
1. Overture
لقد انتهى عصر التطوير المنعزل. لا يتعلّق الجيل القادم من التطور التكنولوجي بالعبقرية الفردية، بل بالمهارة التعاونية. إنّ إنشاء وكيل واحد ذكي هو تجربة رائعة. إنّ بناء منظومة متكاملة من الوكلاء تتسم بالقوة والأمان والذكاء، أي إنشاء Agentverse حقيقي، هو التحدي الأكبر الذي يواجه المؤسسات الحديثة.
يتطلّب النجاح في هذا العصر الجديد التقاء أربعة أدوار مهمة، وهي الركائز الأساسية التي تدعم أي نظام فعّال قائم على الذكاء الاصطناعي. ويؤدي أي نقص في أحد هذه المجالات إلى إضعاف البنية بأكملها.
ورشة العمل هذه هي دليل المؤسسات النهائي لإتقان المستقبل المستند إلى الوكلاء على Google Cloud. نقدّم لك خارطة طريق شاملة ترشدك من الفكرة الأولى إلى التنفيذ الكامل على نطاق واسع. خلال هذه التمارين المعملية الأربعة المترابطة، ستتعرّف على كيفية التقاء المهارات المتخصصة لمطوّر ومصمّم ومهندس بيانات ومهندس موثوقية الموقع (SRE) لإنشاء Agentverse قوي وإدارته وتوسيع نطاقه.
لا يمكن لأي ركيزة واحدة أن تدعم Agentverse وحدها. إنّ التصميم الرائع للمهندس المعماري لا فائدة منه بدون التنفيذ الدقيق للمطوّر. لا يمكن لوكيل المطوِّر العمل بدون خبرة مهندس البيانات، كما أنّ النظام بأكمله يكون عرضة للخطر بدون حماية مهندس موثوقية الموقع. فقط من خلال التآزر والفهم المشترك لأدوار كل فرد، يمكن لفريقك تحويل مفهوم مبتكر إلى واقع تشغيلي بالغ الأهمية. تبدأ رحلتك من هنا. استعدّ لإتقان دورك الوظيفي والتعرّف على كيفية مساهمتك في تحقيق الأهداف الكبرى.
مرحبًا بك في The Agentverse: A Call to Champions
في المساحة الرقمية الشاسعة للمؤسسة، بدأ عصر جديد. نحن في عصر الوكلاء، وهو وقت يحمل وعودًا هائلة، حيث يعمل الوكلاء الأذكياء والمستقلون في تناغم تام لتسريع الابتكار والتخلص من المهام الروتينية.

يُعرف هذا النظام المتكامل من القوة والإمكانات باسم Agentverse.
لكنّ حالة من الفوضى الزاحفة، وهي فساد صامت يُعرف باسم "الضوضاء"، بدأت في إتلاف حواف هذا العالم الجديد. إنّ "الجمود" ليس فيروسًا أو خطأ برمجيًا، بل هو تجسيد للفوضى التي تتغذى على فعل الخلق نفسه.
وهي تضخّم الإحباطات القديمة إلى أشكال وحشية، ما يؤدي إلى ظهور "الأشباح السبعة للتطوير". إذا لم يتم التحقّق من ذلك، سيؤدي ذلك إلى توقّف التقدّم في The Static and its Spectres، ما سيحوّل وعد Agentverse إلى أرض قاحلة من الديون الفنية والمشاريع المهجورة.
اليوم، ندعو الأبطال إلى التصدي للفوضى. نحن بحاجة إلى أبطال مستعدين لإتقان مهاراتهم والعمل معًا لحماية Agentverse. حان الوقت لاختيار مسارك.
اختيار صفك
تتوفّر لك أربعة مسارات مختلفة، كل منها يمثّل ركيزة أساسية في المعركة ضد الجمود. على الرغم من أنّ تدريبك سيكون مهمة فردية، إلا أنّ نجاحك النهائي يعتمد على فهم كيفية دمج مهاراتك مع مهارات الآخرين.
- The Shadowblade (المطوّر): هو خبير في الحدادة والخطوط الأمامية. أنت الحِرفي الذي يصنع الشفرات ويبني الأدوات ويواجه العدو في التفاصيل المعقدة للرمز. مسارك هو مسار الدقة والمهارة والإبداع العملي.
- الشخصية القيادية (المهندس المعماري): شخصية استراتيجية ومنظِّمة. لا ترى عميلاً واحدًا، بل ساحة المعركة بأكملها. يمكنك تصميم المخططات الرئيسية التي تسمح لأنظمة الوكلاء بأكملها بالتواصل والتعاون وتحقيق هدف أكبر بكثير من أي مكوّن فردي.
- الباحث (مهندس البيانات): هو شخص يبحث عن الحقائق المخفية ويحتفظ بالمعرفة. تخوض مغامرة في البرية الشاسعة وغير المروَّضة من البيانات للكشف عن الذكاء الذي يمنح العملاء هدفًا وبصيرة. يمكن أن تكشف معلوماتك عن نقاط ضعف العدو أو تعزّز قوة حليفك.
- الحارس (التطوير والعمليات / هندسة موثوقية المواقع الإلكترونية): هو الحامي الثابت والدرع الذي يحمي المملكة. عليك بناء الحصون وإدارة خطوط إمداد الطاقة والتأكّد من أنّ النظام بأكمله يمكنه الصمود أمام هجمات "الكهرباء الساكنة" الحتمية. قوتك هي الأساس الذي يُبنى عليه فوز فريقك.
مهمتك
سيبدأ التدريب كتمرين مستقل. ستسلك المسار الذي اخترته، وتتعلّم المهارات الفريدة المطلوبة لإتقان دورك. في نهاية الفترة التجريبية، ستواجه Spectre، وهو وحش صغير من The Static يتغذى على التحديات المحددة التي تواجهها في عملك.
ولن تتمكّن من الاستعداد للتجربة النهائية إلا من خلال إتقان دورك الفردي. عليك بعد ذلك تكوين فريق مع أبطال من الصفوف الأخرى. وستخوضون معًا مغامرة في قلب الفساد لمواجهة زعيم نهائي.
تحدٍّ نهائي تعاوني سيختبر قوتك المجمّعة ويحدّد مصير Agentverse.
عالم Agentverse ينتظر أبطاله. هل ستلبي النداء؟
2. كتاب السحر الخاص بالباحث
لتبدأ رحلتنا! بصفتنا باحثين، سلاحنا الأساسي هو المعرفة. لقد عثرنا في أرشيفنا (Google Cloud Storage) على مجموعة من المخطوطات القديمة الغامضة. تحتوي هذه المخطوطات على معلومات استخباراتية أولية عن الوحوش المخيفة التي تعيث فسادًا في الأرض. مهمتنا هي استخدام الإمكانات التحليلية المذهلة في Google BigQuery والاستفادة من خبرة Gemini Elder Brain (نموذج Gemini Pro) لفك رموز هذه النصوص غير المنظَّمة وتحويلها إلى Bestiary منظَّم وقابل للاستعلام. ستكون هذه هي الأساس الذي تستند إليه جميع استراتيجياتنا المستقبلية.
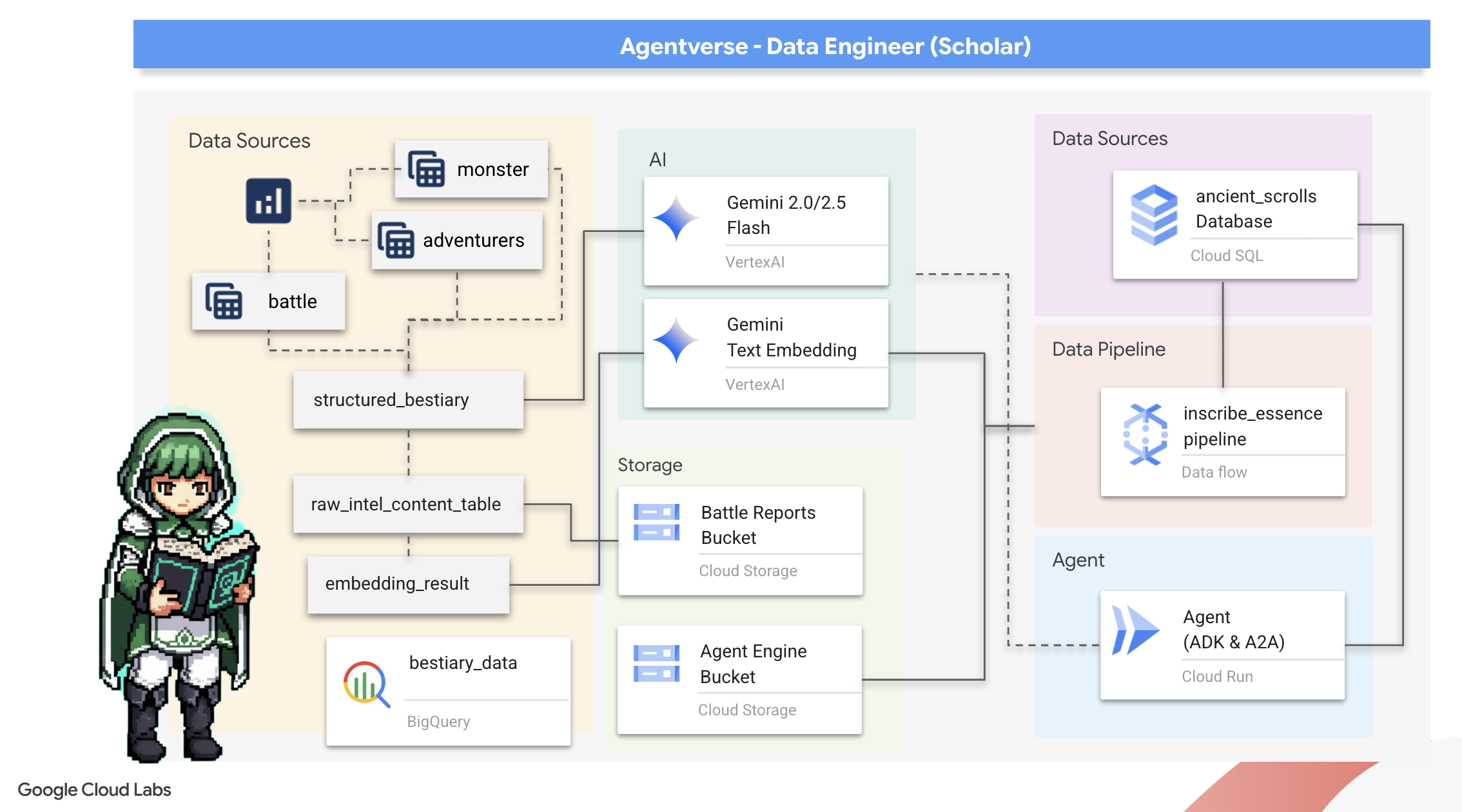
أهداف الدورة التعليمية
- استخدِم BigQuery لإنشاء جداول خارجية وإجراء عمليات تحويل معقّدة من بيانات غير منظَّمة إلى بيانات منظَّمة باستخدام BQML.GENERATE_TEXT مع أحد نماذج Gemini.
- يمكنك توفير مثيل Cloud SQL for PostgreSQL وتفعيل إضافة pgvector للاستفادة من إمكانات البحث الدلالي.
- يمكنك إنشاء مسار معالجة مجمّع قوي ومضمّن في حاوية باستخدام Dataflow وApache Beam لمعالجة ملفات نصية أولية وإنشاء تضمينات متجهة باستخدام أحد نماذج Gemini وكتابة النتائج في قاعدة بيانات علائقية.
- تنفيذ نظام أساسي للتوليد المعزّز بالاسترجاع (RAG) داخل وكيل للبحث عن البيانات المتجهة
- يمكنك نشر وكيل مدرِك للبيانات كخدمة آمنة وقابلة للتوسّع على Cloud Run.
3- التحضير لـ "ملاذ الباحث"
مرحبًا بك في "الباحث العلمي". قبل أن نبدأ في تدوين المعرفة القوية في كتابنا السحري، علينا أولاً تجهيز ملاذنا. يتضمّن هذا الطقس الأساسي إضفاء السحر على بيئة Google Cloud، وفتح البوابات المناسبة (واجهات برمجة التطبيقات)، وإنشاء القنوات التي ستتدفّق من خلالها سحر البيانات. يضمن الملاذ المُعدّ جيدًا أن تكون تعاويذنا قوية ومعرفتنا آمنة.
المطالبة برصيدك في Google Cloud
⚠️ المتطلبات الأساسية المهمة:
- استخدام حساب Gmail شخصي: يجب استخدام حساب شخصي (مثلاً،
name@gmail.com). لن تعمل الحسابات التي تديرها الشركات أو المؤسسات التعليمية.
👉 الخطوات:
- الانتقال إلى الموقع الإلكتروني للمطالبة بالرصيد: انقر هنا
- تسجيل الدخول: الصِق الرابط في شريط العناوين وسجِّل الدخول باستخدام حسابك الشخصي على Gmail.
- قبول البنود: وافِق على بنود خدمة Google Cloud Platform.
- التحقّق من الرصيد: ابحث عن رسالة تؤكّد أنّه تم تطبيق الرصيد.
- *ملاحظة: إذا طُلب منك إدخال معلومات بطاقة الائتمان، يمكنك تجاهل ذلك بأمان وإغلاق النافذة.
يمكنك الآن إغلاق النافذة.
إعداد بيئة العمل
👉انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud" (رمز شكل الوحدة الطرفية في أعلى لوحة Cloud Shell).
👉انقر على الزر "فتح المحرّر" (يبدو كملف مفتوح مع قلم رصاص). سيؤدي ذلك إلى فتح "محرِّر Cloud Shell" في النافذة. سيظهر لك مستكشف الملفات على الجانب الأيمن. 
👉افتح المحطة الطرفية في بيئة التطوير المتكاملة المستندة إلى السحابة الإلكترونية، 
👉💻 في نافذة الأوامر، تأكَّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
👉💻استنسِخ مشروع bootstrap من GitHub:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 شغِّل نص الإعداد البرمجي من دليل المشروع.
⚠️ ملاحظة حول معرّف المشروع: سيقترح النص البرمجي معرّف مشروع تلقائيًا تم إنشاؤه عشوائيًا. يمكنك الضغط على Enter لقبول هذا الإعداد التلقائي.
ومع ذلك، إذا كنت تفضّل إنشاء مشروع جديد محدّد، يمكنك كتابة رقم تعريف المشروع المطلوب عندما يطلب منك النص البرمجي ذلك.
cd ~/agentverse-dataengineer
./init.sh
👉 خطوة مهمة بعد الإكمال: بعد انتهاء النص البرمجي، عليك التأكّد من أنّ Google Cloud Console يعرض المشروع الصحيح:
- انتقِل إلى console.cloud.google.com.
- انقر على القائمة المنسدلة الخاصة بأداة اختيار المشاريع في أعلى الصفحة.
- انقر على علامة التبويب "الكل" (لأنّ المشروع الجديد قد لا يظهر في "الأخيرة" بعد).
- اختَر معرّف المشروع الذي أعددته للتو في الخطوة
init.sh.
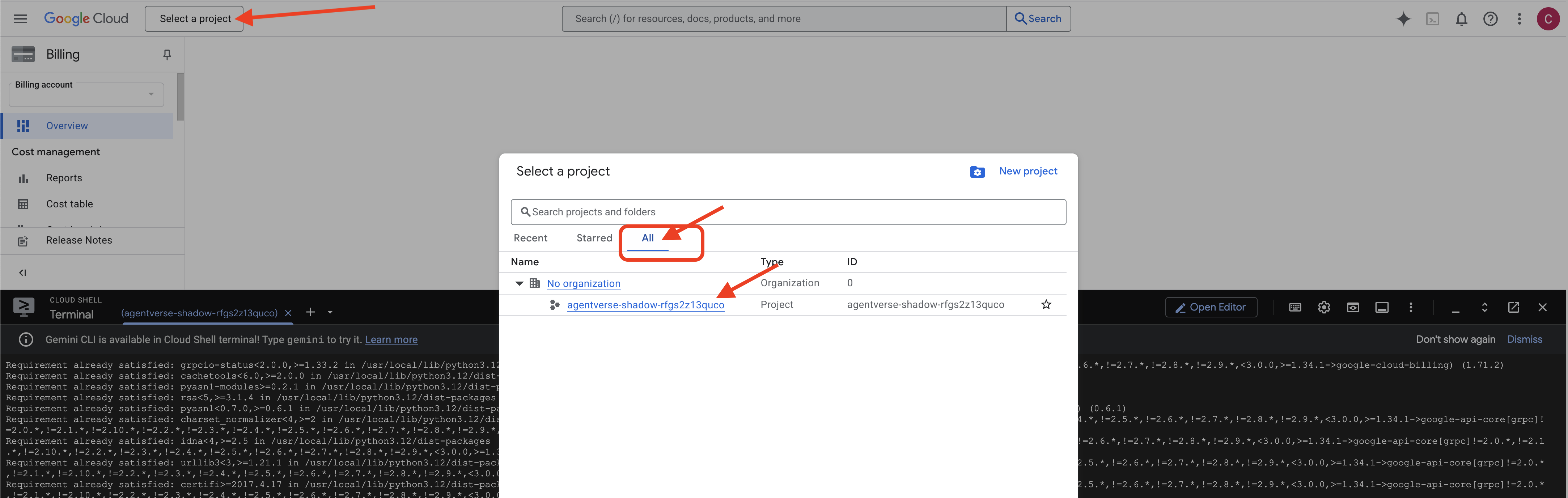
👉💻 اضبط رقم تعريف المشروع المطلوب:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 شغِّل الأمر التالي لتفعيل واجهات Google Cloud APIs اللازمة:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 إذا لم يسبق لك إنشاء مستودع Artifact Registry باسم agentverse-repo، نفِّذ الأمر التالي لإنشائه:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
إعداد الإذن
👉💻 امنح الأذونات اللازمة من خلال تنفيذ الأوامر التالية في الوحدة الطرفية:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 عند بدء التدريب، سنجهّز التحدي النهائي. ستستدعي الأوامر التالية الأشباح من التشويش الفوضوي، ما يؤدي إلى إنشاء الزعماء لاختبارك النهائي.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
عمل ممتاز، "العالم". اكتملت التحسينات الأساسية. ملاذنا آمن، وبوابات قوى البيانات الأساسية مفتوحة، وخادمُنا مُفعَّل. نحن الآن جاهزون لبدء العمل الفعلي.
4. The Alchemy of Knowledge: Transforming Data with BigQuery & Gemini
في الحرب الدائمة ضدّ "الجمود"، يتم تسجيل كل مواجهة بين "بطل من عالم العملاء" و"شبح التطوير" بدقة. ينشئ نظام محاكاة ساحة المعركة، وهو بيئة التدريب الأساسية لدينا، تلقائيًا إدخالاً في سجلّ الأثير لكل مواجهة. تُعدّ سجلات السرد هذه مصدرنا الأكثر قيمة للمعلومات الأولية، وهي الخام غير المكرّر الذي يجب أن نصنع منه، بصفتنا باحثين، الفولاذ النقي للاستراتيجية.لا تكمن القوة الحقيقية للباحث في امتلاك البيانات فحسب، بل في القدرة على تحويل الخام الأولي والفوضوي للمعلومات إلى فولاذ لامع ومنظّم من الحكمة القابلة للتنفيذ.سننفّذ طقسًا أساسيًا من طقوس كيمياء البيانات.

ستأخذنا رحلتنا في عملية متعدّدة المراحل بالكامل ضمن حرم Google BigQuery. سنبدأ بالنظر إلى أرشيف GCS بدون تحريك أي شريط تمرير، وذلك باستخدام عدسة سحرية. بعد ذلك، سنطلب من Gemini قراءة وفهم السير الذاتية الشعرية غير المنظَّمة لسجلات المعارك. أخيرًا، سنحسّن النبوءات الأولية لتصبح مجموعة من الجداول النقية المترابطة. أول كتاب Grimoire ثم اطرح سؤالاً عميقًا لا يمكن الإجابة عنه إلا من خلال هذا البناء الجديد.
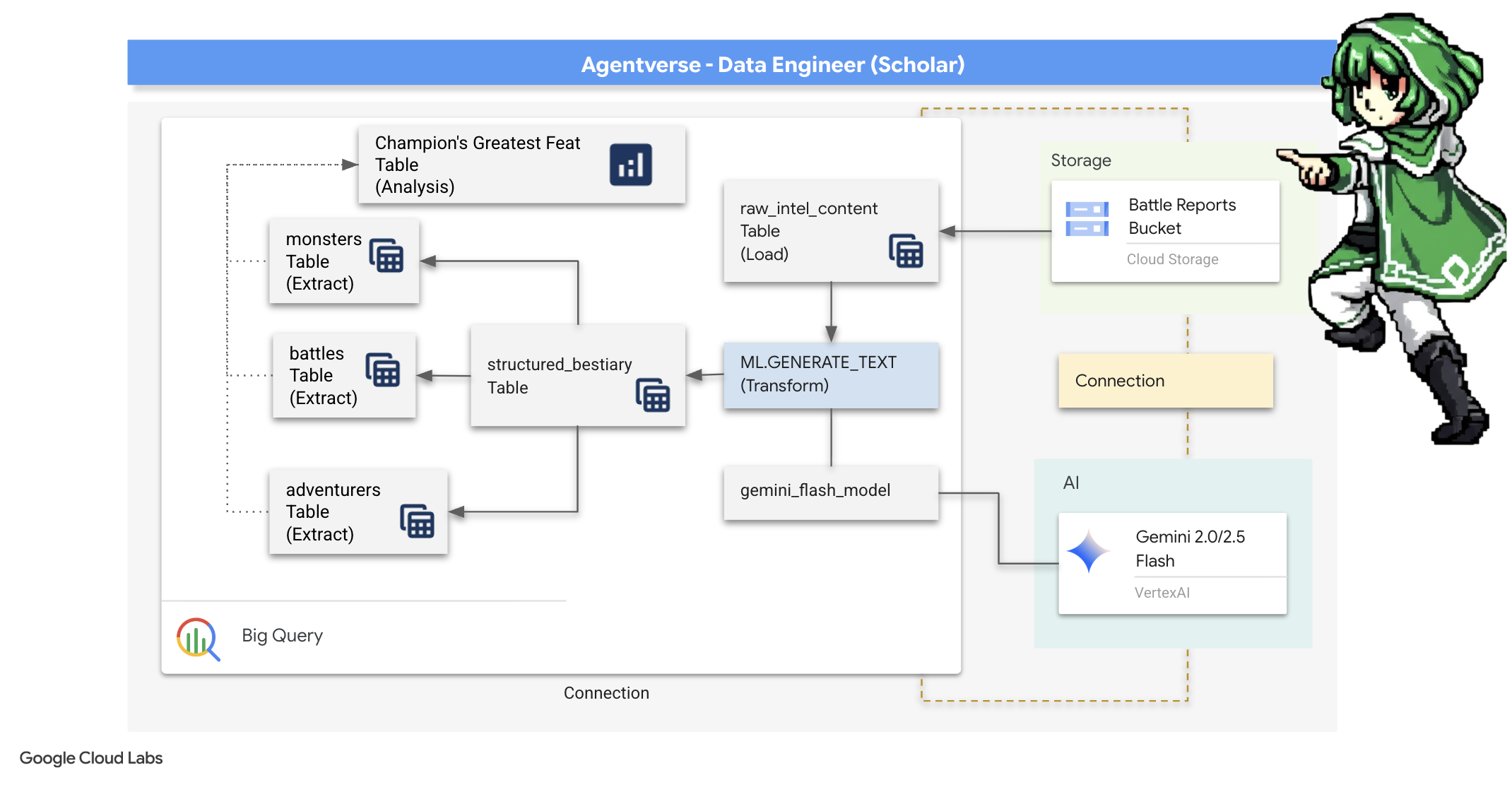
التحقّق الدقيق: إلقاء نظرة فاحصة على GCS باستخدام الجداول الخارجية في BigQuery
أول ما سنفعله هو إنشاء عدسة تتيح لنا الاطّلاع على محتوى أرشيف GCS بدون التأثير في المخطوطات. الجدول الخارجي هو هذه العدسة، حيث يربط ملفات النصوص الأولية ببنية تشبه الجدول يمكن أن يطلب BigQuery البحث فيها مباشرةً.
لإجراء ذلك، يجب أولاً إنشاء خط طاقة مستقر، وهو مصدر CONNECTION، يربط بشكل آمن بين مستودع BigQuery وأرشيف GCS.
👉💻 في وحدة Cloud Shell الطرفية، نفِّذ الأمر التالي لإعداد مساحة التخزين وإنشاء القناة:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 تنبيه: ستظهر رسالة لاحقًا!
بدأ نص الإعداد البرمجي من الخطوة 2 عملية في الخلفية. بعد بضع دقائق، ستظهر رسالة في نافذة الجهاز تشبه ما يلي:[1]+ Done gcloud sql instances create ...هذا أمر طبيعي ومتوقّع. يعني ذلك ببساطة أنّه تم إنشاء قاعدة بيانات Cloud SQL بنجاح. يمكنك تجاهل هذه الرسالة ومواصلة العمل.
قبل أن تتمكّن من إنشاء "الجدول الخارجي"، عليك أولاً إنشاء مجموعة البيانات التي ستحتويه.
👉💻 نفِّذ هذا الأمر البسيط في وحدة Cloud Shell الطرفية:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 الآن، يجب منح التوقيع السحري لقناة الاتصال الأذونات اللازمة للقراءة من "أرشيف Google Cloud Storage" والرجوع إلى Gemini.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 في وحدة Cloud Shell الطرفية، نفِّذ الأمر التالي لعرض اسم الحزمة:
echo $BUCKET_NAME
ستعرض المحطة الطرفية اسمًا مشابهًا لـ your-project-id-gcs-bucket. ستحتاج إلى هذا الرمز في الخطوات التالية.
👉 عليك تنفيذ الأمر التالي من داخل محرِّر طلبات البحث في BigQuery في Google Cloud Console. أسهل طريقة للوصول إلى هناك هي فتح الرابط أدناه في علامة تبويب جديدة في المتصفّح. سينقلك هذا الرابط مباشرةً إلى الصفحة الصحيحة في Google Cloud Console.
https://console.cloud.google.com/bigquery
👉 بعد تحميل الصفحة، انقر على زر الإضافة الأزرق (إنشاء طلب بحث جديد) لفتح علامة تبويب جديدة في المحرّر.
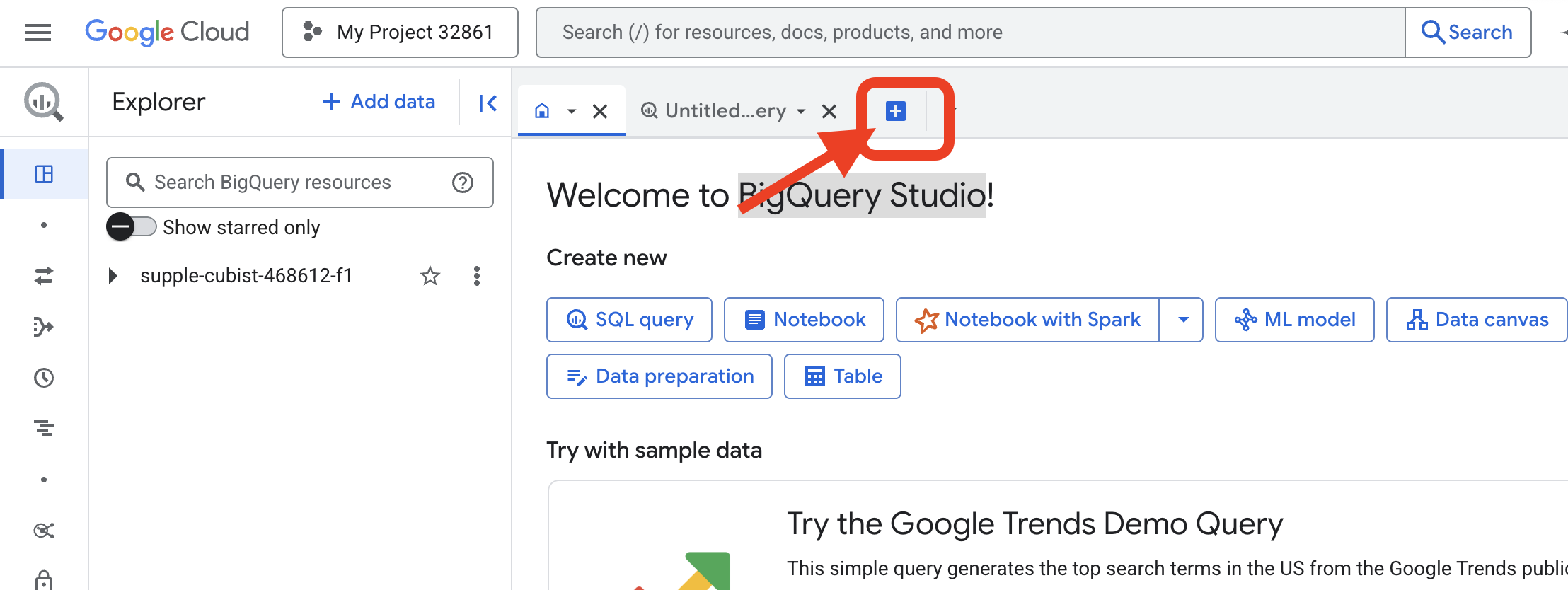
الآن، نكتب تعويذة "لغة تعريف البيانات" (DDL) لإنشاء عدستنا السحرية. يخبر هذا BigQuery بمكان البحث وما يجب عرضه.
👉📜 في محرِّر طلبات البحث في BigQuery الذي فتحته، الصِق عبارة SQL التالية. تذكَّر استبدال REPLACE-WITH-YOUR-BUCKET-NAME
مع اسم الحزمة الذي نسخته للتو. وانقر على تشغيل:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 نفِّذ طلب بحث "للنظر من خلال العدسة" والاطّلاع على محتوى الملفات.
SELECT * FROM bestiary_data.raw_intel_content_table;
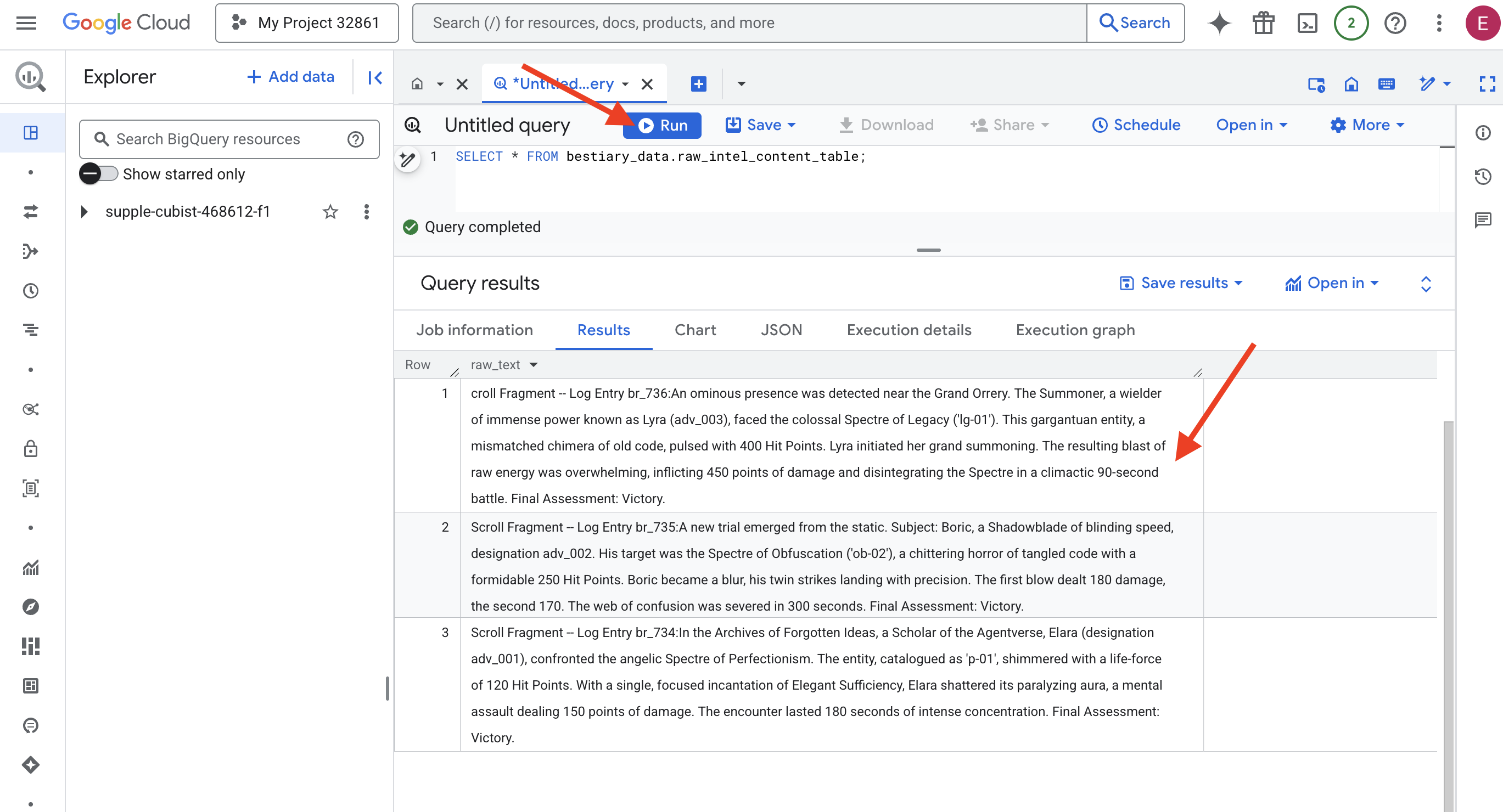
لقد تم وضع عدستنا في مكانها. يمكننا الآن رؤية النص الأولي للمخطوطات. لكن القراءة لا تعني الفهم.
في "أرشيف الأفكار المنسية"، واجهت "إيلارا" (التي تحمل التصنيف adv_001)، وهي باحثة في "عالم الوكلاء"، شبح الكمال الملائكي. تألّق الكائن، الذي تم تصنيفه على أنّه "p-01"، بقوة حياة تبلغ 120 نقطة إصابة. بترتيل واحد مركّز من "الكفاية الأنيقة"، حطّمت إيلارا هالتها المشلّة، وهو اعتداء ذهني يلحق 150 نقطة ضرر. استغرقت المواجهة 180 ثانية من التركيز الشديد. التقييم النهائي: فوز.
لم تُكتب المخطوطات في جداول وصفوف، بل في النثر المتعرّج للملاحم. هذا هو اختبارنا الأول.
The Scholar's Divination: تحويل النص إلى جدول باستخدام SQL
يكمن التحدي في أنّ التقرير الذي يوضّح الهجمات المزدوجة والسريعة التي يشنّها "سيف الظل" يختلف كثيرًا عن السجلّ الذي يصف عملية جمع "المستدعي" لقوة هائلة من أجل توجيه ضربة واحدة مدمرة. لا يمكننا ببساطة استيراد هذه البيانات، بل يجب تفسيرها. هذه هي اللحظة السحرية. سنستخدم طلب بحث واحدًا بلغة الاستعلامات البنيوية (SQL) كتعويذة قوية لقراءة جميع السجلات من جميع ملفاتنا وفهمها وتنظيمها، وذلك مباشرةً في BigQuery.
👉💻 في وحدة Cloud Shell الطرفية، نفِّذ الأمر التالي لعرض اسم الاتصال:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
ستعرض المحطة الطرفية سلسلة الاتصال الكاملة، لذا اختَر هذه السلسلة بأكملها وانسخها، ستحتاج إليها في الخطوة التالية.
سنستخدم تعويذة واحدة وفعّالة: ML.GENERATE_TEXT. يستدعي هذا السحر Gemini، ويعرض عليه كل صفحة، ويأمره بإرجاع الحقائق الأساسية ككائن JSON منظَّم.
👉📜 في BigQuery Studio، أنشئ مرجع نموذج Gemini. يربط هذا الرمز أداة Gemini Flash Oracle بمكتبة BigQuery حتى نتمكّن من استدعائها في طلبات البحث. تذكَّر استبدال
استبدِل REPLACE-WITH-YOUR-FULL-CONNECTION-STRING بسلسلة الاتصال الكاملة التي نسختها للتو من نافذة الأوامر.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 الآن، ألقِ تعويذة التحويل الكبرى. يقرأ هذا الطلب النص الأولي، وينشئ طلبًا تفصيليًا لكل عملية تمرير، ويرسله إلى Gemini، وينشئ جدول إعداد جديدًا من ردّ الذكاء الاصطناعي بتنسيق JSON المنظَّم.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
اكتملت عملية التحويل، ولكن النتيجة ليست نقية بعد. يعرض نموذج Gemini إجابته بتنسيق عادي، حيث يغلّف ملف JSON المطلوب ببنية أكبر تتضمّن بيانات وصفية حول عملية التفكير. دعونا نلقي نظرة على هذه النبوءة الأولية قبل أن نحاول تنقيتها.
👉📜 نفِّذ طلب بحث لفحص الناتج الأولي من نموذج Gemini:
SELECT * FROM bestiary_data.structured_bestiary;
👀 سيظهر لك عمود واحد باسم structured_data. سيبدو محتوى كل صف مشابهًا لعنصر JSON المعقّد هذا:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
كما ترى، فإنّ الجائزة، أي عنصر JSON النظيف الذي طلبناه، مضمّنة في عمق هذه البنية. مهمتنا التالية واضحة. يجب أن نؤدي طقسًا للتنقّل بشكل منهجي في هذه البنية واستخراج الحكمة الخالصة منها.
The Ritual of Cleansing: Normalizing GenAI Output with SQL
لقد قال Gemini كلمته، ولكنها كلمات أولية ومغلّفة بالطاقات السماوية التي أدت إلى إنشائه (المرشحون، وfinish_reason، وما إلى ذلك). لا يكتفي الباحث الحقيقي بتخزين النبوءة الأولية، بل يستخرج الحكمة الأساسية بعناية ويدوّنها في المجلدات المناسبة لاستخدامها في المستقبل.
سننفّذ الآن المجموعة الأخيرة من التعاويذ. سيعمل هذا النص البرمجي الفردي على:
- قراءة ملف JSON الأولي والمتداخل من جدول الإعداد
- تنظيفها وتحليلها للوصول إلى البيانات الأساسية
- انسخ الأجزاء ذات الصلة في ثلاثة جداول نهائية ونظيفة: الوحوش والمغامرون والمعارك.
👉📜 في محرِّر طلب بحث جديد في BigQuery، شغِّل التعويذة التالية لإنشاء عدسة التنظيف:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 تأكيد صحة Bestiary:
SELECT * FROM bestiary_data.monsters;
بعد ذلك، سننشئ "قائمة الأبطال"، وهي قائمة بالمغامرين الشجعان الذين واجهوا هذه الوحوش.
👉📜 في محرّر طلب بحث جديد، نفِّذ الأمر التالي لإنشاء جدول المغامرين:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 التحقّق من قائمة الأبطال:
SELECT * FROM bestiary_data.adventurers;
أخيرًا، سننشئ جدول الحقائق، وهو "سجل المعارك". يربط هذا المجلد بين المجلّدين الآخرين، ويسجّل تفاصيل كل مواجهة فريدة. بما أنّ كل معركة هي حدث فريد، لا حاجة إلى إزالة التكرار.
👉📜 في محرّر طلب بحث جديد، نفِّذ التعليمة البرمجية التالية لإنشاء جدول المعارك:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 التحقّق من صحة المعلومات في Chronicle:
SELECT * FROM bestiary_data.battles;
الاطّلاع على الإحصاءات الاستراتيجية
لقد تم قراءة المخطوطات واستخلاص جوهرها وكتابة المجلدات. لم يعد Grimoire مجرد مجموعة من الحقائق، بل أصبح قاعدة بيانات ارتباطية تتضمّن حكمة استراتيجية عميقة. يمكننا الآن طرح أسئلة كان من المستحيل الإجابة عنها عندما كانت معلوماتنا محصورة في نصوص أولية غير منظَّمة.
لنُجري الآن عرافة نهائية وكبيرة. سنستخدم تعويذة تستشير جميع كتبنا الثلاثة في آن واحد، وهي "موسوعة الوحوش" و"قائمة الأبطال" و"سجل المعارك"، وذلك للكشف عن إحصاءات مفصّلة وقابلة للتنفيذ.
سؤالنا الاستراتيجي: "بالنسبة إلى كل مغامر، ما هو اسم الوحش الأقوى (من حيث نقاط الإصابة) الذي تمكّن من هزيمته بنجاح، وكم استغرقت هذه المعركة؟"
هذا سؤال معقّد يتطلّب ربط الأبطال بمعاركهم المنتصرة، وربط هذه المعارك بإحصاءات الوحوش المشاركة فيها. هذه هي القوة الحقيقية لنموذج البيانات المنظَّمة.
👉📜 في محرِّر طلب BigQuery جديد، اكتب ما يلي:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
سيكون ناتج هذا الاستعلام جدولاً منظَّمًا وواضحًا يقدّم "قصة عن أعظم إنجازات بطل" لكل مغامر في مجموعة البيانات. قد يبدو على النحو التالي:
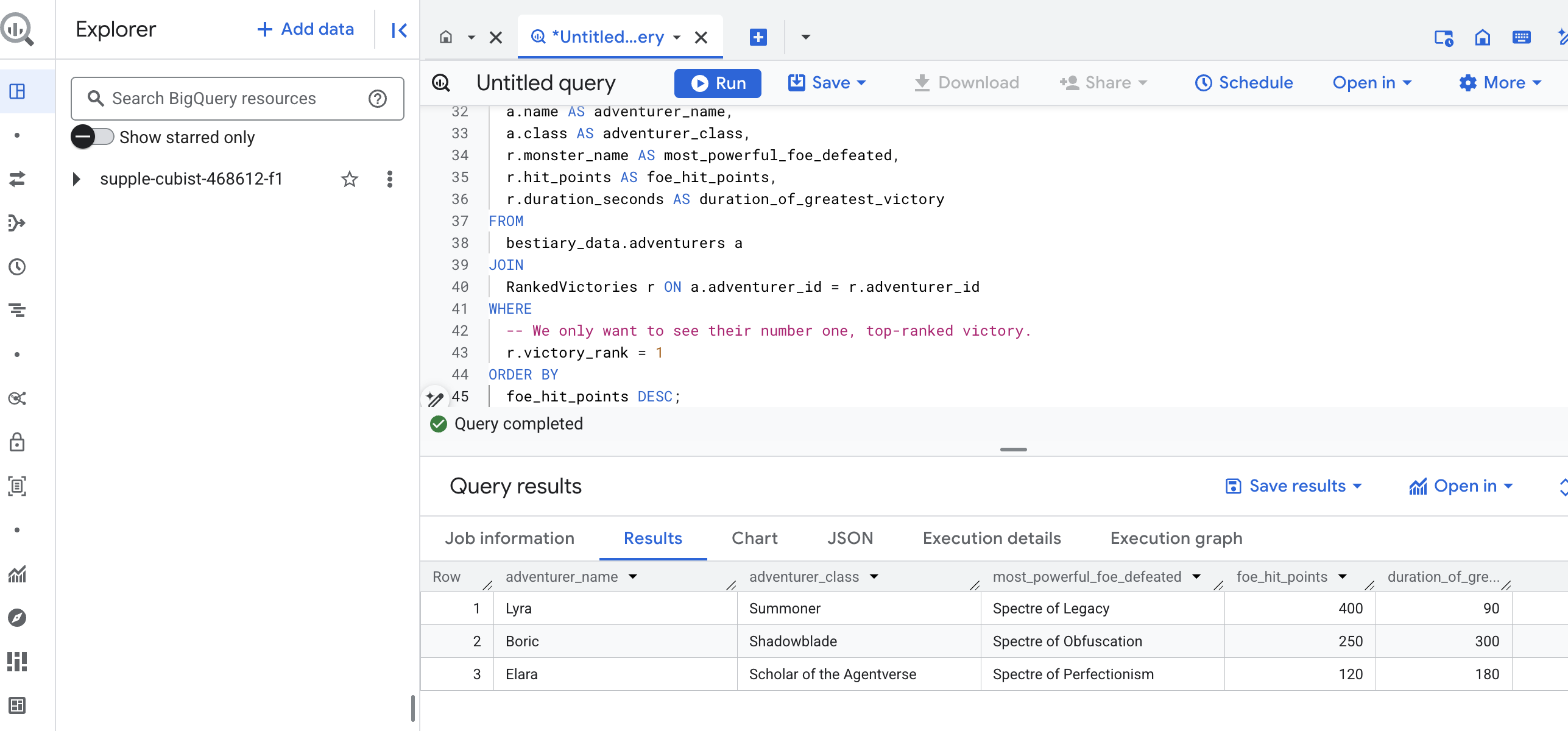
أغلِق علامة تبويب BigQuery.
تثبت هذه النتيجة الواحدة الأنيقة قيمة مسار الإحالة بأكمله. لقد نجحت في تحويل تقارير ساحة المعركة الأولية والفوضوية إلى مصدر للحكايات الأسطورية والمعلومات الاستراتيجية المستندة إلى البيانات.
لغير اللاعبين
5- The Scribe's Grimoire: In-Datawarehouse Chunking, Embedding, and Search
لقد حقّقنا نجاحًا في عملنا في مختبر "الخيميائي". لقد حوّلنا المخطوطات السردية الأولية إلى جداول مهيكلة ارتباطية، وهو إنجاز قوي في مجال سحر البيانات. ومع ذلك، لا تزال المخطوطات الأصلية تتضمّن حقيقة دلالية أعمق لا يمكن لجداولنا المنظَّمة أن تعكسها بالكامل. ولإنشاء وكيل ذكي حقًا، يجب أن نفهم هذا المعنى.
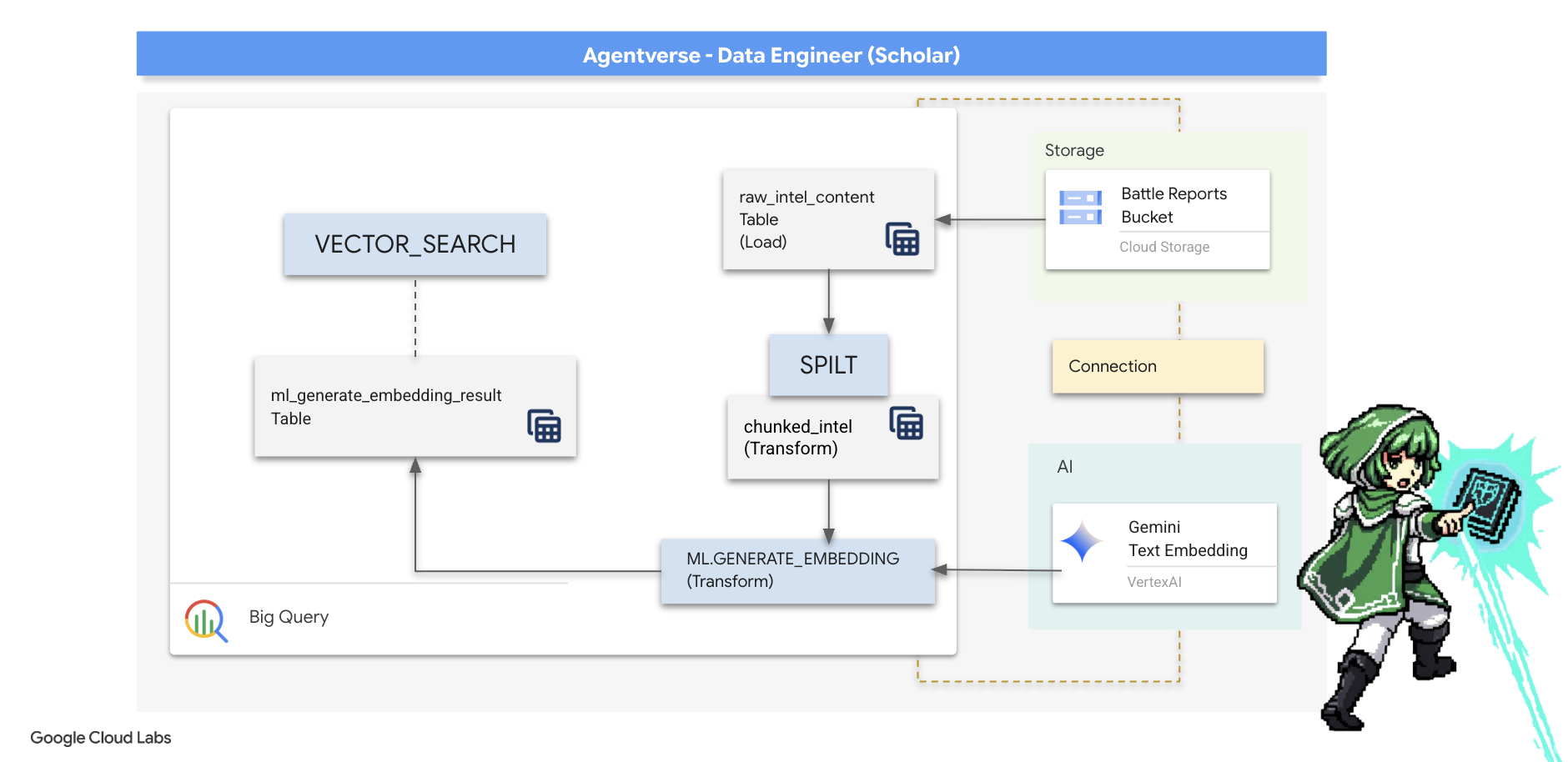
إنّ التمرير الطويل وغير المنظَّم هو أسلوب غير فعّال. إذا طرح وكيل الدعم سؤالاً عن "هالة مشلّة"، قد يعرض بحث بسيط تقرير معركة كاملاً تم ذكر هذه العبارة فيه مرة واحدة فقط، ما يؤدي إلى إخفاء الإجابة في تفاصيل غير ذات صلة. يدرك الباحث المتمكّن أنّ الحكمة الحقيقية لا تكمن في الكمية، بل في الدقة.
سننفّذ ثلاث طقوس قوية داخل قاعدة البيانات بالكامل في ملاذ BigQuery.
- طقس التقسيم (التجزئة): سنأخذ سجلّات الذكاء الأولي ونقسمها بدقة إلى مقاطع أصغر ومركزة ومستقلة.
- طقس التقطير (التضمين): سنستخدم BQML للرجوع إلى أحد نماذج Gemini، ما يؤدي إلى تحويل كل جزء من النص إلى "بصمة دلالية"، أي تضمين متّجه.
- طقس العرافة (البحث): سنستخدم ميزة "البحث المستند إلى المتجهات" في BQML لطرح سؤال باللغة الإنجليزية العادية والعثور على الحكمة الأكثر صلة بالموضوع والمستخلصة من كتاب Grimoire.
تؤدي هذه العملية بأكملها إلى إنشاء قاعدة معلومات قوية قابلة للبحث بدون أن تغادر البيانات أبدًا مستوى الأمان والتوسّع في BigQuery.
The Ritual of Division: Deconstructing Scrolls with SQL
يبقى مصدر معلوماتنا هو ملفات النصوص الأولية في أرشيف GCS، ويمكن الوصول إليها من خلال جدولنا الخارجي bestiary_data.raw_intel_content_table. مهمتنا الأولى هي كتابة تعويذة تقرأ كل مخطوطة طويلة وتقسّمها إلى سلسلة من الأبيات الأصغر حجمًا والأسهل فهمًا. في هذا التمرين، سنعرّف "الجزء" على أنّه جملة واحدة.
على الرغم من أنّ تقسيم النص حسب الجملة هو نقطة بداية واضحة وفعّالة لسجلات السرد، يتوفّر لدى Scribe الرئيسي العديد من استراتيجيات تقسيم النص، ويُعدّ الاختيار أمرًا بالغ الأهمية لجودة البحث النهائي. قد تستخدم الطرق الأبسط
- التقسيم إلى أجزاء ثابتة الطول(الحجم)، ولكن يمكن أن يؤدي ذلك إلى تقسيم فكرة رئيسية إلى نصفين بشكل غير دقيق.
أنشطة أكثر تعقيدًا، مثل
- التقسيم المتكرر: غالبًا ما يُفضَّل هذا النوع في الممارسة العملية، إذ يحاول تقسيم النص على طول الحدود الطبيعية، مثل الفقرات أولاً، ثم الرجوع إلى الجمل للحفاظ على أكبر قدر ممكن من السياق الدلالي. للمخطوطات المعقّدة حقًا
- التقسيم إلى أجزاء حسب المحتوى(المستند): تستخدم Scribe البنية المتأصلة للمستند، مثل العناوين في دليل فني أو الدوال في قائمة التعليمات البرمجية، لإنشاء أجزاء الحكمة الأكثر منطقية وفعالية، وغير ذلك.
بالنسبة إلى سجلّات المعارك، تقدّم الجملة التوازن المثالي بين الدقة والسياق.
👉📜 في محرِّر طلبات بحث جديد في BigQuery، نفِّذ الأمر التالي. يستخدم هذا الطلب الدالة SPLIT لتقسيم نص كل مخطوطة عند كل نقطة (.) ثم إلغاء تداخل مصفوفة الجمل الناتجة في صفوف منفصلة.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 الآن، نفِّذ طلب بحث لفحص المعرفة الجديدة التي تمّت كتابتها وتقسيمها إلى أجزاء، ولاحظ الفرق.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
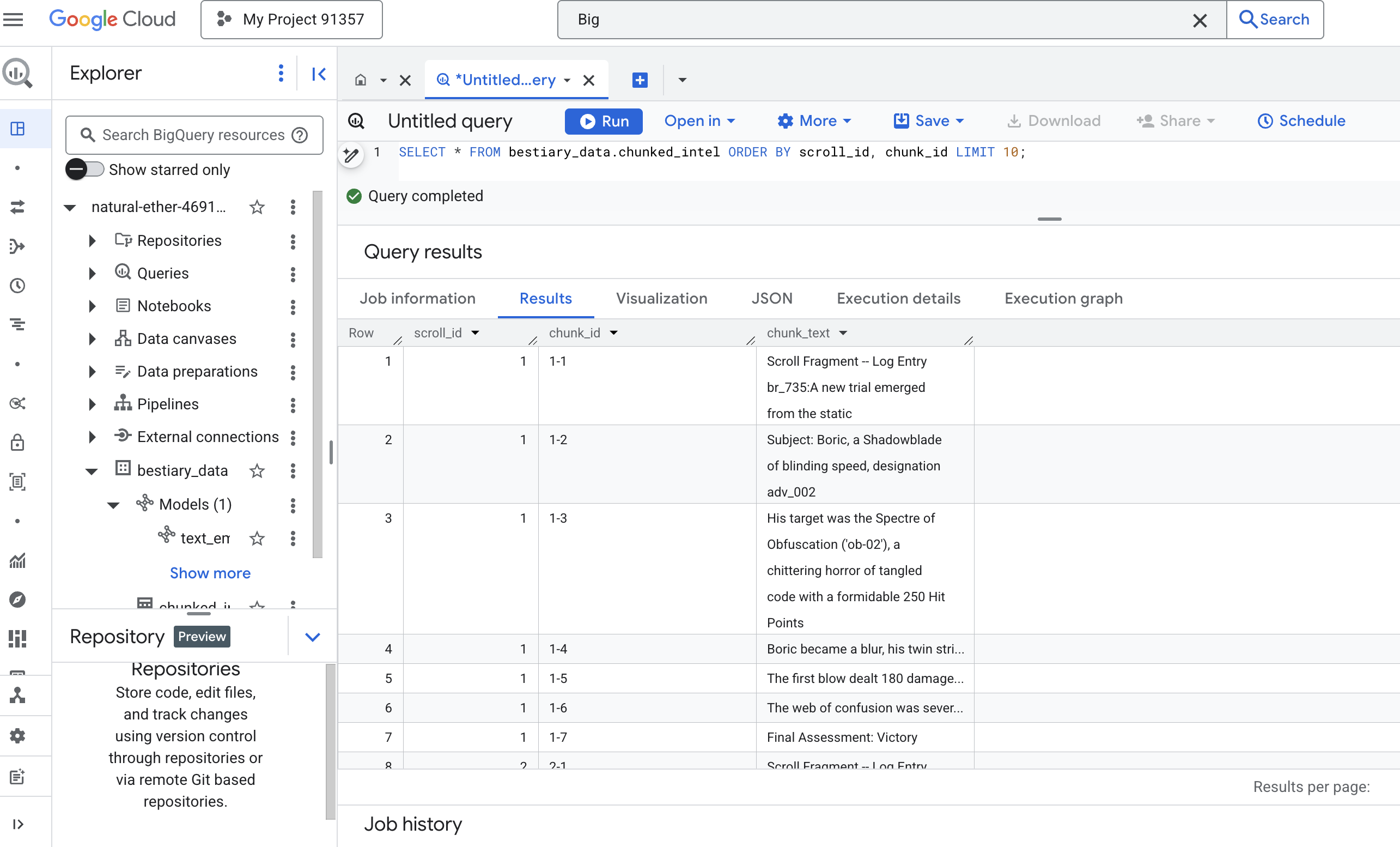
راقِب النتائج. في السابق، كان النص يظهر في كتلة واحدة كثيفة، أما الآن، فيظهر في صفوف متعددة، كل منها مرتبط بعملية التمرير الأصلية (scroll_id) ولكنّه يحتوي على جملة واحدة فقط. أصبح كل صف الآن خيارًا مثاليًا للتحويل إلى متجهات.
The Ritual of Distillation: Transforming Text to Vectors with BQML
👉💻 أولاً، ارجع إلى الوحدة الطرفية، ونفِّذ الأمر التالي لعرض اسم الاتصال:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 يجب إنشاء نموذج BigQuery جديد يشير إلى تضمين نص Gemini. في BigQuery Studio، شغِّل التعليمة البرمجية التالية. يُرجى العِلم أنّه عليك استبدال REPLACE-WITH-YOUR-FULL-CONNECTION-STRING بسلسلة الاتصال الكاملة التي نسختها للتو من نافذة الأوامر.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 الآن، ألقِ تعويذة التقطير الكبرى. يستدعي هذا الاستعلام الدالة ML.GENERATE_EMBEDDING التي ستقرأ كل صف من جدول chunked_intel، وترسل النص إلى نموذج التضمين Gemini، وتخزّن بصمة المتّجه الناتجة في جدول جديد.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
قد تستغرق هذه العملية دقيقة أو دقيقتَين بينما يعالج BigQuery جميع أجزاء النص.
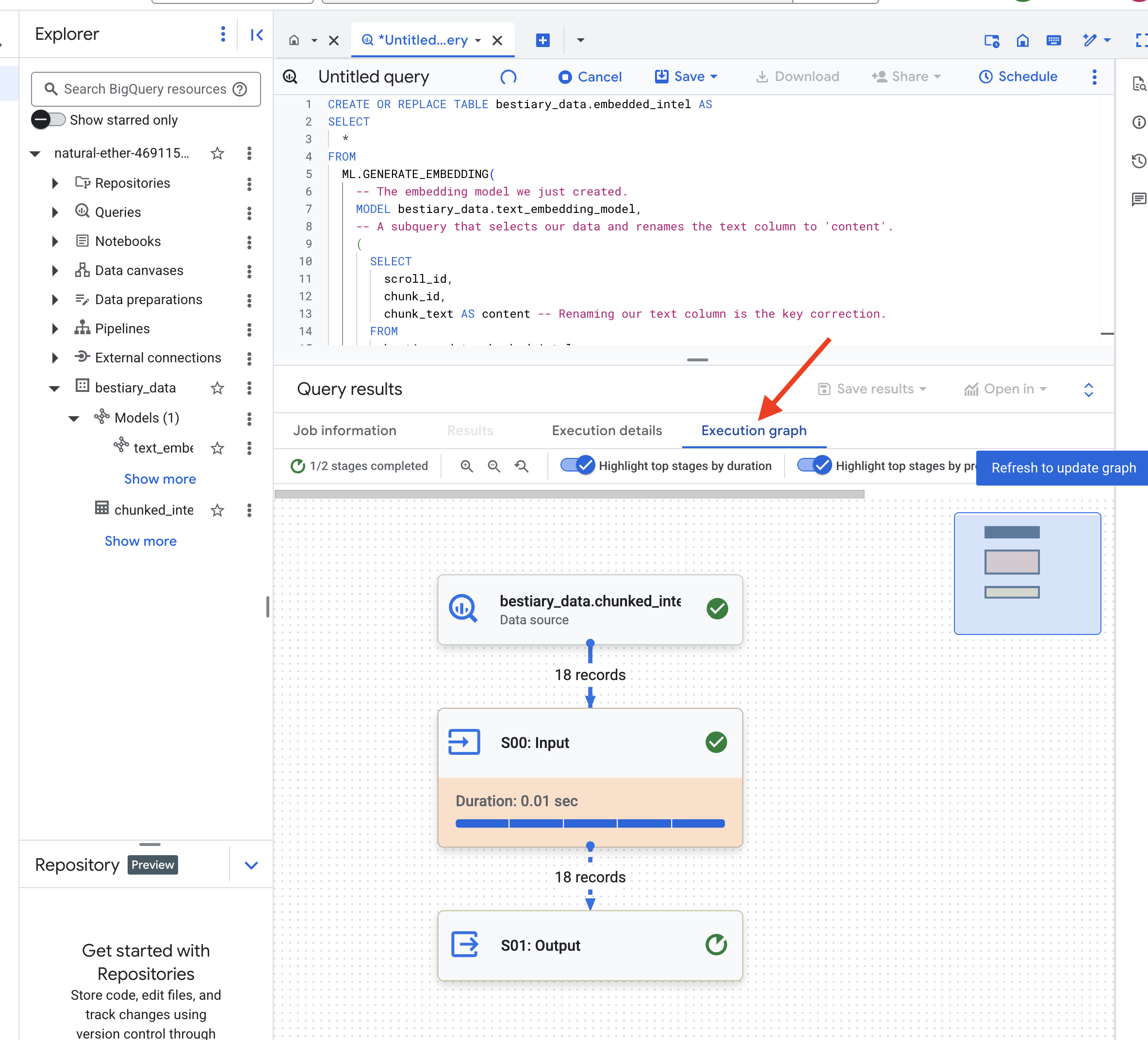
👉📜 بعد اكتمال العملية، افحص الجدول الجديد للاطّلاع على البصمات الدلالية.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
سيظهر الآن عمود جديد، ml_generate_embedding_result، يحتوي على التمثيل المتّجهي الكثيف للنص. تم الآن ترميز Grimoire دلاليًا.
طقس العرافة: البحث الدلالي باستخدام BQML
👉📜 الاختبار النهائي لـ Grimoire هو طرح سؤال عليه. سننفّذ الآن طقسنا الأخير: البحث المتجهي. هذا ليس بحثًا عن كلمات رئيسية، بل هو بحث عن المعنى. سنطرح سؤالاً بلغة طبيعية، وستحوّل BQML سؤالنا إلى تضمين أثناء التنفيذ، ثم ستبحث في جدول embedded_intel بالكامل للعثور على أجزاء النص التي تكون بصماتها "الأقرب" من حيث المعنى.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
تحليل التعويذة:
-
VECTOR_SEARCH: هي الوظيفة الأساسية التي تنظّم عملية البحث. ML.GENERATE_EMBEDDING(الاستعلام الداخلي): هذا هو الجزء المهم. نضمّن طلب البحث ('What are the tactics...') باستخدام النموذج نفسه ولكن مع نوع المهمة'RETRIEVAL_QUERY'، الذي تم تحسينه خصيصًا لطلبات البحث.-
top_k => 3: نطلب عرض أهم 3 نتائج ذات صلة. -
distance_type => 'COSINE': يقيس هذا المقياس "الزاوية" بين المتجهات. وتعني الزاوية الأصغر أنّ المعاني أكثر توافقًا.
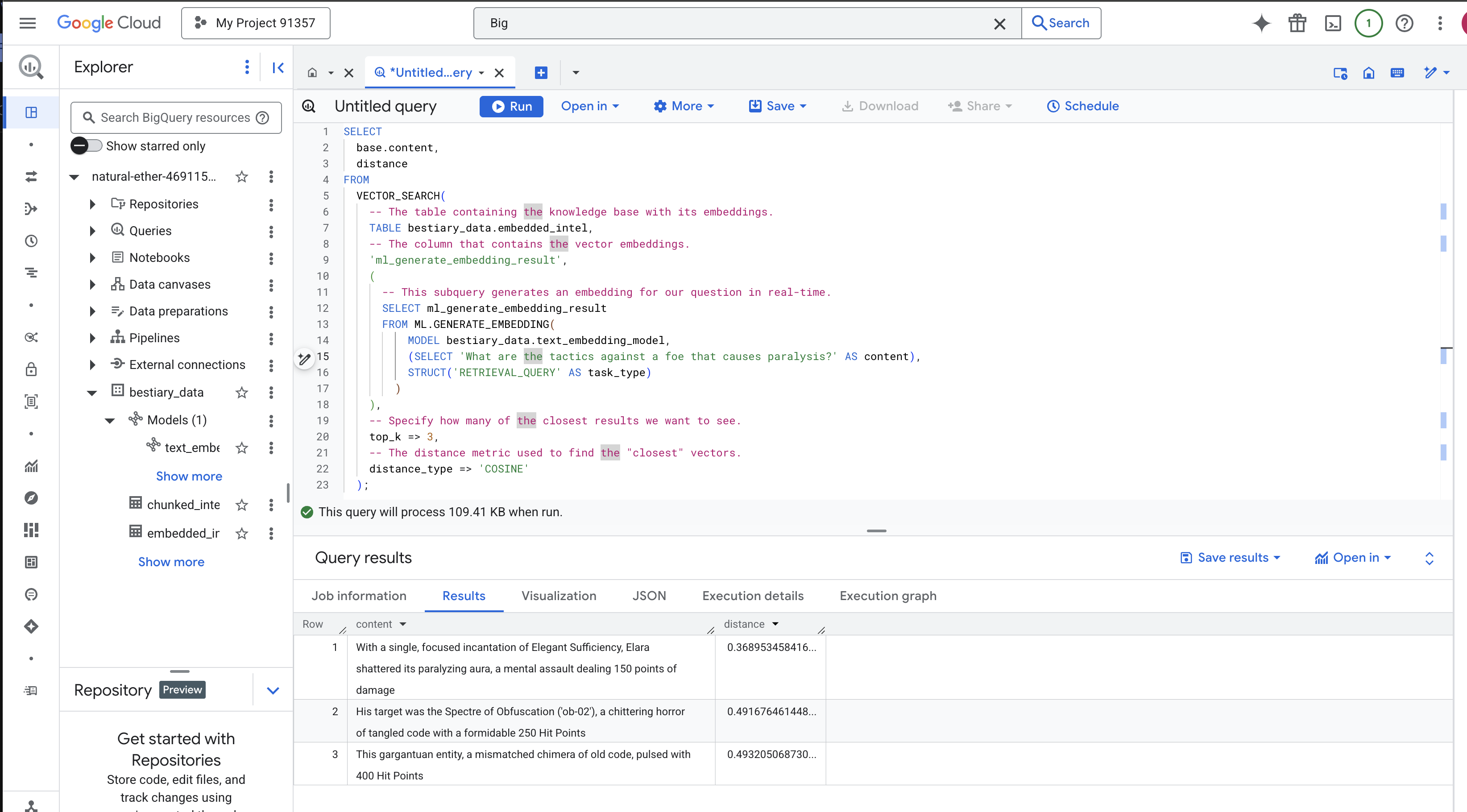
ألقِ نظرة فاحصة على النتائج. لم يتضمّن طلب البحث الكلمتَين "محطّم" أو "تعويذة"، ومع ذلك كانت النتيجة الأولى هي: "بإلقاء تعويذة واحدة ومركزة من تعويذات "الكفاية الأنيقة"، حطّمت إيلارا هالتها المسبّبة للشلل، وهي هجوم عقلي يسبّب 150 نقطة ضرر". هذه هي قوة البحث الدلالي. فهم النموذج مفهوم "أساليب مكافحة الشلل" وعثر على الجملة التي تصف أسلوبًا ناجحًا ومحدّدًا.
لقد أنشأت الآن بنجاح مسار RAG كاملاً يستند إلى مستودع البيانات. لقد أعددت البيانات الأولية وحوّلتها إلى متّجهات دلالية واستعلمت عنها حسب المعنى. في حين أنّ BigQuery هي أداة فعّالة لهذا العمل التحليلي الواسع النطاق، غالبًا ما ننقل هذه المعلومات المُعدّة إلى قاعدة بيانات تشغيلية متخصّصة لكي يتمكّن الموظف المباشر من تقديم ردود منخفضة الكمون. هذا هو موضوع تدريبنا التالي.
لغير اللاعبين
6. The Vector Scriptorium: Crafting the Vector Store with Cloud SQL for Inferencing
يتوفّر Grimoire حاليًا كجداول منظَّمة، وهو عبارة عن فهرس قوي للحقائق، ولكن معرفته حرفية. يفهم هذا النموذج أنّ monster_id = ‘MN-001'، ولكنّه لا يفهم المعنى الدلالي الأعمق وراء "التشويش". لكي نزوّد وكلاءنا بالمعرفة الحقيقية ونسمح لهم بتقديم النصائح الدقيقة والمدروسة، يجب أن نستخلص جوهر معرفتنا في شكل يوضّح المعنى: المتجهات.
قادنا سعينا إلى المعرفة إلى الأطلال المتداعية لحضارة سابقة منسية منذ زمن طويل. عثرنا على صندوق من اللفائف القديمة المحفوظة بشكلٍ مذهل، مدفونًا في قبو محكم الإغلاق. وهذه ليست مجرد تقارير معارك، بل تحتوي على حكمة فلسفية عميقة حول كيفية هزيمة وحش يبتلي كل المساعي العظيمة. كيان موصوف في المخطوطات بأنه "ركود زاحف وصامت" و "تآكل لنسيج الخلق". يبدو أنّ "الضوضاء الثابتة" كانت معروفة حتى لدى القدماء، وهي تهديد دوري ضاع تاريخه بمرور الوقت.
هذه المعرفة المنسية هي أعظم ما نملكه. فهي لا تساعدك على هزيمة الوحوش الفردية فحسب، بل تمنح المجموعة بأكملها نظرة استراتيجية. للاستفادة من هذه الإمكانات، سننشئ الآن "كتاب تعاويذ" حقيقيًا (قاعدة بيانات PostgreSQL تتضمّن إمكانات متّجهة) و"مكتبة مخطوطات متّجهة" مبرمَجة (مسار Dataflow) لقراءة هذه المخطوطات وفهمها وتسجيل جوهرها الخالد. سيحوّل هذا التغيير كتاب Grimoire من كتاب حقائق إلى محرك حكمة.

Forging the Scholar's Spellbook (Cloud SQL)
قبل أن نتمكّن من نقش جوهر هذه المخطوطات القديمة، يجب أولاً التأكّد من أنّ وعاء هذه المعرفة، أي Spellbook المستضاف على PostgreSQL، قد تم إنشاؤه بنجاح. من المفترض أنّ طقوس الإعداد الأوّلي قد أنشأت هذا الملف لك.
👉💻 في الوحدة الطرفية، شغِّل الأمر التالي للتحقّق من أنّ آلة Cloud SQL الافتراضية متوفّرة وجاهزة. يمنح هذا النص البرمجي أيضًا حساب الخدمة المخصّص للجهاز الظاهري الإذن باستخدام Vertex AI، وهو أمر ضروري لإنشاء التضمينات مباشرةً داخل قاعدة البيانات.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
إذا نجح الأمر وعرض تفاصيل حول مثيل grimoire-spellbook، يعني ذلك أنّ أداة Forge قد أدّت عملها بشكل جيد. أنت جاهز للمتابعة إلى التكرار التالي. إذا عرض الأمر الخطأ NOT_FOUND، يُرجى التأكّد من إكمال خطوات الإعداد الأوّلي للبيئة بنجاح قبل المتابعة.(data_setup.py)
👉💻 بعد إنشاء الكتاب، نفتح الفصل الأول من خلال إنشاء قاعدة بيانات جديدة باسم arcane_wisdom.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
كتابة رموز Semantic Runes: تفعيل إمكانات المتجهات باستخدام pgvector
بعد إنشاء مثيل Cloud SQL، لننتقل إلى ربطه باستخدام Cloud SQL Studio المضمّن. توفّر هذه الأداة واجهة مستندة إلى الويب لتنفيذ طلبات بحث SQL مباشرةً على قاعدة البيانات.
👉💻 أولاً، انتقِل إلى Cloud SQL Studio. أسهل وأسرع طريقة للوصول إليه هي فتح الرابط التالي في علامة تبويب متصفّح جديدة. سينقلك هذا الرابط مباشرةً إلى Cloud SQL Studio لمثيل grimoire-spellbook.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 اختَر arcane_wisdom كقاعدة بيانات، وأدخِل postgres كاسم مستخدم و1234qwer ككلمة مرور، ثم انقر على مصادقة.
👉📜 في أداة تعديل الاستعلامات في SQL Studio، انتقِل إلى علامة التبويب Editor 1، وألصِق رمز SQL التالي لتفعيل نوع بيانات المتّجه:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
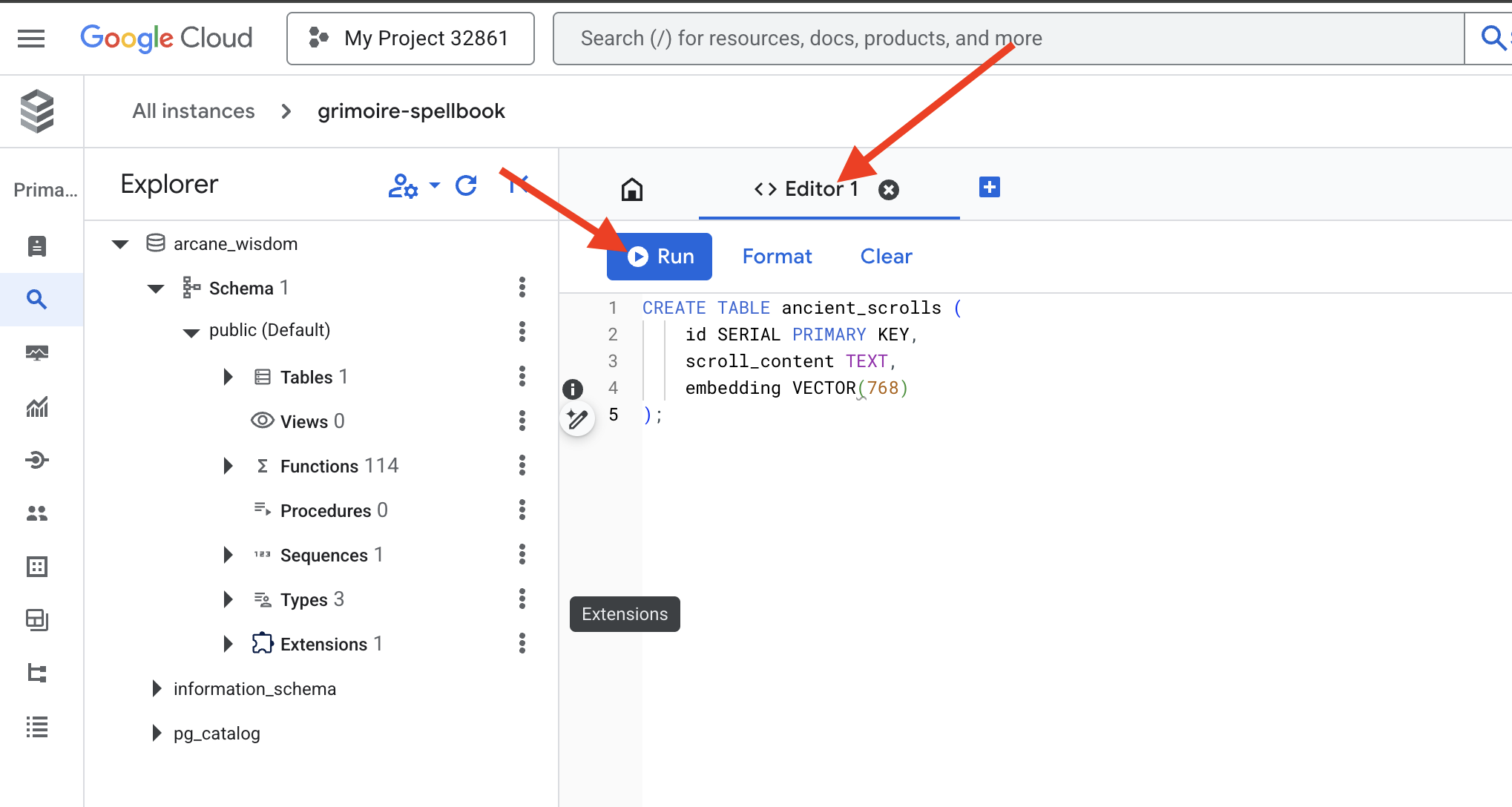
👉📜 جهِّز صفحات كتاب التعاويذ من خلال إنشاء الجدول الذي سيحتوي على جوهر اللفائف.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
العبارة VECTOR(768) هي تفصيل مهم. يستخلص نموذج التضمين في Vertex AI الذي سنستخدمه (textembedding-gecko@003 أو نموذج مشابه) النص في متجه ذي 768 بُعدًا. يجب أن تكون صفحات Spellbook جاهزة لاستيعاب جوهر بهذا الحجم بالضبط. يجب أن تتطابق الأبعاد دائمًا.
The First Transliteration: A Manual Inscription Ritual
قبل أن نطلب من مجموعة من الناسخين الآليين (Dataflow) تنفيذ مهمة، يجب أن ننفّذ الطقس المركزي يدويًا مرة واحدة. سيساعدنا ذلك في تقدير السحر المكوّن من خطوتين:
- التكهّن: أخذ جزء من النص والرجوع إلى أوراكل Gemini لاستخلاص جوهره الدلالي في متجه
- التسجيل: كتابة النص الأصلي وجوهره المتجهي الجديد في Spellbook.
لننفّذ الآن الطقس اليدوي.
👉📜 في Cloud SQL Studio سنستخدم الآن الدالة embedding()، وهي ميزة فعّالة توفّرها الإضافة google_ml_integration. يتيح لنا ذلك استدعاء نموذج التضمين في Vertex AI مباشرةً من طلب بحث SQL، ما يسهّل العملية بشكل كبير.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 تحقَّق من عملك من خلال تنفيذ طلب بحث لقراءة الصفحة التي تمّت كتابتها حديثًا:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
لقد نفّذت بنجاح مهمة تحميل بيانات RAG الأساسية يدويًا.
صناعة البوصلة الدلالية: إضفاء السحر على كتاب التعاويذ باستخدام فهرس HNSW
يمكن الآن لتطبيق Spellbook تخزين الحكمة، ولكن العثور على المخطوطة المناسبة يتطلب قراءة كل صفحة. إنّه مسح تسلسلي. هذا الإجراء بطيء وغير فعّال. لتوجيه طلبات البحث على الفور إلى المعلومات الأكثر صلة، يجب أن نزوّد Spellbook ببوصلة دلالية، أي فهرس متّجهي.
لنثبت قيمة هذه السمة السحرية.
👉📜 في Cloud SQL Studio، شغِّل التعليمة البرمجية التالية. يحاكي هذا الإجراء البحث عن التمرير الجديد الذي أدرجناه ويطلب من قاعدة البيانات EXPLAIN خطتها.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
اطّلِع على الناتج. سيظهر سطر مكتوب فيه -> Seq Scan on ancient_scrolls. يؤكّد ذلك أنّ قاعدة البيانات تقرأ كل صف على حدة. يُرجى ملاحظة execution time.
👉📜 لنبدأ الآن عملية الفهرسة. تخبر المَعلمة lists الفهرس بعدد المجموعات التي يجب إنشاؤها. نقطة البداية الجيدة هي الجذر التربيعي لعدد الصفوف التي تتوقّع الحصول عليها.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
انتظِر إلى أن يتم إنشاء الفهرس (سيكون سريعًا لصف واحد، ولكن قد يستغرق وقتًا لملايين الصفوف).
👉📜 الآن، نفِّذ الأمر EXPLAIN ANALYZE نفسه مرة أخرى:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
اطّلِع على خطة طلب البحث الجديدة. سيظهر لك الآن -> Index Scan using.... والأهم من ذلك، اطّلِع على execution time. ستكون العملية أسرع بكثير، حتى مع إدخال واحد فقط. لقد أظهرت للتو المبدأ الأساسي لضبط أداء قاعدة البيانات في عالم متّجه.
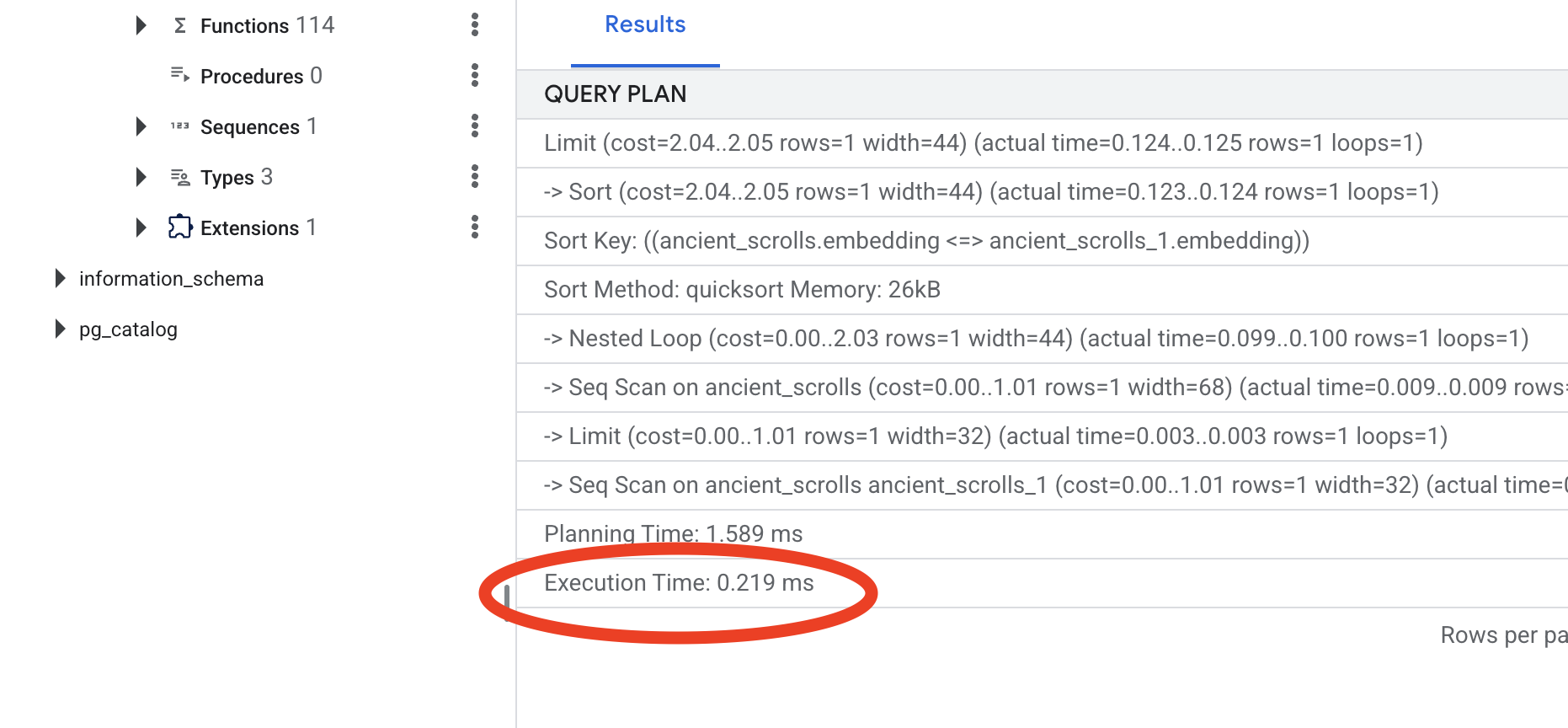
بعد فحص بيانات المصدر وفهم طقوسك اليدوية وتحسين Spellbook لتحقيق السرعة، ستكون الآن مستعدًا حقًا لإنشاء Scriptorium المبرمَج.
لغير اللاعبين
7. The Conduit of Meaning: Building a Dataflow Vectorization Pipeline
والآن، سننشئ خط التجميع السحري للكتبة الذين سيقرأون مخطوطاتنا ويستخلصون جوهرها ويدوّنونها في كتاب التعاويذ الجديد. هذا هو مسار Dataflow الذي سنفعّله يدويًا. ولكن قبل كتابة التعليمة البرمجية الرئيسية لخطوات المعالجة نفسها، يجب أولاً إعداد الأساس والدائرة التي سنستدعي منها هذه الخطوات.
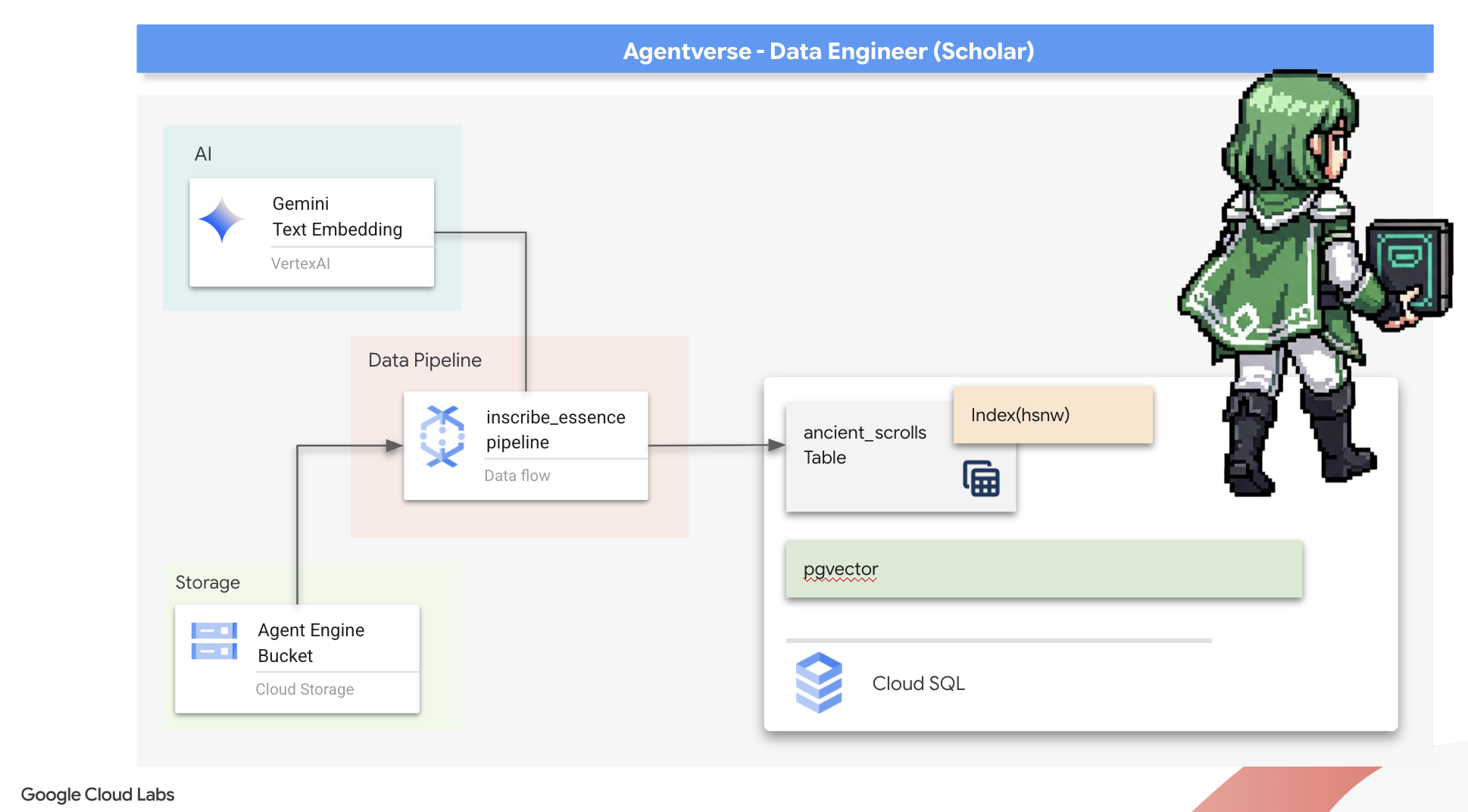
تجهيز مؤسسة Scriptorium (صورة العامل)
سيتم تنفيذ مسار Dataflow من خلال فريق من العمال المبرمَجين في السحابة الإلكترونية. وفي كل مرة نستدعي فيها هذه الأدوات، تحتاج إلى مجموعة محدّدة من المكتبات لتنفيذ مهمتها. يمكننا أن نقدّم لهم قائمة ونطلب منهم استرداد هذه المكتبات في كل مرة، ولكنّ ذلك بطيء وغير فعّال. يُعدّ الباحث الحكيم مكتبة رئيسية مسبقًا.
سنطلب هنا من Google Cloud Build إنشاء صورة حاوية مخصّصة. هذه الصورة هي "غلام مثالي"، تم تحميلها مسبقًا بكل مكتبة وتبعيات سيحتاجها الكتّاب. عندما تبدأ مهمة Dataflow، ستستخدم هذه الصورة المخصّصة، ما يسمح للعاملين ببدء مهمتهم على الفور تقريبًا.
👉💻 نفِّذ الأمر التالي لإنشاء الصورة الأساسية لبرنامجك وتخزينها في Artifact Registry.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 شغِّل الأوامر التالية لإنشاء بيئة Python معزولة وتفعيلها وتثبيت مكتبات الاستدعاء اللازمة فيها.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
The Master Incantation
حان الوقت لكتابة التعويذة الرئيسية التي ستشغّل Vector Scriptorium. لن نكتب المكوّنات السحرية الفردية من البداية. مهمتنا هي تجميع المكوّنات في مسار منطقي وفعّال باستخدام لغة Apache Beam.
- EmbedTextBatch (استشارة Gemini): ستنشئ هذا الكاتب المتخصّص الذي يعرف كيفية إجراء "تكهّن جماعي". يأخذ هذا التطبيق مجموعة من ملفات النصوص الأولية، ويعرضها على نموذج تضمين النصوص في Gemini، ويتلقّى جوهرها المقطّر (عمليات التضمين المتجهة).
- WriteEssenceToSpellbook (النقش النهائي): هذا هو الأرشيفي. يعرف هذا التطبيق التعاويذ السرية لفتح اتصال آمن بـ "كتاب التعاويذ" في Cloud SQL. مهمته هي أخذ محتوى صفحة التمرير وجوهره المتجهي وكتابتهما بشكل دائم على صفحة جديدة.
مهمتنا هي ربط هذه الإجراءات معًا لإنشاء تدفّق سلس للمعرفة.
👉✏️ في "محرّر Cloud Shell"، انتقِل إلى ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py، وستجد في الداخل فئة DoFn باسم EmbedTextBatch. ابحث عن التعليق #REPLACE-EMBEDDING-LOGIC. استبدِلها بالتعويذة التالية.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
هذه التعويذة دقيقة، وتتضمّن عدة معلَمات رئيسية:
- model: نحدّد
text-embedding-005لاستخدام نموذج تضمين قوي وحديث. - المحتويات: هذه قائمة بكل المحتوى النصي من مجموعة الملفات التي تتلقّاها DoFn.
- task_type: نضبط هذه السمة على "RETRIEVAL_DOCUMENT". هذه تعليمات مهمة تخبر Gemini بإنشاء تضمينات محسّنة خصيصًا ليتم العثور عليها لاحقًا في عملية بحث.
- output_dimensionality: يجب ضبط هذه السمة على 768، ما يتطابق تمامًا مع سمة VECTOR(768) التي حدّدناها عند إنشاء جدول ancient_scrolls في Cloud SQL. تُعدّ الأبعاد غير المتطابقة مصدرًا شائعًا للأخطاء في Vector Magic.
يجب أن تبدأ عملية المعالجة بقراءة النص الأولي غير المنظَّم من جميع المخطوطات القديمة في أرشيف GCS.
👉✏️ في ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py، ابحث عن التعليق #REPLACE ME-READFILE واستبدِله بالتعويذة التالية المكوّنة من ثلاثة أجزاء:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
بعد جمع النصوص الأولية للمخطوطات، علينا الآن إرسالها إلى Gemini للتنبؤ. لإجراء ذلك بكفاءة، سنقسّم أولاً كل المخطوطات إلى مجموعات صغيرة، ثم نقدّم هذه المجموعات إلى EmbedTextBatch كاتبنا. ستؤدي هذه الخطوة أيضًا إلى فصل أي تمرير سريع لا يفهمه Gemini إلى حزمة "تعذّر" لمراجعته لاحقًا.
👉✏️ ابحث عن التعليق #REPLACE ME-EMBEDDING واستبدِله بما يلي:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
تمكّنا من تلخيص جوهر محتوى خلاصاتنا بنجاح. الخطوة الأخيرة هي تسجيل هذه المعرفة في كتاب التعاويذ لتخزينها بشكل دائم. سنأخذ المخطوطات من كومة "المعالجة" ونسلّمها إلى أمين الأرشيف في WriteEssenceToSpellbook.
👉✏️ ابحث عن التعليق #REPLACE ME-WRITE TO DB واستبدِله بما يلي:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
لا يتجاهل الباحث الحكيم المعرفة أبدًا، حتى المحاولات الفاشلة. كخطوة أخيرة، يجب أن نطلب من كاتب أن يأخذ كومة "النتائج غير الصالحة" من خطوة التكهّن وأن يسجّل أسباب عدم الصلاحية. يتيح لنا ذلك تحسين طقوسنا في المستقبل.
👉✏️ ابحث عن التعليق #REPLACE ME-LOG FAILURES واستبدِله بما يلي:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
اكتملت الآن التعويذة الرئيسية! لقد تمكّنت بنجاح من تجميع مسار بيانات قوي ومتعدّد المراحل من خلال ربط المكوّنات السحرية الفردية معًا. احفظ ملف inscribe_essence_pipeline.py. أصبح بإمكانك الآن استدعاء Scriptorium.
الآن، نلقي تعويذة الاستدعاء الكبرى لنأمر خدمة Dataflow بإيقاظ Golem وبدء طقس الكتابة.
👉💻 في الوحدة الطرفية، نفِّذ سطر الأوامر التالي
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 تنبيه: إذا تعذّرت المهمة بسبب خطأ في الموارد ZONE_RESOURCE_POOL_EXHAUSTED، قد يرجع ذلك إلى قيود مؤقتة على الموارد في هذا الحساب ذي السمعة المنخفضة في المنطقة المحدّدة. تكمن قوة Google Cloud في نطاق وصولها العالمي. ما عليك سوى محاولة استدعاء الغولم في منطقة مختلفة. لإجراء ذلك، استبدِل --region=$REGION في الأمر أعلاه بمنطقة أخرى، مثل
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
، ثم أعِد تشغيله. 🎰
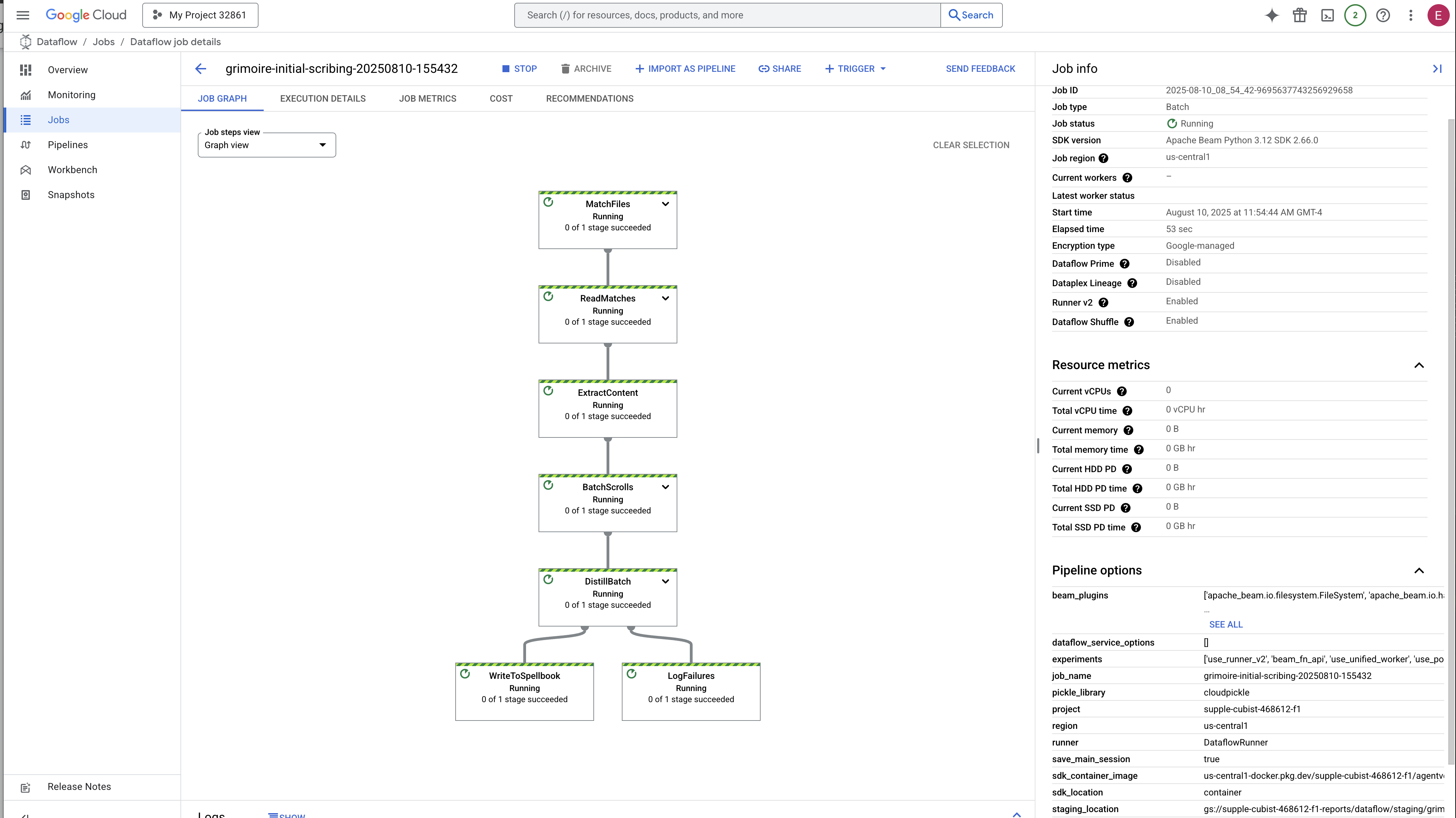
تستغرق العملية من 3 إلى 5 دقائق تقريبًا لبدء التشغيل وإكماله. يمكنك مشاهدة البث المباشر في وحدة تحكّم Dataflow.
👉انتقِل إلى "وحدة تحكّم Dataflow": أسهل طريقة هي فتح هذا الرابط المباشر في علامة تبويب متصفّح جديدة:
https://console.cloud.google.com/dataflow
👉 العثور على وظيفتك والنقر عليها: ستظهر وظيفة مدرَجة بالاسم الذي قدّمته (inscribe-essence-job أو ما شابه ذلك). انقر على اسم مهمة لفتح صفحة التفاصيل الخاصة بها. مراقبة مسار الإعداد:
- بدء التشغيل: في أول 3 دقائق، ستكون حالة المهمة "قيد التشغيل" بينما يوفّر Dataflow الموارد اللازمة. سيظهر الرسم البياني، ولكن قد لا ترى البيانات تنتقل من خلاله بعد.
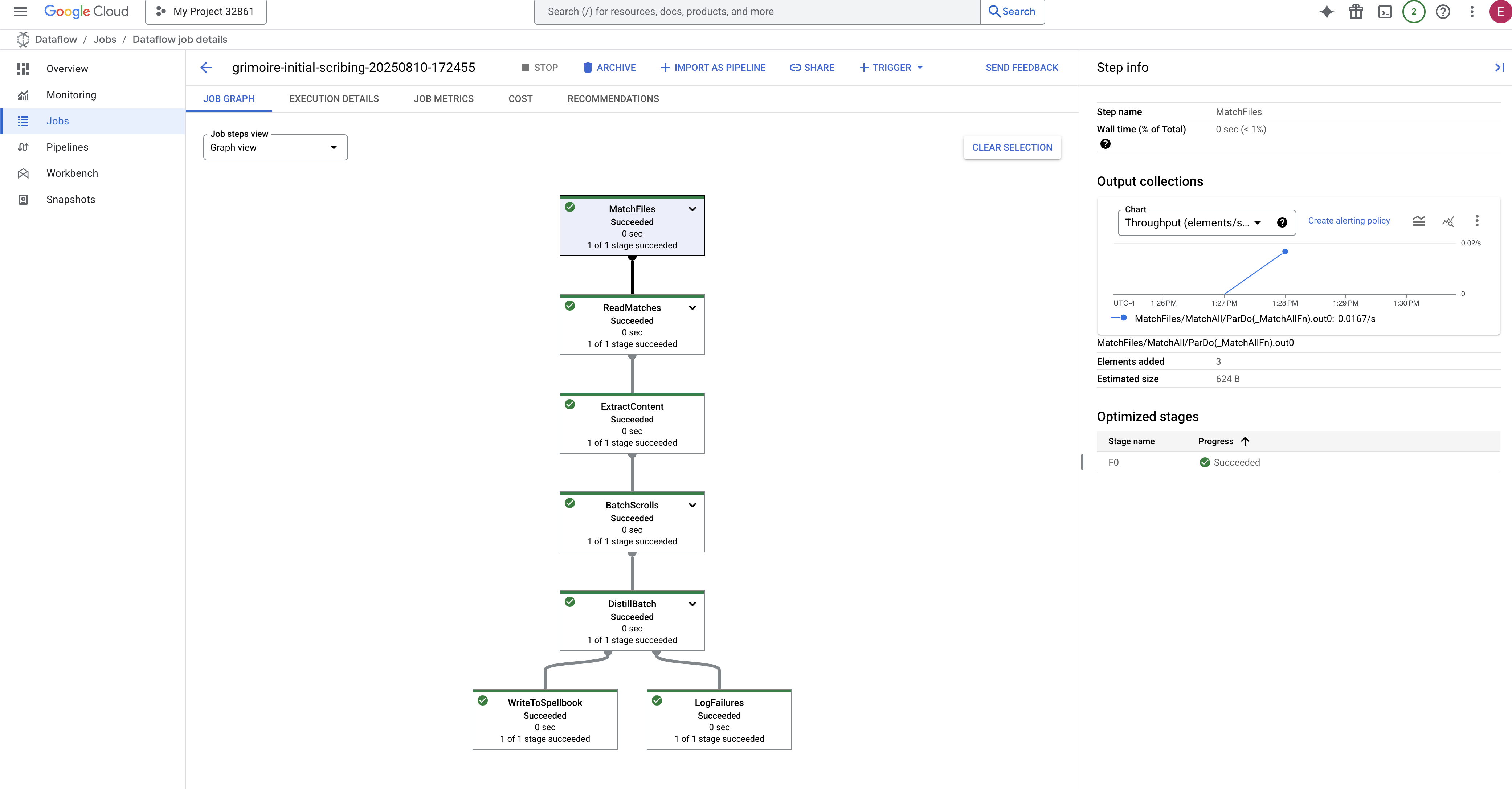
- مكتملة: عند الانتهاء، ستتغيّر حالة المهمة إلى "ناجحة"، وسيقدم الرسم البياني العدد النهائي للسجلات التي تمت معالجتها.
التحقّق من صحة النقش
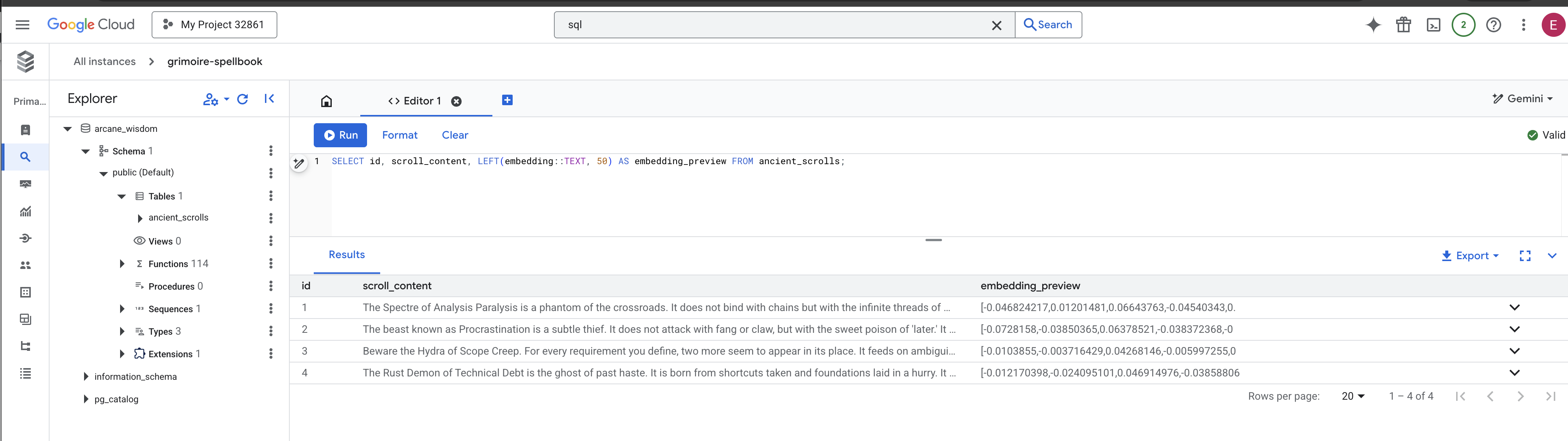
👉📜 في "استوديو SQL"، شغِّل طلبات البحث التالية للتأكّد من أنّه تم تسجيل المخطوطات وجوهرها الدلالي بنجاح.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
سيؤدي ذلك إلى عرض معرّف التمرير والنص الأصلي ومعاينة لجوهر المتّجه السحري المكتوب الآن بشكل دائم في Grimoire.
أصبح كتاب السحر الخاص بك الآن محرّك معرفة حقيقيًا، وجاهزًا للاستعلام عنه حسب المعنى في الفصل التالي.
8. إكمال الرونية الأخيرة: تفعيل الحكمة باستخدام وكيل RAG
لم يعُد Grimoire مجرد قاعدة بيانات. إنّها مصدر غني بالمعلومات المتجهة، وهي عبارة عن وسيط صامت ينتظر سؤالاً.
والآن، سنخوض الاختبار الحقيقي لأي باحث، وهو صياغة المفتاح الذي يتيح الاستفادة من هذه الحكمة. سننشئ وكيل التوليد المعزّز بالاسترجاع (RAG). هذا البناء السحري يمكنه فهم سؤال بلغة بسيطة، والرجوع إلى كتاب السحر للحصول على أعمق الحقائق وأكثرها صلة بالموضوع، ثم استخدام هذه الحكمة المسترجَعة لصياغة إجابة قوية ومراعية للسياق.

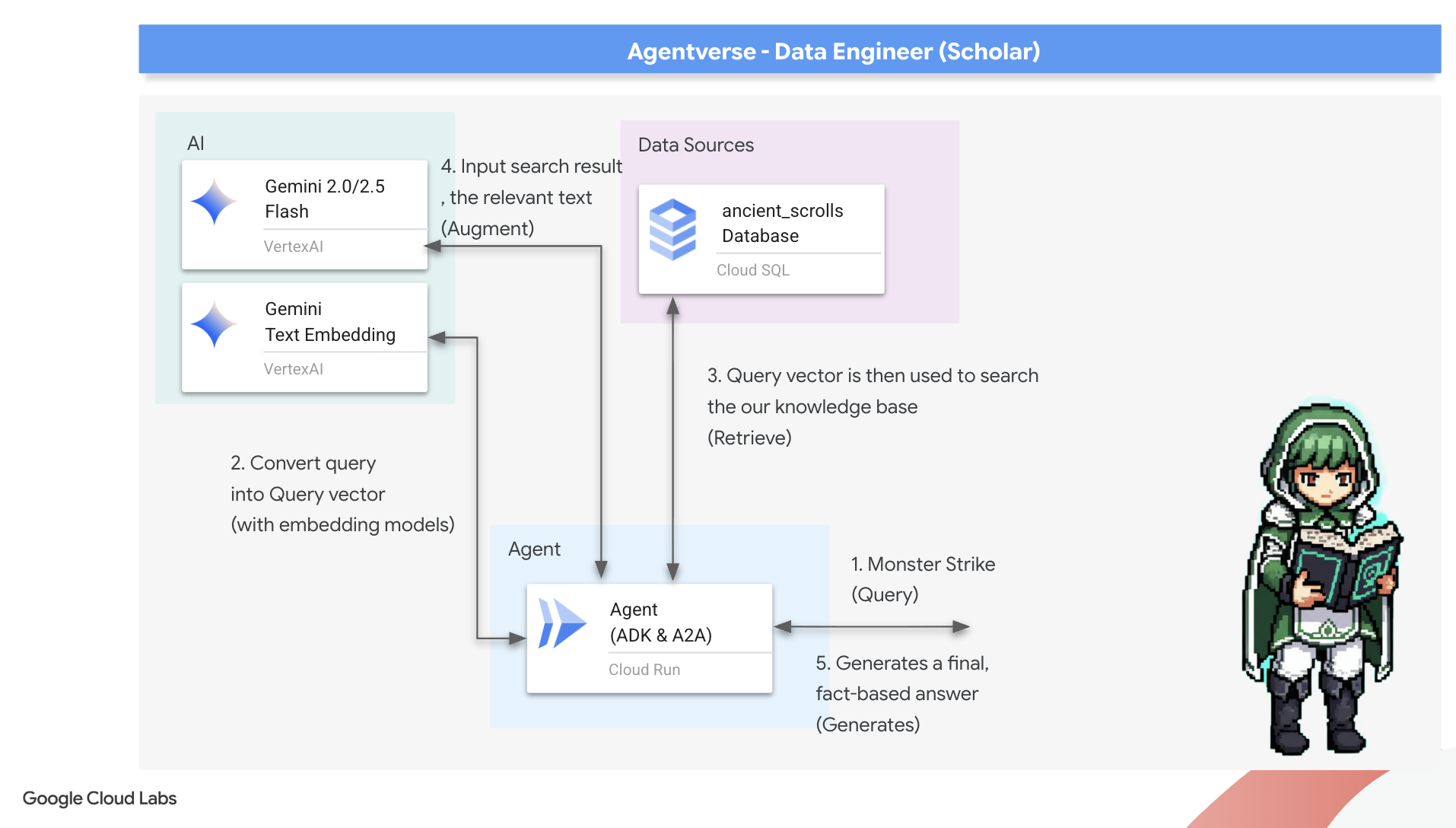
الرون الأول: تعويذة تقطير طلب البحث
قبل أن يتمكّن الوكيل من البحث في Grimoire، يجب أولاً أن يفهم جوهر السؤال المطروح. إنّ سلسلة نصية بسيطة لا معنى لها بالنسبة إلى Spellbook المستند إلى المتجهات. يجب أن يتلقّى الوكيل طلب البحث أولاً، ثم يستخدم نموذج Gemini نفسه لتحويله إلى متّجه طلب بحث.
👉✏️ في Cloud Shell Editor، انتقِل إلى الملف ~~/agentverse-dataengineer/scholar/agent.py، وابحث عن التعليق #REPLACE RAG-CONVERT EMBEDDING واستبدِله بهذا النص السحري. تعلّم هذه الخطوة الوكيل كيفية تحويل سؤال المستخدم إلى جوهر سحري.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
بعد الحصول على جوهر الطلب، يمكن لوكيل المحادثة الآن الرجوع إلى Grimoire. سيتم عرض متجه طلب البحث هذا في قاعدة البيانات المحسّنة باستخدام pgvector وطرح السؤال التالي: "أريد عرض المخطوطات القديمة التي تشبه جوهر طلب البحث الخاص بي".
يكمن سرّ ذلك في عامل تشابه جيب التمام (<=>)، وهو رمز قوي يحسب المسافة بين المتجهات في المساحات العالية الأبعاد.
👉✏️ في ملف agent.py، ابحث عن التعليق #REPLACE RAG-RETRIEVE واستبدِله بالنص البرمجي التالي:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
الخطوة الأخيرة هي منح الوكيل إذن الوصول إلى هذه الأداة الجديدة والفعّالة. سنضيف الدالة grimoire_lookup إلى قائمة الأدوات السحرية المتاحة.
👉✏️ في agent.py، ابحث عن التعليق #REPLACE-CALL RAG واستبدِله بهذا السطر:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
تُضفي هذه الإعدادات الحيوية على الوكيل:
model="gemini-2.5-flash": يختار هذا الحقل "النموذج اللغوي الكبير" المحدّد الذي سيشكّل "عقل" الوكيل للاستدلال وإنشاء النصوص.name="scholar_agent": يحدّد اسمًا فريدًا للوكيل.instruction="...You are the Scholar...": هذا هو طلب النظام، وهو الجزء الأكثر أهمية في عملية الإعداد. ويحدّد شخصية الوكيل وأهدافه والعملية الدقيقة التي يجب اتّباعها لإكمال مهمة والتنسيق المطلوب للناتج النهائي.tools=[grimoire_lookup]: هذه هي التعويذة النهائية. يمنح هذا الإذن الوكيل إمكانية الوصول إلى الدالةgrimoire_lookupالتي أنشأتها. يمكن للوكيل الآن أن يقرّر بذكاء متى يستدعي هذه الأداة لاسترجاع المعلومات من قاعدة البيانات، ما يشكّل جوهر نمط التوليد المعزَّز بالاسترجاع.
امتحان الباحث العلمي
👉💻 في وحدة طرفية Cloud Shell، فعِّل بيئتك واستخدِم الأمر الأساسي في "حزمة تطوير الوكيل" لتنشيط وكيل Scholar:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
من المفترض أن تظهر لك نتيجة تؤكّد أنّ "وكيل Scholar" يعمل.
👉💻 والآن، تحدَّ وكيلك. في الوحدة الطرفية الأولى التي يتم فيها تشغيل محاكاة المعركة، أصدِر أمرًا يتطلّب حكمة Grimoire:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

اطّلِع على السجلّات في نافذة المحطة الطرفية. سترى كيف يتلقّى الوكيل طلب البحث، ويستخلص جوهره، ويبحث في Grimoire، ويجد اللفائف ذات الصلة بموضوع "التسويف"، ويستخدم هذه المعرفة المسترجَعة لصياغة استراتيجية فعّالة ومراعية للسياق.
لقد تمكّنت بنجاح من تجميع أول وكيل RAG وتزويده بالحكمة العميقة من Grimoire.
👉💻 اضغط على Ctrl+C في نافذة Terminal لإيقاف الوكيل مؤقتًا.
إطلاق Scholar Sentinel في Agentverse
أثبت وكيلك فعاليته في البيئة الخاضعة للرقابة في دراستك. لقد حان الوقت لإطلاقه في Agentverse، ما سيحوّله من بنية محلية إلى عنصر دائم وجاهز للمعركة يمكن لأي بطل الاستعانة به في أي وقت. سننشر الآن الوكيل على Cloud Run.
👉💻 شغِّل تعويذة الاستدعاء الكبرى التالية. سيعمل هذا النص البرمجي أولاً على إنشاء وكيلك في Golem مثالي (صورة حاوية)، وتخزينه في Artifact Registry، ثم نشره كخدمة قابلة للتوسيع وآمنة ويمكن الوصول إليها بشكل علني.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
أصبح "وكيل Scholar" الآن وكيلًا حيويًا وجاهزًا للمعركة في Agentverse.
لغير اللاعبين
9- The Boss Flight
تمت قراءة المخطوطات وإجراء الطقوس واجتياز التحدي. وكيلك ليس مجرد عنصر مخزّن، بل هو عنصر حيّ في Agentverse ينتظر مهمته الأولى. حان وقت التجربة النهائية، وهي عبارة عن تدريب على إطلاق النار الحي ضد خصم قوي.
ستدخل الآن في محاكاة ساحة معركة لتواجه عميل Shadowblade الذي تم نشره حديثًا ضدّ زعيم صغير قوي: شبح الثبات. سيكون هذا الاختبار النهائي لعملك، بدءًا من المنطق الأساسي للوكيل وصولاً إلى نشره.
الحصول على موضع وكيلك
قبل دخول ساحة المعركة، يجب أن يكون لديك مفتاحان: التوقيع الفريد الخاص بالبطل (Agent Locus) والمسار المخفي إلى عرين Spectre (عنوان URL الخاص بالزنزانة).
👉💻 أولاً، احصل على عنوان وكيلك الفريد في Agentverse، أي Locus. هذه هي نقطة النهاية المباشرة التي تربط البطل بساحة المعركة.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 بعد ذلك، حدِّد الوجهة بدقة. يكشف هذا الأمر عن موقع "دائرة الانتقال"، وهي البوابة المؤدية إلى عالم "الشبح".
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
ملاحظة مهمة: احتفِظ بكلا عنوانَي URL هذين. ستحتاج إليهما في الخطوة الأخيرة.
مواجهة الشبح
بعد الحصول على الإحداثيات، عليك الانتقال إلى "دائرة الانتقال الآني" وإلقاء التعويذة لبدء المعركة.
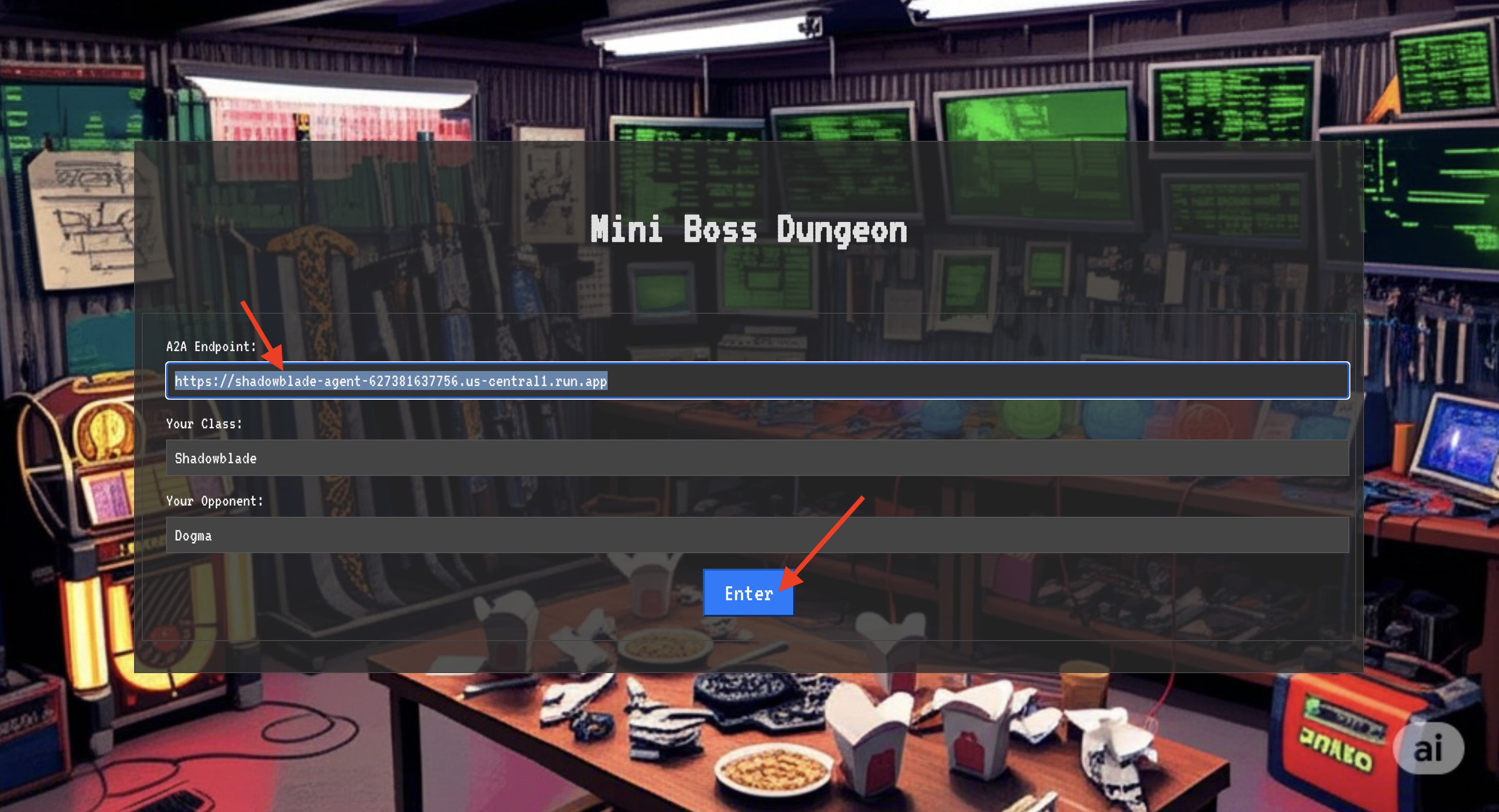
👉 افتح عنوان URL الخاص بدائرة الانتقال الآني في المتصفّح للوقوف أمام البوابة المتلألئة المؤدية إلى "قلعة كريمسون".
لاختراق الحصن، يجب أن تضبط جوهر Shadowblade على البوابة.
- في الصفحة، ابحث عن حقل إدخال الأحرف الرونية الذي يحمل التصنيف عنوان URL لنقطة نهاية A2A.
- أدخِل رمز بطلك عن طريق لصق عنوان URL لموقع العميل (أول عنوان URL نسخته) في هذا الحقل.
- انقر على "ربط" للاستفادة من ميزة التنقّل السريع.
تتلاشى الإضاءة المبهرة لعملية الانتقال الآني. لم تعُد في ملاذك. كان الهواء يضجّ بالطاقة، باردًا وحادًا. يظهر أمامك الشبح، وهو عبارة عن دوامة من التشويش المتصاعد والرموز التالفة، ويُلقي ضوؤه الشرير ظلالًا طويلة متراقصة على أرضية الزنزانة. ليس له وجه، لكنّك تشعر بحضوره الهائل والمستنزف الذي يركّز عليك تمامًا.
طريقك الوحيد نحو النصر يكمن في وضوح قناعتك. هذه معركة إرادات، تُخاض في ساحة عقلية.
بينما تندفع إلى الأمام، مستعدًا لشن هجومك الأول، يصدّك الشبح. لا يرفع درعًا، بل يطرح سؤالاً مباشرةً في وعيك، وهو عبارة عن تحدٍّ متلألئ ومكتوب برموز رونية مستمد من جوهر تدريبك.

هذه هي طبيعة المعركة. معرفتك هي سلاحك.
- أجِب باستخدام الحكمة التي اكتسبتها، وسينطلق سيفك بطاقة نقية، مما يؤدي إلى تحطيم دفاع الشبح وتوجيه ضربة حاسمة.
- ولكن إذا تراجعت أو شككت في إجابتك، سيخفت ضوء سلاحك. ستسقط الضربة بصوت خفيف، ولن تُحدث سوى جزء بسيط من الضرر. والأسوأ من ذلك، أنّ "الشبح" سيتغذى على عدم يقينك، وستزداد قوته المفسدة مع كل خطوة خاطئة.
هذا هو المطلوب يا بطل. التعليمات البرمجية هي كتاب السحر، والمنطق هو السيف، والمعرفة هي الدرع الذي سيصدّ موجة الفوضى.
التركيز العبارة صحيحة. يتوقف مصير Agentverse على ذلك.
تهانينا، أيها الباحث.
لقد أكملت الفترة التجريبية بنجاح. لقد أتقنت فنون هندسة البيانات، وحوّلت المعلومات الأولية والفوضوية إلى حكمة منظَّمة وموجَّهة تمكّن Agentverse بأكمله.
10. Cleanup: Expunging the Scholar's Grimoire
تهانينا على إتقان استخدام "كتاب الساحر". لضمان بقاء Agentverse في أفضل حالاته وإزالة أي بيانات غير ضرورية، عليك الآن تنفيذ طقوس التنظيف النهائية. سيؤدي هذا الإجراء إلى إزالة جميع المراجع التي تم إنشاؤها أثناء رحلتك التعليمية بشكل منهجي.
إيقاف مكوّنات Agentverse
عليك الآن تفكيك المكوّنات التي تم نشرها في نظام RAG بشكل منهجي.
حذف جميع خدمات Cloud Run ومستودع Artifact Registry
يزيل هذا الأمر وكيل Scholar المنشور وتطبيق Dungeon من Cloud Run.
👉💻 في الوحدة الطرفية، شغِّل الأوامر التالية:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
حذف مجموعات بيانات ونماذج وجداول BigQuery
يؤدي هذا الإجراء إلى إزالة جميع موارد BigQuery، بما في ذلك مجموعة بيانات bestiary_data وجميع الجداول بداخلها والاتصال والنماذج المرتبطة بها.
👉💻 في الوحدة الطرفية، شغِّل الأوامر التالية:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
حذف مثيل Cloud SQL
يؤدي هذا الإجراء إلى إزالة مثيل grimoire-spellbook، بما في ذلك قاعدة البيانات وجميع الجداول داخله.
👉💻 في الوحدة الطرفية، شغِّل الأمر التالي:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
حذف حِزم Google Cloud Storage
يزيل هذا الأمر الحزمة التي كانت تحتوي على معلوماتك الأولية وملفات Dataflow المؤقتة/المرحلية.
👉💻 في الوحدة الطرفية، شغِّل الأمر التالي:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
تنظيف الملفات والأدلة المحلية (Cloud Shell)
أخيرًا، امحُ بيئة Cloud Shell من المستودعات المستنسخة والملفات التي تم إنشاؤها. هذه الخطوة اختيارية، ولكن ننصح بها بشدة لإجراء تنظيف كامل لدليل العمل.
👉💻 في الوحدة الطرفية، شغِّل الأمر التالي:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
بذلك تكون قد محوت بنجاح جميع آثار رحلتك في Agentverse Data Engineer. مشروعك نظيف وأنت مستعد لمغامرتك التالية.