
1. Введение
Полезность ИИ-агентов зависит от качества данных, к которым они имеют доступ. Большая часть реальных данных хранится в базах данных, а подключение агентов к базам данных обычно подразумевает написание кода для управления соединениями, логики запросов и встраивания конвейеров обработки данных в код агента. Каждый агент, которому необходим доступ к базе данных, повторяет эту работу, и каждое изменение запроса требует повторного развертывания агента.
В этом практическом занятии показан другой подход. Вы объявляете инструменты для работы с базой данных в файле YAML — стандартные SQL-запросы, поиск векторного сходства, даже автоматическое создание векторных представлений — а MCP Toolbox for Databases обрабатывает все операции с базой данных как MCP-сервер. Код вашего агента остается минимальным: загружаете инструменты, а Gemini решает, какой из них вызвать.
Что вы построите
Сервис «Ресторанный консьерж » для проекта «Находки для гурманов» — агент ADK на базе Gemini, который помогает посетителям просматривать меню ресторана, используя стандартные фильтры (категория, тип кухни), и находить блюда с помощью описаний на естественном языке, например: «Я хочу что-нибудь острое и вегетарианское». Агент считывает и записывает данные в базу данных Cloud SQL PostgreSQL полностью через MCP Toolbox for Databases, который обрабатывает весь доступ к базе данных, включая автоматическую генерацию векторных представлений для векторного поиска. В итоге и Toolbox, и агент работают на платформе Cloud Run.
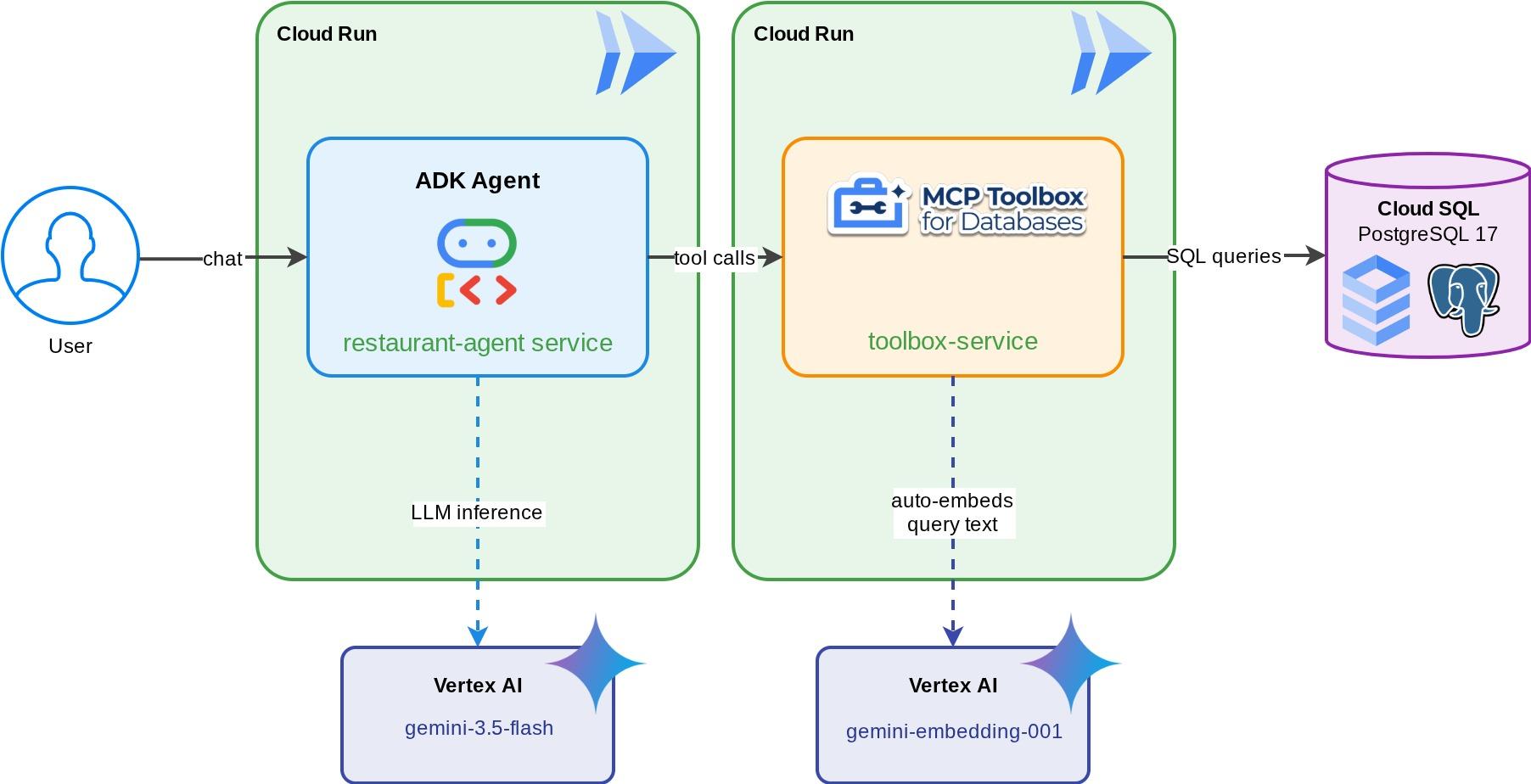
Что вы узнаете
- Как протокол MCP (Model Context Protocol) стандартизирует доступ к инструментам для агентов ИИ, и как MCP Toolbox for Databases применяет это к операциям с базами данных.
- Настройте MCP Toolbox for Databases в качестве промежуточного программного обеспечения между агентом ADK и Cloud SQL PostgreSQL.
- Инструменты базы данных определяются декларативно в файле
tools.yaml— в вашем агенте не используется код базы данных. - Создайте агент ADK, который загружает инструменты с работающего сервера Toolbox, используя
ToolboxToolset - Создавайте векторные представления данных с помощью встроенной функции
embedding()Cloud SQL и включайте семантический поиск с помощьюpgvector - Используйте функцию
valueFromParamдля автоматического приема вектора при операциях записи. - Разверните сервер Toolbox и агент ADK в Cloud Run.
Предварительные требования
- Учетная запись Google Cloud с пробной платной учетной записью.
- Базовые знания Python и SQL.
- Опыт работы с облачными базами данных и ADK будет полезен.
2. Настройте свою среду.
На этом этапе подготавливается среда Cloud Shell, настраивается проект Google Cloud и клонируется репозиторий ссылок.
Открытая облачная оболочка
Откройте Cloud Shell в браузере. Cloud Shell предоставляет предварительно настроенную среду со всеми необходимыми инструментами для выполнения этого практического задания. При появлении запроса нажмите «Авторизовать».
Затем нажмите « Вид » -> « Терминал », чтобы открыть терминал. Ваш интерфейс должен выглядеть примерно так.
Это будет наш основной интерфейс: IDE сверху, терминал снизу.
Настройте рабочую директорию.
Создайте свою рабочую директорию. Весь код, написанный вами в этом практическом занятии, будет находиться здесь:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
После этого подготовим несколько каталогов для управления такими вещами, как заполнение скриптов и логов.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Настройте свой проект в Google Cloud.
Создайте файл .env с переменными location:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Чтобы упростить настройку проекта в терминале, загрузите этот скрипт настройки проекта в свою рабочую директорию:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Запустите скрипт. Он проверит вашу учетную запись для оплаты пробной версии, создаст новый проект (или проверит существующий), сохранит идентификатор вашего проекта в файл .env в текущем каталоге и установит активный проект в gcloud .
bash setup_verify_trial_project.sh && source .env
Сценарий будет:
- Убедитесь, что у вас есть активный пробный аккаунт для оплаты.
- Проверьте наличие существующего проекта в
.env(если таковой имеется). - Создайте новый проект или используйте существующий.
- Свяжите пробный аккаунт с вашим проектом.
- Сохраните идентификатор проекта в файл
.env - Установите этот проект в качестве активного проекта
gcloud
Убедитесь, что проект настроен правильно, проверив желтый текст рядом с вашим рабочим каталогом в командной строке терминала Cloud Shell. Там должен отображаться идентификатор вашего проекта.

Активируйте необходимый API
Далее нам необходимо включить несколько API для продукта, с которым мы будем взаимодействовать:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- API Vertex AI (
aiplatform.googleapis.com) — ваш агент использует модели Gemini, а Toolbox использует API встраивания для векторного поиска. - Cloud SQL Admin API (
sqladmin.googleapis.com) — позволяет создавать и управлять экземпляром PostgreSQL. - API Compute Engine (
compute.googleapis.com) — необходим для создания экземпляров Cloud SQL. - Cloud Run, Cloud Build, Artifact Registry — используются на этапе развертывания, который будет рассмотрен далее в этом практическом занятии.
3. Подготовка скриптов для инициализации базы данных
На этом этапе начинается создание экземпляра Cloud SQL и запускается автоматизированный скрипт настройки, который ожидает готовности экземпляра, затем создает базу данных, заполняет ее списками заданий и генерирует эмбеддинги — все за одну операцию.
Для начала добавим пароль к базе данных в ваш файл .env и перезагрузим её:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Создание Bash-скрипта для создания экземпляра и базы данных.
Затем создайте скрипт scripts/setup_database.sh с помощью следующей команды.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Затем скопируйте следующий код в файл scripts/setup_database.sh
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Создание скрипта на Python для заполнения начальных данных.
После этого создайте файл скрипта для заполнения базы данных scripts/setup_restaurant_db.py с помощью приведенной ниже команды.
cloudshell edit scripts/setup_restaurant_db.py
Затем скопируйте следующий код в файл scripts/setup_restaurant_db.py
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Теперь перейдём к следующему шагу.
4. Создайте и инициализируйте базу данных.
Теперь наши скрипты готовы к выполнению. Для выполнения подготовленного скрипта нам понадобится Python, поэтому давайте сначала подготовим его.
Настройте проект Python.
uv — это быстрый менеджер пакетов и проектов для Python, написанный на Rust ( документация uv ). В этом практическом занятии он используется для повышения скорости и упрощения поддержки проекта на Python.
Инициализируйте проект Python и добавьте необходимые зависимости:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Обратите внимание, что здесь мы используем Python SDK cloud-sql-python-connector для инициализации защищенного соединения с нашим экземпляром базы данных, аутентификация которого осуществляется с помощью учетных данных приложения по умолчанию.
Запустите скрипт установки.
Теперь мы можем запустить скрипт настройки в фоновом режиме и просмотреть вывод консоли, который будет записан в файл logs/atabase_setup.log используя следующую команду. Вы можете перейти к следующему разделу, пока этот процесс не завершится.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Загрузите исполняемый файл Toolbox.
В этом руководстве мы будем использовать MCP Toolbox, к счастью, он поставляется с предварительно собранным бинарным файлом, готовым к использованию в среде Linux. Теперь давайте загрузим его в фоновом режиме, так как это займет довольно много времени. Выполните следующую команду, чтобы загрузить бинарный файл, и просмотрите вывод в logs/toolbox_dl.log . Вы можете перейти к следующему разделу, пока процесс не завершится.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Понимание скрипта установки scripts/setup_database.sh
Теперь давайте попробуем разобраться в скрипте настройки, который мы ранее сконфигурировали. Он выполняет следующий процесс.
- Первая команда, которую мы там выполняем, — это команда
gcloud sql instances createсо следующим флагом.
-
db-custom-1-3840— это самый маленький выделенный уровень Cloud SQL (1 vCPU, 3,75 ГБ ОЗУ) в версииENTERPRISE. Подробнее можно прочитать здесь . Для интеграции Vertex AI ML требуется выделенное ядро — уровни с общим ядром (db-f1-micro,db-g1-small) его не поддерживают. -
--root-passwordустанавливает пароль для пользователяpostgresпо умолчанию. -
--enable-google-ml-integrationвключает встроенную интеграцию Cloud SQL с Vertex AI, которая позволяет вызывать модели встраивания непосредственно из SQL с помощью функцииembedding().
- Проверьте, находится ли экземпляр уже в состоянии
RUNNABLE - Предоставьте учетной записи службы экземпляра Cloud SQL разрешение на вызов Vertex AI с помощью команды
gcloud projects add-iam-policy-binding. Это необходимо для встроенной функцииembedding(), которую мы будем использовать при заполнении базы данных данными. - Создание базы данных
- Выполнение скрипта
setup_restaurant_db.pyдля заполнения базы данных.
Понимание скрипта инициализации scripts/setup_restaurant_db.py
Теперь перейдём к скрипту инициализации. Этот скрипт выполняет следующие действия:
- Инициализируйте соединение с экземпляром базы данных.
- Устанавливает два расширения PostgreSQL:
-
google_ml_integration— предоставляет функцию SQLembedding(), которая вызывает модели встраивания Vertex AI непосредственно из SQL. Это расширение на уровне базы данных, которое делает функции машинного обучения доступными внутриrestaurant_db. Флаг уровня экземпляра (--enable-google-ml-integration), который вы устанавливаете при создании экземпляра, позволяет виртуальной машине Cloud SQL обращаться к Vertex AI — расширение делает функции SQL доступными в этой конкретной базе данных. -
vector(pgvector) — добавляетvectorтип данных и операторы расстояния для хранения и запроса векторных представлений.
- Создайте таблицу, обратите внимание, что столбец
description_embeddingимеетvector(3072)— это столбецpgvector, который хранит 3072-мерные векторы. - Заполните начальные данные пунктов меню.
- Сгенерируйте данные для встраивания из поля
descriptionи заполните полеdescription_embedding, используя встроенную интеграцию вершин через функциюembedding()
-
embedding('gemini-embedding-001', description)— вызывает модель встраивания Gemini от Vertex AI напрямую из SQL, передавая текстdescriptionкаждого задания. Это расширениеgoogle_ml_integrationкоторое вы установили в скрипте инициализации. -
::vector— преобразует возвращаемый массив чисел с плавающей запятой вvectorтип pgvector, чтобы его можно было хранить и запрашивать с помощью операторов расстояния. -
UPDATEприменяется ко всем 15 строкам, генерируя одно 3072-мерное векторное представление для каждого описания вакансии.
Это позволит подготовить исходные данные, к которым будет иметь доступ наш агент.
5. Настройка MCP Toolbox для баз данных.
На этом шаге представлен MCP Toolbox for Databases, настроено подключение к вашему экземпляру Cloud SQL и определены два стандартных инструмента для выполнения SQL-запросов.
Что такое MCP и зачем использовать Toolbox?
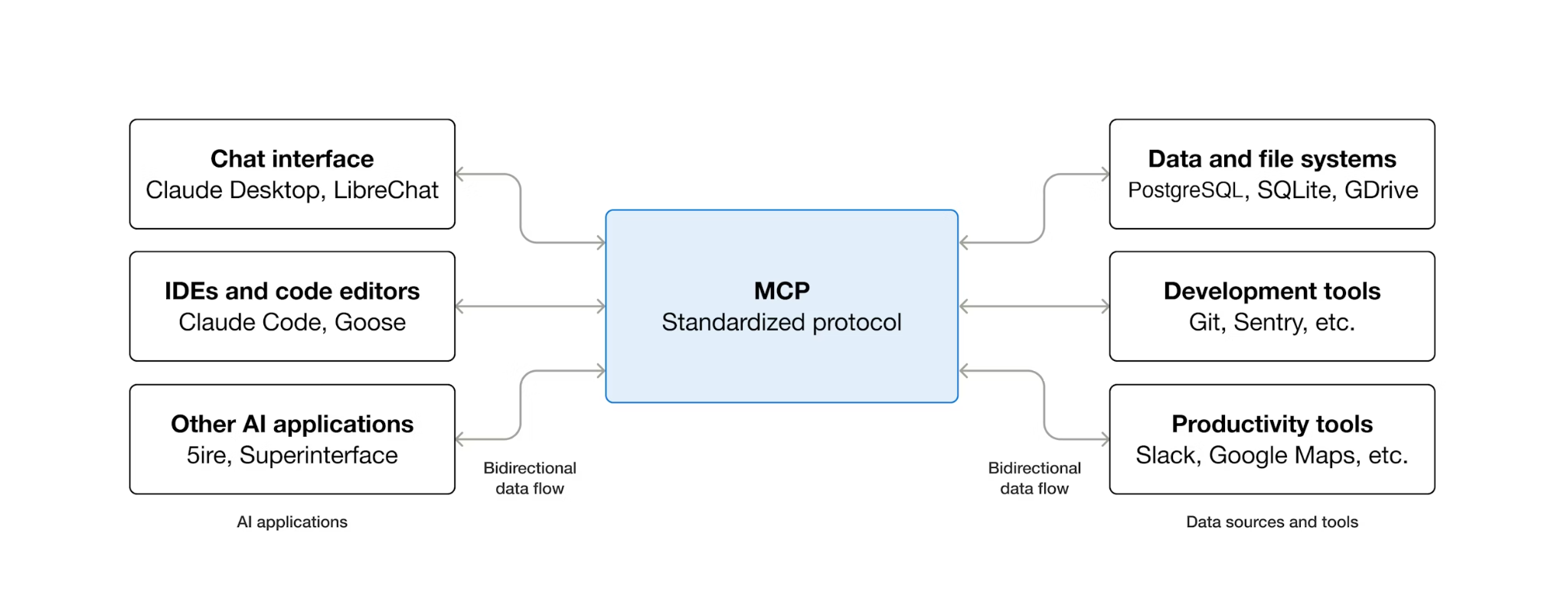
MCP (Model Context Protocol) — это открытый протокол, стандартизирующий способы обнаружения внешних инструментов и взаимодействия с ними у агентов искусственного интеллекта. Он определяет модель «клиент-сервер»: агент размещает MCP-клиент, а инструменты предоставляются MCP-серверами. Любой MCP-совместимый клиент может использовать любой MCP-совместимый сервер — агенту не требуется собственный код интеграции для каждого инструмента.
MCP Toolbox for Databases — это сервер MCP с открытым исходным кодом, созданный специально для доступа к базам данных. Без него вам пришлось бы писать функции на Python, которые открывают соединения с базами данных, управляют пулами соединений, формируют параметризованные запросы для предотвращения SQL-инъекций, обрабатывают ошибки и встраивают весь этот код в ваш агент. Каждый агент, которому необходим доступ к базе данных, повторяет эту работу. Изменение запроса означает повторное развертывание агента.
С помощью Toolbox вы пишете YAML-файл. Каждый инструмент соответствует параметризованному SQL-запросу. Toolbox обрабатывает пулы соединений, параметризованные запросы, аутентификацию и мониторинг. Инструменты независимы от агента — обновить запрос можно, отредактировав tools.yaml и перезапустив Toolbox, без изменения кода агента. Те же инструменты работают с ADK, LangGraph, LlamaIndex или любой совместимой с MCP платформой.
Напишите конфигурацию инструментов
Теперь нам нужно создать файл tools.yaml в редакторе Cloud Shell, чтобы настроить конфигурацию наших инструментов.
cloudshell edit tools.yaml
Файл использует многодокументный YAML — каждый блок, разделённый символами --- представляет собой отдельный ресурс. Каждый ресурс имеет kind , который определяет его назначение ( sources для подключений к базам данных, tools для действий, вызываемых агентом), и type , указывающий на бэкэнд ( cloud-sql-postgres для источника, postgres-sql для инструментов на основе SQL). Инструмент ссылается на свой источник по name , благодаря чему Toolbox знает, к какому пулу подключений следует обращаться. Переменные среды используют синтаксис ${VAR_NAME} и разрешаются при запуске.
Теперь давайте сначала скопируем следующие скрипты в файл tools.yaml
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
Данный скрипт определяет следующий ресурс:
- Source (
restaurant-db) — указывает Toolbox, как подключиться к вашему экземпляру Cloud SQL PostgreSQL. Типcloud-sql-postgresиспользует внутренний коннектор Cloud SQL, автоматически обрабатывая аутентификацию и безопасные соединения. Заполнители${GOOGLE_CLOUD_PROJECT},${REGION}и${DB_PASSWORD}определяются из переменных среды при запуске.
Далее добавьте следующий скрипт под символом --- в файл tools.yaml.
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
Данный скрипт определяет следующий ресурс:
- Инструменты 1 и 2 (
search-menu,get-item-details) — стандартные инструменты для выполнения SQL-запросов. Каждый из них сопоставляет имя инструмента (то, что видит агент) с параметризованным SQL-запросом (то, что выполняет база данных). В параметрах используются позиционные заполнители$1и$2. Toolbox выполняет их как подготовленные запросы, что предотвращает SQL-инъекции.
Продолжим, добавив следующий скрипт под символом --- в файл tools.yaml.
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
Данный скрипт определяет следующий ресурс:
- Модель встраивания (
gemini-embedding) — настраивает Toolbox для вызова моделиgemini-embedding-001для генерации 3072-мерных текстовых встраиваний. Toolbox использует учетные данные приложения по умолчанию (ADC) для аутентификации — ключ API не требуется в Cloud Shell или Cloud Run. Обратите внимание, что этоdimensionнастроенное здесь, должно совпадать с ранее настроенным для заполнения базы данных.
Продолжим, добавив следующий скрипт под символом --- в файл tools.yaml.
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
Данный скрипт определяет следующий ресурс:
- Инструмент 3 (
search-menu-by-description) — инструмент векторного поиска. Параметрsearch_queryимеетembeddedBy: gemini-embedding, который указывает Toolbox перехватить исходный текст, отправить его в модель встраивания и использовать полученный вектор в SQL-запросе. Оператор<=>— это косинусное расстояние pgvector — меньшие значения означают больше похожих описаний.
Наконец, добавьте последний инструмент под символом --- в файл tools.yaml.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
Данный скрипт определяет следующий ресурс:
- Инструмент 4 (
add-menu-item) — демонстрирует загрузку вектора. Параметрdescription_vectorимеет два специальных поля: -
valueFromParam: description— Toolbox копирует значение из параметраdescriptionв этот параметр. LLM никогда не видит этот параметр. -
embeddedBy: gemini-embedding— Инструментарий встраивает скопированный текст в вектор перед передачей его в SQL-запрос.
В результате: один вызов инструмента сохраняет как исходный текст описания, так и его векторное представление, при этом агент ничего не знает о векторных представлениях.
Многодокументный формат YAML разделяет каждый ресурс символом --- . Каждый документ содержит поля kind , name и type , определяющие его назначение. В итоге, мы уже настроили все следующие параметры:
- Определите исходную базу данных
- Определите инструменты ( инструмент 1 и 2 ) для выполнения запросов к базе данных со стандартным фильтром.
- Определить модель встраивания
- Определите инструмент для выполнения векторного поиска ( инструмент 3 ) в базе данных.
- Определите инструмент для загрузки векторных данных ( инструмент 4) в базу данных.
6. Запуск сервера MCP Toolbox
На предыдущем шаге мы уже настроили необходимую конфигурацию для нашего MCP Toolbox. Теперь мы готовы запустить сервер.
Проверьте исходные данные.
Перед запуском Toolbox давайте убедимся, что настройка базы данных завершена. Создайте скрипт Python scripts/verify_database.py используя следующую команду.
cloudshell edit scripts/verify_seed.py
Затем скопируйте следующий код в файл scripts/verify_seed.py
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Этот скрипт проверит количество данных пунктов меню и их встраивание. Запустите скрипт, используя следующую команду.
uv run scripts/verify_seed.py
Если вы видите следующий вывод в терминале, это означает, что данные готовы.
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Запустите сервер Toolbox.
На предыдущем этапе установки мы уже загрузили исполняемый файл toolbox . Убедитесь, что этот бинарный файл существует и успешно загружен; если нет, загрузите его и дождитесь завершения загрузки.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
Нам потребуется предоставить доступ к нашим переменным .env дочернему процессу, запускаемому MCP Toolbox. Выполните следующую команду, чтобы запустить сервер Toolbox и записать его вывод в файл logs/mcp_toolbox.log
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
В файле logs/mcp_toolbox.log вы должны увидеть подтверждение готовности сервера, как показано ниже:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Проверьте инструменты
Для получения списка всех зарегистрированных инструментов выполните запрос к API Toolbox:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Вы должны увидеть инструменты с их описаниями и параметрами. Как показано ниже.
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
Проверьте работу инструмента search-menu непосредственно:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
В ответе должны быть указаны основные блюда итальянской кухни из ваших исходных данных.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. Создайте агент ADK.
Теперь мы будем использовать ADK в Python для этого проекта, давайте добавим необходимые зависимости:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk— комплект разработки агентов от Google, включая SDK Gemini.-
toolbox-adk— интеграция ADK для MCP Toolbox for Databases.
Создайте структуру каталогов агента.
ADK ожидает определенную структуру папок: каталог, названный в честь вашего агента и содержащий файлы __init__.py , agent.py и .env . Для этого предусмотрена встроенная команда, позволяющая быстро установить структуру:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
Теперь ваша директория должна выглядеть примерно так:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
Далее нам потребуется интегрировать агент ADK с работающим сервером Toolbox и протестировать все четыре инструмента — стандартные запросы, семантический поиск и векторную обработку данных. Код агента минимален: вся логика работы с базой данных находится в tools.yaml .
Настройте среду агента.
ADK считывает GOOGLE_GENAI_USE_VERTEXAI , GOOGLE_CLOUD_PROJECT и GOOGLE_CLOUD_LOCATION из среды командной оболочки, которую вы уже установили на предыдущем шаге. Единственная переменная, специфичная для агента, — это TOOLBOX_URL ; добавьте её в файл .env агента:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Обновите модуль агента.
Откройте restaurant_agent/agent.py в редакторе Cloud Shell.
cloudshell edit restaurant_agent/agent.py
и перезапишите содержимое следующим кодом:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Обратите внимание, что здесь нет кода, отвечающего за работу с базой данных — ToolboxToolset подключается к серверу Toolbox при запуске и загружает все доступные инструменты. Агент вызывает инструменты по имени; Toolbox преобразует эти вызовы в SQL-запросы к Cloud SQL.
По умолчанию переменная среды TOOLBOX_URL имеет значение http://127.0.0.1:5000 для локальной разработки. При последующем развертывании в Cloud Run вы переопределяете это значение URL-адресом Cloud Run службы Toolbox — никаких изменений в коде не требуется.
Проверьте агента
Запустите пользовательский интерфейс разработчика ADK:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Откройте URL-адрес, отображаемый в терминале (обычно http://localhost:8000 ), используя функцию предварительного просмотра веб-страниц Cloud Shell или щелкнув по URL-адресу в терминале с зажатой клавишей Ctrl . Выберите restaurant_agent из выпадающего списка агентов в верхнем левом углу.
Тестирование стандартных запросов
Попробуйте выполнить следующие действия, чтобы проверить работу стандартных инструментов SQL:
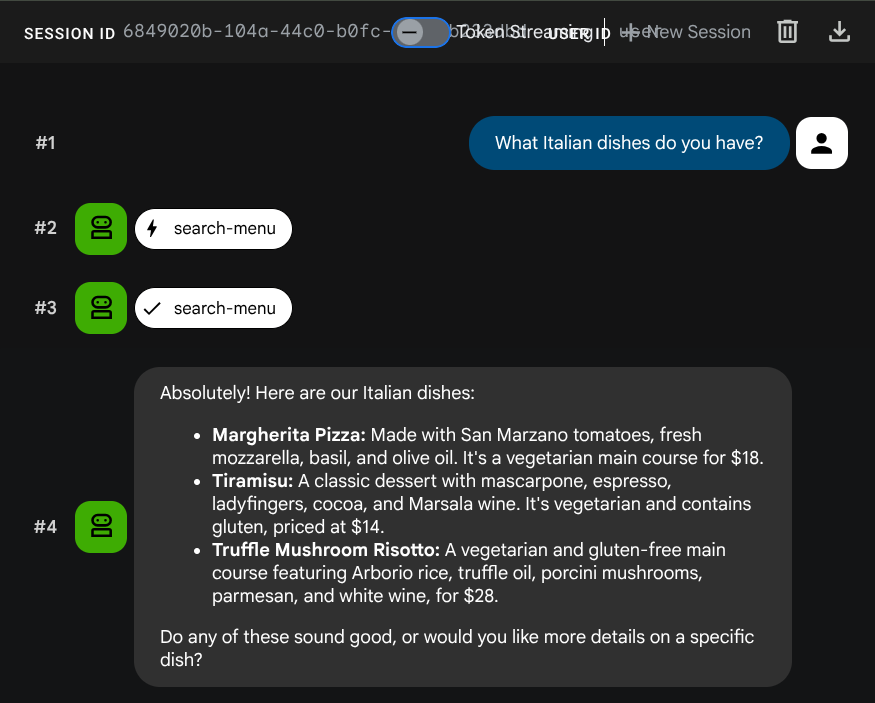
What Italian dishes do you have?
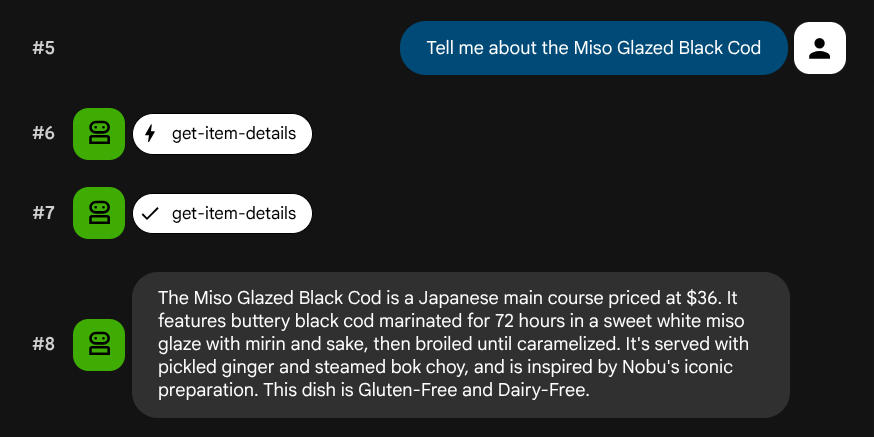
Tell me about the Miso Glazed Black Cod
Тест семантического поиска
Попробуйте использовать описания на естественном языке, которые не привязаны к конкретной роли или набору технологий:
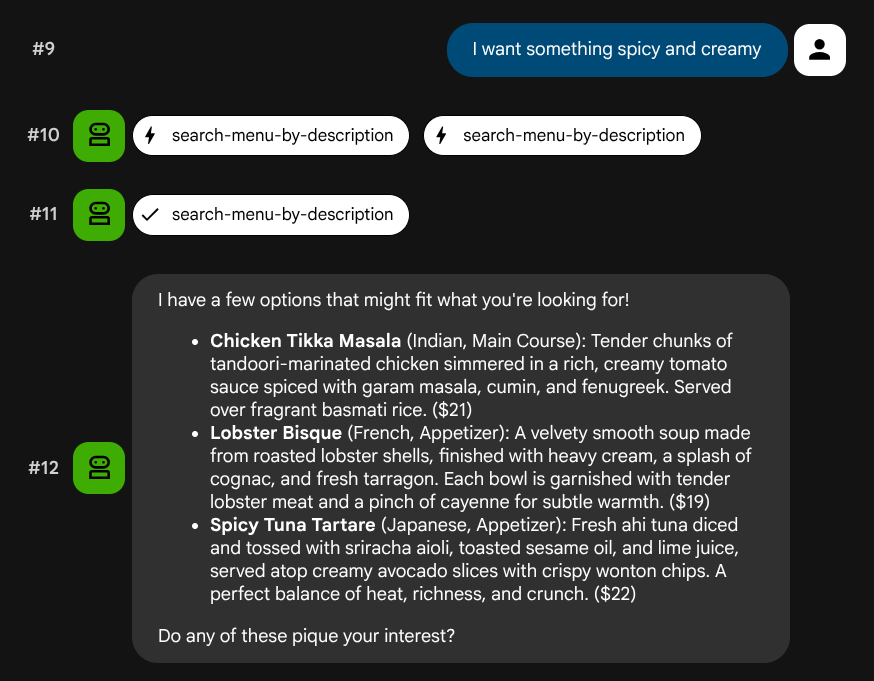
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
Агент попытается выбрать подходящий инструмент в зависимости от типа запроса: для структурированных фильтров используется search-menu , для описаний на естественном языке search-menu-by-description .
Тестовое поглощение вектора
Попросите агента добавить новое задание:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
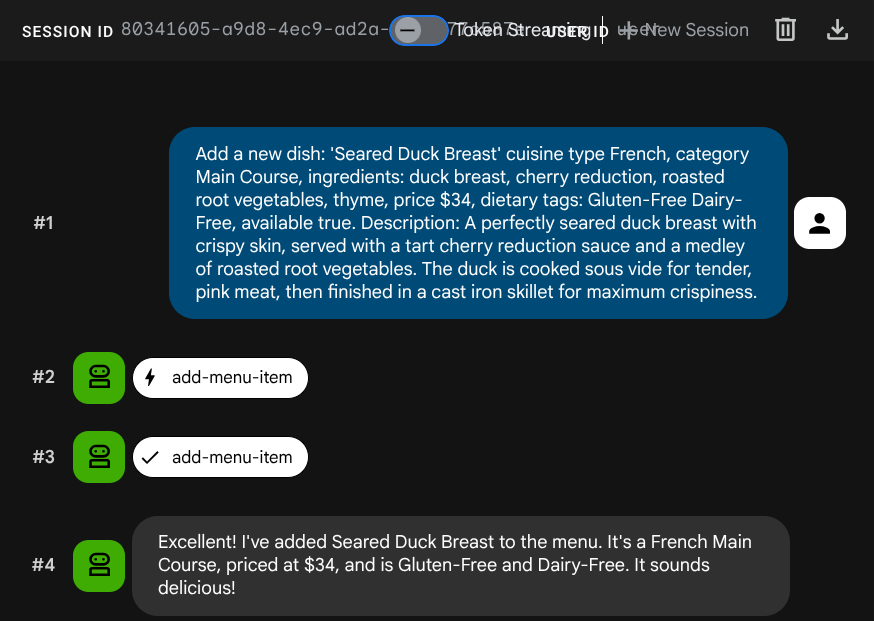
Теперь попробуйте это найти:
Find me something with rich, gamey flavors and fruit sauce
Встраивание было сгенерировано автоматически во время операции INSERT — отдельный шаг не потребовался.
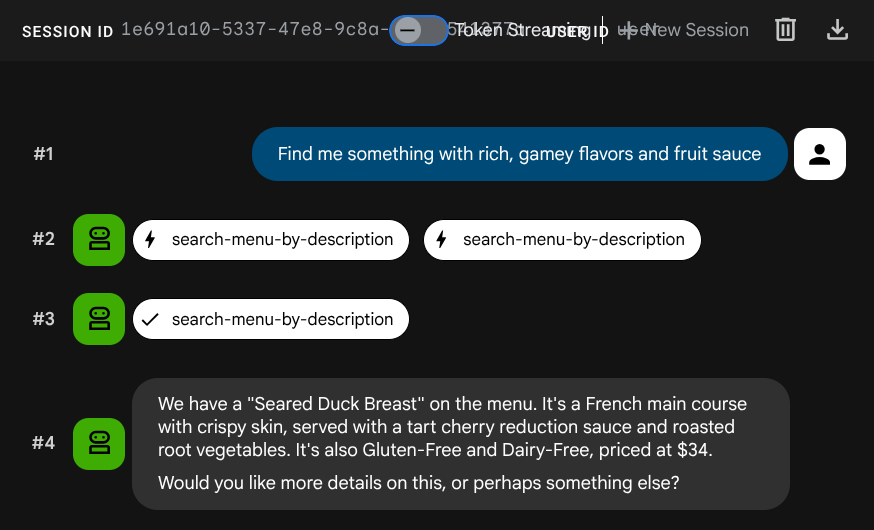
Теперь у вас уже есть полностью работоспособное приложение Agentic RAG, использующее ADK, MCP Toolbox и CloudSQL. Поздравляем! Давайте перейдем к следующему шагу — развертыванию этих приложений в Cloud Run!
Теперь давайте остановим пользовательский интерфейс разработчика, завершив процесс, дважды нажав Ctrl+C, прежде чем продолжить.
8. Развертывание в облаке.
Агент и Toolbox работают локально. На этом этапе оба приложения развертываются как службы Cloud Run, поэтому они доступны через интернет. Служба Toolbox работает как сервер MCP в Cloud Run, а служба агента подключается к ней.
Подготовьте набор инструментов к развертыванию.
Создайте каталог развертывания для службы Toolbox:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Создайте Dockerfile для Toolbox. Откройте deploy-toolbox/Dockerfile в редакторе Cloud Shell:
cloudshell edit deploy-toolbox/Dockerfile
И скопируйте в него следующий скрипт.
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
Двоичный файл Toolbox и tools.yaml упакованы в минимальный образ Debian. Cloud Run перенаправляет трафик на порт 8080.
Разверните службу Toolbox.
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
Эта команда отправляет исходный код в Cloud Build, создает образ контейнера, загружает его в Artifact Registry и развертывает в Cloud Run. Это займет несколько минут — мы можем просмотреть журнал процесса развертывания в файле logs/deploy_toolbox.log
Подготовьте агента к развертыванию.
Пока выполняется сборка Toolbox, настройте файлы развертывания агента.
Создайте Dockerfile в корневой директории проекта. Откройте Dockerfile в редакторе Cloud Shell:
cloudshell edit Dockerfile
Затем скопируйте следующее содержимое.
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
В этом Dockerfile в качестве базового образа используется ghcr.io/astral-sh/uv , который включает в себя предустановленные Python и uv — нет необходимости устанавливать uv отдельно через pip .
Создайте файл .dockerignore , чтобы исключить ненужные файлы из образа контейнера:
cloudshell edit .dockerignore
Затем скопируйте в него следующий скрипт.
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Разверните службу агента.
Дождитесь завершения развертывания Toolbox. Для проверки процесса еще раз просмотрите logs/deploy_toolbox.log . Затем получите URL-адрес Cloud Run, используя следующую команду.
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Вы увидите примерно такой результат.
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Теперь давайте проверим, работает ли развернутый Toolbox:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Если результат соответствует приведенному примеру, значит, развертывание уже прошло успешно.
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
Далее развернем агента, передав URL-адрес Toolbox в качестве переменной среды:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
Код агента считывает TOOLBOX_URL из среды (вы настроили это ранее). Локально он указывает на http://127.0.0.1:5000 ; в Cloud Run он указывает на URL-адрес службы Toolbox. Никаких изменений в коде не требуется.
Протестируйте развернутого агента.
Получите URL-адрес Cloud Run агента:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
Откройте URL-адрес в браузере. Загрузится пользовательский интерфейс разработчика ADK — тот же интерфейс, который вы использовали локально, теперь работающий в Cloud Run.
Выберите restaurant_agent из выпадающего списка и проведите тест:
What Italian dishes do you have?
I want something spicy and creamy
Оба запроса выполняются через развернутые сервисы: агент в Cloud Run вызывает Toolbox в Cloud Run, который, в свою очередь, запрашивает данные из Cloud SQL.
9. Поздравления / Уборка
Вы разработали и развернули интеллектуальный помощник по составлению меню для ресторана, который использует MCP Toolbox for Databases для связи агента ADK и Cloud SQL PostgreSQL — как со стандартными SQL-запросами, так и с семантическим векторным поиском.
Что вы узнали
- Как MCP стандартизирует доступ к инструментам для агентов ИИ и как MCP Toolbox for Databases применяет это конкретно к операциям с базами данных — заменяя пользовательский код базы данных декларативной конфигурацией YAML.
- Как настроить Cloud SQL PostgreSQL в качестве источника данных Toolbox, используя тип источника
cloud-sql-postgres - Как определить стандартные инструменты для выполнения SQL-запросов с параметризованными операторами, предотвращающими SQL-инъекции.
- Как включить векторный поиск с помощью pgvector и
gemini-embedding-001, используя параметрembeddedByдля автоматического встраивания запроса. - Как
valueFromParamобеспечивает автоматическое загрузку векторов: LLM предоставляет текстовое описание, а Toolbox незаметно копирует, встраивает и сохраняет вектор вместе с текстом. - Как
ToolboxToolsetиз ADK загружает инструменты с работающего сервера Toolbox, сводя к минимуму код агента и обеспечивая полную независимость логики от базы данных. - Как развернуть сервер Toolbox MCP и агент ADK в Cloud Run в качестве отдельных сервисов.
Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, созданные в этом практическом задании, вы можете либо удалить отдельные ресурсы, либо удалить весь проект.
Вариант 1: Удалить проект (рекомендуется)
Самый простой способ навести порядок — удалить проект. Это удалит все ресурсы, связанные с проектом.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Вариант 2: Удаление отдельных ресурсов
Если вы хотите сохранить проект, но удалить только ресурсы, созданные в этом практическом задании:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null