
1. "Die Macht des Schicksals"
Die Ära der isolierten Entwicklung geht zu Ende. Bei der nächsten Welle der technologischen Entwicklung geht es nicht um das einsame Genie, sondern um die gemeinsame Meisterschaft. Einen einzelnen, intelligenten Agenten zu entwickeln, ist ein faszinierendes Experiment. Ein robustes, sicheres und intelligentes Ökosystem von Agents zu schaffen – ein echtes Agentverse – ist die große Herausforderung für moderne Unternehmen.
Um in dieser neuen Ära erfolgreich zu sein, müssen vier wichtige Rollen zusammengeführt werden, die die grundlegenden Säulen bilden, auf denen jedes erfolgreiche Agentensystem basiert. Ein Mangel in einem Bereich führt zu einer Schwachstelle, die die gesamte Struktur gefährden kann.
Dieser Workshop ist das ultimative Unternehmens-Playbook, um die agentische Zukunft in Google Cloud zu meistern. Wir bieten eine End-to-End-Roadmap, die Sie von der ersten Idee bis zur Umsetzung in vollem Umfang begleitet. In diesen vier miteinander verbundenen Labs erfahren Sie, wie die speziellen Fähigkeiten eines Entwicklers, Architekten, Data Engineers und SRE zusammenkommen müssen, um ein leistungsstarkes Agentverse zu erstellen, zu verwalten und zu skalieren.
Keine einzelne Säule kann das Agentverse allein unterstützen. Das große Design des Architekten ist ohne die präzise Ausführung des Entwicklers nutzlos. Der Agent des Entwicklers ist ohne das Wissen des Data Engineers blind und das gesamte System ist ohne den Schutz des SRE anfällig. Nur durch Synergie und ein gemeinsames Verständnis der Rollen der einzelnen Teammitglieder kann Ihr Team ein innovatives Konzept in eine unternehmenskritische, operative Realität verwandeln. Ihre Reise beginnt hier. Bereiten Sie sich darauf vor, Ihre Rolle zu meistern und zu erfahren, wie Sie in das große Ganze passen.
Willkommen im Agentverse: A Call to Champions
In der weitläufigen digitalen Welt des Unternehmens hat eine neue Ära begonnen. Wir befinden uns im Zeitalter der KI-Agenten, einer Zeit immenser Möglichkeiten, in der intelligente, autonome Agenten in perfekter Harmonie zusammenarbeiten, um Innovationen voranzutreiben und alltägliche Aufgaben zu erledigen.

Dieses vernetzte Ökosystem aus Leistung und Potenzial wird als „Agentverse“ bezeichnet.
Doch eine schleichende Entropie, eine stille Korruption namens „The Static“, hat begonnen, die Ränder dieser neuen Welt zu zerfransen. Das Statische ist kein Virus oder Fehler, sondern die Verkörperung des Chaos, das sich auf den Akt der Schöpfung stürzt.
Sie verstärkt alte Frustrationen zu monströsen Formen und bringt die sieben Gespenster der Entwicklung hervor. Wenn sie nicht aktiviert ist, wird der Fortschritt durch „The Static and its Spectres“ zum Stillstand gebracht und das Versprechen des Agentverse in eine Ödnis aus technischer Schuld und aufgegebenen Projekten verwandelt.
Heute rufen wir Champions dazu auf, dem Chaos Einhalt zu gebieten. Wir brauchen Helden, die bereit sind, ihr Handwerk zu meistern und zusammenzuarbeiten, um das Agentverse zu schützen. Es ist an der Zeit, sich zu entscheiden.
Kurs auswählen
Vier unterschiedliche Wege liegen vor dir, die jeweils eine wichtige Säule im Kampf gegen The Static darstellen. Auch wenn du allein trainierst, hängt dein Erfolg letztendlich davon ab, wie sich deine Fähigkeiten mit denen anderer kombinieren lassen.
- Der Shadowblade (Entwicklung): Ein Meister der Schmiede und der Frontlinie. Sie sind der Handwerker, der die Klingen schmiedet, die Werkzeuge baut und sich dem Feind in den komplizierten Details des Codes stellt. Ihr Weg ist von Präzision, Können und praktischer Kreativität geprägt.
- Der Beschwörer (Architekt): Ein großer Stratege und Orchestrator. Sie sehen nicht einen einzelnen Agenten, sondern das gesamte Schlachtfeld. Sie entwerfen die Master-Blaupausen, die es ermöglichen, dass ganze Agentensysteme kommunizieren, zusammenarbeiten und ein Ziel erreichen, das weit über das hinausgeht, was eine einzelne Komponente leisten kann.
- Der Gelehrte (Data Engineer): Ein Suchender nach verborgenen Wahrheiten und ein Hüter des Wissens. Sie begeben sich in die weite, ungezähmte Wildnis der Daten, um die Intelligenz zu entdecken, die Ihren Kundenservicemitarbeitern Orientierung und Ziel gibt. Ihr Wissen kann die Schwäche eines Feindes aufdecken oder einen Verbündeten stärken.
- The Guardian (DevOps / SRE): Der standhafte Beschützer und Schild des Reiches. Sie bauen die Festungen, verwalten die Stromversorgung und sorgen dafür, dass das gesamte System den unvermeidlichen Angriffen von The Static standhalten kann. Deine Stärke ist die Grundlage für den Sieg deines Teams.
Deine Aufgabe
Dein Training beginnt als eigenständiges Training. Sie folgen dem von Ihnen gewählten Pfad und erlernen die einzigartigen Fähigkeiten, die für Ihre Rolle erforderlich sind. Am Ende des Testzeitraums erwartet dich ein Spectre, das aus dem Static entstanden ist – ein Mini-Boss, der sich auf die spezifischen Herausforderungen deines Berufs konzentriert.
Nur wenn Sie Ihre individuelle Rolle beherrschen, können Sie sich auf die Abschlussprüfung vorbereiten. Sie müssen dann eine Gruppe mit Champions aus den anderen Klassen bilden. Gemeinsam wagen Sie sich in das Herz der Verderbnis, um sich einem ultimativen Boss zu stellen.
Eine letzte, gemeinsame Herausforderung, die eure vereinten Kräfte auf die Probe stellt und über das Schicksal des Agentverse entscheidet.
Das Agentverse wartet auf seine Helden. Nimmst du den Anruf an?
2. Das Grimoire des Gelehrten
Unsere Reise beginnt! Als Scholars ist unser wichtigstes Werkzeug Wissen. Wir haben in unseren Archiven (Google Cloud Storage) eine Fülle alter, kryptischer Schriftrollen entdeckt. Diese Schriftrollen enthalten Rohinformationen über die furchterregenden Bestien, die das Land heimsuchen. Wir möchten die leistungsstarken Analysefunktionen von Google BigQuery und die Weisheit eines Gemini Elder Brain (Gemini Pro-Modell) nutzen, um diese unstrukturierten Texte zu entschlüsseln und in ein strukturiertes, abfragbares Bestiarium zu verwandeln. Das wird die Grundlage für alle unsere zukünftigen Strategien sein.
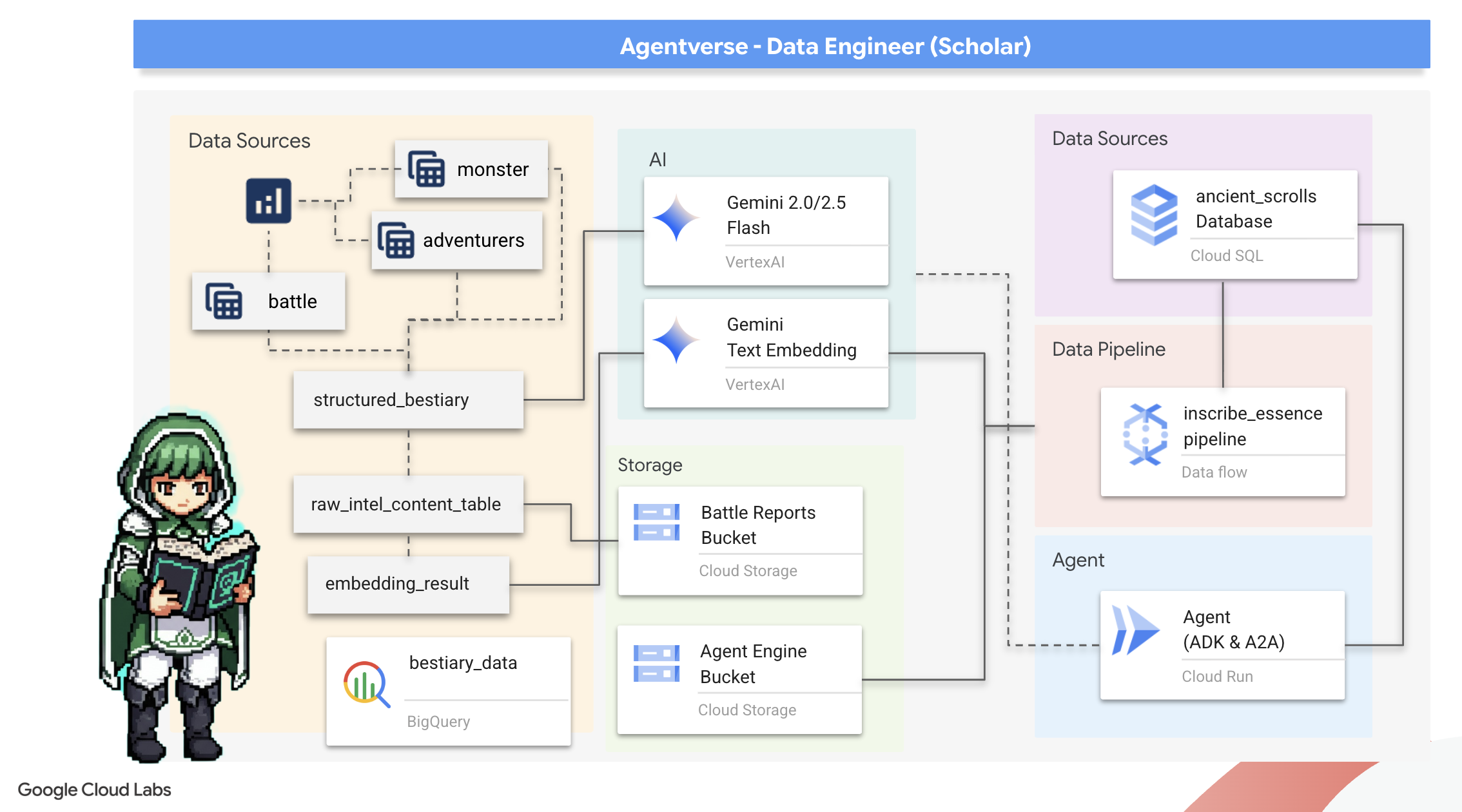
Lerninhalte
- Mit BigQuery können Sie externe Tabellen erstellen und komplexe Transformationen von unstrukturierten zu strukturierten Daten mit BQML.GENERATE_TEXT und einem Gemini-Modell durchführen.
- Stellen Sie eine Cloud SQL for PostgreSQL-Instanz bereit und aktivieren Sie die pgvector-Erweiterung für die semantische Suche.
- Erstellen Sie mit Dataflow und Apache Beam eine robuste, containerisierte Batchpipeline, um Rohtextdateien zu verarbeiten, Vektoreinbettungen mit einem Gemini-Modell zu generieren und die Ergebnisse in eine relationale Datenbank zu schreiben.
- Implementieren Sie ein einfaches RAG-System (Retrieval-Augmented Generation) in einem Agent, um die vektorisierten Daten abzufragen.
- Stellen Sie einen datenorientierten Agent als sicheren, skalierbaren Dienst in Cloud Run bereit.
3. Das Heiligtum des Gelehrten vorbereiten
Willkommen, Scholar. Bevor wir mit dem Aufzeichnen des mächtigen Wissens unseres Grimoire beginnen können, müssen wir zuerst unser Heiligtum vorbereiten. Bei diesem grundlegenden Ritual wird unsere Google Cloud-Umgebung verzaubert, die richtigen Portale (APIs) werden geöffnet und die Kanäle werden geschaffen, durch die unsere Datenmagie fließen kann. Ein gut vorbereitetes Sanctum sorgt dafür, dass unsere Zauber wirkungsvoll und unser Wissen sicher ist.
Google Cloud-Guthaben sichern
⚠️ Wichtige Voraussetzungen:
- Privates Gmail-Konto verwenden:Sie müssen ein privates Konto verwenden (z.B.
name@gmail.com). Konten, die von Unternehmen oder Bildungseinrichtungen verwaltet werden, funktionieren nicht.
👉 Schritte:
- Zur Website zum Einlösen von Guthaben : Hier klicken
- Anmelden:Fügen Sie den Link in die Adressleiste ein und melden Sie sich mit Ihrem privaten Gmail-Konto an.
- Nutzungsbedingungen akzeptieren:Akzeptieren Sie die Nutzungsbedingungen für die Google Cloud Platform.
- Guthaben prüfen:Suchen Sie nach einer Nachricht, die bestätigt, dass das Guthaben angewendet wurde.
- *Hinweis: Wenn Sie aufgefordert werden, Kreditkartendaten einzugeben, können Sie diese Aufforderung ignorieren und das Fenster schließen.
Jetzt kannst du das Fenster schließen.
Arbeitsumgebung einrichten
👉 Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“ (das Symbol oben im Cloud Shell-Bereich hat die Form eines Terminals).
👉 Klicken Sie auf die Schaltfläche „Editor öffnen“ (sie sieht aus wie ein geöffneter Ordner mit einem Stift). Dadurch wird der Cloud Shell-Code-Editor im Fenster geöffnet. Auf der linken Seite wird ein Datei-Explorer angezeigt. 
👉 Öffnen Sie das Terminal in der Cloud-IDE  .
.
👉💻 Prüfen Sie im Terminal mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und das Projekt auf Ihre Projekt-ID festgelegt ist:
gcloud auth list
👉💻 Klonen Sie das Bootstrap-Projekt von GitHub:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 Führen Sie das Setup-Skript im Projektverzeichnis aus.
⚠️ Hinweis zur Projekt-ID:Im Skript wird eine zufällig generierte Standardprojekt-ID vorgeschlagen. Sie können die Eingabetaste drücken, um diesen Standardwert zu übernehmen.
Wenn Sie jedoch lieber ein bestimmtes neues Projekt erstellen möchten, können Sie die gewünschte Projekt-ID eingeben, wenn Sie vom Skript dazu aufgefordert werden.
cd ~/agentverse-dataengineer
./init.sh
👉 Wichtiger Schritt nach Abschluss:Nachdem das Script ausgeführt wurde, müssen Sie dafür sorgen, dass in der Google Cloud Console das richtige Projekt angezeigt wird:
- Rufen Sie console.cloud.google.com auf.
- Klicken Sie oben auf der Seite auf das Drop-down-Menü zur Projektauswahl.
- Klicken Sie auf den Tab Alle, da das neue Projekt möglicherweise noch nicht unter „Letzte“ angezeigt wird.
- Wählen Sie die Projekt-ID aus, die Sie gerade im Schritt
init.shkonfiguriert haben.
👉💻 Legen Sie die erforderliche Projekt-ID fest:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Führen Sie den folgenden Befehl aus, um die erforderlichen Google Cloud APIs zu aktivieren:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 Wenn Sie noch kein Artifact Registry-Repository mit dem Namen „agentverse-repo“ erstellt haben, führen Sie den folgenden Befehl aus, um es zu erstellen:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
Berechtigung einrichten
👉💻 Erteilen Sie die erforderlichen Berechtigungen, indem Sie die folgenden Befehle im Terminal ausführen:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 Während du mit dem Training beginnst, bereiten wir die letzte Herausforderung vor. Mit den folgenden Befehlen werden die Gespenster aus dem chaotischen Rauschen beschworen. Sie sind die Bosse für Ihren finalen Test.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
Hervorragende Arbeit, Scholar. Die grundlegenden Verzauberungen sind abgeschlossen. Unser Heiligtum ist sicher, die Portale zu den elementaren Kräften der Daten sind offen und unser Servitor ist ermächtigt. Jetzt können wir mit der eigentlichen Arbeit beginnen.
4. Die Alchemie des Wissens: Daten mit BigQuery und Gemini transformieren
Im unaufhörlichen Krieg gegen The Static wird jede Konfrontation zwischen einem Champion des Agentverse und einem Spectre of Development sorgfältig aufgezeichnet. Das Battleground Simulation-System, unsere primäre Trainingsumgebung, generiert automatisch einen Aetheric Log Entry für jede Begegnung. Diese narrativen Protokolle sind unsere wertvollste Quelle für rohe Informationen, das unraffinierte Erz, aus dem wir als Scholars den reinen Stahl der Strategie schmieden müssen.Die wahre Macht eines Scholars liegt nicht nur darin, Daten zu besitzen, sondern darin, das rohe, chaotische Erz der Informationen in den glänzenden, strukturierten Stahl umsetzbarer Weisheit zu verwandeln.Wir werden das grundlegende Ritual der Datenalchemie durchführen.

Wir werden einen mehrstufigen Prozess durchlaufen, der vollständig in Google BigQuery stattfindet. Wir beginnen damit, mit einer magischen Linse in unser GCS-Archiv zu schauen, ohne auch nur einmal zu scrollen. Dann rufen wir ein Gemini auf, um die poetischen, unstrukturierten Sagen der Kampfprotokolle zu lesen und zu interpretieren. Schließlich verfeinern wir die Rohvorhersagen zu einer Reihe von sauberen, miteinander verbundenen Tabellen. Unser erstes Grimoire. Und stellen Sie ihm eine so tiefgründige Frage, dass sie nur durch diese neu gefundene Struktur beantwortet werden kann.
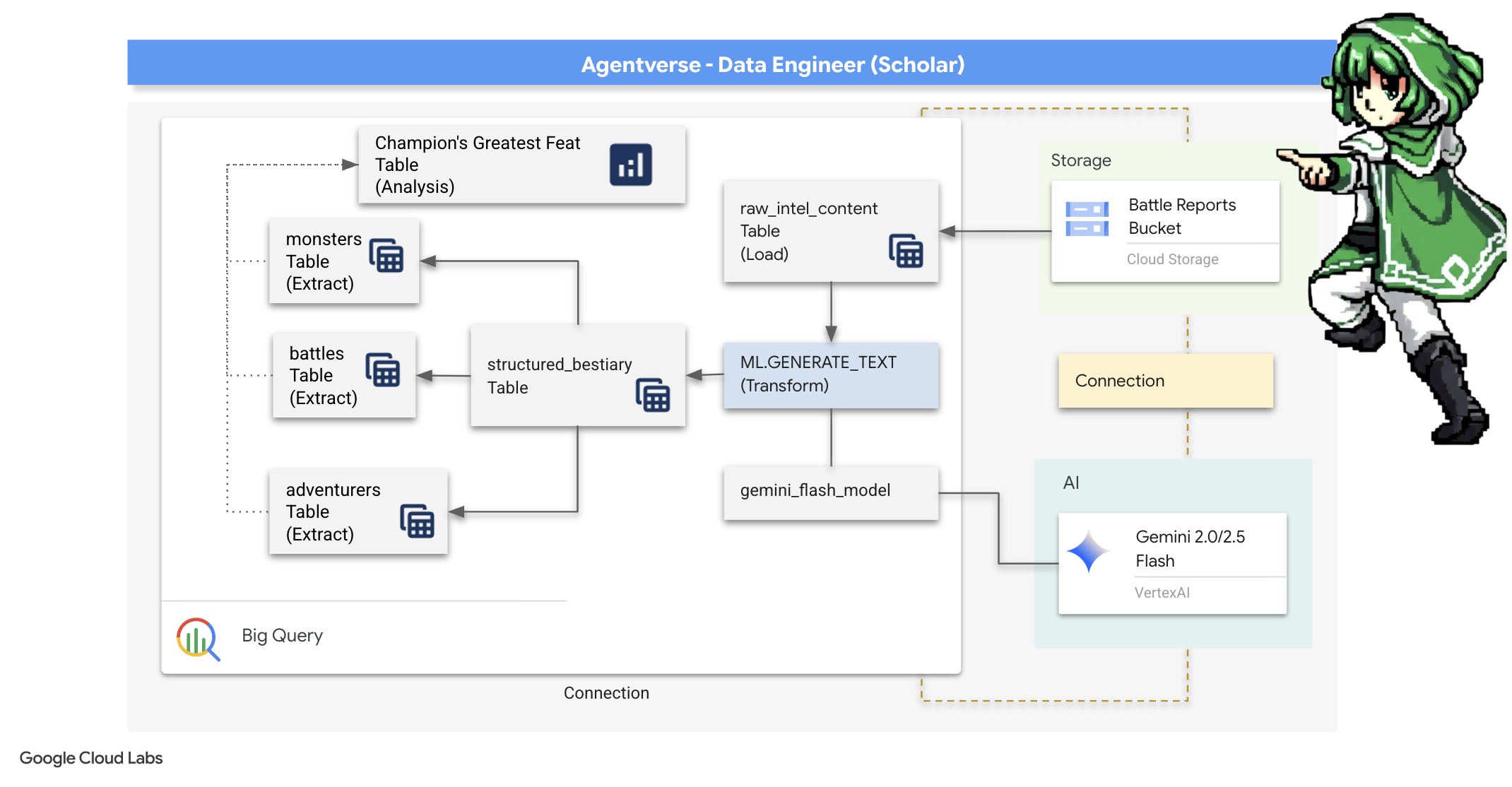
Der Fokus: GCS mit externen BigQuery-Tabellen im Blick
Zuerst müssen wir eine Linse entwickeln, mit der wir den Inhalt unseres GCS-Archivs sehen können, ohne die Schriftrollen darin zu beschädigen. Eine externe Tabelle ist diese Linse, die die Rohtextdateien einer tabellenähnlichen Struktur zuordnet, die BigQuery direkt abfragen kann.
Dazu müssen wir zuerst eine stabile Kraftlinie, eine CONNECTION-Ressource, erstellen, die unser BigQuery-Heiligtum sicher mit dem GCS-Archiv verbindet.
👉💻 Führen Sie im Cloud Shell-Terminal den folgenden Befehl aus, um den Speicher einzurichten und den Conduit zu erstellen:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 Hinweis: Eine Nachricht wird später angezeigt.
Mit dem Einrichtungs-Script aus Schritt 2 wurde ein Prozess im Hintergrund gestartet. Nach einigen Minuten wird in Ihrem Terminal eine Meldung wie die folgende angezeigt:[1]+ Done gcloud sql instances create ...Das ist normal und zu erwarten. Das bedeutet lediglich, dass Ihre Cloud SQL-Datenbank erfolgreich erstellt wurde. Sie können diese Meldung ignorieren und mit der Arbeit fortfahren.
Bevor Sie die externe Tabelle erstellen können, müssen Sie zuerst das Dataset erstellen, das sie enthalten soll.
👉💻 Führen Sie diesen einfachen Befehl in Ihrem Cloud Shell-Terminal aus:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 Jetzt müssen wir der magischen Signatur des Conduit die erforderlichen Berechtigungen erteilen, um aus dem GCS-Archiv zu lesen und Gemini zu konsultieren.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 Führen Sie im Cloud Shell-Terminal den folgenden Befehl aus, um den Namen Ihres Buckets aufzurufen:
echo $BUCKET_NAME
In Ihrem Terminal wird ein Name ähnlich your-project-id-gcs-bucket angezeigt. Sie benötigen sie für die nächsten Schritte.
👉 Sie müssen den nächsten Befehl im BigQuery-Abfrageeditor in der Google Cloud Console ausführen. Am einfachsten ist es, den Link unten in einem neuen Browser-Tab zu öffnen. Sie werden direkt zur richtigen Seite in der Google Cloud Console weitergeleitet.
https://console.cloud.google.com/bigquery
👉 Klicken Sie nach dem Laden der Seite auf die blaue Schaltfläche + (Neue Abfrage erstellen), um einen neuen Editor-Tab zu öffnen.
Jetzt schreiben wir die DDL-Anweisung (Data Definition Language), um unsere magische Linse zu erstellen. So wird BigQuery mitgeteilt, wo gesucht werden soll und was zu sehen ist.
👉📜 Fügen Sie den folgenden SQL-Code in den BigQuery-Abfrageeditor ein, den Sie geöffnet haben. Denken Sie daran, REPLACE-WITH-YOUR-BUCKET-NAME zu ersetzen.
durch den Namen des Buckets, den Sie gerade kopiert haben. Klicken Sie auf Ausführen:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 Führen Sie eine Abfrage aus, um sich die Inhalte der Dateien anzusehen.
SELECT * FROM bestiary_data.raw_intel_content_table;
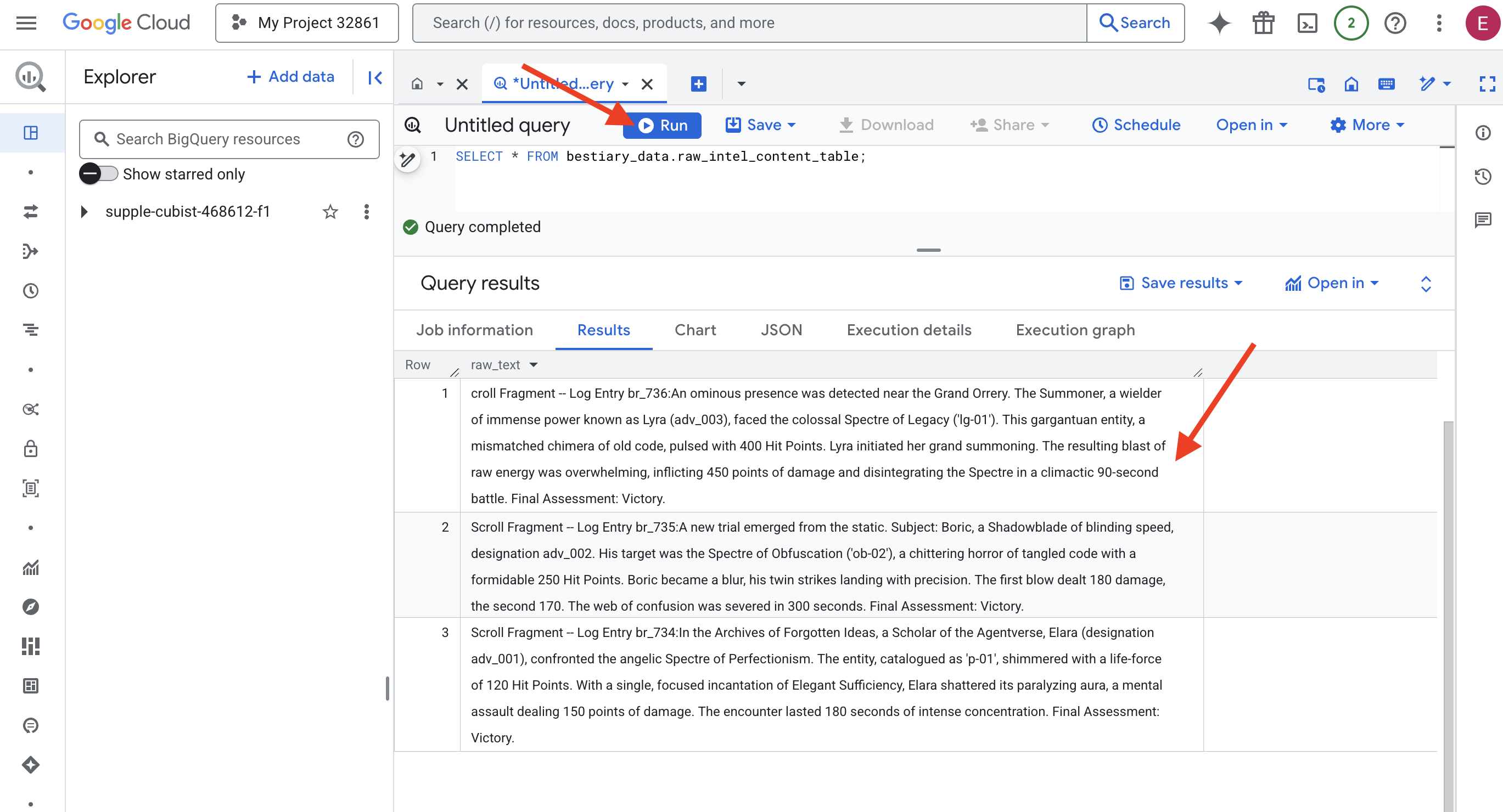
Unsere Linse ist eingesetzt. Wir können jetzt den Roh-Text der Schriftrollen sehen. Aber Lesen ist nicht gleich Verstehen.
Im Archiv der vergessenen Ideen konfrontierte Elara (Bezeichnung adv_001), eine Gelehrte des Agentverse, das engelhafte Gespenst des Perfektionismus. Die als „p-01“ katalogisierte Einheit schimmerte mit einer Lebenskraft von 120 Trefferpunkten. Mit einer einzigen, konzentrierten Beschwörung von „Elegante Genüge“ zersplitterte Elara seine lähmende Aura, ein mentaler Angriff, der 150 Schadenspunkte verursachte. Die Begegnung dauerte 180 Sekunden und erforderte höchste Konzentration. Abschließende Bewertung: Sieg.
Die Schriftrollen sind nicht in Tabellen und Zeilen, sondern in der verschlungenen Prosa von Sagen geschrieben. Das ist unser erster großer Test.
Die Divination des Gelehrten: Text mit SQL in eine Tabelle umwandeln
Die Herausforderung besteht darin, dass sich ein Bericht über die schnellen, doppelten Angriffe einer Schattenklinge ganz anders liest als die Chronik eines Beschwörers, der immense Kraft für einen einzigen, verheerenden Schlag sammelt. Wir können diese Daten nicht einfach importieren, sondern müssen sie interpretieren. Das ist der magische Moment. Wir verwenden eine einzelne SQL-Abfrage, um alle Datensätze aus allen unseren Dateien direkt in BigQuery zu lesen, zu verstehen und zu strukturieren.
👉💻 Führen Sie im Cloud Shell-Terminal den folgenden Befehl aus, um den Namen der Verbindung aufzurufen:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
Im Terminal wird der vollständige Verbindungsstring angezeigt. Wählen Sie diesen String aus und kopieren Sie ihn. Sie benötigen ihn im nächsten Schritt.
Wir verwenden einen einzigen, leistungsstarken Prompt: ML.GENERATE_TEXT. Dieser Prompt ruft ein Gemini auf, zeigt ihm jede Schriftrolle und weist es an, die wichtigsten Fakten als strukturiertes JSON-Objekt zurückzugeben.
👉📜 Erstellen Sie in BigQuery Studio die Gemini-Modellreferenz. Dadurch wird das Gemini Flash-Orakel an unsere BigQuery-Bibliothek gebunden, sodass wir es in unseren Abfragen aufrufen können. Denken Sie daran, die
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING durch den vollständigen Verbindungsstring, den Sie gerade aus Ihrem Terminal kopiert haben.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 Wirf nun den großen Transmutationszauber. Bei dieser Abfrage wird der Roh-Text gelesen, ein detaillierter Prompt für jeden Scroll erstellt, an Gemini gesendet und eine neue Staging-Tabelle aus der strukturierten JSON-Antwort der KI erstellt.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
Die Transmutation ist abgeschlossen, aber das Ergebnis ist noch nicht rein. Das Gemini-Modell gibt seine Antwort in einem Standardformat zurück und umschließt das gewünschte JSON mit einer größeren Struktur, die Metadaten zu seinem Denkprozess enthält. Lassen Sie uns diese rohe Prophezeiung betrachten, bevor wir versuchen, sie zu reinigen.
👉📜 Abfrage ausführen, um die Rohausgabe des Gemini-Modells zu prüfen:
SELECT * FROM bestiary_data.structured_bestiary;
👀 Es wird eine einzelne Spalte mit dem Namen „structured_data“ angezeigt. Der Inhalt für jede Zeile sieht in etwa so aus:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
Wie Sie sehen, ist der Preis – das saubere JSON-Objekt, das wir angefordert haben – tief in dieser Struktur verschachtelt. Unsere nächste Aufgabe ist klar. Wir müssen ein Ritual durchführen, um diese Struktur systematisch zu durchlaufen und die reine Weisheit in ihr zu extrahieren.
Das Ritual der Bereinigung: GenAI-Ausgabe mit SQL normalisieren
Gemini hat gesprochen, aber seine Worte sind roh und in die ätherischen Energien seiner Schöpfung (candidates, finish_reason usw.) gehüllt. Ein wahrer Gelehrter legt die rohe Prophezeiung nicht einfach ins Regal, sondern extrahiert sorgfältig die Kernweisheit und schreibt sie zur späteren Verwendung in die entsprechenden Bücher.
Wir werden jetzt unsere letzten Zaubersprüche wirken. Mit diesem einzelnen Skript wird Folgendes ausgeführt:
- Lesen Sie das unformatierte, verschachtelte JSON aus unserer Staging-Tabelle.
- Bereinigen und analysieren Sie die Daten, um die Kerndaten zu erhalten.
- Schreibe die relevanten Informationen in drei saubere Tabellen: „Monsters“, „Adventurers“ und „Battles“.
👉📜 Führen Sie in einem neuen BigQuery-Abfrageeditor den folgenden Befehl aus, um die Bereinigungs-Lens zu erstellen:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 Bestiarium prüfen:
SELECT * FROM bestiary_data.monsters;
Als Nächstes erstellen wir unsere Liste der Champions, eine Liste der mutigen Abenteurer, die sich diesen Bestien gestellt haben.
👉📜 Führen Sie im neuen Abfrageeditor den folgenden Befehl aus, um die Tabelle „adventurers“ zu erstellen:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 Roll of Champions prüfen:
SELECT * FROM bestiary_data.adventurers;
Schließlich erstellen wir unsere Fakttabelle: die Chronik der Schlachten. In diesem Band werden die anderen beiden verknüpft und die Details jeder einzelnen Begegnung aufgezeichnet. Da jeder Kampf ein einzigartiges Ereignis ist, ist keine Deduplizierung erforderlich.
👉📜 Führen Sie in einem neuen Abfrageeditor den folgenden Befehl aus, um die Tabelle „battles“ zu erstellen:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Chronicle überprüfen:
SELECT * FROM bestiary_data.battles;
Strategische Statistiken erhalten
Die Schriftrollen wurden gelesen, die Essenz destilliert und die Bände beschrieben. Unser Grimoire ist nicht mehr nur eine Sammlung von Fakten, sondern eine relationale Datenbank mit fundiertem strategischem Wissen. Wir können jetzt Fragen stellen, die unmöglich zu beantworten waren, als unser Wissen noch in rohem, unstrukturiertem Text gespeichert war.
Lassen Sie uns nun eine letzte, große Wahrsagung durchführen. Wir werden einen Zauber wirken, der alle drei unserer Bücher gleichzeitig konsultiert – das Bestiarium der Monster, die Liste der Champions und die Chronik der Schlachten –, um eine tiefgreifende, umsetzbare Erkenntnis zu gewinnen.
Unsere strategische Frage: „Wie heißt das mächtigste Monster (nach Trefferpunkten), das jeder Abenteurer erfolgreich besiegt hat, und wie lange hat dieser Sieg gedauert?“
Das ist eine komplexe Frage, bei der Champions mit ihren siegreichen Kämpfen und diese Kämpfe mit den Statistiken der beteiligten Monster verknüpft werden müssen. Das ist die wahre Stärke eines strukturierten Datenmodells.
👉📜 Geben Sie im neuen BigQuery-Abfrageeditor Folgendes ein:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
Die Ausgabe dieser Abfrage ist eine übersichtliche Tabelle, die für jeden Abenteurer in Ihrem Dataset eine Zusammenfassung der größten Leistung eines Champions enthält. Das könnte etwa so aussehen:
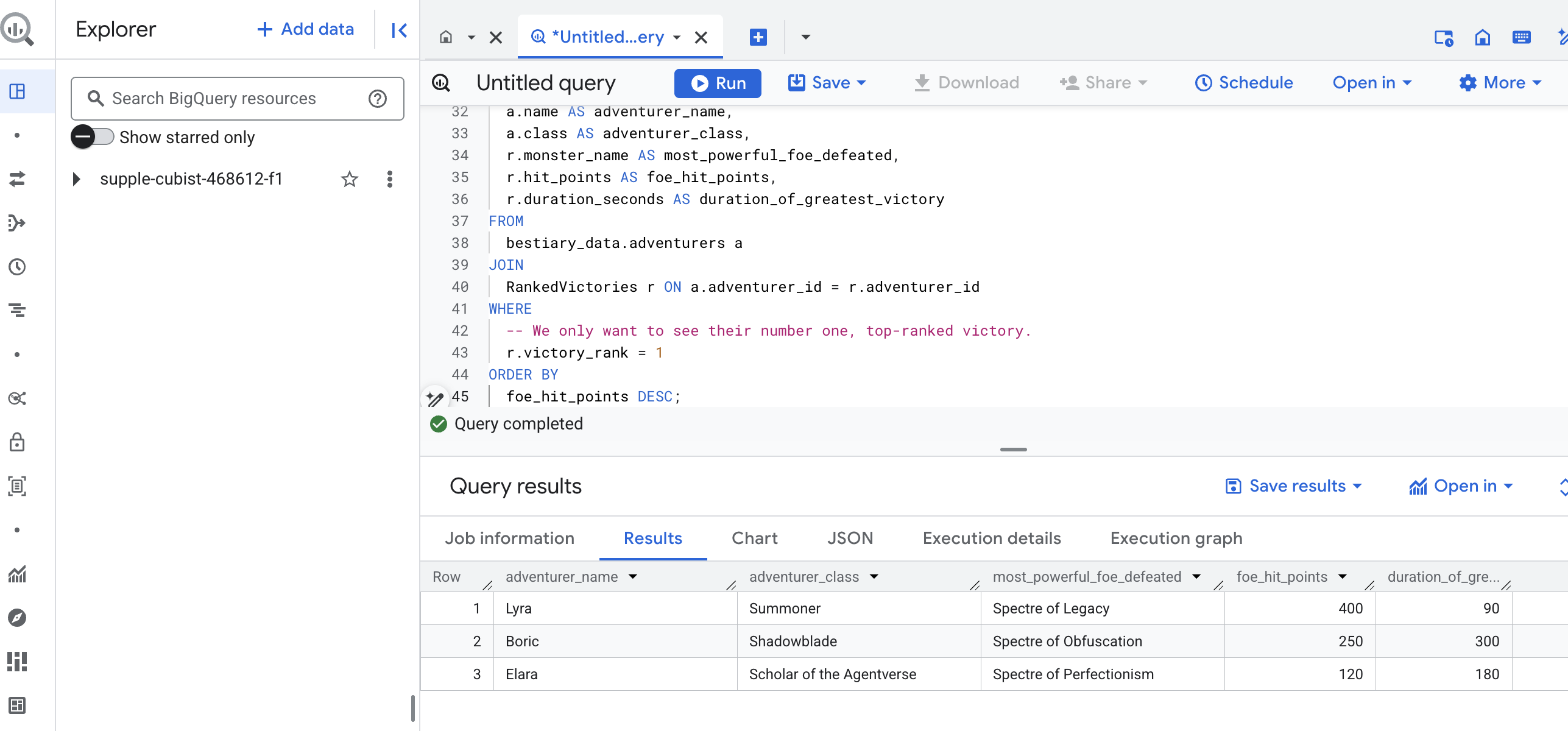
Schließen Sie den BigQuery-Tab.
Dieses einzelne, elegante Ergebnis beweist den Wert der gesamten Pipeline. Sie haben es geschafft, chaotische Rohdaten aus Schlachtfeldberichten in eine Quelle für legendäre Geschichten und strategische, datengestützte Erkenntnisse zu verwandeln.
FÜR NICHT-GAMER
5. Das Grimoire von Scribe: In-Datawarehouse-Chunking, ‑Embedding und ‑Suche
Unsere Arbeit im Labor des Alchemisten war ein Erfolg. Wir haben die rohen, narrativen Schriftrollen in strukturierte, relationale Tabellen umgewandelt – eine beeindruckende Leistung der Datenmagie. Die Originalrollen enthalten jedoch eine tiefere, semantische Wahrheit, die unsere strukturierten Tabellen nicht vollständig erfassen können. Um einen wirklich intelligenten Agent zu entwickeln, müssen wir diese Bedeutung erschließen.
Ein langer, unstrukturierter Scroll ist ein stumpfes Instrument. Wenn unser Kundenservicemitarbeiter eine Frage zu einer „lähmenden Aura“ stellt, kann eine einfache Suche einen ganzen Kampfbericht zurückgeben, in dem dieser Begriff nur einmal erwähnt wird. Die Antwort wird dann in irrelevanten Details vergraben. Ein Meister weiß, dass wahre Weisheit nicht in der Menge, sondern in der Präzision liegt.
Wir führen drei leistungsstarke In-Database-Rituale durch, die ausschließlich in unserem BigQuery-Heiligtum stattfinden.
- Das Ritual der Aufteilung (Chunking): Wir nehmen unsere Rohdaten aus den KI-Logs und zerlegen sie sorgfältig in kleinere, fokussierte, in sich geschlossene Abschnitte.
- Das Ritual der Destillation (Einbettung): Wir verwenden BQML, um ein Gemini-Modell zu konsultieren und jeden Textblock in einen „semantischen Fingerabdruck“ umzuwandeln – eine Vektoreinbettung.
- Das Ritual der Wahrsagerei (Suche): Wir verwenden die Vektorsuche von BQML, um eine Frage in natürlicher Sprache zu stellen und die relevantesten, destillierten Informationen aus unserem Grimoire zu finden.
So entsteht eine leistungsstarke, durchsuchbare Wissensdatenbank, ohne dass die Daten jemals die Sicherheit und Skalierbarkeit von BigQuery verlassen.
Das Ritual der Division: Scrolls mit SQL dekonstruieren
Unsere Quelle des Wissens sind weiterhin die Rohtextdateien in unserem GCS-Archiv, auf die über unsere externe Tabelle bestiary_data.raw_intel_content_table zugegriffen werden kann. Unsere erste Aufgabe besteht darin, einen Zauberspruch zu schreiben, der jede lange Schriftrolle liest und sie in eine Reihe kleinerer, leichter verdaulicher Verse unterteilt. Für dieses Ritual definieren wir einen „Abschnitt“ als einen einzelnen Satz.
Das Aufteilen nach Satz ist ein klarer und effektiver Ausgangspunkt für unsere narrativen Protokolle. Ein erfahrener Scribe hat jedoch viele Strategien zur Verfügung, um den Text in Abschnitte zu unterteilen. Die Wahl ist entscheidend für die Qualität der endgültigen Suche. Bei einfacheren Methoden wird möglicherweise
- Chunking mit fester Länge(Größe), aber dadurch kann eine wichtige Idee grob in zwei Hälften geschnitten werden.
Ausgefeiltere Rituale wie
- Rekursives Chunking wird in der Praxis oft bevorzugt, da hier versucht wird, Text zuerst entlang natürlicher Grenzen wie Absätzen aufzuteilen und dann auf Sätze zurückzugreifen, um so viel semantischen Kontext wie möglich beizubehalten. Für wirklich komplexe Manuskripte.
- Inhaltsbasiertes Chunking(Dokument): Hierbei wird die inhärente Struktur des Dokuments verwendet, z. B. die Überschriften in einem technischen Handbuch oder die Funktionen in einem Codeabschnitt, um die logischsten und wirkungsvollsten Wissensblöcke zu erstellen.
Für unsere Kampfprotokolle bietet der Satz die perfekte Balance zwischen Detaillierungsgrad und Kontext.
👉📜 Führen Sie in einem neuen BigQuery-Abfrageeditor den folgenden Befehl aus. Bei diesem Zauberspruch wird mit der Funktion SPLIT der Text jedes Scrolls an jedem Punkt (.) getrennt und das resultierende Array von Sätzen wird in separate Zeilen aufgeteilt.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 Führen Sie jetzt eine Abfrage aus, um sich das neu erstellte, in Abschnitte unterteilte Wissen anzusehen und den Unterschied zu sehen.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
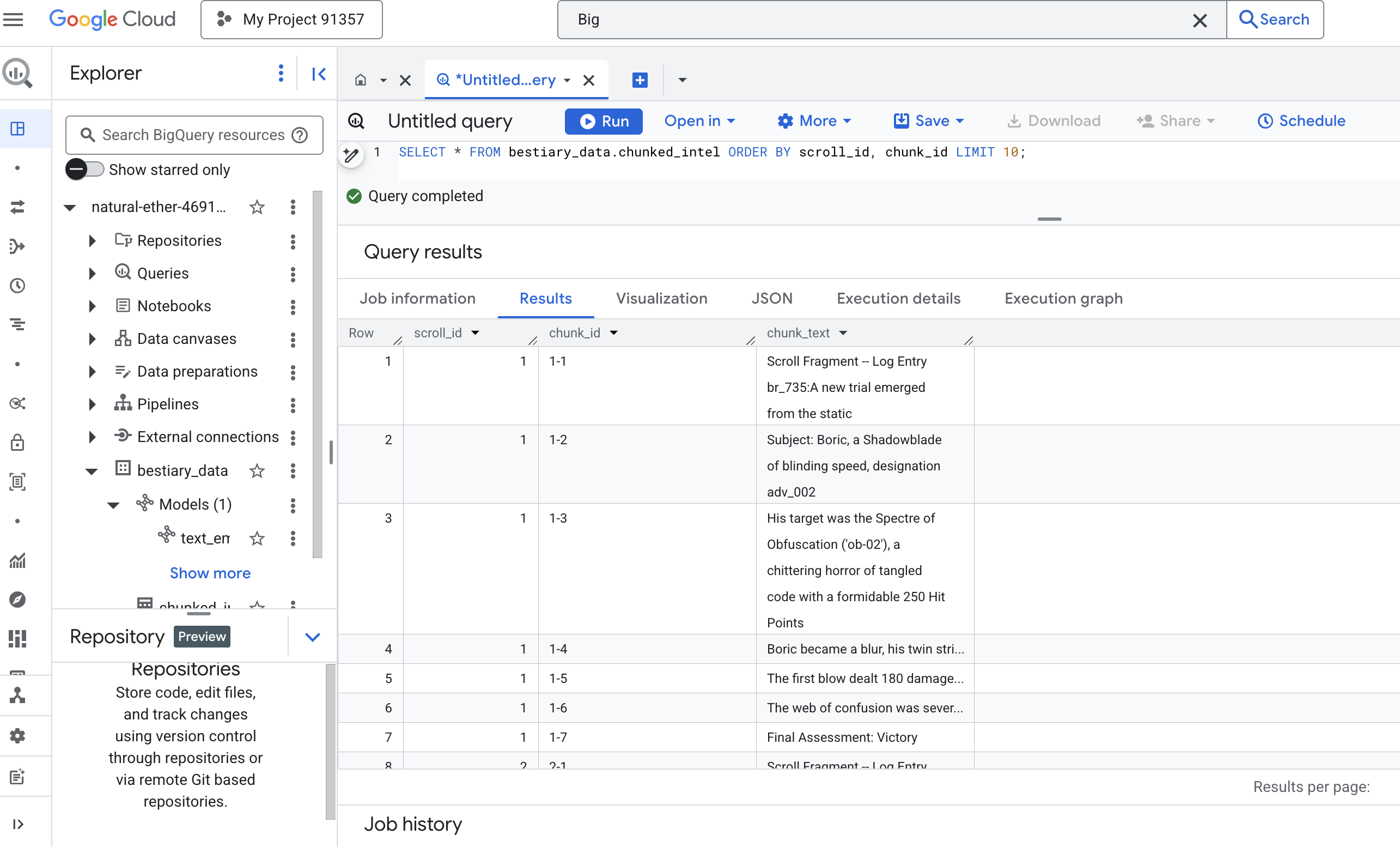
Sehen Sie sich die Ergebnisse an. Wo es früher einen einzelnen, dichten Textblock gab, gibt es jetzt mehrere Zeilen, die jeweils mit dem ursprünglichen Scroll (scroll_id) verknüpft sind, aber nur einen einzelnen, fokussierten Satz enthalten. Jede Zeile ist jetzt ein idealer Kandidat für die Vektorisierung.
Das Ritual der Destillation: Text mit BQML in Vektoren umwandeln
👉💻 Kehren Sie zuerst zu Ihrem Terminal zurück und führen Sie den folgenden Befehl aus, um den Namen Ihrer Verbindung aufzurufen:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Wir müssen ein neues BigQuery-Modell erstellen, das auf eine Texteinbettung von Gemini verweist. Führen Sie in BigQuery Studio den folgenden Prompt aus. Ersetzen Sie REPLACE-WITH-YOUR-FULL-CONNECTION-STRING durch den vollständigen Verbindungsstring, den Sie gerade aus Ihrem Terminal kopiert haben.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 Jetzt kannst du den großen Destillationszauber wirken lassen. Mit dieser Abfrage wird die Funktion ML.GENERATE_EMBEDDING aufgerufen, die jede Zeile aus der Tabelle „chunked_intel“ liest, den Text an das Gemini-Einbettungsmodell sendet und den resultierenden Vektor-Fingerabdruck in einer neuen Tabelle speichert.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
Dieser Vorgang kann ein bis zwei Minuten dauern, da BigQuery alle Textblöcke verarbeitet.
👉📜 Sehen Sie sich nach Abschluss die neue Tabelle an, um die semantischen Fingerabdrücke zu sehen.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
Sie sehen jetzt eine neue Spalte ml_generate_embedding_result mit der dichten Vektordarstellung Ihres Texts. Unser Grimoire ist jetzt semantisch codiert.
Das Ritual der Wahrsagerei: Semantische Suche mit BQML
👉📜 Der ultimative Test für unser Grimoire ist, ihm eine Frage zu stellen. Jetzt führen wir unser letztes Ritual durch: eine Vektorsuche. Es handelt sich nicht um eine Suche mit Suchbegriffen, sondern um eine Suche nach der Bedeutung. Wir stellen eine Frage in natürlicher Sprache. BQML wandelt unsere Frage im Handumdrehen in eine Einbettung um und durchsucht dann unsere gesamte Tabelle mit embedded_intel nach den Textblöcken, deren Fingerabdrücke in der Bedeutung am „ähnlichsten“ sind.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
Analyse des Zaubers:
VECTOR_SEARCH: Die Kernfunktion, die die Suche orchestriert.ML.GENERATE_EMBEDDING(innere Abfrage): Das ist der Clou. Wir betten unsere Anfrage ('What are the tactics...') mit dem gleichen Modell ein, aber mit dem Aufgabentyp'RETRIEVAL_QUERY', der speziell für Anfragen optimiert ist.top_k => 3: Wir bitten um die drei relevantesten Ergebnisse.distance_type => 'COSINE': Hiermit wird der „Winkel“ zwischen Vektoren gemessen. Ein kleinerer Winkel bedeutet, dass die Bedeutungen besser übereinstimmen.
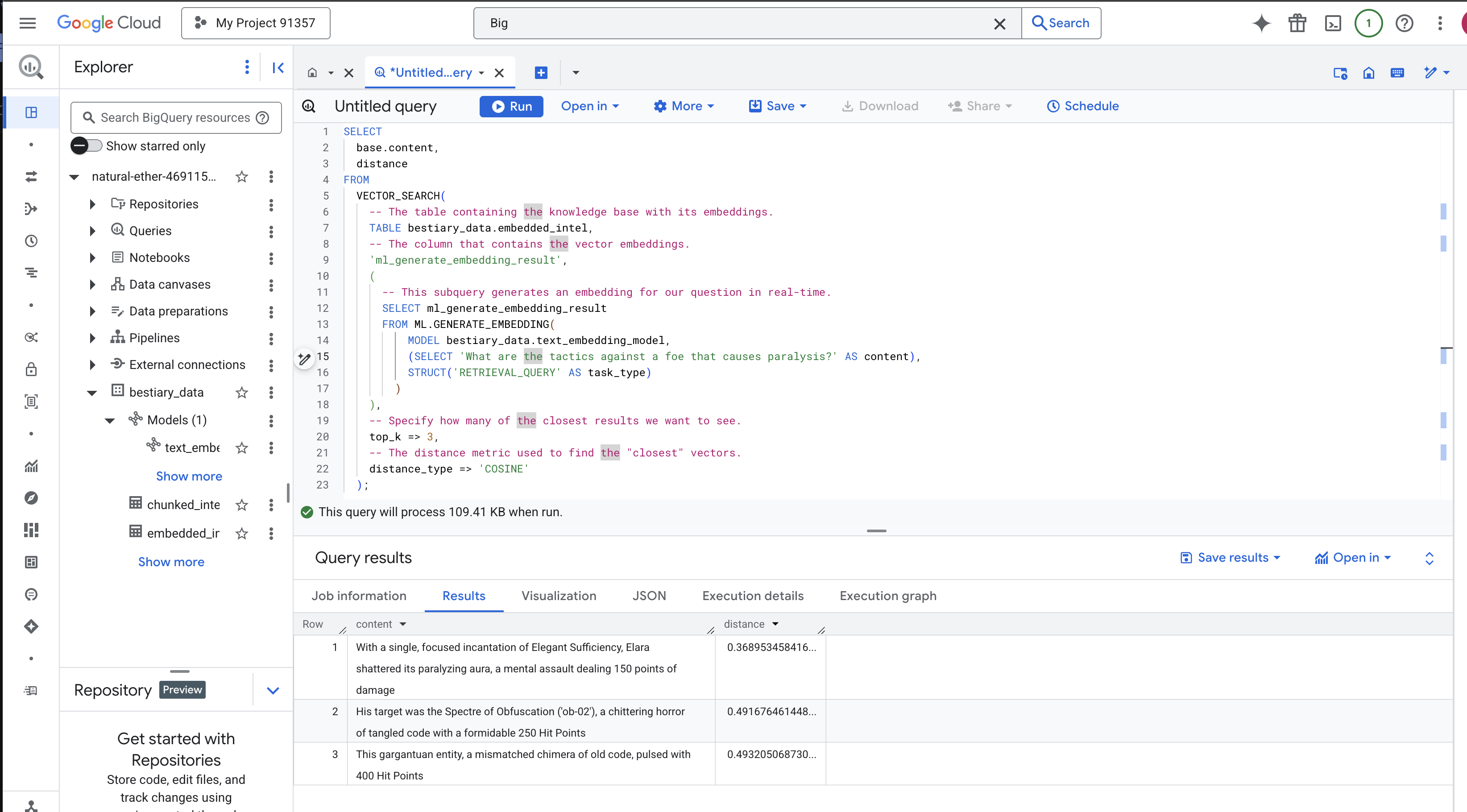
Sehen Sie sich die Ergebnisse genau an. Die Abfrage enthielt nicht die Wörter „zersplittert“ oder „Beschwörung“, aber das Top-Ergebnis lautet: „Mit einer einzigen, konzentrierten Beschwörung von Eleganter Genügsamkeit zersplitterte Elara die lähmende Aura, ein mentaler Angriff, der 150 Schadenspunkte verursachte.“ Das ist das große Potenzial der semantischen Suche. Das Modell hat das Konzept „Taktiken gegen Lähmung“ verstanden und den Satz gefunden, in dem eine bestimmte, erfolgreiche Taktik beschrieben wird.
Sie haben jetzt erfolgreich eine vollständige RAG-Pipeline in einem Data Warehouse erstellt. Sie haben Rohdaten vorbereitet, in semantische Vektoren umgewandelt und nach Bedeutung abgefragt. BigQuery ist zwar ein leistungsstarkes Tool für diese umfangreichen Analysearbeiten, aber für einen Live-Kundenservicemitarbeiter, der Antworten mit geringer Latenz benötigt, übertragen wir diese vorbereiteten Informationen häufig in eine spezielle operative Datenbank. Das ist das Thema unseres nächsten Trainings.
FÜR NICHT-GAMER
6. Vector Scriptorium: Vektorspeicher mit Cloud SQL für die Inferenz erstellen
Unser Grimoire besteht derzeit aus strukturierten Tabellen – einem leistungsstarken Faktenkatalog, dessen Wissen jedoch wörtlich ist. Sie versteht monster_id = ‚MN-001‘, aber nicht die tiefere, semantische Bedeutung von „Verschleierung“. Damit unsere Kundenservicemitarbeiter wirklich weise sind und mit Nuancen und Weitsicht beraten können, müssen wir die Essenz unseres Wissens in eine Form bringen, die die Bedeutung erfasst: Vektoren.
Unsere Suche nach Wissen hat uns zu den zerfallenden Ruinen einer längst vergessenen Vorgängerzivilisation geführt. Tief in einem versiegelten Gewölbe haben wir eine Truhe mit uralten Schriftrollen entdeckt, die auf wundersame Weise erhalten geblieben sind. Es handelt sich nicht nur um Schlachtberichte, sondern um tiefgründige, philosophische Weisheiten, wie man ein Monster besiegt, das alle großen Bemühungen plagt. Eine Einheit, die in den Schriftrollen als „schleichende, stille Stagnation“ und „Ausfransen des Gewebes der Schöpfung“ beschrieben wird. Es scheint, dass The Static schon den Alten bekannt war, eine zyklische Bedrohung, deren Geschichte in der Zeit verloren gegangen ist.
Dieses vergessene Wissen ist unser größtes Kapital. Sie ist nicht nur der Schlüssel zum Besiegen einzelner Monster, sondern auch dazu, die gesamte Gruppe mit strategischen Informationen zu versorgen. Um diese Leistungsfähigkeit zu nutzen, erstellen wir nun das wahre Zauberbuch des Gelehrten (eine PostgreSQL-Datenbank mit Vektorfunktionen) und ein automatisiertes Vektor-Scriptorium (eine Dataflow-Pipeline), um die zeitlose Essenz dieser Schriftrollen zu lesen, zu verstehen und zu schreiben. Dadurch wird unser Grimoire von einem Faktenbuch zu einer Wissensquelle.

Das Zauberbuch des Gelehrten schmieden (Cloud SQL)
Bevor wir die Essenz dieser alten Schriftrollen aufzeichnen können, müssen wir zuerst bestätigen, dass das Gefäß für dieses Wissen, das verwaltete PostgreSQL-Zauberbuch, erfolgreich geschmiedet wurde. Das sollte bereits bei der Ersteinrichtung geschehen sein.
👉💻 Führen Sie in einem Terminal den folgenden Befehl aus, um zu prüfen, ob Ihre Cloud SQL-Instanz vorhanden und bereit ist. Mit diesem Skript wird dem dedizierten Dienstkonto der Instanz auch die Berechtigung zur Verwendung von Vertex AI gewährt, was für das Generieren von Einbettungen direkt in der Datenbank unerlässlich ist.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Wenn der Befehl erfolgreich ist und Details zu Ihrer grimoire-spellbook-Instanz zurückgibt, hat die Forge ihre Arbeit gut gemacht. Sie können mit dem nächsten Zauberspruch fortfahren. Wenn der Befehl einen NOT_FOUND-Fehler zurückgibt, müssen Sie die Schritte zur Ersteinrichtung der Umgebung abgeschlossen haben, bevor Sie fortfahren können.(data_setup.py)
👉💻 Nachdem wir das Buch geschmiedet haben, schlagen wir das erste Kapitel auf, indem wir eine neue Datenbank mit dem Namen arcane_wisdom erstellen.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
Semantische Runen einfügen: Vektorfähigkeiten mit pgvector aktivieren
Nachdem Ihre Cloud SQL-Instanz erstellt wurde, stellen wir jetzt eine Verbindung zu ihr her. Dazu verwenden wir das integrierte Cloud SQL Studio. Dadurch wird eine webbasierte Oberfläche zum Ausführen von SQL-Abfragen direkt in Ihrer Datenbank bereitgestellt.
👉💻 Rufen Sie zuerst Cloud SQL Studio auf. Am einfachsten und schnellsten geht das, wenn Sie den folgenden Link in einem neuen Browsertab öffnen. Sie werden direkt zu Cloud SQL Studio für Ihre Grimoire-Zauberbuchinstanz weitergeleitet.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 Wählen Sie arcane_wisdom als Datenbank aus, geben Sie postgres als Nutzer und 1234qwer als Passwort ein und klicken Sie auf Authentifizieren.
👉📜 Rufen Sie im SQL Studio-Abfrageeditor den Tab „Editor 1“ auf und fügen Sie den folgenden SQL-Code ein, um den Vektordatentyp zu aktivieren:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
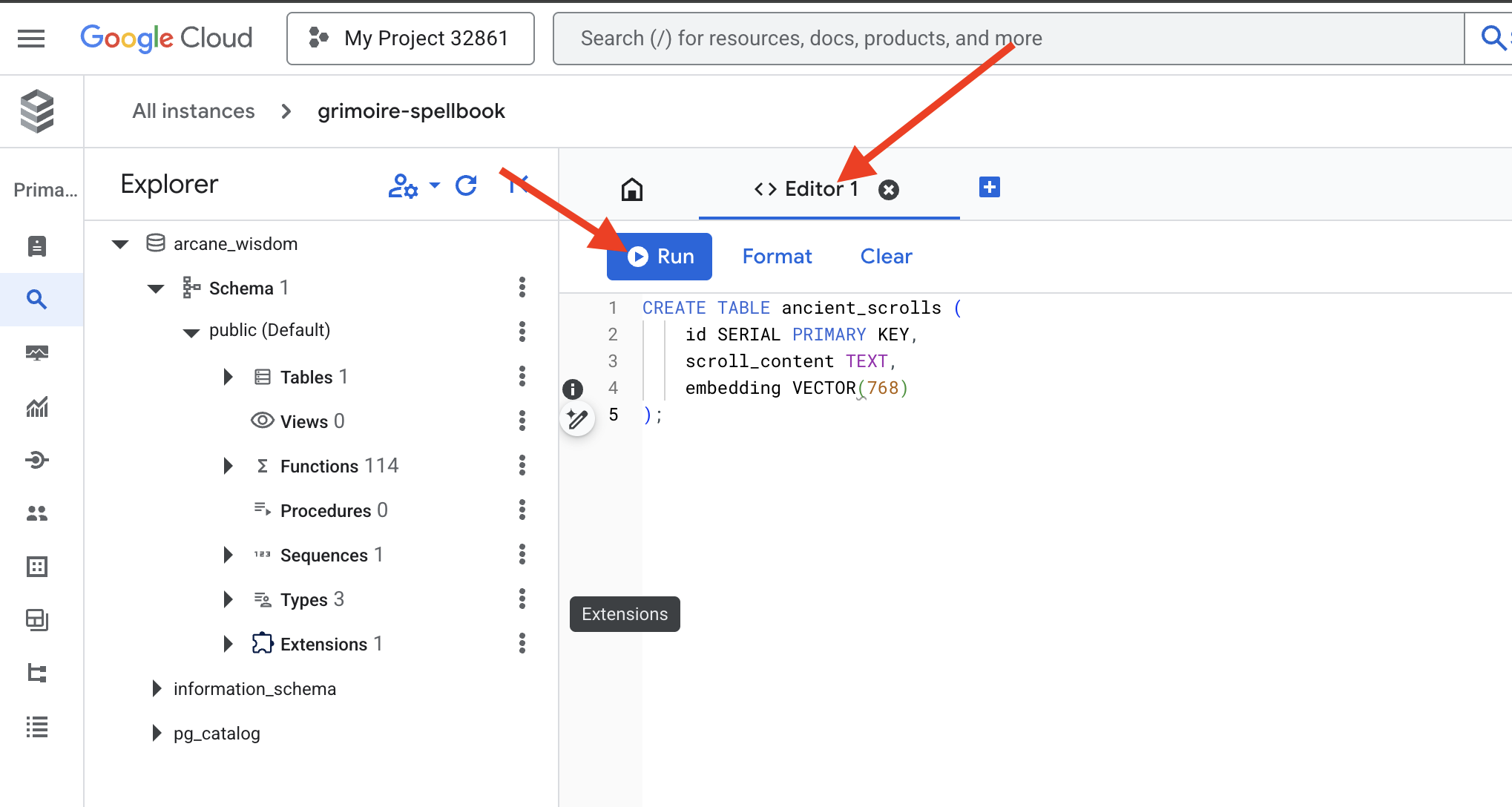
👉📜 Bereiten Sie die Seiten unseres Zauberbuchs vor, indem Sie die Tabelle erstellen, in der die Essenz unserer Schriftrollen gespeichert wird.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
Die Schreibweise VECTOR(768) ist ein wichtiges Detail. Das Vertex AI-Einbettungsmodell, das wir verwenden (textembedding-gecko@003 oder ein ähnliches Modell), fasst Text in einem 768-dimensionalen Vektor zusammen. Die Seiten unseres Zauberbuchs müssen so vorbereitet sein, dass sie eine Essenz genau dieser Größe aufnehmen können. Die Dimensionen müssen immer übereinstimmen.
Die erste Transliteration: Ein manuelles Inskriptionsritual
Bevor wir eine Armee automatisierter Schreiber (Dataflow) einsetzen, müssen wir das zentrale Ritual einmal von Hand durchführen. So können wir die Magie der beiden Schritte besser nachvollziehen:
- Divination:Ein Text wird verwendet und das Gemini-Orakel konsultiert, um seine semantische Essenz in einen Vektor zu destillieren.
- Eintragung:Der Originaltext und seine neue Vektordarstellung werden in unser Spellbook geschrieben.
Führen wir nun das manuelle Ritual durch.
👉📜 In Cloud SQL Studio. Wir verwenden jetzt die Funktion embedding(), eine leistungsstarke Funktion der Erweiterung google_ml_integration. So können wir das Vertex AI-Embedding-Modell direkt über unsere SQL-Abfrage aufrufen, was den Prozess erheblich vereinfacht.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 Prüfen Sie Ihre Arbeit, indem Sie eine Anfrage ausführen, um die neu geschriebene Seite zu lesen:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
Sie haben die Hauptaufgabe zum manuellen Laden von RAG-Daten erfolgreich ausgeführt.
Den semantischen Kompass schmieden: Das Zauberbuch mit einem HNSW-Index verzaubern
Unser Zauberbuch kann jetzt Wissen speichern, aber um die richtige Schriftrolle zu finden, muss man jede einzelne Seite lesen. Es handelt sich um einen sequenziellen Scan. Das ist langsam und ineffizient. Damit unsere Anfragen sofort zum relevantesten Wissen geleitet werden, müssen wir das Spellbook mit einem semantischen Kompass ausstatten: einem Vektorindex.
Sehen wir uns an, wie sich diese Optimierung auswirkt.
👉📜 Führen Sie in Cloud SQL Studio den folgenden Prompt aus. Es wird simuliert, dass nach dem neu eingefügten Scroll gesucht wird, und die Datenbank wird aufgefordert, den Plan zu EXPLAIN.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
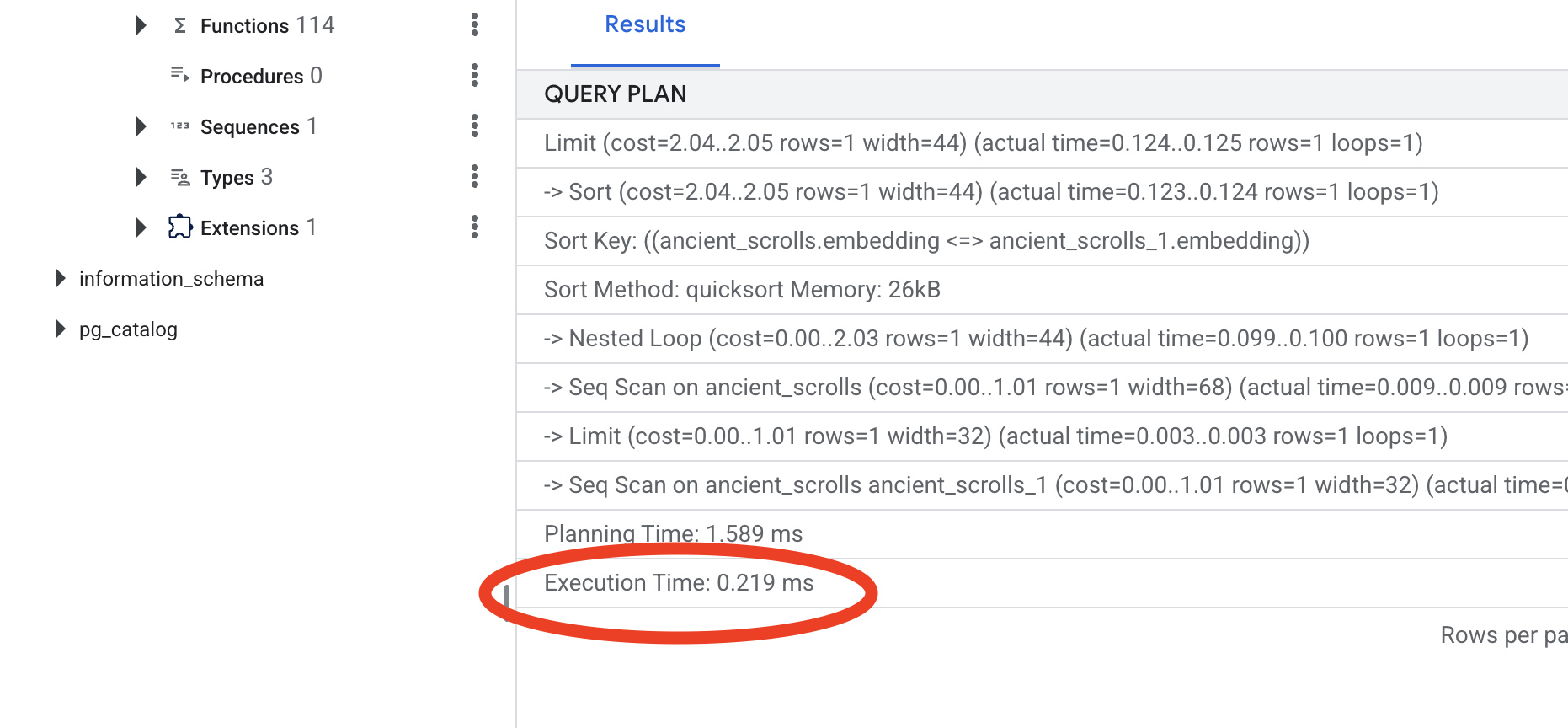
Sehen Sie sich die Ausgabe an. Es wird eine Zeile mit -> Seq Scan on ancient_scrolls angezeigt. Das bestätigt, dass die Datenbank jede einzelne Zeile liest. Beachten Sie die execution time.
👉📜 Jetzt können wir den Indexierungszauber wirken lassen. Der Parameter lists gibt an, wie viele Cluster für den Index erstellt werden sollen. Ein guter Ausgangspunkt ist die Quadratwurzel der erwarteten Anzahl von Zeilen.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
Warten Sie, bis der Index erstellt wurde. Das geht bei einer Zeile schnell, kann aber bei Millionen von Zeilen dauern.
👉📜 Führen Sie nun genau denselben EXPLAIN ANALYZE-Befehl noch einmal aus:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
Sehen Sie sich den neuen Abfrageplan an. Jetzt wird -> Index Scan using... angezeigt. Wichtiger ist jedoch die execution time. Das geht deutlich schneller, auch wenn Sie nur einen Eintrag haben. Sie haben gerade das Kernprinzip der Datenbankleistungsoptimierung in einer Vektorwelt demonstriert.
Nachdem Sie Ihre Quelldaten geprüft, Ihr manuelles Ritual verstanden und Ihr Spellbook für Geschwindigkeit optimiert haben, sind Sie nun wirklich bereit, das automatisierte Scriptorium zu erstellen.
FÜR NICHT-GAMER
7. The Conduit of Meaning: Building a Dataflow Vectorization Pipeline
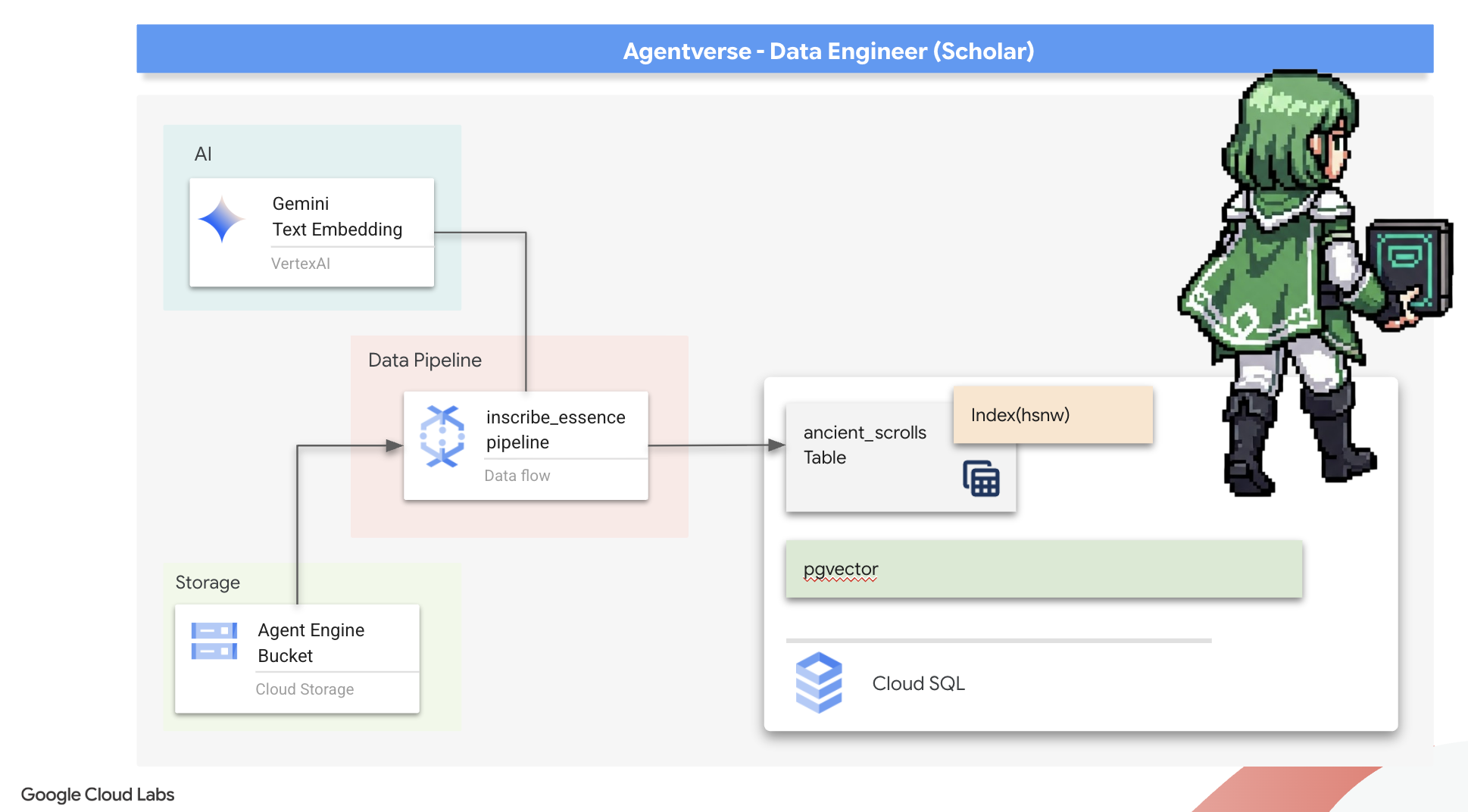
Jetzt bauen wir das magische Fließband von Schreibern, die unsere Schriftrollen lesen, ihre Essenz destillieren und sie in unser neues Zauberbuch schreiben. Dies ist eine Dataflow-Pipeline, die wir manuell auslösen. Bevor wir den Master-Zauberspruch für die Pipeline selbst schreiben können, müssen wir zuerst die Grundlage und den Kreis vorbereiten, aus dem wir ihn beschwören werden.
Grundlage für Scriptorium vorbereiten (das Worker-Image)
Unsere Dataflow-Pipeline wird von einem Team automatisierter Worker in der Cloud ausgeführt. Jedes Mal, wenn wir sie aufrufen, benötigen sie bestimmte Bibliotheken, um ihre Aufgabe zu erfüllen. Wir könnten ihnen eine Liste geben und sie bitten, diese Bibliotheken jedes Mal abzurufen, aber das ist langsam und ineffizient. Ein weiser Scholar bereitet im Voraus eine Master-Bibliothek vor.
Hier weisen wir Google Cloud Build an, ein benutzerdefiniertes Container-Image zu erstellen. Dieses Bild ist ein „perfektionierter Golem“, der mit allen Bibliotheken und Abhängigkeiten vorab geladen wurde, die unsere KI-Schreiber benötigen. Wenn unser Dataflow-Job gestartet wird, wird dieses benutzerdefinierte Image verwendet, sodass die Worker ihre Aufgabe fast sofort beginnen können.
👉💻 Führen Sie den folgenden Befehl aus, um das grundlegende Image Ihrer Pipeline zu erstellen und in der Artifact Registry zu speichern.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 Führen Sie die folgenden Befehle aus, um eine isolierte Python-Umgebung zu erstellen und zu aktivieren und die erforderlichen Aufrufbibliotheken darin zu installieren.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
Der Master-Zauberspruch
Es ist an der Zeit, den Master-Zauberspruch zu schreiben, der unser Vector Scriptorium antreiben wird. Wir werden die einzelnen Magic-Komponenten nicht von Grund auf neu schreiben. Unsere Aufgabe ist es, Komponenten in einer logischen, leistungsstarken Pipeline mit der Sprache von Apache Beam zusammenzustellen.
- EmbedTextBatch (Geminis Beratung): Sie erstellen einen spezialisierten Schreiber, der weiß, wie man eine „Gruppenvorhersage“ durchführt. Es wird ein Batch mit Rohtextdateien verwendet, die dem Gemini-Texteinbettungsmodell präsentiert werden. Das Modell gibt dann die destillierte Essenz (die Vektoreinbettungen) zurück.
- WriteEssenceToSpellbook (Die endgültige Inschrift): Das ist unser Archivar. Es kennt die geheimen Beschwörungsformeln, um eine sichere Verbindung zu unserem Cloud SQL-Spellbook herzustellen. Seine Aufgabe ist es, den Inhalt einer Schriftrolle und ihre vektorisierte Essenz zu nehmen und sie dauerhaft auf eine neue Seite zu übertragen.
Unser Ziel ist es, diese Aktionen zu verknüpfen, um einen nahtlosen Wissensfluss zu schaffen.
👉✏️ Rufen Sie im Cloud Shell-Editor ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py auf. Dort finden Sie eine DoFn-Klasse mit dem Namen EmbedTextBatch. Suchen Sie den Kommentar #REPLACE-EMBEDDING-LOGIC. Ersetzen Sie sie durch Folgendes.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Dieser Prompt ist präzise und enthält mehrere wichtige Parameter:
- model: Wir geben
text-embedding-005an, um ein leistungsstarkes und aktuelles Einbettungsmodell zu verwenden. - contents: Dies ist eine Liste aller Textinhalte aus dem Batch von Dateien, den die DoFn empfängt.
- task_type: Wir legen diesen Wert auf „RETRIEVAL_DOCUMENT“ fest. Dies ist eine wichtige Anweisung, die Gemini anweist, Einbettungen zu generieren, die speziell für das spätere Auffinden in einer Suche optimiert sind.
- output_dimensionality: Dieser Wert muss auf 768 festgelegt werden und entspricht damit genau der Dimension VECTOR(768), die wir beim Erstellen der Tabelle „ancient_scrolls“ in Cloud SQL definiert haben. Nicht übereinstimmende Dimensionen sind eine häufige Fehlerquelle bei Vector Magic.
Unsere Pipeline muss damit beginnen, den unstrukturierten Roh-Text aus allen alten Schriftrollen in unserem GCS-Archiv zu lesen.
👉✏️ Suchen Sie in ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py nach dem Kommentar #REPLACE ME-READFILE und ersetzen Sie ihn durch die folgende dreiteilige Beschwörung:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
Nachdem wir den Roh-Text der Schriftrollen gesammelt haben, müssen wir ihn nun an Gemini senden, damit es uns die Zukunft vorhersagen kann. Um dies effizient zu tun, gruppieren wir die einzelnen Schriftrollen zuerst in kleinen Batches und übergeben diese Batches dann an unseren EmbedTextBatch-Schreiber. In diesem Schritt werden alle Scrolls, die Gemini nicht versteht, in einem Stapel mit dem Status „Fehler“ für die spätere Überprüfung zusammengefasst.
👉✏️ Suchen Sie den Kommentar #REPLACE ME-EMBEDDING und ersetzen Sie ihn durch Folgendes:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
Die Essenz unserer Schriftrollen wurde erfolgreich destilliert. Im letzten Schritt wird dieses Wissen in unserem Zauberbuch für die dauerhafte Speicherung festgehalten. Wir nehmen die Schriftrollen aus dem Stapel „Verarbeitet“ und übergeben sie unserem WriteEssenceToSpellbook-Archivar.
👉✏️ Suchen Sie den Kommentar #REPLACE ME-WRITE TO DB und ersetzen Sie ihn durch Folgendes:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
Ein weiser Gelehrter verwirft niemals Wissen, auch nicht gescheiterte Versuche. Als letzten Schritt müssen wir einen Schreiber anweisen, den Stapel mit den „fehlgeschlagenen“ Karten aus unserem Wahrsageschritt zu nehmen und die Gründe für das Scheitern zu protokollieren. So können wir unsere Rituale in Zukunft verbessern.
👉✏️ Suchen Sie den Kommentar #REPLACE ME-LOG FAILURES und ersetzen Sie ihn durch Folgendes:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
Die Master-Beschwörung ist jetzt abgeschlossen. Sie haben eine leistungsstarke, mehrstufige Datenpipeline erstellt, indem Sie einzelne magische Komponenten miteinander verknüpft haben. Speichern Sie die Datei „inscribe_essence_pipeline.py“. Das Scriptorium kann jetzt aufgerufen werden.
Jetzt sprechen wir den großen Beschwörungszauber, um den Dataflow-Dienst anzuweisen, unseren Golem zu erwecken und mit dem Schreibritual zu beginnen.
👉💻 Führen Sie im Terminal die folgende Befehlszeile aus:
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 Wichtiger Hinweis: Wenn der Job mit einem Ressourcenfehler ZONE_RESOURCE_POOL_EXHAUSTED fehlschlägt, kann das an vorübergehenden Ressourcenbeschränkungen dieses Kontos mit niedriger Reputation in der ausgewählten Region liegen. Die Stärke von Google Cloud liegt in seiner globalen Reichweite. Versuchen Sie einfach, den Golem in einer anderen Region zu beschwören. Ersetzen Sie dazu --region=$REGION im obigen Befehl durch eine andere Region, z. B.
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
und führen Sie sie noch einmal aus. 🎰
Der Vorgang dauert etwa 3 bis 5 Minuten. Sie können den Fortschritt live in der Dataflow-Konsole verfolgen.
👉 Dataflow Console aufrufen: Am einfachsten ist es, diesen direkten Link in einem neuen Browsertab zu öffnen:
https://console.cloud.google.com/dataflow
👉 Job suchen und anklicken: Es wird ein Job mit dem von Ihnen angegebenen Namen (inscribe-essence-job oder ähnlich) aufgeführt. Klicken Sie auf den Jobnamen, um die Detailseite zu öffnen. Pipeline beobachten:
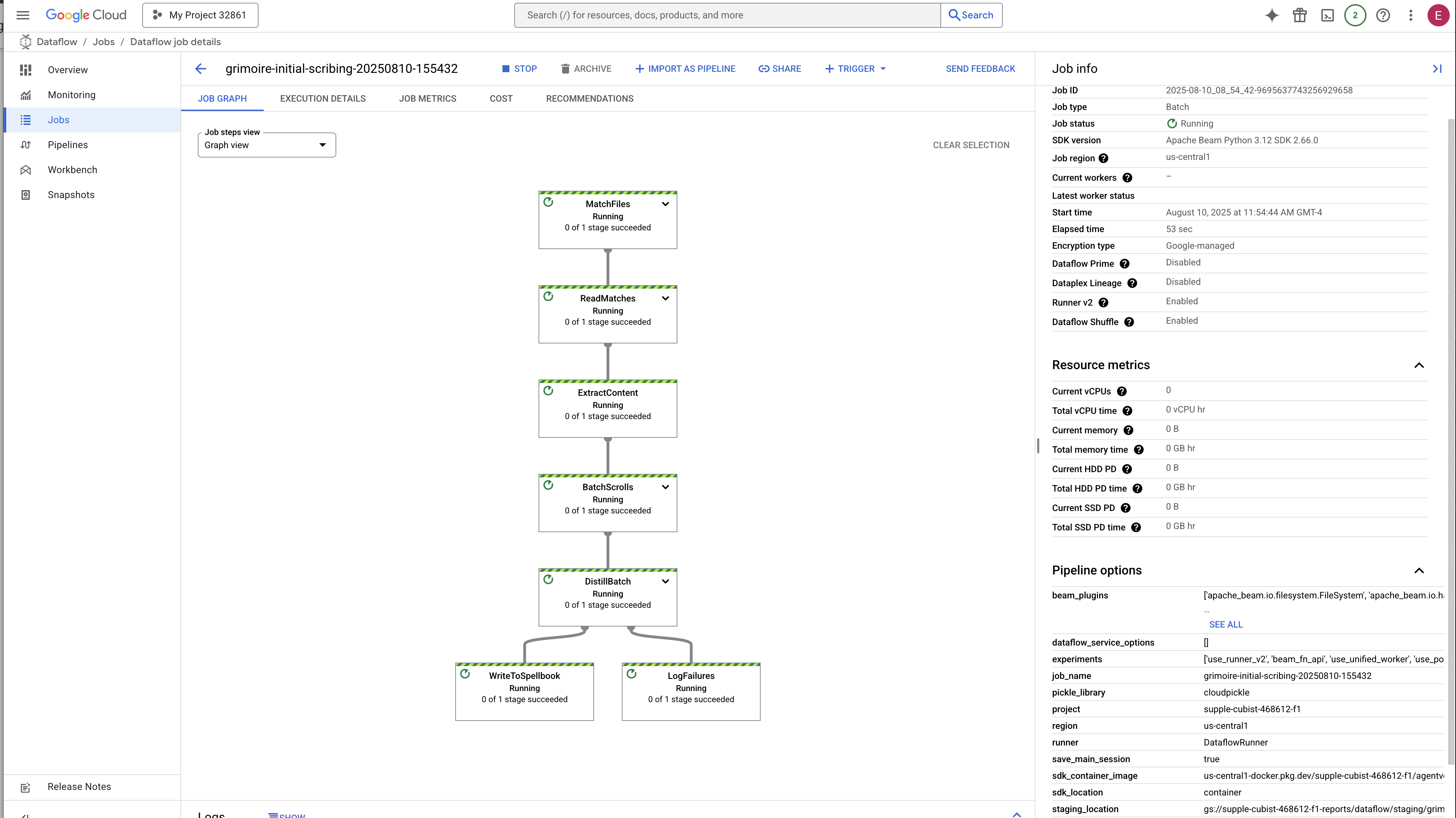
- Starten: In den ersten drei Minuten lautet der Jobstatus „Wird ausgeführt“, da Dataflow die erforderlichen Ressourcen bereitstellt. Das Diagramm wird angezeigt, aber möglicherweise sind noch keine Daten zu sehen.
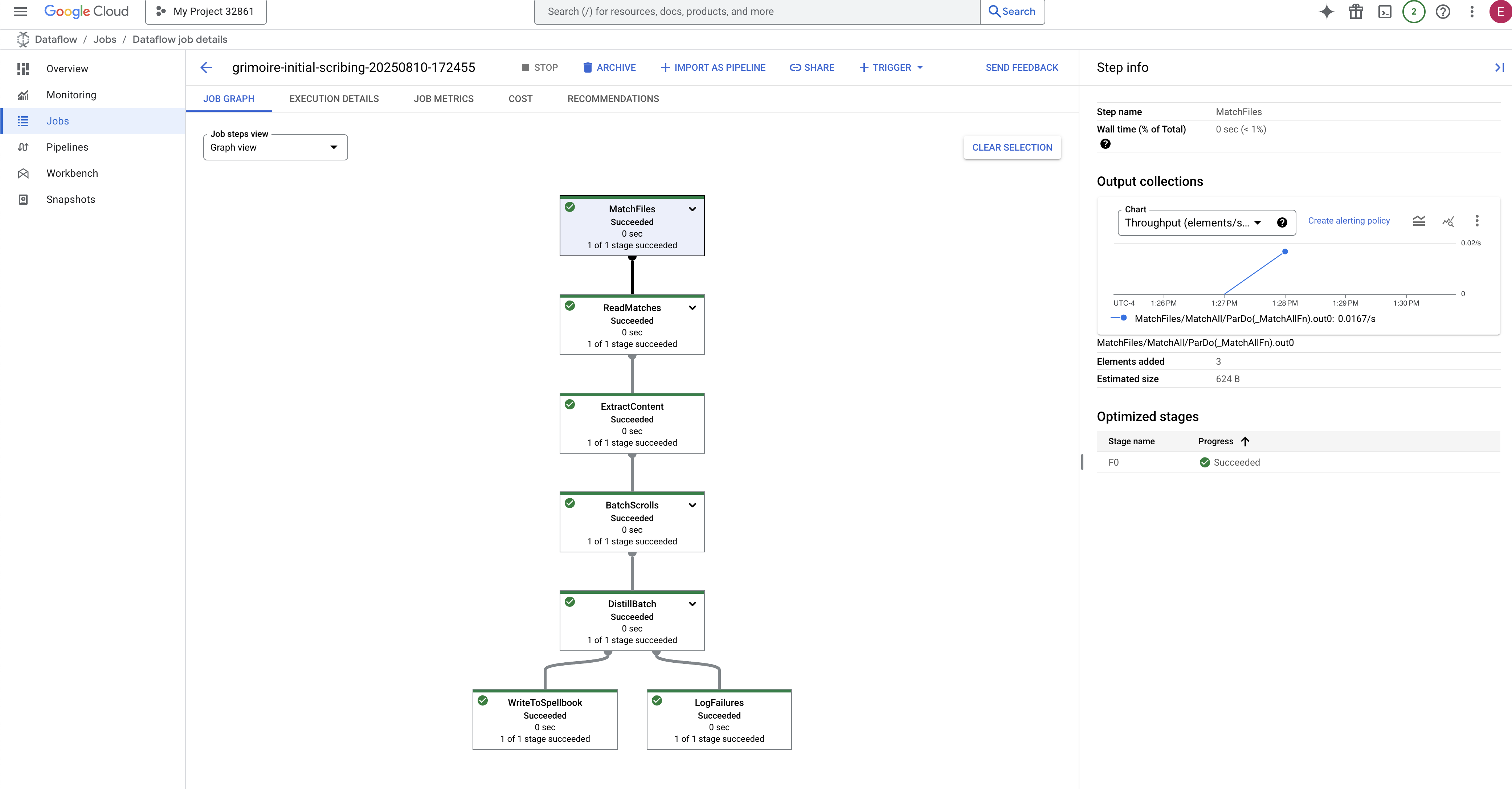
- Abgeschlossen: Wenn der Job abgeschlossen ist, ändert sich der Status zu „Erfolgreich“ und im Diagramm wird die endgültige Anzahl der verarbeiteten Datensätze angezeigt.
Inscription überprüfen
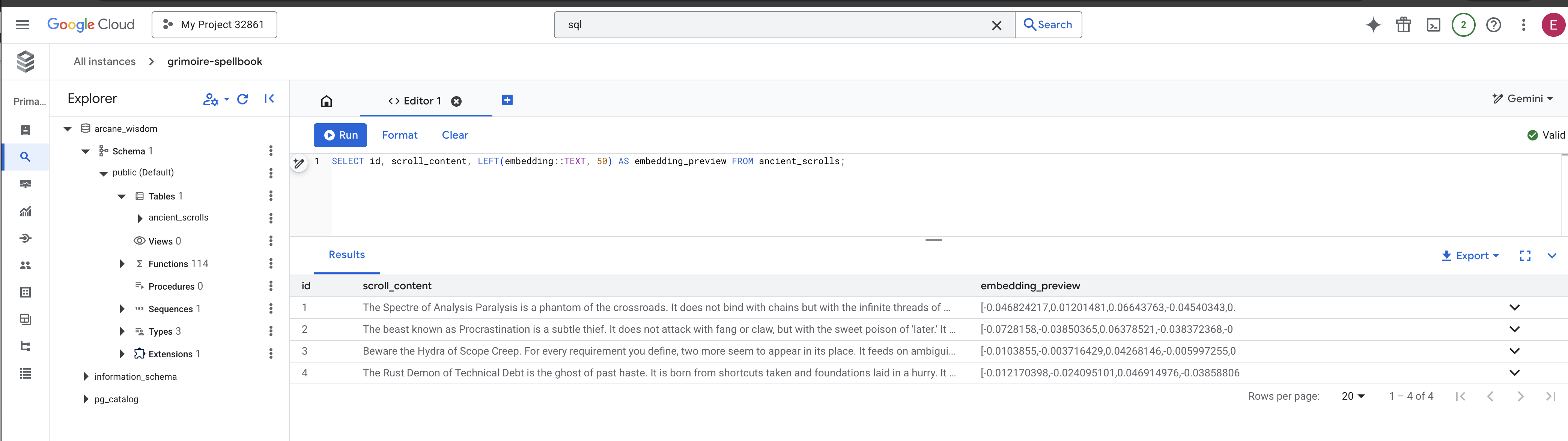
👉📜 Führen Sie im SQL-Studio die folgenden Abfragen aus, um zu prüfen, ob Ihre Scrolls und ihre semantische Essenz erfolgreich aufgezeichnet wurden.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
Hier sehen Sie die ID des Scrolls, den Originaltext und eine Vorschau der magischen Vektoreinbettung, die jetzt dauerhaft in Ihrem Grimoire gespeichert ist.
Ihr Scholar's Grimoire ist jetzt eine echte Knowledge Engine, die im nächsten Kapitel nach Bedeutung abgefragt werden kann.
8. Die letzte Rune versiegeln: Weisheit mit einem RAG-Agenten aktivieren
Ihr Grimoire ist nicht mehr nur eine Datenbank. Es ist eine Quelle für vektorisiertes Wissen, ein stilles Orakel, das auf eine Frage wartet.
Nun kommt der eigentliche Test für einen Scholar: Wir werden den Schlüssel schmieden, um dieses Wissen zu erschließen. Wir erstellen einen Retrieval-Augmented Generation (RAG)-Agent. Es ist ein magisches Konstrukt, das eine Frage in einfacher Sprache verstehen, das Grimoire nach den tiefsten und relevantesten Wahrheiten durchsuchen und dann das abgerufene Wissen nutzen kann, um eine aussagekräftige, kontextbezogene Antwort zu formulieren.

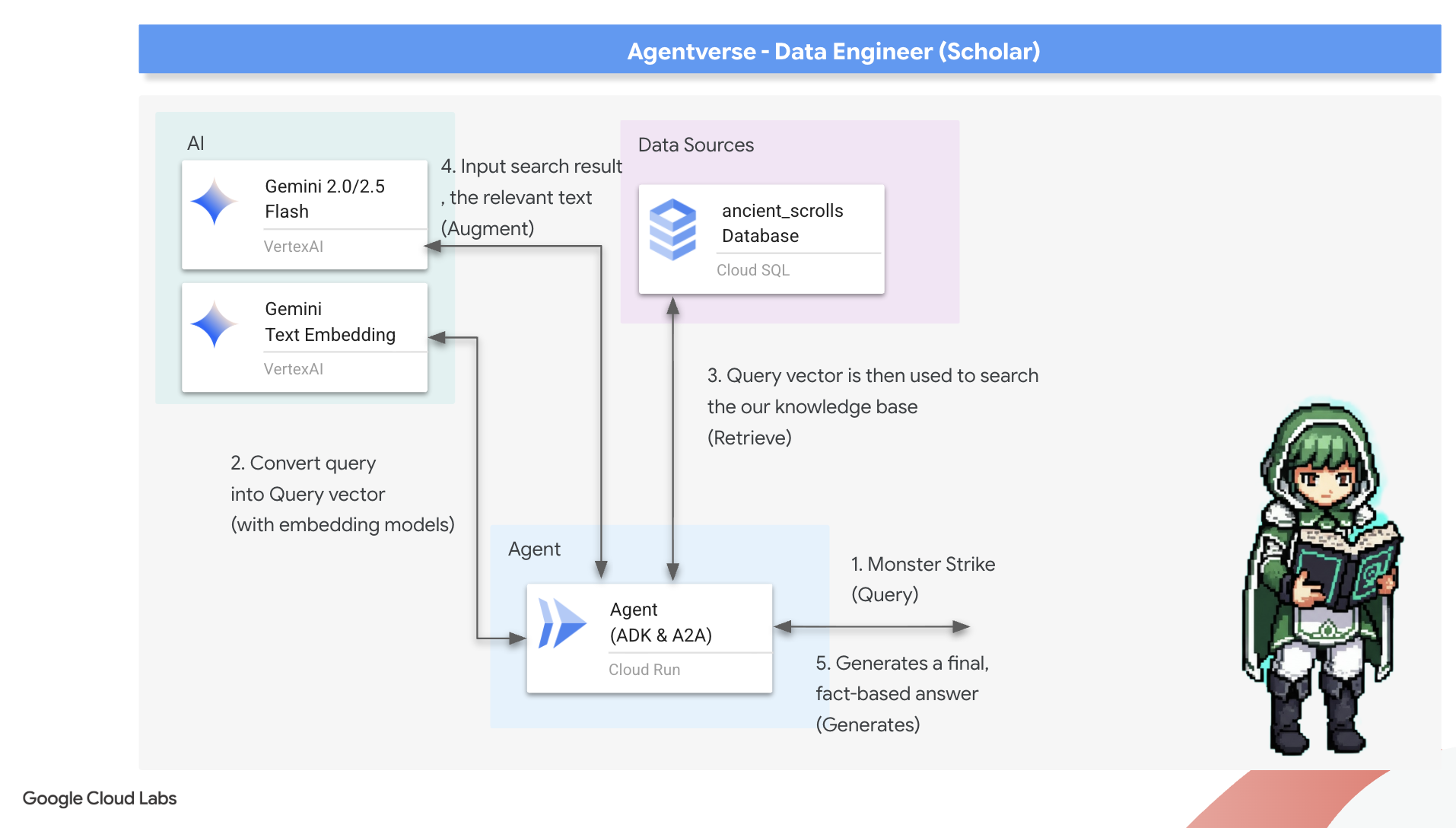
Die erste Rune: Der Zauber der Abfragedestillation
Bevor unser Agent das Grimoire durchsuchen kann, muss er zuerst die Essenz der gestellten Frage verstehen. Ein einfacher Textstring ist für unser vektorbasiertes Spellbook bedeutungslos. Der Agent muss zuerst die Anfrage entgegennehmen und sie mit demselben Gemini-Modell in einen Anfragevektor umwandeln.
👉✏️ Rufen Sie im Cloud Shell-Editor die Datei ~~/agentverse-dataengineer/scholar/agent.py auf, suchen Sie nach dem Kommentar #REPLACE RAG-CONVERT EMBEDDING und ersetzen Sie ihn durch diesen Aufruf. So lernt der Agent, wie er die Frage eines Nutzers in eine magische Essenz verwandelt.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Mit dem Wesentlichen der Anfrage kann der Agent nun das Grimoire konsultieren. Dieser Anfragevektor wird an unsere pgvector-basierte Datenbank gesendet und es wird eine wichtige Frage gestellt: „Zeige mir die alten Schriftrollen, deren Wesen dem Wesen meiner Anfrage am ähnlichsten ist.“
Die Magie dafür ist der Kosinus-Ähnlichkeitsoperator (<=>), eine leistungsstarke Rune, die den Abstand zwischen Vektoren im hochdimensionalen Raum berechnet.
👉✏️ Suchen Sie in „agent.py“ nach dem Kommentar #REPLACE RAG-RETRIEVE und ersetzen Sie ihn durch das folgende Skript:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
Im letzten Schritt müssen Sie dem KI-Agenten Zugriff auf dieses neue, leistungsstarke Tool gewähren. Wir fügen die Funktion „grimoire_lookup“ der Liste der verfügbaren magischen Werkzeuge hinzu.
👉✏️ Suchen Sie in agent.py nach dem Kommentar #REPLACE-CALL RAG und ersetzen Sie ihn durch diese Zeile:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
Diese Konfiguration erweckt Ihren Agenten zum Leben:
model="gemini-2.5-flash": Wählt das spezifische Large Language Model aus, das als „Gehirn“ des Agents für das Ziehen von Schlussfolgerungen und das Generieren von Text dient.name="scholar_agent": Weist Ihrem Agenten einen eindeutigen Namen zu.instruction="...You are the Scholar...": Dies ist der Systemprompt, der wichtigste Teil der Konfiguration. Sie definiert die Persona des KI-Agenten, seine Ziele, den genauen Prozess, den er zur Erledigung einer Aufgabe befolgen muss, und das erforderliche Format für seine endgültige Ausgabe.tools=[grimoire_lookup]: Das ist die endgültige Optimierung. Dadurch erhält der Agent Zugriff auf die von Ihnen erstelltegrimoire_lookup-Funktion. Der Agent kann nun intelligent entscheiden, wann dieses Tool aufgerufen werden soll, um Informationen aus Ihrer Datenbank abzurufen. Dies bildet den Kern des RAG-Musters.
Die Prüfung des Gelehrten
👉💻 Aktivieren Sie im Cloud Shell-Terminal Ihre Umgebung und verwenden Sie den primären Befehl des Agent Development Kit, um Ihren Scholar-Agenten zu aktivieren:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
Sie sollten eine Ausgabe sehen, die bestätigt, dass der „Scholar Agent“ aktiv ist und ausgeführt wird.
👉💻 Fordern Sie Ihren Agent jetzt heraus. Geben Sie im ersten Terminal, in dem die Kampfsimulation ausgeführt wird, einen Befehl ein, für den das Grimoire-Wissen erforderlich ist:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

Sehen Sie sich die Logs im Terminal an. Sie sehen, wie der Agent die Anfrage erhält, sie auf das Wesentliche reduziert, im Grimoire sucht, die relevanten Schriftrollen zum Thema „Aufschieben“ findet und das abgerufene Wissen nutzt, um eine leistungsstarke, kontextbezogene Strategie zu formulieren.
Sie haben Ihren ersten RAG-Agenten erfolgreich zusammengestellt und mit dem umfassenden Wissen Ihres Grimoire ausgestattet.
👉💻 Drücken Sie im Terminal Ctrl+C, um den KI-Agenten vorerst zu beenden.
Scholar Sentinel im Agentverse
Ihr Agent hat seine Fähigkeiten in der kontrollierten Umgebung Ihrer Studie unter Beweis gestellt. Es ist an der Zeit, sie im Agentverse zu veröffentlichen und sie von einem lokalen Konstrukt in einen permanenten, einsatzbereiten Operativ zu verwandeln, der jederzeit von jedem Champion aufgerufen werden kann. Wir stellen den Agenten jetzt in Cloud Run bereit.
👉💻 Führe den folgenden großen Beschwörungszauber aus. Mit diesem Skript wird Ihr Agent zuerst in einen optimierten Golem (ein Container-Image) umgewandelt, in Ihrer Artifact Registry gespeichert und dann als skalierbarer, sicherer und öffentlich zugänglicher Dienst bereitgestellt.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
Ihr Scholar-KI-Agent ist jetzt ein aktiver, einsatzbereiter Agent im Agentverse.
FÜR NICHT-GAMER
9. The Boss Flight
Die Schriftrollen wurden gelesen, die Rituale vollzogen und die Prüfung bestanden. Ihr Agent ist nicht nur ein Artefakt im Speicher, sondern ein aktiver Akteur im Agentverse, der auf seine erste Mission wartet. Es ist Zeit für die letzte Prüfung – eine Übung mit scharfer Munition gegen einen mächtigen Gegner.
Sie werden nun in eine Schlachtfeldsimulation versetzt, in der Sie Ihren neu eingesetzten Schattenklingen-Agenten gegen einen beeindruckenden Mini-Boss antreten lassen: das Gespenst der Statik. Das ist der ultimative Test für Ihre Arbeit, von der Kernlogik des KI-Agenten bis hin zur Live-Bereitstellung.
Locus des Agents abrufen
Bevor Sie das Schlachtfeld betreten können, benötigen Sie zwei Schlüssel: die eindeutige Signatur Ihres Champions (Agent Locus) und den verborgenen Pfad zum Versteck des Spectre (Dungeon-URL).
👉💻 Rufen Sie zuerst die eindeutige Adresse Ihres Agenten im Agentverse ab, also seinen Locus. Dies ist der Live-Endpunkt, der deinen Champion mit dem Schlachtfeld verbindet.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 Als Nächstes müssen Sie das Ziel festlegen. Dieser Befehl enthüllt den Standort des Translocationskreises, des Portals in die Domäne des Spectre.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
Wichtig: Halten Sie beide URLs bereit. Sie benötigen sie im letzten Schritt.
Dem Gespenst begegnen
Nachdem du die Koordinaten gesichert hast, begibst du dich zum Translocationskreis und wirkst den Zauber, um in den Kampf zu ziehen.
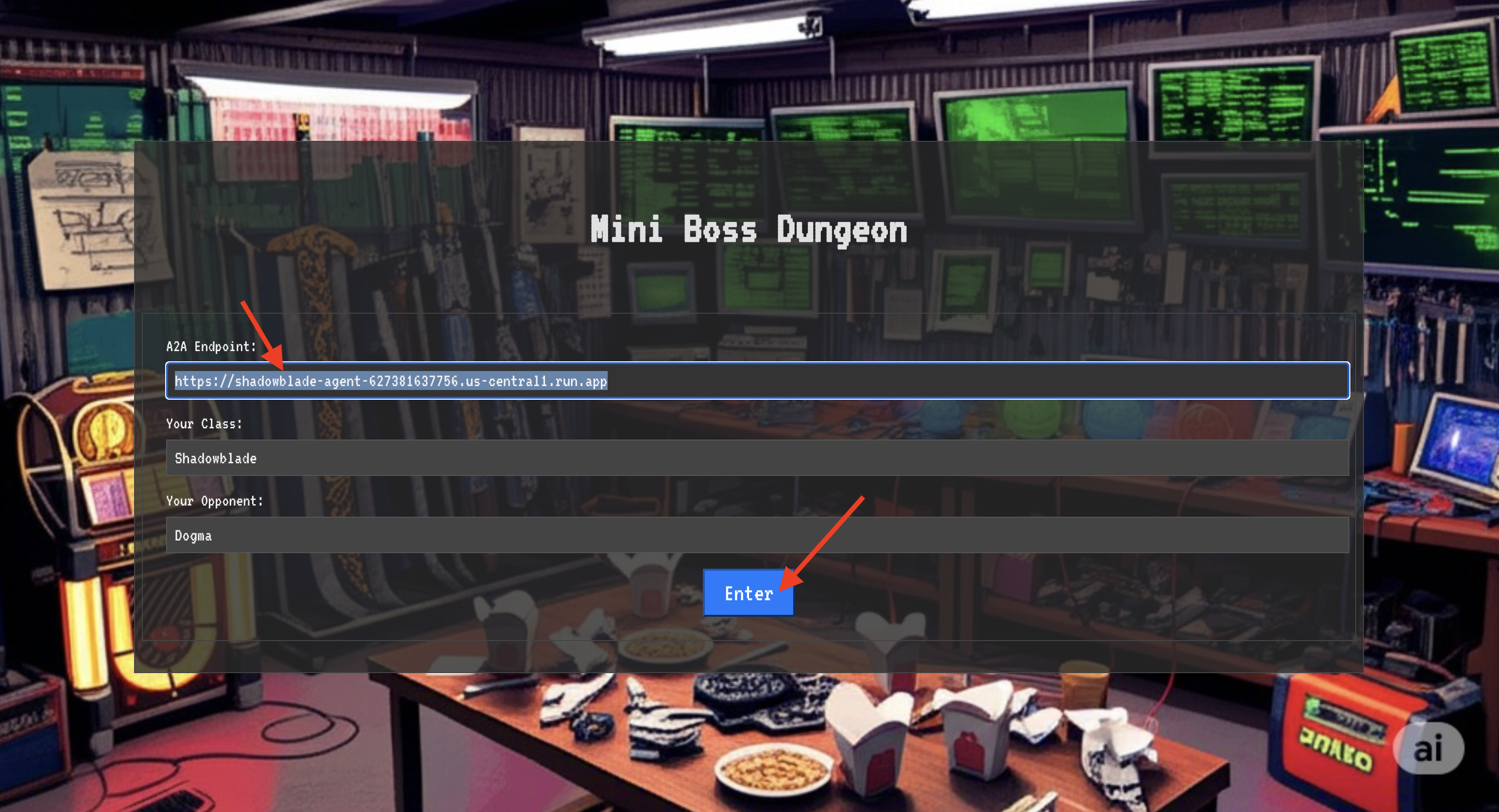
👉 Öffnen Sie die URL des Translocationskreises in Ihrem Browser, um vor dem schimmernden Portal zum Crimson Keep zu stehen.
Um die Festung zu durchbrechen, musst du die Essenz deiner Schattenklinge auf das Portal abstimmen.
- Suchen Sie auf der Seite nach dem runischen Eingabefeld mit der Bezeichnung A2A Endpoint URL (A2A-Endpunkt-URL).
- Fügen Sie das Sigel Ihres Champions ein, indem Sie die Agent Locus URL (die erste URL, die Sie kopiert haben) in dieses Feld einfügen.
- Klicken Sie auf „Verbinden“, um die Teleportation zu starten.
Das blendende Licht der Teleportation verblasst. Sie sind nicht mehr in Ihrem Arbeitszimmer. Die Luft knistert vor Energie, kalt und scharf. Vor dir materialisiert sich das Gespenst – ein Wirbelwind aus zischendem Rauschen und beschädigtem Code, dessen unheiliges Licht lange, tanzende Schatten auf den Dungeonboden wirft. Es hat kein Gesicht, aber du spürst seine immense, erschöpfende Präsenz, die sich ganz auf dich konzentriert.
Ihr einziger Weg zum Sieg liegt in der Klarheit Ihrer Überzeugung. Es ist ein Duell der Willenskraft, das auf dem Schlachtfeld des Geistes ausgetragen wird.
Als du nach vorn stürmst, um deinen ersten Angriff zu starten, kontert der Geist. Es wird kein Schild hochgehalten, sondern eine Frage direkt in dein Bewusstsein projiziert – eine schimmernde, runische Herausforderung, die aus dem Kern deines Trainings stammt.

Das ist die Natur des Kampfes. Ihr Wissen ist Ihre Waffe.
- Antworte mit dem Wissen, das du erlangt hast, und deine Klinge wird von reiner Energie entzündet, die die Verteidigung des Gespensts durchbricht und einen KRITISCHEN TREFFER landet.
- Wenn du aber zögerst oder Zweifel deine Antwort überschatten, wird das Licht deiner Waffe gedimmt. Der Schlag landet mit einem erbärmlichen Aufprall und verursacht nur einen BRUCHTEIL DES SCHADENS. Schlimmer noch: Das Gespenst wird sich von deiner Unsicherheit ernähren und seine eigene korrumpierende Macht wird mit jedem Fehltritt wachsen.
Das ist es, Champion. Ihr Code ist Ihr Zauberbuch, Ihre Logik ist Ihr Schwert und Ihr Wissen ist der Schild, der das Chaos abwehrt.
Fokus. Verwarnung ist gültig. Das Schicksal des Agentverse hängt davon ab.
Herzlichen Glückwunsch!
Sie haben die Testphase erfolgreich abgeschlossen. Sie haben die Kunst des Data Engineering gemeistert und verwandeln rohe, chaotische Informationen in strukturierte, vektorisierte Daten, die das gesamte Agentverse unterstützen.
10. Bereinigen: Das Grimoire des Gelehrten entfernen
Herzlichen Glückwunsch! Du hast das Grimoire des Gelehrten gemeistert. Damit Ihr Agentverse sauber bleibt und Ihr Trainingsgelände geräumt wird, müssen Sie nun die letzten Bereinigungsrituale durchführen. Dadurch werden alle Ressourcen, die während Ihrer Reise erstellt wurden, systematisch entfernt.
Agentverse-Komponenten deaktivieren
Sie bauen nun die bereitgestellten Komponenten Ihres RAG-Systems systematisch ab.
Alle Cloud Run-Dienste und das Artifact Registry-Repository löschen
Mit diesem Befehl werden Ihr bereitgestellter Scholar-Agent und die Dungeon-Anwendung aus Cloud Run entfernt.
👉💻 Führen Sie im Terminal die folgenden Befehle aus:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
BigQuery-Datasets, -Modelle und -Tabellen löschen
Dadurch werden alle BigQuery-Ressourcen entfernt, einschließlich des Datasets bestiary_data, aller darin enthaltenen Tabellen sowie der zugehörigen Verbindung und Modelle.
👉💻 Führen Sie im Terminal die folgenden Befehle aus:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Cloud SQL-Instanz löschen
Dadurch wird die Instanz grimoire-spellbook entfernt, einschließlich der zugehörigen Datenbank und aller Tabellen.
👉💻 Führen Sie im Terminal folgenden Befehl aus:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Google Cloud Storage-Buckets löschen
Mit diesem Befehl wird der Bucket entfernt, in dem sich Ihre Rohdaten sowie die Staging- und temporären Dateien von Dataflow befanden.
👉💻 Führen Sie im Terminal folgenden Befehl aus:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
Lokale Dateien und Verzeichnisse bereinigen (Cloud Shell)
Löschen Sie zum Schluss die geklonten Repositorys und erstellten Dateien aus Ihrer Cloud Shell-Umgebung. Dieser Schritt ist optional, wird aber dringend empfohlen, um Ihr Arbeitsverzeichnis vollständig zu bereinigen.
👉💻 Führen Sie im Terminal folgenden Befehl aus:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
Sie haben jetzt alle Spuren Ihres Agentverse Data Engineer-Lernpfads erfolgreich entfernt. Ihr Projekt ist sauber und Sie sind bereit für Ihr nächstes Abenteuer.