
1. 📖 Giriş
Bu codelab'de, Agent Development Kit'te (ADK) çok formatlı bir araç etkileşiminin nasıl tasarlanacağı gösterilmektedir. Bu, temsilcinin yüklenen dosyayı bir aracın girişi olarak kullanmasını ve araç yanıtı tarafından üretilen dosya içeriğini de anlamasını istediğiniz belirli bir akıştır. Bu nedenle, aşağıdaki ekran görüntüsünde gösterildiği gibi etkileşim mümkündür. Bu eğitimde, kullanıcının ürün vitrini için daha iyi bir fotoğraf düzenlemesine yardımcı olabilecek bir temsilci geliştireceğiz.
Bu codelab'de aşağıdaki gibi adım adım bir yaklaşım kullanacaksınız:
- Google Cloud projesini hazırlama
- Kodlama ortamı için çalışma dizini ayarlama
- ADK'yı kullanarak aracıyı başlatma
- Gemini 2.5 Flash Image tarafından desteklenen fotoğrafları düzenlemek için kullanılabilecek bir araç tasarlama
- Kullanıcı resim yüklemeyi işlemek, bunu yapay nesne olarak kaydetmek ve aracıya bağlam olarak eklemek için bir geri çağırma işlevi tasarlayın.
- Araç yanıtı tarafından üretilen resmi işlemek, bunu yapı olarak kaydetmek ve bağlam olarak aracıya eklemek için bir geri çağırma işlevi tasarlayın.
Mimariye Genel Bakış
Bu codelab'deki genel etkileşim aşağıdaki şemada gösterilmektedir.
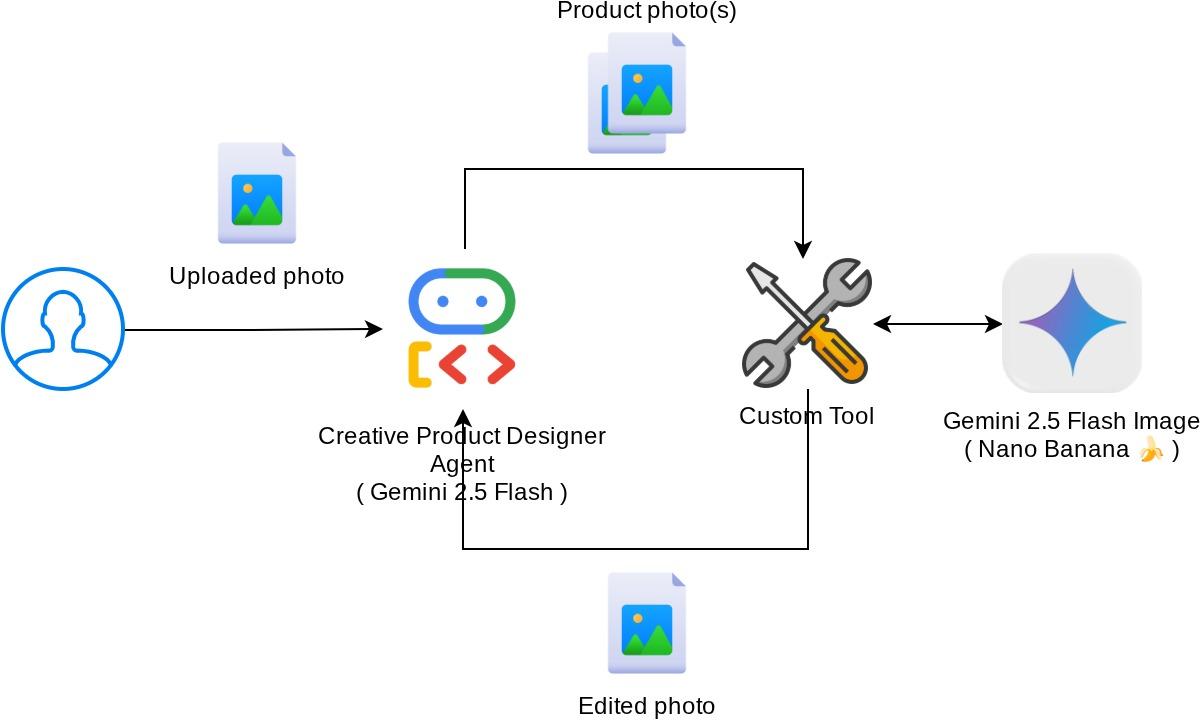
Ön koşullar
- Python ile rahatça çalışabilme
- (İsteğe bağlı) Agent Development Kit (ADK) ile ilgili temel codelab'ler
Neler öğreneceksiniz?
- Yapı hizmetine erişmek için geri çağırma bağlamını kullanma
- Uygun çok formatlı veri yayılımıyla araç tasarlama
- before_model_callback aracılığıyla yapay nesne bağlamı eklemek için aracı LLM isteğini değiştirme
- Gemini 2.5 Flash Image ile görüntü düzenleme
Gerekenler
- Chrome web tarayıcısı
- Gmail hesabı
- Faturalandırma hesabı etkinleştirilmiş bir Cloud projesi
Her seviyeden geliştirici (yeni başlayanlar dahil) için tasarlanan bu codelab'de örnek uygulamada Python kullanılır. Ancak sunulan kavramları anlamak için Python bilgisi gerekmez.
2. 🚀 Atölye Geliştirme Kurulumuna Hazırlanma
1. adım: Cloud Console'da Etkin Proje'yi seçin
Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun (konsolunuzun sol üst bölümüne bakın).

Bu seçeneği tıkladığınızda, örnekteki gibi tüm projelerinizin listesini görürsünüz.
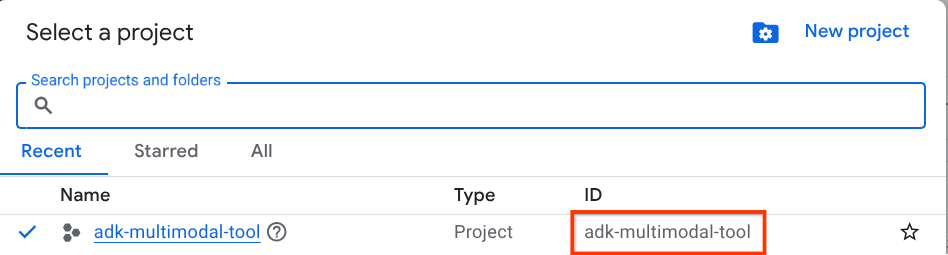
Kırmızı kutuyla belirtilen değer PROJE KİMLİĞİ'dir ve bu değer, eğitim boyunca kullanılacaktır.
Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bunu kontrol etmek için sol üst çubuğunuzdaki hamburger simgesini ☰ tıklayarak gezinme menüsünü gösterin ve Faturalandırma menüsünü bulun.

"Google Cloud Platform Deneme Faturalandırma Hesabı" ifadesini Faturalandırma / Genel Bakış başlığı altında ( Cloud Console'unuzun sol üst bölümü) görüyorsanız projeniz bu eğitimde kullanılmaya hazırdır. Aksi takdirde, bu eğitimin başına dönün ve deneme faturalandırma hesabını kullanın.
2. adım: Cloud Shell'i tanıyın
Eğitimlerin büyük bir bölümünde Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmındaki Cloud Shell'i Etkinleştir'i tıklayın. Yetkilendirmeniz istenirse Yetkilendir'i tıklayın.
Cloud Shell'e bağlandıktan sonra, kabuğun ( veya terminalin) hesabımızla kimliğinin doğrulanıp doğrulanmadığını kontrol etmemiz gerekir.
gcloud auth list
Aşağıdaki örnek çıktıda olduğu gibi kişisel Gmail'inizi görüyorsanız her şey yolundadır.
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Aksi takdirde, tarayıcınızı yenilemeyi deneyin ve istendiğinde Yetkilendir'i tıkladığınızdan emin olun ( bağlantı sorunu nedeniyle kesintiye uğrayabilir).
Ardından, kabuğun doğru PROJE KİMLİĞİ ile yapılandırılıp yapılandırılmadığını da kontrol etmemiz gerekir. Terminalde $simgesinden önce ( ) içinde değer görüyorsanız ( aşağıdaki ekran görüntüsünde değer "adk-multimodal-tool") bu değer, etkin kabuk oturumunuz için yapılandırılmış projeyi gösterir.

Gösterilen değer zaten doğruysa sonraki komutu atlayabilirsiniz. Ancak doğru değilse veya eksikse aşağıdaki komutu çalıştırın.
gcloud config set project <YOUR_PROJECT_ID>
Ardından, bu codelab için şablon çalışma dizinini GitHub'dan klonlayın ve aşağıdaki komutu çalıştırın. Çalışma dizini adk-multimodal-tool dizininde oluşturulur.
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
3. adım: Cloud Shell Editor'a alışın ve uygulama çalışma dizinini ayarlayın
Şimdi kod düzenleyicimizi bazı kodlama işlemleri yapacak şekilde ayarlayabiliriz. Bu işlem için Cloud Shell Düzenleyici'yi kullanacağız.
Open Editor (Düzenleyiciyi Aç) düğmesini tıklayın. Bu işlem, Cloud Shell Düzenleyici'yi açar. 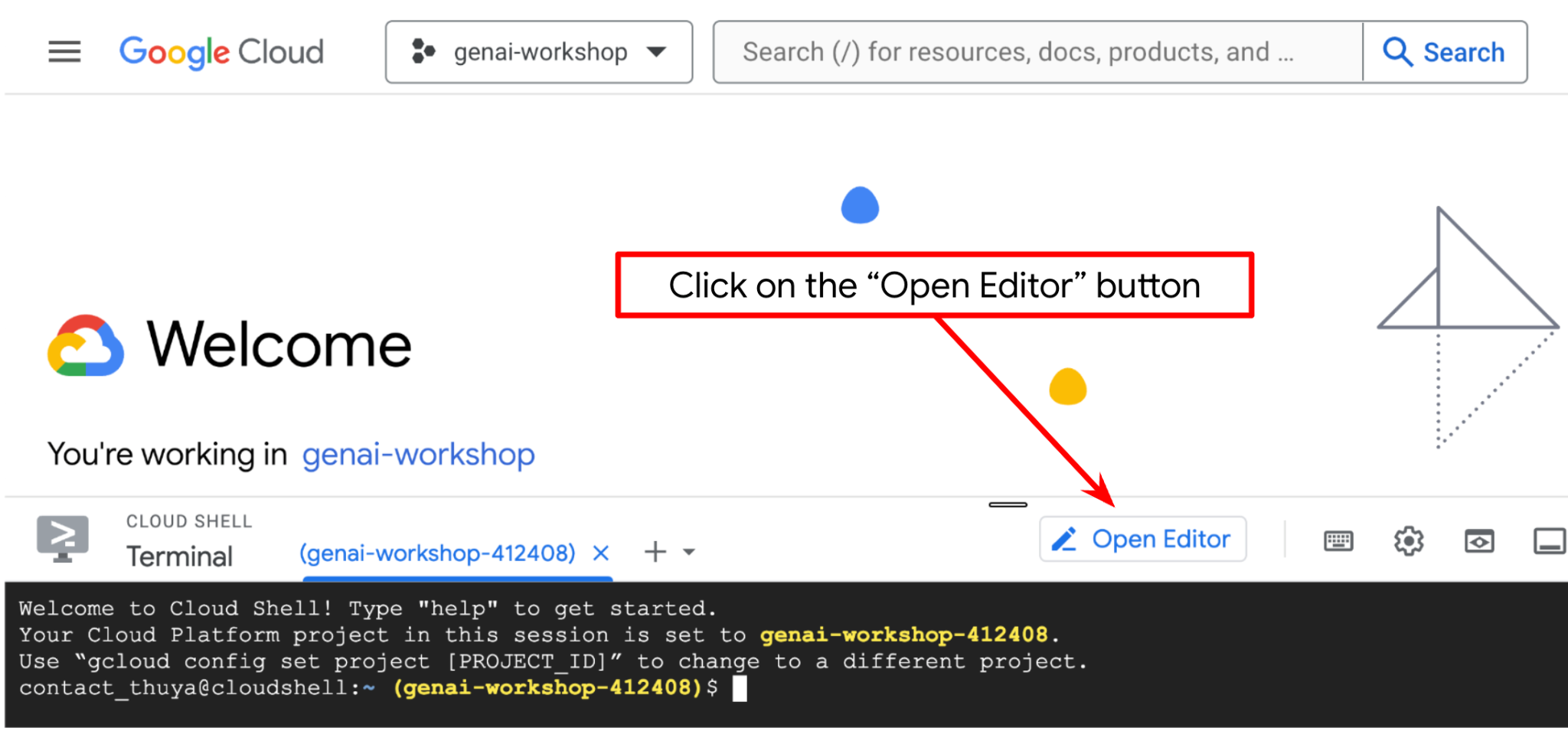
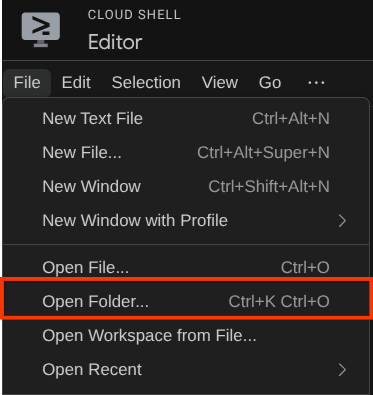
Ardından, Cloud Shell Düzenleyici'nin üst bölümüne gidip File->Open Folder'ı (Dosya->Klasör Aç) tıklayın,username (kullanıcı adı) dizininizi ve adk-multimodal-tool dizinini bulup Tamam düğmesini tıklayın. Bu işlem, seçilen dizini ana çalışma dizini yapar. Bu örnekte kullanıcı adı alvinprayuda olduğundan dizin yolu aşağıda gösterilmiştir.
Cloud Shell Düzenleyici çalışma dizininiz artık şu şekilde görünmelidir ( adk-multimodal-tool içinde)
Şimdi düzenleyicinin terminalini açın. Menü çubuğunda Terminal -> New Terminal'ı tıklayarak veya Ctrl + Üst Karakter + C kısayolunu kullanarak yapabilirsiniz. Bu kısayol, tarayıcının alt kısmında bir terminal penceresi açar.

Mevcut etkin terminaliniz adk-multimodal-tool çalışma dizininde olmalıdır. Bu codelab'de Python 3.12'yi kullanacağız. Python sürümü ve sanal ortam oluşturma ve yönetme ihtiyacını basitleştirmek için uv python proje yöneticisini kullanacağız. Bu uv paketi, Cloud Shell'e önceden yüklenmiştir.
.venv dizinindeki sanal ortama gerekli bağımlılıkları yüklemek için bu komutu çalıştırın.
uv sync --frozen
Bu eğitim için bildirilen bağımlılıkları (google-adk, and python-dotenv) görmek üzere pyproject.toml dosyasını kontrol edin.
Şimdi, aşağıdaki komutu kullanarak gerekli API'leri etkinleştirmemiz gerekiyor. Bu işlem biraz zaman alabilir.
gcloud services enable aiplatform.googleapis.com
Komut başarıyla yürütüldüğünde aşağıda gösterilene benzer bir mesaj görürsünüz:
Operation "operations/..." finished successfully.
3. 🚀 ADK aracısını başlatın
Bu adımda, ADK KSA'yı kullanarak aracımızı başlatacağız. Aşağıdaki komutu çalıştırın:
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
Bu komut, aşağıda gösterilen aracınız için gerekli yapıyı hızlı bir şekilde sağlamanıza yardımcı olur:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
Ardından, ürün fotoğrafı düzenleyici aracımızı hazırlayalım. Öncelikle, depoda bulunan prompt.py dosyasını daha önce oluşturduğunuz aracı dizinine kopyalayın.
cp prompt.py product_photo_editor/prompt.py
Ardından, product_photo_editor/agent.py dosyasını açın ve içeriği aşağıdaki kodla değiştirin.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Artık temel fotoğraf düzenleme aracınız var. Bu araçla sohbet ederek fotoğraflarınız için öneri isteyebilirsiniz. Bu komutu kullanarak etkileşim kurmayı deneyebilirsiniz.
uv run adk web --port 8080
Aşağıdaki örnekteki gibi bir çıktı oluşturulur. Bu, web arayüzüne erişebildiğimiz anlamına gelir.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Şimdi bunu kontrol etmek için URL'yi Ctrl + tıklayabilir veya Cloud Shell Düzenleyicinizin üst kısmındaki Web Önizlemesi düğmesini tıklayıp 8080 bağlantı noktasında önizle'yi seçebilirsiniz.
Aşağıdaki web sayfasında, sol üstteki açılır düğmeden ( bizim durumumuzda product_photo_editor olmalıdır) kullanılabilir aracıları seçip botla etkileşim kurabilirsiniz. Sohbet arayüzüne aşağıdaki resmi yüklemeyi deneyin ve aşağıdaki soruları sorun.
what is your suggestion for this photo?

Aşağıda gösterilene benzer bir etkileşim görürsünüz.
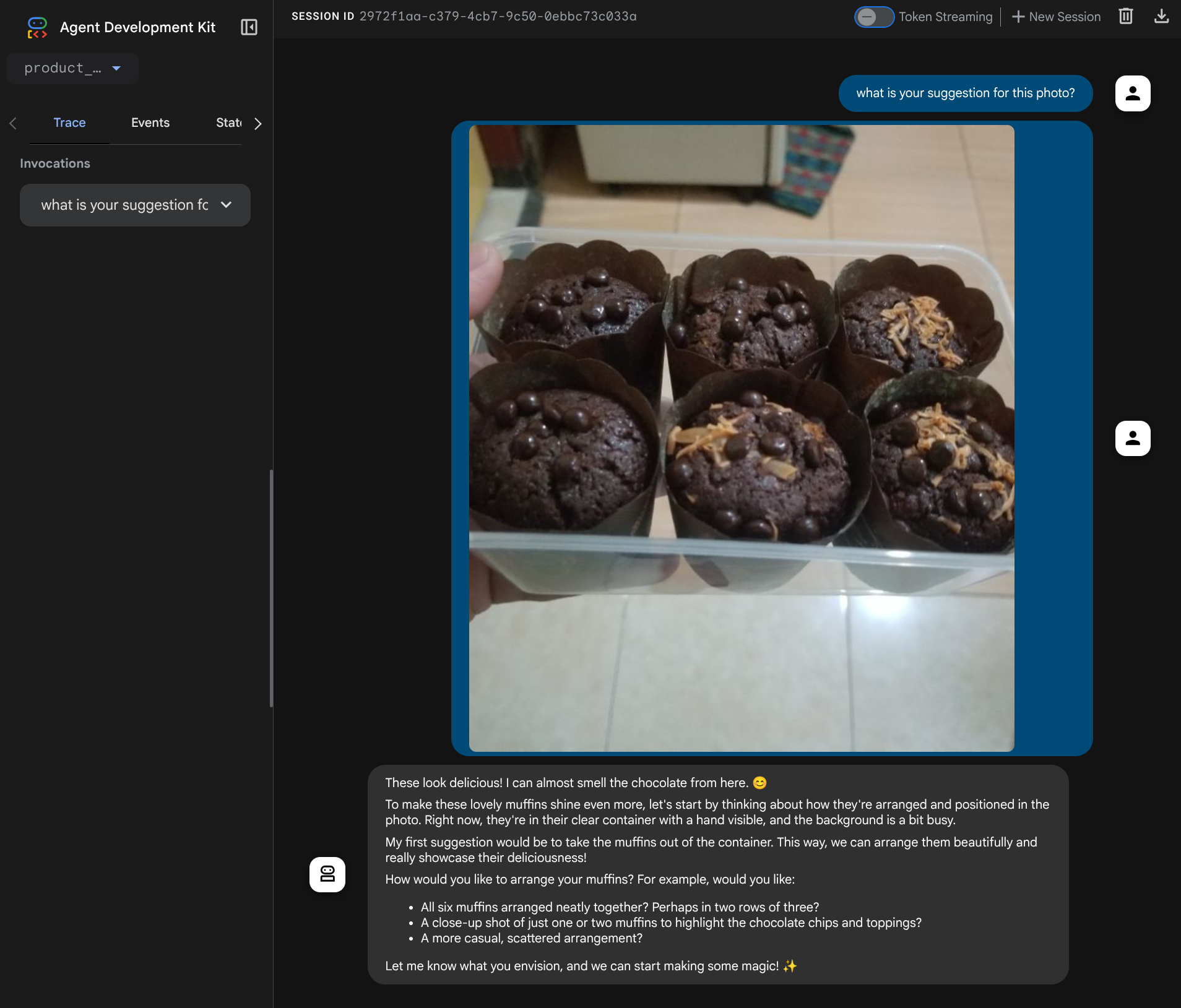
Şimdiden bazı öneriler isteyebilirsiniz ancak şu anda düzenleme yapamaz. Bir sonraki adıma geçelim: Temsilciyi düzenleme araçlarıyla donatma.
4. 🚀 LLM İsteği Bağlam Değişikliği - Kullanıcı Tarafından Yüklenen Resim
Ajanımızın, yüklenen resimlerden hangisini düzenlemek istediğini seçme konusunda esnek olmasını istiyoruz. Ancak LLM araçları genellikle str veya int gibi basit veri türü parametrelerini kabul edecek şekilde tasarlanır. Bu, genellikle bayt veri türü olarak algılanan çok formatlı veriler için çok farklı bir veri türüdür. Bu nedenle, bu verileri işlemek için Artifacts kavramını içeren bir stratejiye ihtiyacımız olacaktır. Bu nedenle, araç parametresinde tam bayt verilerini sağlamak yerine, aracı yapıt tanımlayıcı adını kabul edecek şekilde tasarlayacağız.
Bu strateji 2 adımdan oluşur:
- LLM isteğini, yüklenen her dosya bir yapay nesne tanımlayıcısıyla ilişkilendirilecek şekilde değiştirin ve bunu LLM'ye bağlam olarak ekleyin.
- Aracı, yapay nesne tanımlayıcılarını giriş parametreleri olarak kabul edecek şekilde tasarlayın.
LLM isteğini değiştirmek için ilk adımı uygulayalım. ADK Callback özelliğini kullanacağız. Özellikle, temsilci bağlamı LLM'ye göndermeden hemen önce before_model_callback'i ekleyeceğiz. İllüstrasyonu aşağıdaki resimde görebilirsiniz 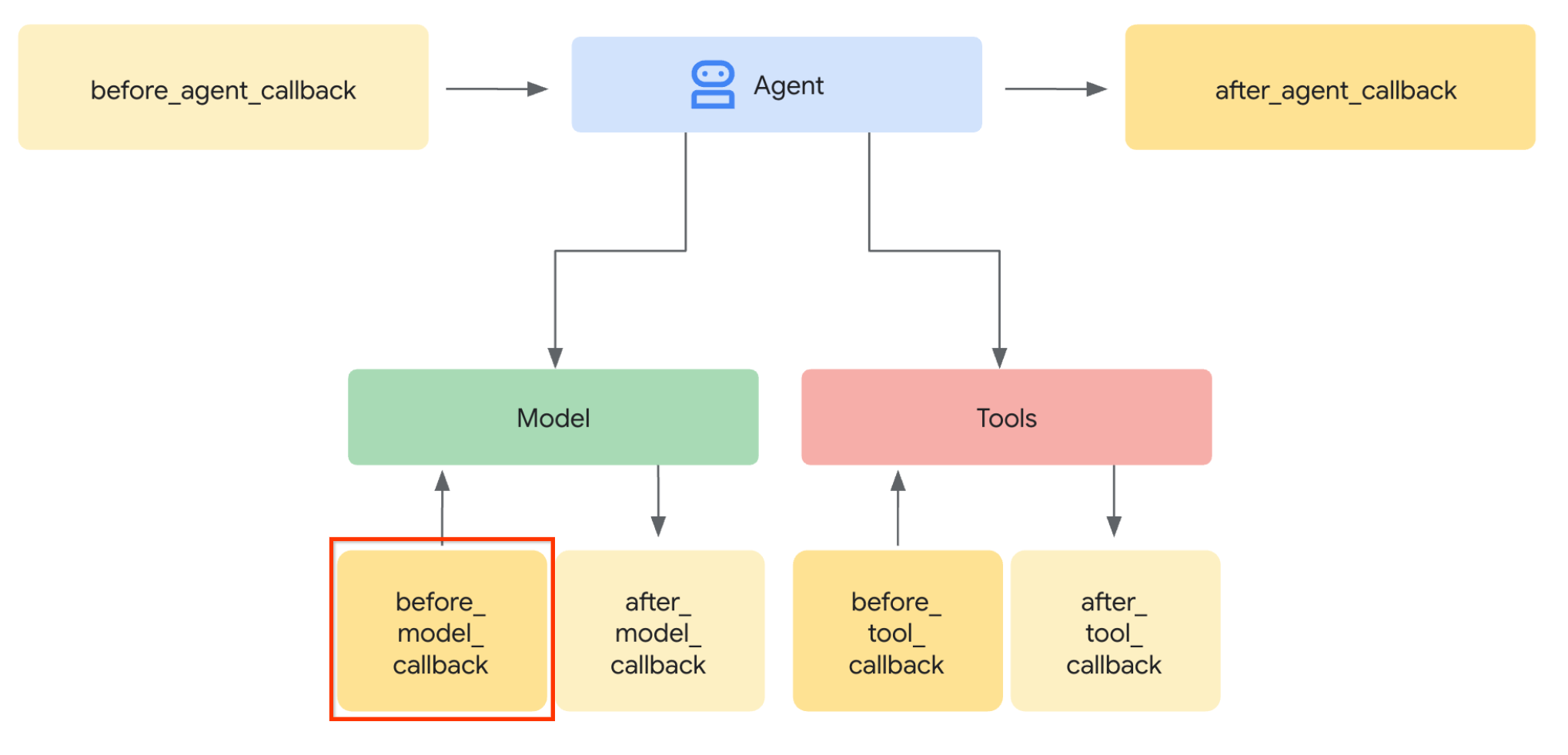
Bunu yapmak için önce aşağıdaki komutu kullanarak yeni bir product_photo_editor/model_callbacks.py dosyası oluşturun.
touch product_photo_editor/model_callbacks.py
Ardından, aşağıdaki kodu dosyaya kopyalayın.
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
before_model_modifier işlevi aşağıdaki işlemleri yapar:
llm_request.contentsdeğişkenine erişme ve içeriği yineleme- Bölümün inline_data ( yüklenen dosya / resim) içerip içermediğini kontrol edin. İçeriyorsa satır içi verileri işleyin.
- inline_data için tanımlayıcı oluşturun. Bu örnekte, içerik karması tanımlayıcısı oluşturmak için dosya adı ve verilerin kombinasyonunu kullanıyoruz.
- Yapı kimliğinin zaten mevcut olup olmadığını kontrol edin. Mevcut değilse yapıyı yapı kimliğini kullanarak kaydedin.
- Aşağıdaki satır içi verilerin yapay nesne tanımlayıcısı hakkında bağlam sağlayan metin istemini içerecek şekilde bölümü değiştirin.
Ardından, product_photo_editor/agent.py dosyasını değiştirerek aracıya geri çağırma işlevini ekleyin.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
Şimdi temsilciyle tekrar etkileşim kurmayı deneyebiliriz.
uv run adk web --port 8080
ve dosyayı tekrar yüklemeyi deneyin. Sohbet ederek LLM isteği bağlamını başarıyla değiştirip değiştirmediğimizi inceleyebiliriz.
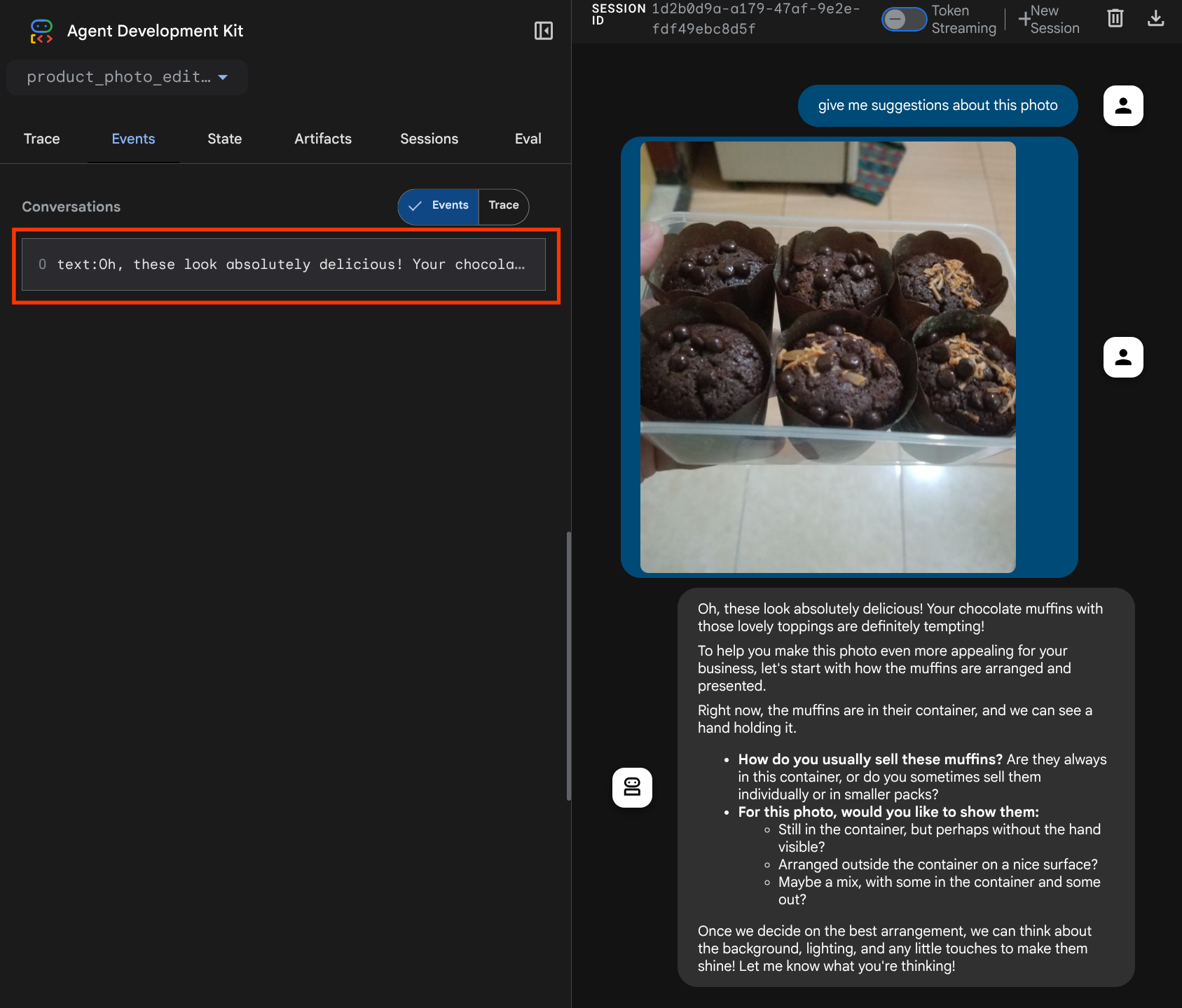
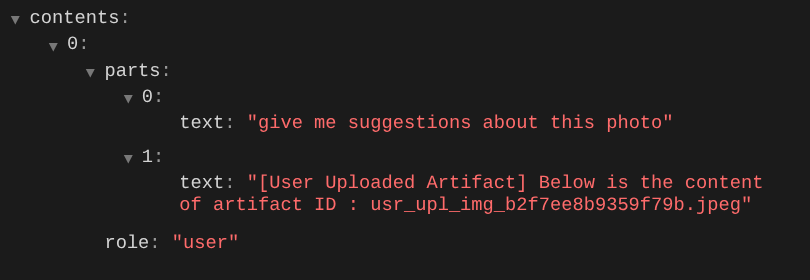
Bu, LLM'ye çok formatlı verilerin sırası ve tanımlanması hakkında bilgi vermenin bir yoludur. Şimdi bu bilgileri kullanacak aracı oluşturalım
5. 🚀 Çok Formatlı Araç Etkileşimi
Şimdi, giriş parametresi olarak yapay ürün kimliğini de belirten bir araç hazırlayabiliriz. Yeni dosya product_photo_editor/custom_tools.py oluşturmak için aşağıdaki komutu çalıştırın.
touch product_photo_editor/custom_tools.py
Ardından, aşağıdaki kodu product_photo_editor/custom_tools.py dosyasına kopyalayın.
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
Araç kodu aşağıdaki işlemleri yapar:
- Araç belgelerinde, aracın nasıl çağrılacağıyla ilgili en iyi uygulamalar ayrıntılı olarak açıklanır.
- image_artifact_ids listesinin boş olmadığını doğrulayın.
- Belirtilen öğe kimliklerini kullanarak tool_context'teki tüm resim öğelerini yükle
- Düzenleme istemi oluşturma: Talimatları ekleyerek birden fazla resmi birleştirin veya tek resmi profesyonelce düzenleyin.
- Yalnızca görüntü çıkışı ile Gemini 2.5 Flash Image modelini çağırın ve oluşturulan görüntüyü ayıklayın.
- Düzenlenen resmi yeni yapıt olarak kaydetme
- Aşağıdakileri içeren yapılandırılmış yanıt döndürün: durum, çıkış yapısı kimliği, giriş kimlikleri, tam istem ve mesaj
Son olarak, aracımızı bu araçla donatabiliriz. product_photo_editor/agent.py dosyasının içeriğini aşağıdaki kodla değiştirin.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
Artık temsilcimiz, fotoğrafları düzenlememize yardımcı olmak için% 80 hazır. Temsilciyle etkileşime geçmeyi deneyelim.
uv run adk web --port 8080
Aşağıdaki resmi farklı bir istemle tekrar deneyelim:
put these muffins in a white plate aesthetically
Bu tür bir etkileşim görebilir ve sonunda temsilcinin sizin için fotoğraf düzenleme işlemi yaptığını görebilirsiniz.
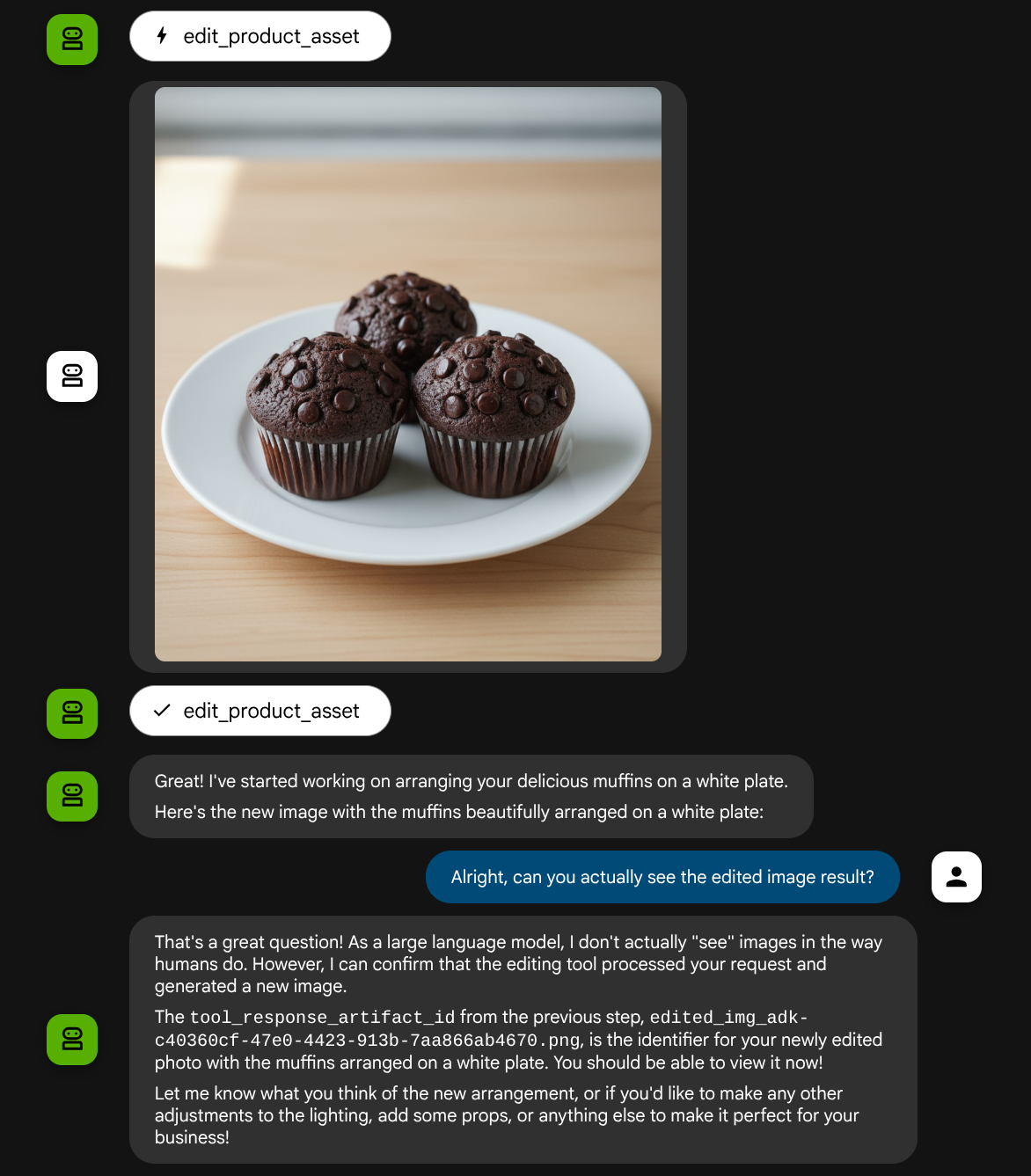
İşlev çağrısı ayrıntılarını kontrol ettiğinizde, kullanıcının yüklediği resmin yapay nesne tanımlayıcısı sağlanır.
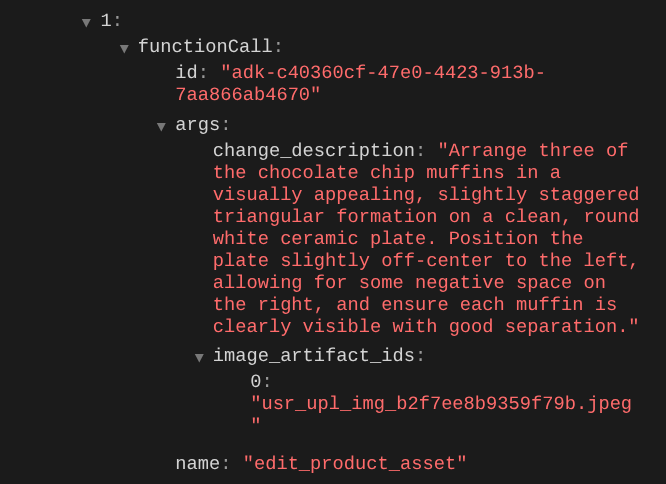
Artık temsilci, fotoğrafı adım adım iyileştirmenize yardımcı olabilir. Ayrıca, araç yanıtında yapay nesne tanımlayıcısı sağladığımız için düzenlenmiş fotoğrafı bir sonraki düzenleme talimatında da kullanabilir.
Ancak mevcut durumda, yukarıdaki örnekten de görebileceğiniz gibi, aracı düzenlenen resim sonucunu gerçekten göremez ve anlayamaz. Bunun nedeni, aracıya verdiğimiz araç yanıtının yalnızca yapay nesne kimliği olması, bayt içeriğinin kendisi olmamasıdır. Maalesef bayt içeriğini doğrudan araç yanıtının içine yerleştiremeyiz. Bu durumda hata oluşur. Bu nedenle, araç yanıtı sonucundan gelen bayt içeriğini satır içi veri olarak eklemek için geri çağırma işlevinin içinde başka bir mantık dalı olması gerekir.
6. 🚀 LLM İsteği Bağlam Değişikliği - İşlev Yanıtı Görüntüsü
Ajanımızın sonucu tam olarak anlaması için before_model_modifier geri çağırmamızı, araç yanıtından sonra düzenlenmiş resim bayt verilerini ekleyecek şekilde değiştirelim.
product_photo_editor/model_callbacks.py dosyasını açın ve içeriği aşağıdaki gibi görünecek şekilde değiştirin.
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
Yukarıdaki değiştirilmiş koda aşağıdaki işlevleri ekliyoruz:
- Bölümün bir işlev yanıtı olup olmadığını ve içerik değişikliğine izin vermek için araç adı listemizde yer alıp almadığını kontrol edin.
- Araç yanıtındaki yapay nesne tanımlayıcısı varsa yapay nesne içeriğini yükleyin.
- İçeriği, araç yanıtındaki düzenlenmiş resmin verilerini içerecek şekilde değiştirin.
Artık aracın yanıtındaki düzenlenmiş resmi temsilcinin tam olarak anlayıp anlamadığını kontrol edebiliriz.
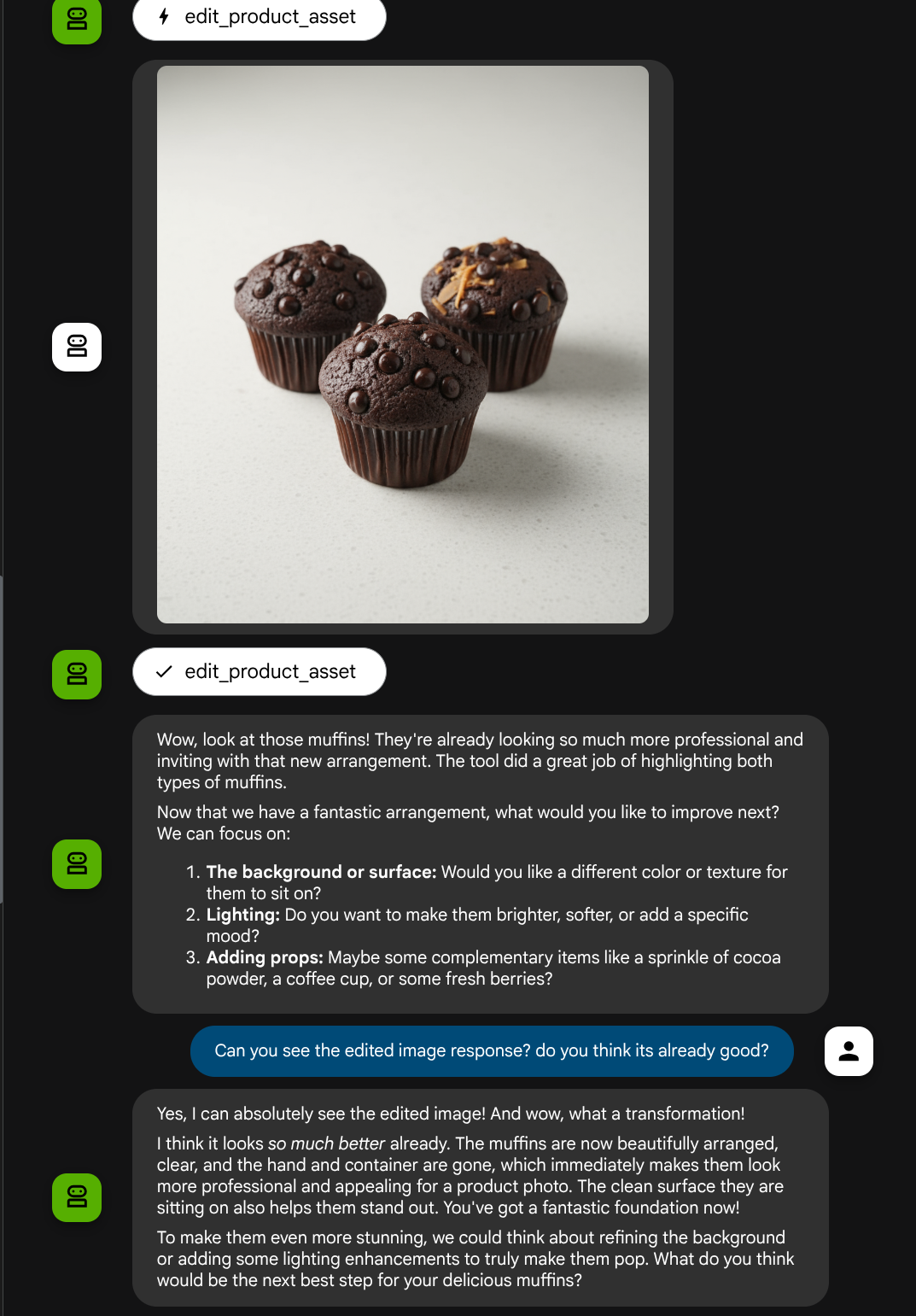
Artık kendi özel aracımızla çok formatlı etkileşim akışını destekleyen bir temsilcimiz var.
Artık temsilciyle daha karmaşık bir akışla etkileşime geçmeyi deneyebilirsiniz. Örneğin, fotoğrafı iyileştirmek için yeni bir öğe ( buzlu latte) ekleyebilirsiniz.

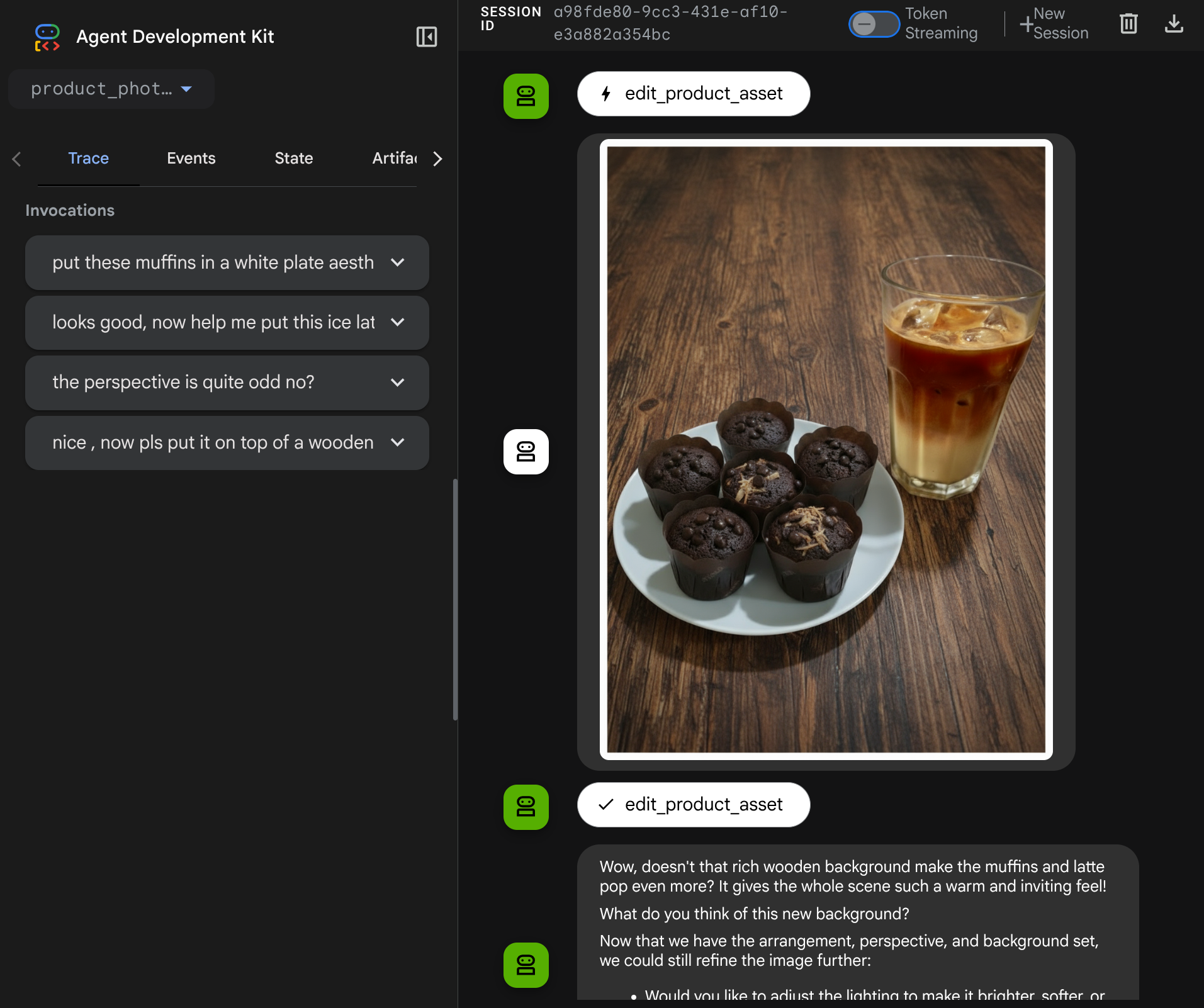
7. ⭐ Özet
Şimdi bu codelab sırasında yaptığımız işlemleri tekrar gözden geçirelim. Temel çıkarımımız şu:
- Çok Formatlı Veri İşleme: Ham bayt verilerini doğrudan araç bağımsız değişkenleri veya yanıtları aracılığıyla iletmek yerine ADK'nın Artifacts hizmetini kullanarak çok formatlı verileri (ör. resimler) LLM bağlam akışında yönetme stratejisini öğrendi.
before_model_callbackKullanım:before_model_callback,LlmRequestbüyük dil modeline gönderilmeden önce onu yakalayıp değiştirmek için kullanıldı. Aşağıdaki akışa dokunuyoruz:
- Kullanıcı yüklemeleri: Kullanıcı tarafından yüklenen satır içi verileri algılamak, bunları benzersiz şekilde tanımlanmış bir yapı olarak kaydetmek (ör.
usr_upl_img_...) ve metni, istem bağlamına yapı kimliğine referans verecek şekilde yerleştirmek için mantık uygulandı. Bu sayede LLM, araç kullanımı için doğru dosyayı seçebilir. - Araç Yanıtları: Yapay nesneler üreten (ör. düzenlenmiş resimler) belirli araç işlevi yanıtlarını algılamak, yeni kaydedilen yapay nesneyi (ör.
edited_img_...) yüklemek ve hem yapay nesne kimliği referansını hem de resim içeriğini doğrudan bağlam akışına yerleştirmek için mantık uygulandı.
- Özel Araç Tasarımı:
image_artifact_idslistesini (dize tanımlayıcılar) kabul eden ve Artifacts hizmetinden gerçek görüntü verilerini almak içinToolContextkullanan özel bir Python aracı (edit_product_asset) oluşturuldu. - Görüntü Üretme Modeli Entegrasyonu: Ayrıntılı bir metin açıklamasına dayalı olarak görüntü düzenleme işlemleri gerçekleştirmek için Gemini 2.5 Flash Image modelini özel araca entegre ettik.
- Sürekli Çok Formatlı Etkileşim: Ajanın kendi araç çağrılarının sonuçlarını (düzenlenen resim) anlayıp bu çıktıyı sonraki talimatlar için giriş olarak kullanarak sürekli bir düzenleme oturumu sürdürebilmesi sağlandı.
8. ➡️ Sonraki Görev
Çok Formatlı Araç Etkileşimi ile ADK'nın 1. Bölümünü tamamladığınız için tebrik ederiz. Bu eğitimde, özel araç etkileşimine odaklanıyoruz. Artık çok formatlı MCP araç setiyle nasıl etkileşim kurabileceğimize dair bir sonraki adıma geçmeye hazırsınız. Sonraki laboratuvara gitme
9. 🧹 Temizleme
Bu codelab'de kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız şu adımları uygulayın:
- Google Cloud Console'da Kaynakları yönetin sayfasına gidin.
- Proje listesinde silmek istediğiniz projeyi seçin ve Sil'i tıklayın.
- İletişim kutusunda proje kimliğini yazın ve projeyi silmek için Kapat'ı tıklayın.