
1. Introduzione
L'utilità degli agenti AI dipende dai dati a cui possono accedere. La maggior parte dei dati reali si trova nei database e il collegamento degli agenti ai database in genere comporta la scrittura della gestione delle connessioni, della logica delle query e delle pipeline di incorporamento all'interno del codice dell'agente. Ogni agente che ha bisogno dell'accesso al database ripete questo lavoro e ogni modifica della query richiede il redeploy dell'agente.
Questo codelab mostra un approccio diverso. Dichiari gli strumenti di database in un file YAML, incluse query SQL standard, ricerca di somiglianza vettoriale e persino generazione automatica di embedding, e MCP Toolbox for Databases gestisce tutte le operazioni del database come server MCP. Il codice dell'agente rimane minimo: carica gli strumenti e lascia che Gemini decida quale chiamare.
Cosa creerai
Un concierge del ristorante per "Foodie Finds", un agente ADK basato su Gemini che aiuta i clienti a sfogliare il menu di un ristorante utilizzando filtri standard (categoria, tipo di cucina) e a scoprire i piatti tramite descrizioni in linguaggio naturale come "Voglio qualcosa di piccante e vegetariano". L'agente legge e scrive in un database Cloud SQL PostgreSQL interamente tramite MCP Toolbox for Databases, che gestisce tutto l'accesso al database, inclusa la generazione automatica di embedding per la ricerca vettoriale. Alla fine, sia Toolbox che l'agente vengono eseguiti su Cloud Run.
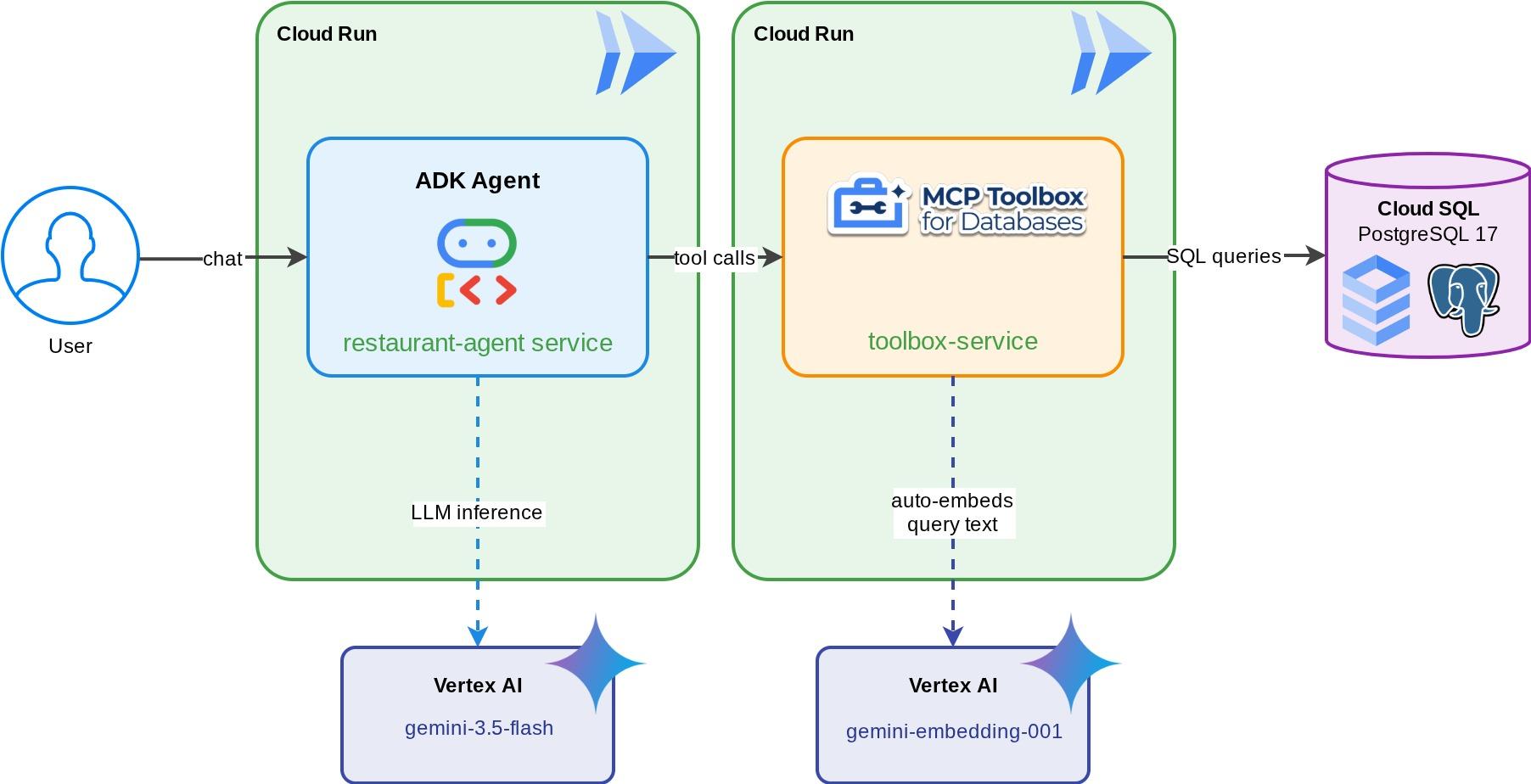
Cosa imparerai a fare
- In che modo MCP (Model Context Protocol) standardizza l'accesso agli strumenti per gli agenti AI e in che modo MCP Toolbox for Databases lo applica alle operazioni del database
- Configura MCP Toolbox for Databases come middleware tra un agente ADK e Cloud SQL PostgreSQL
- Definisci gli strumenti di database in modo dichiarativo in
tools.yaml, senza codice di database nell'agente - Crea un agente ADK che carica gli strumenti da un server Toolbox in esecuzione utilizzando
ToolboxToolset - Genera vector embedding utilizzando la funzione
embedding()integrata di Cloud SQL e abilita la ricerca semantica conpgvector - Utilizza la funzionalità
valueFromParamper l'inserimento automatico di vettori nelle operazioni di scrittura - Esegui il deployment del server Toolbox e dell'agente ADK su Cloud Run
Prerequisiti
- Un account Google Cloud con un account di fatturazione di prova
- Conoscenza di base di Python e SQL
- L'esperienza pregressa con Cloud Database e ADK sarà utile
2. Configura l'ambiente
Questo passaggio prepara l'ambiente Cloud Shell, configura il progetto Google Cloud e clona il repository di riferimento.
Apri Cloud Shell
Apri Cloud Shell nel browser. Cloud Shell fornisce un ambiente preconfigurato con tutti gli strumenti necessari per questo codelab. Quando richiesto, fai clic su Autorizza.
Poi fai clic su "Visualizza" -> "Terminale" per aprire il terminale.L'interfaccia dovrebbe avere un aspetto simile a questo

Questa sarà la nostra interfaccia principale, con l'IDE in alto e il terminale in basso.
Configurare la directory di lavoro
Crea la directory di lavoro. Tutto il codice che scrivi in questo codelab si trova qui:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
Dopodiché, prepariamo diverse directory per gestire elementi come script di seeding e log.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Configurare il progetto Google Cloud
Crea il file .env con le variabili di località:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Per semplificare la configurazione del progetto nel terminale, scarica questo script di configurazione del progetto nella tua directory di lavoro:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Esegui lo script. Verifica il tuo account di fatturazione di prova, crea un nuovo progetto (o ne convalida uno esistente), salva l'ID progetto in un file .env nella directory corrente e imposta il progetto attivo in gcloud.
bash setup_verify_trial_project.sh && source .env
Lo script:
- Verificare di avere un account di fatturazione di prova attivo
- Controlla se esiste un progetto in
.env(se presente) - Crea un nuovo progetto o riutilizza quello esistente
- Collega l'account di fatturazione di prova al tuo progetto
- Salva l'ID progetto in
.env - Imposta il progetto come progetto
gcloudattivo
Verifica che il progetto sia impostato correttamente controllando il testo giallo accanto alla directory di lavoro nel prompt del terminale Cloud Shell. Dovrebbe essere visualizzato l'ID progetto.

Attiva l'API richiesta
Successivamente, dobbiamo abilitare diverse API per il prodotto con cui interagiremo:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- API Vertex AI (
aiplatform.googleapis.com): l'agente utilizza i modelli Gemini e Toolbox utilizza l'API Embedding per la ricerca vettoriale. - API Cloud SQL Admin (
sqladmin.googleapis.com): esegui il provisioning e la gestione di un'istanza PostgreSQL. - API Compute Engine (
compute.googleapis.com): necessaria per creare istanze Cloud SQL. - Cloud Run, Cloud Build, Artifact Registry: utilizzati nel passaggio di deployment più avanti in questo codelab
3. Preparazione degli script per l'inizializzazione del database
Questo passaggio avvia la creazione dell'istanza Cloud SQL ed esegue uno script di configurazione automatizzato che attende che l'istanza sia pronta, quindi crea il database, lo inizializza con le offerte di lavoro e genera gli incorporamenti, tutto in un'unica operazione.
Per prima cosa, aggiungiamo la password del database al file .env e ricarichiamolo:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Creazione dello script Bash per la creazione dell'istanza e del database
Quindi, crea lo script scripts/setup_database.sh con il seguente comando
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Quindi, copia il seguente codice nel file scripts/setup_database.sh
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Creazione dello script Python per il seeding dei dati
Dopodiché, crea il file Python dello script di seeding scripts/setup_restaurant_db.py utilizzando il comando riportato di seguito.
cloudshell edit scripts/setup_restaurant_db.py
Quindi, copia il seguente codice nel file scripts/setup_restaurant_db.py
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Ora passiamo al passaggio successivo.
4. Crea e inizializza il database
Ora gli script sono pronti per essere eseguiti. Avremo bisogno di Python per eseguire lo script preparato, quindi prepariamolo prima.
Configurare il progetto Python
uv è un gestore di progetti e pacchetti Python veloce scritto in Rust ( documentazione di uv). Questo codelab lo utilizza per la velocità e la semplicità di manutenzione del progetto Python
Inizializza un progetto Python e aggiungi le dipendenze richieste:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Tieni presente che qui utilizziamo l'SDK Python cloud-sql-python-connector per inizializzare una connessione sicura con la nostra istanza di database, autenticata utilizzando le credenziali predefinite dell'applicazione.
Esegui lo script di configurazione
Ora possiamo eseguire lo script di configurazione in background ed esaminare l'output della console che verrà scritto nel file logs/atabase_setup.log utilizzando il seguente comando. Puoi passare alla sezione successiva mentre aspetti che l'operazione venga completata.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Scarica il binario di Toolbox
In questo tutorial utilizzeremo MCP Toolbox, che fortunatamente include un file binario precompilato pronto per essere utilizzato nell'ambiente Linux. Ora scarichiamolo in background, perché ci vuole un po' di tempo. Esegui questo comando per scaricare il file binario ed esaminare il log di output su logs/toolbox_dl.log . Puoi continuare con la sezione successiva mentre aspetti che l'operazione venga completata.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Informazioni sullo script di configurazione scripts/setup_database.sh
Ora proviamo a capire lo script di configurazione che abbiamo configurato in precedenza. Esegue la seguente procedura
- Il primo comando che eseguiamo è
gcloud sql instances createcon il seguente flag
db-custom-1-3840è il livello Cloud SQL con core dedicato più piccolo (1 vCPU, 3,75 GB di RAM) nell'edizioneENTERPRISE.Puoi leggere ulteriori dettagli qui. Per l'integrazione di Vertex AI ML è necessario un core dedicato. I livelli con core condiviso (db-f1-micro,db-g1-small) non lo supportano.--root-passwordimposta la password per l'utentepostgrespredefinito.--enable-google-ml-integrationabilita l'integrazione integrata di Cloud SQL con Vertex AI, che consente di chiamare i modelli di embedding direttamente da SQL utilizzando la funzioneembedding().
- Verifica se l'istanza è già nello stato
RUNNABLE - Concedi al service account dell'istanza Cloud SQL l'autorizzazione per chiamare Vertex AI utilizzando il comando
gcloud projects add-iam-policy-binding. Questo è necessario per la funzioneembedding()integrata che utilizzeremo per inizializzare il database. - Creazione del database
- Esecuzione dello script di seeding
setup_restaurant_db.py
Informazioni sullo script iniziale scripts/setup_restaurant_db.py
Ora, passando allo script di seeding, questo script esegue le seguenti operazioni:
- Inizializza la connessione all'istanza di database.
- Installa due estensioni PostgreSQL:
google_ml_integration: fornisce la funzione SQLembedding(), che chiama i modelli di incorporamento di Vertex AI direttamente da SQL. Si tratta di un'estensione a livello di database che rende disponibili le funzioni di ML all'interno direstaurant_db. Il flag a livello di istanza (--enable-google-ml-integration) che imposti durante la creazione dell'istanza consente alla VM Cloud SQL di raggiungere Vertex AI. L'estensione rende disponibili le funzioni SQL all'interno di questo database specifico.vector(pgvector): aggiunge il tipo di dativectore gli operatori di distanza per archiviare ed eseguire query sugli incorporamenti.
- Crea la tabella, nota che la colonna
description_embeddingèvector(3072), ovvero una colonnapgvectorche memorizza vettori a 3072 dimensioni. - Inserisci i dati iniziali delle voci di menu
- Genera i dati di embedding dal campo
descriptione compiladescription_embeddingutilizzando l'integrazione Vertex integrata tramite la funzioneembedding()
embedding('gemini-embedding-001', description): chiama il modello di embedding Gemini di Vertex AI direttamente da SQL, passando il testodescriptiondi ogni job. Questa è l'estensionegoogle_ml_integrationche hai installato nello script seed.::vector: esegue il cast dell'array float restituito al tipovectordi pgvector in modo che possa essere archiviato ed eseguito query con gli operatori di distanza.UPDATEviene eseguito su tutte le 15 righe, generando un embedding a 3072 dimensioni per ogni descrizione del lavoro.
In questo modo verranno preparati i dati iniziali a cui accederà il nostro agente
5. Configura MCP Toolbox for Databases
Questo passaggio introduce MCP Toolbox for Databases, lo configura per la connessione all'istanza Cloud SQL e definisce due strumenti di query SQL standard.
Che cos'è MCP e perché utilizzare Toolbox?
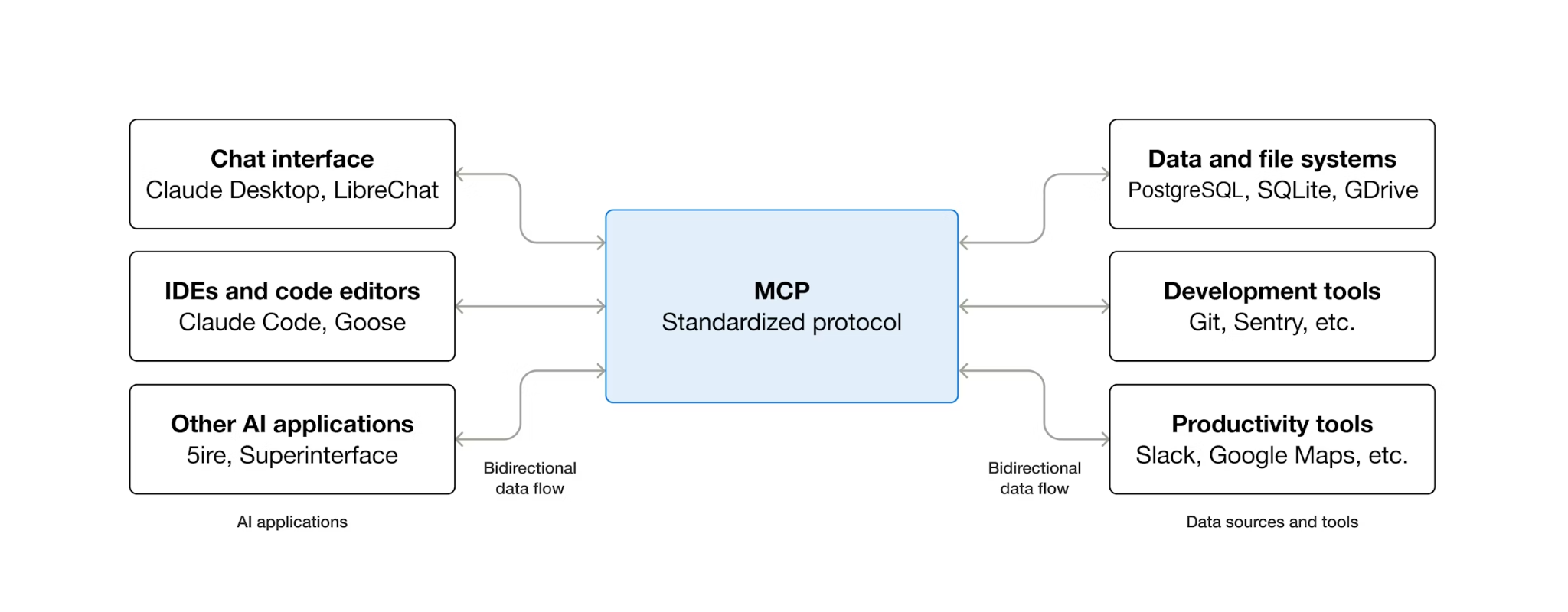
MCP (Model Context Protocol) è un protocollo aperto che standardizza il modo in cui gli agenti AI scoprono e interagiscono con strumenti esterni. Definisce un modello client-server: l'agente ospita un client MCP e gli strumenti vengono esposti dai server MCP. Qualsiasi client compatibile con MCP può utilizzare qualsiasi server compatibile con MCP. L'agente non ha bisogno di codice di integrazione personalizzato per ogni strumento.
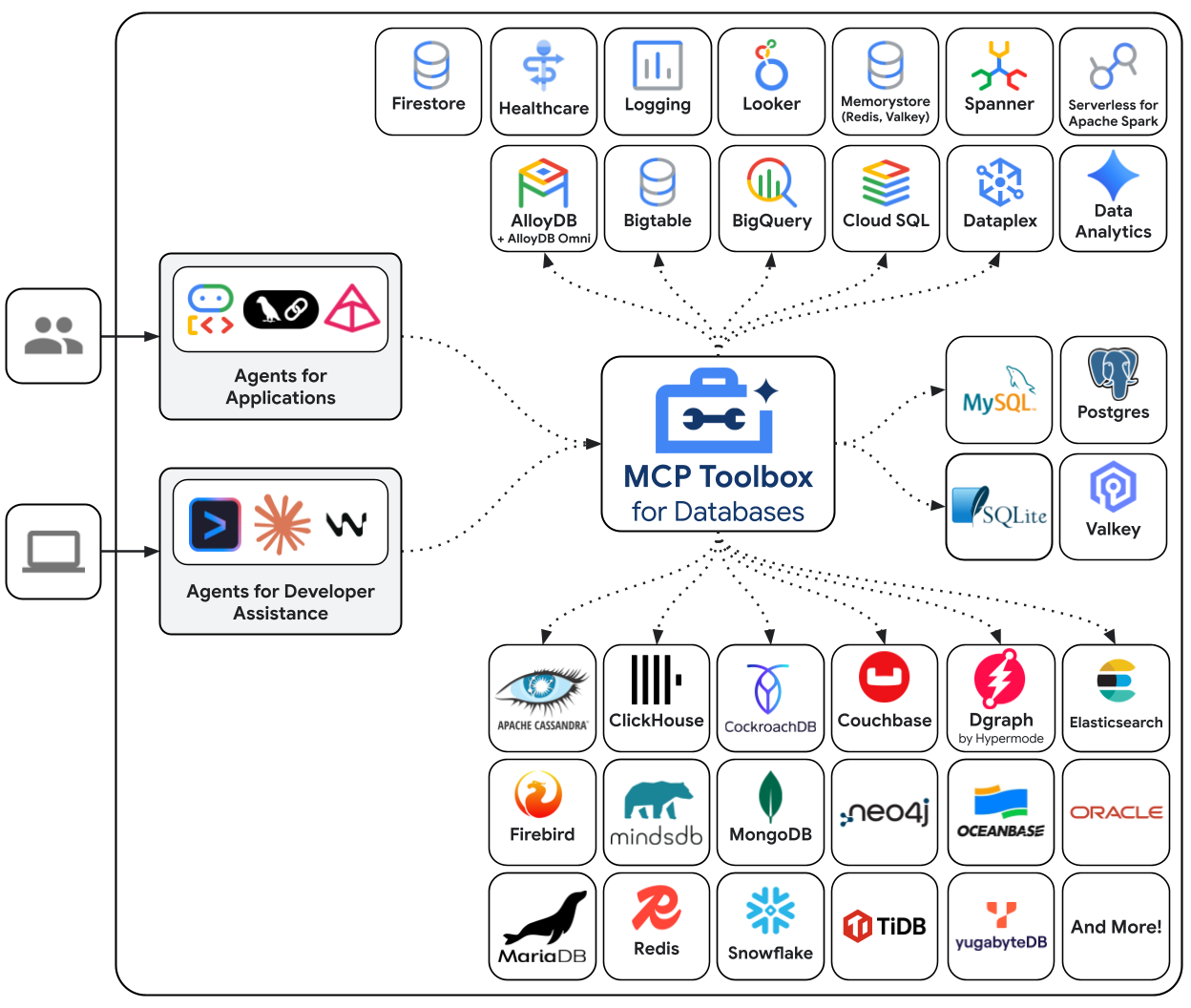
MCP Toolbox for Databases è un server MCP open source creato appositamente per l'accesso al database. Senza, dovresti scrivere funzioni Python che aprono connessioni al database, gestiscono pool di connessioni, creano query parametrizzate per impedire l'SQL injection, gestiscono gli errori e incorporano tutto questo codice all'interno dell'agente. Ogni agente che ha bisogno dell'accesso al database ripete questa operazione. La modifica di una query comporta il nuovo deployment dell'agente.
Con Toolbox, scrivi un file YAML. Ogni strumento viene mappato a un'istruzione SQL con parametri. Toolbox gestisce il pool di connessioni, le query con parametri, l'autenticazione e l'osservabilità. Gli strumenti sono disaccoppiati dall'agente: aggiorna una query modificando tools.yaml e riavviando Toolbox, senza toccare il codice dell'agente. Gli stessi strumenti funzionano con ADK, LangGraph, LlamaIndex o qualsiasi framework compatibile con MCP.
Scrivere la configurazione degli strumenti
Ora dobbiamo creare un file denominato tools.yaml nell'editor di Cloud Shell per configurare gli strumenti.
cloudshell edit tools.yaml
Il file utilizza YAML multiformato: ogni blocco separato da --- è una risorsa autonoma. Ogni risorsa ha un kind che dichiara di cosa si tratta (sources per le connessioni al database, tools per le azioni richiamabili dall'agente) e un type che specifica il backend (cloud-sql-postgres per l'origine, postgres-sql per gli strumenti basati su SQL). Uno strumento fa riferimento alla sua origine tramite name, in modo che Toolbox sappia quale pool di connessioni eseguire. Le variabili di ambiente utilizzano la sintassi ${VAR_NAME} e vengono risolte all'avvio.
Ora, copia prima i seguenti script nel file tools.yaml
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
Questo script definisce la seguente risorsa:
- Origine (
restaurant-db): indica a Toolbox come connettersi all'istanza Cloud SQL PostgreSQL. Il tipocloud-sql-postgresutilizza internamente il connettore Cloud SQL, gestendo automaticamente l'autenticazione e le connessioni sicure. I segnaposto${GOOGLE_CLOUD_PROJECT},${REGION}e${DB_PASSWORD}vengono risolti dalle variabili di ambiente all'avvio.
Successivamente, aggiungi il seguente script sotto il simbolo --- nel file tools.yaml.
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
Questo script definisce la seguente risorsa:
- Strumenti 1 e 2 (
search-menu,get-item-details): strumenti di query SQL standard. Ognuno associa un nome di strumento (ciò che vede l'agente) a un'istruzione SQL parametrizzata (ciò che esegue il database). I parametri utilizzano i segnaposto posizionali$1e$2. Toolbox li esegue come istruzioni preparate, il che impedisce l'SQL injection.
Continuiamo aggiungendo il seguente script sotto il simbolo --- nel file tools.yaml
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
Questo script definisce la seguente risorsa:
- Modello di incorporamento (
gemini-embedding): configura Toolbox per chiamare il modellogemini-embedding-001di Gemini per generare incorporamenti di testo a 3072 dimensioni. Toolbox utilizza le credenziali predefinite dell'applicazione (ADC) per l'autenticazione, senza bisogno di una chiave API in Cloud Shell o Cloud Run. Tieni presente che questodimensionconfigurato qui deve essere lo stesso di quello configurato in precedenza per inizializzare il database.
Continuiamo aggiungendo il seguente script sotto il simbolo --- nel file tools.yaml
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
Questo script definisce la seguente risorsa:
- Strumento 3 (
search-menu-by-description): uno strumento di ricerca vettoriale. Il parametrosearch_queryhaembeddedBy: gemini-embedding, che indica a Strumenti amministrativi di intercettare il testo non elaborato, inviarlo al modello di embedding e utilizzare il vettore risultante nell'istruzione SQL. L'operatore<=>è la distanza del coseno di pgvector: valori più piccoli indicano descrizioni più simili.
Infine, aggiungi l'ultimo strumento sotto il simbolo --- nel file tools.yaml.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
Questo script definisce la seguente risorsa:
- Strumento 4 (
add-menu-item): mostra l'importazione di vettori. Il parametrodescription_vectorha due campi speciali: valueFromParam: description: Toolbox copia il valore dal parametrodescriptionin questo. L'LLM non vede mai questo parametro.embeddedBy: gemini-embedding: Toolbox incorpora il testo copiato in un vettore prima di passarlo a SQL.
Il risultato è che una chiamata allo strumento memorizza sia il testo della descrizione non elaborato sia il relativo incorporamento vettoriale, senza che l'agente sappia nulla degli incorporamenti.
Il formato YAML multi-documento separa ogni risorsa con ---. Ogni documento ha campi kind, name e type che ne definiscono il contenuto. In sintesi, abbiamo già configurato tutti gli elementi seguenti:
- Definisci il database di origine
- Definisci gli strumenti ( strumento 1 e 2) per eseguire query sul database con il filtro standard
- Definisci il modello di embedding
- Definisci lo strumento per eseguire la ricerca vettoriale ( strumento 3) nel database
- Definisci lo strumento per l'importazione dei dati vettoriali ( strumento 4) nel database
6. Esecuzione del server MCP Toolbox
Nel passaggio precedente, abbiamo già impostato la configurazione necessaria per la nostra casella degli strumenti MCP. Ora siamo pronti per eseguire il server.
Verificare i dati iniziali
Prima di avviare Toolbox, verifichiamo che la configurazione del database sia stata completata. Crea uno script Python scripts/verify_database.py utilizzando il seguente comando
cloudshell edit scripts/verify_seed.py
Quindi, copia il seguente codice nel file scripts/verify_seed.py
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Questo script controllerà il numero di dati degli articoli delle voci di menu e il relativo embedding. Esegui lo script utilizzando questo comando
uv run scripts/verify_seed.py
Se vedi il seguente output del terminale, significa che i dati sono pronti
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Avviare il server di Toolbox
Nel passaggio di configurazione precedente, abbiamo già scaricato l'eseguibile toolbox. Assicurati che questo file binario esista e sia stato scaricato correttamente. In caso contrario, scaricalo e attendi il completamento.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
Dobbiamo esporre le nostre variabili .env al processo secondario eseguito dalla casella degli strumenti MCP. Esegui il comando seguente per avviare il server della toolbox e registrare l'output della console nel file logs/mcp_toolbox.log
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
Dovresti vedere un output nel file logs/mcp_toolbox.log che conferma che il server è pronto, come mostrato di seguito:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Verificare gli strumenti
Esegui una query sull'API Toolbox per elencare tutti gli strumenti registrati:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Dovresti visualizzare gli strumenti con le relative descrizioni e i parametri. Come mostrato di seguito
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
Testa direttamente lo strumento search-menu:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
La risposta deve contenere i piatti principali italiani dei dati iniziali.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. Crea l'agente ADK
Ora utilizzeremo ADK in Python per questo progetto. Aggiungiamo le dipendenze richieste:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk: l'Agent Development Kit di Google, incluso l'SDK Geminitoolbox-adk: integrazione di ADK per MCP Toolbox for Databases.
Creare la struttura di directory dell'agente
L'ADK prevede un layout di cartelle specifico: una directory denominata in base al tuo agente contenente __init__.py, agent.py e .env. Per facilitare questa operazione, è stato integrato un comando per stabilire rapidamente la struttura:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
La directory dovrebbe ora avere il seguente aspetto:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
Successivamente, dovremo integrare l'agente ADK nel server Toolbox in esecuzione e testare tutti e quattro gli strumenti: query standard, ricerca semantica e importazione vettoriale. Il codice dell'agente è minimo: tutta la logica del database si trova in tools.yaml.
Configurare l'ambiente dell'agente
ADK legge GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT e GOOGLE_CLOUD_LOCATION dall'ambiente shell, che hai già impostato nel passaggio precedente. L'unica variabile specifica dell'agente è TOOLBOX_URL. Aggiungila al file .env dell'agente:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Aggiornare il modulo dell'agente
Apri restaurant_agent/agent.py nell'editor di Cloud Shell
cloudshell edit restaurant_agent/agent.py
e sovrascrivi i contenuti con il seguente codice:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Tieni presente che qui non è presente alcun codice di database. ToolboxToolset si connette al server Toolbox all'avvio e carica tutti gli strumenti disponibili. L'agente chiama gli strumenti per nome; Toolbox traduce queste chiamate in query SQL su Cloud SQL.
La variabile di ambiente TOOLBOX_URL è impostata su http://127.0.0.1:5000 per lo sviluppo locale. Quando esegui il deployment su Cloud Run in un secondo momento, esegui l'override con l'URL Cloud Run del servizio Toolbox, senza bisogno di modifiche al codice.
Testare l'agente
Avvia l'interfaccia utente di sviluppo ADK:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Apri l'URL mostrato nel terminale (in genere http://localhost:8000) utilizzando la funzionalità Anteprima web di Cloud Shell o Ctrl + clic sull'URL mostrato nel terminale. Seleziona restaurant_agent dal menu a discesa degli agenti nell'angolo in alto a sinistra.
Testare le query standard
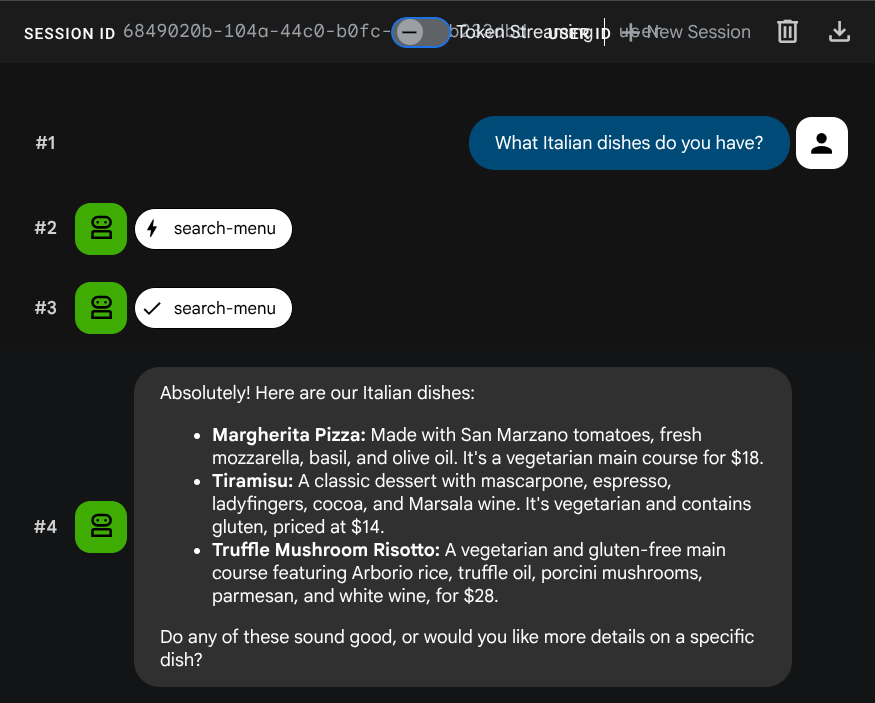
Prova questi prompt per verificare gli strumenti SQL standard:
What Italian dishes do you have?
Tell me about the Miso Glazed Black Cod
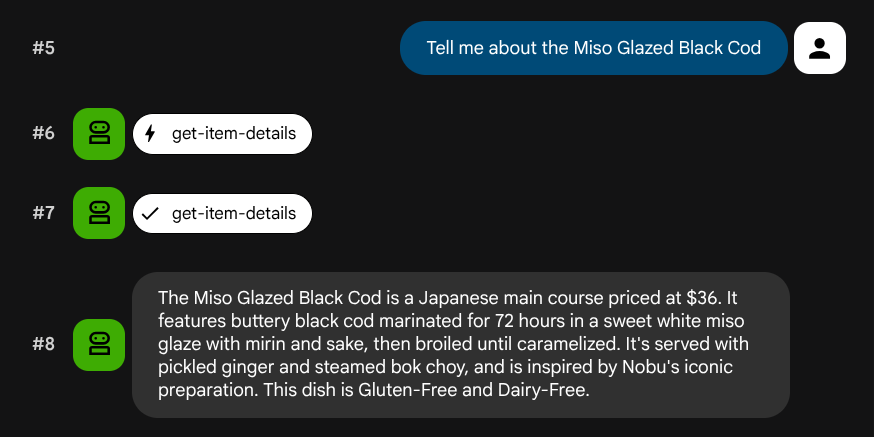
Testare la ricerca semantica
Prova descrizioni in linguaggio naturale che non corrispondono a un ruolo o a uno stack tecnologico specifico:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
L'agente cercherà di scegliere lo strumento giusto in base al tipo di query: i filtri strutturati vengono elaborati tramite search-menu, le descrizioni in linguaggio naturale tramite search-menu-by-description.
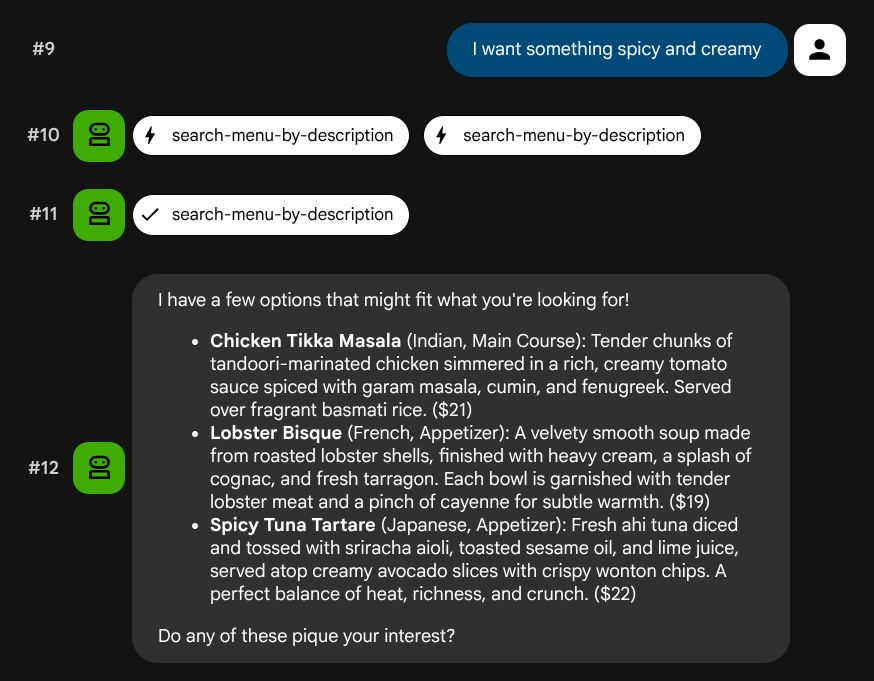
Testare l'importazione di vettori
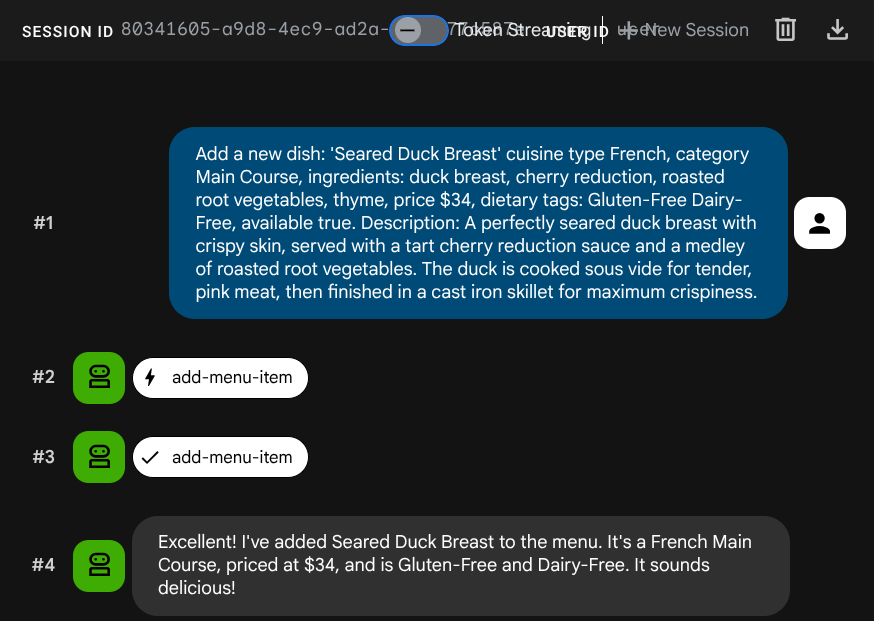
Chiedi all'agente di aggiungere un nuovo job:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
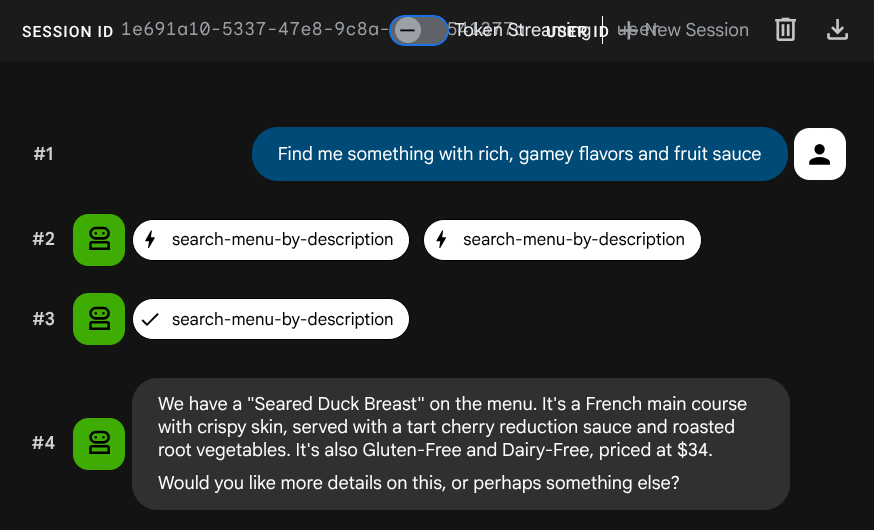
Ora prova a cercarlo:
Find me something with rich, gamey flavors and fruit sauce
L'incorporamento è stato generato automaticamente durante l'inserimento, senza bisogno di un passaggio separato.
Ora hai già un'applicazione RAG agentica completamente funzionante che utilizza ADK, MCP Toolbox e CloudSQL. Complimenti! Facciamo un ulteriore passo avanti per eseguire il deployment di queste app su Cloud Run.
Ora, interrompiamo l'interfaccia utente per sviluppatori terminando il processo premendo Ctrl+C due volte prima di procedere.
8. Esegui il deployment in Cloud Run
L'agente e Toolbox funzionano localmente. Questo passaggio esegue il deployment di entrambi come servizi Cloud Run, in modo che siano accessibili su internet. Il servizio Toolbox viene eseguito come server MCP su Cloud Run e il servizio agente si connette a questo server.
Preparare la Toolbox per il deployment
Crea una directory di deployment per il servizio Toolbox:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Crea il Dockerfile per la toolbox. Apri deploy-toolbox/Dockerfile nell'editor di Cloud Shell:
cloudshell edit deploy-toolbox/Dockerfile
e copia il seguente script
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
Il binario Toolbox e tools.yaml sono inclusi in un'immagine Debian minima. Cloud Run instrada il traffico alla porta 8080.
Esegui il deployment del servizio Strumenti
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
Questo comando invia l'origine a Cloud Build, crea un'immagine container, la invia ad Artifact Registry ed esegue il deployment su Cloud Run. Ci vorranno alcuni minuti. Possiamo esaminare il log del processo di deployment nel file logs/deploy_toolbox.log.
Preparare l'agente per il deployment
Mentre viene creata la casella degli strumenti, configura i file di deployment dell'agente.
Crea un Dockerfile nella radice del progetto. Apri Dockerfile nell'editor di Cloud Shell:
cloudshell edit Dockerfile
Quindi, copia i seguenti contenuti
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
Questo Dockerfile utilizza ghcr.io/astral-sh/uv come immagine di base, che include sia Python che uv preinstallati. Non è necessario installare uv separatamente tramite pip.
Crea un file .dockerignore per escludere i file non necessari dall'immagine container:
cloudshell edit .dockerignore
Poi copia il seguente script
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Esegui il deployment del servizio dell'agente
Attendi il completamento del deployment di Toolbox. Controlla di nuovo la procedura di deployment su logs/deploy_toolbox.log per verificarla. Quindi, recupera il relativo URL Cloud Run utilizzando il comando seguente
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Vedrai un output simile a questo
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Quindi, verifichiamo che Toolbox di Google Workspace sia in funzione:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Se l'output viene visualizzato come in questo esempio, il deployment è già riuscito
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
Ora eseguiamo il deployment dell'agente, passando l'URL di Toolbox come variabile di ambiente:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
Il codice dell'agente legge TOOLBOX_URL dall'ambiente (che hai configurato in precedenza). A livello locale punta a http://127.0.0.1:5000; su Cloud Run punta all'URL del servizio Toolbox. Non sono necessarie modifiche al codice.
Testare l'agente di cui è stato eseguito il deployment
Recupera l'URL Cloud Run dell'agente:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
Apri l'URL nel browser. Viene caricata l'interfaccia utente di sviluppo dell'ADK, la stessa che hai utilizzato localmente, ora in esecuzione su Cloud Run.
Seleziona restaurant_agent dal menu a discesa e testa:
What Italian dishes do you have?
I want something spicy and creamy
Entrambe le query funzionano tramite i servizi di cui è stato eseguito il deployment: l'agente su Cloud Run chiama Toolbox su Cloud Run, che esegue query su Cloud SQL.
9. Congratulazioni / Pulizia
Hai creato e implementato un assistente per menu di ristoranti intelligenti che utilizza MCP Toolbox for Databases per collegare un agente ADK e Cloud SQL PostgreSQL, con query SQL standard e ricerca vettoriale semantica.
Che cosa hai imparato
- In che modo MCP standardizza l'accesso agli strumenti per gli agenti AI e in che modo MCP Toolbox for Databases lo applica in modo specifico alle operazioni del database, sostituendo il codice del database personalizzato con la configurazione YAML dichiarativa
- Come configurare Cloud SQL PostgreSQL come origine dati di Toolbox utilizzando il tipo di origine
cloud-sql-postgres - Come definire strumenti di query SQL standard con istruzioni parametrizzate che impediscono SQL injection
- Come attivare la ricerca vettoriale utilizzando pgvector e
gemini-embedding-001, con il parametroembeddedByper l'embedding automatico delle query - In che modo
valueFromParamconsente l'inserimento automatico di vettori: il modello LLM fornisce una descrizione testuale e Toolbox copia, incorpora e archivia il vettore insieme al testo in modo invisibile - In che modo
ToolboxToolsetdi ADK carica gli strumenti da un server Toolbox in esecuzione, mantenendo il codice dell'agente minimo e la logica del database completamente disaccoppiata - Come eseguire il deployment del server MCP Toolbox e dell'agente ADK su Cloud Run come servizi separati
Pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse create in questo codelab, puoi eliminare le singole risorse o l'intero progetto.
Opzione 1: elimina il progetto (consigliata)
Il modo più semplice per liberare spazio è eliminare il progetto. Vengono rimosse tutte le risorse associate al progetto.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Opzione 2: elimina singole risorse
Se vuoi conservare il progetto, ma rimuovere solo le risorse create in questo codelab:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null