
1. מבוא
התועלת של סוכני AI תלויה בנתונים שהם יכולים לגשת אליהם. רוב הנתונים בעולם האמיתי נמצאים במסדי נתונים – ובדרך כלל, כדי לקשר סוכנים למסדי נתונים צריך לכתוב ניהול חיבורים, לוגיקה של שאילתות וצינורות הטמעה בתוך קוד הסוכן. כל נציג שזקוק לגישה למסד הנתונים צריך לחזור על הפעולה הזו, וכל שינוי בשאילתה מחייב פריסה מחדש של הנציג.
ב-Codelab הזה נציג גישה שונה. אתם מגדירים את כלי מסד הנתונים בקובץ YAML – שאילתות SQL סטנדרטיות, חיפוש דמיון וקטורי ואפילו יצירה אוטומטית של הטמעה – ו-MCP Toolbox for Databases מטפל בכל פעולות מסד הנתונים כשרת MCP. קוד הסוכן נשאר מינימלי: טוענים את הכלים ומאפשרים ל-Gemini להחליט לאיזה כלי להתקשר.
מה תפַתחו
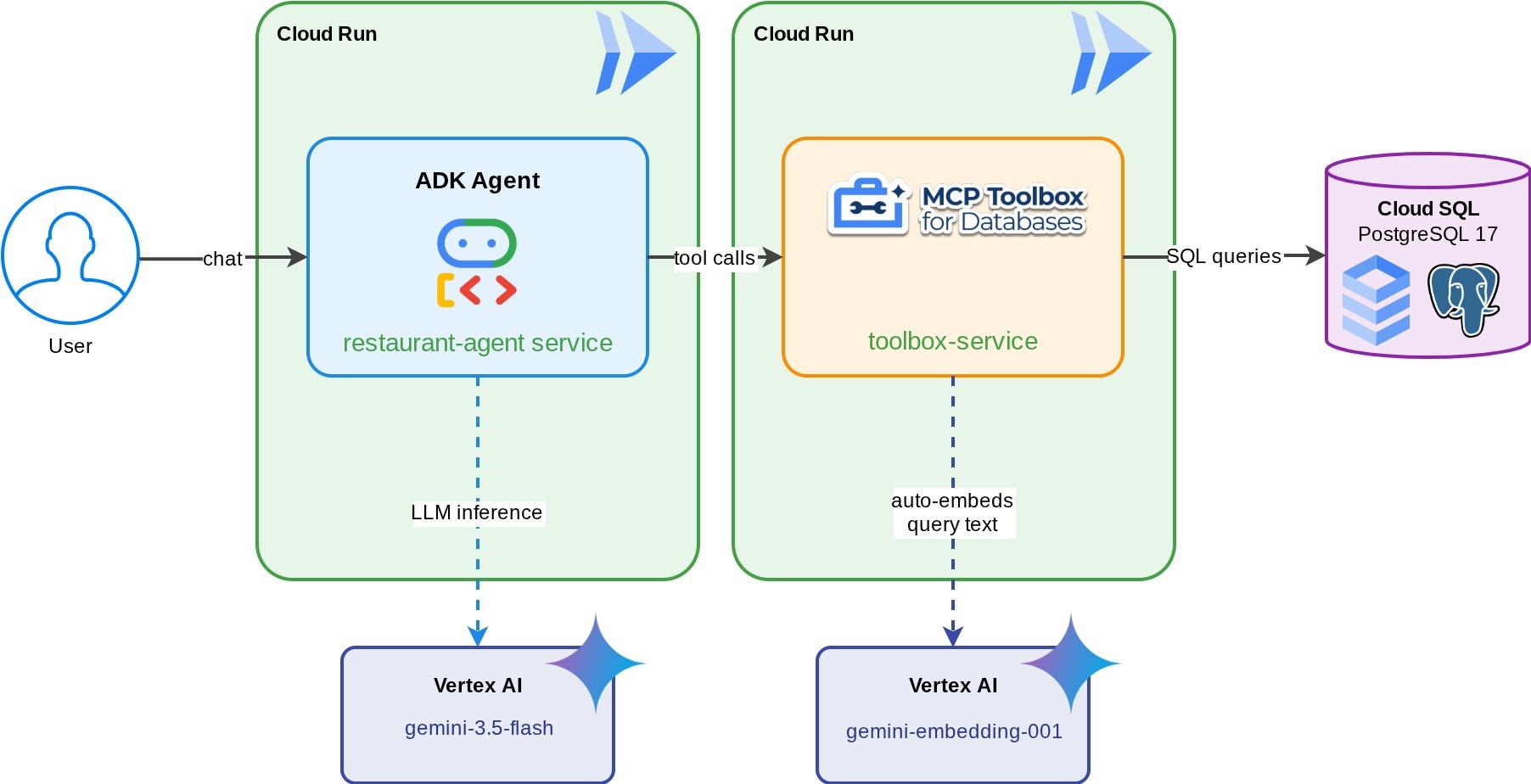
מלצר וירטואלי למסעדה בשם "Foodie Finds" – סוכן ADK שמבוסס על Gemini ועוזר לסועדים לעיין בתפריט של המסעדה באמצעות מסננים רגילים (קטגוריה, סוג מטבח) ולגלות מנות באמצעות תיאורים בשפה טבעית כמו "אני רוצה משהו חריף וצמחוני". הסוכן קורא מתוך מסד נתונים של Cloud SQL PostgreSQL וכותב לתוכו אך ורק דרך MCP Toolbox for Databases, שמטפל בכל הגישה למסד הנתונים – כולל יצירה אוטומטית של הטמעה לחיפוש וקטורי. בסוף התהליך, גם ה-Toolbox וגם הסוכן יפעלו ב-Cloud Run.
מה תלמדו
- איך תקן MCP (Model Context Protocol) מאפשר גישה סטנדרטית לכלים לסוכני AI, ואיך MCP Toolbox for Databases מיישם את זה בפעולות שקשורות למסדי נתונים
- הגדרת MCP Toolbox for Databases כתוכנת ביניים בין סוכן ADK לבין Cloud SQL PostgreSQL
- הגדרת כלי מסד נתונים באופן הצהרתי ב-
tools.yaml– אין קוד מסד נתונים בסוכן - יצירת סוכן ADK שמעמיס כלים משרת Toolbox פעיל באמצעות
ToolboxToolset - יצירת הטמעות וקטורים באמצעות הפונקציה המובנית
embedding()של Cloud SQL והפעלת חיפוש סמנטי באמצעותpgvector - שימוש בתכונה
valueFromParamלהוספה אוטומטית של וקטורים בפעולות כתיבה - פריסה של השרת Toolbox וסוכן ה-ADK ב-Cloud Run
דרישות מוקדמות
- חשבון Google Cloud עם חשבון לחיוב בתקופת ניסיון
- היכרות בסיסית עם Python ו-SQL
- ניסיון קודם עם Cloud Database ו-ADK יעזור לכם
2. הגדרת הסביבה
בשלב הזה מכינים את סביבת Cloud Shell, מגדירים את הפרויקט ב-Google Cloud ומשכפלים את מאגר ההפניות.
פתיחת Cloud Shell
פותחים את Cloud Shell בדפדפן. Cloud Shell מספקת סביבה שהוגדרה מראש עם כל הכלים שדרושים ל-Codelab הזה. כשמופיעה בקשה, לוחצים על Authorize.
אחר כך לוחצים על View (תצוגה) -> Terminal (טרמינל) כדי לפתוח את הטרמינל.הממשק אמור להיראות בערך כך:
זה יהיה הממשק הראשי שלנו, סביבת הפיתוח המשולבת (IDE) בחלק העליון והטרמינל בחלק התחתון
הגדרת ספריית העבודה
יוצרים את ספריית העבודה. כל הקוד שכותבים ב-Codelab הזה נמצא כאן:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
אחרי זה, נכין כמה ספריות לניהול דברים כמו סקריפטים של הפעלה ויומנים
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
הגדרת הפרויקט ב-Google Cloud
יוצרים את קובץ .env עם משתני המיקום:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
כדי לפשט את הגדרת הפרויקט במסוף, מורידים את סקריפט הגדרת הפרויקט הזה לספריית העבודה:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
מריצים את הסקריפט. הוא מאמת את החשבון לחיוב של תקופת הניסיון, יוצר פרויקט חדש (או מאמת פרויקט קיים), שומר את מזהה הפרויקט בקובץ .env בספרייה הנוכחית ומגדיר את הפרויקט הפעיל ב-gcloud.
bash setup_verify_trial_project.sh && source .env
הסקריפט:
- אימות שיש לכם חשבון לחיוב עם תקופת ניסיון פעילה
- בודקים אם יש פרויקט קיים ב-
.env(אם יש) - יוצרים פרויקט חדש או משתמשים בפרויקט קיים
- קישור החשבון לחיוב בתקופת הניסיון לפרויקט
- שומרים את מזהה הפרויקט ב-
.env - הגדרת הפרויקט כפרויקט פעיל ב-
gcloud
כדי לוודא שהפרויקט מוגדר בצורה נכונה, בודקים את הטקסט הצהוב שליד ספריית העבודה בהנחיית הטרמינל של Cloud Shell. מזהה הפרויקט צריך להופיע בו.

הפעלת API נדרש
לאחר מכן, צריך להפעיל כמה ממשקי API למוצר שאיתו תהיה אינטראקציה:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- Vertex AI API (
aiplatform.googleapis.com) – הסוכן משתמש במודלים של Gemini, וכלי העזר משתמש ב-Embedding API לחיפוש וקטורי. - Cloud SQL Admin API (
sqladmin.googleapis.com) – אתם מקצים ומנהלים מופע PostgreSQL. - Compute Engine API (
compute.googleapis.com) – נדרש ליצירת מופעים של Cloud SQL. - Cloud Run, Cloud Build, Artifact Registry – השירותים האלה ישמשו בשלב הפריסה בהמשך שיעור ה-Codelab הזה
3. הכנת סקריפטים לאתחול מסד נתונים
בשלב הזה מתחילה יצירה של מופע Cloud SQL ומופעל סקריפט הגדרה אוטומטי שממתין עד שהמופע יהיה מוכן, ואז יוצר את מסד הנתונים, מאכלס אותו בפרטי משרות ויוצר הטבעות – והכול בפעולה אחת.
קודם צריך להוסיף את הסיסמה של מסד הנתונים לקובץ .env ולטעון אותו מחדש:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
יצירת סקריפט Bash ליצירת מכונה ומסד נתונים
לאחר מכן, יוצרים את הסקריפט scripts/setup_database.sh באמצעות הפקודה הבאה
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
לאחר מכן, מעתיקים את הקוד הבא לקובץ scripts/setup_database.sh
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
יצירת סקריפט Python לנתוני התחלה
לאחר מכן, יוצרים את קובץ ה-Python של סקריפט ההרצה scripts/setup_restaurant_db.py באמצעות הפקודה הבאה
cloudshell edit scripts/setup_restaurant_db.py
לאחר מכן, מעתיקים את הקוד הבא לקובץ scripts/setup_restaurant_db.py
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
עכשיו אפשר לעבור לשלב הבא
4. יצירה ואתחול של מסד הנתונים
עכשיו הסקריפטים שלנו מוכנים להרצה. נצטרך Python כדי להריץ את הסקריפט שהכנו, אז נכין אותו קודם.
הגדרת פרויקט Python
uv הוא מנהל פרויקטים וחבילות Python מהיר שנכתב ב-Rust ( מסמכי uv ). אנחנו משתמשים בו בשיעור Codelab הזה כדי לשמור על מהירות ופשטות בתחזוקת פרויקט Python
מאתחלים פרויקט Python ומוסיפים את התלות הנדרשת:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
שימו לב: אנחנו משתמשים כאן ב-cloud-sql-python-connector Python SDK כדי להפעיל חיבור מאובטח למופע מסד הנתונים שלנו, שמאומת באמצעות Application Default Credentials.
הפעלת סקריפט ההגדרה
עכשיו אפשר להריץ את סקריפט ההגדרה ברקע ולבדוק את הפלט של המסוף שייכתב לקובץ logs/atabase_setup.log באמצעות הפקודה הבאה. אפשר להמשיך לקטע הבא בזמן ההמתנה לסיום התהליך.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
הורדת קובץ הבינארי של Toolbox
במדריך הזה נשתמש ב-MCP Toolbox. למרבה המזל, הוא מגיע עם קובץ בינארי מוכן מראש שאפשר להשתמש בו בסביבת Linux. עכשיו נוריד אותו ברקע כי זה לוקח די הרבה זמן. מריצים את הפקודה הבאה כדי להוריד את הקובץ הבינארי ולבדוק את יומן הפלט ב-logs/toolbox_dl.log . אפשר להמשיך לקטע הבא בזמן ההמתנה לסיום התהליך.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
הסבר על סקריפט ההגדרה scripts/setup_database.sh
עכשיו ננסה להבין את סקריפט ההגדרה שהגדרנו קודם. התהליך הבא מתבצע
- הפקודה הראשונה שמריצים היא
gcloud sql instances createעם הדגל הבא
-
db-custom-1-3840היא הרמה הקטנה ביותר של Cloud SQL עם ליבה ייעודית (1 vCPU, 3.75 GB RAM) במהדורתENTERPRISE. פרטים נוספים זמינים כאן. נדרשת ליבה ייעודית לשילוב של Vertex AI ML – שכבות של ליבת מעבד משותפת (db-f1-micro,db-g1-small) לא תומכות בה. -
--root-passwordמגדיר את הסיסמה למשתמש ברירת המחדלpostgres. -
--enable-google-ml-integrationמאפשרת את השילוב המובנה של Cloud SQL עם Vertex AI, שמאפשר לכם להפעיל מודלים של הטמעות ישירות מ-SQL באמצעות הפונקציהembedding().
- בודקים אם המופע כבר בסטטוס
RUNNABLE - נותנים לחשבון השירות של מכונת Cloud SQL הרשאה לקרוא ל-Vertex AI באמצעות הפקודה
gcloud projects add-iam-policy-binding. הפעולה הזו נדרשת עבור הפונקציה המובניתembedding()שבה נשתמש כשנזרע את מסד הנתונים - יצירת מסד הנתונים
- הרצת סקריפט ההרצה הראשונית
setup_restaurant_db.py
הסבר על סקריפט הזרע scripts/setup_restaurant_db.py
עכשיו נעבור לסקריפט ההגדרה הראשונית. הסקריפט הזה מבצע את הפעולות הבאות:
- הפעלת החיבור למופע של מסד הנתונים
- הכלי מתקין שני תוספים ל-PostgreSQL:
-
google_ml_integration— מספק את פונקציית ה-SQLembedding(), שקוראת למודלים של הטמעה ב-Vertex AI ישירות מ-SQL. זהו תוסף ברמת מסד הנתונים שמאפשר להשתמש בפונקציות של למידת מכונה בתוךrestaurant_db. הדגל ברמת המופע (--enable-google-ml-integration) שאתם מגדירים במהלך יצירת המופע מאפשר למכונה הווירטואלית של Cloud SQL להגיע אל Vertex AI – התוסף מאפשר להשתמש בפונקציות ה-SQL במסד הנתונים הספציפי הזה. -
vector(pgvector) – מוסיף את סוג הנתוניםvectorואת אופרטורי המרחק לאחסון ולשאילתת הטמעה.
- יוצרים את הטבלה, ומציינים שהעמודה
description_embeddingהיאvector(3072)– עמודה מסוגpgvectorשמאחסנת וקטורים תלת-ממדיים של 3,072. - הזנת נתונים ראשוניים של פריטים בתפריט
- יצירת נתוני ההטמעה מהשדה
descriptionומילוי השדהdescription_embeddingבאמצעות השילוב המובנה של Vertex דרך הפונקציהembedding()
-
embedding('gemini-embedding-001', description)— קורא למודל ההטמעה של Gemini ב-Vertex AI ישירות מ-SQL, ומעביר אתdescriptionהטקסט של כל משרה. זהו התוסףgoogle_ml_integrationשהתקנתם בסקריפט ה-seed. -
::vector— מבצע המרה של מערך המספרים הממשיים שמוחזר לסוגvectorשל pgvector, כדי שאפשר יהיה לאחסן אותו ולשאול עליו שאילתות באמצעות אופרטורים של מרחק. - המודל
UPDATEפועל על כל 15 השורות, ויוצר הטמעה אחת בת 3,072 ממדים לכל תיאור משרה.
הפעולה הזו תכין נתונים ראשוניים שהסוכן שלנו יוכל לגשת אליהם
5. הגדרת MCP Toolbox for Databases
בשלב הזה נציג את MCP Toolbox for Databases, נגדיר אותו לחיבור למופע Cloud SQL ונגדיר שני כלים לשאילתות SQL סטנדרטי.
מה זה MCP ולמה כדאי להשתמש ב-Toolbox?
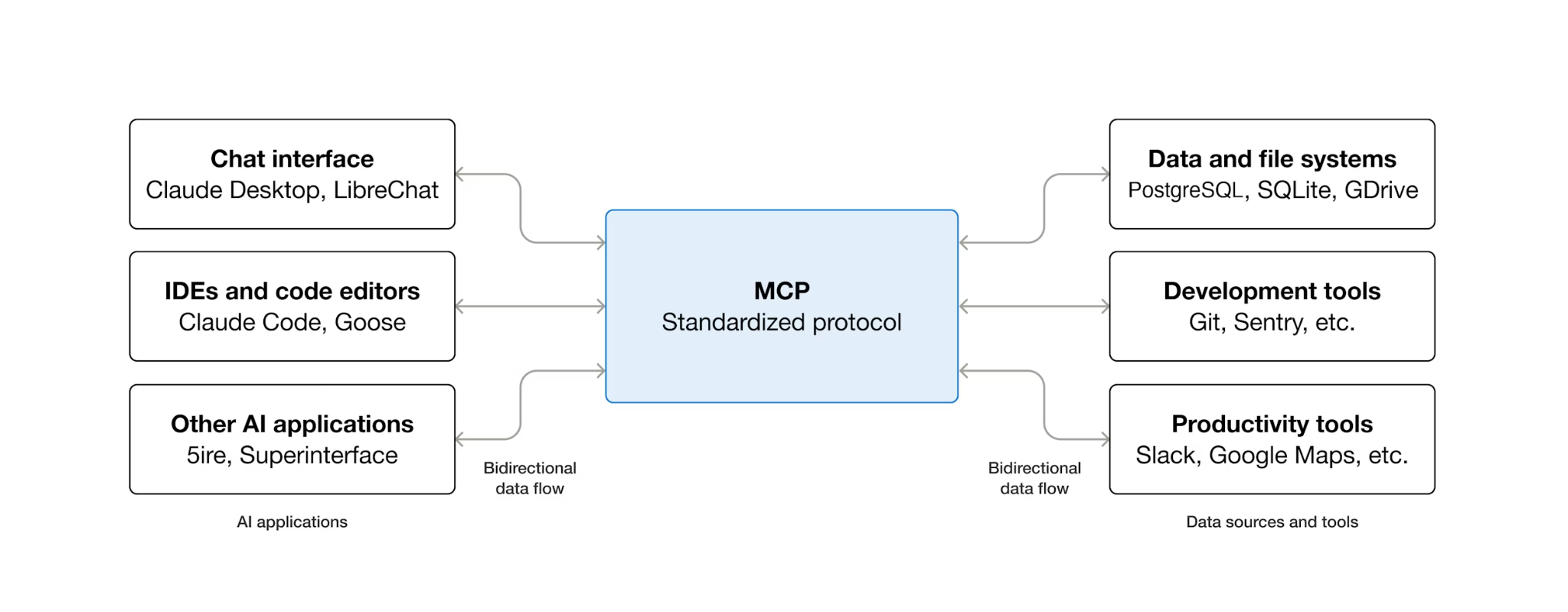
MCP (Model Context Protocol) הוא פרוטוקול פתוח שקובע תקן לאופן שבו סוכני AI מגלים כלים חיצוניים ומקיימים איתם אינטראקציות. הוא מגדיר מודל לקוח-שרת: הסוכן מארח לקוח MCP, והכלים נחשפים על ידי שרתי MCP. כל לקוח שתואם ל-MCP יכול להשתמש בכל שרת שתואם ל-MCP – לא צריך קוד שילוב מותאם אישית לסוכן עבור כל כלי.
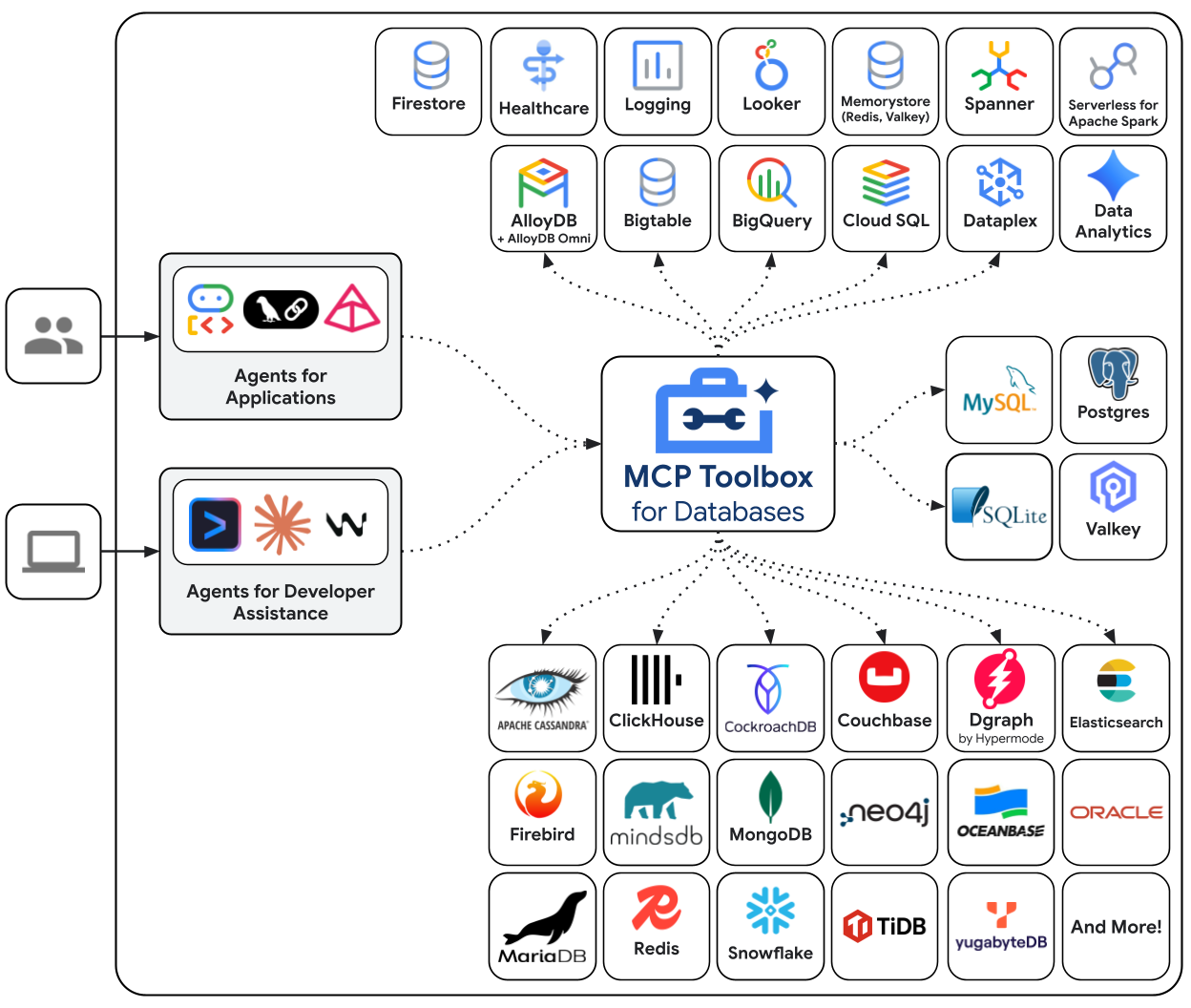
MCP Toolbox for Databases הוא שרת MCP בקוד פתוח שנבנה במיוחד לגישה למסדי נתונים. בלי זה, תצטרכו לכתוב פונקציות Python שפותחות חיבורים למסד נתונים, מנהלות מאגרי חיבורים, בונות שאילתות עם פרמטרים כדי למנוע הזרקת SQL, מטפלות בשגיאות ומשבצות את כל הקוד הזה בתוך הסוכן. כל נציג שזקוק לגישה למסד הנתונים חוזר על הפעולה הזו. שינוי שאילתה מחייב פריסה מחדש של הסוכן.
כדי להשתמש ב-Toolbox, צריך לכתוב קובץ YAML. כל כלי ממופה להצהרת SQL עם פרמטרים. Toolbox מטפל בניהול חיבורים, בשאילתות עם פרמטרים, באימות ובניטור. הכלים מופרדים מהסוכן – כדי לעדכן שאילתה, צריך לערוך את tools.yaml ולהפעיל מחדש את Toolbox, בלי לגעת בקוד של הסוכן. אותם כלים פועלים ב-ADK, ב-LangGraph, ב-LlamaIndex או בכל מסגרת תואמת ל-MCP.
כתיבת ההגדרה של כלי
עכשיו צריך ליצור קובץ בשם tools.yaml ב-Cloud Shell Editor כדי להגדיר את כלי ההגדרה
cloudshell edit tools.yaml
הקובץ משתמש ב-YAML עם כמה מסמכים – כל בלוק שמופרד על ידי --- הוא משאב עצמאי. לכל משאב יש מאפיין kind שמצהיר מהו (sources לחיבורי מסד נתונים, tools לפעולות שאפשר להפעיל באמצעות סוכן) ומאפיין type שמציין את ה-Backend (cloud-sql-postgres למקור, postgres-sql לכלים מבוססי SQL). כלי מפנה למקור שלו באמצעות name, וכך ארגז הכלים יודע מול איזה מאגר חיבורים לבצע את הפעולה. משתני הסביבה משתמשים בתחביר ${VAR_NAME} ונפתרים בעת ההפעלה.
עכשיו מעתיקים את הסקריפטים הבאים לקובץ tools.yaml
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
הסקריפט הזה מגדיר את המשאב הבא:
- מקור (
restaurant-db) – מציין לארגז הכלים איך להתחבר למופע Cloud SQL PostgreSQL. הסוגcloud-sql-postgresמשתמש במחבר Cloud SQL באופן פנימי, ומטפל באימות ובחיבורים מאובטחים באופן אוטומטי. ה-placeholders${GOOGLE_CLOUD_PROJECT}, ${REGION}ו-${DB_PASSWORD}נפתרים ממשתני סביבה בזמן ההפעלה.
בשלב הבא, מוסיפים את הסקריפט הבא מתחת לסמל --- בקובץ tools.yaml
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
הסקריפט הזה מגדיר את המשאב הבא:
- כלי 1 ו-2 (
search-menu,get-item-details) – כלי שאילתות SQL סטנדרטיים. כל אחד ממפה שם של כלי (מה שהסוכן רואה) להצהרת SQL עם פרמטרים (מה שמסד הנתונים מבצע). הפרמטרים משתמשים ב-$1,$2placeholders מיקומיים. ארגז הכלים מבצע את הפעולות האלה כהצהרות מוכנות, מה שמונע הזרקת SQL.
ממשיכים ומוסיפים את הסקריפט הבא מתחת לסמל --- בקובץ tools.yaml
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
הסקריפט הזה מגדיר את המשאב הבא:
- מודל להטמעה (
gemini-embedding) – מגדיר את Toolbox לקריאה למודלgemini-embedding-001של Gemini כדי ליצור הטמעות טקסט ב-3,072 ממדים. Toolbox משתמש ב-Application Default Credentials (ADC) כדי לבצע אימות – אין צורך במפתח API ב-Cloud Shell או ב-Cloud Run. הערה: המודלdimensionשהוגדר כאן חייב להיות זהה למודל שהוגדר קודם כדי לאכלס את מסד הנתונים.
ממשיכים ומוסיפים את הסקריפט הבא מתחת לסמל --- בקובץ tools.yaml
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
הסקריפט הזה מגדיר את המשאב הבא:
- כלי 3 (
search-menu-by-description) – כלי לחיפוש וקטורים. לפרמטרsearch_queryיש את הערךembeddedBy: gemini-embedding, שמורה ל-Toolbox ליירט את הטקסט הגולמי, לשלוח אותו למודל ההטמעה ולהשתמש בווקטור שמתקבל בהצהרת ה-SQL. האופרטור<=>הוא המרחק הקוסינוסי של pgvector – ערכים קטנים יותר מציינים תיאורים דומים יותר.
לבסוף, מוסיפים את הכלי האחרון מתחת לסמל --- בקובץ tools.yaml
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
הסקריפט הזה מגדיר את המשאב הבא:
- כלי 4 (
add-menu-item) – הדגמה של הטמעה של וקטורים. לפרמטרdescription_vectorיש שני שדות מיוחדים: -
valueFromParam: description— הכלי מעתיק את הערך מהפרמטרdescriptionאל הפרמטר הזה. ה-LLM אף פעם לא רואה את הפרמטר הזה. -
embeddedBy: gemini-embedding— Toolbox מטמיע את הטקסט שהועתק בווקטור לפני שהוא מעביר אותו ל-SQL.
התוצאה: קריאה אחת לכלי מאחסנת גם את הטקסט הגולמי של התיאור וגם את הטמעת הווקטור שלו, בלי שהסוכן יודע משהו על הטמעות.
פורמט ה-YAML של כמה מסמכים מפריד בין כל משאב באמצעות ---. לכל מסמך יש שדות kind, name ו-type שמגדירים מה הוא. לסיכום, כבר הגדרנו את כל הדברים הבאים:
- הגדרת מסד הנתונים של המקור
- הגדרת כלים ( tool 1 ו-2 ) לשליחת שאילתות למסד נתונים עם מסנן רגיל
- הגדרת מודל להטמעה
- הגדרת כלי לביצוע חיפוש וקטורי ( כלי 3 ) במסד הנתונים
- הגדרת כלי להטמעת נתוני וקטור ( כלי 4 ) במסד נתונים
6. הפעלת שרת MCP Toolbox
בשלב הקודם כבר הגדרנו את התצורה הנדרשת ל-MCP Toolbox. עכשיו אנחנו מוכנים להריץ את השרת
אימות הנתונים הראשוניים
לפני שמתחילים להשתמש ב-Toolbox, צריך לוודא שהגדרת מסד הנתונים הושלמה. יוצרים סקריפט Python scripts/verify_database.py באמצעות הפקודה הבאה
cloudshell edit scripts/verify_seed.py
לאחר מכן, מעתיקים את הקוד הבא לקובץ scripts/verify_seed.py
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
הסקריפט הזה יבדוק את מספר נתוני פריטי התפריט וההטמעה שלהם. מריצים את הסקריפט באמצעות הפקודה הבאה
uv run scripts/verify_seed.py
אם מופיע פלט הטרמינל הבא, המשמעות היא שהנתונים מוכנים
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
הפעלת השרת של ארגז הכלים
בשלב ההגדרה הקודם, כבר הורדנו את קובץ ההפעלה toolbox. מוודאים שהקובץ הבינארי הזה קיים והורד בהצלחה. אם לא, מורידים אותו וממתינים עד לסיום ההורדה.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
נצטרך לחשוף את המשתנים .env לתהליך הצאצא שמופעל על ידי ערכת הכלים של MCP. מריצים את הפקודה הבאה כדי להפעיל את שרת ערכת הכלים ולרשום את הפלט של המסוף בקובץ logs/mcp_toolbox.log
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
אמור להופיע פלט בקובץ logs/mcp_toolbox.log שמאשר שהשרת מוכן, כמו שמוצג בהמשך:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
אימות הכלים
מריצים שאילתה ב-Toolbox API כדי לראות רשימה של כל הכלים הרשומים:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
יוצגו כלים עם התיאורים והפרמטרים שלהם. כמו שמוצג בהמשך
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
בודקים את הכלי search-menu ישירות:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
התשובה צריכה לכלול את המנות העיקריות האיטלקיות מנתוני הבסיס שלך.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. יצירת סוכן ADK
עכשיו נשתמש ב-ADK ב-Python לפרויקט הזה. נוסיף את התלויות הנדרשות:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
-
google-adk— ערכת הכלים לפיתוח סוכנים של Google, כולל Gemini SDK -
toolbox-adk— שילוב ADK ב-MCP Toolbox for Databases.
יצירת מבנה ספריות של סוכנים
ערכת ה-ADK מצפה לפריסת תיקיות ספציפית: ספרייה שנקראת על שם הסוכן שלכם ומכילה את הקבצים __init__.py, agent.py ו-.env. כדי לעזור לכם, יש פקודה מובנית ליצירת המבנה במהירות:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
עכשיו הספריה אמורה להיראות כך:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
לאחר מכן, נצטרך לשלב את סוכן ה-ADK עם שרת Toolbox הפועל ולבדוק את כל ארבעת הכלים – שאילתות רגילות, חיפוש סמנטי והטמעה של וקטורים. קוד הסוכן מינימלי: כל הלוגיקה של מסד הנתונים נמצאת ב-tools.yaml.
הגדרת הסביבה של הסוכן
ADK קורא את GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT ו-GOOGLE_CLOUD_LOCATION מסביבת מעטפת, שכבר הגדרתם בשלב הקודם. המשתנה היחיד שספציפי לסוכן הוא TOOLBOX_URL – צריך לצרף אותו לקובץ .env של הסוכן:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
עדכון מודול הסוכן
פתיחה של restaurant_agent/agent.py ב-Cloud Shell Editor
cloudshell edit restaurant_agent/agent.py
ומחליפים את התוכן בקוד הבא:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
שימו לב שאין כאן קוד של מסד נתונים – ToolboxToolset מתחבר לשרת של Toolbox בהפעלה וטוען את כל הכלים הזמינים. הסוכן קורא לכלים לפי שם, ו-Toolbox מתרגם את הקריאות האלה לשאילתות SQL מול Cloud SQL.
משתנה הסביבה TOOLBOX_URL מוגדר כברירת מחדל ל-http://127.0.0.1:5000 לפיתוח מקומי. כשפורסים ל-Cloud Run בהמשך, מחליפים את כתובת ה-URL הזו בכתובת ה-URL של שירות Toolbox ב-Cloud Run – אין צורך לשנות את הקוד.
בדיקת הסוכן
מפעילים את ממשק המשתמש של ADK למפתחים:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
פותחים את כתובת ה-URL שמוצגת במסוף (בדרך כלל http://localhost:8000) באמצעות התכונה Web Preview של Cloud Shell או באמצעות ctrl + click על כתובת ה-URL שמוצגת במסוף. בוחרים באפשרות restaurant_agent בתפריט הנפתח של הסוכן בפינה הימנית העליונה.
בדיקת שאילתות רגילות
כדי לאמת את הכלים של SQL סטנדרטי, אפשר לנסות את ההנחיות הבאות:
What Italian dishes do you have?
Tell me about the Miso Glazed Black Cod
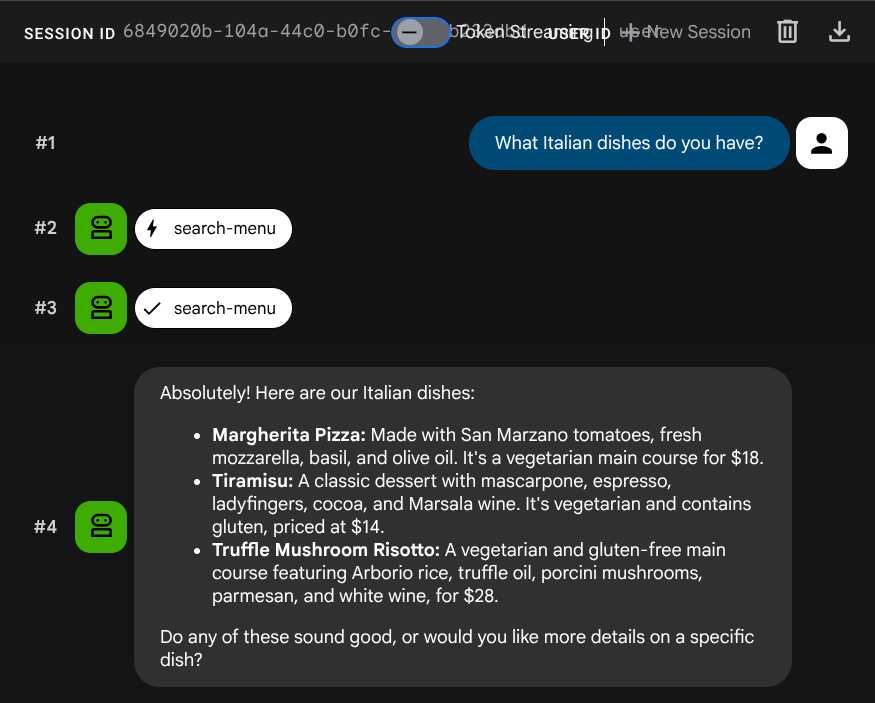
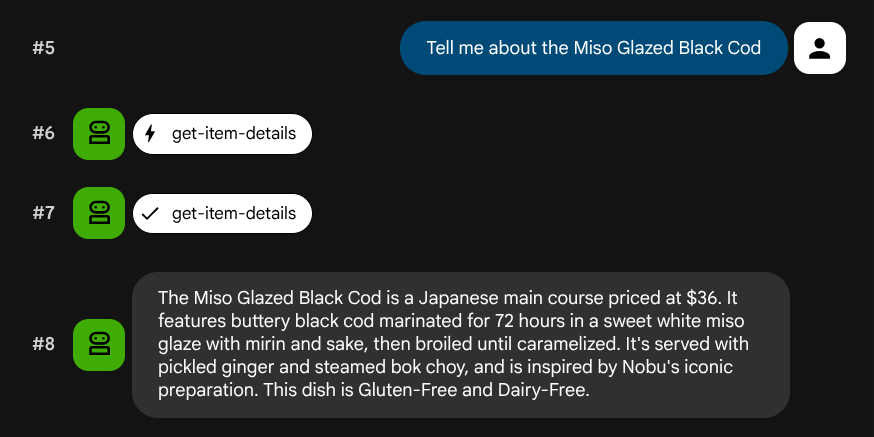
בדיקת חיפוש סמנטי
נסו להשתמש בתיאורים בשפה טבעית שלא מתאימים לתפקיד ספציפי או לסט טכנולוגיות ספציפי:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
הנציג ינסה לבחור את הכלי הנכון על סמך סוג השאילתה: מסננים מובנים עוברים דרך search-menu, ותיאורים בשפה טבעית עוברים דרך search-menu-by-description.
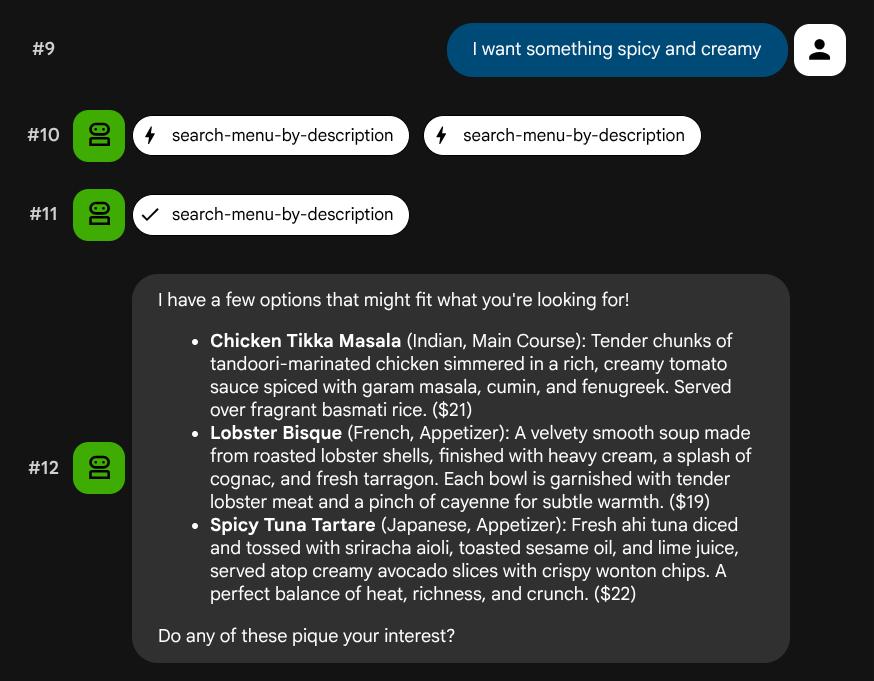
בדיקה של הטמעת וקטורים
מבקשים מהנציג להוסיף משרה חדשה:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
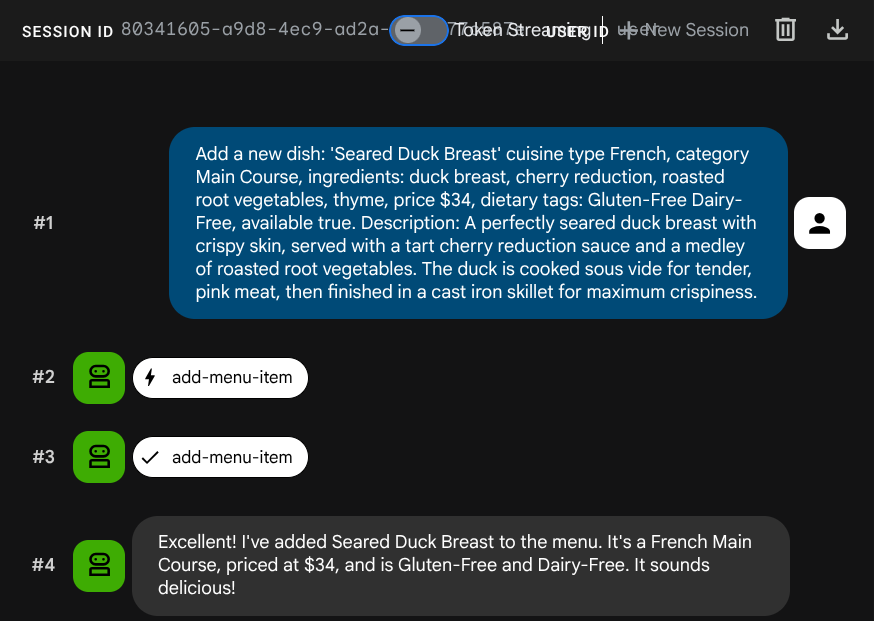
עכשיו נסו לחפש אותו:
Find me something with rich, gamey flavors and fruit sauce
ההטמעה נוצרה אוטומטית במהלך הפעולה INSERT – לא נדרש שלב נפרד.
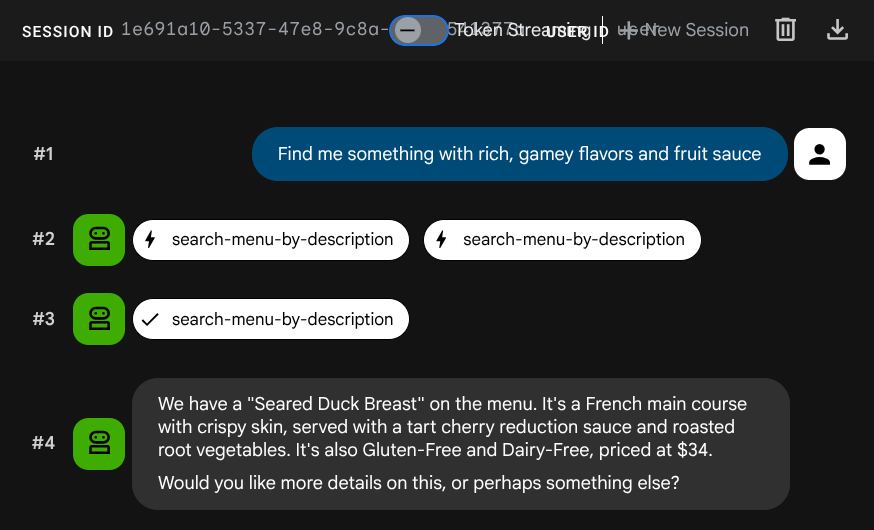
עכשיו יש לכם אפליקציית Agentic RAG שעובדת באופן מלא ומבוססת על ADK, MCP Toolbox ו-CloudSQL. מזל טוב! בשלב הבא נסביר איך פורסים את האפליקציות האלה ב-Cloud Run.
עכשיו, כדי להמשיך, צריך לעצור את ממשק המשתמש למפתחים. לשם כך, מקישים על Ctrl+C פעמיים כדי להפסיק את התהליך.
8. פריסה ב-Cloud Run
הסוכן וה-Toolbox פועלים באופן מקומי. בשלב הזה פורסים את שניהם כשירותי Cloud Run כדי שאפשר יהיה לגשת אליהם דרך האינטרנט. שירות ה-Toolbox פועל כשרת MCP ב-Cloud Run, ושירות הסוכן מתחבר אליו.
הכנת ערכת הכלים לפריסה
יוצרים ספריית פריסה לשירות Toolbox:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
יוצרים את קובץ ה-Dockerfile עבור ערכת הכלים. פותחים את deploy-toolbox/Dockerfile ב-Cloud Shell Editor:
cloudshell edit deploy-toolbox/Dockerfile
מעתיקים אליו את הסקריפט הבא
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
קובץ ההפעלה של Toolbox ו-tools.yaml נארזים בתמונת Debian מינימלית. Cloud Run מעביר את התנועה ליציאה 8080.
פריסת שירות ארגז הכלים
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
הפקודה הזו שולחת את המקור ל-Cloud Build, יוצרת קובץ אימג' של קונטיינר, מעבירה אותו בדחיפה ל-Artifact Registry ופורסת אותו ב-Cloud Run. התהליך יימשך כמה דקות. אפשר לבדוק את יומן הפריסה בקובץ logs/deploy_toolbox.log.
הכנת הסוכן לפריסה
בזמן שהכלי לבניית אפליקציות יוצר את הקבצים, מגדירים את קובצי הפריסה של הסוכן.
יוצרים Dockerfile בספריית הבסיס של הפרויקט. פותחים את Dockerfile ב-Cloud Shell Editor:
cloudshell edit Dockerfile
לאחר מכן, מעתיקים את התוכן הבא
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
קובץ Dockerfile הזה משתמש ב-ghcr.io/astral-sh/uv כקובץ האימג' הבסיסי, שכולל את Python ואת uv שהותקנו מראש – אין צורך להתקין את uv בנפרד דרך pip.
יוצרים קובץ .dockerignore כדי להחריג קבצים מיותרים מקובץ אימג' של קונטיינר:
cloudshell edit .dockerignore
לאחר מכן מעתיקים לתוכו את הסקריפט הבא
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
פריסת שירות הסוכן
ממתינים עד שהפריסה של Toolbox תסתיים. כדי לאמת את התהליך, בודקים שוב את תהליך הפריסה ב-logs/deploy_toolbox.log. לאחר מכן, מאחזרים את כתובת ה-URL של Cloud Run באמצעות הפקודה הבאה
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
הפלט שיוצג יהיה דומה לזה:
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
עכשיו נבדוק שה-Toolbox שהטמענו פועל:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
אם הפלט נראה כמו בדוגמה הזו, הפריסה כבר הצליחה
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
בשלב הבא, פורסים את הסוכן ומעבירים את כתובת ה-URL של ארגז הכלים כמשתנה סביבה:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
קוד הסוכן קורא את TOOLBOX_URL מהסביבה (הגדרתם את זה קודם). באופן מקומי, הוא מצביע על http://127.0.0.1:5000. ב-Cloud Run הוא מצביע על כתובת ה-URL של שירות Toolbox. אין צורך לשנות את הקוד.
בדיקת הסוכן הפעיל
מאחזרים את כתובת ה-URL של הסוכן ב-Cloud Run:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
פותחים את כתובת ה-URL בדפדפן. ממשק המשתמש של ADK Dev נטען – אותו ממשק שבו השתמשתם באופן מקומי, ועכשיו הוא פועל ב-Cloud Run.
בוחרים באפשרות restaurant_agent מהתפריט הנפתח ומבצעים בדיקה:
What Italian dishes do you have?
I want something spicy and creamy
שתי השאילתות פועלות דרך השירותים שנפרסו: הסוכן ב-Cloud Run קורא ל-Toolbox ב-Cloud Run, ששולח שאילתה ל-Cloud SQL.
9. Congratulations / Clean Up
יצרתם ופרסתם עוזר חכם לתפריט מסעדה שמשתמש ב-MCP Toolbox for Databases כדי לגשר בין סוכן ADK לבין Cloud SQL PostgreSQL – עם שאילתות SQL סטנדרטיות וחיפוש סמנטי של וקטורים.
מה למדתם
- איך MCP מתקנן את הגישה של סוכני AI לכלים, ואיך MCP Toolbox for Databases מיישם את זה באופן ספציפי על פעולות במסד נתונים – החלפת קוד מותאם אישית של מסד נתונים בהגדרת YAML הצהרתית
- איך מגדירים את Cloud SQL PostgreSQL כמקור נתונים ב-Toolbox באמצעות
cloud-sql-postgresסוג המקור - איך מגדירים כלי שאילתות SQL סטנדרטי עם הצהרות פרמטריות שמונעות הזרקת SQL
- איך מפעילים חיפוש וקטורים באמצעות pgvector ו-
gemini-embedding-001, עם הפרמטרembeddedByלהטמעה אוטומטית של שאילתות - איך
valueFromParamמאפשרת הטמעה אוטומטית של וקטורים – מודל ה-LLM מספק תיאור טקסט, והכלי מעתיק, מטמיע ומאחסן את הווקטור לצד הטקסט באופן שקט - איך
ToolboxToolsetב-ADK טוען כלים משרת Toolbox פעיל, כדי לשמור על קוד הסוכן מינימלי ולנתק לחלוטין את הלוגיקה של מסד הנתונים - איך פורסים את השרת MCP Toolbox ואת סוכן ה-ADK ב-Cloud Run כשירותים נפרדים
פינוי נפח
כדי להימנע מחיובים בחשבון Google Cloud על המשאבים שנוצרו ב-Codelab הזה, אתם יכולים למחוק את המשאבים בנפרד או למחוק את הפרויקט כולו.
אפשרות 1: מחיקת הפרויקט (מומלץ)
הדרך הקלה ביותר לנקות היא למחוק את הפרויקט. כך יוסרו כל המשאבים שמשויכים לפרויקט.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
אפשרות 2: מחיקת משאבים ספציפיים
אם אתם רוצים לשמור את הפרויקט אבל להסיר רק את המשאבים שנוצרו ב-Codelab הזה:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null