
1. Giới thiệu
Độ hữu ích của các tác nhân AI phụ thuộc vào dữ liệu mà chúng có thể truy cập. Hầu hết dữ liệu trong thế giới thực đều nằm trong cơ sở dữ liệu và việc kết nối các tác nhân với cơ sở dữ liệu thường có nghĩa là bạn phải viết quy trình quản lý kết nối, logic truy vấn và quy trình nhúng bên trong mã tác nhân. Mọi tác nhân cần quyền truy cập vào cơ sở dữ liệu đều lặp lại công việc này và mọi thay đổi về truy vấn đều yêu cầu bạn phải triển khai lại tác nhân.
Lớp học lập trình này trình bày một phương pháp khác. Bạn khai báo các công cụ cơ sở dữ liệu trong một tệp YAML (truy vấn SQL chuẩn, tìm kiếm mức độ tương đồng của vectơ, thậm chí là tạo vectơ nhúng tự động) và Bộ công cụ MCP dành cho cơ sở dữ liệu sẽ xử lý tất cả các thao tác cơ sở dữ liệu dưới dạng một máy chủ MCP. Mã tác nhân của bạn vẫn ở mức tối thiểu: tải các công cụ, để Gemini quyết định gọi công cụ nào.
Sản phẩm bạn sẽ tạo ra
Một Lễ tân nhà hàng cho "Foodie Finds" – một tác nhân ADK dựa trên Gemini giúp thực khách duyệt xem thực đơn của nhà hàng bằng các bộ lọc tiêu chuẩn (danh mục, loại ẩm thực) và khám phá các món ăn thông qua nội dung mô tả bằng ngôn ngữ tự nhiên như "Tôi muốn ăn món gì đó cay và chay". Tác nhân này đọc và ghi vào cơ sở dữ liệu Cloud SQL PostgreSQL hoàn toàn thông qua Bộ công cụ MCP cho cơ sở dữ liệu, bộ công cụ này xử lý mọi quyền truy cập vào cơ sở dữ liệu – bao gồm cả việc tự động tạo vectơ nhúng để tìm kiếm vectơ. Đến cuối cùng, cả Bộ công cụ và tác nhân đều chạy trên Cloud Run.
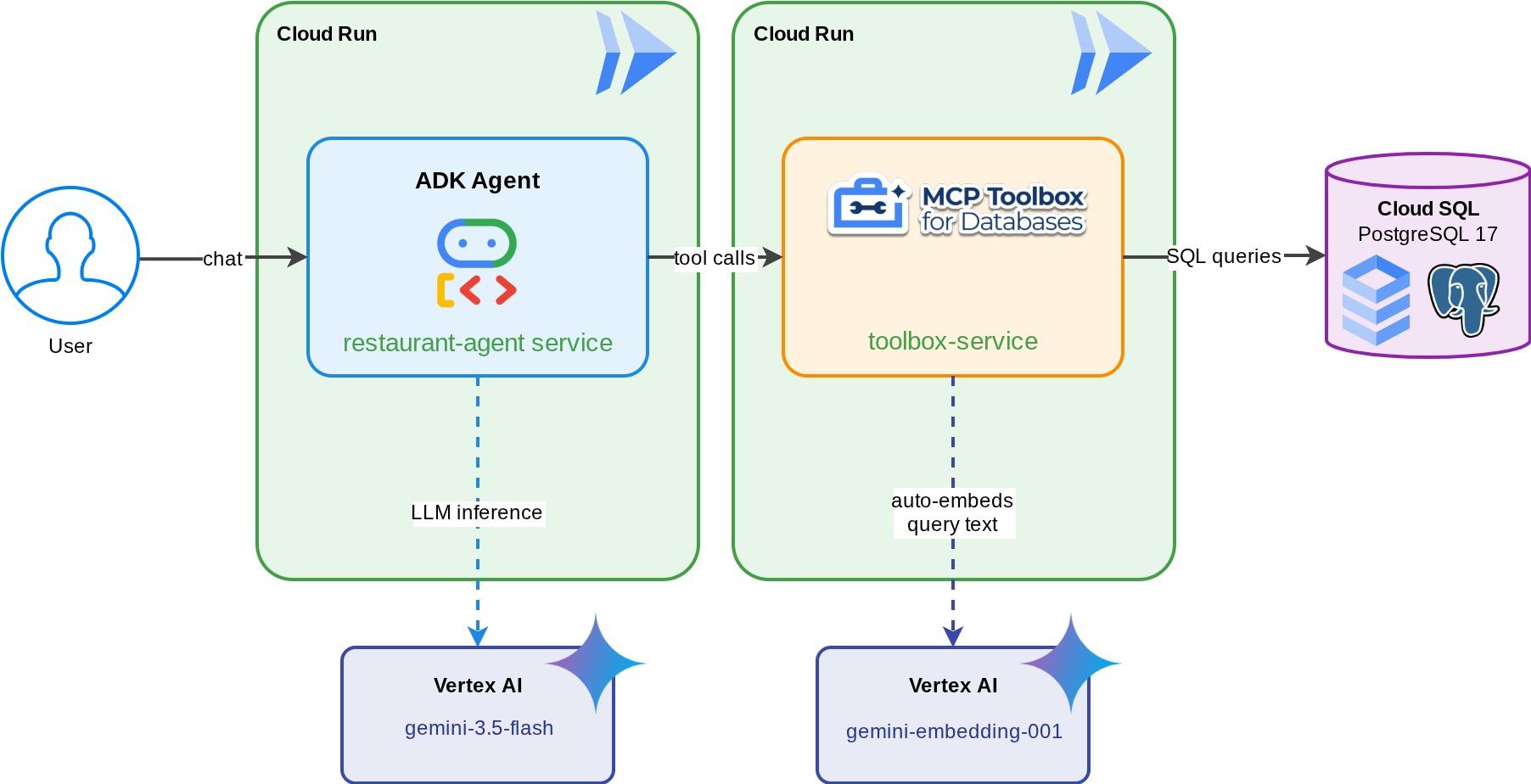
Kiến thức bạn sẽ học được
- Cách MCP (Giao thức ngữ cảnh mô hình) chuẩn hoá quyền truy cập vào công cụ cho các tác nhân AI và cách Bộ công cụ MCP cho cơ sở dữ liệu áp dụng điều này cho các hoạt động trên cơ sở dữ liệu
- Thiết lập Bộ công cụ MCP cho cơ sở dữ liệu làm phần mềm trung gian giữa một tác nhân ADK và Cloud SQL PostgreSQL
- Xác định các công cụ cơ sở dữ liệu một cách khai báo trong
tools.yaml– không có mã cơ sở dữ liệu trong tác nhân của bạn - Tạo một tác nhân ADK tải các công cụ từ một máy chủ Bộ công cụ đang chạy bằng cách sử dụng
ToolboxToolset - Tạo các vectơ nhúng bằng hàm
embedding()tích hợp của Cloud SQL và bật tính năng tìm kiếm ngữ nghĩa bằngpgvector - Sử dụng tính năng
valueFromParamđể tự động nạp vectơ trong các thao tác ghi - Triển khai cả máy chủ Toolbox và tác nhân ADK lên Cloud Run
Điều kiện tiên quyết
- Tài khoản Google Cloud có tài khoản thanh toán dùng thử
- Có kiến thức cơ bản về Python và SQL
- Kinh nghiệm sử dụng Cơ sở dữ liệu đám mây và ADK sẽ rất hữu ích
2. Thiết lập môi trường
Bước này chuẩn bị môi trường Cloud Shell, định cấu hình dự án trên đám mây của bạn và sao chép kho lưu trữ tham chiếu.
Mở Cloud Shell
Mở Cloud Shell trong trình duyệt. Cloud Shell cung cấp một môi trường được định cấu hình sẵn với tất cả các công cụ bạn cần cho lớp học lập trình này. Nhấp vào Uỷ quyền khi được nhắc
Sau đó, nhấp vào "View" (Xem) -> "Terminal" (Thiết bị đầu cuối) để mở thiết bị đầu cuối.Giao diện của bạn sẽ trông tương tự như thế này
Đây sẽ là giao diện chính của chúng ta, IDE ở trên cùng, thiết bị đầu cuối ở dưới cùng
Thiết lập thư mục làm việc
Tạo thư mục làm việc. Tất cả mã bạn viết trong lớp học lập trình này đều nằm ở đây:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
Sau đó, hãy chuẩn bị một số thư mục để quản lý những thứ như tập lệnh gieo hạt và nhật ký
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
Thiết lập dự án trên đám mây của bạn
Tạo tệp .env bằng các biến vị trí:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
Để đơn giản hoá việc thiết lập dự án trong thiết bị đầu cuối, hãy tải tập lệnh thiết lập dự án này xuống thư mục làm việc của bạn:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Chạy tập lệnh. Lệnh này xác minh tài khoản thanh toán dùng thử của bạn, tạo một dự án mới (hoặc xác thực một dự án hiện có), lưu mã dự án vào một tệp .env trong thư mục hiện tại và đặt dự án đang hoạt động trong gcloud.
bash setup_verify_trial_project.sh && source .env
Tập lệnh sẽ:
- Xác minh rằng bạn có một tài khoản thanh toán dùng thử đang hoạt động
- Kiểm tra xem có dự án nào trong
.envhay không (nếu có) - Tạo dự án mới hoặc sử dụng lại dự án hiện có
- Liên kết tài khoản thanh toán dùng thử với dự án của bạn
- Lưu mã dự án vào
.env - Đặt dự án làm dự án
gcloudđang hoạt động
Xác minh rằng dự án được thiết lập đúng cách bằng cách kiểm tra văn bản màu vàng bên cạnh thư mục đang hoạt động trong dấu nhắc của thiết bị đầu cuối Cloud Shell. Văn bản này sẽ hiển thị mã dự án của bạn.

Kích hoạt API bắt buộc
Tiếp theo, chúng ta cần bật một số API cho sản phẩm mà chúng ta sẽ tương tác:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- Vertex AI API (
aiplatform.googleapis.com) – tác nhân của bạn sử dụng các mô hình Gemini và Toolbox sử dụng API nhúng để tìm kiếm vectơ. - Cloud SQL Admin API (
sqladmin.googleapis.com) – bạn cung cấp và quản lý một phiên bản PostgreSQL. - Compute Engine API (
compute.googleapis.com) – bắt buộc để tạo phiên bản Cloud SQL. - Cloud Run, Cloud Build, Artifact Registry – được dùng trong bước triển khai sau này trong lớp học lập trình này
3. Chuẩn bị tập lệnh để khởi chạy cơ sở dữ liệu
Bước này bắt đầu quá trình tạo phiên bản Cloud SQL và chạy một tập lệnh thiết lập tự động. Tập lệnh này sẽ đợi phiên bản sẵn sàng, sau đó tạo cơ sở dữ liệu, gieo dữ liệu vào cơ sở dữ liệu bằng danh sách việc làm và tạo các mục nhúng – tất cả trong một thao tác.
Trước tiên, hãy thêm mật khẩu cơ sở dữ liệu vào tệp .env rồi tải lại tệp đó:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
Tạo tập lệnh Bash để tạo phiên bản và cơ sở dữ liệu
Sau đó, hãy tạo tập lệnh scripts/setup_database.sh bằng lệnh sau
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
Sau đó, hãy sao chép mã sau vào tệp scripts/setup_database.sh
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
Tạo tập lệnh Python để gieo dữ liệu
Sau đó, hãy tạo tệp python tập lệnh gieo hạt scripts/setup_restaurant_db.py bằng lệnh bên dưới
cloudshell edit scripts/setup_restaurant_db.py
Sau đó, sao chép mã sau vào tệp scripts/setup_restaurant_db.py
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
Bây giờ, hãy chuyển sang bước tiếp theo
4. Tạo và khởi chạy cơ sở dữ liệu
Giờ đây, các tập lệnh của chúng ta đã sẵn sàng để thực thi. Chúng ta sẽ cần Python để thực thi tập lệnh đã chuẩn bị, vì vậy, trước tiên, hãy chuẩn bị tập lệnh đó
Thiết lập dự án Python
uv là một trình quản lý dự án và gói Python nhanh được viết bằng Rust ( tài liệu uv ). Lớp học lập trình này sử dụng uv để duy trì dự án Python một cách nhanh chóng và đơn giản
Khởi động một dự án Python và thêm các phần phụ thuộc bắt buộc:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
Xin lưu ý rằng ở đây, chúng ta đang sử dụng cloud-sql-python-connector Python SDK để khởi chạy một kết nối an toàn với phiên bản cơ sở dữ liệu được xác thực bằng Thông tin đăng nhập mặc định của ứng dụng.
Thực thi tập lệnh thiết lập
Giờ đây, chúng ta có thể chạy tập lệnh thiết lập ở chế độ nền và kiểm tra đầu ra của bảng điều khiển sẽ được ghi vào tệp logs/atabase_setup.log bằng lệnh sau. Bạn có thể tiếp tục chuyển sang phần tiếp theo trong khi chờ quá trình này hoàn tất
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
Tải tệp nhị phân của Hộp công cụ xuống
Chúng ta sẽ sử dụng MCP Toolbox trong hướng dẫn này. May mắn là công cụ này đi kèm với một tệp nhị phân được tạo sẵn và sẵn sàng sử dụng trong môi trường Linux. Giờ đây, hãy tải tệp nhị phân này xuống ở chế độ nền vì quá trình này mất khá nhiều thời gian. Chạy lệnh sau để tải tệp nhị phân xuống và kiểm tra nhật ký đầu ra trên logs/toolbox_dl.log. Bạn có thể tiếp tục chuyển sang phần tiếp theo trong khi chờ quá trình này hoàn tất
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
Tìm hiểu về tập lệnh thiết lập scripts/setup_database.sh
Bây giờ, hãy thử tìm hiểu tập lệnh thiết lập mà chúng ta đã định cấu hình trước đó. Quy trình này thực hiện những việc sau
- Lệnh đầu tiên mà chúng ta thực thi ở đó là lệnh
gcloud sql instances createcó cờ sau
db-custom-1-3840là cấp Cloud SQL nhỏ nhất có lõi chuyên dụng (1 vCPU, RAM 3,75 GB) trong phiên bảnENTERPRISE. Bạn có thể đọc thêm thông tin chi tiết tại đây. Bạn cần có một lõi chuyên dụng để tích hợp Vertex AI ML – các cấp lõi dùng chung (db-f1-micro,db-g1-small) không hỗ trợ tính năng này.--root-passwordđặt mật khẩu cho người dùngpostgresmặc định.--enable-google-ml-integrationcho phép tích hợp sẵn Cloud SQL với Vertex AI, giúp bạn gọi các mô hình nhúng trực tiếp từ SQL bằng hàmembedding().
- Xác minh xem phiên bản đã ở trạng thái
RUNNABLEhay chưa - Cấp cho tài khoản dịch vụ của phiên bản Cloud SQL quyền gọi Vertex AI bằng lệnh
gcloud projects add-iam-policy-binding. Đây là yêu cầu bắt buộc đối với hàmembedding()tích hợp mà chúng ta sẽ dùng khi gieo dữ liệu vào cơ sở dữ liệu - Tạo cơ sở dữ liệu
- Thực thi tập lệnh gieo hạt
setup_restaurant_db.py
Tìm hiểu về tập lệnh ban đầu scripts/setup_restaurant_db.py
Bây giờ, hãy chuyển sang tập lệnh gieo hạt. Tập lệnh này sẽ thực hiện những việc sau:
- Khởi tạo kết nối đến phiên bản cơ sở dữ liệu
- Cài đặt 2 tiện ích PostgreSQL:
google_ml_integration– cung cấp hàm SQLembedding(), gọi các mô hình nhúng Vertex AI trực tiếp từ SQL. Đây là một tiện ích ở cấp cơ sở dữ liệu giúp các hàm ML có sẵn trongrestaurant_db. Cờ cấp phiên bản (--enable-google-ml-integration) mà bạn đặt trong quá trình tạo phiên bản cho phép VM Cloud SQL truy cập vào Vertex AI – tiện ích này cung cấp các hàm SQL trong cơ sở dữ liệu cụ thể này.vector(pgvector) – thêm kiểu dữ liệuvectorvà các toán tử khoảng cách để lưu trữ và truy vấn các mục nhúng.
- Tạo bảng, lưu ý rằng cột
description_embeddinglàvector(3072)— một cộtpgvectorlưu trữ các vectơ 3072 chiều. - Gieo dữ liệu ban đầu cho các mục trong trình đơn
- Tạo dữ liệu nhúng từ trường
descriptionvà điền vàodescription_embeddingbằng cách sử dụng tính năng tích hợp đỉnh được tích hợp sẵn thông qua hàmembedding()
embedding('gemini-embedding-001', description)– gọi mô hình nhúng Gemini của Vertex AI trực tiếp từ SQL, truyền văn bảndescriptioncủa từng công việc. Đây là tiện íchgoogle_ml_integrationmà bạn đã cài đặt trong tập lệnh ban đầu.::vector– truyền mảng số thực được trả về sang kiểuvectorcủa pgvector để có thể lưu trữ và truy vấn bằng các toán tử khoảng cách.UPDATEchạy trên cả 15 hàng, tạo ra một vectơ nhúng 3072 chiều cho mỗi nội dung mô tả công việc.
Thao tác này sẽ chuẩn bị dữ liệu ban đầu mà tác nhân của chúng tôi sẽ truy cập
5. Định cấu hình Bộ công cụ MCP cho cơ sở dữ liệu
Bước này giới thiệu Bộ công cụ MCP dành cho cơ sở dữ liệu, định cấu hình bộ công cụ này để kết nối với phiên bản Cloud SQL của bạn và xác định 2 công cụ truy vấn SQL tiêu chuẩn.
MCP là gì và tại sao nên sử dụng Toolbox?
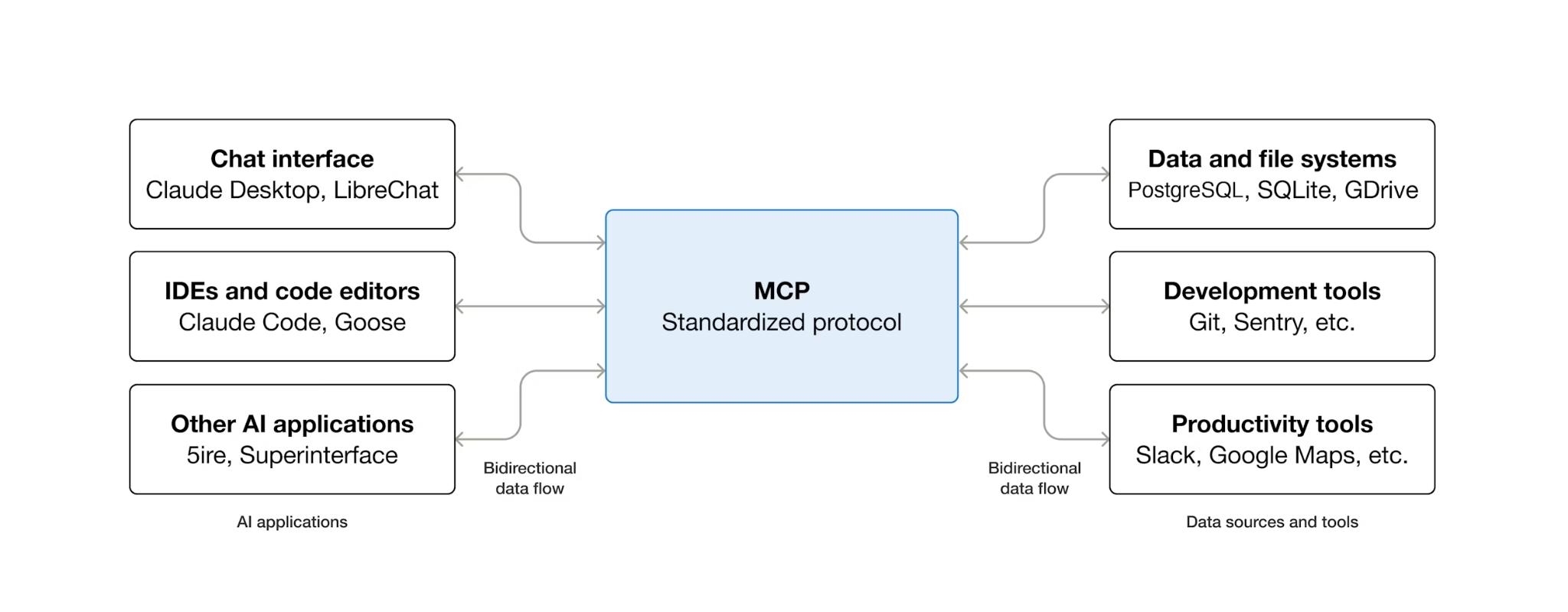
MCP (Giao thức ngữ cảnh mô hình) là một giao thức mở giúp chuẩn hoá cách các tác nhân AI khám phá và tương tác với các công cụ bên ngoài. Nó xác định một mô hình ứng dụng-máy chủ: tác nhân lưu trữ một ứng dụng MCP và các công cụ được máy chủ MCP hiển thị. Mọi ứng dụng tương thích với MCP đều có thể sử dụng mọi máy chủ tương thích với MCP – tác nhân không cần mã tích hợp tuỳ chỉnh cho từng công cụ.
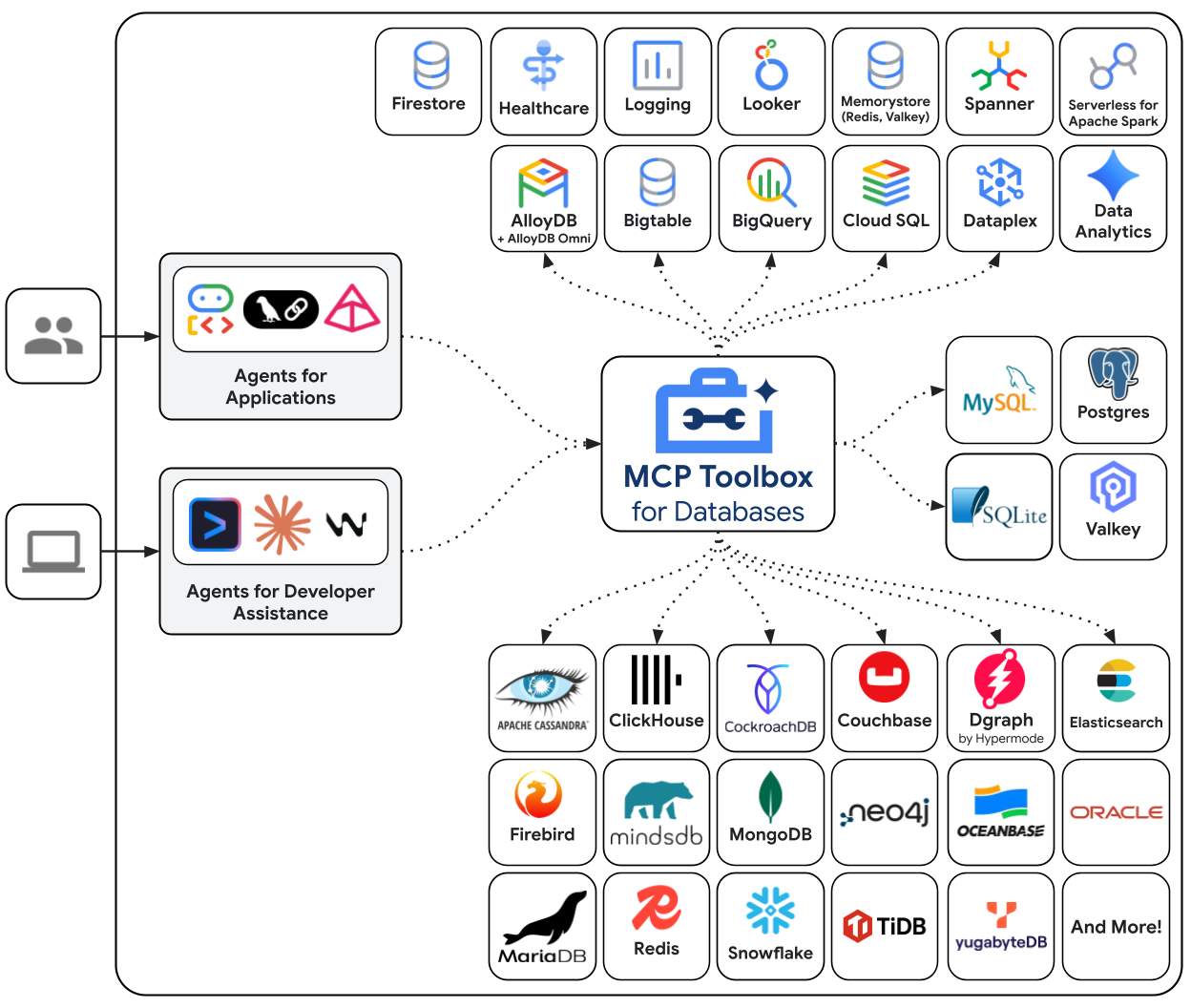
Bộ công cụ MCP dành cho cơ sở dữ liệu là một máy chủ MCP nguồn mở được xây dựng dành riêng cho quyền truy cập vào cơ sở dữ liệu. Nếu không có bộ công cụ này, bạn sẽ viết các hàm Python mở kết nối cơ sở dữ liệu, quản lý nhóm kết nối, tạo truy vấn được tham số hoá để ngăn chặn kỹ thuật chèn SQL, xử lý lỗi và nhúng tất cả mã đó vào tác nhân của bạn. Mọi tác nhân cần có quyền truy cập vào cơ sở dữ liệu đều lặp lại công việc này. Việc thay đổi một truy vấn có nghĩa là triển khai lại tác nhân.
Với Toolbox, bạn sẽ viết một tệp YAML. Mỗi công cụ sẽ liên kết đến một câu lệnh SQL có tham số. Toolbox xử lý việc gộp kết nối, truy vấn có tham số, xác thực và khả năng quan sát. Các công cụ được tách biệt khỏi tác nhân – cập nhật truy vấn bằng cách chỉnh sửa tools.yaml và khởi động lại Toolbox mà không cần chỉnh sửa mã tác nhân. Các công cụ này hoạt động trên ADK, LangGraph, LlamaIndex hoặc bất kỳ khung tương thích nào với MCP.
Viết cấu hình công cụ
Bây giờ, chúng ta cần tạo một tệp có tên là tools.yaml trong Cloud Shell Editor để thiết lập cấu hình công cụ
cloudshell edit tools.yaml
Tệp này sử dụng YAML nhiều tài liệu – mỗi khối được phân tách bằng --- là một tài nguyên độc lập. Mỗi tài nguyên đều có một kind khai báo tài nguyên đó là gì (sources cho các mối kết nối cơ sở dữ liệu, tools cho các thao tác có thể gọi của tác nhân) và một type chỉ định phần phụ trợ (cloud-sql-postgres cho nguồn, postgres-sql cho các công cụ dựa trên SQL). Một công cụ tham chiếu nguồn của nó bằng name. Đây là cách Toolbox biết nên thực thi nhóm kết nối nào. Các biến môi trường sử dụng cú pháp ${VAR_NAME} và được phân giải khi khởi động.
Bây giờ, trước tiên hãy sao chép các tập lệnh sau vào tệp tools.yaml
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
Tập lệnh này xác định tài nguyên sau:
- Nguồn (
restaurant-db) – cho biết cách Toolbox kết nối với phiên bản Cloud SQL PostgreSQL của bạn. Loạicloud-sql-postgressử dụng trình kết nối Cloud SQL nội bộ, tự động xử lý việc xác thực và các kết nối an toàn. Các phần giữ chỗ${GOOGLE_CLOUD_PROJECT},${REGION}và${DB_PASSWORD}được phân giải từ các biến môi trường khi khởi động.
Tiếp theo, hãy thêm tập lệnh sau vào bên dưới biểu tượng --- trong tools.yaml
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
Tập lệnh này xác định tài nguyên sau:
- Công cụ 1 và 2 (
search-menu,get-item-details) – công cụ truy vấn SQL chuẩn. Mỗi mục ánh xạ một tên công cụ (những gì mà tác nhân nhìn thấy) với một câu lệnh SQL được tham số hoá (những gì mà cơ sở dữ liệu thực thi). Các tham số sử dụng phần giữ chỗ vị trí$1,$2. Hộp công cụ thực thi các câu lệnh này dưới dạng câu lệnh được chuẩn bị, giúp ngăn chặn việc chèn SQL.
Hãy tiếp tục, thêm tập lệnh sau đây vào biểu tượng --- trong tools.yaml
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
Tập lệnh này xác định tài nguyên sau:
- Mô hình nhúng (
gemini-embedding) – định cấu hình Toolbox để gọi mô hìnhgemini-embedding-001của Gemini nhằm tạo các vectơ nhúng văn bản 3072 chiều. Toolbox sử dụng Thông tin xác thực mặc định của ứng dụng (ADC) để xác thực – không cần khoá API trong Cloud Shell hoặc Cloud Run. Lưu ý rằngdimensionđược định cấu hình ở đây phải giống vớidimensionmà chúng ta đã định cấu hình trước đó để gieo dữ liệu vào cơ sở dữ liệu
Hãy tiếp tục, thêm tập lệnh sau đây vào biểu tượng --- trong tools.yaml
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
Tập lệnh này xác định tài nguyên sau:
- Công cụ 3 (
search-menu-by-description) – một công cụ tìm kiếm vectơ. Tham sốsearch_querycóembeddedBy: gemini-embedding, cho biết Toolbox sẽ chặn văn bản thô, gửi văn bản đó đến mô hình nhúng và sử dụng vectơ kết quả trong câu lệnh SQL. Toán tử<=>là khoảng cách cosin của pgvector – giá trị càng nhỏ thì nội dung mô tả càng giống nhau.
Cuối cùng, hãy thêm công cụ cuối cùng vào biểu tượng --- trong tools.yaml
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
Tập lệnh này xác định tài nguyên sau:
- Công cụ 4 (
add-menu-item) – minh hoạ việc sử dụng vectơ. Tham sốdescription_vectorcó 2 trường đặc biệt: valueFromParam: description– Hộp công cụ sao chép giá trị từ tham sốdescriptionvào tham số này. LLM không bao giờ thấy tham số này.embeddedBy: gemini-embedding– Toolbox nhúng văn bản đã sao chép vào một vectơ trước khi chuyển văn bản đó đến SQL.
Kết quả: một lệnh gọi công cụ lưu trữ cả văn bản mô tả thô và vectơ nhúng của văn bản đó, mà không cần tác nhân biết bất kỳ thông tin nào về các vectơ nhúng.
Định dạng YAML nhiều tài liệu sẽ phân tách từng tài nguyên bằng ---. Mỗi tài liệu có các trường kind, name và type xác định nội dung của tài liệu. Tóm lại, chúng ta đã định cấu hình tất cả những điều sau:
- Xác định cơ sở dữ liệu nguồn
- Xác định các công cụ ( công cụ 1 và 2) để truy vấn cơ sở dữ liệu bằng bộ lọc tiêu chuẩn
- Xác định mô hình nhúng
- Xác định công cụ để thực hiện tìm kiếm vectơ ( công cụ 3 ) cho cơ sở dữ liệu
- Xác định công cụ để thực hiện việc nhập dữ liệu vectơ ( công cụ 4) vào cơ sở dữ liệu
6. Chạy máy chủ MCP Toolbox
Ở bước trước, chúng ta đã thiết lập cấu hình cần thiết cho MCP Toolbox. Giờ đây, chúng ta đã sẵn sàng chạy máy chủ
Xác minh dữ liệu ban đầu
Trước khi bắt đầu Toolbox, hãy xác nhận rằng bạn đã hoàn tất quá trình thiết lập cơ sở dữ liệu. Tạo tập lệnh python scripts/verify_database.py bằng lệnh sau
cloudshell edit scripts/verify_seed.py
Sau đó, sao chép mã sau vào tệp scripts/verify_seed.py
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
Tập lệnh này sẽ kiểm tra số lượng dữ liệu mục trong trình đơn và việc nhúng dữ liệu đó. Chạy tập lệnh bằng lệnh sau
uv run scripts/verify_seed.py
Nếu bạn thấy đầu ra sau đây trên cửa sổ dòng lệnh, tức là dữ liệu đã sẵn sàng
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
Khởi động máy chủ Hộp công cụ
Trong bước thiết lập trước đó, chúng ta đã tải tệp thực thi toolbox xuống. Đảm bảo rằng tệp nhị phân này tồn tại và đã tải xuống thành công. Nếu chưa, hãy tải tệp xuống và đợi cho đến khi hoàn tất
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
Chúng ta sẽ cần hiển thị các biến .env cho quy trình con do hộp công cụ MCP chạy. Chạy lệnh sau để khởi động máy chủ hộp công cụ và ghi đầu ra của bảng điều khiển vào tệp logs/mcp_toolbox.log
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
Bạn sẽ thấy kết quả trong tệp logs/mcp_toolbox.log xác nhận rằng máy chủ đã sẵn sàng như minh hoạ bên dưới:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
Xác minh các công cụ
Truy vấn Toolbox API để liệt kê tất cả các công cụ đã đăng ký:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
Bạn sẽ thấy các công cụ cùng với nội dung mô tả và thông số của chúng. Như minh hoạ bên dưới
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
Kiểm thử trực tiếp công cụ search-menu:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
Phản hồi phải chứa các món ăn chính của Ý trong dữ liệu ban đầu.
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. Tạo tác nhân ADK
Bây giờ, chúng ta sẽ sử dụng ADK trong Python cho dự án này. Hãy thêm các phần phụ thuộc bắt buộc:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk– Bộ công cụ phát triển tác nhân của Google, bao gồm cả Gemini SDKtoolbox-adk– Tích hợp ADK cho Bộ công cụ MCP cho cơ sở dữ liệu.
Tạo cấu trúc thư mục của tác nhân
ADK yêu cầu một bố cục thư mục cụ thể: một thư mục được đặt tên theo tác nhân của bạn chứa __init__.py, agent.py và .env. Để giúp bạn làm việc này, công cụ này có sẵn lệnh để nhanh chóng thiết lập cấu trúc:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
Thư mục của bạn hiện sẽ có dạng như sau:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
Tiếp theo, chúng ta sẽ cần tích hợp tác nhân ADK vào máy chủ Toolbox đang chạy và kiểm thử cả 4 công cụ: truy vấn tiêu chuẩn, tìm kiếm ngữ nghĩa và truyền vectơ. Mã tác nhân là tối thiểu: tất cả logic cơ sở dữ liệu đều nằm trong tools.yaml.
Định cấu hình môi trường của tác nhân
ADK đọc GOOGLE_GENAI_USE_VERTEXAI, GOOGLE_CLOUD_PROJECT và GOOGLE_CLOUD_LOCATION từ môi trường shell mà bạn đã đặt ở bước trước. Biến dành riêng cho tác nhân duy nhất là TOOLBOX_URL – hãy thêm biến này vào tệp .env của tác nhân:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
Cập nhật mô-đun tác nhân
Mở restaurant_agent/agent.py trong Trình chỉnh sửa Cloud Shell
cloudshell edit restaurant_agent/agent.py
và ghi đè nội dung bằng mã sau:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
Xin lưu ý rằng không có mã cơ sở dữ liệu nào ở đây – ToolboxToolset kết nối với máy chủ Toolbox khi khởi động và tải tất cả các công cụ có sẵn. Tác nhân gọi các công cụ theo tên; Bộ công cụ sẽ dịch những lệnh gọi đó thành các truy vấn SQL đối với Cloud SQL.
Biến môi trường TOOLBOX_URL mặc định là http://127.0.0.1:5000 để phát triển cục bộ. Khi triển khai lên Cloud Run sau này, bạn sẽ ghi đè giá trị này bằng URL Cloud Run của dịch vụ Toolbox mà không cần thay đổi mã.
Kiểm thử tác nhân
Khởi động giao diện người dùng dành cho nhà phát triển ADK:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
Mở URL xuất hiện trong thiết bị đầu cuối (thường là http://localhost:8000) bằng tính năng Xem trước trên web của Cloud Shell hoặc nhấn ctrl + nhấp vào URL xuất hiện trong thiết bị đầu cuối. Chọn restaurant_agent trong trình đơn thả xuống của tác nhân ở góc trên cùng bên trái.
Kiểm thử các truy vấn tiêu chuẩn
Hãy thử những câu lệnh sau để xác minh các công cụ SQL chuẩn:
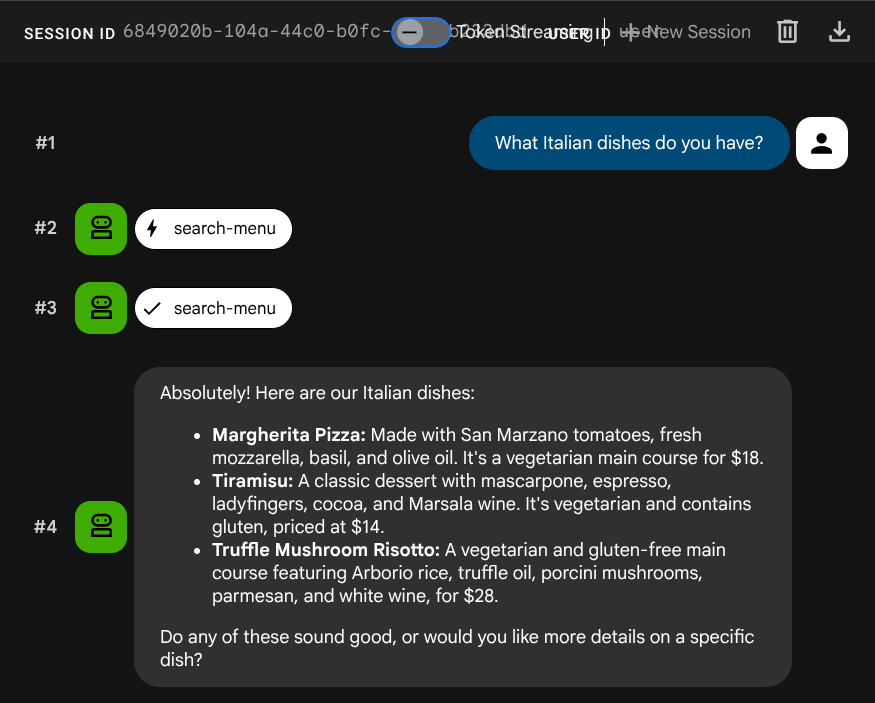
What Italian dishes do you have?
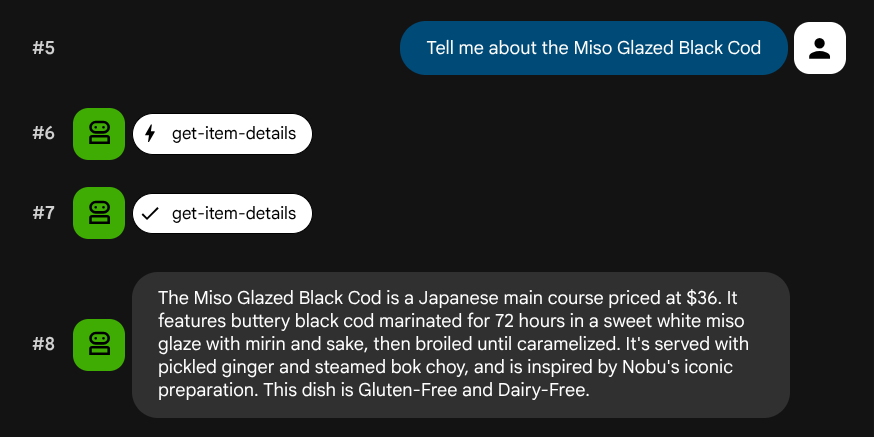
Tell me about the Miso Glazed Black Cod
Kiểm thử tính năng tìm kiếm ngữ nghĩa
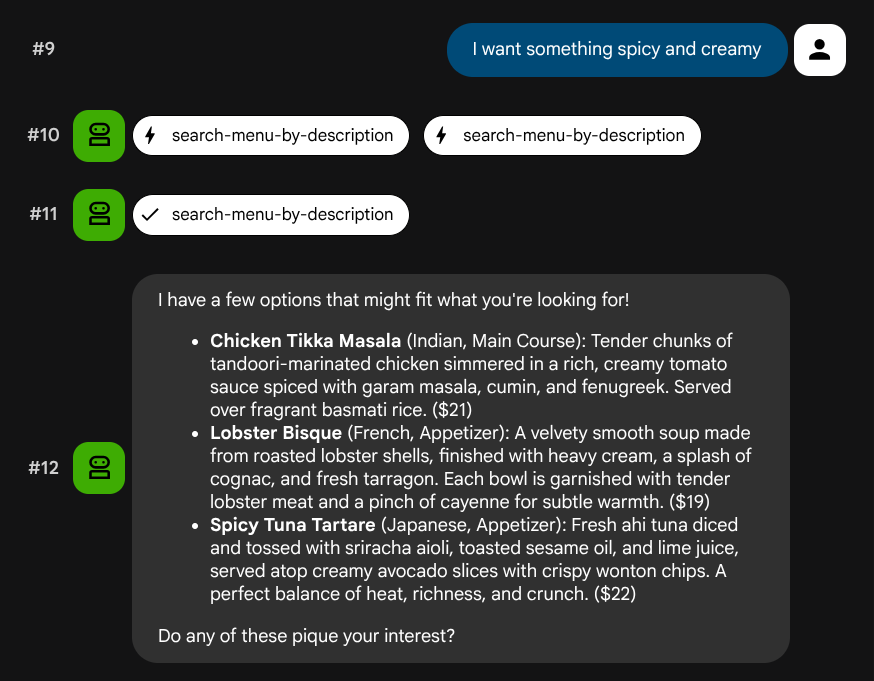
Hãy thử nội dung mô tả bằng ngôn ngữ tự nhiên không liên kết với một vai trò hoặc bộ phần mềm cơ sở cụ thể:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
Trợ lý sẽ cố gắng chọn công cụ phù hợp dựa trên loại truy vấn: bộ lọc có cấu trúc sẽ đi qua search-menu, nội dung mô tả bằng ngôn ngữ tự nhiên sẽ đi qua search-menu-by-description.
Kiểm thử việc truyền dẫn vectơ
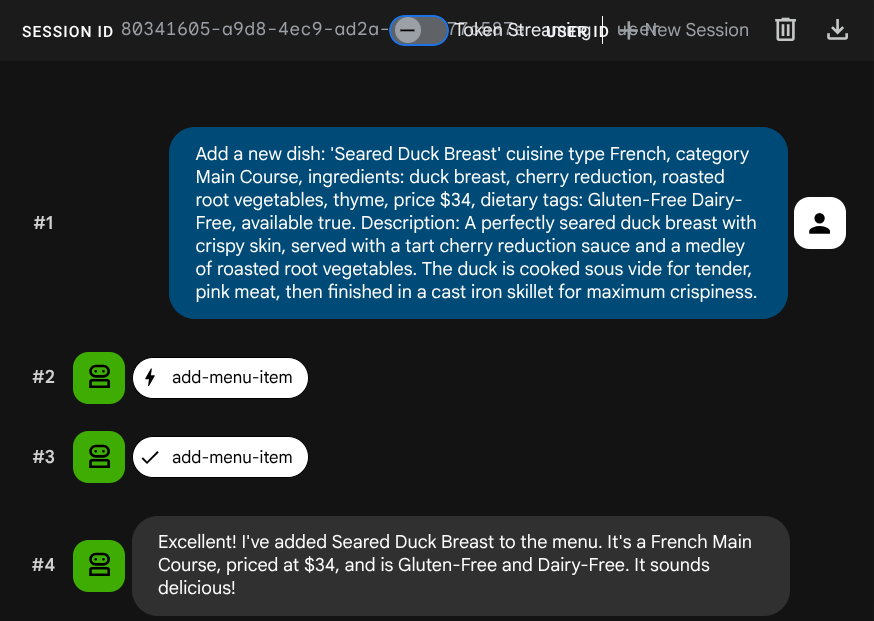
Yêu cầu trợ lý ảo thêm một công việc mới:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
Bây giờ, hãy thử tìm kiếm:
Find me something with rich, gamey flavors and fruit sauce
Hoạt động nhúng được tạo tự động trong quá trình INSERT – không cần thực hiện bước riêng biệt.
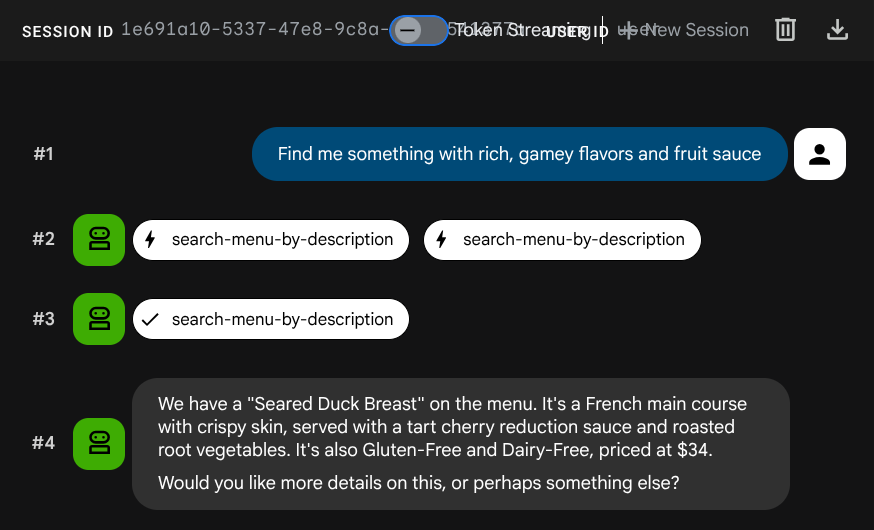
Giờ đây, bạn đã có một ứng dụng Agentic RAG hoạt động đầy đủ, sử dụng ADK, Bộ công cụ MCP và CloudSQL. Xin chúc mừng! Hãy tiến thêm một bước nữa để triển khai các ứng dụng này lên Cloud Run!
Bây giờ, hãy dừng giao diện người dùng dành cho nhà phát triển bằng cách kết thúc quy trình này bằng cách nhấn tổ hợp phím Ctrl+C hai lần trước khi tiếp tục.
8. Triển khai lên Cloud Run
Tác nhân và Toolbox hoạt động cục bộ. Bước này triển khai cả hai dưới dạng các dịch vụ Cloud Run để có thể truy cập qua Internet. Dịch vụ Toolbox chạy dưới dạng một máy chủ MCP trên Cloud Run và dịch vụ tác nhân kết nối với máy chủ đó.
Chuẩn bị Hộp công cụ để triển khai
Tạo một thư mục triển khai cho dịch vụ Toolbox:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
Tạo Dockerfile cho Toolbox. Mở deploy-toolbox/Dockerfile trong Trình chỉnh sửa Cloud Shell:
cloudshell edit deploy-toolbox/Dockerfile
Sao chép tập lệnh sau vào đó
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
Tệp nhị phân Toolbox và tools.yaml được đóng gói vào một hình ảnh Debian tối thiểu. Cloud Run định tuyến lưu lượng truy cập đến cổng 8080.
Triển khai dịch vụ Hộp công cụ
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
Lệnh này sẽ gửi nguồn đến Cloud Build, tạo một hình ảnh vùng chứa, đẩy hình ảnh đó vào Artifact Registry và triển khai hình ảnh đó lên Cloud Run. Quá trình này sẽ mất vài phút. Chúng ta có thể kiểm tra nhật ký quy trình triển khai trên tệp logs/deploy_toolbox.log
Chuẩn bị tác nhân để triển khai
Trong khi Toolbox đang tạo, hãy thiết lập các tệp triển khai của tác nhân.
Tạo một Dockerfile trong thư mục gốc của dự án. Mở Dockerfile trong Trình chỉnh sửa Cloud Shell:
cloudshell edit Dockerfile
Sau đó, hãy sao chép nội dung sau
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
Dockerfile này dùng ghcr.io/astral-sh/uv làm hình ảnh cơ sở, bao gồm cả Python và uv đã được cài đặt sẵn – không cần cài đặt uv riêng biệt thông qua pip.
Tạo tệp .dockerignore để loại trừ các tệp không cần thiết khỏi hình ảnh vùng chứa:
cloudshell edit .dockerignore
Sau đó, sao chép tập lệnh sau vào đó
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
Triển khai dịch vụ tác nhân
Đợi quá trình triển khai Toolbox hoàn tất. Kiểm tra lại quy trình triển khai trên logs/deploy_toolbox.log để xác minh quy trình. Sau đó, truy xuất URL Cloud Run của quy trình này bằng lệnh sau
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
Bạn sẽ thấy kết quả tương tự như sau
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
Sau đó, hãy xác minh rằng Toolbox đã triển khai đang hoạt động:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
Nếu kết quả hiển thị như ví dụ này, tức là quá trình triển khai đã thành công
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
Tiếp theo, hãy triển khai tác nhân bằng cách truyền URL của Hộp công cụ dưới dạng một biến môi trường:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
Mã tác nhân đọc TOOLBOX_URL từ môi trường (bạn đã thiết lập mã này trước đó). Ở cấp độ cục bộ, tham số này trỏ đến http://127.0.0.1:5000; trên Cloud Run, tham số này trỏ đến URL dịch vụ Toolbox. Bạn không cần thay đổi mã.
Kiểm thử nhân viên hỗ trợ đã triển khai
Truy xuất URL Cloud Run của nhân viên hỗ trợ:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
Mở URL trong trình duyệt. Giao diện người dùng dành cho nhà phát triển ADK sẽ tải – đây là giao diện mà bạn đã sử dụng cục bộ, hiện đang chạy trên Cloud Run.
Chọn restaurant_agent trong trình đơn thả xuống và kiểm thử:
What Italian dishes do you have?
I want something spicy and creamy
Cả hai truy vấn đều hoạt động thông qua các dịch vụ đã triển khai: tác nhân trên Cloud Run gọi Toolbox trên Cloud Run, truy vấn Cloud SQL.
9. Chúc mừng / Dọn dẹp
Bạn đã tạo và triển khai một trợ lý thực đơn thông minh cho nhà hàng sử dụng Bộ công cụ MCP cho cơ sở dữ liệu để kết nối một tác nhân ADK và Cloud SQL PostgreSQL – bằng cả truy vấn SQL tiêu chuẩn và tìm kiếm vectơ ngữ nghĩa.
Kiến thức bạn học được
- Cách MCP chuẩn hoá quyền truy cập vào công cụ cho các tác nhân AI và cách MCP Toolbox for Databases áp dụng điều này cụ thể cho các thao tác trên cơ sở dữ liệu – thay thế mã cơ sở dữ liệu tuỳ chỉnh bằng cấu hình YAML khai báo
- Cách định cấu hình Cloud SQL PostgreSQL làm nguồn dữ liệu Bộ công cụ bằng cách sử dụng loại nguồn
cloud-sql-postgres - Cách xác định các công cụ truy vấn SQL chuẩn bằng các câu lệnh có tham số giúp ngăn chặn việc chèn SQL
- Cách bật tính năng tìm kiếm vectơ bằng pgvector và
gemini-embedding-001, với tham sốembeddedByđể nhúng truy vấn tự động - Cách
valueFromParamcho phép tự động nhập vectơ – LLM cung cấp nội dung mô tả bằng văn bản và Toolbox sẽ sao chép, nhúng và lưu trữ vectơ cùng với văn bản một cách âm thầm - Cách
ToolboxToolsetcủa ADK tải các công cụ từ một máy chủ Bộ công cụ đang chạy, giúp mã đại lý ở mức tối thiểu và logic cơ sở dữ liệu hoàn toàn tách biệt - Cách triển khai cả máy chủ MCP Toolbox và tác nhân ADK lên Cloud Run dưới dạng các dịch vụ riêng biệt
Dọn dẹp
Để tránh bị tính phí cho tài khoản Google Cloud đối với các tài nguyên được tạo trong lớp học lập trình này, bạn có thể xoá từng tài nguyên hoặc xoá toàn bộ dự án.
Cách 1: Xoá dự án (nên dùng)
Cách dọn dẹp dễ nhất là xoá dự án. Thao tác này sẽ xoá tất cả tài nguyên liên kết với dự án.
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Cách 2: Xoá từng tài nguyên
Nếu bạn muốn giữ lại dự án nhưng chỉ xoá các tài nguyên đã tạo trong lớp học lập trình này, hãy làm như sau:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null