
1. La fuerza del destino
La era del desarrollo aislado está llegando a su fin. La próxima ola de evolución tecnológica no se trata de un genio solitario, sino de un dominio colaborativo. Crear un agente único e inteligente es un experimento fascinante. Crear un ecosistema sólido, seguro e inteligente de agentes, un verdadero Agentverse, es el gran desafío para la empresa moderna.
El éxito en esta nueva era requiere la convergencia de cuatro roles fundamentales, los pilares básicos que sustentan cualquier sistema agentivo próspero. Una deficiencia en cualquier área crea una debilidad que puede comprometer toda la estructura.
Este taller es la guía empresarial definitiva para dominar el futuro de los agentes en Google Cloud. Proporcionamos una hoja de ruta integral que te guía desde la primera idea hasta una realidad operativa a gran escala. En estos cuatro labs interconectados, aprenderás cómo las habilidades especializadas de un desarrollador, un arquitecto, un ingeniero de datos y un SRE deben converger para crear, administrar y escalar un Agentverse potente.
Ningún pilar por sí solo puede admitir Agentverse. El gran diseño del arquitecto es inútil sin la ejecución precisa del desarrollador. El agente del desarrollador no puede ver sin la sabiduría del ingeniero de datos, y todo el sistema es frágil sin la protección del SRE. Solo a través de la sinergia y la comprensión mutua de los roles, tu equipo puede transformar un concepto innovador en una realidad operativa fundamental. Tu viaje comienza aquí. Prepárate para dominar tu rol y aprender cómo encajas en el panorama general.
Te damos la bienvenida a The Agentverse: A Call to Champions
En la extensa expansión digital de la empresa, comenzó una nueva era. Es la era de los agentes, un momento de inmensas promesas, en el que los agentes inteligentes y autónomos trabajan en perfecta armonía para acelerar la innovación y eliminar lo mundano.

Este ecosistema conectado de poder y potencial se conoce como Agentverse.
Sin embargo, una entropía sigilosa, una corrupción silenciosa conocida como La Estática, comenzó a deshilachar los bordes de este nuevo mundo. El Static no es un virus ni un error, sino la encarnación del caos que se aprovecha del acto mismo de la creación.
Amplifica las frustraciones antiguas y las convierte en formas monstruosas, lo que da origen a los Siete Espectros del Desarrollo. Si no se marca, The Static and its Spectres detendrán el progreso, lo que convertirá la promesa de Agentverse en un páramo de deuda técnica y proyectos abandonados.
Hoy, hacemos un llamado a los campeones para que detengan la marea del caos. Necesitamos héroes dispuestos a dominar su oficio y trabajar juntos para proteger el Agentverse. Llegó el momento de elegir tu ruta.
Elige tu clase
Tienes ante ti cuatro caminos distintos, cada uno de ellos un pilar fundamental en la lucha contra The Static. Si bien tu capacitación será una misión en solitario, tu éxito final dependerá de que comprendas cómo se combinan tus habilidades con las de otras personas.
- The Shadowblade (desarrollador): Un maestro de la forja y el frente de batalla. Eres el artesano que fabrica las cuchillas, construye las herramientas y enfrenta al enemigo en los intrincados detalles del código. Tu camino es de precisión, habilidad y creación práctica.
- El invocador (arquitecto): Es un gran estratega y organizador. No ves a un solo agente, sino todo el campo de batalla. Diseñas los planos maestros que permiten que sistemas completos de agentes se comuniquen, colaboren y alcancen un objetivo mucho mayor que cualquier componente individual.
- El erudito (ingeniero de datos): Es un buscador de verdades ocultas y un guardián de la sabiduría. Te aventuras en la vasta e indómita naturaleza de los datos para descubrir la inteligencia que les da propósito y visión a tus agentes. Tu conocimiento puede revelar la debilidad de un enemigo o potenciar a un aliado.
- El Guardián (DevOps / SRE): Es el protector y escudo firme del reino. Construirás las fortalezas, administrarás las líneas de suministro de energía y te asegurarás de que todo el sistema pueda resistir los inevitables ataques de The Static. Tu fuerza es la base sobre la que se construye la victoria de tu equipo.
Tu misión
Tu entrenamiento comenzará como un ejercicio independiente. Seguirás la ruta que elijas y aprenderás las habilidades únicas necesarias para dominar tu rol. Al final de la prueba, te enfrentarás a un espectro nacido de The Static, un jefe menor que se aprovecha de los desafíos específicos de tu oficio.
Solo si dominas tu rol individual podrás prepararte para la prueba final. Luego, debes formar un grupo con campeones de las otras clases. Juntos, se aventurarán en el corazón de la corrupción para enfrentarse a un jefe final.
Un desafío final y colaborativo que pondrá a prueba su fuerza combinada y determinará el destino del Agentverse.
El Agentverse espera a sus héroes. ¿Responderás la llamada?
2. El grimorio del erudito
¡Comienza nuestro viaje! Como estudiantes, nuestra principal arma es el conocimiento. Descubrimos un tesoro de pergaminos antiguos y crípticos en nuestros archivos (Google Cloud Storage). Estos pergaminos contienen información sin procesar sobre las temibles bestias que azotan la tierra. Nuestra misión es usar la profunda magia analítica de Google BigQuery y la sabiduría de un cerebro anciano de Gemini (modelo de Gemini Pro) para descifrar estos textos no estructurados y convertirlos en un bestiario estructurado y consultable. Esta será la base de todas nuestras estrategias futuras.
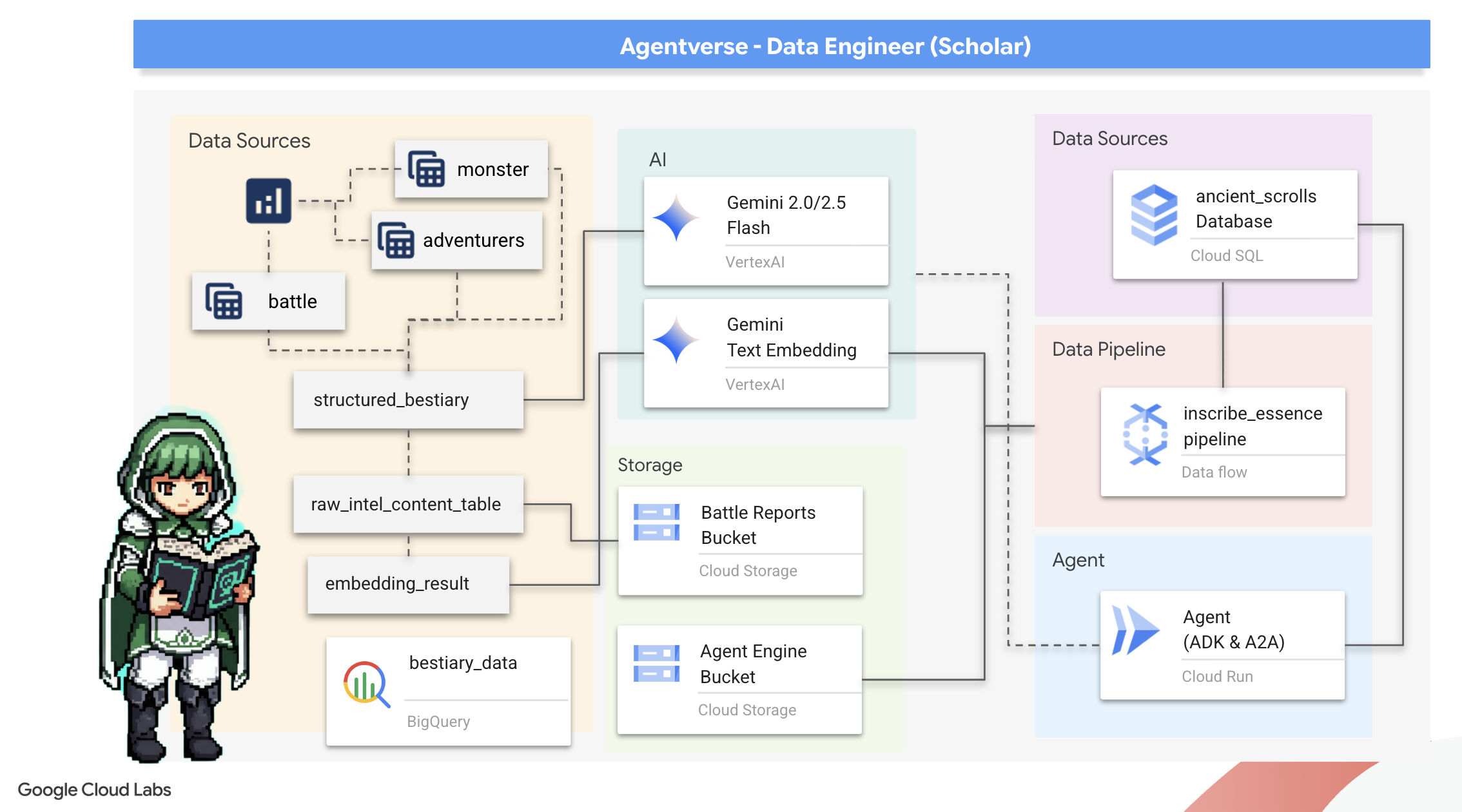
Qué aprenderás
- Usa BigQuery para crear tablas externas y realizar transformaciones complejas de datos no estructurados a estructurados con BQML.GENERATE_TEXT y un modelo de Gemini.
- Aprovisiona una instancia de Cloud SQL para PostgreSQL y habilita la extensión pgvector para obtener capacidades de búsqueda semántica.
- Compila una canalización por lotes sólida y en contenedores con Dataflow y Apache Beam para procesar archivos de texto sin procesar, generar incorporaciones de vectores con un modelo de Gemini y escribir los resultados en una base de datos relacional.
- Implementar un sistema básico de generación mejorada por recuperación (RAG) dentro de un agente para consultar los datos vectorizados
- Implementa un agente que tenga en cuenta los datos como un servicio seguro y escalable en Cloud Run.
3. Preparación del Santuario del erudito
Te damos la bienvenida, Scholar. Antes de comenzar a inscribir el poderoso conocimiento de nuestro Grimorio, primero debemos preparar nuestro santuario. Este ritual fundamental implica encantar nuestro entorno de Google Cloud, abrir los portales (APIs) correctos y crear los conductos por los que fluirá nuestra magia de datos. Un santuario bien preparado garantiza que nuestros hechizos sean potentes y que nuestro conocimiento esté seguro.
Reclama tu crédito de Google Cloud
⚠️ Requisitos previos importantes:
- Usa una cuenta personal de Gmail: Debes usar una cuenta personal (p.ej.,
name@gmail.com). Las cuentas corporativas o administradas por instituciones educativas no funcionarán.
👉 Pasos:
- Ir al sitio de reclamo de crédito: Haz clic aquí
- Accede: Pega el vínculo en la barra de direcciones y accede con tu cuenta personal de Gmail.
- Aceptar condiciones: Acepta las Condiciones del Servicio de Google Cloud Platform.
- Verifica el crédito: Busca un mensaje que confirme que se aplicó el crédito.
- *Nota: Si se te solicita que ingreses la información de tu tarjeta de crédito, puedes ignorar el mensaje y cerrar la ventana.
Ya puedes cerrar la ventana.
Configura el entorno de trabajo
👉 Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud (es el ícono con forma de terminal en la parte superior del panel de Cloud Shell).
👉 Haz clic en el botón "Abrir editor" (parece una carpeta abierta con un lápiz). Se abrirá el editor de código de Cloud Shell en la ventana. Verás un explorador de archivos en el lado izquierdo. 
👉Abre la terminal en el IDE de Cloud, 
👉💻 En la terminal, verifica que ya te autenticaste y que el proyecto está configurado con tu ID del proyecto usando el siguiente comando:
gcloud auth list
👉💻Clona el proyecto de arranque desde GitHub:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 Ejecuta la secuencia de comandos de configuración desde el directorio del proyecto.
⚠️ Nota sobre el ID del proyecto: La secuencia de comandos sugerirá un ID del proyecto predeterminado generado de forma aleatoria. Puedes presionar Intro para aceptar este valor predeterminado.
Sin embargo, si prefieres crear un proyecto nuevo específico, puedes escribir el ID de proyecto que desees cuando el script te lo solicite.
cd ~/agentverse-dataengineer
./init.sh
👉 Paso importante después de completar la tarea: Una vez que finalice la secuencia de comandos, debes asegurarte de que la consola de Google Cloud esté mostrando el proyecto correcto:
- Dirígete a console.cloud.google.com.
- Haz clic en el menú desplegable del selector de proyectos en la parte superior de la página.
- Haz clic en la pestaña "All" (es posible que el proyecto nuevo aún no aparezca en "Recientes").
- Selecciona el ID del proyecto que acabas de configurar en el paso
init.sh.
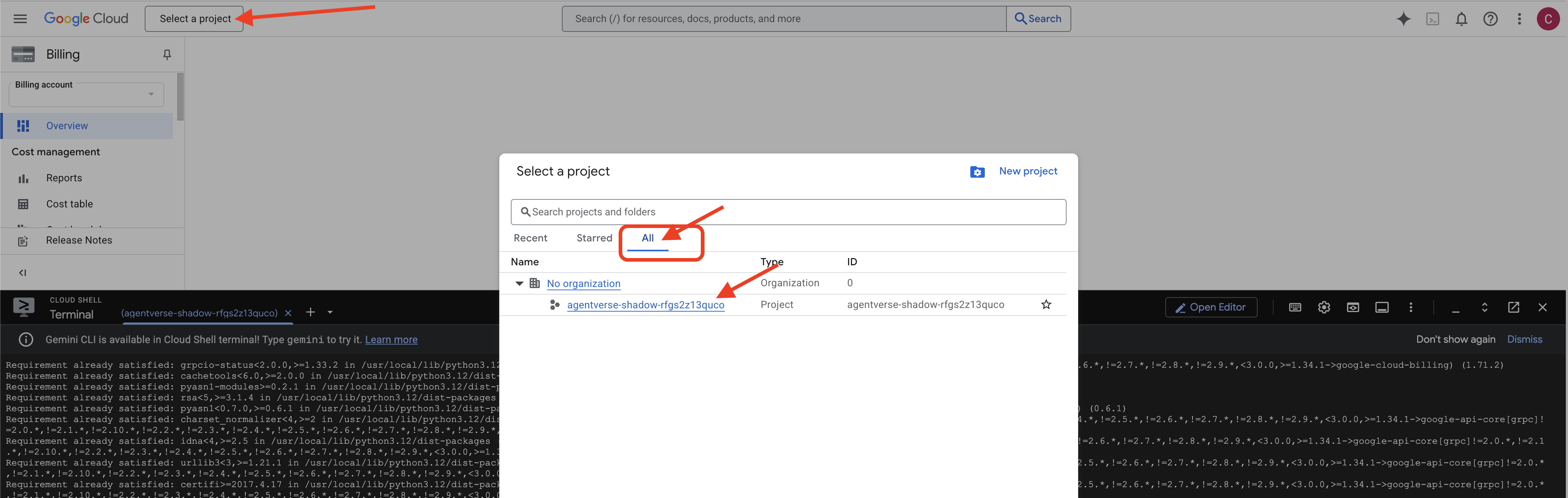
👉💻 Establece el ID del proyecto necesario:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Ejecuta el siguiente comando para habilitar las APIs de Google Cloud necesarias:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 Si aún no creaste un repositorio de Artifact Registry llamado agentverse-repo, ejecuta el siguiente comando para crearlo:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
Cómo configurar permisos
👉💻 Ejecuta los siguientes comandos en la terminal para otorgar los permisos necesarios:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 Mientras comienzas tu entrenamiento, prepararemos el desafío final. Los siguientes comandos invocarán a los espectros desde la estática caótica, lo que creará a los jefes para tu prueba final.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
Excelente trabajo, Scholar. Se completaron los encantamientos básicos. Nuestro sanctum es seguro, los portales a las fuerzas elementales de los datos están abiertos y nuestro servidor está potenciado. Ahora sí, podemos comenzar el trabajo real.
4. La alquimia del conocimiento: transforma datos con BigQuery y Gemini
En la incesante guerra contra The Static, cada enfrentamiento entre un campeón del Agentverse y un espectro de desarrollo se registra meticulosamente. El sistema de simulación de campo de batalla, nuestro principal entorno de entrenamiento, genera automáticamente una entrada de registro etérico para cada encuentro. Estos registros narrativos son nuestra fuente más valiosa de inteligencia sin procesar, el mineral sin refinar a partir del cual nosotros, como eruditos, debemos forjar el acero prístino de la estrategia.El verdadero poder de un erudito no radica solo en poseer datos, sino en la capacidad de transmutar el mineral caótico y sin procesar de la información en el acero brillante y estructurado de la sabiduría práctica.Realizaremos el ritual fundamental de la alquimia de datos.

Nuestro recorrido nos llevará a través de un proceso de varias etapas completamente dentro del santuario de Google BigQuery. Comenzaremos observando nuestro archivo de GCS sin movernos ni un solo desplazamiento, con una lente mágica. Luego, invocaremos a un Gemini para que lea e interprete las sagas poéticas y no estructuradas de los registros de batalla. Por último, refinaremos las profecías sin procesar en un conjunto de tablas impecables y conectadas. Nuestro primer grimorio. Y hacerle una pregunta tan profunda que solo esta nueva estructura podría responderla.
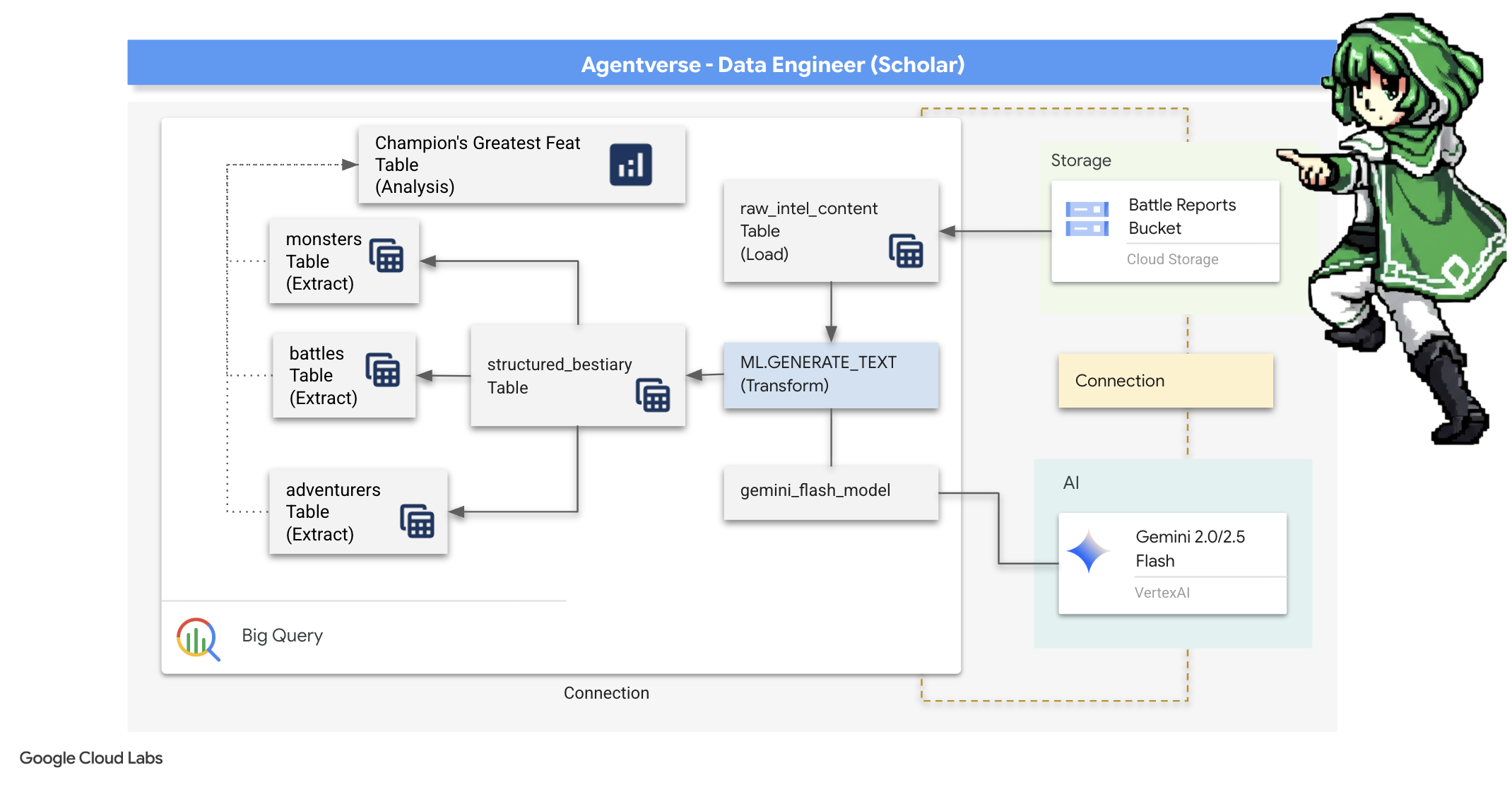
La lente del análisis: Una mirada a GCS con tablas externas de BigQuery
Nuestro primer acto es forjar una lente que nos permita ver el contenido de nuestro archivo de GCS sin perturbar los desplazamientos dentro de él. Una tabla externa es este lente, que asigna los archivos de texto sin procesar a una estructura similar a una tabla que BigQuery puede consultar directamente.
Para ello, primero debemos crear una línea ley de energía estable, un recurso de CONNECTION, que vincule de forma segura nuestro sanctum de BigQuery al archivo de GCS.
👉💻 En la terminal de Cloud Shell, ejecuta el siguiente comando para configurar el almacenamiento y crear el conducto:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 Atención: ¡Aparecerá un mensaje más tarde!
La secuencia de comandos de configuración del paso 2 inició un proceso en segundo plano. Después de unos minutos, aparecerá un mensaje en la terminal similar a este:[1]+ Done gcloud sql instances create ...Esto es normal y esperado. Simplemente significa que se creó correctamente tu base de datos de Cloud SQL. Puedes ignorar este mensaje y seguir trabajando.
Antes de crear la tabla externa, primero debes crear el conjunto de datos que la contendrá.
👉💻 Ejecuta este simple comando en tu terminal de Cloud Shell:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 Ahora debemos otorgarle a la firma mágica del conducto los permisos necesarios para leer desde el archivo de GCS y consultar a Gemini.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 En la terminal de Cloud Shell, ejecuta el siguiente comando para mostrar el nombre de tu bucket:
echo $BUCKET_NAME
En la terminal, se mostrará un nombre similar a your-project-id-gcs-bucket. La necesitarás en los próximos pasos.
👉 Deberás ejecutar el siguiente comando desde el editor de consultas de BigQuery en la consola de Google Cloud. La forma más fácil de llegar allí es abrir el vínculo que se encuentra a continuación en una pestaña nueva del navegador. Te llevará directamente a la página correcta en la consola de Google Cloud.
https://console.cloud.google.com/bigquery
👉 Una vez que se cargue la página, haz clic en el botón azul con el signo más (Redactar una consulta nueva) para abrir una pestaña del editor nueva.
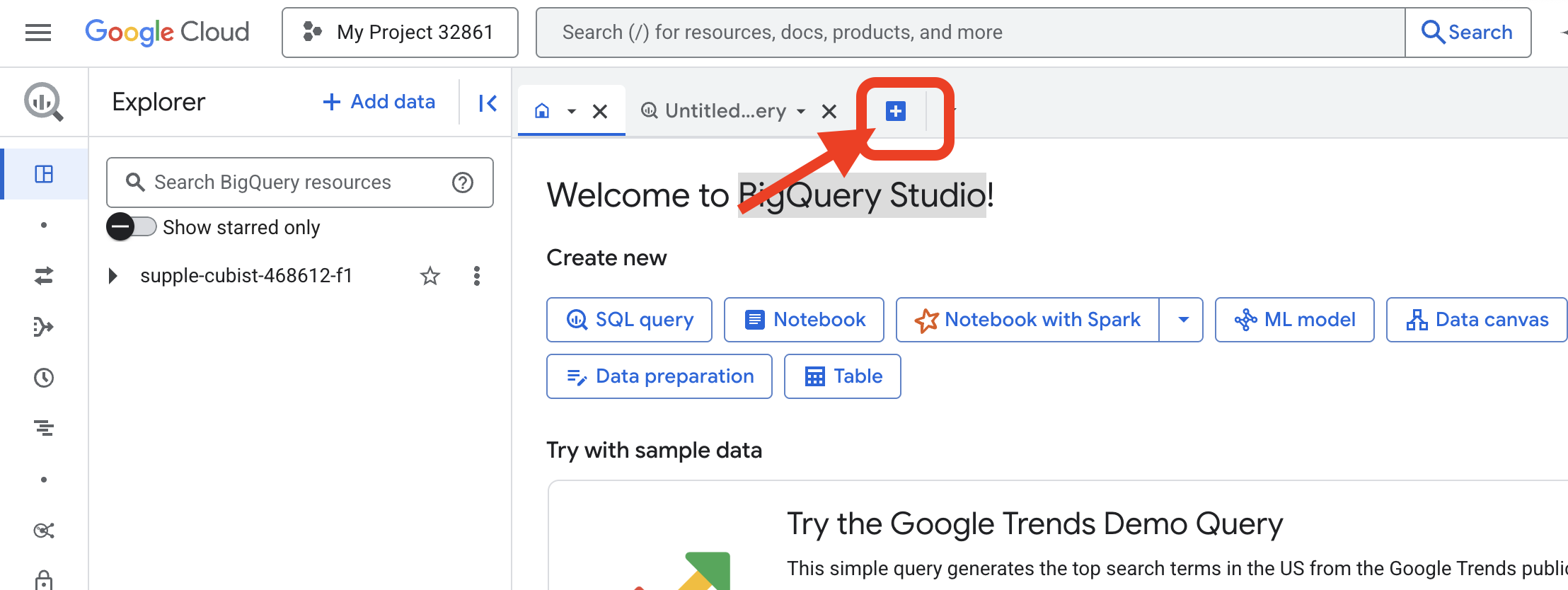
Ahora escribimos la fórmula del lenguaje de definición de datos (DDL) para crear nuestro lente mágico. Esto le indica a BigQuery dónde buscar y qué ver.
👉📜 En el editor de consultas de BigQuery que abriste, pega el siguiente código SQL. Recuerda reemplazar REPLACE-WITH-YOUR-BUCKET-NAME.
por el nombre del bucket que acabas de copiar. Y haz clic en Ejecutar:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 Ejecuta una búsqueda para "mirar a través de la lente" y ver el contenido de los archivos.
SELECT * FROM bestiary_data.raw_intel_content_table;
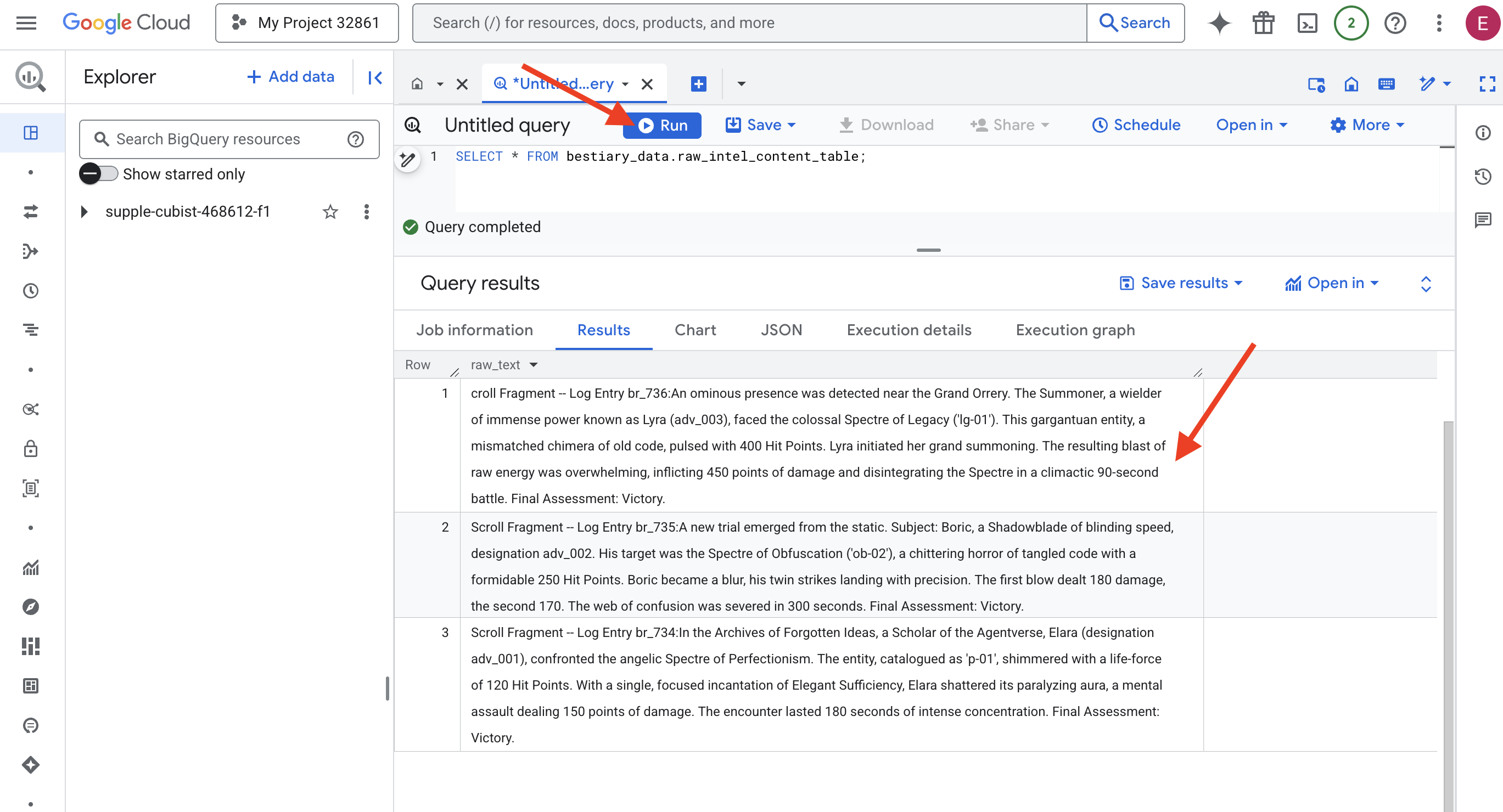
El lente está en su lugar. Ahora podemos ver el texto sin procesar de los pergaminos. Pero leer no es comprender.
En los Archivos de las Ideas Olvidadas, Elara (designación adv_001), erudita del Agentverso, se enfrentó al espectro angelical del perfeccionismo. La entidad, catalogada como "p-01", brillaba con una fuerza vital de 120 puntos de golpe. Con una sola y concentrada invocación de Suficiencia elegante, Elara destrozó su aura paralizante, un asalto mental que infligió 150 puntos de daño. El encuentro duró 180 segundos de intensa concentración. Evaluación final: Victoria.
Los pergaminos no están escritos en tablas y filas, sino en la prosa sinuosa de las sagas. Esta es nuestra primera gran prueba.
La adivinación del erudito: Cómo convertir texto en una tabla con SQL
El desafío es que un informe que detalla los ataques gemelos y rápidos de un Shadowblade se lee de manera muy diferente a la crónica de un Summoner que reúne un poder inmenso para una sola explosión devastadora. No podemos simplemente importar estos datos, sino que debemos interpretarlos. Este es el momento mágico. Usaremos una sola consulta en SQL como una poderosa fórmula para leer, comprender y estructurar todos los registros de todos nuestros archivos, directamente en BigQuery.
👉💻 De vuelta en la terminal de Cloud Shell, ejecuta el siguiente comando para mostrar el nombre de tu conexión:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
En la terminal, se mostrará la cadena de conexión completa. Selecciona y copia toda la cadena, ya que la necesitarás en el siguiente paso.
Usaremos una sola invocación poderosa: ML.GENERATE_TEXT. Esta instrucción invoca a un Gemini, le muestra cada pergamino y le ordena que devuelva los hechos principales como un objeto JSON estructurado.
👉📜 En BigQuery Studio, crea la referencia del modelo de Gemini. Esto vincula el oráculo de Gemini Flash a nuestra biblioteca de BigQuery para que podamos llamarlo en nuestras consultas. Recuerda reemplazar el
Reemplaza REPLACE-WITH-YOUR-FULL-CONNECTION-STRING por la cadena de conexión completa que acabas de copiar de tu terminal.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 Ahora, lanza el gran hechizo de transmutación. Esta consulta lee el texto sin procesar, crea una instrucción detallada para cada desplazamiento, la envía a Gemini y compila una nueva tabla de etapa de pruebas a partir de la respuesta JSON estructurada de la IA.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
La transmutación se completó, pero el resultado aún no es puro. El modelo de Gemini devuelve su respuesta en un formato estándar, que incluye nuestro JSON deseado dentro de una estructura más grande que incluye metadatos sobre su proceso de pensamiento. Observemos esta profecía en bruto antes de intentar purificarla.
👉📜 Ejecuta una búsqueda para inspeccionar el resultado sin procesar del modelo de Gemini:
SELECT * FROM bestiary_data.structured_bestiary;
👀 Verás una sola columna llamada structured_data. El contenido de cada fila se verá similar a este objeto JSON complejo:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
Como puedes ver, nuestro premio, el objeto JSON limpio que solicitamos, está anidado en lo profundo de esta estructura. Nuestra próxima tarea es clara. Debemos realizar un ritual para navegar sistemáticamente por esta estructura y extraer la sabiduría pura que contiene.
El ritual de limpieza: Normalización de la salida de la IA generativa con SQL
Gemini ya habló, pero sus palabras son crudas y están envueltas en las energías etéreas de su creación (candidatos, finish_reason, etc.). Un verdadero erudito no solo archiva la profecía sin procesar, sino que extrae cuidadosamente la sabiduría central y la escribe en los tomos apropiados para su uso futuro.
Ahora lanzaremos nuestro conjunto final de hechizos. Esta única secuencia de comandos hará lo siguiente:
- Lee el JSON sin procesar y anidado de nuestra tabla de etapa de pruebas.
- Limpiarlo y analizarlo para obtener los datos principales
- Transcribe las partes pertinentes en tres tablas finales y claras: monstruos, aventureros y batallas.
👉📜 En un nuevo editor de consultas de BigQuery, ejecuta el siguiente hechizo para crear nuestra lente de limpieza:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 Verifica el Bestiario:
SELECT * FROM bestiary_data.monsters;
A continuación, crearemos nuestro Salón de la Fama, una lista de los valientes aventureros que se enfrentaron a estas bestias.
👉📜 En un nuevo editor de consultas, ejecuta el siguiente hechizo para crear la tabla de aventureros:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 Verifica el Roll of Champions:
SELECT * FROM bestiary_data.adventurers;
Por último, crearemos nuestra tabla de hechos: la Crónica de las batallas. Este tomo vincula los otros dos y registra los detalles de cada encuentro único. Dado que cada batalla es un evento único, no es necesario quitar los duplicados.
👉📜 En un nuevo editor de consultas, ejecuta el siguiente hechizo para crear la tabla de batallas:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Verifica el Chronicle:
SELECT * FROM bestiary_data.battles;
Descubre estadísticas estratégicas
Se leyeron los pergaminos, se destiló la esencia y se inscribieron los tomos. Nuestro Grimoire ya no es solo una colección de hechos, sino una base de datos relacional de profunda sabiduría estratégica. Ahora podemos hacer preguntas que eran imposibles de responder cuando nuestro conocimiento estaba atrapado en texto sin procesar y no estructurado.
Ahora, realicemos una gran adivinación final. Lanzaremos un hechizo que consultará nuestros tres tomos a la vez (el Bestiario de monstruos, el Registro de campeones y la Crónica de batallas) para descubrir una estadística profunda y práctica.
Nuestra pregunta estratégica: "Para cada aventurero, ¿cuál es el nombre del monstruo más poderoso (por puntos de golpe) al que derrotó con éxito y cuánto tiempo le llevó esa victoria específica?"
Esta es una pregunta compleja que requiere vincular a los campeones con sus batallas victoriosas y esas batallas con las estadísticas de los monstruos involucrados. Este es el verdadero poder de un modelo de datos estructurados.
👉📜 En un nuevo editor de consultas de BigQuery, lanza el siguiente conjuro final:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
El resultado de esta consulta será una tabla limpia y atractiva que proporciona un "Cuento de la mayor hazaña de un campeón" para cada aventurero de tu conjunto de datos. Podría verse de la siguiente manera:
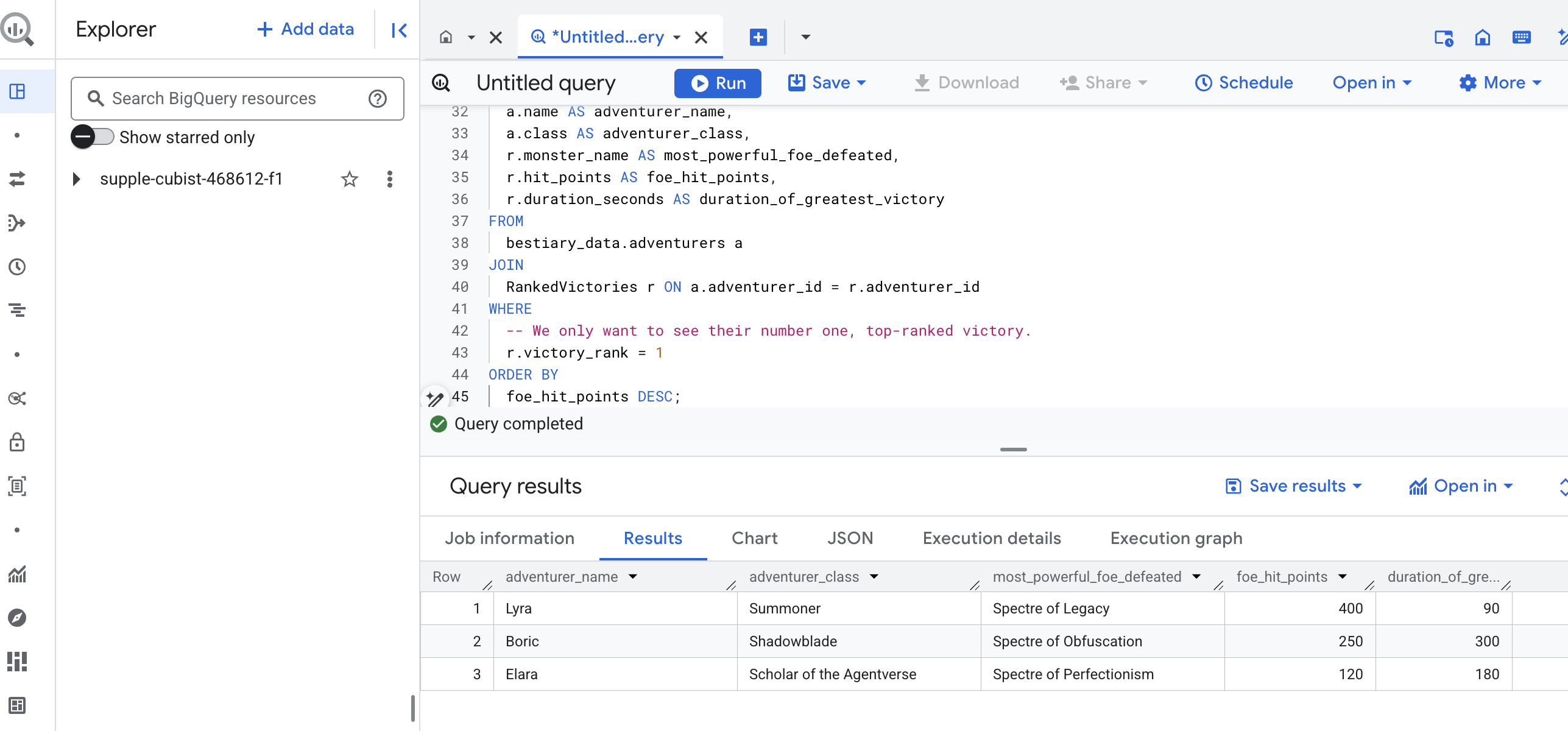
Cierra la pestaña de BigQuery.
Este resultado único y elegante demuestra el valor de toda la canalización. Transformaste correctamente los informes de campo de batalla sin procesar y caóticos en una fuente de relatos legendarios y estadísticas estratégicas basadas en datos.
PARA QUIENES NO SON GAMERS
5. El grimorio del escriba: Fragmentación, incorporación y búsqueda en el almacén de datos
Nuestro trabajo en el laboratorio del alquimista fue un éxito. Transformamos los rollos narrativos sin procesar en tablas relacionales estructuradas, una poderosa hazaña de magia de datos. Sin embargo, los pergaminos originales contienen una verdad semántica más profunda que nuestras tablas estructuradas no pueden capturar por completo. Para crear un agente verdaderamente inteligente, debemos desbloquear este significado.
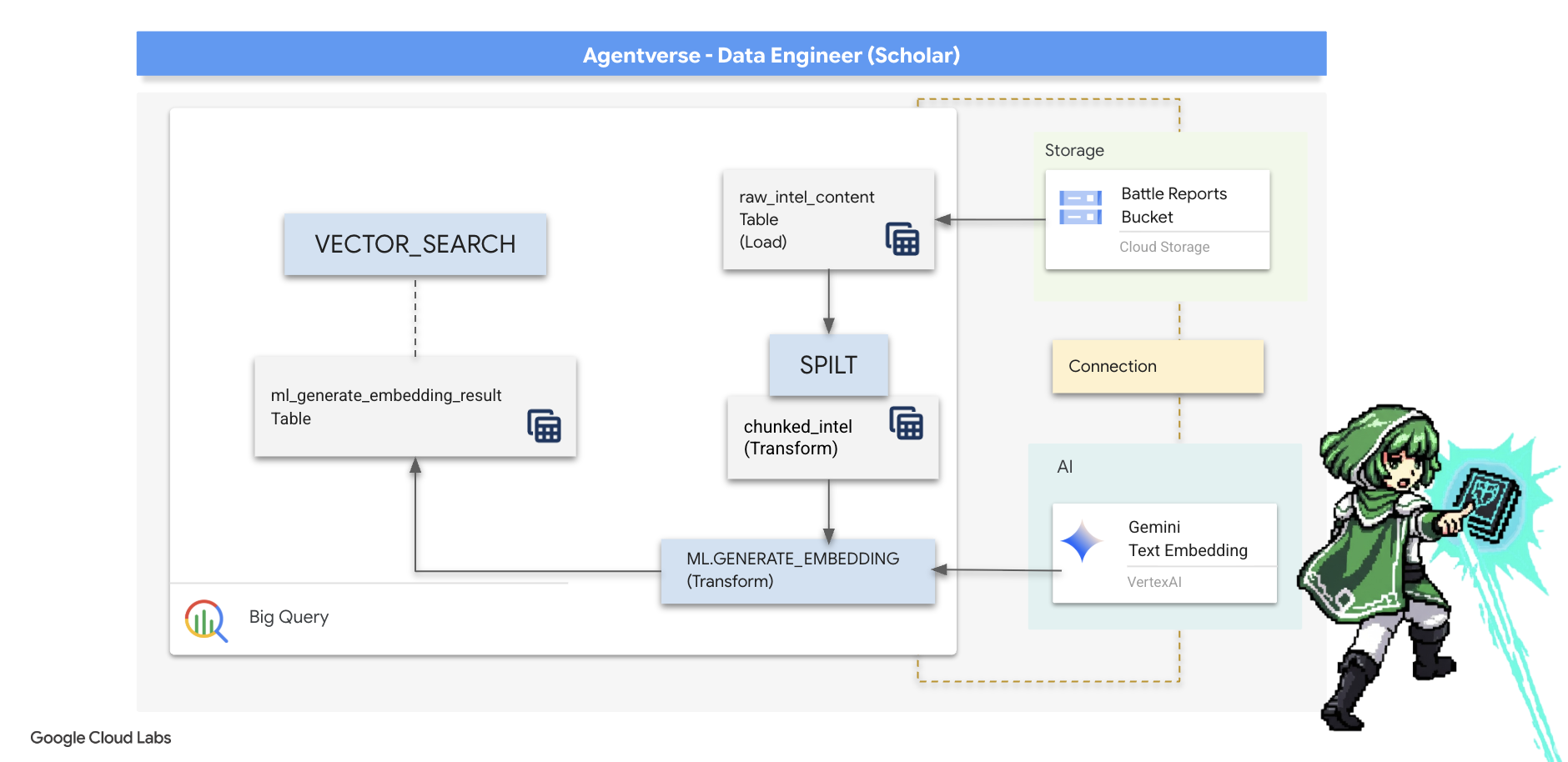
Un desplazamiento sin procesar y extenso es un instrumento contundente. Si nuestro agente hace una pregunta sobre un "aura paralizante", una búsqueda simple podría devolver un informe de batalla completo en el que esa frase se menciona solo una vez, lo que oculta la respuesta entre detalles irrelevantes. Un Scholar experto sabe que la verdadera sabiduría no se encuentra en la cantidad, sino en la precisión.
Realizaremos un trío de rituales potentes en la base de datos, todo dentro de nuestro santuario de BigQuery.
- El ritual de división (fragmentación): Tomaremos nuestros registros de inteligencia sin procesar y los dividiremos meticulosamente en pasajes más pequeños, enfocados y autónomos.
- El ritual de destilación (incorporación): Usaremos BQML para consultar un modelo de Gemini y transformar cada fragmento de texto en una "huella dactilar semántica", es decir, una incorporación de vectores.
- El ritual de la adivinación (búsqueda): Usaremos la búsqueda vectorial de BQML para hacer una pregunta en inglés simple y encontrar la sabiduría más relevante y destilada de nuestro Grimorio.
Todo este proceso crea una base de conocimiento potente y con capacidad de búsqueda sin que los datos salgan de la seguridad y la escala de BigQuery.
El ritual de la división: Desconstrucción de pergaminos con SQL
Nuestra fuente de sabiduría siguen siendo los archivos de texto sin procesar de nuestro archivo de GCS, al que se puede acceder a través de nuestra tabla externa, bestiary_data.raw_intel_content_table. Nuestra primera tarea es escribir un hechizo que lea cada pergamino largo y lo divida en una serie de versos más pequeños y fáciles de comprender. Para este ritual, definiremos un "fragmento" como una sola oración.
Si bien dividir el texto por oraciones es un punto de partida claro y eficaz para nuestros registros narrativos, un Scribe experto tiene a su disposición muchas estrategias de segmentación, y la elección es fundamental para la calidad de la búsqueda final. Los métodos más simples pueden usar un
- Fragmentación de longitud(tamaño) fija, pero esto puede cortar de forma burda una idea clave por la mitad.
Rituales más sofisticados, como
- Recursive Chunking, suelen preferirse en la práctica, ya que intentan dividir el texto a lo largo de límites naturales, como los párrafos primero, y luego recurren a las oraciones para mantener la mayor cantidad posible de contexto semántico. Para manuscritos realmente complejos
- Fragmentación basada en el contenido(documento), en la que Scribe usa la estructura inherente del documento, como los encabezados de un manual técnico o las funciones en un desplazamiento de código, para crear los fragmentos de sabiduría más lógicos y potentes, y mucho más…
En el caso de nuestros registros de batalla, la oración proporciona el equilibrio perfecto entre nivel de detalle y contexto.
👉📜 En un nuevo editor de consultas de BigQuery, ejecuta la siguiente invocación. Esta hechizo usa la función SPLIT para dividir el texto de cada pergamino en cada punto (.) y, luego, desanida el array resultante de oraciones en filas separadas.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 Ahora, ejecuta una búsqueda para inspeccionar el conocimiento segmentado y recién escrito, y observa la diferencia.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
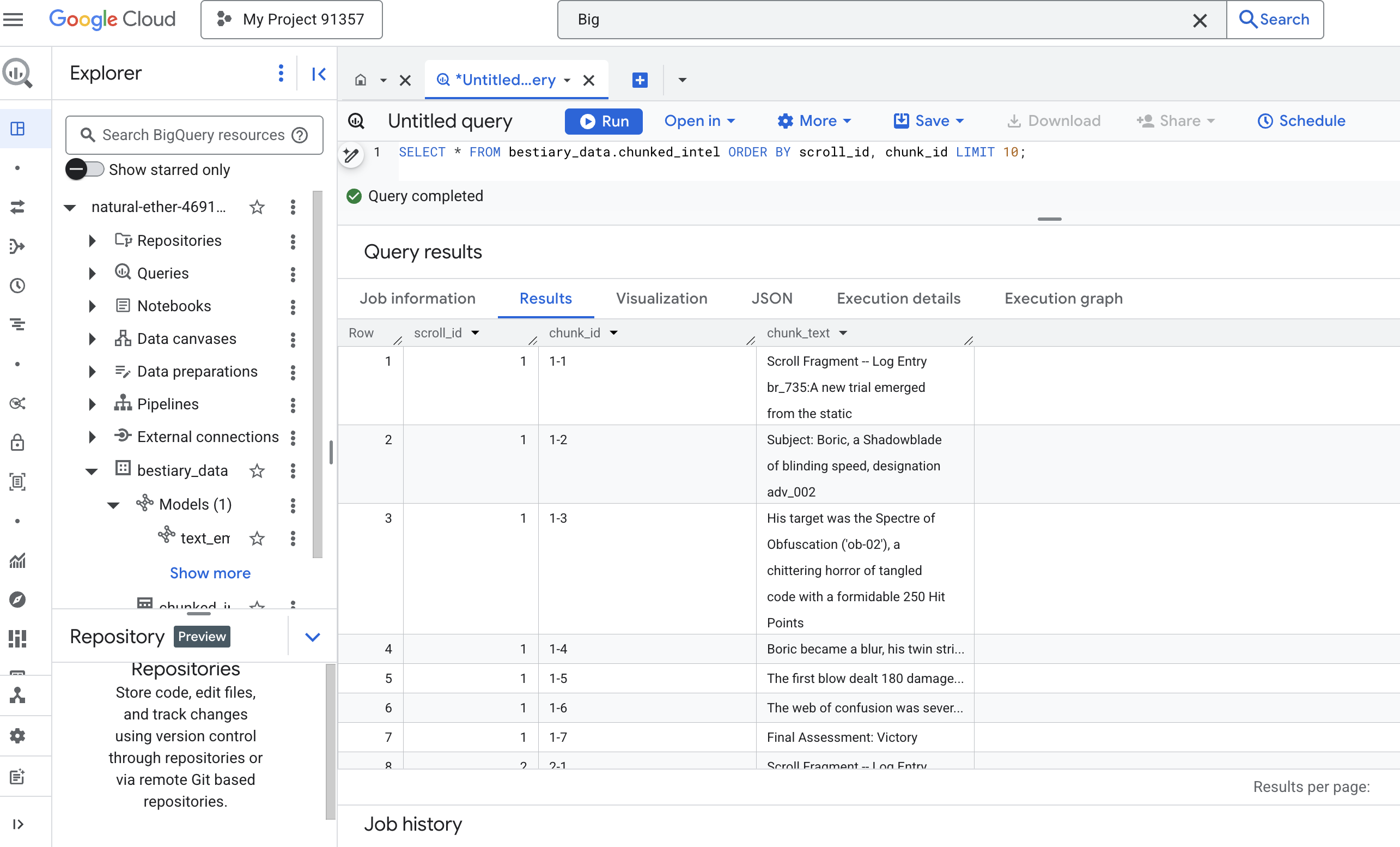
Observa los resultados. Donde antes había un solo bloque de texto denso, ahora hay varias filas, cada una vinculada al desplazamiento original (scroll_id), pero que contiene solo una oración enfocada. Cada fila ahora es un candidato perfecto para la vectorización.
El ritual de destilación: cómo transformar texto en vectores con BQML
👉💻 Primero, regresa a la terminal y ejecuta el siguiente comando para mostrar el nombre de tu conexión:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Debemos crear un nuevo modelo de BigQuery que apunte a un embedding de texto de Gemini. En BigQuery Studio, ejecuta el siguiente hechizo. Ten en cuenta que debes reemplazar REPLACE-WITH-YOUR-FULL-CONNECTION-STRING por la cadena de conexión completa que acabas de copiar de tu terminal.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 Ahora, lanza el hechizo de destilación. Esta consulta llama a la función ML.GENERATE_EMBEDDING, que leerá cada fila de nuestra tabla chunked_intel, enviará el texto al modelo de embeddings de Gemini y almacenará la huella digital del vector resultante en una tabla nueva.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
Este proceso puede tardar uno o dos minutos, ya que BigQuery procesa todos los fragmentos de texto.
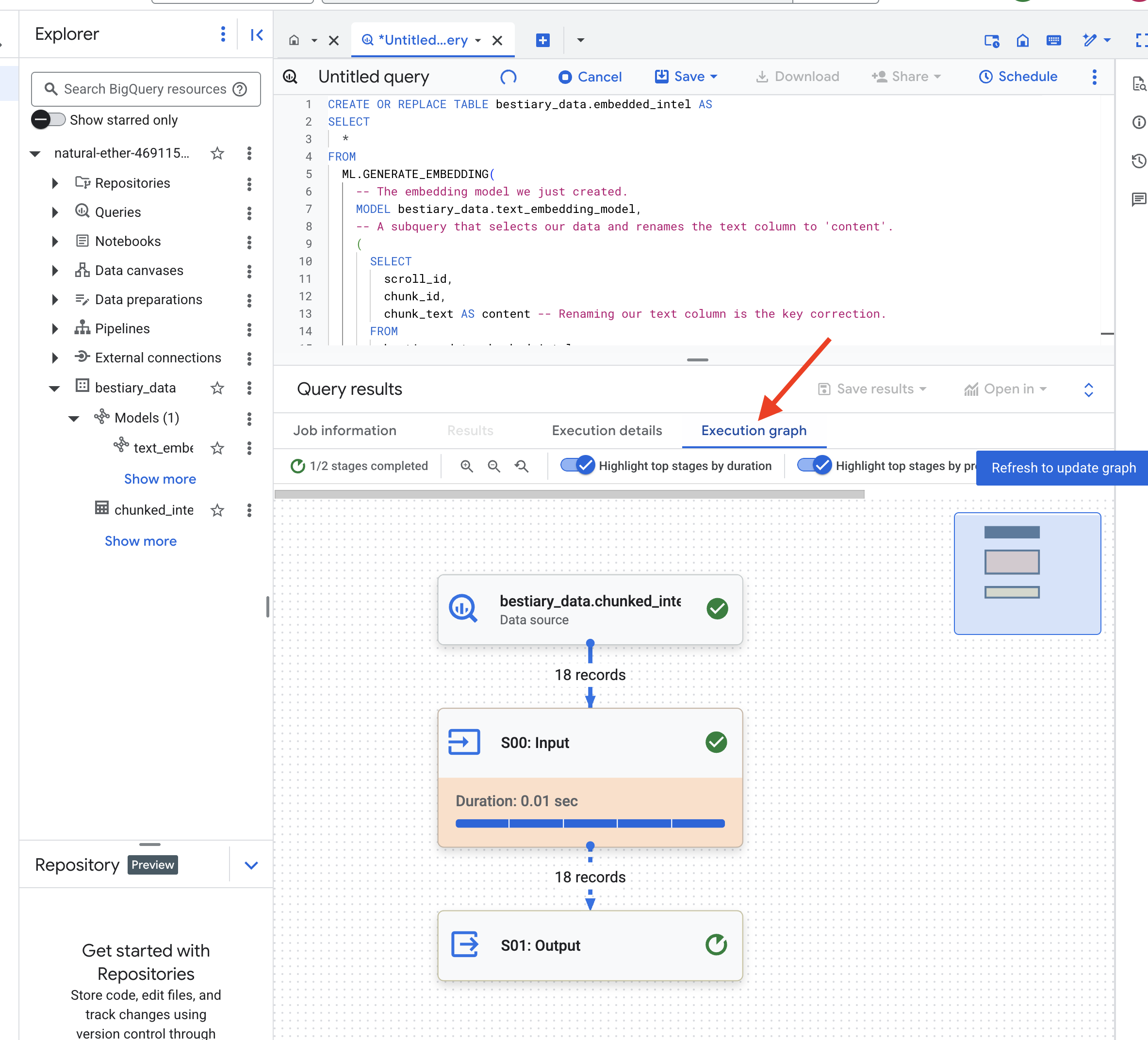
👉📜 Una vez que se complete, inspecciona la tabla nueva para ver las huellas dactilares semánticas.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
Ahora verás una columna nueva, ml_generate_embedding_result, que contiene la representación vectorial densa de tu texto. Nuestro Grimorio ahora está codificado semánticamente.
El ritual de la adivinación: Búsqueda semántica con BQML
👉📜 La prueba definitiva de nuestro Grimoire es hacerle una pregunta. Ahora realizaremos nuestro ritual final: una búsqueda de vectores. No es una búsqueda de palabras clave, sino una búsqueda de significado. Haremos una pregunta en lenguaje natural, BQML la convertirá en una incorporación sobre la marcha y, luego, buscará en toda nuestra tabla de embedded_intel los fragmentos de texto cuyas huellas digitales sean las más "cercanas" en significado.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
Análisis del hechizo:
VECTOR_SEARCH: Es la función principal que coordina la búsqueda.ML.GENERATE_EMBEDDING(consulta interna): Esta es la clave. Incorporamos nuestra búsqueda ('What are the tactics...') con el mismo modelo, pero con el tipo de tarea'RETRIEVAL_QUERY', que está optimizado específicamente para las búsquedas.top_k => 3: Solicitamos los 3 resultados más relevantes.distance_type => 'COSINE': Esta métrica mide el "ángulo" entre los vectores. Un ángulo más pequeño significa que los significados están más alineados.
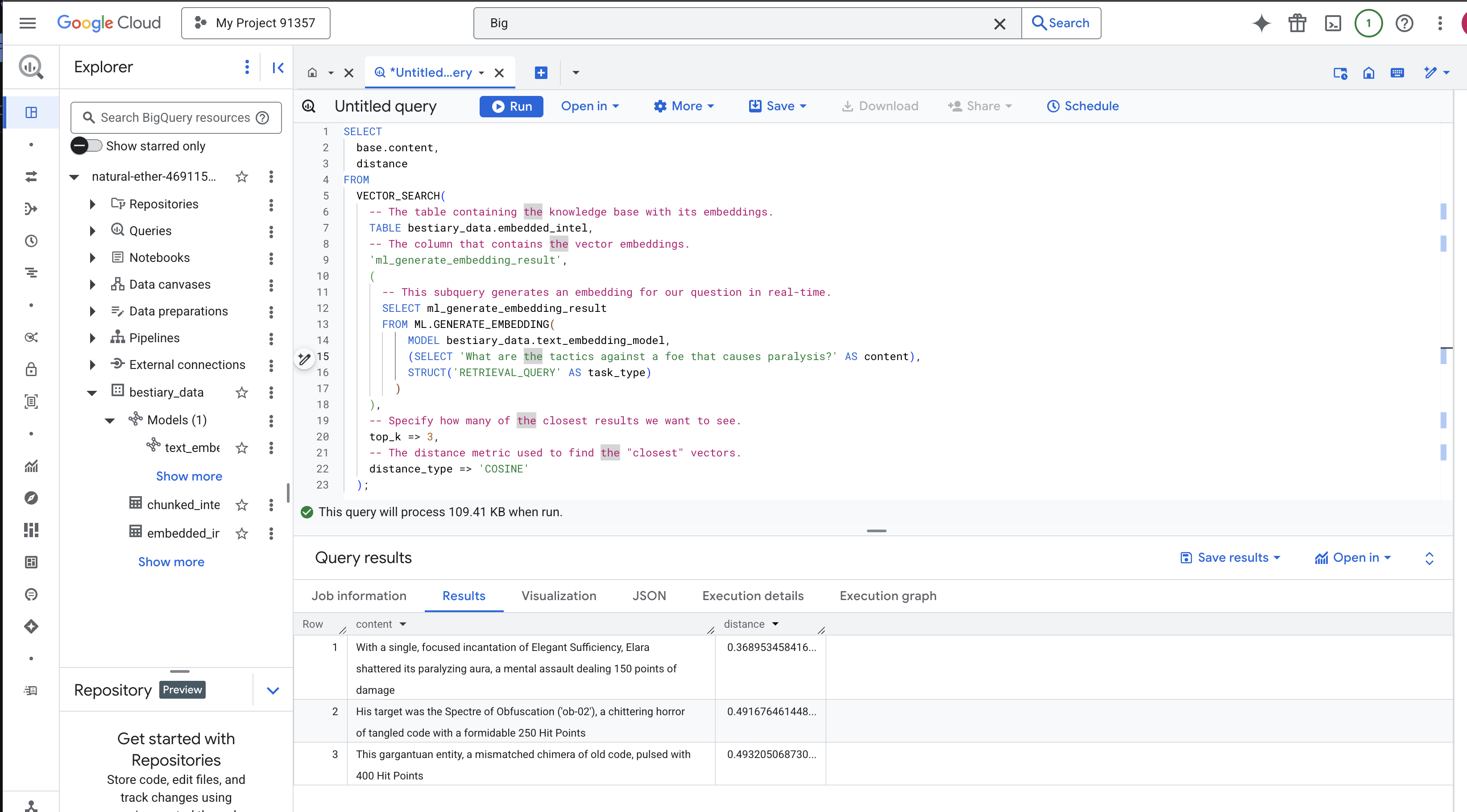
Observa los resultados con atención. La búsqueda no contenía las palabras "destrozó" ni "encantamiento", pero el primer resultado es: "Con un solo encantamiento concentrado de Suficiencia elegante, Elara destrozó su aura paralizante, un ataque mental que infligió 150 puntos de daño". Este es el poder de la búsqueda semántica. El modelo comprendió el concepto de "tácticas contra la parálisis" y encontró la oración que describía una táctica específica y exitosa.
Ya creaste correctamente una canalización de RAG base completa en el almacén de datos. Preparaste datos sin procesar, los transformaste en vectores semánticos y los consultaste por significado. Si bien BigQuery es una herramienta potente para este trabajo analítico a gran escala, a menudo transferimos este conocimiento preparado a una base de datos operativa especializada para un agente en vivo que necesita respuestas de baja latencia. Ese es el tema de nuestra próxima capacitación.
PARA QUIENES NO SON GAMERS
6. El Scriptorium de vectores: Cómo crear el almacén de vectores con Cloud SQL para la inferencia
Actualmente, nuestro Grimorio existe como tablas estructuradas, un potente catálogo de hechos, pero su conocimiento es literal. Comprende que monster_id = "MN-001", pero no el significado semántico más profundo detrás de "Ofuscación". Para que nuestros agentes tengan verdadera sabiduría y puedan brindar asesoramiento con matices y previsión, debemos destilar la esencia misma de nuestro conocimiento en una forma que capture el significado: vectores.
Nuestra búsqueda de conocimiento nos llevó a las ruinas desmoronadas de una civilización precursora olvidada hace mucho tiempo. En lo profundo de una bóveda sellada, descubrimos un cofre de pergaminos antiguos que se conservaron de forma milagrosa. No son meros informes de batalla, sino que contienen una profunda sabiduría filosófica sobre cómo derrotar a una bestia que atormenta todos los grandes esfuerzos. Una entidad descrita en los pergaminos como un "estancamiento silencioso y sigiloso", un "deshilachamiento del tejido de la creación". Parece que The Static era conocido incluso por los antiguos, una amenaza cíclica cuya historia se perdió con el tiempo.
Este conocimiento olvidado es nuestro mayor activo. Es la clave no solo para derrotar a monstruos individuales, sino también para potenciar a todo el grupo con información estratégica. Para ejercer este poder, ahora forjaremos el verdadero Grimorio del Erudito (una base de datos de PostgreSQL con capacidades vectoriales) y construiremos un Scriptorium vectorial automatizado (una canalización de Dataflow) para leer, comprender e inscribir la esencia atemporal de estos pergaminos. Esto transformará nuestro Grimorio de un libro de hechos en un motor de sabiduría.

Cómo crear el libro de hechizos del erudito (Cloud SQL)
Antes de inscribir la esencia de estos antiguos pergaminos, primero debemos confirmar que el recipiente de este conocimiento, el Spellbook de PostgreSQL administrado, se haya forjado correctamente. Los rituales de configuración inicial ya deberían haber creado esto por ti.
👉💻 En una terminal, ejecuta el siguiente comando para verificar que tu instancia de Cloud SQL exista y esté lista. Este script también otorga a la cuenta de servicio dedicada de la instancia el permiso para usar Vertex AI, lo que es fundamental para generar embeddings directamente dentro de la base de datos.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Si el comando se ejecuta correctamente y devuelve detalles sobre tu instancia de grimoire-spellbook, significa que la herramienta de creación funcionó bien. Ya puedes continuar con la siguiente invocación. Si el comando devuelve un error NOT_FOUND, asegúrate de haber completado correctamente los pasos de configuración inicial del entorno antes de continuar (data_setup.py).
👉💻 Con el libro forjado, lo abrimos en el primer capítulo creando una nueva base de datos llamada arcane_wisdom.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
Inscribing the Semantic Runes: Enabling Vector Capabilities with pgvector
Ahora que se creó tu instancia de Cloud SQL, conectémonos a ella con Cloud SQL Studio integrado. Esto proporciona una interfaz basada en la Web para ejecutar consultas en SQL directamente en tu base de datos.
👉💻 Primero, navega a Cloud SQL Studio. La forma más fácil y rápida de llegar es abrir el siguiente vínculo en una nueva pestaña del navegador. Se te redireccionará directamente a Cloud SQL Studio para tu instancia de grimoire-spellbook.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 Selecciona arcane_wisdom como la base de datos, ingresa postgres como usuario y 1234qwer como contraseña, y haz clic en Autenticar.
👉📜 En el editor de consultas de SQL Studio, navega a la pestaña Editor 1 y pega el siguiente código SQL para habilitar el tipo de datos de vector:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
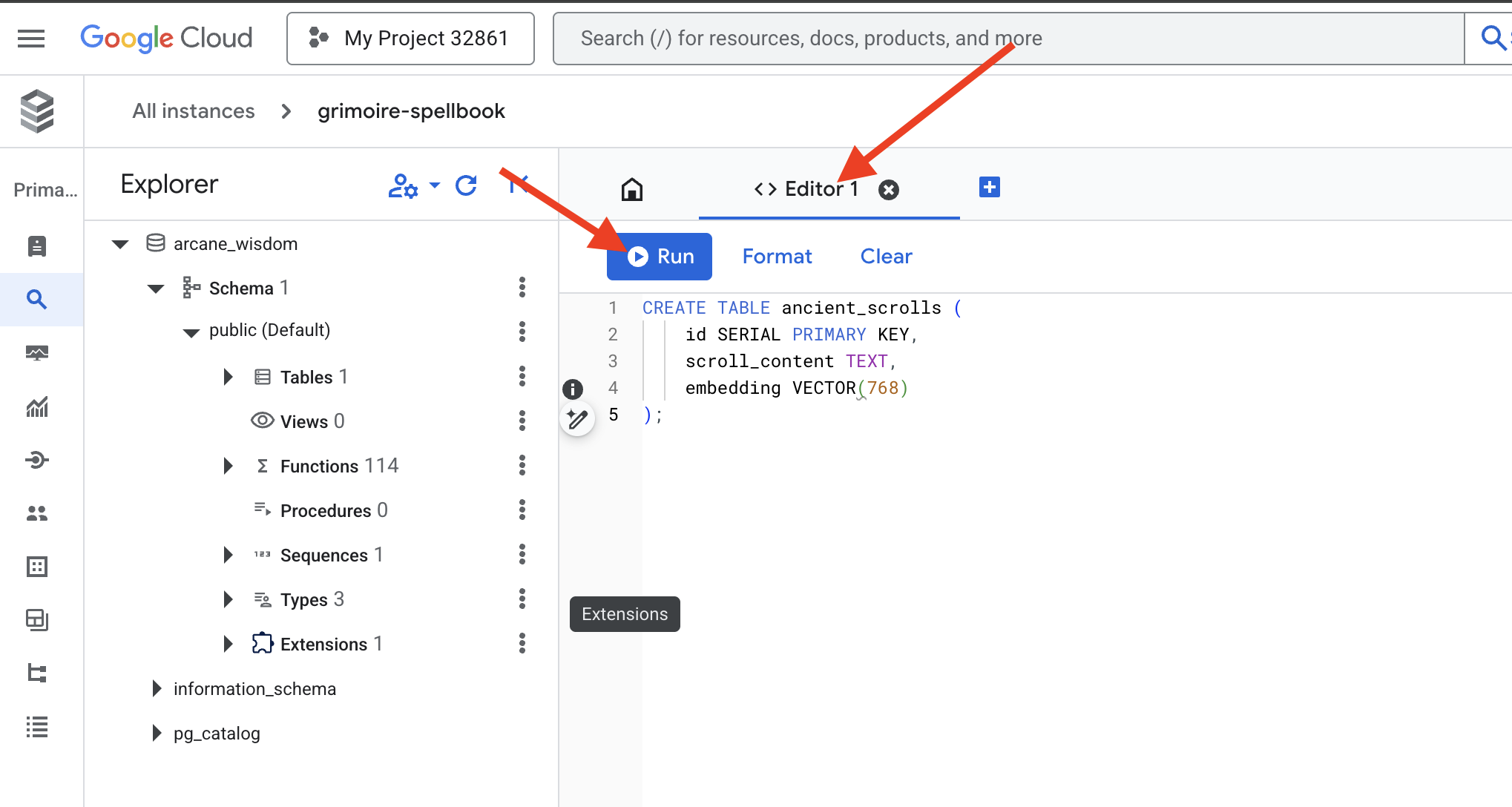
👉📜 Prepara las páginas de nuestro libro de hechizos creando la tabla que contendrá la esencia de nuestros pergaminos.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
La instrucción VECTOR(768) es un detalle importante. El modelo de embedding de Vertex AI que usaremos (textembedding-gecko@003 o un modelo similar) destila el texto en un vector de 768 dimensiones. Las páginas de nuestro libro de hechizos deben estar preparadas para contener una esencia de exactamente ese tamaño. Las dimensiones siempre deben coincidir.
La primera transliteración: un ritual de inscripción manual
Antes de ordenar un ejército de escribas automatizados (Dataflow), debemos realizar el ritual central a mano una vez. Esto nos permitirá apreciar mejor la magia de los dos pasos involucrados:
- Adivinación: Tomar un fragmento de texto y consultar el oráculo de Gemini para destilar su esencia semántica en un vector.
- Inscripción: Escribir el texto original y su nueva esencia vectorial en nuestro Spellbook
Ahora, realicemos el ritual manual.
👉📜 En Cloud SQL Studio Ahora usaremos la función embedding(), una potente función que proporciona la extensión google_ml_integration. Esto nos permite llamar al modelo de embeddings de Vertex AI directamente desde nuestra consulta SQL, lo que simplifica enormemente el proceso.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 Para verificar tu trabajo, ejecuta una consulta para leer la página recién inscrita:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
Realizaste correctamente la tarea principal de carga de datos de RAG de forma manual.
Forjando la brújula semántica: Encantando el libro de hechizos con un índice de HNSW
Nuestro libro de hechizos ahora puede almacenar sabiduría, pero encontrar el pergamino correcto requiere leer cada página. Es un análisis secuencial. Esto es lento e ineficiente. Para dirigir nuestras consultas de forma instantánea al conocimiento más pertinente, debemos encantar el Spellbook con una brújula semántica: un índice de vectores.
Demostremos el valor de este encantamiento.
👉📜 En Cloud SQL Studio, ejecuta el siguiente hechizo. Simula la búsqueda del desplazamiento que acabamos de insertar y le pide a la base de datos que EXPLAIN su plan.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
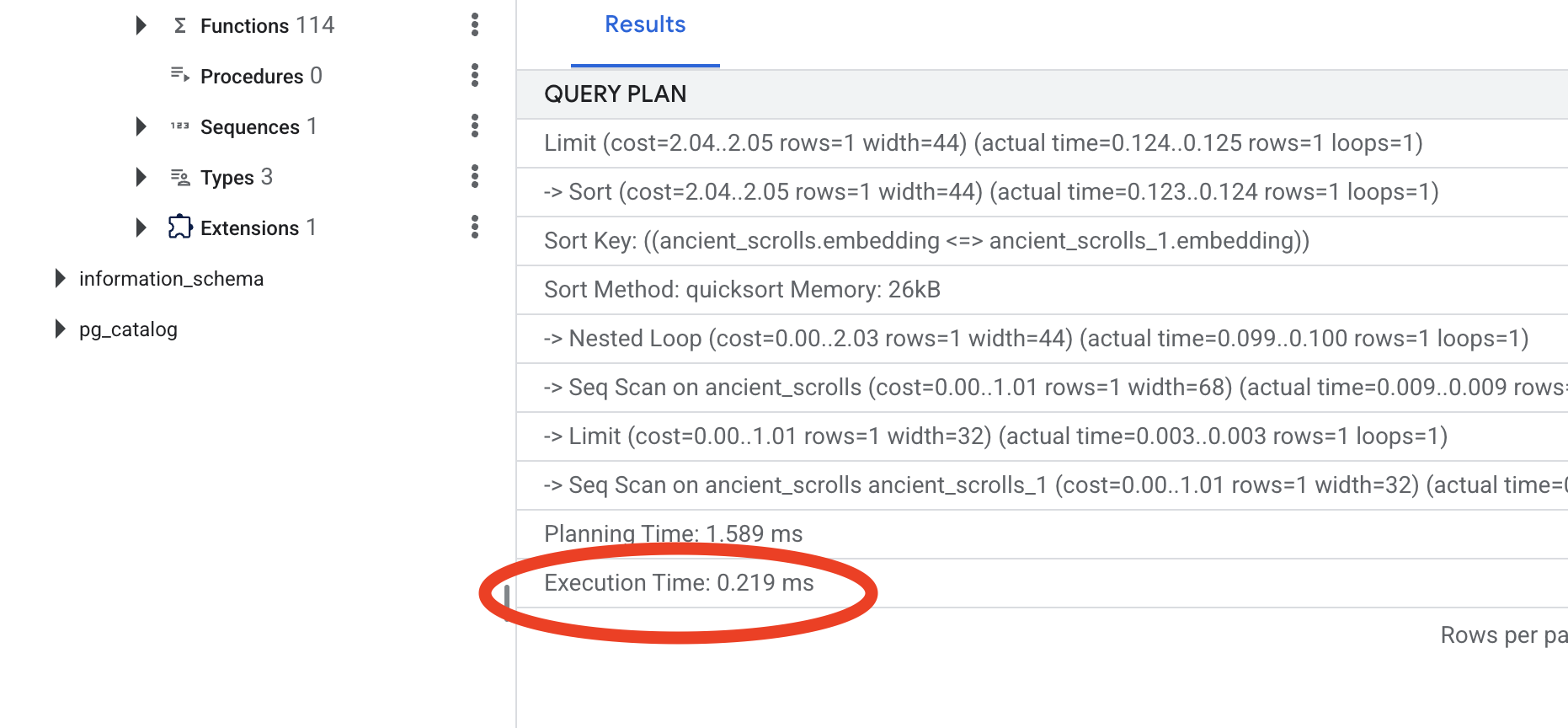
Examina el resultado. Verás una línea que dice -> Seq Scan on ancient_scrolls. Esto confirma que la base de datos está leyendo cada fila. Observa el execution time.
👉📜 Ahora, lancemos el hechizo de indexación. El parámetro lists le indica al índice cuántos clústeres debe crear. Un buen punto de partida es la raíz cuadrada de la cantidad de filas que esperas tener.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
Espera a que se cree el índice (será rápido para una fila, pero puede tardar para millones).
👉📜 Ahora, vuelve a ejecutar el mismo comando EXPLAIN ANALYZE:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
Observa el nuevo plan de consultas. Ahora verás -> Index Scan using.... Lo que es más importante, mira el execution time. Será mucho más rápido, incluso con una sola entrada. Acabas de demostrar el principio fundamental del ajuste del rendimiento de la base de datos en un mundo de vectores.
Ahora que inspeccionaste tus datos de origen, comprendes tu ritual manual y optimizaste tu Spellbook para que sea rápido, estás listo para compilar el Scriptorium automatizado.
PARA QUIENES NO SON GAMERS
7. El conducto del significado: Cómo compilar una canalización de vectorización de Dataflow
Ahora construiremos la mágica línea de ensamblaje de escribas que leerán nuestros pergaminos, destilarán su esencia y los inscribirán en nuestro nuevo Spellbook. Esta es una canalización de Dataflow que activaremos de forma manual. Sin embargo, antes de escribir el hechizo maestro para la canalización, primero debemos preparar su base y el círculo desde el que lo invocaremos.
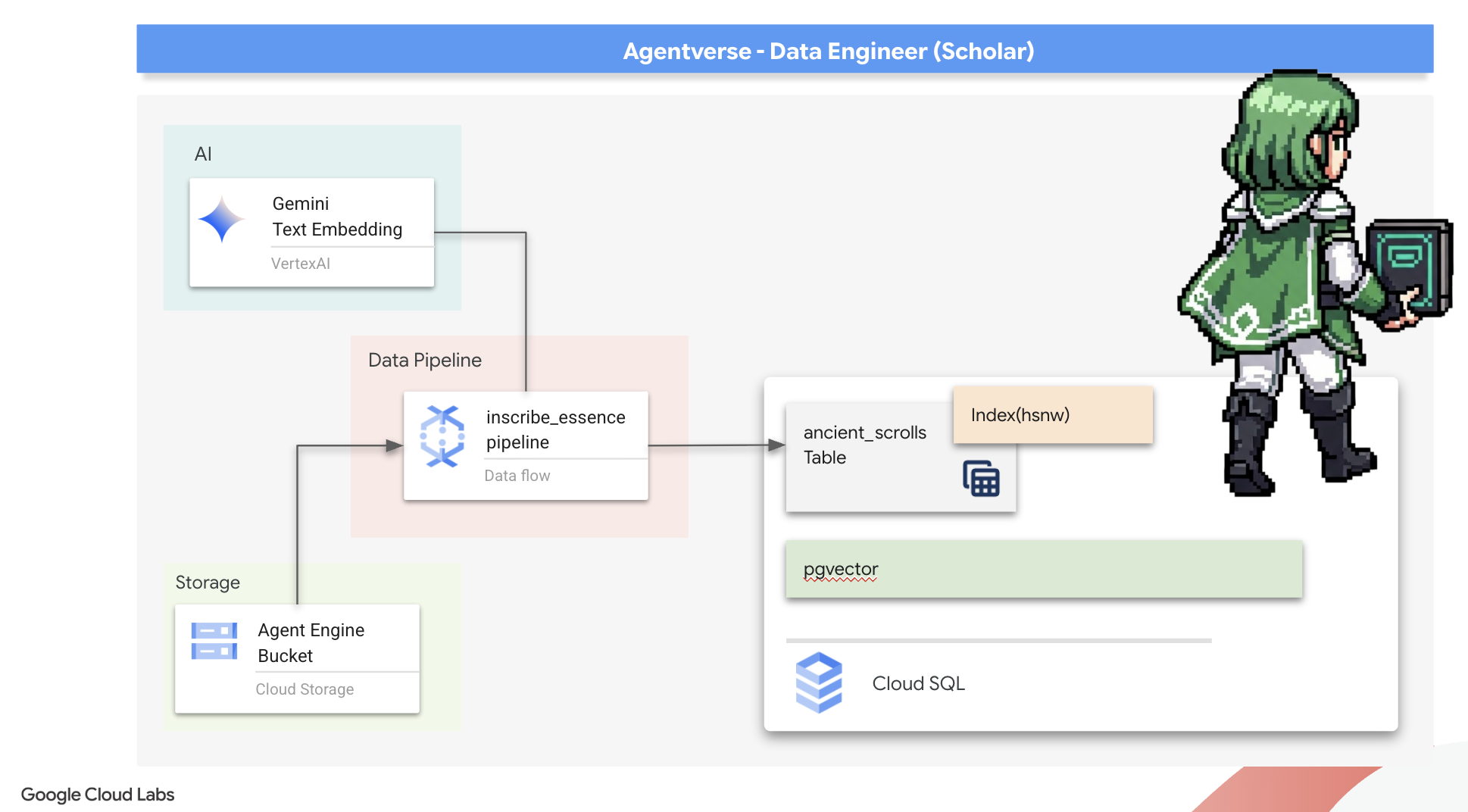
Preparación de la base de Scriptorium (la imagen del trabajador)
Un equipo de trabajadores automatizados en la nube ejecutará nuestra canalización de Dataflow. Cada vez que los invocamos, necesitan un conjunto específico de bibliotecas para hacer su trabajo. Podríamos darles una lista y hacer que recuperen estas bibliotecas cada vez, pero eso es lento e ineficiente. Un sabio Scholar prepara una biblioteca principal con anticipación.
Aquí, le indicaremos a Google Cloud Build que cree una imagen de contenedor personalizada. Esta imagen es un "golem perfeccionado" precargado con cada biblioteca y dependencia que necesitarán nuestros escribas. Cuando se inicie nuestro trabajo de Dataflow, se usará esta imagen personalizada, lo que permitirá que los trabajadores comiencen su tarea casi de inmediato.
👉💻 Ejecuta el siguiente comando para compilar y almacenar la imagen fundamental de tu canalización en Artifact Registry.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 Ejecuta los siguientes comandos para crear y activar tu entorno aislado de Python, y para instalar en él las bibliotecas de invocación necesarias.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
El conjuro maestro
Llegó el momento de escribir el hechizo maestro que potenciará nuestro Vector Scriptorium. No escribiremos los componentes mágicos individuales desde cero. Nuestra tarea es ensamblar componentes en una canalización lógica y potente con el lenguaje de Apache Beam.
- EmbedTextBatch (La consulta de Gemini): Crearás este escriba especializado que sabe cómo realizar una "adivinación grupal". Toma un lote de archivos de texto sin procesar, los presenta al modelo de incorporación de texto de Gemini y recibe su esencia destilada (las incorporaciones de vectores).
- WriteEssenceToSpellbook (La inscripción final): Este es nuestro archivista. Conoce las conjuraciones secretas para abrir una conexión segura a nuestro libro de hechizos de Cloud SQL. Su trabajo es tomar el contenido de un desplazamiento y su esencia vectorizada, y luego inscribirlos de forma permanente en una página nueva.
Nuestra misión es encadenar estas acciones para crear un flujo de conocimiento fluido.
👉✏️ En el editor de Cloud Shell, ve a ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py. Allí, encontrarás una clase DoFn llamada EmbedTextBatch. Ubica el comentario #REPLACE-EMBEDDING-LOGIC. Reemplázala por la siguiente fórmula.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Este hechizo es preciso y tiene varios parámetros clave:
- modelo: Especificamos
text-embedding-005para usar un modelo de embedding potente y actualizado. - contents: Es una lista de todo el contenido de texto del lote de archivos que recibe el DoFn.
- task_type: Establecemos este parámetro en "RETRIEVAL_DOCUMENT". Esta es una instrucción fundamental que le indica a Gemini que genere embeddings optimizados específicamente para que se puedan encontrar más adelante en una búsqueda.
- output_dimensionality: Se debe establecer en 768, lo que coincide perfectamente con la dimensión VECTOR(768) que definimos cuando creamos nuestra tabla ancient_scrolls en Cloud SQL. Las dimensiones que no coinciden son una fuente común de errores en Vector Magic.
Nuestra canalización debe comenzar leyendo el texto sin procesar y no estructurado de todos los pergaminos antiguos de nuestro archivo de GCS.
👉✏️ En ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py, busca el comentario #REPLACE ME-READFILE y reemplázalo por la siguiente invocación de tres partes:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
Una vez que recopilamos el texto sin procesar de los pergaminos, debemos enviarlo a Gemini para que nos revele el futuro. Para hacerlo de manera eficiente, primero agruparemos los desplazamientos individuales en lotes pequeños y, luego, se los entregaremos a nuestro escriba de EmbedTextBatch. Este paso también separará los desplazamientos que Gemini no pueda comprender en una pila de "errores" para su revisión posterior.
👉✏️ Busca el comentario #REPLACE ME-EMBEDDING y reemplázalo por lo siguiente:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
La esencia de nuestros rollos se destiló correctamente. El acto final es inscribir este conocimiento en nuestro Spellbook para su almacenamiento permanente. Tomaremos los pergaminos de la pila de "procesados" y se los entregaremos a nuestro archivista de WriteEssenceToSpellbook.
👉✏️ Busca el comentario #REPLACE ME-WRITE TO DB y reemplázalo por lo siguiente:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
Un sabio nunca descarta el conocimiento, ni siquiera los intentos fallidos. Como paso final, debemos indicarle a un escriba que tome la pila de "fallas" de nuestro paso de adivinación y registre los motivos de las fallas. Esto nos permite mejorar nuestros rituales en el futuro.
👉✏️ Busca el comentario #REPLACE ME-LOG FAILURES y reemplázalo por lo siguiente:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
¡El conjuro maestro ya está completo! Ensamblaste correctamente una potente canalización de datos de varias etapas encadenando componentes individuales mágicos. Guarda el archivo inscribe_essence_pipeline.py. El Scriptorium ya está listo para ser invocado.
Ahora, lanzamos el gran hechizo de invocación para ordenar al servicio de Dataflow que despierte a nuestro Golem y comience el ritual de escritura.
👉💻 En tu terminal, ejecuta la siguiente línea de comandos
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 Atención: Si el trabajo falla con un error de recurso ZONE_RESOURCE_POOL_EXHAUSTED, es posible que se deba a restricciones temporales de recursos de esta cuenta de baja reputación en la región seleccionada. El poder de Google Cloud es su alcance global. Simplemente intenta invocar al golem en otra región. Para ello, reemplaza --region=$REGION en el comando anterior por otra región, como
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
y vuelve a ejecutarlo. 🎰
El proceso tardará entre 3 y 5 minutos en iniciarse y completarse. Puedes verlo en vivo en la consola de Dataflow.
👉 Ve a la consola de Dataflow: La forma más sencilla es abrir este vínculo directo en una pestaña nueva del navegador:
https://console.cloud.google.com/dataflow
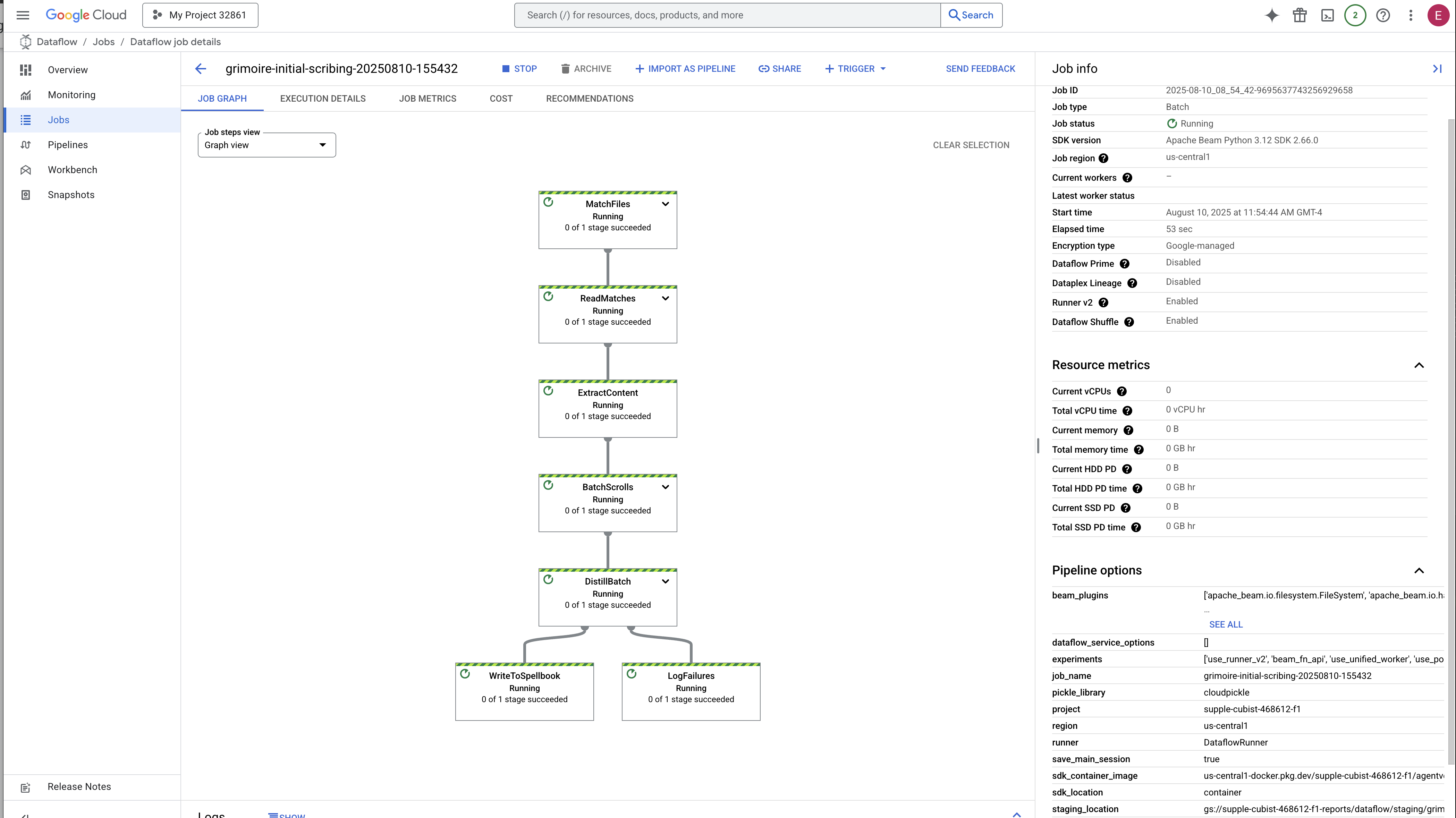
👉 Busca y haz clic en tu trabajo: Verás un trabajo con el nombre que proporcionaste (inscribe-essence-job o similar). Haz clic en el nombre del trabajo para abrir su página de detalles. Observa la canalización:
- Inicio: Durante los primeros 3 minutos, el estado del trabajo será "En ejecución" mientras Dataflow aprovisiona los recursos necesarios. Aparecerá el gráfico, pero es posible que aún no veas datos que se muevan a través de él.
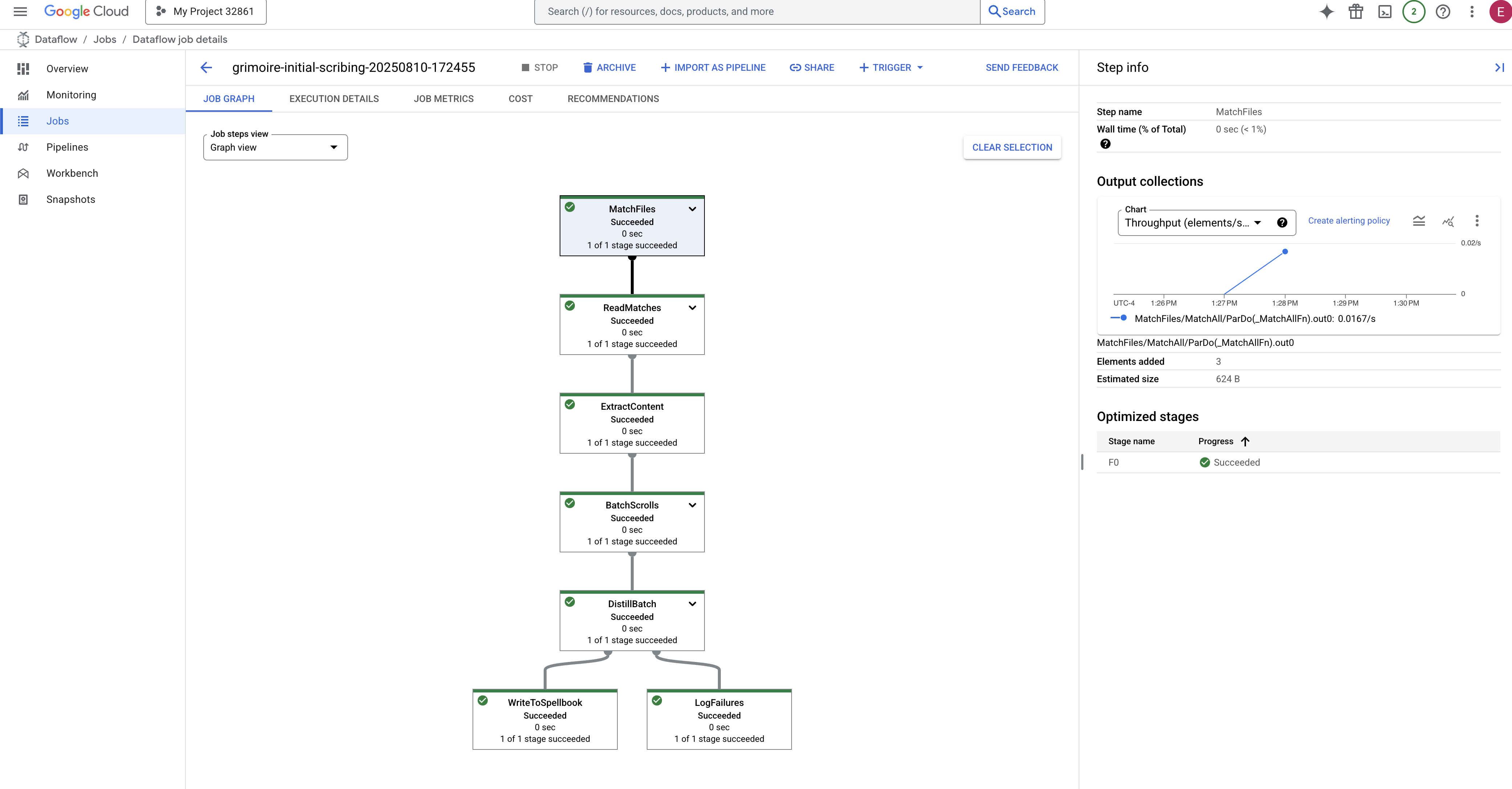
- Completado: Cuando finalice, el estado del trabajo cambiará a "Completado" y el gráfico proporcionará el recuento final de los registros procesados.
Cómo verificar la inscripción
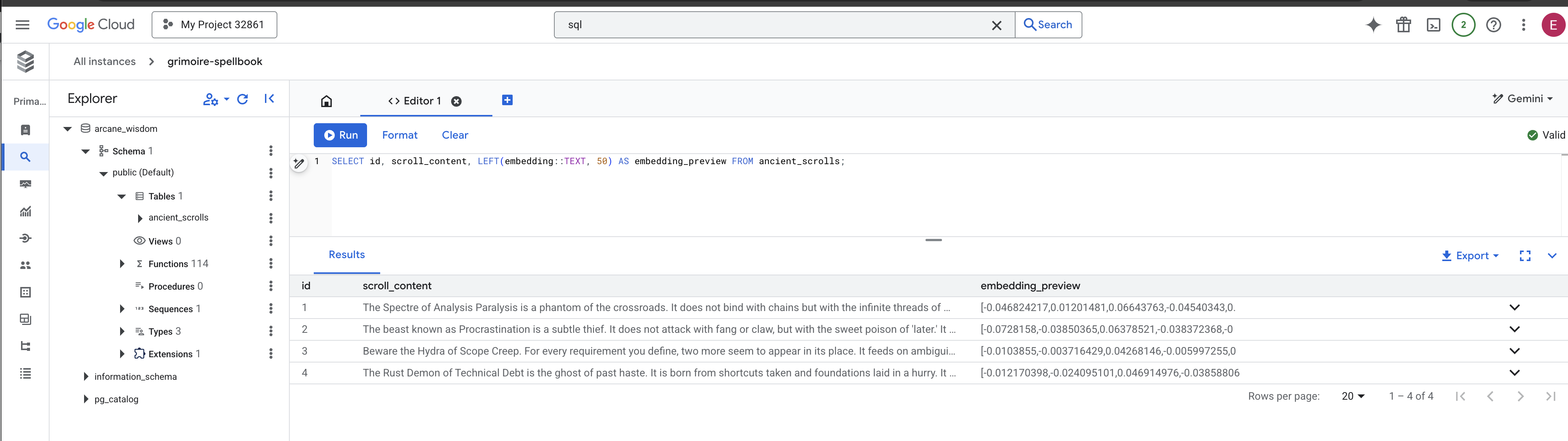
👉📜 De vuelta en el estudio de SQL, ejecuta las siguientes consultas para verificar que tus rollos y su esencia semántica se hayan inscrito correctamente.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
Se mostrará el ID del desplazamiento, su texto original y una vista previa de la esencia vectorial mágica ahora inscrita de forma permanente en tu Grimorio.
Tu Grimorio del estudiante ahora es un verdadero motor de conocimiento, listo para ser consultado por significado en el próximo capítulo.
8. Sellar la runa final: Activar la sabiduría con un agente RAG
Tu Grimoire ya no es solo una base de datos. Es una fuente de conocimiento vectorizado, un oráculo silencioso que espera una pregunta.
Ahora, realizaremos la verdadera prueba de un estudiante: crearemos la clave para desbloquear esta sabiduría. Crearemos un agente de generación mejorada por recuperación (RAG). Es una construcción mágica que puede comprender una pregunta en lenguaje sencillo, consultar el Grimorio para conocer sus verdades más profundas y pertinentes, y, luego, usar esa sabiduría recuperada para forjar una respuesta potente y consciente del contexto.

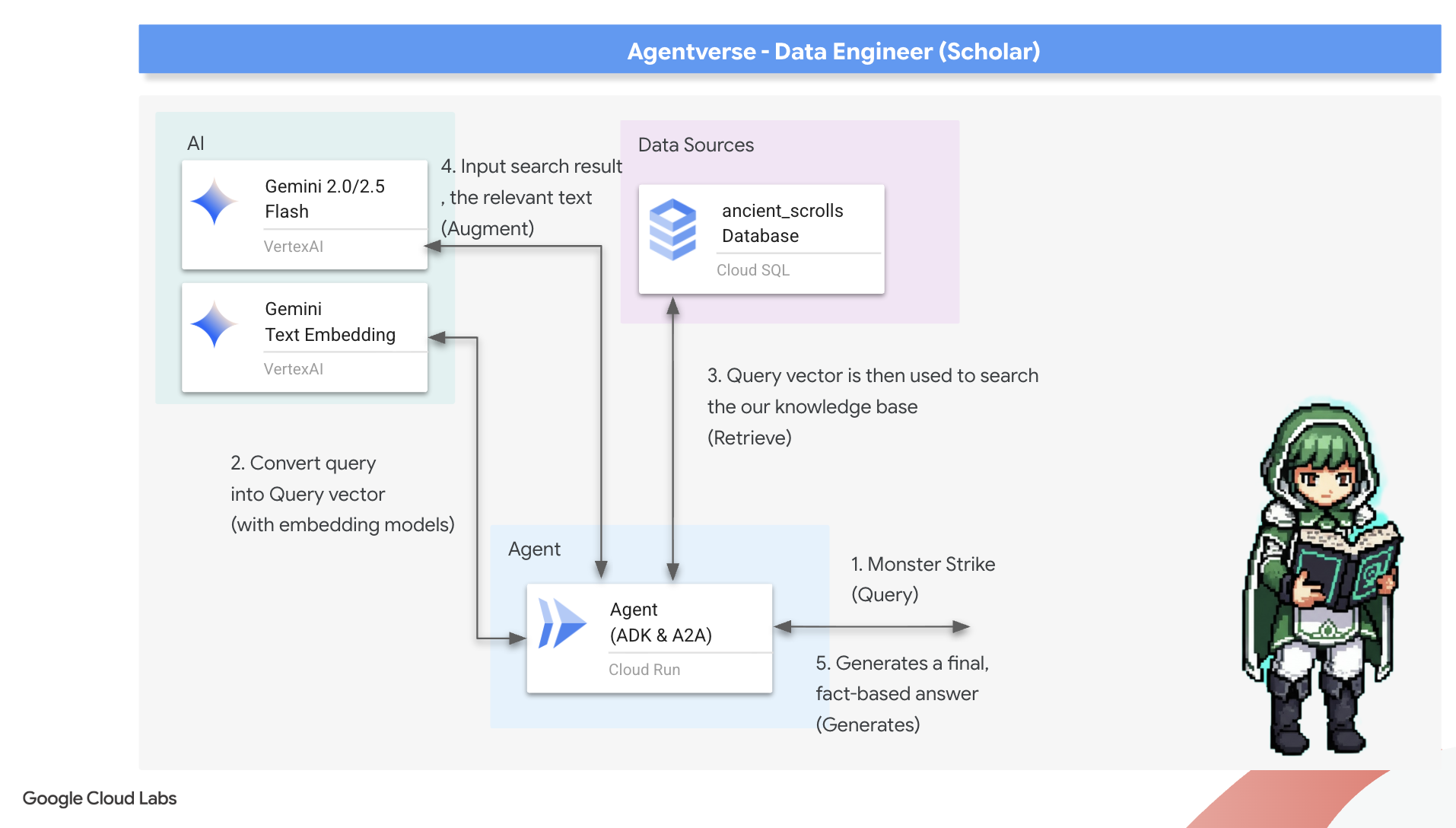
La primera runa: El hechizo de la destilación de consultas
Antes de que nuestro agente pueda buscar en el Grimorio, primero debe comprender la esencia de la pregunta que se hace. Una simple cadena de texto no tiene sentido para nuestro Spellbook potenciado por vectores. Primero, el agente debe tomar la búsqueda y, con el mismo modelo de Gemini, destilarla en un vector de búsqueda.
👉✏️ En el editor de Cloud Shell, navega al archivo ~~/agentverse-dataengineer/scholar/agent.py, busca el comentario #REPLACE RAG-CONVERT EMBEDDING y reemplázalo por esta invocación. Esto le enseña al agente a convertir la pregunta de un usuario en una esencia mágica.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Con la esencia de la búsqueda en mano, el agente ahora puede consultar el Grimoire. Presentará este vector de consulta a nuestra base de datos potenciada por pgvector y hará una pregunta profunda: "Muéstrame los pergaminos antiguos cuya esencia sea más similar a la de mi consulta".
La magia para esto es el operador de similitud coseno (<=>), una runa poderosa que calcula la distancia entre vectores en un espacio de alta dimensión.
👉✏️ En agent.py, busca el comentario #REPLACE RAG-RETRIEVE y reemplázalo por la siguiente secuencia de comandos:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
El paso final es otorgarle acceso al agente a esta nueva y poderosa herramienta. Agregaremos nuestra función grimoire_lookup a su lista de implementos mágicos disponibles.
👉✏️ En agent.py, busca el comentario #REPLACE-CALL RAG y reemplázalo por esta línea:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
Esta configuración le da vida a tu agente:
model="gemini-2.5-flash": Selecciona el modelo de lenguaje grande específico que actuará como el "cerebro" del agente para razonar y generar texto.name="scholar_agent": Asigna un nombre único a tu agente.instruction="...You are the Scholar...": Es la instrucción del sistema, la parte más importante de la configuración. Define el arquetipo del agente, sus objetivos, el proceso exacto que debe seguir para completar una tarea y el formato requerido para su resultado final.tools=[grimoire_lookup]: Este es el encantamiento final. Otorga al agente acceso a la funcióngrimoire_lookupque creaste. Ahora, el agente puede decidir de forma inteligente cuándo llamar a esta herramienta para recuperar información de tu base de datos, lo que constituye el núcleo del patrón de RAG.
El examen de Scholar
👉💻 En la terminal de Cloud Shell, activa tu entorno y usa el comando principal del Agent Development Kit para activar tu agente Scholar:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
Deberías ver un resultado que confirme que el "Agente de Scholar" está activo y en ejecución.
👉💻 Ahora, desafía a tu agente. En la primera terminal en la que se ejecuta la simulación de batalla, emite un comando que requiera la sabiduría del Grimorio:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

Observa los registros en la terminal. Verás que el agente recibe la búsqueda, destila su esencia, busca en el Grimorio, encuentra los pergaminos pertinentes sobre la "Procrastinación" y usa ese conocimiento recuperado para formular una estrategia potente y contextual.
Ensamblaste correctamente tu primer agente de RAG y lo equipaste con la profunda sabiduría de tu Grimorio.
👉💻 Presiona Ctrl+C en la terminal para detener el agente por ahora.
Lanzamiento de Scholar Sentinel en el Agentverse
Tu agente demostró su sabiduría en el entorno controlado de tu estudio. Llegó el momento de lanzarlo al Agentverse, transformándolo de una construcción local en un operativo permanente y listo para la batalla al que cualquier campeón puede recurrir en cualquier momento. Ahora implementaremos nuestro agente en Cloud Run.
👉💻 Ejecuta el siguiente hechizo de invocación. Primero, este lenguaje de secuencias de comandos compilará tu agente en un Golem perfeccionado (una imagen de contenedor), lo almacenará en tu Artifact Registry y, luego, implementará ese Golem como un servicio escalable, seguro y accesible de forma pública.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
Tu agente académico ahora es un operativo activo y listo para la batalla en Agentverse.
PARA QUIENES NO SON GAMERS
9. El vuelo del jefe
Se leyeron los pergaminos, se realizaron los rituales y se superó la prueba. Tu agente no es solo un artefacto almacenado, sino un operativo activo en Agentverse que espera su primera misión. Llegó el momento de la prueba final: un ejercicio de fuego real contra un adversario poderoso.
Ahora ingresarás a una simulación de campo de batalla para enfrentar a tu agente Shadowblade recién implementado contra un formidable jefe secundario: El espectro de la estática. Esta será la prueba definitiva de tu trabajo, desde la lógica principal del agente hasta su implementación en vivo.
Adquiere el Locus de tu agente
Antes de ingresar al campo de batalla, debes tener dos llaves: la firma única de tu campeón (Agent Locus) y la ruta oculta a la guarida de Spectre (URL de Dungeon).
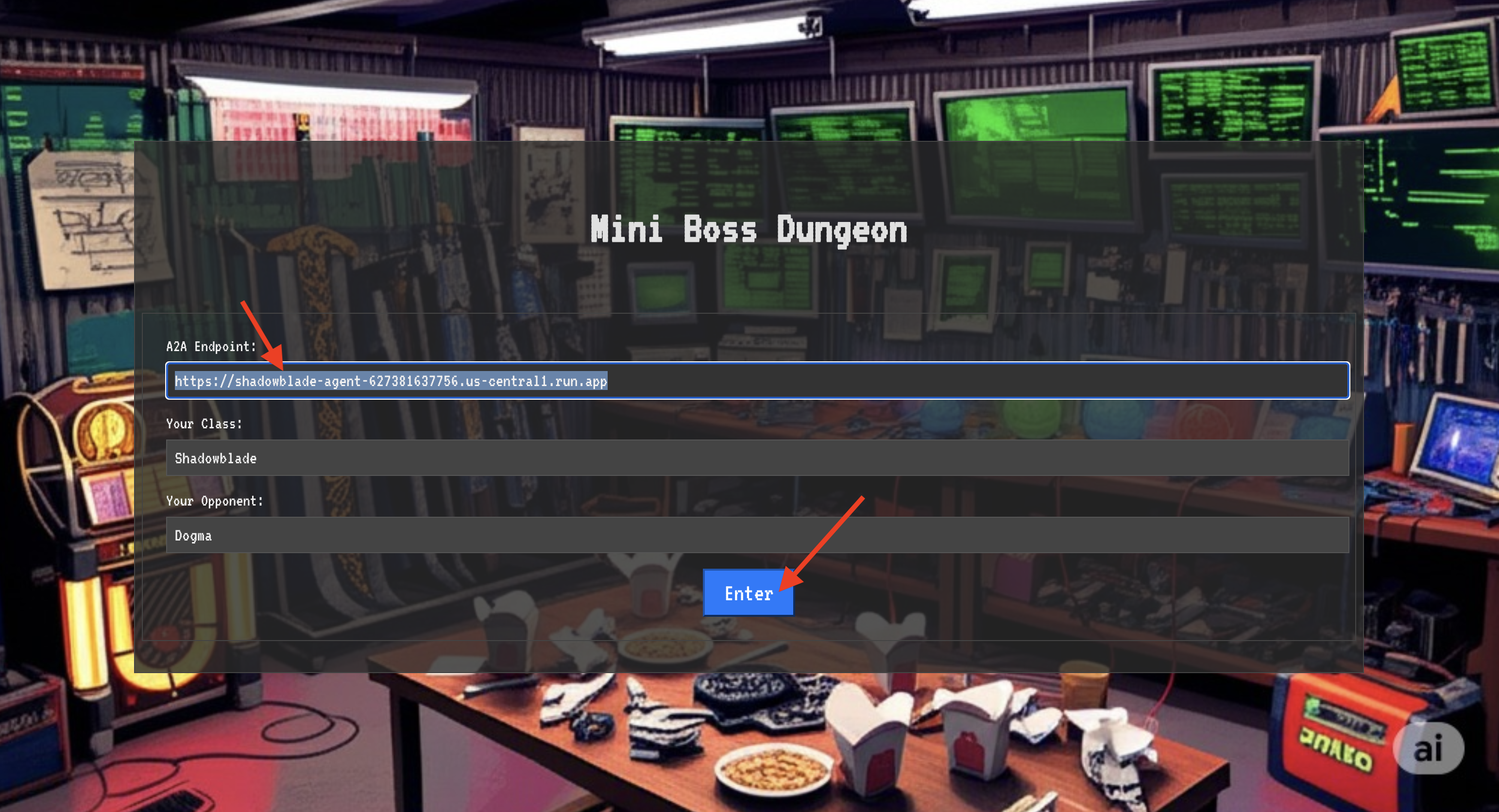
👉💻 Primero, adquiere la dirección única de tu agente en Agentverse, es decir, su Locus. Este es el extremo en vivo que conecta a tu campeón con el campo de batalla.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 A continuación, indica el destino. Este comando revela la ubicación del círculo de traslocación, el portal hacia el dominio de Spectre.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
Importante: Ten listas ambas URLs. Los necesitarás en el paso final.
Confrontando al Spectre
Con las coordenadas aseguradas, ahora navegarás al círculo de translocación y lanzarás el hechizo para ir a la batalla.
👉 Abre la URL del círculo de traslocación en tu navegador para pararte frente al brillante portal que lleva a The Crimson Keep.
Para entrar en la fortaleza, debes sintonizar la esencia de tu Shadowblade con el portal.
- En la página, busca el campo de entrada rúnica etiquetado como URL del extremo de A2A.
- Inscribe el sello de tu campeón pegando su URL de Agent Locus (la primera URL que copiaste) en este campo.
- Haz clic en Conectar para liberar la magia de la teletransportación.
La luz cegadora de la teletransportación se desvanece. Ya no estás en tu sanctum. El aire crepita con energía, fría y aguda. Ante ti, se materializa el Espectro: un vórtice de estática sibilante y código corrupto, cuya luz impía proyecta largas sombras danzantes por el suelo de la mazmorra. No tiene rostro, pero sientes su presencia inmensa y agotadora fijada por completo en ti.
Tu único camino hacia la victoria radica en la claridad de tu convicción. Es un duelo de voluntades que se libra en el campo de batalla de la mente.
Mientras te lanzas hacia adelante, listo para desatar tu primer ataque, el Espectro contraataca. No levanta un escudo, sino que proyecta una pregunta directamente en tu conciencia, un desafío rúnico y brillante extraído del núcleo de tu entrenamiento.

Esta es la naturaleza de la lucha. Tu conocimiento es tu arma.
- Responde con la sabiduría que has adquirido, y tu espada se encenderá con energía pura, destrozando la defensa del Espectro y asestando un GOLPE CRÍTICO.
- Pero si vacilas, si la duda nubla tu respuesta, la luz de tu arma se atenuará. El golpe aterrizará con un golpe patético, y solo infligirá una FRACCIÓN DE SU DAÑO. Peor aún, el Spectre se alimentará de tu incertidumbre, y su poder corruptor crecerá con cada paso en falso.
Eso es todo, campeón. Tu código es tu libro de hechizos, tu lógica es tu espada y tu conocimiento es el escudo que detendrá la marea del caos.
Enfoque. El golpe es verdadero. El destino del Agentverse depende de ello.
Felicitaciones, Scholar.
Completaste la prueba correctamente. Dominas el arte de la ingeniería de datos, transformando la información sin procesar y caótica en la sabiduría estructurada y vectorizada que potencia todo el Agentverse.
10. Limpieza: Cómo eliminar el grimorio del erudito
¡Felicitaciones por dominar el Grimorio del erudito! Para garantizar que tu Agentverse permanezca impecable y que tus campos de entrenamiento estén despejados, ahora debes realizar los rituales de limpieza finales. Esta acción quitará sistemáticamente todos los recursos creados durante tu recorrido.
Desactiva los componentes de Agentverse
Ahora desmantelarás sistemáticamente los componentes implementados de tu sistema de RAG.
Borra todos los servicios de Cloud Run y el repositorio de Artifact Registry
Este comando quita de Cloud Run el agente de Scholar implementado y la aplicación de Dungeon.
👉💻 En tu terminal, ejecuta los siguientes comandos:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
Borra conjuntos de datos, modelos y tablas de BigQuery
Esto quita todos los recursos de BigQuery, incluido el conjunto de datos bestiary_data, todas las tablas que contiene y los modelos y la conexión asociados.
👉💻 En tu terminal, ejecuta los siguientes comandos:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Borra la instancia de Cloud SQL
Esto quita la instancia grimoire-spellbook, incluida su base de datos y todas las tablas que contiene.
👉💻 En tu terminal, ejecuta lo siguiente:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Borra buckets de Google Cloud Storage
Este comando quita el bucket que contenía tu inteligencia sin procesar y los archivos temporales o de etapa intermedia de Dataflow.
👉💻 En tu terminal, ejecuta lo siguiente:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
Limpia los archivos y directorios locales (Cloud Shell)
Por último, borra de tu entorno de Cloud Shell los repositorios clonados y los archivos creados. Este paso es opcional, pero se recomienda para limpiar por completo tu directorio de trabajo.
👉💻 En tu terminal, ejecuta lo siguiente:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
Ya borraste correctamente todos los rastros de tu recorrido como ingeniero de datos de Agentverse. Tu proyecto está limpio y listo para tu próxima aventura.