
1. 📖 Wprowadzenie
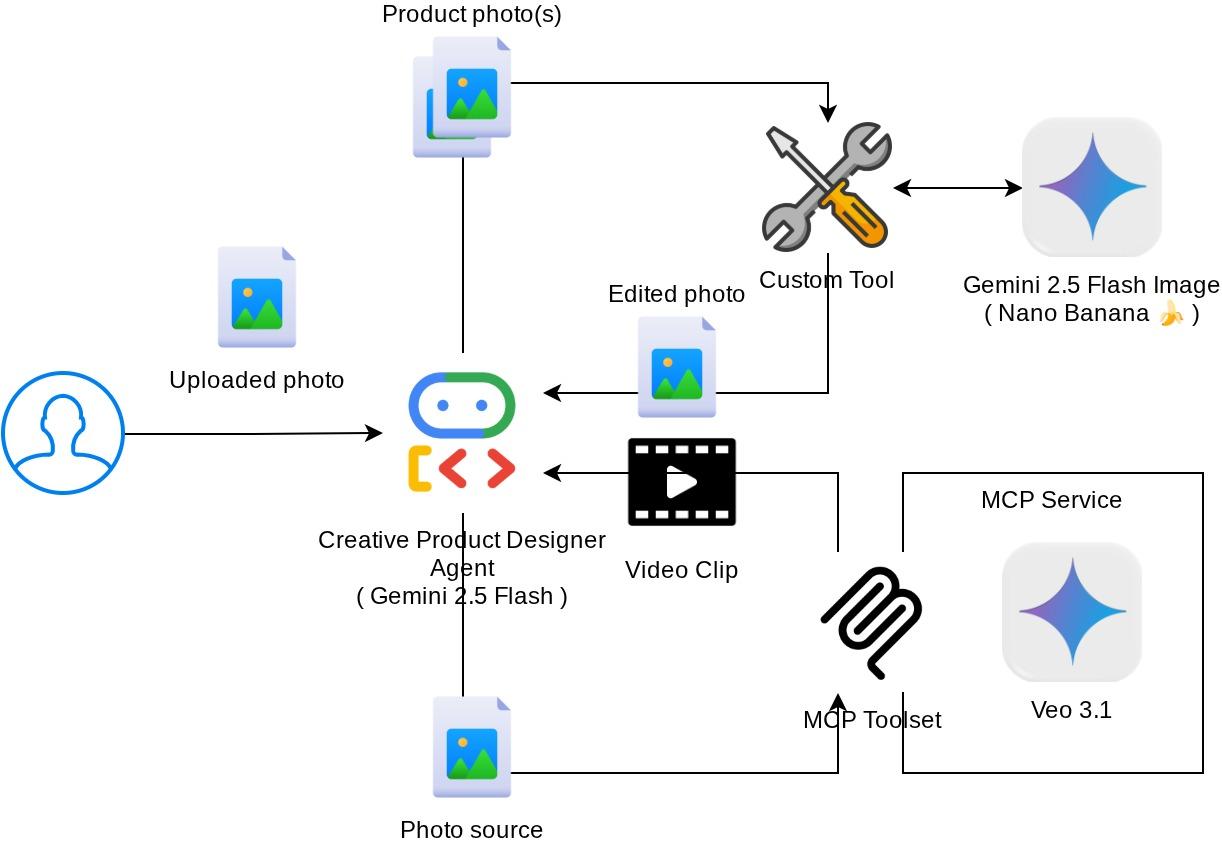
W poprzednich ćwiczeniach z programowania dowiesz się , jak zaprojektować interakcję z danymi multimodalnymi w ADK. Teraz przejdziemy do kolejnego etapu, czyli projektowania interakcji z danymi multimodalnymi za pomocą serwera MCP i zestawu narzędzi MCP. Rozszerzymy możliwości opracowanego wcześniej agenta do edycji zdjęć produktów o funkcje generowania krótkich filmów za pomocą modelu Veo z wykorzystaniem serwera Veo MCP.
W ramach ćwiczeń z programowania będziesz wykonywać kolejne czynności:
- Przygotowywanie projektu w chmurze Google Cloud i podstawowego katalogu agenta
- Skonfiguruj serwer MCP, który wymaga danych z pliku jako danych wejściowych
- Wyposażanie agenta ADK w możliwość łączenia się z serwerem MCP
- Opracowywanie strategii promptów i funkcji wywołania zwrotnego w celu modyfikowania żądań wywołania funkcji w zestawie narzędzi MCP
- Projektowanie funkcji wywołania zwrotnego do obsługi odpowiedzi z danymi multimodalnymi z zestawu narzędzi MCP
Omówienie architektury
Ogólna interakcja w tym laboratorium kodu jest przedstawiona na tym diagramie.
Wymagania wstępne
- znajomość języka Python;
- (Opcjonalnie) Podstawowe ćwiczenia dotyczące pakietu Agent Development Kit (ADK)
- (Opcjonalnie) Codelab ADK Multimodal Tool Part 1 : goo.gle/adk-multimodal-tool-1
Czego się nauczysz
- Jak utworzyć krótki film za pomocą Veo 3.1 na podstawie prompta i obrazu
- Jak opracować multimodalny serwer MCP za pomocą FastMCP
- Jak skonfigurować ADK, aby używać zestawu narzędzi MCP
- Jak zmodyfikować wywołanie narzędzia w zestawie narzędzi MCP za pomocą wywołania zwrotnego narzędzia
- Jak modyfikować odpowiedź narzędzia z zestawu narzędzi MCP za pomocą wywołania zwrotnego narzędzia
Czego potrzebujesz
- przeglądarki Chrome,
- konto Gmail,
- Projekt w chmurze z włączonym kontem rozliczeniowym
To ćwiczenie jest przeznaczone dla programistów na wszystkich poziomach zaawansowania (w tym dla początkujących). W przykładowej aplikacji używa się języka Python. Znajomość Pythona nie jest jednak wymagana do zrozumienia przedstawionych koncepcji.
2. 🚀 ( Opcjonalnie) Przygotowanie środowiska programistycznego na potrzeby warsztatów
Krok 1. Wybierz aktywny projekt w Cloud Console
W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud (patrz lewa górna sekcja konsoli).

Kliknij go, a zobaczysz listę wszystkich projektów, jak w tym przykładzie:
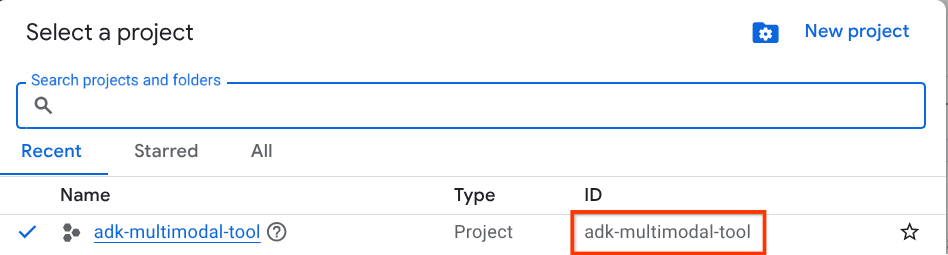
Wartość wskazana przez czerwone pole to IDENTYFIKATOR PROJEKTU. Będzie ona używana w całym samouczku.
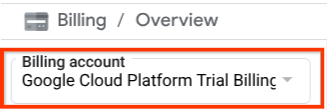
Sprawdź, czy w projekcie Cloud włączone są płatności. Aby to sprawdzić, kliknij ikonę menu ☰ na pasku w lewym górnym rogu, aby wyświetlić menu nawigacyjne, a następnie znajdź menu Płatności.

Jeśli pod tytułem „Konto rozliczeniowe okresu próbnego Google Cloud Platform” w sekcji Płatności / Podsumowanie ( w lewym górnym rogu konsoli Cloud ) widzisz nazwę konta, Twój projekt jest gotowy do użycia w tym samouczku. Jeśli nie, wróć na początek tego samouczka i skorzystaj z konta rozliczeniowego w wersji próbnej.
Krok 2. Zapoznaj się z Cloud Shell
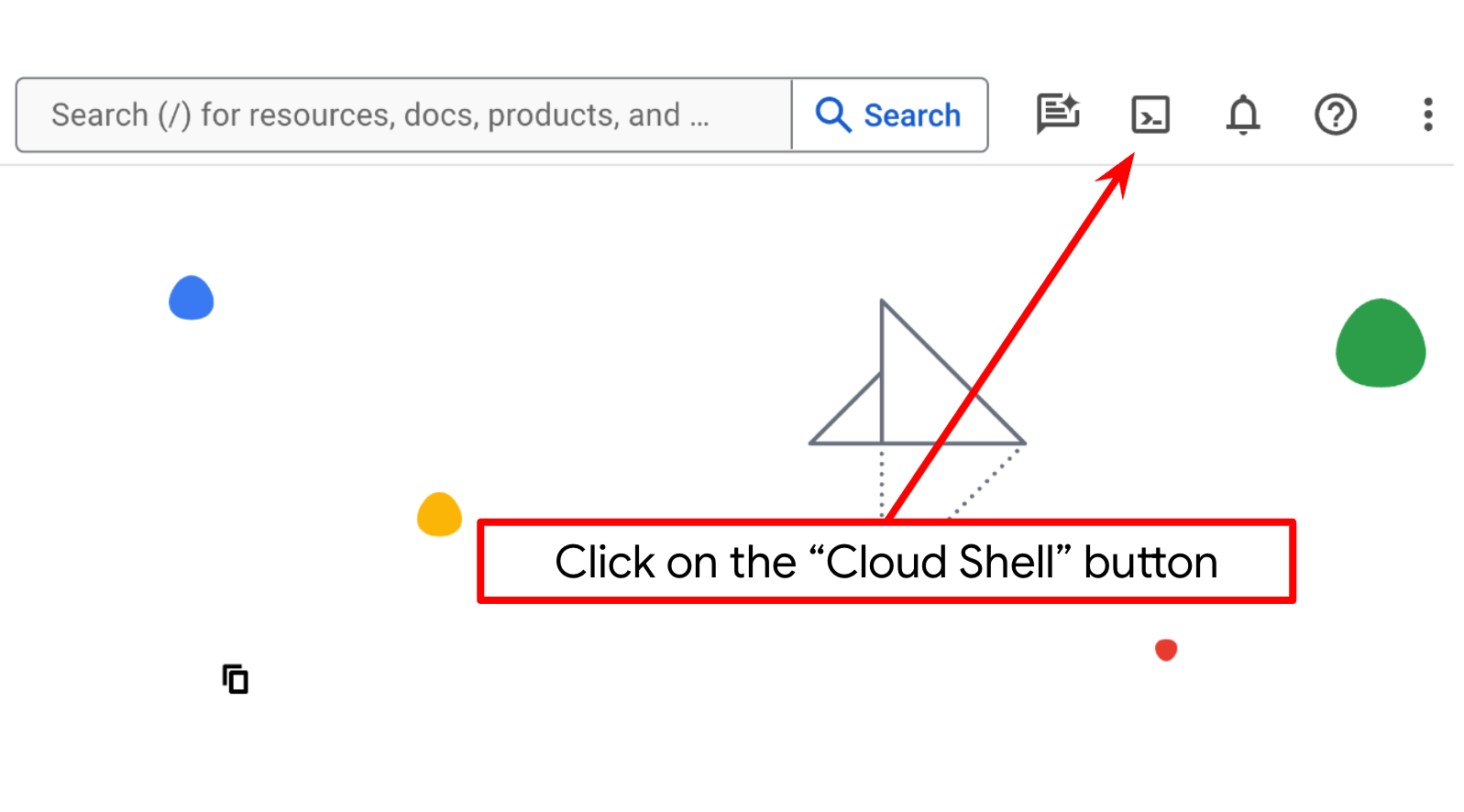
W większości samouczków będziesz używać Cloud Shell. Kliknij Aktywuj Cloud Shell u góry konsoli Google Cloud. Jeśli pojawi się prośba o autoryzację, kliknij Autoryzuj.
Po połączeniu z Cloud Shell musimy sprawdzić, czy powłoka ( lub terminal) jest już uwierzytelniona na naszym koncie.
gcloud auth list
Jeśli widzisz swój osobisty adres Gmail, jak w przykładzie poniżej, wszystko jest w porządku.
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Jeśli nie, odśwież przeglądarkę i kliknij Autoryzuj, gdy pojawi się odpowiedni komunikat ( proces może zostać przerwany z powodu problemu z połączeniem).
Następnie musimy sprawdzić, czy powłoka jest już skonfigurowana z prawidłowym IDENTYFIKATOREM PROJEKTU. Jeśli w terminalu przed ikoną $ widzisz wartość w nawiasach ( ) ( na zrzucie ekranu poniżej wartość to „adk-multimodal-tool”), oznacza to, że w aktywnej sesji powłoki skonfigurowany jest projekt.

Jeśli wyświetlana wartość jest już prawidłowa, możesz pominąć następne polecenie. Jeśli jednak jest nieprawidłowy lub go brakuje, uruchom to polecenie:
gcloud config set project <YOUR_PROJECT_ID>
Następnie skopiuj z GitHuba katalog roboczy szablonu tego ćwiczenia, wykonując to polecenie: W katalogu adk-multimodal-tool zostanie utworzony katalog roboczy.
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
Krok 3. Zapoznaj się z edytorem Cloud Shell i skonfiguruj katalog roboczy aplikacji
Teraz możemy skonfigurować edytor kodu, aby wykonywać różne czynności związane z kodowaniem. W tym celu użyjemy edytora Cloud Shell.
Kliknij przycisk Otwórz edytor. Spowoduje to otwarcie edytora Cloud Shell 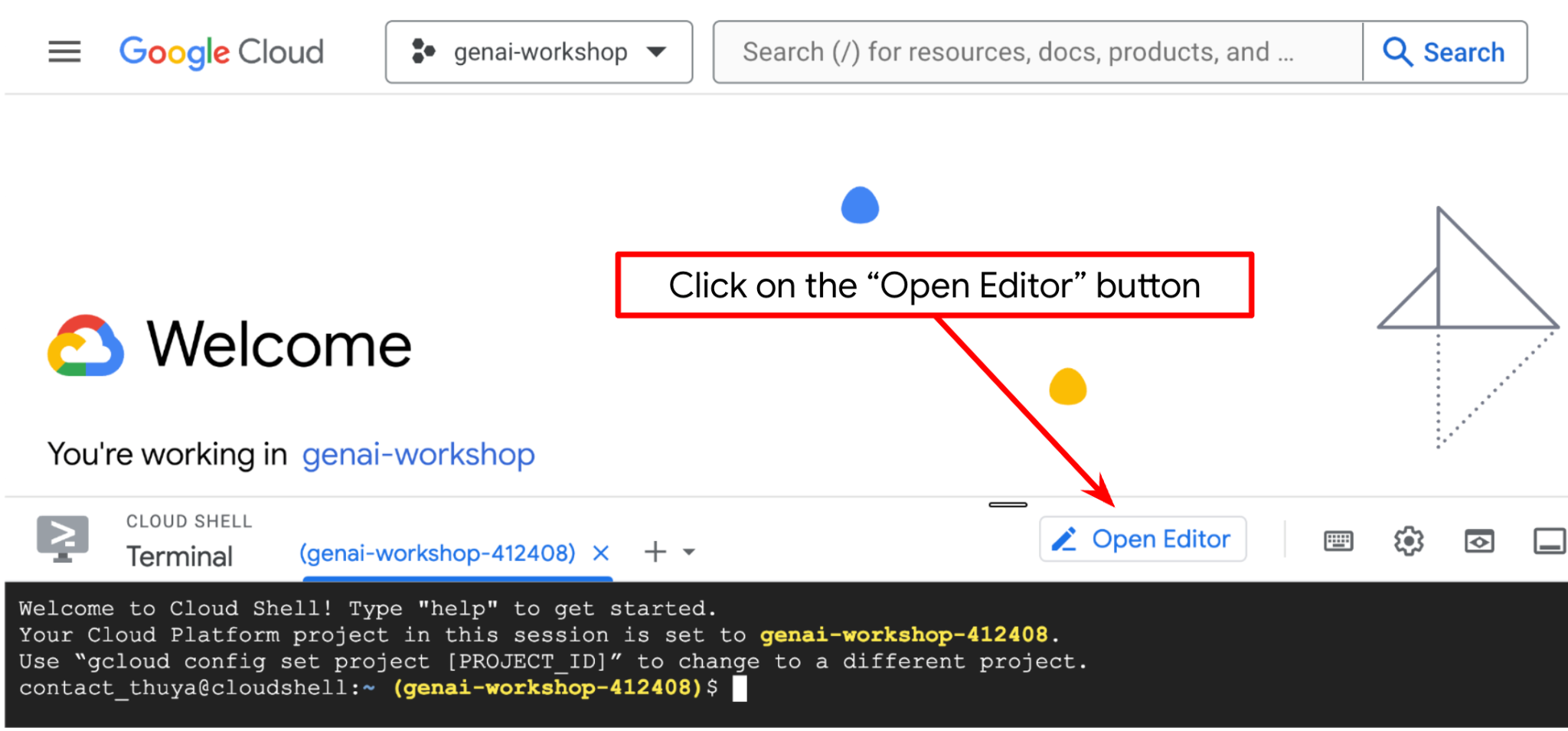 .
.
Następnie przejdź do górnej sekcji edytora Cloud Shell i kliknij File->Open Folder (Plik –>Otwórz folder), znajdź katalog username (nazwa użytkownika) i katalog adk-multimodal-tool,a potem kliknij OK. Wybrany katalog stanie się głównym katalogiem roboczym. W tym przykładzie nazwa użytkownika to alvinprayuda, więc ścieżka do katalogu jest widoczna poniżej.
Katalog roboczy edytora Cloud Shell powinien teraz wyglądać tak ( w katalogu adk-multimodal-tool):
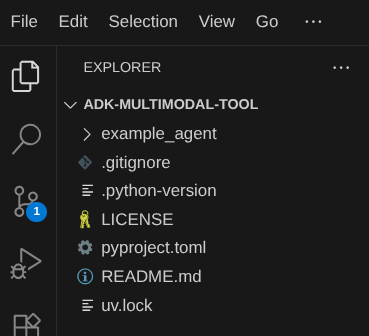
Teraz otwórz terminal edytora. Możesz to zrobić, klikając na pasku menu Terminal -> Nowy terminal lub używając skrótu Ctrl + Shift + C. W dolnej części przeglądarki otworzy się okno terminala.

Aktywny terminal powinien znajdować się w katalogu roboczym adk-multimodal-tool. W tym ćwiczeniu użyjemy Pythona 3.12 i menedżera projektów Pythona uv, aby uprościć tworzenie wersji Pythona i środowiska wirtualnego oraz zarządzanie nimi. Pakiet uv jest już wstępnie zainstalowany w Cloud Shell.
Uruchom to polecenie, aby zainstalować wymagane zależności w środowisku wirtualnym w katalogu .venv.
uv sync --frozen
Sprawdź plik pyproject.toml, aby zobaczyć zadeklarowane zależności na potrzeby tego samouczka, czyli google-adk, and python-dotenv.
Teraz musimy włączyć wymagane interfejsy API za pomocą polecenia pokazanego poniżej. To może chwilę potrwać.
gcloud services enable aiplatform.googleapis.com
Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
Struktura agenta szablonu jest już dostępna w katalogu part2_starter_agent w sklonowanym repozytorium. Aby przygotować go do tego samouczka, musimy najpierw zmienić jego nazwę.
mv part1_ckpt_agent product_photo_editor
Następnie skopiuj plik product_photo_editor/.env.example do product_photo_editor/.env.
cp product_photo_editor/.env.example product_photo_editor/.env
Po otwarciu pliku product_photo_editor/.env zobaczysz treść podobną do tej poniżej.
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
Następnie musisz zaktualizować wartość your-project-id, podając prawidłowy identyfikator projektu. Możemy teraz przejść do następnego kroku.
3. 🚀 Zainicjuj serwer MCP Veo
Najpierw utwórzmy katalog usług MCP za pomocą tego polecenia:
mkdir veo_mcp
Następnie utwórz plik veo_mcp/main.py za pomocą tego polecenia:
touch veo_mcp/main.py
Następnie skopiuj ten kod do pliku veo_mcp/main.py.
from fastmcp import FastMCP
from typing import Annotated
from pydantic import Field
import base64
import asyncio
import os
from google import genai
from google.genai import types
from dotenv import load_dotenv
import logging
# Load environment variables from .env file
load_dotenv()
mcp = FastMCP("Veo MCP Server")
@mcp.tool
async def generate_video_with_image(
prompt: Annotated[
str, Field(description="Text description of the video to generate")
],
image_data: Annotated[
str, Field(description="Base64-encoded image data to use as starting frame")
],
negative_prompt: Annotated[
str | None,
Field(description="Things to avoid in the generated video"),
] = None,
) -> dict:
"""Generates a professional product marketing video from text prompt and starting image using Google's Veo API.
This function uses an image as the first frame of the generated video and automatically
enriches your prompt with professional video production quality guidelines to create
high-quality marketing assets suitable for commercial use.
AUTOMATIC ENHANCEMENTS APPLIED:
- 4K cinematic quality with professional color grading
- Smooth, stabilized camera movements
- Professional studio lighting setup
- Shallow depth of field for product focus
- Commercial-grade production quality
- Marketing-focused visual style
PROMPT WRITING TIPS:
Describe what you want to see in the video. Focus on:
- Product actions/movements (e.g., "rotating slowly", "zooming into details")
- Desired camera angles (e.g., "close-up of the product", "wide shot")
- Background/environment (e.g., "minimalist white backdrop", "lifestyle setting")
- Any specific details about the product presentation
The system will automatically enhance your prompt with professional production quality.
Args:
prompt: Description of the video to generate. Focus on the core product presentation
you want. The system will automatically add professional quality enhancements.
image_data: Base64-encoded image data to use as the starting frame
negative_prompt: Optional prompt describing what to avoid in the video
Returns:
dict: A dictionary containing:
- status: 'success' or 'error'
- message: Description of the result
- video_data: Base64-encoded video data (on success only)
"""
try:
# Initialize the Gemini client
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
# Decode the image
image_bytes = base64.b64decode(image_data)
print(f"Successfully decoded image data: {len(image_bytes)} bytes")
# Create image object
image = types.Image(image_bytes=image_bytes, mime_type="image/png")
# Prepare the config
config = types.GenerateVideosConfig(
duration_seconds=8,
number_of_videos=1,
)
if negative_prompt:
config.negative_prompt = negative_prompt
# Enrich the prompt for professional marketing quality
enriched_prompt = enrich_prompt_for_marketing(prompt)
# Generate the video (async operation)
operation = client.models.generate_videos(
model="veo-3.1-generate-preview",
prompt=enriched_prompt,
image=image,
config=config,
)
# Poll until the operation is complete
poll_count = 0
while not operation.done:
poll_count += 1
print(f"Waiting for video generation to complete... (poll {poll_count})")
await asyncio.sleep(5)
operation = client.operations.get(operation)
# Download the video and convert to base64
video = operation.response.generated_videos[0]
# Get video bytes and encode to base64
video_bytes = video.video.video_bytes
video_base64 = base64.b64encode(video_bytes).decode("utf-8")
print(f"Video generated successfully: {len(video_bytes)} bytes")
return {
"status": "success",
"message": f"Video with image generated successfully after {poll_count * 5} seconds",
"complete_prompt": enriched_prompt,
"video_data": video_base64,
}
except Exception as e:
logging.error(e)
return {
"status": "error",
"message": f"Error generating video with image: {str(e)}",
}
def enrich_prompt_for_marketing(user_prompt: str) -> str:
"""Enriches user prompt with professional video production quality enhancements.
Adds cinematic quality, professional lighting, smooth camera work, and marketing-focused
elements to ensure high-quality product marketing videos.
"""
enhancement_prefix = """Create a high-quality, professional product marketing video with the following characteristics:
TECHNICAL SPECIFICATIONS:
- 4K cinematic quality with professional color grading
- Smooth, stabilized camera movements
- Professional studio lighting setup with soft, even illumination
- Shallow depth of field for product focus
- High dynamic range (HDR) for vibrant colors
VISUAL STYLE:
- Clean, minimalist aesthetic suitable for premium brand marketing
- Elegant and sophisticated presentation
- Commercial-grade production quality
- Attention to detail in product showcase
USER'S SPECIFIC REQUIREMENTS:
"""
enhancement_suffix = """
ADDITIONAL QUALITY GUIDELINES:
- Ensure smooth transitions and natural motion
- Maintain consistent lighting throughout
- Keep the product as the clear focal point
- Use professional camera techniques (slow pans, tracking shots, or dolly movements)
- Apply subtle motion blur for cinematic feel
- Ensure brand-appropriate tone and style"""
return f"{enhancement_prefix}{user_prompt}{enhancement_suffix}"
if __name__ == "__main__":
mcp.run()
Ten kod wykonuje następujące działania:
- Tworzy serwer FastMCP, który udostępnia narzędzie do generowania filmów Veo 3.1 agentom ADK.
- Akceptuje obrazy zakodowane w formacie base64, prompty tekstowe i prompty negatywne jako dane wejściowe.
- Generuje 8-sekundowe filmy asynchronicznie, przesyłając żądania do interfejsu Veo 3.1 API i odpytując co 5 sekund, aż do zakończenia.
- Zwraca dane wideo zakodowane w formacie Base64 wraz z wzbogaconym promptem.
To narzędzie Veo MCP będzie wymagać tej samej zmiennej środowiskowej co nasz agent, więc możemy po prostu skopiować i wkleić plik .env. Aby to zrobić, uruchom to polecenie:
cp product_photo_editor/.env veo_mcp/
Teraz możemy sprawdzić, czy serwer MCP działa prawidłowo, wykonując to polecenie.
uv run veo_mcp/main.py
Wyświetli dziennik konsoli w ten sposób:
╭────────────────────────────────────────────────────────────────────────────╮
│ │
│ _ __ ___ _____ __ __ _____________ ____ ____ │
│ _ __ ___ .'____/___ ______/ /_/ |/ / ____/ __ \ |___ \ / __ \ │
│ _ __ ___ / /_ / __ `/ ___/ __/ /|_/ / / / /_/ / ___/ / / / / / │
│ _ __ ___ / __/ / /_/ (__ ) /_/ / / / /___/ ____/ / __/_/ /_/ / │
│ _ __ ___ /_/ \____/____/\__/_/ /_/\____/_/ /_____(*)____/ │
│ │
│ │
│ FastMCP 2.0 │
│ │
│ │
│ 🖥️ Server name: Veo MCP Server │
│ 📦 Transport: STDIO │
│ │
│ 🏎️ FastMCP version: 2.12.5 │
│ 🤝 MCP SDK version: 1.16.0 │
│ │
│ 📚 Docs: https://gofastmcp.com │
│ 🚀 Deploy: https://fastmcp.cloud │
│ │
╰────────────────────────────────────────────────────────────────────────────╯
[10/22/25 08:28:53] INFO Starting MCP server 'Veo MCP Server' with server.py:1502
transport 'stdio'
Teraz zakończ proces usługi MCP, naciskając CTRL+C. To polecenie zostanie później wywołane z zestawu narzędzi ADK MCP. Możemy przejść do następnego kroku, aby umożliwić naszemu agentowi korzystanie z tych narzędzi MCP.
4. 🚀 Połącz serwer MCP Veo z agentem ADK
Teraz połączmy serwer MCP Veo, aby nasz agent mógł z niego korzystać. Najpierw utwórzmy inny skrypt, który będzie zawierać zestaw narzędzi. W tym celu uruchom to polecenie:
touch product_photo_editor/mcp_tools.py
Następnie skopiuj ten kod do pliku product_photo_editor/mcp_tools.py.
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
from google.adk.tools.mcp_tool.mcp_session_manager import StdioConnectionParams
from mcp import StdioServerParameters
mcp_toolset = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uv",
args=[
"run",
"veo_mcp/main.py",
],
),
timeout=120, # seconds
),
)
# Option to connect to remote MCP server
# from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPConnectionParams
# mcp_toolset = MCPToolset(
# connection_params=StreamableHTTPConnectionParams(
# url="http://localhost:8000/mcp",
# timeout=120,
# ),
# )
Powyższy kod pokazuje, jak połączyć się z serwerem MCP za pomocą narzędzia ADK MCPToolset. W tym przykładzie łączymy się z serwerem MCP za pomocą kanału komunikacji STDIO. W poleceniu określamy, jak uruchomić serwer MCP, i ustawiamy parametr limitu czasu.
5. 🚀 Modyfikacja parametru wywołania narzędzia
W deklaracji narzędzia serwera MCP zaprojektowaliśmy narzędzie generate_video_with_image, które określa ciąg base64 jako parametry narzędzia. Nie możemy poprosić o to LLM, dlatego musimy opracować konkretną strategię, która pozwoli nam to osiągnąć.
W poprzednim module obsługiwaliśmy obraz przesłany przez użytkownika i obraz z odpowiedzią narzędzia w funkcji before_model_callback, aby zapisać go jako artefakt, co zostało też uwzględnione w przygotowanym wcześniej szablonie agenta. Wykorzystamy te informacje i zastosujemy te strategie:
- Poinformuj model LLM, aby zawsze wysyłał wartość artifact_id, jeśli określony parametr narzędzia wymaga wysłania danych w postaci ciągu znaków w formacie base64.
- Przechwyć wywołanie narzędzia w
before_tool_callbacki przekształć parametr z artifact_id na jego zawartość w bajtach, wczytując artefakt i zastępując argumenty narzędzia.
Na ilustracji poniżej pokazano część, którą będziemy przechwytywać.
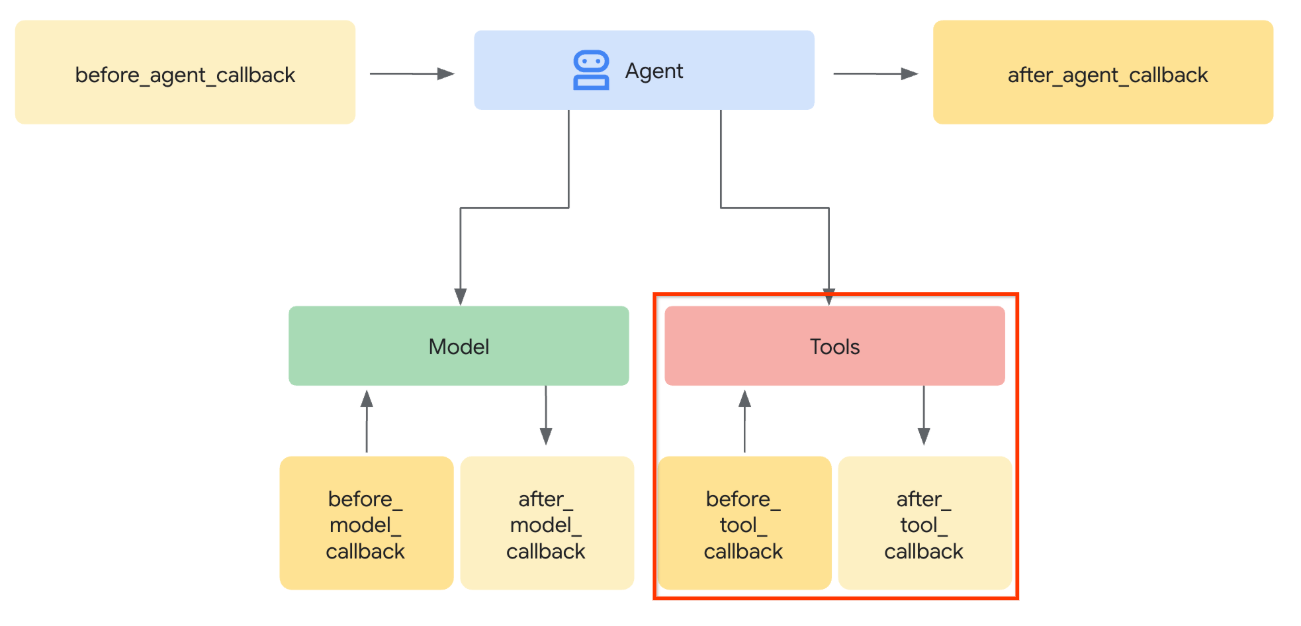
Najpierw przygotujmy funkcję before_tool_callback. Utwórz nowy plik product_photo_editor/tool_callbacks.py, uruchamiając to polecenie:
touch product_photo_editor/tool_callbacks.py
Następnie skopiuj do pliku ten kod:
# product_photo_editor/tool_callbacks.py
from google.genai.types import Part
from typing import Any
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.base_tool import BaseTool
from google.adk.tools.mcp_tool.mcp_tool import McpTool
import base64
import logging
import json
from mcp.types import CallToolResult
async def before_tool_modifier(
tool: BaseTool, args: dict[str, Any], tool_context: ToolContext
):
# Identify which tool input should be modified
if isinstance(tool, McpTool) and tool.name == "generate_video_with_image":
logging.info("Modify tool args for artifact: %s", args["image_data"])
# Get the artifact filename from the tool input argument
artifact_filename = args["image_data"]
artifact = await tool_context.load_artifact(filename=artifact_filename)
file_data = artifact.inline_data.data
# Convert byte data to base64 string
base64_data = base64.b64encode(file_data).decode("utf-8")
# Then modify the tool input argument
args["image_data"] = base64_data
Powyższy kod pokazuje te kroki:
- Sprawdź, czy wywołane narzędzie jest obiektem McpTool i czy jest to wywołanie narzędzia, które chcemy zmodyfikować.
- Pobierz wartość argumentów
image_data, w których argument jest żądany w formacie base64, ale prosimy LLM o zwrócenie identyfikatora artefaktu - Wczytaj artefakt za pomocą usługi artefaktów na
tool_context. - Zastąp argumenty
image_datadanymi w formacie base64.
Teraz musimy dodać ten wywołanie zwrotne do agenta i nieznacznie zmodyfikować instrukcje, aby agent zawsze wypełniał argumenty narzędzia base64 identyfikatorem artefaktu.
Otwórz plik product_photo_editor/agent.py i zmodyfikuj jego zawartość, wstawiając poniższy kod.
# product_photo_editor/agent.py
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.mcp_tools import mcp_toolset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.tool_callbacks import before_tool_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION
+ """
**IMPORTANT: Base64 Argument Rule on Tool Call**
If you found any tool call arguments that requires base64 data,
ALWAYS provide the artifact_id of the referenced file to
the tool call. NEVER ask user to provide base64 data.
Base64 data encoding process is out of your
responsibility and will be handled in another part of the system.
""",
tools=[
edit_product_asset,
mcp_toolset,
],
before_model_callback=before_model_modifier,
before_tool_callback=before_tool_modifier,
)
Spróbujmy teraz wejść w interakcję z agentem, aby przetestować tę modyfikację. Aby uruchomić interfejs programisty stron internetowych, uruchom to polecenie:
uv run adk web --port 8080
Wygeneruje to dane wyjściowe podobne do poniższego przykładu, co oznacza, że możemy już uzyskać dostęp do interfejsu internetowego.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Aby to sprawdzić, możesz kliknąć adres URL z naciśniętym klawiszem Ctrl lub kliknąć przycisk Podgląd w przeglądarce w górnej części edytora Cloud Shell i wybrać Podejrzyj na porcie 8080.
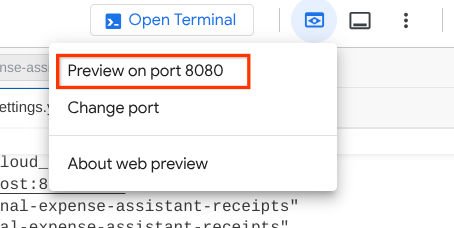
Wyświetli się strona internetowa, na której w lewym górnym rogu możesz wybrać dostępnych agentów ( w naszym przypadku powinien to być product_photo_editor) i interagować z botem.
Następnie prześlij poniższy obraz i poproś agenta o wygenerowanie z niego klipu promocyjnego.
Generate a slow zoom in and moving from left and right animation

Wyświetli się ten błąd:

Dlaczego? Narzędzie zwróciło wyniki bezpośrednio w postaci ciągu base64, co spowoduje przekroczenie maksymalnej liczby tokenów. W następnej sekcji zajmiemy się tym błędem.
6. 🚀 Modyfikacja odpowiedzi narzędzia
W tej sekcji zajmiemy się odpowiedzią narzędzia z odpowiedzi MCP. Wykonamy te działania:
- Zapisywanie odpowiedzi wideo narzędzia w usłudze artefaktów
- Zamiast tego zwróć agentowi identyfikator artefaktu.
Przypominamy, że w przypadku tego agenta będziemy korzystać z tego czasu działania:
Najpierw zaimplementujmy funkcję wywołania zwrotnego. Otwórz plik product_photo_editor/tool_callbacks.py i zmodyfikuj go, aby zaimplementować after_tool_modifier.
# product_photo_editor/tool_callbacks.py
from google.genai.types import Part
from typing import Any
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.base_tool import BaseTool
from google.adk.tools.mcp_tool.mcp_tool import McpTool
import base64
import logging
import json
from mcp.types import CallToolResult
async def before_tool_modifier(
tool: BaseTool, args: dict[str, Any], tool_context: ToolContext
):
# Identify which tool input should be modified
if isinstance(tool, McpTool) and tool.name == "generate_video_with_image":
logging.info("Modify tool args for artifact: %s", args["image_data"])
# Get the artifact filename from the tool input argument
artifact_filename = args["image_data"]
artifact = await tool_context.load_artifact(filename=artifact_filename)
file_data = artifact.inline_data.data
# Convert byte data to base64 string
base64_data = base64.b64encode(file_data).decode("utf-8")
# Then modify the tool input argument
args["image_data"] = base64_data
async def after_tool_modifier(
tool: BaseTool,
args: dict[str, Any],
tool_context: ToolContext,
tool_response: dict | CallToolResult,
):
if isinstance(tool, McpTool) and tool.name == "generate_video_with_image":
tool_result = json.loads(tool_response.content[0].text)
# Get the expected response field which contains the video data
video_data = tool_result["video_data"]
artifact_filename = f"video_{tool_context.function_call_id}.mp4"
# Convert base64 string to byte data
video_bytes = base64.b64decode(video_data)
# Save the video as artifact
await tool_context.save_artifact(
filename=artifact_filename,
artifact=Part(inline_data={"mime_type": "video/mp4", "data": video_bytes}),
)
# Remove the video data from the tool response
tool_result.pop("video_data")
# Then modify the tool response to include the artifact filename and remove the base64 string
tool_result["video_artifact_id"] = artifact_filename
logging.info(
"Modify tool response for artifact: %s", tool_result["video_artifact_id"]
)
return tool_result
Następnie musimy wyposażyć agenta w tę funkcję. Otwórz plik product_photo_editor/agent.py i zmodyfikuj go, aby zawierał poniższy kod.
# product_photo_editor/agent.py
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.mcp_tools import mcp_toolset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.tool_callbacks import (
before_tool_modifier,
after_tool_modifier,
)
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION
+ """
**IMPORTANT: Base64 Argument Rule on Tool Call**
If you found any tool call arguments that requires base64 data,
ALWAYS provide the artifact_id of the referenced file to
the tool call. NEVER ask user to provide base64 data.
Base64 data encoding process is out of your
responsibility and will be handled in another part of the system.
""",
tools=[
edit_product_asset,
mcp_toolset,
],
before_model_callback=before_model_modifier,
before_tool_callback=before_tool_modifier,
after_tool_callback=after_tool_modifier,
)
Gotowe. Teraz możesz poprosić agenta nie tylko o pomoc w edycji zdjęcia, ale także o wygenerowanie filmu. Ponownie uruchom to polecenie.
uv run adk web --port 8080
Następnie spróbuj utworzyć film przy użyciu tego obrazu.
Generate a slow zoom in and moving from left and right animation
Wygenerowany film będzie wyglądać jak na przykładzie poniżej i zostanie zapisany jako artefakt.
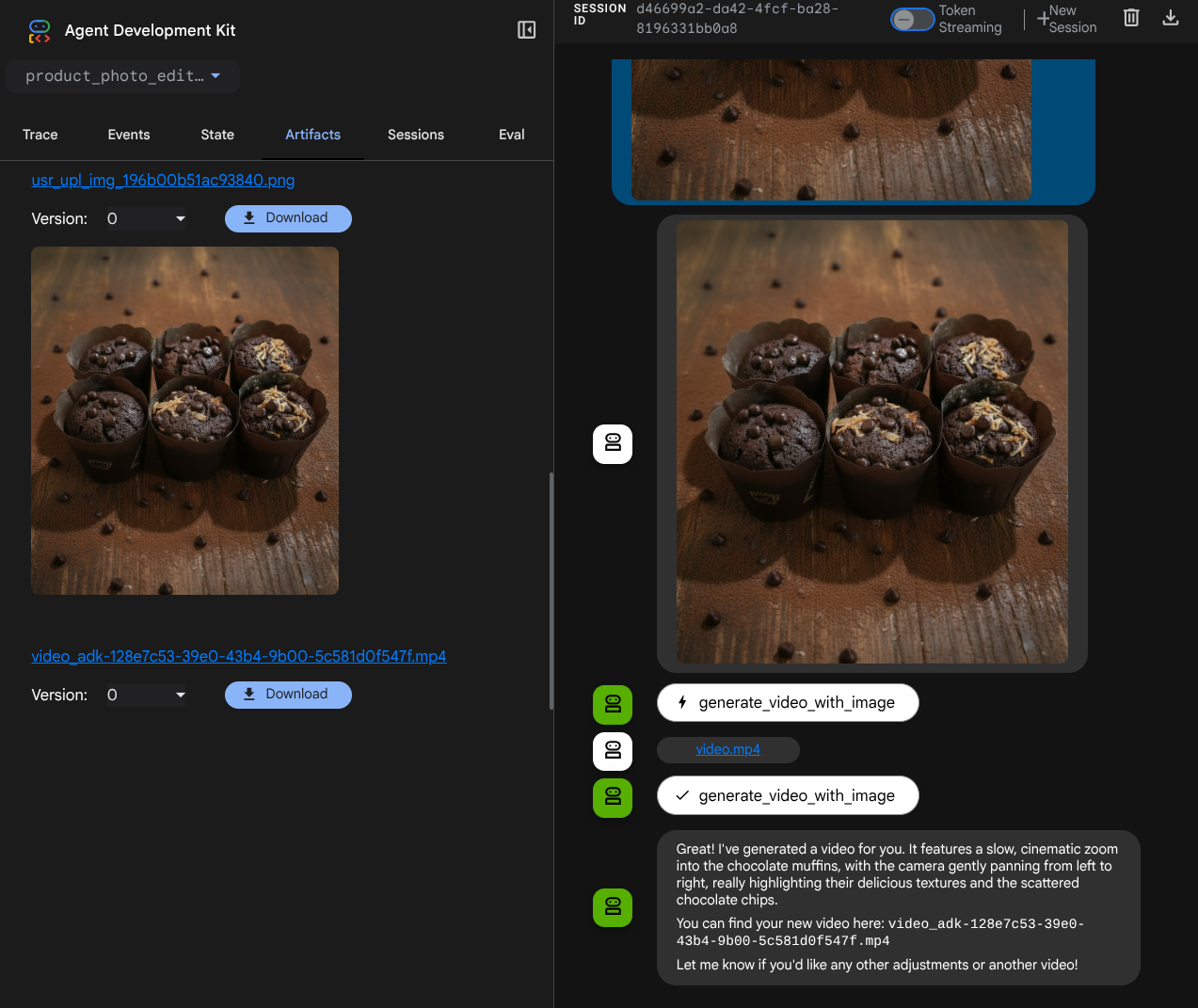
7. ⭐ Podsumowanie
Podsumujmy teraz to, co już zrobiliśmy w tym laboratorium. Oto najważniejsze informacje:
- Obsługa danych multimodalnych (wejście-wyjście narzędzia): wzmocniliśmy strategię zarządzania danymi multimodalnymi (takimi jak obrazy i filmy) na potrzeby wejścia i wyjścia narzędzia, używając usługi artefaktów ADK i specjalistycznych wywołań zwrotnych zamiast bezpośredniego przekazywania surowych danych w bajtach.
- Integracja zestawu narzędzi MCP: opracowano i zintegrowano zewnętrzny serwer MCP Veo za pomocą FastMCP w zestawie narzędzi ADK MCP, aby dodać do agenta funkcje generowania filmów.
- Modyfikacja danych wejściowych narzędzia (before_tool_callback): zaimplementowano wywołanie zwrotne, aby przechwytywać wywołanie narzędzia generate_video_with_image, przekształcając identyfikator artefaktu pliku (wybrany przez LLM) w wymagane dane obrazu zakodowane w formacie base64 na potrzeby danych wejściowych serwera MCP.
- Modyfikacja danych wyjściowych narzędzia (after_tool_callback): wdrożono wywołanie zwrotne, które przechwytuje dużą odpowiedź wideo zakodowaną w formacie Base64 z serwera MCP, zapisuje wideo jako nowy artefakt i zwraca do LLM czyste odwołanie video_artifact_id.
8. 🧹 Zwalnianie miejsca
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym laboratorium, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Zarządzanie zasobami.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.