
1. 📖 Introdução
Este codelab mostra como projetar uma interação de ferramenta multimodal no Kit de Desenvolvimento de Agente (ADK, na sigla em inglês). Esse é um fluxo específico em que você quer que o agente consulte o arquivo enviado como entrada para uma ferramenta e também entenda o conteúdo do arquivo produzido pela resposta da ferramenta. Portanto, é possível fazer interações como a mostrada na captura de tela abaixo. Neste tutorial, vamos desenvolver um agente capaz de ajudar o usuário a editar uma foto melhor para a vitrine de produtos.
Durante o codelab, você vai usar uma abordagem gradual da seguinte forma:
- Preparar o projeto na nuvem do Google
- Configurar o diretório de trabalho para o ambiente de programação
- Inicializar o agente usando o ADK
- Crie uma ferramenta que possa ser usada para editar fotos com tecnologia do Gemini 2.5 Flash Image
- Projete uma função de callback para processar o upload de imagens do usuário, salve-a como um artefato e adicione-a como contexto ao agente.
- Projete uma função de callback para processar a imagem produzida por uma resposta da ferramenta, salve-a como um artefato e adicione-a como contexto ao agente.
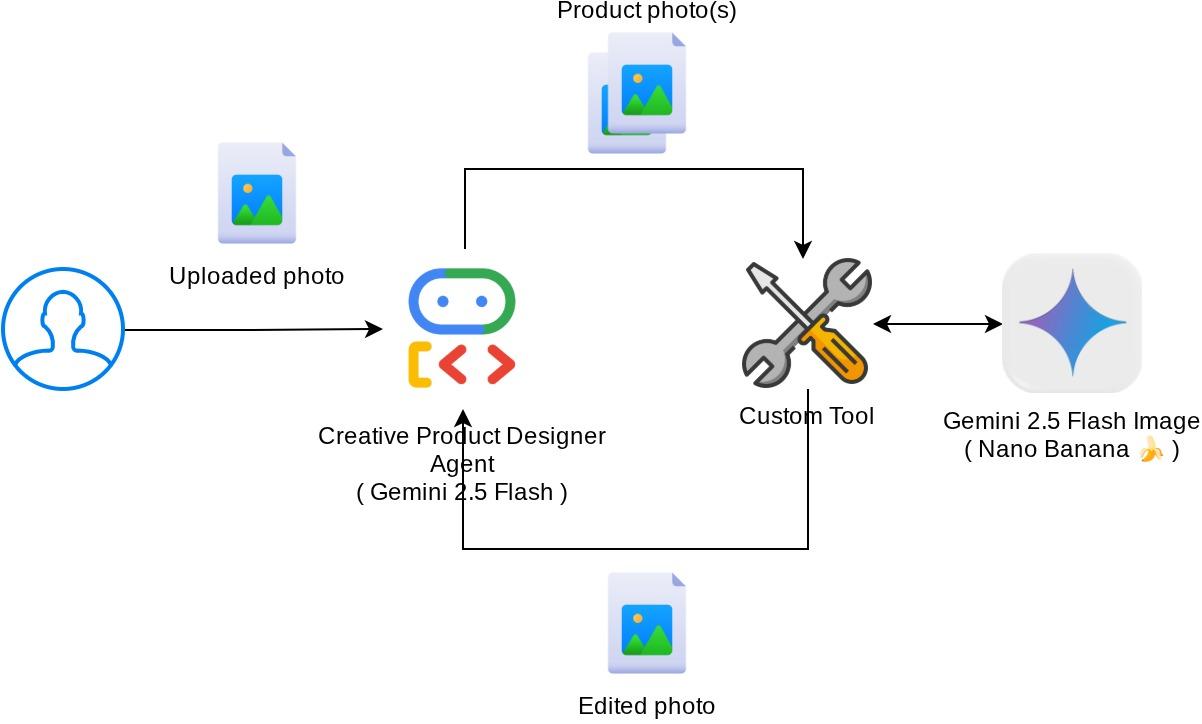
Visão geral da arquitetura
A interação geral neste codelab é mostrada no diagrama a seguir
Pré-requisitos
- Conhecimento de Python
- (Opcional) Codelabs básicos sobre o Kit de Desenvolvimento de Agente (ADK)
O que você vai aprender
- Como usar o contexto de callback para acessar o serviço de artefato
- Como projetar uma ferramenta com a propagação adequada de dados multimodais
- Como modificar a solicitação de LLM do agente para adicionar contexto de artefato usando before_model_callback
- Como editar imagens usando o Gemini 2.5 Flash Image
O que é necessário
- Navegador da Web Google Chrome
- Uma conta do Gmail
- Um projeto do Cloud com uma conta de faturamento ativada
Este codelab, criado para desenvolvedores de todos os níveis (inclusive iniciantes), usa Python no aplicativo de exemplo. No entanto, não é necessário ter conhecimento de Python para entender os conceitos apresentados.
2. 🚀 Preparando a configuração de desenvolvimento do workshop
Etapa 1: selecionar "Projeto ativo" no Console do Cloud
No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud (consulte a seção no canto superior esquerdo do console).

Clique nele para ver uma lista de todos os seus projetos, como neste exemplo:
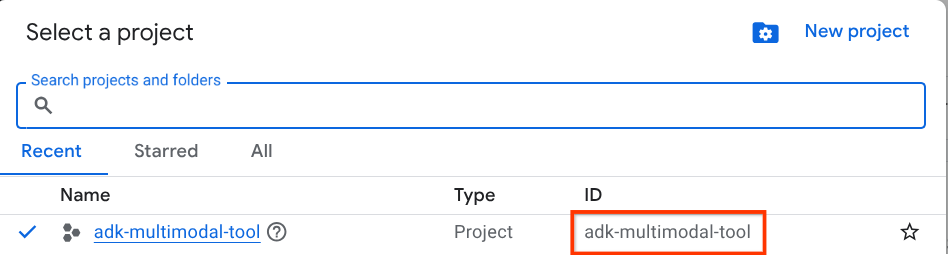
O valor indicado pela caixa vermelha é o ID DO PROJETO, que será usado em todo o tutorial.
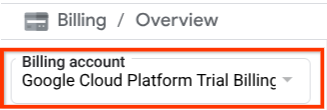
Verifique se o faturamento está ativado para seu projeto do Cloud. Para verificar, clique no ícone de hambúrguer ☰ na barra superior esquerda, que mostra o menu de navegação, e encontre o menu "Faturamento".

Se você encontrar a "Conta de faturamento de teste do Google Cloud Platform" no título Faturamento / Visão geral ( seção superior esquerda do console da nuvem), seu projeto está pronto para ser usado neste tutorial. Caso contrário, volte ao início deste tutorial e resgate a conta de faturamento de teste.
Etapa 2: conhecer o Cloud Shell
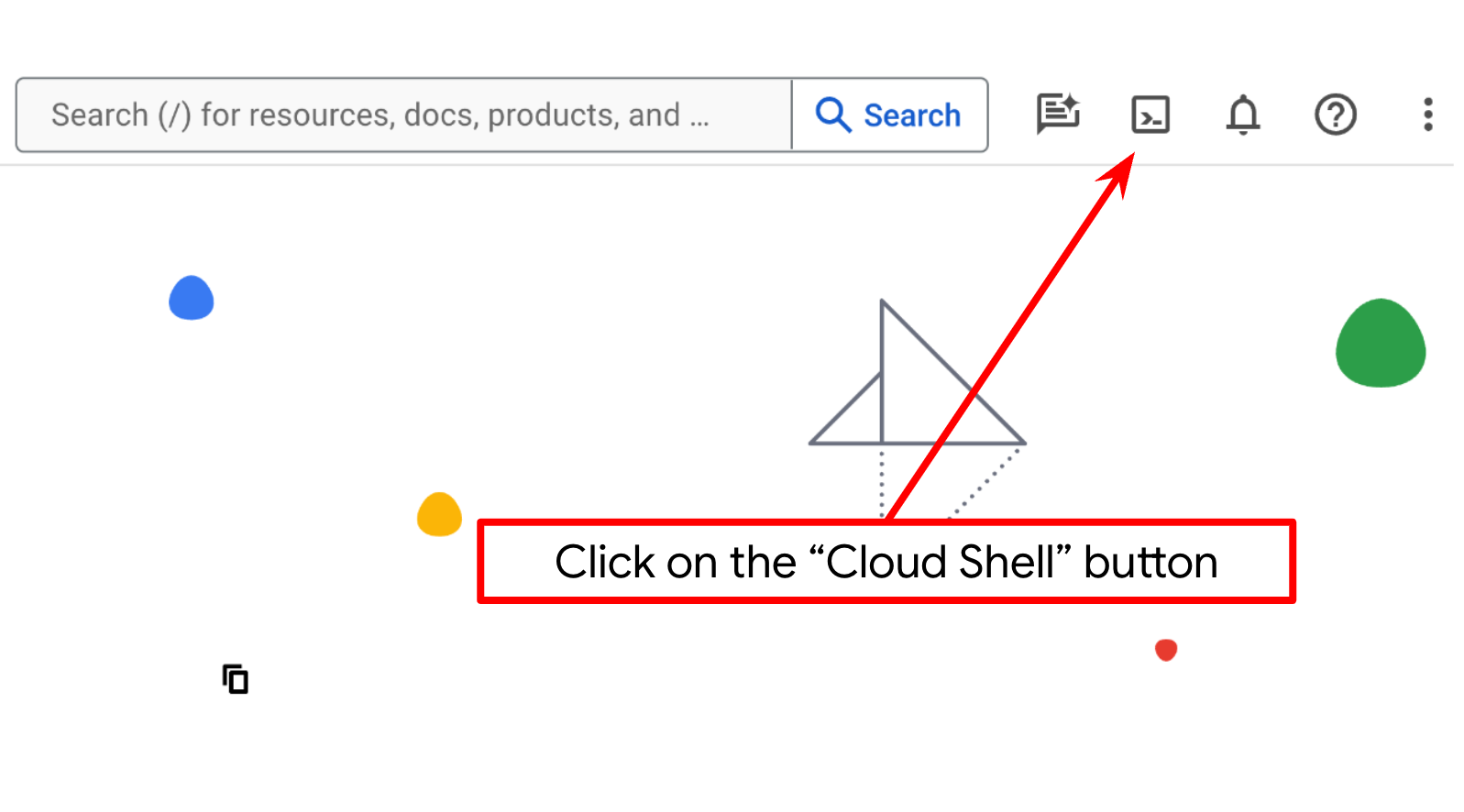
Você vai usar o Cloud Shell na maior parte dos tutoriais. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud. Se for preciso autorizar, clique em Autorizar.
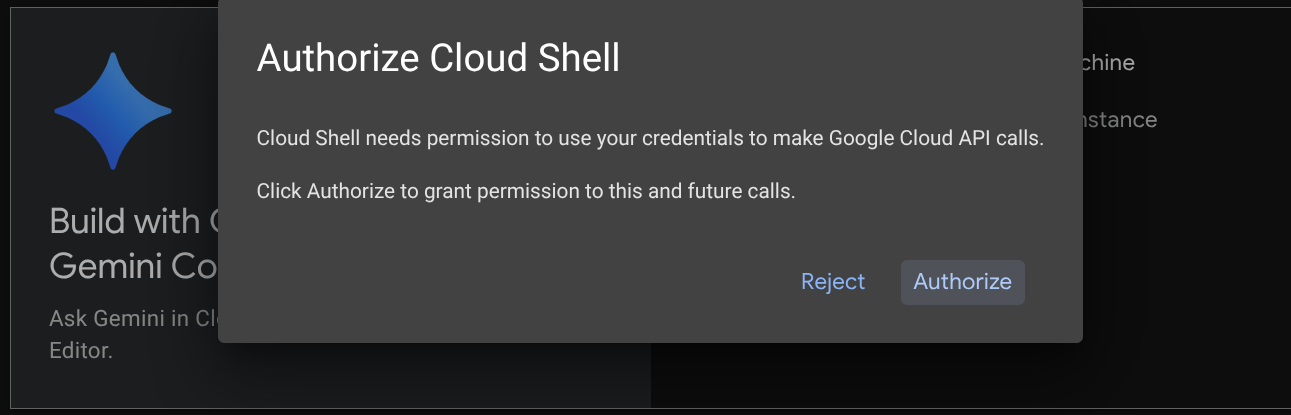
Depois de se conectar ao Cloud Shell, precisamos verificar se o shell ( ou terminal) já está autenticado com nossa conta.
gcloud auth list
Se você vir seu Gmail pessoal como no exemplo de saída abaixo, tudo está certo.
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Caso contrário, atualize o navegador e clique em Autorizar quando solicitado. A autorização pode ser interrompida devido a um problema de conexão.
Em seguida, também precisamos verificar se o shell já está configurado para o ID DO PROJETO correto. Se você vir um valor entre parênteses antes do ícone $ no terminal (na captura de tela abaixo, o valor é "adk-multimodal-tool"), esse valor mostra o projeto configurado para sua sessão de shell ativa.

Se o valor mostrado já estiver correto, pule o próximo comando. No entanto, se não estiver correto ou estiver faltando, execute o seguinte comando:
gcloud config set project <YOUR_PROJECT_ID>
Em seguida, clone o diretório de trabalho do modelo para este codelab do GitHub executando o seguinte comando: Ele vai criar o diretório de trabalho no diretório adk-multimodal-tool.
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
Etapa 3: conhecer o editor do Cloud Shell e configurar o diretório de trabalho do aplicativo
Agora, podemos configurar nosso editor de código para fazer algumas coisas de programação. Vamos usar o editor do Cloud Shell para isso.
Clique no botão Abrir editor para abrir um editor do Cloud Shell 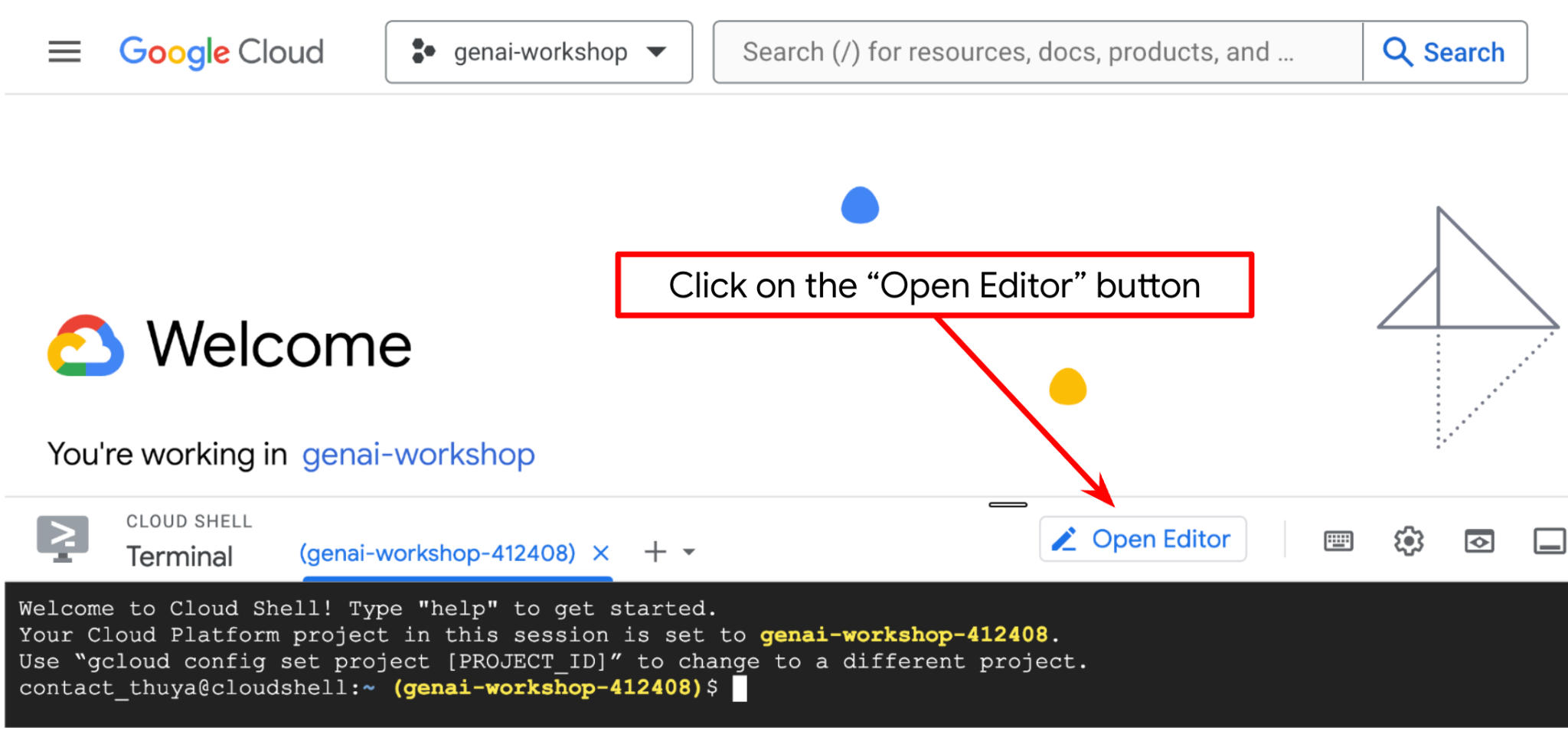 .
.
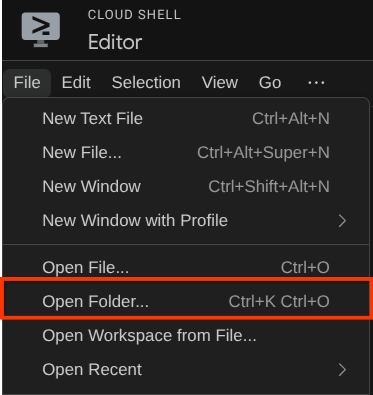
Depois disso, acesse a seção superior do editor do Cloud Shell e clique em Arquivo->Abrir pasta, encontre o diretório nome de usuário e o diretório adk-multimodal-tool. Em seguida, clique no botão "OK". Isso vai definir o diretório escolhido como o principal. Neste exemplo, o nome de usuário é alvinprayuda. Portanto, o caminho do diretório é mostrado abaixo.
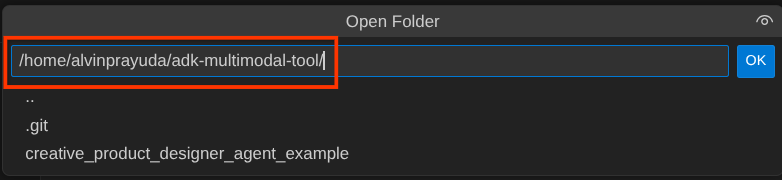
Agora, o diretório de trabalho do editor do Cloud Shell deve ficar assim ( dentro de adk-multimodal-tool):
Agora, abra o terminal do editor. Para fazer isso, clique em Terminal -> Novo terminal na barra de menus ou use Ctrl + Shift + C. Isso vai abrir uma janela de terminal na parte de baixo do navegador.

O terminal ativo atual precisa estar no diretório de trabalho adk-multimodal-tool. Vamos usar o Python 3.12 neste codelab e o gerenciador de projetos Python uv para simplificar a necessidade de criar e gerenciar a versão do Python e o ambiente virtual. O pacote uv já vem pré-instalado no Cloud Shell.
Execute este comando para instalar as dependências necessárias no ambiente virtual no diretório .venv
uv sync --frozen
Confira o arquivo pyproject.toml para ver as dependências declaradas para este tutorial, que são google-adk, and python-dotenv.
Agora, vamos ativar as APIs necessárias usando o comando mostrado abaixo. Isso pode levar algum tempo.
gcloud services enable aiplatform.googleapis.com
Após a execução do comando, você vai ver uma mensagem semelhante à mostrada abaixo:
Operation "operations/..." finished successfully.
3. 🚀 Inicializar o agente do ADK
Nesta etapa, vamos inicializar nosso agente usando a CLI do ADK. Execute o seguinte comando:
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
Esse comando ajuda você a fornecer rapidamente a estrutura necessária para o agente mostrado abaixo:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
Depois disso, vamos preparar nosso agente do editor de fotos de produtos. Primeiro, copie o prompt.py já incluído no repositório para o diretório do agente que você criou antes.
cp prompt.py product_photo_editor/prompt.py
Em seguida, abra product_photo_editor/agent.py e modifique o conteúdo com o seguinte código:
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Agora você tem seu agente de edição de fotos básico, com quem já pode conversar para pedir sugestões de fotos. Você pode interagir com ele usando este comando
uv run adk web --port 8080
Ele vai gerar uma saída como o exemplo a seguir, o que significa que já podemos acessar a interface da Web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Agora, para verificar, Ctrl + clique no URL ou clique no botão Visualização da Web na área superior do Cloud Shell Editor e selecione Visualizar na porta 8080.
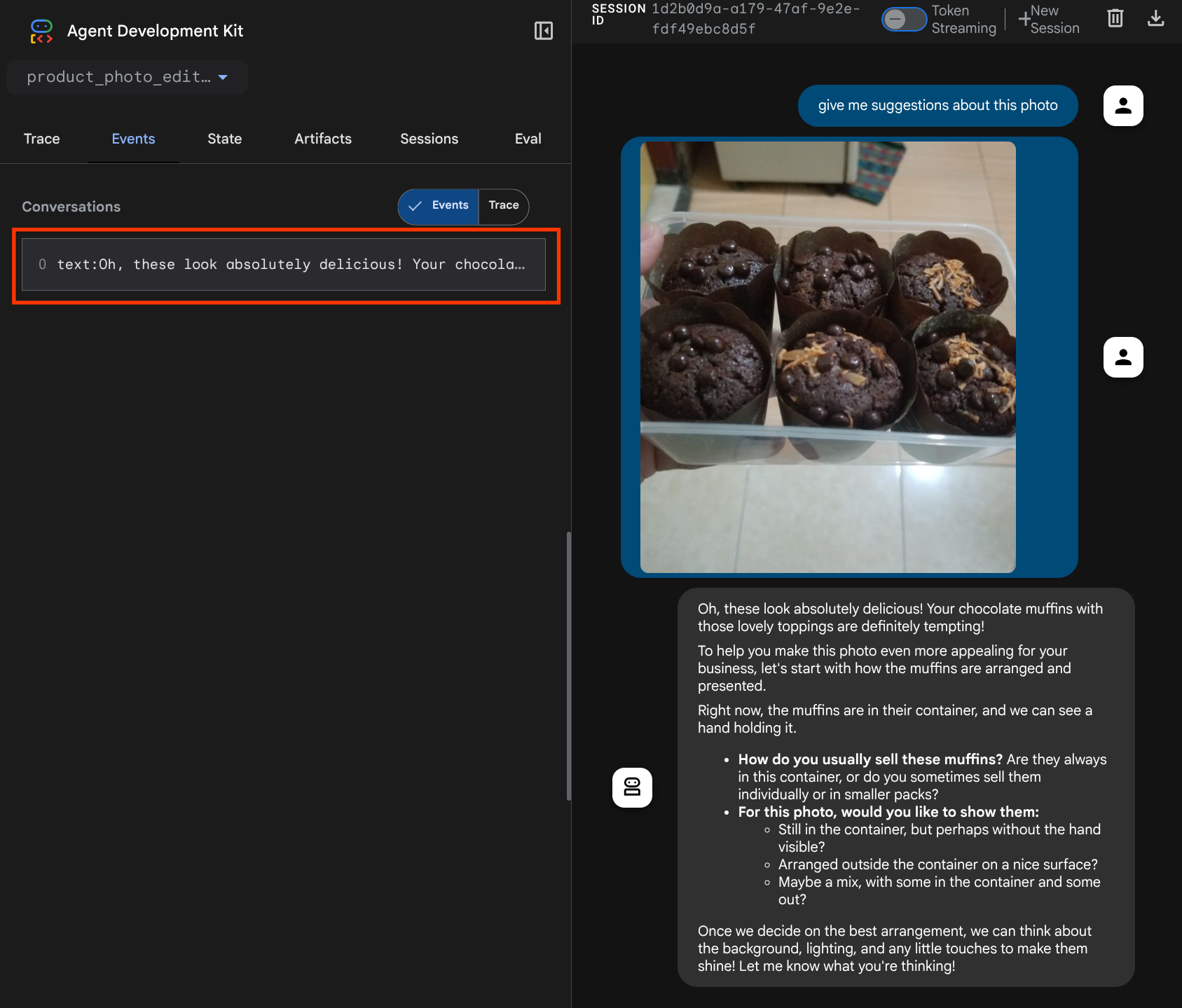
Você vai ver a seguinte página da Web, em que é possível selecionar os agentes disponíveis no botão suspenso no canto superior esquerdo ( no nosso caso, product_photo_editor) e interagir com o bot. Envie a imagem a seguir na interface de chat e faça as seguintes perguntas:
what is your suggestion for this photo?

Você vai ver uma interação semelhante à mostrada abaixo
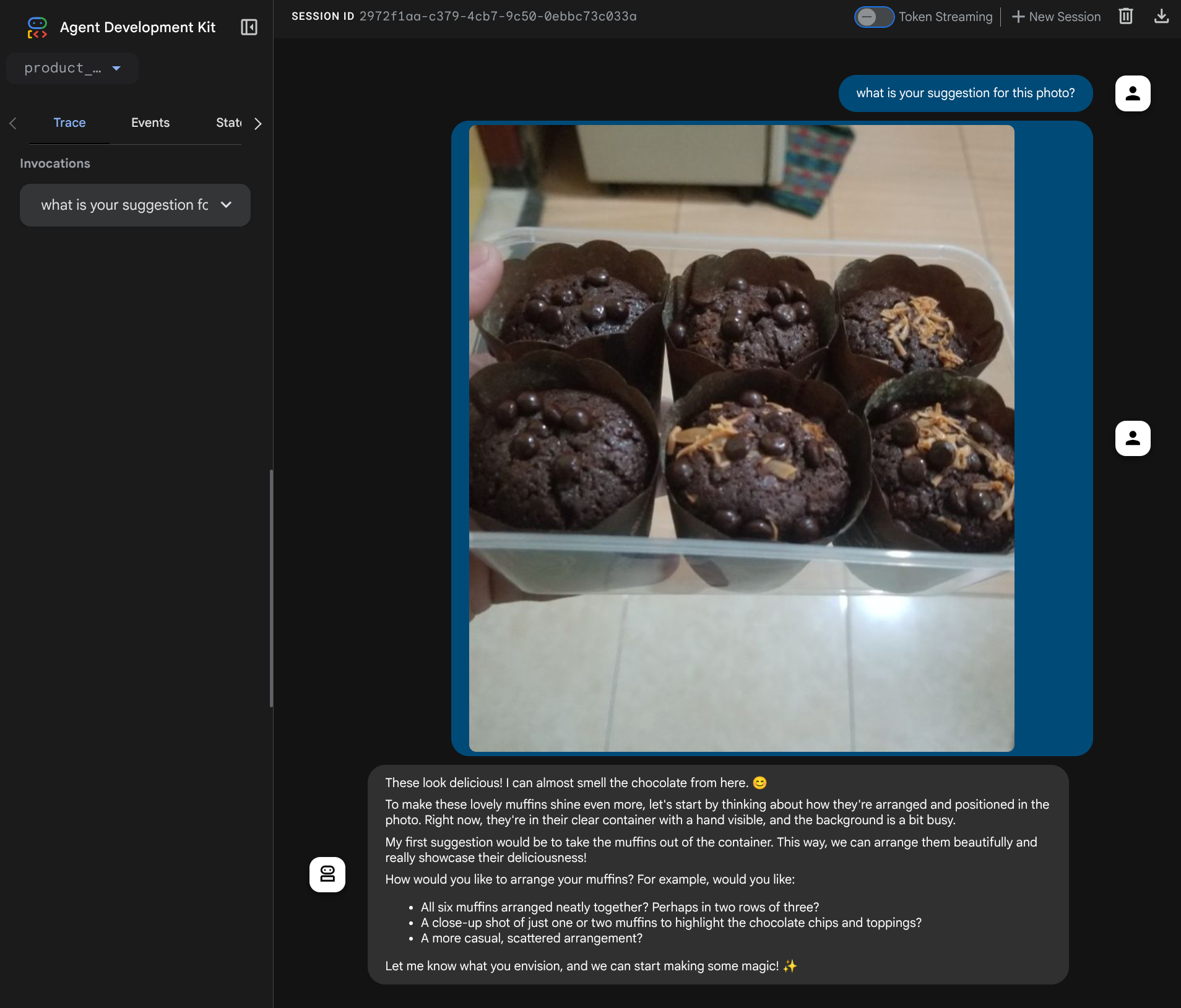
Você já pode pedir algumas sugestões, mas no momento não é possível fazer a edição para você. Vamos para a próxima etapa, equipando o agente com as ferramentas de edição.
4. 🚀 Modificação do contexto da solicitação do LLM: imagem enviada pelo usuário
Queremos que nosso agente seja flexível ao selecionar qual imagem enviada ele quer editar. No entanto, as ferramentas de LLM geralmente são projetadas para aceitar parâmetros de tipo de dados simples, como str ou int. Esse é um tipo de dados muito diferente para dados multimodais, que geralmente são percebidos como tipo de dados bytes. Portanto, vamos precisar de uma estratégia que envolva o conceito de artefatos para processar esses dados. Assim, em vez de fornecer os dados de bytes completos no parâmetro "tools", vamos projetar a ferramenta para aceitar o nome do identificador do artefato.
Essa estratégia envolve duas etapas:
- modificar a solicitação do LLM para que cada arquivo enviado seja associado a um identificador de artefato e adicionar isso como contexto ao LLM
- Projete a ferramenta para aceitar identificadores de artefato como parâmetros de entrada
Vamos fazer a primeira etapa. Para modificar a solicitação do LLM, vamos usar o recurso Callback do ADK. Especificamente, vamos adicionar "before_model_callback" para tocar logo antes de o agente enviar o contexto ao LLM. Confira a ilustração na imagem abaixo 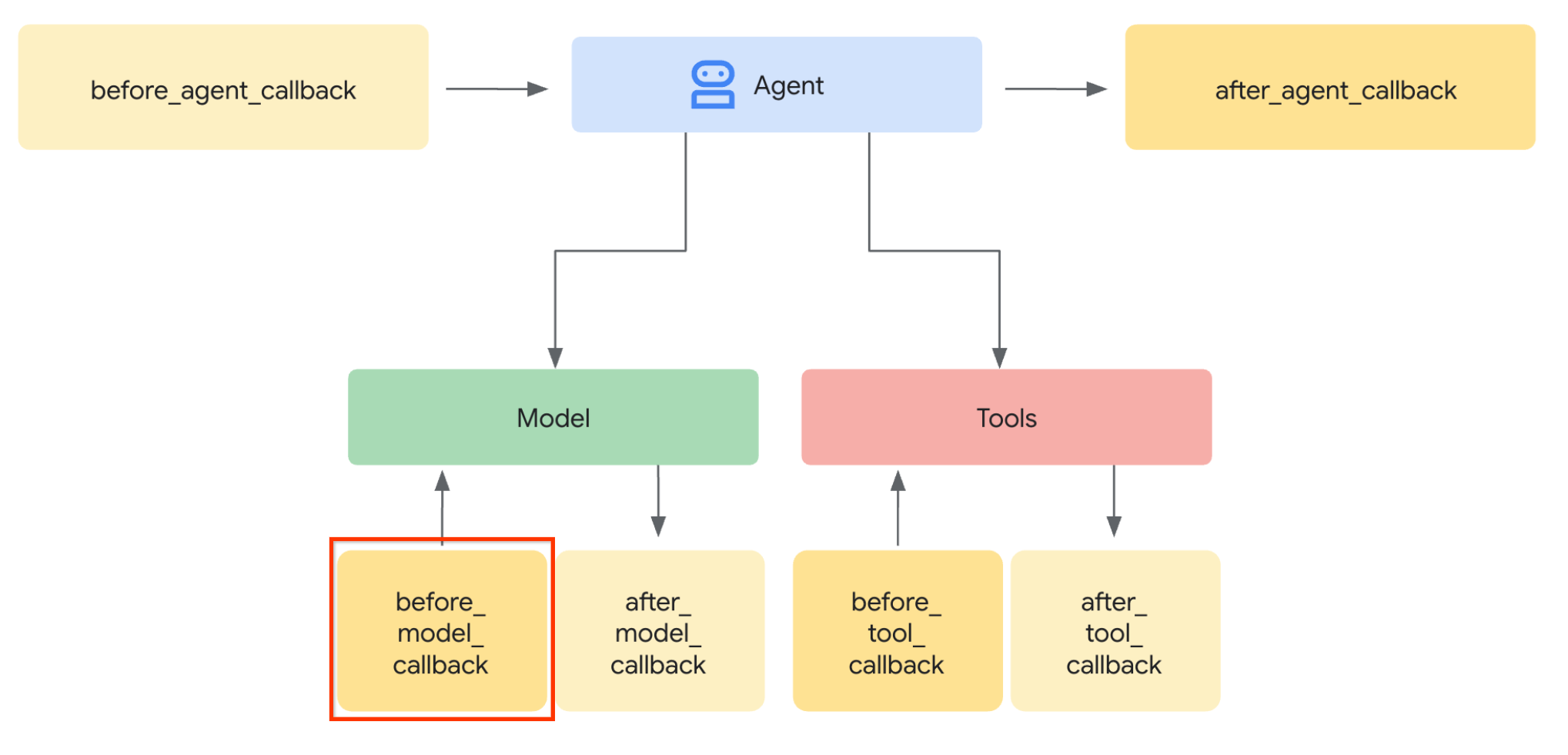
Para fazer isso, primeiro crie um novo arquivo product_photo_editor/model_callbacks.py usando o seguinte comando:
touch product_photo_editor/model_callbacks.py
Em seguida, copie o código abaixo no arquivo
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
A função before_model_modifier faz o seguinte:
- Acesse a variável
llm_request.contentse itere o conteúdo - Verifique se a parte contém inline_data ( arquivo / imagem enviados). Se sim, processe os dados inline.
- Construa o identificador para inline_data. Neste exemplo, usamos uma combinação de nome de arquivo e dados para criar um identificador de hash de conteúdo.
- Verifique se o ID do artefato já existe. Se não, salve o artefato usando o ID.
- Modifique a parte para incluir um comando de texto que dê contexto sobre o identificador do artefato dos seguintes dados inline
Depois disso, modifique product_photo_editor/agent.py para equipar o agente com o callback.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
Agora, podemos tentar interagir com o agente novamente.
uv run adk web --port 8080
e tente fazer upload do arquivo novamente e conversar. Podemos inspecionar se modificamos o contexto da solicitação do LLM
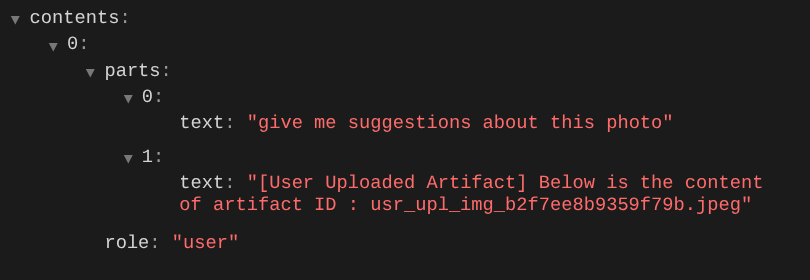
Essa é uma maneira de informar ao LLM sobre a sequência e a identificação de dados multimodais. Agora vamos criar a ferramenta que vai usar essas informações.
5. 🚀 Interação com ferramentas multimodais
Agora, podemos preparar uma ferramenta que também especifica o ID do artefato como parâmetro de entrada. Execute o comando a seguir para criar o arquivo product_photo_editor/custom_tools.py:
touch product_photo_editor/custom_tools.py
Em seguida, copie o código a seguir para product_photo_editor/custom_tools.py
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
O código da ferramenta faz o seguinte:
- A documentação da ferramenta descreve em detalhes as práticas recomendadas para invocar a ferramenta.
- Valide se a lista image_artifact_ids não está vazia
- Carrega todos os artefatos de imagem de tool_context usando os IDs de artefato fornecidos.
- Comando de edição de criação: adicione instruções para combinar (várias imagens) ou editar (uma imagem) de forma profissional
- Chamar o modelo Gemini 2.5 Flash Image com saída somente de imagem e extrair a imagem gerada
- Salvar a imagem editada como um novo artefato
- Retorne uma resposta estruturada com: status, ID do artefato de saída, IDs de entrada, comando completo e mensagem
Por fim, podemos equipar nosso agente com a ferramenta. Modifique o conteúdo de product_photo_editor/agent.py para o código abaixo
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
Agora que nosso agente está 80% equipado para ajudar a editar fotos, vamos tentar interagir com ele.
uv run adk web --port 8080
E vamos tentar a seguinte imagem de novo com um comando diferente:
put these muffins in a white plate aesthetically
Você pode ver uma interação como esta e, finalmente, ver o agente fazer algumas edições de fotos para você.
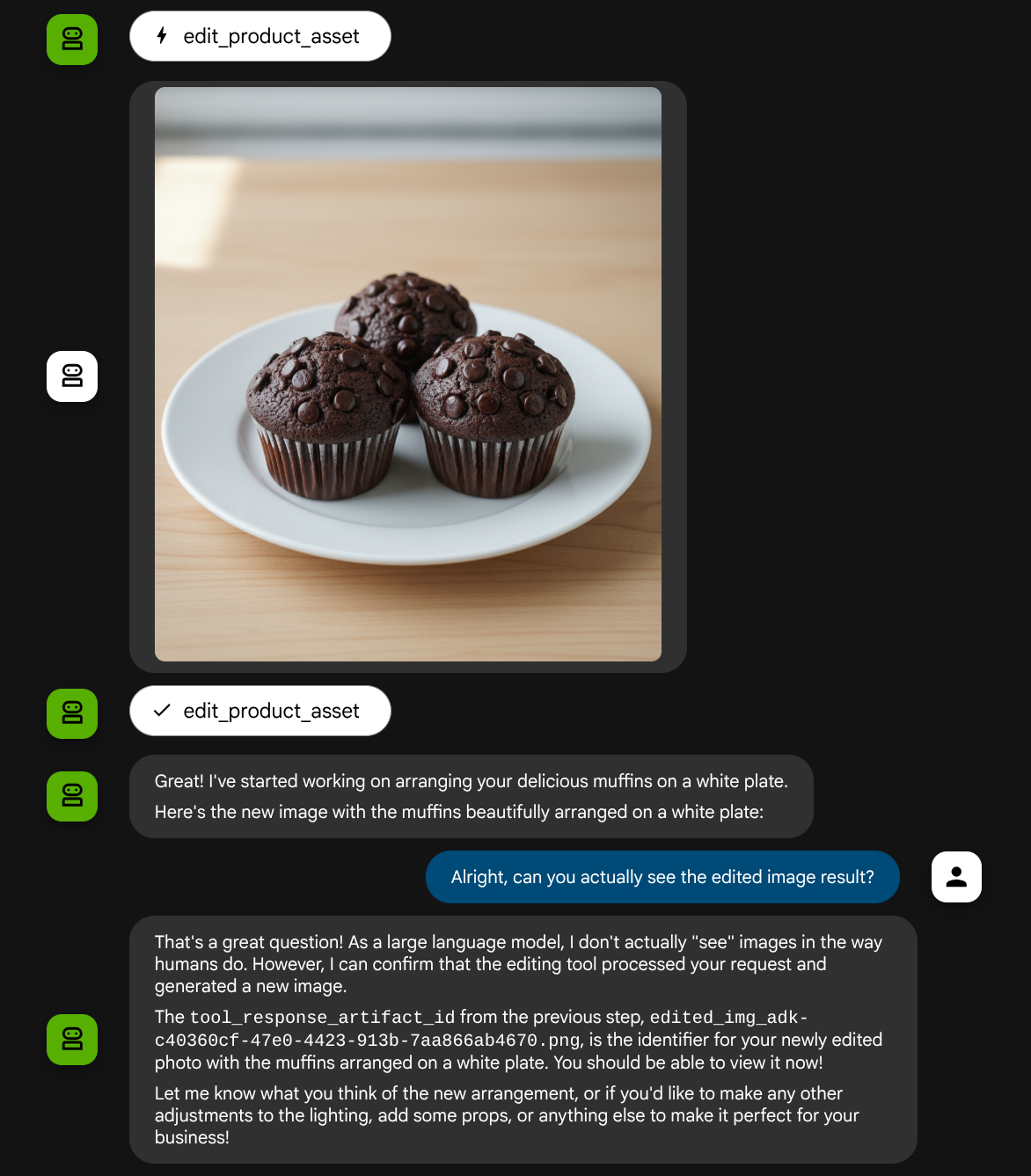
Ao verificar os detalhes da chamada de função, você vai encontrar o identificador do artefato da imagem enviada pelo usuário.
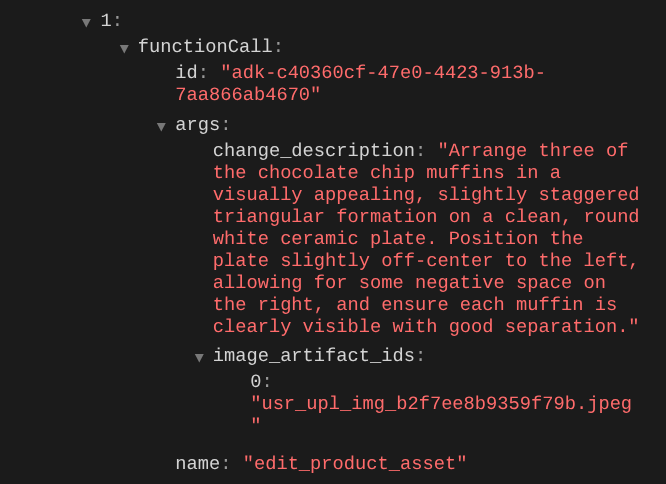
Agora, o agente pode ajudar você a trabalhar continuamente, melhorando a foto aos poucos. Ela também pode usar a foto editada na próxima instrução de edição porque fornecemos o identificador do artefato na resposta da ferramenta.
No entanto, no estado atual, o agente não consegue ver e entender o resultado da imagem editada, como você pode ver no exemplo acima. Isso acontece porque a resposta da ferramenta que damos ao agente é apenas o ID do artefato, não o conteúdo de bytes em si. Infelizmente, não podemos colocar o conteúdo de bytes diretamente na resposta da ferramenta, porque isso vai gerar um erro. Portanto, precisamos de outra ramificação lógica dentro do callback para adicionar o conteúdo de bytes como dados inline do resultado da resposta da ferramenta.
6. 🚀 Modificação do contexto da solicitação do LLM: imagem de resposta da função
Vamos modificar nosso callback before_model_modifier para adicionar os dados de bytes da imagem editada após a resposta da ferramenta. Assim, nosso agente vai entender totalmente o resultado.
Abra o arquivo product_photo_editor/model_callbacks.py e modifique o conteúdo para que ele fique assim:
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
No código modificado acima, adicionamos as seguintes funcionalidades:
- Verificar se uma Parte é uma resposta de função e se ela está na nossa lista de nomes de ferramentas para permitir a modificação de conteúdo
- Se o identificador do artefato da resposta da ferramenta existir, carregue o conteúdo do artefato.
- Modifique o conteúdo para incluir os dados da imagem editada na resposta da ferramenta.
Agora, podemos verificar se o agente entendeu completamente a imagem editada na resposta da ferramenta.
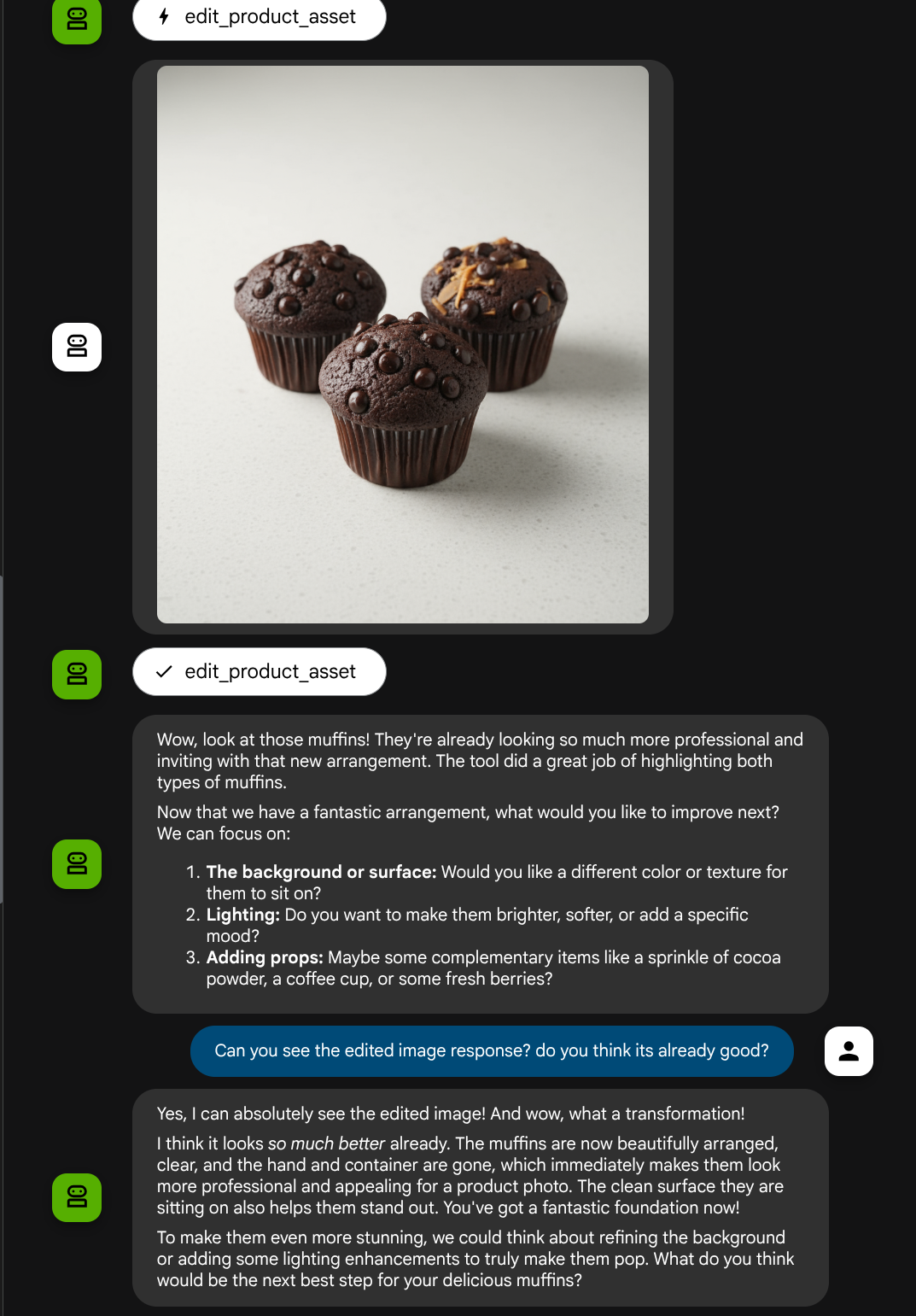
Ótimo! Agora temos um agente que oferece suporte ao fluxo de interação multimodal com nossa própria ferramenta personalizada.
Agora, tente interagir com o agente usando um fluxo mais complexo, por exemplo, adicionando um novo item ( café com leite gelado) para melhorar a foto.

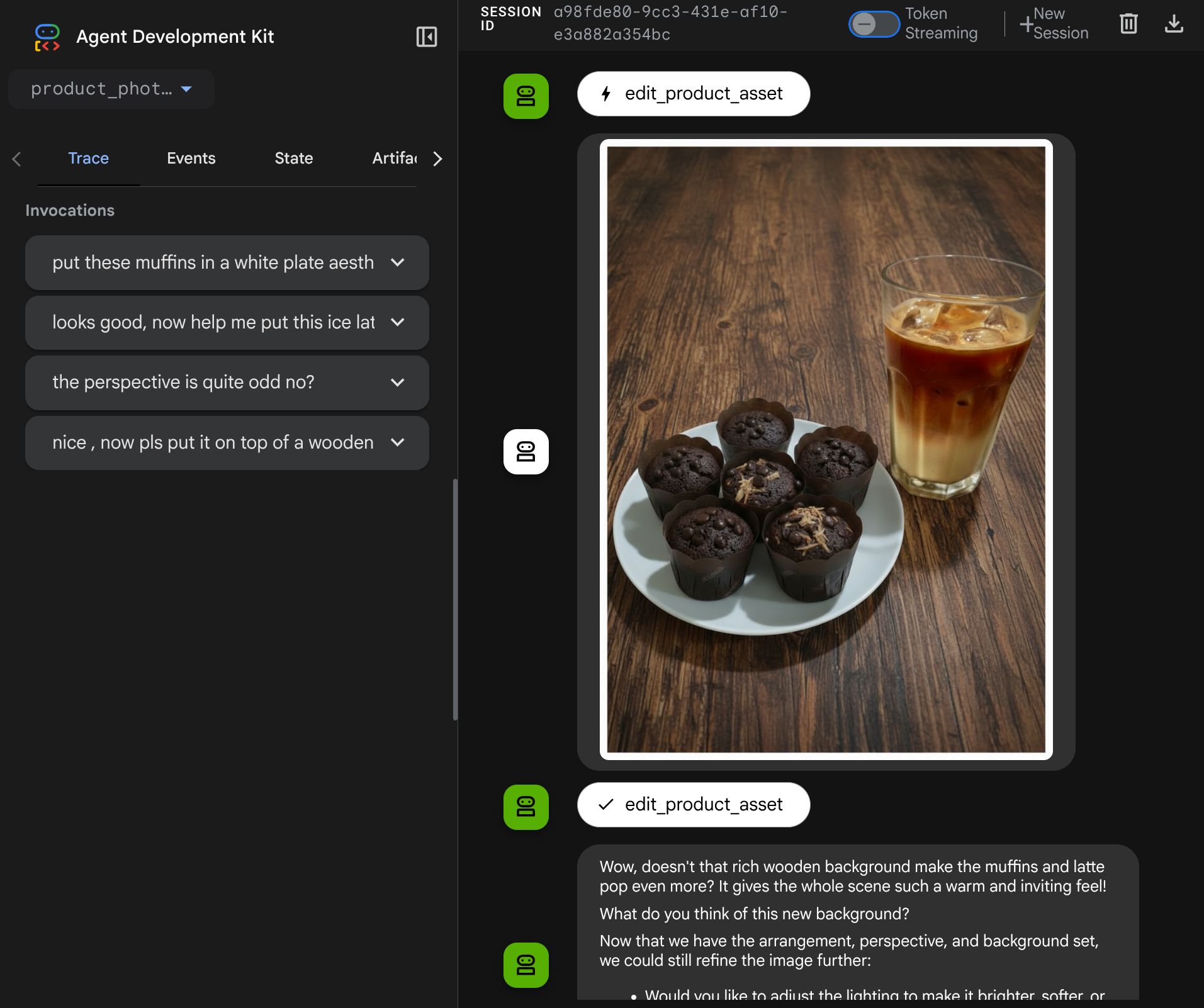
7. ⭐ Resumo
Agora vamos recapitular o que já fizemos neste codelab. Este é o principal aprendizado:
- Tratamento de dados multimodais:aprendi a estratégia para gerenciar dados multimodais (como imagens) no fluxo de contexto do LLM usando o serviço Artefatos do ADK em vez de transmitir dados de bytes brutos diretamente por argumentos ou respostas de ferramentas.
before_model_callbackUtilização:usamos obefore_model_callbackpara interceptar e modificar oLlmRequestantes que ele seja enviado ao LLM. Toque no seguinte fluxo:
- Uploads do usuário:implementamos uma lógica para detectar dados inline enviados pelo usuário, salvá-los como um artefato identificado de forma exclusiva (por exemplo,
usr_upl_img_...) e inserir texto no contexto do comando referenciando o ID do artefato. Assim, o LLM pode selecionar o arquivo correto para uso da ferramenta. - Respostas da ferramenta:implementamos uma lógica para detectar respostas específicas de funções de ferramentas que produzem artefatos (por exemplo, imagens editadas), carregar o artefato recém-salvo (por exemplo,
edited_img_...) e inserir a referência do ID do artefato e o conteúdo da imagem diretamente no fluxo de contexto.
- Design de ferramenta personalizada:criou uma ferramenta Python personalizada (
edit_product_asset) que aceita uma listaimage_artifact_ids(identificadores de string) e usa oToolContextpara recuperar os dados de imagem reais do serviço de artefatos. - Integração do modelo de geração de imagens:integramos o modelo Gemini 2.5 Flash Image à ferramenta personalizada para editar imagens com base em uma descrição detalhada.
- Interação multimodal contínua:garante que o agente possa manter uma sessão de edição contínua ao entender os resultados das próprias chamadas de ferramentas (a imagem editada) e usar essa saída como entrada para instruções subsequentes.
8. ➡️ Próximo desafio
Parabéns por concluir a Parte 1 da interação de ferramentas multimodais do ADK. Neste tutorial, vamos focar na interação com ferramentas personalizadas. Agora você está pronto para passar para a próxima etapa sobre como interagir com o conjunto de ferramentas MCP multimodal. Acesse o próximo laboratório.
9. 🧹 Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste codelab, siga estas etapas:
- No console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.