
1. Einführung
KI-Agents sind nur so nützlich wie die Daten, auf die sie zugreifen können. Die meisten realen Daten befinden sich in Datenbanken. Wenn Sie Agents mit Datenbanken verbinden möchten, müssen Sie in der Regel das Verbindungsmanagement, die Abfragelogik und die Einbettungspipelines in den Agent-Code schreiben. Bei jedem Agent, der Datenbankzugriff benötigt, wird diese Arbeit wiederholt. Bei jeder Abfrageänderung muss der Agent neu bereitgestellt werden.
In diesem Codelab wird ein anderer Ansatz vorgestellt. Sie deklarieren Ihre Datenbanktools in einer YAML-Datei – Standard-SQL-Abfragen, Vektorähnlichkeitssuche und sogar die automatische Einbettungsgenerierung – und die MCP Toolbox for Databases übernimmt alle Datenbankvorgänge als MCP-Server. Ihr Agent-Code bleibt minimal: Laden Sie die Tools und lassen Sie Gemini entscheiden, welches aufgerufen werden soll.
Umfang
Ein Restaurant Concierge für „Foodie Finds“ – ein ADK-Agent, der auf Gemini basiert und Gästen hilft, die Speisekarte eines Restaurants mit Standardfiltern (Kategorie, Art der Küche) zu durchsuchen und Gerichte anhand von Beschreibungen in natürlicher Sprache wie „Ich möchte etwas Scharfes und Vegetarisches“ zu finden. Der Agent liest aus einer Cloud SQL PostgreSQL-Datenbank und schreibt in diese, und zwar ausschließlich über die MCP Toolbox for Databases, die den gesamten Datenbankzugriff übernimmt, einschließlich der automatischen Einbettungsgenerierung für die Vektorsuche. Am Ende werden sowohl die Toolbox als auch der Agent in Cloud Run ausgeführt.
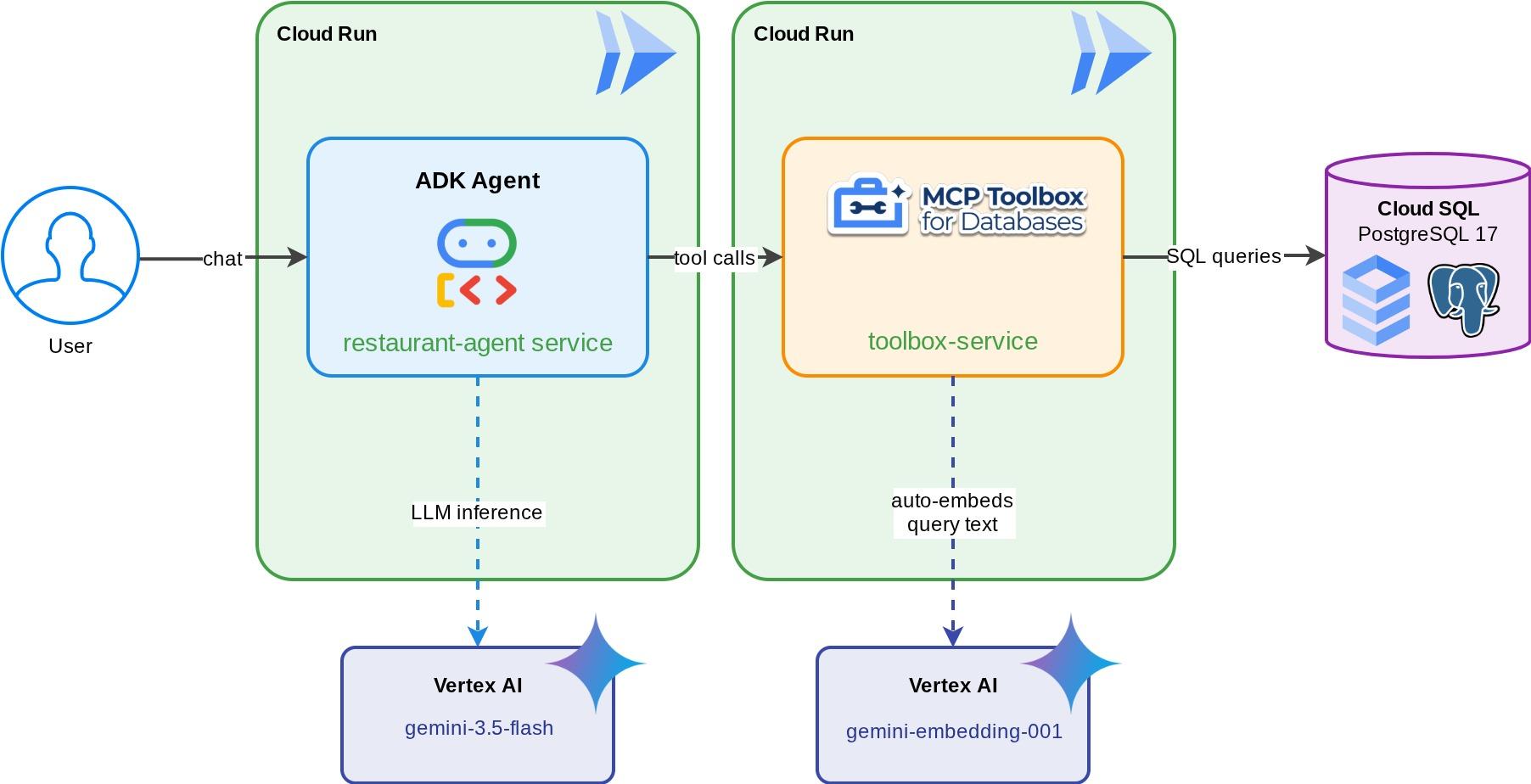
Lerninhalte
- Wie das MCP (Model Context Protocol) den Toolzugriff für KI-Agents standardisiert und wie die MCP Toolbox for Databases dies auf Datenbankvorgänge anwendet
- MCP Toolbox for Databases als Middleware zwischen einem ADK-Agenten und Cloud SQL for PostgreSQL einrichten
- Datenbanktools deklarativ in
tools.yamldefinieren – kein Datenbankcode in Ihrem Agent - Einen ADK-Agenten erstellen, der Tools von einem laufenden Toolbox-Server mit
ToolboxToolsetlädt - Vektoreinbettungen mit der integrierten
embedding()-Funktion von Cloud SQL generieren und semantische Suche mitpgvectoraktivieren valueFromParam-Funktion für die automatische Vektoreingabe bei Schreibvorgängen verwenden- Toolbox-Server und ADK-Agent in Cloud Run bereitstellen
Voraussetzungen
- Ein Google Cloud-Konto mit einem Testabrechnungskonto
- Grundkenntnisse in Python und SQL
- Vorkenntnisse mit Cloud Database und ADK sind hilfreich.
2. Umgebung einrichten
In diesem Schritt wird Ihre Cloud Shell-Umgebung vorbereitet, Ihr Google Cloud-Projekt konfiguriert und das Referenz-Repository geklont.
Cloud Shell öffnen
Öffnen Sie Cloud Shell in Ihrem Browser. Cloud Shell bietet eine vorkonfigurierte Umgebung mit allen Tools, die Sie für dieses Codelab benötigen. Klicken Sie auf Autorisieren, wenn Sie dazu aufgefordert werden.
Klicken Sie dann auf Ansicht -> Terminal, um das Terminal zu öffnen.Die Benutzeroberfläche sollte so aussehen:
Das ist unsere Hauptoberfläche: oben die IDE, unten das Terminal.
Arbeitsverzeichnis einrichten
Erstellen Sie Ihr Arbeitsverzeichnis. Der gesamte Code, den Sie in diesem Codelab schreiben, befindet sich hier:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
Danach bereiten wir mehrere Verzeichnisse vor, um Dinge wie Seeding-Skripts und Logs zu verwalten.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Google Cloud-Projekt einrichten
Erstellen Sie die Datei .env mit den Standortvariablen:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Um die Einrichtung des Projekts in Ihrem Terminal zu vereinfachen, laden Sie dieses Setupscript in Ihr Arbeitsverzeichnis herunter:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Führen Sie das Skript aus. Dabei wird Ihr Probeabo-Rechnungskonto überprüft, ein neues Projekt erstellt (oder ein vorhandenes Projekt validiert), Ihre Projekt-ID in einer .env-Datei im aktuellen Verzeichnis gespeichert und das aktive Projekt in gcloud festgelegt.
bash setup_verify_trial_project.sh && source .env
Das Skript führt Folgendes aus:
- Prüfen, ob Sie ein aktives Testabrechnungskonto haben
- Prüfen Sie, ob in
.envein Projekt vorhanden ist. - Neues Projekt erstellen oder vorhandenes Projekt wiederverwenden
- Test-Rechnungskonto mit Ihrem Projekt verknüpfen
- Speichern Sie die Projekt-ID in
.env. - Projekt als aktives
gcloud-Projekt festlegen
Prüfen Sie, ob das Projekt richtig festgelegt ist. Sehen Sie dazu im Cloud Shell-Terminal-Prompt nach dem gelben Text neben Ihrem Arbeitsverzeichnis. Dort sollte Ihre Projekt-ID angezeigt werden.

Erforderliche API aktivieren
Als Nächstes müssen wir mehrere APIs für das Produkt aktivieren, mit dem wir interagieren werden:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- Vertex AI API (
aiplatform.googleapis.com): Ihr Agent verwendet Gemini-Modelle und Toolbox verwendet die Embedding API für die Vektorsuche. - Cloud SQL Admin API (
sqladmin.googleapis.com): Sie stellen eine PostgreSQL-Instanz bereit und verwalten sie. - Compute Engine API (
compute.googleapis.com): Erforderlich zum Erstellen von Cloud SQL-Instanzen. - Cloud Run, Cloud Build, Artifact Registry: werden im Bereitstellungsschritt weiter unten in diesem Codelab verwendet.
3. Skripts für die Datenbankinitialisierung vorbereiten
In diesem Schritt wird die Cloud SQL-Instanz erstellt und ein automatisiertes Setupscript ausgeführt, das wartet, bis die Instanz bereit ist. Anschließend wird die Datenbank erstellt, mit Stellenangeboten gefüllt und es werden Einbettungen generiert – alles in einem Vorgang.
Fügen Sie zuerst das Datenbankpasswort in die Datei .env ein und laden Sie sie neu:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Bash-Skript zum Erstellen von Instanzen und Datenbanken erstellen
Erstellen Sie dann das scripts/setup_database.sh-Skript mit dem folgenden Befehl:
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Kopieren Sie dann den folgenden Code in die Datei scripts/setup_database.sh.
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Python-Script für Data Seed erstellen
Erstellen Sie dann mit dem folgenden Befehl die Python-Datei scripts/setup_restaurant_db.py für das Seeding-Skript.
cloudshell edit scripts/setup_restaurant_db.py
Kopieren Sie dann den folgenden Code in die Datei scripts/setup_restaurant_db.py.
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Kommen wir nun zum nächsten Schritt.
4. Datenbank erstellen und initialisieren
Jetzt können wir unsere Skripts ausführen. Dazu benötigen wir Python.
Python-Projekt einrichten
uv ist ein schneller Python-Paket- und Projektmanager, der in Rust geschrieben wurde ( uv-Dokumentation). In diesem Codelab wird er verwendet, um das Python-Projekt schnell und einfach zu verwalten.
Initialisieren Sie ein Python-Projekt und fügen Sie die erforderlichen Abhängigkeiten hinzu:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Wir verwenden hier das cloud-sql-python-connector Python SDK, um eine sichere Verbindung mit unserer Datenbankinstanz zu initialisieren, die mit Standardanmeldedaten für Anwendungen authentifiziert wird.
Setup-Skript ausführen
Jetzt können wir das Einrichtungs-Script im Hintergrund ausführen und die Konsolenausgabe, die in die Datei logs/atabase_setup.log geschrieben wird, mit dem folgenden Befehl prüfen. Sie können mit dem nächsten Abschnitt fortfahren, während Sie darauf warten, dass dieser Vorgang abgeschlossen wird.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Toolbox-Binärdatei herunterladen
In dieser Anleitung verwenden wir die MCP Toolbox. Glücklicherweise ist sie mit einem vorgefertigten Binärprogramm ausgestattet, das in der Linux-Umgebung verwendet werden kann. Laden wir es jetzt im Hintergrund herunter, da es eine Weile dauert. Führen Sie den folgenden Befehl aus, um das Binärprogramm herunterzuladen, und sehen Sie sich das Ausgabeprotokoll auf der logs/toolbox_dl.log an. Sie können mit dem nächsten Abschnitt fortfahren, während der Download läuft.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Das Setup-Skript scripts/setup_database.sh
Sehen wir uns nun das Setupskript an, das wir zuvor konfiguriert haben. Es führt die folgenden Schritte aus:
- Der erste Befehl, den wir dort ausführen, ist der Befehl
gcloud sql instances createmit dem folgenden Flag:
db-custom-1-3840ist die kleinste Cloud SQL-Stufe mit dedizierten Kernen (1 vCPU, 3,75 GB RAM) in derENTERPRISE-Version. Weitere Informationen Für die Vertex AI ML-Integration ist ein dedizierter Core erforderlich. Tarife mit gemeinsam genutztem Kern (db-f1-micro,db-g1-small) werden nicht unterstützt.- Mit
--root-passwordwird das Passwort für den Standardnutzerpostgresfestgelegt. --enable-google-ml-integrationermöglicht die integrierte Einbindung von Cloud SQL in Vertex AI. So können Sie Einbettungsmodelle mit der Funktionembedding()direkt über SQL aufrufen.
- Prüfen Sie, ob die Instanz bereits den Status
RUNNABLEhat. - Gewähren Sie dem Dienstkonto der Cloud SQL-Instanz die Berechtigung, Vertex AI mit dem Befehl
gcloud projects add-iam-policy-bindingaufzurufen. Dies ist für die integrierteembedding()-Funktion erforderlich, die wir beim Seeding der Datenbank verwenden. - Datenbank erstellen
- Das Seeding-Skript
setup_restaurant_db.pyausführen
Grundlegendes zum Seed-Skript scripts/setup_restaurant_db.py
Das Seeding-Script führt folgende Aktionen aus:
- Verbindung zur Datenbankinstanz initialisieren
- Installiert zwei PostgreSQL-Erweiterungen:
google_ml_integration: Stellt die SQL-Funktionembedding()bereit, mit der Vertex AI-Embedding-Modelle direkt über SQL aufgerufen werden können. Dies ist eine Erweiterung auf Datenbankebene, die ML-Funktionen inrestaurant_dbverfügbar macht. Das Flag auf Instanzebene (--enable-google-ml-integration), das Sie beim Erstellen der Instanz festlegen, ermöglicht es der Cloud SQL-VM, Vertex AI zu erreichen. Die Erweiterung macht die SQL-Funktionen in dieser bestimmten Datenbank verfügbar.vector(pgvector): Fügt den Datentypvectorund Distanzoperatoren zum Speichern und Abfragen von Einbettungen hinzu.
- Erstellen Sie die Tabelle. Beachten Sie, dass die Spalte
description_embeddingvector(3072)ist – einepgvector-Spalte, in der 3.072-dimensionale Vektoren gespeichert werden. - Erste Menüpunkte übertragen
- Generieren Sie die Einbettungsdaten aus dem Feld
descriptionund füllen Sie das Felddescription_embeddingmithilfe der integrierten Vertex-Integration über die Funktionembedding()aus.
embedding('gemini-embedding-001', description)– ruft das Gemini-Einbettungsmodell von Vertex AI direkt über SQL auf und übergibt dendescription-Text jedes Jobs. Das ist diegoogle_ml_integration-Erweiterung, die Sie im Seed-Script installiert haben.::vector: Wandelt das zurückgegebene Float-Array in den Typvectorvon pgvector um, damit es mit Distanzoperatoren gespeichert und abgefragt werden kann.- Die
UPDATEwird für alle 15 Zeilen ausgeführt und generiert ein 3.072-dimensionales Embedding pro Stellenbeschreibung.
Dadurch werden die ersten Daten vorbereitet, auf die unser Agent zugreifen kann.
5. MCP Toolbox for Databases konfigurieren
In diesem Schritt wird die MCP Toolbox für Datenbanken eingeführt, so konfiguriert, dass sie eine Verbindung zu Ihrer Cloud SQL-Instanz herstellt, und es werden zwei Standard-SQL-Abfragetools definiert.
Was ist MCP und warum sollte ich die Toolbox verwenden?
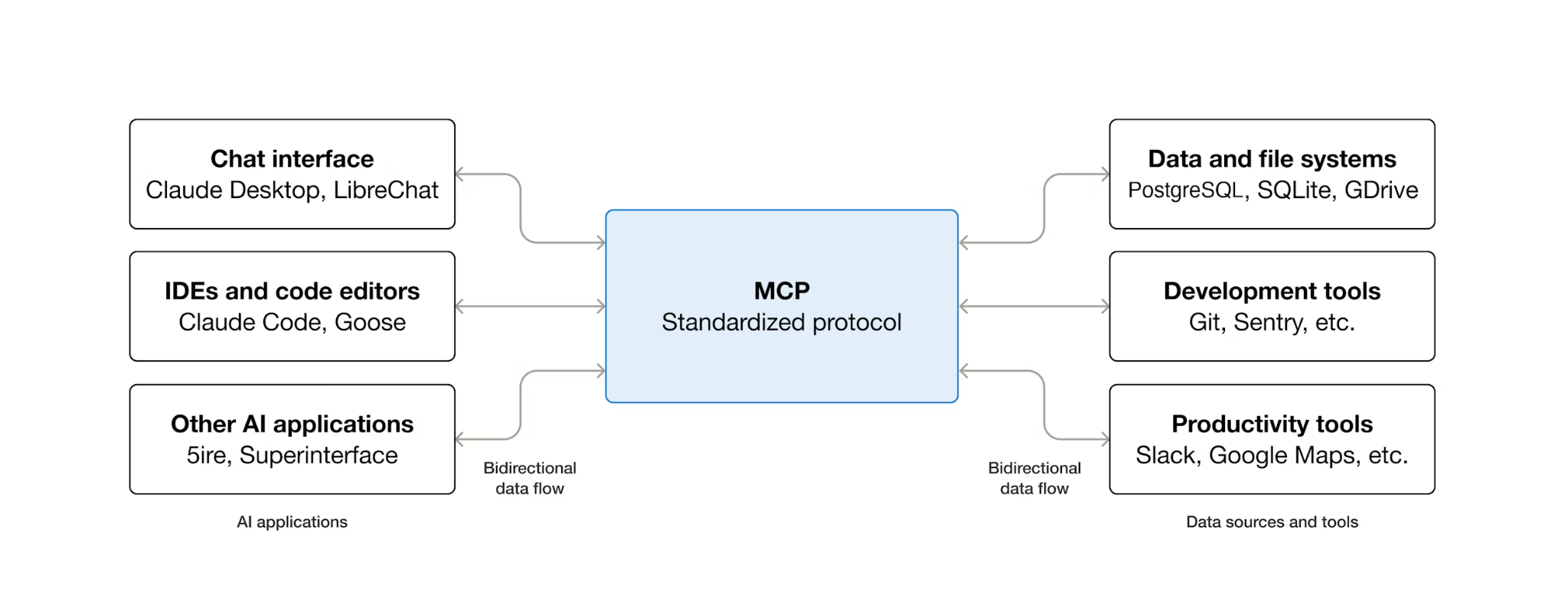
MCP (Model Context Protocol) ist ein offenes Protokoll, das die Art und Weise standardisiert, wie KI-Agenten externe Tools erkennen und mit ihnen interagieren. Es wird ein Client-Server-Modell definiert: Der Agent hostet einen MCP-Client und Tools werden von MCP-Servern bereitgestellt. Jeder MCP-kompatible Client kann jeden MCP-kompatiblen Server verwenden. Der Agent benötigt also keinen benutzerdefinierten Integrationscode für jedes Tool.
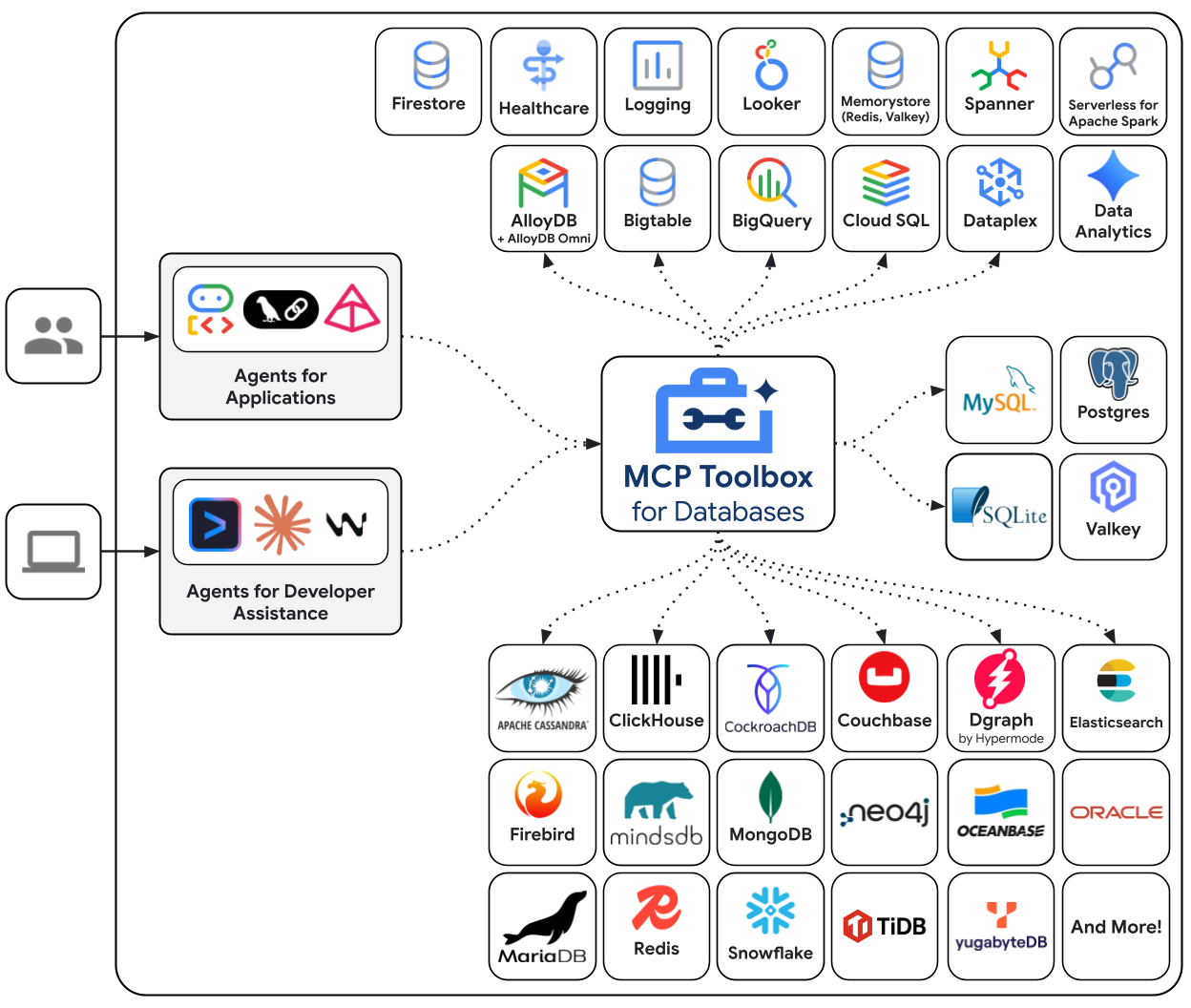
Die MCP Toolbox for Databases ist ein Open-Source-MCP-Server, der speziell für den Datenbankzugriff entwickelt wurde. Andernfalls müssten Sie Python-Funktionen schreiben, die Datenbankverbindungen öffnen, Verbindungspools verwalten, parametrisierte Abfragen erstellen, um SQL-Injection zu verhindern, Fehler verarbeiten und den gesamten Code in Ihren Agent einbetten. Jeder Agent, der Datenbankzugriff benötigt, wiederholt diese Schritte. Wenn Sie eine Abfrage ändern, müssen Sie den Agenten neu bereitstellen.
Mit Toolbox schreiben Sie eine YAML-Datei. Jedes Tool wird einer parametrisierten SQL-Anweisung zugeordnet. Die Toolbox übernimmt das Verbindungs-Pooling, parametrisierte Abfragen, die Authentifizierung und die Beobachtbarkeit. Tools sind vom Agent entkoppelt – aktualisieren Sie eine Anfrage, indem Sie tools.yaml bearbeiten und die Toolbox neu starten, ohne den Agentencode zu ändern. Die gleichen Tools funktionieren mit dem ADK, LangGraph, LlamaIndex oder einem anderen MCP-kompatiblen Framework.
Tool-Konfiguration schreiben
Jetzt müssen wir im Cloud Shell-Editor eine Datei mit dem Namen tools.yaml erstellen, um die Konfiguration unserer Tools einzurichten.
cloudshell edit tools.yaml
In der Datei wird YAML mit mehreren Dokumenten verwendet. Jeder Block, der durch --- getrennt ist, ist eine eigenständige Ressource. Jede Ressource hat ein kind, das angibt, was sie ist (sources für Datenbankverbindungen, tools für von Agenten aufrufbare Aktionen), und ein type, das das Backend angibt (cloud-sql-postgres für die Quelle, postgres-sql für SQL-basierte Tools). Ein Tool verweist mit name auf seine Quelle. So weiß Toolbox, welcher Verbindungspool verwendet werden soll. Umgebungsvariablen verwenden die ${VAR_NAME}-Syntax und werden beim Start aufgelöst.
Kopieren wir nun die folgenden Skripts zuerst in die Datei tools.yaml.
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
In diesem Skript wird die folgende Ressource definiert:
- Quelle (
restaurant-db): Gibt an, wie Toolbox eine Verbindung zu Ihrer Cloud SQL for PostgreSQL-Instanz herstellt. Der Typcloud-sql-postgresverwendet intern den Cloud SQL-Connector und übernimmt automatisch die Authentifizierung und sichere Verbindungen. Die Platzhalter${GOOGLE_CLOUD_PROJECT},${REGION}und${DB_PASSWORD}werden beim Start aus Umgebungsvariablen aufgelöst.
Fügen Sie als Nächstes das folgende Skript in der tools.yaml unter dem Symbol --- ein.
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
In diesem Skript wird die folgende Ressource definiert:
- Tool 1 und Tool 2 (
search-menu,get-item-details): Standard-SQL-Abfragetools. Jedes Tool ordnet einen Toolnamen (was der Agent sieht) einer parametrisierten SQL-Anweisung (was die Datenbank ausführt) zu. Für Parameter werden die Platzhalter$1und$2verwendet. Die Toolbox führt diese als vorbereitete Anweisungen aus, wodurch SQL-Injection verhindert wird.
Fügen Sie das folgende Skript unter dem Symbol --- in der Datei tools.yaml ein:
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
In diesem Skript wird die folgende Ressource definiert:
- Embedding-Modell (
gemini-embedding): Konfiguriert die Toolbox so, dass das Modellgemini-embedding-001von Gemini aufgerufen wird, um 3072‑dimensionale Texteinbettungen zu generieren. Die Toolbox verwendet Standardanmeldedaten für Anwendungen (Application Default Credentials, ADC) zur Authentifizierung. In Cloud Shell oder Cloud Run ist kein API-Schlüssel erforderlich. Hinweis: Der hier konfiguriertedimensionmuss mit dem übereinstimmen, den wir zuvor zum Initialisieren der Datenbank konfiguriert haben.
Fügen Sie das folgende Skript unter dem Symbol --- in der Datei tools.yaml ein:
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
In diesem Skript wird die folgende Ressource definiert:
- Tool 3 (
search-menu-by-description): ein Vektorsuchtool. Der Parametersearch_queryhat den WertembeddedBy: gemini-embedding. Dadurch wird Toolbox angewiesen, den Roh-Text abzufangen, an das Einbettungsmodell zu senden und den resultierenden Vektor in der SQL-Anweisung zu verwenden. Der Operator<=>ist die Kosinusdistanz von pgvector. Kleinere Werte bedeuten ähnliche Beschreibungen.
Hängen Sie das letzte Tool schließlich unter dem Symbol --- in der Datei tools.yaml an.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
In diesem Skript wird die folgende Ressource definiert:
- Tool 4 (
add-menu-item): Hier wird die Vektoreingabe veranschaulicht. Der Parameterdescription_vectorhat zwei spezielle Felder: valueFromParam: description: Toolbox kopiert den Wert aus dem Parameterdescriptionin diesen Parameter. Das LLM sieht diesen Parameter nie.embeddedBy: gemini-embedding: Die Toolbox bettet den kopierten Text in einen Vektor ein, bevor sie ihn an den SQL-Code übergibt.
Das Ergebnis: Bei einem Tool-Aufruf werden sowohl der Rohbeschreibungstext als auch die zugehörige Vektoreinbettung gespeichert, ohne dass der Agent etwas über Einbettungen weiß.
Im YAML-Format mit mehreren Dokumenten wird jede Ressource durch --- getrennt. Jedes Dokument hat die Felder kind, name und type, die definieren, was es ist. Zusammenfassend haben wir bereits Folgendes konfiguriert:
- Quelldatenbank definieren
- Definieren Sie Tools ( tool 1 und tool 2), um die Datenbank mit einem Standardfilter abzufragen.
- Einbettungsmodell definieren
- Tool für die Vektorsuche ( tool 3 ) für die Datenbank definieren
- Tool zum Definieren der Datenaufnahme von Vektordaten ( Tool 4 )) in die Datenbank
6. MCP-Toolbox-Server ausführen
Im vorherigen Schritt haben wir bereits die erforderliche Konfiguration für unsere MCP Toolbox festgelegt. Jetzt können wir den Server ausführen.
Seed-Daten prüfen
Bevor wir Toolbox starten, prüfen wir, ob die Datenbank eingerichtet wurde. Erstellen Sie mit dem folgenden Befehl ein Python-Skript scripts/verify_database.py:
cloudshell edit scripts/verify_seed.py
Kopieren Sie dann den folgenden Code in die Datei scripts/verify_seed.py.
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Mit diesem Script wird die Anzahl der Menüelementdaten und ihre Einbettung geprüft. Führen Sie das Script mit dem folgenden Befehl aus:
uv run scripts/verify_seed.py
Wenn Sie die folgende Terminalausgabe sehen, sind die Daten bereit.
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Toolbox-Server starten
Im vorherigen Einrichtungsschritt haben wir die ausführbare Datei toolbox bereits heruntergeladen. Prüfen Sie, ob diese Binärdatei vorhanden und erfolgreich heruntergeladen wurde. Wenn nicht, laden Sie sie herunter und warten Sie, bis der Vorgang abgeschlossen ist.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
Wir müssen unsere .env-Variablen für den untergeordneten Prozess verfügbar machen, der von der MCP-Toolbox ausgeführt wird. Führen Sie den folgenden Befehl aus, um den Toolbox-Server zu starten und die Konsolenausgabe in der Datei logs/mcp_toolbox.log zu protokollieren.
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
In der Datei logs/mcp_toolbox.log sollte eine Ausgabe angezeigt werden, die bestätigt, dass der Server bereit ist. Diese sieht in etwa so aus:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Tools überprüfen
Fragen Sie die Toolbox API ab, um alle registrierten Tools aufzulisten:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Sie sollten Tools mit ihren Beschreibungen und Parametern sehen. Wie unten dargestellt
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
Testen Sie das search-menu-Tool direkt:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
Die Antwort sollte die italienischen Hauptgerichte aus Ihren Ausgangsdaten enthalten.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. ADK-KI-Agenten erstellen
Jetzt verwenden wir das ADK in Python für dieses Projekt. Fügen wir die erforderlichen Abhängigkeiten hinzu:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk– Das Agent Development Kit von Google, einschließlich des Gemini SDKtoolbox-adk– ADK-Integration für die MCP Toolbox for Databases.
Verzeichnisstruktur für den Agenten erstellen
Das ADK erwartet ein bestimmtes Ordnerlayout: ein Verzeichnis, das nach Ihrem Agenten benannt ist und __init__.py, agent.py und .env enthält. Dazu gibt es einen integrierten Befehl, mit dem sich die Struktur schnell erstellen lässt:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
Ihr Verzeichnis sollte nun so aussehen:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
Als Nächstes müssen wir den ADK-Agenten in den laufenden Toolbox-Server einbinden und alle vier Tools testen: Standardabfragen, semantische Suche und Vektoraufnahme. Der Agentencode ist minimal: Die gesamte Datenbanklogik befindet sich in tools.yaml.
Umgebung des KI-Agenten konfigurieren
Das ADK liest GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT und GOOGLE_CLOUD_LOCATION aus der Shell-Umgebung, die Sie bereits im vorherigen Schritt festgelegt haben. Die einzige agentspezifische Variable ist TOOLBOX_URL. Hängen Sie sie an die .env-Datei des Agents an:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Agent-Modul aktualisieren
restaurant_agent/agent.py im Cloud Shell-Editor öffnen
cloudshell edit restaurant_agent/agent.py
und überschreiben Sie den Inhalt mit dem folgenden Code:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Beachten Sie, dass hier kein Datenbankcode vorhanden ist – ToolboxToolset stellt beim Start eine Verbindung zum Toolbox-Server her und lädt alle verfügbaren Tools. Der Agent ruft Tools anhand des Namens auf. Toolbox übersetzt diese Aufrufe in SQL-Abfragen für Cloud SQL.
Die Umgebungsvariable TOOLBOX_URL hat standardmäßig den Wert http://127.0.0.1:5000 für die lokale Entwicklung. Wenn Sie die Anwendung später in Cloud Run bereitstellen, wird dieser Wert durch die Cloud Run-URL des Toolbox-Dienstes überschrieben. Es sind keine Codeänderungen erforderlich.
Agent testen
Starten Sie die ADK-Entwicklungsoberfläche:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Öffnen Sie die im Terminal angezeigte URL (in der Regel http://localhost:8000) mit der Funktion Webvorschau von Cloud Shell oder indem Sie Strg + Klick auf die im Terminal angezeigte URL ausführen. Wählen Sie links oben im Drop-down-Menü für Agents restaurant_agent aus.
Standardabfragen testen
Mit diesen Prompts können Sie die Standard-SQL-Tools testen:
What Italian dishes do you have?
Tell me about the Miso Glazed Black Cod
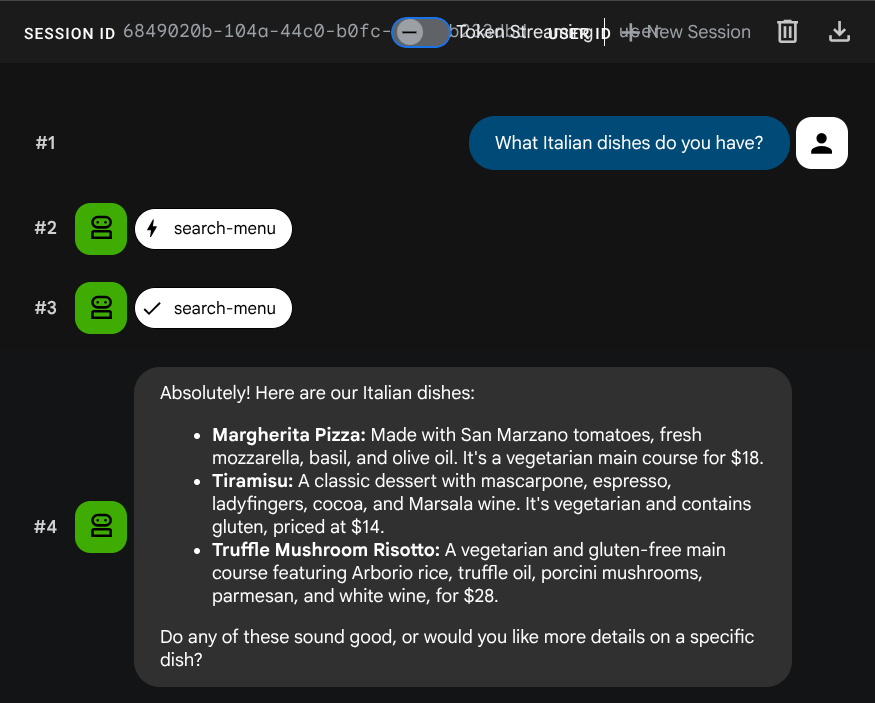
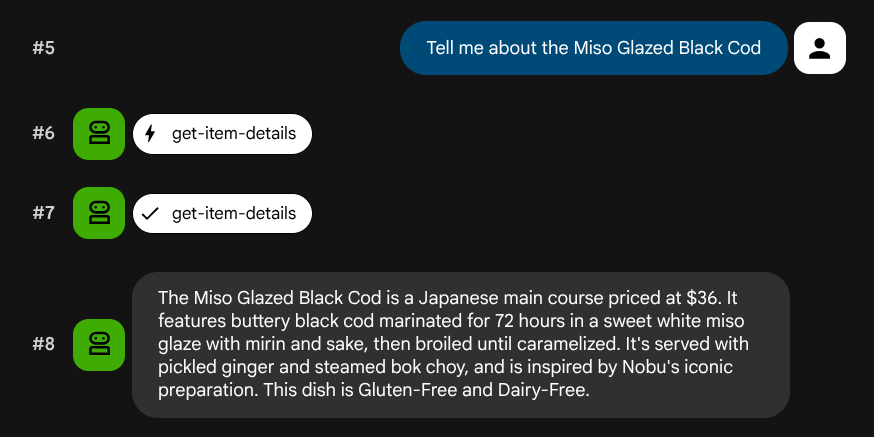
Semantische Suche testen
Versuchen Sie es mit Beschreibungen in natürlicher Sprache, die keiner bestimmten Rolle oder keinem bestimmten Technologie-Stack zugeordnet sind:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
Der Agent versucht, das richtige Tool basierend auf dem Abfragetyp auszuwählen: Strukturierte Filter werden über search-menu und Beschreibungen in natürlicher Sprache über search-menu-by-description verarbeitet.
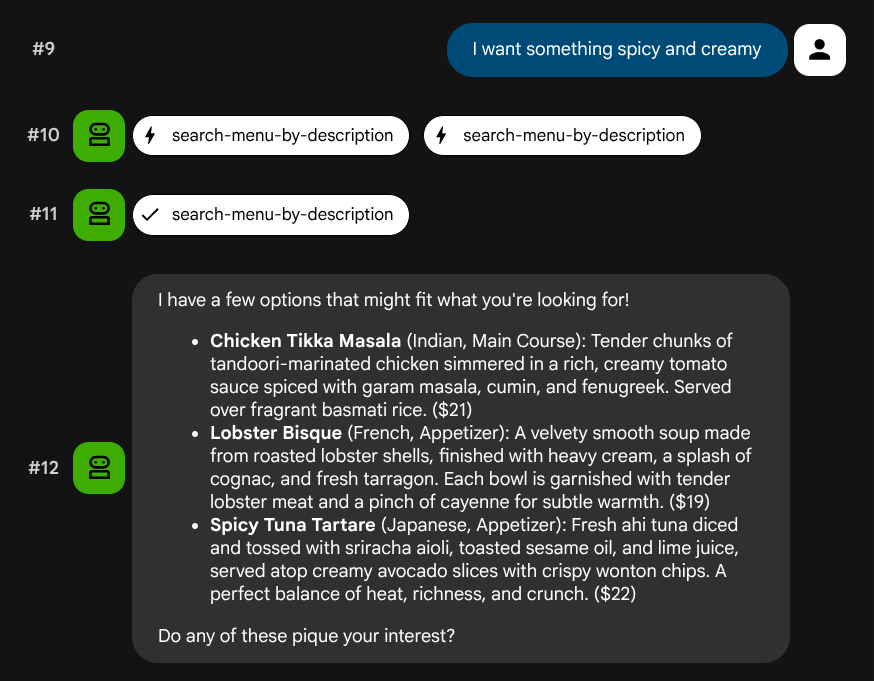
Testen der Aufnahme von Vektoren
Bitten Sie den Kundenservicemitarbeiter, einen neuen Job hinzuzufügen:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
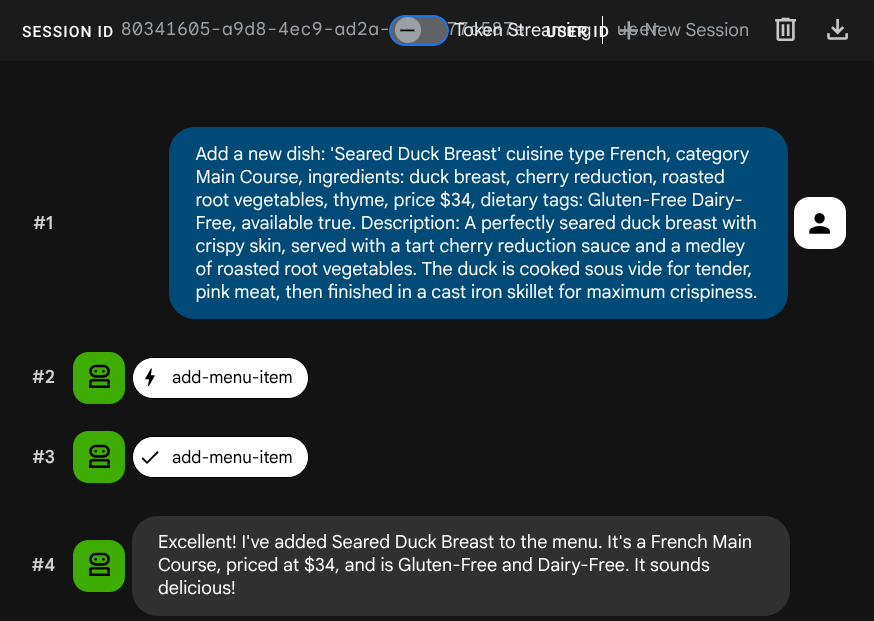
Versuchen Sie jetzt, danach zu suchen:
Find me something with rich, gamey flavors and fruit sauce
Die Einbettung wurde automatisch während des INSERT-Vorgangs generiert. Es ist kein separater Schritt erforderlich.
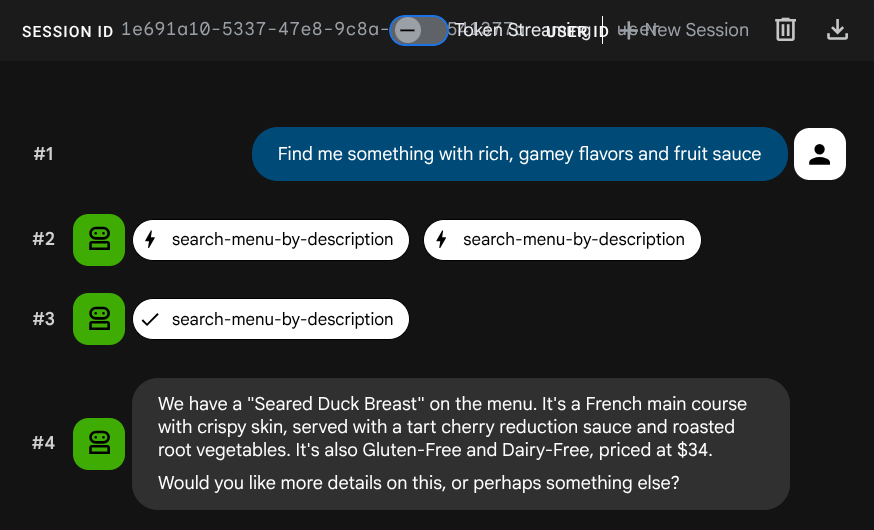
Sie haben jetzt bereits eine voll funktionsfähige agentische RAG-Anwendung mit ADK, MCP Toolbox und Cloud SQL. Das wars! Im nächsten Schritt stellen wir diese Apps in Cloud Run bereit.
Stoppen Sie nun die Entwickler-UI, indem Sie den Prozess beenden. Drücken Sie dazu zweimal Strg+C, bevor Sie fortfahren.
8. In Cloud Run bereitstellen
Der Agent und die Toolbox funktionieren lokal. In diesem Schritt werden beide als Cloud Run-Dienste bereitgestellt, sodass sie über das Internet zugänglich sind. Der Toolbox-Dienst wird als MCP-Server in Cloud Run ausgeführt und der Agent-Dienst stellt eine Verbindung zu ihm her.
Toolbox für die Bereitstellung vorbereiten
Erstellen Sie ein Bereitstellungsverzeichnis für den Toolbox-Dienst:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Erstellen Sie das Dockerfile für die Toolbox. Öffnen Sie deploy-toolbox/Dockerfile im Cloud Shell-Editor:
cloudshell edit deploy-toolbox/Dockerfile
Kopieren Sie das folgende Skript in die Datei.
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
Die Toolbox-Binärdatei und tools.yaml werden in ein minimales Debian-Image gepackt. Cloud Run leitet Traffic an Port 8080 weiter.
Toolbox-Dienst bereitstellen
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
Mit diesem Befehl wird die Quelle an Cloud Build gesendet, ein Container-Image erstellt, in Artifact Registry gepusht und in Cloud Run bereitgestellt. Das dauert einige Minuten. Wir können das Bereitstellungsprozessprotokoll in der Datei logs/deploy_toolbox.log einsehen.
Agent für die Bereitstellung vorbereiten
Richten Sie während des Build-Vorgangs der Toolbox die Bereitstellungsdateien des Agents ein.
Erstellen Sie eine Dockerfile im Stammverzeichnis des Projekts. Öffnen Sie Dockerfile im Cloud Shell-Editor:
cloudshell edit Dockerfile
Kopieren Sie dann den folgenden Inhalt.
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
Dieses Dockerfile verwendet ghcr.io/astral-sh/uv als Basis-Image, das sowohl Python als auch uv vorinstalliert enthält. uv muss also nicht separat über pip installiert werden.
Erstellen Sie eine .dockerignore-Datei, um unnötige Dateien aus dem Container-Image auszuschließen:
cloudshell edit .dockerignore
Kopieren Sie dann das folgende Skript hinein.
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Agent-Dienst bereitstellen
Warten Sie, bis die Toolbox bereitgestellt wurde. Prüfen Sie den Bereitstellungsprozess noch einmal auf logs/deploy_toolbox.log, um ihn zu bestätigen. Rufen Sie dann die Cloud Run-URL mit dem folgenden Befehl ab:
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Die Ausgabe sollte in etwa so aussehen:
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Prüfen Sie dann, ob die bereitgestellte Toolbox funktioniert:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Wenn die Ausgabe wie in diesem Beispiel aussieht, war die Bereitstellung bereits erfolgreich.
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
Als Nächstes stellen wir den Agent bereit und übergeben die Toolbox-URL als Umgebungsvariable:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
Der Agent-Code liest TOOLBOX_URL aus der Umgebung (die Sie zuvor eingerichtet haben). Lokal verweist sie auf http://127.0.0.1:5000, in Cloud Run auf die Toolbox-Dienst-URL. Es sind keine Codeänderungen erforderlich.
Bereitgestellten KI-Agenten testen
Rufen Sie die Cloud Run-URL des Agents ab:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
Rufen Sie die URL in Ihrem Browser auf. Die ADK-Entwickler-UI wird geladen – dieselbe Oberfläche, die Sie lokal verwendet haben, wird jetzt in Cloud Run ausgeführt.
Wählen Sie im Drop-down-Menü restaurant_agent aus und testen Sie:
What Italian dishes do you have?
I want something spicy and creamy
Beide Abfragen funktionieren über die bereitgestellten Dienste: Der Agent in Cloud Run ruft die Toolbox in Cloud Run auf, die Cloud SQL abfragt.
9. Glückwunsch / Bereinigen
Sie haben einen intelligenten Assistenten für Restaurantmenüs erstellt und bereitgestellt, der die MCP Toolbox for Databases verwendet, um einen ADK-Agenten und Cloud SQL for PostgreSQL zu verbinden – sowohl mit Standard-SQL-Abfragen als auch mit semantischer Vektorsuche.
Lerninhalte
- Wie MCP den Tool-Zugriff für KI-Agents standardisiert und wie die MCP Toolbox for Databases dies speziell auf Datenbankvorgänge anwendet – benutzerdefinierter Datenbankcode wird durch deklarative YAML-Konfiguration ersetzt
- Cloud SQL PostgreSQL als Toolbox-Datenquelle mit dem Quelltyp
cloud-sql-postgreskonfigurieren - Standard-SQL-Abfragetools mit parametrisierten Anweisungen definieren, um SQL-Injection zu verhindern
- Vektorsuche mit pgvector und
gemini-embedding-001aktivieren und verwenden, mit dem ParameterembeddedByfür die automatische Einbettung von Anfragen - Wie
valueFromParamdie automatische Vektoreingabe ermöglicht: Das LLM liefert eine Textbeschreibung und Toolbox kopiert, bettet ein und speichert den Vektor zusammen mit dem Text. - Wie
ToolboxToolsetdes ADK Tools von einem laufenden Toolbox-Server lädt, wodurch der Agent-Code minimal und die Datenbanklogik vollständig entkoppelt bleibt - Bereitstellung des Toolbox-MCP-Servers und des ADK-Agenten als separate Dienste in Cloud Run
Aufräumen
Damit Ihrem Google Cloud-Konto die in diesem Codelab erstellten Ressourcen nicht in Rechnung gestellt werden, können Sie entweder die einzelnen Ressourcen oder das gesamte Projekt löschen.
Option 1: Projekt löschen (empfohlen)
Am einfachsten bereinigen Sie, indem Sie das Projekt löschen. Dadurch werden alle mit dem Projekt verknüpften Ressourcen entfernt.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Option 2: Einzelne Ressourcen löschen
Wenn Sie das Projekt behalten, aber nur die in diesem Codelab erstellten Ressourcen entfernen möchten:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null