
۱. مقدمه
عاملهای هوش مصنوعی فقط به اندازه دادههایی که میتوانند به آنها دسترسی داشته باشند، مفید هستند. بیشتر دادههای دنیای واقعی در پایگاههای داده قرار دارند - و اتصال عاملها به پایگاههای داده معمولاً به معنای نوشتن مدیریت اتصال، منطق پرسوجو و تعبیه خطوط لوله در داخل کد عامل شماست. هر عاملی که به دسترسی به پایگاه داده نیاز دارد، این کار را تکرار میکند و هر تغییر پرسوجو نیاز به استقرار مجدد عامل دارد.
این آزمایشگاه کد رویکرد متفاوتی را نشان میدهد. شما ابزارهای پایگاه داده خود را در یک فایل YAML تعریف میکنید - کوئریهای استاندارد SQL، جستجوی شباهت برداری، حتی تولید خودکار جاسازی - و MCP Toolbox for Databases تمام عملیات پایگاه داده را به عنوان یک سرور MCP مدیریت میکند. کد عامل شما مینیمال باقی میماند: ابزارها را بارگذاری کنید، بگذارید Gemini تصمیم بگیرد کدام یک را فراخوانی کند.
آنچه خواهید ساخت
یک متصدی رستوران برای «Foodie Finds» - یک عامل ADK که توسط Gemini پشتیبانی میشود و به مشتریان کمک میکند تا با استفاده از فیلترهای استاندارد (دستهبندی، نوع غذا) منوی رستوران را مرور کنند و غذاها را از طریق توضیحات زبان طبیعی مانند «من چیزی تند و گیاهی میخواهم» کشف کنند. این عامل از طریق MCP Toolbox for Databases، که تمام دسترسی به پایگاه داده - از جمله تولید خودکار جاسازی برای جستجوی برداری - را مدیریت میکند، از یک پایگاه داده Cloud SQL PostgreSQL میخواند و در آن مینویسد. در نهایت، هم Toolbox و هم عامل روی Cloud Run اجرا میشوند.
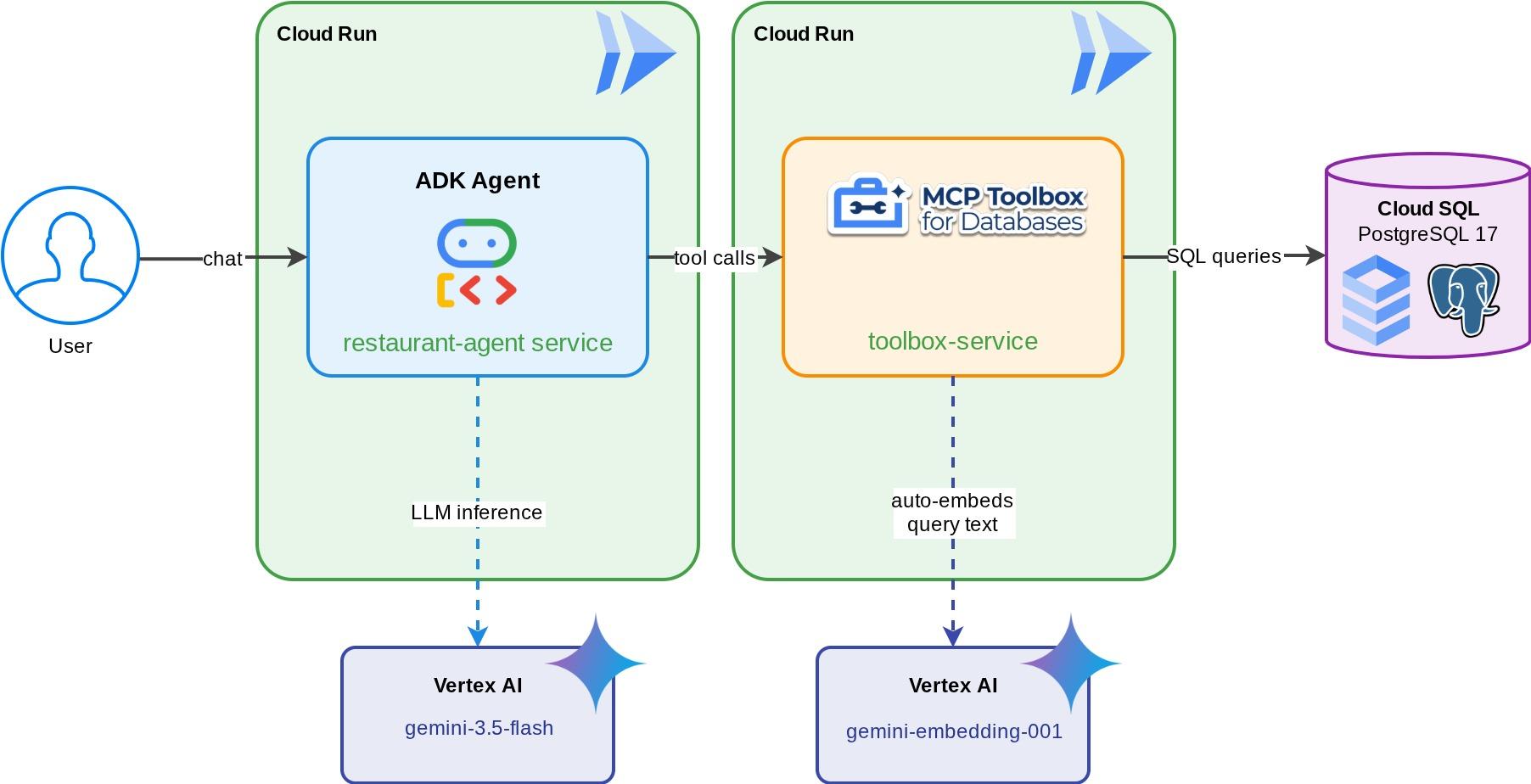
آنچه یاد خواهید گرفت
- چگونه MCP (پروتکل زمینه مدل) دسترسی به ابزار را برای عوامل هوش مصنوعی استاندارد میکند، و چگونه MCP Toolbox for Databases این را در عملیات پایگاه داده اعمال میکند
- جعبه ابزار MCP برای پایگاههای داده را به عنوان میانافزار بین یک عامل ADK و Cloud SQL PostgreSQL تنظیم کنید.
- ابزارهای پایگاه داده را به صورت اعلانی در
tools.yamlتعریف کنید - هیچ کد پایگاه دادهای در عامل شما وجود ندارد - با استفاده از
ToolboxToolsetیک عامل ADK بسازید که ابزارها را از یک سرور Toolbox در حال اجرا بارگیری کند. - با استفاده از
embedding()داخلی Cloud SQL، جاسازیهای برداری ایجاد کنید و جستجوی معنایی را باpgvectorفعال کنید. - از ویژگی
valueFromParamبرای دریافت خودکار بردار در عملیات نوشتن استفاده کنید - سرور Toolbox و ADK agent را روی Cloud Run مستقر کنید.
پیشنیازها
- یک حساب Google Cloud با یک حساب پرداخت آزمایشی
- آشنایی اولیه با پایتون و SQL
- تجربه قبلی با Cloud Database و ADK مفید خواهد بود.
۲. محیط خود را آماده کنید
این مرحله محیط Cloud Shell شما را آماده میکند، پروژه Google Cloud شما را پیکربندی میکند و مخزن مرجع را کلون میکند.
پوسته ابری را باز کنید
Cloud Shell را در مرورگر خود باز کنید. Cloud Shell یک محیط از پیش پیکربندی شده با تمام ابزارهای مورد نیاز برای این آزمایشگاه کد را فراهم میکند. در صورت درخواست، روی تأیید (Authorize) کلیک کنید.
سپس روی « مشاهده » -> « ترمینال » کلیک کنید تا ترمینال باز شود. رابط کاربری شما باید شبیه به این باشد.
این رابط اصلی ما خواهد بود، IDE در بالا، ترمینال در پایین
دایرکتوری کاری خود را تنظیم کنید
دایرکتوری کاری خود را ایجاد کنید. تمام کدهایی که در این آزمایشگاه کد مینویسید، در اینجا قرار دارند:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
پس از آن، بیایید چندین دایرکتوری را برای مدیریت مواردی مانند بارگذاری اسکریپتها و گزارشها آماده کنیم.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
پروژه گوگل کلود خود را راهاندازی کنید
فایل .env را با متغیرهای مکان ایجاد کنید:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
برای سادهسازی راهاندازی پروژه در ترمینال خود، این اسکریپت راهاندازی پروژه را در دایرکتوری کاری خود دانلود کنید:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
اسکریپت را اجرا کنید. این اسکریپت حساب کاربری آزمایشی شما را تأیید میکند، یک پروژه جدید ایجاد میکند (یا یک پروژه موجود را تأیید میکند)، شناسه پروژه شما را در یک فایل .env در دایرکتوری فعلی ذخیره میکند و پروژه فعال را در gcloud تنظیم میکند.
bash setup_verify_trial_project.sh && source .env
اسکریپت:
- تأیید کنید که یک حساب پرداخت آزمایشی فعال دارید
- بررسی وجود یک پروژه موجود در
.env(در صورت وجود) - یک پروژه جدید ایجاد کنید یا از پروژه موجود دوباره استفاده کنید
- حساب پرداخت آزمایشی را به پروژه خود پیوند دهید
- شناسه پروژه را در
.envذخیره کنید - پروژه را به عنوان پروژه فعال
gcloudتنظیم کنید
با بررسی متن زرد رنگ کنار دایرکتوری کاری خود در اعلان ترمینال Cloud Shell، مطمئن شوید که پروژه به درستی تنظیم شده است. باید شناسه پروژه شما نمایش داده شود.

فعالسازی API مورد نیاز
در مرحله بعد، باید چندین API را برای محصولی که با آن تعامل خواهیم داشت، فعال کنیم:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- رابط برنامهنویسی کاربردی هوش مصنوعی ورتکس (
aiplatform.googleapis.com) — عامل شما از مدلهای Gemini استفاده میکند و تولباکس از رابط برنامهنویسی کاربردی جاسازی برای جستجوی برداری استفاده میکند. - رابط برنامهنویسی کاربردی مدیریت SQL ابری (
sqladmin.googleapis.com) - شما یک نمونه PostgreSQL را تهیه و مدیریت میکنید. - رابط برنامهنویسی کاربردی موتور محاسبات (compute Engine API ) (
compute.googleapis.com) — برای ایجاد نمونههای Cloud SQL مورد نیاز است. - Cloud Run، Cloud Build، Artifact Registry - که در مرحله استقرار بعداً در این آزمایشگاه کد استفاده میشود
۳. آمادهسازی اسکریپتها برای مقداردهی اولیه پایگاه داده
این مرحله ایجاد نمونه Cloud SQL را آغاز میکند و یک اسکریپت راهاندازی خودکار را اجرا میکند که منتظر آماده شدن نمونه میماند، سپس پایگاه داده را ایجاد میکند، فهرست مشاغل را به آن اضافه میکند و جاسازیها را ایجاد میکند - همه اینها در یک عملیات.
ابتدا، بیایید رمز عبور پایگاه داده را به فایل .env خود اضافه کنیم و آن را مجدداً بارگذاری کنیم:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
ایجاد اسکریپت Bash برای مثال و ایجاد پایگاه داده
سپس، اسکریپت scripts/setup_database.sh را با دستور زیر ایجاد کنید
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
سپس، کد زیر را در فایل scripts/setup_database.sh کپی کنید.
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
ایجاد اسکریپت پایتون برای ایجاد پایگاه داده
پس از آن، با استفاده از دستور زیر، فایل پایتون scripts/setup_restaurant_db.py مربوط به اسکریپت seeding را ایجاد کنید.
cloudshell edit scripts/setup_restaurant_db.py
سپس، کد زیر را در فایل scripts/setup_restaurant_db.py کپی کنید.
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
حالا بریم مرحله بعدی
۴. ایجاد و مقداردهی اولیه پایگاه داده
اکنون اسکریپتهای ما آماده اجرا هستند. برای اجرای اسکریپت آماده شده به پایتون نیاز داریم، بنابراین ابتدا آن را آماده میکنیم.
پروژه پایتون را تنظیم کنید
uv یک پکیج سریع پایتون و مدیر پروژه است که با زبان Rust نوشته شده است ( مستندات uv ). این codelab از آن برای سرعت و سادگی در نگهداری پروژه پایتون استفاده میکند.
یک پروژه پایتون را راهاندازی کنید و وابستگیهای مورد نیاز را اضافه کنید:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
توجه داشته باشید که ما در اینجا cloud-sql-python-connector Python SDK برای ایجاد یک اتصال امن با نمونه پایگاه داده خود استفاده میکنیم که با استفاده از Application Default Credentials احراز هویت میشود.
اسکریپت راهاندازی را اجرا کنید
اکنون میتوانیم اسکریپت راهاندازی را در پسزمینه اجرا کنیم و خروجی کنسول را که با استفاده از دستور زیر در فایل logs/atabase_setup.log نوشته خواهد شد، بررسی کنیم. میتوانید در حالی که منتظر پایان این بخش هستید، به بخش بعدی بروید.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
دانلود فایل باینری جعبه ابزار
ما در این آموزش از MCP Toolbox استفاده خواهیم کرد، خوشبختانه این ابزار با یک فایل باینری از پیش ساخته شده ارائه میشود که آماده استفاده در محیط لینوکس است. اکنون، بیایید آن را در پسزمینه دانلود کنیم، زیرا زمان زیادی طول میکشد. دستور زیر را برای دانلود فایل باینری و بررسی گزارش خروجی در logs/toolbox_dl.log اجرا کنید. میتوانید در حالی که منتظر پایان این بخش هستید، به بخش بعدی بروید.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
آشنایی با اسکریپت راهاندازی scripts/setup_database.sh
حالا بیایید سعی کنیم اسکریپت راهاندازی که قبلاً پیکربندی کردیم را بفهمیم. این اسکریپت فرآیند زیر را انجام میدهد.
- اولین دستوری که در آنجا اجرا میکنیم، دستور
gcloud sql instances createبا پرچم زیر است.
-
db-custom-1-3840کوچکترین لایه اختصاصی Cloud SQL با هسته اختصاصی (1 vCPU، 3.75 GB RAM) در نسخهENTERPRISEاست. میتوانید جزئیات بیشتر را اینجا بخوانید. برای ادغام Vertex AI ML به یک هسته اختصاصی نیاز است - لایههای مشترک هسته (db-f1-micro،db-g1-small) از آن پشتیبانی نمیکنند. -
--root-password رمز عبور را برای کاربر پیشفرضpostgresتنظیم میکند. -
--enable-google-ml-integrationامکان ادغام داخلی Cloud SQL با Vertex AI را فراهم میکند، که به شما امکان میدهد مدلهای جاسازی را مستقیماً از SQL با استفاده از تابعembedding()فراخوانی کنید.
- بررسی کنید که آیا نمونه از قبل در وضعیت
RUNNABLEقرار دارد یا خیر - به حساب سرویس نمونهی Cloud SQL اجازه دهید تا با استفاده از دستور
gcloud projects add-iam-policy-bindingVertex AI را فراخوانی کند. این مجوز برای تابع داخلیembedding()که هنگام seeding پایگاه داده از آن استفاده خواهیم کرد، لازم است. - ایجاد پایگاه داده
- اجرای اسکریپت seeding اسکریپت
setup_restaurant_db.py
آشنایی با scripts/setup_restaurant_db.py
حالا، به سراغ اسکریپت seeding میرویم، این اسکریپت کارهای زیر را انجام میدهد:
- مقداردهی اولیه اتصال به نمونه پایگاه داده
- دو افزونه PostgreSQL را نصب میکند:
-
google_ml_integration— تابعembedding()SQL را فراهم میکند که مدلهای تعبیه هوش مصنوعی Vertex را مستقیماً از SQL فراخوانی میکند. این یک افزونه در سطح پایگاه داده است که توابع یادگیری ماشین را در داخلrestaurant_dbدر دسترس قرار میدهد. پرچم سطح نمونه (--enable-google-ml-integration) که هنگام ایجاد نمونه تنظیم میکنید، به ماشین مجازی Cloud SQL اجازه میدهد تا به Vertex AI دسترسی پیدا کند — این افزونه توابع SQL را در این پایگاه داده خاص در دسترس قرار میدهد. -
vector(pgvector) - نوع دادهvectorو عملگرهای فاصله را برای ذخیره و جستجوی جاسازیها اضافه میکند.
- جدول را ایجاد کنید، توجه داشته باشید که ستون
description_embeddingvector(3072)است - یک ستونpgvectorکه بردارهای 3072 بعدی را ذخیره میکند. - دادههای اولیهی آیتمهای منو را بارگذاری کنید
- دادههای جاسازی را از فیلد
descriptionتولید کنید وdescription_embeddingبا استفاده از ادغام رأس داخلی از طریق تابعembedding()پر کنید.
-
embedding('gemini-embedding-001', description)— مدل embedding Gemini مربوط به Vertex AI را مستقیماً از SQL فراخوانی میکند و متنdescriptionهر کار را ارسال میکند. این افزونهgoogle_ml_integrationاست که شما در اسکریپت seed نصب کردهاید. -
::vector— آرایه اعشاری برگشتی را به نوعvectorpgvector تبدیل میکند تا بتوان آن را ذخیره و با عملگرهای فاصله پرسوجو کرد. -
UPDATEدر هر ۱۵ ردیف اجرا میشود و به ازای هر شرح شغل، یک جاسازی ۳۰۷۲ بعدی ایجاد میکند.
این دادههای اولیهای را که توسط نماینده ما قابل دسترسی خواهد بود، آماده میکند.
۵. پیکربندی جعبه ابزار MCP برای پایگاههای داده
این مرحله جعبه ابزار MCP برای پایگاههای داده را معرفی میکند، آن را برای اتصال به نمونه Cloud SQL شما پیکربندی میکند و دو ابزار استاندارد پرسوجوی SQL را تعریف میکند.
MCP چیست و چرا از جعبه ابزار استفاده کنیم؟
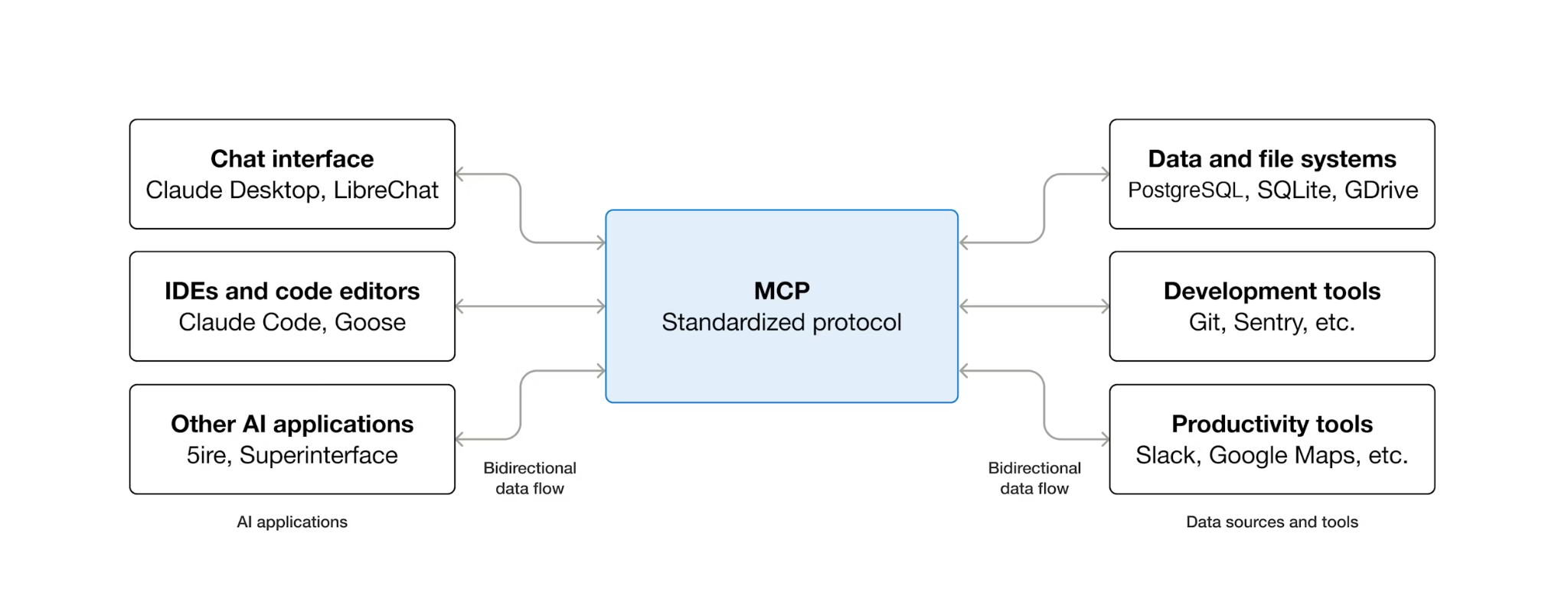
MCP (پروتکل زمینه مدل) یک پروتکل باز است که نحوه کشف و تعامل عاملهای هوش مصنوعی با ابزارهای خارجی را استاندارد میکند. این پروتکل یک مدل کلاینت-سرور را تعریف میکند: عامل میزبان یک کلاینت MCP است و ابزارها توسط سرورهای MCP در معرض دید قرار میگیرند. هر کلاینت سازگار با MCP میتواند از هر سرور سازگار با MCP استفاده کند - عامل برای هر ابزار به کد یکپارچهسازی سفارشی نیاز ندارد.
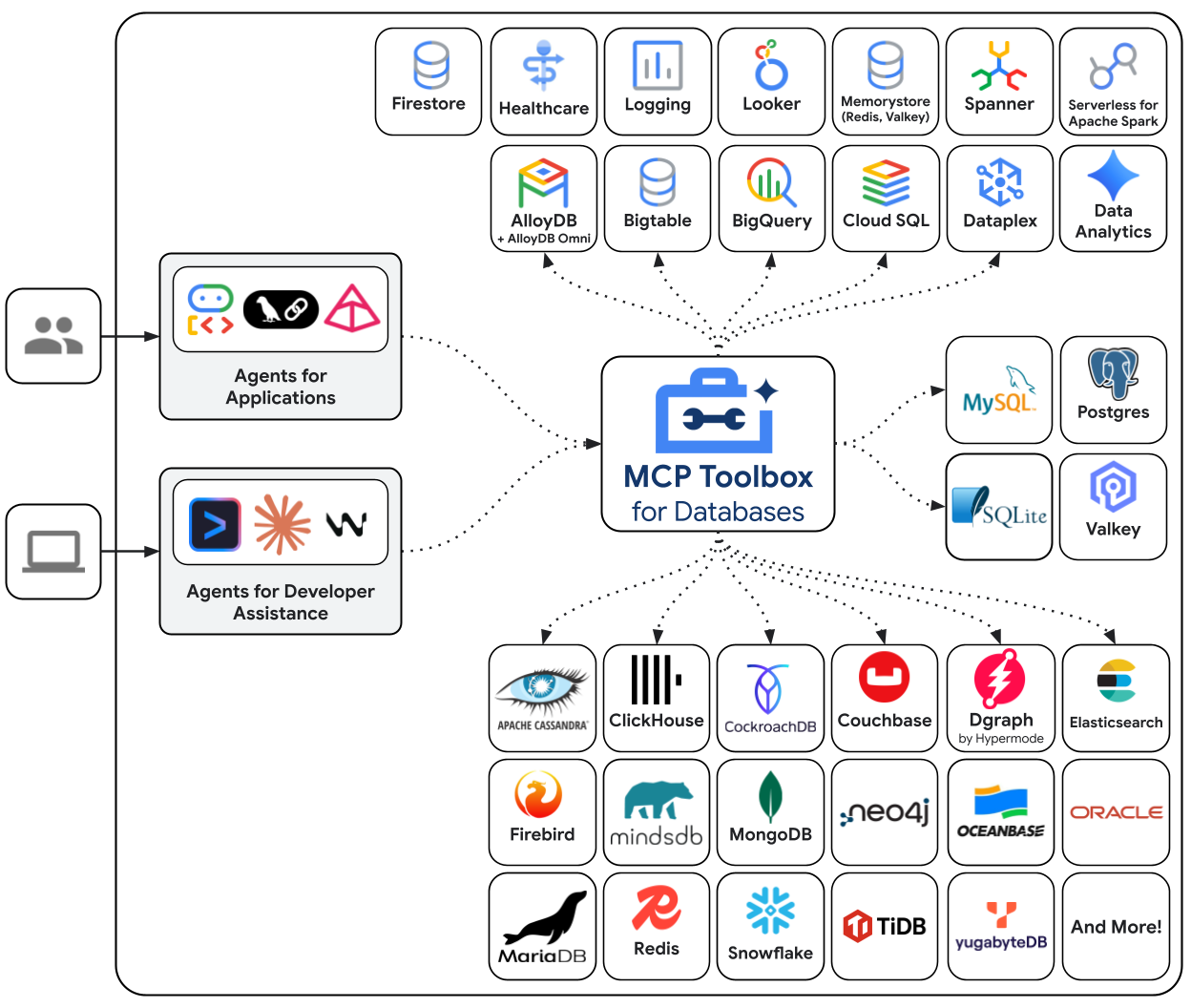
جعبه ابزار MCP برای پایگاههای داده، یک سرور MCP متنباز است که بهطور خاص برای دسترسی به پایگاه داده ساخته شده است. بدون آن، شما باید توابع پایتونی بنویسید که اتصالات پایگاه داده را باز میکنند، مجموعههای اتصال را مدیریت میکنند، کوئریهای پارامتری برای جلوگیری از تزریق SQL میسازند، خطاها را مدیریت میکنند و تمام آن کد را درون عامل خود جاسازی میکنند. هر عاملی که به دسترسی به پایگاه داده نیاز دارد، این کار را تکرار میکند. تغییر یک کوئری به معنای استقرار مجدد عامل است.
با Toolbox، شما یک فایل YAML مینویسید. هر ابزار به یک دستور SQL پارامتری نگاشت میشود. Toolbox ادغام اتصال، پرسوجوهای پارامتری، احراز هویت و مشاهدهپذیری را مدیریت میکند. ابزارها از عامل جدا شدهاند - یک پرسوجو را با ویرایش tools.yaml و راهاندازی مجدد Toolbox، بدون دست زدن به کد عامل، بهروزرسانی کنید. همین ابزارها در ADK، LangGraph، LlamaIndex یا هر چارچوب سازگار با MCP کار میکنند.
پیکربندی ابزارها را بنویسید
حالا، باید فایلی به نام tools.yaml در ویرایشگر Cloud Shell ایجاد کنیم تا پیکربندی ابزارهایمان را تنظیم کنیم.
cloudshell edit tools.yaml
این فایل از YAML چند سندی استفاده میکند - هر بلوک جدا شده با --- یک منبع مستقل است. هر منبع یک kind دارد که ماهیت آن را اعلام میکند ( sources برای اتصالات پایگاه داده، tools برای اقدامات قابل فراخوانی توسط عامل) و یک type که backend را مشخص میکند ( cloud-sql-postgres برای منبع، postgres-sql برای ابزارهای مبتنی بر SQL). یک ابزار منبع خود را با name ارجاع میدهد، به این ترتیب Toolbox میداند که در کدام مخزن اتصال اجرا شود. متغیرهای محیطی از سینتکس ${VAR_NAME} استفاده میکنند و در هنگام راهاندازی حل میشوند.
حالا، بیایید اسکریپتهای زیر را ابتدا در فایل tools.yaml کپی کنیم.
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
این اسکریپت منبع زیر را تعریف میکند:
- منبع (
restaurant-db) — به جعبه ابزار میگوید که چگونه به نمونه Cloud SQL PostgreSQL شما متصل شود. نوعcloud-sql-postgresاز رابط Cloud SQL به صورت داخلی استفاده میکند و احراز هویت و اتصالات امن را به طور خودکار مدیریت میکند. متغیرهای${GOOGLE_CLOUD_PROJECT}،${REGION}و${DB_PASSWORD}در هنگام راهاندازی از متغیرهای محیطی دریافت میشوند.
سپس، اسکریپت زیر را زیر نماد --- در فایل tools.yaml اضافه کنید.
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
این اسکریپت منبع زیر را تعریف میکند:
- ابزارهای ۱ و ۲ (
search-menu،get-item-details) — ابزارهای استاندارد پرسوجوی SQL. هر کدام نام یک ابزار (آنچه عامل میبیند) را به یک عبارت SQL پارامتری (آنچه پایگاه داده اجرا میکند) نگاشت میکنند. پارامترها از متغیرهای موقعیتی$1و$2استفاده میکنند. جعبه ابزار اینها را به عنوان عبارات آماده اجرا میکند که از تزریق SQL جلوگیری میکند.
بیایید ادامه دهیم، اسکریپت زیر را زیر نماد --- در فایل tools.yaml اضافه کنید.
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
این اسکریپت منبع زیر را تعریف میکند:
- مدل جاسازی (
gemini-embedding) — Toolbox را طوری پیکربندی میکند که مدلgemini-embedding-001مربوط به Gemini را برای تولید جاسازیهای متنی 3072 بعدی فراخوانی کند. Toolbox از Application Default Credentials (ADC) برای احراز هویت استفاده میکند — هیچ کلید API در Cloud Shell یا Cloud Run مورد نیاز نیست. توجه داشته باشید که اینdimensionپیکربندی شده در اینجا باید با بُعدی که قبلاً برای seed کردن پایگاه داده پیکربندی کردهایم، یکسان باشد.
بیایید ادامه دهیم، اسکریپت زیر را زیر نماد --- در فایل tools.yaml اضافه کنید.
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
این اسکریپت منبع زیر را تعریف میکند:
- ابزار ۳ (
search-menu-by-description) — یک ابزار جستجوی برداری. پارامترsearch_queryدارایembeddedBy: gemini-embeddingاست که به Toolbox میگوید متن خام را رهگیری کند، آن را به مدل جاسازی ارسال کند و بردار حاصل را در عبارت SQL استفاده کند. عملگر<=>فاصله کسینوسی pgvector است — مقادیر کوچکتر به معنای توصیفات مشابهتر هستند.
در نهایت، آخرین ابزار را زیر نماد --- در فایل tools.yaml اضافه کنید.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
این اسکریپت منبع زیر را تعریف میکند:
- ابزار ۴ (
add-menu-item) — مصرف بردار را نشان میدهد. پارامترdescription_vectorدو فیلد ویژه دارد: -
valueFromParam: description— جعبه ابزار مقدار پارامترdescriptionرا در این پارامتر کپی میکند. LLM هرگز این پارامتر را نمیبیند. -
embeddedBy: gemini-embedding— جعبه ابزار، متن کپی شده را قبل از ارسال به SQL، در یک بردار جاسازی میکند.
نتیجه: یک فراخوانی ابزار، هم متن توصیف خام و هم جاسازی برداری آن را ذخیره میکند، بدون اینکه عامل چیزی در مورد جاسازیها بداند.
قالب YAML چند سندی، هر منبع را با --- از هم جدا میکند. هر سند دارای فیلدهای kind ، name و type است که ماهیت آن را تعریف میکنند. به طور خلاصه، ما قبلاً همه موارد زیر را پیکربندی کردهایم:
- تعریف پایگاه داده منبع
- تعریف ابزارها ( ابزار ۱ و ۲ ) برای پرس و جو از پایگاه داده با فیلتر استاندارد
- تعریف مدل جاسازی
- تعریف ابزاری برای جستجوی برداری ( ابزار ۳ ) در پایگاه داده
- تعریف ابزاری برای انجام دریافت دادههای برداری ( ابزار ۴) به پایگاه داده
۶. اجرای سرور جعبه ابزار MCP
در مرحله قبل، ما پیکربندی لازم را برای جعبه ابزار MCP خود تنظیم کردهایم. اکنون آماده اجرای سرور هستیم.
دادههای ذخیرهشده را تأیید کنید
قبل از شروع Toolbox، بیایید تأیید کنیم که راهاندازی پایگاه داده تکمیل شده است. با استفاده از دستور زیر، یک scripts/verify_database.py ایجاد کنید.
cloudshell edit scripts/verify_seed.py
سپس، کد زیر را در فایل scripts/verify_seed.py کپی کنید.
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
این اسکریپت تعداد دادههای آیتمهای منو و نحوهی جاسازی آنها را بررسی میکند. اسکریپت را با استفاده از دستور زیر اجرا کنید
uv run scripts/verify_seed.py
اگر خروجی ترمینال زیر را مشاهده کردید، به این معنی است که دادهها آماده هستند.
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
سرور Toolbox را شروع کنید
در مرحلهی راهاندازی قبلی، ما فایل اجرایی toolbox را دانلود کردیم. مطمئن شوید که این فایل باینری وجود دارد و با موفقیت دانلود شده است، در غیر این صورت، آن را دانلود کنید و منتظر بمانید تا دانلود تمام شود.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
ما باید متغیرهای .env خود را در اختیار فرآیند فرزندی که توسط جعبه ابزار MCP اجرا میشود، قرار دهیم. دستور زیر را اجرا کنید تا سرور جعبه ابزار شروع به کار کند و خروجی کنسول آن را در فایل logs/mcp_toolbox.log ثبت کند.
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
شما باید خروجی را در فایل logs/mcp_toolbox.log مشاهده کنید که تأیید میکند سرور آماده است، مانند تصویر زیر:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
ابزارها را تأیید کنید
برای لیست کردن تمام ابزارهای ثبت شده، از API جعبه ابزار کوئری بگیرید:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
شما باید ابزارها را به همراه توضیحات و پارامترهایشان ببینید. مانند تصویر زیر.
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
ابزار search-menu را مستقیماً آزمایش کنید:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
پاسخ باید شامل غذاهای اصلی ایتالیایی از دادههای اولیه شما باشد.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
۷. عامل ADK را بسازید
اکنون، ما از ADK در پایتون برای این پروژه استفاده خواهیم کرد، بیایید وابستگیهای مورد نیاز را اضافه کنیم:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk— کیت توسعه عامل گوگل، شامل Gemini SDK-
toolbox-adk— یکپارچهسازی ADK برای جعبه ابزار MCP برای پایگاههای داده.
ساختار دایرکتوری عامل را ایجاد کنید
ADK انتظار یک طرح پوشه خاص را دارد: یک پوشه به نام عامل شما که شامل __init__.py ، agent.py و .env باشد. برای کمک به این امر، دستوری را برای ایجاد سریع ساختار تعبیه کرده است:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
اکنون دایرکتوری شما باید به این شکل باشد:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
در مرحله بعد، باید عامل ADK را با سرور Toolbox در حال اجرا ادغام کنیم و هر چهار ابزار - پرسوجوهای استاندارد، جستجوی معنایی و دریافت بردار - را آزمایش کنیم. کد عامل حداقل است: تمام منطق پایگاه داده در tools.yaml قرار دارد.
پیکربندی محیط عامل
ADK GOOGLE_GENAI_USE_VERTEXAI ، GOOGLE_CLOUD_PROJECT و GOOGLE_CLOUD_LOCATION را از محیط shell میخواند، که شما در مرحله قبل تنظیم کردهاید. تنها متغیر مختص agent، TOOLBOX_URL است - آن را به فایل .env مربوط به agent اضافه کنید:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
ماژول عامل را بهروزرسانی کنید
restaurant_agent/agent.py را در ویرایشگر Cloud Shell باز کنید.
cloudshell edit restaurant_agent/agent.py
و محتوا را با کد زیر بازنویسی کنید:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
توجه داشته باشید که هیچ کد پایگاه دادهای در اینجا وجود ندارد - ToolboxToolset در هنگام راهاندازی به سرور Toolbox متصل میشود و تمام ابزارهای موجود را بارگذاری میکند. عامل، ابزارها را با نام فراخوانی میکند؛ Toolbox این فراخوانیها را به کوئریهای SQL در Cloud SQL ترجمه میکند.
متغیر محیطی TOOLBOX_URL برای توسعه محلی به طور پیشفرض روی http://127.0.0.1:5000 تنظیم شده است. وقتی بعداً در Cloud Run مستقر میشوید، این را با Cloud Run URL سرویس Toolbox جایگزین میکنید - نیازی به تغییر کد نیست.
عامل را آزمایش کنید
رابط کاربری ADK dev را شروع کنید:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
آدرس اینترنتی (URL) نمایش داده شده در ترمینال (معمولاً http://localhost:8000 ) را با استفاده از ویژگی پیشنمایش وب Cloud Shell یا با نگه داشتن کلید ctrl + کلیک روی آدرس اینترنتی نمایش داده شده در ترمینال باز کنید. از منوی کشویی agent در گوشه بالا سمت چپ، restaurant_agent را انتخاب کنید.
پرسوجوهای استاندارد را آزمایش کنید
برای تأیید ابزارهای استاندارد SQL، این دستورالعملها را امتحان کنید:
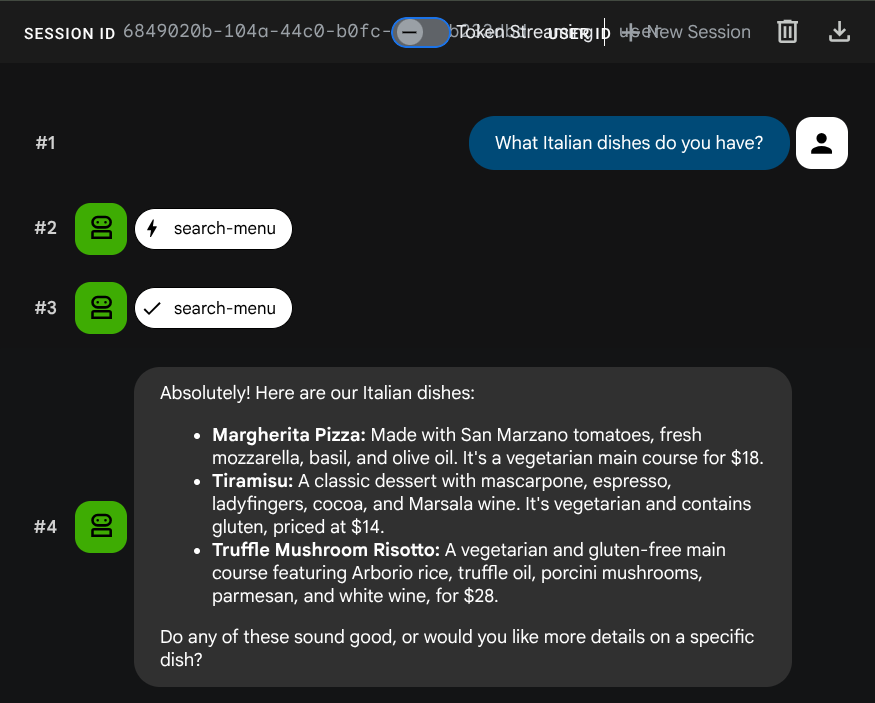
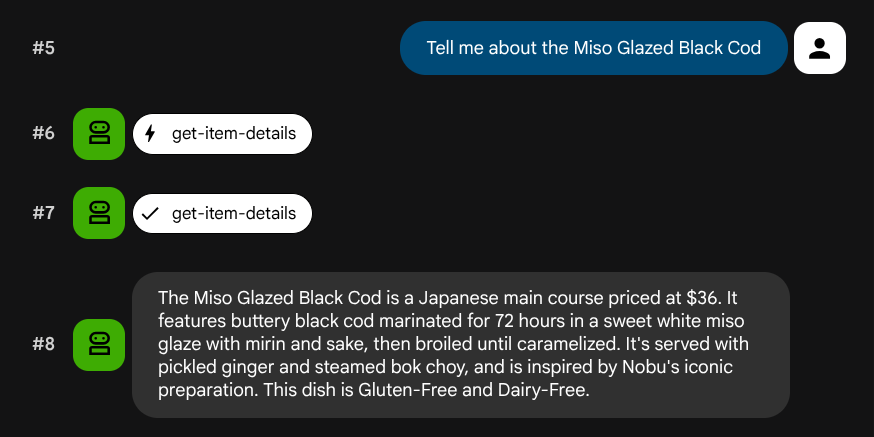
What Italian dishes do you have?
Tell me about the Miso Glazed Black Cod
جستجوی معنایی را آزمایش کنید
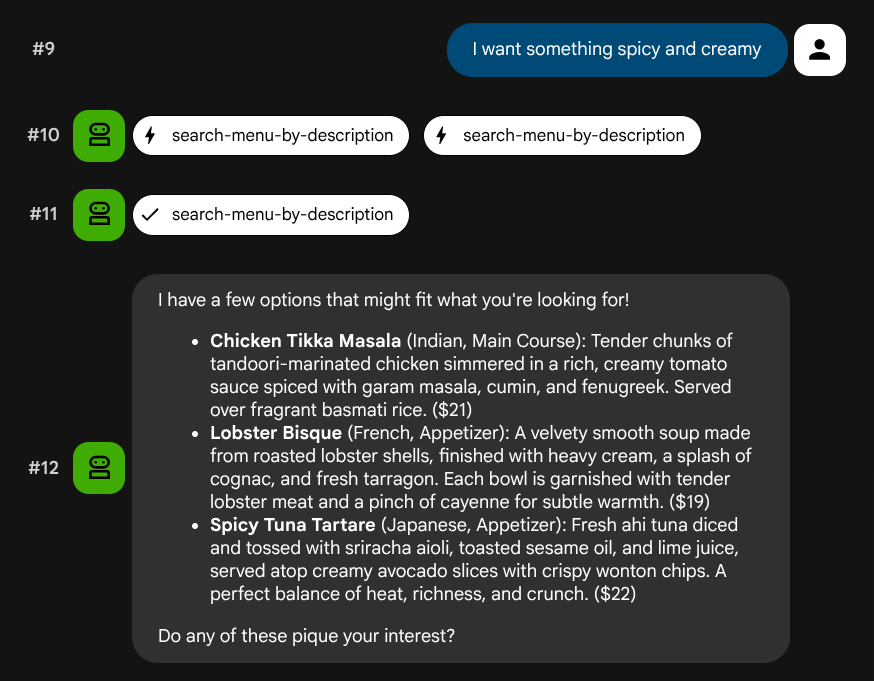
توصیفات زبان طبیعی را امتحان کنید که به یک نقش یا فناوری خاص مربوط نمیشوند:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
عامل سعی خواهد کرد ابزار مناسب را بر اساس نوع پرس و جو انتخاب کند: فیلترهای ساختاریافته از طریق search-menu و توضیحات زبان طبیعی از طریق search-menu-by-description انجام میشوند.
بلعیدن ناقل آزمایشی
از نماینده بخواهید شغل جدیدی اضافه کند:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
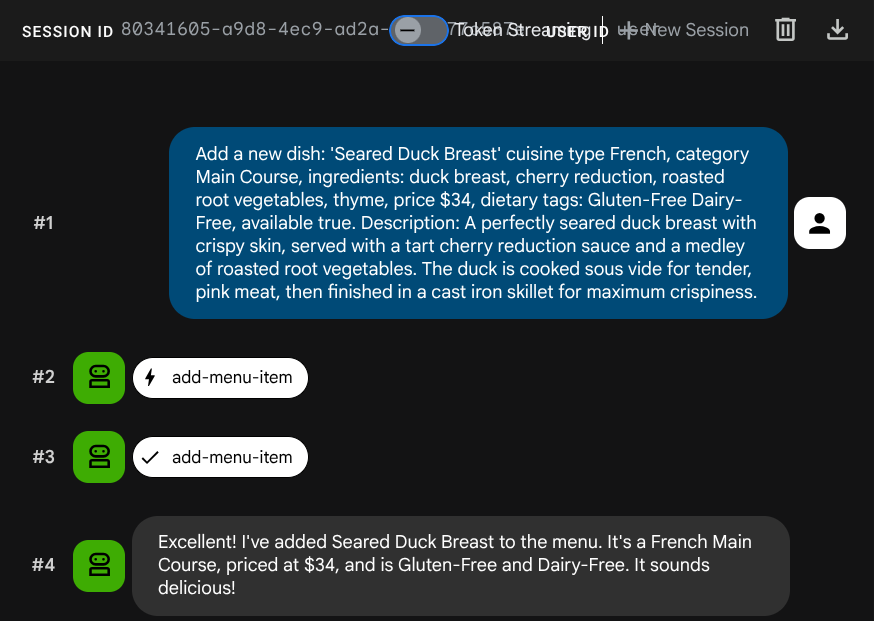
حالا سعی کنید آن را جستجو کنید:
Find me something with rich, gamey flavors and fruit sauce
جاسازی به طور خودکار در طول INSERT ایجاد شد - هیچ مرحله جداگانهای لازم نیست.
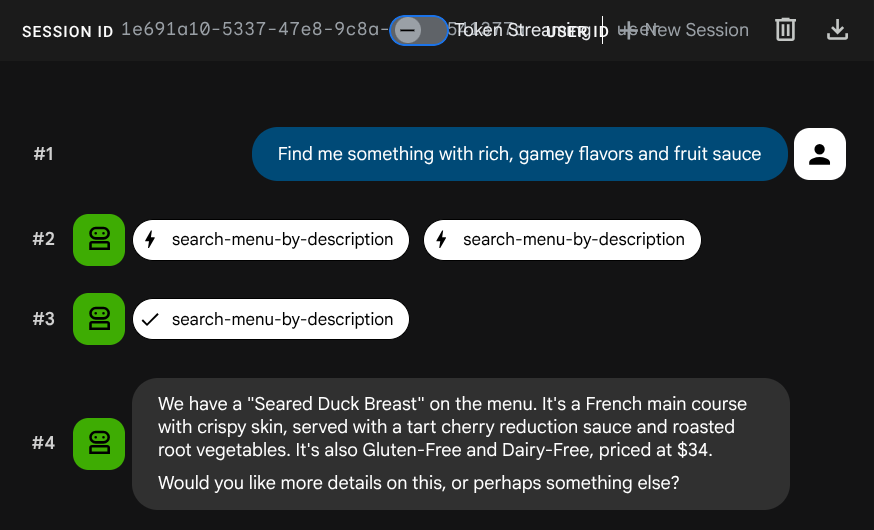
حالا، شما یک برنامهی Agentic RAG کامل و کارآمد با استفاده از ADK، MCP Toolbox و CloudSQL دارید. تبریک میگویم! بیایید یک قدم جلوتر برویم و این برنامهها را روی Cloud Run مستقر کنیم!
حالا، بیایید رابط کاربری توسعهدهنده را با متوقف کردن فرآیند با دو بار فشردن Ctrl+C قبل از ادامه، متوقف کنیم.
۸. استقرار در Cloud Run
عامل و جعبه ابزار به صورت محلی کار میکنند. این مرحله هر دو را به عنوان سرویسهای Cloud Run مستقر میکند تا از طریق اینترنت قابل دسترسی باشند. سرویس جعبه ابزار به عنوان یک سرور MCP در Cloud Run اجرا میشود و سرویس عامل به آن متصل میشود.
جعبه ابزار را برای استقرار آماده کنید
یک دایرکتوری استقرار برای سرویس Toolbox ایجاد کنید:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
فایل Dockerfile را برای جعبه ابزار ایجاد کنید. deploy-toolbox/Dockerfile را در ویرایشگر Cloud Shell باز کنید:
cloudshell edit deploy-toolbox/Dockerfile
و اسکریپت زیر را در آن کپی کنید
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
فایلهای باینری Toolbox و tools.yaml در یک تصویر مینیمال دبیان بستهبندی شدهاند. Cloud Run ترافیک را به پورت ۸۰۸۰ هدایت میکند.
سرویس Toolbox را مستقر کنید
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
این دستور منبع را به Cloud Build ارسال میکند، یک تصویر کانتینر میسازد، آن را به Artifact Registry ارسال میکند و آن را در Cloud Run مستقر میکند. این کار چند دقیقه طول میکشد - میتوانیم گزارش فرآیند استقرار را در فایل logs/deploy_toolbox.log بررسی کنیم.
آمادهسازی عامل برای استقرار
در حین ساخت Toolbox، فایلهای استقرار عامل را تنظیم کنید.
یک Dockerfile در ریشه پروژه ایجاد کنید. Dockerfile در ویرایشگر Cloud Shell باز کنید:
cloudshell edit Dockerfile
سپس، محتوای زیر را کپی کنید
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
این داکرفایل از ghcr.io/astral-sh/uv به عنوان ایمیج پایه استفاده میکند که شامل پایتون و uv از پیش نصب شده است - نیازی به نصب جداگانه uv از طریق pip نیست.
یک فایل .dockerignore ایجاد کنید تا فایلهای غیرضروری از تصویر کانتینر حذف شوند:
cloudshell edit .dockerignore
سپس اسکریپت زیر را در آن کپی کنید
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
سرویس عامل را مستقر کنید
منتظر بمانید تا استقرار Toolbox تکمیل شود. برای تأیید فرآیند، دوباره فرآیند استقرار را در logs/deploy_toolbox.log بررسی کنید. سپس، آدرس Cloud Run آن را با استفاده از دستور زیر بازیابی کنید.
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
خروجی مشابهی مانند این را مشاهده خواهید کرد
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
سپس، بیایید بررسی کنیم که جعبه ابزار مستقر شده کار میکند:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
اگر خروجی مانند این مثال نشان داده شود، استقرار از قبل موفقیتآمیز بوده است.
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
در مرحله بعد، بیایید عامل را مستقر کنیم و URL جعبه ابزار را به عنوان یک متغیر محیطی ارسال کنیم:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
کد عامل، TOOLBOX_URL از محیط میخواند (شما قبلاً این را تنظیم کردهاید). به صورت محلی به http://127.0.0.1:5000 اشاره میکند؛ در Cloud Run به URL سرویس Toolbox اشاره میکند. نیازی به تغییر کد نیست.
عامل مستقر شده را آزمایش کنید
آدرس اینترنتی Cloud Run مربوط به عامل را بازیابی کنید:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
URL را در مرورگر خود باز کنید. رابط کاربری ADK dev بارگذاری میشود - همان رابط کاربری که به صورت محلی استفاده میکردید، اکنون روی Cloud Run اجرا میشود.
از منوی کشویی، restaurant_agent را انتخاب کنید و تست کنید:
What Italian dishes do you have?
I want something spicy and creamy
هر دو پرسوجو از طریق سرویسهای مستقر شده کار میکنند: عامل موجود در Cloud Run، Toolbox موجود در Cloud Run را فراخوانی میکند که Cloud SQL را پرسوجو میکند.
۹. تبریک / تمیزکاری
شما یک دستیار هوشمند منوی رستوران ساخته و مستقر کردهاید که از MCP Toolbox for Databases برای ایجاد پل ارتباطی بین یک عامل ADK و Cloud SQL PostgreSQL استفاده میکند - هم با پرسوجوهای استاندارد SQL و هم با جستجوی برداری معنایی.
آنچه آموختهاید
- چگونه MCP دسترسی به ابزار را برای عاملهای هوش مصنوعی استاندارد میکند، و چگونه MCP Toolbox for Databases این را به طور خاص برای عملیات پایگاه داده اعمال میکند - جایگزینی کد پایگاه داده سفارشی با پیکربندی YAML اعلانی
- نحوه پیکربندی Cloud SQL PostgreSQL به عنوان منبع داده Toolbox با استفاده از نوع منبع
cloud-sql-postgres - نحوه تعریف ابزارهای استاندارد پرس و جوی SQL با دستورات پارامتری که از تزریق SQL جلوگیری میکنند
- نحوه فعال کردن جستجوی برداری با استفاده از pgvector و
gemini-embedding-001، با پارامترembeddedByبرای جاسازی خودکار پرس و جو - چگونه
valueFromParamامکان دریافت خودکار بردار را فراهم میکند - LLM توضیحی متنی ارائه میدهد و Toolbox به طور بیصدا بردار را در کنار متن کپی، جاسازی و ذخیره میکند - نحوهی بارگذاری
ToolboxToolsetاز سرور Toolbox در ADK، به حداقل رساندن کد عامل و جداسازی کامل منطق پایگاه داده - نحوه استقرار سرور Toolbox MCP و عامل ADK در Cloud Run به عنوان سرویسهای جداگانه
تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع ایجاد شده در این codelab، میتوانید منابع را به صورت جداگانه یا کل پروژه را حذف کنید.
گزینه ۱: حذف پروژه (توصیه میشود)
سادهترین راه برای پاکسازی، حذف پروژه است. این کار تمام منابع مرتبط با پروژه را حذف میکند.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
گزینه ۲: حذف منابع تکی
اگر میخواهید پروژه را نگه دارید اما فقط منابع ایجاد شده در این codelab را حذف کنید:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null