
1. Introducción
Los agentes de IA solo son útiles en la medida en que pueden acceder a los datos. La mayoría de los datos del mundo real se encuentran en bases de datos, y conectar agentes a bases de datos suele significar escribir código de administración de conexiones, lógica de consultas y canalizaciones de incorporación dentro del código del agente. Cada agente que necesita acceso a la base de datos repite este trabajo, y cada cambio en la consulta requiere volver a implementar el agente.
En este codelab, se muestra un enfoque diferente. Declaras tus herramientas de bases de datos en un archivo YAML (consultas en SQL estándar, búsqueda de similitud de vectores y hasta generación automática de embeddings), y MCP Toolbox para bases de datos controla todas las operaciones de la base de datos como un servidor de MCP. El código del agente sigue siendo mínimo: carga las herramientas y deja que Gemini decida a cuál llamar.
Qué compilarás
Un conserje de restaurantes para "Descubrimientos gastronómicos": Un agente del ADK potenciado por Gemini que ayuda a los comensales a explorar el menú de un restaurante con filtros estándar (categoría, tipo de cocina) y a descubrir platos a través de descripciones en lenguaje natural, como "Quiero algo picante y vegetariano". El agente lee y escribe en una base de datos de Cloud SQL PostgreSQL completamente a través de MCP Toolbox para bases de datos, que controla todo el acceso a la base de datos, incluida la generación automática de embeddings para la búsqueda de vectores. Al final, tanto Toolbox como el agente se ejecutan en Cloud Run.
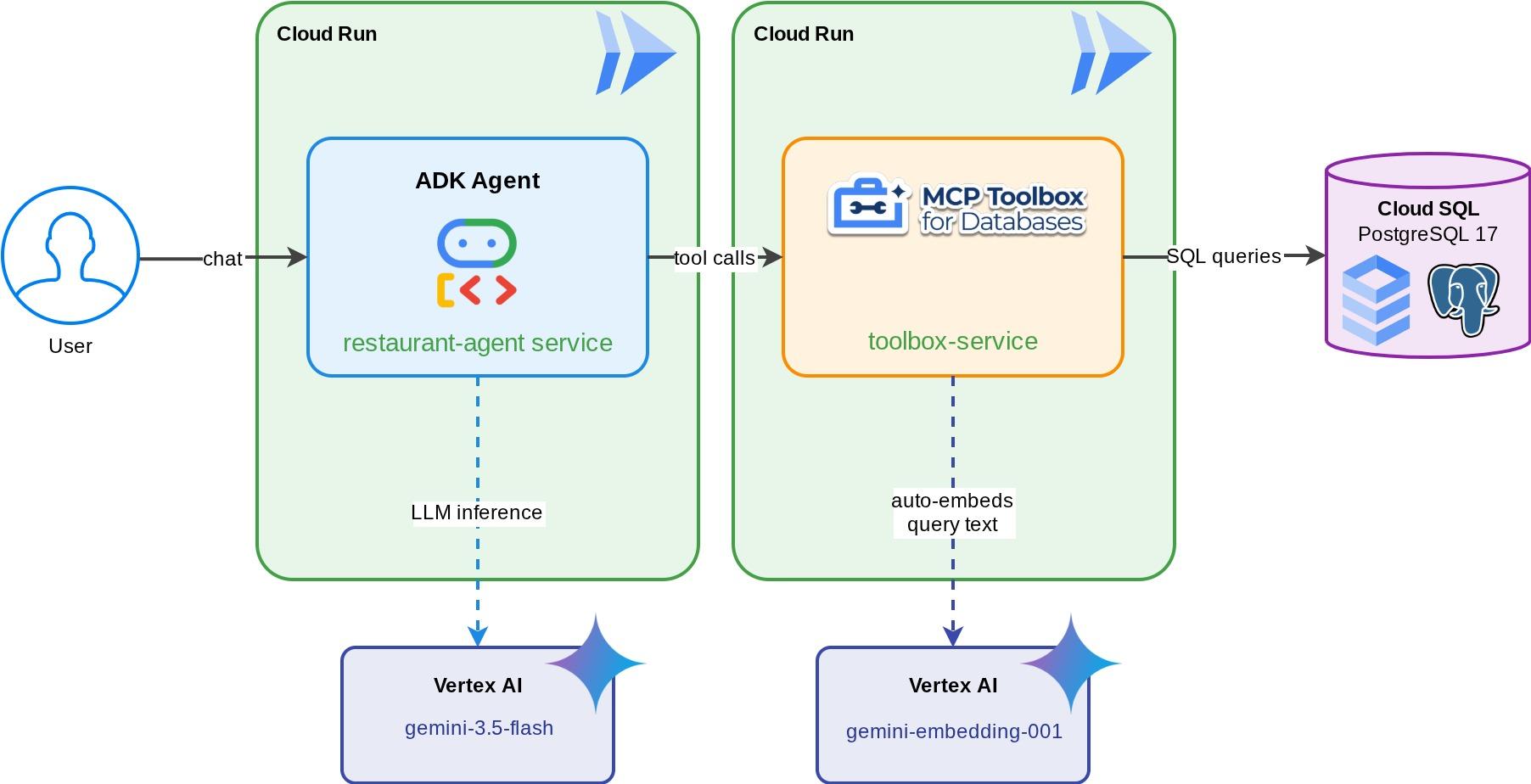
Qué aprenderás
- Cómo el MCP (Protocolo de contexto del modelo) estandariza el acceso a las herramientas para los agentes de IA y cómo MCP Toolbox para bases de datos aplica esto a las operaciones de bases de datos
- Configura MCP Toolbox para bases de datos como middleware entre un agente de ADK y Cloud SQL PostgreSQL
- Define herramientas de bases de datos de forma declarativa en
tools.yaml: no hay código de base de datos en tu agente - Crea un agente del ADK que cargue herramientas desde un servidor de Toolbox en ejecución con
ToolboxToolset - Genera embeddings de vectores con la función
embedding()integrada de Cloud SQL y habilita la búsqueda semántica conpgvector - Usa la función
valueFromParampara la transferencia automática de vectores en operaciones de escritura - Implementa el servidor de Toolbox y el agente de ADK en Cloud Run
Requisitos previos
- Una cuenta de Google Cloud con una cuenta de facturación de prueba
- Conocimientos básicos de Python y SQL
- Será útil tener experiencia previa con Cloud Database y el ADK.
2. Configura tu entorno
En este paso, se prepara tu entorno de Cloud Shell, se configura tu proyecto de Google Cloud y se clona el repositorio de referencia.
Abra Cloud Shell
Abre Cloud Shell en tu navegador. Cloud Shell proporciona un entorno preconfigurado con todas las herramientas que necesitas para este codelab. Haz clic en Autorizar cuando se te solicite
Luego, haz clic en "Ver" -> "Terminal" para abrir la terminal.Tu interfaz debería verse similar a esta:
Esta será nuestra interfaz principal, con el IDE en la parte superior y la terminal en la parte inferior.
Configura tu directorio de trabajo
Crea tu directorio de trabajo. Todo el código que escribas en este codelab se encontrará aquí:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
Luego, preparemos varios directorios para administrar elementos como los registros y las secuencias de comandos de inicialización.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Configura el proyecto de Google Cloud
Crea el archivo .env con las variables de ubicación:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Para simplificar la configuración del proyecto en tu terminal, descarga esta secuencia de comandos de configuración del proyecto en tu directorio de trabajo:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Ejecuta la secuencia de comandos. Verifica tu cuenta de facturación de prueba, crea un proyecto nuevo (o valida uno existente), guarda tu ID del proyecto en un archivo .env en el directorio actual y establece el proyecto activo en gcloud.
bash setup_verify_trial_project.sh && source .env
La secuencia de comandos hará lo siguiente:
- Verifica que tengas una cuenta de facturación de prueba activa
- Verifica si existe un proyecto en
.env(si corresponde) - Crea un proyecto nuevo o reutiliza el existente
- Vincula la cuenta de facturación de prueba a tu proyecto
- Guarda el ID del proyecto en
.env. - Configura el proyecto como el proyecto
gcloudactivo
Verifica que el proyecto esté configurado correctamente. Para ello, revisa el texto amarillo junto a tu directorio de trabajo en el mensaje de la terminal de Cloud Shell. Debería mostrar el ID de tu proyecto.

Activa la API requerida
A continuación, debemos habilitar varias APIs para el producto con el que interactuaremos:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- API de Vertex AI (
aiplatform.googleapis.com): Tu agente usa modelos de Gemini, y Toolbox usa la API de Embedding para la búsqueda vectorial. - API de Cloud SQL Admin (
sqladmin.googleapis.com): Aprovisionas y administras una instancia de PostgreSQL. - API de Compute Engine (
compute.googleapis.com): Se requiere para crear instancias de Cloud SQL. - Cloud Run, Cloud Build y Artifact Registry: Se usan en el paso de implementación más adelante en este codelab.
3. Preparación de secuencias de comandos para la inicialización de la base de datos
En este paso, se inicia la creación de la instancia de Cloud SQL y se ejecuta una secuencia de comandos de configuración automatizada que espera a que la instancia esté lista, luego crea la base de datos, la inicializa con ofertas de empleo y genera incorporaciones, todo en una sola operación.
Primero, agreguemos la contraseña de la base de datos a tu archivo .env y vuelve a cargarlo:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Crea una secuencia de comandos de Bash para la creación de instancias y bases de datos
Luego, crea el script scripts/setup_database.sh con el siguiente comando:
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Luego, copia el siguiente código en el archivo scripts/setup_database.sh.
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Cómo crear una secuencia de comandos de Python para la inicialización de datos
Después, crea el archivo de Python de la secuencia de comandos de inicialización scripts/setup_restaurant_db.py con el siguiente comando.
cloudshell edit scripts/setup_restaurant_db.py
Luego, copia el siguiente código en el archivo scripts/setup_restaurant_db.py.
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Ahora, pasemos al siguiente paso.
4. Crea e inicializa la base de datos
Ahora nuestros scripts están listos para ejecutarse. Necesitaremos Python para ejecutar nuestro script preparado, así que primero prepararemos ese.
Configura el proyecto de Python
uv es un administrador de proyectos y paquetes de Python rápido escrito en Rust ( documentación de uv). Este codelab lo usa para mantener el proyecto de Python de forma rápida y sencilla.
Inicializa un proyecto de Python y agrega las dependencias necesarias:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Ten en cuenta que aquí utilizamos el SDK de Python cloud-sql-python-connector para inicializar una conexión segura con nuestra instancia de base de datos, que se autentica con las credenciales predeterminadas de la aplicación.
Ejecuta la secuencia de comandos de configuración
Ahora, podemos ejecutar la secuencia de comandos de configuración en segundo plano y, luego, inspeccionar el resultado de la consola que se escribirá en el archivo logs/atabase_setup.log con el siguiente comando. Puedes continuar con la siguiente sección mientras esperas que finalice este proceso.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Descarga el objeto binario de Toolbox
En este instructivo, utilizaremos MCP Toolbox, que, afortunadamente, incluye un objeto binario compilado previamente que está listo para usarse en el entorno de Linux. Ahora, descarguémoslo en segundo plano, ya que tardará bastante. Ejecuta el siguiente comando para descargar el objeto binario y, luego, inspecciona el registro de salida en logs/toolbox_dl.log . Puedes continuar con la siguiente sección mientras esperas que finalice este proceso.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Información sobre la secuencia de comandos de configuración scripts/setup_database.sh
Ahora, intentemos comprender la secuencia de comandos de configuración que establecimos anteriormente. Realiza el siguiente proceso:
- El primer comando que ejecutamos allí es el comando
gcloud sql instances createcon la siguiente marca
db-custom-1-3840es el nivel de Cloud SQL de núcleos dedicados más pequeño (1 CPU virtual, 3.75 GB de RAM) en la ediciónENTERPRISE. Puedes obtener más información aquí. Se requiere un núcleo dedicado para la integración de AA de Vertex AI. Los niveles con núcleo compartido (db-f1-micro,db-g1-small) no son compatibles con esta integración.--root-passwordestablece la contraseña para el usuariopostgrespredeterminado.--enable-google-ml-integrationhabilita la integración integrada de Cloud SQL con Vertex AI, lo que te permite llamar a modelos de embedding directamente desde SQL con la funciónembedding().
- Verifica si la instancia ya está en estado
RUNNABLE. - Otorga permiso a la cuenta de servicio de la instancia de Cloud SQL para llamar a Vertex AI con el comando
gcloud projects add-iam-policy-binding. Esto es necesario para la funciónembedding()integrada que usaremos cuando inicialicemos la base de datos. - Crea la base de datos
- Ejecuta la secuencia de comandos de inicialización
setup_restaurant_db.py
Información sobre la secuencia de comandos de inicialización scripts/setup_restaurant_db.py
Ahora, pasando a la secuencia de comandos de inicialización, esta secuencia de comandos hace lo siguiente:
- Inicializa la conexión a la instancia de la base de datos
- Se instalan dos extensiones de PostgreSQL:
google_ml_integration: Proporciona la funciónembedding()de SQL, que llama a los modelos de embeddings de Vertex AI directamente desde SQL. Esta es una extensión a nivel de la base de datos que hace que las funciones de AA estén disponibles dentro derestaurant_db. La marca a nivel de la instancia (--enable-google-ml-integration) que estableces durante la creación de la instancia permite que la VM de Cloud SQL llegue a Vertex AI. La extensión hace que las funciones de SQL estén disponibles dentro de esta base de datos específica.vector(pgvector): Agrega el tipo de datosvectory los operadores de distancia para almacenar y consultar incorporaciones.
- Crea la tabla y observa que la columna
description_embeddingesvector(3072), una columnapgvectorque almacena vectores de 3,072 dimensiones. - Propaga los datos iniciales de los elementos del menú
- Genera los datos de incorporación del campo
descriptiony completa eldescription_embeddingcon la integración de Vertex integrada a través de la funciónembedding().
embedding('gemini-embedding-001', description): Llama al modelo de embedding de Gemini de Vertex AI directamente desde SQL y pasa el textodescriptionde cada trabajo. Esta es la extensióngoogle_ml_integrationque instalaste en la secuencia de comandos inicial.::vector: Convierte el array de números de punto flotante devuelto al tipovectorde pgvector para que se pueda almacenar y consultar con operadores de distancia.- El
UPDATEse ejecuta en las 15 filas y genera una incorporación de 3, 072 dimensiones por descripción del empleo.
Esto preparará los datos iniciales a los que accederá nuestro agente.
5. Configura MCP Toolbox para bases de datos
En este paso, se presenta MCP Toolbox para bases de datos, se configura para que se conecte a tu instancia de Cloud SQL y se definen dos herramientas de consultas en SQL estándar.
¿Qué es el MCP y por qué usar Toolbox?
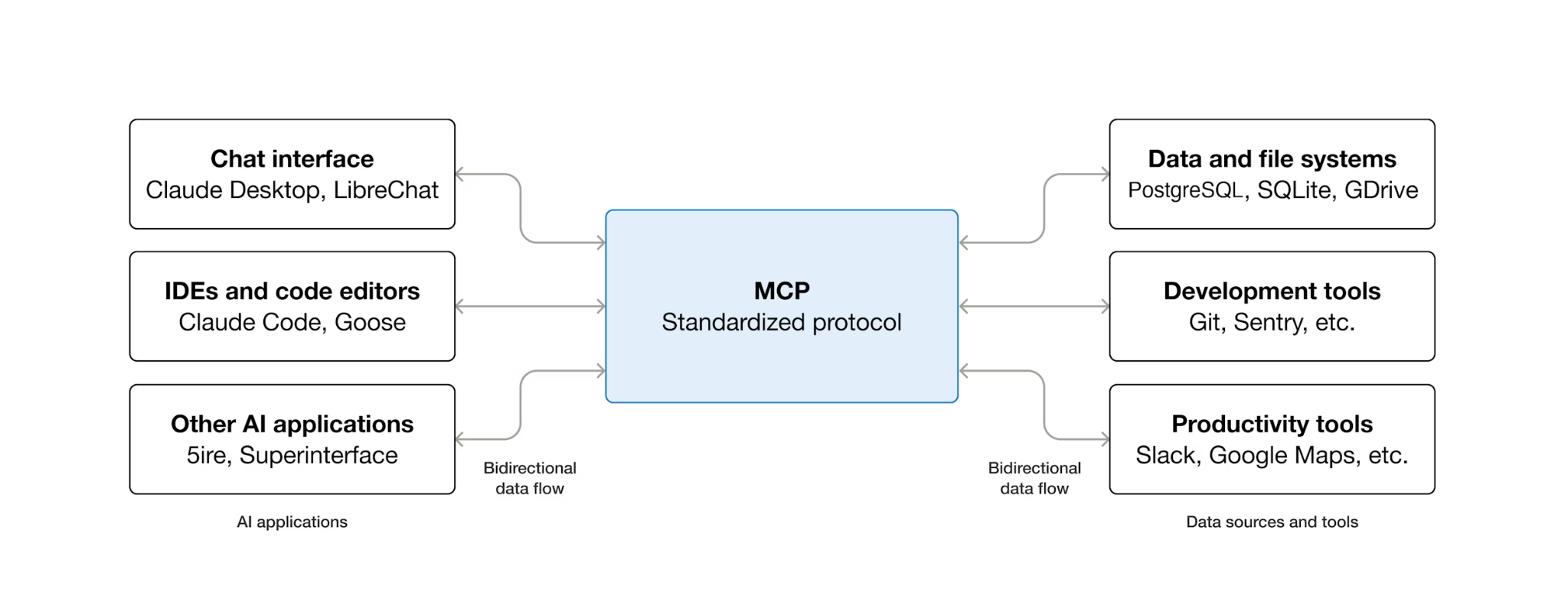
El MCP (protocolo de contexto del modelo) es un protocolo abierto que estandariza la forma en que los agentes de IA descubren herramientas externas y cómo interactúan con ellas. Define un modelo cliente-servidor: el agente aloja un cliente de MCP y los servidores de MCP exponen las herramientas. Cualquier cliente compatible con MCP puede usar cualquier servidor compatible con MCP. El agente no necesita código de integración personalizado para cada herramienta.
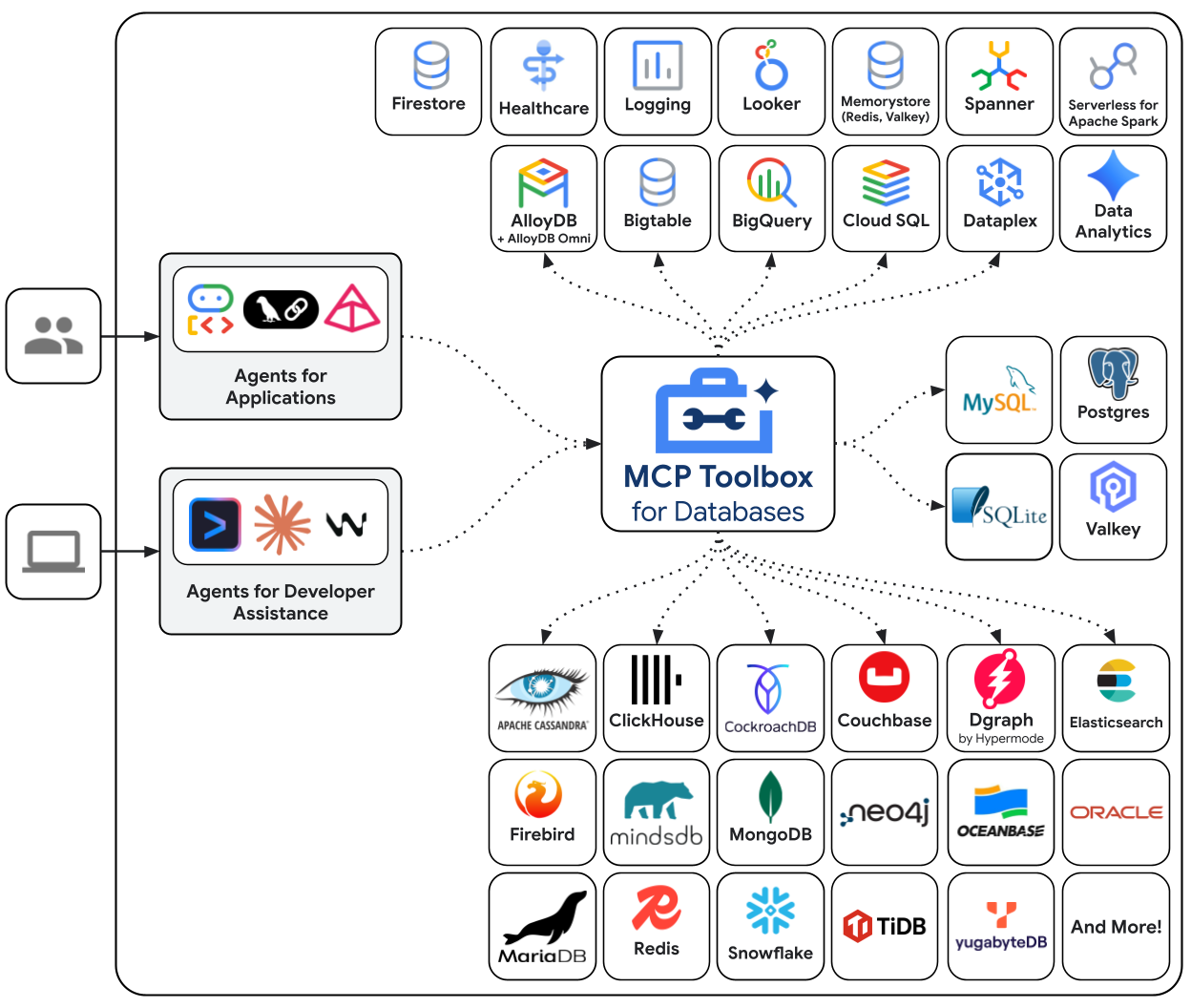
MCP Toolbox para bases de datos es un servidor de MCP de código abierto creado específicamente para el acceso a bases de datos. Sin él, escribirías funciones de Python que abren conexiones de bases de datos, administran grupos de conexiones, construyen consultas parametrizadas para evitar la inyección de SQL, controlan errores y, luego, incorporan todo ese código dentro de tu agente. Cada agente que necesita acceso a la base de datos repite este trabajo. Cambiar una pregunta significa volver a implementar el agente.
Con Toolbox, escribes un archivo YAML. Cada herramienta se asigna a una sentencia de SQL con parámetros. Toolbox controla la reducción de conexiones, las consultas parametrizadas, la autenticación y la observabilidad. Las herramientas están desacopladas del agente: actualiza una búsqueda editando tools.yaml y reiniciando Toolbox, sin tocar el código del agente. Las mismas herramientas funcionan en ADK, LangGraph, LlamaIndex o cualquier framework compatible con el MCP.
Escribe la configuración de las herramientas
Ahora, debemos crear un archivo llamado tools.yaml en el editor de Cloud Shell para configurar nuestras herramientas.
cloudshell edit tools.yaml
El archivo usa YAML de varios documentos: cada bloque separado por --- es un recurso independiente. Cada recurso tiene un kind que declara lo que es (sources para las conexiones de bases de datos, tools para las acciones que pueden llamar a agentes) y un type que especifica el backend (cloud-sql-postgres para la fuente, postgres-sql para las herramientas basadas en SQL). Una herramienta hace referencia a su fuente por medio de name, que es la forma en que Toolbox sabe con qué grupo de conexiones debe ejecutar. Las variables de entorno usan la sintaxis de ${VAR_NAME} y se resuelven durante el inicio.
Ahora, primero copiemos las siguientes secuencias de comandos en el archivo tools.yaml.
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
Esta secuencia de comandos define el siguiente recurso:
- Source (
restaurant-db): Indica a Toolbox cómo conectarse a tu instancia de Cloud SQL para PostgreSQL. El tipocloud-sql-postgresusa el conector de Cloud SQL de forma interna, lo que controla la autenticación y las conexiones seguras de forma automática. Los marcadores de posición${GOOGLE_CLOUD_PROJECT},${REGION}y${DB_PASSWORD}se resuelven a partir de las variables de entorno durante el inicio.
A continuación, agrega la siguiente secuencia de comandos debajo del símbolo --- en tools.yaml
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
Esta secuencia de comandos define el siguiente recurso:
- Herramientas 1 y 2 (
search-menu,get-item-details): Son herramientas de consulta en SQL estándar. Cada una asocia un nombre de herramienta (lo que ve el agente) a una sentencia de SQL con parámetros (lo que ejecuta la base de datos). Los parámetros usan marcadores de posición posicionales$1y$2. La caja de herramientas ejecuta estos elementos como sentencias preparadas, lo que evita la inyección de SQL.
Continuemos. Agrega la siguiente secuencia de comandos debajo del símbolo --- en tools.yaml.
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
Esta secuencia de comandos define el siguiente recurso:
- Modelo de embedding (
gemini-embedding): Configura Toolbox para llamar al modelogemini-embedding-001de Gemini y generar embeddings de texto de 3,072 dimensiones. Toolbox usa las credenciales predeterminadas de la aplicación (ADC) para la autenticación. No se necesita ninguna clave de API en Cloud Shell ni en Cloud Run. Indica que estedimensionconfigurado aquí debe ser el mismo que configuramos anteriormente para inicializar la base de datos.
Continuemos. Agrega la siguiente secuencia de comandos debajo del símbolo --- en tools.yaml.
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
Esta secuencia de comandos define el siguiente recurso:
- Herramienta 3 (
search-menu-by-description): Es una herramienta de búsqueda de vectores. El parámetrosearch_querytieneembeddedBy: gemini-embedding, que le indica a Toolbox que intercepte el texto sin procesar, lo envíe al modelo de embedding y use el vector resultante en la sentencia de SQL. El operador<=>es la distancia de coseno de pgvector. Los valores más pequeños significan descripciones más similares.
Por último, agrega la última herramienta debajo del símbolo --- en tools.yaml.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
Esta secuencia de comandos define el siguiente recurso:
- Tool 4 (
add-menu-item): Demuestra la transferencia de vectores. El parámetrodescription_vectortiene dos campos especiales: valueFromParam: description: Toolbox copia el valor del parámetrodescriptionen este. El LLM nunca ve este parámetro.embeddedBy: gemini-embedding: La Caja de herramientas incorpora el texto copiado en un vector antes de pasarlo a SQL.
El resultado es que una llamada a la herramienta almacena tanto el texto de la descripción sin procesar como su embedding de vector, sin que el agente sepa nada sobre los embeddings.
El formato YAML de varios documentos separa cada recurso con ---. Cada documento tiene campos kind, name y type que definen qué es. En resumen, ya configuramos todo lo siguiente:
- Define la base de datos de origen
- Define herramientas ( herramienta 1 y 2) para consultar la base de datos con un filtro estándar.
- Define el modelo de embedding
- Define la herramienta para realizar la búsqueda de vectores ( herramienta 3) en la base de datos.
- Define la herramienta para transferir datos vectoriales ( herramienta 4) a la base de datos
6. Ejecuta el servidor de MCP Toolbox
En el paso anterior, ya establecimos la configuración necesaria para nuestro MCP Toolbox. Ahora, ya podemos ejecutar el servidor.
Verifica los datos iniciales
Antes de iniciar Toolbox, confirmemos que se completó la configuración de la base de datos. Crea una secuencia de comandos de Python scripts/verify_database.py con el siguiente comando:
cloudshell edit scripts/verify_seed.py
Luego, copia el siguiente código en el archivo scripts/verify_seed.py.
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Esta secuencia de comandos verificará la cantidad de datos de elementos del menú y su incorporación. Ejecuta la secuencia de comandos con el siguiente comando:
uv run scripts/verify_seed.py
Si ves el siguiente resultado en la terminal, significa que los datos están listos.
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Inicia el servidor de Toolbox
En el paso de configuración anterior, ya descargamos el ejecutable toolbox. Asegúrate de que este archivo binario exista y se haya descargado correctamente. Si no es así, descárgalo y espera a que finalice la descarga.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
Tendremos que exponer nuestras variables .env al proceso secundario que ejecuta la caja de herramientas de MCP. Ejecuta el siguiente comando para iniciar el servidor de la caja de herramientas y registrar su salida de la consola en el archivo logs/mcp_toolbox.log.
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
Deberías ver un resultado en el archivo logs/mcp_toolbox.log que confirme que el servidor está listo, como se muestra a continuación:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Verifica las herramientas
Consulta la API de Toolbox para enumerar todas las herramientas registradas:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Deberías ver las herramientas con sus descripciones y parámetros. Como se muestra a continuación
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
Prueba la herramienta de search-menu directamente:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
La respuesta debe contener los platos principales italianos de tus datos iniciales.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. Compila el agente del ADK
Ahora, utilizaremos el ADK en Python para este proyecto. Agreguemos las dependencias necesarias:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk: Kit de desarrollo de agentes de Google, incluido el SDK de Geminitoolbox-adk: Integración del ADK para MCP Toolbox para bases de datos.
Crea la estructura de directorios del agente
El ADK espera un diseño de carpetas específico: un directorio con el nombre de tu agente que contenga __init__.py, agent.py y .env. Para ayudarte con esto, tiene un comando integrado para establecer rápidamente la estructura:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
Ahora, tu directorio debería verse así:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
A continuación, deberemos integrar el agente del ADK al servidor de Toolbox en ejecución y probar las cuatro herramientas: consultas estándar, búsqueda semántica y transferencia de vectores. El código del agente es mínimo: toda la lógica de la base de datos reside en tools.yaml.
Configura el entorno del agente
El ADK lee GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT y GOOGLE_CLOUD_LOCATION del entorno de shell, que ya configuraste en el paso anterior. La única variable específica del agente es TOOLBOX_URL. Agrégala al archivo .env del agente:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Actualiza el módulo del agente
Abre restaurant_agent/agent.py en el editor de Cloud Shell.
cloudshell edit restaurant_agent/agent.py
y reemplaza el contenido con el siguiente código:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Ten en cuenta que aquí no hay código de base de datos: ToolboxToolset se conecta al servidor de Toolbox durante el inicio y carga todas las herramientas disponibles. El agente llama a las herramientas por su nombre; Toolbox traduce esas llamadas en consultas SQL contra Cloud SQL.
La variable de entorno TOOLBOX_URL tiene el valor predeterminado http://127.0.0.1:5000 para el desarrollo local. Cuando realices la implementación en Cloud Run más adelante, anularás este valor con la URL de Cloud Run del servicio de Toolbox. No se necesitan cambios en el código.
Prueba el agente
Inicia la IU de desarrollo del ADK:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Abre la URL que se muestra en la terminal (por lo general, http://localhost:8000) con la función Vista previa web de Cloud Shell o Ctrl + clic en la URL que se muestra en la terminal. Selecciona restaurant_agent en el menú desplegable de agentes en la esquina superior izquierda.
Prueba búsquedas estándar
Prueba estas instrucciones para verificar las herramientas de SQL estándar:
What Italian dishes do you have?
Tell me about the Miso Glazed Black Cod
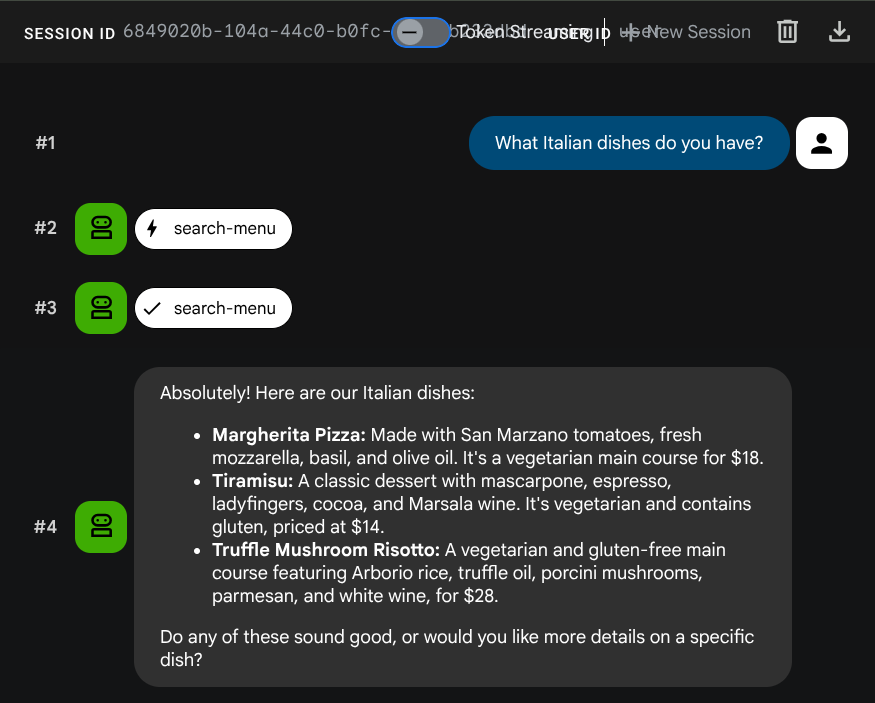
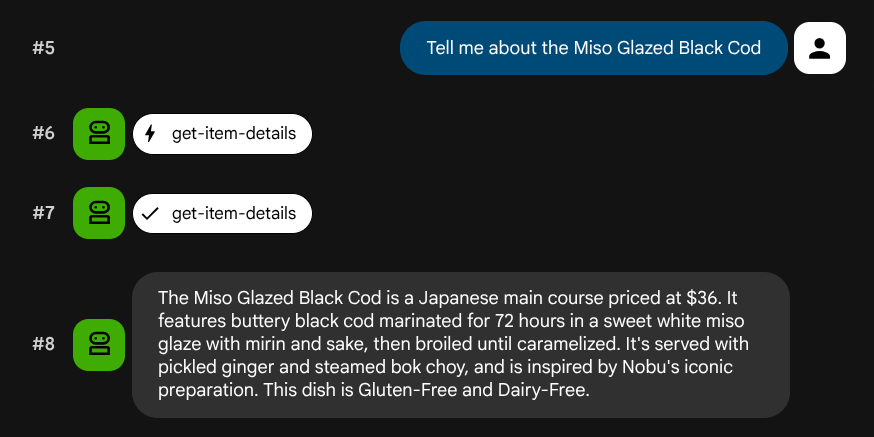
Prueba la búsqueda semántica
Prueba con descripciones en lenguaje natural que no se asignen a un rol o pila tecnológica específicos:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
El agente intentará elegir la herramienta adecuada según el tipo de búsqueda: los filtros estructurados pasan por search-menu y las descripciones en lenguaje natural pasan por search-menu-by-description.
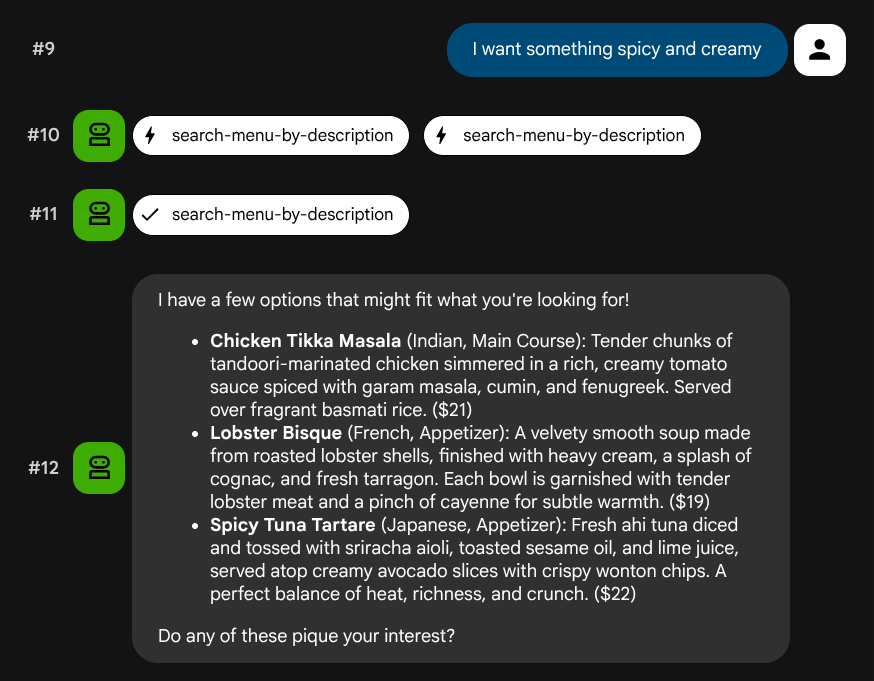
Transferencia de vectores de prueba
Pídele al agente que agregue un trabajo nuevo:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
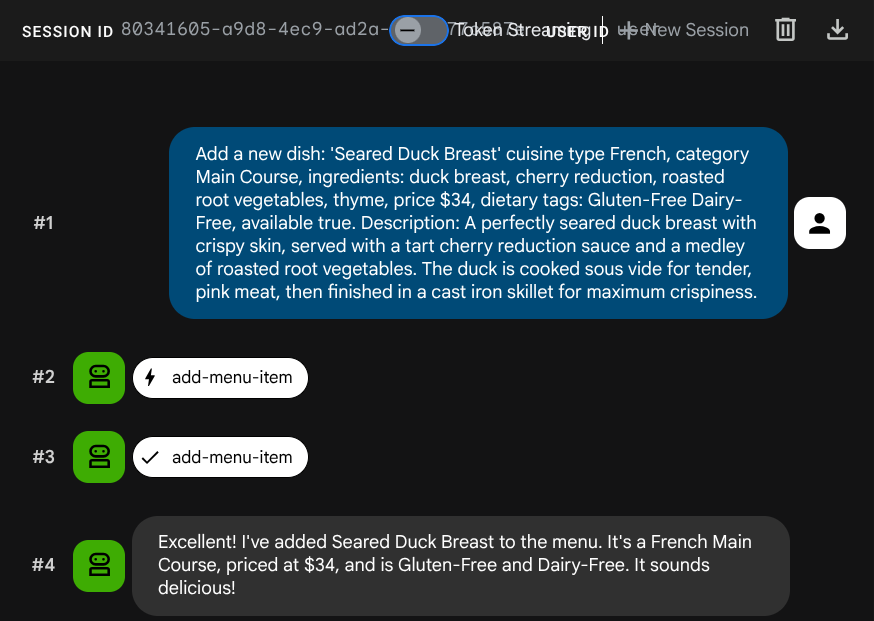
Ahora intenta buscarlo:
Find me something with rich, gamey flavors and fruit sauce
La incorporación se generó automáticamente durante la operación INSERT, por lo que no se necesita ningún paso adicional.
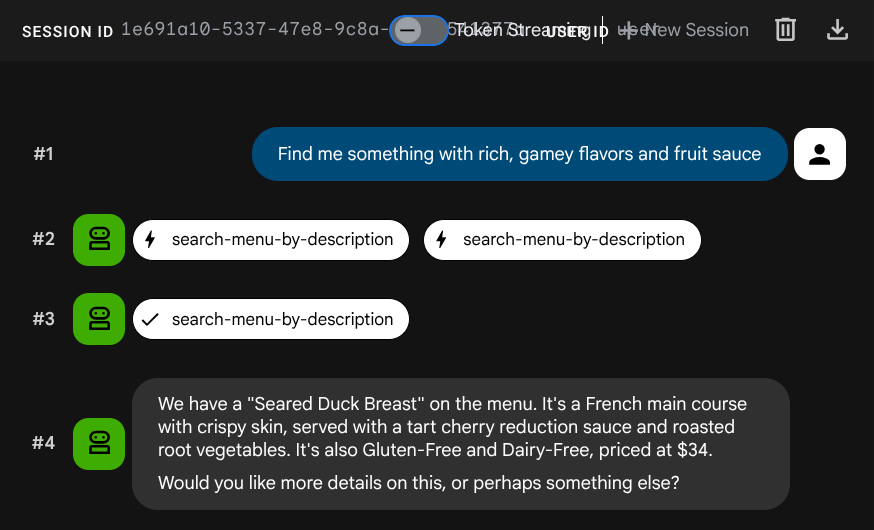
Ahora ya tienes una aplicación de RAG basada en agentes completamente funcional que utiliza ADK, MCP Toolbox y Cloud SQL. ¡Felicitaciones! Demos un paso más y, luego, implementemos estas apps en Cloud Run.
Ahora, detengamos la IU de desarrollo. Para ello, presiona Ctrl + C dos veces antes de continuar.
8. Implementa en Cloud Run
El agente y la Caja de herramientas funcionan de forma local. En este paso, se implementan ambos como servicios de Cloud Run para que sean accesibles a través de Internet. El servicio de Toolbox se ejecuta como un servidor de MCP en Cloud Run, y el servicio de agente se conecta a él.
Prepara la caja de herramientas para la implementación
Crea un directorio de implementación para el servicio de Toolbox:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Crea el Dockerfile para la caja de herramientas. Abre deploy-toolbox/Dockerfile en el editor de Cloud Shell:
cloudshell edit deploy-toolbox/Dockerfile
Copia la siguiente secuencia de comandos en él
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
El objeto binario de Toolbox y tools.yaml se empaquetan en una imagen mínima de Debian. Cloud Run enruta el tráfico al puerto 8080.
Implementa el servicio de Toolbox
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
Este comando envía el código fuente a Cloud Build, compila una imagen de contenedor, la envía a Artifact Registry y la implementa en Cloud Run. Tardará unos minutos. Podemos inspeccionar el registro del proceso de implementación en el archivo logs/deploy_toolbox.log.
Prepara el agente para la implementación
Mientras se compila Toolbox, configura los archivos de implementación del agente.
Crea un Dockerfile en la raíz del proyecto. Abre Dockerfile en el editor de Cloud Shell:
cloudshell edit Dockerfile
Luego, copia el siguiente contenido
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
Este Dockerfile usa ghcr.io/astral-sh/uv como imagen base, que incluye Python y uv preinstalados. No es necesario instalar uv por separado a través de pip.
Crea un archivo .dockerignore para excluir los archivos innecesarios de la imagen de contenedor:
cloudshell edit .dockerignore
Luego, copia la siguiente secuencia de comandos en él.
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Implementa el servicio del agente
Espera a que se complete la implementación de la Caja de herramientas. Vuelve a verificar el proceso de implementación en logs/deploy_toolbox.log para verificar el proceso. Luego, recupera su URL de Cloud Run con el siguiente comando.
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Verás un resultado similar al siguiente:
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Luego, verifiquemos que la Caja de herramientas implementada funcione:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Si el resultado se muestra como en este ejemplo, la implementación ya se realizó correctamente.
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
A continuación, implementemos el agente y pasemos la URL de Toolbox como una variable de entorno:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
El código del agente lee TOOLBOX_URL del entorno (ya configuraste esto). De forma local, apunta a http://127.0.0.1:5000; en Cloud Run, apunta a la URL del servicio de Toolbox. No es necesario realizar cambios en el código.
Prueba el agente implementado
Recupera la URL de Cloud Run del agente:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
Abre la URL en tu navegador. Se carga la IU para desarrolladores del ADK, la misma interfaz que usaste de forma local, pero ahora se ejecuta en Cloud Run.
Selecciona restaurant_agent en el menú desplegable y realiza la prueba:
What Italian dishes do you have?
I want something spicy and creamy
Ambas consultas funcionan a través de los servicios implementados: el agente en Cloud Run llama a la Caja de herramientas en Cloud Run, que consulta Cloud SQL.
9. Felicitaciones / Limpieza
Compilaste e implementaste un asistente inteligente de menú de restaurante que usa MCP Toolbox para bases de datos para conectar un agente de ADK y Cloud SQL PostgreSQL, con búsquedas de vectores semánticos y consultas de SQL estándar.
Qué aprendiste
- Cómo MCP estandariza el acceso a las herramientas para los agentes de IA y cómo MCP Toolbox para bases de datos aplica esto específicamente a las operaciones de bases de datos, reemplazando el código de bases de datos personalizado por una configuración declarativa en YAML
- Cómo configurar Cloud SQL PostgreSQL como fuente de datos de Toolbox con el tipo de fuente
cloud-sql-postgres - Cómo definir herramientas de consultas en SQL estándar con instrucciones parametrizadas que evitan la inyección de SQL
- Cómo habilitar la búsqueda de vectores con pgvector y
gemini-embedding-001, con el parámetroembeddedBypara la incorporación automática de consultas - Cómo
valueFromParamhabilita la incorporación automática de vectores: El LLM proporciona una descripción de texto y Toolbox copia, incorpora y almacena el vector junto con el texto de forma silenciosa. - Cómo
ToolboxToolsetdel ADK carga herramientas desde un servidor de Toolbox en ejecución, lo que mantiene el código del agente al mínimo y la lógica de la base de datos completamente desacoplada - Cómo implementar el servidor de MCP de Toolbox y el agente de ADK en Cloud Run como servicios independientes
Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos creados en este codelab, puedes borrar los recursos individuales o todo el proyecto.
Opción 1: Borra el proyecto (recomendada)
La manera más fácil de liberar espacio es borrar el proyecto. Esto quita todos los recursos asociados con el proyecto.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Opción 2: Borra los recursos individuales
Si deseas conservar el proyecto, pero quitar solo los recursos creados en este codelab, haz lo siguiente:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null