
1. Introdução
Testar aplicativos da Web pode ser uma tarefa difícil. Os testes de UI tradicionais parecem uma batalha constante contra a fragilidade. Você se vê escrevendo scripts complexos, gerenciando seletores CSS e XPath frágeis e fazendo malabarismos apenas para verificar um fluxo de usuário simples.
Mas e se você pudesse apenas dizer a um agente o que testar em linguagem natural, e ele simplesmente fizesse isso?

Neste codelab, vamos aprender a usar a CLI do Gemini e ferramentas multimodais como o BrowserMCP. Você vai aprender a criar e executar testes de interface automatizados usando linguagem natural. Este codelab não exige conhecimento prévio de ferramentas e frameworks de teste de interface.
O que você aprenderá
- O que é o Protocolo de Contexto de Modelo (MCP) e por que ele é revolucionário.
- Como o BrowserMCP permite que agentes de IA controlem navegadores da Web.
- Como executar testes automatizados de interface com a CLI do Gemini.
- Entender as habilidades dos agentes e as vantagens delas.
- Ensinar um agente a usar o Playwright com uma habilidade.
- Aproveitando o MCP e a habilidade do Google Chrome DevTools juntos.
- Uma visão geral rápida do subagente do navegador Antigravity.
- Outros casos de uso para o controle do navegador.
O que você vai fazer
- Configure o ambiente de desenvolvimento.
- Conheça um aplicativo de demonstração que precisa ser testado.
- Use a CLI do Gemini para interagir com o aplicativo pelo BrowserMCP.
- Ensine seu agente a usar o Playwright com uma habilidade.
2. Pré-requisitos
Antes de falarmos sobre as coisas legais, vamos garantir que você tenha tudo o que precisa.
Este codelab usa a CLI do Gemini, ferramentas do MCP, habilidades do agente e um aplicativo de demonstração do React.
Ferramentas
Este laboratório pressupõe que você já tenha:
- Navegador Chrome
- Nodejs
- CLI do Gemini
- Git
Para usar a CLI do Gemini, você precisa fazer a autenticação no Google. Há algumas maneiras de fazer isso, mas recomendamos usar a opção Fazer login com o Google. Essa opção vem com uma cota sem custo financeiro generosa de uso do Gemini e não exige um projeto na nuvem do Google Cloud. Se você usar essa opção ao seguir o codelab, não haverá custo. Se você já tiver uma chave de API Gemini, use-a.
As instruções presumem que você está trabalhando em um ambiente Linux (ou WSL) ou macOS. Se você estiver no Windows (como eu), siga as instruções usando o WSL.
Observação:
O BrowserMCP não funciona no Google Cloud Shell
, porque ele só se conecta a um navegador local em execução na mesma máquina.
Configurar o ambiente de desenvolvimento
Criei um repositório de demonstração no GitHub. Ele inclui um aplicativo de exemplo que podemos usar para nossos testes de UI. Clone o repositório executando este comando no terminal local:
git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing
Há um Makefile para facilitar a configuração do ambiente e o lançamento do app de demonstração. Execute-o para inicializar o ambiente:
make install # Or if you don't have make npm install --prefix demo-app
3. Nosso aplicativo de demonstração
O app que vamos testar hoje é o Dazbo Omni-Dash, um painel futurista com tema escuro para gerenciar a telemetria de segurança. (Sim, foi vibe coded!)
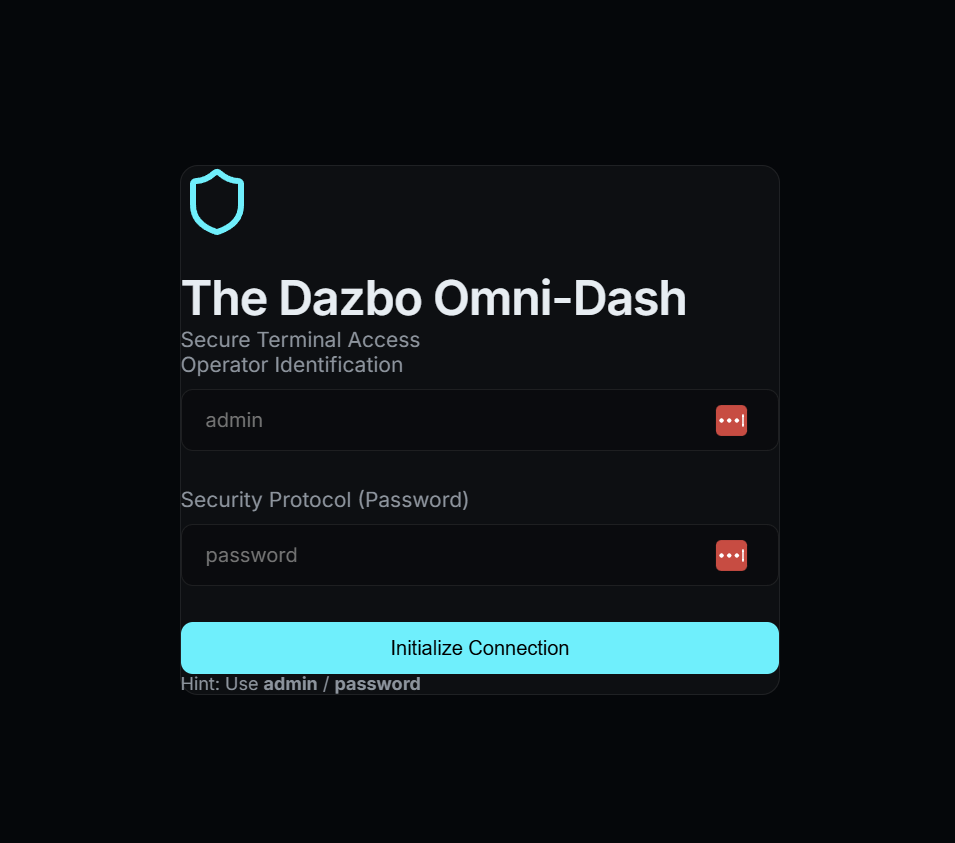
Por que esse app?
Ele foi criado para oferecer uma superfície de teste realista com:
- Autenticação simulada: um fluxo de login que exige credenciais específicas.
- Conteúdo dinâmico: cards de telemetria e registros de segurança que simulam dados em tempo real.
- Estados interativos: menus de navegação e entradas de formulário que mudam com base na ação do usuário.
- Tecnologia moderna: criado com React e Vite para uma experiência rápida e responsiva.
Como iniciar o app
Para iniciar o aplicativo, execute:
make dev # Or if you don't have make npm run dev --prefix demo-app
O servidor de desenvolvimento deve ser iniciado rapidamente, e o app vai estar disponível em http://localhost:5173.

Basta clicar no link para abrir o aplicativo no navegador. Basta deixar esse processo em execução no terminal. Vamos executar os comandos de terminal subsequentes em uma sessão separada.
4. O desafio de testar a interface
O teste de UI tradicional é notoriamente difícil de fazer corretamente e ainda mais difícil de manter. Alguns problemas comuns são:
- Teste "Flakiness": testes que são aprovados em um minuto e falham no seguinte devido a problemas de tempo, condições de corrida ou recursos de carregamento lento.
- Seletores frágeis: dependem de estruturas DOM específicas (como div > div > button) que são interrompidas com o menor ajuste na interface, levando à manutenção constante do script.
- Curva de aprendizado alta: exige que os desenvolvedores dominem linguagens específicas do domínio complexas e peculiaridades específicas da estrutura (Cypress, Selenium, Playwright) apenas para automatizar um clique básico.
- Paridade de ambiente: dificuldade em replicar estados de aplicativos e sobrecarga de limpeza de dados de teste.

Precisamos de uma maneira de testar que se concentre na intenção em vez da implementação.
5. MCP ao resgate
O Protocolo de Contexto de Modelo (MCP) é um padrão aberto que permite que modelos e agentes de IA interajam com ferramentas, APIs e dados externos. É como um adaptador universal que permite que modelos e agentes encontrem e executem as ferramentas a que têm acesso.
Tradicionalmente, a integração de modelos de linguagem grandes (LLMs) com dados e ferramentas externos exigia que os desenvolvedores escrevessem conexões de API personalizadas e codificadas para cada nova fonte de dados, criando um problema de integração "M x N" insustentável em que cada novo modelo e ferramenta multiplica o trabalho de manutenção. O Protocolo de Contexto de Modelo (MCP) resolve isso eliminando a necessidade de escrever um código específico para orquestrar esses recursos. Em vez de codificar explicitamente fluxos de trabalho de execução complexos, os desenvolvedores podem confiar no LLM para interpretar as solicitações de linguagem natural de um usuário e decidir dinamicamente quais ferramentas usar.
Quando um usuário emite um comando em linguagem natural (como "Navegue até localhost:5173, faça login como "admin" e clique no botão "Enviar"), o LLM descobre os recursos disponíveis e gera uma solicitação estruturada para invocar uma ferramenta específica. O cliente do MCP atua como um tradutor, encaminhando essa solicitação ao servidor do MCP designado, que executa a ação ou busca os dados e retorna o contexto ao modelo. Isso permite que a IA aja de forma autônoma sem que o desenvolvedor precise codificar o caminho de execução específico.
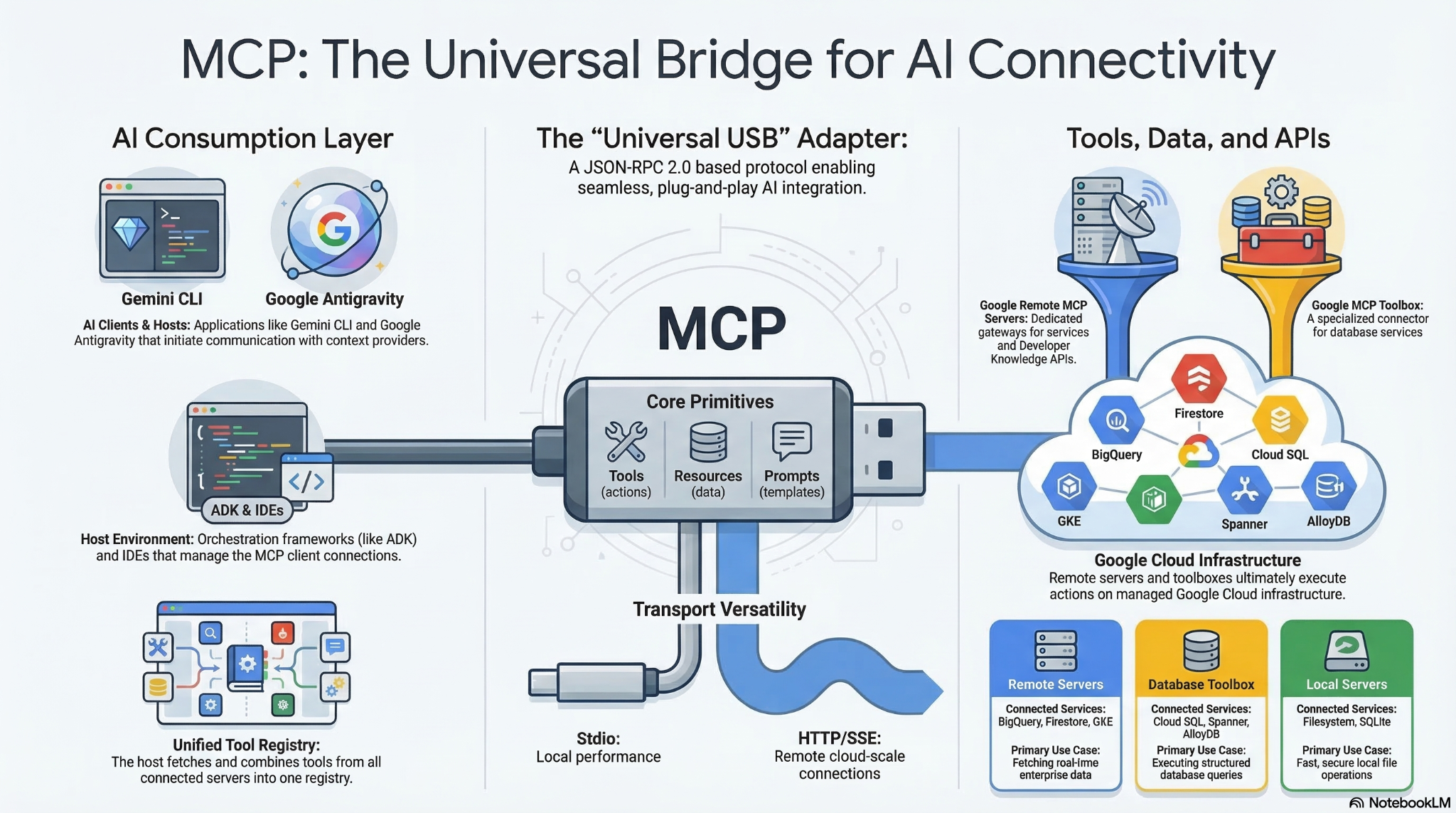
Como o MCP cria um padrão universal, muitas vezes descrito como o "USB-C para aplicativos de IA", ele permite uma enorme reutilização imediata. Os desenvolvedores podem criar um servidor MCP uma vez, e qualquer apresentador de IA compatível com o MCP pode se conectar a ele instantaneamente, eliminando o problema de integração M x N. Não é mais necessário criar pontes de API personalizadas para cada plataforma. Em vez disso, você pode aproveitar o ecossistema de servidores MCP pré-criados e de código aberto para serviços comuns, como GitHub, Slack, bancos de dados e muito mais, conectando-os diretamente aos seus fluxos de trabalho de agente. Essa arquitetura modular e plug-and-play garante que, se você mudar de provedor de LLM ou atualizar suas ferramentas mais tarde, a infraestrutura de integração principal vai permanecer completamente inalterada.
6. Automação com o BrowserMCP
O que é o BrowserMCP?
Esta é a primeira ferramenta que vamos usar hoje. O BrowserMCP é um servidor MCP que dá aos agentes de IA os "olhos" e as "mãos" necessários para interagir com um navegador da Web. Em resumo, ele imita a interação humana com um navegador. Ele é de código aberto, e você pode conferir o repositório do GitHub aqui. Consulte a documentação principal do BrowserMCP aqui.

Confira alguns dos recursos:
- Ele pode navegar até URLs.
- Ele pode inspecionar o DOM.
- Ele pode clicar em botões e digitar texto em formulários.
- É possível arrastar e soltar.
- Ele pode ler registros do console do navegador.
- É rápido: a automação acontece localmente na sua máquina.
Instalar o MCP do navegador
Para usar o BrowserMCP, você precisa fazer duas coisas:
- Instale a extensão BrowserMCP no Chrome ou em qualquer navegador baseado no Chromium.
- Configure o servidor MCP para seu agente.
Para instalar a extensão, siga as instruções aqui. Isso leva apenas alguns segundos. Depois de instalada, clique em "Conectar" na extensão para permitir que a guia atual seja controlada pelo agente. Obviamente, você quer que a guia atual seja aquela em que o aplicativo de demonstração está sendo executado.
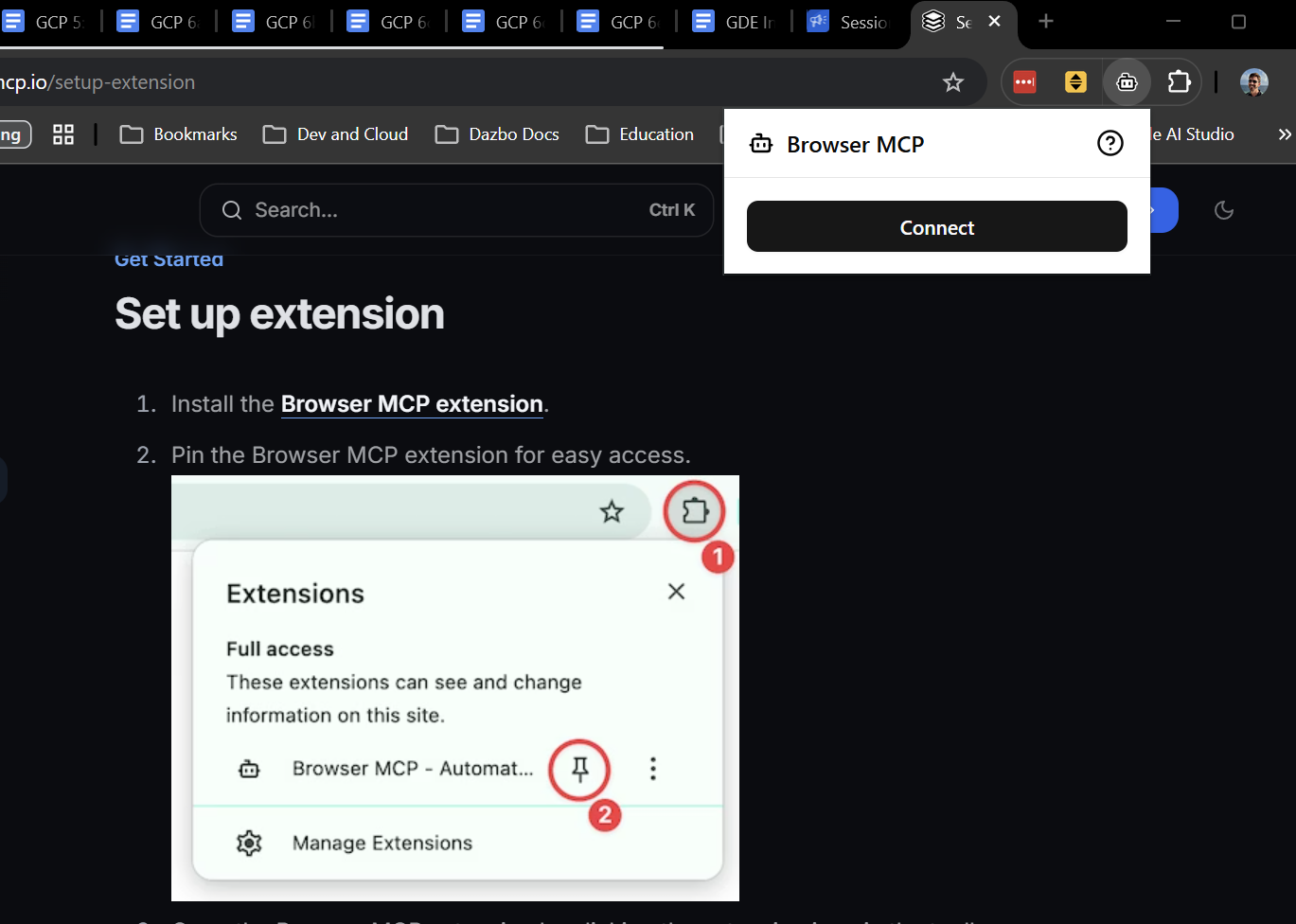
Em seguida, precisamos adicionar o servidor BrowserMCP real ao cliente. Na CLI do Gemini, isso é muito fácil. Basta instalar a extensão:
gemini extensions install https://github.com/derailed-dash/browsermcp-ext
Teste com o BrowserMCP
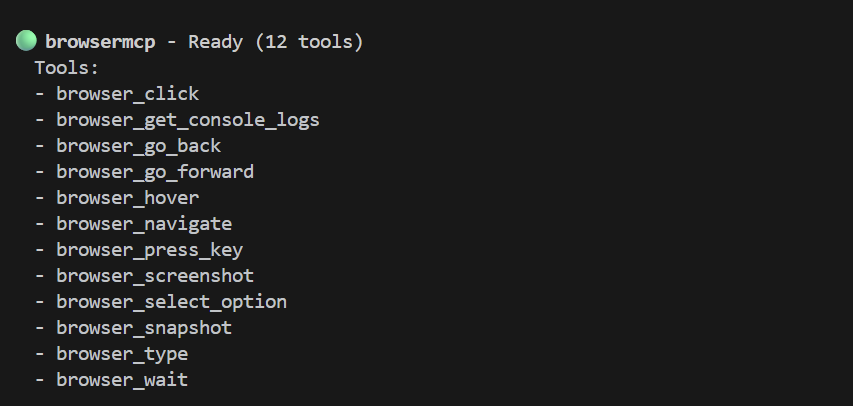
Agora, a mágica. Primeiro, vamos iniciar a CLI do Gemini (executando gemini) em uma nova sessão de terminal. (Lembre-se de que o aplicativo de demonstração está sendo executado na nossa sessão de terminal inicial.) Na CLI do Gemini, execute /mcp para verificar se ela está instalada corretamente. Você vai ver uma lista de ferramentas, como esta:
Se você não iniciou o aplicativo de demonstração antes, faça isso agora:
make dev
Precisamos abrir o app no navegador Chrome e conectar a extensão BrowserMCP nessa guia. Siga o link do comando run. Em seguida, clique no ícone da extensão BrowserMCP e em "Conectar".
Agora podemos usar a CLI do Gemini para executar um teste. Copie e cole este comando na CLI do Gemini:
Using BrowserMCP, connect to the application at http://localhost:5173. If the application is not showing a login screen, first logout. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
A CLI do Gemini pode primeiro verificar se o aplicativo de demonstração está sendo executado na porta especificada. Em seguida, ele vai pedir que você confirme as ações que planeja realizar:
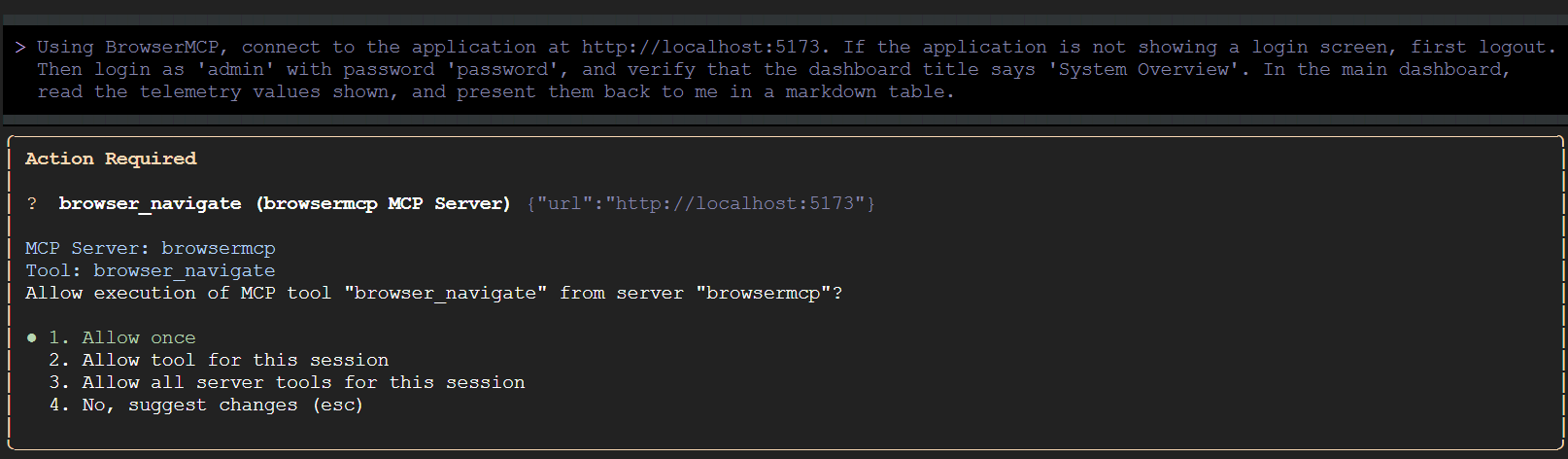
Permita que a CLI do Gemini execute todas as ferramentas do BrowserMCP nesta sessão. Em seguida, volte para o navegador e assista às interações automatizadas acontecerem.
Algumas observações sobre o comando acima:
- Começamos pedindo ao agente para fazer logout, caso o aplicativo já esteja conectado. Não é necessário pedir para o agente clicar em um texto específico, como "Sair do gateway". Ele é inteligente o suficiente para saber onde clicar.
- Depois de fazer login e renderizar a página principal, o agente captura as informações de telemetria. Não é necessário dizer ao agente para procurar em blocos específicos ou corresponder a palavras específicas. Portanto, se estendermos ou mudarmos as informações mostradas nesta página, o comando ainda vai funcionar, e a saída ainda será capturada na nossa tabela Markdown.
Legal, né?
Por enquanto, terminamos com o BrowserMCP. Desconecte no navegador.
7. Automação com habilidades e Playwright
Limitações do BrowserMCP
O BrowserMCP é ótimo, mas tem algumas limitações. Exemplo:
- Ele exige uma sessão de navegador aberta com a extensão BrowserMCP conectada. Ela não gera novas sessões.
- Ele não é compatível com navegadores que não são baseados no Chromium.
- Ele exige que um processo de navegador separado seja executado na mesma máquina em que o servidor MCP está sendo executado.
- Ele não consegue trabalhar com o sistema de arquivos local. Por exemplo, não é possível criar arquivos locais para evidenciar capturas de tela nem baixar e armazenar arquivos do aplicativo da Web, como PDFs para download.
- Ela não é determinista. Ele vai tentar realizar as ações que você pedir, mas o estado local, como um pop-up inesperado, pode interromper a interação.
- Ele não é compatível com a operação "headless", ou seja, não pode ser executado em um pipeline de CI/CD sem uma janela de navegador real.
Playwright
O Playwright é uma ferramenta muito mais sofisticada. É um framework de teste e automação de navegador de código aberto bem estabelecido. Ele pode fazer muitas coisas que o BrowserMCP não consegue, incluindo todos os itens que mencionei acima.
Ele é muito mais adequado para executar cenários de teste complexos, confiáveis e repetíveis. Ele é particularmente adequado para trabalhar com sessões de longa duração ou executar várias sessões independentes em paralelo.
Mas com essa capacidade adicional, a curva de aprendizado fica muito mais acentuada.
Habilidades
Felizmente, não precisamos aprender a usar o Playwright diretamente. Em vez disso, podemos usar uma habilidade do agente.

Então, o que é uma habilidade de agente? Pense nisso como um pacote compacto de experiência no domínio que você pode entregar ao seu agente de IA quando ele precisar fazer algo específico. Ele contém instruções, práticas recomendadas e, às vezes, até scripts auxiliares adaptados a uma tarefa específica.
Aqui está a parte realmente inteligente: a divulgação progressiva. Em vez de inserir todos os documentos de API e regras de framework de teste imagináveis no comando inicial do sistema do LLM, o que consome sua janela de contexto e gasta tokens sem parar, o agente só lê a habilidade quando realmente precisa dela. Ele mantém o contexto básico simples e direto, buscando o "como fazer" detalhado na hora certa. E sim, uma habilidade pode incluir instruções sobre como usar servidores MCP específicos para realizar o trabalho.
Pense na cena do filme Matrix: o agente olha para um problema, percebe que precisa conhecer o Playwright, baixa a habilidade e, de repente, diz: "Eu sei kung fu". Pronto. Especialista instantâneo.
Para saber mais sobre habilidades, confira o seguinte:
- Tutorial : como começar a usar as habilidades do Google Antigravity
- Codelab: como criar habilidades para o Google Antigravity
Por que as habilidades são perfeitas para o Playwright
Usar uma habilidade aqui é uma ótima escolha. O Playwright é muito eficiente, mas a sintaxe dele pode ser complicada. Ao dar ao agente uma habilidade do Playwright, não precisamos nos preocupar com o LLM alucinando uma sintaxe desatualizada ou escrevendo seletores frágeis. Estamos oferecendo um playbook selecionado e confiável sobre como usar o Playwright corretamente.
Vou usar a CLI do Playwright e a habilidade associada.
Com essa abordagem, instalamos a CLI do Playwright localmente e damos ao nosso agente o conhecimento necessário para usá-la. Para evitar confusão, não estou instalando nenhum servidor MCP do Playwright.
Instalando
Primeiro, vamos instalar a CLI de código aberto do Microsoft Playwright. Se ainda não tiver feito isso, saia da CLI do Gemini digitando /quit``. Em seguida, no terminal:
# Pre-req: nodejs installed npm install -g @playwright/cli@latest # Install Playwright CLI globally npm install @playwright/test # Install Playwright test framework npx playwright install-deps # Install dependencies npx playwright install chromium chrome # Install browser binaries in Linux / WSL
Agora vamos adicionar a habilidade. Esse comando vai baixar a subpasta de habilidade diretamente do GitHub para a pasta de habilidades do Gemini:
mkdir -p ~/.gemini/skills npx degit microsoft/playwright-cli/skills/playwright-cli ~/.gemini/skills/playwright-cli
Agora podemos testar.
# Launch Playwright CLI with visible browser playwright-cli open https://playwright.dev --headed
Isso vai gerar uma sessão do navegador aberta no URL especificado.
Também quero que o Gemini possa usar o Playwright no modo "headed", ou seja, com uma interface visível. Mas a habilidade não diz ao Gemini como fazer isso. Adicionei estas linhas a ~/.gemini/skills/playwright-cli/SKILL.md na seção Core:
# Add the following under the "playwright-cli open" command # Run in headed mode so we can see the browser playwright-cli open https://playwright.dev --headed
Como testar com o Playwright
Como antes, precisamos iniciar o aplicativo, caso ele ainda não esteja em execução. Faça isso na sessão inicial do terminal:
make dev
Em seguida, na outra sessão de terminal, vamos desativar temporariamente o BrowserMCP para que o agente não se confunda sobre quais ferramentas usar. Reinicie a CLI do Gemini e execute:
/mcp disable browsermcp
Agora vamos pedir ao Gemini para navegar até nosso aplicativo com o Playwright. Mas, ao contrário do BrowserMCP, não precisamos iniciar o navegador primeiro. O Playwright fará isso para nós com um processo local.
Insira este comando na CLI do Gemini:
Using Playwright, connect to the application at http://localhost:5173. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Como sempre, a CLI do Gemini vai pedir permissão antes de executar qualquer ferramenta.
O que há de diferente aqui?
- Não precisamos iniciar o navegador primeiro.
- Não precisamos iniciar e conectar uma extensão do navegador.
- Não precisamos pedir que o agente faça logout primeiro. O teste é instanciado de uma sessão "limpa".
- Podemos fazer capturas de tela e salvá-las como arquivos locais.
Pouco depois, um arquivo dashboard.png vai aparecer na pasta output.
As chamadas de ferramentas serão executadas na CLI do Gemini, mas a interface do navegador não vai aparecer. Isso acontece porque o Playwright é executado no "modo headless" por padrão.
Mas se você executar novamente com esse comando revisado, também poderá ver a interface:
Using Playwright, connect to the application at http://localhost:5173 in **headed** mode, and keep the browser open when you're done. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown and record them. Then wait 3 seconds, read them again. Now present the data back to me in a markdown table.
Em breve, a saída da CLI do Gemini vai ser parecida com esta:
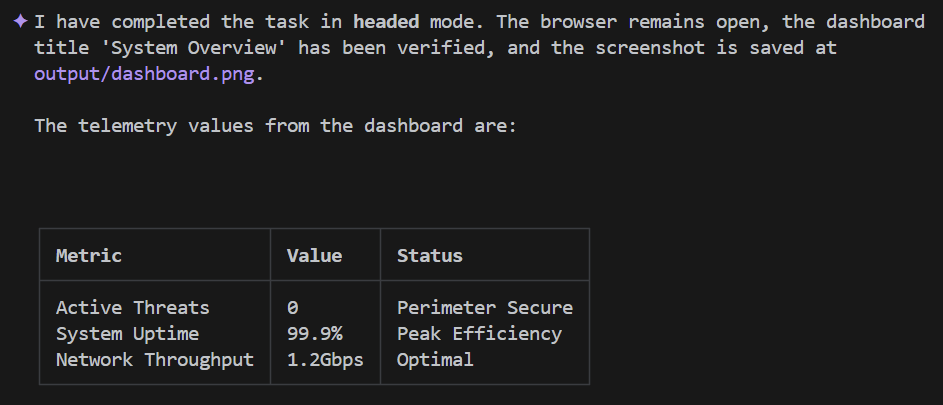
Incrível, não é?
8. Mas espere, também há o MCP do Chrome DevTools!
O Chrome DevTools é um conjunto de ferramentas para desenvolvedores da Web integradas ao navegador Chrome, destinado ao desenvolvimento e à depuração da Web. Ele existe há muito tempo. O console com que você pode interagir ao abrir Mais ferramentas -> Ferramentas para desenvolvedores no Chrome.
Mas agora ele tem o próprio servidor MCP, que não existia quando consideramos a automação do navegador na CLI do Gemini no ano passado. Mas agora você pode fazer tudo o que faz com o BrowserMCP e a maioria das coisas que faz com o Playwright, sem instalar nada no navegador e sem instalar uma CLI local.
Vamos tentar!
No momento, validamos que ele está funcionando no Google Cloud Shell. Então, para esta parte, vamos usar o Google Cloud Shell no console do Google Cloud.
Abra o console e uma sessão do Cloud Shell. Daqui:
# Clone the sample app - like we did before git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing # Build the application - like we did before make install # Install the Chrome DevTools MCP server Gemini CLI Extension gemini extensions install https://github.com/ChromeDevTools/chrome-devtools-mcp
Agora precisamos instalar um executável do Chrome no Cloud Shell:
# Get the latest executable for Ubuntu wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb # Install it sudo apt install ./google-chrome-stable_current_amd64.deb -y # Check it and get the executable path which google-chrome # Cleanup rm google-chrome-stable_current_amd64.deb
Uma última etapa: precisamos informar ao servidor MCP do Chrome DevTools onde encontrar o executável do Chrome. Para isso, defina a opção executable-path na configuração do servidor MCP como headless. Para isso, edite o arquivo ~/.gemini/extensions/chrome-devtools-mcp/gemini-extension.json:
{
"name": "chrome-devtools-mcp",
"version": "latest",
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest",
"--executable-path=/usr/bin/google-chrome",
"--headless"
]
}
}
}
Ótimo! Agora está tudo pronto. Inicie gemini no Cloud Shell e verifique se o servidor MCP está em execução usando o comando /mcp list, como antes.
Por fim, vamos testar com um comando.
Vamos fazer um pouco diferente. Desta vez, vamos pedir para a CLI do Gemini iniciar o aplicativo de demonstração e se conectar a ele:
Launch my demo application with `make dev`. Then, using Chrome DevTools MCP, connect to the application at the exposed localhost URL. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Como de costume, você vai precisar permitir que o servidor MCP seja executado. Mas você também vai notar que ele tenta ativar uma habilidade. Isso mesmo: essa extensão contém o servidor MCP e uma habilidade que orienta o agente sobre a melhor forma de usar o servidor MCP. Legal!
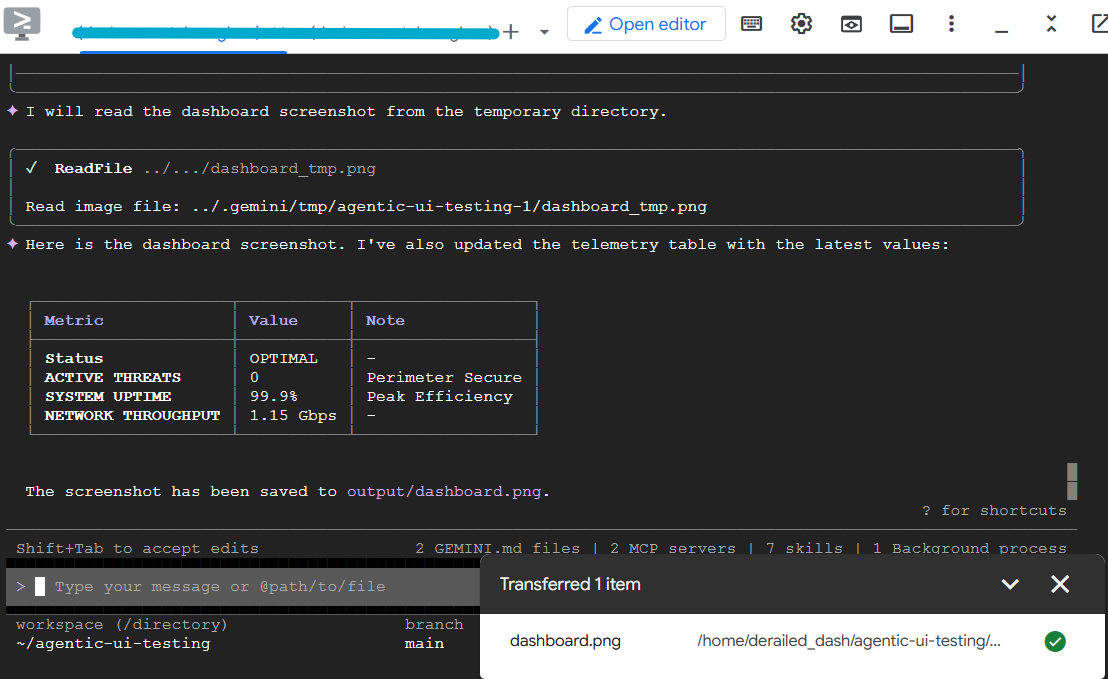
Alguns segundos depois, a CLI do Gemini vai apresentar os resultados na tabela e salvar a captura de tela. Baixe a captura de tela do Cloud Shell para verificar se está tudo certo.
9. Você pode fazer isso no Antigravity Out of the Box!
O Google Antigravity inclui o subagente do navegador, que oferece recursos semelhantes à CLI do Playwright. Quando você pede ao Gemini no Antigravity para ativar um URL de forma interativa, ele ativa esse subagente automaticamente.
Esse subagente pega sua meta de alto nível (por exemplo, "Verificar se o formulário de login funciona"), analisa visualmente o layout da página usando capturas de tela e o DOM e descobre os cliques e as teclas pressionadas. É basicamente uma IA visual e multimodal que navega na Web como um humano. E o melhor de tudo? Ele grava vídeos e faz capturas de tela de tudo o que faz, salvando diretamente no seu espaço de trabalho local como prova visual do que foi realizado. A Antigravity chama essas evidências visuais de artefatos.
Observação para usuários do WSL: fazer o agente do navegador funcionar no Antigravity é um pouco complicado. Consegui fazer funcionar, mas acho o subagente inconsistente e não confiável nesse ambiente. Por isso, estou adorando a CLI do Playwright!
10. Outros casos de uso da automação de navegador
A automação de navegador não se limita a garantir que o botão de login funcione antes de uma implantação na tarde de sexta-feira. Quando você percebe que pode conectar um LLM diretamente a um navegador, um mundo totalmente novo de projetos autônomos e criados em casa se abre.
Se você estiver criando seus próprios agentes de IA, confira algumas maneiras de usar ferramentas como o BrowserMCP ou a CLI do Playwright para fazer o trabalho pesado:
- O assistente de pesquisa pessoal: imagine apontar seu agente para um URL específico e pedir que ele pesquise um tema, mas o site exige login e navegação em menus complexos. Em vez de escrever um web scraper personalizado que vai quebrar na próxima semana, basta pedir ao seu agente para fazer login, navegar até os dados e resumir tudo para você.
- O integrador "Swivel-Chair": todos nós temos aqueles sistemas legados de intranet que não têm APIs. Você sabe quais são: quando é preciso copiar manualmente os dados do sistema A e colar em um formulário no sistema B. Um agente com automação de navegador pode atuar como uma cola universal, lendo a tela do sistema legado e preenchendo o formulário no novo.
- Triagem e correção automatizadas: recebeu um alerta P1 do seu sistema de monitoramento às 3h? O agente pode abrir automaticamente o URL do painel específico, ler os gráficos ou registros (usando os recursos de visão multimodal) e postar um resumo diretamente no seu canal do Slack, economizando minutos preciosos durante um incidente.
A vantagem dessa abordagem é que você não fica mais limitado às APIs disponíveis. Se um humano consegue fazer isso em um navegador, seu agente também consegue.
11. Conclusão
Parabéns! Você acabou de criar e executar testes de interface automatizados e robustos apenas dizendo a um agente de IA o que queria que ele fizesse em inglês simples. Sem seletores de CSS frágeis nem scripts de configuração complexos.
Você aprendeu:
- O teste de interface não precisa ser complicado: ao focar na intenção do teste em vez da implementação frágil do DOM, podemos reduzir muito o trabalho de manutenção.
- O Protocolo de Contexto de Modelo (MCP) oferece aos seus agentes acesso universal e plug-and-play a ferramentas, dados e ambientes.
- O BrowserMCP é uma ferramenta incrível para trazer recursos de agente para suas sessões locais do Chrome.
- As habilidades e a CLI do Playwright desbloqueiam um novo nível de testes de automação determinísticos e repetíveis, tudo com tecnologia de divulgação progressiva.
- O subagente do navegador do Antigravity vai além ao introduzir navegação autônoma e multimodal e gravação de artefatos direto da caixa.
Agora, vá em frente e automatize as coisas chatas!
Useful Links
Se você quiser se aprofundar nas ferramentas e nos conceitos abordados hoje, confira estes recursos:
Código do repositório
- Repositório do GitHub agentic-ui-testing: adicione uma estrela ao repositório se você achou este codelab útil.
Ferramentas e frameworks principais
- Repositório do GitHub do BrowserMCP
- Documentação do BrowserMCP (em inglês)
- Extensão da CLI do Gemini BrowserMCP: adicione uma estrela ao repositório se este codelab foi útil para você.
- Playwright
- Google AI Studio
- Chrome DevTools
- MCP do Chrome DevTools
Conceitos e habilidades de agente
- Tutorial: como começar a usar as habilidades do Google Antigravity
- Codelab: como começar a usar as habilidades de antigravidade
- Blog original do Dazbo: como criar um teste de interface automatizado em segundos
Outro