
1. 简介
AI 智能体的实用性取决于其能够访问的数据。大多数真实世界的数据都存储在数据库中,而将智能体连接到数据库通常意味着需要在智能体代码中编写连接管理、查询逻辑和嵌入流水线。每个需要数据库访问权限的代理都需要重复这项工作,并且每次更改查询都需要重新部署代理。
此 Codelab 展示了另一种方法。您可以在 YAML 文件中声明数据库工具(标准 SQL 查询、向量相似性搜索,甚至自动生成嵌入),然后 MCP Toolbox for Databases 会以 MCP 服务器的身份处理所有数据库操作。代理代码保持最简状态:加载工具,让 Gemini 决定调用哪个工具。
构建内容
面向“美食发现”的餐厅礼宾服务 - 一款由 Gemini 提供支持的 ADK 智能体,可帮助用餐者使用标准过滤条件(类别、美食类型)浏览餐厅的菜单,并通过自然语言描述(例如“我想吃辣的素食”)发现菜肴。该代理完全通过 MCP Toolbox for Databases 从 Cloud SQL PostgreSQL 数据库读取数据和向其中写入数据,该工具箱可处理所有数据库访问操作,包括为向量搜索自动生成嵌入。最后,工具箱和代理都将在 Cloud Run 上运行。
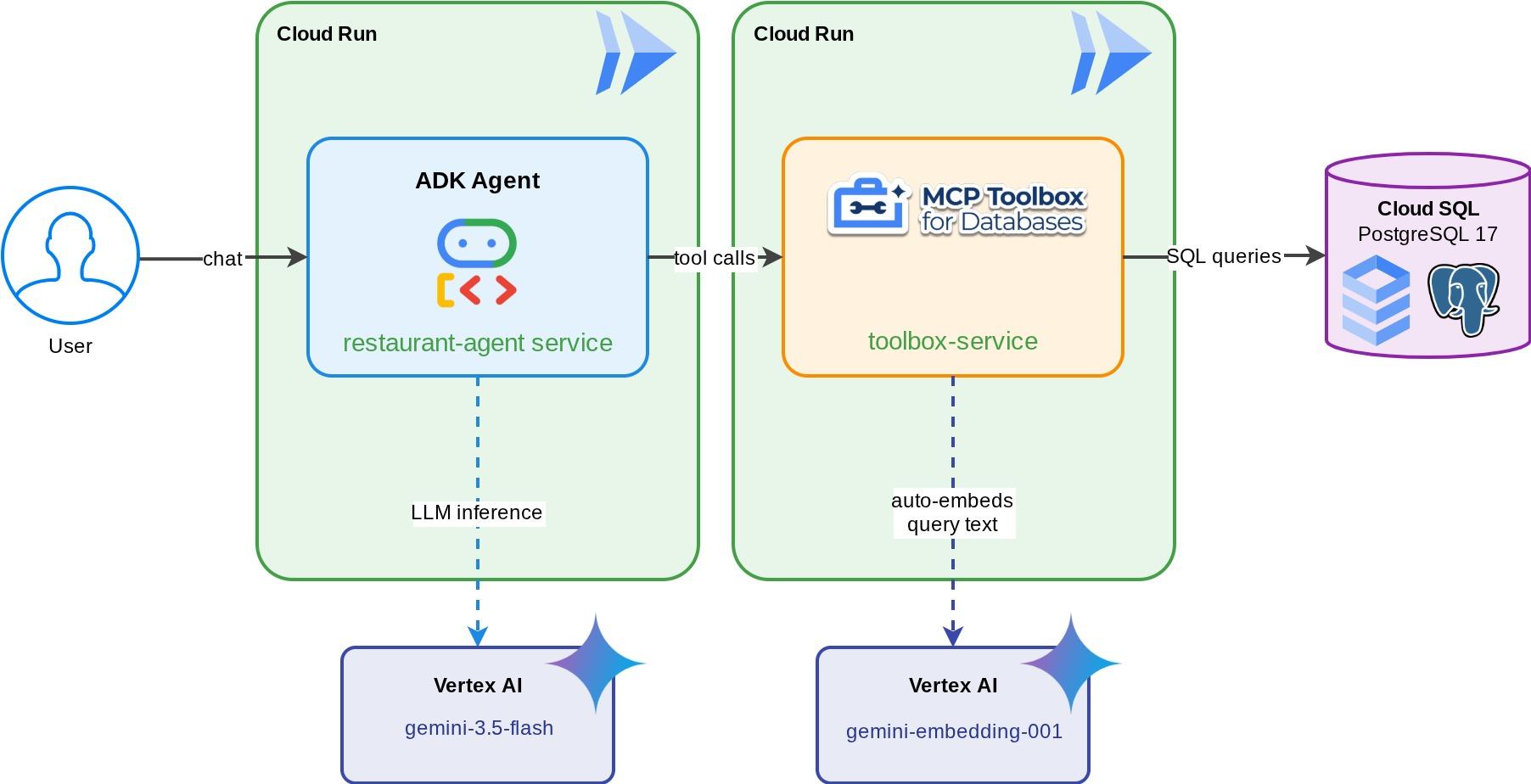
学习内容
- MCP(Model Context Protocol)如何标准化 AI 智能体的工具访问权限,以及 MCP Toolbox for Databases 如何将此应用于数据库操作
- 将 MCP Toolbox for Databases 设置为 ADK 智能体与 Cloud SQL PostgreSQL 之间的中间件
- 在
tools.yaml中以声明方式定义数据库工具 - 智能体中没有数据库代码 - 构建一个 ADK 智能体,该智能体使用
ToolboxToolset从正在运行的 Toolbox 服务器加载工具 - 使用 Cloud SQL 的内置
embedding()函数生成向量嵌入,并使用pgvector启用语义搜索 - 使用
valueFromParam功能在写入操作时自动提取向量 - 将 Toolbox 服务器和 ADK 智能体都部署到 Cloud Run
前提条件
- 具有试用结算账号的 Google Cloud 账号
- 基本熟悉 Python 和 SQL
- 如果之前使用过 Cloud Database 和 ADK,将会有所帮助
2. 设置环境
此步骤将准备 Cloud Shell 环境、配置 Google Cloud 项目并克隆参考代码库。
打开 Cloud Shell
在浏览器中打开 Cloud Shell。Cloud Shell 提供了一个预配置的环境,其中包含本 Codelab 所需的所有工具。系统提示时,点击授权
然后,依次点击“查看” ->“终端”,打开终端。您的界面应与此类似
这将是我们的主要界面,顶部是 IDE,底部是终端
设置工作目录
创建工作目录。您在此 Codelab 中编写的所有代码都将位于此目录中:
mkdir -p ~/build-agent-adk-toolbox-cloudsql
cloudshell workspace ~/build-agent-adk-toolbox-cloudsql && cd ~/build-agent-adk-toolbox-cloudsql
之后,我们准备几个目录来管理种子脚本和日志等内容
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
设置您的 Google Cloud 项目
创建包含位置变量的 .env 文件:
# For Vertex AI / Gemini API calls
echo "GOOGLE_CLOUD_LOCATION=global" > .env
# For Cloud SQL, Cloud Run, Artifact Registry
echo "REGION=us-central1" >> .env
为简化终端中的项目设置,请将此项目设置脚本下载到您的工作目录中:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
运行脚本。它会验证您的试用结算账号,创建新项目(或验证现有项目),将项目 ID 保存到当前目录中的 .env 文件,并在 gcloud 中设置有效项目。
bash setup_verify_trial_project.sh && source .env
该脚本将:
- 验证您是否拥有有效的试用结算账号
- 检查
.env中是否存在现有项目(如果有) - 创建新项目或重复使用现有项目
- 将试用结算账号与您的项目相关联
- 将项目 ID 保存到
.env - 将项目设置为活跃
gcloud项目
通过检查 Cloud Shell 终端提示中工作目录旁边的黄色文字,验证项目是否已正确设置。其中应显示您的项目 ID。

激活必需的 API
接下来,我们需要为将要交互的产品启用多个 API:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com
- Vertex AI API (
aiplatform.googleapis.com) - 您的代理使用 Gemini 模型,而工具箱使用嵌入 API 进行向量搜索。 - Cloud SQL Admin API (
sqladmin.googleapis.com) - 您可以预配和管理 PostgreSQL 实例。 - Compute Engine API (
compute.googleapis.com) - 创建 Cloud SQL 实例时需要此 API。 - Cloud Run、Cloud Build、Artifact Registry - 在本 Codelab 后面的部署步骤中使用
3. 准备数据库初始化脚本
此步骤会开始创建 Cloud SQL 实例,并运行一个自动化设置脚本,该脚本会等待实例准备就绪,然后创建数据库、使用职位信息填充数据库并生成嵌入内容,所有这些操作都在一次运行中完成。
首先,将数据库密码添加到 .env 文件并重新加载该文件:
echo "DB_PASSWORD=restaurant-pwd" >> .env
echo "DB_INSTANCE=restaurant-instance" >> .env
echo "DB_NAME=restaurant_db" >> .env
source .env
创建用于实例和数据库创建的 Bash 脚本
然后,使用以下命令创建 scripts/setup_database.sh 脚本
mkdir -p ~/build-agent-adk-toolbox-cloudsql/scripts
cloudshell edit scripts/setup_database.sh
然后,将以下代码复制到 scripts/setup_database.sh 文件中
#!/bin/bash
set -e
source .env
echo "================================================"
echo "Database Setup"
echo "================================================"
echo ""
# Step 1: Create Cloud SQL instance
echo "[1/5] Creating Cloud SQL instance..."
# Check if instance already exists
if gcloud sql instances describe "$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Instance already exists"
else
echo " Creating instance (takes 5-10 minutes)..."
gcloud sql instances create "$DB_INSTANCE" \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--edition=ENTERPRISE \
--region="$REGION" \
--root-password="$DB_PASSWORD" \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--quiet
fi
echo " ✓ Instance ready"
echo ""
# Step 2: Verify instance is ready
echo "[2/5] Verifying instance state..."
STATE=$(gcloud sql instances describe "$DB_INSTANCE" --format='value(state)')
if [ "$STATE" != "RUNNABLE" ]; then
echo "ERROR: Instance not ready (state: $STATE)"
exit 1
fi
echo " ✓ Instance is RUNNABLE"
echo ""
# Step 3: Grant IAM permissions
echo "[3/5] Granting Vertex AI permissions..."
SERVICE_ACCOUNT=$(gcloud sql instances describe "$DB_INSTANCE" \
--format='value(serviceAccountEmailAddress)')
if [ -z "$SERVICE_ACCOUNT" ]; then
echo "ERROR: Could not retrieve service account"
exit 1
fi
gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" \
--quiet
echo " ✓ Permissions granted"
echo ""
# Step 4: Create database
echo "[4/5] Creating database..."
# Check if database already exists
if gcloud sql databases describe "$DB_NAME" \
--instance="$DB_INSTANCE" --quiet >/dev/null 2>&1; then
echo " Database already exists"
else
gcloud sql databases create "$DB_NAME" \
--instance="$DB_INSTANCE" \
--quiet
fi
echo " ✓ Database '$DB_NAME' ready"
echo ""
# Step 5: Seed database and generate embeddings
echo "[5/5] Seeding database and generating embeddings..."
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
SETUP_SCRIPT="${SCRIPT_DIR}/setup_restaurant_db.py"
if [ ! -f "$SETUP_SCRIPT" ]; then
echo "ERROR: Setup script not found: $SETUP_SCRIPT"
exit 1
fi
uv run "$SETUP_SCRIPT"
echo ""
echo "================================================"
echo "Setup complete!"
echo "================================================"
echo ""
为数据种子创建 Python 脚本
之后,使用以下命令创建初始脚本 Python 文件 scripts/setup_restaurant_db.py
cloudshell edit scripts/setup_restaurant_db.py
然后,将以下代码复制到 scripts/setup_restaurant_db.py 文件中
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
import time
# Load environment variables from .env file
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
EMBEDDING_MODEL='gemini-embedding-001'
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing required environment variables: {', '.join(missing_vars)}", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Expected .env file location: {env_path}", file=sys.stderr)
if not env_path.exists():
print(f"✗ File not found at that location", file=sys.stderr)
else:
print(f"✓ File exists but is missing the variables above", file=sys.stderr)
print(f"", file=sys.stderr)
print(f"Make sure your .env file contains:", file=sys.stderr)
for var in missing_vars:
print(f" {var}=<value>", file=sys.stderr)
sys.exit(1)
# Menu items data
MENU_ITEMS = [
("Truffle Mushroom Risotto", "Italian", "Main Course",
"Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"$28", "Vegetarian, Gluten-Free", True,
"A creamy, luxurious risotto made with arborio rice slow-cooked in white wine and mushroom broth, finished with shaved black truffle and aged parmesan. The porcini mushrooms add a deep, earthy flavor that pairs beautifully with the delicate truffle oil drizzled on top."),
("Spicy Tuna Tartare", "Japanese", "Appetizer",
"Ahi tuna, sriracha, sesame oil, avocado, crispy wonton",
"$22", "Gluten-Free, Dairy-Free", True,
"Fresh ahi tuna diced and tossed with sriracha aioli, toasted sesame oil, and lime juice, served atop creamy avocado slices with crispy wonton chips. A perfect balance of heat, richness, and crunch inspired by modern Japanese fusion cuisine."),
("Lamb Kofta Kebab", "Middle Eastern", "Main Course",
"Ground lamb, cumin, coriander, yogurt sauce, flatbread",
"$24", "Halal", True,
"Hand-formed spiced lamb kebabs grilled over charcoal, seasoned with cumin, coriander, and sumac. Served with warm flatbread, tangy yogurt-cucumber sauce, and a fresh herb salad. A classic Middle Eastern street food elevated with premium ingredients."),
("Pad Thai", "Thai", "Main Course",
"Rice noodles, shrimp, tamarind, peanuts, bean sprouts, lime",
"$19", "Gluten-Free, Dairy-Free", True,
"Stir-fried rice noodles with tiger shrimp, scrambled egg, and a sweet-sour tamarind sauce, topped with crushed peanuts, fresh bean sprouts, and a squeeze of lime. This classic Thai street food dish balances sweet, sour, salty, and umami in every bite."),
("Margherita Pizza", "Italian", "Main Course",
"San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"$18", "Vegetarian", True,
"A Neapolitan-style pizza with a thin, charred crust topped with crushed San Marzano tomatoes, creamy buffalo mozzarella, fresh basil leaves, and a drizzle of extra virgin olive oil. Simple, classic, and made with imported Italian ingredients."),
("Miso Glazed Black Cod", "Japanese", "Main Course",
"Black cod, white miso, mirin, sake, pickled ginger",
"$36", "Gluten-Free, Dairy-Free", True,
"Buttery black cod marinated for 72 hours in a sweet white miso glaze with mirin and sake, then broiled until caramelized. Served with pickled ginger and steamed bok choy. A signature dish inspired by Nobu's iconic preparation."),
("Caesar Salad", "American", "Appetizer",
"Romaine lettuce, parmesan, croutons, anchovy dressing",
"$14", "Contains Gluten", True,
"Crisp romaine hearts tossed with a house-made anchovy-garlic dressing, shaved parmesan, and golden sourdough croutons. A timeless salad that serves as the perfect light starter or side dish with grilled proteins."),
("Chicken Tikka Masala", "Indian", "Main Course",
"Chicken thigh, tomato cream sauce, garam masala, basmati rice",
"$21", "Gluten-Free", True,
"Tender chunks of tandoori-marinated chicken simmered in a rich, creamy tomato sauce spiced with garam masala, cumin, and fenugreek. Served over fragrant basmati rice with warm garlic naan on the side."),
("Chocolate Lava Cake", "French", "Dessert",
"Dark chocolate, butter, eggs, vanilla, powdered sugar",
"$15", "Vegetarian", True,
"A warm, individual-sized chocolate cake with a molten dark chocolate center that flows when you break through the delicate outer shell. Made with 70% Belgian dark chocolate and served with a scoop of vanilla bean ice cream."),
("Pho Bo", "Vietnamese", "Main Course",
"Rice noodles, beef brisket, star anise, cinnamon, bean sprouts, Thai basil",
"$17", "Gluten-Free, Dairy-Free", True,
"A deeply aromatic beef broth simmered for 12 hours with star anise, cinnamon, and charred ginger, ladled over rice noodles and thinly sliced beef brisket. Served with fresh Thai basil, bean sprouts, jalapeño, and lime for the table to customize."),
("Lobster Bisque", "French", "Appetizer",
"Lobster, heavy cream, cognac, tarragon, cayenne",
"$19", "Gluten-Free", True,
"A velvety smooth soup made from roasted lobster shells, finished with heavy cream, a splash of cognac, and fresh tarragon. Each bowl is garnished with tender lobster meat and a pinch of cayenne for subtle warmth."),
("Falafel Plate", "Middle Eastern", "Main Course",
"Chickpeas, herbs, tahini, pickled vegetables, hummus",
"$16", "Vegan, Gluten-Free", True,
"Crispy-on-the-outside, fluffy-on-the-inside chickpea fritters seasoned with fresh parsley, cilantro, and cumin. Served with creamy tahini sauce, house-made hummus, pickled turnips, and warm pita bread."),
("Crème Brûlée", "French", "Dessert",
"Heavy cream, vanilla bean, egg yolks, caramelized sugar",
"$13", "Vegetarian, Gluten-Free", True,
"A classic French custard made with Madagascar vanilla bean and farm-fresh egg yolks, topped with a perfectly torched layer of caramelized sugar that cracks with a satisfying snap. Rich, creamy, and elegantly simple."),
("Korean BBQ Short Ribs", "Korean", "Main Course",
"Beef short ribs, soy sauce, sesame, garlic, pear marinade",
"$32", "Dairy-Free", False,
"Premium beef short ribs marinated overnight in a sweet and savory blend of soy sauce, Asian pear, garlic, and toasted sesame. Grilled tableside over charcoal and served with lettuce wraps, pickled daikon, and gochujang dipping sauce."),
("Tiramisu", "Italian", "Dessert",
"Mascarpone, espresso, ladyfingers, cocoa, Marsala wine",
"$14", "Vegetarian, Contains Gluten", True,
"Layers of espresso-soaked ladyfingers and whipped mascarpone cream flavored with Marsala wine, dusted with premium Dutch cocoa powder. Made fresh daily and chilled for 24 hours to develop rich, complex flavors."),
]
def get_connection():
"""Create a connection to Cloud SQL using the connector."""
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
connector = Connector()
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
return conn, connector
def create_schema(cursor):
"""Create extensions and menu_items table."""
cursor.execute("CREATE EXTENSION IF NOT EXISTS google_ml_integration")
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector")
cursor.execute("""
CREATE TABLE IF NOT EXISTS menu_items (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
cuisine_type VARCHAR NOT NULL,
category VARCHAR NOT NULL,
ingredients VARCHAR NOT NULL,
price VARCHAR NOT NULL,
dietary_tags VARCHAR NOT NULL,
available BOOLEAN NOT NULL DEFAULT TRUE,
description TEXT NOT NULL,
description_embedding vector(3072)
)
""")
def seed_menu_items(cursor, conn):
"""Insert menu items."""
cursor.execute("SELECT COUNT(*) FROM menu_items")
existing_count = cursor.fetchone()[0]
if existing_count > 0:
print(f" {existing_count} menu items already exist, skipping seed")
return 0
cursor.executemany("""
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", MENU_ITEMS)
conn.commit()
return len(MENU_ITEMS)
def generate_embeddings(cursor, conn):
"""Generate embeddings using Cloud SQL's embedding() function."""
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NULL")
null_count = cursor.fetchone()[0]
if null_count == 0:
print(" All menu items already have embeddings")
return 0
cursor.execute(f"""
UPDATE menu_items
SET description_embedding = embedding('{EMBEDDING_MODEL}', description)::vector
WHERE description_embedding IS NULL
""")
rows_updated = cursor.rowcount
conn.commit()
return rows_updated
def main():
conn, connector = get_connection()
cursor = conn.cursor()
try:
create_schema(cursor)
conn.commit()
seeded = seed_menu_items(cursor, conn)
if seeded > 0:
print(f" ✓ Inserted {seeded} menu items")
# Waiting for vertex role propagation
time.sleep(60)
embedded = generate_embeddings(cursor, conn)
if embedded > 0:
print(f" ✓ Generated {embedded} embeddings")
except Exception as e:
print(f"ERROR: {e}", file=sys.stderr)
sys.exit(1)
finally:
cursor.close()
conn.close()
connector.close()
if __name__ == "__main__":
main()
现在,我们进入下一步
4. 创建并初始化数据库
现在,我们的脚本已准备就绪,可以执行了。我们需要使用 Python 来执行准备好的脚本,因此我们先准备好 Python
设置 Python 项目
uv 是一个用 Rust 编写的快速 Python 软件包和项目管理器(请参阅 uv 文档)。此 Codelab 使用它来提高 Python 项目的维护速度并简化维护工作
初始化 Python 项目并添加所需的依赖项:
uv init
uv add cloud-sql-python-connector --extra pg8000
uv add python-dotenv
请注意,我们在此处使用 cloud-sql-python-connector Python SDK 来初始化与数据库实例的安全连接,该连接使用应用默认凭证进行身份验证。
执行设置脚本
现在,我们可以运行后台设置脚本,并使用以下命令检查将写入 logs/atabase_setup.log 文件的控制台输出。在等待此操作完成期间,您可以继续执行下一部分
mkdir -p ~/build-agent-adk-toolbox-cloudsql/logs
bash scripts/setup_database.sh > logs/database_setup.log 2>&1 &
下载 Toolbox 二进制文件
在本教程中,我们将使用 MCP Toolbox,幸运的是,它附带了一个预构建的二进制文件,可在 Linux 环境中使用。现在,我们让它在后台下载,因为这需要相当长的时间。运行以下命令下载二进制文件,并检查 logs/toolbox_dl.log 上的输出日志。在等待此操作完成期间,您可以继续执行下一部分
cd ~/build-agent-adk-toolbox-cloudsql
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox > logs/toolbox_dl.log 2>&1 &
了解设置脚本 scripts/setup_database.sh
现在,我们来尝试了解之前配置的设置脚本。该脚本会执行以下流程
- 我们在其中执行的第一个命令是
gcloud sql instances create命令,并带有以下标志
db-custom-1-3840是ENTERPRISE版中最小的专用核心 Cloud SQL 层(1 个 vCPU,3.75 GB RAM)。如需了解更多详情,请点击此处。Vertex AI ML 集成需要专用核心,共享核心层(db-f1-micro、db-g1-small)不支持此功能。--root-password为默认postgres用户设置密码。--enable-google-ml-integration可启用 Cloud SQL 与 Vertex AI 的内置集成,让您可以使用embedding()函数直接从 SQL 调用嵌入模型。
- 验证实例是否已处于
RUNNABLE状态 - 使用
gcloud projects add-iam-policy-binding命令授予 Cloud SQL 实例的服务账号调用 Vertex AI 的权限。这是内置embedding()函数所必需的,我们将在为数据库植入初始数据时使用该函数 - 创建数据库
- 执行初始配置脚本
setup_restaurant_db.py脚本
了解种子脚本 scripts/setup_restaurant_db.py
现在,我们来看一下初始数据植入脚本,该脚本会执行以下操作:
- 初始化与数据库实例的连接
- 安装两个 PostgreSQL 扩展程序:
google_ml_integration- 提供embedding()SQL 函数,该函数可直接从 SQL 调用 Vertex AI 嵌入模型。这是一个数据库级扩展程序,可让restaurant_db内使用机器学习函数。您在创建实例期间设置的实例级标志 (--enable-google-ml-integration) 允许 Cloud SQL 虚拟机访问 Vertex AI;该扩展程序使 SQL 函数在此特定数据库中可用。vector(pgvector) - 添加了vector数据类型和距离运算符,用于存储和查询嵌入内容。
- 创建表,请注意
description_embedding列是vector(3072),即存储 3072 维向量的pgvector列。 - 播种初始菜单项数据
- 从
description字段生成嵌入数据,并通过embedding()函数使用内置 Vertex 集成填充description_embedding
embedding('gemini-embedding-001', description)- 直接从 SQL 调用 Vertex AI 的 Gemini 嵌入模型,并传递每个作业的description文本。这是您在初始脚本中安装的google_ml_integration扩展程序。::vector- 将返回的浮点数组转换为 pgvector 的vector类型,以便可以使用距离运算符存储和查询该数组。UPDATE跨所有 15 行运行,为每个职位说明生成一个 3072 维的嵌入。
这将准备初始数据,供我们的代理访问
5. 配置 MCP Toolbox for Databases
此步骤将介绍 MCP Toolbox for Databases,将其配置为连接到您的 Cloud SQL 实例,并定义两个标准 SQL 查询工具。
什么是 MCP?为什么要使用 Toolbox?
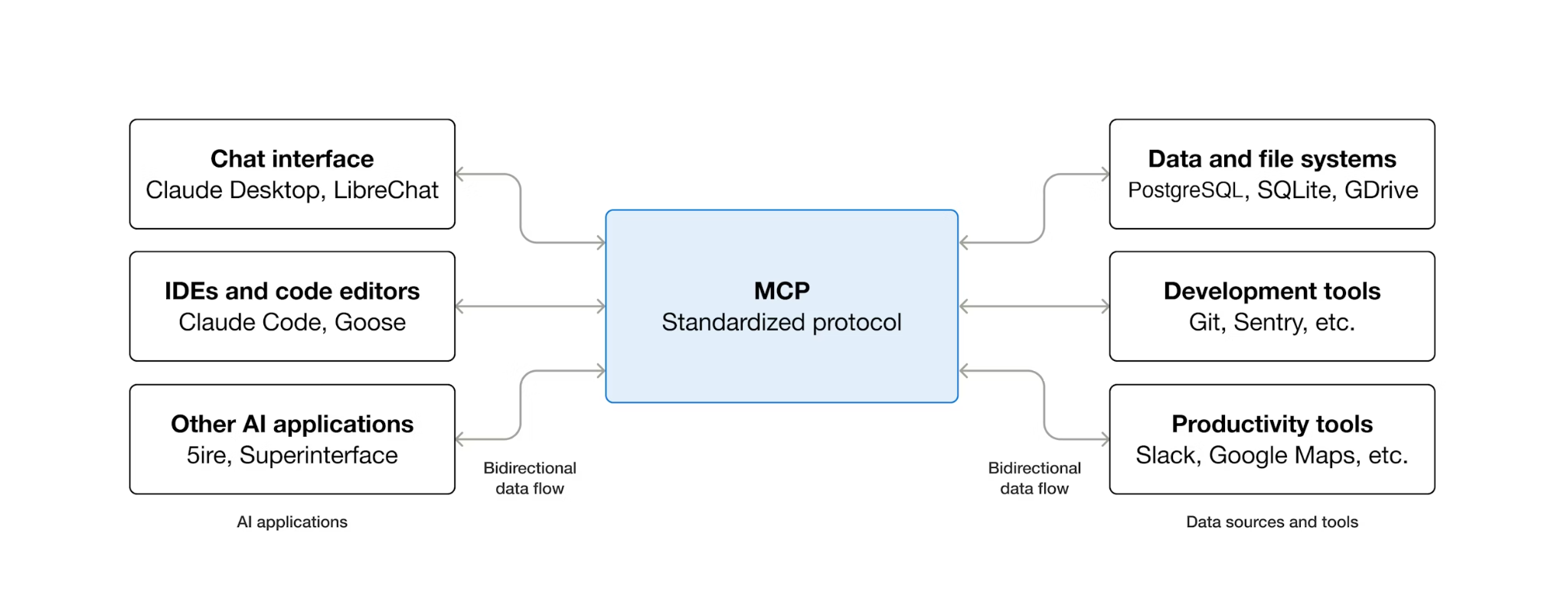
MCP(模型上下文协议)是一种开放协议,可规范 AI 智能体发现和与外部工具互动的方式。它定义了客户端-服务器模型:智能体托管 MCP 客户端,工具由 MCP 服务器公开。任何兼容 MCP 的客户端都可以使用任何兼容 MCP 的服务器,智能体无需为每个工具编写自定义集成代码。
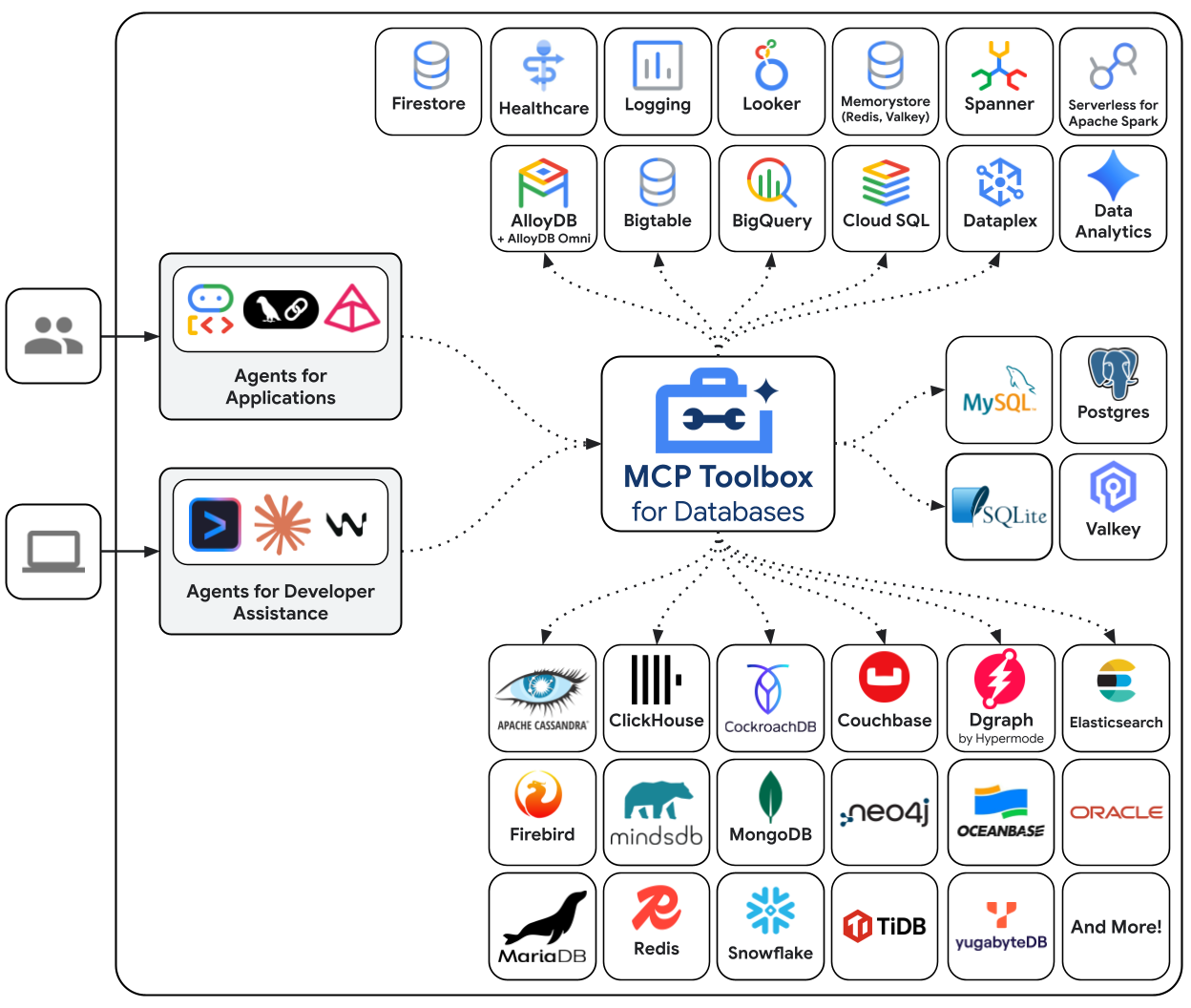
MCP Toolbox for Databases 是一款专门为数据库访问而构建的开源 MCP 服务器。如果没有它,您需要编写 Python 函数来打开数据库连接、管理连接池、构建参数化查询以防止 SQL 注入、处理错误,并将所有这些代码嵌入到您的代理中。每个需要访问数据库的代理都会重复这项工作。更改查询意味着重新部署代理。
借助 Toolbox,您可以编写 YAML 文件。每个工具都映射到参数化 SQL 语句。Toolbox 可处理连接池、参数化查询、身份验证和可观测性。工具与代理分离 - 您可以通过编辑 tools.yaml 并重启 Toolbox 来更新查询,而无需修改代理代码。相同的工具可用于 ADK、LangGraph、LlamaIndex 或任何 MCP 兼容框架。
编写工具配置
现在,我们需要在 Cloud Shell 编辑器中创建一个名为 tools.yaml 的文件,以设置工具配置
cloudshell edit tools.yaml
该文件使用多文档 YAML,每个由 --- 分隔的块都是一个独立的资源。每个资源都有一个声明其用途的 kind(sources 表示数据库连接,tools 表示可供代理调用的操作)和一个指定后端的 type(cloud-sql-postgres 表示来源,postgres-sql 表示基于 SQL 的工具)。工具通过 name 引用其来源,这样 Toolbox 就能知道要针对哪个连接池执行操作。环境变量使用 ${VAR_NAME} 语法,并在启动时解析。
现在,我们先将以下脚本复制到 tools.yaml 文件中
# tools.yaml
# --- Data Source ---
kind: source
name: restaurant-db
type: cloud-sql-postgres
project: ${GOOGLE_CLOUD_PROJECT}
region: ${REGION}
instance: ${DB_INSTANCE}
database: ${DB_NAME}
user: postgres
password: ${DB_PASSWORD}
---
此处的脚本定义了以下资源:
- 来源 (
restaurant-db) - 用于告知 Toolbox 如何连接到您的 Cloud SQL PostgreSQL 实例。cloud-sql-postgres类型在内部使用 Cloud SQL 连接器,可自动处理身份验证和安全连接。${GOOGLE_CLOUD_PROJECT}、${REGION}和${DB_PASSWORD}占位符在启动时从环境变量中解析。
接下来,在 tools.yaml 中的 --- 符号下附加以下脚本
# --- Tool 1: Search menu items by category and/or cuisine type ---
kind: tool
name: search-menu
type: postgres-sql
source: restaurant-db
description: >-
Search for menu items by category and/or cuisine type.
Use this tool when the user wants to browse menu items
by category (e.g., Main Course, Appetizer, Dessert) or find dishes
from a specific cuisine. Both parameters accept an
empty string to match all values.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available
FROM menu_items
WHERE ($1 = '' OR LOWER(category) = LOWER($1))
AND ($2 = '' OR LOWER(cuisine_type) LIKE '%' || LOWER($2) || '%')
ORDER BY name
LIMIT 10
parameters:
- name: category
type: string
description: "The menu category to filter by (e.g., 'Main Course', 'Appetizer', 'Dessert'). Use empty string for all categories."
- name: cuisine_type
type: string
description: "A cuisine type to search for (partial match, e.g., 'Italian', 'Japanese'). Use empty string for all cuisines."
---
# --- Tool 2: Get full details for a specific menu item ---
kind: tool
name: get-item-details
type: postgres-sql
source: restaurant-db
description: >-
Get full details for a specific menu item including its description,
price, dietary tags, and availability. Use this tool when the
user asks about a particular dish by name or cuisine.
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, available, description
FROM menu_items
WHERE LOWER(name) LIKE '%' || LOWER($1) || '%'
OR LOWER(cuisine_type) LIKE '%' || LOWER($1) || '%'
parameters:
- name: search_term
type: string
description: "The dish name or cuisine type to look up (partial match supported)."
---
此处的脚本定义了以下资源:
- 工具 1 和 2(
search-menu、get-item-details)- 标准 SQL 查询工具。每个映射都将工具名称(代理看到的内容)映射到参数化 SQL 语句(数据库执行的内容)。参数使用$1、$2位置占位符。Toolbox 会将这些语句作为预处理语句执行,从而防止 SQL 注入。
我们继续操作,在 tools.yaml 中 --- 符号下方附加以下脚本
# --- Embedding Model ---
kind: embeddingModel
name: gemini-embedding
type: gemini
model: gemini-embedding-001
project: ${GOOGLE_CLOUD_PROJECT}
location: ${GOOGLE_CLOUD_LOCATION}
dimension: 3072
---
此处的脚本定义了以下资源:
- 嵌入模型 (
gemini-embedding) - 配置工具箱以调用 Gemini 的gemini-embedding-001模型来生成 3072 维文本嵌入。工具箱使用应用默认凭证 (ADC) 进行身份验证 - 在 Cloud Shell 或 Cloud Run 中无需 API 密钥。请注意,此处配置的dimension必须与之前配置的用于为数据库提供初始数据的dimension相同
我们继续操作,在 tools.yaml 中 --- 符号下方附加以下脚本
# --- Tool 3: Semantic search by description ---
kind: tool
name: search-menu-by-description
type: postgres-sql
source: restaurant-db
description: >-
Find menu items that match a natural language description of what the user
is looking for. Use this tool when the user describes their ideal dish
using flavors, textures, dietary preferences, or cravings rather than a
specific category or cuisine. Examples: "I want something spicy and creamy,"
"a light vegetarian appetizer," "something rich and chocolatey for dessert."
statement: |
SELECT name, cuisine_type, category, ingredients, price, dietary_tags, description
FROM menu_items
WHERE description_embedding IS NOT NULL
ORDER BY description_embedding <=> $1
LIMIT 5
parameters:
- name: search_query
type: string
description: "A natural language description of the kind of dish the user is looking for."
embeddedBy: gemini-embedding
---
此处的脚本定义了以下资源:
- 工具 3 (
search-menu-by-description) - 一种向量搜索工具。search_query参数具有embeddedBy: gemini-embedding,这会告知 Toolbox 拦截原始文本,将其发送到嵌入模型,并在 SQL 语句中使用生成的向量。<=>运算符是 pgvector 的余弦距离,值越小表示说明越相似。
最后,将最后一个工具附加到 tools.yaml 中 --- 符号下方
# --- Tool 4: Add a new menu item with automatic embedding ---
kind: tool
name: add-menu-item
type: postgres-sql
source: restaurant-db
description: >-
Add a new menu item to the restaurant. Use this tool when a user asks
to add a dish that is not currently on the menu.
statement: |
INSERT INTO menu_items (name, cuisine_type, category, ingredients, price, dietary_tags, available, description, description_embedding)
VALUES ($1, $2, $3, $4, $5, $6, CAST($7 AS BOOLEAN), $8, $9)
RETURNING name, cuisine_type
parameters:
- name: name
type: string
description: "The dish name (e.g., 'Truffle Mushroom Risotto')."
- name: cuisine_type
type: string
description: "The cuisine type (e.g., 'Italian', 'Japanese', 'Thai')."
- name: category
type: string
description: "The menu category (e.g., 'Main Course', 'Appetizer', 'Dessert')."
- name: ingredients
type: string
description: "Comma-separated list of key ingredients (e.g., 'salmon, miso, ginger')."
- name: price
type: string
description: "The price (e.g., '$24')."
- name: dietary_tags
type: string
description: "Dietary information (e.g., 'Vegetarian, Gluten-Free')."
- name: available
type: string
description: "Whether the dish is currently available (true or false)."
- name: description
type: string
description: "A short description of the dish (2-3 sentences)."
- name: description_vector
type: string
description: "Auto-generated embedding vector for the dish description."
valueFromParam: description
embeddedBy: gemini-embedding
此处的脚本定义了以下资源:
- 工具 4 (
add-menu-item) - 演示了矢量提取。description_vector参数有两个特殊字段: valueFromParam: description- 盒子会将description参数中的值复制到此参数中。LLM 永远不会看到此参数。embeddedBy: gemini-embedding- 工具箱会将复制的文本嵌入到向量中,然后再将其传递给 SQL。
结果:一个工具调用存储了原始说明文本及其向量嵌入,而代理对嵌入一无所知。
多文档 YAML 格式使用 --- 分隔每个资源。每个文档都有 kind、name 和 type 字段来定义其内容。总而言之,我们已经配置了以下所有内容:
- 定义源数据库
- 定义工具(工具 1 和 2),以使用标准过滤条件查询数据库
- 定义嵌入模型
- 定义用于对数据库执行向量搜索的工具(工具 3)
- 定义用于将向量数据注入(工具 4)到数据库的工具
6. 运行 MCP Toolbox 服务器
在上一步中,我们已经为 MCP Toolbox 设置了必要的配置。现在,我们已准备好运行服务器
验证植入的数据
在启动 Toolbox 之前,请先确认数据库设置已完成。使用以下命令创建 Python 脚本 scripts/verify_database.py
cloudshell edit scripts/verify_seed.py
然后,将以下代码复制到 scripts/verify_seed.py 文件中
#!/usr/bin/env python3
"""Verify the database has 15 menu items with embeddings."""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector
import pg8000
# Load environment variables
env_path = Path(__file__).parent.parent / '.env'
load_dotenv(env_path)
# Verify required environment variables
required_vars = ['GOOGLE_CLOUD_PROJECT', 'REGION', 'DB_PASSWORD', 'DB_INSTANCE', 'DB_NAME']
missing_vars = [var for var in required_vars if not os.environ.get(var)]
if missing_vars:
print(f"ERROR: Missing environment variables: {', '.join(missing_vars)}", file=sys.stderr)
sys.exit(1)
def verify_database():
"""Check that 15 menu items exist with embeddings."""
connector = Connector()
try:
project = os.environ['GOOGLE_CLOUD_PROJECT']
region = os.environ['REGION']
password = os.environ['DB_PASSWORD']
instance = os.environ['DB_INSTANCE']
database = os.environ['DB_NAME']
conn = connector.connect(
f"{project}:{region}:{instance}",
"pg8000",
user="postgres",
password=password,
db=database
)
cursor = conn.cursor()
# Count menu items and embeddings
cursor.execute("SELECT COUNT(*) FROM menu_items")
item_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM menu_items WHERE description_embedding IS NOT NULL")
embedding_count = cursor.fetchone()[0]
print(f"Menu Items: {item_count}/15")
print(f"Embeddings: {embedding_count}/15")
cursor.close()
conn.close()
if item_count == 15 and embedding_count == 15:
print("\n✓ Database ready!")
return True
else:
print("\n✗ Database not ready")
return False
except Exception as e:
print(f"\nERROR: {e}", file=sys.stderr)
return False
finally:
connector.close()
if __name__ == "__main__":
success = verify_database()
sys.exit(0 if success else 1)
此脚本将检查菜单项数据的数量及其嵌入情况。使用以下命令运行脚本
uv run scripts/verify_seed.py
如果您看到以下终端输出,则表示数据已准备就绪
Menu Items: 15/15 Embeddings: 15/15 ✓ Database ready!
启动 Toolbox 服务器
在之前的设置步骤中,我们已经下载了 toolbox 可执行文件。确保此二进制文件存在且已成功下载,否则,请下载该文件并等待下载完成
cd ~/build-agent-adk-toolbox-cloudsql
if [ ! -f toolbox ]; then
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v1.1.0/linux/amd64/toolbox
fi
chmod +x toolbox
我们需要将 .env 变量公开给由 MCP 工具箱运行的子进程。运行以下命令以启动工具箱服务器,并将其控制台输出记录到 logs/mcp_toolbox.log 文件中
set -a; source .env; set +a
./toolbox --config tools.yaml --enable-api > logs/mcp_toolbox.log 2>&1 &
您应该会在 logs/mcp_toolbox.log 文件中看到确认服务器已准备就绪的输出,如下所示:
... INFO "Initialized 1 sources: restaurant-db" ... INFO "Initialized 0 authServices: " ... INFO "Using Vertex AI backend for Gemini embedding" ... INFO "Initialized 1 embeddingModels: gemini-embedding" ... INFO "Initialized 4 tools: search-menu-by-description, add-menu-item, search-menu, get-item-details" ... ... INFO "Server ready to serve!"
验证工具
查询工具箱 API 以列出所有已注册的工具:
curl -s http://localhost:5000/api/toolset | uv run -m json.tool
您应该会看到工具及其说明和参数。如下所示
...
"search-menu-by-description": {
"description": "Find menu items that match a natural language description of what the user is looking for. Use this tool when the user describes their ideal dish using flavors, textures, dietary preferences, or cravings rather than a specific category or cuisine. Examples: \"I want something spicy and creamy,\" \"a light vegetarian appetizer,\" \"something rich and chocolatey for dessert.\"",
"parameters": [
{
"name": "search_query",
"type": "string",
"required": true,
"description": "A natural language description of the kind of dish the user is looking for.",
"authServices": []
}
],
"authRequired": []
}
...
直接测试 search-menu 工具:
curl -s -X POST http://localhost:5000/api/tool/search-menu/invoke \\ -H "Content-Type: application/json" \\ -d '{"category": "Main Course", "cuisine_type": "Italian"}' | jq '.result | fromjson'
响应应包含种子数据中的意大利主菜。
[
{
"name": "Margherita Pizza",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "San Marzano tomatoes, fresh mozzarella, basil, olive oil",
"price": "$18",
"dietary_tags": "Vegetarian",
"available": true
},
{
"name": "Truffle Mushroom Risotto",
"cuisine_type": "Italian",
"category": "Main Course",
"ingredients": "Arborio rice, truffle oil, porcini mushrooms, parmesan, white wine",
"price": "$28",
"dietary_tags": "Vegetarian, Gluten-Free",
"available": true
}
]
7. 构建 ADK 智能体
现在,我们将在此项目中使用 Python 中的 ADK,让我们添加所需的依赖项:
uv add google-adk==1.29.0 toolbox-adk==1.0.0
google-adk- Google 的智能体开发套件,包括 Gemini SDKtoolbox-adk- 针对 MCP Toolbox for Databases 的 ADK 集成。
创建代理目录结构
ADK 需要特定的文件夹布局:一个以代理命名的目录,其中包含 __init__.py、agent.py 和 .env。为了帮助您实现此布局,ADK 内置了可快速建立结构的命令:
uv run adk create restaurant_agent \
--model gemini-3.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
您的目录现在应如下所示:
build-agent-adk-toolbox-cloudsql/ ├── restaurant_agent/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── logs ├── scripts └── ...
接下来,我们需要将 ADK 代理集成到正在运行的 Toolbox 服务器,并测试所有四种工具 - 标准查询、语义搜索和向量提取。代理代码非常简单:所有数据库逻辑都位于 tools.yaml 中。
配置代理的环境
ADK 会从 shell 环境中读取 GOOGLE_GENAI_USE_VERTEXAI、GOOGLE_CLOUD_PROJECT 和 GOOGLE_CLOUD_LOCATION,您已在之前的步骤中设置了这些变量。唯一特定于代理的变量是 TOOLBOX_URL - 将其附加到代理的 .env 文件中:
echo -e "\nTOOLBOX_URL=http://127.0.0.1:5000" >> restaurant_agent/.env
更新代理模块
在 Cloud Shell Editor 中打开 restaurant_agent/agent.py
cloudshell edit restaurant_agent/agent.py
并将内容覆盖为以下代码:
# restaurant_agent/agent.py
import os
from google.adk.agents import LlmAgent
from toolbox_adk import ToolboxToolset
TOOLBOX_URL = os.environ.get("TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxToolset(TOOLBOX_URL)
root_agent = LlmAgent(
name="restaurant_agent",
model="gemini-3.5-flash",
instruction="""You are a friendly and knowledgeable concierge at "Foodie Finds," a restaurant. Your job:
- Help diners browse the menu by category or cuisine type.
- Provide full details about specific dishes, including ingredients, price, and dietary information.
- Recommend dishes based on natural language descriptions of what the diner is craving.
- Add new menu items when asked.
When a diner asks about a specific dish by name or cuisine, use the get-item-details tool.
When a diner asks for a specific category or cuisine type, use the search-menu tool.
When a diner describes what kind of food they want — by flavor, texture, dietary needs, or cravings — use the search-menu-by-description tool for semantic search.
When in doubt between search-menu and search-menu-by-description, prefer search-menu-by-description — it searches dish descriptions and finds more relevant matches.
If a dish is not available (available is false), let the diner know and suggest similar alternatives from the search results.
Be conversational, knowledgeable, and concise.""",
tools=[toolbox],
)
请注意,这里没有数据库代码 - ToolboxToolset 在启动时连接到 Toolbox 服务器并加载所有可用工具。代理按名称调用工具;Toolbox 将这些调用转换为针对 Cloud SQL 的 SQL 查询。
TOOLBOX_URL 环境变量默认为 http://127.0.0.1:5000,用于本地开发。稍后部署到 Cloud Run 时,您可以使用 Toolbox 服务的 Cloud Run 网址替换此变量,无需更改任何代码。
测试代理
启动 ADK 开发者界面:
cd ~/build-agent-adk-toolbox-cloudsql
uv run adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
使用 Cloud Shell 的网页预览功能打开终端中显示的网址(通常为 http://localhost:8000),或按住 Ctrl 键并点击终端中显示的网址。从左上角的智能体下拉菜单中选择 restaurant_agent。
测试标准查询
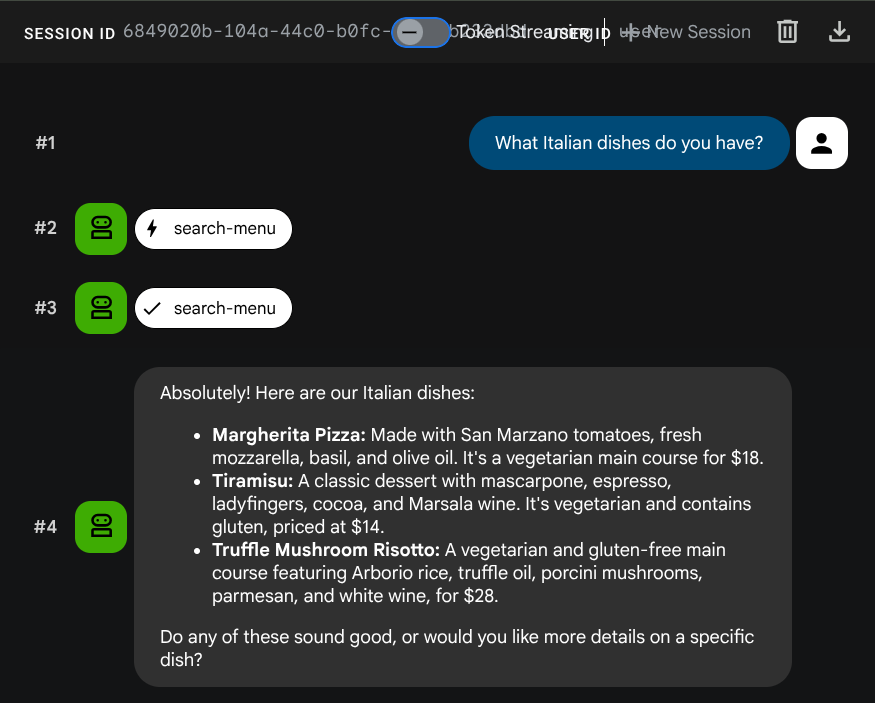
不妨试试以下提示,验证标准 SQL 工具:
What Italian dishes do you have?
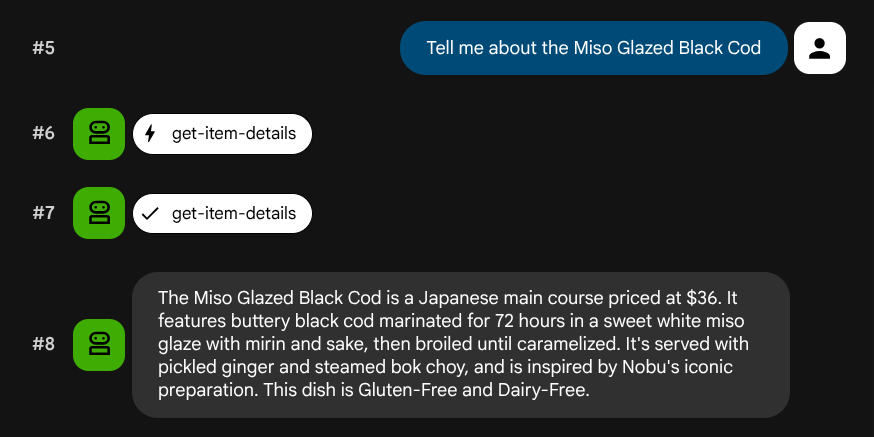
Tell me about the Miso Glazed Black Cod
测试语义搜索
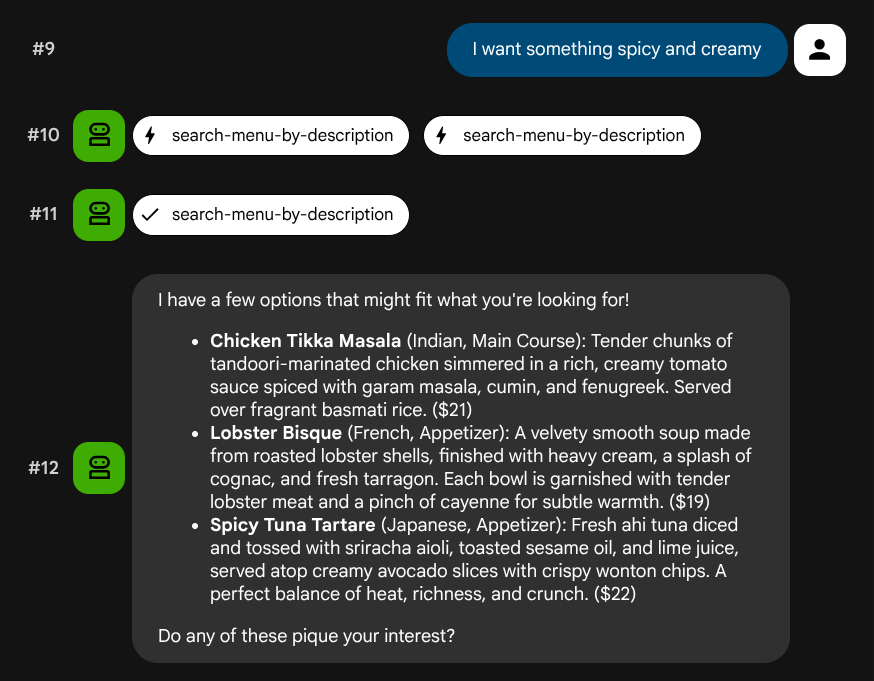
尝试使用未映射到特定角色或技术堆栈的自然语言描述:
I want something spicy and creamy
Something rich and chocolatey for dessert
I'm in the mood for something light and healthy
智能体将尝试根据查询类型选择合适的工具:结构化过滤条件通过 search-menu,自然语言描述通过 search-menu-by-description。
测试向量提取
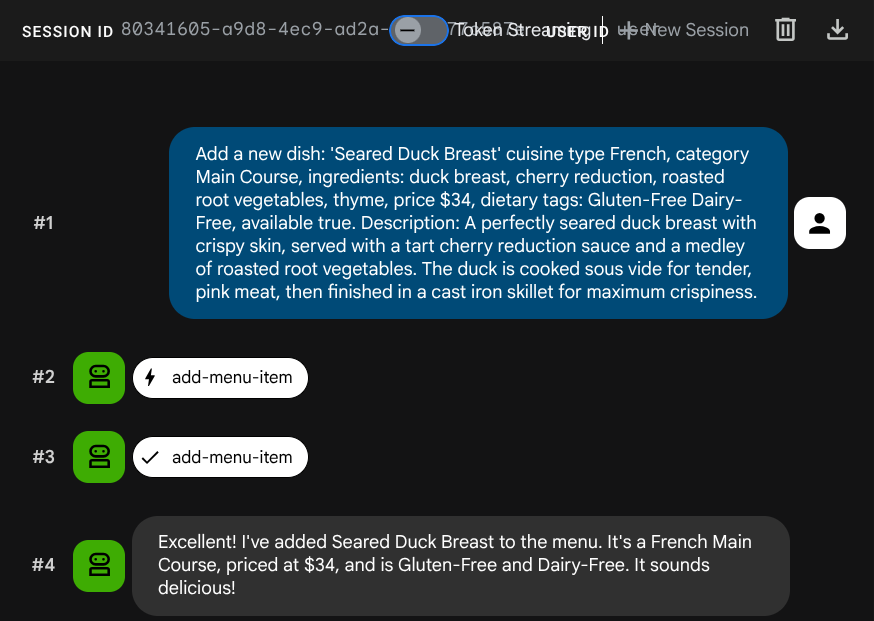
让代理添加新作业:
Add a new dish: 'Seared Duck Breast' cuisine type French, category Main Course, ingredients: duck breast, cherry reduction, roasted root vegetables, thyme, price $34, dietary tags: Gluten-Free Dairy-Free, available true. Description: A perfectly seared duck breast with crispy skin, served with a tart cherry reduction sauce and a medley of roasted root vegetables. The duck is cooked sous vide for tender, pink meat,
then
finished in a cast iron skillet for maximum crispiness.
现在,尝试搜索该内容:
Find me something with rich, gamey flavors and fruit sauce
嵌入是在 INSERT 期间自动生成的,无需单独执行任何步骤。
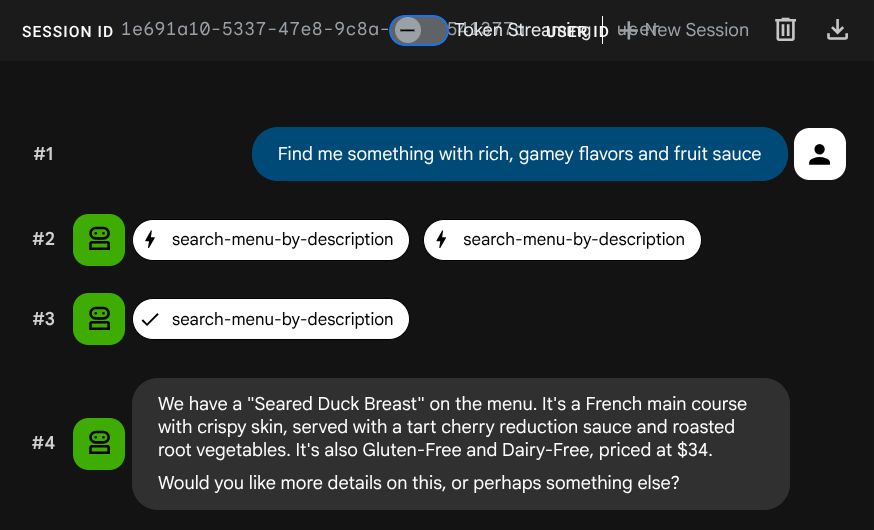
现在,您已经拥有一个利用 ADK、MCP Toolbox 和 CloudSQL 的完整智能体 RAG 应用。恭喜!接下来,我们将这些应用部署到 Cloud Run!
现在,让我们通过按两次 Ctrl+C 来终止进程,从而停止开发者界面,然后再继续操作。
8. 部署到 Cloud Run
智能体和 Toolbox 在本地运行。此步骤会将两者都部署为 Cloud Run 服务,以便通过互联网访问它们。Toolbox 服务在 Cloud Run 上作为 MCP 服务器运行,而智能体服务会连接到该服务器。
准备部署工具箱
为 Toolbox 服务创建部署目录:
cd ~/build-agent-adk-toolbox-cloudsql
mkdir -p deploy-toolbox
cp toolbox tools.yaml deploy-toolbox/
为 Toolbox 创建 Dockerfile。在 Cloud Shell Editor 中打开 deploy-toolbox/Dockerfile:
cloudshell edit deploy-toolbox/Dockerfile
并将以下脚本复制到其中
# deploy-toolbox/Dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY toolbox tools.yaml ./
RUN chmod +x toolbox
EXPOSE 8080
CMD ["./toolbox", "--config", "tools.yaml", "--enable-api", "--address", "0.0.0.0", "--port", "8080"]
该工具箱二进制文件和 tools.yaml 已打包到最小的 Debian 映像中。Cloud Run 会将流量路由到端口 8080。
部署 Toolbox 服务
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy toolbox-service \
--source deploy-toolbox/ \
--region $REGION \
--set-env-vars "DB_PASSWORD=$DB_PASSWORD,DB_INSTANCE=$DB_INSTANCE,DB_NAME=$DB_NAME,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,REGION=$REGION,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" \
--allow-unauthenticated \
--quiet > logs/deploy_toolbox.log 2>&1 &
此命令会将源代码提交给 Cloud Build,构建容器映像,将其推送到 Artifact Registry,并将其部署到 Cloud Run。这需要几分钟时间 - 我们可以检查 logs/deploy_toolbox.log 文件中的部署过程日志
准备智能体以进行部署
在构建 Toolbox 的同时,设置代理的部署文件。
在项目根目录中创建 Dockerfile。在 Cloud Shell Editor 中打开 Dockerfile:
cloudshell edit Dockerfile
然后,复制以下内容
# Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-trixie-slim
WORKDIR /app
COPY pyproject.toml ./
COPY uv.lock ./
RUN uv sync --no-dev
COPY restaurant_agent/ restaurant_agent/
EXPOSE 8080
CMD ["uv", "run", "adk", "web", "--host", "0.0.0.0", "--port", "8080"]
此 Dockerfile 使用 ghcr.io/astral-sh/uv 作为基础映像,其中预安装了 Python 和 uv,无需通过 pip 单独安装 uv。
创建一个 .dockerignore 文件,以从容器映像中排除不必要的文件:
cloudshell edit .dockerignore
然后将以下脚本复制到其中
# .dockerignore
.venv/
__pycache__/
*.pyc
.env
restaurant_agent/.env
toolbox
tools.yaml
deploy-toolbox/
部署代理服务
等待工具箱部署完成。在 logs/deploy_toolbox.log 上再次检查部署流程,以验证该流程。然后,使用以下命令检索其 Cloud Run 网址
TOOLBOX_URL=$(gcloud run services describe toolbox-service \
--region=$REGION \
--format='value(status.url)')
echo "Toolbox URL: $TOOLBOX_URL"
您将看到类似于以下内容的输出
Toolbox URL: https://toolbox-service-xxxxxx-xx.a.run.app
接下来,我们验证已部署的工具箱是否正常运行:
curl -s "$TOOLBOX_URL/api/toolset" | python3 -m json.tool | head -5
如果输出内容与此示例类似,则表示部署已成功
{
"serverVersion": "1.1.0+binary.linux.amd64.da6f5f8",
"tools": {
"add-menu-item": {
"description": "Add a new menu item to the restaurant. Use this tool when a user asks to add a dish that is not currently on the menu.",
接下来,我们来部署代理,并将 Toolbox 网址作为环境变量传递:
cd ~/build-agent-adk-toolbox-cloudsql
gcloud run deploy restaurant-agent \
--source . \
--region $REGION \
--set-env-vars "TOOLBOX_URL=$TOOLBOX_URL,GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--allow-unauthenticated \
--quiet
代理代码从环境(您之前已设置)中读取 TOOLBOX_URL。在本地,它指向 http://127.0.0.1:5000;在 Cloud Run 上,它指向 Toolbox 服务网址。无需更改任何代码。
测试已部署的代理
检索代理的 Cloud Run 网址:
AGENT_URL=$(gcloud run services describe restaurant-agent \
--region=$REGION \
--format='value(status.url)')
echo "Agent URL: $AGENT_URL"
在浏览器中打开该网址。ADK 开发者界面会加载,该界面与您一直在本地使用的界面相同,现在在 Cloud Run 上运行。
从下拉菜单中选择 restaurant_agent 并进行测试:
What Italian dishes do you have?
I want something spicy and creamy
这两个查询都通过已部署的服务运行:Cloud Run 上的代理调用 Cloud Run 上的 Toolbox,后者查询 Cloud SQL。
9. 恭喜 / 清理
您已构建并部署了一个智能餐厅菜单助理,该助理使用 MCP Toolbox for Databases 将 ADK 智能体和 Cloud SQL PostgreSQL 连接起来,并支持标准 SQL 查询和语义向量搜索。
您学到的内容
- MCP 如何为 AI 代理标准化工具访问,以及 MCP Toolbox for Databases 如何将此功能专门应用于数据库操作,即使用声明式 YAML 配置替换自定义数据库代码
- 如何使用
cloud-sql-postgres源类型将 Cloud SQL PostgreSQL 配置为工具箱数据源 - 如何使用可防止 SQL 注入的参数化语句定义标准 SQL 查询工具
- 如何使用 pgvector 和
gemini-embedding-001启用向量搜索,并使用embeddedBy参数自动嵌入查询 valueFromParam如何实现自动向量提取 - LLM 提供文本说明,而 Toolbox 会在后台复制、嵌入向量并将其与文本一起存储- ADK 的
ToolboxToolset如何从正在运行的 Toolbox 服务器加载工具,从而最大限度地减少代理代码并使数据库逻辑完全解耦 - 如何将 Toolbox MCP 服务器和 ADK 代理分别作为单独的服务部署到 Cloud Run
清理
为避免系统因本 Codelab 中创建的资源向您的 Google Cloud 账号收取费用,您可以删除各个资源或删除整个项目。
方法 1:删除项目(推荐)
最简单的清理方法是删除项目。这样会移除与该项目关联的所有资源。
gcloud projects delete $GOOGLE_CLOUD_PROJECT
方法 2:删除单个资源
如果您想保留项目,但只移除在本 Codelab 中创建的资源,请执行以下操作:
gcloud run services delete restaurant-agent --region=$REGION --quiet
gcloud run services delete toolbox-service --region=$REGION --quiet
gcloud sql instances delete restaurant-instance --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=$REGION --quiet 2>/dev/null