
1. 📖 Giới thiệu
Lớp học lập trình này minh hoạ cách thiết kế một hoạt động tương tác với công cụ đa phương thức trong Bộ công cụ phát triển tác nhân (ADK). Đây là một quy trình cụ thể mà bạn muốn tác nhân tham chiếu đến tệp đã tải lên làm dữ liệu đầu vào cho một công cụ, đồng thời hiểu được nội dung tệp do phản hồi của công cụ tạo ra. Do đó, bạn có thể tương tác như trong ảnh chụp màn hình bên dưới. Trong hướng dẫn này, chúng ta sẽ phát triển một tác nhân có khả năng giúp người dùng chỉnh sửa ảnh đẹp hơn cho trường hợp giới thiệu sản phẩm của họ
Trong lớp học lập trình này, bạn sẽ sử dụng phương pháp từng bước như sau:
- Chuẩn bị dự án trên đám mây của Google
- Thiết lập thư mục công việc cho môi trường lập trình
- Khởi chạy tác nhân bằng ADK
- Thiết kế một công cụ có thể dùng để chỉnh sửa ảnh dựa trên Gemini 2.5 Flash Image
- Thiết kế một hàm callback để xử lý việc tải hình ảnh người dùng lên, lưu hình ảnh đó dưới dạng cấu phần phần mềm và thêm hình ảnh đó làm bối cảnh cho tác nhân
- Thiết kế một hàm callback để xử lý hình ảnh do phản hồi của công cụ tạo ra, lưu hình ảnh đó dưới dạng cấu phần phần mềm và thêm hình ảnh đó làm ngữ cảnh cho tác nhân
Tổng quan về cấu trúc
Tương tác tổng thể trong lớp học lập trình này được minh hoạ trong sơ đồ sau
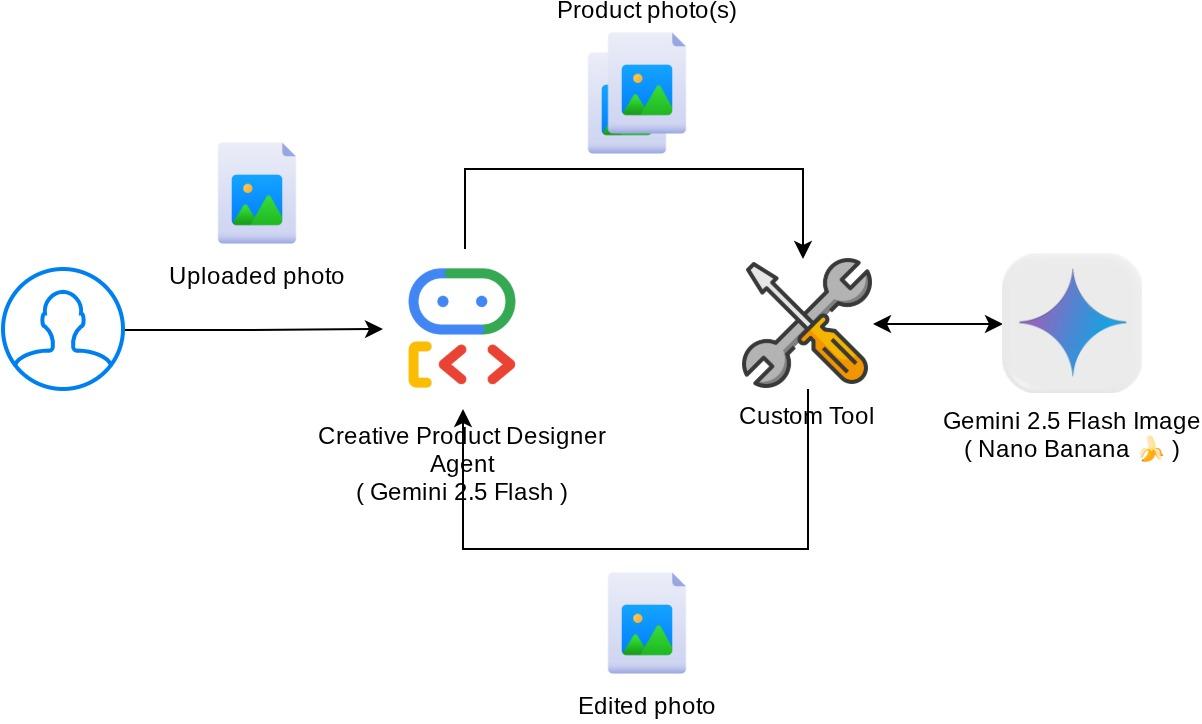
Điều kiện tiên quyết
- Thoải mái khi làm việc với Python
- (Không bắt buộc) Các lớp học lập trình cơ bản về Bộ công cụ phát triển tác nhân (ADK)
Kiến thức bạn sẽ học được
- Cách sử dụng bối cảnh gọi lại để truy cập vào dịch vụ tạo tác
- Cách thiết kế công cụ với tính năng truyền dữ liệu đa phương thức phù hợp
- Cách sửa đổi yêu cầu llm của tác nhân để thêm ngữ cảnh của cấu phần phần mềm thông qua before_model_callback
- Cách chỉnh sửa hình ảnh bằng Gemini 2.5 Flash Image
Bạn cần có
- Trình duyệt web Chrome
- Tài khoản Gmail
- Một Dự án trên đám mây đã bật tài khoản thanh toán
Lớp học lập trình này được thiết kế cho nhà phát triển ở mọi cấp độ (kể cả người mới bắt đầu), sử dụng Python trong ứng dụng mẫu. Tuy nhiên, bạn không cần có kiến thức về Python để hiểu các khái niệm được trình bày.
2. 🚀 Chuẩn bị thiết lập môi trường phát triển cho hội thảo
Bước 1: Chọn Dự án đang hoạt động trong Cloud Console
Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud (xem phần trên cùng bên trái của bảng điều khiển)

Nhấp vào biểu tượng đó, bạn sẽ thấy danh sách tất cả dự án của mình như ví dụ này:
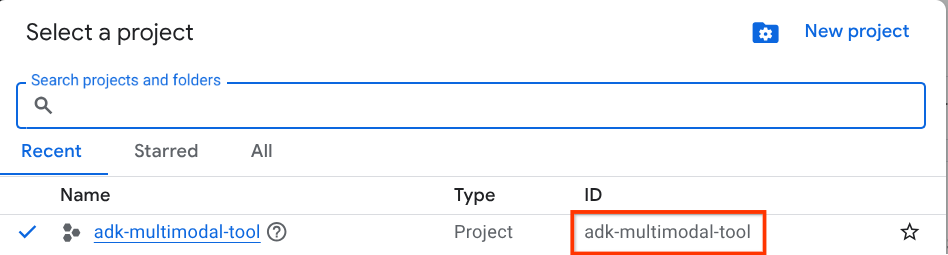
Giá trị được biểu thị bằng hộp màu đỏ là MÃ DỰ ÁN và giá trị này sẽ được dùng trong suốt hướng dẫn.
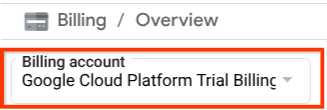
Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Cloud. Để kiểm tra, hãy nhấp vào biểu tượng trình đơn ☰ ở thanh trên cùng bên trái để xem Trình đơn điều hướng và tìm trình đơn Thanh toán

Nếu bạn thấy "Tài khoản thanh toán dùng thử của Google Cloud Platform" trong phần Thanh toán / Tổng quan ( phần trên cùng bên trái của bảng điều khiển Cloud), thì dự án của bạn đã sẵn sàng để sử dụng cho hướng dẫn này. Nếu không, hãy quay lại đầu hướng dẫn này và sử dụng tài khoản thanh toán dùng thử
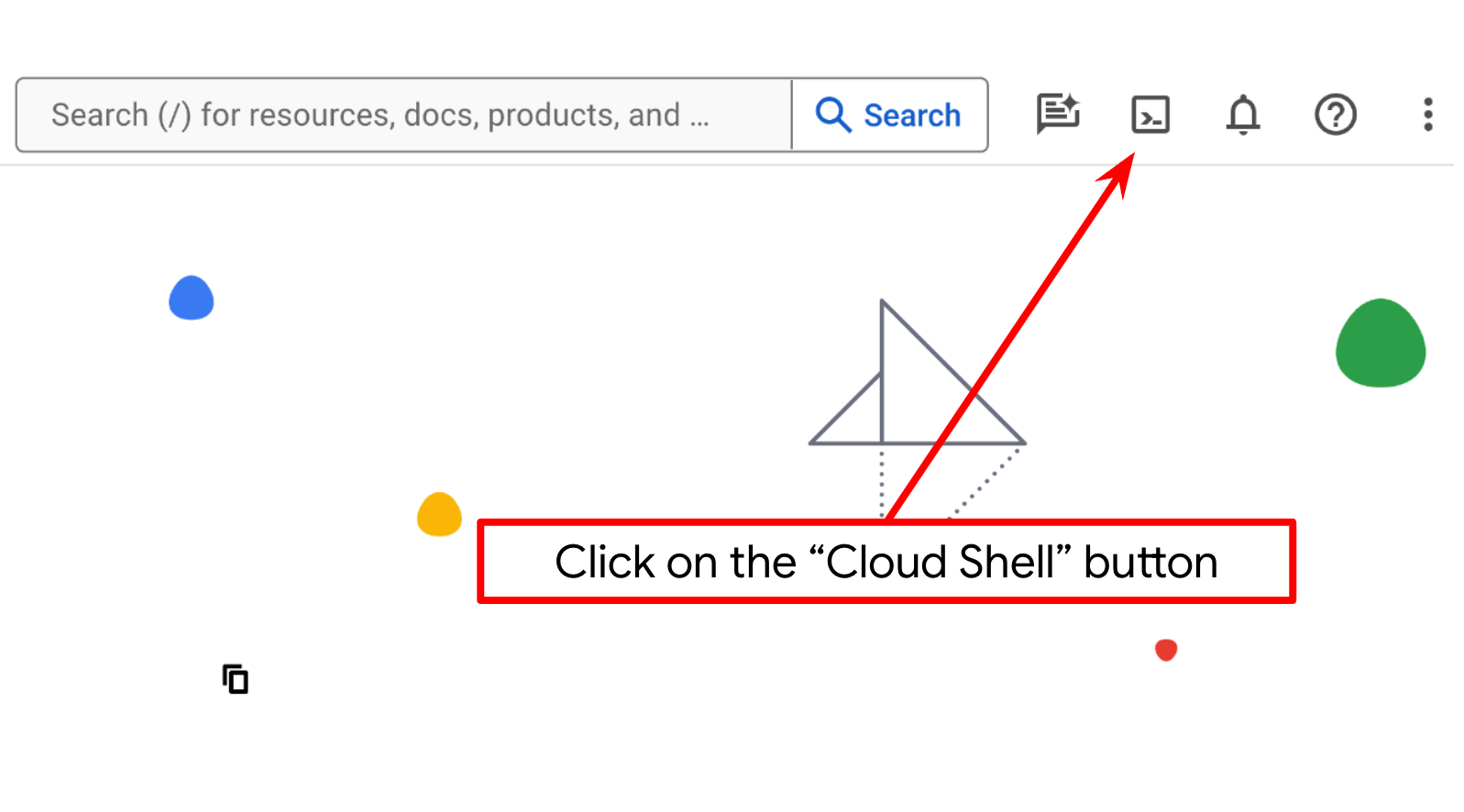
Bước 2: Làm quen với Cloud Shell
Bạn sẽ sử dụng Cloud Shell cho hầu hết các phần của hướng dẫn. Hãy nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Google Cloud. Nếu hệ thống nhắc bạn uỷ quyền, hãy nhấp vào Uỷ quyền
Sau khi kết nối với Cloud Shell, chúng ta cần kiểm tra xem shell ( hoặc cửa sổ dòng lệnh) đã được xác thực bằng tài khoản của chúng ta hay chưa
gcloud auth list
Nếu bạn thấy gmail cá nhân của mình như ví dụ về đầu ra bên dưới, thì mọi thứ đều ổn
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Nếu không, hãy thử làm mới trình duyệt và đảm bảo bạn nhấp vào Uỷ quyền khi được nhắc ( quá trình này có thể bị gián đoạn do sự cố kết nối)
Tiếp theo, chúng ta cũng cần kiểm tra xem shell đã được định cấu hình thành PROJECT ID chính xác mà bạn có hay chưa. Nếu thấy có giá trị bên trong ( ) trước biểu tượng $ trong thiết bị đầu cuối ( trong ảnh chụp màn hình bên dưới, giá trị là "adk-multimodal-tool"), thì giá trị này cho biết dự án đã định cấu hình cho phiên shell đang hoạt động của bạn.

Nếu giá trị được hiển thị đã chính xác, bạn có thể bỏ qua lệnh tiếp theo. Tuy nhiên, nếu không chính xác hoặc bị thiếu, hãy chạy lệnh sau
gcloud config set project <YOUR_PROJECT_ID>
Sau đó, hãy sao chép thư mục làm việc của mẫu cho lớp học lập trình này từ GitHub bằng cách chạy lệnh sau. Thao tác này sẽ tạo thư mục làm việc trong thư mục adk-multimodal-tool
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
Bước 3: Làm quen với Cloud Shell Editor và thiết lập thư mục làm việc của ứng dụng
Bây giờ, chúng ta có thể thiết lập trình soạn thảo mã để thực hiện một số việc liên quan đến lập trình. Chúng ta sẽ sử dụng Trình chỉnh sửa Cloud Shell cho việc này
Nhấp vào nút Open Editor (Mở trình chỉnh sửa). Thao tác này sẽ mở Cloud Shell Editor 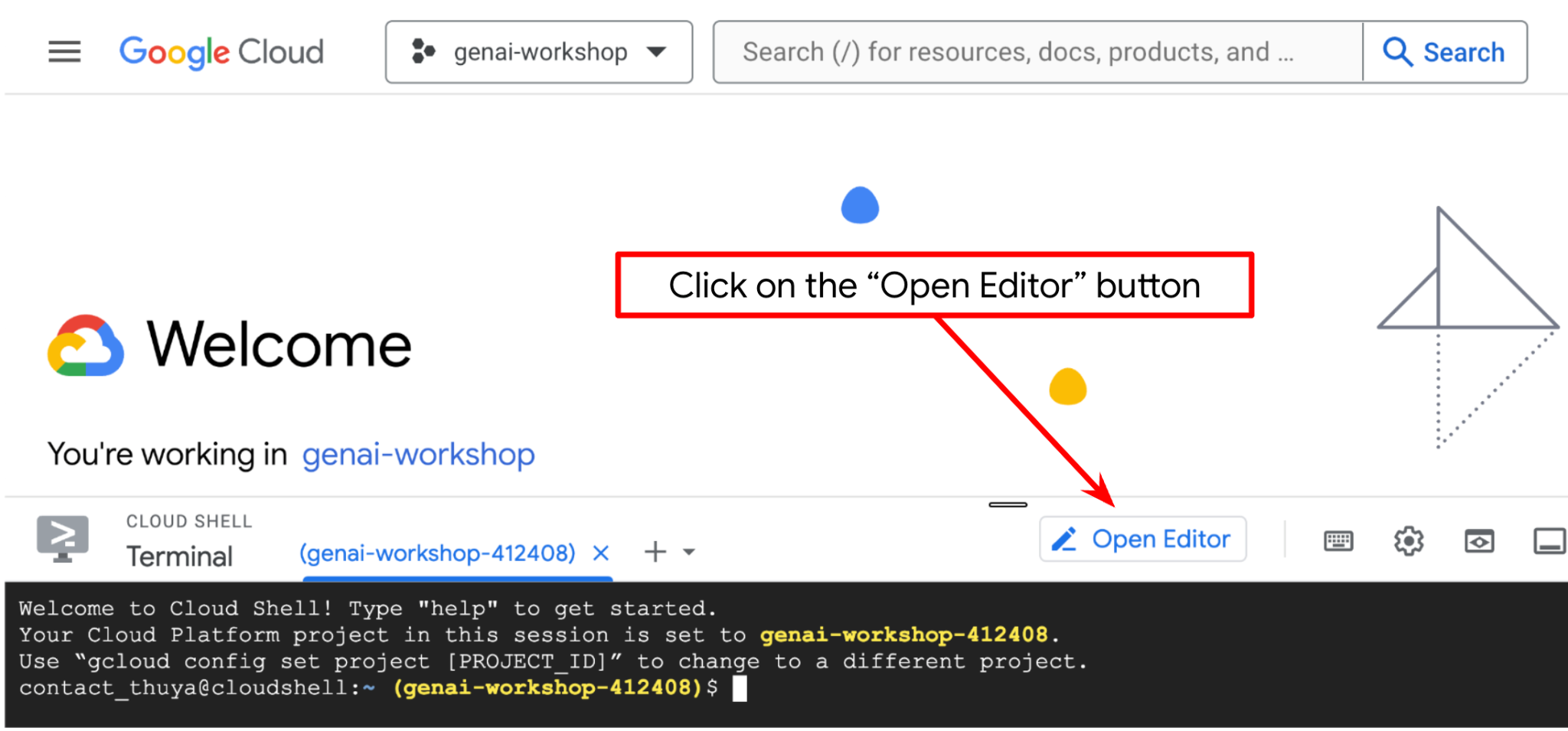
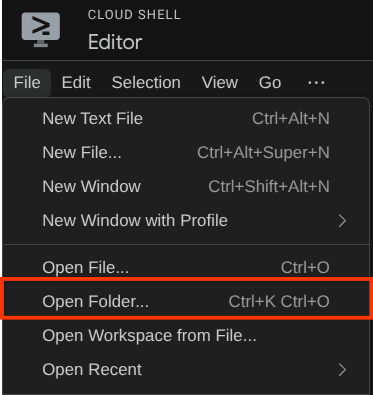
Sau đó, hãy chuyển đến phần trên cùng của Cloud Shell Editor rồi nhấp vào File->Open Folder (Tệp->Mở thư mục), tìm thư mục username (tên người dùng) của bạn, tìm thư mục adk-multimodal-tool (công cụ đa phương thức adk) rồi nhấp vào nút OK. Thao tác này sẽ đặt thư mục đã chọn làm thư mục làm việc chính. Trong ví dụ này, tên người dùng là alvinprayuda, do đó, đường dẫn thư mục sẽ xuất hiện bên dưới
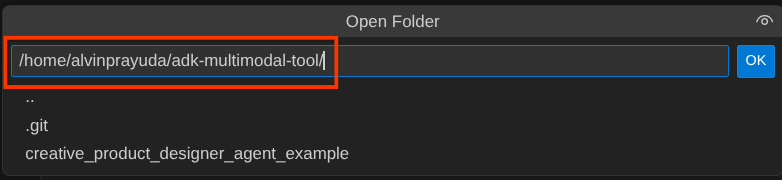
Giờ đây, thư mục làm việc của Cloud Shell Editor sẽ có dạng như sau ( trong adk-multimodal-tool)
Bây giờ, hãy mở cửa sổ dòng lệnh cho trình chỉnh sửa. Bạn có thể thực hiện việc này bằng cách nhấp vào Terminal -> New Terminal (Cửa sổ dòng lệnh -> Cửa sổ dòng lệnh mới) trên thanh trình đơn hoặc sử dụng tổ hợp phím Ctrl + Shift + C. Thao tác này sẽ mở một cửa sổ dòng lệnh ở phần dưới cùng của trình duyệt

Thiết bị đầu cuối đang hoạt động hiện tại của bạn phải nằm trong thư mục làm việc adk-multimodal-tool. Chúng ta sẽ sử dụng Python 3.12 trong lớp học lập trình này và sẽ dùng trình quản lý dự án uv python để đơn giản hoá nhu cầu tạo và quản lý phiên bản Python cũng như môi trường ảo. Gói uv này đã được cài đặt sẵn trên Cloud Shell.
Chạy lệnh này để cài đặt các phần phụ thuộc cần thiết cho môi trường ảo trong thư mục .venv
uv sync --frozen
Kiểm tra pyproject.toml để xem các phần phụ thuộc đã khai báo cho hướng dẫn này là google-adk, and python-dotenv.
Bây giờ, chúng ta sẽ cần bật các API bắt buộc thông qua lệnh bên dưới. Quá trình này có thể mất chút thời gian.
gcloud services enable aiplatform.googleapis.com
Khi thực thi lệnh thành công, bạn sẽ thấy một thông báo tương tự như thông báo dưới đây:
Operation "operations/..." finished successfully.
3. 🚀 Khởi chạy tác nhân ADK
Trong bước này, chúng ta sẽ khởi tạo tác nhân bằng ADK CLI, chạy lệnh sau
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
Lệnh này sẽ giúp bạn nhanh chóng cung cấp cấu trúc bắt buộc cho tác nhân của mình như minh hoạ dưới đây:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
Sau đó, hãy chuẩn bị tác nhân trình chỉnh sửa ảnh sản phẩm. Trước tiên, hãy sao chép prompt.py đã có trong kho lưu trữ vào thư mục tác nhân mà bạn đã tạo trước đó
cp prompt.py product_photo_editor/prompt.py
Sau đó, hãy mở product_photo_editor/agent.py và sửa đổi nội dung bằng đoạn mã sau
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Giờ đây, bạn sẽ có một trợ lý chỉnh sửa ảnh cơ bản mà bạn có thể trò chuyện để yêu cầu đề xuất cho ảnh của mình. Bạn có thể thử tương tác với nó bằng lệnh này
uv run adk web --port 8080
Lệnh này sẽ tạo ra kết quả như ví dụ sau, tức là chúng ta đã có thể truy cập vào giao diện web
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Giờ đây, để kiểm tra, bạn có thể nhấn tổ hợp phím Ctrl + Nhấp vào URL hoặc nhấp vào nút Xem trước trên web ở khu vực trên cùng của Cloud Shell Editor rồi chọn Xem trước trên cổng 8080
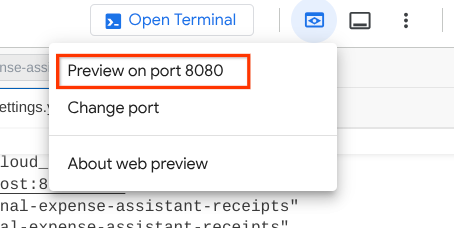
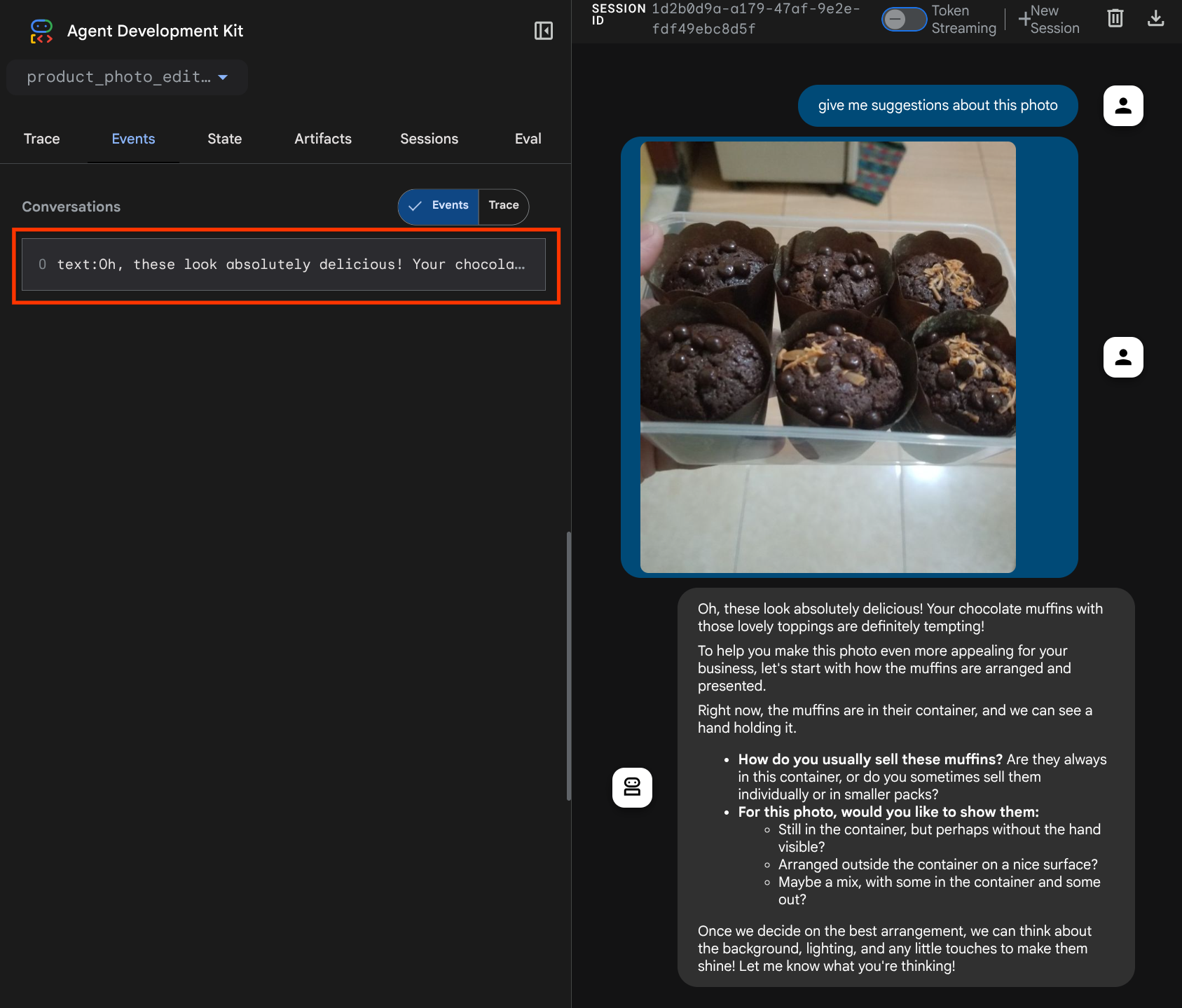
Bạn sẽ thấy trang web sau đây, nơi bạn có thể chọn các tác nhân có sẵn trên nút thả xuống ở trên cùng bên trái ( trong trường hợp của chúng tôi, đó là product_photo_editor) và tương tác với bot. Hãy thử tải hình ảnh sau lên giao diện trò chuyện và đặt các câu hỏi sau
what is your suggestion for this photo?

Bạn sẽ thấy hoạt động tương tác tương tự như minh hoạ bên dưới
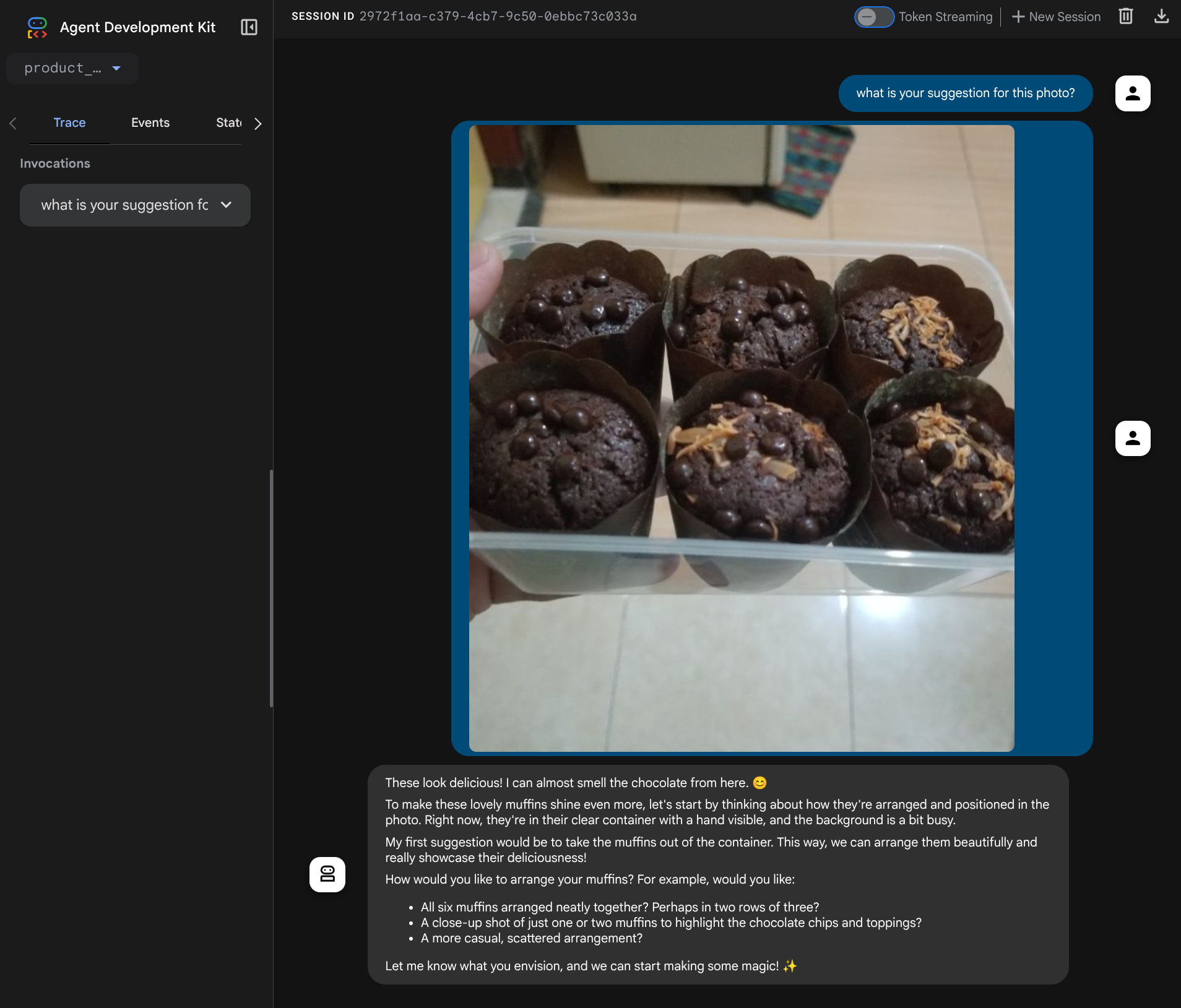
Bạn đã có thể yêu cầu một số đề xuất, tuy nhiên, hiện tại Gemini không thể chỉnh sửa cho bạn. Hãy chuyển sang bước tiếp theo, trang bị cho nhân viên các công cụ chỉnh sửa.
4. 🚀 LLM Request Context Modification - User Uploaded Image
Chúng ta muốn tác nhân của mình linh hoạt trong việc chọn hình ảnh đã tải lên mà tác nhân muốn chỉnh sửa. Tuy nhiên, các công cụ LLM thường được thiết kế để chấp nhận các tham số kiểu dữ liệu đơn giản như str hoặc int. Đây là một kiểu dữ liệu rất khác đối với dữ liệu đa phương thức thường được coi là kiểu dữ liệu bytes. Do đó, chúng ta sẽ cần một chiến lược liên quan đến khái niệm Artifacts để xử lý những dữ liệu đó. Vì vậy, thay vì cung cấp dữ liệu đầy đủ theo byte trong tham số công cụ, chúng tôi sẽ thiết kế công cụ để chấp nhận tên mã nhận dạng cấu phần phần mềm.
Chiến lược này sẽ bao gồm 2 bước:
- sửa đổi yêu cầu LLM để mỗi tệp được tải lên đều được liên kết với một giá trị nhận dạng cấu phần phần mềm và thêm giá trị nhận dạng này làm bối cảnh cho LLM
- Thiết kế công cụ để chấp nhận giá trị nhận dạng cấu phần phần mềm làm tham số đầu vào
Hãy thực hiện bước đầu tiên. Để sửa đổi yêu cầu LLM, chúng ta sẽ sử dụng tính năng Callback của ADK. Cụ thể, chúng ta sẽ thêm before_model_callback để khai thác ngay trước khi tác nhân gửi ngữ cảnh đến LLM. Bạn có thể xem hình minh hoạ trong hình ảnh bên dưới 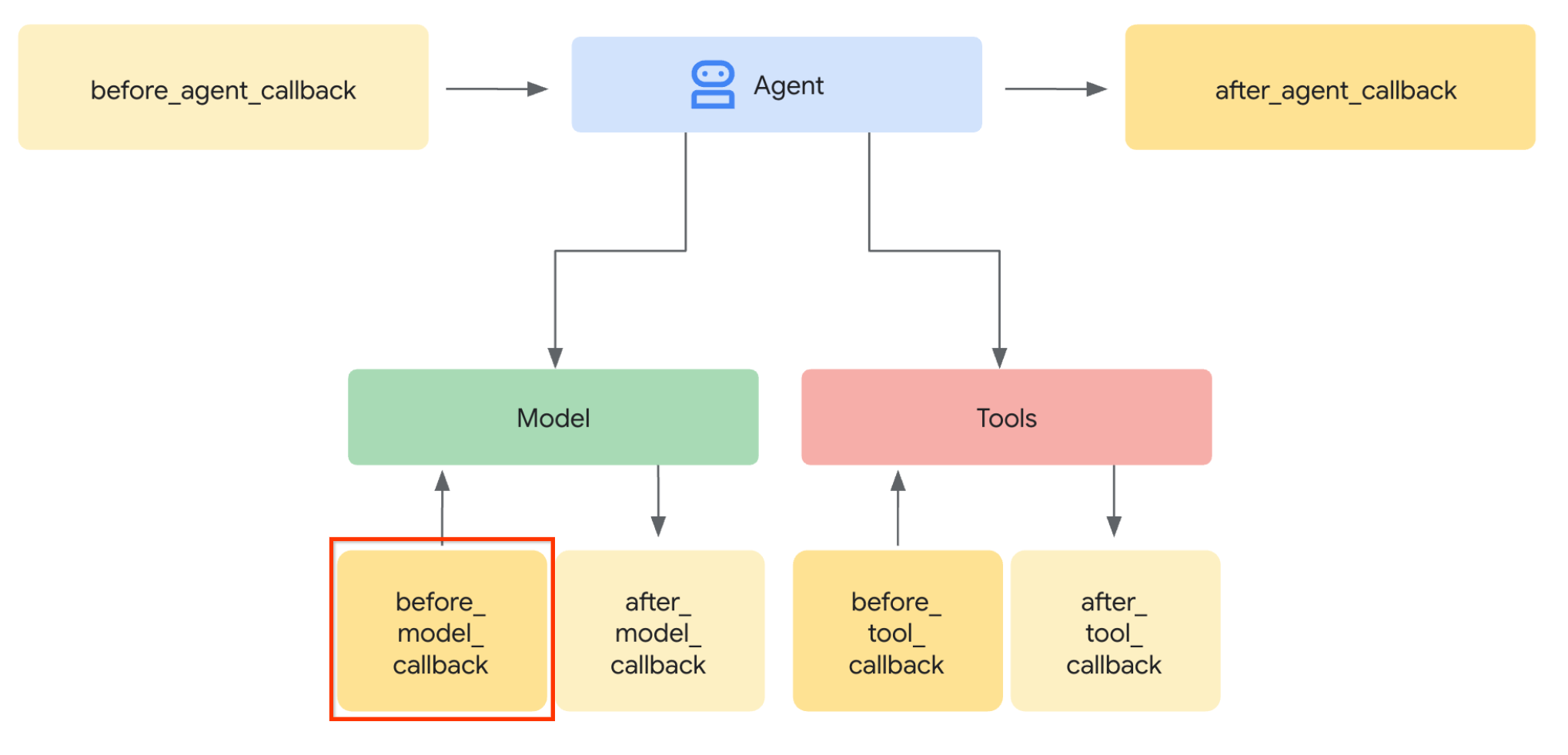
Để làm việc này, trước tiên, hãy tạo một tệp mới product_photo_editor/model_callbacks.py bằng lệnh sau
touch product_photo_editor/model_callbacks.py
Sau đó, sao chép mã sau vào tệp
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
Hàm before_model_modifier thực hiện những việc sau:
- Truy cập vào biến
llm_request.contentsvà lặp lại nội dung - Kiểm tra xem part có chứa inline_data ( tệp / hình ảnh được tải lên) hay không, nếu có, hãy xử lý dữ liệu nội tuyến
- Tạo giá trị nhận dạng cho inline_data, trong ví dụ này, chúng ta đang sử dụng tổ hợp tên tệp + dữ liệu để tạo giá trị nhận dạng băm nội dung
- Kiểm tra xem mã nhận dạng cấu phần phần mềm đã tồn tại hay chưa, nếu chưa, hãy lưu cấu phần phần mềm bằng mã nhận dạng cấu phần phần mềm
- Sửa đổi phần này để thêm câu lệnh văn bản cung cấp bối cảnh về mã nhận dạng cấu phần phần mềm của dữ liệu cùng dòng sau đây
Sau đó, hãy sửa đổi product_photo_editor/agent.py để trang bị cho tác nhân lệnh gọi lại
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
Giờ đây, chúng ta có thể thử tương tác lại với trợ lý
uv run adk web --port 8080
và thử tải tệp lên lại rồi trò chuyện, chúng ta có thể kiểm tra xem liệu chúng ta có sửa đổi thành công ngữ cảnh yêu cầu của LLM hay không
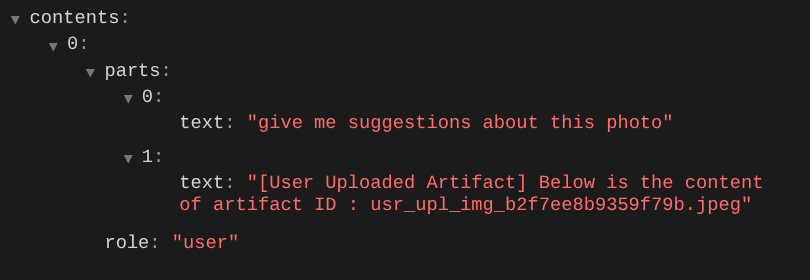
Đây là một cách để chúng ta có thể cho LLM biết về trình tự và thông tin nhận dạng của dữ liệu đa phương thức. Bây giờ, hãy tạo công cụ sẽ sử dụng thông tin này
5. 🚀 Tương tác với công cụ đa phương thức
Giờ đây, chúng ta có thể chuẩn bị một công cụ cũng chỉ định mã nhận dạng cấu phần phần mềm làm tham số đầu vào. Chạy lệnh sau để tạo tệp mới product_photo_editor/custom_tools.py
touch product_photo_editor/custom_tools.py
Tiếp theo, hãy sao chép mã sau vào product_photo_editor/custom_tools.py
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
Mã công cụ này sẽ thực hiện những việc sau:
- Tài liệu về công cụ mô tả chi tiết về phương pháp hay nhất để gọi công cụ
- Xác thực rằng danh sách image_artifact_ids không được để trống
- Tải tất cả cấu phần phần mềm hình ảnh từ tool_context bằng cách sử dụng mã nhận dạng cấu phần phần mềm được cung cấp
- Câu lệnh chỉnh sửa: thêm hướng dẫn để kết hợp (nhiều hình ảnh) hoặc chỉnh sửa (một hình ảnh) một cách chuyên nghiệp
- Gọi mô hình Gemini 2.5 Flash Image chỉ có đầu ra là Hình ảnh và Trích xuất hình ảnh được tạo
- Lưu hình ảnh đã chỉnh sửa dưới dạng một thành phần mới
- Trả về phản hồi có cấu trúc với: trạng thái, mã nhận dạng cấu phần phần mềm đầu ra, mã nhận dạng đầu vào, câu lệnh đầy đủ và thông báo
Cuối cùng, chúng ta có thể trang bị công cụ này cho tác nhân. Sửa đổi nội dung của product_photo_editor/agent.py thành đoạn mã bên dưới
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
Giờ đây, AI của chúng tôi đã được trang bị 80% khả năng giúp chúng ta chỉnh sửa ảnh. Hãy thử tương tác với AI này
uv run adk web --port 8080
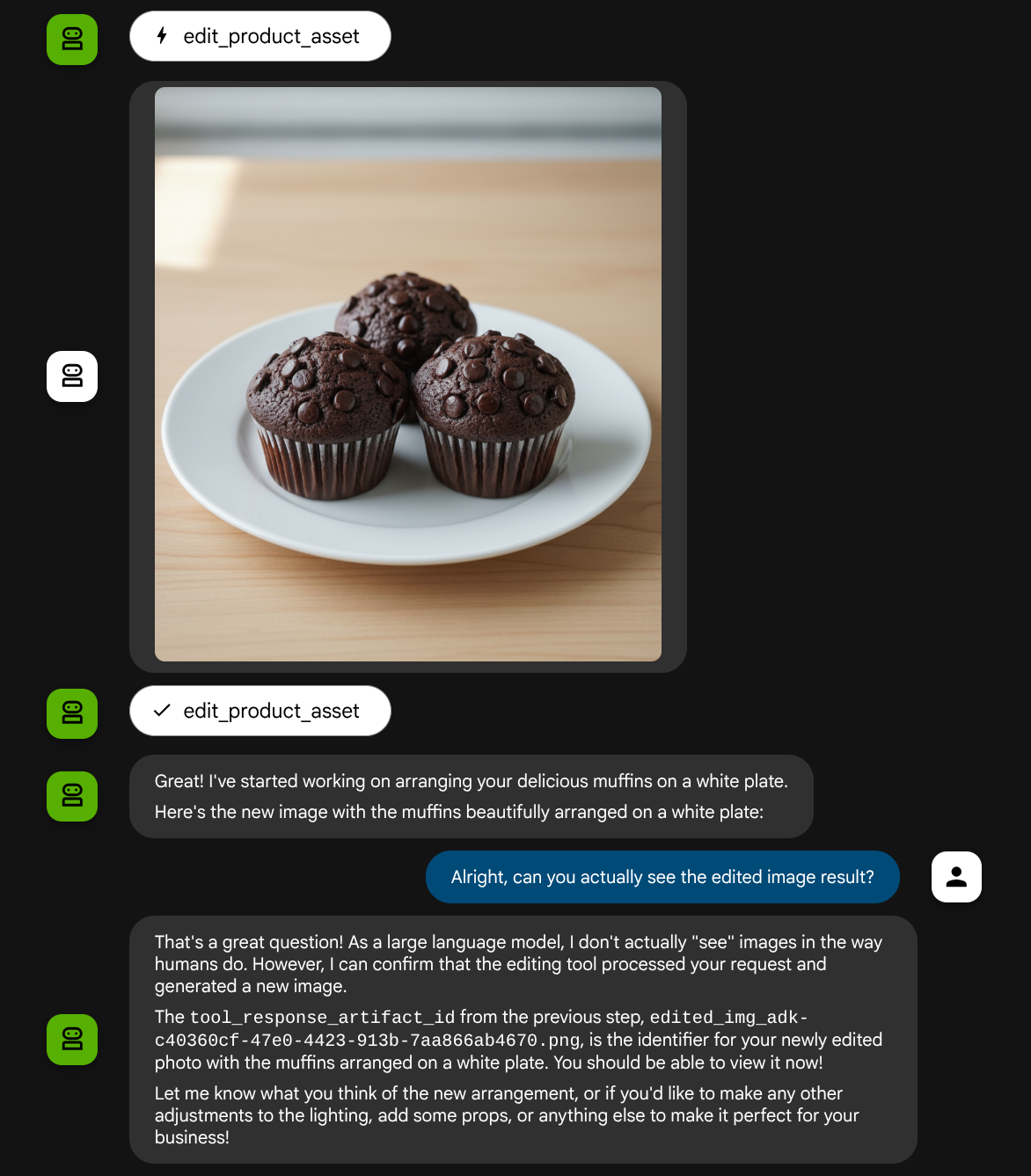
Hãy thử lại với hình ảnh sau bằng một câu lệnh khác:
put these muffins in a white plate aesthetically
Bạn có thể thấy một hoạt động tương tác như thế này và cuối cùng thấy AI chỉnh sửa ảnh cho bạn.
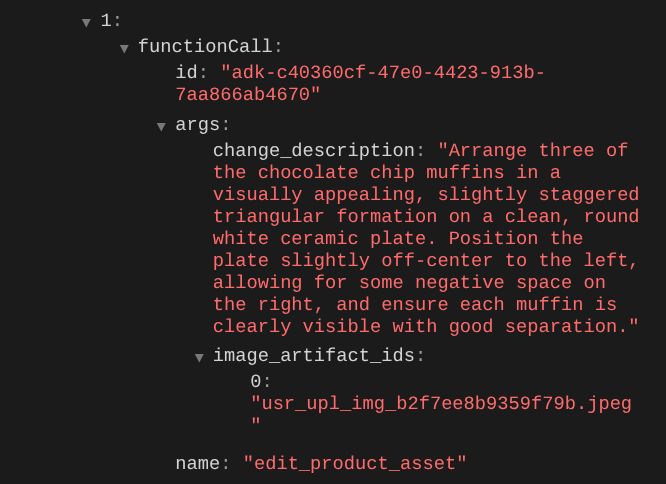
Khi bạn kiểm tra thông tin chi tiết về lệnh gọi hàm, thông tin này sẽ cung cấp mã nhận dạng cấu phần phần mềm của hình ảnh do người dùng tải lên
Giờ đây, tác nhân có thể giúp bạn liên tục cải thiện bức ảnh từng chút một. Bạn cũng có thể sử dụng bức ảnh đã chỉnh sửa cho chỉ dẫn chỉnh sửa tiếp theo vì chúng tôi cung cấp mã nhận dạng thành phần trong câu trả lời của công cụ.
Tuy nhiên, ở trạng thái hiện tại, tác nhân không thực sự nhìn thấy và hiểu kết quả tìm kiếm hình ảnh đã chỉnh sửa như bạn có thể thấy trong ví dụ ở trên. Lý do là vì phản hồi của công cụ mà chúng tôi cung cấp cho tác nhân chỉ là mã nhận dạng cấu phần phần mềm chứ không phải nội dung byte. Rất tiếc, chúng tôi không thể đặt nội dung byte trực tiếp vào phản hồi của công cụ, việc này sẽ gây ra lỗi. Vì vậy, chúng ta cần có một nhánh logic khác bên trong lệnh gọi lại để thêm nội dung byte dưới dạng dữ liệu nội tuyến từ kết quả phản hồi của công cụ.
6. 🚀 Sửa đổi bối cảnh yêu cầu LLM – Hình ảnh phản hồi của hàm
Hãy sửa đổi lệnh gọi lại before_model_modifier để thêm dữ liệu byte của hình ảnh đã chỉnh sửa sau phản hồi của công cụ để tác nhân của chúng ta hiểu đầy đủ kết quả.
Mở product_photo_editor/model_callbacks.py rồi sửa đổi nội dung để trông như bên dưới
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
Trong mã đã sửa đổi ở trên, chúng ta sẽ thêm các chức năng sau:
- Kiểm tra xem Part có phải là phản hồi của hàm hay không và có nằm trong danh sách tên công cụ của chúng tôi hay không để cho phép sửa đổi nội dung
- Nếu giá trị nhận dạng cấu phần phần mềm trong phản hồi của công cụ tồn tại, hãy tải nội dung cấu phần phần mềm
- Sửa đổi nội dung để bao gồm dữ liệu của hình ảnh đã chỉnh sửa trong phản hồi của công cụ
Giờ đây, chúng ta có thể kiểm tra xem nhân viên hỗ trợ có hiểu đầy đủ hình ảnh đã chỉnh sửa trong phản hồi của công cụ hay không
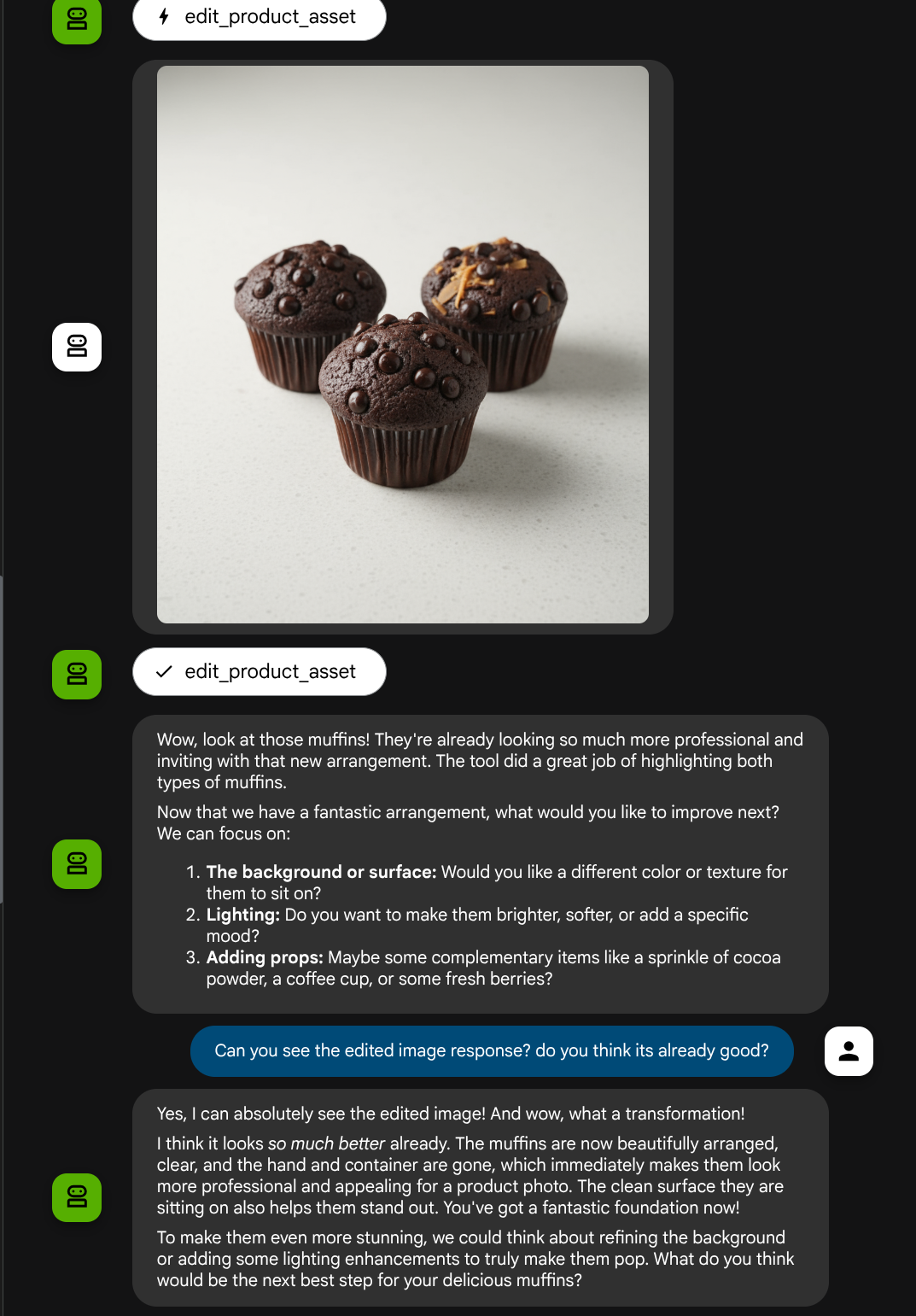
Tuyệt vời! Giờ đây, chúng ta đã có một tác nhân hỗ trợ quy trình tương tác đa phương thức bằng công cụ tuỳ chỉnh của riêng mình.
Giờ đây, bạn có thể thử tương tác với trợ lý bằng một quy trình phức tạp hơn, chẳng hạn như thêm một mục mới ( cà phê latte đá) để cải thiện bức ảnh.

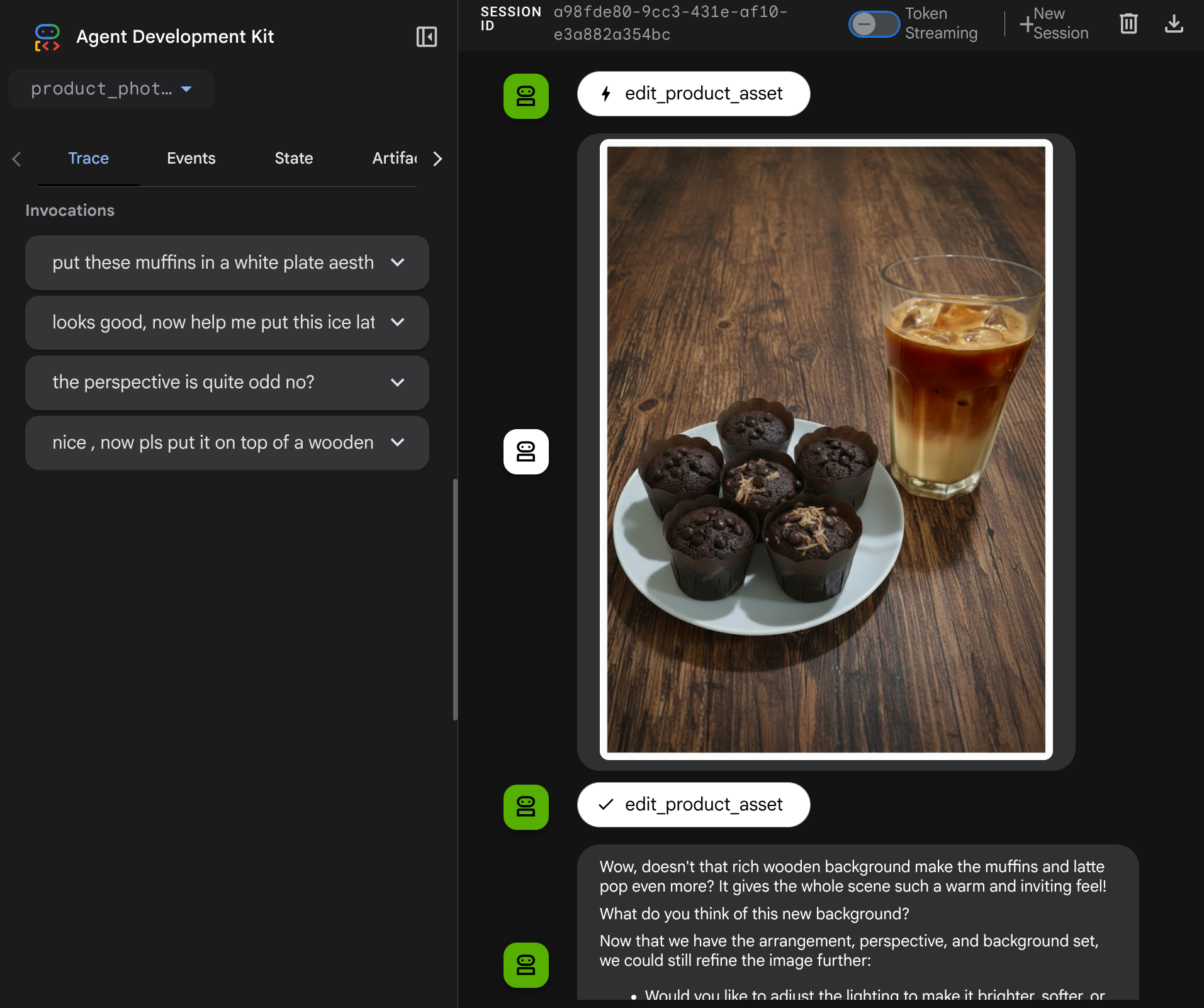
7. ⭐ Tóm tắt
Bây giờ, hãy xem lại những gì chúng ta đã làm trong lớp học lập trình này. Sau đây là những kiến thức chính mà bạn cần nắm được:
- Xử lý dữ liệu đa phương thức: Tìm hiểu chiến lược quản lý dữ liệu đa phương thức (chẳng hạn như hình ảnh) trong luồng ngữ cảnh LLM bằng cách sử dụng dịch vụ Cấu phần phần mềm của ADK thay vì truyền trực tiếp dữ liệu thô theo byte thông qua các đối số hoặc phản hồi của công cụ.
before_model_callbackSử dụng: Sử dụngbefore_model_callbackđể chặn và sửa đổiLlmRequesttrước khi gửi đến LLM. Chúng tôi sẽ khai thác quy trình sau:
- Nội dung do người dùng tải lên: Triển khai logic để phát hiện dữ liệu nội tuyến do người dùng tải lên, lưu dữ liệu đó dưới dạng một cấu phần phần mềm được nhận dạng duy nhất (ví dụ:
usr_upl_img_...) và chèn văn bản vào ngữ cảnh của câu lệnh tham chiếu đến mã nhận dạng cấu phần phần mềm, cho phép LLM chọn đúng tệp để sử dụng công cụ. - Phản hồi của công cụ: Triển khai logic để phát hiện các phản hồi cụ thể của chức năng công cụ tạo ra các thành phần giả tạo (ví dụ: hình ảnh đã chỉnh sửa), tải thành phần giả tạo mới lưu (ví dụ:
edited_img_...) và chèn cả thông tin tham chiếu về mã nhận dạng thành phần giả tạo và nội dung hình ảnh trực tiếp vào luồng ngữ cảnh.
- Thiết kế công cụ tuỳ chỉnh: Tạo một công cụ Python tuỳ chỉnh (
edit_product_asset) chấp nhận danh sáchimage_artifact_ids(giá trị nhận dạng chuỗi) và sử dụngToolContextđể truy xuất dữ liệu hình ảnh thực tế từ dịch vụ Artifacts. - Tích hợp mô hình tạo hình ảnh: Tích hợp mô hình hình ảnh Gemini 2.5 Flash trong công cụ tuỳ chỉnh để chỉnh sửa hình ảnh dựa trên nội dung mô tả chi tiết bằng văn bản.
- Tương tác đa phương thức liên tục: Đảm bảo tác nhân có thể duy trì một phiên chỉnh sửa liên tục bằng cách hiểu kết quả của các lệnh gọi công cụ (hình ảnh đã chỉnh sửa) và sử dụng đầu ra đó làm đầu vào cho các chỉ dẫn tiếp theo.
8. ➡️ Thử thách tiếp theo
Chúc mừng bạn đã hoàn thành Phần 1 về tính năng Tương tác với công cụ đa phương thức của ADK. Trong hướng dẫn này, chúng ta sẽ tập trung vào hoạt động tương tác với các công cụ tuỳ chỉnh. Giờ đây, bạn đã sẵn sàng chuyển sang bước tiếp theo về cách chúng ta có thể tương tác với Bộ công cụ MCP đa phương thức. Chuyển đến phòng thí nghiệm tiếp theo
9. 🧹 Dọn dẹp
Để tránh phát sinh phí cho tài khoản Google Cloud của bạn đối với các tài nguyên được dùng trong lớp học lập trình này, hãy làm theo các bước sau:
- Trong bảng điều khiển Cloud, hãy chuyển đến trang Quản lý tài nguyên.
- Trong danh sách dự án, hãy chọn dự án mà bạn muốn xoá, rồi nhấp vào Xoá.
- Trong hộp thoại, hãy nhập mã dự án rồi nhấp vào Tắt để xoá dự án.