
1. Wprowadzenie
Agenty AI są tak przydatne, jak dane, do których mają dostęp. Większość danych w świecie rzeczywistym znajduje się w bazach danych, a łączenie agentów z bazami danych zwykle oznacza pisanie kodu zarządzania połączeniami, logiki zapytań i potoków osadzania w kodzie agenta. Każdy agent, który potrzebuje dostępu do bazy danych, powtarza tę pracę, a każda zmiana zapytania wymaga ponownego wdrożenia agenta.
W tym laboratorium znajdziesz inne podejście. Narzędzia bazy danych deklarujesz w pliku YAML – standardowa wersja SQL, wyszukiwanie podobieństwa wektorowego, a nawet automatyczne generowanie wektorów dystrybucyjnych. MCP Toolbox for Databases obsługuje wszystkie operacje na bazie danych jako serwer MCP. Kod agenta pozostaje minimalny: wczytaj narzędzia i pozwól Gemini zdecydować, które z nich wywołać.
Co utworzysz
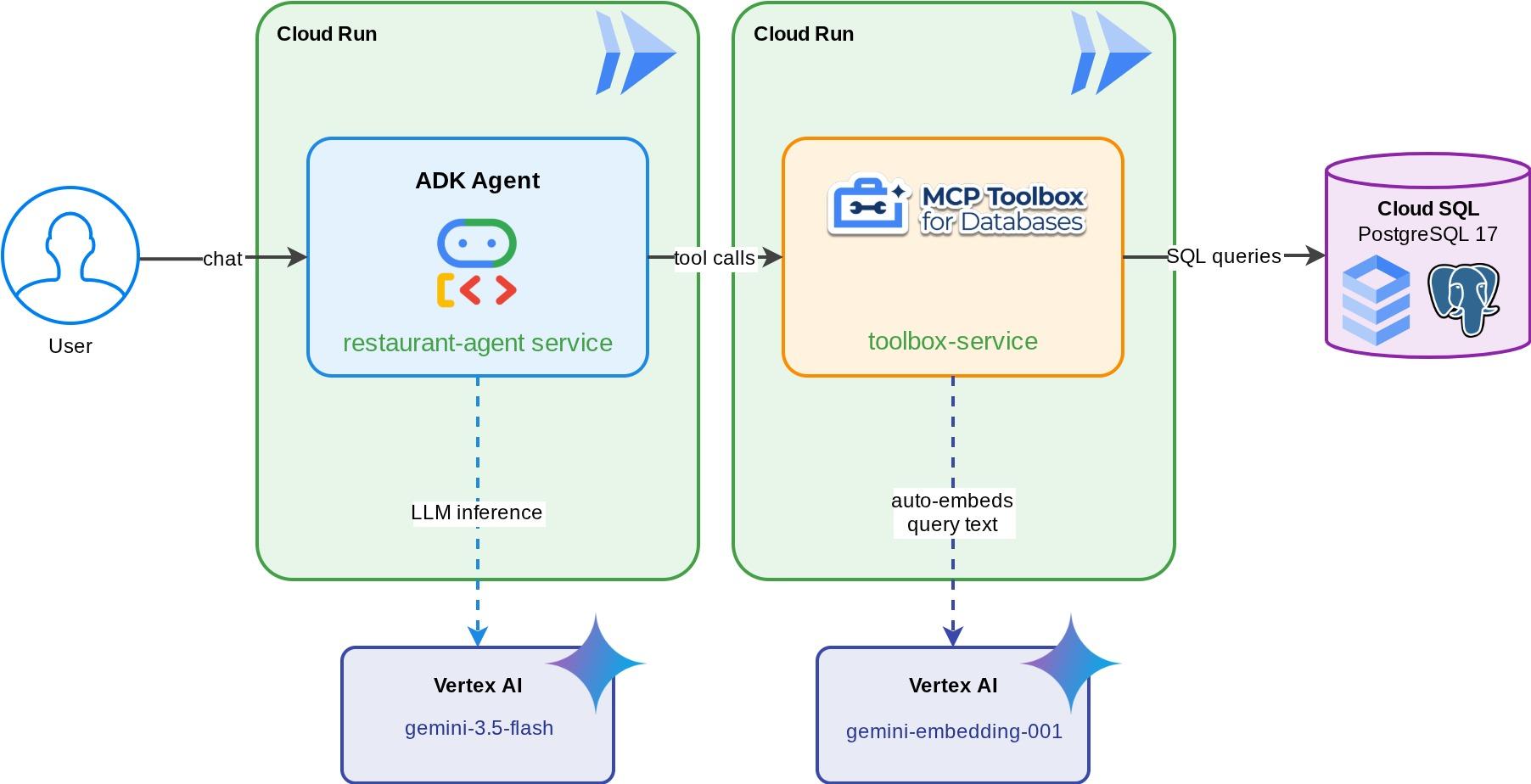
Konsjerż restauracyjny w sekcji „Odkrycia kulinarne” – agent ADK oparty na Gemini, który pomaga gościom przeglądać menu restauracji za pomocą standardowych filtrów (kategoria, rodzaj kuchni) i odkrywać dania na podstawie opisów w języku naturalnym, np. „Chcę coś pikantnego i wegetariańskiego”. Agent odczytuje dane z bazy danych Cloud SQL PostgreSQL i zapisuje w niej dane w całości za pomocą MCP Toolbox for Databases, który obsługuje cały dostęp do bazy danych, w tym automatyczne generowanie wektorów dystrybucyjnych na potrzeby wyszukiwania wektorowego. Na koniec zarówno Toolbox, jak i agent będą działać w Cloud Run.
Czego się nauczysz
- Jak MCP (Model Context Protocol) standaryzuje dostęp do narzędzi dla agentów AI i jak MCP Toolbox for Databases stosuje to do operacji na bazie danych
- Konfigurowanie MCP Toolbox for Databases jako oprogramowania pośredniczącego między agentem ADK a Cloud SQL PostgreSQL
- Zdefiniuj narzędzia bazy danych deklaratywnie w
tools.yaml– w agencie nie ma kodu bazy danych. - Tworzenie agenta ADK, który wczytuje narzędzia z działającego serwera zestawu narzędzi za pomocą
ToolboxToolset - Generowanie wektorów dystrybucyjnych za pomocą wbudowanej funkcji
embedding()Cloud SQL i włączanie wyszukiwania semantycznego za pomocą funkcjipgvector - Używanie funkcji
valueFromParamdo automatycznego wczytywania wektorów podczas operacji zapisu - Wdrażanie serwera Toolbox i agenta pakietu ADK w Cloud Run
Wymagania wstępne
- Konto Google Cloud z próbnym kontem rozliczeniowym
- podstawowa znajomość języków Python i SQL;
- Przydatne będzie wcześniejsze doświadczenie z bazą danych w chmurze i zestawem ADK.
2. Konfigurowanie środowiska
Ten krok przygotowuje środowisko Cloud Shell, konfiguruje projekt Google Cloud i klonuje repozytorium referencyjne.
Otwieranie Cloud Shell
Otwórz Cloud Shell w przeglądarce. Cloud Shell zapewnia wstępnie skonfigurowane środowisko ze wszystkimi narzędziami potrzebnymi do tego ćwiczenia. Gdy pojawi się prośba o autoryzację, kliknij Autoryzuj.
Następnie kliknij „Widok” –> „Terminal”, aby otworzyć terminal.Interfejs powinien wyglądać podobnie do tego:
Będzie to nasz główny interfejs: IDE u góry, terminal u dołu.
Konfigurowanie katalogu roboczego
Utwórz katalog roboczy. Cały kod, który napiszesz w tym ćwiczeniu, będzie się znajdować tutaj:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
Następnie przygotuj kilka katalogów do zarządzania takimi elementami jak skrypty początkowe i logi.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Konfigurowanie projektu Google Cloud
Utwórz plik .env ze zmiennymi lokalizacji:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Aby uprościć konfigurację projektu w terminalu, pobierz ten skrypt konfiguracji projektu do katalogu roboczego:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Uruchom skrypt. Weryfikuje ono Twoje próbne konto rozliczeniowe, tworzy nowy projekt (lub weryfikuje istniejący), zapisuje identyfikator projektu w pliku .env w bieżącym katalogu i ustawia aktywny projekt w gcloud.
bash setup_verify_trial_project.sh && source .env
Skrypt:
- Sprawdź, czy masz aktywne konto rozliczeniowe w wersji próbnej
- Sprawdź, czy w
.envistnieje projekt (jeśli tak) - Utwórz nowy projekt lub użyj istniejącego.
- Połącz próbne konto rozliczeniowe z projektem
- Zapisz identyfikator projektu w
.env. - Ustaw projekt jako aktywny projekt
gcloud.
Sprawdź, czy projekt jest prawidłowo ustawiony, sprawdzając żółty tekst obok katalogu roboczego w wierszu poleceń terminala Cloud Shell. Powinien wyświetlać identyfikator projektu.

Aktywowanie wymaganego interfejsu API
Następnie musimy włączyć kilka interfejsów API dla usługi, z którą będziemy wchodzić w interakcje:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- Vertex AI API (
aiplatform.googleapis.com) – Twój agent korzysta z modeli Gemini, a Toolbox używa interfejsu Embedding API do wyszukiwania wektorowego. - Cloud SQL Admin API (
sqladmin.googleapis.com) – możesz udostępniać instancję PostgreSQL i nią zarządzać. - Interfejs Compute Engine API (
compute.googleapis.com) – wymagany do tworzenia instancji Cloud SQL. - Cloud Run, Cloud Build, Artifact Registry – używane w kroku wdrażania w dalszej części tego samouczka
3. Przygotowywanie skryptów do inicjowania bazy danych
Ten krok rozpoczyna tworzenie instancji Cloud SQL i uruchamia automatyczny skrypt konfiguracji, który czeka na gotowość instancji, a następnie tworzy bazę danych, wypełnia ją ofertami pracy i generuje osadzanie – wszystko w ramach jednej operacji.
Najpierw dodaj hasło do bazy danych do pliku .env i wczytaj go ponownie:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Tworzenie skryptu Bash do utworzenia instancji i bazy danych
Następnie utwórz skrypt scripts/setup_database.sh za pomocą tego polecenia:
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Następnie skopiuj ten kod do pliku scripts/setup_database.sh.
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Tworzenie skryptu w Pythonie do wypełniania danych
Następnie utwórz plik Pythona ze skryptem początkowym scripts/setup_restaurant_db.py za pomocą poniższego polecenia.
cloudshell edit scripts/setup_restaurant_db.py
Następnie skopiuj ten kod do pliku scripts/setup_restaurant_db.py.
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Przejdźmy teraz do następnego kroku.
4. Tworzenie i inicjowanie bazy danych
Skrypty są teraz gotowe do wykonania. Do wykonania przygotowanego skryptu potrzebujemy Pythona, więc najpierw przygotujmy go.
Konfigurowanie projektu w Pythonie
uv to szybki menedżer pakietów i projektów Pythona napisany w języku Rust ( dokumentacja uv ). W tym ćwiczeniu używamy go ze względu na szybkość i prostotę utrzymywania projektu w Pythonie.
Zainicjuj projekt w Pythonie i dodaj wymagane zależności:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Pamiętaj, że do zainicjowania bezpiecznego połączenia z instancją bazy danych, która jest uwierzytelniana za pomocą domyślnych danych logowania aplikacji, używamy tutaj cloud-sql-python-connectorpakietu SDK Pythona.
Uruchom skrypt konfiguracji
Teraz możemy uruchomić skrypt konfiguracji w tle i sprawdzić dane wyjściowe konsoli, które zostaną zapisane w pliku logs/atabase_setup.log za pomocą tego polecenia. Nie musisz czekać na zakończenie tego procesu. Możesz przejść do następnej sekcji.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Pobierz plik binarny Toolbox
W tym samouczku użyjemy zestawu narzędzi MCP. Na szczęście zawiera on gotowy plik binarny, który można wykorzystać w środowisku Linux. Pobierzmy go teraz w tle, ponieważ zajmie to trochę czasu. Aby pobrać plik binarny i sprawdzić dziennik danych wyjściowych na urządzeniu logs/toolbox_dl.log, uruchom to polecenie . Nie musisz czekać na zakończenie tego procesu. Możesz przejść do następnej sekcji.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Informacje o skrypcie konfiguracji scripts/setup_database.sh
Teraz spróbujmy zrozumieć skrypt konfiguracji, który został wcześniej skonfigurowany. Wykonuje on te czynności:
- Pierwsze polecenie, które tam wykonujemy, to polecenie
gcloud sql instances createz tą flagą:
db-custom-1-3840to najmniejsza warstwa Cloud SQL z dedykowanym rdzeniem (1 vCPU, 3,75 GB pamięci RAM) w wersjiENTERPRISE. Więcej informacji znajdziesz tutaj. Dedykowany rdzeń jest wymagany w przypadku integracji Vertex AI ML – warstwy ze współużytkowanym rdzeniem (db-f1-micro,db-g1-small) nie obsługują tej funkcji.--root-passwordustawia hasło domyślnego użytkownikapostgres.--enable-google-ml-integrationwłącza wbudowaną integrację Cloud SQL z Vertex AI, która umożliwia wywoływanie modeli osadzania bezpośrednio z SQL za pomocą funkcjiembedding().
- Sprawdź, czy instancja ma już stan
RUNNABLE. - Przyznaj kontu usługi instancji Cloud SQL uprawnienia do wywoływania Vertex AI za pomocą polecenia
gcloud projects add-iam-policy-binding. Jest to wymagane w przypadku wbudowanej funkcjiembedding(), której użyjemy podczas wypełniania bazy danych. - Tworzenie bazy danych
- Uruchamianie skryptu początkowego
setup_restaurant_db.pyscript
Informacje o skrypcie początkowym scripts/setup_restaurant_db.py
Skrypt początkowy wykonuje te czynności:
- Inicjowanie połączenia z instancją bazy danych
- Instaluje 2 rozszerzenia PostgreSQL:
google_ml_integration– udostępnia funkcję SQLembedding(), która wywołuje modele wektorów dystrybucyjnych Vertex AI bezpośrednio z SQL. Jest to rozszerzenie na poziomie bazy danych, które udostępnia funkcje ML wrestaurant_db. Flaga na poziomie instancji (--enable-google-ml-integration) ustawiona podczas tworzenia instancji umożliwia maszynie wirtualnej Cloud SQL dostęp do Vertex AI – rozszerzenie udostępnia funkcje SQL w tej konkretnej bazie danych.vector(pgvector) – dodaje typ danychvectori operatory odległości do przechowywania i wysyłania zapytań dotyczących wektorów.
- Utwórz tabelę. Zwróć uwagę, że kolumna
description_embeddingtovector(3072)– kolumnapgvector, która przechowuje wektory 3072-wymiarowe. - Wypełnianie początkowych danych pozycji menu
- Wygeneruj dane wektorowe z pola
descriptioni wypełnij poledescription_embeddingza pomocą wbudowanej integracji Vertex za pomocą funkcjiembedding().
embedding('gemini-embedding-001', description)– wywołuje model wektorów dystrybucyjnych Gemini w Vertex AI bezpośrednio z SQL, przekazując tekstdescriptionkażdego zadania. Jest to rozszerzeniegoogle_ml_integrationzainstalowane w skrypcie początkowym.::vector– rzutuje zwróconą tablicę liczb zmiennoprzecinkowych na typvectorpgvector, aby można było ją przechowywać i wykonywać na niej zapytania za pomocą operatorów odległości.- Funkcja
UPDATEjest uruchamiana we wszystkich 15 wierszach, generując 1 osadzenie o 3072 wymiarach dla każdego opisu stanowiska.
Przygotuje to wstępne dane, do których będzie miał dostęp nasz agent.
5. Konfigurowanie zestawu narzędzi MCP dla baz danych
W tym kroku przedstawiamy MCP Toolbox for Databases, konfigurujemy go tak, aby łączył się z instancją Cloud SQL, i definiujemy 2 standardowe narzędzia do wykonywania zapytań SQL.
Czym jest MCP i dlaczego warto korzystać z Toolbox?
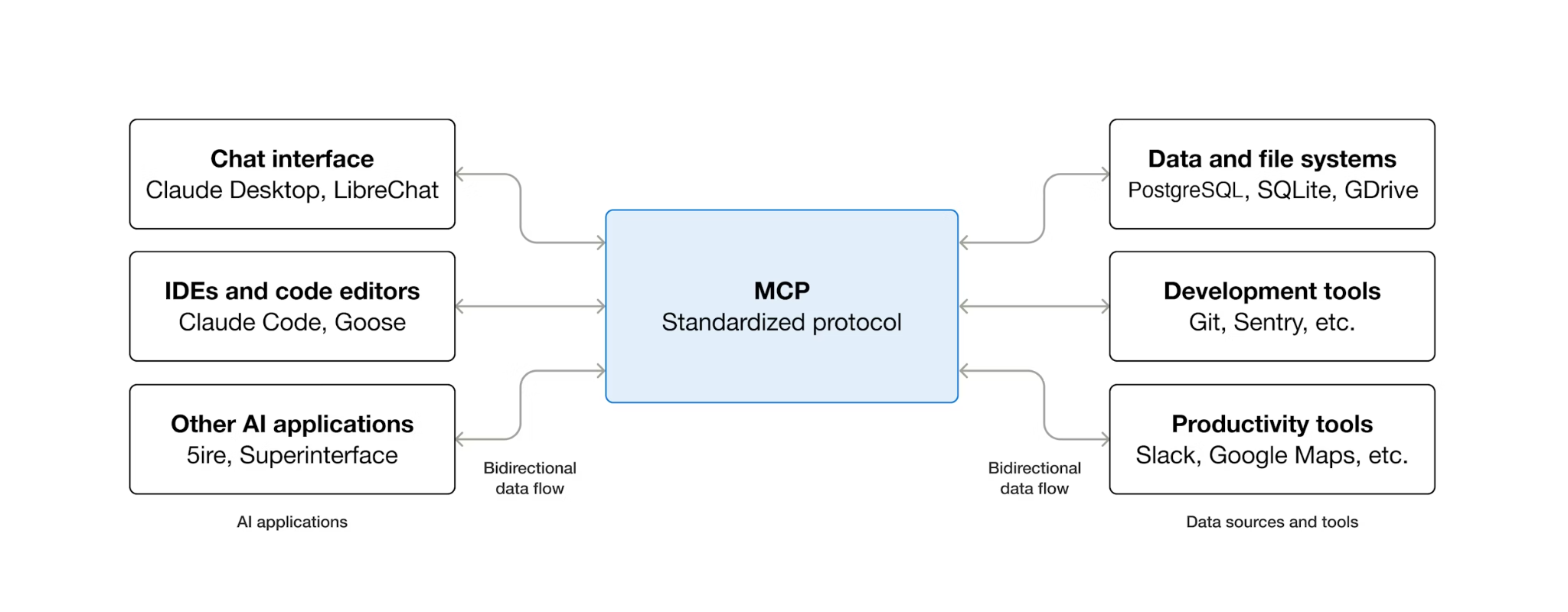
MCP (Model Context Protocol) to otwarty protokół, który standaryzuje sposób, w jaki agenty AI wykrywają narzędzia zewnętrzne i wchodzą z nimi w interakcje. Definiuje model klient-serwer: agent hostuje klienta MCP, a narzędzia są udostępniane przez serwery MCP. Każdy klient zgodny z MCP może używać dowolnego serwera zgodnego z MCP – agent nie potrzebuje niestandardowego kodu integracji dla każdego narzędzia.
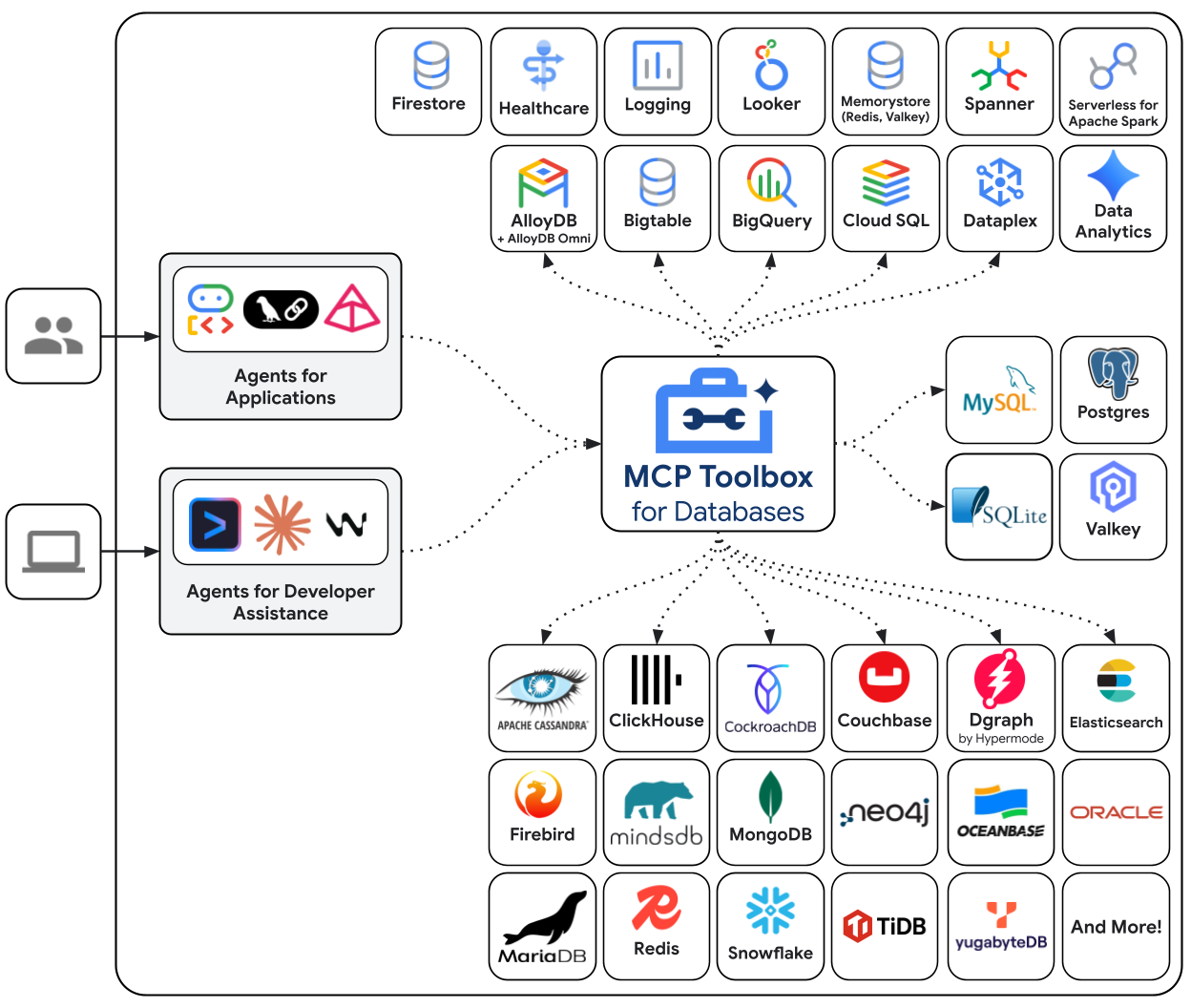
MCP Toolbox for Databases to serwer MCP typu open source stworzony specjalnie z myślą o dostępie do baz danych. Bez niego musisz pisać funkcje Pythona, które otwierają połączenia z bazą danych, zarządzają pulami połączeń, tworzą sparametryzowane zapytania, aby zapobiegać wstrzyknięciu kodu SQL, obsługują błędy i osadzają cały ten kod w agencie. Każdy agent, który potrzebuje dostępu do bazy danych, powtarza tę pracę. Zmiana zapytania oznacza ponowne wdrożenie agenta.
W narzędziu Toolbox piszesz plik YAML. Każde narzędzie jest mapowane na sparametryzowaną instrukcję SQL. Toolbox obsługuje pulę połączeń, zapytania parametryzowane, uwierzytelnianie i obserwację. Narzędzia są odłączone od agenta – możesz zaktualizować zapytanie, edytując tools.yaml i ponownie uruchamiając Toolbox, bez modyfikowania kodu agenta. Te same narzędzia działają w przypadku ADK, LangGraph, LlamaIndex i każdej platformy zgodnej z MCP.
Zapisz konfigurację narzędzi
Teraz musimy utworzyć plik o nazwie tools.yaml w edytorze Cloud Shell, aby skonfigurować narzędzia.
cloudshell edit tools.yaml
Plik używa wielodokumentowego formatu YAML – każdy blok oddzielony znakiem --- jest samodzielnym zasobem. Każdy zasób ma pole kind, które deklaruje, czym jest (sources w przypadku połączeń z bazą danych, tools w przypadku działań wywoływanych przez agenta), oraz pole type, które określa backend (cloud-sql-postgres w przypadku źródła, postgres-sql w przypadku narzędzi opartych na SQL). Narzędzie odwołuje się do swojego źródła za pomocą pola name, dzięki czemu Toolbox wie, z której puli połączeń ma korzystać. Zmienne środowiskowe używają składni ${VAR_NAME} i są rozwiązywane podczas uruchamiania.
Teraz skopiuj te skrypty do pliku tools.yaml.
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
Ten skrypt definiuje ten zasób:
- Źródło (
restaurant-db) – informuje Toolbox, jak połączyć się z instancją Cloud SQL PostgreSQL. Typcloud-sql-postgreswewnętrznie korzysta z oprogramowania sprzęgającego Cloud SQL, które automatycznie obsługuje uwierzytelnianie i bezpieczne połączenia. Obiekty zastępcze${GOOGLE_CLOUD_PROJECT},${REGION}i${DB_PASSWORD}są rozwiązywane ze zmiennych środowiskowych podczas uruchamiania.
Następnie dodaj ten skrypt pod symbolem --- w pliku tools.yaml.
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
Ten skrypt definiuje ten zasób:
- Narzędzia 1 i 2 (
search-menu,get-item-details) – standardowe narzędzia do zapytań SQL. Każda z nich mapuje nazwę narzędzia (widoczną dla agenta) na sparametryzowaną instrukcję SQL (wykonywaną przez bazę danych). Parametry używają symboli zastępczych pozycji$1,$2. Narzędzia wykonują je jako przygotowane instrukcje, co zapobiega wstrzyknięciu kodu SQL.
Kontynuujmy. Dodaj ten skrypt pod symbolem --- w pliku tools.yaml.
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
Ten skrypt definiuje ten zasób:
- Model wektorów dystrybucyjnych (
gemini-embedding) – konfiguruje Toolbox do wywoływania modelugemini-embedding-001Gemini w celu generowania 3072-wymiarowych wektorów dystrybucyjnych tekstu. Toolbox używa domyślnego uwierzytelniania aplikacji (ADC) do uwierzytelniania – w Cloud Shell ani Cloud Run nie jest potrzebny klucz interfejsu API. Zwróć uwagę, żedimensionskonfigurowane tutaj musi być takie samo jak wcześniej skonfigurowane do wypełnienia bazy danych.
Kontynuujmy. Dodaj ten skrypt pod symbolem --- w pliku tools.yaml.
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
Ten skrypt definiuje ten zasób:
- Narzędzie 3 (
search-menu-by-description) – narzędzie do wyszukiwania wektorowego. Parametrsearch_queryma wartośćembeddedBy: gemini-embedding, która informuje Zestaw narzędzi, że ma przechwycić tekst w formie surowej, wysłać go do modelu osadzania i użyć powstałego wektora w instrukcji SQL. Operator<=>to odległość kosinusowa pgvector – mniejsze wartości oznaczają bardziej podobne opisy.
Na koniec dodaj ostatnie narzędzie pod symbolem --- w pliku tools.yaml.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
Ten skrypt definiuje ten zasób:
- Narzędzie 4 (
add-menu-item) – pokazuje wczytywanie wektorów. Parametrdescription_vectorma 2 pola specjalne: valueFromParam: description– Toolbox kopiuje wartość z parametrudescriptiondo tego parametru. Model LLM nigdy nie widzi tego parametru.embeddedBy: gemini-embedding– Toolbox osadza skopiowany tekst w wektorze przed przekazaniem go do SQL.
W rezultacie jedno wywołanie narzędzia przechowuje zarówno tekst opisu w formie surowej, jak i jego wektor dystrybucyjny, a agent nie ma żadnej wiedzy o wektorach dystrybucyjnych.
Format YAML z wieloma dokumentami rozdziela poszczególne zasoby znakiem ---. Każdy dokument ma pola kind, name i type, które określają, czym jest. Podsumowując, skonfigurowaliśmy już wszystkie te elementy:
- Określ źródłową bazę danych
- Zdefiniuj narzędzia ( narzędzie 1 i 2), aby wysyłać zapytania do bazy danych za pomocą standardowego filtra.
- Definiowanie modelu wektora dystrybucyjnego
- Zdefiniuj narzędzie do wyszukiwania wektorowego ( narzędzie 3) w bazie danych.
- Zdefiniuj narzędzie do pozyskiwania danych wektorowych ( narzędzie 4) do bazy danych.
6. Uruchamianie serwera MCP Toolbox
W poprzednim kroku skonfigurowaliśmy już niezbędne ustawienia dla narzędzi MCP. Teraz możemy uruchomić serwer.
Sprawdzanie danych początkowych
Zanim uruchomisz Toolbox, sprawdź, czy konfiguracja bazy danych została zakończona. Utwórz skrypt w Pythonie scripts/verify_database.py za pomocą tego polecenia:
cloudshell edit scripts/verify_seed.py
Następnie skopiuj ten kod do pliku scripts/verify_seed.py.
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Ten skrypt sprawdzi liczbę danych pozycji menu i ich osadzanie. Uruchom go za pomocą tego polecenia:
uv run scripts/verify_seed.py
Jeśli zobaczysz w terminalu te dane wyjściowe, oznacza to, że dane są gotowe.
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Uruchamianie serwera Zestawu narzędzi
W poprzednim kroku konfiguracji pobraliśmy już plik wykonywalny toolbox. Sprawdź, czy ten plik binarny istnieje i czy został pobrany. Jeśli nie, pobierz go i poczekaj na zakończenie.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
Musimy udostępnić nasze zmienne .env procesowi podrzędnemu, który jest uruchamiany przez zestaw narzędzi MCP. Aby uruchomić serwer zestawu narzędzi i zapisać jego dane wyjściowe konsoli w pliku logs/mcp_toolbox.log, wykonaj to polecenie:
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
W pliku logs/mcp_toolbox.log powinny pojawić się dane wyjściowe potwierdzające gotowość serwera, jak pokazano poniżej:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Weryfikowanie narzędzi
Wyślij zapytanie do interfejsu Toolbox API, aby wyświetlić listę wszystkich zarejestrowanych narzędzi:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Powinny się wyświetlić narzędzia wraz z opisami i parametrami. Jak pokazano poniżej
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
Przetestuj narzędzie search-menu bezpośrednio:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
Odpowiedź powinna zawierać włoskie dania główne z danych początkowych.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. Tworzenie agenta ADK
Teraz użyjemy w tym projekcie ADK w Pythonie. Dodajmy wymagane zależności:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk– pakiet Agent Development Kit od Google, w tym pakiet SDK Gemini.toolbox-adk– integracja ADK z MCP Toolbox for Databases.
Tworzenie struktury katalogów agenta
ADK oczekuje określonego układu folderów: katalogu o nazwie agenta zawierającego pliki __init__.py, agent.py i .env. Aby ułatwić to zadanie, ma wbudowane polecenie, które pozwala szybko ustalić strukturę:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
Twój katalog powinien teraz wyglądać tak:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
Następnie musimy zintegrować agenta ADK z działającym serwerem Toolbox i przetestować wszystkie 4 narzędzia: zapytania standardowe, wyszukiwanie semantyczne i przetwarzanie wektorowe. Kod agenta jest minimalny: cała logika bazy danych znajduje się w tools.yaml.
Konfigurowanie środowiska agenta
Pakiet ADK odczytuje zmienne GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT i GOOGLE_CLOUD_LOCATION ze środowiska powłoki, które zostały już ustawione w poprzednim kroku. Jedyną zmienną specyficzną dla agenta jest TOOLBOX_URL – dodaj ją do pliku .env agenta:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Aktualizowanie modułu agenta
Otwórz plik restaurant_agent/agent.py w edytorze Cloud Shell.
cloudshell edit restaurant_agent/agent.py
i zastąp zawartość tym kodem:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Zwróć uwagę, że nie ma tu kodu bazy danych – ToolboxToolset łączy się z serwerem Toolbox przy uruchamianiu i wczytuje wszystkie dostępne narzędzia. Agent wywołuje narzędzia po nazwie, a Toolbox tłumaczy te wywołania na zapytania SQL dotyczące Cloud SQL.
Zmienna środowiskowa TOOLBOX_URL ma domyślnie wartość http://127.0.0.1:5000 w przypadku programowania lokalnego. Gdy później wdrożysz aplikację w Cloud Run, zastąpisz tę wartość adresem URL Cloud Run usługi Toolbox – nie musisz wprowadzać żadnych zmian w kodzie.
Testowanie agenta
Uruchom interfejs programisty ADK:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Otwórz adres URL wyświetlany w terminalu (zwykle http://localhost:8000) za pomocą funkcji Podgląd w internecie Cloud Shell lub kliknij adres URL wyświetlany w terminalu, przytrzymując Ctrl. W menu agenta w lewym górnym rogu wybierz restaurant_agent.
Testowanie standardowych zapytań
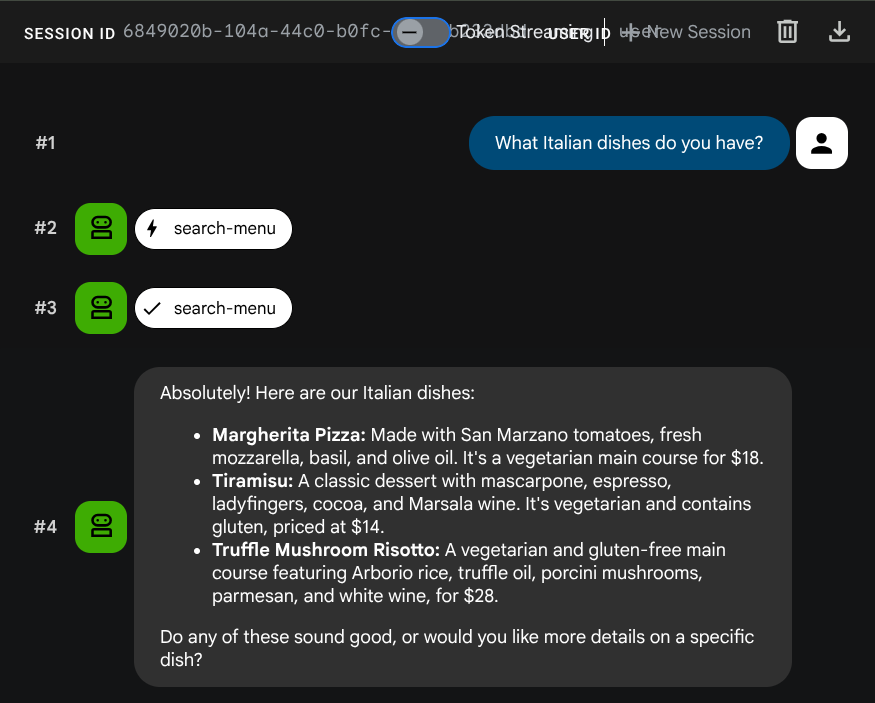
Aby sprawdzić narzędzia standardowej wersji SQL, wypróbuj te prompty:
What Italian dishes do you have?
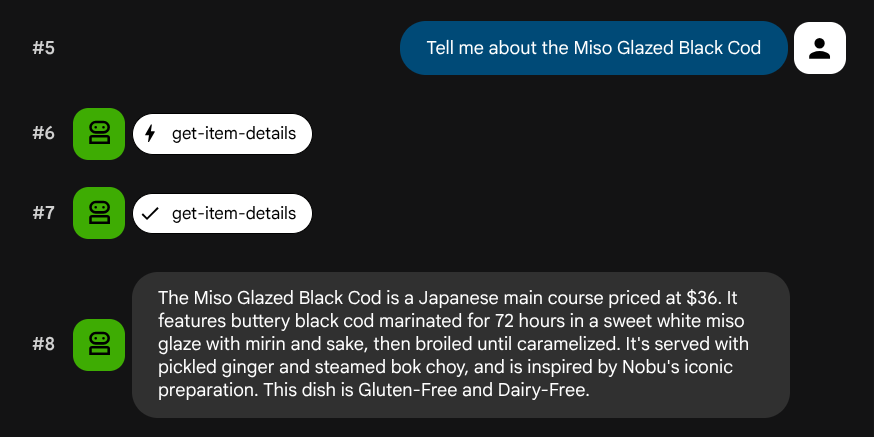
Tell me about the Miso Glazed Black Cod
Testowanie wyszukiwania semantycznego
Wypróbuj opisy w języku naturalnym, które nie są powiązane z określoną rolą ani zestawem technologii:
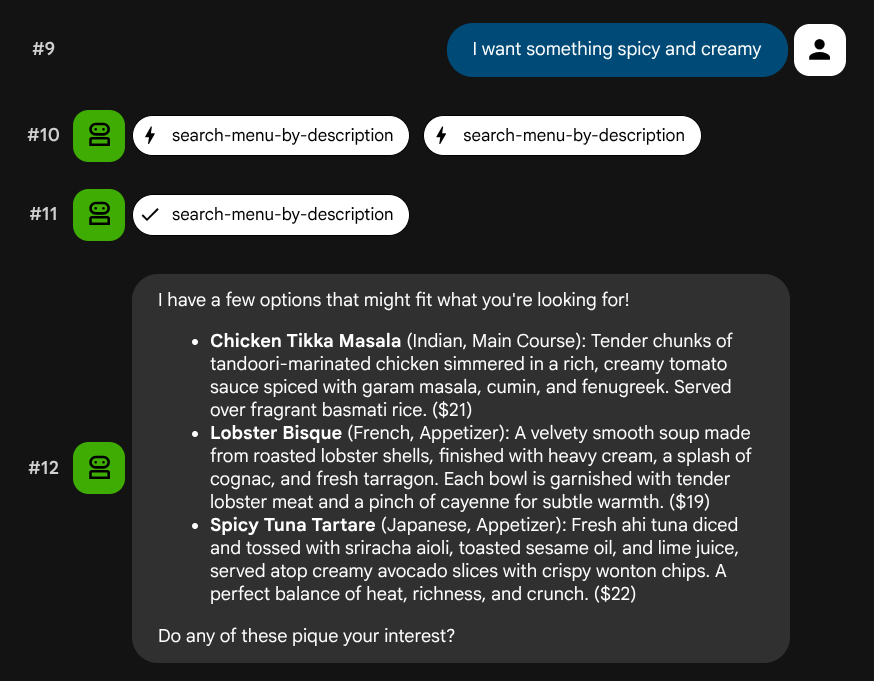
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
W zależności od typu zapytania agent spróbuje wybrać odpowiednie narzędzie: zapytania z filtrami strukturalnymi są przetwarzane przez search-menu, a opisy w języku naturalnym – przez search-menu-by-description.
Testowanie przetwarzania wektorów
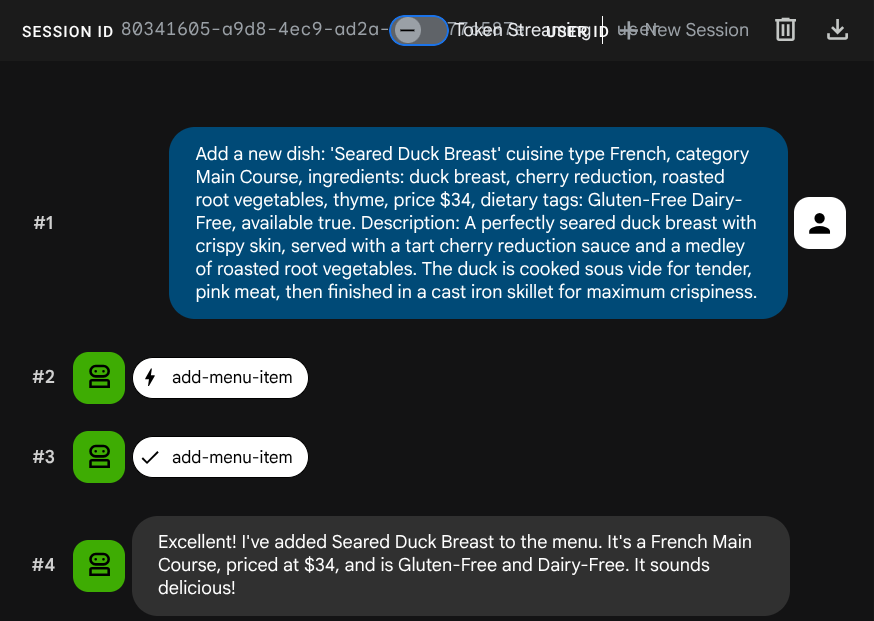
Poproś agenta o dodanie nowego zadania:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
Spróbuj teraz wyszukać:
Find me something with rich, gamey flavors and fruit sauce
Osadzenie zostało wygenerowane automatycznie podczas operacji INSERT – nie jest potrzebny żaden dodatkowy krok.
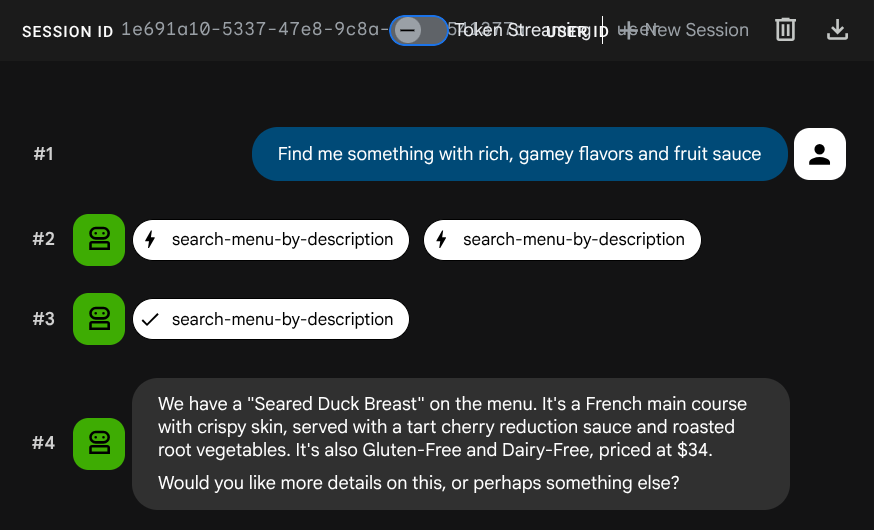
Masz już w pełni działającą aplikację Agentic RAG, która korzysta z ADK, MCP Toolbox i Cloud SQL. Gratulacje! Przejdźmy dalej i wdróżmy te aplikacje w Cloud Run.
Teraz zatrzymajmy interfejs programisty, kończąc proces przez dwukrotne naciśnięcie Ctrl+C.
8. Wdrożenie w Cloud Run
Agent i narzędzia działają lokalnie. Ten krok wdraża je jako usługi Cloud Run, dzięki czemu są dostępne w internecie. Usługa Toolbox działa jako serwer MCP w Cloud Run, a usługa agenta łączy się z nim.
Przygotowywanie zestawu narzędzi do wdrożenia
Utwórz katalog wdrożenia usługi Toolbox:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Utwórz plik Dockerfile dla zestawu narzędzi. Otwórz plik deploy-toolbox/Dockerfile w edytorze Cloud Shell:
cloudshell edit deploy-toolbox/Dockerfile
i skopiuj do niego ten skrypt:
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
Plik binarny Toolbox i tools.yaml są spakowane w minimalnym obrazie Debiana. Cloud Run kieruje ruch na port 8080.
Wdrażanie usługi Zestaw narzędzi
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
To polecenie przesyła źródło do Cloud Build, tworzy obraz kontenera, przenosi go do Artifact Registry i wdraża w Cloud Run. Zajmie to kilka minut. Możemy sprawdzić dziennik procesu wdrażania w pliku logs/deploy_toolbox.log.
Przygotowywanie agenta do wdrożenia
Podczas tworzenia pakietu narzędzi skonfiguruj pliki wdrożenia agenta.
Utwórz plik Dockerfile w katalogu głównym projektu. Otwórz plik Dockerfile w edytorze Cloud Shell:
cloudshell edit Dockerfile
Następnie skopiuj tę treść:
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
Ten plik Dockerfile używa obrazu bazowego ghcr.io/astral-sh/uv, który zawiera wstępnie zainstalowane Pythona i uv. Nie musisz więc instalować uv osobno za pomocą pip.
Utwórz plik .dockerignore, aby wykluczyć niepotrzebne pliki z obrazu kontenera:
cloudshell edit .dockerignore
Następnie skopiuj do niego ten skrypt:
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Wdróż usługę agenta
Poczekaj na zakończenie wdrażania Toolboxa. Aby sprawdzić proces wdrażania, ponownie otwórz stronę logs/deploy_toolbox.log. Następnie pobierz adres URL Cloud Run za pomocą tego polecenia:
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Zobaczysz dane wyjściowe podobne do tych:
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Następnie sprawdź, czy wdrożony zestaw narzędzi działa:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Jeśli wynik jest podobny do tego przykładu, wdrożenie zostało już zakończone.
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
Następnie wdróżmy agenta, przekazując adres URL Toolbox jako zmienną środowiskową:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
Kod agenta odczytuje wartość TOOLBOX_URL ze środowiska (zostało to wcześniej skonfigurowane). Lokalnie wskazuje http://127.0.0.1:5000, a w Cloud Run wskazuje adres URL usługi Toolbox. Nie wymaga to żadnych zmian w kodzie.
Testowanie wdrożonego agenta
Pobierz adres URL Cloud Run agenta:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
Otwórz adres URL w przeglądarce. Załaduje się interfejs programistyczny ADK – ten sam interfejs, którego używasz lokalnie, ale teraz działający w Cloud Run.
Wybierz z menu restaurant_agent i przetestuj:
What Italian dishes do you have?
I want something spicy and creamy
Oba zapytania działają za pomocą wdrożonych usług: agent w Cloud Run wywołuje Toolbox w Cloud Run, który wysyła zapytanie do Cloud SQL.
9. Gratulacje / Czyszczenie
Masz już utworzonego i wdrożonego inteligentnego asystenta menu restauracji, który używa MCP Toolbox for Databases do łączenia agenta ADK z Cloud SQL PostgreSQL – zarówno za pomocą standardowej wersji SQL, jak i semantycznego wyszukiwania wektorowego.
Czego się nauczysz
- Jak MCP standaryzuje dostęp do narzędzi dla agentów AI i jak MCP Toolbox for Databases stosuje to w przypadku operacji na bazach danych – zastępowanie niestandardowego kodu bazy danych deklaratywną konfiguracją YAML
- Jak skonfigurować Cloud SQL PostgreSQL jako źródło danych w Toolbox przy użyciu typu źródła
cloud-sql-postgres - Jak zdefiniować standardowe narzędzia do zapytań SQL z instrukcjami sparametryzowanymi, które zapobiegają wstrzykiwaniu kodu SQL
- Jak włączyć wyszukiwanie wektorowe za pomocą pgvector i
gemini-embedding-001z parametremembeddedBydo automatycznego osadzania zapytań - Jak
valueFromParamumożliwia automatyczne wczytywanie wektorów – model LLM podaje opis tekstowy, a Toolbox cicho kopiuje, osadza i przechowuje wektor obok tekstu. - Jak
ToolboxToolsetADK wczytuje narzędzia z działającego serwera Toolbox, dzięki czemu kod agenta jest minimalny, a logika bazy danych jest w pełni odseparowana - Jak wdrożyć serwer MCP Toolbox i agenta ADK w Cloud Run jako oddzielne usługi
Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby utworzone w tym laboratorium, możesz usunąć poszczególne zasoby lub cały projekt.
Opcja 1. Usuwanie projektu (zalecane)
Najprostszym sposobem na zwolnienie miejsca jest usunięcie projektu. Spowoduje to usunięcie wszystkich zasobów powiązanych z projektem.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Opcja 2. Usuwanie poszczególnych zasobów
Jeśli chcesz zachować projekt, ale usunąć tylko zasoby utworzone w tym laboratorium:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null