
1. Giriş
Yapay zeka temsilcileri, yalnızca erişebildikleri veriler kadar faydalıdır. Gerçek dünyadaki verilerin çoğu veritabanlarında bulunur ve temsilcileri veritabanlarına bağlamak genellikle temsilci kodunuzda bağlantı yönetimi, sorgu mantığı ve yerleştirme işlem hatları yazmak anlamına gelir. Veritabanı erişimi gerektiren her temsilci bu çalışmayı tekrarlar ve her sorgu değişikliği, temsilcinin yeniden dağıtılmasını gerektirir.
Bu codelab'de farklı bir yaklaşım gösterilmektedir. Veritabanı araçlarınızı bir YAML dosyasında (standart SQL sorguları, vektör benzerliği araması ve hatta otomatik yerleştirme oluşturma) tanımlarsınız. Veritabanları için MCP Araç Kutusu, tüm veritabanı işlemlerini bir MCP sunucusu olarak yönetir. Aracı kodunuz en az düzeyde kalır: Araçları yükleyin, hangi aracın çağrılacağına Gemini karar versin.
Ne oluşturacaksınız?
"Yemek Tutkunlarına Özel" için Restoran Concierge: Gemini destekli bir ADK aracısıdır. Yemek yiyenlerin standart filtreleri (kategori, mutfak türü) kullanarak restoranın menüsüne göz atmasına ve "Acı ve vejetaryen bir yemek istiyorum" gibi doğal dil açıklamalarıyla yemekleri keşfetmesine yardımcı olur. Aracı, vektör araması için otomatik yerleştirme oluşturma da dahil olmak üzere tüm veritabanı erişimini işleyen MCP Toolbox for Databases aracılığıyla Cloud SQL PostgreSQL veritabanından okuma ve bu veritabanına yazma işlemleri gerçekleştirir. Sonunda hem Toolbox hem de aracı Cloud Run'da çalışır.
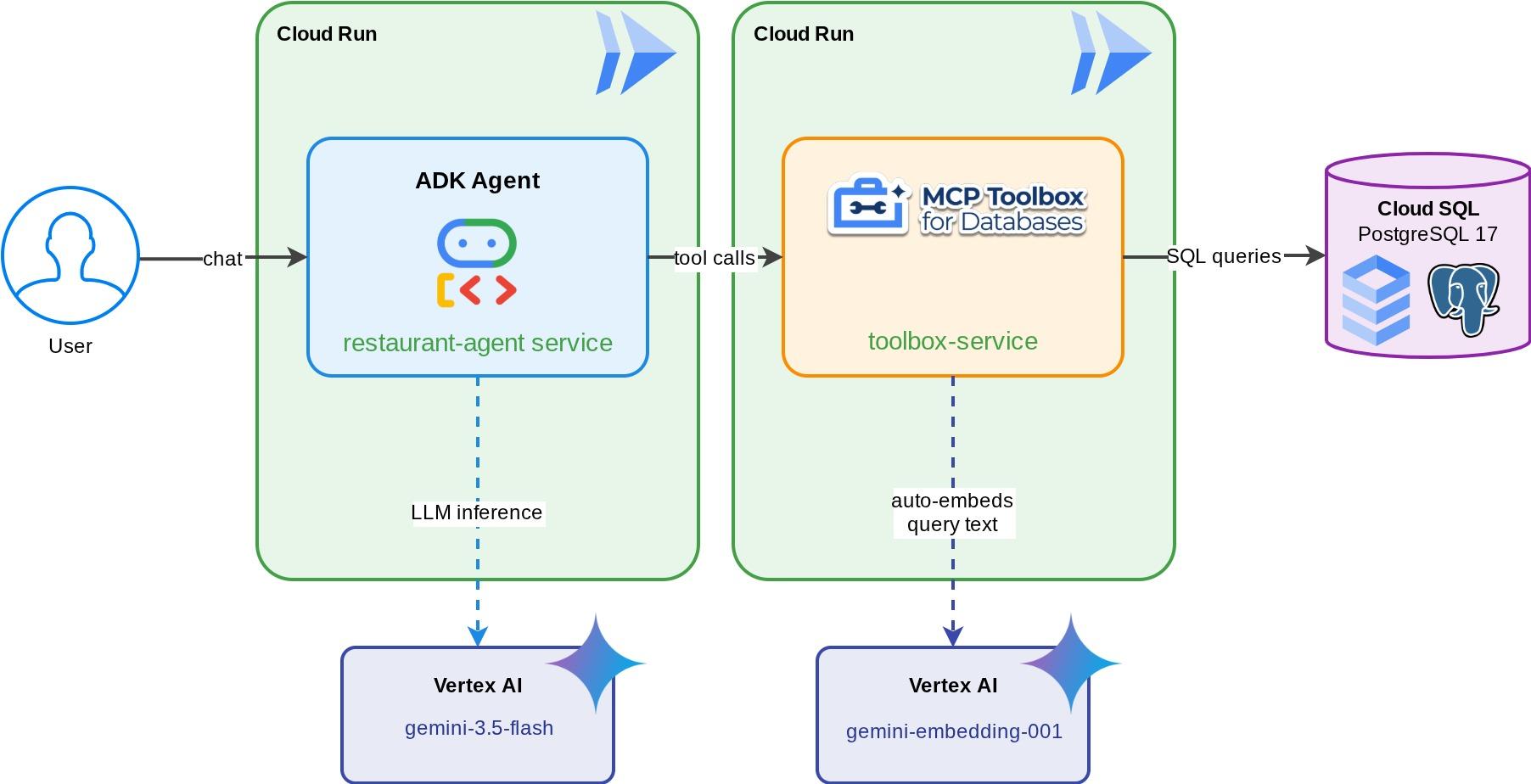
Neler öğreneceksiniz?
- MCP (Model Context Protocol) standardının, yapay zeka ajanlarının araç erişimini nasıl standartlaştırdığı ve MCP Toolbox for Databases'in bunu veritabanı işlemlerine nasıl uyguladığı
- Veritabanları için MCP Toolbox'ı ADK aracısı ile Cloud SQL PostgreSQL arasında ara katman yazılımı olarak ayarlama
- Veritabanı araçlarını
tools.yamliçinde bildirimsel olarak tanımlayın. Temsilcinizde veritabanı kodu bulunmaz. ToolboxToolsetkullanarak çalışan bir Araç Kutusu sunucusundan araç yükleyen bir ADK aracısı oluşturma- Cloud SQL'in yerleşik
embedding()işlevini kullanarak vektör yerleştirmeleri oluşturma vepgvectorile semantik aramayı etkinleştirme - Yazma işlemlerinde otomatik vektör alımı için
valueFromParamözelliğini kullanma - Toolbox sunucusunu ve ADK aracısını Cloud Run'a dağıtma
Ön koşullar
- Deneme faturalandırma hesabına sahip bir Google Cloud hesabı
- Python ve SQL ile ilgili temel bilgiler
- Cloud Database ve ADK ile ilgili önceki deneyimler yardımcı olacaktır.
2. Ortamınızı ayarlama
Bu adımda Cloud Shell ortamınız hazırlanır, Google Cloud projeniz yapılandırılır ve referans deposu klonlanır.
Cloud Shell'i açma
Tarayıcınızda Cloud Shell'i açın. Cloud Shell, bu codelab için ihtiyacınız olan tüm araçların bulunduğu önceden yapılandırılmış bir ortam sağlar. İstendiğinde Yetkilendir'i tıklayın.
Ardından, terminali açmak için "Görünüm" -> "Terminal"i tıklayın. Arayüzünüz aşağıdaki gibi görünmelidir.
Bu, ana arayüzümüz olacak. Üstte IDE, altta terminal yer alacak.
Çalışma dizininizi ayarlama
Çalışma dizininizi oluşturun. Bu codelab'de yazdığınız tüm kodlar burada bulunur:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
Ardından, seeding komut dosyaları ve günlükler gibi öğeleri yönetmek için birkaç dizin hazırlayalım.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Google Cloud projenizi oluşturun
Konum değişkenlerini içeren .env dosyasını oluşturun:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Terminalinizde proje kurulumunu basitleştirmek için bu proje kurulum komut dosyasını çalışma dizininize indirin:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Komut dosyasını çalıştırın. Bu komut, deneme faturalandırma hesabınızı doğrular, yeni bir proje oluşturur (veya mevcut bir projeyi doğrular), proje kimliğinizi geçerli dizindeki bir .env dosyasına kaydeder ve gcloud'de etkin projeyi ayarlar.
bash setup_verify_trial_project.sh && source .env
Komut dosyası:
- Etkin bir deneme faturalandırma hesabınız olduğunu doğrulayın.
.enviçinde mevcut bir proje olup olmadığını kontrol edin (varsa)- Yeni bir proje oluşturun veya mevcut projeyi yeniden kullanın
- Deneme faturalandırma hesabını projenize bağlama
- Proje kimliğini
.envdosyasına kaydedin. - Projeyi etkin
gcloudprojesi olarak ayarlayın
Cloud Shell terminal isteminde çalışma dizininizin yanındaki sarı metni kontrol ederek projenin doğru şekilde ayarlandığını doğrulayın. Proje kimliğiniz gösterilmelidir.

Gerekli API'yi Etkinleştirme
Ardından, etkileşimde bulunacağımız ürün için birkaç API'yi etkinleştirmemiz gerekir:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- Vertex AI API (
aiplatform.googleapis.com): Aracınız Gemini modellerini kullanır ve Toolbox, vektör araması için yerleştirme API'sini kullanır. - Cloud SQL Admin API (
sqladmin.googleapis.com): PostgreSQL örneği sağlarsınız ve yönetirsiniz. - Compute Engine API (
compute.googleapis.com): Cloud SQL örnekleri oluşturmak için gereklidir. - Cloud Run, Cloud Build, Artifact Registry: Bu codelab'in ilerleyen bölümlerinde dağıtım adımında kullanılır.
3. Veritabanı başlatma için komut dosyaları hazırlama
Bu adımda Cloud SQL örneği oluşturma işlemi başlatılır ve örneğin hazır olmasını bekleyen, ardından veritabanını oluşturan, iş ilanlarıyla dolduran ve yerleştirmeler oluşturan otomatik bir kurulum komut dosyası çalıştırılır. Tüm bu işlemler tek bir işlemde gerçekleştirilir.
Öncelikle, veritabanı şifresini .env dosyanıza ekleyip yeniden yükleyelim:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Örnek ve veritabanı oluşturma için Bash komut dosyası oluşturma
Ardından, aşağıdaki komutla scripts/setup_database.sh komut dosyasını oluşturun.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Ardından, aşağıdaki kodu scripts/setup_database.sh dosyasına kopyalayın.
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Veri başlangıcı için Python komut dosyası oluşturma
Ardından, aşağıdaki komutu kullanarak seeding_script.py adlı Python dosyasını scripts/setup_restaurant_db.py oluşturun.
cloudshell edit scripts/setup_restaurant_db.py
Ardından, aşağıdaki kodu scripts/setup_restaurant_db.py dosyasına kopyalayın.
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Şimdi bir sonraki adıma geçelim.
4. Veritabanını Oluşturma ve Başlatma
Artık komut dosyalarımız yürütülmeye hazır. Hazırladığımız komut dosyasını yürütmek için Python'a ihtiyacımız olacak. Bu nedenle, önce Python'ı hazırlayalım.
Python projesini oluşturma
uv, Rust ile yazılmış hızlı bir Python paketi ve proje yöneticisidir ( uv belgeleri ). Bu codelab'de, Python projesinin bakımında hız ve basitlik sağlamak için kullanılır.
Bir Python projesi başlatın ve gerekli bağımlılıkları ekleyin:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Uygulama Varsayılan Kimlik Bilgileri kullanılarak kimliği doğrulanmış veritabanı örneğimizle güvenli bir bağlantı başlatmak için burada cloud-sql-python-connector Python SDK'sını kullandığımızı unutmayın.
Kurulum komut dosyasını yürütme
Artık kurulum komut dosyasını arka planda çalıştırabilir ve aşağıdaki komutu kullanarak logs/atabase_setup.log dosyasına yazılacak konsol çıkışını inceleyebiliriz. Bu işlemin tamamlanmasını beklerken sonraki bölüme geçebilirsiniz.
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Araç kutusu ikilisini indirin
Bu eğitimde MCP Toolbox'ı kullanacağız. Neyse ki bu araç, Linux ortamında kullanıma hazır önceden oluşturulmuş bir ikili dosya ile birlikte gelir. Şimdi de arka planda indirelim. Bu işlem biraz zaman alabilir. İkili dosyayı indirmek ve çıkış günlüğünü logs/toolbox_dl.log üzerinde incelemek için aşağıdaki komutu çalıştırın . Bu işlemin tamamlanmasını beklerken sonraki bölüme geçebilirsiniz.
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Kurulum komut dosyasını anlama scripts/setup_database.sh
Şimdi de daha önce yapılandırdığımız kurulum komut dosyasını anlamaya çalışalım. Aşağıdaki işlemi yapar:
- Burada yürüttüğümüz ilk komut, aşağıdaki işaretle birlikte
gcloud sql instances createkomutudur.
db-custom-1-3840,ENTERPRISEsürümündeki en küçük ayrılmış çekirdekli Cloud SQL katmanıdır (1 vCPU, 3,75 GB RAM). Daha fazla bilgiyi burada bulabilirsiniz. Vertex AI ML entegrasyonu için özel bir çekirdek gerekir. Paylaşılan çekirdek katmanları (db-f1-micro,db-g1-small) bu entegrasyonu desteklemez.--root-password, varsayılanpostgreskullanıcısının şifresini ayarlar.--enable-google-ml-integration, Cloud SQL'in Vertex AI ile yerleşik entegrasyonunu etkinleştirir. Bu entegrasyon,embedding()işlevini kullanarak doğrudan SQL'den yerleştirme modellerini çağırmanıza olanak tanır.
- Örneğin
RUNNABLEdurumunda olup olmadığını doğrulayın. gcloud projects add-iam-policy-bindingkomutunu kullanarak Cloud SQL örneğinin hizmet hesabına Vertex AI'ı çağırma izni verin. Bu, veritabanını doldururken kullanacağımız yerleşikembedding()işlevi için gereklidir.- Veritabanını oluşturma
- İlk veri komut dosyası
setup_restaurant_db.pykomut dosyasını yürütme
Başlangıç komut dosyasını anlama scripts/setup_restaurant_db.py
Şimdi de başlangıç komut dosyasına geçelim. Bu komut dosyası aşağıdaki işlemleri yapar:
- Veritabanı örneğiyle bağlantıyı başlatma
- İki PostgreSQL uzantısı yükler:
google_ml_integration: Vertex AI yerleştirme modellerini doğrudan SQL'den çağıranembedding()SQL işlevini sağlar. Bu,restaurant_dbiçinde makine öğrenimi işlevlerini kullanılabilir hale getiren bir veritabanı düzeyinde uzantıdır. Örnek oluşturma sırasında ayarladığınız örnek düzeyindeki işaret (--enable-google-ml-integration), Cloud SQL VM'nin Vertex AI'ye ulaşmasına olanak tanır. Uzantı, SQL işlevlerini bu belirli veritabanında kullanılabilir hale getirir.vector(pgvector): Yerleştirmeleri depolamak ve sorgulamak içinvectorveri türünü ve mesafe operatörlerini ekler.
- Tabloyu oluşturun.
description_embeddingsütunununvector(3072)olduğunu unutmayın. Bu, 3072 boyutlu vektörleri depolayan birpgvectorsütunudur. - İlk menü öğeleri verilerini doldurma
descriptionalanından yerleştirme verilerini oluşturun veembedding()işlevi aracılığıyla yerleşik Vertex entegrasyonunu kullanarakdescription_embeddingalanını doldurun.
embedding('gemini-embedding-001', description): Her işindescriptionmetnini ileterek doğrudan SQL'den Vertex AI'ın Gemini yerleştirme modelini çağırır. Bu, başlangıç komut dosyasında yüklediğinizgoogle_ml_integrationuzantısıdır.::vector: Döndürülen kayan nokta dizisini, pgvector'ınvectortürüne yayınlar. Böylece, mesafe operatörleriyle depolanabilir ve sorgulanabilir.UPDATE, 15 satırın tamamında çalışarak her iş açıklaması için 3072 boyutlu bir yerleştirme oluşturur.
Bu işlem, ajanımız tarafından erişilecek ilk verileri hazırlar.
5. Veritabanları için MCP Araç Kutusu'nu yapılandırma
Bu adımda, MCP Toolbox for Databases tanıtılır, Cloud SQL örneğinize bağlanmak için yapılandırılır ve iki standart SQL sorgu aracı tanımlanır.
ÇMY nedir ve neden Araç Kutusu'nu kullanmalısınız?
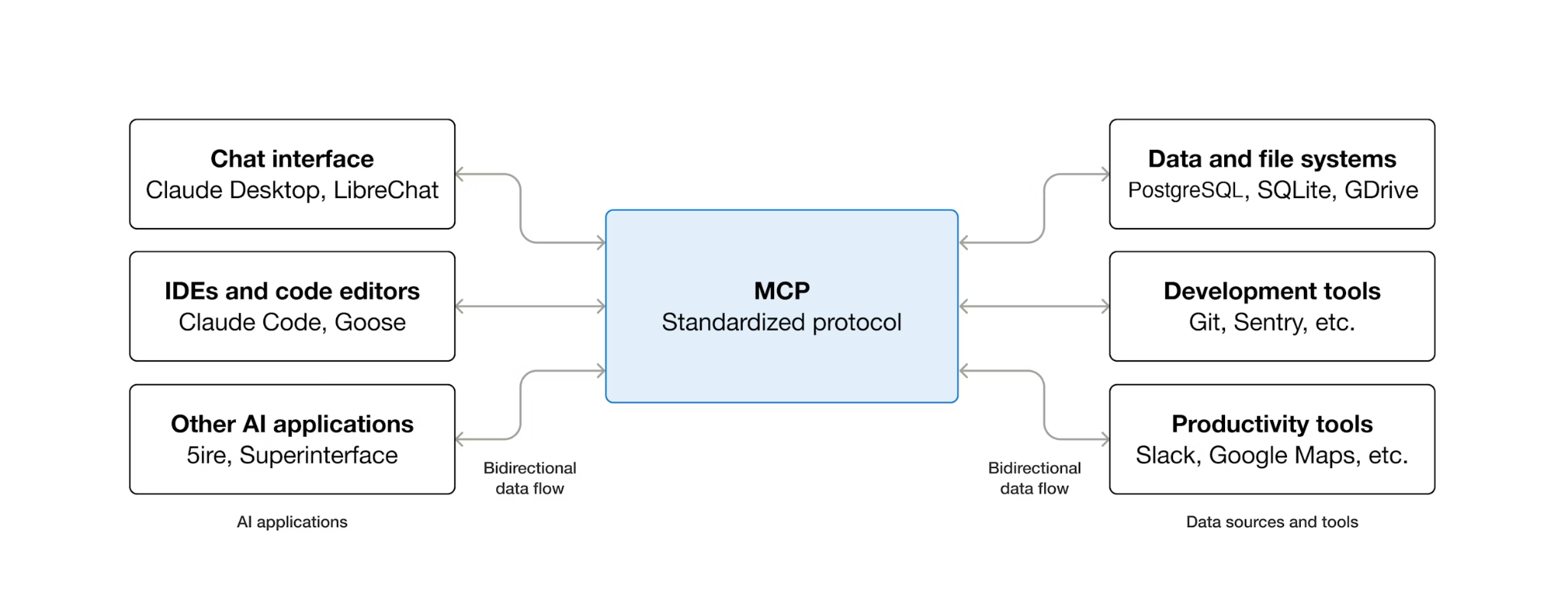
MCP (Model Context Protocol), yapay zeka ajanlarının harici araçları keşfetme ve bunlarla etkileşime girme şeklini standartlaştıran açık bir protokoldür. Bu modelde bir istemci-sunucu modeli tanımlanır: Ajan, bir MCP istemcisine ev sahipliği yapar ve araçlar MCP sunucuları tarafından kullanıma sunulur. MCP ile uyumlu tüm istemciler, MCP ile uyumlu tüm sunucuları kullanabilir. Aracının her araç için özel entegrasyon koduna ihtiyacı yoktur.
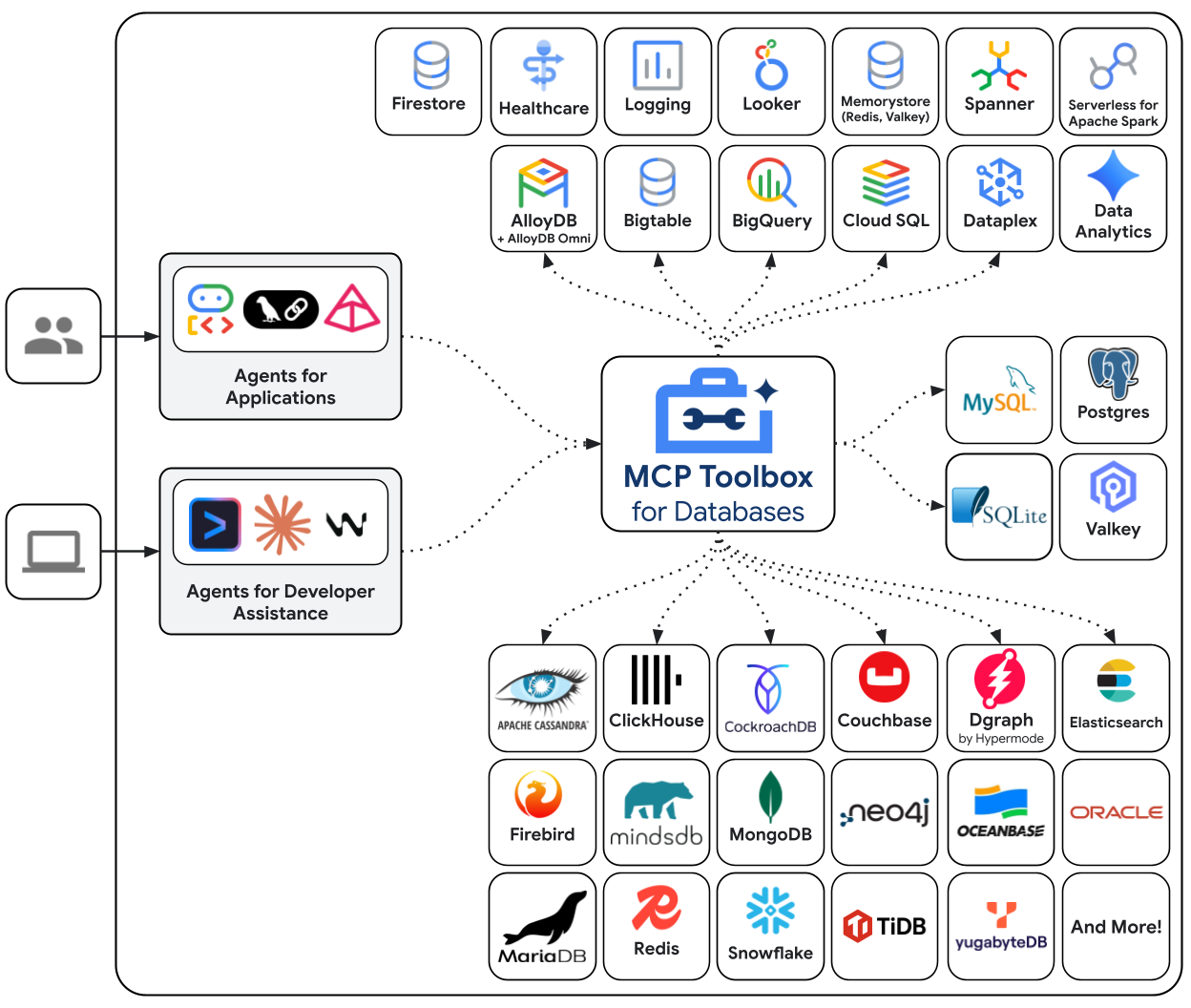
Veritabanları için MCP Araç Kutusu, özellikle veritabanı erişimi için oluşturulmuş açık kaynaklı bir MCP sunucusudur. Bu olmadan, veritabanı bağlantılarını açan, bağlantı havuzlarını yöneten, SQL eklemeyi önlemek için parametreli sorgular oluşturan, hataları işleyen ve tüm bu kodu aracınıza yerleştiren Python işlevleri yazmanız gerekir. Veritabanı erişimi gereken her temsilci bu çalışmayı tekrarlar. Bir sorguyu değiştirmek, temsilcinin yeniden dağıtılması anlamına gelir.
Toolbox ile bir YAML dosyası yazarsınız. Her araç, parametrelendirilmiş bir SQL ifadesiyle eşlenir. Toolbox, bağlantı havuzunu, parametrelendirilmiş sorguları, kimlik doğrulamayı ve gözlemlenebilirliği yönetir. Araçlar, aracıdan ayrılmıştır. Sorguyu, aracı koduna dokunmadan tools.yaml dosyasını düzenleyip Toolbox'ı yeniden başlatarak güncelleyebilirsiniz. Aynı araçlar ADK, LangGraph, LlamaIndex veya MCP ile uyumlu herhangi bir çerçevede çalışır.
Araç yapılandırmasını yazma
Şimdi araç yapılandırmamızı ayarlamak için Cloud Shell Düzenleyici'de tools.yaml adlı bir dosya oluşturmamız gerekiyor.
cloudshell edit tools.yaml
Dosyada çok dokümanlı YAML kullanılır. --- ile ayrılan her blok bağımsız bir kaynaktır. Her kaynağın, ne olduğunu bildiren bir kind (veritabanı bağlantıları için sources, aracı tarafından çağrılabilir işlemler için tools) ve arka ucu belirten bir type (kaynak için cloud-sql-postgres, SQL tabanlı araçlar için postgres-sql) vardır. Bir araç, kaynağına name ile referans verir. Bu, Araç Kutusu'nun hangi bağlantı havuzuna karşı yürütüleceğini bilmesini sağlar. Ortam değişkenleri ${VAR_NAME} söz dizimini kullanır ve başlatma sırasında çözümlenir.
Şimdi aşağıdaki komut dosyalarını önce tools.yaml dosyasına kopyalayalım.
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
Buradaki komut dosyası aşağıdaki kaynağı tanımlar:
- Kaynak (
restaurant-db): Toolbox'ın Cloud SQL PostgreSQL örneğinize nasıl bağlanacağını belirtir.cloud-sql-postgrestürü, kimlik doğrulama ve güvenli bağlantıları otomatik olarak işleyerek dahili olarak Cloud SQL bağlayıcısını kullanır.${GOOGLE_CLOUD_PROJECT},${REGION}ve${DB_PASSWORD}yer tutucuları, başlangıçta ortam değişkenlerinden çözümlenir.
Ardından, tools.yaml dosyasında --- simgesinin altına aşağıdaki komut dosyasını ekleyin.
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
Buradaki komut dosyası aşağıdaki kaynağı tanımlar:
- 1. ve 2. araçlar (
search-menu,get-item-details): Standart SQL sorgu araçlarıdır. Her biri bir araç adını (aracının gördüğü) parametreli bir SQL ifadesiyle (veritabanının yürüttüğü) eşler. Parametreler$1,$2konum tutucularını kullanır. Araç kutusu bunları hazırlanmış ifadeler olarak yürütür ve bu da SQL yerleştirmeyi önler.
Devam edelim. tools.yaml dosyasında --- sembolünün altına aşağıdaki komut dosyasını ekleyin.
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
Buradaki komut dosyası aşağıdaki kaynağı tanımlar:
- Yerleştirme modeli (
gemini-embedding): Araç kutusunu, 3.072 boyutlu metin yerleştirmeleri oluşturmak için Gemini'ıngemini-embedding-001modelini çağıracak şekilde yapılandırır. Araç kutusu, kimlik doğrulamak için Uygulama Varsayılan Kimlik Bilgileri'ni (ADC) kullanır. Cloud Shell veya Cloud Run'da API anahtarı gerekmez. Burada yapılandırılandimension, veritabanını başlatmak için daha önce yapılandırdığımızdimensionile aynı olmalıdır.
Devam edelim. tools.yaml dosyasında --- sembolünün altına aşağıdaki komut dosyasını ekleyin.
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
Buradaki komut dosyası aşağıdaki kaynağı tanımlar:
- 3. Araç (
search-menu-by-description): Vektör arama aracıdır.search_queryparametresindeembeddedBy: gemini-embeddingbulunur. Bu parametre, Araç Kutusu'na ham metni yakalamasını, yerleştirme modeline göndermesini ve sonuçtaki vektörü SQL ifadesinde kullanmasını söyler.<=>operatörü, pgvector'ın kosinüs uzaklığıdır. Daha küçük değerler, daha benzer açıklamalar anlamına gelir.
Son olarak, tools.yaml dosyasında --- simgesinin altına son aracı ekleyin.
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
Buradaki komut dosyası aşağıdaki kaynağı tanımlar:
- 4. Araç (
add-menu-item): Vektör alımını gösterir.description_vectorparametresinin iki özel alanı vardır: valueFromParam: description: Araç kutusu,descriptionparametresindeki değeri bu parametreye kopyalar. LLM bu parametreyi hiçbir zaman görmez.embeddedBy: gemini-embedding: Araç kutusu, kopyalanan metni SQL'e iletmeden önce bir vektöre yerleştirir.
Sonuç: Bir araç çağrısı, hem ham açıklama metnini hem de vektör yerleştirmesini depolar. Aracı, yerleştirmeler hakkında hiçbir şey bilmez.
Çok dokümanlı YAML biçimi, her kaynağı --- ile ayırır. Her dokümanda, ne olduğunu tanımlayan kind, name ve type alanları bulunur. Özetle, aşağıdakilerin tümünü zaten yapılandırdık:
- Kaynak veritabanını tanımlama
- Veritabanına standart filtreyle sorgu uygulamak için araçlar ( 1. ve 2. araç ) tanımlayın.
- Yerleştirme modelini tanımlama
- Veritabanında vektör araması yapacak aracı tanımlayın ( tool 3 ).
- Vektör verilerini veritabanına aktarmak için bir araç tanımlayın ( 4. araç ).
6. MCP Toolbox Sunucusunu Çalıştırma
Önceki adımda, MCP Toolbox'ımız için gerekli yapılandırmayı zaten ayarladık. Artık sunucuyu çalıştırmaya hazırız.
Başlangıç verilerini doğrulama
Toolbox'ı başlatmadan önce veritabanı kurulumunun tamamlandığını onaylayalım. Aşağıdaki komutu kullanarak scripts/verify_database.py adlı bir Python komut dosyası oluşturun.
cloudshell edit scripts/verify_seed.py
Ardından, aşağıdaki kodu scripts/verify_seed.py dosyasına kopyalayın.
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Bu komut dosyası, menü öğesi verilerinin sayısını ve yerleştirilmesini kontrol eder. Aşağıdaki komutu kullanarak komut dosyasını çalıştırın.
uv run scripts/verify_seed.py
Aşağıdaki terminal çıkışını görüyorsanız veriler hazır demektir.
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Araç Kutusu sunucusunu başlatma
Kurulumun önceki adımında toolbox yürütülebilir dosyasını indirmiştik. Bu ikili program dosyasının mevcut olduğundan ve başarıyla indirildiğinden emin olun. Aksi takdirde dosyayı indirip işlemin tamamlanmasını bekleyin.
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
MCP araç kutusu tarafından çalıştırılan alt işleme .env değişkenlerimizi göstermemiz gerekir. Araç kutusu sunucusunu başlatmak ve konsol çıkışını logs/mcp_toolbox.log dosyasına kaydetmek için aşağıdaki komutu çalıştırın.
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
logs/mcp_toolbox.log dosyasında, sunucunun hazır olduğunu onaylayan aşağıdaki gibi bir çıkış görmeniz gerekir:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Araçları doğrulama
Kayıtlı tüm araçları listelemek için Araç Kutusu API'sini sorgulayın:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Aşağıda gösterildiği gibi, açıklamaları ve parametreleriyle birlikte araçları görürsünüz.
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
search-menu aracını doğrudan test edin:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
Yanıt, başlangıç verilerinizdeki İtalyan ana yemeklerini içermelidir.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. ADK aracısını oluşturma
Şimdi bu proje için Python'da ADK'yı kullanacağız. Gerekli bağımlılıkları ekleyelim:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk: Gemini SDK dahil olmak üzere Google'ın Agent Development Kit'itoolbox-adk— Veritabanları için MCP Araç Kutusu'nda ADK entegrasyonu.
Temsilci dizin yapısını oluşturma
ADK, belirli bir klasör düzeni bekler: __init__.py, agent.py ve .env içeren, aracınızın adını taşıyan bir dizin. Bu konuda yardımcı olmak için yapıyı hızlıca oluşturmaya yönelik yerleşik bir komut vardır:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
Dizininiz aşağıdaki gibi görünmelidir:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
Ardından, ADK aracısını çalışan Toolbox sunucusuna entegre etmemiz ve dört aracı da (standart sorgular, semantik arama ve vektör alımı) test etmemiz gerekir. Aracı kodu minimum düzeydedir: Tüm veritabanı mantığı tools.yaml içinde yer alır.
Aracının ortamını yapılandırma
ADK, GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT ve GOOGLE_CLOUD_LOCATION değerlerini, önceki adımda zaten ayarladığınız kabuk ortamından okur. Ajanlara özel tek değişken TOOLBOX_URL'dır. Bu değişkeni, ajanın .env dosyasına ekleyin:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Aracı modülünü güncelleme
Cloud Shell Düzenleyici'de restaurant_agent/agent.py dosyasını açın.
cloudshell edit restaurant_agent/agent.py
ve içeriğin üzerine aşağıdaki kodu yazın:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Burada veritabanı kodu olmadığını unutmayın. ToolboxToolset, başlangıçta Toolbox sunucusuna bağlanır ve mevcut tüm araçları yükler. Aracı, araçları adıyla çağırır. Toolbox, bu çağrıları Cloud SQL'e karşı SQL sorgularına çevirir.
TOOLBOX_URL ortam değişkeni, yerel geliştirme için varsayılan olarak http://127.0.0.1:5000 değerini alır. Daha sonra Cloud Run'a dağıtım yaptığınızda bunu Toolbox hizmetinin Cloud Run URL'siyle geçersiz kılarsınız. Kod değişikliği yapmanız gerekmez.
Temsilciyi test etme
ADK geliştirici kullanıcı arayüzünü başlatın:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Cloud Shell'in Web Önizleme özelliğini kullanarak veya terminalde gösterilen URL'yi ctrl + tıklayarak terminalde gösterilen URL'yi (genellikle http://localhost:8000) açın. Sol üst köşedeki temsilci açılır listesinden restaurant_agent'ı seçin.
Standart sorguları test etme
Standart SQL araçlarını doğrulamak için aşağıdaki istemleri deneyin:
What Italian dishes do you have?
Tell me about the Miso Glazed Black Cod
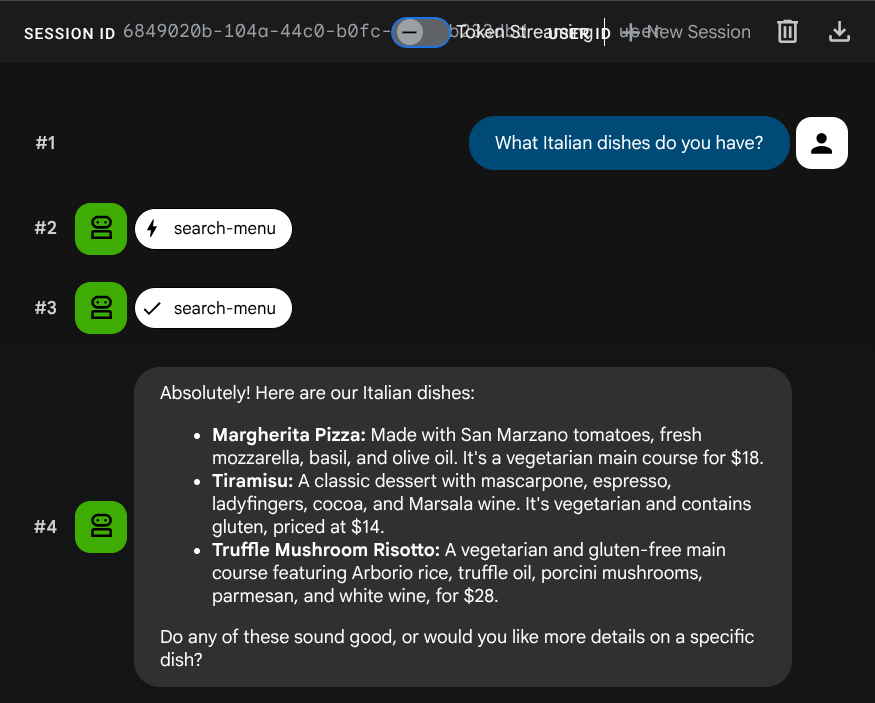
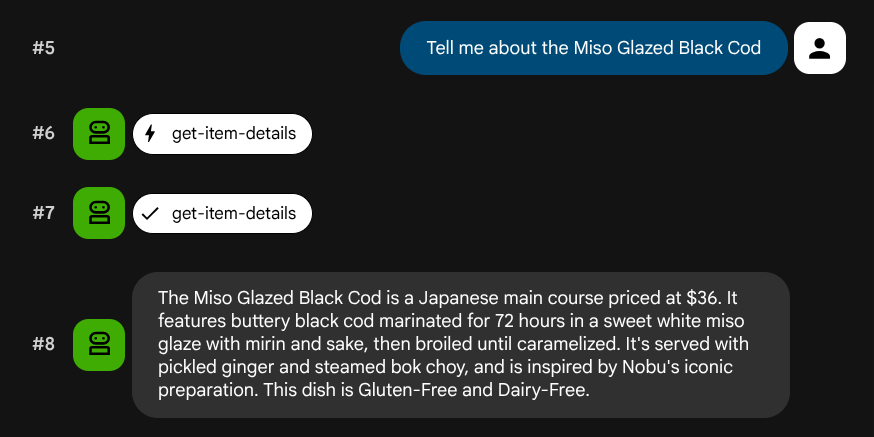
Semantik aramayı test etme
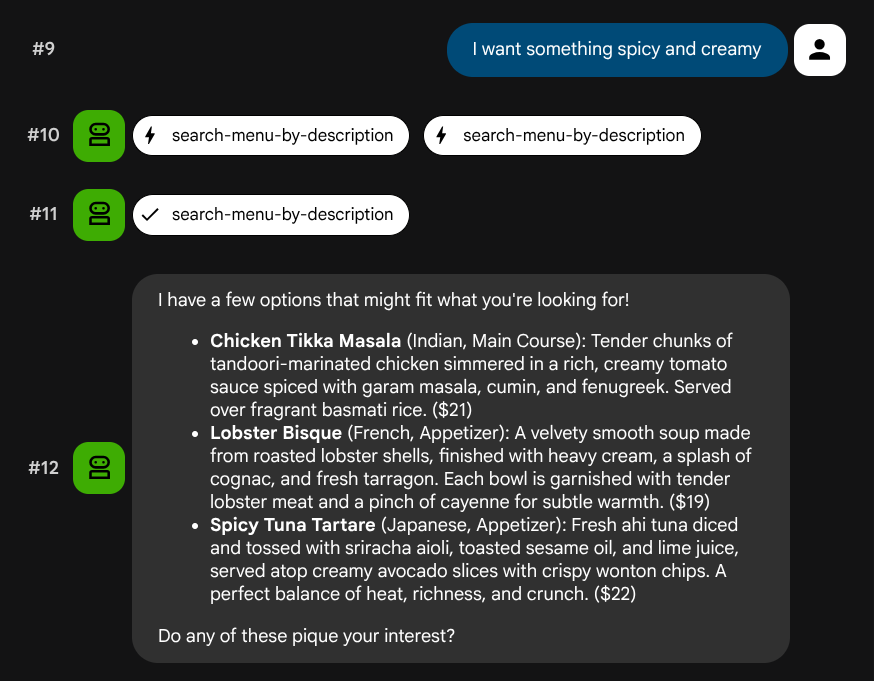
Belirli bir role veya teknoloji yığınına karşılık gelmeyen doğal dil açıklamalarını deneyin:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
Temsilci, sorgu türüne göre doğru aracı seçmeye çalışır: Yapılandırılmış filtreler search-menu, doğal dil açıklamaları ise search-menu-by-description üzerinden geçer.
Vektör beslemeyi test etme
Temsilciden yeni bir iş eklemesini isteyin:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
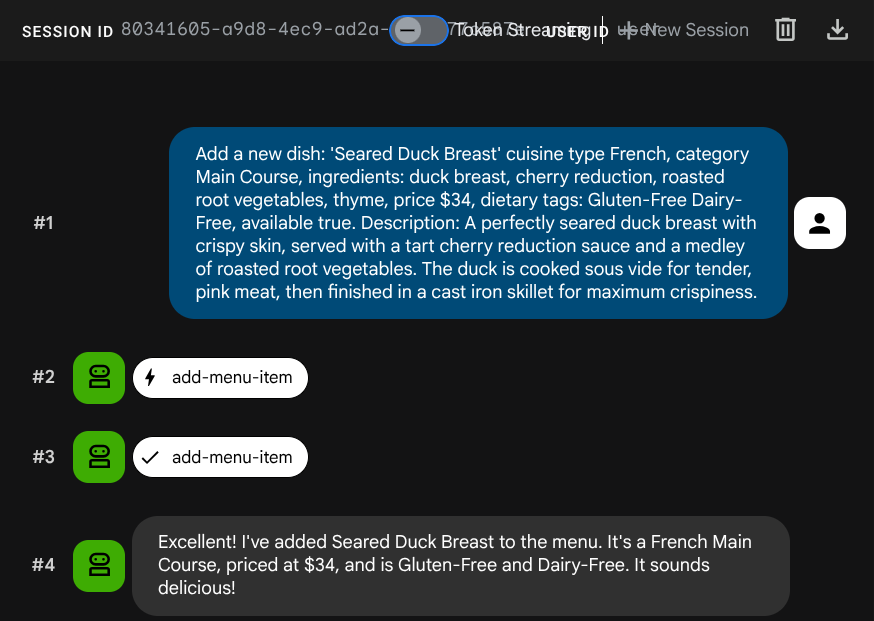
Şimdi aramayı deneyin:
Find me something with rich, gamey flavors and fruit sauce
Yerleştirme, INSERT sırasında otomatik olarak oluşturuldu. Ayrı bir adım gerekmez.
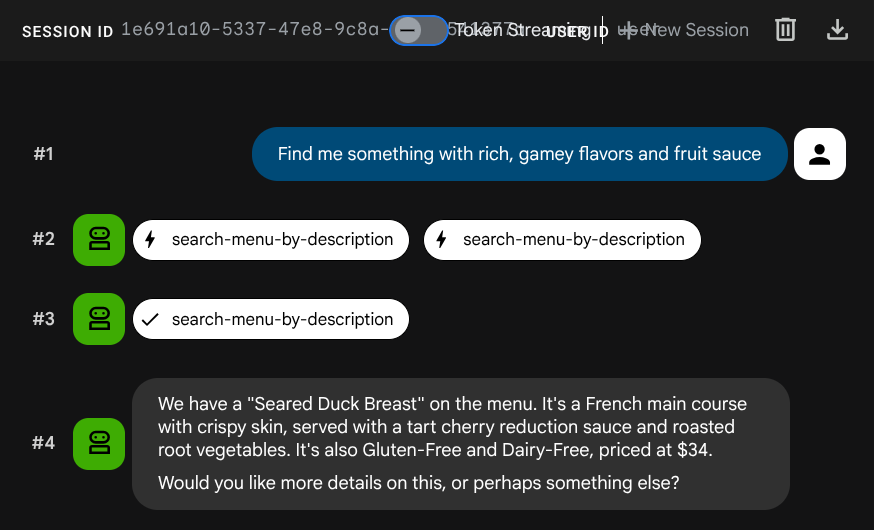
Artık ADK, MCP Toolbox ve CloudSQL'i kullanan, tam işlevsel bir ajan tabanlı RAG uygulamanız var. Tebrikler! Şimdi bu uygulamaları Cloud Run'a dağıtmak için bir adım daha atalım.
Şimdi devam etmeden önce Ctrl+C tuşlarına iki kez basarak işlemi sonlandırıp geliştirici kullanıcı arayüzünü durduralım.
8. Cloud Run'a dağıt
Aracı ve Toolbox yerel olarak çalışır. Bu adımda her ikisi de internet üzerinden erişilebilmesi için Cloud Run hizmetleri olarak dağıtılır. Toolbox hizmeti Cloud Run'da MCP sunucusu olarak çalışır ve aracı hizmeti buna bağlanır.
Araç kutusunu dağıtıma hazırlama
Araç kutusu hizmeti için bir dağıtım dizini oluşturun:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Araç kutusu için Dockerfile'ı oluşturun. Cloud Shell Düzenleyici'de deploy-toolbox/Dockerfile dosyasını açın:
cloudshell edit deploy-toolbox/Dockerfile
Aşağıdaki komut dosyasını bu dosyaya kopyalayın.
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
Toolbox ikili programı ve tools.yaml, minimum Debian görüntüsünde paketlenir. Cloud Run, trafiği 8080 numaralı bağlantı noktasına yönlendirir.
Araç Kutusu hizmetini dağıtma
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
Bu komut, kaynağı Cloud Build'e gönderir, bir kapsayıcı görüntüsü oluşturur, bunu Artifact Registry'ye aktarır ve Cloud Run'a dağıtır. Bu işlem birkaç dakika sürer. Dağıtım süreci günlüğünü logs/deploy_toolbox.log dosyasında inceleyebiliriz.
Aracı dağıtıma hazırlama
Araç kutusu oluşturulurken aracının dağıtım dosyalarını ayarlayın.
Proje kökünde Dockerfile oluşturun. Cloud Shell Düzenleyici'de Dockerfile dosyasını açın:
cloudshell edit Dockerfile
Ardından, aşağıdaki içeriği kopyalayın.
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
Bu Dockerfile, temel görüntü olarak ghcr.io/astral-sh/uv kullanır. Bu görüntüde hem Python hem de uv önceden yüklenmiştir. uv'ı pip üzerinden ayrı olarak yüklemeniz gerekmez.
Gereksiz dosyaları kapsayıcı görüntüsünden hariç tutmak için .dockerignore dosyası oluşturun:
cloudshell edit .dockerignore
Ardından, aşağıdaki komut dosyasını kopyalayıp yapıştırın.
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Temsilci hizmetini dağıtma
Araç kutusu dağıtımının tamamlanmasını bekleyin. İşlemi doğrulamak için logs/deploy_toolbox.log adresinde dağıtım sürecini tekrar kontrol edin. Ardından, aşağıdaki komutu kullanarak Cloud Run URL'sini alın.
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Aşağıdakine benzer bir çıkış görürsünüz:
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Ardından, dağıtılan araç kutusunun çalıştığını doğrulayalım:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Çıkış bu örnekteki gibi gösteriliyorsa dağıtım zaten başarılı olmuştur.
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
Ardından, Toolbox URL'sini ortam değişkeni olarak ileterek aracı dağıtalım:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
Aracı kodu, ortamdan TOOLBOX_URL değerini okur (bunu daha önce ayarlamıştınız). Yerel olarak http://127.0.0.1:5000 değerini, Cloud Run'da ise Toolbox hizmeti URL'sini gösterir. Kod değişikliği yapmanız gerekmez.
Dağıtılan temsilciyi test etme
Temsilcinin Cloud Run URL'sini alın:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
URL'yi tarayıcınızda açın. ADK geliştirici kullanıcı arayüzü yüklenir. Bu arayüz, yerel olarak kullandığınız arayüzün aynısıdır ve artık Cloud Run'da çalışır.
Açılır listeden restaurant_agent'ı seçip test edin:
What Italian dishes do you have?
I want something spicy and creamy
Her iki sorgu da dağıtılan hizmetler üzerinden çalışır: Cloud Run'daki aracı, Cloud Run'daki Toolbox'ı çağırır ve bu da Cloud SQL'i sorgular.
9. Tebrikler / Temizleme
Hem standart SQL sorgularını hem de semantik vektör aramasını kullanarak bir ADK aracısı ile Cloud SQL PostgreSQL arasında köprü kurmak için Veritabanları için MCP Araç Kutusu'nu kullanan akıllı bir restoran menüsü asistanı oluşturup dağıttınız.
Öğrendikleriniz
- MCP'nin yapay zeka aracıları için araç erişimini nasıl standartlaştırdığı ve MCP Toolbox for Databases'in bunu özellikle veritabanı işlemlerine nasıl uyguladığı (özel veritabanı kodunu bildirimsel YAML yapılandırmasıyla değiştirme)
cloud-sql-postgreskaynak türünü kullanarak Cloud SQL PostgreSQL'i Toolbox veri kaynağı olarak yapılandırma- SQL yerleştirilmesini önleyen parametreli ifadelerle standart SQL sorgu araçları tanımlama
- Otomatik sorgu yerleştirme için
embeddedByparametresiyle birlikte pgvector vegemini-embedding-001kullanarak vektör aramasını etkinleştirme valueFromParam, otomatik vektör alımını nasıl sağlar? LLM, metin açıklaması sağlar ve Toolbox, vektörü metinle birlikte sessizce kopyalar, yerleştirir ve depolar.- ADK'nın
ToolboxToolset, çalışan bir Araç Kutusu sunucusundan araçları nasıl yüklediği, aracı kodunu minimumda tuttuğu ve veritabanı mantığını tamamen ayrıştırdığı - Toolbox MCP sunucusunu ve ADK aracısını ayrı hizmetler olarak Cloud Run'a dağıtma
Temizleme
Bu codelab'de oluşturulan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız kaynakları tek tek veya projenin tamamını silebilirsiniz.
1. seçenek: Projeyi silme (önerilir)
Temizliğin en kolay yolu projeyi silmektir. Bu işlem, projeyle ilişkili tüm kaynakları kaldırır.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
2. seçenek: Kaynakları tek tek silme
Projeyi korumak ancak yalnızca bu codelab'de oluşturulan kaynakları kaldırmak istiyorsanız:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null