
1. Introduction
L'utilité des agents d'IA dépend des données auxquelles ils peuvent accéder. La plupart des données réelles se trouvent dans des bases de données. Pour connecter des agents à des bases de données, il faut généralement écrire du code d'agent pour la gestion des connexions, la logique des requêtes et les pipelines d'intégration. Chaque agent qui a besoin d'accéder à une base de données répète ce travail, et chaque modification de requête nécessite de redéployer l'agent.
Cet atelier de programmation présente une approche différente. Vous déclarez vos outils de base de données dans un fichier YAML (requêtes SQL standards, recherche de similarité vectorielle, voire génération automatique d'embeddings), et MCP Toolbox for Databases gère toutes les opérations de base de données en tant que serveur MCP. Votre code d'agent reste minimal : chargez les outils et laissez Gemini décider lequel appeler.
Objectifs de l'atelier
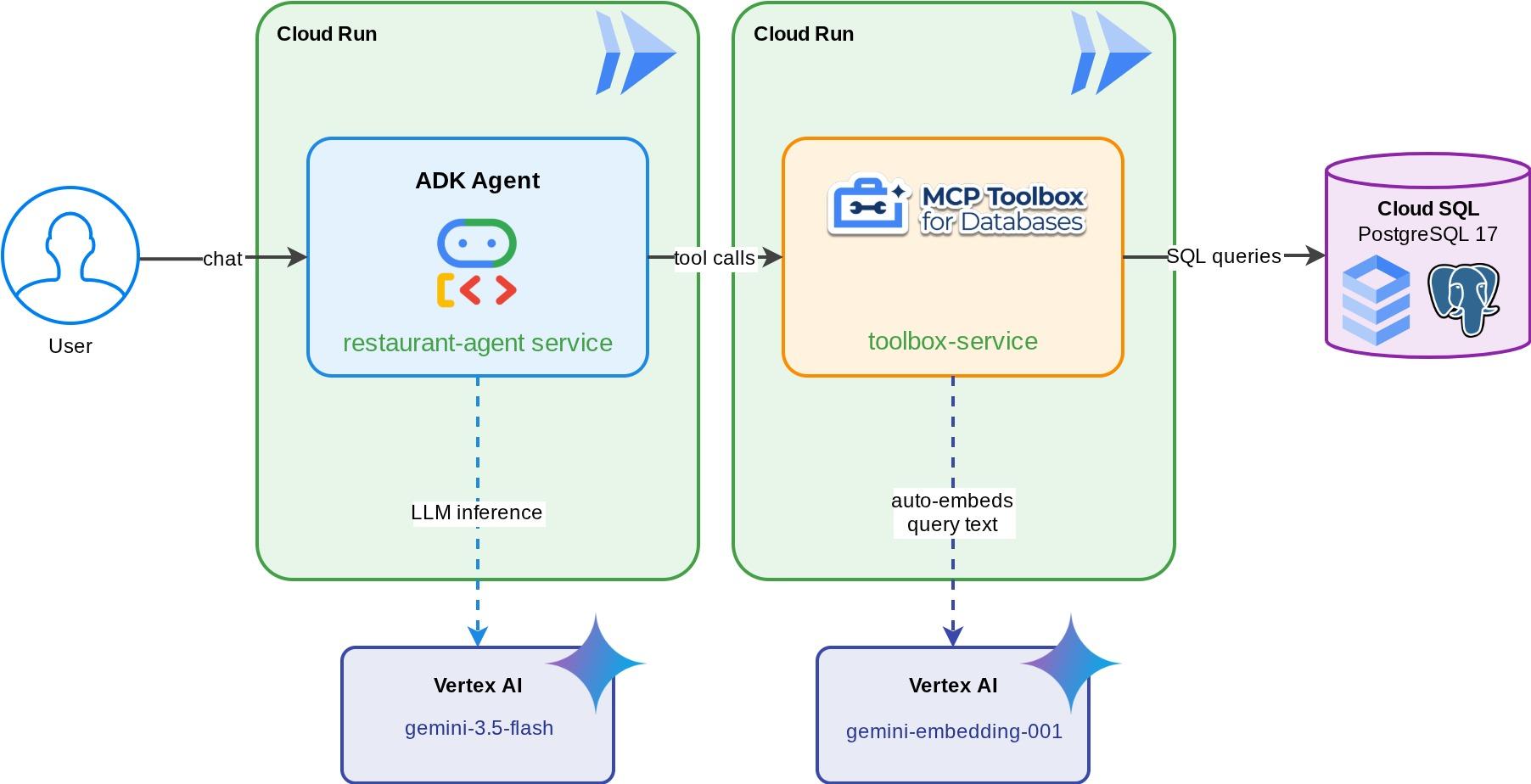
Un concierge de restaurant pour "Foodie Finds" : un agent ADK optimisé par Gemini qui aide les clients à parcourir le menu d'un restaurant à l'aide de filtres standards (catégorie, type de cuisine) et à découvrir des plats grâce à des descriptions en langage naturel comme "Je veux quelque chose de pimenté et de végétarien". L'agent lit et écrit dans une base de données Cloud SQL PostgreSQL entièrement via MCP Toolbox for Databases, qui gère tous les accès à la base de données, y compris la génération automatique d'embeddings pour la recherche vectorielle. À la fin, la boîte à outils et l'agent s'exécutent sur Cloud Run.
Points abordés
- Comment le protocole MCP (Model Context Protocol) standardise l'accès aux outils pour les agents d'IA et comment MCP Toolbox for Databases l'applique aux opérations de base de données
- Configurer MCP Toolbox for Databases en tant que middleware entre un agent ADK et Cloud SQL PostgreSQL
- Définissez les outils de base de données de manière déclarative dans
tools.yaml: aucun code de base de données dans votre agent - Créer un agent ADK qui charge les outils à partir d'un serveur Toolbox en cours d'exécution à l'aide de
ToolboxToolset - Générez des embeddings vectoriels à l'aide de la fonction
embedding()intégrée de Cloud SQL et activez la recherche sémantique avecpgvector. - Utiliser la fonctionnalité
valueFromParampour l'ingestion automatique de vecteurs lors des opérations d'écriture - Déployer le serveur Toolbox et l'agent ADK sur Cloud Run
Prérequis
- Un compte Google Cloud avec un compte de facturation d'essai
- Connaître les bases de Python et de SQL
- Une expérience préalable avec Cloud Database et l'ADK sera utile.
2. Configurer votre environnement
Cette étape prépare votre environnement Cloud Shell, configure votre projet Google Cloud et clone le dépôt de référence.
Ouvrir Cloud Shell
Ouvrez Cloud Shell dans votre navigateur. Cloud Shell fournit un environnement préconfiguré avec tous les outils dont vous avez besoin pour cet atelier de programmation. Cliquez sur Autoriser lorsque vous y êtes invité.
Cliquez ensuite sur Afficher > Terminal pour ouvrir le terminal.Votre interface devrait ressembler à ceci :
Ce sera notre interface principale, avec l'IDE en haut et le terminal en bas.
Configurer votre répertoire de travail
Créez votre répertoire de travail. Tout le code que vous écrivez dans cet atelier de programmation se trouve ici :
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
Ensuite, préparons plusieurs répertoires pour gérer des éléments tels que les scripts de seeding et les journaux.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Configurer un projet Google Cloud
Créez le fichier .env avec les variables de localisation :
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Pour simplifier la configuration du projet dans votre terminal, téléchargez ce script de configuration du projet dans votre répertoire de travail :
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Exécutez le script. Il valide votre compte de facturation d'essai, crée un projet (ou en valide un existant), enregistre l'ID de votre projet dans un fichier .env du répertoire actuel et définit le projet actif dans gcloud.
bash setup_verify_trial_project.sh && source .env
Le script va :
- Vérifier que vous disposez d'un compte de facturation d'essai actif
- Recherchez un projet existant dans
.env(le cas échéant). - Créez un projet ou réutilisez-en un existant.
- Associer le compte de facturation d'essai à votre projet
- Enregistrez l'ID du projet dans
.env. - Définir le projet comme projet
gcloudactif
Vérifiez que le projet est correctement défini en examinant le texte jaune à côté de votre répertoire de travail dans l'invite du terminal Cloud Shell. L'ID de votre projet devrait s'afficher.

Activer l'API requise
Ensuite, nous devons activer plusieurs API pour le produit avec lequel nous allons interagir :
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- API Vertex AI (
aiplatform.googleapis.com) : votre agent utilise les modèles Gemini, et Toolbox utilise l'API d'embedding pour la recherche vectorielle. - API Cloud SQL Admin (
sqladmin.googleapis.com) : vous provisionnez et gérez une instance PostgreSQL. - L'API Compute Engine (
compute.googleapis.com) est requise pour créer des instances Cloud SQL. - Cloud Run, Cloud Build, Artifact Registry : utilisés lors de l'étape de déploiement plus loin dans cet atelier
3. Préparer des scripts pour l'initialisation de la base de données
Cette étape lance la création de l'instance Cloud SQL et exécute un script de configuration automatisé qui attend que l'instance soit prête, puis crée la base de données, l'alimente avec des offres d'emploi et génère des embeddings, le tout en une seule opération.
Commençons par ajouter le mot de passe de la base de données à votre fichier .env et à le recharger :
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Créer un script Bash pour créer une instance et une base de données
Créez ensuite le script scripts/setup_database.sh à l'aide de la commande suivante :
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Ensuite, copiez le code suivant dans le fichier scripts/setup_database.sh.
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Créer un script Python pour l'amorçage des données
Créez ensuite le fichier Python de script de seeding scripts/setup_restaurant_db.py à l'aide de la commande ci-dessous.
cloudshell edit scripts/setup_restaurant_db.py
Copiez ensuite le code suivant dans le fichier scripts/setup_restaurant_db.py.
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Passons maintenant à l'étape suivante.
4. Créer et initialiser la base de données
Nos scripts sont maintenant prêts à être exécutés. Nous aurons besoin de Python pour exécuter notre script préparé. Préparons-le d'abord.
Configurer le projet Python
uv est un gestionnaire de packages et de projets Python rapide écrit en Rust ( documentation uv ). Cet atelier de programmation l'utilise pour la rapidité et la simplicité de la maintenance du projet Python.
Initialisez un projet Python et ajoutez les dépendances requises :
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Notez que nous utilisons ici le SDK Python cloud-sql-python-connector pour initialiser une connexion sécurisée avec notre instance de base de données, qui est authentifiée à l'aide des identifiants par défaut de l'application.
Exécuter le script de configuration
Nous pouvons maintenant exécuter le script d'installation en arrière-plan et inspecter la sortie de la console qui sera écrite dans le fichier logs/atabase_setup.log à l'aide de la commande suivante. Vous pouvez passer à la section suivante en attendant la fin de cette opération.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Télécharger le fichier binaire de la boîte à outils
Dans ce tutoriel, nous allons utiliser MCP Toolbox. Heureusement, il est fourni avec un fichier binaire prédéfini qui est prêt à être utilisé dans l'environnement Linux. Maintenant, téléchargeons-le en arrière-plan, car cela prendra un certain temps. Exécutez la commande suivante pour télécharger le fichier binaire et inspecter le journal de sortie sur le logs/toolbox_dl.log . Vous pouvez passer à la section suivante en attendant la fin de cette opération.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Comprendre le script de configuration scripts/setup_database.sh
Essayons maintenant de comprendre le script de configuration que nous avons configuré précédemment. Il effectue les opérations suivantes :
- La toute première commande que nous exécutons est la commande
gcloud sql instances createavec l'option suivante :
db-custom-1-3840est le plus petit niveau Cloud SQL à cœur dédié (1 vCPU, 3,75 Go de RAM) de l'éditionENTERPRISE.Pour en savoir plus, cliquez ici. Un cœur dédié est requis pour l'intégration de Vertex AI ML. Les niveaux à cœur partagé (db-f1-micro,db-g1-small) ne sont pas compatibles.--root-passworddéfinit le mot de passe de l'utilisateurpostgrespar défaut.--enable-google-ml-integrationactive l'intégration intégrée de Cloud SQL à Vertex AI, ce qui vous permet d'appeler des modèles d'embedding directement depuis SQL à l'aide de la fonctionembedding().
- Vérifiez si l'instance est déjà à l'état
RUNNABLE. - Accordez au compte de service de l'instance Cloud SQL l'autorisation d'appeler Vertex AI à l'aide de la commande
gcloud projects add-iam-policy-binding. Cette opération est requise pour la fonctionembedding()intégrée que nous utiliserons pour initialiser la base de données. - Créer la base de données
- Exécuter le script d'amorçage
setup_restaurant_db.py
Comprendre le script d'amorçage scripts/setup_restaurant_db.py
Passons maintenant au script de seeding. Il effectue les opérations suivantes :
- Initialiser la connexion à l'instance de base de données
- Installe deux extensions PostgreSQL :
google_ml_integration: fournit la fonction SQLembedding(), qui appelle les modèles d'embedding Vertex AI directement à partir de SQL. Il s'agit d'une extension au niveau de la base de données qui rend les fonctions de ML disponibles dansrestaurant_db. Le flag au niveau de l'instance (--enable-google-ml-integration) que vous définissez lors de la création de l'instance permet à la VM Cloud SQL d'accéder à Vertex AI. L'extension rend les fonctions SQL disponibles dans cette base de données spécifique.vector(pgvector) : ajoute le type de donnéesvectoret les opérateurs de distance pour stocker et interroger les embeddings.
- Créez la table et notez que la colonne
description_embeddingestvector(3072), c'est-à-dire une colonnepgvectorqui stocke des vecteurs de dimension 3072. - Déplacer les données des éléments de menu initiaux
- Générez les données d'embedding à partir du champ
descriptionet remplissezdescription_embeddingà l'aide de l'intégration Vertex intégrée via la fonctionembedding().
embedding('gemini-embedding-001', description): appelle le modèle d'embedding Gemini de Vertex AI directement depuis SQL, en transmettant le textedescriptionde chaque offre d'emploi. Il s'agit de l'extensiongoogle_ml_integrationque vous avez installée dans le script de seed.::vector: convertit le tableau float renvoyé au typevectorde pgvector afin qu'il puisse être stocké et interrogé avec des opérateurs de distance.UPDATEs'exécute sur les 15 lignes, générant un embedding de dimension 3072 par description de poste.
Cela préparera les données initiales auxquelles notre agent accédera.
5. Configurer MCP Toolbox for Databases
Cette étape présente MCP Toolbox for Databases, le configure pour qu'il se connecte à votre instance Cloud SQL et définit deux outils de requête SQL standards.
Qu'est-ce que MCP et pourquoi utiliser Toolbox ?
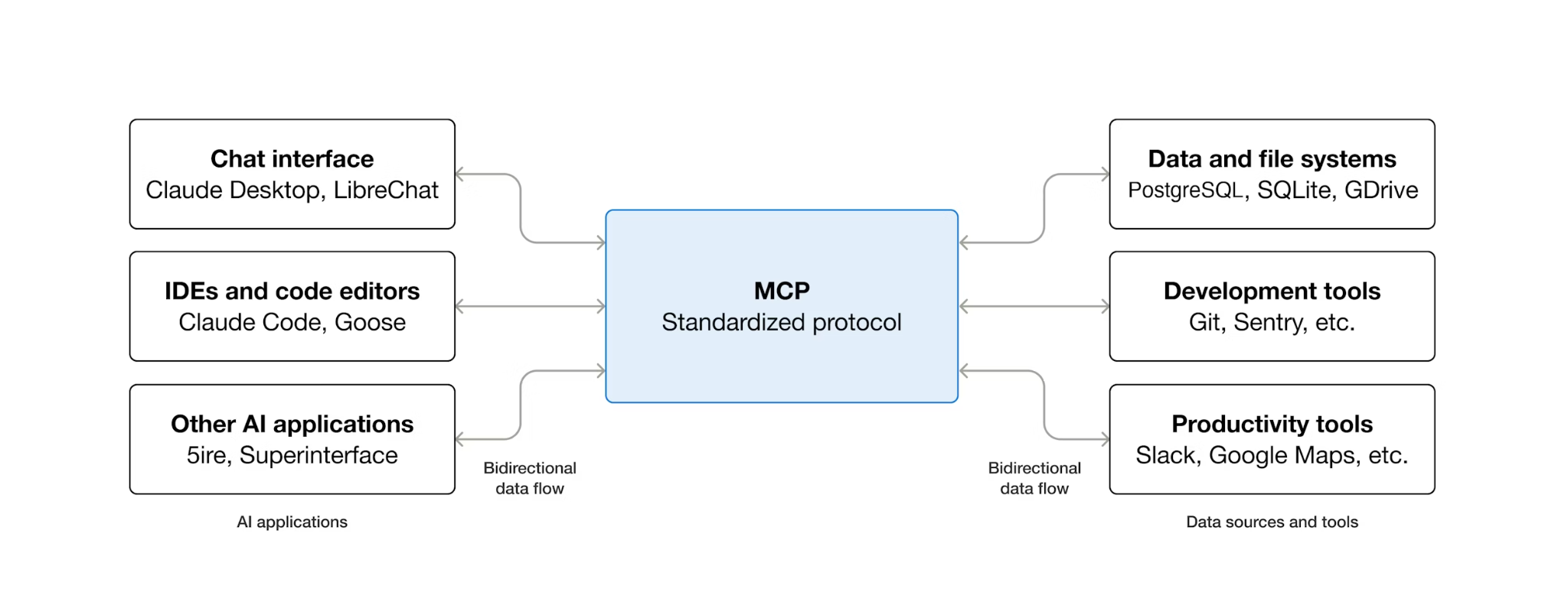
MCP (Model Context Protocol) est un protocole ouvert qui standardise la façon dont les agents d'IA découvrent les outils externes et interagissent avec eux. Il définit un modèle client-serveur : l'agent héberge un client MCP et les outils sont exposés par les serveurs MCP. N'importe quel client compatible avec MCP peut utiliser n'importe quel serveur compatible avec MCP. L'agent n'a pas besoin de code d'intégration personnalisé pour chaque outil.
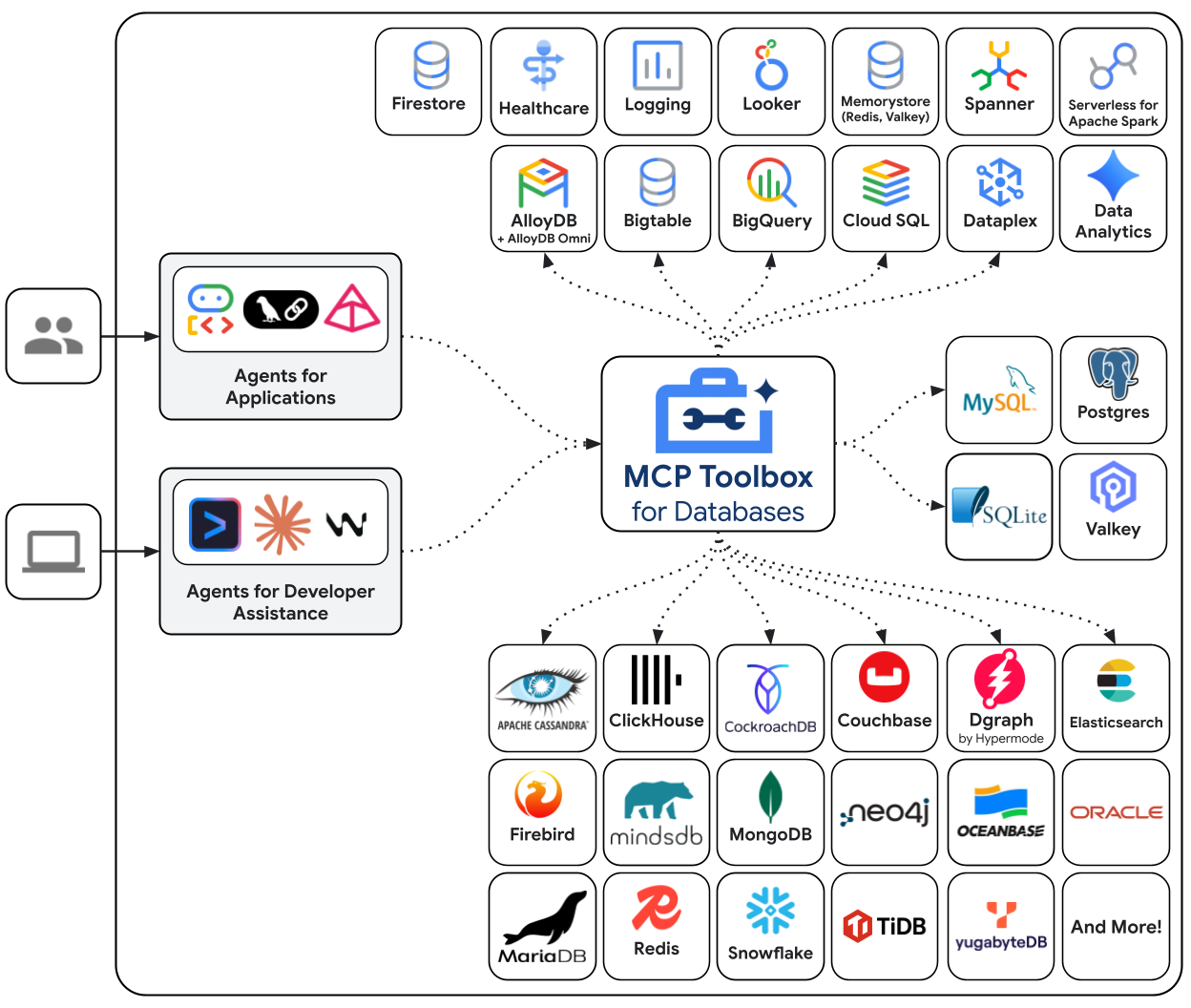
MCP Toolbox for Databases est un serveur MCP Open Source conçu spécifiquement pour l'accès aux bases de données. Sans cela, vous devriez écrire des fonctions Python qui ouvrent des connexions à la base de données, gèrent les pools de connexions, construisent des requêtes paramétrées pour éviter les injections SQL, gèrent les erreurs et intègrent tout ce code dans votre agent. Chaque agent ayant besoin d'accéder à la base de données répète cette opération. Pour modifier une requête, vous devez redéployer l'agent.
Avec Toolbox, vous écrivez un fichier YAML. Chaque outil correspond à une instruction SQL paramétrée. La boîte à outils gère le regroupement des connexions, les requêtes paramétrées, l'authentification et l'observabilité. Les outils sont dissociés de l'agent. Vous pouvez mettre à jour une requête en modifiant tools.yaml et en redémarrant la boîte à outils, sans toucher au code de l'agent. Les mêmes outils fonctionnent avec ADK, LangGraph, LlamaIndex ou tout framework compatible avec MCP.
Écrire la configuration des outils
Nous devons maintenant créer un fichier nommé tools.yaml dans l'éditeur Cloud Shell pour configurer nos outils.
cloudshell edit tools.yaml
Le fichier utilise le format YAML multidocument : chaque bloc séparé par --- est une ressource autonome. Chaque ressource comporte un kind qui déclare ce qu'elle est (sources pour les connexions à la base de données, tools pour les actions appelables par l'agent) et un type qui spécifie le backend (cloud-sql-postgres pour la source, postgres-sql pour les outils basés sur SQL). Un outil fait référence à sa source par name, ce qui permet à Toolbox de savoir quel pool de connexions exécuter. Les variables d'environnement utilisent la syntaxe ${VAR_NAME} et sont résolues au démarrage.
Copions d'abord les scripts suivants dans le fichier tools.yaml.
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
Ce script définit la ressource suivante :
- Source (
restaurant-db) : indique à Toolbox comment se connecter à votre instance Cloud SQL pour PostgreSQL. Le typecloud-sql-postgresutilise le connecteur Cloud SQL en interne, en gérant automatiquement l'authentification et les connexions sécurisées. Les espaces réservés${GOOGLE_CLOUD_PROJECT},${REGION}et${DB_PASSWORD}sont résolus à partir des variables d'environnement au démarrage.
Ensuite, ajoutez le script suivant sous le symbole --- dans tools.yaml.
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
Ce script définit la ressource suivante :
- Outils 1 et 2 (
search-menu,get-item-details) : outils de requête SQL standard. Chacun mappe un nom d'outil (ce que l'agent voit) à une instruction SQL paramétrée (ce que la base de données exécute). Les paramètres utilisent des espaces réservés positionnels$1et$2. Toolbox les exécute en tant qu'instructions préparées, ce qui empêche l'injection SQL.
Continuons. Ajoutez le script suivant sous le symbole --- dans le fichier tools.yaml.
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
Ce script définit la ressource suivante :
- Modèle d'embedding (
gemini-embedding) : configure la boîte à outils pour appeler le modèlegemini-embedding-001de Gemini afin de générer des embeddings de texte à 3 072 dimensions. La boîte à outils utilise les identifiants par défaut de l'application (ADC) pour l'authentification. Aucune clé API n'est requise dans Cloud Shell ni dans Cloud Run. Note that thisdimensionconfigured here must be the same with previously we config to seed the database
Continuons. Ajoutez le script suivant sous le symbole --- dans le fichier tools.yaml.
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
Ce script définit la ressource suivante :
- Outil 3 (
search-menu-by-description) : outil de recherche vectorielle. Le paramètresearch_querya la valeurembeddedBy: gemini-embedding, ce qui indique à Toolbox d'intercepter le texte brut, de l'envoyer au modèle d'embedding et d'utiliser le vecteur résultant dans l'instruction SQL. L'opérateur<=>est la distance cosinus de pgvector. Plus les valeurs sont petites, plus les descriptions sont similaires.
Enfin, ajoutez le dernier outil sous le symbole --- dans tools.yaml.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
Ce script définit la ressource suivante :
- Outil 4 (
add-menu-item) : montre l'ingestion de vecteurs. Le paramètredescription_vectorcomporte deux champs spéciaux : valueFromParam: description: la boîte à outils copie la valeur du paramètredescriptiondans celui-ci. Le LLM ne voit jamais ce paramètre.embeddedBy: gemini-embedding: la boîte à outils intègre le texte copié dans un vecteur avant de le transmettre au code SQL.
Résultat : un appel d'outil stocke à la fois le texte de description brut et son embedding vectoriel, sans que l'agent n'ait aucune connaissance des embeddings.
Le format YAML multidocument sépare chaque ressource par ---. Chaque document comporte des champs kind, name et type qui définissent ce qu'il est. En résumé, nous avons déjà configuré tous les éléments suivants :
- Définir la base de données source
- Définir des outils ( outil 1 et outil 2) pour interroger la base de données avec un filtre standard
- Définir le modèle d'embedding
- Définir l'outil de recherche vectorielle ( outil 3) pour la base de données
- Définissez l'outil d'ingestion de données vectorielles ( outil 4) dans la base de données.
6. Exécuter le serveur MCP Toolbox
À l'étape précédente, nous avons déjà défini la configuration nécessaire pour notre MCP Toolbox. Nous sommes maintenant prêts à exécuter le serveur.
Vérifier les données d'amorçage
Avant de démarrer Toolbox, vérifions que la configuration de la base de données est terminée. Créez un script Python scripts/verify_database.py à l'aide de la commande suivante :
cloudshell edit scripts/verify_seed.py
Copiez ensuite le code suivant dans le fichier scripts/verify_seed.py.
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Ce script vérifie le nombre de données sur les articles de menu et leur intégration. Exécutez le script à l'aide de la commande suivante :
uv run scripts/verify_seed.py
Si le résultat suivant s'affiche dans le terminal, cela signifie que les données sont prêtes.
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Démarrer le serveur de la boîte à outils
Lors de l'étape de configuration précédente, nous avons déjà téléchargé l'exécutable toolbox. Assurez-vous que ce fichier binaire existe et qu'il a été téléchargé correctement. Si ce n'est pas le cas, téléchargez-le et attendez la fin du téléchargement.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
Nous devrons exposer nos variables .env au processus enfant exécuté par la boîte à outils MCP. Exécutez la commande suivante pour démarrer le serveur de la boîte à outils et consigner la sortie de la console dans le fichier logs/mcp_toolbox.log.
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
Dans le fichier logs/mcp_toolbox.log, vous devriez voir un résultat confirmant que le serveur est prêt, comme indiqué ci-dessous :
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Vérifier les outils
Interrogez l'API Toolbox pour lister tous les outils enregistrés :
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Vous devriez voir les outils avec leurs descriptions et leurs paramètres. Comme indiqué ci-dessous
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
Testez directement l'outil search-menu :
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
La réponse doit contenir les plats principaux italiens de vos données de départ.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. Créer l'agent ADK
Nous allons maintenant utiliser ADK en Python pour ce projet. Ajoutons les dépendances requises :
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk: Agent Development Kit de Google, y compris le SDK Geminitoolbox-adk: intégration ADK pour MCP Toolbox for Databases.
Créer la structure de répertoires de l'agent
L'ADK s'attend à une structure de dossier spécifique : un répertoire nommé d'après votre agent contenant __init__.py, agent.py et .env. Pour vous aider, il dispose d'une commande intégrée permettant d'établir rapidement la structure :
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
Votre répertoire devrait maintenant se présenter comme suit :
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
Nous devons ensuite intégrer l'agent ADK au serveur Toolbox en cours d'exécution et tester les quatre outils : requêtes standards, recherche sémantique et ingestion de vecteurs. Le code de l'agent est minimal : toute la logique de la base de données se trouve dans tools.yaml.
Configurer l'environnement de l'agent
L'ADK lit GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT et GOOGLE_CLOUD_LOCATION à partir de l'environnement de shell, que vous avez déjà défini à l'étape précédente. La seule variable spécifique à l'agent est TOOLBOX_URL. Ajoutez-la au fichier .env de l'agent :
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Mettre à jour le module d'agent
Ouvrez restaurant_agent/agent.py dans l'éditeur Cloud Shell.
cloudshell edit restaurant_agent/agent.py
et remplacez le contenu par le code suivant :
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Notez qu'il n'y a pas de code de base de données ici : ToolboxToolset se connecte au serveur de la boîte à outils au démarrage et charge tous les outils disponibles. L'agent appelle les outils par leur nom. Toolbox traduit ces appels en requêtes SQL sur Cloud SQL.
La variable d'environnement TOOLBOX_URL est définie par défaut sur http://127.0.0.1:5000 pour le développement local. Lorsque vous déploierez sur Cloud Run ultérieurement, vous remplacerez cette valeur par l'URL Cloud Run du service Toolbox. Aucune modification de code n'est nécessaire.
Tester l'agent
Démarrez l'UI de développement ADK :
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Ouvrez l'URL affichée dans le terminal (généralement http://localhost:8000) à l'aide de la fonctionnalité Aperçu sur le Web de Cloud Shell ou en cliquant sur l'URL tout en appuyant sur la touche Ctrl. Sélectionnez restaurant_agent dans le menu déroulant des agents en haut à gauche.
Tester les requêtes standards
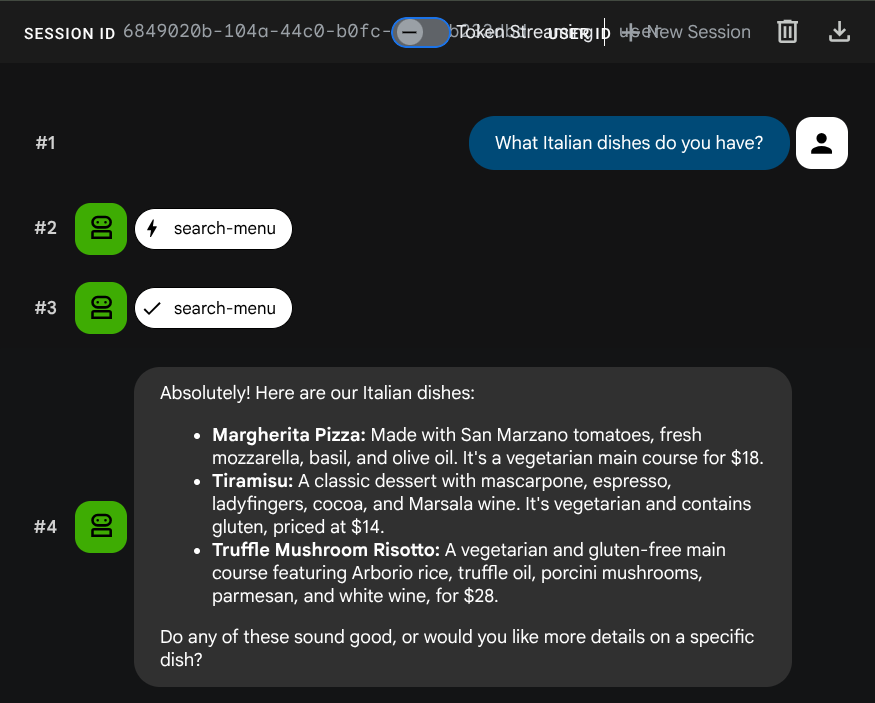
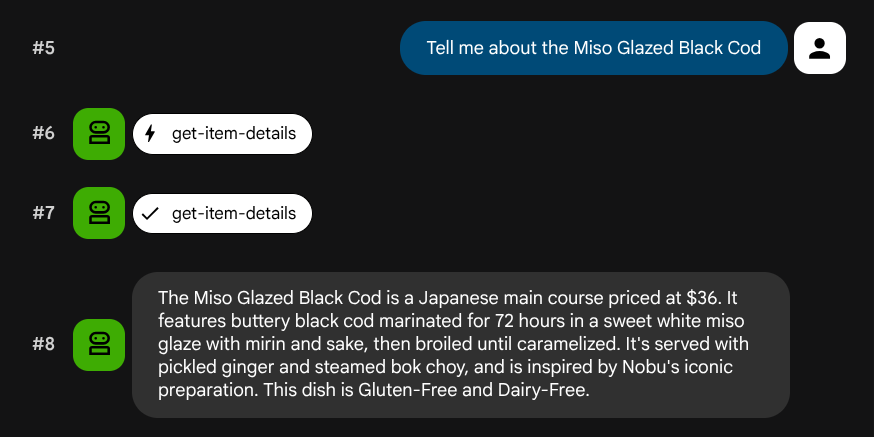
Essayez ces requêtes pour vérifier les outils SQL standard :
What Italian dishes do you have?
Tell me about the Miso Glazed Black Cod
Tester la recherche sémantique
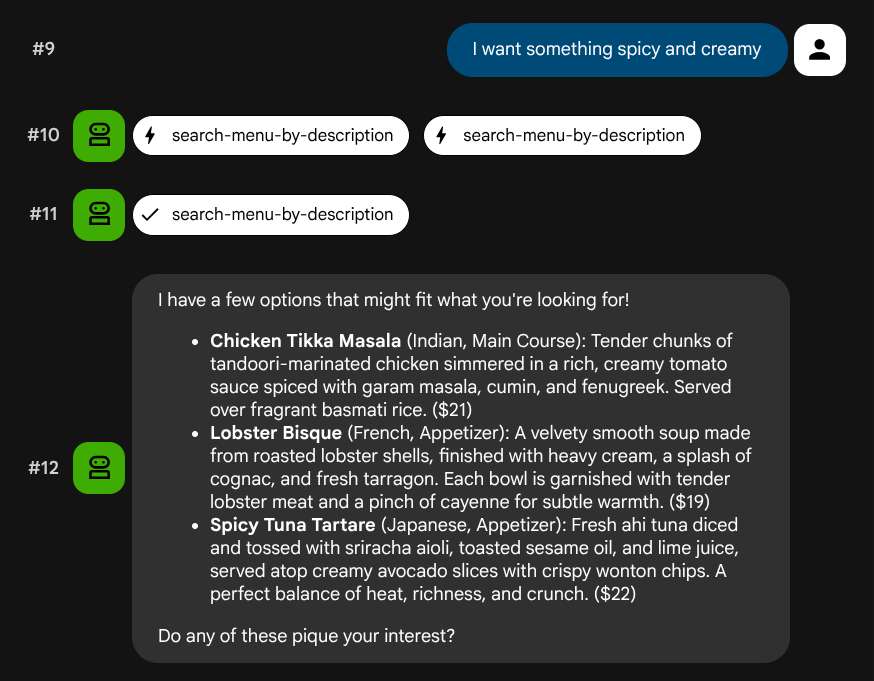
Essayez des descriptions en langage naturel qui ne correspondent pas à un rôle ou à une pile technologique spécifiques :
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
L'agent essaiera de choisir le bon outil en fonction du type de requête : les filtres structurés passent par search-menu, tandis que les descriptions en langage naturel passent par search-menu-by-description.
Tester l'ingestion de vecteurs
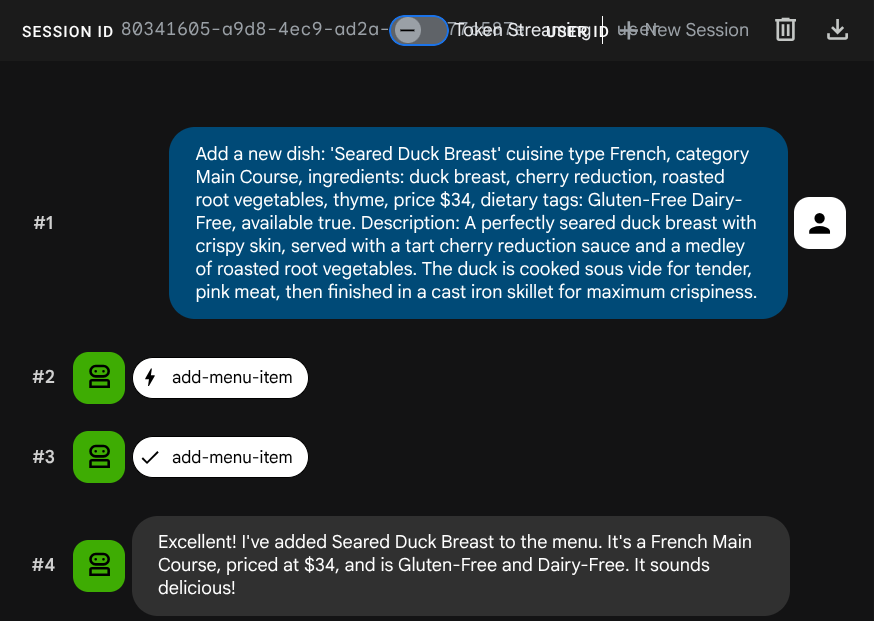
Demandez à l'agent d'ajouter un job :
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
Essayez maintenant de le rechercher :
Find me something with rich, gamey flavors and fruit sauce
L'embedding a été généré automatiquement lors de l'insertion. Aucune étape distincte n'est nécessaire.
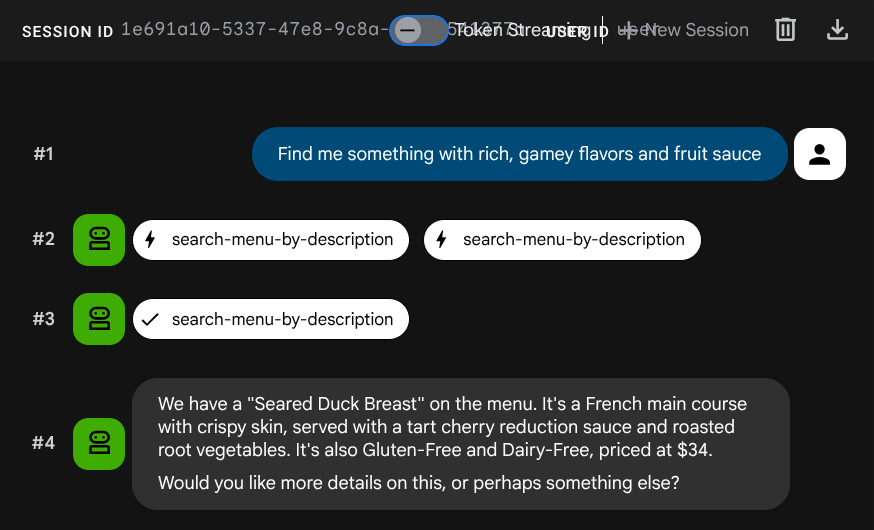
Vous disposez désormais d'une application RAG agentique entièrement fonctionnelle utilisant ADK, MCP Toolbox et Cloud SQL. Félicitations ! Allons plus loin et déployons ces applications sur Cloud Run.
Maintenant, arrêtons l'UI de développement en arrêtant le processus en appuyant deux fois sur Ctrl+C avant de continuer.
8. Déployer dans Cloud Run
L'agent et la boîte à outils fonctionnent en local. Cette étape déploie les deux en tant que services Cloud Run afin qu'ils soient accessibles sur Internet. Le service Toolbox s'exécute en tant que serveur MCP sur Cloud Run, auquel se connecte le service d'agent.
Préparer la boîte à outils pour le déploiement
Créez un répertoire de déploiement pour le service Toolbox :
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Créez le fichier Dockerfile pour la boîte à outils. Ouvrez deploy-toolbox/Dockerfile dans l'éditeur Cloud Shell :
cloudshell edit deploy-toolbox/Dockerfile
Copiez-y le script suivant :
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
Le binaire Toolbox et tools.yaml sont inclus dans une image Debian minimale. Cloud Run achemine le trafic vers le port 8080.
Déployer le service de boîte à outils
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
Cette commande envoie la source à Cloud Build, crée une image de conteneur, la transmet à Artifact Registry et la déploie sur Cloud Run. Cela prendra quelques minutes. Nous pouvons inspecter le journal du processus de déploiement dans le fichier logs/deploy_toolbox.log.
Préparer l'agent pour le déploiement
Pendant la compilation de la boîte à outils, configurez les fichiers de déploiement de l'agent.
Créez un fichier Dockerfile à la racine du projet. Ouvrez Dockerfile dans l'éditeur Cloud Shell :
cloudshell edit Dockerfile
Copiez ensuite le contenu suivant :
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
Ce fichier Dockerfile utilise ghcr.io/astral-sh/uv comme image de base, qui inclut Python et uv préinstallés. Il n'est donc pas nécessaire d'installer uv séparément via pip.
Créez un fichier .dockerignore pour exclure les fichiers inutiles de l'image de conteneur :
cloudshell edit .dockerignore
Copiez ensuite le script suivant dans le fichier.
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Déployer le service d'agent
Attendez que le déploiement de Toolbox soit terminé. Vérifiez à nouveau le processus de déploiement sur logs/deploy_toolbox.log pour le valider. Récupérez ensuite son URL Cloud Run à l'aide de la commande suivante :
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Vous obtiendrez un résultat semblable à celui-ci :
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Vérifions ensuite que la boîte à outils déployée fonctionne :
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Si le résultat est semblable à cet exemple, le déploiement a déjà réussi.
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
Ensuite, déployons l'agent en transmettant l'URL de la boîte à outils en tant que variable d'environnement :
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
Le code de l'agent lit TOOLBOX_URL à partir de l'environnement (que vous avez configuré précédemment). Localement, il pointe vers http://127.0.0.1:5000. Sur Cloud Run, il pointe vers l'URL du service Toolbox. Aucune modification de code n'est nécessaire.
Tester l'agent déployé
Récupérez l'URL Cloud Run de l'agent :
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
Ouvrez l'URL dans votre navigateur. L'UI de développement ADK se charge. Il s'agit de la même interface que celle que vous avez utilisée en local, mais elle s'exécute désormais sur Cloud Run.
Sélectionnez restaurant_agent dans le menu déroulant et testez :
What Italian dishes do you have?
I want something spicy and creamy
Les deux requêtes fonctionnent via les services déployés : l'agent sur Cloud Run appelle la boîte à outils sur Cloud Run, qui interroge Cloud SQL.
9. Félicitations / Nettoyage
Vous avez créé et déployé un assistant de menu de restaurant intelligent qui utilise MCP Toolbox for Databases pour faire le lien entre un agent ADK et Cloud SQL PostgreSQL, à la fois avec des requêtes SQL standards et une recherche vectorielle sémantique.
Connaissances acquises
- Comment MCP standardise l'accès aux outils pour les agents d'IA et comment MCP Toolbox for Databases applique cela spécifiquement aux opérations de base de données, en remplaçant le code de base de données personnalisé par une configuration YAML déclarative
- Configurer Cloud SQL PostgreSQL comme source de données Boîte à outils à l'aide du type de source
cloud-sql-postgres - Définir des outils de requête SQL standard avec des instructions paramétrées qui empêchent l'injection SQL
- Activer la recherche vectorielle à l'aide de pgvector et de
gemini-embedding-001, avec le paramètreembeddedBypour l'embedding automatique des requêtes - Comment
valueFromParampermet l'ingestion automatique de vecteurs : le LLM fournit une description textuelle, et la boîte à outils copie, intègre et stocke silencieusement le vecteur à côté du texte. - Comment
ToolboxToolsetd'ADK charge-t-il les outils à partir d'un serveur Toolbox en cours d'exécution, en gardant le code de l'agent minimal et la logique de la base de données entièrement découplée ? - Déployer le serveur MCP Toolbox et l'agent ADK sur Cloud Run en tant que services distincts
Nettoyage
Pour éviter que les ressources créées dans cet atelier de programmation ne soient facturées sur votre compte Google Cloud, vous pouvez supprimer les ressources individuelles ou l'intégralité du projet.
Option 1 : Supprimer le projet (recommandé)
Le moyen le plus simple de libérer de l'espace consiste à supprimer le projet. Toutes les ressources associées au projet sont supprimées.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Option 2 : Supprimer des ressources individuelles
Si vous souhaitez conserver le projet, mais supprimer uniquement les ressources créées dans cet atelier de programmation :
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null