
1. Pengantar
Kualitas agen AI bergantung pada kualitas data yang dapat diaksesnya. Sebagian besar data dunia nyata berada di database — dan menghubungkan agen ke database biasanya berarti menulis pengelolaan koneksi, logika kueri, dan menyematkan pipeline di dalam kode agen Anda. Setiap agen yang memerlukan akses database mengulangi pekerjaan ini, dan setiap perubahan kueri memerlukan deployment ulang agen.
Codelab ini menunjukkan pendekatan yang berbeda. Anda mendeklarasikan alat database dalam file YAML — kueri SQL standar, penelusuran kemiripan vektor, bahkan pembuatan embedding otomatis — dan MCP Toolbox for Databases menangani semua operasi database sebagai server MCP. Kode agen Anda tetap minimal: muat alat, biarkan Gemini memutuskan alat mana yang akan dipanggil.
Yang akan Anda build
Restaurant Concierge untuk "Foodie Finds" — agen ADK yang didukung oleh Gemini yang membantu pengunjung menjelajahi menu restoran menggunakan filter standar (kategori, jenis masakan) dan menemukan hidangan melalui deskripsi bahasa alami seperti "Saya ingin sesuatu yang pedas dan vegetarian". Agen membaca dan menulis ke database Cloud SQL PostgreSQL sepenuhnya melalui MCP Toolbox for Databases, yang menangani semua akses database — termasuk pembuatan embedding otomatis untuk penelusuran vektor. Pada akhirnya, Toolbox dan agen akan berjalan di Cloud Run.
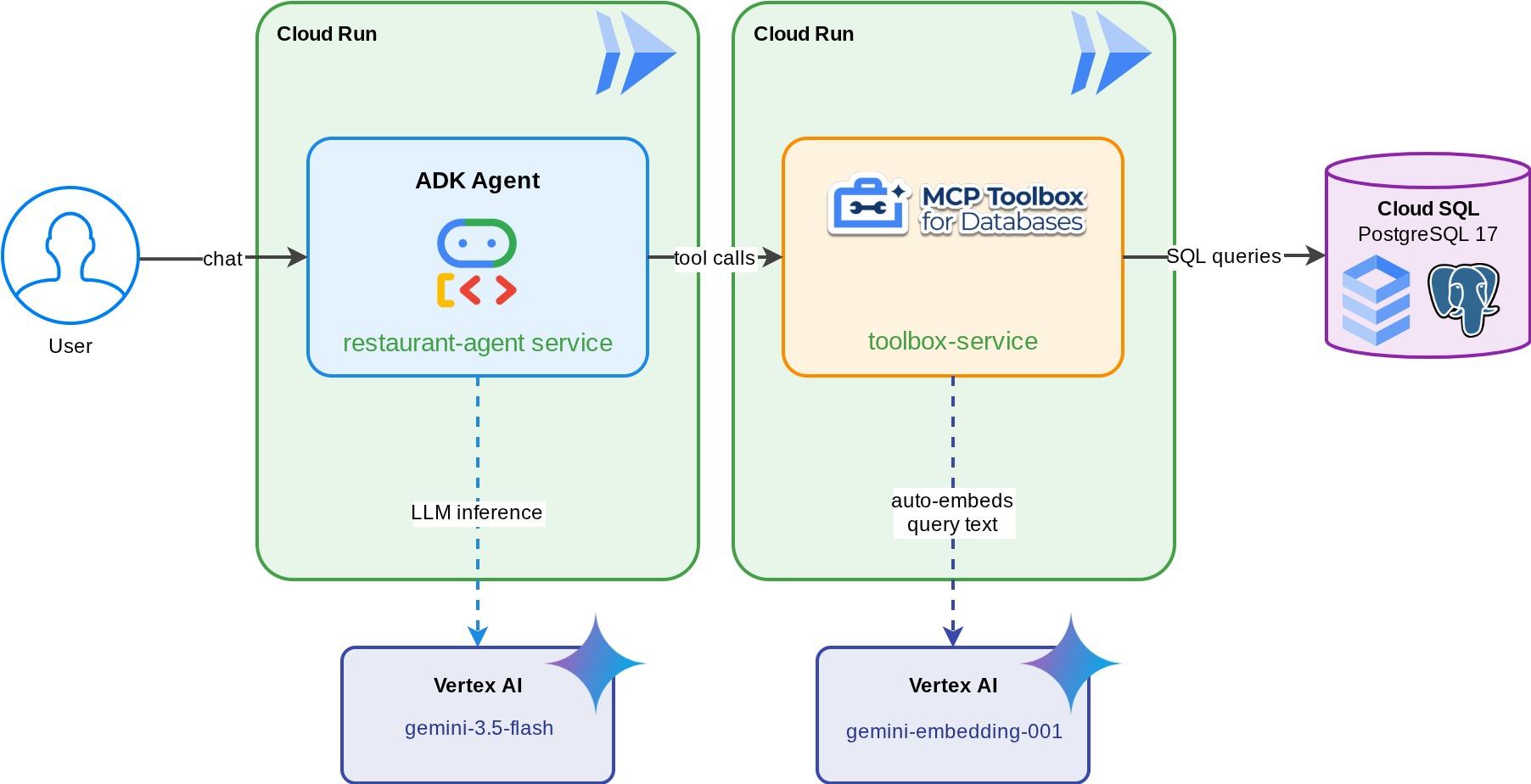
Yang akan Anda pelajari
- Cara MCP (Model Context Protocol) menstandarkan akses alat untuk agen AI, dan cara MCP Toolbox for Databases menerapkan hal ini pada operasi database
- Menyiapkan MCP Toolbox for Databases sebagai middleware antara agen ADK dan Cloud SQL PostgreSQL
- Tentukan alat database secara deklaratif di
tools.yaml— tidak ada kode database di agen Anda - Membangun agen ADK yang memuat alat dari server Toolbox yang sedang berjalan menggunakan
ToolboxToolset - Buat embedding vektor menggunakan fungsi
embedding()bawaan Cloud SQL dan aktifkan penelusuran semantik denganpgvector - Menggunakan fitur
valueFromParamuntuk penyerapan vektor otomatis pada operasi tulis - Men-deploy server Toolbox dan agen ADK ke Cloud Run
Prasyarat
- Akun Google Cloud dengan akun penagihan uji coba
- Pemahaman dasar tentang Python dan SQL
- Pengalaman sebelumnya dengan Cloud Database dan ADK akan sangat membantu
2. Menyiapkan Lingkungan Anda
Langkah ini menyiapkan lingkungan Cloud Shell, mengonfigurasi project Google Cloud, dan meng-clone repositori referensi.
Buka Cloud Shell
Buka Cloud Shell di browser Anda. Cloud Shell menyediakan lingkungan yang telah dikonfigurasi sebelumnya dengan semua alat yang Anda perlukan untuk codelab ini. Klik Authorize saat diminta untuk
Kemudian, klik "View" -> "Terminal" untuk membuka terminal.Antarmuka Anda akan terlihat mirip dengan ini
Ini akan menjadi antarmuka utama kita, IDE di atas, terminal di bawah
Menyiapkan direktori kerja Anda
Buat direktori kerja Anda. Semua kode yang Anda tulis dalam codelab ini ada di sini:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
Setelah itu, siapkan beberapa direktori untuk mengelola hal-hal seperti skrip dan log seeding
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Menyiapkan project Google Cloud
Buat file .env dengan variabel lokasi:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Untuk menyederhanakan penyiapan project di terminal, download skrip penyiapan project ini ke direktori kerja Anda:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Jalankan skrip. Skrip ini memverifikasi akun penagihan uji coba Anda, membuat project baru (atau memvalidasi project yang ada), menyimpan ID project Anda ke file .env di direktori saat ini, dan menetapkan project aktif di gcloud.
bash setup_verify_trial_project.sh && source .env
Skrip akan:
- Pastikan Anda memiliki akun penagihan uji coba yang aktif
- Periksa project yang ada di
.env(jika ada) - Buat project baru atau gunakan kembali project yang sudah ada
- Menautkan akun penagihan uji coba ke project Anda
- Simpan project ID ke
.env - Menetapkan project sebagai project
gcloudyang aktif
Pastikan project disetel dengan benar dengan memeriksa teks kuning di samping direktori kerja Anda di perintah terminal Cloud Shell. Project ID Anda akan ditampilkan.

Aktifkan API yang Diperlukan
Selanjutnya, kita perlu mengaktifkan beberapa API untuk produk yang akan kita gunakan:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- Vertex AI API (
aiplatform.googleapis.com) — agen Anda menggunakan model Gemini, dan Toolbox menggunakan embedding API untuk penelusuran vektor. - Cloud SQL Admin API (
sqladmin.googleapis.com) — Anda menyediakan dan mengelola instance PostgreSQL. - Compute Engine API (
compute.googleapis.com) — diperlukan untuk membuat instance Cloud SQL. - Cloud Run, Cloud Build, Artifact Registry — digunakan dalam langkah deployment nanti di codelab ini
3. Menyiapkan Skrip untuk Inisialisasi Database
Langkah ini memulai pembuatan instance Cloud SQL dan menjalankan skrip penyiapan otomatis yang menunggu hingga instance siap, lalu membuat database, mengisinya dengan listingan pekerjaan, dan membuat penyematan — semuanya dalam satu operasi.
Pertama, tambahkan sandi database ke file .env dan muat ulang:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Membuat skrip Bash untuk pembuatan instance dan database
Kemudian, buat skrip scripts/setup_database.sh dengan perintah berikut
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Kemudian, salin kode berikut ke dalam file scripts/setup_database.sh
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Membuat skrip Python untuk pengisian data
Setelah itu, buat file python skrip pengisian data scripts/setup_restaurant_db.py menggunakan perintah di bawah
cloudshell edit scripts/setup_restaurant_db.py
Kemudian, salin kode berikut ke dalam file scripts/setup_restaurant_db.py
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Sekarang, mari kita lanjutkan ke langkah berikutnya
4. Membuat dan Menginisialisasi Database
Sekarang skrip kita siap dieksekusi. Kita akan memerlukan Python untuk mengeksekusi skrip yang sudah disiapkan, jadi mari kita siapkan terlebih dahulu
Menyiapkan project Python
uv adalah pengelola project dan paket Python yang cepat dan ditulis dalam Rust ( dokumentasi uv ). Codelab ini menggunakannya untuk kecepatan dan kesederhanaan dalam memelihara project Python
Inisialisasi project Python dan tambahkan dependensi yang diperlukan:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Perhatikan bahwa kita menggunakan cloud-sql-python-connector Python SDK di sini untuk melakukan inisialisasi koneksi yang aman dengan instance database yang diautentikasi menggunakan Kredensial Default Aplikasi.
Jalankan skrip penyiapan
Sekarang, kita dapat menjalankan skrip penyiapan di latar belakang dan memeriksa output konsol yang akan ditulis ke file logs/atabase_setup.log menggunakan perintah berikut. Anda dapat melanjutkan ke bagian berikutnya sambil menunggu proses ini selesai
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Download biner Toolbox
Kita akan menggunakan MCP Toolbox dalam tutorial ini. Untungnya, MCP Toolbox dilengkapi dengan program biner yang telah dibuat sebelumnya dan siap digunakan di lingkungan Linux. Sekarang, mari kita download di latar belakang karena prosesnya akan memakan waktu cukup lama. Jalankan perintah berikut untuk mendownload program biner dan memeriksa log output di logs/toolbox_dl.log. Anda dapat melanjutkan ke bagian berikutnya sambil menunggu proses ini selesai
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Memahami skrip penyiapan scripts/setup_database.sh
Sekarang, mari kita coba memahami skrip penyiapan yang sebelumnya kita konfigurasi. Proses ini melakukan hal berikut
- Perintah pertama yang kita jalankan di sana adalah perintah
gcloud sql instances createdengan tanda berikut
db-custom-1-3840adalah tingkat Cloud SQL dengan core khusus terkecil (1 vCPU, RAM 3,75 GB) dalam edisiENTERPRISE. Anda dapat membaca detail selengkapnya di sini. Core khusus diperlukan untuk integrasi ML Vertex AI — tingkat inti bersama (db-f1-micro,db-g1-small) tidak mendukungnya.--root-passwordmenyetel sandi untuk penggunapostgresdefault.--enable-google-ml-integrationmemungkinkan integrasi bawaan Cloud SQL dengan Vertex AI, yang memungkinkan Anda memanggil model embedding langsung dari SQL menggunakan fungsiembedding().
- Verifikasi apakah instance sudah dalam status
RUNNABLE - Berikan izin akun layanan instance Cloud SQL untuk memanggil Vertex AI menggunakan perintah
gcloud projects add-iam-policy-binding. Hal ini diperlukan untuk fungsiembedding()bawaan yang akan kita gunakan saat mengisi database - Membuat database
- Mengeksekusi skrip pengisian data
setup_restaurant_db.py
Memahami skrip awal scripts/setup_restaurant_db.py
Sekarang, beralih ke skrip pengisian data, skrip ini melakukan hal berikut:
- Melakukan inisialisasi koneksi ke instance database
- Menginstal dua ekstensi PostgreSQL:
google_ml_integration— menyediakan fungsi SQLembedding(), yang memanggil model embedding Vertex AI langsung dari SQL. Ini adalah ekstensi tingkat database yang membuat fungsi ML tersedia di dalamrestaurant_db. Flag tingkat instance (--enable-google-ml-integration) yang Anda tetapkan selama pembuatan instance memungkinkan VM Cloud SQL menjangkau Vertex AI — ekstensi ini membuat fungsi SQL tersedia dalam database tertentu ini.vector(pgvector) — menambahkan jenis datavectordan operator jarak untuk menyimpan dan membuat kueri penyematan.
- Buat tabel, perhatikan bahwa kolom
description_embeddingadalahvector(3072)— kolompgvectoryang menyimpan vektor 3072 dimensi. - Menambahkan data item menu awal
- Buat data embedding dari kolom
descriptiondan isidescription_embeddingmenggunakan integrasi Vertex bawaan melalui fungsiembedding()
embedding('gemini-embedding-001', description)— memanggil model embedding Gemini Vertex AI langsung dari SQL, dengan meneruskan teksdescriptionsetiap tugas. Ini adalah ekstensigoogle_ml_integrationyang Anda instal dalam skrip awal.::vector— mentransmisikan array float yang ditampilkan ke jenisvectorpgvector sehingga dapat disimpan dan dikueri dengan operator jarak.UPDATEberjalan di semua 15 baris, menghasilkan satu penyematan 3072 dimensi per deskripsi pekerjaan.
Tindakan ini akan menyiapkan data awal yang akan diakses oleh agen kita
5. Mengonfigurasi MCP Toolbox for Databases
Langkah ini memperkenalkan MCP Toolbox for Databases, mengonfigurasinya untuk terhubung ke instance Cloud SQL Anda, dan menentukan dua alat kueri SQL standar.
Apa itu MCP dan mengapa menggunakan Toolbox?
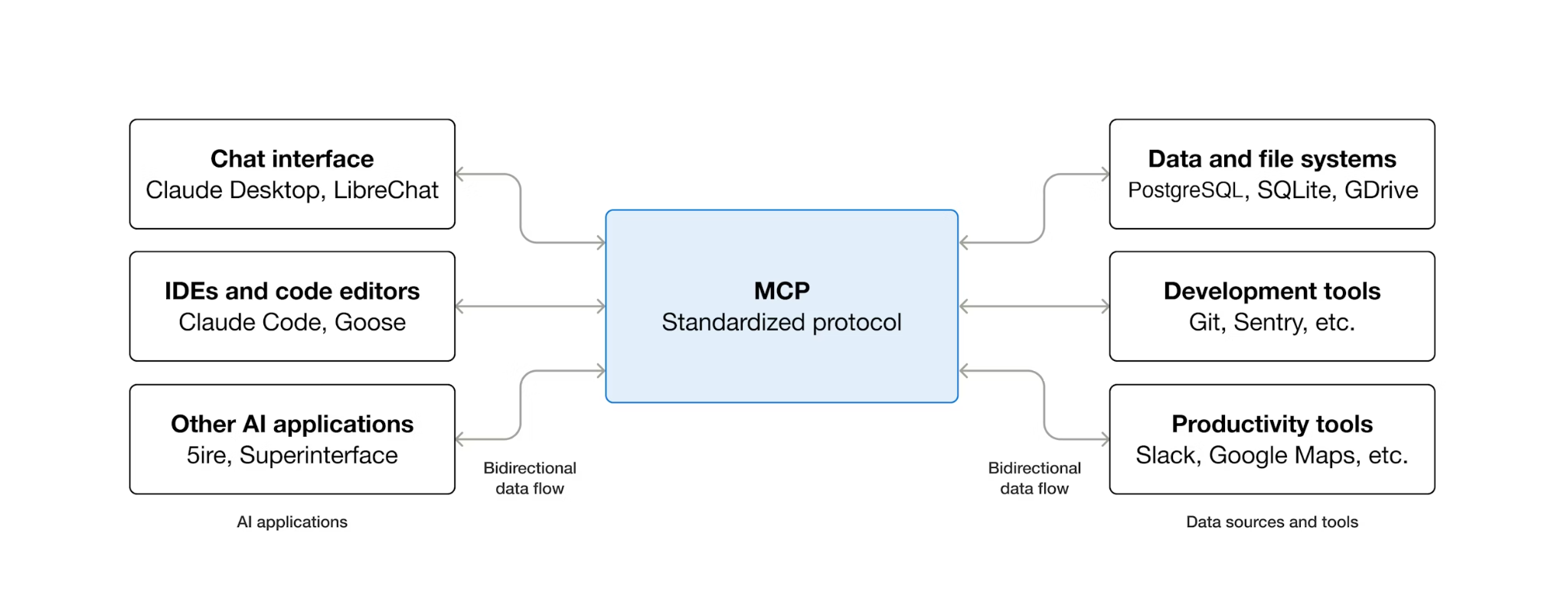
MCP (Model Context Protocol) adalah protokol terbuka yang menstandarkan cara agen AI menemukan dan berinteraksi dengan alat eksternal. Model ini menentukan model klien-server: agen menghosting klien MCP, dan alat diekspos oleh server MCP. Klien yang kompatibel dengan MCP dapat menggunakan server yang kompatibel dengan MCP — agen tidak memerlukan kode integrasi kustom untuk setiap alat.
MCP Toolbox for Databases adalah server MCP open source yang dibuat khusus untuk akses database. Tanpa itu, Anda akan menulis fungsi Python yang membuka koneksi database, mengelola kumpulan koneksi, membuat kueri berparameter untuk mencegah injeksi SQL, menangani error, dan menyematkan semua kode tersebut di dalam agen Anda. Setiap agen yang memerlukan akses database mengulangi pekerjaan ini. Mengubah kueri berarti men-deploy ulang agen.
Dengan Toolbox, Anda menulis file YAML. Setiap alat dipetakan ke pernyataan SQL berparameter. Toolbox menangani penggabungan koneksi, kueri berparameter, autentikasi, dan kemampuan observasi. Alat dipisahkan dari agen — perbarui kueri dengan mengedit tools.yaml dan memulai ulang Toolbox, tanpa menyentuh kode agen. Alat yang sama berfungsi di ADK, LangGraph, LlamaIndex, atau framework yang kompatibel dengan MCP.
Menulis konfigurasi alat
Sekarang, kita perlu membuat file bernama tools.yaml di Cloud Shell Editor untuk menyiapkan konfigurasi alat
cloudshell edit tools.yaml
File menggunakan YAML multi-dokumen — setiap blok yang dipisahkan oleh --- adalah resource mandiri. Setiap resource memiliki kind yang menyatakan apa resource tersebut (sources untuk koneksi database, tools untuk tindakan yang dapat dipanggil agen) dan type yang menentukan backend (cloud-sql-postgres untuk sumber, postgres-sql untuk alat berbasis SQL). Alat mereferensikan sumbernya berdasarkan name, sehingga Toolbox mengetahui kumpulan koneksi mana yang akan dijalankan. Variabel lingkungan menggunakan sintaksis ${VAR_NAME} dan diselesaikan saat startup.
Sekarang, salin skrip berikut terlebih dahulu ke dalam file tools.yaml
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
Skrip ini menentukan resource berikut:
- Sumber (
restaurant-db) — memberi tahu Toolbox cara terhubung ke instance Cloud SQL PostgreSQL Anda. Jeniscloud-sql-postgresmenggunakan konektor Cloud SQL secara internal, menangani autentikasi dan koneksi yang aman secara otomatis. Placeholder${GOOGLE_CLOUD_PROJECT},${REGION}, dan${DB_PASSWORD}di-resolve dari variabel lingkungan saat startup.
Selanjutnya, tambahkan skrip berikut di bawah simbol --- dalam tools.yaml
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
Skrip ini menentukan resource berikut:
- Alat 1 dan 2 (
search-menu,get-item-details) — alat kueri SQL standar. Setiap peta nama alat (yang dilihat agen) ke pernyataan SQL berparameter (yang dieksekusi database). Parameter menggunakan placeholder posisi$1,$2. Toolbox menjalankan perintah ini sebagai pernyataan yang sudah disiapkan, sehingga mencegah injeksi SQL.
Lanjutkan, tambahkan skrip berikut di bawah simbol --- dalam tools.yaml
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
Skrip ini menentukan resource berikut:
- Model embedding (
gemini-embedding) — mengonfigurasi Toolbox untuk memanggil modelgemini-embedding-001Gemini guna membuat embedding teks 3072 dimensi. Toolbox menggunakan Kredensial Default Aplikasi (ADC) untuk melakukan autentikasi — tidak memerlukan kunci API di Cloud Shell atau Cloud Run. Mencatat bahwadimensionyang dikonfigurasi di sini harus sama dengan yang sebelumnya kita konfigurasi untuk mengisi database
Lanjutkan, tambahkan skrip berikut di bawah simbol --- dalam tools.yaml
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
Skrip ini menentukan resource berikut:
- Alat 3 (
search-menu-by-description) — alat penelusuran vektor. Parametersearch_querymemilikiembeddedBy: gemini-embedding, yang memberi tahu Toolbox untuk mencegat teks mentah, mengirimkannya ke model embedding, dan menggunakan vektor yang dihasilkan dalam pernyataan SQL. Operator<=>adalah jarak kosinus pgvector — nilai yang lebih kecil berarti deskripsi yang lebih mirip.
Terakhir, tambahkan alat terakhir di bawah simbol --- dalam tools.yaml
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
Skrip ini menentukan resource berikut:
- Alat 4 (
add-menu-item) — menunjukkan penyerapan vektor. Parameterdescription_vectormemiliki dua kolom khusus: valueFromParam: description— Toolbox menyalin nilai dari parameterdescriptionke parameter ini. LLM tidak pernah melihat parameter ini.embeddedBy: gemini-embedding— Toolbox menyematkan teks yang disalin ke dalam vektor sebelum meneruskannya ke SQL.
Hasilnya: satu panggilan alat menyimpan teks deskripsi mentah dan embedding vektornya, tanpa agen mengetahui apa pun tentang embedding.
Format YAML multi-dokumen memisahkan setiap resource dengan ---. Setiap dokumen memiliki kolom kind, name, dan type yang menentukan isinya. Singkatnya, kita telah mengonfigurasi semua hal berikut:
- Menentukan database sumber
- Tentukan alat ( alat 1 dan 2 ) untuk membuat kueri database dengan filter standar
- Menentukan model embedding
- Menentukan alat untuk melakukan penelusuran vektor ( tool 3 ) ke database
- Tentukan alat untuk melakukan penyerapan data vektor ( alat 4 ) ke database
6. Menjalankan Server MCP Toolbox
Pada langkah sebelumnya, kita telah menetapkan konfigurasi yang diperlukan untuk MCP Toolbox. Sekarang kita siap menjalankan server
Memverifikasi data yang di-seed
Sebelum memulai Toolbox, mari kita konfirmasi bahwa penyiapan database telah selesai. Buat skrip python scripts/verify_database.py menggunakan perintah berikut
cloudshell edit scripts/verify_seed.py
Kemudian, salin kode berikut ke dalam file scripts/verify_seed.py
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Skrip ini akan memeriksa jumlah data item menu dan sematan item menu. Jalankan skrip menggunakan perintah berikut
uv run scripts/verify_seed.py
Jika Anda melihat output terminal berikut, berarti data sudah siap
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Mulai server Toolbox
Pada langkah penyiapan sebelumnya, kita telah mendownload file yang dapat dieksekusi toolbox. Pastikan file biner ini ada dan berhasil didownload. Jika tidak, download file tersebut dan tunggu hingga selesai
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
Kita perlu mengekspos variabel .env ke proses turunan yang dijalankan oleh toolbox MCP. Jalankan perintah berikut untuk memulai server toolbox dan mencatat output konsolnya ke file logs/mcp_toolbox.log
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
Anda akan melihat output dalam file logs/mcp_toolbox.log yang mengonfirmasi bahwa server sudah siap seperti yang ditunjukkan di bawah:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Memverifikasi alat
Kueri Toolbox API untuk mencantumkan semua alat terdaftar:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Anda akan melihat alat beserta deskripsi dan parameternya. Seperti yang ditunjukkan di bawah
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
Uji alat search-menu secara langsung:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
Respons harus berisi hidangan utama Italia dari data awal Anda.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. Membangun Agen ADK
Sekarang, kita akan menggunakan ADK di Python untuk project ini. Mari tambahkan dependensi yang diperlukan:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk— Agent Development Kit Google, termasuk Gemini SDKtoolbox-adk— Integrasi ADK untuk MCP Toolbox for Databases.
Buat struktur direktori agen
ADK mengharapkan tata letak folder tertentu: direktori yang dinamai sesuai agen Anda yang berisi __init__.py, agent.py, dan .env. Untuk membantu hal ini, terdapat perintah bawaan untuk membuat struktur dengan cepat:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
Direktori Anda sekarang akan terlihat seperti ini:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
Selanjutnya, kita perlu mengintegrasikan agen ADK ke server Toolbox yang sedang berjalan dan menguji keempat alat — kueri standar, penelusuran semantik, dan penyerapan vektor. Kode agennya minimal: semua logika database ada di tools.yaml.
Mengonfigurasi lingkungan agen
ADK membaca GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT, dan GOOGLE_CLOUD_LOCATION dari lingkungan shell, yang telah Anda tetapkan pada langkah sebelumnya. Satu-satunya variabel khusus agen adalah TOOLBOX_URL — tambahkan ke file .env agen:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Memperbarui modul agen
Buka restaurant_agent/agent.py di Cloud Shell Editor
cloudshell edit restaurant_agent/agent.py
dan timpa konten dengan kode berikut:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Perhatikan bahwa tidak ada kode database di sini — ToolboxToolset terhubung ke server Toolbox saat startup dan memuat semua alat yang tersedia. Agen memanggil alat berdasarkan nama; Toolbox menerjemahkan panggilan tersebut menjadi kueri SQL terhadap Cloud SQL.
Variabel lingkungan TOOLBOX_URL secara default adalah http://127.0.0.1:5000 untuk pengembangan lokal. Saat men-deploy ke Cloud Run nanti, Anda akan mengganti URL ini dengan URL Cloud Run layanan Toolbox — tidak perlu mengubah kode.
Menguji agen
Mulai UI dev ADK:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Buka URL yang ditampilkan di terminal (biasanya http://localhost:8000) menggunakan fitur Pratinjau Web Cloud Shell atau ctrl + klik URL yang ditampilkan di terminal. Pilih restaurant_agent dari dropdown agen di sudut kiri atas.
Menguji kueri standar
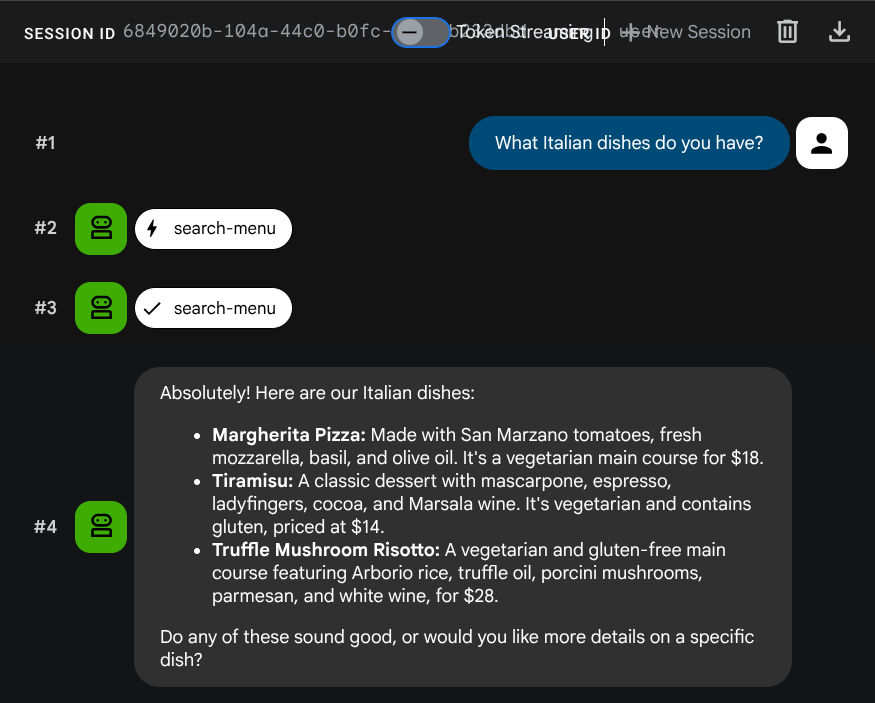
Coba perintah ini untuk memverifikasi alat SQL standar:
What Italian dishes do you have?
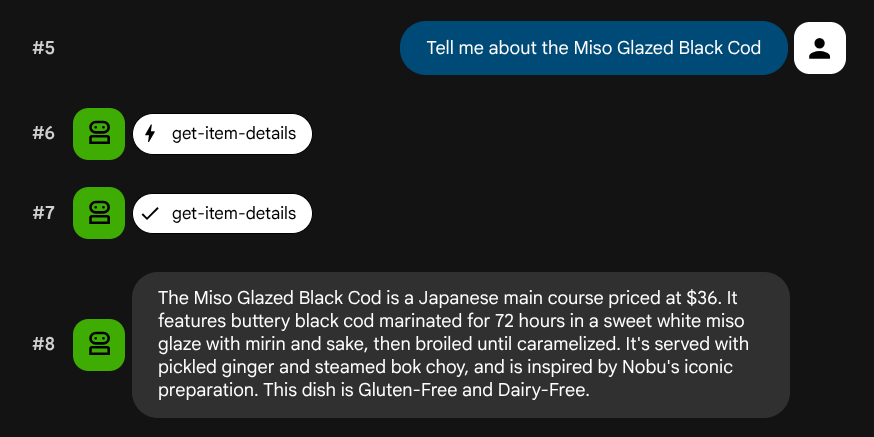
Tell me about the Miso Glazed Black Cod
Menguji penelusuran semantik
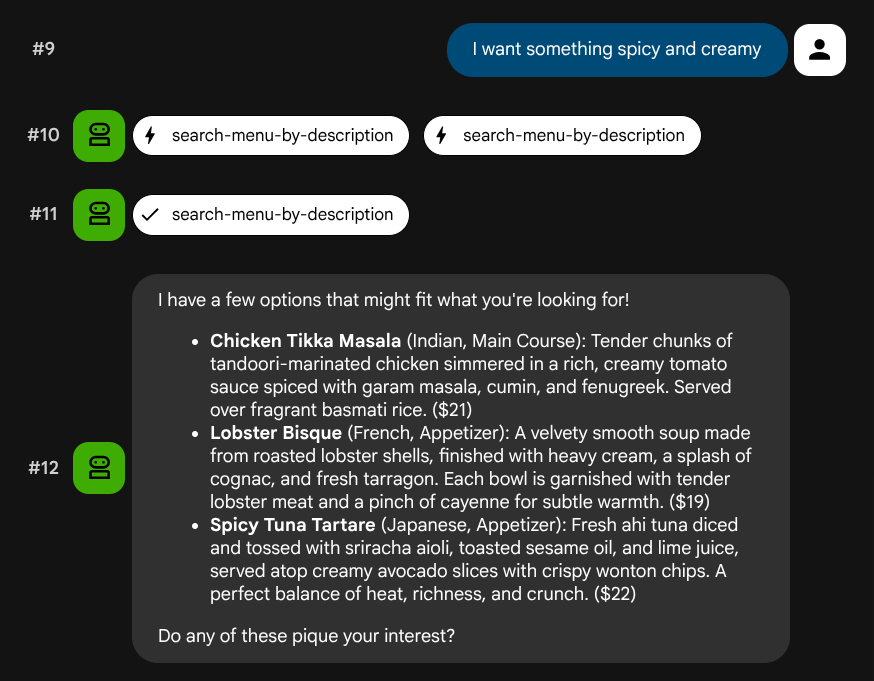
Coba deskripsi bahasa alami yang tidak dipetakan ke peran atau tech stack tertentu:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
Agen akan mencoba memilih alat yang tepat berdasarkan jenis kueri: filter terstruktur diproses melalui search-menu, deskripsi bahasa alami diproses melalui search-menu-by-description.
Menguji penyerapan vektor
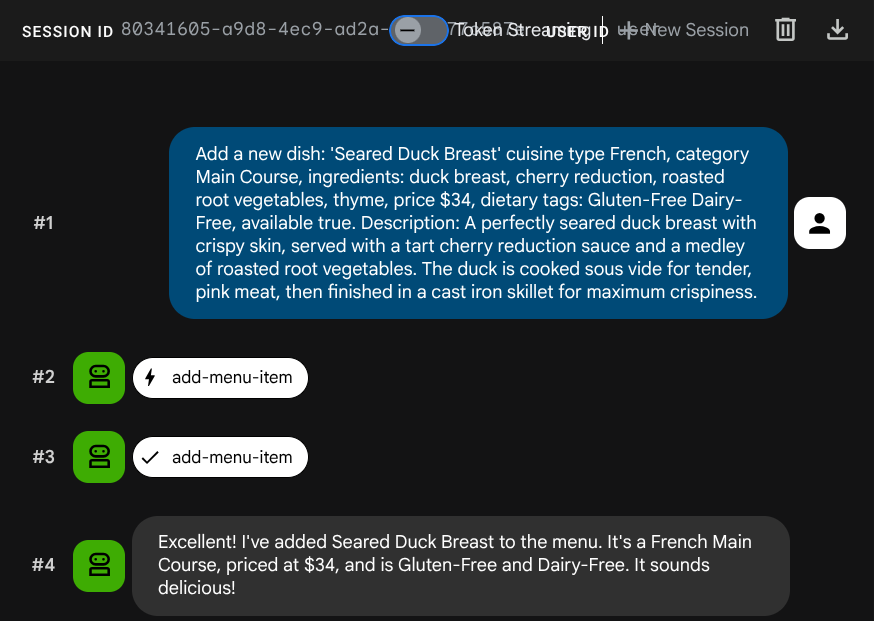
Minta agen untuk menambahkan tugas baru:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
Sekarang coba telusuri:
Find me something with rich, gamey flavors and fruit sauce
Penyematan dibuat secara otomatis selama INSERT — tidak diperlukan langkah terpisah.
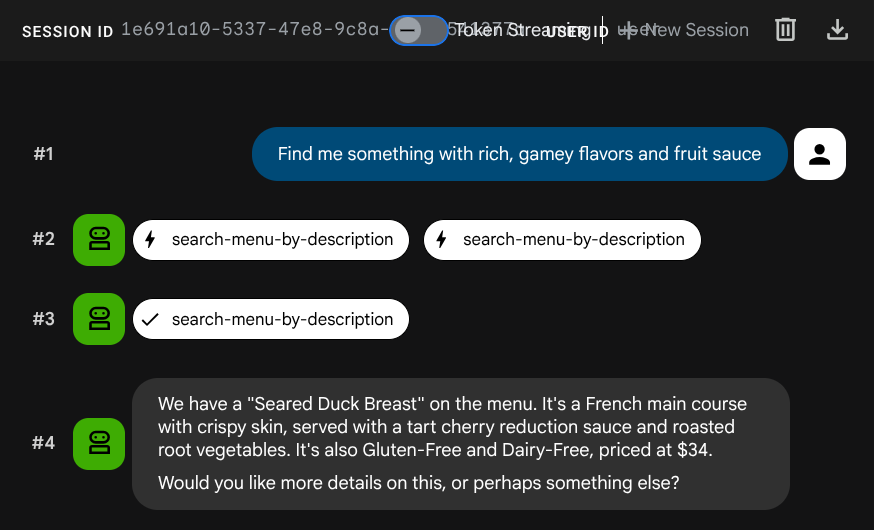
Sekarang, Anda sudah memiliki aplikasi RAG Agentic yang berfungsi penuh menggunakan ADK, MCP Toolbox, dan CloudSQL. Selamat! Mari kita lanjutkan langkah-langkah untuk men-deploy aplikasi ini ke Cloud Run.
Sekarang, hentikan UI dev dengan menghentikan proses dengan menekan Ctrl+C dua kali sebelum melanjutkan.
8. Men-deploy ke Cloud Run
Agen dan Toolbox berfungsi secara lokal. Langkah ini men-deploy keduanya sebagai layanan Cloud Run sehingga dapat diakses melalui internet. Layanan Toolbox berjalan sebagai server MCP di Cloud Run, dan layanan agen terhubung ke layanan tersebut.
Menyiapkan Toolbox untuk deployment
Buat direktori deployment untuk layanan Toolbox:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Buat Dockerfile untuk Toolbox. Buka deploy-toolbox/Dockerfile di Cloud Shell Editor:
cloudshell edit deploy-toolbox/Dockerfile
Kemudian, salin skrip berikut ke dalamnya
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
Biner Toolbox dan tools.yaml dikemas ke dalam image Debian minimal. Cloud Run mengarahkan traffic ke port 8080.
Men-deploy layanan Toolbox
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
Perintah ini mengirimkan sumber ke Cloud Build, membangun image container, mengirimkannya ke Artifact Registry, dan men-deploy-nya ke Cloud Run. Proses ini akan memakan waktu beberapa menit — kita dapat memeriksa log proses deployment pada file logs/deploy_toolbox.log
Menyiapkan agen untuk deployment
Saat Toolbox membangun, siapkan file deployment agen.
Buat Dockerfile di root project. Buka Dockerfile di Cloud Shell Editor:
cloudshell edit Dockerfile
Kemudian, salin konten berikut
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
Dockerfile ini menggunakan ghcr.io/astral-sh/uv sebagai image dasar, yang mencakup Python dan uv yang telah diinstal sebelumnya — tidak perlu menginstal uv secara terpisah melalui pip.
Buat file .dockerignore untuk mengecualikan file yang tidak diperlukan dari image container:
cloudshell edit .dockerignore
Kemudian, salin skrip berikut ke dalamnya
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Men-deploy layanan agen
Tunggu hingga deployment Toolbox selesai. Periksa kembali proses deployment di logs/deploy_toolbox.log untuk memverifikasi prosesnya. Kemudian, ambil URL Cloud Run-nya menggunakan perintah berikut
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Anda akan melihat output yang serupa seperti ini
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Kemudian, mari kita verifikasi bahwa Toolbox yang di-deploy berfungsi:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Jika output ditampilkan seperti contoh ini, deployment sudah berhasil
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
Selanjutnya, mari kita deploy agen dengan meneruskan URL Toolbox sebagai variabel lingkungan:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
Kode agen membaca TOOLBOX_URL dari lingkungan (Anda telah menyiapkannya sebelumnya). Secara lokal, variabel ini mengarah ke http://127.0.0.1:5000; di Cloud Run, variabel ini mengarah ke URL layanan Toolbox. Tidak perlu mengubah kode.
Menguji agen yang di-deploy
Ambil URL Cloud Run agen:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
Buka URL di browser Anda. UI dev ADK dimuat — antarmuka yang sama yang telah Anda gunakan secara lokal, kini berjalan di Cloud Run.
Pilih restaurant_agent dari dropdown dan uji:
What Italian dishes do you have?
I want something spicy and creamy
Kedua kueri berfungsi melalui layanan yang di-deploy: agen di Cloud Run memanggil Toolbox di Cloud Run, yang mengkueri Cloud SQL.
9. Selamat / Pembersihan
Anda telah membuat dan men-deploy asisten menu restoran pintar yang menggunakan MCP Toolbox for Databases untuk menghubungkan agen ADK dan Cloud SQL PostgreSQL — dengan kueri SQL standar dan penelusuran vektor semantik.
Yang telah Anda pelajari
- Cara MCP menstandardisasi akses alat untuk agen AI, dan cara MCP Toolbox for Databases menerapkannya secara khusus pada operasi database — menggantikan kode database kustom dengan konfigurasi YAML deklaratif
- Cara mengonfigurasi Cloud SQL PostgreSQL sebagai sumber data Toolbox menggunakan jenis sumber
cloud-sql-postgres - Cara menentukan alat kueri SQL standar dengan pernyataan berparameter yang mencegah injeksi SQL
- Cara mengaktifkan penelusuran vektor menggunakan pgvector dan
gemini-embedding-001, dengan parameterembeddedByuntuk penyematan kueri otomatis - Cara
valueFromParammemungkinkan penyerapan vektor otomatis — LLM memberikan deskripsi teks, dan Toolbox secara diam-diam menyalin, menyematkan, dan menyimpan vektor bersama teks - Cara
ToolboxToolsetADK memuat alat dari server Toolbox yang sedang berjalan, sehingga kode agen tetap minimal dan logika database sepenuhnya terpisah - Cara men-deploy server MCP Toolbox dan agen ADK ke Cloud Run sebagai layanan terpisah
Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang dibuat dalam codelab ini, Anda dapat menghapus setiap resource atau menghapus seluruh project.
Opsi 1: Menghapus project (direkomendasikan)
Cara termudah untuk membersihkan adalah dengan menghapus project. Tindakan ini akan menghapus semua resource yang terkait dengan project.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Opsi 2: Menghapus resource satu per satu
Jika Anda ingin mempertahankan project, tetapi hanya menghapus resource yang dibuat di codelab ini:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null