
1. مقدمة
تكون الوكلاء المستندون إلى الذكاء الاصطناعي مفيدين بقدر البيانات التي يمكنهم الوصول إليها فقط. وتتوفّر معظم البيانات الواقعية في قواعد البيانات، وعادةً ما يعني ربط الوكلاء بقواعد البيانات كتابة إدارة الاتصال ومنطق طلب البحث وتضمين قنوات العرض داخل رمز الوكيل. ويكرّر كل وكيل يحتاج إلى الوصول إلى قاعدة البيانات هذه العملية، ويتطلّب كل تغيير في طلب البحث إعادة نشر الوكيل.
يوضّح هذا الدرس التطبيقي العملي طريقة مختلفة. يمكنك تحديد أدوات قاعدة البيانات في ملف YAML، مثل طلبات البحث بلغة الاستعلامات البنيوية (SQL) العادية، والبحث عن التشابه بين المتّجهات، وحتى إنشاء عمليات تضمين تلقائية، ويتولّى MCP Toolbox for Databases جميع عمليات قاعدة البيانات كخادم MCP. يظل رمز الوكيل بسيطًا: حمِّل الأدوات، ودَع Gemini يقرّر الأداة التي سيستخدمها.
ما ستنشئه
مساعد المطاعم في "اكتشاف أطباق جديدة": هو وكيل ADK يستند إلى Gemini ويساعد روّاد المطعم في تصفّح قائمة الطعام باستخدام الفلاتر العادية (الفئة ونوع المطبخ) واكتشاف الأطباق من خلال أوصاف باللغة الطبيعية، مثل "أريد طبقًا حارًا ونباتيًا". يقرأ الوكيل من قاعدة بيانات Cloud SQL PostgreSQL ويكتب فيها بالكامل من خلال MCP Toolbox for Databases، التي تتعامل مع جميع عمليات الوصول إلى قاعدة البيانات، بما في ذلك إنشاء عمليات تضمين تلقائية للبحث عن المتّجهات. وفي النهاية، يتم تشغيل كلّ من Toolbox والوكيل على Cloud Run.
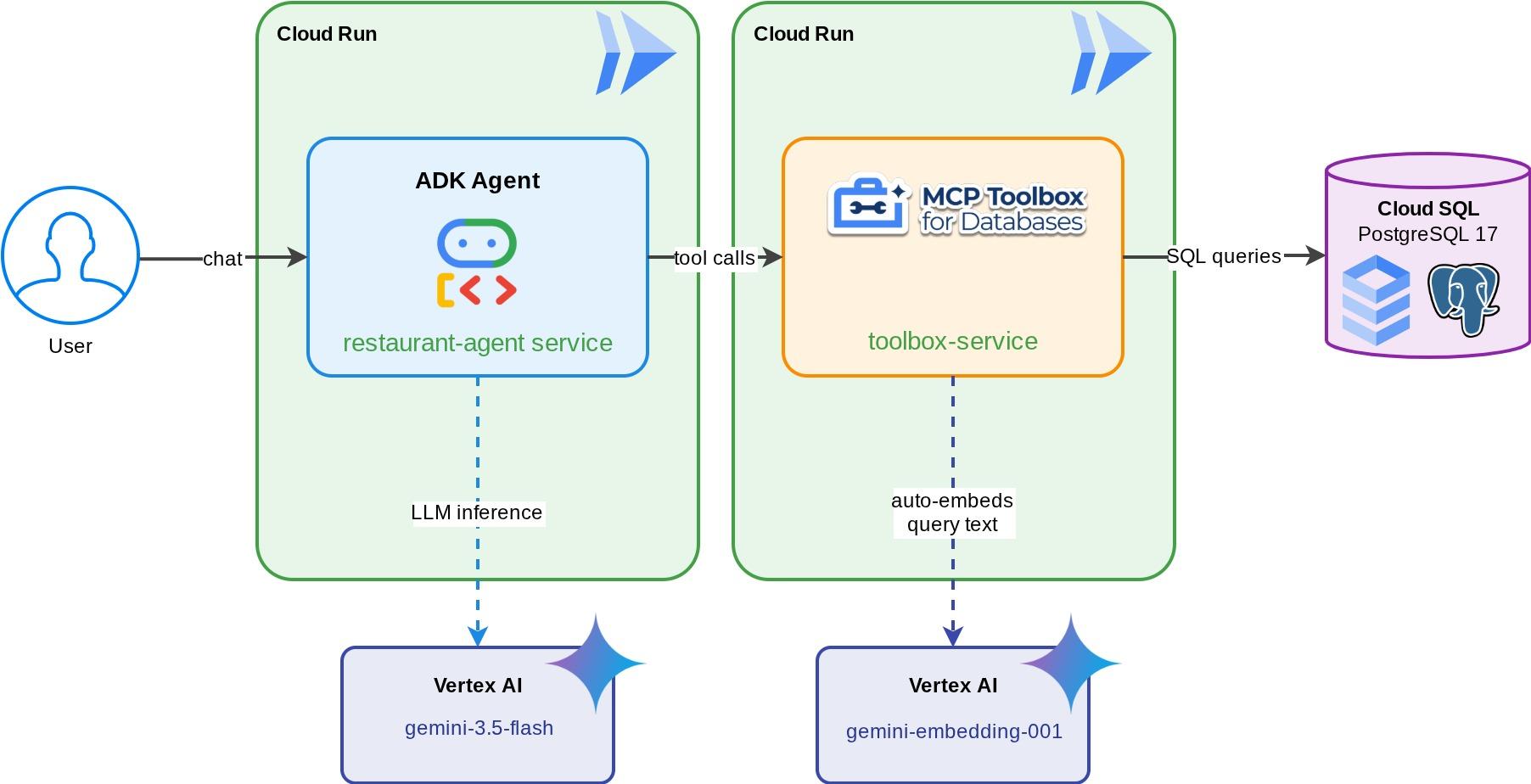
ما ستتعلمه
- كيف يوحّد بروتوكول MCP (بروتوكول سياق النموذج) إمكانية الوصول إلى الأدوات لوكلاء الذكاء الاصطناعي، وكيف تطبّق أداة MCP Toolbox for Databases ذلك على عمليات قواعد البيانات
- إعداد MCP Toolbox for Databases كبرنامج وسيط بين وكيل ADK وCloud SQL PostgreSQL
- تحديد أدوات قاعدة البيانات بشكل تعريفي في
tools.yaml- بدون رمز قاعدة بيانات في الوكيل - إنشاء وكيل ADK يحمّل الأدوات من خادم Toolbox قيد التشغيل باستخدام
ToolboxToolset - إنشاء تضمينات متجهة باستخدام الدالة المضمّنة
embedding()في Cloud SQL وتفعيل البحث الدلالي باستخدامpgvector - استخدام ميزة
valueFromParamلإدخال المتجهات تلقائيًا في عمليات الكتابة - نشر كلّ من خادم Toolbox ووكيل ADK على Cloud Run
المتطلبات الأساسية
- حساب Google Cloud يتضمّن حساب فوترة تجريبيًا
- معرفة أساسية بلغة Python وSQL
- ستكون الخبرة السابقة في Cloud Database وADK مفيدة
2. إعداد البيئة
تجهّز هذه الخطوة بيئة Cloud Shell وتضبط مشروعك على Google Cloud وتستنسخ المستودع المرجعي.
فتح Cloud Shell
افتح Cloud Shell في المتصفّح. توفّر Cloud Shell بيئة تم ضبطها مسبقًا تتضمّن جميع الأدوات التي تحتاج إليها في هذا الدرس التطبيقي حول الترميز. انقر على تفويض عندما يُطلب منك ذلك
بعد ذلك، انقر على عرض -> وحدة طرفية لفتح الوحدة الطرفية.يجب أن تبدو واجهتك مشابهة لما يلي
ستكون هذه هي واجهتنا الرئيسية، مع وضع بيئة التطوير المتكاملة في الأعلى والوحدة الطرفية في الأسفل.
إعداد دليل العمل
أنشئ دليل العمل. يتم تخزين جميع الرموز التي تكتبها في هذا الدرس التطبيقي حول الترميز هنا:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
بعد ذلك، لنجهّز عدة أدلة لإدارة أمور مثل نصوص البرامج الأولية والسجلات
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
إعداد مشروعك على Google Cloud
أنشئ ملف .env يحتوي على متغيّرات الموقع الجغرافي:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
لتبسيط عملية إعداد المشاريع في الوحدة الطرفية، نزِّل نص برمجي لإعداد المشاريع في دليل العمل:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
نفِّذ النص البرمجي. سيتحقّق من حساب الفوترة التجريبي، وينشئ مشروعًا جديدًا (أو يتحقّق من صحة مشروع حالي)، ويحفظ رقم تعريف مشروعك في ملف .env في الدليل الحالي، ويضبط المشروع النشط في gcloud.
bash setup_verify_trial_project.sh && source .env
سيؤدي النص البرمجي إلى ما يلي:
- التأكّد من أنّ لديك حساب فوترة نشطًا لفترة تجريبية
- التحقّق من وجود مشروع حالي في
.env(إن وُجد) - إنشاء مشروع جديد أو إعادة استخدام المشروع الحالي
- ربط حساب الفوترة التجريبي بمشروعك
- احفظ رقم تعريف المشروع في
.env - ضبط المشروع كمشروع
gcloudنشط
تأكَّد من ضبط المشروع بشكل صحيح من خلال التحقّق من النص الأصفر بجانب دليل العمل في طلب Cloud Shell. من المفترض أن يعرض رقم تعريف مشروعك.

تفعيل واجهة برمجة التطبيقات المطلوبة
بعد ذلك، علينا تفعيل عدة واجهات برمجة تطبيقات للمنتج الذي سنتفاعل معه:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- Vertex AI API (
aiplatform.googleapis.com): يستخدم الوكيل نماذج Gemini، وتستخدم "مجموعة الأدوات" واجهة برمجة التطبيقات الخاصة بالترميز للبحث المتّجه. - واجهة برمجة التطبيقات Cloud SQL Admin API (
sqladmin.googleapis.com): يمكنك توفير مثيل PostgreSQL وإدارته. - Compute Engine API (
compute.googleapis.com): مطلوب لإنشاء مثيلات Cloud SQL. - Cloud Run وCloud Build وArtifact Registry: يتم استخدامها في خطوة النشر لاحقًا في هذا الدرس التطبيقي حول الترميز
3- تجهيز النصوص البرمجية لإعداد قاعدة البيانات
تبدأ هذه الخطوة بإنشاء مثيل Cloud SQL وتشغيل نص التهيئة البرمجي المُبرمَج للإعداد ينتظر إلى أن يصبح المثيل جاهزًا، ثم ينشئ قاعدة البيانات ويملأها ببيانات الوظائف الشاغرة وينشئ عمليات التضمين، وكل ذلك في عملية واحدة.
أولاً، لنضِف كلمة مرور قاعدة البيانات إلى ملف .env ثم نعيد تحميله:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
إنشاء نص برمجي Bash لإنشاء مثيل وقاعدة بيانات
بعد ذلك، أنشئ النص البرمجي scripts/setup_database.sh باستخدام الأمر التالي
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
بعد ذلك، انسخ الرمز التالي في ملف scripts/setup_database.sh
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
إنشاء نص برمجي بلغة Python لإنشاء بيانات أولية
بعد ذلك، أنشئ ملف python الخاص بنص التعبئة scripts/setup_restaurant_db.py باستخدام الأمر أدناه
cloudshell edit scripts/setup_restaurant_db.py
بعد ذلك، انسخ الرمز التالي في ملف scripts/setup_restaurant_db.py
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
لننتقل الآن إلى الخطوة التالية
4. إنشاء قاعدة البيانات وتهيئتها
أصبحت النصوص البرمجية جاهزة للتنفيذ، ولكننا سنحتاج إلى Python لتنفيذ النص البرمجي الذي أعددناه، لذا لنبدأ بإعداد Python أولاً.
إعداد مشروع Python
uv هي حزمة Python سريعة وأداة لإدارة المشاريع مكتوبة بلغة Rust ( مستندات uv). تستخدم هذه التجربة العملية هذه الحزمة لتحقيق السرعة والبساطة في الحفاظ على مشروع Python.
ابدأ مشروع Python وأضِف التبعيات المطلوبة:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
يُرجى العِلم أنّنا نستخدم حزمة تطوير البرامج (SDK) الخاصة بلغة Python هنا لإنشاء اتصال آمن بنسخة قاعدة البيانات التي يتمّ إثبات صحتها باستخدام بيانات الاعتماد التلقائية للتطبيق.cloud-sql-python-connector
تنفيذ نص التهيئة البرمجي
يمكننا الآن تشغيل نص التهيئة البرمجي في الخلفية وفحص ناتج وحدة التحكّم الذي سيتمّ كتابته في ملف logs/atabase_setup.log باستخدام الأمر التالي. يمكنك الانتقال إلى القسم التالي أثناء انتظار انتهاء هذه العملية.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
تنزيل ملف Toolbox الثنائي
سنستخدم أداة MCP Toolbox في هذا البرنامج التعليمي، وهي تتضمّن لحسن الحظ ملفًا ثنائيًا مُعدًا مسبقًا وجاهزًا للاستخدام في بيئة Linux. لننزّله الآن في الخلفية لأنّ العملية تستغرق بعض الوقت. شغِّل الأمر التالي لتنزيل الملف الثنائي وفحص سجل الإخراج على logs/toolbox_dl.log. يمكنك الانتقال إلى القسم التالي أثناء انتظار انتهاء العملية.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
فهم نص التهيئة البرمجي scripts/setup_database.sh
لنحاول الآن فهم نص التهيئة البرمجي الذي سبق أن أعددناه. تتضمّن هذه العملية الخطوات التالية:
- أول أمر ننفّذه هو الأمر
gcloud sql instances createمع العلامة التالية
-
db-custom-1-3840هي أصغر فئة من فئات Cloud SQL ذات النواة المخصّصة (وحدة معالجة مركزية افتراضية واحدة، وذاكرة وصول عشوائي سعتها 3.75 غيغابايت) في إصدارENTERPRISE. يمكنك الاطّلاع على مزيد من التفاصيل هنا. يجب توفّر نواة مخصّصة لإتاحة دمج تعلُّم الآلة من Vertex AI، ولا تتوافق فئات النواة المشتركة (db-f1-microوdb-g1-small) مع هذه الميزة. --root-passwordيضبط كلمة المرور للمستخدم التلقائيpostgres.- تتيح
--enable-google-ml-integrationإمكانية الدمج المضمّن في Cloud SQL مع Vertex AI، ما يتيح لك استدعاء نماذج التضمين مباشرةً من SQL باستخدام الدالةembedding().
- التحقّق ممّا إذا كانت الآلة الافتراضية في الحالة
RUNNABLE - امنح حساب خدمة مثيل Cloud SQL الإذن باستدعاء Vertex AI باستخدام الأمر
gcloud projects add-iam-policy-binding. هذا مطلوب للدالةembedding()المضمّنة التي سنستخدمها عند إنشاء قاعدة البيانات - إنشاء قاعدة البيانات
- تنفيذ النص البرمجي
setup_restaurant_db.pyالخاص بإنشاء البيانات الأولية
فهم النص البرمجي الأوّلي scripts/setup_restaurant_db.py
بالانتقال الآن إلى نص التعبئة، ينفّذ هذا النص الإجراءات التالية:
- تهيئة عملية الربط بمثيل قاعدة البيانات
- تثبِّت هذه الحزمة إضافتَين إلى PostgreSQL:
google_ml_integration: توفّر دالةembedding()SQL التي تستدعي نماذج التضمين في Vertex AI مباشرةً من SQL. هذا هو امتداد على مستوى قاعدة البيانات يتيح استخدام دوال تعلُّم الآلة داخلrestaurant_db. يتيح الخيار على مستوى المثيل (--enable-google-ml-integration) الذي تحدّده أثناء إنشاء المثيل لجهاز Cloud SQL الظاهري الوصول إلى Vertex AI، ويوفّر الامتداد دوال SQL داخل قاعدة البيانات المحدّدة هذه.vector(pgvector): يضيف نوع البياناتvectorوعوامل تشغيل المسافة لتخزين عمليات التضمين والاستعلام عنها.
- أنشئ الجدول، مع العلم أنّ العمود
description_embeddingهوvector(3072)، أي عمودpgvectorيخزّن متجهات ذات 3072 بُعدًا. - تعبئة بيانات عناصر القائمة الأولية
- إنشاء بيانات التضمين من الحقل
descriptionوملءdescription_embeddingباستخدام عملية التكامل المضمّنة في Vertex من خلال الدالةembedding()
embedding('gemini-embedding-001', description): تستدعي نموذج التضمين Gemini في Vertex AI مباشرةً من SQL، مع تمرير نصdescriptionلكل مهمة. هذه هي إضافةgoogle_ml_integrationالتي ثبَّتها في النص البرمجي الأوّلي.-
::vector: تحويل مصفوفة الأعداد العشرية التي تم إرجاعها إلى نوعvectorفي pgvector حتى يمكن تخزينها والاستعلام عنها باستخدام عوامل تشغيل المسافة - يتم تشغيل
UPDATEعلى جميع الصفوف الـ 15، ما يؤدي إلى إنشاء تضمين واحد بـ 3072 بُعدًا لكل وصف وظيفي.
سيؤدي ذلك إلى إعداد البيانات الأولية التي سيصل إليها الوكيل
5- ضبط إعدادات MCP Toolbox for Databases
تتضمّن هذه الخطوة تقديم MCP Toolbox for Databases، وإعدادها للاتصال بمثيل Cloud SQL، وتحديد أداتَي طلب بحث SQL عاديتَين.
ما هو بروتوكول MCP ولماذا يجب استخدام "مجموعة الأدوات"؟
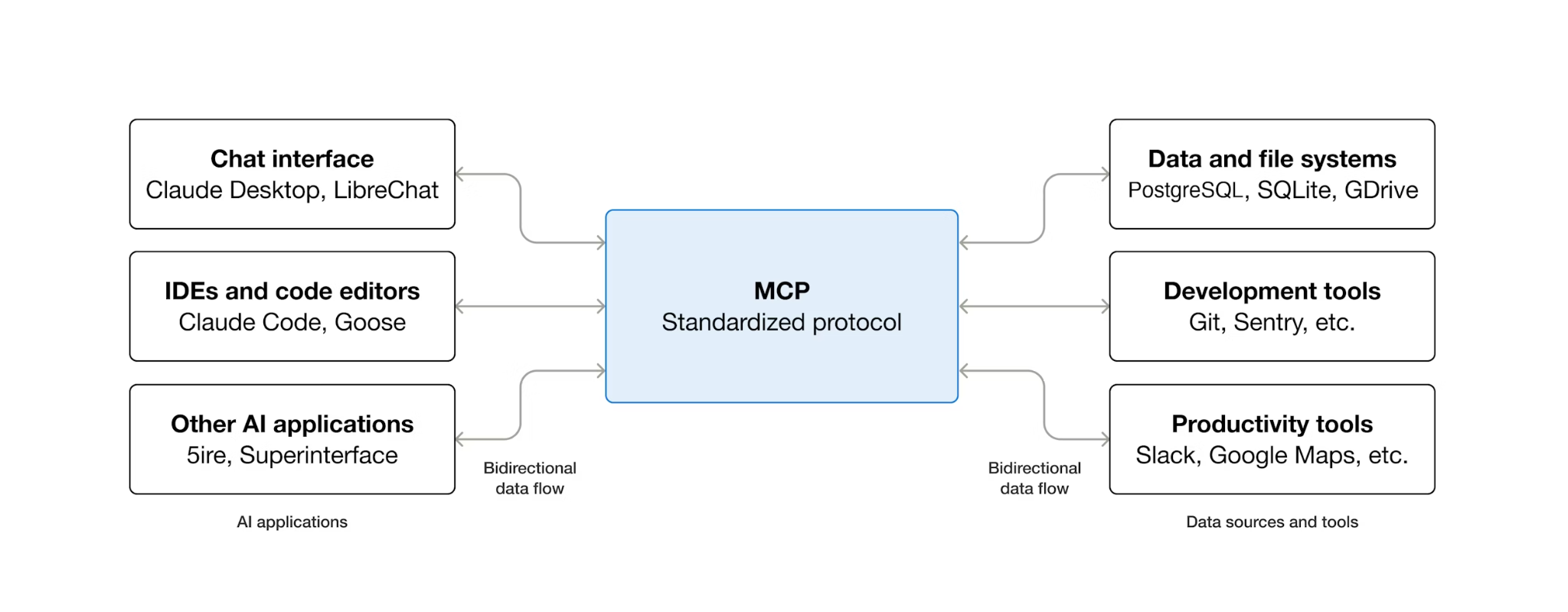
بروتوكول سياق النموذج (MCP) هو بروتوكول مفتوح يوحّد طريقة عثور وكلاء الذكاء الاصطناعي على الأدوات الخارجية والتفاعل معها. يحدّد هذا النموذج نموذجًا للعميل والخادم: يستضيف الوكيل عميل MCP، وتوفّر خوادم MCP الأدوات. يمكن لأي عميل متوافق مع MCP استخدام أي خادم متوافق مع MCP، ولا يحتاج الوكيل إلى رمز دمج مخصّص لكل أداة.
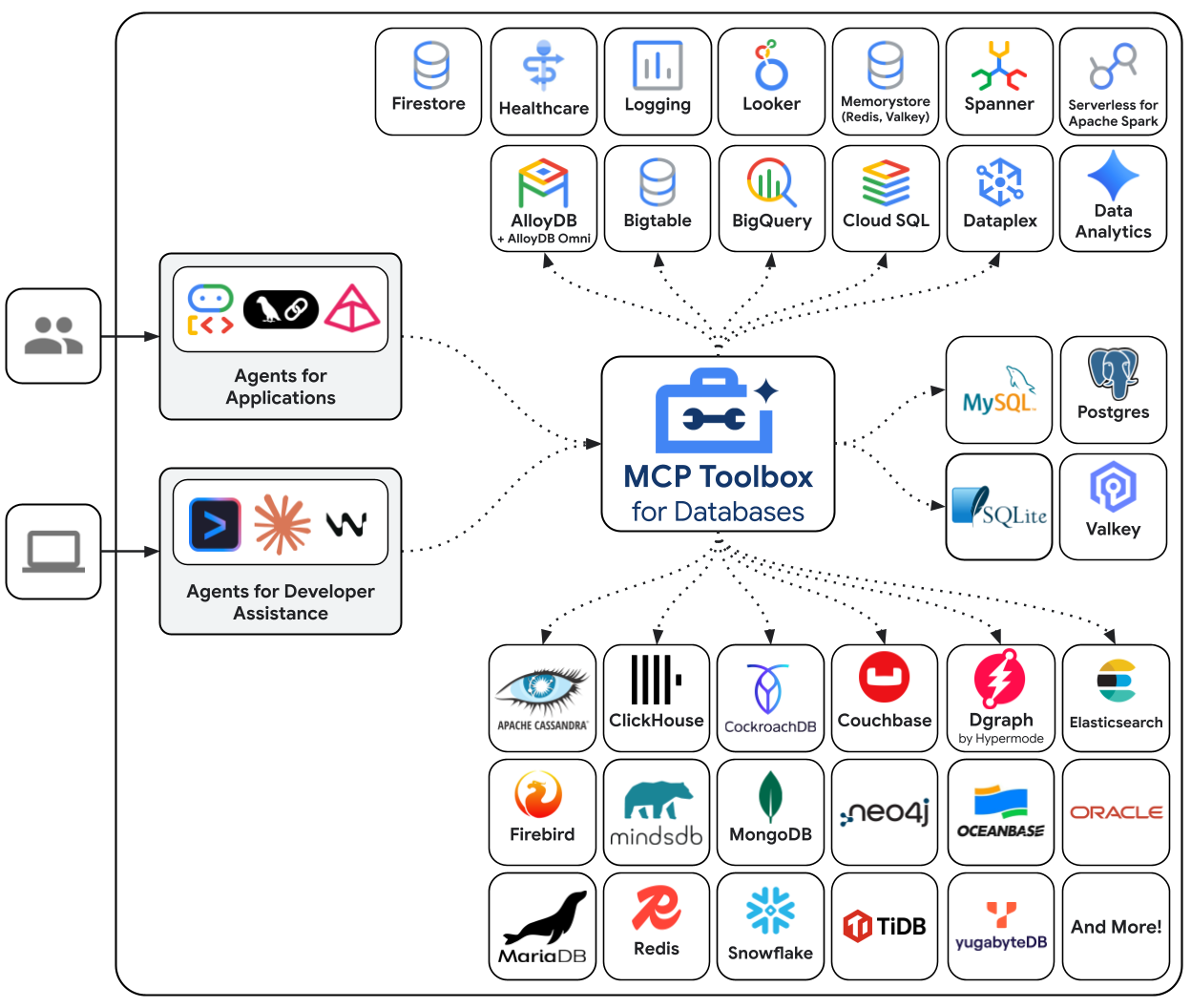
MCP Toolbox for Databases هو خادم MCP مفتوح المصدر تم إنشاؤه خصيصًا للوصول إلى قواعد البيانات. بدون ذلك، ستكتب دوال Python التي تفتح اتصالات بقاعدة البيانات، وتدير مجموعات الاتصال، وتنشئ استعلامات ذات معلَمات لمنع إدخال تعليمات برمجية SQL ضارة، وتتعامل مع الأخطاء، وتضمّن كل هذا الرمز البرمجي داخل برنامجك. ويكرّر كل وكيل يحتاج إلى الوصول إلى قاعدة البيانات هذه العملية. يعني تغيير الاستعلام إعادة نشر الوكيل.
باستخدام Toolbox، يمكنك كتابة ملف YAML. ترتبط كل أداة بعبارة SQL ذات معلَمات. تتعامل "مجموعة الأدوات" مع تجميع الاتصالات، والاستعلامات التي تتضمّن مَعلمات، والمصادقة، وإمكانية المراقبة. يتم فصل الأدوات عن الوكيل، ويمكنك تعديل طلب بحث من خلال تعديل tools.yaml وإعادة تشغيل Toolbox بدون تعديل رمز الوكيل. تعمل الأدوات نفسها على جميع إطارات العمل المتوافقة مع MCP، مثل ADK أو LangGraph أو LlamaIndex.
كتابة إعدادات الأدوات
الآن، علينا إنشاء ملف باسم tools.yaml في "محرّر Cloud Shell" لإعداد ضبط الأدوات.
cloudshell edit tools.yaml
يستخدم الملف YAML متعدد المستندات، وكل كتلة مفصولة بـ --- هي مورد مستقل. يحتوي كل مصدر على kind يوضّح نوعه (sources لعمليات ربط قواعد البيانات، وtools للإجراءات التي يمكن أن ينفّذها الوكيل) وtype يحدّد الخلفية (cloud-sql-postgres للمصدر، وpostgres-sql للأدوات المستندة إلى SQL). تشير الأداة إلى مصدرها باستخدام name، وهي الطريقة التي تعرف بها Toolbox مجموعة الاتصال التي سيتم تنفيذها. تستخدم متغيرات البيئة بنية ${VAR_NAME} ويتم تحديدها عند بدء التشغيل.
لننسخ الآن البرامج النصية التالية أولاً إلى ملف tools.yaml
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
يحدّد هذا النص البرمجي المورد التالي:
- المصدر (
restaurant-db): يوضّح هذا الحقل لـ "مجموعة الأدوات" كيفية الاتصال بمثيل Cloud SQL PostgreSQL. يستخدم النوعcloud-sql-postgresموصّل Cloud SQL داخليًا، ويتعامل مع المصادقة والاتصالات الآمنة تلقائيًا. يتم تحديد قيم العناصر النائبة${GOOGLE_CLOUD_PROJECT}و${REGION}و${DB_PASSWORD}من متغيرات البيئة عند بدء التشغيل.
بعد ذلك، أضِف النص البرمجي التالي تحت الرمز --- في ملف tools.yaml.
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
يحدّد هذا النص البرمجي المورد التالي:
- الأداتان 1 و2 (
search-menuوget-item-details): أدوات طلبات بحث SQL عادية، حيث تربط كل أداة اسمًا (ما يراه الوكيل) بعبارة SQL ذات مَعلمات (ما تنفّذه قاعدة البيانات). تستخدم المَعلمات عناصر نائبة موضعية$1و$2. تنفّذ "صندوق الأدوات" هذه المَعلمات كعبارات مُعدّة، ما يمنع اختراق SQL.
لنتابع، أضِف النص البرمجي التالي تحت الرمز --- في tools.yaml
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
يحدّد هذا النص البرمجي المورد التالي:
- نموذج التضمين (
gemini-embedding): يضبط هذا النموذج "مجموعة الأدوات" لاستدعاء نموذجgemini-embedding-001من Gemini لإنشاء عمليات تضمين نصية ذات 3072 بُعدًا. تستخدم "مجموعة الأدوات" بيانات الاعتماد التلقائية للتطبيق (ADC) للمصادقة، ولا يلزم توفير مفتاح واجهة برمجة التطبيقات في Cloud Shell أو Cloud Run. تجدر الإشارة إلى أنّdimensionالذي تم ضبطه هنا يجب أن يكون هو نفسه الذي تم ضبطه سابقًا لإنشاء قاعدة البيانات.
لنتابع، أضِف النص البرمجي التالي تحت الرمز --- في tools.yaml
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
يحدّد هذا النص البرمجي المورد التالي:
- الأداة 3 (
search-menu-by-description): هي أداة بحث متّجه. تحتوي المَعلمةsearch_queryعلىembeddedBy: gemini-embedding، ما يطلب من Toolbox اعتراض النص الأولي وإرساله إلى نموذج التضمين واستخدام المتّجه الناتج في عبارة SQL. عامل التشغيل<=>هو مسافة جيب التمام في pgvector، وتعني القيم الأصغر أوصافًا أكثر تشابهًا.
أخيرًا، أضِف الأداة الأخيرة تحت الرمز --- في ملف tools.yaml.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
يحدّد هذا النص البرمجي المورد التالي:
- الأداة 4 (
add-menu-item): توضّح عملية استيعاب المتّجهات. تحتوي المَعلمةdescription_vectorعلى حقلَين خاصَّين: valueFromParam: description: تنسخ "أدوات المطوّرين" القيمة من المَعلمةdescriptionإلى هذه المَعلمة، ولا يرى النموذج اللغوي الكبير هذه المَعلمة أبدًا.embeddedBy: gemini-embedding: تدمج "أداة الترميز" النص المنسوخ في متّجه قبل تمريره إلى لغة SQL.
والنتيجة هي أنّ استدعاء أداة واحد يخزّن كلاً من نص الوصف الأولي والتضمين المتجهي، بدون أن يعرف الوكيل أي شيء عن عمليات التضمين.
يفصل تنسيق YAML المتعدد المستندات كل مورد باستخدام ---. يحتوي كل مستند على الحقول kind وname وtype التي تحدّد نوعه. لقد سبق أن أعددنا كل ما يلي:
- تحديد قاعدة البيانات المصدر
- تحديد الأدوات ( الأداة 1 والأداة 2 ) لطلب البحث من قاعدة البيانات باستخدام فلتر عادي
- تحديد نموذج التضمين
- تحديد أداة لإجراء البحث عن المتّجهات ( الأداة 3 ) في قاعدة البيانات
- تحديد أداة لنقل بيانات المتّجهات ( الأداة 4 ) إلى قاعدة البيانات
6. تشغيل خادم MCP Toolbox
في الخطوة السابقة، ضبطنا الإعدادات اللازمة لـ MCP Toolbox. والآن، نحن مستعدون لتشغيل الخادم
التحقّق من البيانات الأولية
قبل بدء استخدام Toolbox، لنؤكّد أنّ عملية إعداد قاعدة البيانات قد اكتملت. أنشئ نصًا برمجيًا بلغة Python scripts/verify_database.py باستخدام الأمر التالي
cloudshell edit scripts/verify_seed.py
بعد ذلك، انسخ الرمز التالي في ملف scripts/verify_seed.py
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
سيفحص هذا النص البرمجي عدد بيانات المنتج وتضمينها. شغِّل النص البرمجي باستخدام الأمر التالي
uv run scripts/verify_seed.py
إذا ظهر لك الناتج التالي في الوحدة الطرفية، يعني ذلك أنّ البيانات جاهزة
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
بدء تشغيل خادم "مجموعة الأدوات"
في خطوة الإعداد السابقة، نزّلنا ملف toolbox القابل للتنفيذ. تأكَّد من توفّر هذا الملف الثنائي وتنزيله بنجاح، وإذا لم يكن متوفّرًا، نزِّله وانتظر إلى أن تنتهي العملية.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
علينا عرض متغيرات .env على العملية الفرعية التي يتم تشغيلها بواسطة مجموعة أدوات MCP. نفِّذ الأمر التالي لبدء خادم مجموعة الأدوات وتسجيل ناتج وحدة التحكّم في ملف logs/mcp_toolbox.log
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
من المفترض أن يظهر لك الناتج في الملف logs/mcp_toolbox.log الذي يؤكّد أنّ الخادم جاهز كما هو موضّح أدناه:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
التحقّق من الأدوات
استخدِم طلب بحث في Toolbox API لإدراج جميع الأدوات المسجّلة:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
من المفترض أن تظهر الأدوات مع أوصافها ومَعلماتها. كما هو موضّح أدناه
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
اختبِر أداة search-menu مباشرةً:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
يجب أن يتضمّن الرد أطباق الأطباق الرئيسية الإيطالية من بياناتك الأولية.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. إنشاء وكيل ADK
الآن، سنستخدم ADK في Python لهذا المشروع، لذا لنضِف التبعيات المطلوبة:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
-
google-adk: حزمة تطوير الوكلاء من Google، بما في ذلك حزمة تطوير البرامج (SDK) الخاصة بـ Gemini toolbox-adk: دمج ADK مع MCP Toolbox for Databases
إنشاء بنية دليل الوكيل
يتوقّع ADK تنسيق مجلد محدّد: دليل مسمّى باسم وكيلك يحتوي على __init__.py وagent.py و.env. للمساعدة في ذلك، يتضمّن الأمر التالي لإنشاء البنية بسرعة:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
يجب أن يبدو دليلك الآن على النحو التالي:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
بعد ذلك، علينا دمج وكيل ADK مع خادم Toolbox قيد التشغيل واختبار جميع الأدوات الأربع: طلبات البحث العادية والبحث الدلالي واستيعاب المتّجهات. رمز الوكيل بسيط للغاية، إذ إنّ جميع منطق قاعدة البيانات مضمّن في tools.yaml.
ضبط بيئة الوكيل
يقرأ ADK GOOGLE_GENAI_USE_VERTEXAI وGOOGLE_CLOUD_PROJECT وGOOGLE_CLOUD_LOCATION من بيئة shell التي سبق لك ضبطها في الخطوة السابقة. المتغير الوحيد الخاص بالوكيل هو TOOLBOX_URL، لذا أضِفه إلى ملف .env الخاص بالوكيل:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
تعديل وحدة الوكيل
افتح restaurant_agent/agent.py في "محرِّر Cloud Shell".
cloudshell edit restaurant_agent/agent.py
واستبدِل المحتوى بالرمز التالي:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
يُرجى العِلم أنّه لا يوجد رمز قاعدة بيانات هنا، إذ يتصل ToolboxToolset بخادم Toolbox عند بدء التشغيل ويحمّل جميع الأدوات المتاحة. يستدعي الوكيل الأدوات بالاسم، ويحوّل Toolbox هذه الاستدعاءات إلى طلبات بحث SQL مقابل Cloud SQL.
يتم ضبط قيمة متغيّر البيئة TOOLBOX_URL تلقائيًا على http://127.0.0.1:5000 عند التطوير على الجهاز. عند التوزيع على Cloud Run لاحقًا، يمكنك تجاهل هذا الإعداد واستخدام عنوان URL لخدمة Toolbox على Cloud Run، بدون الحاجة إلى إجراء أي تغييرات في الرمز البرمجي.
اختبار الوكيل
ابدأ واجهة مستخدم مطوّر ADK:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
افتح عنوان URL المعروض في النافذة الطرفية (عادةً http://localhost:8000) باستخدام ميزة المعاينة على الويب في Cloud Shell أو اضغط على ctrl + النقر على عنوان URL المعروض في النافذة الطرفية. اختَر restaurant_agent من القائمة المنسدلة الخاصة بالوكيل في أعلى يمين الصفحة.
اختبار طلبات البحث العادية
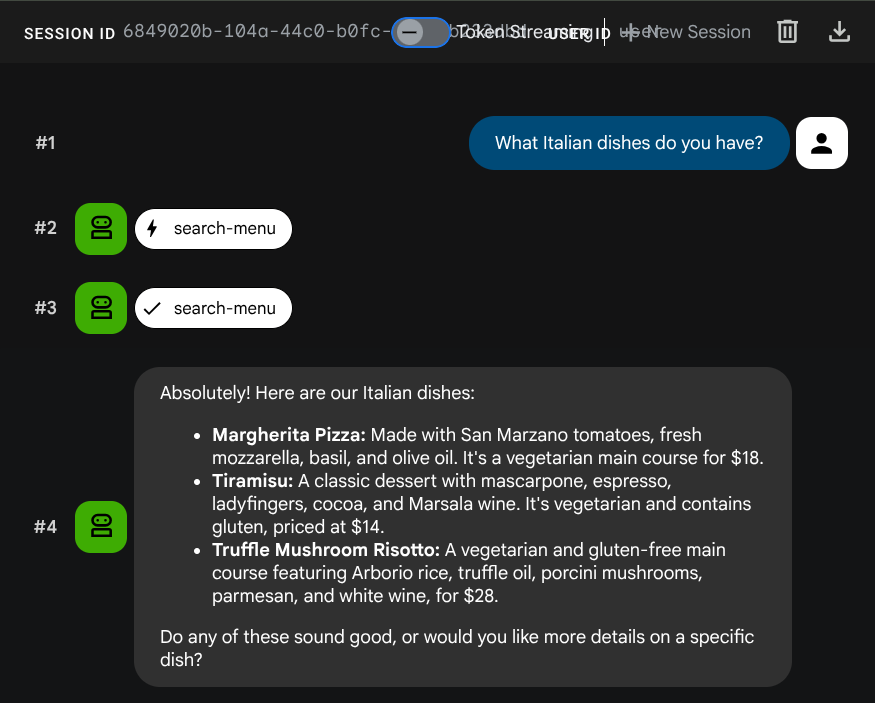
جرِّب الطلبات التالية للتحقّق من أدوات SQL العادية:
What Italian dishes do you have?
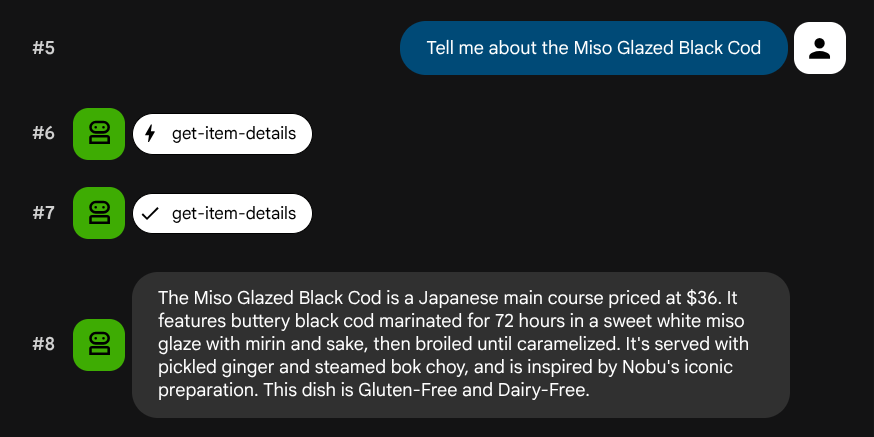
Tell me about the Miso Glazed Black Cod
تجربة البحث الدلالي
جرِّب أوصافًا باللغة الطبيعية لا تتوافق مع دور أو حزمة التكنولوجيا محدّدة:
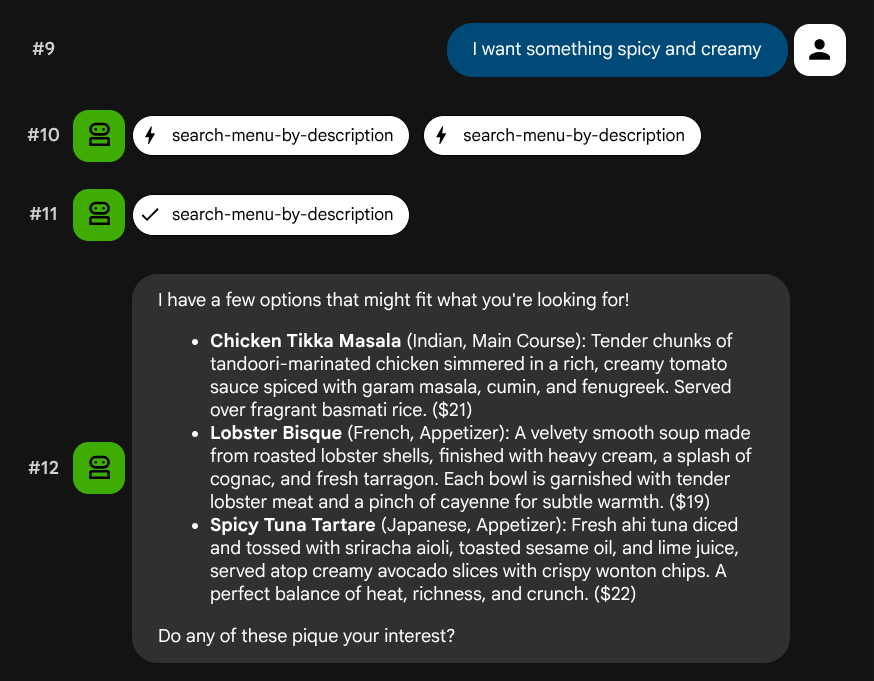
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
سيحاول الوكيل اختيار الأداة المناسبة استنادًا إلى نوع طلب البحث: تمر الفلاتر المنظَّمة عبر search-menu، بينما تمر الأوصاف المكتوبة بلغة طبيعية عبر search-menu-by-description.
اختبار عرض المتّجهات
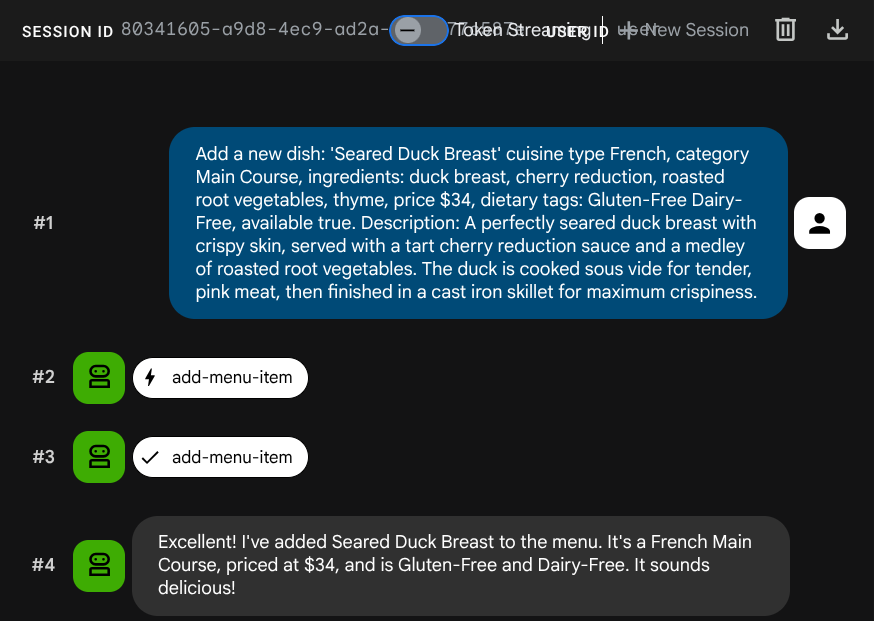
اطلب من الموظف إضافة وظيفة جديدة:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
الآن، جرِّب البحث عنه:
Find me something with rich, gamey flavors and fruit sauce
تم إنشاء التضمين تلقائيًا أثناء عملية INSERT، بدون الحاجة إلى اتّخاذ خطوة منفصلة.
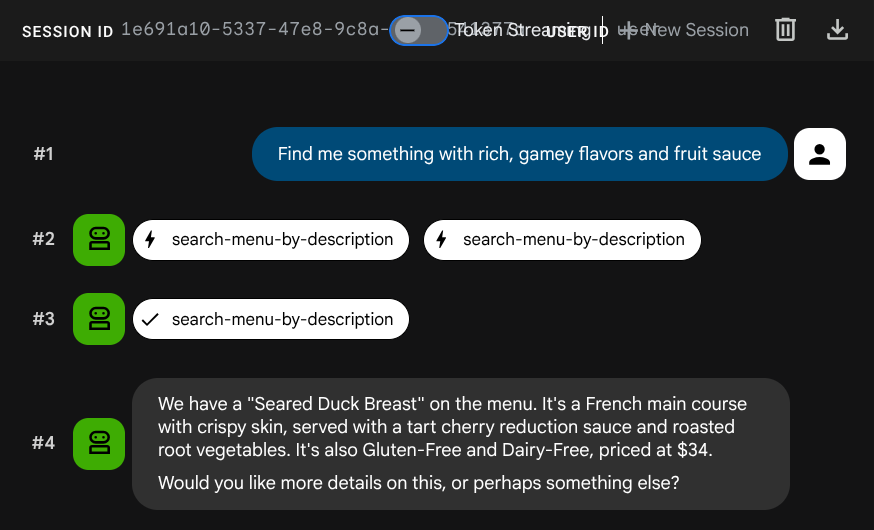
أصبح لديك الآن تطبيق توليد معزّز بالاسترجاع (RAG) مستنِد إلى الذكاء الاصطناعي الوكيل يعمل بكامل طاقته ويستخدم ADK وMCP Toolbox وCloudSQL. تهانينا! لننتقل إلى خطوة أخرى لنشر هذه التطبيقات على Cloud Run.
الآن، لنوقف واجهة مستخدم أدوات المطوّرين عن طريق إنهاء العملية من خلال الضغط على Ctrl+C مرّتين قبل المتابعة.
8- النشر على Cloud Run
يعمل الوكيل وToolbox محليًا. تنشر هذه الخطوة كليهما كخدمات Cloud Run حتى يمكن الوصول إليهما عبر الإنترنت. تعمل خدمة Toolbox كخادم MCP على Cloud Run، وتتصل بها خدمة الوكيل.
تحضير "صندوق الأدوات" للنشر
أنشئ دليل نشر لخدمة "مجموعة الأدوات":
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
أنشئ ملف Dockerfile لـ Toolbox. افتح deploy-toolbox/Dockerfile في "محرِّر Cloud Shell":
cloudshell edit deploy-toolbox/Dockerfile
ونسخ النص البرمجي التالي إليه
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
يتم تجميع ملفات Toolbox الثنائية وtools.yaml في صورة Debian بسيطة. توجّه Cloud Run حركة المرور إلى المنفذ 8080.
تفعيل خدمة "مجموعة الأدوات"
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
يرسل هذا الأمر المصدر إلى Cloud Build، وينشئ صورة حاوية، ويدفعها إلى Artifact Registry، وينشرها على Cloud Run. سيستغرق ذلك بضع دقائق، ويمكننا فحص سجلّ عملية النشر في الملف logs/deploy_toolbox.log.
تحضير الوكيل للنشر
أثناء إنشاء "مجموعة الأدوات"، يمكنك إعداد ملفات نشر الوكيل.
أنشئ Dockerfile في جذر المشروع. افتح Dockerfile في "محرِّر Cloud Shell":
cloudshell edit Dockerfile
بعد ذلك، انسخ المحتوى التالي
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
يستخدم ملف Dockerfile هذا ghcr.io/astral-sh/uv كصورة أساسية، ويتضمّن كلاً من Python وuv مثبّتَين مسبقًا، لذا لا حاجة إلى تثبيت uv بشكل منفصل من خلال pip.
أنشئ ملف .dockerignore لاستبعاد الملفات غير الضرورية من صورة الحاوية:
cloudshell edit .dockerignore
ثم انسخ النص البرمجي التالي والصقه فيه
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
نشر خدمة الوكيل
انتظِر إلى أن يكتمل نشر "مجموعة الأدوات". راجِع عملية النشر مرة أخرى على logs/deploy_toolbox.log للتأكّد من العملية. بعد ذلك، استرجِع عنوان URL الخاص بخدمة Cloud Run باستخدام الأمر التالي
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
ستظهر لك نتيجة مشابهة لما يلي
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
بعد ذلك، يجب التحقّق من أنّ "أدوات المطوّرين" المنشورة تعمل بشكل صحيح:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
إذا كانت المخرجات معروضة مثل هذا المثال، يعني ذلك أنّ عملية النشر قد نجحت.
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
بعد ذلك، لننشئ الوكيل ونمرّر عنوان URL الخاص بـ "مجموعة الأدوات" كمتغيّر بيئة:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
يقرأ رمز الوكيل TOOLBOX_URL من البيئة (يجب إعداد ذلك مسبقًا). يشير هذا المتغير محليًا إلى http://127.0.0.1:5000، بينما يشير على Cloud Run إلى عنوان URL الخاص بخدمة Toolbox. لا يلزم إجراء أي تغييرات على الرموز البرمجية.
اختبار الوكيل الذي تم نشره
استرداد عنوان URL الخاص بالوكيل على Cloud Run:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
افتح عنوان URL في المتصفّح. يتم تحميل واجهة مستخدم مطوّر ADK، وهي الواجهة نفسها التي كنت تستخدمها على جهازك، ولكنها تعمل الآن على Cloud Run.
اختَر restaurant_agent من القائمة المنسدلة واختبِرها:
What Italian dishes do you have?
I want something spicy and creamy
يعمل كلا الطلبين من خلال الخدمات التي تم نشرها: يطلب الوكيل على Cloud Run من Toolbox على Cloud Run، الذي يطلب بدوره من Cloud SQL.
9- تهانينا / تنظيف
لقد أنشأت ونشرت مساعدًا ذكيًا لقائمة الطعام في المطعم يستخدم MCP Toolbox for Databases لربط وكيل ADK بخدمة Cloud SQL PostgreSQL، وذلك باستخدام طلبات البحث بلغة الاستعلامات البنيوية (SQL) العادية والبحث الدلالي عن المتّجهات.
ما تعلّمته
- كيف يوحّد MCP إمكانية الوصول إلى الأدوات لوكلاء الذكاء الاصطناعي، وكيف تطبّق MCP Toolbox for Databases ذلك تحديدًا على عمليات قواعد البيانات، ما يؤدي إلى استبدال رمز قاعدة البيانات المخصّص بإعداد YAML تعريفي
- كيفية ضبط Cloud SQL PostgreSQL كمصدر بيانات في "مجموعة الأدوات" باستخدام نوع المصدر
cloud-sql-postgres - كيفية تحديد أدوات طلب بحث SQL العادية باستخدام عبارات ذات مَعلمات تمنع حقن SQL
- كيفية تفعيل البحث عن المتّجهات باستخدام pgvector و
gemini-embedding-001، مع المَعلمةembeddedByلتضمين طلبات البحث تلقائيًا - الطريقة التي تتيح بها أداة
valueFromParamإدخال المتجهات تلقائيًا: يقدّم النموذج اللغوي الكبير وصفًا نصيًا، وتعمل "أدوات الذكاء الاصطناعي" على نسخ المتجه وتضمينه وتخزينه بصمت إلى جانب النص - كيفية تحميل
ToolboxToolsetفي ADK للأدوات من خادم Toolbox قيد التشغيل، مع الحفاظ على الحد الأدنى من رموز الوكيل وفصل منطق قاعدة البيانات بالكامل - كيفية نشر كلّ من خادم MCP الخاص بـ Toolbox ووكيل ADK على Cloud Run كخدمات منفصلة
إخلاء مساحة
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد التي تم إنشاؤها في هذا الدرس التطبيقي حول الترميز، يمكنك حذف الموارد الفردية أو حذف المشروع بأكمله.
الخيار 1: حذف المشروع (مقترَح)
أسهل طريقة لتنظيف مساحة التخزين هي حذف المشروع. يؤدي هذا الإجراء إلى إزالة جميع الموارد المرتبطة بالمشروع.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
الخيار 2: حذف موارد فردية
إذا كنت تريد الاحتفاظ بالمشروع ولكن إزالة الموارد التي تم إنشاؤها في هذا الدرس العملي فقط، اتّبِع الخطوات التالية:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null