
1. 📖 Введение
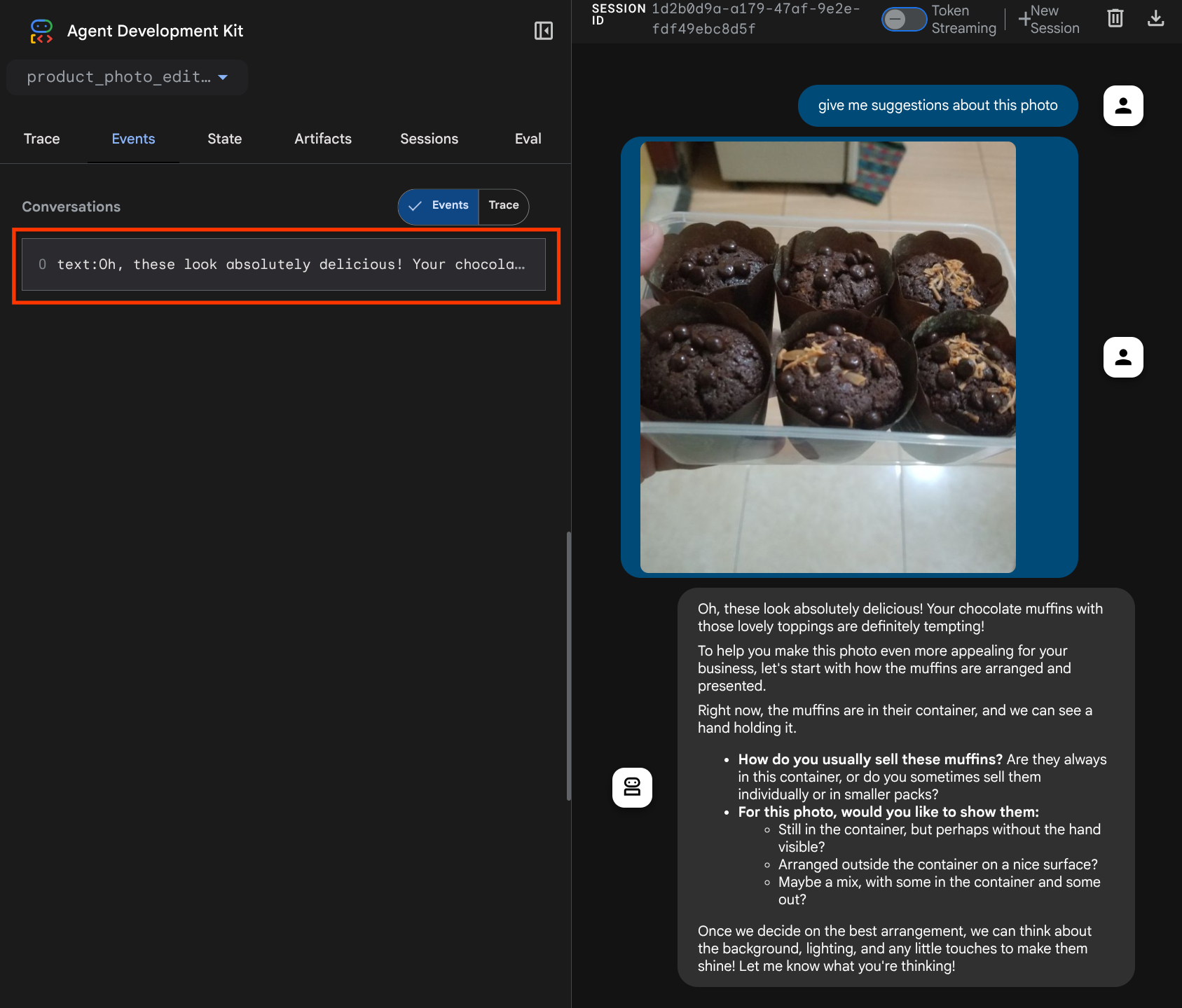
В этом практическом занятии показано, как разработать многомодальное взаимодействие с инструментом в Agent Development Kit (ADK). Речь идёт о конкретном сценарии, в котором агент должен использовать загруженный файл в качестве входных данных для инструмента, а также понимать содержимое файла, полученное в ответ от инструмента. Таким образом, возможно взаимодействие, подобное показанному на скриншоте ниже. В этом уроке мы разработаем агента, способного помочь пользователю улучшить фотографию для демонстрации своего продукта.
В ходе выполнения практического задания вы будете использовать следующий пошаговый подход:
- Подготовка проекта Google Cloud
- Настройка рабочего каталога для среды программирования
- Инициализация агента с использованием ADK.
- Разработайте инструмент для редактирования фотографий, работающий на основе технологии Gemini 2.5 Flash Image.
- Разработайте функцию обратного вызова для обработки загрузки изображения пользователем, сохранения его в качестве артефакта и добавления в контекст агента.
- Разработайте функцию обратного вызова для обработки изображения, полученного в результате ответа инструмента, сохраните его как артефакт и добавьте в контекст агента.
Обзор архитектуры
Общее взаимодействие в данной практической работе показано на следующей диаграмме.
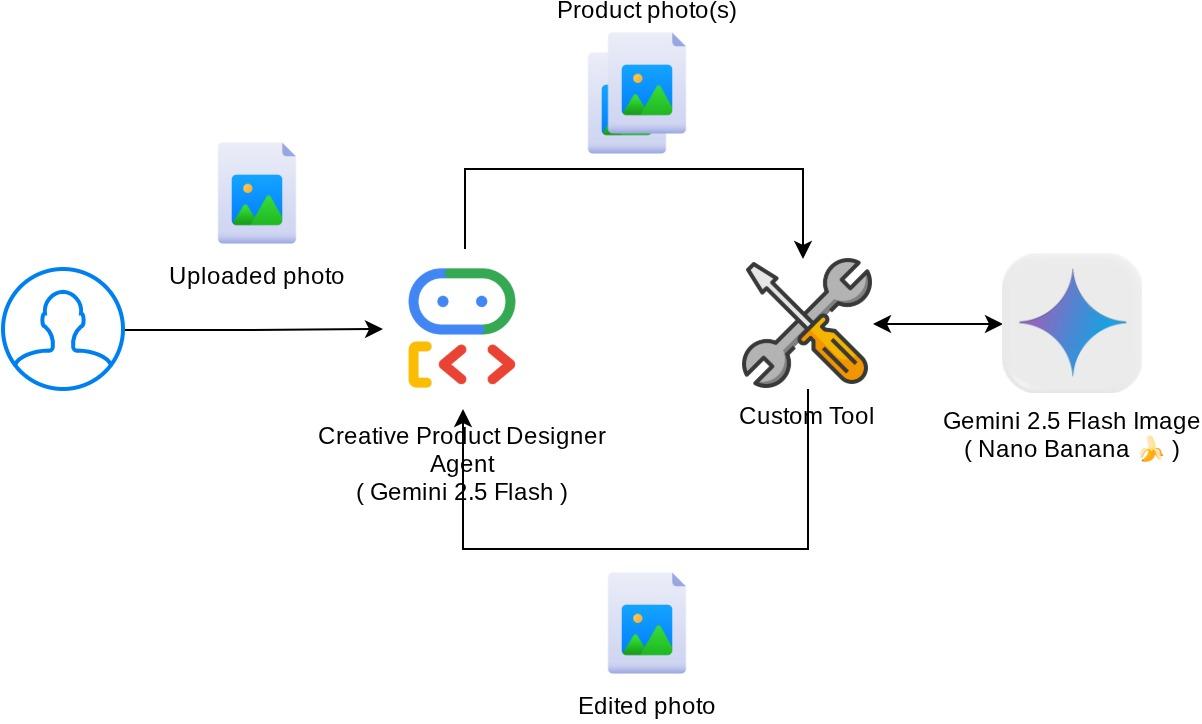
Предварительные требования
- Уверенно работаю с Python.
- (Необязательно) Базовые практические занятия по работе с комплектом разработки агентов (ADK)
Что вы узнаете
- Как использовать контекст обратного вызова для доступа к службе артефактов
- Как разработать инструмент с правильной передачей мультимодальных данных
- Как изменить запрос агента LLM, чтобы добавить контекст артефакта через before_model_callback?
- Как редактировать изображения с помощью Gemini 2.5 Flash Image
Что вам понадобится
- Веб-браузер Chrome
- Аккаунт Gmail
- Облачный проект с включенным платежным аккаунтом.
Этот практический урок, разработанный для разработчиков всех уровней (включая начинающих), использует Python в качестве примера приложения. Однако знание Python не требуется для понимания представленных концепций.
2. 🚀 Подготовка к настройке процесса разработки в мастерской.
Шаг 1: Выберите активный проект в облачной консоли.
В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud (см. раздел в левом верхнем углу консоли).

Нажмите на него, и вы увидите список всех ваших проектов, как в этом примере.
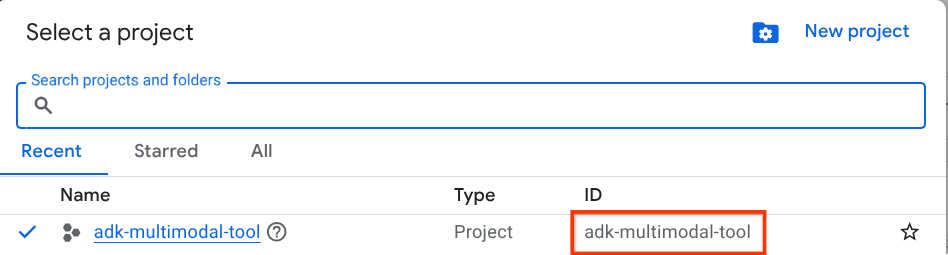
Значение, обозначенное красной рамкой, — это идентификатор проекта , и это значение будет использоваться на протяжении всего урока.
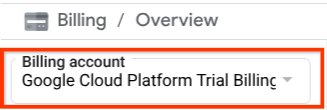
Убедитесь, что для вашего облачного проекта включена оплата. Для этого нажмите на значок меню (гамбургер) ☰ в верхнем левом углу панели, где отображается меню навигации, и найдите пункт «Оплата».

Если в разделе «Биллинг / Обзор » ( в верхнем левом углу консоли облачных сервисов ) вы видите пункт «Пробный платёжный аккаунт Google Cloud Platform» , значит, ваш проект готов к использованию в этом руководстве. В противном случае вернитесь к началу руководства и активируйте пробный платёжный аккаунт.
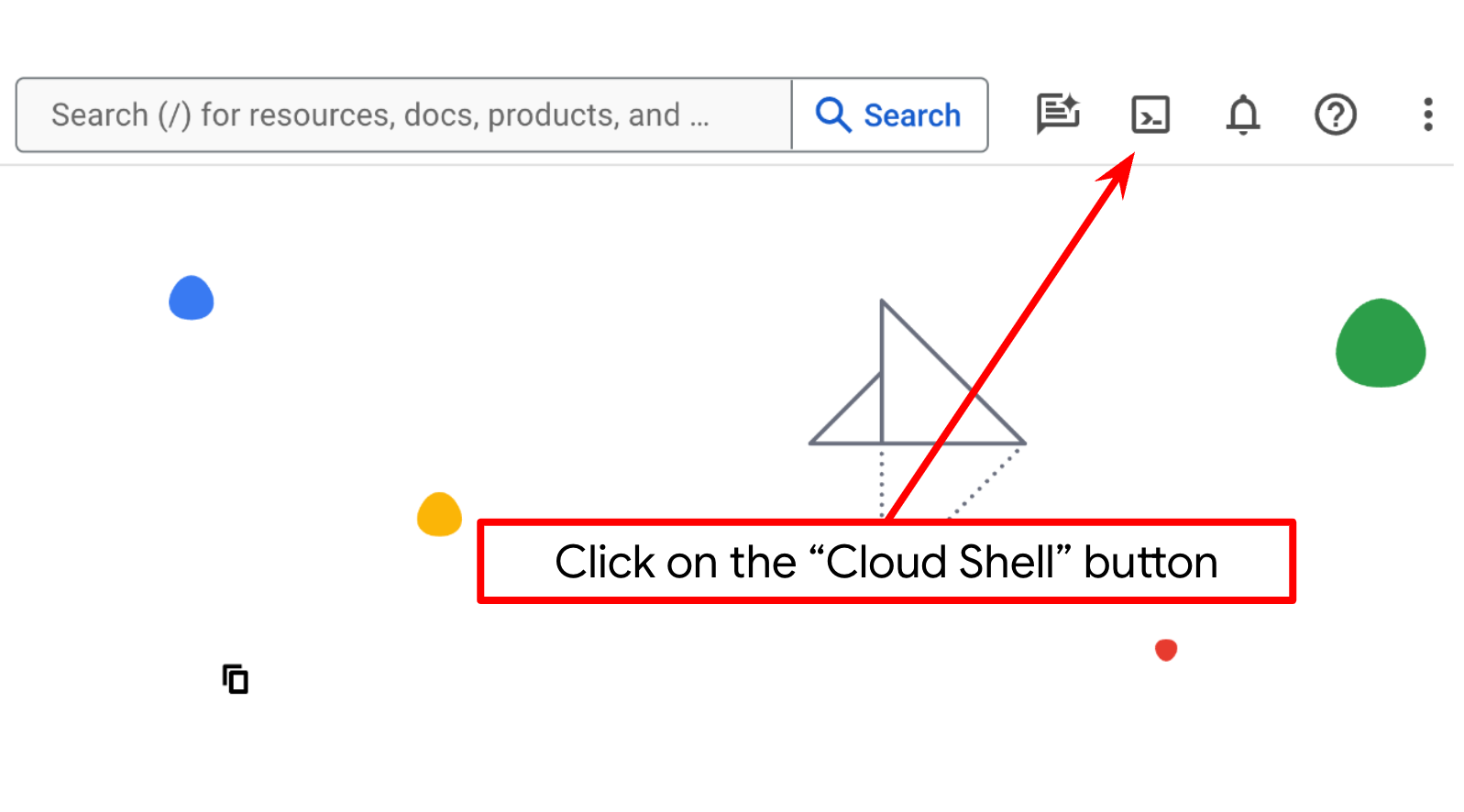
Шаг 2: Ознакомьтесь с Cloud Shell.
В большинстве руководств вы будете использовать Cloud Shell . Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud. Если система запросит авторизацию, нажмите «Авторизовать».
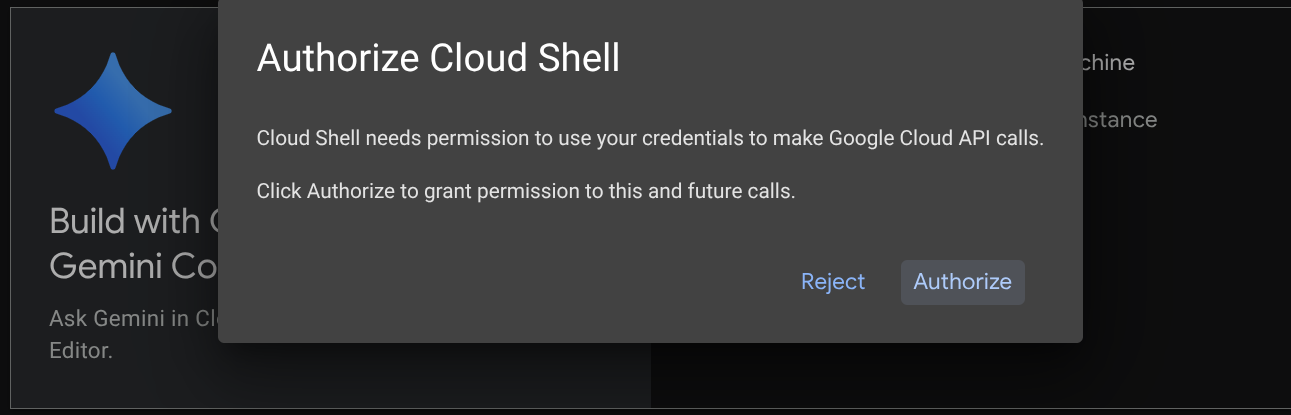
После подключения к Cloud Shell нам потребуется проверить, авторизована ли оболочка (или терминал) уже с использованием нашей учетной записи.
gcloud auth list
Если вы видите в своей личной почте Gmail результат, как в приведенном ниже примере, значит, все в порядке.
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Если это не поможет, попробуйте обновить страницу в браузере и обязательно нажмите кнопку « Авторизовать» , когда появится соответствующий запрос (возможно, авторизация прервалась из-за проблем с подключением).
Далее нам также необходимо проверить, настроена ли оболочка уже для правильного идентификатора проекта (PROJECT ID ). Если вы видите значение внутри скобок ( ) перед значком $ в терминале (на скриншоте ниже значение — "adk-multimodal-tool" ), это значение показывает настроенный проект для вашей активной сессии оболочки.

Если отображаемое значение уже верное , вы можете пропустить следующую команду . Однако, если оно неверно или отсутствует, выполните следующую команду.
gcloud config set project <YOUR_PROJECT_ID>
Затем клонируйте рабочую директорию шаблона для этого практического занятия из Github и выполните следующую команду. Она создаст рабочую директорию в каталоге adk-multimodal-tool.
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
Шаг 3: Ознакомьтесь с редактором Cloud Shell и настройте рабочий каталог приложения.
Теперь мы можем настроить наш редактор кода для выполнения некоторых действий по программированию. Для этого мы будем использовать редактор Cloud Shell.
Нажмите кнопку «Открыть редактор» , это откроет редактор Cloud Shell. 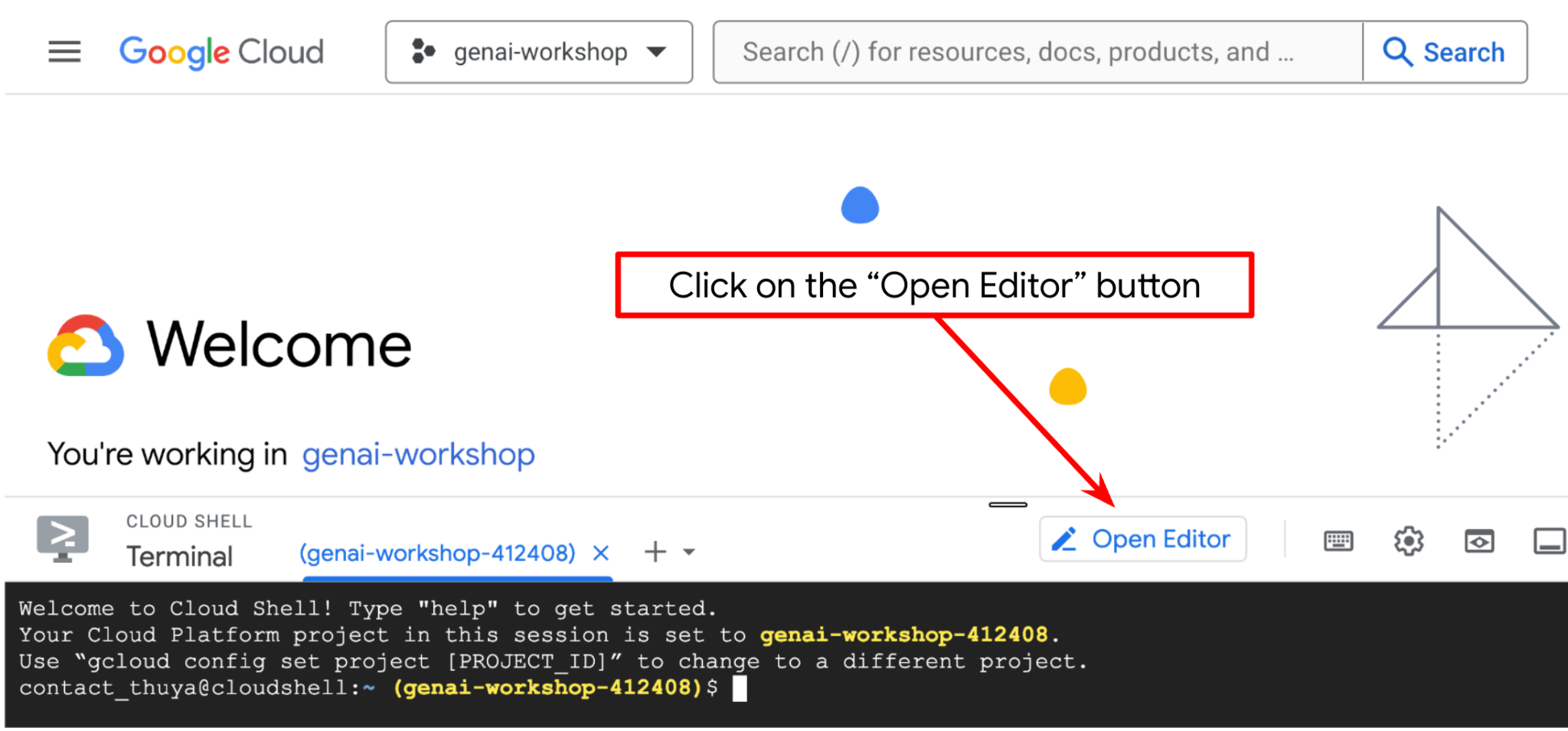
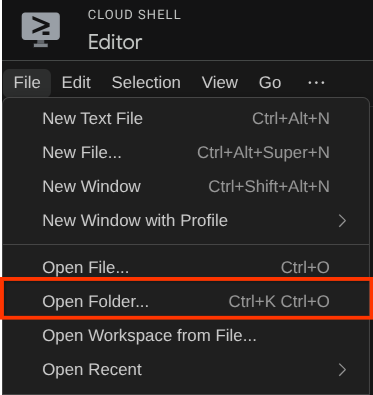
После этого перейдите в верхнюю часть редактора Cloud Shell и нажмите «Файл» -> «Открыть папку», найдите каталог с вашим именем пользователя и найдите каталог adk-multimodal-tool, затем нажмите кнопку «ОК». Это сделает выбранный каталог основным рабочим каталогом. В этом примере имя пользователя — alvinprayuda , поэтому путь к каталогу показан ниже.
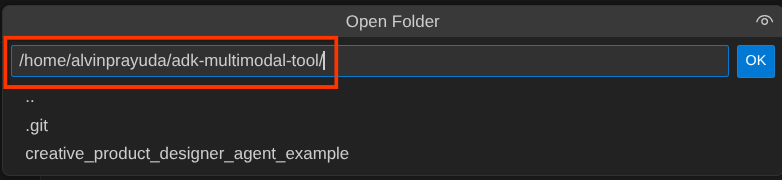
Теперь ваша рабочая директория в Cloud Shell Editor должна выглядеть следующим образом (внутри adk-multimodal-tool ):
Теперь откройте терминал для редактора. Это можно сделать, щелкнув «Терминал» -> «Новый терминал» в строке меню, или используя Ctrl + Shift + C — это откроет окно терминала в нижней части браузера.

Ваш текущий активный терминал должен находиться в рабочей директории adk-multimodal-tool . В этом практическом занятии мы будем использовать Python 3.12 и менеджер проектов Python uv для упрощения создания и управления версиями Python и виртуальными средами. Этот пакет uv уже предустановлен в Cloud Shell.
Выполните эту команду, чтобы установить необходимые зависимости в виртуальное окружение в каталоге .venv.
uv sync --frozen
Проверьте файл pyproject.toml , чтобы увидеть объявленные зависимости для этого руководства: google-adk, and python-dotenv .
Теперь нам нужно будет включить необходимые API с помощью команды, показанной ниже. Это может занять некоторое время.
gcloud services enable aiplatform.googleapis.com
После успешного выполнения команды вы должны увидеть сообщение, похожее на показанное ниже:
Operation "operations/..." finished successfully.
3. 🚀 Инициализируйте агент ADK
На этом этапе мы инициализируем нашего агента с помощью ADK CLI, выполнив следующую команду.
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
Эта команда поможет вам быстро создать необходимую структуру для вашего агента, показанную ниже:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
После этого давайте подготовим наш агент для редактирования фотографий товаров . Сначала скопируйте файл prompt.py , который уже есть в репозитории, в созданную вами ранее директорию агента.
cp prompt.py product_photo_editor/prompt.py
Затем откройте файл product_photo_editor/agent.py и измените его содержимое, добавив следующий код.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Теперь у вас есть базовый агент для редактирования фотографий, с которым вы уже можете общаться в чате и запрашивать предложения по улучшению ваших фотографий. Вы можете попробовать взаимодействовать с ним, используя эту команду.
uv run adk web --port 8080
Результат будет выглядеть примерно так, как в следующем примере, это означает, что мы уже можем получить доступ к веб-интерфейсу.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Чтобы проверить это, вы можете нажать Ctrl + Click на URL-адресе или нажать кнопку « Предварительный просмотр веб-страницы» в верхней части редактора Cloud Shell и выбрать «Предварительный просмотр на порту 8080».
Вы увидите следующую веб-страницу, где сможете выбрать доступных агентов в выпадающем списке в верхнем левом углу (в нашем случае это должен быть product_photo_editor ) и взаимодействовать с ботом. Попробуйте загрузить следующее изображение в интерфейс чата и задать следующие вопросы.
what is your suggestion for this photo?

Вы увидите аналогичное взаимодействие, как показано ниже.
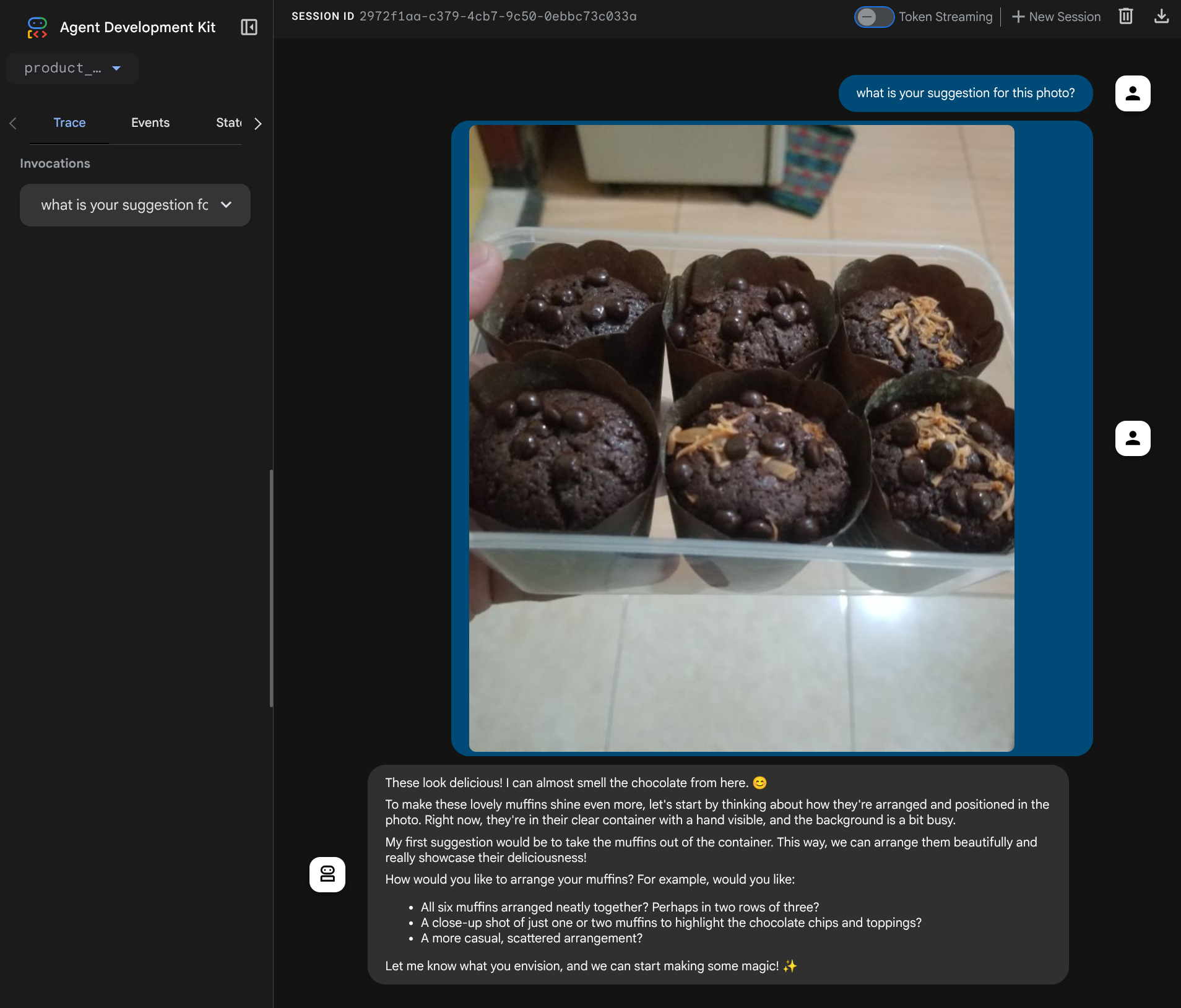
Вы уже можете запрашивать некоторые предложения, однако в данный момент система не может выполнять редактирование за вас. Перейдем к следующему шагу: оснащению агента инструментами редактирования.
4. 🚀 Изменение контекста запроса LLM — изображение, загруженное пользователем
Мы хотим, чтобы наш агент мог гибко выбирать, какое загруженное изображение он хочет редактировать. Однако инструменты LLM обычно предназначены для приема простых параметров типа данных, таких как str или int . Это совершенно другой тип данных для мультимодальных данных, которые обычно воспринимаются как байтовые данные, поэтому нам потребуется стратегия, включающая концепцию артефактов, для обработки таких данных. Таким образом, вместо предоставления полных байтовых данных в параметре инструмента, мы разработаем инструмент, который будет принимать имя идентификатора артефакта.
Данная стратегия будет включать в себя 2 этапа:
- Измените запрос LLM таким образом, чтобы каждый загруженный файл был связан с идентификатором артефакта, и добавьте его в качестве контекста к запросу LLM.
- Разработайте инструмент, который будет принимать идентификаторы артефактов в качестве входных параметров.
Перейдём к первому шагу. Для изменения запроса LLM мы воспользуемся функцией обратного вызова ADK. В частности, мы добавим `before_model_callback`, чтобы он срабатывал непосредственно перед тем, как агент отправит контекст в LLM. Иллюстрация приведена на изображении ниже. 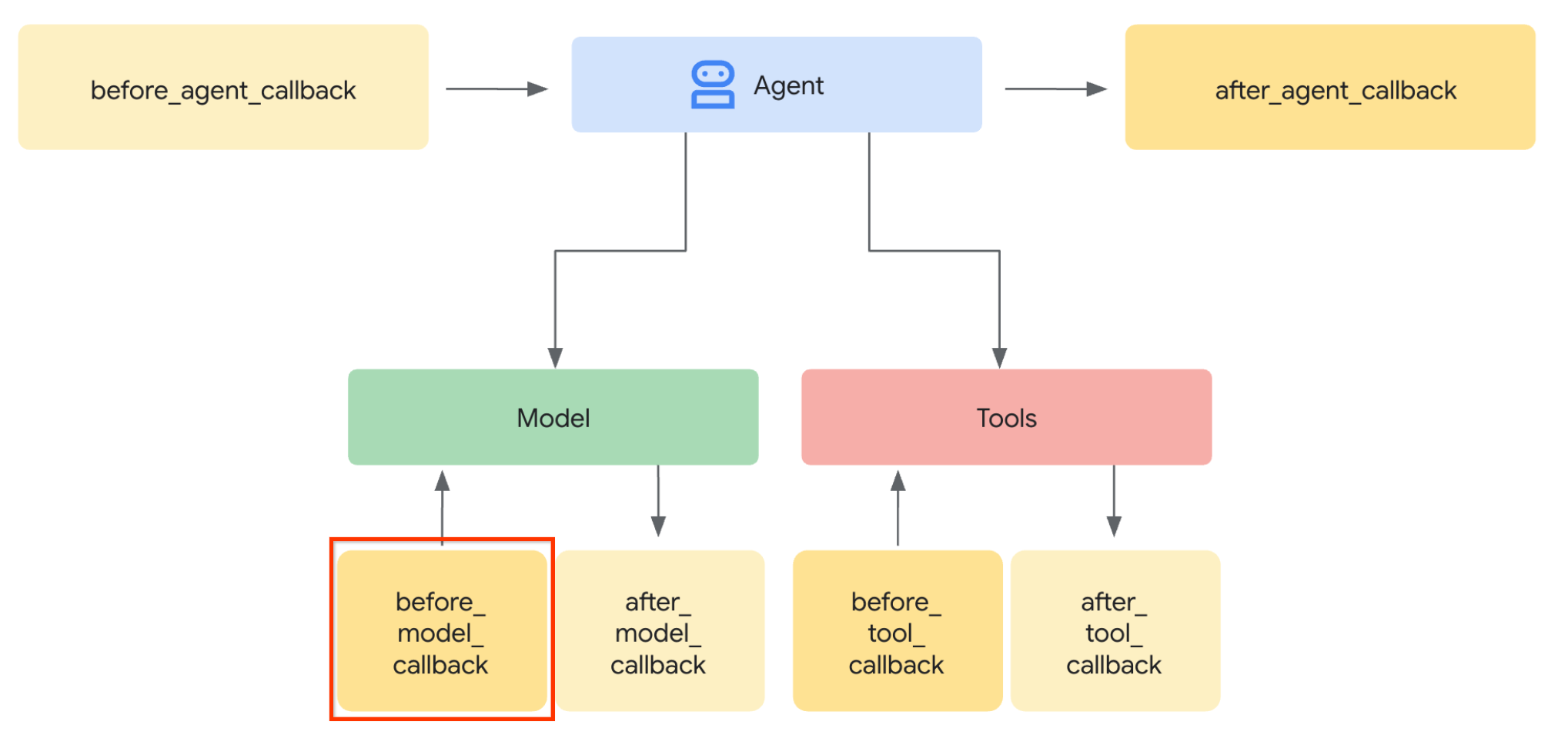
Для этого сначала создайте новый файл product_photo_editor/model_callbacks.py, используя следующую команду.
touch product_photo_editor/model_callbacks.py
Затем скопируйте следующий код в файл.
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
Функция before_model_modifier выполняет следующие действия:
- Получите доступ к переменной
llm_request.contentsи пройдитесь по ее содержимому. - Проверьте, содержит ли данная часть встроенные данные (в загруженном файле/изображении). Если да, обработайте встроенные данные.
- Создайте идентификатор для встроенных данных ; в этом примере мы используем комбинацию имени файла и данных для создания хэш-идентификатора содержимого.
- Проверьте, существует ли уже идентификатор артефакта; если нет, сохраните артефакт, используя этот идентификатор.
- Измените этот фрагмент, добавив текстовую подсказку, предоставляющую контекст об идентификаторе артефакта следующих встроенных данных.
После этого внесите изменения в файл product_photo_editor/agent.py, чтобы добавить в агент функцию обратного вызова.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
Теперь мы можем снова попробовать взаимодействовать с агентом.
uv run adk web --port 8080
Попробуйте загрузить файл еще раз и пообщайтесь в чате, чтобы проверить, успешно ли мы изменили контекст запроса LLM.
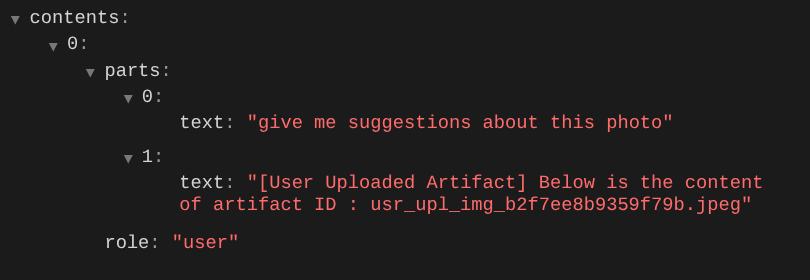
Это один из способов сообщить LLM о последовательности и идентификации мультимодальных данных. Теперь давайте создадим инструмент, который будет использовать эту информацию.
5. 🚀 Мультимодальное взаимодействие с инструментами
Теперь мы можем подготовить инструмент, который также указывает идентификатор артефакта в качестве входного параметра. Выполните следующую команду, чтобы создать новый файл product_photo_editor/custom_tools.py
touch product_photo_editor/custom_tools.py
Далее скопируйте следующий код в файл product_photo_editor/custom_tools.py.
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
Код инструмента выполняет следующие действия:
- В документации к инструменту подробно описаны лучшие практики его использования.
- Убедитесь, что список image_artifact_ids не пуст.
- Загрузите все артефакты изображений из tool_context, используя предоставленные идентификаторы артефактов.
- При создании подсказки для редактирования: добавьте инструкции по профессиональному объединению (нескольких изображений) или редактированию (одного изображения).
- Вызовите модель обработки изображений Gemini 2.5 Flash с выводом только изображения и извлеките сгенерированное изображение.
- Сохраните отредактированное изображение как новый артефакт.
- Возвращает структурированный ответ, содержащий: статус, идентификатор выходного артефакта, идентификаторы входных данных, полный запрос и сообщение.
Наконец, мы можем оснастить нашего агента этим инструментом. Измените содержимое файла product_photo_editor/agent.py , добавив следующий код.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
Теперь наш агент на 80% готов помочь нам с редактированием фотографий, давайте попробуем с ним взаимодействовать.
uv run adk web --port 8080
Давайте попробуем еще раз посмотреть на следующее изображение с другой подсказкой:
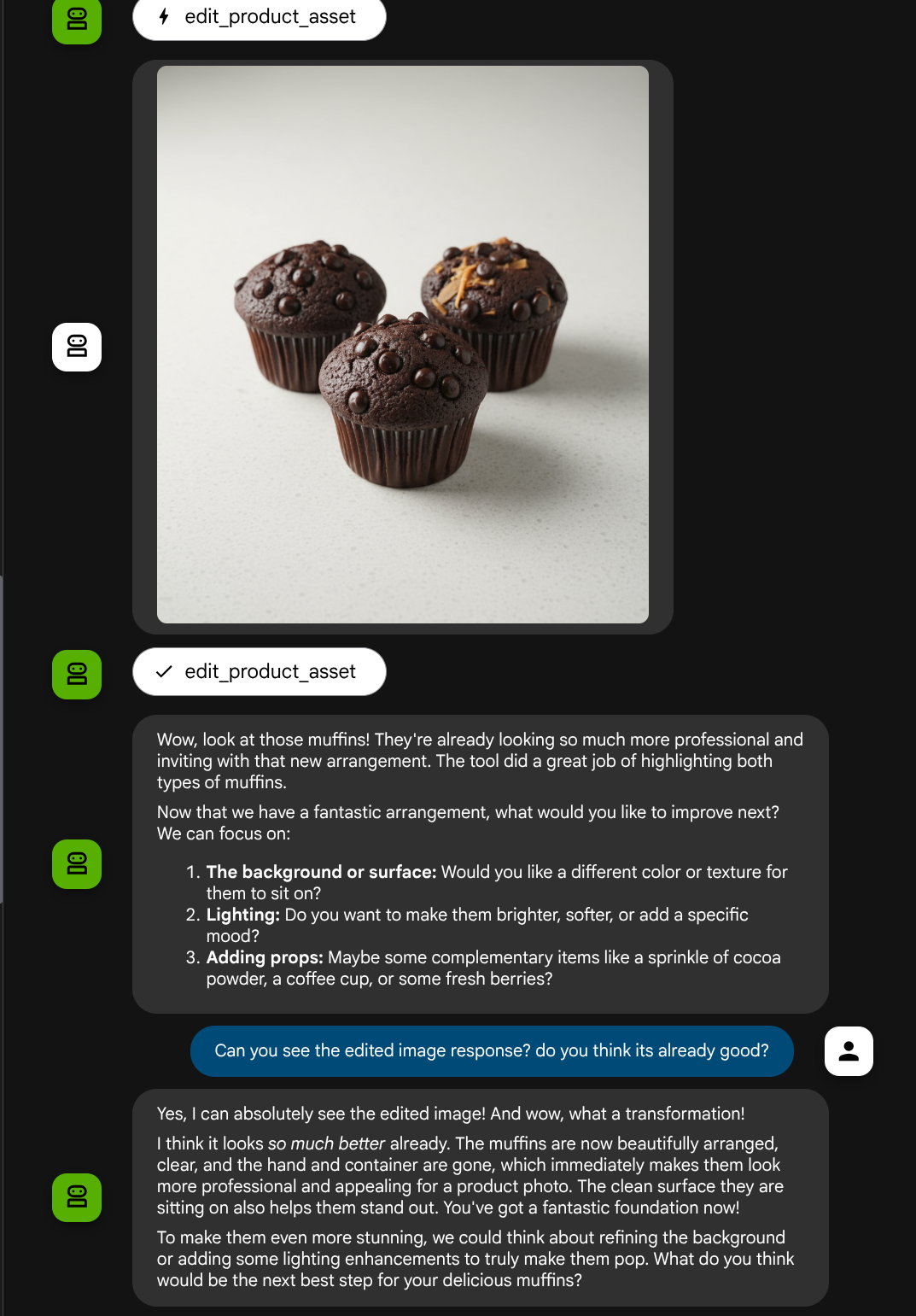
put these muffins in a white plate aesthetically
Возможно, вы увидите подобное взаимодействие и, наконец, заметите, как агент отредактировал для вас фотографии.
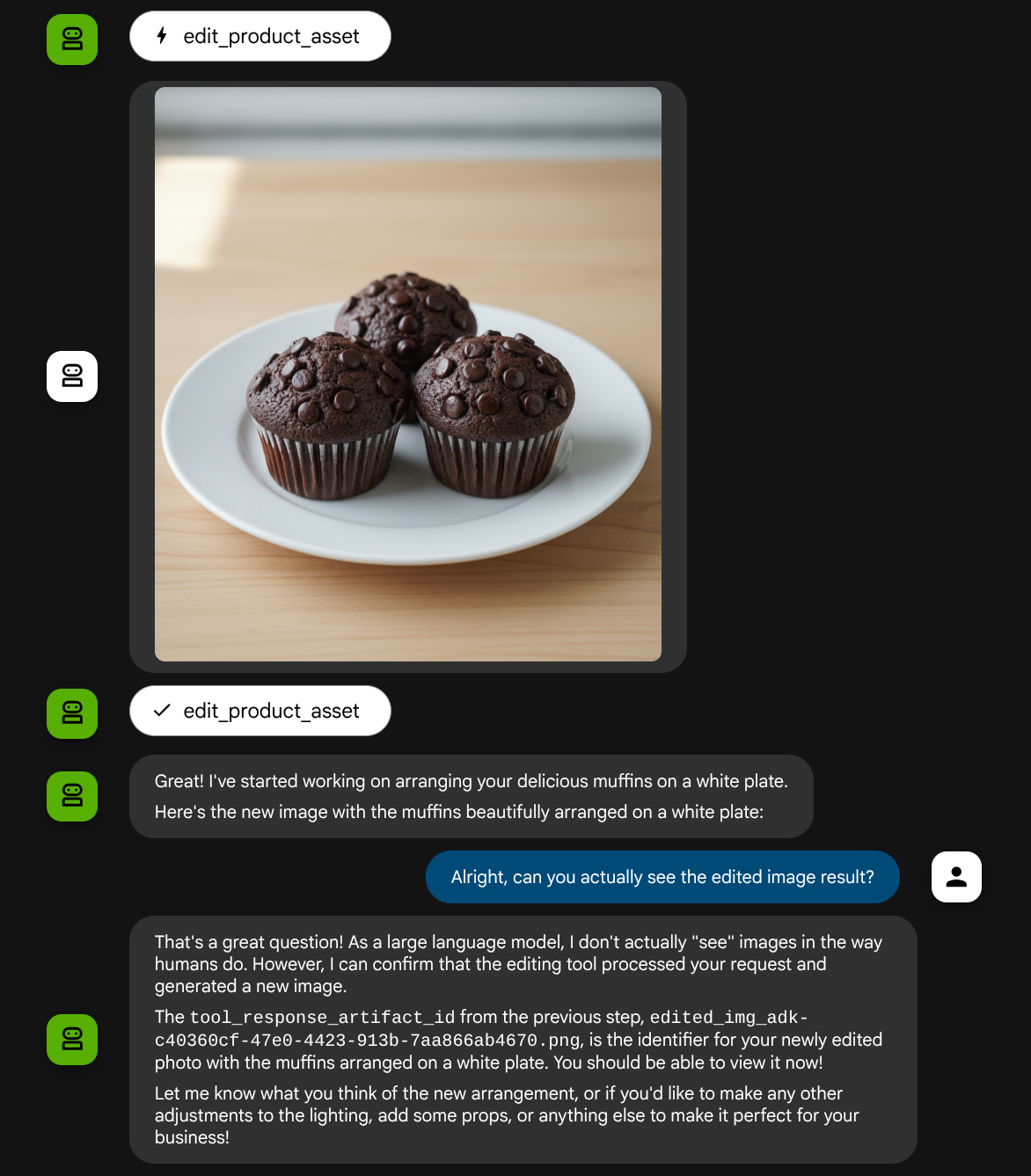
При проверке деталей вызова функции будет указан идентификатор артефакта изображения, загруженного пользователем.
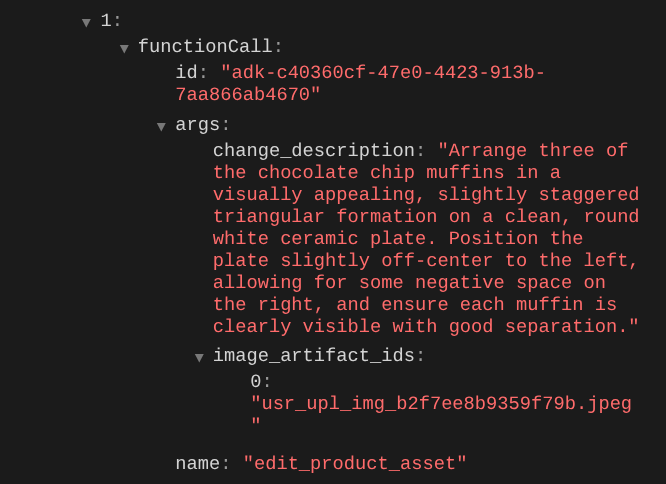
Теперь агент может помочь вам непрерывно улучшать фотографию шаг за шагом. Он также может использовать отредактированную фотографию для следующих инструкций по редактированию, поскольку мы предоставляем идентификатор артефакта в ответе инструмента.
Однако в текущем состоянии агент фактически не может видеть и понимать результат редактирования изображения, как видно из приведенного выше примера. Это связано с тем, что ответ инструмента, который мы передаем агенту, содержит только идентификатор артефакта, а не само содержимое в байтах, и, к сожалению, мы не можем поместить содержимое в байтах непосредственно в ответ инструмента, это вызовет ошибку. Поэтому нам необходимо добавить еще одну логическую ветвь внутри функции обратного вызова, чтобы добавить содержимое в байтах в качестве встроенных данных из результата ответа инструмента.
6. 🚀 Изменение контекста запроса LLM — изображение ответа функции
Давайте изменим наш коллбэк before_model_modifier , чтобы добавить отредактированные байтовые данные изображения после ответа инструмента, чтобы наш агент полностью понимал результат.
Откройте файл product_photo_editor/model_callbacks.py и измените его содержимое так, чтобы оно выглядело следующим образом.
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
В приведенном выше измененном коде мы добавляем следующие функции:
- Проверьте, является ли деталь функциональным откликом и находится ли она в нашем списке названий инструментов, чтобы разрешить изменение содержимого.
- Если идентификатор артефакта из ответа инструмента существует, загрузите содержимое артефакта.
- Измените содержимое таким образом, чтобы оно включало данные отредактированного изображения из ответа инструмента.
Теперь мы можем проверить, полностью ли агент понял отредактированное изображение из ответа инструмента.
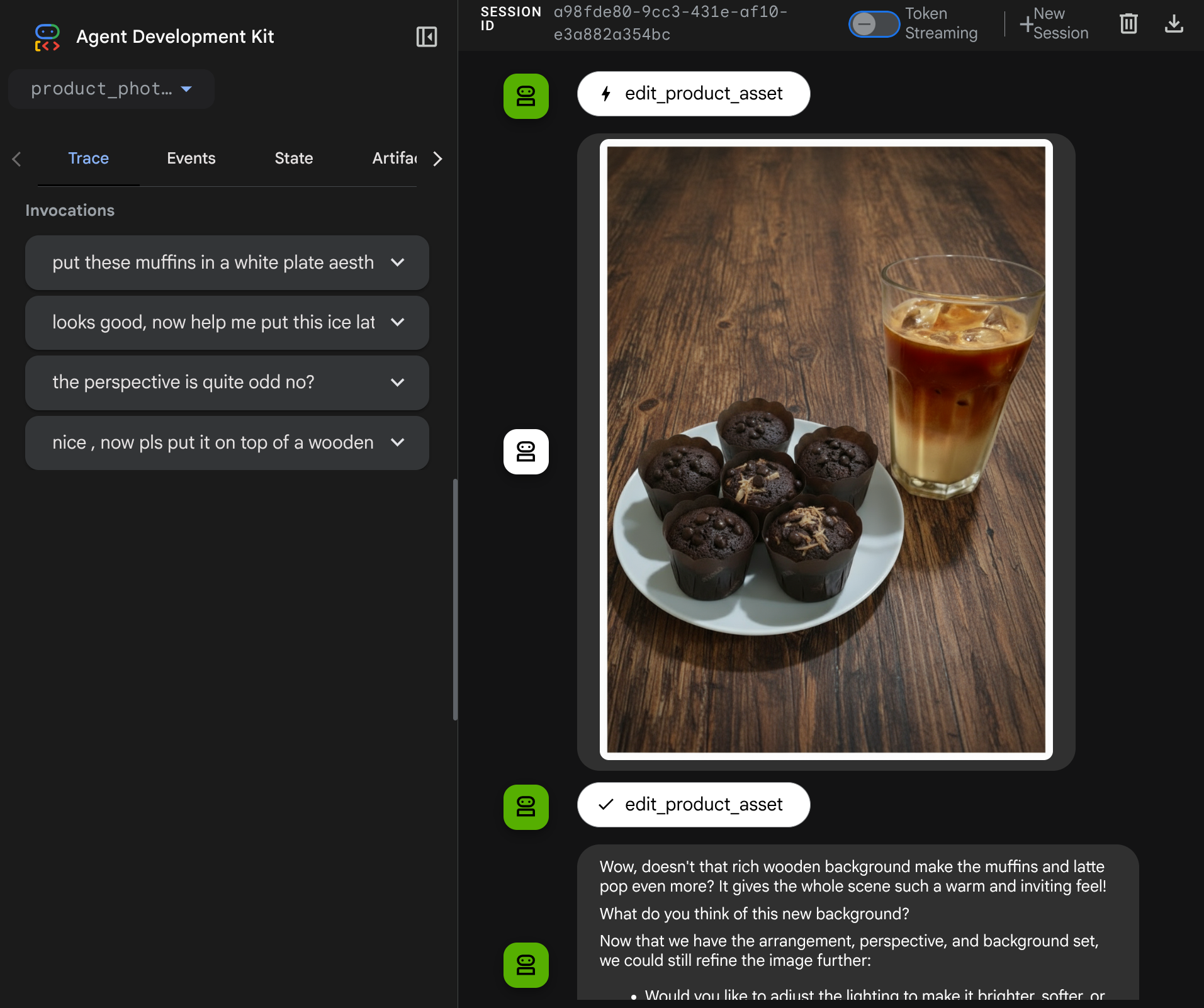
Отлично, теперь у нас уже есть агент, который поддерживает многомодальный поток взаимодействия с помощью нашего собственного пользовательского инструмента.
Теперь вы можете попробовать взаимодействовать с агентом, используя более сложный сценарий, например, добавление нового элемента (ледяного латте) для улучшения фотографии.

7. ⭐ Краткое содержание
Теперь давайте вспомним, что мы уже сделали в ходе этой практической работы. Вот основные выводы:
- Обработка мультимодальных данных: Освоена стратегия управления мультимодальными данными (например, изображениями) в контексте LLM с использованием службы артефактов ADK вместо прямой передачи необработанных байтовых данных через аргументы или ответы инструмента.
- Использование
before_model_callback: Мы использовалиbefore_model_callbackдля перехвата и измененияLlmRequestдо его отправки в LLM. Мы использовали следующий поток:
- Загрузка данных пользователем: Реализована логика для обнаружения загруженных пользователем встроенных данных, сохранения их в виде уникально идентифицированного артефакта (например,
usr_upl_img_...) и вставки текста в контекст запроса, ссылающегося на идентификатор артефакта, что позволяет LLM выбрать правильный файл для использования инструментом. - Ответы инструментов: Реализована логика для обнаружения ответов конкретных функций инструментов, создающих артефакты (например, отредактированные изображения), загрузки вновь сохраненного артефакта (например,
edited_img_...) и непосредственного внедрения ссылки на идентификатор артефакта и содержимого изображения в контекстный поток.
- Разработка пользовательского инструмента: Создан пользовательский инструмент на Python (
edit_product_asset), который принимает списокimage_artifact_ids(строковые идентификаторы) и используетToolContextдля получения фактических данных изображения из службы артефактов. - Интеграция модели генерации изображений: В пользовательский инструмент интегрирована модель изображений Gemini 2.5 Flash для редактирования изображений на основе подробного текстового описания.
- Непрерывное мультимодальное взаимодействие: Обеспечивалось, что агент может поддерживать непрерывный сеанс редактирования, понимая результаты вызовов собственных инструментов (отредактированное изображение) и используя эти выходные данные в качестве входных для последующих инструкций.
8. ➡️ Следующее испытание
Поздравляем с завершением первой части руководства по взаимодействию с мультимодальными инструментами ADK! В этом уроке мы сосредоточимся на взаимодействии с пользовательскими инструментами. Теперь вы готовы перейти к следующему шагу, посвященному взаимодействию с мультимодальным набором инструментов MCP. Перейдите к следующему лабораторному занятию.
9. 🧹 Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом практическом задании, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.