
১. ভূমিকা
এআই এজেন্টগুলো ঠিক ততটাই কার্যকর, যতটা ডেটা তারা অ্যাক্সেস করতে পারে। বাস্তব জগতের বেশিরভাগ ডেটা ডেটাবেসে থাকে — এবং এজেন্টদের ডেটাবেসের সাথে সংযুক্ত করার অর্থ হলো সাধারণত আপনার এজেন্ট কোডের মধ্যে কানেকশন ম্যানেজমেন্ট, কোয়েরি লজিক লেখা এবং পাইপলাইন এমবেড করা। ডেটাবেস অ্যাক্সেসের প্রয়োজন এমন প্রতিটি এজেন্টকে এই কাজটি বারবার করতে হয়, এবং প্রতিটি কোয়েরি পরিবর্তনের জন্য এজেন্টটিকে পুনরায় ডেপ্লয় করতে হয়।
এই কোডল্যাবটি একটি ভিন্ন পদ্ধতি দেখায়। আপনি একটি YAML ফাইলে আপনার ডাটাবেস টুলগুলো ঘোষণা করেন — যেমন সাধারণ SQL কোয়েরি, ভেক্টর সিমিলারিটি সার্চ, এমনকি স্বয়ংক্রিয় এমবেডিং জেনারেশন — এবং MCP টুলবক্স ফর ডাটাবেস একটি MCP সার্ভার হিসেবে সমস্ত ডাটাবেস অপারেশন পরিচালনা করে। আপনার এজেন্ট কোড ন্যূনতম থাকে: টুলগুলো লোড করুন, এবং কোনটি কল করতে হবে তা জেমিনিকে সিদ্ধান্ত নিতে দিন।
আপনি যা তৈরি করবেন
A Restaurant Concierge for "Foodie Finds" — an ADK agent powered by Gemini that helps diners browse a restaurant's menu using standard filters (category, cuisine type) and discover dishes through natural language descriptions like "I want something spicy and vegetarian." The agent reads from and writes to a Cloud SQL PostgreSQL database entirely through MCP Toolbox for Databases, which handles all database access — including automatic embedding generation for vector search. By the end, both the Toolbox and the agent run on Cloud Run.
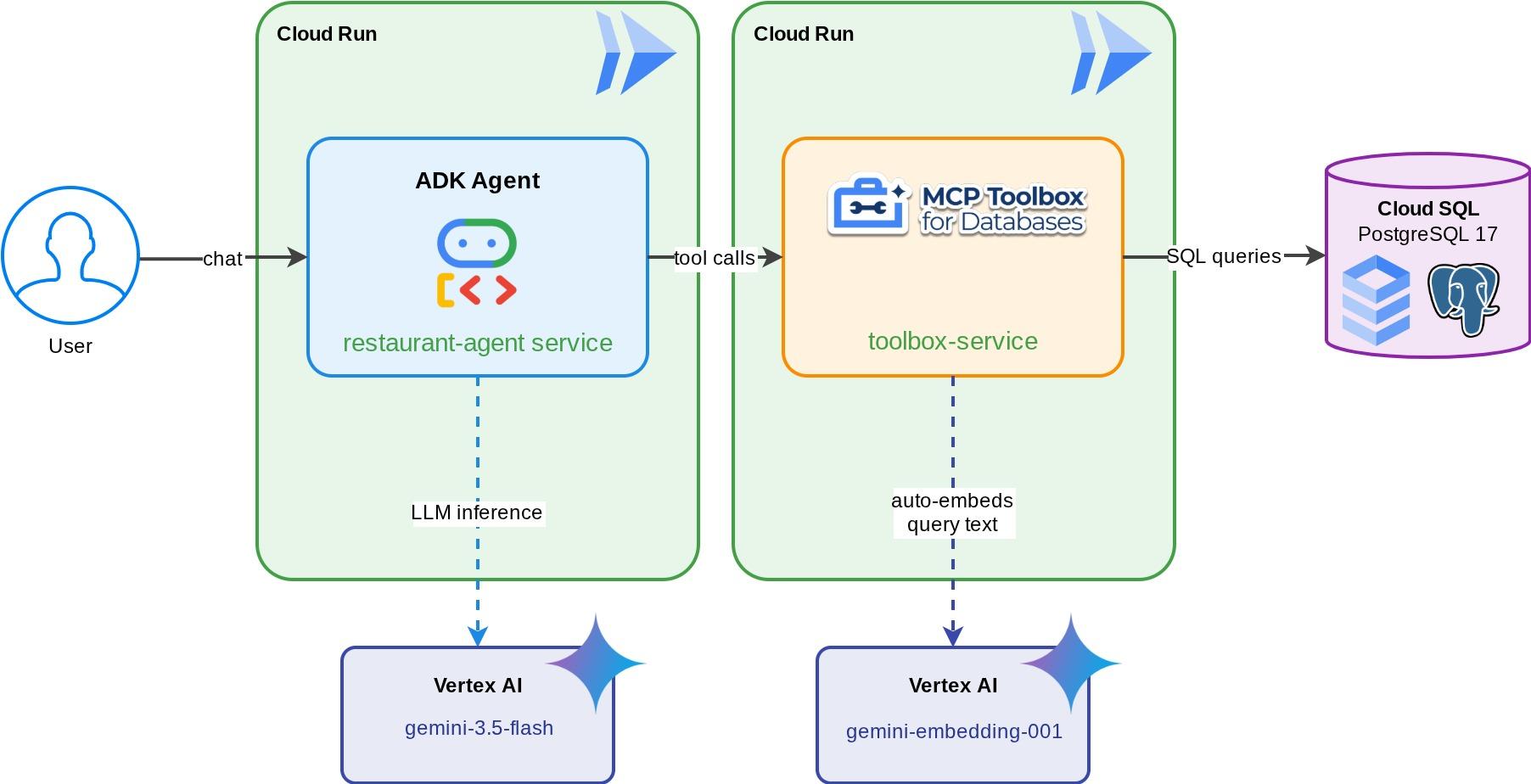
আপনি যা শিখবেন
- কীভাবে এমসিপি (মডেল কনটেক্সট প্রোটোকল) এআই এজেন্টদের জন্য টুল অ্যাক্সেসকে প্রমিত করে, এবং কীভাবে এমসিপি টুলবক্স ফর ডেটাবেসেস এটিকে ডেটাবেস অপারেশনে প্রয়োগ করে।
- ADK এজেন্ট এবং ক্লাউড SQL PostgreSQL-এর মধ্যে মিডলওয়্যার হিসেবে MCP টুলবক্স ফর ডেটাবেস সেট আপ করুন।
-
tools.yamlফাইলে ডিক্লারেটিভভাবে ডাটাবেস টুলস সংজ্ঞায়িত করুন — আপনার এজেন্টে কোনো ডাটাবেস কোড থাকবে না -
ToolboxToolsetব্যবহার করে একটি ADK এজেন্ট তৈরি করুন যা একটি চলমান টুলবক্স সার্ভার থেকে টুল লোড করে। - Cloud SQL-এর বিল্ট-ইন
embedding()ফাংশন ব্যবহার করে ভেক্টর এমবেডিং তৈরি করুন এবংpgvectorসাহায্যে সিমান্টিক সার্চ সক্রিয় করুন। - রাইট অপারেশনে স্বয়ংক্রিয় ভেক্টর ইনজেশনের জন্য
valueFromParamফিচারটি ব্যবহার করুন। - টুলবক্স সার্ভার এবং ADK এজেন্ট উভয়কেই ক্লাউড রান-এ স্থাপন করুন।
পূর্বশর্ত
- ট্রায়াল বিলিং অ্যাকাউন্ট সহ একটি গুগল ক্লাউড অ্যাকাউন্ট
- পাইথন এবং SQL সম্পর্কে প্রাথমিক ধারণা।
- ক্লাউড ডেটাবেস এবং ADK-এর পূর্ব অভিজ্ঞতা থাকলে সহায়ক হবে।
২. আপনার পরিবেশ প্রস্তুত করুন
এই ধাপে আপনার ক্লাউড শেল এনভায়রনমেন্ট প্রস্তুত করা হয়, আপনার গুগল ক্লাউড প্রজেক্ট কনফিগার করা হয় এবং রেফারেন্স রিপোজিটরি ক্লোন করা হয়।
ওপেন ক্লাউড শেল
আপনার ব্রাউজারে ক্লাউড শেল খুলুন। ক্লাউড শেল এই কোডল্যাবের জন্য আপনার প্রয়োজনীয় সমস্ত সরঞ্জাম সহ একটি পূর্ব-কনফিগার করা পরিবেশ প্রদান করে। অনুরোধ করা হলে অনুমোদন করুন (Authorize) বোতামে ক্লিক করুন।
এরপর টার্মিনাল খোলার জন্য " ভিউ " -> " টার্মিনাল "-এ ক্লিক করুন। আপনার ইন্টারফেসটি দেখতে এইরকম হবে।
এটাই হবে আমাদের মূল ইন্টারফেস, উপরে IDE, নিচে টার্মিনাল।
আপনার ওয়ার্কিং ডিরেক্টরি সেট আপ করুন
আপনার ওয়ার্কিং ডিরেক্টরি তৈরি করুন। এই কোডল্যাবে আপনার লেখা সমস্ত কোড এখানেই থাকবে:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
এরপরে, সিডিং স্ক্রিপ্ট এবং লগের মতো বিষয়গুলো পরিচালনা করার জন্য কয়েকটি ডিরেক্টরি প্রস্তুত করা যাক।
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
আপনার গুগল ক্লাউড প্রজেক্ট সেট আপ করুন
অবস্থান ভেরিয়েবলগুলো দিয়ে .env ফাইলটি তৈরি করুন:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
আপনার টার্মিনালে প্রজেক্ট সেটআপ সহজ করার জন্য, এই প্রজেক্ট সেটআপ স্ক্রিপ্টটি আপনার ওয়ার্কিং ডিরেক্টরিতে ডাউনলোড করুন:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
স্ক্রিপ্টটি চালান। এটি আপনার ট্রায়াল বিলিং অ্যাকাউন্ট যাচাই করে, একটি নতুন প্রজেক্ট তৈরি করে (অথবা বিদ্যমান কোনো প্রজেক্টকে বৈধতা দেয়), আপনার প্রজেক্ট আইডি বর্তমান ডিরেক্টরির একটি .env ফাইলে সংরক্ষণ করে এবং gcloud এ সক্রিয় প্রজেক্টটি সেট করে।
bash setup_verify_trial_project.sh && source .env
স্ক্রিপ্টটি করবে:
- আপনার একটি সক্রিয় ট্রায়াল বিলিং অ্যাকাউন্ট আছে কিনা তা যাচাই করুন।
-
.envফাইলে কোনো বিদ্যমান প্রজেক্ট আছে কিনা তা পরীক্ষা করুন (যদি থাকে)। - একটি নতুন প্রকল্প তৈরি করুন অথবা বিদ্যমান প্রকল্পটি পুনরায় ব্যবহার করুন।
- ট্রায়াল বিলিং অ্যাকাউন্টটি আপনার প্রোজেক্টের সাথে লিঙ্ক করুন।
- প্রজেক্ট আইডিটি
.envফাইলে সংরক্ষণ করুন। - প্রজেক্টটিকে সক্রিয়
gcloudপ্রজেক্ট হিসেবে সেট করুন।
ক্লাউড শেল টার্মিনাল প্রম্পটে আপনার ওয়ার্কিং ডিরেক্টরির পাশে থাকা হলুদ লেখাটি দেখে প্রজেক্টটি সঠিকভাবে সেট করা হয়েছে কিনা তা যাচাই করুন। সেখানে আপনার প্রজেক্ট আইডি প্রদর্শিত হওয়া উচিত।

প্রয়োজনীয় এপিআই সক্রিয় করুন
এরপরে, পণ্যটির জন্য আমাদের কয়েকটি API সক্রিয় করতে হবে, যেগুলোর সাথে আমরা কাজ করব:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- ভার্টেক্স এআই এপিআই (
aiplatform.googleapis.com) — আপনার এজেন্ট জেমিনি মডেল ব্যবহার করে, এবং টুলবক্স ভেক্টর সার্চের জন্য এমবেডিং এপিআই ব্যবহার করে। - ক্লাউড এসকিউএল অ্যাডমিন এপিআই (
sqladmin.googleapis.com) — এর মাধ্যমে আপনি একটি পোস্টগ্রেসকিউএল ইনস্ট্যান্স প্রোভিশন এবং ম্যানেজ করতে পারেন। - কম্পিউট ইঞ্জিন এপিআই (
compute.googleapis.com) — ক্লাউড এসকিউএল ইনস্ট্যান্স তৈরি করার জন্য এটি প্রয়োজন। - ক্লাউড রান, ক্লাউড বিল্ড, আর্টিফ্যাক্ট রেজিস্ট্রি — এই কোডল্যাবের পরবর্তী অংশে ডিপ্লয়মেন্ট ধাপে ব্যবহৃত হবে।
৩. ডাটাবেস প্রারম্ভিককরণের জন্য স্ক্রিপ্ট প্রস্তুত করা
এই ধাপে ক্লাউড এসকিউএল ইনস্ট্যান্স তৈরি শুরু হয় এবং একটি স্বয়ংক্রিয় সেটআপ স্ক্রিপ্ট চলে, যা ইনস্ট্যান্সটি প্রস্তুত হওয়ার জন্য অপেক্ষা করে, তারপর ডেটাবেস তৈরি করে, জব লিস্টিং দিয়ে সেটিকে সিড করে এবং এমবেডিং জেনারেট করে — এই সবকিছু একটিমাত্র অপারেশনেই সম্পন্ন হয়।
প্রথমে, আপনার .env ফাইলে ডাটাবেস পাসওয়ার্ডটি যোগ করুন এবং ফাইলটি রিলোড করুন:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
ইনস্ট্যান্স এবং ডাটাবেস তৈরির জন্য ব্যাশ স্ক্রিপ্ট তৈরি করা
এরপর, নিচের কমান্ডটি ব্যবহার করে scripts/setup_database.sh স্ক্রিপ্টটি তৈরি করুন।
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
এরপর, নিচের কোডটি scripts/setup_database.sh ফাইলে কপি করুন।
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
ডেটা সিডের জন্য পাইথন স্ক্রিপ্ট তৈরি করা
এরপরে, নিচের কমান্ডটি ব্যবহার করে scripts/setup_restaurant_db.py নামের সিডিং স্ক্রিপ্ট পাইথন ফাইলটি তৈরি করুন।
cloudshell edit scripts/setup_restaurant_db.py
এরপর, নিচের কোডটি scripts/setup_restaurant_db.py ফাইলে কপি করুন।
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
এবার, পরবর্তী ধাপে যাওয়া যাক।
৪. ডাটাবেস তৈরি এবং প্রারম্ভিকীকরণ করুন
এখন আমাদের স্ক্রিপ্টগুলো চালানোর জন্য প্রস্তুত। আমাদের তৈরি করা স্ক্রিপ্টটি চালানোর জন্য পাইথন প্রয়োজন হবে, তাই চলুন প্রথমে সেটি প্রস্তুত করে নেওয়া যাক।
পাইথন প্রজেক্টটি সেট আপ করুন
uv হলো রাস্ট (Rust) ভাষায় লেখা একটি দ্রুতগতির পাইথন প্যাকেজ ও প্রজেক্ট ম্যানেজার ( uv ডকুমেন্টেশন দেখুন )। এই কোডল্যাবটি পাইথন প্রজেক্ট রক্ষণাবেক্ষণে গতি ও সরলতার জন্য এটি ব্যবহার করে।
একটি পাইথন প্রজেক্ট শুরু করুন এবং প্রয়োজনীয় ডিপেন্ডেন্সিগুলো যোগ করুন:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
উল্লেখ্য যে, আমরা এখানে আমাদের ডাটাবেস ইনস্ট্যান্সের সাথে একটি সুরক্ষিত সংযোগ স্থাপন করতে cloud-sql-python-connector পাইথন SDK ব্যবহার করছি, যা অ্যাপ্লিকেশন ডিফল্ট ক্রেডেনশিয়াল ব্যবহার করে প্রমাণীকৃত হয়।
সেটআপ স্ক্রিপ্টটি চালান।
এখন, আমরা নিম্নলিখিত কমান্ডটি ব্যবহার করে সেটআপ স্ক্রিপ্টটি ব্যাকগ্রাউন্ডে চালাতে এবং logs/atabase_setup.log ফাইলে লেখা কনসোল আউটপুট পরীক্ষা করতে পারি। এটি শেষ হওয়ার জন্য অপেক্ষা করার সময় আপনি পরবর্তী বিভাগে যেতে পারেন।
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
টুলবক্স বাইনারি ডাউনলোড করুন
We will utilize MCP Toolbox in this tutorial, fortunately it comes with a pre-built binary that is ready to be used in the Linux environment. Now, let's download it in the background as well as it takes quite a while. Run the following command to download the binary and inspect the output log on the logs/toolbox_dl.log . You can continue to the next section while waiting this to be finished
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
সেটআপ স্ক্রিপ্ট scripts/setup_database.sh বোঝা
এখন আমরা পূর্বে কনফিগার করা সেটআপ স্ক্রিপ্টটি বোঝার চেষ্টা করব। এটি নিম্নলিখিত প্রক্রিয়াটি সম্পন্ন করে।
- সেখানে আমরা সর্বপ্রথম যে কমান্ডটি চালাই, সেটি হলো
gcloud sql instances createকমান্ড, সাথে নিম্নলিখিত ফ্ল্যাগটি ব্যবহার করি।
-
db-custom-1-3840হলোENTERPRISEসংস্করণের সবচেয়ে ছোট ডেডিকেটেড-কোর ক্লাউড এসকিউএল টিয়ার (১ vCPU, ৩.৭৫ জিবি র্যাম)। আপনি এখানে আরও বিস্তারিত জানতে পারবেন। ভার্টেক্স এআই এমএল ইন্টিগ্রেশনের জন্য একটি ডেডিকেটেড কোর প্রয়োজন — শেয়ার্ড-কোর টিয়ারগুলো (db-f1-micro,db-g1-small) এটি সমর্থন করে না। -
--root-passwordডিফল্টpostgresব্যবহারকারীর পাসওয়ার্ড সেট করে। -
--enable-google-ml-integrationক্লাউড এসকিউএল-এর ভার্টেক্স এআই (Vertex AI)-এর সাথে অন্তর্নির্মিত ইন্টিগ্রেশন সক্রিয় করে, যা আপনাকেembedding()ফাংশন ব্যবহার করে সরাসরি এসকিউএল (SQL) থেকে এম্বেডিং মডেল কল করতে দেয়।
- ইনস্ট্যান্সটি ইতিমধ্যেই
RUNNABLEঅবস্থায় আছে কিনা যাচাই করুন। -
gcloud projects add-iam-policy-bindingকমান্ডটি ব্যবহার করে ক্লাউড SQL ইনস্ট্যান্সের সার্ভিস অ্যাকাউন্টকে Vertex AI কল করার অনুমতি দিন। ডাটাবেস সিড করার সময় আমরা যে বিল্ট-ইন `embedding()ফাংশনটি ব্যবহার করব, তার জন্য এটি প্রয়োজন। - ডাটাবেস তৈরি করা
- সিডিং স্ক্রিপ্ট
setup_restaurant_db.pyস্ক্রিপ্টটি চালানো হচ্ছে
সিড স্ক্রিপ্ট বোঝা scripts/setup_restaurant_db.py
এবার সিডিং স্ক্রিপ্টের কথায় আসা যাক, এই স্ক্রিপ্টটি নিম্নলিখিত কাজগুলো করে:
- ডাটাবেস ইনস্ট্যান্সের সাথে সংযোগ শুরু করুন
- দুটি PostgreSQL এক্সটেনশন ইনস্টল করে:
-
google_ml_integration— provides theembedding()SQL function, which calls Vertex AI embedding models directly from SQL. This is a database-level extension that makes ML functions available insiderestaurant_db. The instance-level flag (--enable-google-ml-integration) you set during instance creation allows the Cloud SQL VM to reach Vertex AI — the extension makes the SQL functions available within this specific database. -
vector(pgvector) — এমবেডিং সংরক্ষণ এবং কোয়েরি করার জন্যvectorডেটা টাইপ এবং ডিসট্যান্স অপারেটর যোগ করে।
- টেবিলটি তৈরি করুন, লক্ষ্য করুন যে
description_embeddingকলামটি হলোvector(3072)— এটি একটিpgvectorকলাম যা ৩০৭২-মাত্রিক ভেক্টর সংরক্ষণ করে। - প্রাথমিক মেনু আইটেমগুলির ডেটা সিড করুন
-
descriptionফিল্ড থেকে এমবেডিং ডেটা তৈরি করুন এবংembedding()ফাংশনের মাধ্যমে বিল্ট-ইন ভার্টেক্স ইন্টিগ্রেশন ব্যবহার করেdescription_embeddingপূরণ করুন।
-
embedding('gemini-embedding-001', description)— প্রতিটি জবেরdescriptionটেক্সট পাস করে সরাসরি SQL থেকে Vertex AI-এর Gemini এমবেডিং মডেলকে কল করে। এটি হলো সেইgoogle_ml_integrationএক্সটেনশন যা আপনি সিড স্ক্রিপ্টে ইনস্টল করেছেন। -
::vector— রিটার্ন করা ফ্লোট অ্যারেটিকে pgvector-এরvectorটাইপে রূপান্তর করে, যাতে এটিকে ডিসটেন্স অপারেটর ব্যবহার করে সংরক্ষণ ও কোয়েরি করা যায়। -
UPDATE১৫টি সারির সবকটিতে চলে এবং প্রতিটি কাজের বিবরণের জন্য একটি করে ৩০৭২-মাত্রিক এমবেডিং তৈরি করে।
এর মাধ্যমে প্রাথমিক তথ্য প্রস্তুত করা হবে, যা আমাদের এজেন্ট ব্যবহার করতে পারবে।
৫. ডেটাবেসের জন্য এমসিপি টুলবক্স কনফিগার করুন
এই ধাপে MCP টুলবক্স ফর ডেটাবেস-এর সাথে পরিচয় করিয়ে দেওয়া হয়, আপনার ক্লাউড SQL ইনস্ট্যান্সের সাথে সংযোগ করার জন্য এটিকে কনফিগার করা হয় এবং দুটি স্ট্যান্ডার্ড SQL কোয়েরি টুল সংজ্ঞায়িত করা হয়।
এমসিপি কী এবং টুলবক্স কেন ব্যবহার করা হয়?
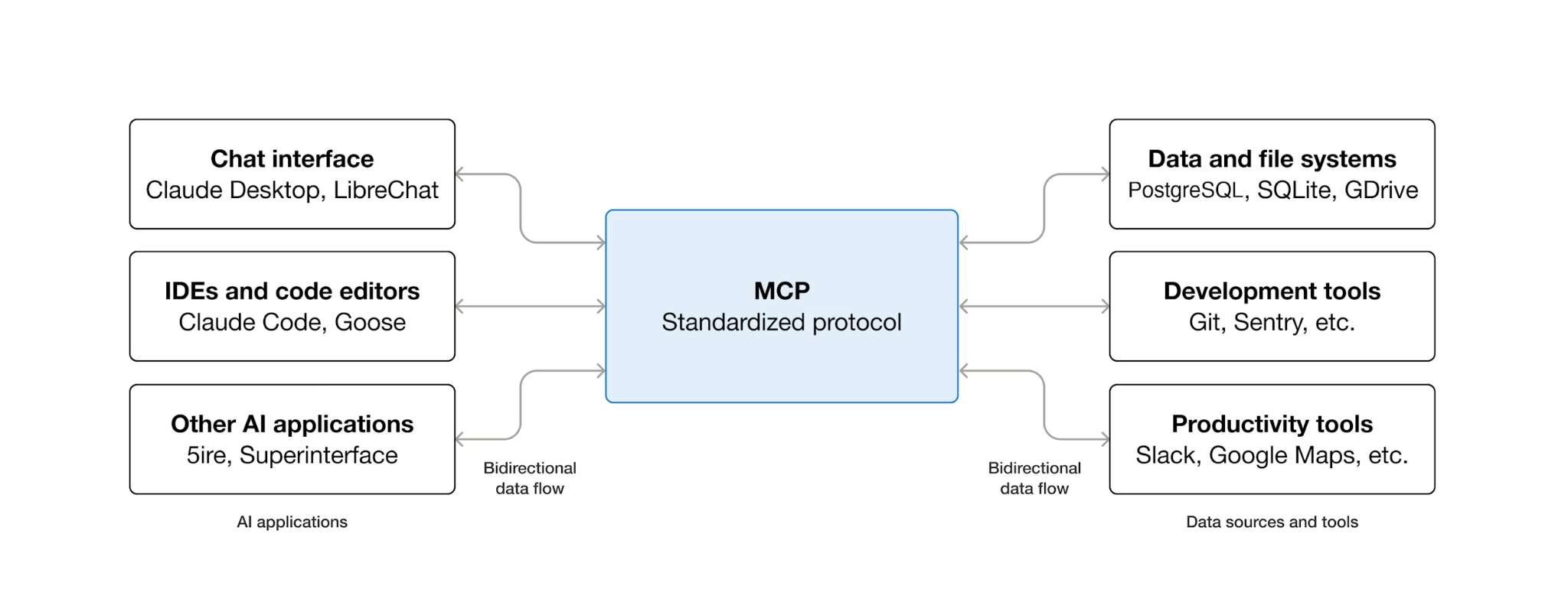
এমসিপি (মডেল কনটেক্সট প্রোটোকল) হলো একটি উন্মুক্ত প্রোটোকল যা এআই এজেন্টরা কীভাবে বাহ্যিক টুলগুলো খুঁজে বের করে এবং সেগুলোর সাথে মিথস্ক্রিয়া করে, তার একটি মান নির্ধারণ করে। এটি একটি ক্লায়েন্ট-সার্ভার মডেল সংজ্ঞায়িত করে: এজেন্ট একটি এমসিপি ক্লায়েন্ট হোস্ট করে এবং এমসিপি সার্ভারগুলোর মাধ্যমে টুলগুলো উন্মুক্ত করা হয়। যেকোনো এমসিপি-উপযোগী ক্লায়েন্ট যেকোনো এমসিপি-উপযোগী সার্ভার ব্যবহার করতে পারে — প্রতিটি টুলের জন্য এজেন্টের আলাদা ইন্টিগ্রেশন কোডের প্রয়োজন হয় না।
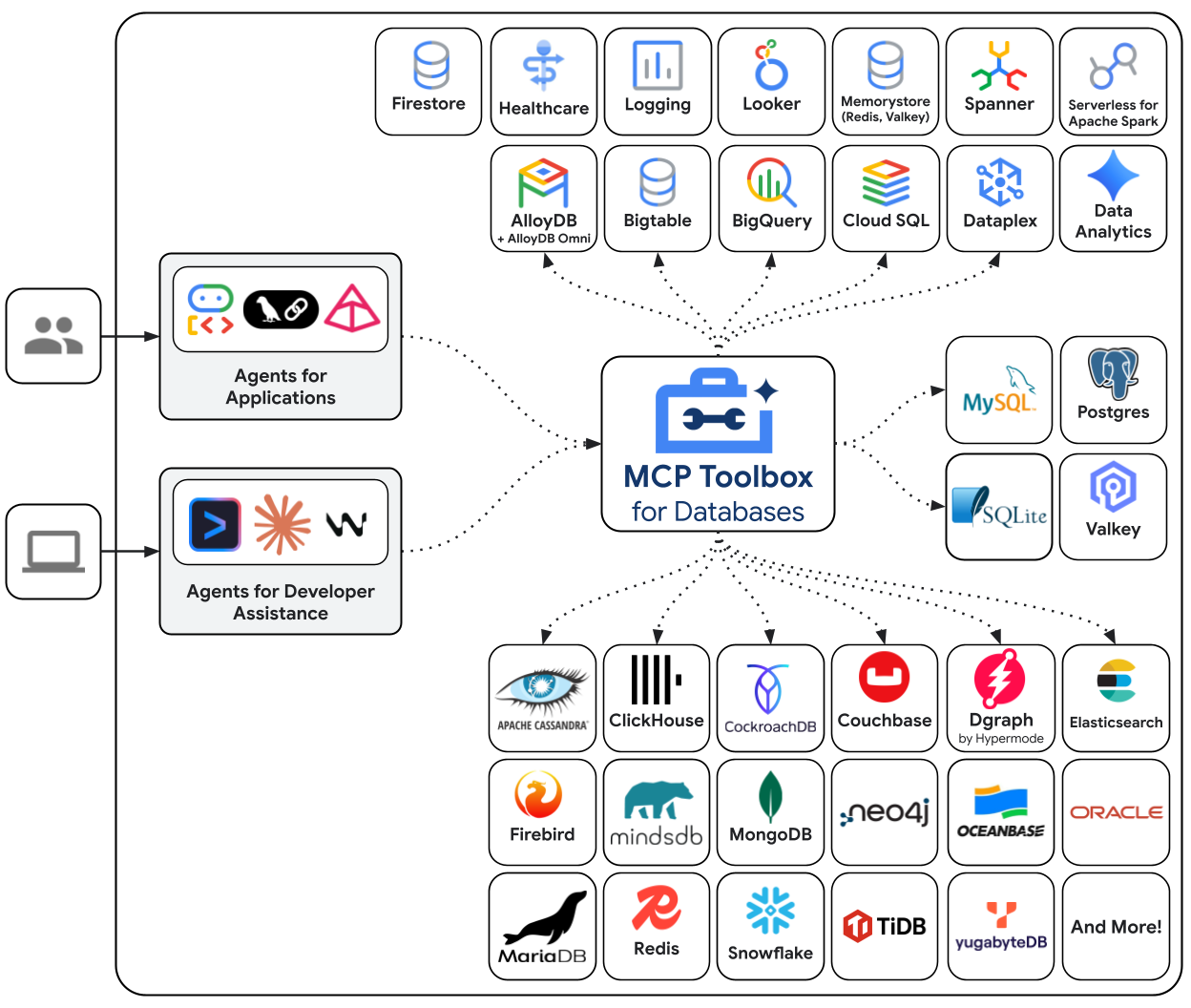
MCP Toolbox for Databases is an open-source MCP server built specifically for database access. Without it, you would write Python functions that open database connections, manage connection pools, construct parameterized queries to prevent SQL injection, handle errors, and embed all of that code inside your agent. Every agent that needs database access repeats this work. Changing a query means redeploying the agent.
With Toolbox, you write a YAML file. Each tool maps to a parameterized SQL statement. Toolbox handles connection pooling, parameterized queries, authentication, and observability. Tools are decoupled from the agent — update a query by editing tools.yaml and restarting Toolbox, without touching agent code. The same tools work across ADK, LangGraph, LlamaIndex, or any MCP-compatible framework.
টুলস কনফিগারেশন লিখুন
এখন, আমাদের টুলস কনফিগারেশন সেট আপ করার জন্য ক্লাউড শেল এডিটরে tools.yaml নামে একটি ফাইল তৈরি করতে হবে।
cloudshell edit tools.yaml
The file uses multi-document YAML — each block separated by --- is a standalone resource. Every resource has a kind that declares what it is ( sources for database connections, tools for agent-callable actions) and a type that specifies the backend ( cloud-sql-postgres for the source, postgres-sql for SQL-based tools). A tool references its source by name , which is how Toolbox knows which connection pool to execute against. Environment variables use ${VAR_NAME} syntax and are resolved at startup.
এখন, প্রথমে নিচের স্ক্রিপ্টগুলো tools.yaml ফাইলে কপি করা যাক।
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
এই স্ক্রিপ্টটি নিম্নলিখিত রিসোর্সটি সংজ্ঞায়িত করে:
- সোর্স (
restaurant-db) — টুলবক্সকে বলে দেয় কীভাবে আপনার ক্লাউড এসকিউএল পোস্টগ্রেসকিউএল ইনস্ট্যান্সের সাথে সংযোগ স্থাপন করতে হবে।cloud-sql-postgresটাইপটি অভ্যন্তরীণভাবে ক্লাউড এসকিউএল কানেক্টর ব্যবহার করে, যা স্বয়ংক্রিয়ভাবে অথেনটিকেশন এবং সুরক্ষিত সংযোগ পরিচালনা করে।${GOOGLE_CLOUD_PROJECT},${REGION}এবং${DB_PASSWORD}প্লেসহোল্ডারগুলো স্টার্টআপের সময় এনভায়রনমেন্ট ভেরিয়েবল থেকে নির্ধারিত হয়।
এরপরে, tools.yaml ফাইলের --- চিহ্নের নিচে নিম্নলিখিত স্ক্রিপ্টটি যুক্ত করুন।
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
এই স্ক্রিপ্টটি নিম্নলিখিত রিসোর্সটি সংজ্ঞায়িত করে:
- টুল ১ এবং ২ (
search-menu,get-item-details) — স্ট্যান্ডার্ড SQL কোয়েরি টুল। প্রতিটি টুলের নামকে (যা এজেন্ট দেখতে পায়) একটি প্যারামিটারযুক্ত SQL স্টেটমেন্টের (যা ডেটাবেস এক্সিকিউট করে) সাথে ম্যাপ করে। প্যারামিটারগুলো$1,$2পজিশনাল প্লেসহোল্ডার ব্যবহার করে। টুলবক্স এগুলোকে প্রিপেয়ার্ড স্টেটমেন্ট হিসেবে এক্সিকিউট করে, যা SQL ইনজেকশন প্রতিরোধ করে।
চলুন, এরপর tools.yaml ফাইলের --- চিহ্নের নিচে নিম্নলিখিত স্ক্রিপ্টটি যুক্ত করুন।
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
এই স্ক্রিপ্টটি নিম্নলিখিত রিসোর্সটি সংজ্ঞায়িত করে:
- এমবেডিং মডেল (
gemini-embedding) — ৩০৭২-মাত্রিক টেক্সট এমবেডিং তৈরি করার জন্য টুলবক্সকে জেমিনিরgemini-embedding-001মডেল কল করতে কনফিগার করে। টুলবক্স প্রমাণীকরণের জন্য অ্যাপ্লিকেশন ডিফল্ট ক্রেডেনশিয়ালস (ADC) ব্যবহার করে — ক্লাউড শেল বা ক্লাউড রানে কোনো এপিআই কী-এর প্রয়োজন নেই। মনে রাখবেন যে, এখানে কনফিগার করা এইdimensionঅবশ্যই সেই ডাইমেনশনের সমান হতে হবে যা আমরা পূর্বে ডাটাবেস সিড করার জন্য কনফিগার করেছিলাম।
চলুন, এরপর tools.yaml ফাইলের --- চিহ্নের নিচে নিম্নলিখিত স্ক্রিপ্টটি যুক্ত করুন।
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
এই স্ক্রিপ্টটি নিম্নলিখিত রিসোর্সটি সংজ্ঞায়িত করে:
- টুল ৩ (
search-menu-by-description) — একটি ভেক্টর সার্চ টুল।search_queryপ্যারামিটারটিতেembeddedBy: gemini-embeddingরয়েছে, যা টুলবক্সকে মূল টেক্সটটি গ্রহণ করে এমবেডিং মডেলে পাঠাতে এবং প্রাপ্ত ভেক্টরটি SQL স্টেটমেন্টে ব্যবহার করতে নির্দেশ দেয়।<=>অপারেটরটি হলো pgvector-এর কোসাইন ডিসট্যান্স — এর ছোট মানগুলো আরও বেশি সাদৃশ্যপূর্ণ বর্ণনা নির্দেশ করে।
অবশেষে, tools.yaml ফাইলে --- চিহ্নের নিচে শেষ টুলটি যুক্ত করুন।
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
এই স্ক্রিপ্টটি নিম্নলিখিত রিসোর্সটি সংজ্ঞায়িত করে:
- টুল ৪ (
add-menu-item) — ভেক্টর ইনজেশন প্রদর্শন করে।description_vectorপ্যারামিটারটির দুটি বিশেষ ফিল্ড রয়েছে: -
valueFromParam: description— টুলবক্সdescriptionপ্যারামিটার থেকে মানটি এই প্যারামিটারে কপি করে। LLM এই প্যারামিটারটি কখনও দেখতে পায় না। -
embeddedBy: gemini-embedding— টুলবক্সটি কপি করা টেক্সটকে SQL-এ পাঠানোর আগে একটি ভেক্টরে এমবেড করে।
এর ফলে: এজেন্ট এমবেডিং সম্পর্কে কিছুই না জেনেই, একটিমাত্র টুল কলের মাধ্যমে মূল বর্ণনামূলক টেক্সট এবং তার ভেক্টর এমবেডিং উভয়ই সংরক্ষিত হয়ে যায়।
মাল্টি-ডকুমেন্ট YAML ফরম্যাট প্রতিটি রিসোর্সকে --- দিয়ে আলাদা করে। প্রতিটি ডকুমেন্টে kind , name , এবং type ফিল্ড থাকে যা সেটির পরিচয় নির্ধারণ করে। সংক্ষেপে, আমরা ইতিমধ্যেই নিম্নলিখিত সমস্ত বিষয় কনফিগার করেছি:
- উৎস ডাটাবেস সংজ্ঞায়িত করুন
- স্ট্যান্ডার্ড ফিল্টার ব্যবহার করে ডাটাবেস কোয়েরি করার জন্য টুল ( টুল ১ এবং ২ ) নির্ধারণ করুন।
- এমবেডিং মডেল সংজ্ঞায়িত করুন
- ডাটাবেসে ভেক্টর অনুসন্ধান করার জন্য টুল ( টুল ৩ ) নির্ধারণ করুন।
- ডাটাবেসে ভেক্টর ডেটা ইনজেশন করার জন্য টুল ( টুল ৪) নির্ধারণ করুন।
৬. এমসিপি টুলবক্স সার্ভার চালানো
পূর্ববর্তী ধাপে, আমরা আমাদের এমসিপি টুলবক্সের জন্য প্রয়োজনীয় কনফিগারেশন ইতিমধ্যেই সেট করে ফেলেছি। এখন আমরা সার্ভারটি চালানোর জন্য প্রস্তুত।
বীজ বপন করা ডেটা যাচাই করুন
টুলবক্স শুরু করার আগে, ডাটাবেস সেটআপ সম্পন্ন হয়েছে কিনা তা নিশ্চিত করে নেওয়া যাক। নিম্নলিখিত কমান্ডটি ব্যবহার করে ` scripts/verify_database.py নামে একটি পাইথন স্ক্রিপ্ট তৈরি করুন।
cloudshell edit scripts/verify_seed.py
এরপর, নিচের কোডটি scripts/verify_seed.py ফাইলে কপি করুন।
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
এই স্ক্রিপ্টটি মেনু আইটেমের ডেটার সংখ্যা এবং সেগুলোর এমবেডিং পরীক্ষা করবে। নিম্নলিখিত কমান্ডটি ব্যবহার করে স্ক্রিপ্টটি চালান।
uv run scripts/verify_seed.py
যদি আপনি নিম্নলিখিত টার্মিনাল আউটপুটটি দেখতে পান, তার মানে ডেটা প্রস্তুত।
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
টুলবক্স সার্ভার চালু করুন
আগের সেটআপ ধাপে আমরা ইতিমধ্যেই toolbox এক্সিকিউটেবলটি ডাউনলোড করে নিয়েছি। নিশ্চিত করুন যে এই বাইনারি ফাইলটি বিদ্যমান এবং সফলভাবে ডাউনলোড হয়েছে; যদি না হয়ে থাকে, তবে এটি ডাউনলোড করুন এবং ডাউনলোড শেষ হওয়া পর্যন্ত অপেক্ষা করুন।
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
আমাদের .env ভেরিয়েবলগুলোকে চাইল্ড প্রসেসের কাছে প্রকাশ করতে হবে, যেটি MCP টুলবক্স দ্বারা চালিত হয়। টুলবক্স সার্ভারটি চালু করতে নিম্নলিখিত কমান্ডটি চালান এবং এর কনসোল আউটপুট logs/mcp_toolbox.log ফাইলে লগ করুন।
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
সার্ভার প্রস্তুত হওয়ার বিষয়টি নিশ্চিত করতে আপনি logs/mcp_toolbox.log ফাইলে নিচের ছবির মতো আউটপুট দেখতে পাবেন:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
সরঞ্জামগুলি যাচাই করুন
সকল নিবন্ধিত টুলের তালিকা পেতে টুলবক্স এপিআই-কে কোয়েরি করুন:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
আপনার টুলগুলো তাদের বিবরণ এবং প্যারামিটারসহ দেখা উচিত। যেমন নিচে দেখানো হয়েছে।
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
search-menu টুলটি সরাসরি পরীক্ষা করুন:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
উত্তরে আপনার সিড ডেটা থেকে ইতালীয় প্রধান খাবারের পদগুলো অন্তর্ভুক্ত থাকতে হবে।
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
৭. ADK এজেন্ট তৈরি করুন
এখন, আমরা এই প্রজেক্টের জন্য পাইথনে ADK ব্যবহার করব, চলুন প্রয়োজনীয় ডিপেন্ডেন্সিগুলো যোগ করে নিই:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk— গুগলের এজেন্ট ডেভেলপমেন্ট কিট, যার মধ্যে জেমিনি এসডিকে অন্তর্ভুক্ত।-
toolbox-adk— MCP টুলবক্স ফর ডেটাবেসেস-এর জন্য ADK ইন্টিগ্রেশন।
এজেন্ট ডিরেক্টরি কাঠামো তৈরি করুন
ADK একটি নির্দিষ্ট ফোল্ডার বিন্যাস আশা করে: আপনার এজেন্টের নামে একটি ডিরেক্টরি, যার মধ্যে __init__.py , agent.py , এবং .env ফাইলগুলো থাকবে। এই কাজে সাহায্য করার জন্য, দ্রুত কাঠামোটি তৈরি করতে এতে একটি বিল্ট-ইন কমান্ড রয়েছে:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
আপনার ডিরেক্টরিটি এখন দেখতে এইরকম হবে:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
এরপরে, আমাদের চলমান টুলবক্স সার্ভারে ADK এজেন্টকে সংযুক্ত করতে হবে এবং চারটি টুলই—স্ট্যান্ডার্ড কোয়েরি, সিমান্টিক সার্চ ও ভেক্টর ইনজেশন—পরীক্ষা করতে হবে। এজেন্টের কোডটি খুবই সংক্ষিপ্ত: সমস্ত ডাটাবেস লজিক tools.yaml ফাইলে থাকে।
এজেন্টের পরিবেশ কনফিগার করুন
ADK শেল এনভায়রনমেন্ট থেকে GOOGLE_GENAI_USE_VERTEXAI , GOOGLE_CLOUD_PROJECT , এবং GOOGLE_CLOUD_LOCATION পড়ে, যা আপনি আগের ধাপেই সেট করেছেন। একমাত্র এজেন্ট-নির্দিষ্ট ভ্যারিয়েবল হলো TOOLBOX_URL — এটিকে এজেন্টের .env ফাইলে যুক্ত করুন:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
এজেন্ট মডিউল আপডেট করুন
ক্লাউড শেল এডিটরে restaurant_agent/agent.py খুলুন।
cloudshell edit restaurant_agent/agent.py
এবং নিম্নলিখিত কোড দিয়ে বিষয়বস্তুটি ওভাররাইট করুন:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
লক্ষ্য করুন, এখানে কোনো ডাটাবেস কোড নেই — ToolboxToolset চালু হওয়ার সময় টুলবক্স সার্ভারের সাথে সংযোগ স্থাপন করে এবং সমস্ত উপলব্ধ টুল লোড করে। এজেন্ট নাম ধরে টুলগুলোকে ডাকে; টুলবক্স সেই কলগুলোকে ক্লাউড এসকিউএল (Cloud SQL)-এর বিরুদ্ধে এসকিউএল কোয়েরিতে রূপান্তরিত করে।
লোকাল ডেভেলপমেন্টের জন্য TOOLBOX_URL এনভায়রনমেন্ট ভেরিয়েবলটির ডিফল্ট মান হলো http://127.0.0.1:5000 । পরবর্তীতে যখন আপনি ক্লাউড রান-এ ডিপ্লয় করবেন, তখন টুলবক্স সার্ভিসের ক্লাউড রান ইউআরএল দিয়ে এটিকে ওভাররাইড করবেন — এর জন্য কোডে কোনো পরিবর্তনের প্রয়োজন নেই।
এজেন্টকে পরীক্ষা করুন
ADK ডেভ UI চালু করুন:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
ক্লাউড শেলের ওয়েব প্রিভিউ ফিচার ব্যবহার করে টার্মিনালে দেখানো URL-টি (সাধারণত http://localhost:8000 ) খুলুন অথবা টার্মিনালে দেখানো URL-টিতে ctrl + ক্লিক করুন । উপরের বাম কোণায় থাকা এজেন্ট ড্রপডাউন থেকে restaurant_agent নির্বাচন করুন।
পরীক্ষার মানক কোয়েরি
স্ট্যান্ডার্ড SQL টুলগুলো যাচাই করতে এই প্রম্পটগুলো ব্যবহার করে দেখুন:
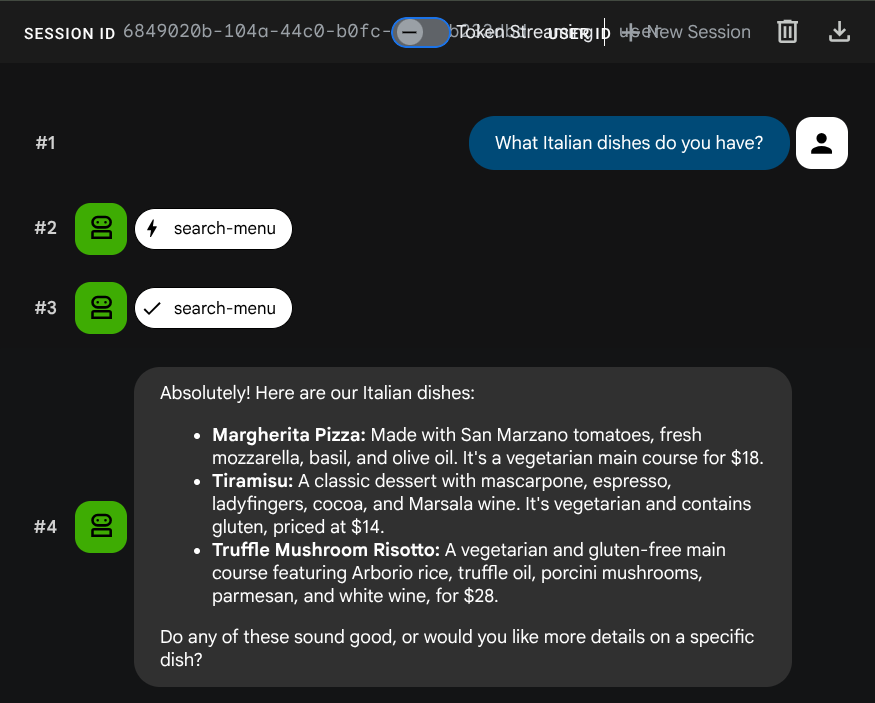
What Italian dishes do you have?
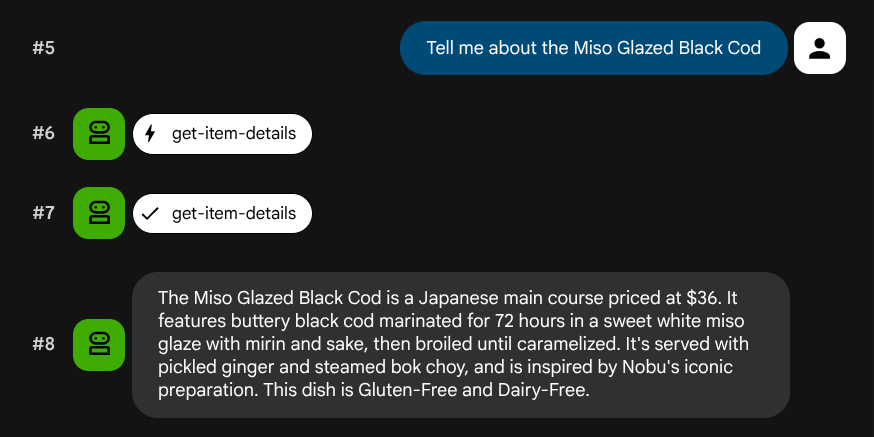
Tell me about the Miso Glazed Black Cod
শব্দার্থিক অনুসন্ধান পরীক্ষা করুন
এমন স্বাভাবিক ভাষার বর্ণনা ব্যবহার করুন যা কোনো নির্দিষ্ট ভূমিকা বা প্রযুক্তিগত কাঠামোর সাথে সম্পর্কিত নয়:
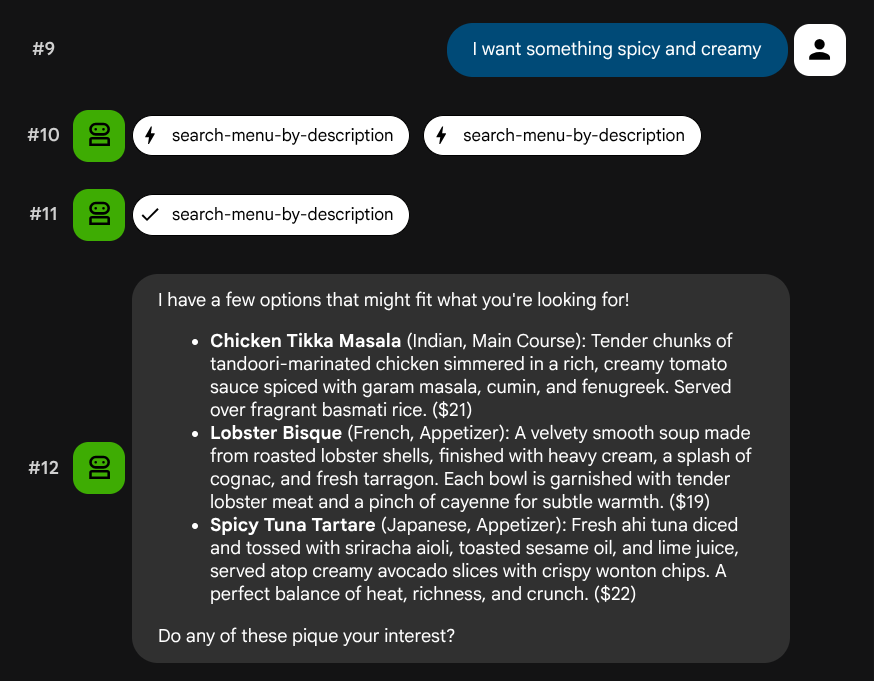
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
এজেন্টটি কোয়েরির ধরনের ওপর ভিত্তি করে সঠিক টুলটি বেছে নেওয়ার চেষ্টা করবে: স্ট্রাকচার্ড ফিল্টারগুলো search-menu মাধ্যমে যাবে, এবং স্বাভাবিক ভাষার বিবরণগুলো search-menu-by-description মাধ্যমে যাবে।
টেস্ট ভেক্টর ইনজেশন
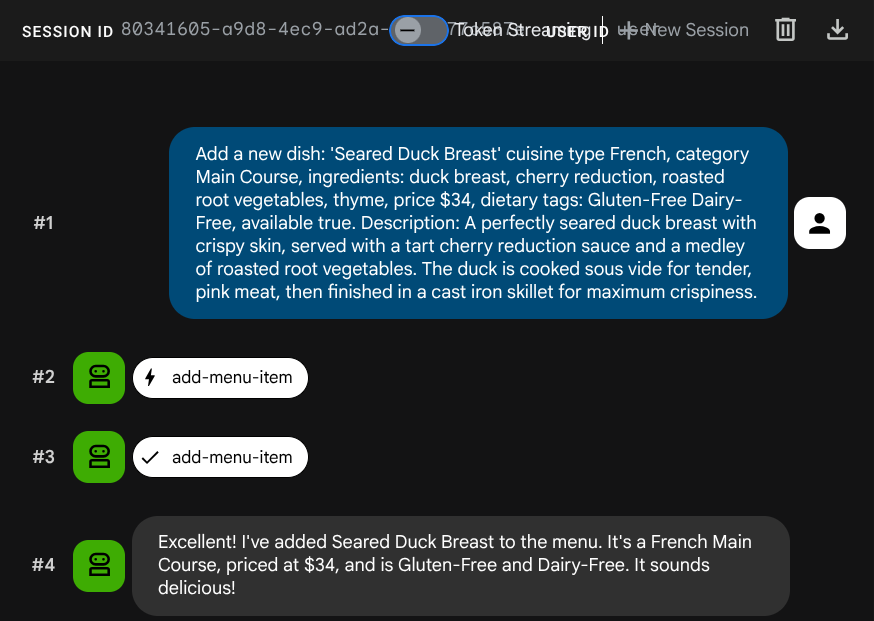
এজেন্টকে একটি নতুন চাকরি যোগ করতে বলুন:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
এখন এটি খোঁজার চেষ্টা করুন:
Find me something with rich, gamey flavors and fruit sauce
INSERT করার সময় এমবেডিংটি স্বয়ংক্রিয়ভাবে তৈরি হয়েছিল — কোনো আলাদা পদক্ষেপের প্রয়োজন ছিল না।
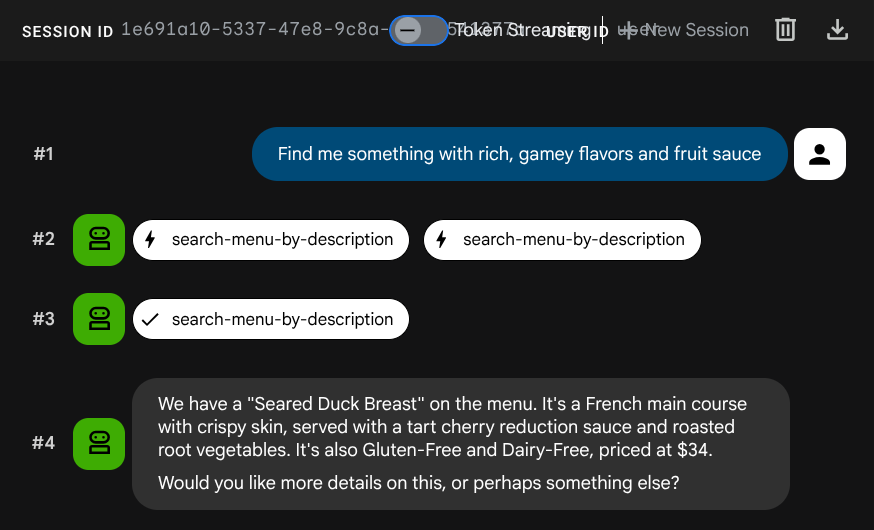
এখন, আপনার কাছে ADK, MCP টুলবক্স এবং CloudSQL ব্যবহার করে তৈরি একটি সম্পূর্ণ কার্যকরী Agentic RAG অ্যাপ্লিকেশন রয়েছে। অভিনন্দন! চলুন, এই অ্যাপগুলোকে Cloud Run-এ ডেপ্লয় করার জন্য আরও এক ধাপ এগিয়ে যাই!
এখন, সামনে এগোনোর আগে দুইবার Ctrl+C চেপে প্রসেসটি কিল করে ডেভ UI বন্ধ করে দেওয়া যাক।
৮. ক্লাউড রানে স্থাপন করুন
এজেন্ট এবং টুলবক্স স্থানীয়ভাবে কাজ করে। এই ধাপে উভয়কে ক্লাউড রান সার্ভিস হিসেবে ডেপ্লয় করা হয়, যাতে সেগুলো ইন্টারনেটের মাধ্যমে অ্যাক্সেসযোগ্য হয়। টুলবক্স সার্ভিসটি ক্লাউড রানে একটি এমসিপি সার্ভার হিসেবে চলে এবং এজেন্ট সার্ভিসটি এর সাথে সংযুক্ত হয়।
মোতায়েনের জন্য টুলবক্স প্রস্তুত করুন
টুলবক্স সার্ভিসের জন্য একটি ডেপ্লয়মেন্ট ডিরেক্টরি তৈরি করুন:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
টুলবক্সের জন্য ডকারফাইল তৈরি করুন। ক্লাউড শেল এডিটরে deploy-toolbox/Dockerfile খুলুন:
cloudshell edit deploy-toolbox/Dockerfile
এবং নিম্নলিখিত স্ক্রিপ্টটি এতে কপি করুন
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
টুলবক্স বাইনারি এবং tools.yaml একটি ন্যূনতম ডেবিয়ান ইমেজে প্যাকেজ করা আছে। ক্লাউড রান ৮০৮০ পোর্টে ট্র্যাফিক রাউট করে।
টুলবক্স পরিষেবাটি স্থাপন করুন
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
এই কমান্ডটি ক্লাউড বিল্ড-এ সোর্স সাবমিট করে, একটি কন্টেইনার ইমেজ তৈরি করে, সেটিকে আর্টিফ্যাক্ট রেজিস্ট্রি-তে পুশ করে এবং ক্লাউড রান-এ ডিপ্লয় করে। এতে কয়েক মিনিট সময় লাগবে — আমরা logs/deploy_toolbox.log ফাইলে ডিপ্লয়মেন্ট প্রক্রিয়ার লগটি দেখতে পারি।
এজেন্টকে মোতায়েনের জন্য প্রস্তুত করুন
টুলবক্সটি তৈরি হওয়ার সময়ে এজেন্টের ডেপ্লয়মেন্ট ফাইলগুলো সেট আপ করুন।
প্রজেক্ট রুটে একটি Dockerfile তৈরি করুন। ক্লাউড শেল এডিটরে Dockerfile খুলুন:
cloudshell edit Dockerfile
তারপর, নিচের বিষয়বস্তু কপি করুন।
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
এই ডকারফাইলটি বেস ইমেজ হিসেবে ghcr.io/astral-sh/uv ব্যবহার করে, যেটিতে পাইথন এবং uv উভয়ই আগে থেকে ইনস্টল করা আছে — pip এর মাধ্যমে আলাদাভাবে uv ইনস্টল করার কোনো প্রয়োজন নেই।
কন্টেইনার ইমেজ থেকে অপ্রয়োজনীয় ফাইল বাদ দিতে একটি .dockerignore ফাইল তৈরি করুন:
cloudshell edit .dockerignore
তারপর নিচের স্ক্রিপ্টটি এতে কপি করুন।
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
এজেন্ট পরিষেবাটি স্থাপন করুন
টুলবক্স ডেপ্লয়মেন্ট সম্পূর্ণ হওয়ার জন্য অপেক্ষা করুন। প্রক্রিয়াটি যাচাই করার জন্য logs/deploy_toolbox.log এ ডেপ্লয়মেন্ট প্রক্রিয়াটি আবার পরীক্ষা করুন। তারপর, নিম্নলিখিত কমান্ডটি ব্যবহার করে এর ক্লাউড রান ইউআরএল (Cloud Run URL) সংগ্রহ করুন।
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
আপনি এরকম একই রকম আউটপুট দেখতে পাবেন।
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
তাহলে, চলুন যাচাই করে দেখি যে ডেপ্লয় করা টুলবক্সটি কাজ করছে কিনা:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
যদি আউটপুট এই উদাহরণের মতো দেখায়, তাহলে ডেপ্লয়মেন্ট ইতিমধ্যেই সফল হয়েছে।
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
এরপরে, টুলবক্স URL-টিকে একটি এনভায়রনমেন্ট ভেরিয়েবল হিসেবে পাস করে এজেন্টটি ডেপ্লয় করা যাক:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
এজেন্ট কোডটি এনভায়রনমেন্ট থেকে TOOLBOX_URL পড়ে নেয় (যা আপনি আগে সেট আপ করেছেন)। লোকালি এটি http://127.0.0.1:5000 কে নির্দেশ করে; ক্লাউড রানে এটি টুলবক্স সার্ভিস ইউআরএল-কে নির্দেশ করে। কোডে কোনো পরিবর্তনের প্রয়োজন নেই।
স্থাপন করা এজেন্ট পরীক্ষা করুন
এজেন্টের ক্লাউড রান ইউআরএলটি পুনরুদ্ধার করুন:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
আপনার ব্রাউজারে URL-টি খুলুন। ADK ডেভ UI লোড হবে — এটি সেই একই ইন্টারফেস যা আপনি লোকালি ব্যবহার করে আসছেন, এবং যা এখন ক্লাউড রানে চলছে।
ড্রপডাউন থেকে restaurant_agent নির্বাচন করুন এবং পরীক্ষা করুন:
What Italian dishes do you have?
I want something spicy and creamy
উভয় কোয়েরিই ডেপ্লয় করা সার্ভিসগুলোর মাধ্যমে কাজ করে: ক্লাউড রানের এজেন্ট ক্লাউড রানের টুলবক্সকে কল করে, যা ক্লাউড এসকিউএল-কে কোয়েরি করে।
৯. অভিনন্দন / পরিচ্ছন্নতা
আপনি একটি স্মার্ট রেস্তোরাঁ মেনু অ্যাসিস্ট্যান্ট তৈরি ও স্থাপন করেছেন, যা MCP টুলবক্স ফর ডেটাবেসেস ব্যবহার করে একটি ADK এজেন্ট এবং ক্লাউড SQL PostgreSQL-এর মধ্যে সংযোগ স্থাপন করে — এতে সাধারণ SQL কোয়েরি এবং সিমান্টিক ভেক্টর সার্চ উভয়ই রয়েছে।
আপনি যা শিখেছেন
- কীভাবে MCP এআই এজেন্টদের জন্য টুল অ্যাক্সেসকে প্রমিত করে, এবং কীভাবে MCP টুলবক্স ফর ডেটাবেসেস বিশেষভাবে ডেটাবেস অপারেশনে এটি প্রয়োগ করে — কাস্টম ডেটাবেস কোডকে ডিক্লারেটিভ YAML কনফিগারেশন দিয়ে প্রতিস্থাপন করে।
-
cloud-sql-postgresসোর্স টাইপ ব্যবহার করে কীভাবে ক্লাউড এসকিউএল পোস্টগ্রেসকিউএল-কে টুলবক্স ডেটা সোর্স হিসেবে কনফিগার করবেন - প্যারামিটারাইজড স্টেটমেন্ট ব্যবহার করে কীভাবে স্ট্যান্ডার্ড SQL কোয়েরি টুল সংজ্ঞায়িত করা যায় যা SQL ইনজেকশন প্রতিরোধ করে
- স্বয়ংক্রিয় কোয়েরি এমবেডিংয়ের জন্য
embeddedByপ্যারামিটার ব্যবহার করে pgvector এবংgemini-embedding-001দিয়ে কীভাবে ভেক্টর সার্চ চালু করবেন -
valueFromParamযেভাবে স্বয়ংক্রিয় ভেক্টর ইনজেশন সক্ষম করে — LLM একটি টেক্সট বিবরণ প্রদান করে, এবং টুলবক্স নীরবে টেক্সটটির পাশাপাশি ভেক্টরটি কপি, এমবেড এবং সংরক্ষণ করে। - কীভাবে ADK-এর
ToolboxToolsetএকটি চলমান টুলবক্স সার্ভার থেকে টুল লোড করে, এজেন্ট কোড ন্যূনতম রেখে এবং ডাটাবেস লজিককে সম্পূর্ণরূপে বিচ্ছিন্ন রেখে। - টুলবক্স এমসিপি সার্ভার এবং এডিকে এজেন্ট উভয়কে ক্লাউড রানে আলাদা পরিষেবা হিসেবে কীভাবে স্থাপন করবেন
পরিষ্কার করা
এই কোডল্যাবে তৈরি করা রিসোর্সগুলোর জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, আপনি আলাদা আলাদা রিসোর্সগুলো অথবা পুরো প্রজেক্টটি ডিলিট করে দিতে পারেন।
বিকল্প ১: প্রজেক্টটি মুছে ফেলুন (প্রস্তাবিত)
পরিষ্কার করার সবচেয়ে সহজ উপায় হলো প্রজেক্টটি ডিলিট করে দেওয়া। এর ফলে প্রজেক্টটির সাথে যুক্ত সমস্ত রিসোর্স মুছে যায়।
gcloud projects delete $GOOGLE_CLOUD_PROJECT
বিকল্প ২: স্বতন্ত্র রিসোর্সগুলো মুছে ফেলুন
আপনি যদি প্রজেক্টটি রাখতে চান কিন্তু শুধুমাত্র এই কোডল্যাবে তৈরি করা রিসোর্সগুলো সরাতে চান:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null