
1. はじめに
AI エージェントの有用性は、アクセスできるデータの質によって決まります。実際のデータのほとんどはデータベースに存在します。エージェントをデータベースに接続するには、通常、接続管理、クエリ ロジック、エージェント コード内のパイプラインの埋め込みを記述する必要があります。データベース アクセスが必要なエージェントはすべてこの作業を繰り返し、クエリを変更するたびにエージェントを再デプロイする必要があります。
この Codelab では、別の方法を紹介します。YAML ファイルでデータベース ツール(標準 SQL クエリ、ベクトル類似性検索、自動エンベディング生成など)を宣言し、データベース向け MCP ツールボックスが MCP サーバーとしてすべてのデータベース オペレーションを処理します。エージェント コードは最小限に抑えられます。ツールを読み込み、Gemini に呼び出すツールを決定させます。
作成するアプリの概要
「Foodie Finds」のレストラン コンシェルジュ - Gemini を搭載した ADK エージェント。標準フィルタ(カテゴリ、料理の種類)を使用してレストランのメニューを閲覧し、「辛くてベジタリアン向けの料理が食べたい」などの自然言語の説明で料理を見つけることができます。エージェントは、データベース向け MCP ツールボックス を介して Cloud SQL PostgreSQL データベースから読み取り、書き込みを行います。データベース向け MCP ツールボックス は、ベクトル検索の自動エンベディング生成など、すべてのデータベース アクセスを処理します。最終的に、ツールボックスとエージェントの両方が Cloud Run で実行されます。
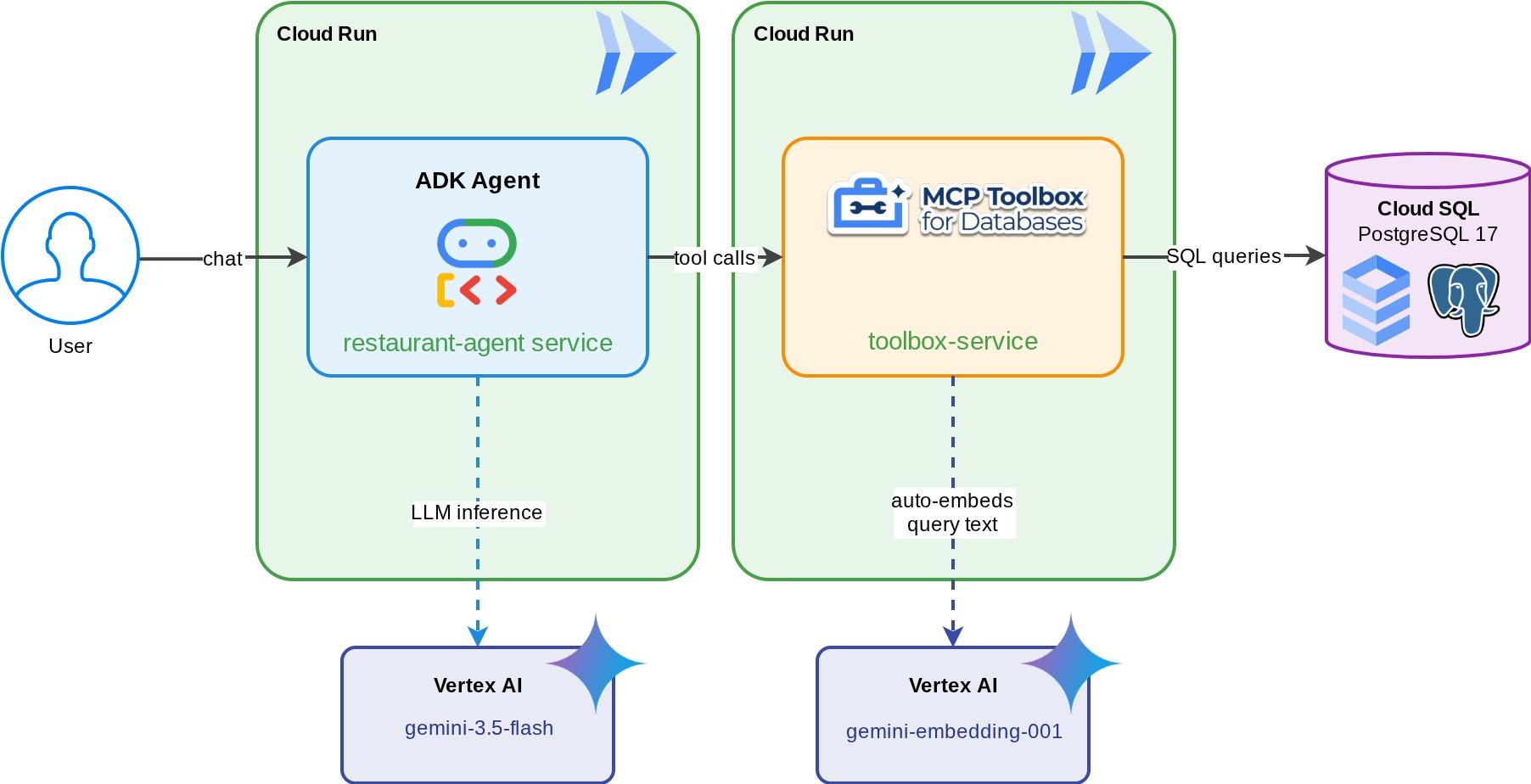
学習内容
- MCP(Model Context Protocol)が AI エージェントのツールアクセスを標準化する方法と、データベース向け MCP ツールボックスがこれをデータベース オペレーションに適用する方法
- ADK エージェントと Cloud SQL PostgreSQL の間のミドルウェアとしてデータベース向け MCP ツールボックスを設定する
tools.yamlでデータベース ツールを宣言的に定義する - エージェントにデータベース コードは不要ToolboxToolsetを使用して、実行中のツールボックス サーバーからツールを読み込む ADK エージェントを構築する- Cloud SQL の組み込みの
embedding()関数を使用してベクトル エンベディングを生成し、pgvectorでセマンティック検索を有効にする - 書き込みオペレーションでベクターを自動的に取り込むには、
valueFromParam機能を使用する - ツールボックス サーバーと ADK エージェントの両方を Cloud Run にデプロイする
前提条件
- トライアルの請求先アカウントを含む Google Cloud アカウント
- Python と SQL に関する基本的な知識
- Cloud Database と ADK の経験があると役立ちます
2. 環境をセットアップする
このステップでは、Cloud Shell 環境を準備し、Google Cloud プロジェクトを構成して、リファレンス リポジトリのクローンを作成します。
Cloud Shell を開く
ブラウザで Cloud Shell を開きます。Cloud Shell には、この Codelab に必要なすべてのツールがプリインストールされた環境が用意されています。プロンプトが表示されたら、[承認] をクリックします。
[表示] -> [ターミナル] をクリックしてターミナルを開きます。インターフェースは次のようになります。
これがメイン インターフェースになります。上部に IDE、下部にターミナルが表示されます。
作業ディレクトリを設定する
作業ディレクトリを作成します。この Codelab で記述するコードはすべて、次の場所にあります。
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
その後、シード スクリプトやログなどを管理するためのディレクトリをいくつか準備します。
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Google Cloud プロジェクトをセットアップする
ロケーション変数を含む .env ファイルを作成します。
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
ターミナルでのプロジェクト設定を簡素化するには、このプロジェクト設定スクリプトを作業ディレクトリにダウンロードします。
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
スクリプトを実行します。トライアルの請求先アカウントを確認し、新しいプロジェクトを作成(または既存のプロジェクトを検証)し、プロジェクト ID を現在のディレクトリの .env ファイルに保存し、gcloud でアクティブ プロジェクトを設定します。
bash setup_verify_trial_project.sh && source .env
このスクリプトによって行われる処理は次のとおりです。
- 有効なトライアルの請求先アカウントがあることを確認する
.envに既存のプロジェクトがあるかどうかを確認します(ある場合)。- 新しいプロジェクトを作成するか、既存のプロジェクトを再利用する
- トライアルの請求先アカウントをプロジェクトにリンクする
- プロジェクト ID を
.envに保存する - プロジェクトをアクティブな
gcloudプロジェクトとして設定する
Cloud Shell ターミナルのプロンプトで、作業ディレクトリの横にある黄色のテキストを確認して、プロジェクトが正しく設定されていることを確認します。プロジェクト ID が表示されているはずです。

必要な API を有効にする
次に、操作するプロダクトに対していくつかの API を有効にする必要があります。
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- Vertex AI API(
aiplatform.googleapis.com) - エージェントは Gemini モデルを使用し、ツールボックスはベクトル検索にエンベディング API を使用します。 - Cloud SQL Admin API(
sqladmin.googleapis.com) - PostgreSQL インスタンスをプロビジョニングして管理します。 - Compute Engine API(
compute.googleapis.com) - Cloud SQL インスタンスの作成に必要です。 - Cloud Run、Cloud Build、Artifact Registry - この Codelab の後半のデプロイ ステップで使用されます。
3. データベースの初期化用のスクリプトを準備する
このステップでは、Cloud SQL インスタンスの作成を開始し、インスタンスの準備が整うまで待機してから、データベースを作成し、求人情報でシードし、エンベディングを生成する自動設定スクリプトを実行します。
まず、データベースのパスワードを .env ファイルに追加して、再読み込みします。
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
インスタンスとデータベースの作成用の Bash スクリプトを作成する
次のコマンドを使用して scripts/setup_database.sh スクリプトを作成します。
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
次に、次のコードを scripts/setup_database.sh ファイルにコピーします。
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
データ シード用の Python スクリプトを作成する
次に、次のコマンドを使用してシード スクリプト Python ファイル scripts/setup_restaurant_db.py を作成します。
cloudshell edit scripts/setup_restaurant_db.py
次に、次のコードを scripts/setup_restaurant_db.py ファイルにコピーします。
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
次のステップに進みましょう
4. データベースを作成して初期化する
これでスクリプトを実行する準備が整いました。準備したスクリプトを実行するには Python が必要なので、まず Python を準備しましょう。
Python プロジェクトを設定する
uv は、Rust で記述された高速な Python パッケージおよびプロジェクト管理ツールです(uv のドキュメント)。このコードラボでは、Python プロジェクトの保守を高速かつ簡単に行うために使用します。
Python プロジェクトを初期化し、必要な依存関係を追加します。
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
ここでは、cloud-sql-python-connector Python SDK を使用して、アプリケーションのデフォルト認証情報を使用して認証されたデータベース インスタンスとの安全な接続を初期化しています。
設定スクリプトを実行する
次のコマンドを使用して、設定スクリプトをバックグラウンドで実行し、logs/atabase_setup.log ファイルに書き込まれるコンソール出力を確認します。この処理が完了するまで、次のセクションに進むことができます。
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Toolbox バイナリをダウンロードする
このチュートリアルでは MCP ツールボックスを使用します。幸いなことに、MCP ツールボックスには Linux 環境ですぐに使用できる事前構築済みのバイナリが付属しています。ダウンロードには時間がかかるため、バックグラウンドでダウンロードしましょう。次のコマンドを実行してバイナリをダウンロードし、logs/toolbox_dl.log で出力ログを確認します。ダウンロードが完了するまで、次のセクションに進んでください。
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
設定スクリプト scripts/setup_database.sh について
次に、前に構成した設定スクリプトについて説明します。このスクリプトは次の処理を行います。
- 最初に実行するコマンドは、次のフラグを指定した
gcloud sql instances createコマンドです。
db-custom-1-3840は、ENTERPRISEエディションで最小の専用コア Cloud SQL 階層(1 vCPU、3.75 GB RAM)です。詳細については、こちらをご覧ください。Vertex AI ML 統合には専用コアが必要です。共有コア階層(db-f1-micro、db-g1-small)ではサポートされていません。--root-passwordは、デフォルトのpostgresユーザーのパスワードを設定します。--enable-google-ml-integrationを使用すると、Cloud SQL と Vertex AI の組み込みインテグレーションが有効になり、embedding()関数を使用して SQL からエンベディング モデルを直接呼び出すことができます。
- インスタンスがすでに
RUNNABLEステータスになっているかどうかを確認する gcloud projects add-iam-policy-bindingコマンドを使用して、Cloud SQL インスタンスのサービス アカウントに Vertex AI を呼び出す権限を付与します。これは、データベースのシード時に使用する組み込みのembedding()関数に必要です。- データベースを作成する
- シーディング スクリプト
setup_restaurant_db.pyスクリプトの実行
シード スクリプト scripts/setup_restaurant_db.py について
次に、シード スクリプトについて説明します。このスクリプトは次の処理を行います。
- データベース インスタンスへの接続を初期化する
- 次の 2 つの PostgreSQL 拡張機能をインストールします。
google_ml_integration-embedding()SQL 関数を提供します。この関数は、SQL から Vertex AI エンベディング モデルを直接呼び出します。これは、restaurant_db内で ML 関数を使用できるようにするデータベース レベルの拡張機能です。インスタンスの作成時に設定するインスタンス レベルのフラグ(--enable-google-ml-integration)により、Cloud SQL VM が Vertex AI にアクセスできるようになります。この拡張機能により、この特定のデータベース内で SQL 関数を使用できるようになります。vector(pgvector) - エンベディングの保存とクエリを行うためのvectorデータ型と距離演算子を追加します。
- テーブルを作成します。
description_embedding列はvector(3072)(3, 072 次元のベクトルを格納するpgvector列)であることに注意してください。 - 初期メニュー項目のデータをシードする
descriptionフィールドからエンベディング データを生成し、embedding()関数を介して組み込みの Vertex インテグレーションを使用してdescription_embeddingを入力します。
embedding('gemini-embedding-001', description)- SQL から Vertex AI の Gemini エンベディング モデルを直接呼び出し、各ジョブのdescriptionテキストを渡します。これは、シードスクリプトでインストールしたgoogle_ml_integration拡張機能です。::vector- 返された浮動小数点配列を pgvector のvector型にキャストして、距離演算子で保存してクエリできるようにします。UPDATEは 15 行すべてで実行され、職務説明ごとに 1 つの 3, 072 次元エンベディングが生成されます。
これにより、エージェントがアクセスする初期データが準備されます。
5. データベース向け MCP ツールボックスを構成する
このステップでは、データベース向け MCP ツールボックス を導入し、Cloud SQL インスタンスに接続するように構成して、2 つの標準 SQL クエリツールを定義します。
MCP とは何か、ツールボックスを使用する理由
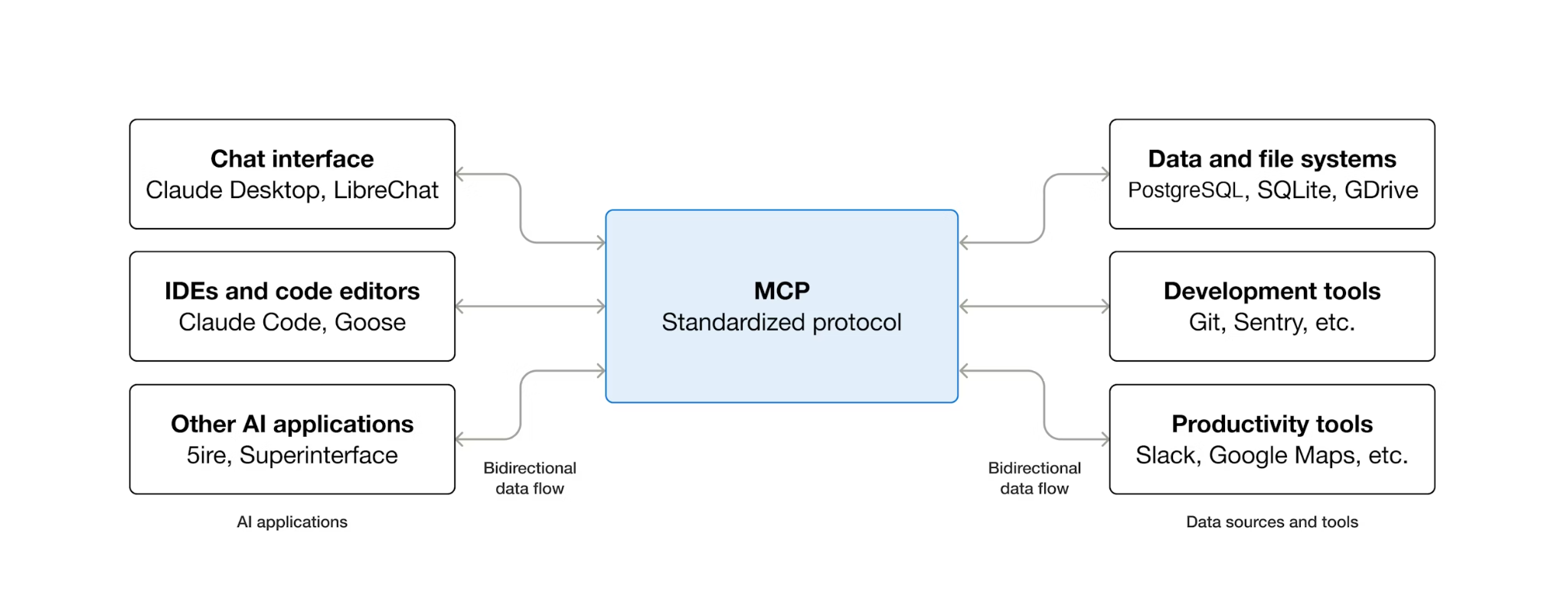
MCP(Model Context Protocol)は、AI エージェントが外部ツールを検出して操作する方法を標準化するオープン プロトコルです。クライアント サーバー モデルを定義します。エージェントは MCP クライアントをホストし、ツールは MCP サーバーによって公開されます。MCP 互換のクライアントは MCP 互換のサーバーを使用できます。エージェントはツールごとにカスタム統合コードを必要としません。
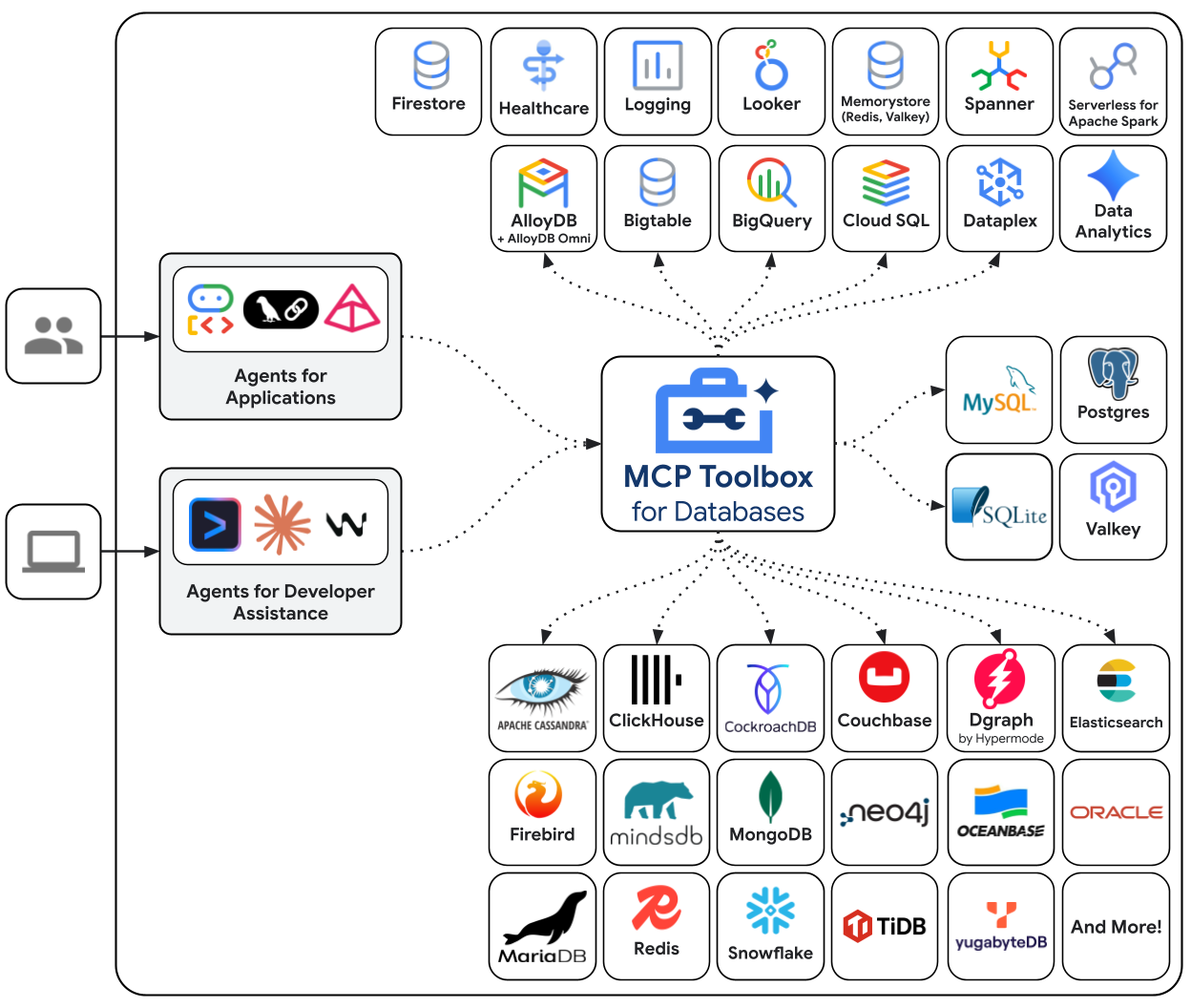
データベース向け MCP ツールボックスは、データベース アクセス専用に構築されたオープンソースの MCP サーバーです。これがないと、データベース接続を開き、接続プールを管理し、SQL インジェクションを防ぐためにパラメータ化されたクエリを構築し、エラーを処理し、そのコードをすべてエージェント内に埋め込む Python 関数を作成する必要があります。データベース アクセスを必要とするすべてのエージェントがこの作業を繰り返します。クエリを変更するには、エージェントを再デプロイする必要があります。
ツールボックスでは、YAML ファイルを記述します。各ツールは、パラメータ化された SQL ステートメントにマッピングされます。ツールボックスは、接続プーリング、パラメータ化されたクエリ、認証、オブザーバビリティを処理します。ツールはエージェントから切り離されています。エージェント コードを変更することなく、tools.yaml を編集してツールボックスを再起動することで、クエリを更新できます。同じツールは、ADK、LangGraph、LlamaIndex、または MCP 互換のフレームワークで動作します。
ツールの構成を記述する
次に、Cloud Shell コードエディタで tools.yaml というファイルを作成して、ツールの構成を設定する必要があります。
cloudshell edit tools.yaml
このファイルはマルチドキュメント YAML を使用します。--- で区切られた各ブロックはスタンドアロン リソースです。すべてのリソースには、そのリソースが何であるかを宣言する kind(データベース接続の場合は sources、エージェント呼び出し可能なアクションの場合は tools)と、バックエンドを指定する type(ソースの場合は cloud-sql-postgres、SQL ベースのツールの場合は postgres-sql)があります。ツールは name でソースを参照します。これにより、Toolbox は実行する接続プールを認識します。環境変数は ${VAR_NAME} 構文を使用し、起動時に解決されます。
次のスクリプトを tools.yaml ファイルにコピーします。
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
このスクリプトでは、次のリソースを定義します。
- Source(
restaurant-db) - Cloud SQL PostgreSQL インスタンスへの接続方法を Toolbox に指示します。cloud-sql-postgresタイプは内部で Cloud SQL コネクタを使用し、認証と安全な接続を自動的に処理します。${GOOGLE_CLOUD_PROJECT}、${REGION}、${DB_PASSWORD}のプレースホルダは、起動時に環境変数から解決されます。
次に、tools.yaml の --- 記号の下に次のスクリプトを追加します。
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
このスクリプトでは、次のリソースを定義します。
- ツール 1 と 2(
search-menu、get-item-details) - 標準 SQL クエリツール。各マッピングは、ツール名(エージェントに表示されるもの)をパラメータ化された SQL ステートメント(データベースで実行されるもの)にマッピングします。パラメータは$1、$2位置プレースホルダを使用します。Toolbox はこれらをプリペアド ステートメントとして実行するため、SQL インジェクションを防ぐことができます。
次に、tools.yaml の --- 記号の下に次のスクリプトを追加します。
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
このスクリプトでは、次のリソースを定義します。
- エンベディング モデル(
gemini-embedding) - 3,072 次元のテキスト エンベディングを生成するために Gemini のgemini-embedding-001モデルを呼び出すように Toolbox を構成します。Toolbox はアプリケーションのデフォルト認証情報(ADC)を使用して認証を行います。Cloud Shell または Cloud Run で API キーは必要ありません。ここで構成するdimensionは、データベースのシード用に以前に構成したdimensionと同じである必要があります。
次に、tools.yaml の --- 記号の下に次のスクリプトを追加します。
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
このスクリプトでは、次のリソースを定義します。
- ツール 3(
search-menu-by-description) - ベクトル検索ツール。search_queryパラメータにはembeddedBy: gemini-embeddingがあります。これは、Toolbox に未加工のテキストをインターセプトしてエンベディング モデルに送信し、結果のベクトルを SQL ステートメントで使用するように指示します。<=>演算子は pgvector のコサイン距離です。値が小さいほど、説明が類似していることを意味します。
最後に、tools.yaml の --- 記号の下に最後のツールを追加します。
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
このスクリプトでは、次のリソースを定義します。
- ツール 4(
add-menu-item) - ベクトル取り込みを示します。description_vectorパラメータには、次の 2 つの特別なフィールドがあります。 valueFromParam: description- ツールボックスは、descriptionパラメータの値をこのパラメータにコピーします。LLM はこのパラメータを認識しません。embeddedBy: gemini-embedding- ツールボックスは、コピーしたテキストをベクトルに埋め込んでから SQL に渡します。
結果: エージェントがエンベディングについて何も知らなくても、1 つのツール呼び出しで未加工の説明テキストとそのベクトル エンベディングの両方が保存されます。
マルチドキュメント YAML 形式では、各リソースが --- で区切られます。各ドキュメントには、その内容を定義する kind、name、type の各フィールドがあります。要約すると、次のすべての項目がすでに構成されています。
- ソース データベースを定義する
- 標準フィルタを使用してデータベースをクエリするツール(ツール 1 と 2)を定義します。
- エンベディング モデルを定義する
- ベクトル検索を行うツール(ツール 3)をデータベースに定義します。
- ベクトルデータの取り込み(ツール 4)を行うツールをデータベースに定義する
6. MCP ツールボックス サーバーの実行
前の手順で、MCP ツールボックスに必要な構成はすでに設定しました。これで、サーバーを実行する準備が整いました。
シードデータを検証する
Toolbox を起動する前に、データベースの設定が完了していることを確認しましょう。次のコマンドを使用して Python スクリプト scripts/verify_database.py を作成します。
cloudshell edit scripts/verify_seed.py
次に、次のコードを scripts/verify_seed.py ファイルにコピーします。
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
このスクリプトは、メニュー アイテムのデータ数とそのエンベディングを確認します。次のコマンドを使用してスクリプトを実行します。
uv run scripts/verify_seed.py
次のターミナル出力が表示された場合は、データが準備完了状態であることを示しています。
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
ツールボックス サーバーを起動する
前の設定手順で、toolbox 実行可能ファイルをダウンロードしました。このバイナリ ファイルが存在し、正常にダウンロードされていることを確認します。存在しない場合は、ダウンロードして完了するまで待ちます。
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
.env 変数を MCP ツールボックスによって実行される子プロセスに公開する必要があります。次のコマンドを実行してツールボックス サーバーを起動し、そのコンソール出力を logs/mcp_toolbox.log ファイルに記録します。
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
logs/mcp_toolbox.log ファイルに、次のようにサーバーの準備が整ったことを確認する出力が表示されます。
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
ツールを確認する
Toolbox API をクエリして、登録されているすべてのツールを一覧表示します。
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
次のように、ツールとその説明とパラメータが表示されます。
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
search-menu ツールを直接テストします。
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
レスポンスには、シードデータからイタリアのメインコース料理が含まれている必要があります。
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. ADK エージェントをビルドする
このプロジェクトでは Python で ADK を使用します。必要な依存関係を追加しましょう。
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk- Google の Agent Development Kit(Gemini SDK を含む)toolbox-adk- データベース向け MCP ツールボックスの ADK 統合。
エージェントのディレクトリ構造を作成する
ADK では、特定フォルダ レイアウト(__init__.py、agent.py、.env を含むエージェントの名前のディレクトリ)が想定されています。このため、構造をすばやく確立するためのコマンドが組み込まれています。
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
ディレクトリは次のようになります。
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
次に、ADK エージェントを実行中のツールボックス サーバーに統合し、標準クエリ、セマンティック検索、ベクトル取り込みの 4 つのツールすべてをテストする必要があります。エージェント コードは最小限で、すべてのデータベース ロジックは tools.yaml に存在します。
エージェントの環境を構成する
ADK は、前の手順で設定したシェル環境から GOOGLE_GENAI_USE_VERTEXAI、GOOGLE_CLOUD_PROJECT、GOOGLE_CLOUD_LOCATION を読み取ります。エージェント固有の変数は TOOLBOX_URL のみです。これをエージェントの .env ファイルに追加します。
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
エージェント モジュールを更新する
Cloud Shell エディタで restaurant_agent/agent.py を開く
cloudshell edit restaurant_agent/agent.py
次のコードで内容を上書きします。
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
ここにはデータベース コードはありません。ToolboxToolset は起動時に Toolbox サーバーに接続し、利用可能なすべてのツールを読み込みます。エージェントはツールを名前で呼び出します。Toolbox は、これらの呼び出しを Cloud SQL に対する SQL クエリに変換します。
TOOLBOX_URL 環境変数は、ローカル開発ではデフォルトで http://127.0.0.1:5000 に設定されます。後で Cloud Run にデプロイするときに、Toolbox サービスの Cloud Run URL でこの値をオーバーライドします。コードを変更する必要はありません。
エージェントをテストする
ADK 開発 UI を起動します。
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Cloud Shell のウェブ プレビュー機能を使用するか、ターミナルに表示された URL を Ctrl+クリックして、ターミナルに表示された URL(通常は http://localhost:8000)を開きます。左上のエージェント プルダウンから [restaurant_agent] を選択します。
標準クエリをテストする
次のプロンプトを試して、標準 SQL ツールを検証します。
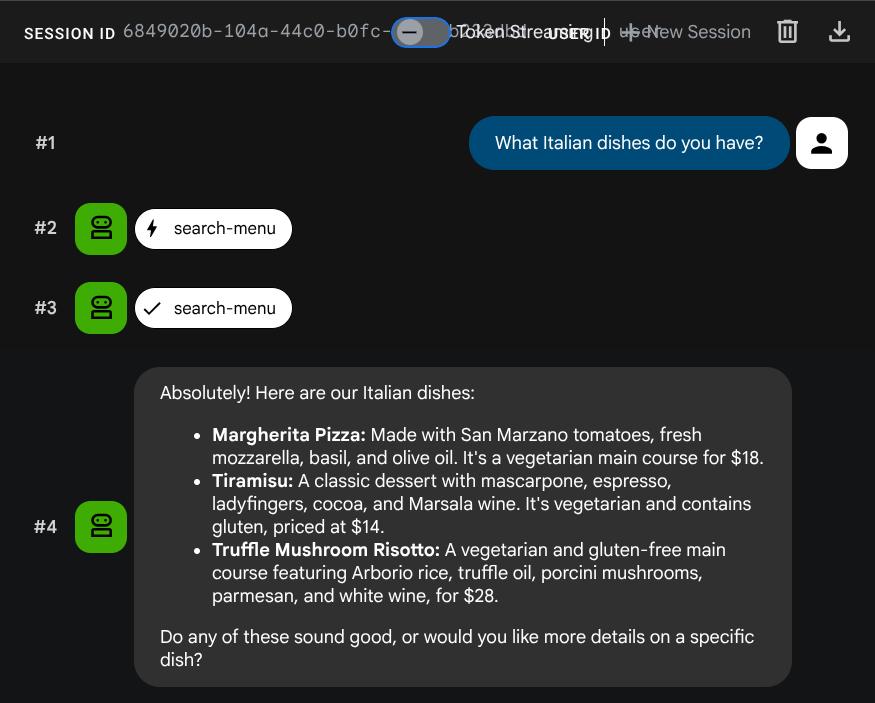
What Italian dishes do you have?
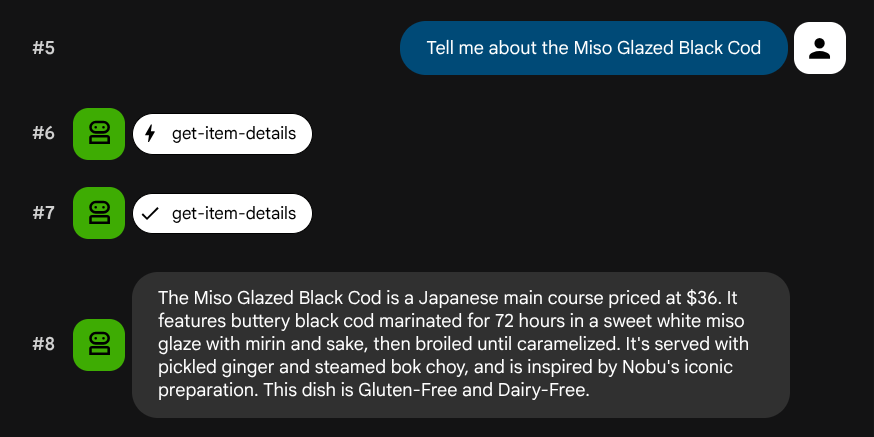
Tell me about the Miso Glazed Black Cod
セマンティック検索をテストする
特定のロールや技術スタックにマッピングされない自然言語の説明を試してください。
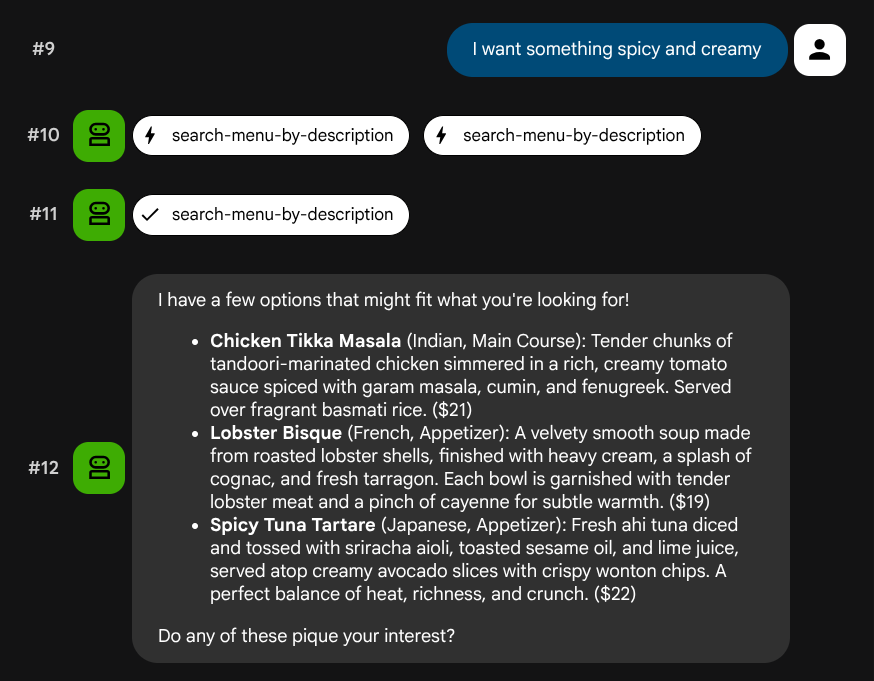
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
エージェントはクエリタイプに基づいて適切なツールを選択しようとします。構造化フィルタは search-menu を通過し、自然言語の説明は search-menu-by-description を通過します。
ベクトル取り込みをテストする
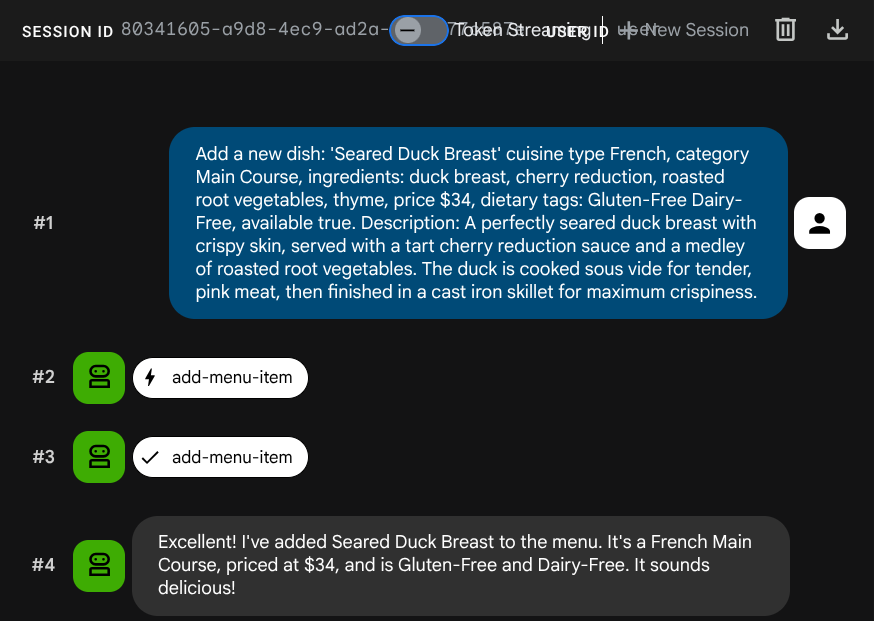
エージェントに新しいジョブを追加するよう依頼します。
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
検索してみましょう。
Find me something with rich, gamey flavors and fruit sauce
エンベディングは INSERT 中に自動的に生成されたため、個別の手順は必要ありません。
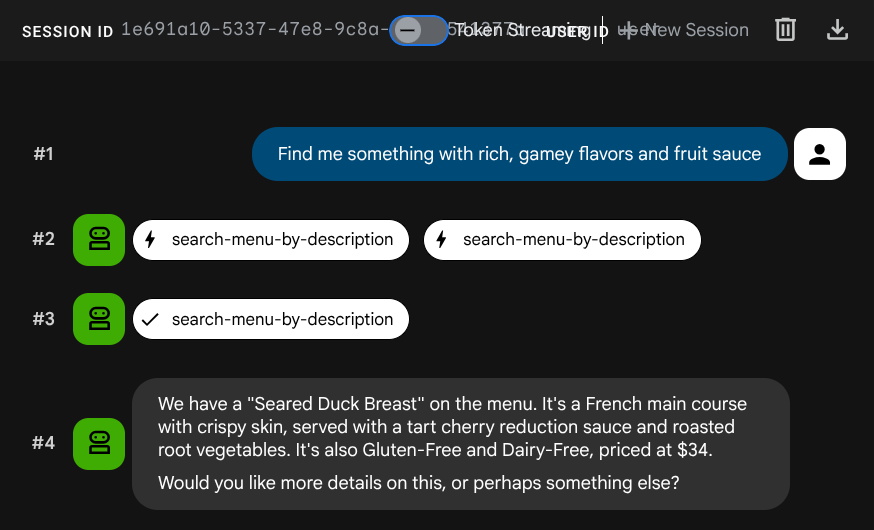
これで、ADK、MCP ツールボックス、CloudSQL を利用した完全なエージェント RAG アプリケーションが完成しました。これで完了です。さらに、これらのアプリを Cloud Run にデプロイしましょう。
次に、Ctrl+C キーを 2 回押してプロセスを終了し、デベロッパー UI を停止してから続行します。
8. Cloud Run にデプロイする
エージェントとツールボックスはローカルで動作します。この手順では、両方を Cloud Run サービスとしてデプロイし、インターネット経由でアクセスできるようにします。ツールボックス サービスは Cloud Run の MCP サーバーとして実行され、エージェント サービスがそれに接続します。
デプロイ用に Toolbox を準備する
Toolbox サービスのデプロイ ディレクトリを作成します。
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Toolbox の Dockerfile を作成します。Cloud Shell エディタで deploy-toolbox/Dockerfile を開きます。
cloudshell edit deploy-toolbox/Dockerfile
次のスクリプトをコピーします。
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
Toolbox バイナリと tools.yaml は最小限の Debian イメージにパッケージ化されます。Cloud Run はトラフィックをポート 8080 に転送します。
ツールボックス サービスをデプロイする
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
このコマンドは、ソースを Cloud Build に送信し、コンテナ イメージをビルドして Artifact Registry に push し、Cloud Run にデプロイします。数分かかります。デプロイ プロセスのログは logs/deploy_toolbox.log ファイルで確認できます。
デプロイ用にエージェントを準備する
ツールボックスのビルド中に、エージェントのデプロイ ファイルを設定します。
プロジェクトのルートに Dockerfile を作成します。Cloud Shell エディタで Dockerfile を開きます。
cloudshell edit Dockerfile
次に、次のコンテンツをコピーします。
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
この Dockerfile は、Python と uv の両方がプリインストールされている ghcr.io/astral-sh/uv をベースイメージとして使用します。pip を介して uv を個別にインストールする必要はありません。
.dockerignore ファイルを作成して、コンテナ イメージから不要なファイルを除外します。
cloudshell edit .dockerignore
次のスクリプトをコピーして貼り付けます。
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
エージェント サービスをデプロイする
ツールボックスのデプロイが完了するまで待ちます。logs/deploy_toolbox.log でデプロイ プロセスを再度確認して、プロセスを確認します。次に、次のコマンドを使用して Cloud Run URL を取得します。
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
次のような出力が表示されます。
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
次に、デプロイされた Toolbox が動作していることを確認します。
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
出力がこの例のように表示された場合、デプロイはすでに成功しています。
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
次に、ツールボックスの URL を環境変数として渡して、エージェントをデプロイします。
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
エージェント コードは環境から TOOLBOX_URL を読み取ります(これは以前に設定しました)。ローカルでは http://127.0.0.1:5000 を指し、Cloud Run では Toolbox サービスの URL を指します。コードの変更は必要ありません。
デプロイしたエージェントをテストする
エージェントの Cloud Run URL を取得します。
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
ブラウザでその URL を開きます。ADK デベロッパー UI が読み込まれます。これは、ローカルで使用していたのと同じインターフェースで、Cloud Run で実行されています。
プルダウンから restaurant_agent を選択してテストします。
What Italian dishes do you have?
I want something spicy and creamy
どちらのクエリも、デプロイされたサービスを介して機能します。Cloud Run のエージェントが Cloud Run の Toolbox を呼び出し、Cloud SQL をクエリします。
9. おめでとうございます / クリーンアップ
データベース向け MCP ツールボックスを使用して ADK エージェントと Cloud SQL PostgreSQL を接続するスマート レストラン メニュー アシスタントを構築してデプロイしました。このアシスタントは、標準 SQL クエリとセマンティック ベクトル検索の両方を使用します。
学習した内容
- MCP が AI エージェントのツールアクセスを標準化する方法と、データベース向け MCP ツールボックスがこれをデータベース オペレーションに適用する方法(カスタム データベース コードを宣言型 YAML 構成に置き換える)
cloud-sql-postgresソースタイプを使用して Cloud SQL PostgreSQL を Toolbox データソースとして構成する方法- SQL インジェクションを防ぐパラメータ化されたステートメントを使用して標準 SQL クエリツールを定義する方法
- pgvector と
gemini-embedding-001を使用してベクトル検索を有効にする方法(自動クエリ エンベディング用のembeddedByパラメータを使用) valueFromParamが自動ベクトル取り込みを可能にする仕組み - LLM がテキストの説明を提供し、Toolbox がテキストとともにベクトルをコピー、埋め込み、保存する- ADK の
ToolboxToolsetが実行中の Toolbox サーバーからツールを読み込み、エージェント コードを最小限に抑え、データベース ロジックを完全に分離する方法 - ツールボックス MCP サーバーと ADK エージェントの両方を個別のサービスとして Cloud Run にデプロイする方法
クリーンアップ
この Codelab で作成したリソースについて、Google Cloud アカウントに課金されないようにするには、個々のリソースを削除するか、プロジェクト全体を削除します。
オプション 1: プロジェクトを削除する(推奨)
最も簡単なクリーンアップ方法は、プロジェクトを削除することです。これにより、プロジェクトに関連付けられているすべてのリソースが削除されます。
gcloud projects delete $GOOGLE_CLOUD_PROJECT
オプション 2: 個々のリソースを削除する
プロジェクトを保持し、この Codelab で作成したリソースのみを削除する場合は:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null