
1. Introdução
A utilidade dos agentes de IA depende dos dados que eles podem acessar. A maioria dos dados do mundo real está em bancos de dados, e conectar agentes a eles geralmente significa escrever gerenciamento de conexões, lógica de consulta e incorporar pipelines no código do agente. Cada agente que precisa de acesso ao banco de dados repete esse trabalho, e cada mudança de consulta exige a nova implantação do agente.
Este codelab mostra uma abordagem diferente. Você declara as ferramentas de banco de dados em um arquivo YAML (consultas SQL padrão, pesquisa de similaridade vetorial e até mesmo geração automática de embeddings), e a MCP Toolbox for Databases processa todas as operações do banco de dados como um servidor MCP. O código do seu agente permanece mínimo: carregue as ferramentas e deixe o Gemini decidir qual chamar.
O que você vai criar
Um concierge de restaurantes para "Foodie Finds", um agente do ADK com tecnologia do Gemini que ajuda os clientes a navegar pelo cardápio de um restaurante usando filtros padrão (categoria, tipo de culinária) e descobrir pratos com descrições em linguagem natural, como "Quero algo picante e vegetariano". O agente lê e grava em um banco de dados do Cloud SQL PostgreSQL totalmente pela MCP Toolbox for Databases, que processa todo o acesso ao banco de dados, incluindo a geração automática de embeddings para pesquisa vetorial. No final, a caixa de ferramentas e o agente serão executados no Cloud Run.
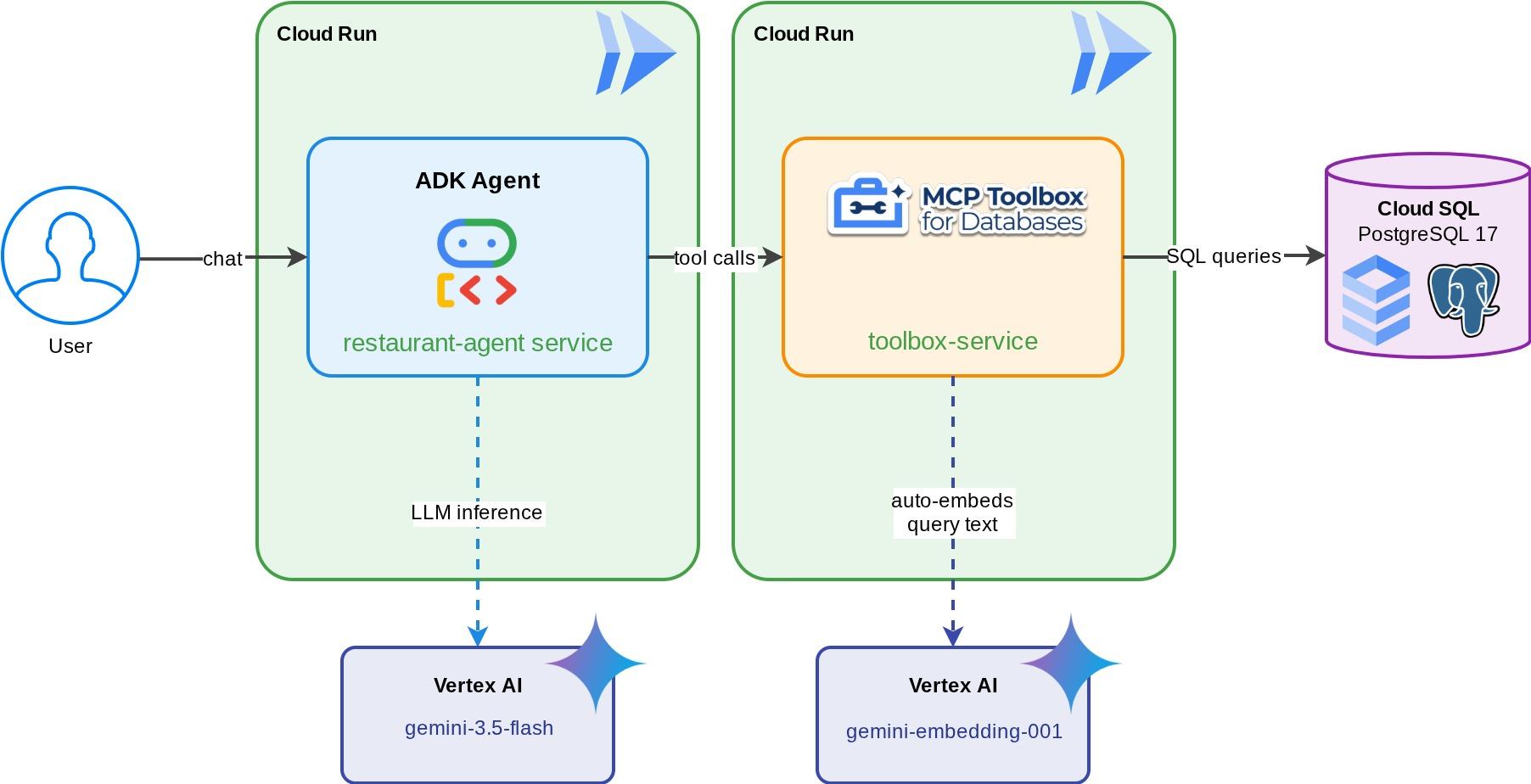
O que você vai aprender
- Como o MCP (Protocolo de Contexto de Modelo) padroniza o acesso a ferramentas para agentes de IA e como a MCP Toolbox for Databases aplica isso a operações de banco de dados
- Configurar o MCP Toolbox for Databases como middleware entre um agente ADK e o Cloud SQL PostgreSQL
- Defina ferramentas de banco de dados de forma declarativa em
tools.yaml. Não há código de banco de dados no seu agente. - Criar um agente do ADK que carrega ferramentas de um servidor da caixa de ferramentas em execução usando
ToolboxToolset - Gerar embeddings de vetores usando a função
embedding()integrada do Cloud SQL e ativar a pesquisa semântica compgvector - Use o recurso
valueFromParampara ingestão automática de vetores em operações de gravação - Implantar o servidor da caixa de ferramentas e o agente do ADK no Cloud Run
Pré-requisitos
- Uma conta do Google Cloud com uma conta de faturamento de teste
- Conhecimento básico de Python e SQL
- Experiência prévia com o Cloud Database e o ADK é útil
2. Configuração de seu ambiente
Esta etapa prepara seu ambiente do Cloud Shell, configura seu projeto do Google Cloud e clona o repositório de referência.
Abra o Cloud Shell
Abra o Cloud Shell no navegador. O Cloud Shell oferece um ambiente pré-configurado com todas as ferramentas necessárias para este codelab. Clique em Autorizar quando solicitado a
Em seguida, clique em Visualizar -> Terminal para abrir o terminal.Sua interface vai ficar parecida com esta:
Essa será nossa interface principal, com o IDE na parte de cima e o terminal na parte de baixo.
Configurar seu diretório de trabalho
Crie seu diretório de trabalho. Todo o código que você escrever neste codelab vai ficar aqui:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
Depois disso, vamos preparar vários diretórios para gerenciar itens como scripts de propagação e registros.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Configuração no projeto do Google Cloud
Crie o arquivo .env com as variáveis de local:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Para simplificar a configuração do projeto no terminal, baixe este script de configuração no diretório de trabalho:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Execute o script. Ele verifica sua conta de faturamento de teste, cria um projeto (ou valida um existente), salva o ID do projeto em um arquivo .env no diretório atual e define o projeto ativo em gcloud.
bash setup_verify_trial_project.sh && source .env
O script faz o seguinte:
- Verificar se você tem uma conta de faturamento de teste ativa
- Verifique se há um projeto em
.env(se houver). - Crie um novo projeto ou reutilize o atual
- Vincular a conta de faturamento de teste ao projeto
- Salve o ID do projeto em
.env - Defina o projeto como o projeto
gcloudativo.
Verifique se o projeto está definido corretamente conferindo o texto amarelo ao lado do diretório de trabalho no prompt do terminal do Cloud Shell. Ele deve mostrar o ID do projeto.

Ativar a API necessária
Em seguida, precisamos ativar várias APIs para o produto com que vamos interagir:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- API Vertex AI (
aiplatform.googleapis.com): seu agente usa modelos do Gemini, e a caixa de ferramentas usa a API Embedding para pesquisa vetorial. - API Cloud SQL Admin (
sqladmin.googleapis.com): você provisiona e gerencia uma instância do PostgreSQL. - API Compute Engine (
compute.googleapis.com): necessária para criar instâncias do Cloud SQL. - Cloud Run, Cloud Build, Artifact Registry: usados na etapa de implantação mais adiante neste codelab.
3. Como preparar scripts para inicialização de banco de dados
Esta etapa inicia a criação da instância do Cloud SQL e executa um script de configuração automatizado que aguarda a instância ficar pronta. Em seguida, ele cria o banco de dados, o preenche com anúncios de emprego e gera incorporações, tudo em uma única operação.
Primeiro, adicione a senha do banco de dados ao arquivo .env e recarregue-o:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Como criar um script Bash para criação de instância e banco de dados
Em seguida, crie o script scripts/setup_database.sh com o seguinte comando:
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Em seguida, copie o código abaixo no arquivo scripts/setup_database.sh.
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Como criar um script Python para propagação de dados
Depois disso, crie o arquivo Python do script de propagação scripts/setup_restaurant_db.py usando o comando abaixo:
cloudshell edit scripts/setup_restaurant_db.py
Em seguida, copie o código abaixo no arquivo scripts/setup_restaurant_db.py.
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Agora, vamos para a próxima etapa
4. Criar e inicializar o banco de dados
Agora nossos scripts estão prontos para serem executados. Vamos precisar do Python para executar o script preparado. Então, vamos preparar isso primeiro.
Configurar o projeto Python
uv é um gerenciador de projetos e pacotes Python rápido escrito em Rust ( documentação do uv). Este codelab o usa para agilidade e simplicidade na manutenção do projeto Python.
Inicialize um projeto Python e adicione as dependências necessárias:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Estamos usando o SDK do Python cloud-sql-python-connector para inicializar uma conexão segura com a instância do banco de dados, que é autenticada usando as credenciais padrão do aplicativo.
Execute o script de configuração
Agora, podemos executar o script de configuração em segundo plano e inspecionar a saída do console, que será gravada no arquivo logs/atabase_setup.log usando o seguinte comando. Você pode continuar para a próxima seção enquanto espera a conclusão.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Baixe o binário da caixa de ferramentas.
Vamos usar a MCP Toolbox neste tutorial. Felizmente, ela vem com um binário pré-criado pronto para ser usado no ambiente Linux. Agora, vamos fazer o download em segundo plano, já que isso leva um tempo. Execute o comando a seguir para baixar o binário e inspecionar o registro de saída no logs/toolbox_dl.log. Você pode continuar para a próxima seção enquanto espera a conclusão.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Como entender o script de configuração scripts/setup_database.sh
Agora vamos tentar entender o script de configuração que configuramos anteriormente. Ele faz o seguinte processo:
- O primeiro comando executado é o
gcloud sql instances createcom a seguinte flag:
db-custom-1-3840é o menor nível do Cloud SQL de núcleo dedicado (1 vCPU, 3,75 GB de RAM) na ediçãoENTERPRISE. Leia mais detalhes aqui. Um núcleo dedicado é necessário para a integração de ML da Vertex AI. Os níveis de núcleo compartilhado (db-f1-micro,db-g1-small) não oferecem suporte a ela.--root-passworddefine a senha do usuáriopostgrespadrão.- O
--enable-google-ml-integrationativa a integração integrada do Cloud SQL com a Vertex AI, permitindo que você chame modelos de embedding diretamente do SQL usando a funçãoembedding().
- Verifique se a instância já está no status
RUNNABLE. - Conceda à conta de serviço da instância do Cloud SQL permissão para chamar a Vertex AI usando o comando
gcloud projects add-iam-policy-binding. Isso é necessário para a funçãoembedding()integrada que usaremos ao propagar o banco de dados. - Criar o banco de dados
- Executar o script de propagação
setup_restaurant_db.py
Como entender o script de inicialização scripts/setup_restaurant_db.py
Agora, passando para o script de propagação, ele faz o seguinte:
- Inicializar a conexão com a instância do banco de dados
- Instala duas extensões do PostgreSQL:
google_ml_integration: fornece a função SQLembedding(), que chama modelos de embedding da Vertex AI diretamente do SQL. É uma extensão no nível do banco de dados que disponibiliza funções de ML norestaurant_db. A flag no nível da instância (--enable-google-ml-integration) definida durante a criação da instância permite que a VM do Cloud SQL alcance a Vertex AI. A extensão disponibiliza as funções SQL nesse banco de dados específico.vector(pgvector): adiciona o tipo de dadosvectore operadores de distância para armazenar e consultar incorporações.
- Crie a tabela. Observe que a coluna
description_embeddingévector(3072), uma colunapgvectorque armazena vetores de 3.072 dimensões. - Propagar os dados iniciais dos itens de menu
- Gere os dados de embedding do campo
descriptione preencha odescription_embeddingusando a integração do Vertex integrada pela funçãoembedding().
embedding('gemini-embedding-001', description): chama o modelo de embedding do Gemini da Vertex AI diretamente do SQL, transmitindo o textodescriptionde cada job. Essa é a extensãogoogle_ml_integrationque você instalou no script de inicialização.::vector: converte a matriz de ponto flutuante retornada para o tipovectordo pgvector para que ela possa ser armazenada e consultada com operadores de distância.- O
UPDATEé executado em todas as 15 linhas, gerando uma incorporação de 3.072 dimensões por descrição de vaga.
Isso vai preparar os dados iniciais que serão acessados pelo nosso agente.
5. Configurar a MCP Toolbox for Databases
Esta etapa apresenta o MCP Toolbox for Databases, configura a conexão com sua instância do Cloud SQL e define duas ferramentas de consulta SQL padrão.
O que é o MCP e por que usar a Toolbox?
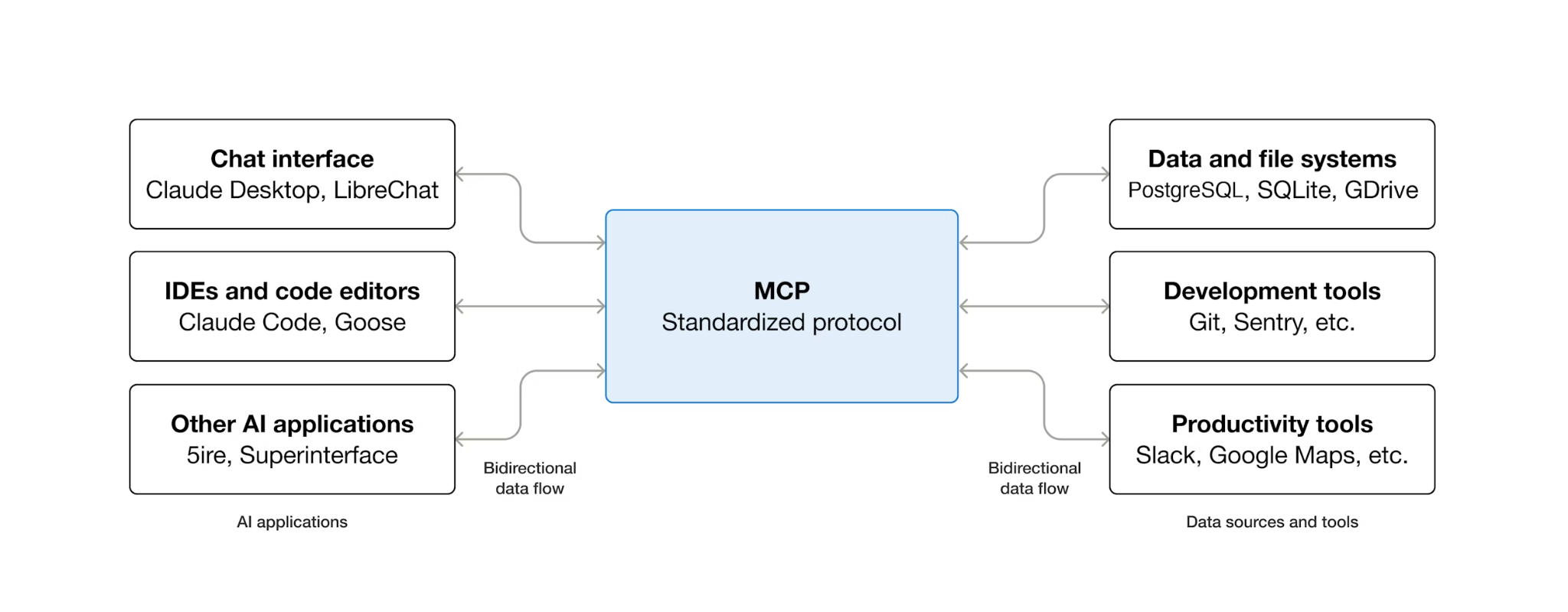
O MCP (Protocolo de Contexto de Modelo) é um protocolo aberto que padroniza como os agentes de IA descobrem e interagem com ferramentas externas. Ele define um modelo cliente-servidor: o agente hospeda um cliente MCP, e as ferramentas são expostas por servidores MCP. Qualquer cliente compatível com o MCP pode usar qualquer servidor compatível com o MCP. O agente não precisa de um código de integração personalizado para cada ferramenta.
O MCP Toolbox for Databases é um servidor MCP de código aberto criado especificamente para acesso a bancos de dados. Sem ele, você escreveria funções Python que abrem conexões de banco de dados, gerenciam pools de conexões, criam consultas parametrizadas para evitar injeção de SQL, processam erros e incorporam todo esse código no seu agente. Cada agente que precisa de acesso ao banco de dados repete esse trabalho. Mudar uma consulta significa reimplantar o agente.
Com a caixa de ferramentas, você grava um arquivo YAML. Cada ferramenta é mapeada para uma instrução SQL parametrizada. A caixa de ferramentas processa o pool de conexões, consultas parametrizadas, autenticação e observabilidade. As ferramentas são dissociadas do agente. Para atualizar uma consulta, edite tools.yaml e reinicie a caixa de ferramentas sem tocar no código do agente. As mesmas ferramentas funcionam no ADK, LangGraph, LlamaIndex ou qualquer framework compatível com o MCP.
Escreva a configuração das ferramentas
Agora, precisamos criar um arquivo chamado tools.yaml no editor do Cloud Shell para configurar a configuração das ferramentas.
cloudshell edit tools.yaml
O arquivo usa YAML de vários documentos. Cada bloco separado por --- é um recurso independente. Todo recurso tem um kind que declara o que ele é (sources para conexões de banco de dados, tools para ações chamáveis por agente) e um type que especifica o back-end (cloud-sql-postgres para a origem, postgres-sql para ferramentas baseadas em SQL). Uma ferramenta faz referência à origem dela por name, que é como a caixa de ferramentas sabe qual pool de conexões executar. As variáveis de ambiente usam a sintaxe ${VAR_NAME} e são resolvidas na inicialização.
Agora, vamos copiar os seguintes scripts primeiro no arquivo tools.yaml
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
Este script define o seguinte recurso:
- Origem (
restaurant-db): informa à caixa de ferramentas como se conectar à sua instância do Cloud SQL PostgreSQL. O tipocloud-sql-postgresusa o conector do Cloud SQL internamente, processando a autenticação e as conexões seguras de forma automática. Os marcadores de posição${GOOGLE_CLOUD_PROJECT},${REGION}e${DB_PASSWORD}são resolvidos das variáveis de ambiente na inicialização.
Em seguida, adicione o script a seguir abaixo do símbolo --- em tools.yaml.
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
Este script define o seguinte recurso:
- Ferramentas 1 e 2 (
search-menu,get-item-details): ferramentas de consulta SQL padrão. Cada um mapeia um nome de ferramenta (o que o agente vê) para uma instrução SQL parametrizada (o que o banco de dados executa). Os parâmetros usam marcadores de posição$1e$2. A caixa de ferramentas executa essas ações como instruções preparadas, o que evita a injeção de SQL.
Vamos continuar. Adicione o script a seguir abaixo do símbolo --- em tools.yaml.
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
Este script define o seguinte recurso:
- Modelo de embedding (
gemini-embedding): configura a caixa de ferramentas para chamar o modelogemini-embedding-001do Gemini e gerar embeddings de texto de 3.072 dimensões. A caixa de ferramentas usa o Application Default Credentials (ADC) para autenticar. Não é necessário ter uma chave de API no Cloud Shell ou no Cloud Run. Observa que essedimensionconfigurado aqui precisa ser o mesmo que configuramos anteriormente para propagar o banco de dados.
Vamos continuar. Adicione o script a seguir abaixo do símbolo --- em tools.yaml.
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
Este script define o seguinte recurso:
- Ferramenta 3 (
search-menu-by-description): uma ferramenta de pesquisa vetorial. O parâmetrosearch_querytemembeddedBy: gemini-embedding, que informa à caixa de ferramentas para interceptar o texto bruto, enviá-lo ao modelo de embedding e usar o vetor resultante na instrução SQL. O operador<=>é a distância do cosseno do pgvector. Valores menores significam descrições mais semelhantes.
Por fim, adicione a última ferramenta abaixo do símbolo --- em tools.yaml.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
Este script define o seguinte recurso:
- Ferramenta 4 (
add-menu-item): demonstra a ingestão de vetores. O parâmetrodescription_vectortem dois campos especiais: valueFromParam: description: a caixa de ferramentas copia o valor do parâmetrodescriptionpara este. O LLM nunca vê esse parâmetro.embeddedBy: gemini-embedding: a caixa de ferramentas incorpora o texto copiado em um vetor antes de transmiti-lo ao SQL.
O resultado: uma chamada de função armazena o texto de descrição bruto e o embedding de vetor dele, sem que o agente saiba nada sobre embeddings.
O formato YAML de vários documentos separa cada recurso com ---. Cada documento tem campos kind, name e type que definem o que ele é. Em resumo, já configuramos tudo o que segue:
- Definir o banco de dados de origem
- Defina ferramentas ( ferramentas 1 e 2) para consultar o banco de dados com um filtro padrão.
- Definir o modelo de embedding
- Definir a ferramenta para fazer a pesquisa de vetor ( ferramenta 3) no banco de dados
- Defina a ferramenta para fazer a ingestão de dados de vetores ( ferramenta 4) no banco de dados.
6. Como executar o servidor da caixa de ferramentas do MCP
Na etapa anterior, já definimos a configuração necessária para a MCP Toolbox. Agora podemos executar o servidor.
Verificar os dados de inicialização
Antes de iniciar a caixa de ferramentas, vamos confirmar se a configuração do banco de dados foi concluída. Crie um script Python scripts/verify_database.py usando o seguinte comando:
cloudshell edit scripts/verify_seed.py
Em seguida, copie o código abaixo no arquivo scripts/verify_seed.py.
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Esse script verifica o número de dados do item de menu e os embeddings deles. Execute o script usando o seguinte comando:
uv run scripts/verify_seed.py
Se você vir a seguinte saída do terminal, isso significa que os dados estão prontos:
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Iniciar o servidor da caixa de ferramentas
Na etapa de configuração anterior, já fizemos o download do executável toolbox. Verifique se esse arquivo binário existe e foi baixado corretamente. Caso contrário, faça o download e aguarde até que ele seja concluído.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
Precisamos expor nossas variáveis .env ao processo secundário executado pela MCP Toolbox. Execute o comando a seguir para iniciar o servidor da caixa de ferramentas e registrar a saída do console no arquivo logs/mcp_toolbox.log.
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
Você vai ver uma saída no arquivo logs/mcp_toolbox.log confirmando que o servidor está pronto, como mostrado abaixo:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Verificar as ferramentas
Consulte a API Toolbox para listar todas as ferramentas registradas:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Você vai encontrar ferramentas com descrições e parâmetros. Como mostrado abaixo
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
Teste a ferramenta search-menu diretamente:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
A resposta precisa conter os pratos principais italianos dos seus dados iniciais.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. criar o agente do ADK
Agora, vamos usar o ADK em Python para este projeto. Adicione as dependências necessárias:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk: o Kit de Desenvolvimento de Agente do Google, incluindo o SDK do Geminitoolbox-adk: integração do ADK com a MCP Toolbox for Databases.
Criar a estrutura de diretórios do agente
O ADK espera um layout de pasta específico: um diretório com o nome do seu agente que contenha __init__.py, agent.py e .env. Para ajudar com isso, ele tem um comando integrado para estabelecer rapidamente a estrutura:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
Seu diretório vai ficar assim:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
Em seguida, vamos integrar o agente do ADK ao servidor da caixa de ferramentas em execução e testar todas as quatro ferramentas: consultas padrão, pesquisa semântica e ingestão de vetores. O código do agente é mínimo: toda a lógica do banco de dados está em tools.yaml.
Configurar o ambiente do agente
O ADK lê GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT e GOOGLE_CLOUD_LOCATION do ambiente shell, que você já definiu na etapa anterior. A única variável específica do agente é TOOLBOX_URL. Anexe-a ao arquivo .env do agente:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Atualizar o módulo do agente
Abra restaurant_agent/agent.py no editor do Cloud Shell
cloudshell edit restaurant_agent/agent.py
e substitua o conteúdo pelo seguinte código:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Não há código de banco de dados aqui. O ToolboxToolset se conecta ao servidor da caixa de ferramentas na inicialização e carrega todas as ferramentas disponíveis. O agente chama as ferramentas por nome, e a caixa de ferramentas traduz essas chamadas em consultas SQL no Cloud SQL.
A variável de ambiente TOOLBOX_URL tem como padrão http://127.0.0.1:5000 para desenvolvimento local. Ao implantar no Cloud Run mais tarde, você vai substituir isso pelo URL do Cloud Run do serviço Toolbox. Não é necessário mudar o código.
Testar o agente
Inicie a interface de desenvolvimento do ADK:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Abra o URL mostrado no terminal (normalmente http://localhost:8000) usando o recurso Visualização na Web do Cloud Shell ou ctrl + clique no URL mostrado no terminal. Selecione restaurant_agent no menu suspenso de agentes no canto superior esquerdo.
Testar consultas padrão
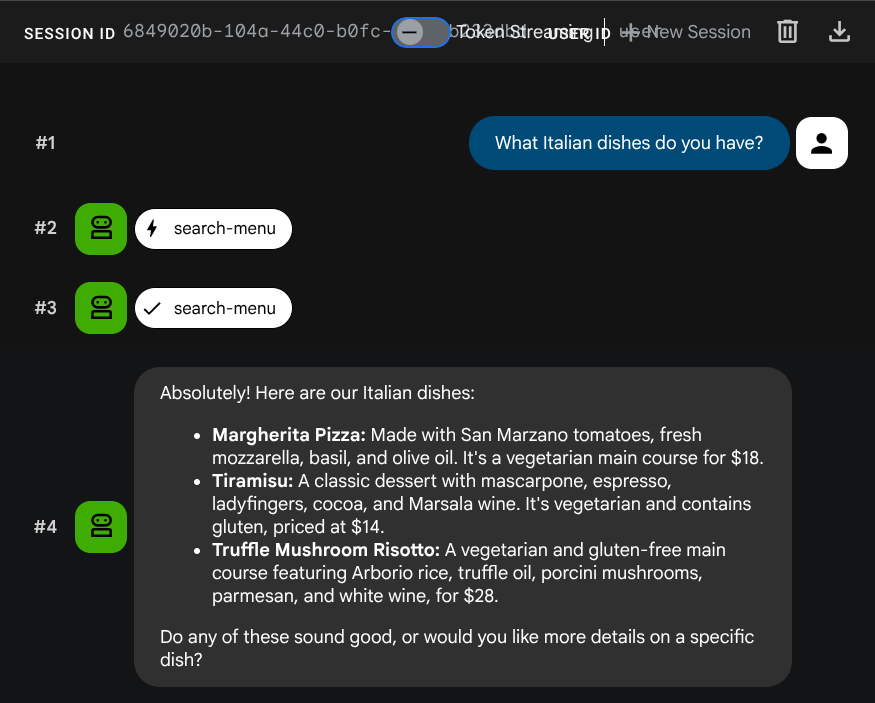
Teste estes comandos para verificar as ferramentas do SQL padrão:
What Italian dishes do you have?
Tell me about the Miso Glazed Black Cod
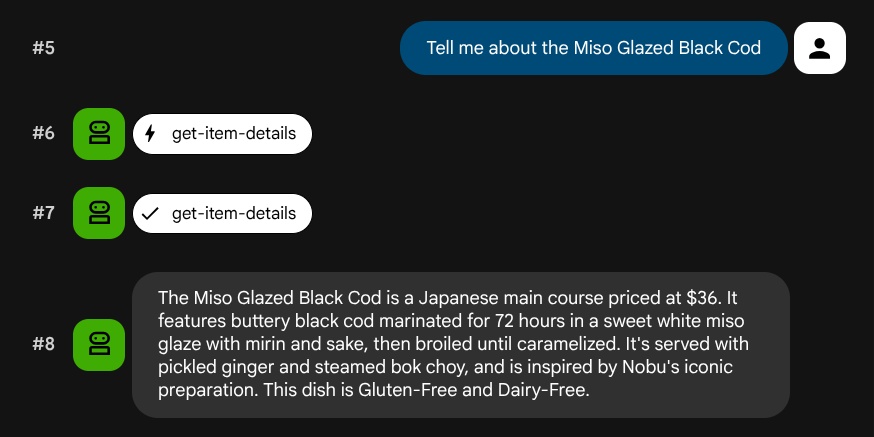
Testar a pesquisa semântica
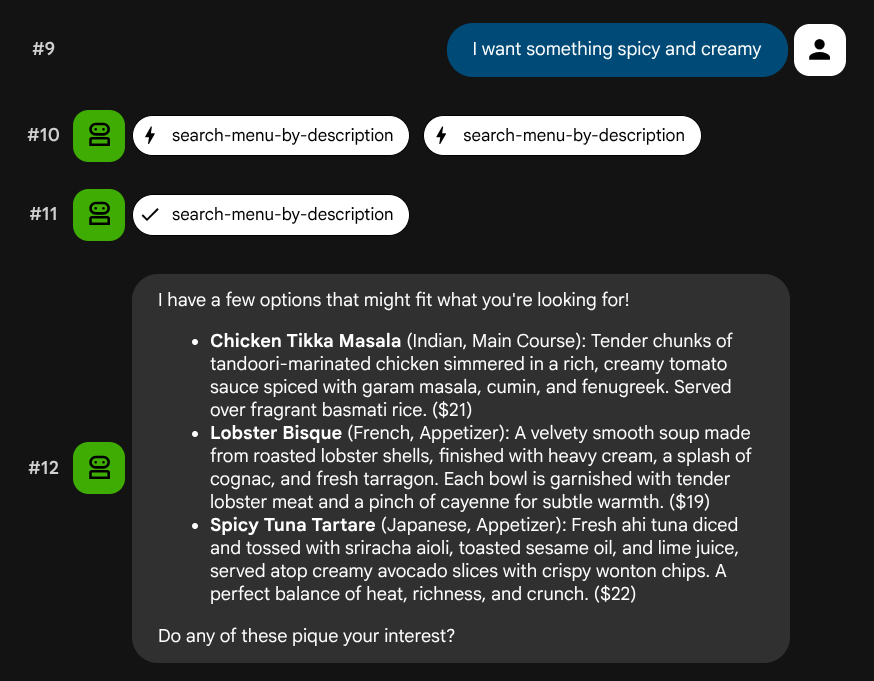
Tente descrições em linguagem natural que não correspondam a uma função ou tecnologia específica:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
O agente tenta escolher a ferramenta certa com base no tipo de consulta: filtros estruturados passam por search-menu, e descrições em linguagem natural passam por search-menu-by-description.
Teste a ingestão de vetores
Peça ao agente para adicionar um novo trabalho:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
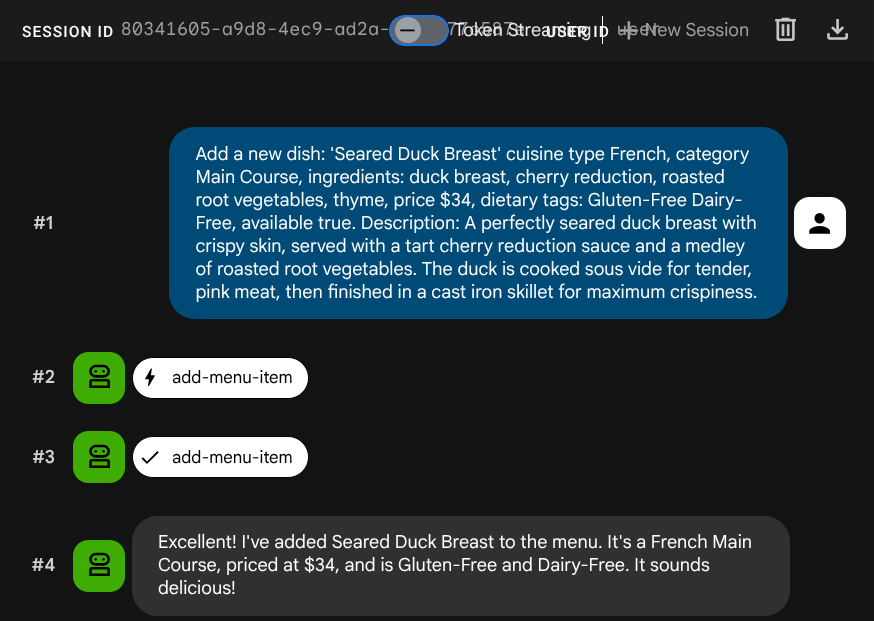
Agora tente pesquisar:
Find me something with rich, gamey flavors and fruit sauce
A incorporação foi gerada automaticamente durante o INSERT. Não é necessário fazer uma etapa separada.
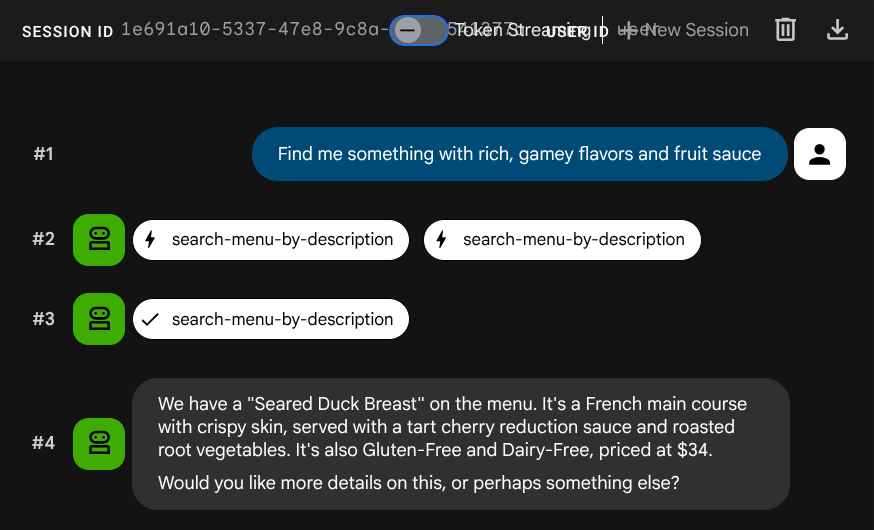
Agora você já tem um aplicativo RAG agêntico totalmente funcional que usa ADK, MCP Toolbox e CloudSQL. Parabéns! Vamos dar mais um passo e implantar esses apps no Cloud Run.
Agora, vamos interromper a interface do usuário de desenvolvimento encerrando o processo. Para isso, pressione Ctrl+C duas vezes antes de continuar.
8. Implantar no Cloud Run
O agente e a caixa de ferramentas funcionam localmente. Esta etapa implanta os dois como serviços do Cloud Run para que possam ser acessados pela Internet. O serviço da caixa de ferramentas é executado como um servidor MCP no Cloud Run, e o serviço do agente se conecta a ele.
Preparar a caixa de ferramentas para implantação
Crie um diretório de implantação para o serviço da caixa de ferramentas:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Crie o Dockerfile para a caixa de ferramentas. Abra deploy-toolbox/Dockerfile no editor do Cloud Shell:
cloudshell edit deploy-toolbox/Dockerfile
e copie o seguinte script nele:
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
O binário da caixa de ferramentas e tools.yaml são empacotados em uma imagem mínima do Debian. O Cloud Run encaminha o tráfego para a porta 8080.
Implantar o serviço da caixa de ferramentas
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
Esse comando envia a origem para o Cloud Build, cria uma imagem de contêiner, envia para o Artifact Registry e implanta no Cloud Run. Isso vai levar alguns minutos. Podemos inspecionar o registro do processo de implantação no arquivo logs/deploy_toolbox.log.
Preparar o agente para implantação
Enquanto a caixa de ferramentas é criada, configure os arquivos de implantação do agente.
Crie um Dockerfile na raiz do projeto. Abra Dockerfile no editor do Cloud Shell:
cloudshell edit Dockerfile
Em seguida, copie o conteúdo abaixo:
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
Esse Dockerfile usa ghcr.io/astral-sh/uv como imagem de base, que inclui Python e uv pré-instalados. Não é necessário instalar o uv separadamente usando o pip.
Crie um arquivo .dockerignore para excluir arquivos desnecessários da imagem do contêiner:
cloudshell edit .dockerignore
Em seguida, copie o script a seguir nele:
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Implantar o serviço de agente
Aguarde a conclusão da implantação da caixa de ferramentas. Verifique o processo de implantação novamente em logs/deploy_toolbox.log. Em seguida, recupere o URL do Cloud Run usando o seguinte comando:
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Você vai ver uma saída semelhante a esta:
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Em seguida, vamos verificar se a caixa de ferramentas implantada está funcionando:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Se a saída for semelhante a este exemplo, a implantação já foi concluída.
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
Em seguida, vamos implantar o agente, transmitindo o URL da caixa de ferramentas como uma variável de ambiente:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
O código do agente lê TOOLBOX_URL do ambiente (você configurou isso antes). Localmente, ele aponta para http://127.0.0.1:5000. No Cloud Run, ele aponta para o URL do serviço da caixa de ferramentas. Não é necessário mudar o código.
Testar o agente implantado
Recupere o URL do Cloud Run do agente:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
Abra o URL no seu navegador. A interface de desenvolvimento do ADK é carregada. É a mesma interface que você usou localmente, agora executada no Cloud Run.
Selecione restaurant_agent no menu suspenso e teste:
What Italian dishes do you have?
I want something spicy and creamy
As duas consultas funcionam pelos serviços implantados: o agente no Cloud Run chama a caixa de ferramentas no Cloud Run, que consulta o Cloud SQL.
9. Parabéns / Limpeza
Você criou e implantou um assistente de cardápio inteligente que usa a MCP Toolbox for Databases para conectar um agente ADK e o Cloud SQL PostgreSQL, com consultas SQL padrão e pesquisa semântica de vetores.
O que você aprendeu
- Como o MCP padroniza o acesso a ferramentas para agentes de IA e como o MCP Toolbox for Databases aplica isso especificamente a operações de banco de dados, substituindo o código personalizado do banco de dados por uma configuração declarativa em YAML
- Como configurar o Cloud SQL PostgreSQL como uma fonte de dados da caixa de ferramentas usando o tipo de fonte
cloud-sql-postgres - Como definir ferramentas de consulta SQL padrão com instruções parametrizadas que evitam a injeção de SQL
- Como ativar a pesquisa vetorial usando pgvector e
gemini-embedding-001, com o parâmetroembeddedBypara embedding automático de consultas - Como o
valueFromParampermite a ingestão automática de vetores: o LLM fornece uma descrição de texto, e a caixa de ferramentas copia, incorpora e armazena o vetor silenciosamente ao lado do texto. - Como o
ToolboxToolsetdo ADK carrega ferramentas de um servidor da caixa de ferramentas em execução, mantendo o código do agente mínimo e a lógica do banco de dados totalmente dissociada - Como implantar o servidor MCP da caixa de ferramentas e o agente do ADK no Cloud Run como serviços separados
Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos criados neste codelab, exclua os recursos individuais ou o projeto inteiro.
Opção 1: excluir o projeto (recomendado)
A maneira mais fácil de fazer a limpeza é excluir o projeto. Isso remove todos os recursos associados ao projeto.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Opção 2: excluir recursos individuais
Se você quiser manter o projeto, mas remover apenas os recursos criados neste codelab:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null