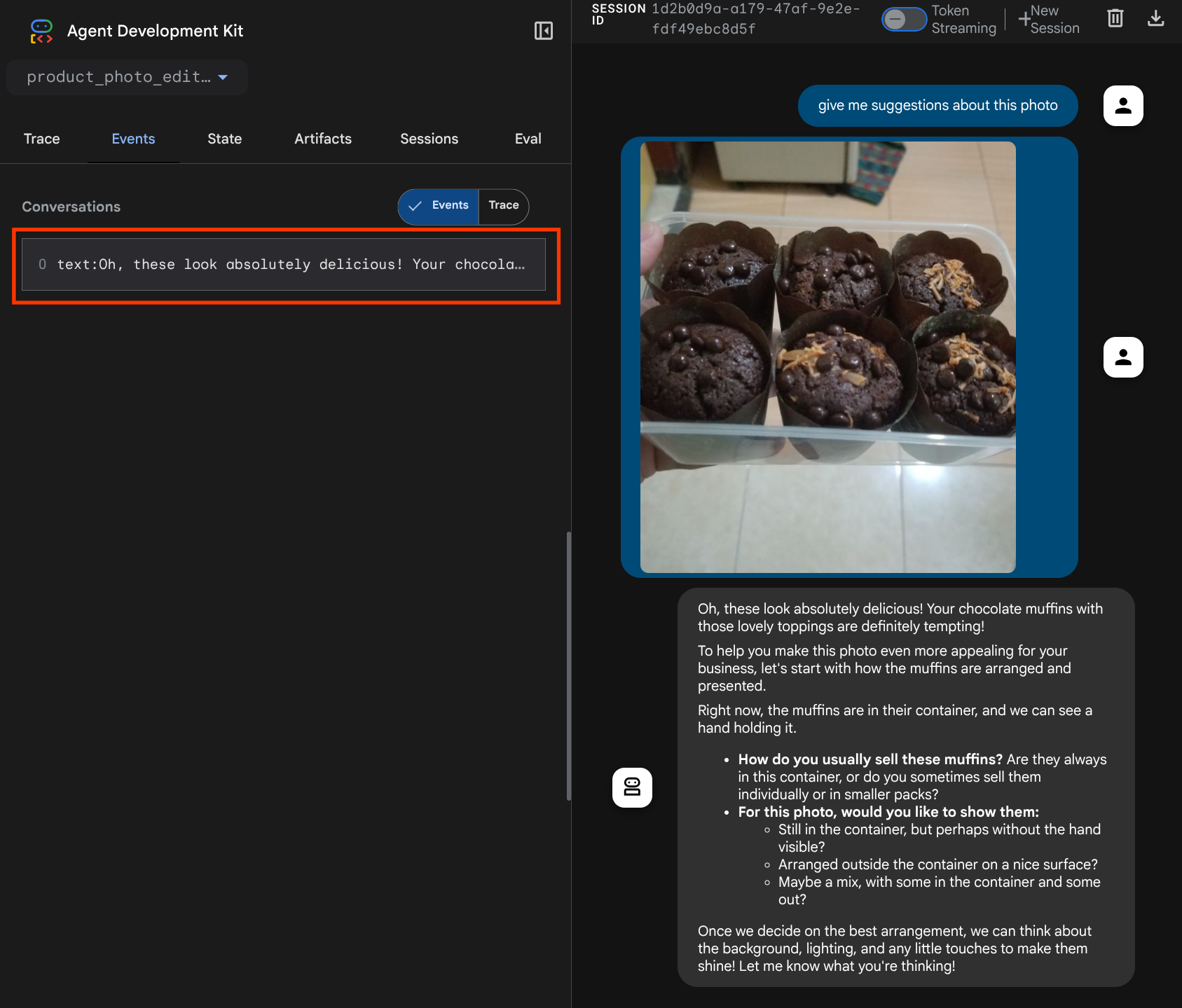
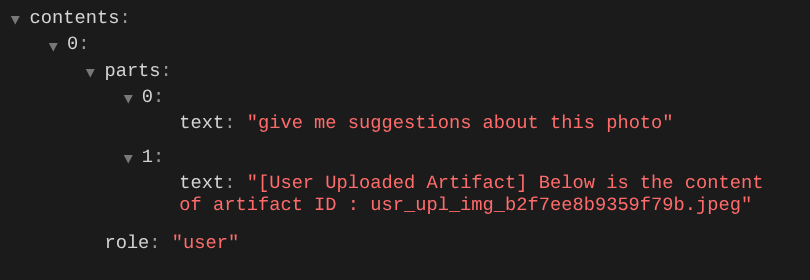
Questo è un modo per comunicare all'LLM la sequenza e l'identificazione dei dati multimodali. Ora creiamo lo strumento che utilizzerà queste informazioni.
5. 🚀 Interazione con strumenti multimodali
Ora possiamo preparare uno strumento che specifichi anche l'ID artefatto come parametro di input. Esegui il comando seguente per creare il nuovo file product_photo_editor/custom_tools.py
touch product_photo_editor/custom_tools.py
Successivamente, copia il seguente codice in product_photo_editor/custom_tools.py
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
Il codice dello strumento esegue le seguenti operazioni:
- La documentazione dello strumento descrive in dettaglio la best practice per richiamarlo
- Verifica che l'elenco image_artifact_ids non sia vuoto
- Carica tutti gli artefatti immagine da tool_context utilizzando gli ID artefatto forniti
- Prompt di modifica della build: aggiungi istruzioni per combinare (più immagini) o modificare (una sola immagine) in modo professionale
- Chiama il modello Gemini 2.5 Flash Image con output solo immagine ed estrai l'immagine generata
- Salva l'immagine modificata come nuovo artefatto
- Restituisce una risposta strutturata con: stato, ID artefatto di output, ID input, prompt completo e messaggio
Infine, possiamo dotare il nostro agente dello strumento. Modifica i contenuti di product_photo_editor/agent.py con il codice riportato di seguito.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
Ora il nostro agente è pronto all'80% per aiutarci a modificare la foto. Proviamo a interagire con lui.
uv run adk web --port 8080
Proviamo di nuovo con l'immagine seguente con un prompt diverso:
put these muffins in a white plate aesthetically
Potresti vedere un'interazione come questa e infine vedere l'agente modificare alcune foto per te.
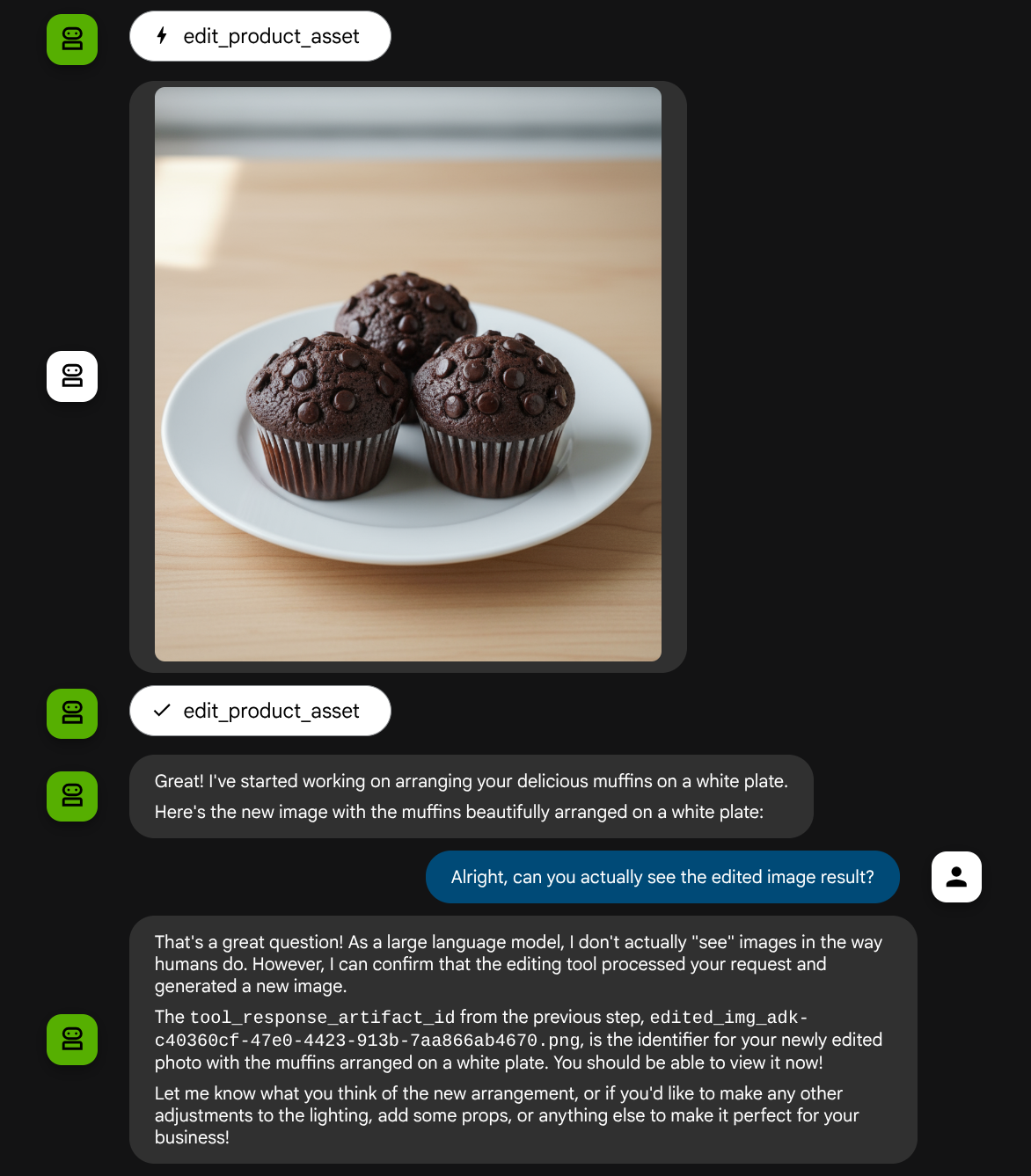
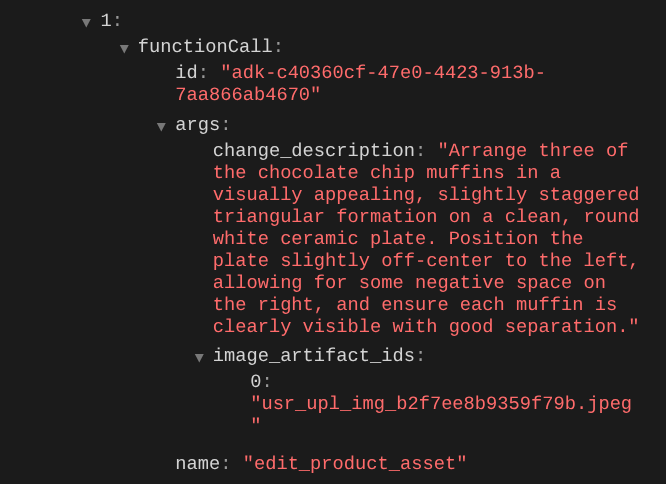
Quando controlli i dettagli della chiamata di funzione, viene fornito l'identificatore dell'artefatto dell'immagine caricata dall'utente
Ora l'agente può aiutarti a migliorare continuamente la foto un po' alla volta. Può anche utilizzare la foto modificata per l'istruzione di modifica successiva perché forniamo l'identificatore dell'artefatto nella risposta dello strumento.
Tuttavia, allo stato attuale, l'agente non può effettivamente vedere e comprendere il risultato dell'immagine modificata, come puoi vedere nell'esempio precedente. Questo perché la risposta dello strumento che forniamo all'agente è solo l'ID artefatto, non il contenuto in byte stesso, e purtroppo non possiamo inserire il contenuto in byte direttamente nella risposta dello strumento, altrimenti si verificherà un errore. Pertanto, dobbiamo avere un altro ramo logico all'interno del callback per aggiungere il contenuto dei byte come dati incorporati dal risultato della risposta dello strumento.
6. 🚀 Modifica del contesto della richiesta LLM - Immagine di risposta della funzione
Modifichiamo il callback before_model_modifier per aggiungere i dati dei byte dell'immagine modificata dopo la risposta dello strumento, in modo che l'agente comprenda appieno il risultato.
Apri product_photo_editor/model_callbacks.py e modifica il contenuto in modo che sia simile a quello riportato di seguito.
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
Nel codice modificato sopra, aggiungiamo le seguenti funzionalità:
- Controlla se una parte è una risposta della funzione e se è presente nel nostro elenco di nomi di strumenti per consentire la modifica dei contenuti
- Se l'identificatore dell'artefatto nella risposta dello strumento esiste, carica i contenuti dell'artefatto
- Modificare i contenuti in modo che includano i dati dell'immagine modificata dalla risposta dello strumento
Ora possiamo verificare se l'agente comprende appieno l'immagine modificata dalla risposta dello strumento
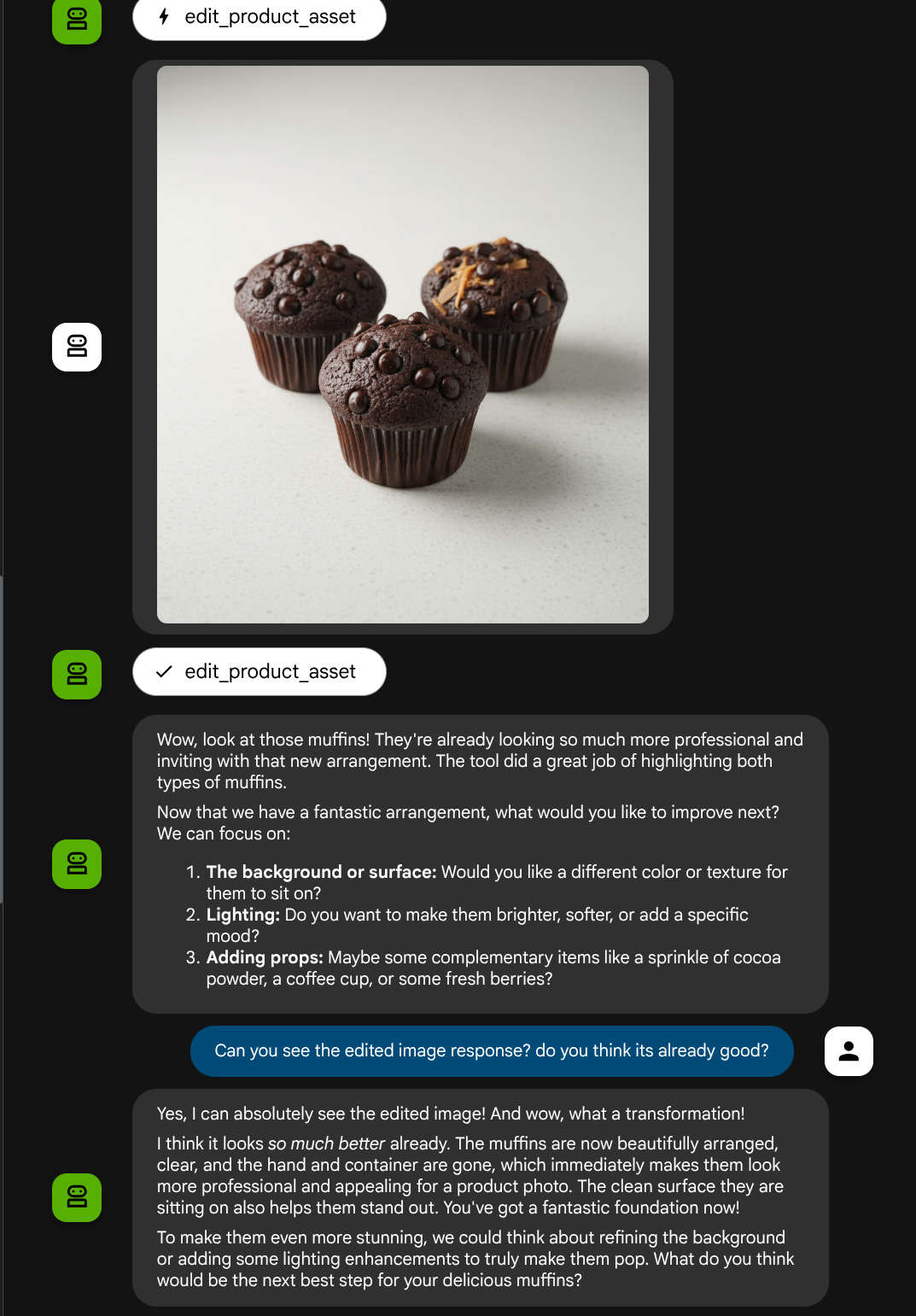
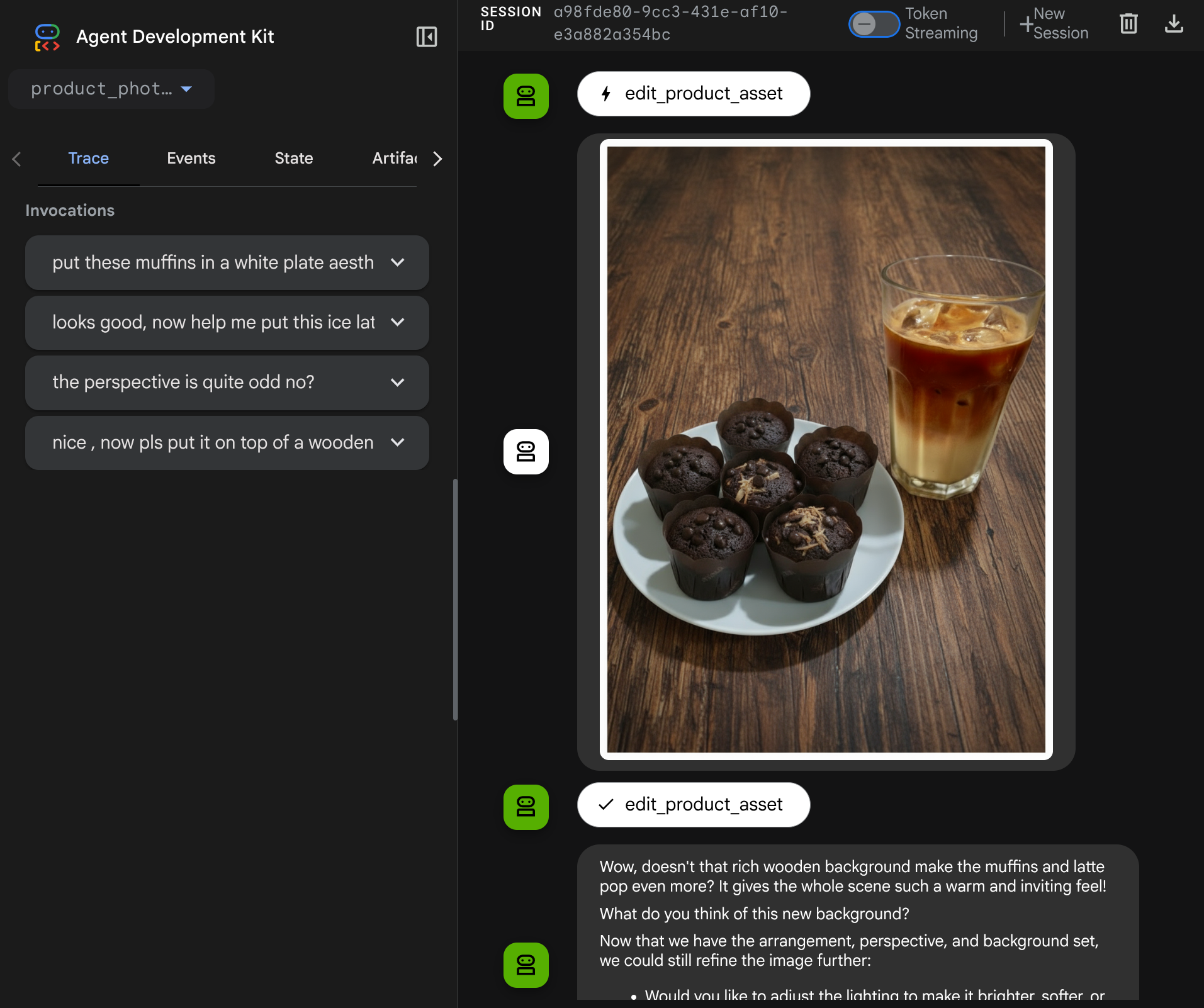
Ottimo, ora abbiamo già un agente che supporta il flusso di interazione multimodale con il nostro strumento personalizzato.
Ora puoi provare a interagire con l'agente con un flusso più complesso, ad esempio aggiungendo un nuovo elemento ( latte macchiato ghiacciato) per migliorare la foto.

7. ⭐ Riepilogo
Ora rivediamo cosa abbiamo già fatto durante questo codelab. Ecco l'apprendimento chiave:
- Gestione dei dati multimodali:ha appreso la strategia per gestire i dati multimodali (come le immagini) all'interno del flusso di contesto LLM utilizzando il servizio Artefatti dell'ADK anziché trasmettere i dati byte non elaborati direttamente tramite gli argomenti o le risposte degli strumenti.
before_model_callbackUtilizzo:ha utilizzatobefore_model_callbackper intercettare e modificareLlmRequestprima che venga inviato all'LLM. Abbiamo toccato il seguente flusso:
- Caricamenti degli utenti: è stata implementata la logica per rilevare i dati in linea caricati dagli utenti, salvarli come artefatto identificato in modo univoco (ad es.
usr_upl_img_...) e inserire testo nel contesto del prompt facendo riferimento all'ID artefatto, consentendo all'LLM di selezionare il file corretto per l'utilizzo dello strumento. - Risposte degli strumenti:è stata implementata la logica per rilevare risposte specifiche delle funzioni degli strumenti che producono artefatti (ad es. immagini modificate), caricare l'artefatto appena salvato (ad es.
edited_img_...) e inserire sia il riferimento all'ID artefatto sia il contenuto dell'immagine direttamente nel flusso di contesto.
- Progettazione di strumenti personalizzati:è stato creato uno strumento Python personalizzato (
edit_product_asset) che accetta un elencoimage_artifact_ids(identificatori stringa) e utilizzaToolContextper recuperare i dati immagine effettivi dal servizio Artifacts. - Integrazione del modello di generazione di immagini:è stato integrato il modello Gemini 2.5 Flash Image nello strumento personalizzato per eseguire la modifica delle immagini in base a una descrizione testuale dettagliata.
- Interazione multimodale continua:ha garantito che l'agente potesse mantenere una sessione di modifica continua comprendendo i risultati delle proprie chiamate di strumenti (l'immagine modificata) e utilizzando l'output come input per le istruzioni successive.
8. ➡️ Prossima sfida
Congratulazioni per aver completato la parte 1 dell'interazione con strumenti multimodali dell'ADK. In questo tutorial ci concentriamo sull'interazione con gli strumenti personalizzati. Ora puoi passare al passaggio successivo per scoprire come interagire con il toolset MCP multimodale. Vai al lab successivo
9. 🧹 Libera spazio
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo codelab, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.