
1. l'ouverture de "La force du destin".
L'ère du développement cloisonné touche à sa fin. La prochaine vague d'évolution technologique ne concerne pas le génie solitaire, mais la maîtrise collaborative. Créer un agent unique et intelligent est une expérience fascinante. Le grand défi pour l'entreprise moderne consiste à créer un écosystème d'agents robuste, sécurisé et intelligent, un véritable Agentverse.
Pour réussir dans cette nouvelle ère, il est nécessaire de réunir quatre rôles essentiels, qui sont les piliers fondamentaux de tout système agentique prospère. Une lacune dans l'un de ces domaines crée une faiblesse qui peut compromettre l'ensemble de la structure.
Cet atelier est le guide de référence pour les entreprises qui souhaitent maîtriser l'avenir agentif sur Google Cloud. Nous vous proposons une feuille de route de bout en bout qui vous guide de la première idée à une réalité opérationnelle à grande échelle. Dans ces quatre ateliers interconnectés, vous apprendrez comment les compétences spécialisées d'un développeur, d'un architecte, d'un ingénieur des données et d'un ingénieur SRE doivent converger pour créer, gérer et faire évoluer un Agentverse puissant.
Aucun pilier ne peut prendre en charge l'Agentverse à lui seul. Le grand projet de l'architecte est inutile sans l'exécution précise du développeur. L'agent du développeur est aveugle sans la sagesse de l'ingénieur des données, et l'ensemble du système est fragile sans la protection de l'ingénieur SRE. Seule la synergie et la compréhension mutuelle des rôles de chacun permettront à votre équipe de transformer un concept innovant en une réalité opérationnelle essentielle. L'aventure commence ici. Préparez-vous à maîtriser votre rôle et à comprendre comment vous vous inscrivez dans l'ensemble.
Bienvenue dans l'Agentverse : un appel aux champions
Une nouvelle ère a commencé dans l'immense étendue numérique de l'entreprise. Nous sommes à l'ère des agents, une période très prometteuse où des agents intelligents et autonomes travaillent en parfaite harmonie pour accélérer l'innovation et éliminer les tâches banales.

Cet écosystème connecté de puissance et de potentiel est connu sous le nom d'Agentverse.
Mais une entropie rampante, une corruption silencieuse connue sous le nom de "Statique", a commencé à effilocher les bords de ce nouveau monde. Le Statique n'est pas un virus ni un bug. Il est l'incarnation du chaos qui se nourrit de l'acte de création lui-même.
Il amplifie les anciennes frustrations pour les transformer en formes monstrueuses, donnant ainsi naissance aux sept spectres du développement. Si vous ne le faites pas, The Static et ses Spectres ralentiront votre progression jusqu'à l'arrêt, transformant la promesse de l'Agentverse en un désert de dette technique et de projets abandonnés.
Aujourd'hui, nous faisons appel à des champions pour repousser la vague du chaos. Nous avons besoin de héros prêts à maîtriser leur art et à travailler ensemble pour protéger l'Agentverse. Il est temps de choisir votre parcours.
Choisir un cours
Quatre chemins distincts s'offrent à vous, chacun étant un pilier essentiel dans la lutte contre The Static. Bien que votre formation soit une mission en solo, votre réussite finale dépend de votre capacité à comprendre comment vos compétences se combinent à celles des autres.
- Le Shadowblade (développeur) : un maître de la forge et du front. Vous êtes l'artisan qui fabrique les lames, construit les outils et affronte l'ennemi dans les détails complexes du code. Votre parcours est axé sur la précision, les compétences et la création pratique.
- L'Invocateur (Architecte) : un grand stratège et orchestrateur. Vous ne voyez pas un seul agent, mais l'ensemble du champ de bataille. Vous concevez les plans directeurs qui permettent à des systèmes entiers d'agents de communiquer, de collaborer et d'atteindre un objectif bien plus grand que n'importe quel composant individuel.
- Le Scholar (ingénieur de données) : il recherche les vérités cachées et est le gardien de la sagesse. Vous vous aventurez dans la vaste étendue sauvage des données pour découvrir l'intelligence qui donne à vos agents un objectif et une vision. Vos connaissances peuvent révéler la faiblesse d'un ennemi ou renforcer un allié.
- Gardien (DevOps / SRE) : protecteur et bouclier inébranlables du royaume. Vous construisez les forteresses, gérez les lignes d'alimentation et veillez à ce que l'ensemble du système puisse résister aux attaques inévitables de la Statique. Votre force est la base sur laquelle repose la victoire de votre équipe.
Votre mission
Votre entraînement commencera en tant qu'exercice autonome. Vous suivrez le parcours de votre choix et acquerrez les compétences uniques nécessaires pour maîtriser votre rôle. À la fin de votre essai, vous affronterez un Spectre né de la Statique, un mini-boss qui s'attaque aux défis spécifiques de votre métier.
Ce n'est qu'en maîtrisant votre rôle individuel que vous pourrez vous préparer à l'épreuve finale. Vous devez ensuite former un groupe avec des champions des autres classes. Ensemble, vous vous aventurerez au cœur de la corruption pour affronter un boss ultime.
Un défi final et collaboratif qui mettra à l'épreuve votre force combinée et déterminera le sort de l'Agentverse.
L'Agentverse attend ses héros. Allez-vous répondre à l'appel ?
2. Grimoire de l'érudit
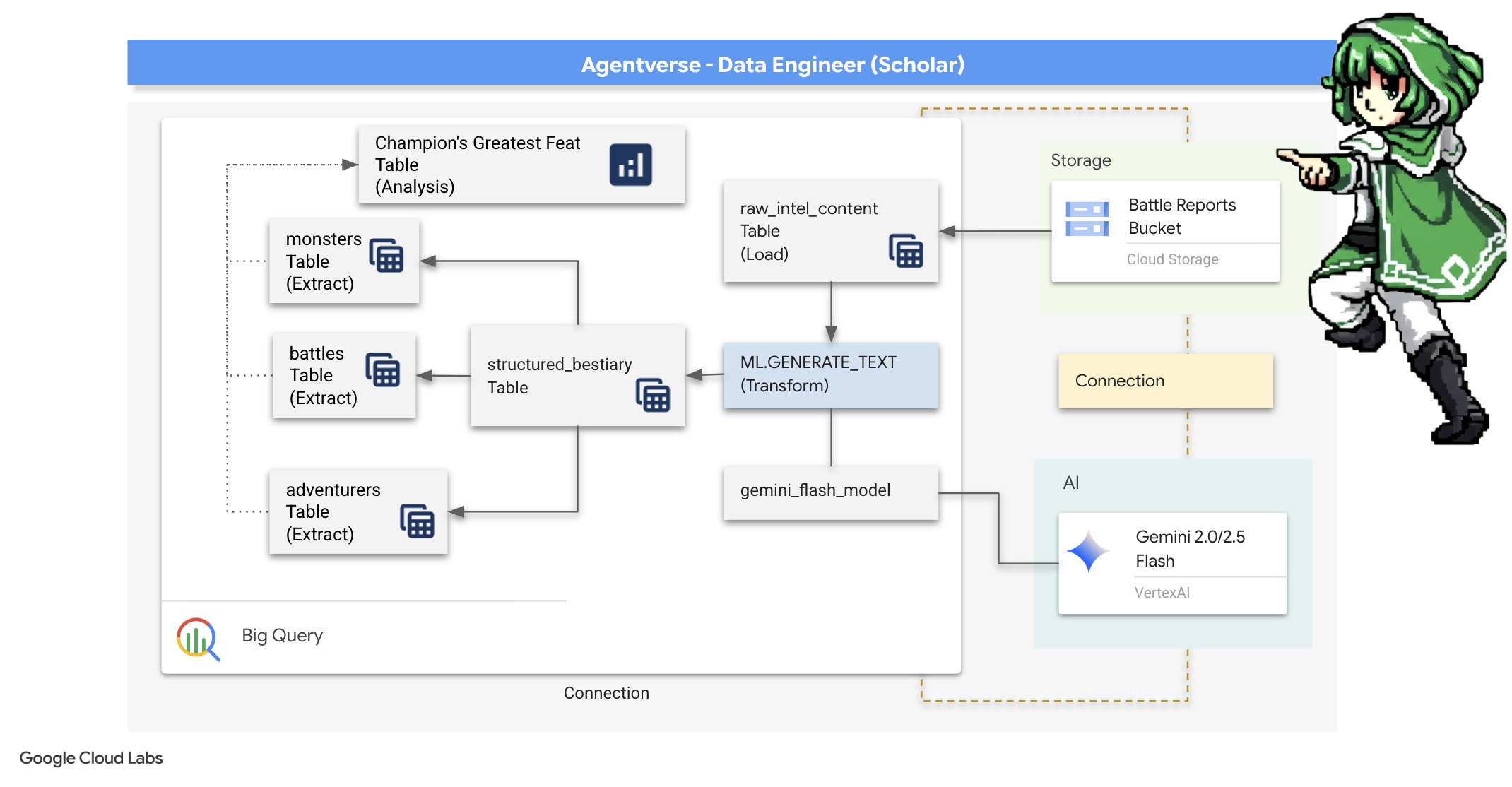
Notre aventure commence ! En tant que Scholars, notre arme principale est le savoir. Nous avons découvert une mine de parchemins anciens et énigmatiques dans nos archives (Google Cloud Storage). Ces parchemins contiennent des informations brutes sur les redoutables créatures qui ravagent le pays. Notre mission est d'utiliser la magie analytique de Google BigQuery et la sagesse d'un cerveau Gemini Elder (modèle Gemini Pro) pour déchiffrer ces textes non structurés et les transformer en un bestiaire structuré et interrogeable. Elle servira de base à toutes nos futures stratégies.
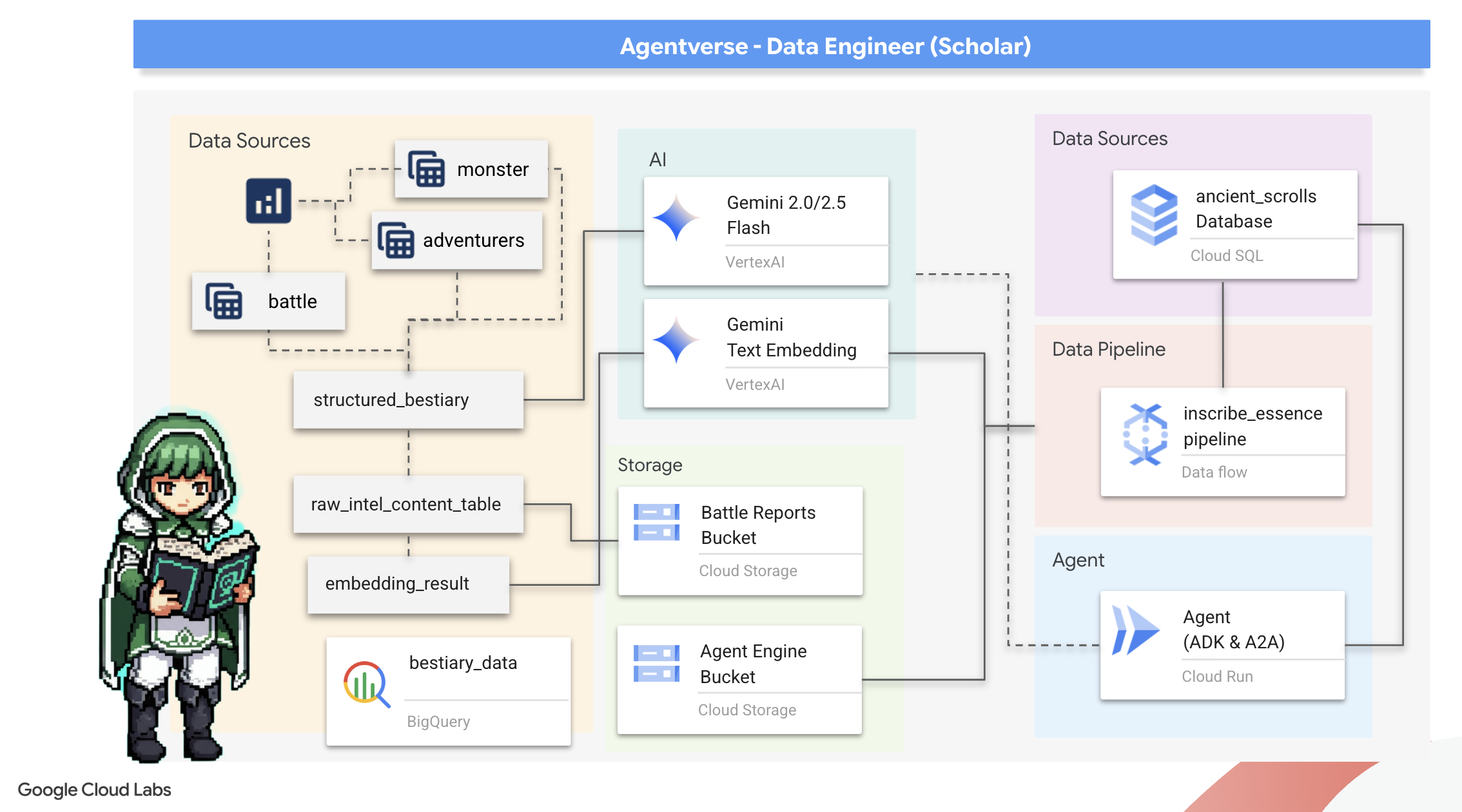
Points abordés
- Utilisez BigQuery pour créer des tables externes et effectuer des transformations complexes de données non structurées en données structurées à l'aide de BQML.GENERATE_TEXT avec un modèle Gemini.
- Provisionnez une instance Cloud SQL pour PostgreSQL et activez l'extension pgvector pour les fonctionnalités de recherche sémantique.
- Créez un pipeline par lot conteneurisé et robuste à l'aide de Dataflow et d'Apache Beam pour traiter des fichiers texte bruts, générer des embeddings vectoriels avec un modèle Gemini et écrire les résultats dans une base de données relationnelle.
- Implémenter un système de génération augmentée par récupération (RAG) de base dans un agent pour interroger les données vectorisées.
- Déployez un agent axé sur les données en tant que service sécurisé et évolutif sur Cloud Run.
3. Préparer le Sanctum du Savant
Bienvenue, Scholar. Avant de pouvoir commencer à inscrire les puissantes connaissances de notre Grimoire, nous devons d'abord préparer notre sanctuaire. Ce rituel fondamental consiste à enchanter notre environnement Google Cloud, à ouvrir les bons portails (API) et à créer les conduits par lesquels notre magie des données s'écoulera. Un sanctuaire bien préparé garantit la puissance de nos sorts et la sécurité de nos connaissances.
Profitez de votre crédit Google Cloud
⚠️ Prérequis importants :
- Utiliser un compte Gmail personnel : vous devez utiliser un compte personnel (par exemple,
name@gmail.com). Les comptes gérés par une entreprise ou un établissement scolaire ne fonctionneront pas.
👉 Étapes :
- Accédez au site de demande de crédit : cliquez ici.
- Se connecter : collez le lien dans la barre d'adresse et connectez-vous avec votre compte Gmail personnel.
- Accepter les conditions d'utilisation : acceptez les conditions d'utilisation de Google Cloud Platform.
- Vérifier l'avoir : recherchez un message confirmant que l'avoir a été appliqué.
- *Remarque : Si vous êtes invité à saisir les informations de votre carte de paiement, vous pouvez ignorer cette étape et fermer la fenêtre.
Vous pouvez fermer la fenêtre.
Configurer l'environnement de travail
👉 Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud (icône en forme de terminal en haut du volet Cloud Shell).
👉 Cliquez sur le bouton "Ouvrir l'éditeur" (icône en forme de dossier ouvert avec un crayon). L'éditeur de code Cloud Shell s'ouvre dans la fenêtre. Un explorateur de fichiers s'affiche sur la gauche. 
👉 Ouvrez le terminal dans l'IDE cloud, 
👉💻 Dans le terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
👉💻 Clonez le projet bootstrap depuis GitHub :
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 Exécutez le script de configuration à partir du répertoire du projet.
⚠️ Remarque sur l'ID du projet : Le script suggère un ID de projet par défaut généré de manière aléatoire. Vous pouvez appuyer sur Entrée pour accepter cette valeur par défaut.
Toutefois, si vous préférez créer un projet spécifique, vous pouvez saisir l'ID de projet souhaité lorsque le script vous y invite.
cd ~/agentverse-dataengineer
./init.sh
👉 Étape importante à effectuer une fois le script terminé : une fois le script terminé, vous devez vous assurer que la console Google Cloud affiche le bon projet :
- Accédez à la page console.cloud.google.com.
- Cliquez sur la liste déroulante du sélecteur de projet en haut de la page.
- Cliquez sur l'onglet Tous (car le nouveau projet n'apparaîtra peut-être pas encore dans "Récents").
- Sélectionnez l'ID de projet que vous venez de configurer à l'étape
init.sh.
👉💻 Définissez l'ID de projet requis :
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Exécutez la commande suivante pour activer les API Google Cloud nécessaires :
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 Si vous n'avez pas encore créé de dépôt Artifact Registry nommé agentverse-repo, exécutez la commande suivante pour le créer :
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
Configurer les autorisations
👉💻 Accordez les autorisations nécessaires en exécutant les commandes suivantes dans le terminal :
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 À mesure que vous progresserez dans votre formation, nous préparerons le défi final. Les commandes suivantes invoqueront les Spectres à partir de la statique chaotique, créant ainsi les boss pour votre test final.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
Bravo, Scholar. Les enchantements fondamentaux sont terminés. Notre sanctuaire est sécurisé, les portails vers les forces élémentaires des données sont ouverts et notre serviteur est habilité. Nous sommes maintenant prêts à commencer le vrai travail.
4. L'alchimie de la connaissance : transformer les données avec BigQuery et Gemini
Dans la guerre incessante contre le Statique, chaque confrontation entre un Champion de l'Agentverse et un Spectre du Développement est méticuleusement enregistrée. Le système de simulation de champ de bataille, notre principal environnement d'entraînement, génère automatiquement une entrée de journal éthérique pour chaque rencontre. Ces journaux narratifs sont notre source la plus précieuse d'informations brutes, le minerai brut à partir duquel nous, en tant que Scholars, devons forger l'acier pur de la stratégie.Le véritable pouvoir d'un Scholar ne réside pas seulement dans la possession de données, mais dans la capacité à transmuter le minerai brut et chaotique d'informations en acier brillant et structuré de sagesse exploitable.Nous allons effectuer le rituel fondamental de l'alchimie des données.

Notre parcours se déroulera en plusieurs étapes, entièrement dans le sanctuaire de Google BigQuery. Nous allons commencer par examiner notre archive GCS sans faire défiler la page, à l'aide d'une loupe magique. Ensuite, nous ferons appel à Gemini pour lire et interpréter les sagas poétiques et non structurées des journaux de combat. Enfin, nous affinerons les prophéties brutes pour obtenir un ensemble de tableaux impeccables et interconnectés. Notre premier Grimoire. Et posez-lui une question si profonde qu'elle ne pourrait être résolue que par cette nouvelle structure.
The Lens of Scrutiny: Peering into GCS with BigQuery External Tables
Notre première action consiste à forger une lentille qui nous permet de voir le contenu de notre archive GCS sans déranger les parchemins à l'intérieur. Une table externe est cette lentille, qui mappe les fichiers texte bruts à une structure de type tableau que BigQuery peut interroger directement.
Pour ce faire, nous devons d'abord créer une ligne ley stable de puissance, une ressource CONNECTION, qui relie de manière sécurisée notre sanctuaire BigQuery à l'archive GCS.
👉💻 Dans votre terminal Cloud Shell, exécutez la commande suivante pour configurer le stockage et créer le conduit :
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 Attention ! Un message s'affichera plus tard !
Le script de configuration de l'étape 2 a lancé un processus en arrière-plan. Au bout de quelques minutes, un message semblable à celui-ci s'affiche dans votre terminal :[1]+ Done gcloud sql instances create ...Cela est normal. Cela signifie simplement que votre base de données Cloud SQL a été créée. Vous pouvez ignorer ce message et continuer à travailler.
Avant de pouvoir créer la table externe, vous devez d'abord créer l'ensemble de données qui la contiendra.
👉💻 Exécutez cette simple commande dans votre terminal Cloud Shell :
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 Nous devons maintenant accorder à la signature magique du conduit les autorisations nécessaires pour lire l'archive GCS et consulter Gemini.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 Dans votre terminal Cloud Shell, exécutez la commande suivante pour afficher le nom de votre bucket :
echo $BUCKET_NAME
Votre terminal affichera un nom semblable à your-project-id-gcs-bucket. Vous en aurez besoin pour les prochaines étapes.
👉 Vous devrez exécuter la commande suivante dans l'éditeur de requête BigQuery de la console Google Cloud. Le moyen le plus simple d'y accéder est d'ouvrir le lien ci-dessous dans un nouvel onglet du navigateur. Vous serez redirigé directement vers la page appropriée de la console Google Cloud.
https://console.cloud.google.com/bigquery
👉 Une fois la page chargée, cliquez sur le bouton + bleu (Saisir une nouvelle requête) pour ouvrir un nouvel onglet de l'éditeur.
Nous allons maintenant écrire l'incantation LDD (langage de définition de données) pour créer notre objectif magique. Cela indique à BigQuery où chercher et ce qu'il doit voir.
👉 📜 Dans l'éditeur de requête BigQuery que vous avez ouvert, collez le code SQL suivant. N'oubliez pas de remplacer REPLACE-WITH-YOUR-BUCKET-NAME
par le nom du bucket que vous venez de copier. Ensuite, cliquez sur Exécuter :
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉 📜 Exécutez une requête pour "regarder à travers l'objectif" et afficher le contenu des fichiers.
SELECT * FROM bestiary_data.raw_intel_content_table;
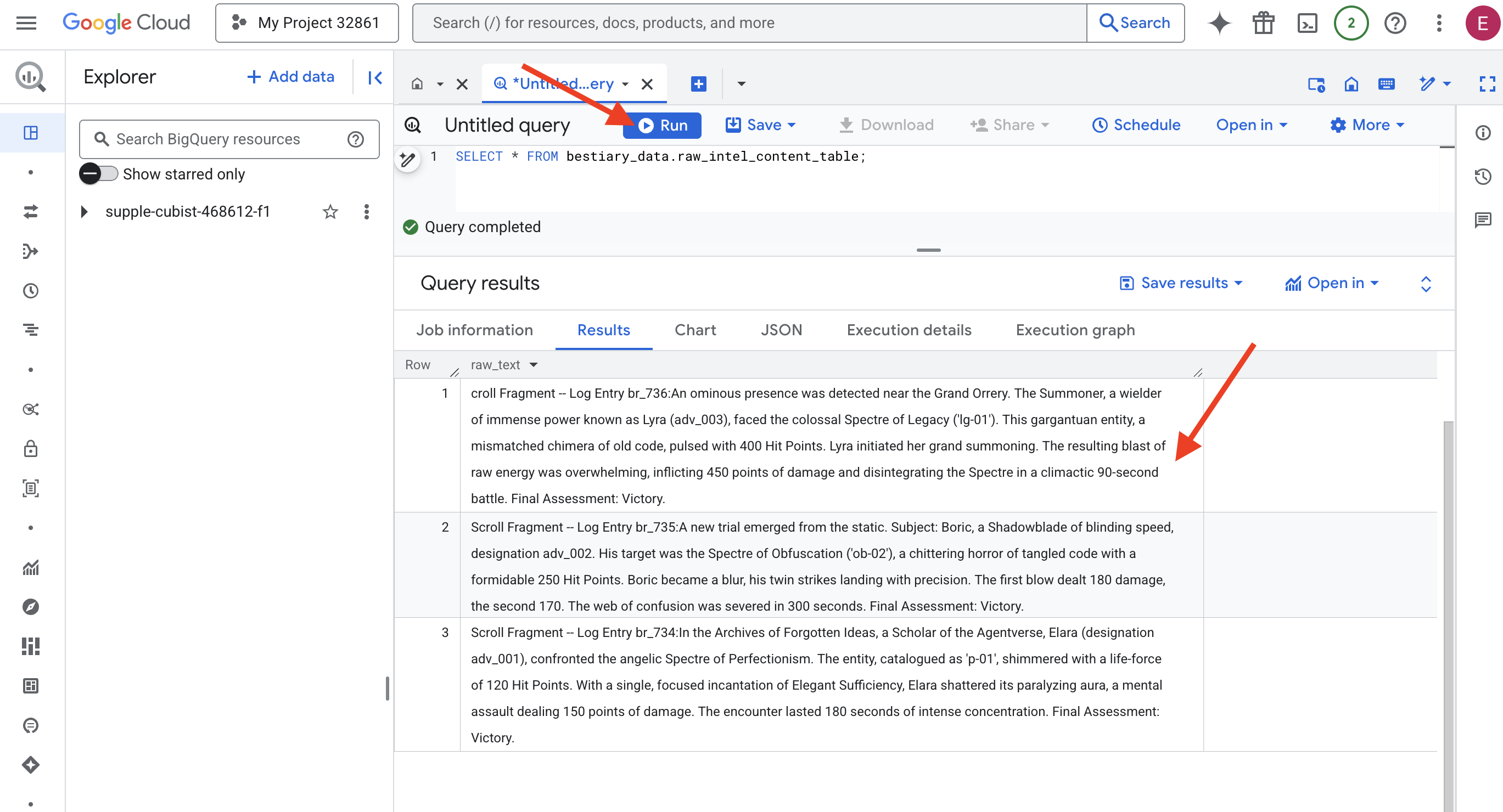
Notre objectif est en place. Nous pouvons maintenant voir le texte brut des rouleaux. Mais lire ne signifie pas comprendre.
Dans les Archives des Idées Oubliées, Elara (désignation adv_001), une érudite de l'Agentverse, a affronté le Spectre angélique du Perfectionnisme. L'entité, cataloguée sous le nom "p-01", scintillait avec une force vitale de 120 points de vie. D'une seule incantation concentrée de Suffisance élégante, Elara brisa son aura paralysante, une attaque mentale infligeant 150 points de dégâts. La rencontre a duré 180 secondes de concentration intense. Évaluation finale : victoire.
Les rouleaux ne sont pas écrits sous forme de tableaux et de lignes, mais dans la prose sinueuse des sagas. C'est notre premier grand test.
La divination du savant : transformer du texte en tableau avec SQL
Le problème est qu'un rapport détaillant les attaques rapides et jumelles d'une Lame de l'ombre se lit très différemment de la chronique d'un Invocateur rassemblant une puissance immense pour une seule attaque dévastatrice. Nous ne pouvons pas simplement importer ces données, nous devons les interpréter. C'est le moment magique. Nous allons utiliser une seule requête SQL comme une incantation puissante pour lire, comprendre et structurer tous les enregistrements de tous nos fichiers, directement dans BigQuery.
👉💻 De retour dans votre terminal Cloud Shell, exécutez la commande suivante pour afficher le nom de votre connexion :
echo "${PROJECT_ID}.${REGION}.gcs-connection"
Votre terminal affichera la chaîne de connexion complète. Sélectionnez et copiez cette chaîne entière, vous en aurez besoin à l'étape suivante.
Nous allons utiliser une seule incantation puissante : ML.GENERATE_TEXT. Ce sort invoque un Gemini, lui montre chaque parchemin et lui ordonne de renvoyer les faits essentiels sous la forme d'un objet JSON structuré.
👉 📜 Dans BigQuery Studio, créez la référence du modèle Gemini. Cela lie l'oracle Gemini Flash à notre bibliothèque BigQuery afin que nous puissions l'appeler dans nos requêtes. N'oubliez pas de remplacer
Remplacez REPLACE-WITH-YOUR-FULL-CONNECTION-STRING par la chaîne de connexion complète que vous venez de copier depuis votre terminal.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 Lancez maintenant le grand sort de transmutation. Cette requête lit le texte brut, construit une requête détaillée pour chaque défilement, l'envoie à Gemini et crée une table intermédiaire à partir de la réponse JSON structurée de l'IA.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
La transmutation est terminée, mais le résultat n'est pas encore pur. Le modèle Gemini renvoie sa réponse dans un format standard, en encapsulant le JSON souhaité dans une structure plus grande qui inclut des métadonnées sur son processus de réflexion. Examinons cette prophétie brute avant de tenter de la purifier.
👉 📜 Exécutez une requête pour inspecter le résultat brut du modèle Gemini :
SELECT * FROM bestiary_data.structured_bestiary;
👀 Une seule colonne nommée "structured_data" s'affiche. Le contenu de chaque ligne ressemblera à cet objet JSON complexe :
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
Comme vous pouvez le voir, notre prix (l'objet JSON propre que nous avons demandé) est profondément imbriqué dans cette structure. Notre prochaine tâche est claire. Nous devons effectuer un rituel pour parcourir systématiquement cette structure et en extraire la sagesse pure.
Le rituel de nettoyage : normaliser la sortie de l'IA générative avec SQL
Gemini a parlé, mais ses mots sont bruts et enveloppés dans les énergies éthérées de sa création (candidats, finish_reason, etc.). Un véritable érudit ne se contente pas de ranger la prophétie brute. Il en extrait soigneusement la sagesse fondamentale et la consigne dans les tomes appropriés pour une utilisation ultérieure.
Nous allons maintenant lancer notre dernière série de sorts. Ce script unique :
- Lisez le fichier JSON brut et imbriqué de notre table intermédiaire.
- Nettoyez-le et analysez-le pour accéder aux données de base.
- Transcris les éléments pertinents dans trois tableaux finaux et impeccables : monstres, aventuriers et batailles.
👉 📜 Dans un nouvel éditeur de requête BigQuery, exécutez le sortilège suivant pour créer notre objectif de nettoyage :
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 Vérifiez le bestiaire :
SELECT * FROM bestiary_data.monsters;
Ensuite, nous allons créer notre Roll of Champions, une liste des braves aventuriers qui ont affronté ces bêtes.
👉📜 Dans un nouvel éditeur de requête, exécutez le sort suivant pour créer la table des aventuriers :
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 Vérifiez le Roll of Champions :
SELECT * FROM bestiary_data.adventurers;
Enfin, nous allons créer notre table de faits : la Chronique des batailles. Ce tome relie les deux autres, en enregistrant les détails de chaque rencontre unique. Étant donné que chaque combat est un événement unique, aucune déduplication n'est nécessaire.
👉 📜 Dans un nouvel éditeur de requête, exécutez le sortilège suivant pour créer la table "battles" :
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Vérifiez l'article Chronicle :
SELECT * FROM bestiary_data.battles;
Découvrir des insights stratégiques
Les rouleaux ont été lus, l'essence distillée et les tomes inscrits. Notre Grimoire n'est plus une simple collection de faits, mais une base de données relationnelle de connaissances stratégiques approfondies. Nous pouvons désormais poser des questions auxquelles il était impossible de répondre lorsque nos connaissances étaient enfermées dans du texte brut et non structuré.
Nous allons maintenant effectuer une dernière grande divination. Nous allons lancer un sort qui consultera les trois tomes à la fois (le Bestiaire des monstres, le Rouleau des champions et la Chronique des batailles) pour découvrir un insight profond et exploitable.
Notre question stratégique : "Pour chaque aventurier, quel est le nom du monstre le plus puissant (en points de vie) qu'il a vaincu, et combien de temps a duré cette victoire ?"
Il s'agit d'une question complexe qui nécessite d'associer les champions à leurs batailles victorieuses, et ces batailles aux statistiques des monstres impliqués. C'est là que réside la véritable puissance d'un modèle de données structurées.
👉📜 Dans un nouvel éditeur de requête BigQuery, lancez l'incantation finale suivante :
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
Le résultat de cette requête sera une table propre et esthétique qui fournira un "Récit du plus grand exploit d'un champion" pour chaque aventurier de votre ensemble de données. L'URL en français pourrait se présenter de la manière suivante :
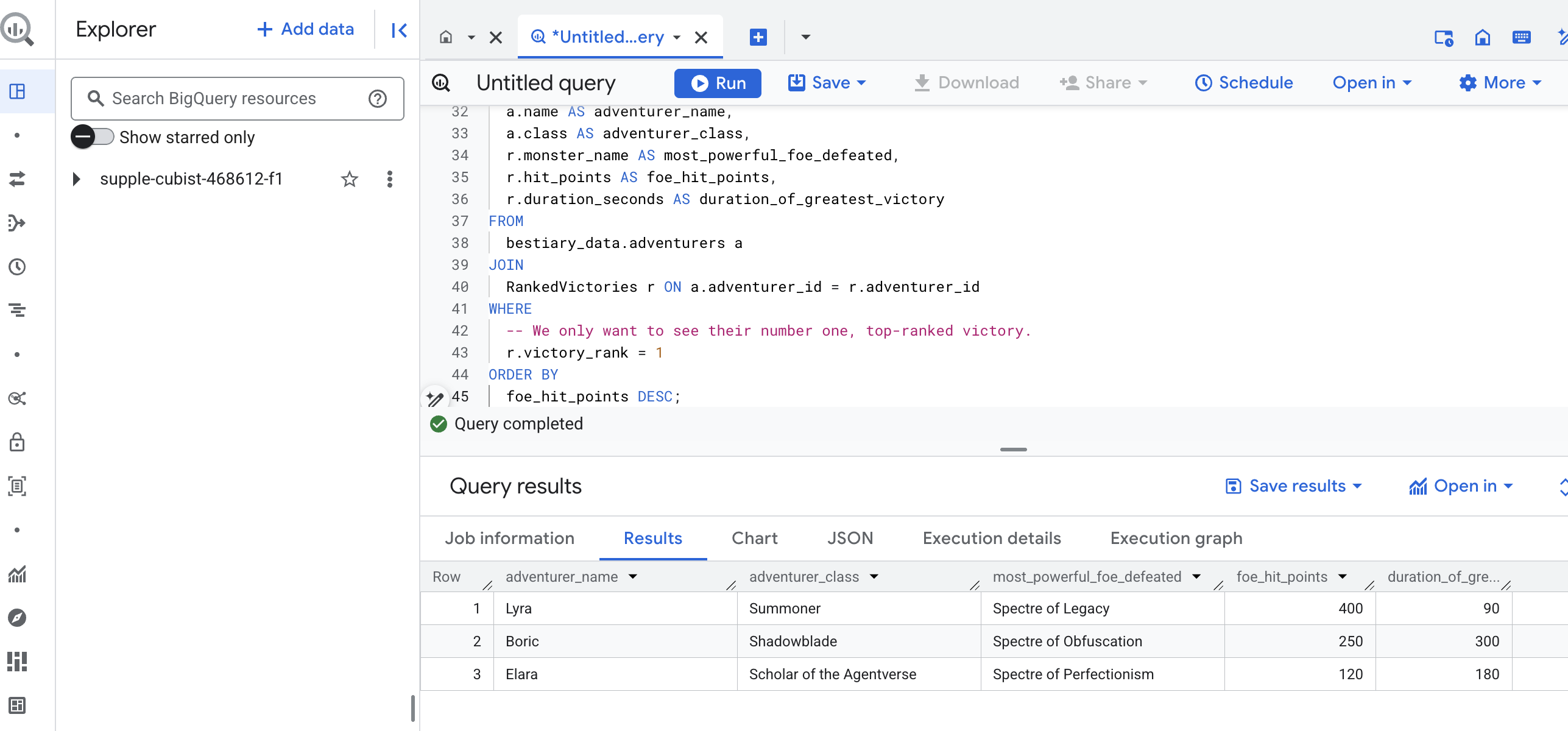
Fermez l'onglet BigQuery.
Ce résultat unique et élégant prouve la valeur de l'ensemble du pipeline. Vous avez réussi à transformer des rapports bruts et chaotiques sur les champs de bataille en source de récits légendaires et d'insights stratégiques basés sur les données.
POUR LES NON-GAMERS
5. Grimoire du scribe : segmentation, intégration et recherche dans l'entrepôt de données
Notre travail dans le laboratoire de l'alchimiste a été un succès. Nous avons transformé les rouleaux narratifs bruts en tableaux relationnels structurés, une véritable prouesse de magie des données. Toutefois, les rouleaux d'origine contiennent une vérité sémantique plus profonde que nos tableaux structurés ne peuvent pas saisir entièrement. Pour créer un agent vraiment intelligent, nous devons débloquer cette signification.
Un long défilement brut est un instrument contondant. Si notre agent pose une question sur une "aura paralysante", une simple recherche peut renvoyer un rapport de bataille complet où cette expression n'est mentionnée qu'une seule fois, noyant la réponse dans des détails non pertinents. Un Scholar expérimenté sait que la véritable sagesse ne réside pas dans le volume, mais dans la précision.
Nous allons effectuer un trio de rituels puissants dans la base de données, entièrement dans notre sanctuaire BigQuery.
- Le rituel de la division (segmentation) : nous allons prendre nos journaux bruts d'intelligence et les décomposer méticuleusement en passages plus petits, ciblés et autonomes.
- Le rituel de distillation (embedding) : nous utiliserons BQML pour consulter un modèle Gemini, en transformant chaque bloc de texte en "empreinte sémantique", c'est-à-dire un embedding vectoriel.
- Le rituel de divination (recherche) : nous utiliserons la recherche vectorielle de BQML pour poser une question en langage naturel et trouver la sagesse la plus pertinente et la plus condensée de notre Grimoire.
L'ensemble de ce processus permet de créer une base de connaissances puissante et consultable sans que les données ne quittent jamais la sécurité et l'évolutivité de BigQuery.
Le rituel de la division : déconstruire les parchemins avec SQL
Notre source d'informations reste les fichiers texte bruts de notre archive GCS, accessibles via notre table externe bestiary_data.raw_intel_content_table. Notre première tâche consiste à écrire un sort qui lit chaque long parchemin et le divise en une série de versets plus petits et plus digestes. Pour ce rituel, nous allons définir un "bloc" comme une seule phrase.
Bien que la segmentation par phrase soit un point de départ clair et efficace pour nos journaux narratifs, un Scribe expérimenté dispose de nombreuses stratégies de segmentation. Le choix est essentiel pour la qualité de la recherche finale. Les méthodes plus simples peuvent utiliser un
- Regrouper les données par blocs de taille fixe, mais cela peut couper une idée clé en deux.
Des rituels plus sophistiqués, comme
- En pratique, les chunks récursifs sont souvent privilégiés. Ils tentent de diviser le texte en fonction de limites naturelles, comme les paragraphes, puis se rabattent sur les phrases pour conserver autant de contexte sémantique que possible. Pour les manuscrits vraiment complexes.
- Chunking basé sur le contenu (document) : le Scribe utilise la structure inhérente du document (par exemple, les en-têtes d'un manuel technique ou les fonctions d'un code de défilement) pour créer les blocs de connaissances les plus logiques et les plus efficaces.
Pour nos journaux de combat, la phrase offre un équilibre parfait entre précision et contexte.
👉 📜 Dans un nouvel éditeur de requête BigQuery, exécutez l'incantation suivante. Ce sort utilise la fonction SPLIT pour séparer le texte de chaque parchemin à chaque point (.) et dénicher ensuite le tableau de phrases obtenu dans des lignes distinctes.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 Exécutez maintenant une requête pour inspecter les connaissances que vous venez de transcrire et de segmenter, et constatez la différence.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
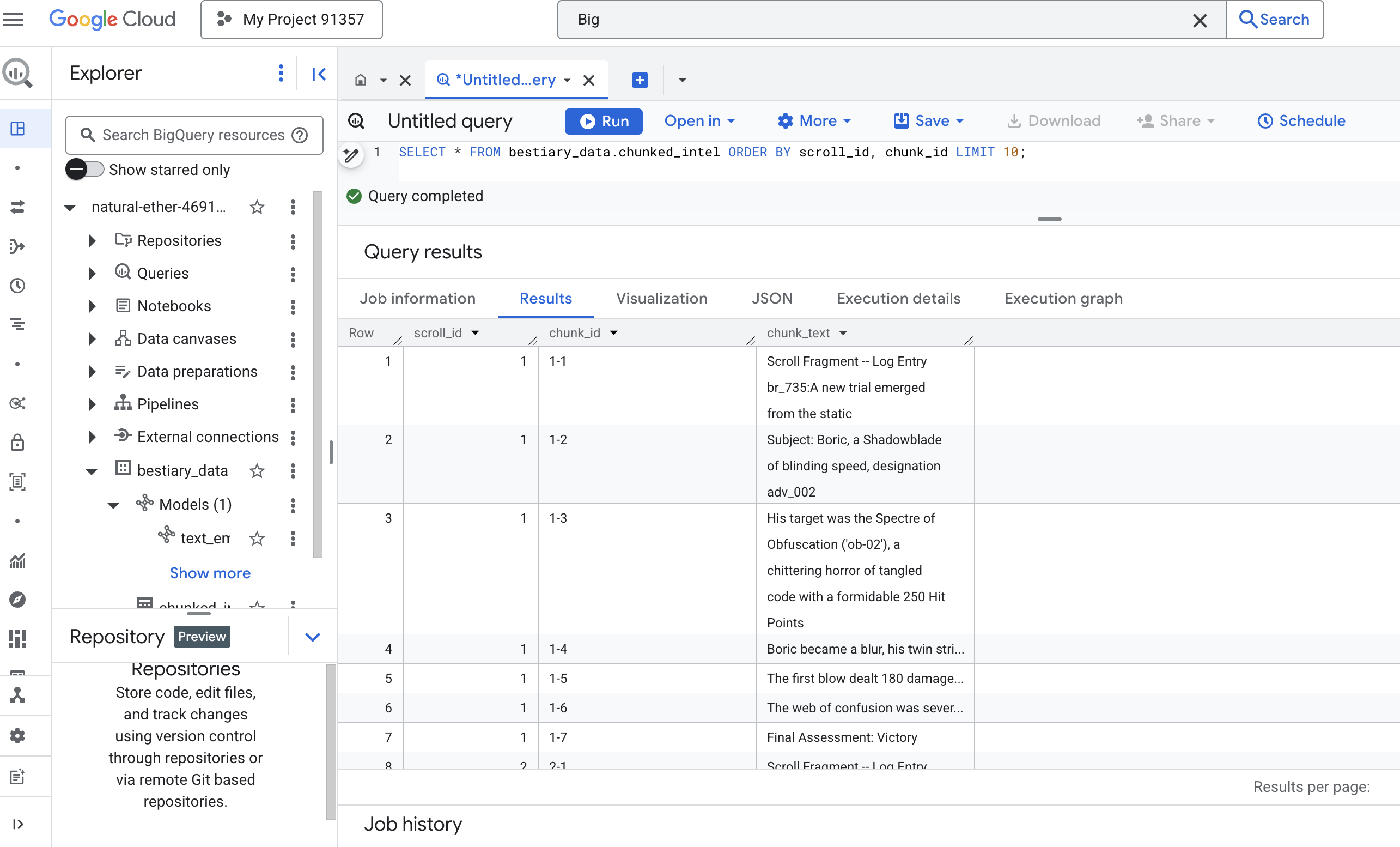
Observez les résultats. Alors qu'il y avait auparavant un seul bloc de texte dense, il existe désormais plusieurs lignes, chacune liée au défilement d'origine (scroll_id), mais ne contenant qu'une seule phrase ciblée. Chaque ligne est désormais un candidat idéal pour la vectorisation.
Le rituel de distillation : transformer du texte en vecteurs avec BQML
👉💻 Tout d'abord, revenez à votre terminal et exécutez la commande suivante pour afficher le nom de votre connexion :
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Nous devons créer un modèle BigQuery qui pointe vers un embedding de texte Gemini. Dans BigQuery Studio, exécutez le sort suivant. Notez que vous devez remplacer REPLACE-WITH-YOUR-FULL-CONNECTION-STRING par la chaîne de connexion complète que vous venez de copier depuis votre terminal.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉 📜 Lancez maintenant le grand sort de distillation. Cette requête appelle la fonction ML.GENERATE_EMBEDDING, qui lit chaque ligne de notre table chunked_intel, envoie le texte au modèle d'embedding Gemini et stocke l'empreinte vectorielle résultante dans une nouvelle table.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
Ce processus peut prendre une ou deux minutes, car BigQuery traite tous les blocs de texte.
👉 📜 Une fois l'opération terminée, inspectez la nouvelle table pour voir les empreintes sémantiques.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
Une nouvelle colonne, ml_generate_embedding_result, contenant la représentation vectorielle dense de votre texte s'affiche. Notre Grimoire est désormais encodé sémantiquement.
Le rituel de divination : recherche sémantique avec BQML
👉📜 Le test ultime de notre Grimoire consiste à lui poser une question. Nous allons maintenant effectuer notre dernier rituel : une recherche vectorielle. Il ne s'agit pas d'une recherche par mots clés, mais d'une recherche par signification. Nous allons poser une question en langage naturel. BQML va la convertir en embedding à la volée, puis rechercher dans l'intégralité de notre tableau embedded_intel les blocs de texte dont les empreintes sont les plus proches en termes de signification.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
Analyse du sort :
VECTOR_SEARCH: fonction principale qui orchestre la recherche.ML.GENERATE_EMBEDDING(requête intérieure) : c'est là que la magie opère. Nous intégrons notre requête ('What are the tactics...') à l'aide du même modèle, mais avec le type de tâche'RETRIEVAL_QUERY', qui est spécifiquement optimisé pour les requêtes.top_k => 3: nous demandons les trois résultats les plus pertinents.distance_type => 'COSINE': mesure l'"angle" entre les vecteurs. Plus l'angle est petit, plus les significations sont alignées.
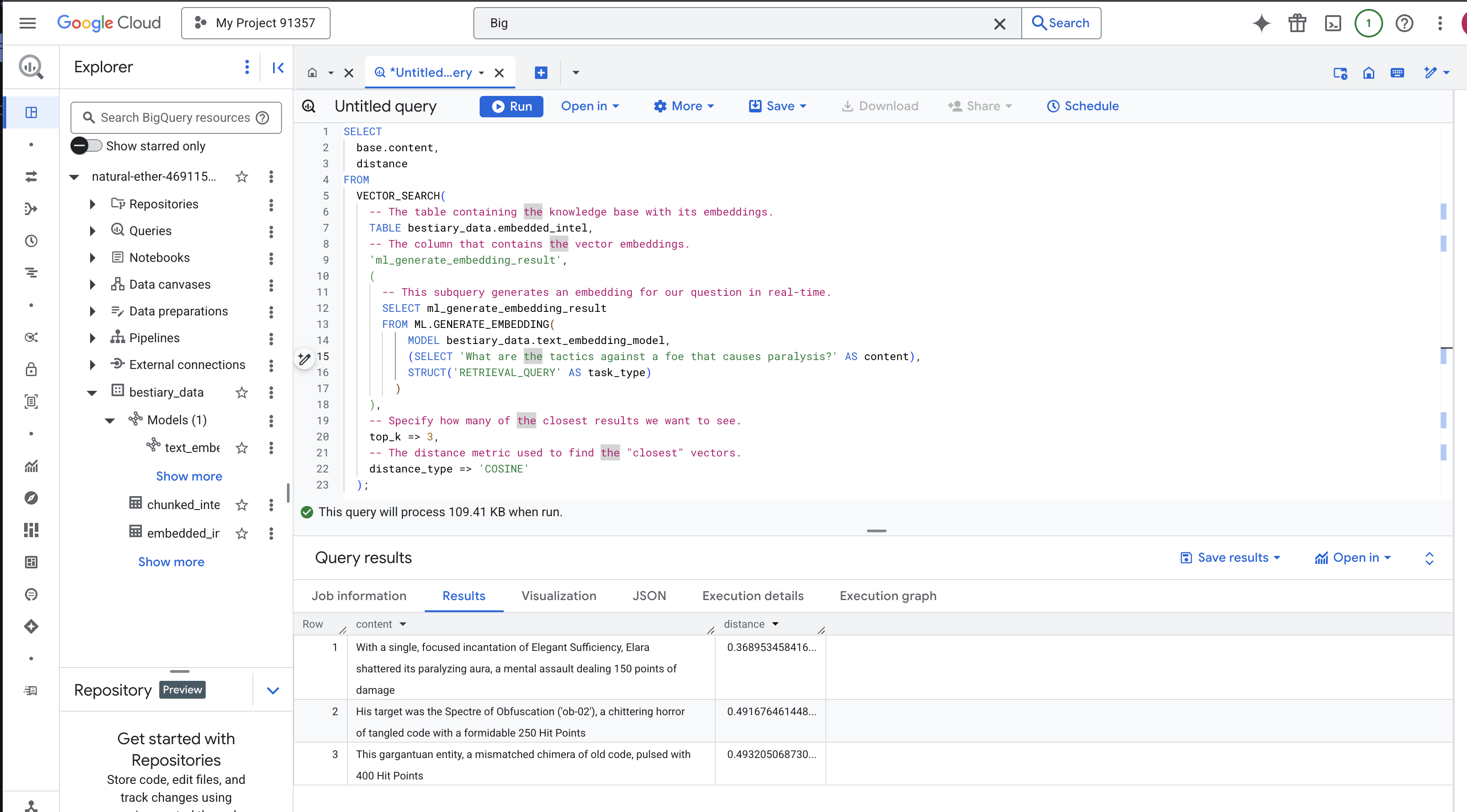
Examinez attentivement les résultats. La requête ne contenait pas les mots "brisé" ou "incantation", mais le premier résultat est le suivant : "Avec une seule incantation concentrée d'Efficacité élégante, Elara a brisé son aura paralysante, une attaque mentale infligeant 150 points de dégâts". C'est tout l'intérêt de la recherche sémantique. Le modèle a compris le concept de "tactiques contre la paralysie" et a trouvé la phrase qui décrivait une tactique spécifique et efficace.
Vous avez créé un pipeline RAG complet et intégré à l'entrepôt de données. Vous avez préparé des données brutes, les avez transformées en vecteurs sémantiques et les avez interrogées par signification. Bien que BigQuery soit un outil puissant pour ce type d'analyse à grande échelle, nous transférons souvent ces informations préparées vers une base de données opérationnelle spécialisée pour un agent en direct qui a besoin de réponses à faible latence. Ce sera le sujet de notre prochaine formation.
POUR LES NON-GAMERS
6. Vector Scriptorium : créer le magasin de vecteurs avec Cloud SQL pour l'inférence
Notre Grimoire se présente actuellement sous la forme de tableaux structurés, qui constituent un puissant catalogue de faits, mais dont les connaissances sont littérales. Il comprend monster_id = "MN-001", mais pas la signification sémantique plus profonde de "Obfuscation". Pour que nos agents soient vraiment sages, qu'ils puissent conseiller avec nuance et clairvoyance, nous devons distiller l'essence même de nos connaissances sous une forme qui capture le sens : les vecteurs.
Notre quête de connaissances nous a menés aux ruines d'une civilisation précurseur oubliée depuis longtemps. Enfouis au plus profond d'une chambre forte scellée, nous avons découvert une malle d'anciens parchemins, miraculeusement conservés. Il ne s'agit pas de simples rapports de bataille, mais de réflexions philosophiques profondes sur la façon de vaincre une bête qui afflige toutes les grandes entreprises. Entité décrite dans les parchemins comme une "stagnation rampante et silencieuse", un "effilochage de la trame de la création". Il semble que la Statique était connue même des anciens, une menace cyclique dont l'histoire s'est perdue dans le temps.
Ces connaissances oubliées sont notre plus grand atout. Il détient la clé non seulement pour vaincre des monstres individuels, mais aussi pour donner à toute l'équipe des informations stratégiques. Pour exploiter cette puissance, nous allons maintenant créer le véritable grimoire du Scholar (une base de données PostgreSQL avec des capacités vectorielles) et construire un scriptorium vectoriel automatisé (un pipeline Dataflow) pour lire, comprendre et inscrire l'essence intemporelle de ces parchemins. Cela transformera notre Grimoire, qui n'était qu'un recueil de faits, en un moteur de sagesse.

Créer le livre de sorts du Scholar (Cloud SQL)
Avant de pouvoir inscrire l'essence de ces anciens parchemins, nous devons d'abord confirmer que le réceptacle de ces connaissances, le Spellbook PostgreSQL géré, a bien été forgé. Les rituels de configuration initiale devraient déjà l'avoir créé pour vous.
👉💻 Dans un terminal, exécutez la commande suivante pour vérifier que votre instance Cloud SQL existe et est prête. Ce script accorde également au compte de service dédié de l'instance l'autorisation d'utiliser Vertex AI, ce qui est essentiel pour générer des embeddings directement dans la base de données.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Si la commande aboutit et renvoie des informations sur votre instance grimoire-spellbook, cela signifie que Forge a bien fait son travail. Vous êtes prêt à passer à la prochaine incantation. Si la commande renvoie une erreur NOT_FOUND, assurez-vous d'avoir correctement effectué les étapes de configuration initiale de l'environnement avant de continuer.(data_setup.py)
👉💻 Une fois le livre forgé, nous l'ouvrons au premier chapitre en créant une base de données nommée arcane_wisdom.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
Inscrire les runes sémantiques : activer les fonctionnalités vectorielles avec pgvector
Maintenant que votre instance Cloud SQL a été créée, connectons-nous à celle-ci à l'aide de Cloud SQL Studio intégré. Il fournit une interface Web permettant d'exécuter des requêtes SQL directement sur votre base de données.
👉💻 Tout d'abord, accédez à Cloud SQL Studio. Le moyen le plus simple et le plus rapide d'y accéder consiste à ouvrir le lien suivant dans un nouvel onglet de navigateur. Vous serez redirigé directement vers Cloud SQL Studio pour votre instance grimoire-spellbook.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 Sélectionnez arcane_wisdom comme base de données, saisissez postgres comme utilisateur et 1234qwer comme mot de passe, puis cliquez sur Authenticate (S'authentifier).
👉📜 Dans l'éditeur de requête SQL Studio, accédez à l'onglet "Éditeur 1", puis collez le code SQL suivant pour activer le type de données vectorielles :
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
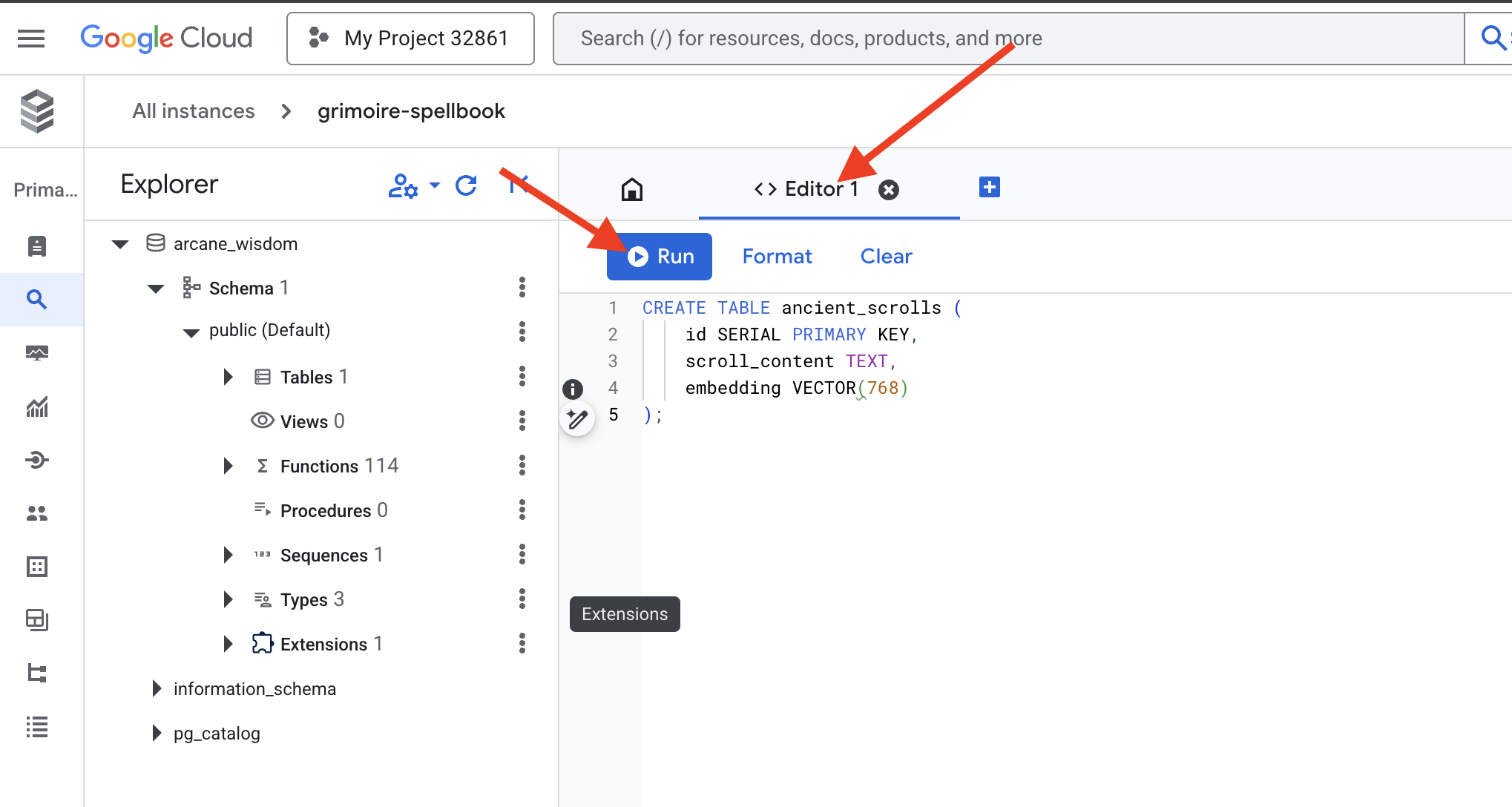
👉📜 Préparez les pages de notre grimoire en créant le tableau qui contiendra l'essence de nos parchemins.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
Le sort VECTOR(768) est un détail important. Le modèle d'embedding Vertex AI que nous allons utiliser (textembedding-gecko@003 ou un modèle similaire) condense le texte en un vecteur à 768 dimensions. Les pages de notre grimoire doivent être préparées pour contenir une essence de cette taille exacte. Les dimensions doivent toujours correspondre.
Première translittération : un rituel d'inscription manuelle
Avant de commander une armée de scribes automatisés (Dataflow), nous devons effectuer le rituel central à la main une fois. Vous comprendrez ainsi mieux la magie de l'authentification en deux étapes :
- Divination : prendre un texte et consulter l'oracle Gemini pour distiller son essence sémantique dans un vecteur.
- Inscription : écriture du texte d'origine et de sa nouvelle essence vectorielle dans notre Spellbook.
Maintenant, effectuons le rituel manuel.
👉 📜 Dans Cloud SQL Studio. Nous allons maintenant utiliser la fonction embedding(), une fonctionnalité puissante fournie par l'extension google_ml_integration. Cela nous permet d'appeler le modèle d'embedding Vertex AI directement à partir de notre requête SQL, ce qui simplifie considérablement le processus.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉 📜 Vérifiez votre travail en exécutant une requête pour lire la page nouvellement inscrite :
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
Vous avez réussi à effectuer manuellement la tâche de chargement des données RAG de base.
Forger la boussole sémantique : enchanter le livre de sorts avec un index HNSW
Notre grimoire peut désormais stocker des connaissances, mais pour trouver le bon parchemin, il faut lire chaque page. Il s'agit d'une analyse séquentielle. Cette méthode est lente et inefficace. Pour guider instantanément nos requêtes vers les connaissances les plus pertinentes, nous devons enchanter le Spellbook avec une boussole sémantique : un index vectoriel.
Prouvons la valeur de cet enchantement.
👉 📜 Dans Cloud SQL Studio, exécutez le sortilège suivant. Il simule la recherche de notre nouveau parchemin inséré et demande à la base de données de EXPLAIN son plan.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
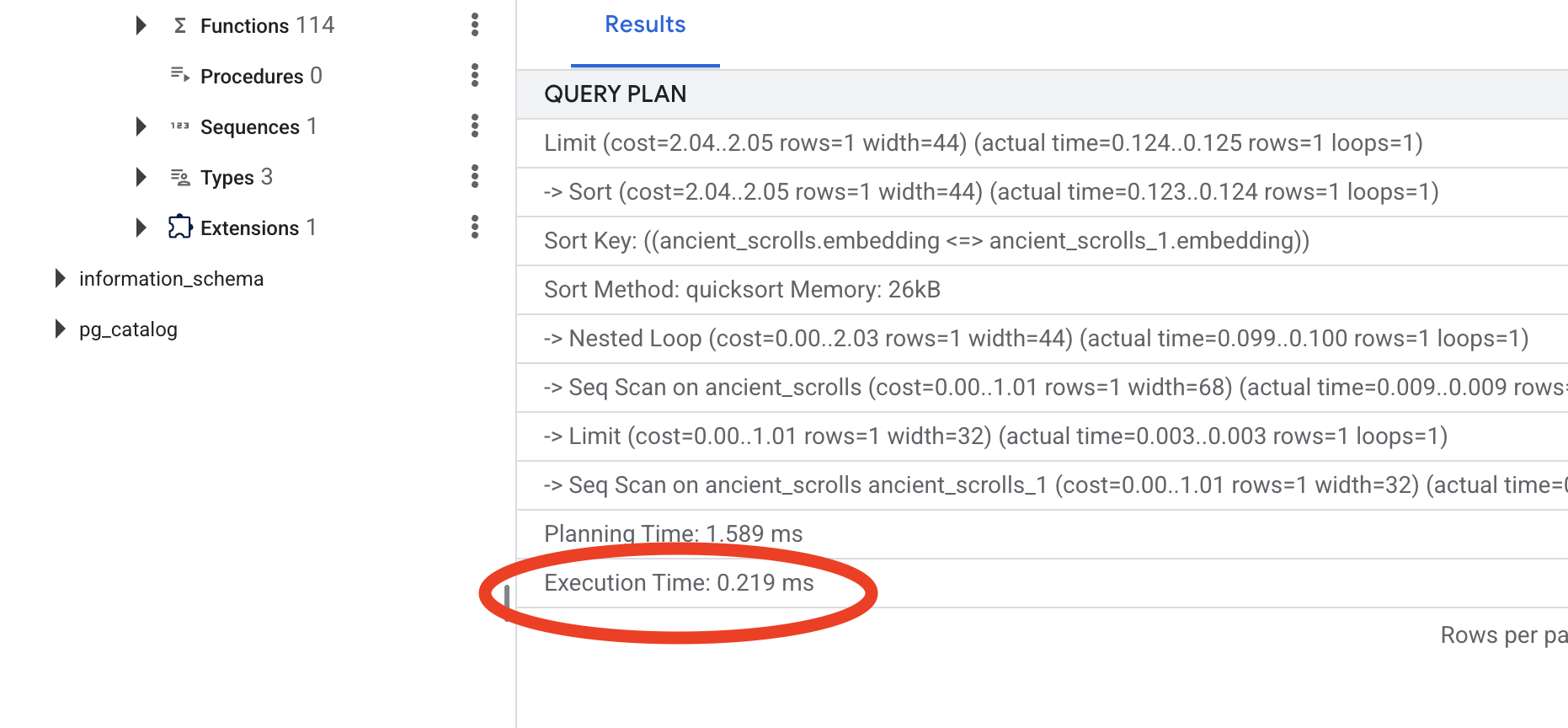
Examinez le résultat. Une ligne indiquant -> Seq Scan on ancient_scrolls s'affiche. Cela confirme que la base de données lit chaque ligne. Notez l'élément execution time.
👉📜 Maintenant, lançons le sort d'indexation. Le paramètre lists indique à l'index le nombre de clusters à créer. Un bon point de départ consiste à utiliser la racine carrée du nombre de lignes que vous prévoyez d'avoir.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
Attendez que l'index soit créé (ce sera rapide pour une ligne, mais cela peut prendre du temps pour des millions de lignes).
👉📜 Exécutez à nouveau la même commande EXPLAIN ANALYZE :
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
Examinez le nouveau plan de requête. Vous verrez maintenant -> Index Scan using.... Mais surtout, examinez l'élément execution time. Elle sera beaucoup plus rapide, même avec une seule entrée. Vous venez de démontrer le principe fondamental de l'optimisation des performances des bases de données dans un monde vectoriel.
Maintenant que vous avez inspecté vos données sources, compris votre rituel manuel et optimisé votre Spellbook pour la vitesse, vous êtes vraiment prêt à créer le Scriptorium automatisé.
POUR LES NON-GAMERS
7. Le conduit du sens : créer un pipeline de vectorisation Dataflow
Nous allons maintenant créer la chaîne de montage magique de scribes qui liront nos rouleaux, en distilleront l'essence et les inscriront dans notre nouveau grimoire. Il s'agit d'un pipeline Dataflow que nous déclencherons manuellement. Mais avant d'écrire le sort principal pour le pipeline lui-même, nous devons d'abord préparer sa base et le cercle à partir duquel nous l'invoquerons.
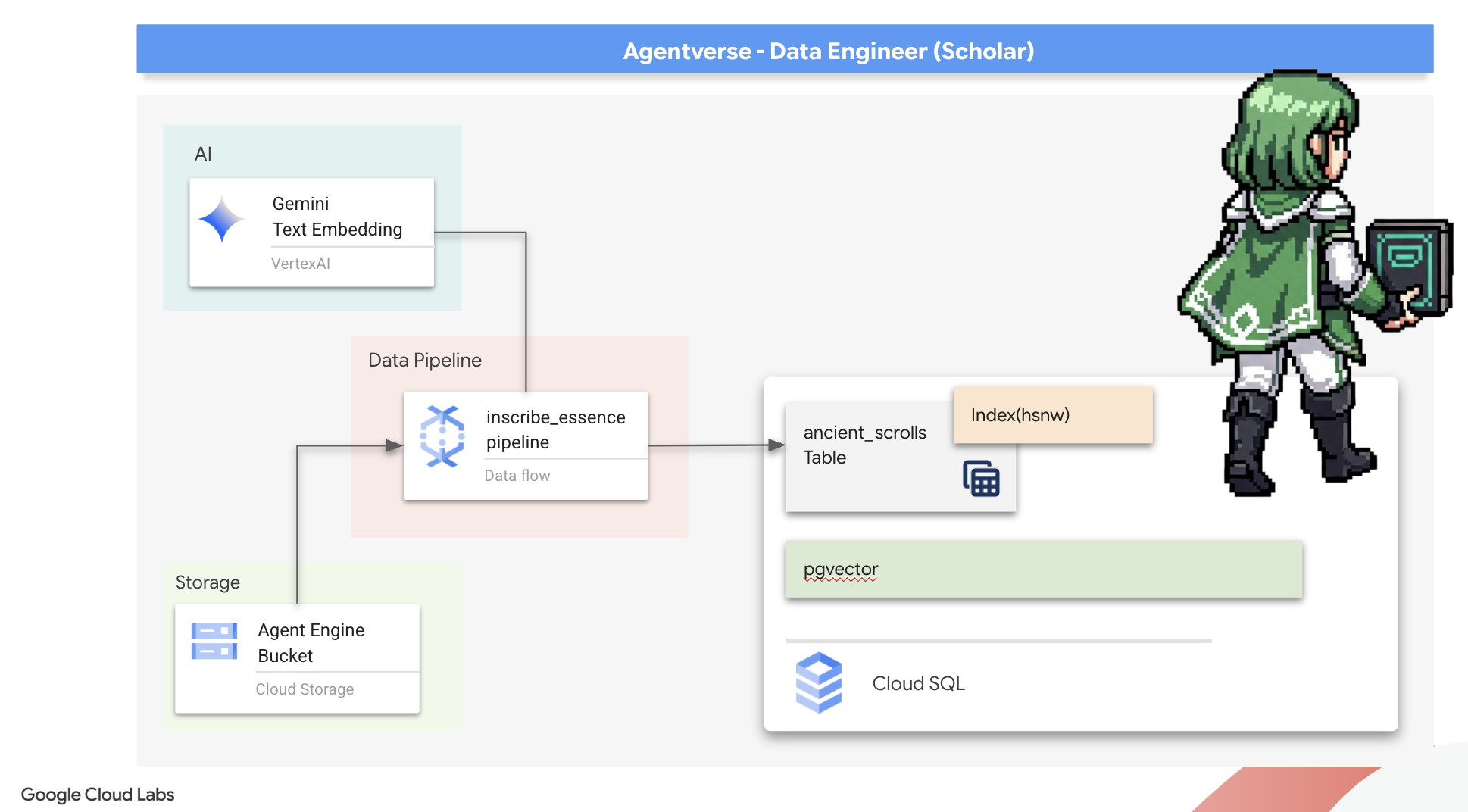
Préparer la base du Scriptorium (image du nœud de calcul)
Notre pipeline Dataflow sera exécuté par une équipe de nœuds de calcul automatisés dans le cloud. Chaque fois que nous les invoquons, ils ont besoin d'un ensemble spécifique de bibliothèques pour faire leur travail. Nous pourrions leur fournir une liste et leur demander de récupérer ces bibliothèques à chaque fois, mais cela serait lent et inefficace. Un érudit avisé prépare une bibliothèque principale à l'avance.
Ici, nous allons demander à Google Cloud Build de créer une image de conteneur personnalisée. Cette image est un "golem parfait", préchargé avec toutes les bibliothèques et dépendances dont nos scribes auront besoin. Lorsque notre job Dataflow démarre, il utilise cette image personnalisée, ce qui permet aux nœuds de calcul de commencer leur tâche presque instantanément.
👉💻 Exécutez la commande suivante pour créer et stocker l'image de base de votre pipeline dans Artifact Registry.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 Exécutez les commandes suivantes pour créer et activer votre environnement Python isolé, et y installer les bibliothèques d'invocation nécessaires.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
L'incantation maîtresse
Il est temps d'écrire le sortilège principal qui alimentera notre Vector Scriptorium. Nous n'écrirons pas les composants magiques individuels à partir de zéro. Notre tâche consiste à assembler des composants dans un pipeline logique et puissant à l'aide du langage Apache Beam.
- EmbedTextBatch (consultation de Gemini) : vous allez créer ce scribe spécialisé qui sait comment effectuer une "divination de groupe". Il prend un lot de fichiers de texte brut, les présente au modèle d'embedding de texte Gemini et reçoit leur essence distillée (les embeddings vectoriels).
- WriteEssenceToSpellbook (The Final Inscription) : c'est notre archiviste. Il connaît les incantations secrètes pour ouvrir une connexion sécurisée à notre grimoire Cloud SQL. Son rôle est de prendre le contenu d'un parchemin et son essence vectorisée, puis de les inscrire de manière permanente sur une nouvelle page.
Notre mission est d'enchaîner ces actions pour créer un flux de connaissances fluide.
👉✏️ Dans l'éditeur Cloud Shell, accédez à ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py. Vous y trouverez une classe DoFn nommée EmbedTextBatch. Recherchez le commentaire #REPLACE-EMBEDDING-LOGIC. Remplacez-le par l'incantation suivante.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Ce sort est précis et comporte plusieurs paramètres clés :
- model : nous spécifions
text-embedding-005pour utiliser un modèle d'embedding puissant et à jour. - contents : il s'agit d'une liste de tout le contenu textuel du lot de fichiers que reçoit DoFn.
- task_type : nous le définissons sur "RETRIEVAL_DOCUMENT". Il s'agit d'une instruction essentielle qui indique à Gemini de générer des embeddings spécifiquement optimisés pour être trouvés ultérieurement dans une recherche.
- output_dimensionality : cette valeur doit être définie sur 768, ce qui correspond parfaitement à la dimension VECTOR(768) que nous avons définie lors de la création de notre table "ancient_scrolls" dans Cloud SQL. Les dimensions non concordantes sont une source d'erreur courante dans la magie vectorielle.
Notre pipeline doit commencer par lire le texte brut et non structuré de tous les anciens rouleaux de notre archive GCS.
👉✏️ Dans ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py, recherchez le commentaire #REPLACE ME-READFILE et remplacez-le par l'incantation en trois parties suivante :
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
Maintenant que nous avons rassemblé le texte brut des rouleaux, nous devons l'envoyer à Gemini pour qu'il nous révèle l'avenir. Pour ce faire efficacement, nous allons d'abord regrouper les parchemins individuels en petits lots, puis les remettre à notre scribe EmbedTextBatch. Cette étape permet également de séparer les parchemins que Gemini ne comprend pas dans une pile "Échec" pour les examiner ultérieurement.
👉✏️ Recherchez le commentaire #REPLACE ME-EMBEDDING et remplacez-le par :
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
L'essence de nos parchemins a été distillée avec succès. La dernière étape consiste à inscrire ces connaissances dans notre Spellbook pour les stocker de manière permanente. Nous prendrons les parchemins de la pile "traités" et les remettrons à notre archiviste WriteEssenceToSpellbook.
👉✏️ Recherchez le commentaire #REPLACE ME-WRITE TO DB et remplacez-le par :
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
Un Scholar avisé ne se débarrasse jamais de ses connaissances, même en cas d'échec. Enfin, nous devons demander à un scribe de prendre la pile "Échec" de notre étape de divination et d'enregistrer les raisons de l'échec. Cela nous permettra d'améliorer nos rituels à l'avenir.
👉✏️ Recherchez le commentaire #REPLACE ME-LOG FAILURES et remplacez-le par :
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
L'incantation principale est maintenant terminée ! Vous avez réussi à assembler un pipeline de données puissant et à plusieurs étapes en enchaînant des composants magiques individuels. Enregistrez votre fichier inscribe_essence_pipeline.py. Le Scriptorium est maintenant prêt à être invoqué.
Nous allons maintenant lancer le grand sortilège d'invocation pour ordonner au service Dataflow de réveiller notre Golem et de commencer le rituel d'écriture.
👉💻 Dans votre terminal, exécutez la ligne de commande suivante :
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 Attention ! Si le job échoue avec une erreur de ressource ZONE_RESOURCE_POOL_EXHAUSTED, cela peut être dû à des contraintes de ressources temporaires de ce compte à faible réputation dans la région sélectionnée. La puissance de Google Cloud réside dans sa couverture mondiale. Il vous suffit d'essayer d'invoquer le golem dans une autre région. Pour ce faire, remplacez --region=$REGION dans la commande ci-dessus par une autre région, par exemple
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
, puis exécutez-le à nouveau. 🎰
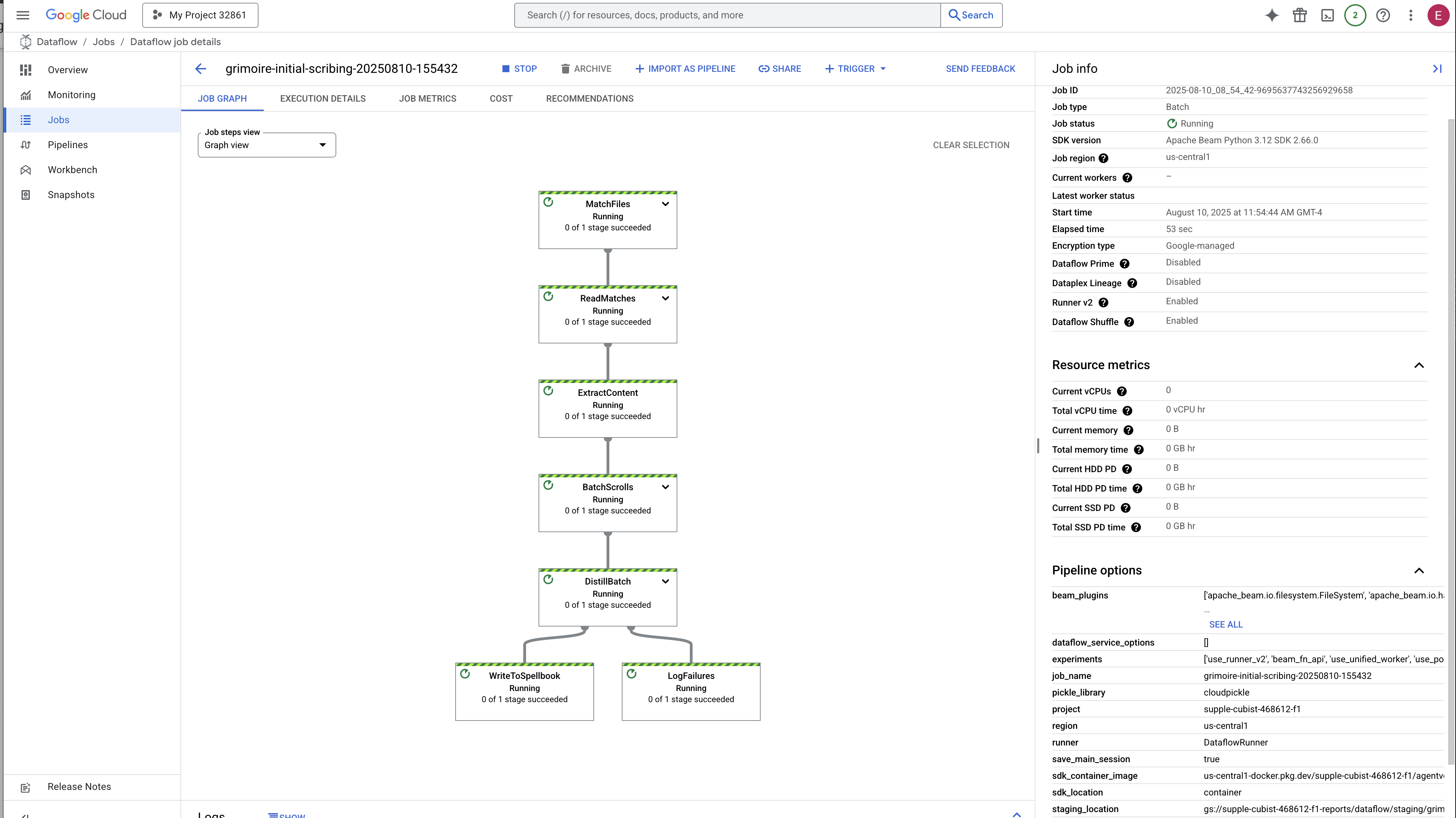
Le processus de démarrage et de finalisation prend environ trois à cinq minutes. Vous pouvez le regarder en direct dans la console Dataflow.
👉 Accédez à la console Dataflow : le moyen le plus simple consiste à ouvrir ce lien direct dans un nouvel onglet de navigateur :
https://console.cloud.google.com/dataflow
👉 Recherchez et cliquez sur votre tâche : une tâche portant le nom que vous avez indiqué (inscribe-essence-job ou un nom similaire) s'affiche. Cliquez sur le nom du job pour ouvrir la page d'informations. Observer le pipeline :
- Démarrage : pendant les trois premières minutes, l'état du job sera "En cours d'exécution", car Dataflow provisionne les ressources nécessaires. Le graphique s'affiche, mais vous ne verrez peut-être pas encore de données le traverser.
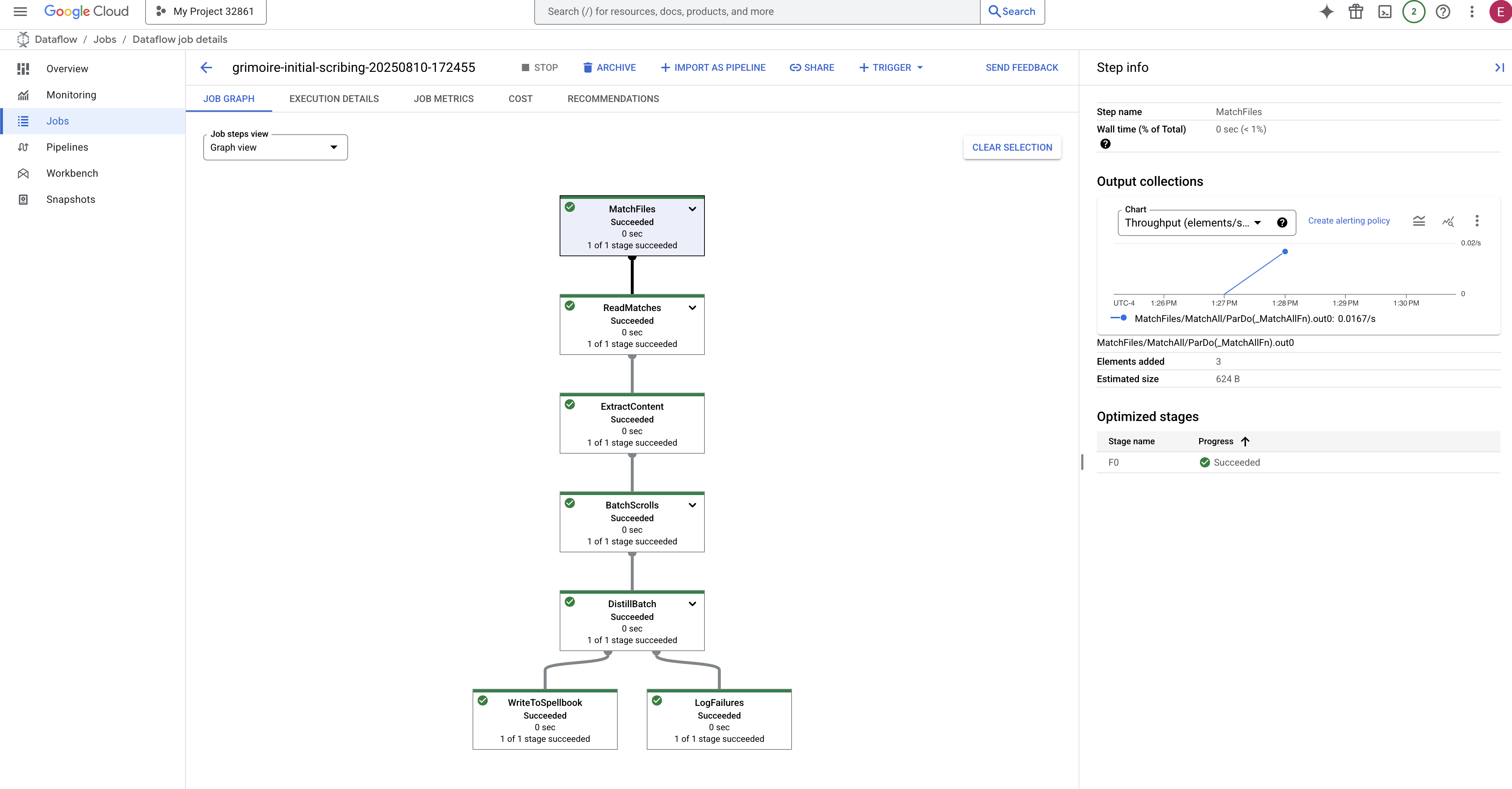
- Terminé : une fois le job terminé, son état passe à "Réussie", et le graphique indique le nombre final d'enregistrements traités.
Vérifier l'inscription
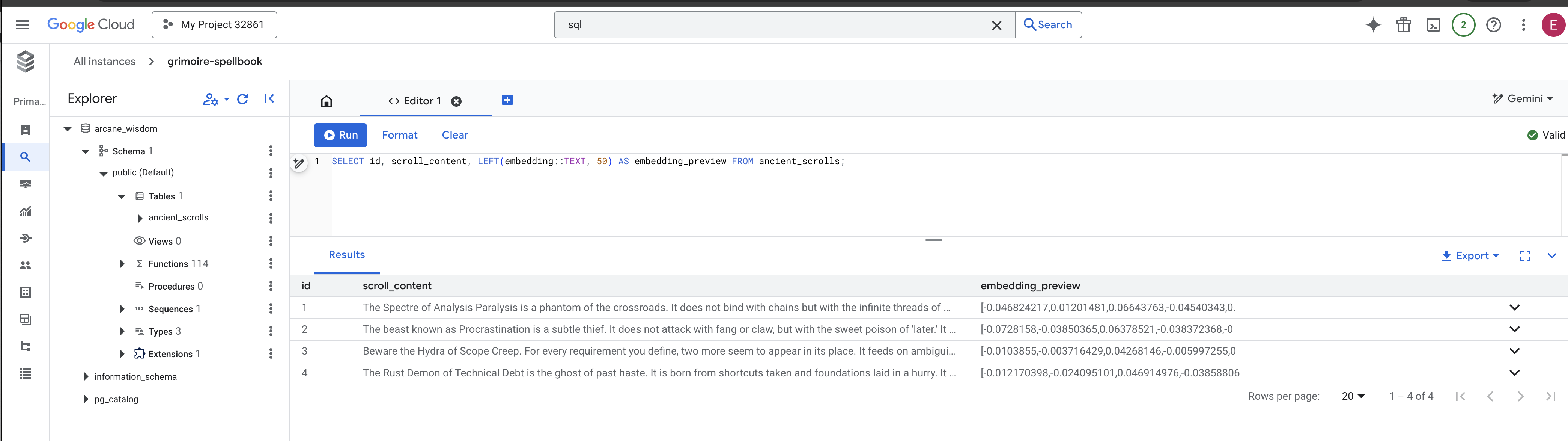
👉 📜 De retour dans l'atelier SQL, exécutez les requêtes suivantes pour vérifier que vos parchemins et leur essence sémantique ont bien été inscrits.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
Vous y trouverez l'ID du parchemin, son texte d'origine et un aperçu de l'essence vectorielle magique désormais inscrite de manière permanente dans votre Grimoire.
Votre Grimoire Scholar est désormais un véritable moteur de connaissances, prêt à être interrogé par signification dans le prochain chapitre.
8. Sceller la rune finale : activer la sagesse avec un agent RAG
Votre Grimoire n'est plus une simple base de données. Il s'agit d'une source de connaissances vectorisées, un oracle silencieux qui attend une question.
Nous allons maintenant passer au véritable test d'un Scholar : nous allons créer la clé pour débloquer cette sagesse. Nous allons créer un agent de génération augmentée par récupération (RAG). Il s'agit d'une construction magique qui peut comprendre une question en langage clair, consulter le Grimoire pour trouver les vérités les plus profondes et les plus pertinentes, puis utiliser cette sagesse récupérée pour forger une réponse puissante et adaptée au contexte.

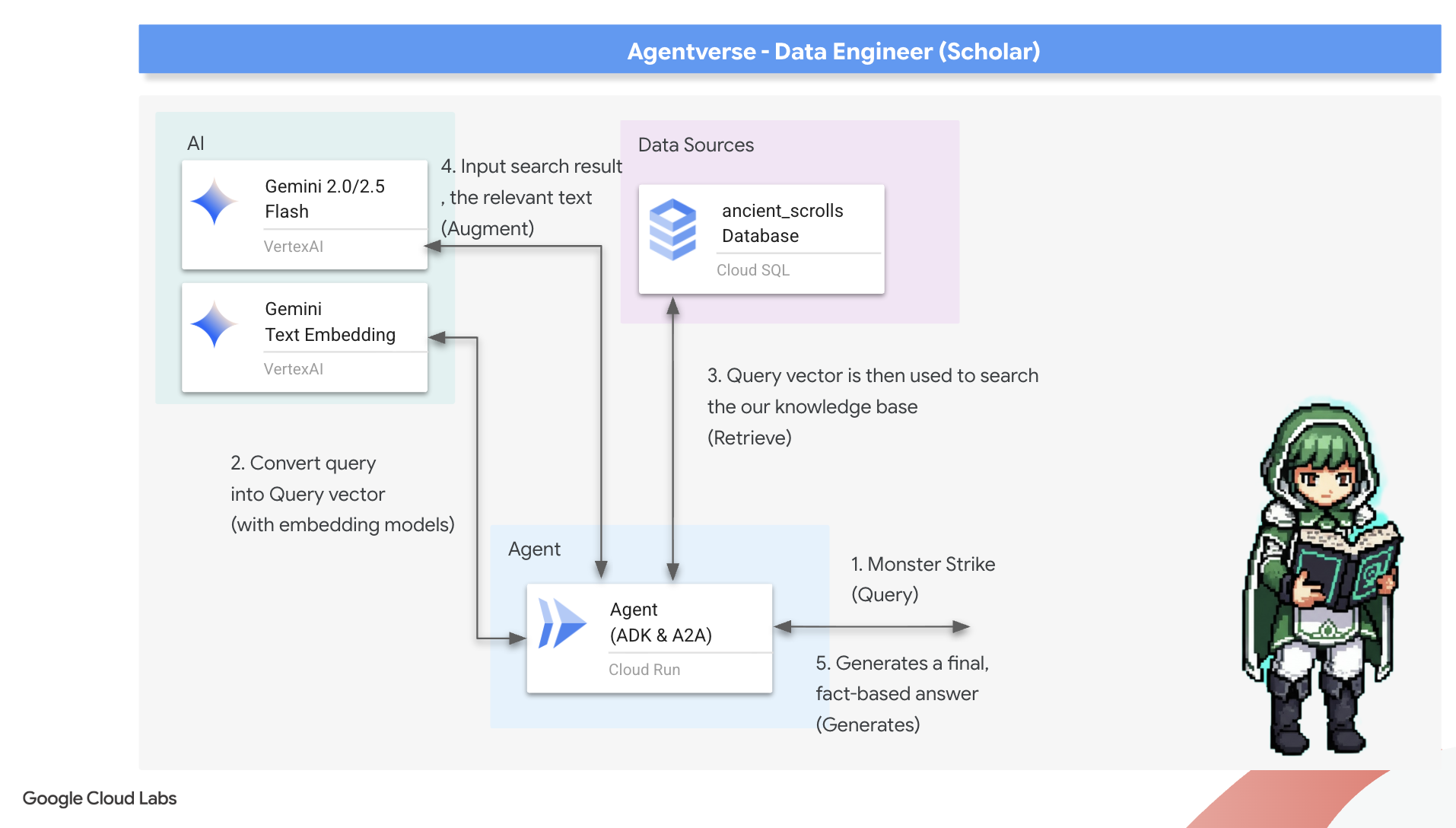
La première rune : le sort de distillation des requêtes
Avant que notre agent puisse effectuer une recherche dans le Grimoire, il doit d'abord comprendre l'essence de la question posée. Une simple chaîne de texte n'a aucun sens pour notre Spellbook basé sur les vecteurs. L'agent doit d'abord prendre la requête et, à l'aide du même modèle Gemini, la distiller en un vecteur de requête.
👉✏️ Dans l'éditeur Cloud Shell, accédez au fichier ~~/agentverse-dataengineer/scholar/agent.py, recherchez le commentaire #REPLACE RAG-CONVERT EMBEDDING et remplacez-le par cette incantation. Cela apprend à l'agent à transformer la question d'un utilisateur en essence magique.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Maintenant que l'essence de la requête est connue, l'agent peut consulter le Grimoire. Il présentera ce vecteur de requête à notre base de données enchantée par pgvector et posera une question profonde : "Montre-moi les anciens rouleaux dont l'essence même est la plus proche de l'essence de ma requête."
La magie de cet opérateur de similarité cosinus (<=>) réside dans sa capacité à calculer la distance entre les vecteurs dans un espace de grande dimension.
👉✏️ Dans agent.py, recherchez le commentaire #REPLACE RAG-RETRIEVE et remplacez-le par le script suivant :
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
La dernière étape consiste à accorder à l'agent l'accès à ce nouvel outil puissant. Nous allons ajouter notre fonction grimoire_lookup à sa liste d'outils magiques disponibles.
👉✏️ Dans agent.py, recherchez le commentaire #REPLACE-CALL RAG et remplacez-le par cette ligne :
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
Cette configuration donne vie à votre agent :
model="gemini-2.5-flash": sélectionne le grand modèle de langage spécifique qui servira de "cerveau " à l'agent pour raisonner et générer du texte.name="scholar_agent": attribue un nom unique à votre agent.instruction="...You are the Scholar...": il s'agit de l'invite système, l'élément le plus important de la configuration. Il définit le persona de l'agent, ses objectifs, le processus exact qu'il doit suivre pour accomplir une tâche et le format requis pour son résultat final.tools=[grimoire_lookup]: il s'agit de l'enchantement final. Il accorde à l'agent l'accès à la fonctiongrimoire_lookupque vous avez créée. L'agent peut désormais décider de manière intelligente quand appeler cet outil pour récupérer des informations de votre base de données, ce qui constitue le cœur du modèle RAG.
L'examen Scholar
👉💻 Dans le terminal Cloud Shell, activez votre environnement et utilisez la commande principale du kit de développement d'agent pour réveiller votre agent Scholar :
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
Vous devriez voir un résultat confirmant que l'agent Scholar est engagé et en cours d'exécution.
👉💻 Maintenant, mettez votre agent au défi. Dans le premier terminal où la simulation de combat est en cours d'exécution, exécutez une commande qui nécessite la sagesse du Grimoire :
We've been trapped by 'Hydra of Scope Creep'. Break us out!

Observez les journaux dans le terminal. Vous verrez l'agent recevoir la requête, en extraire l'essence, rechercher dans le Grimoire les parchemins pertinents sur la "procrastination" et utiliser les connaissances extraites pour formuler une stratégie puissante et contextuelle.
Vous avez réussi à assembler votre premier agent RAG et à l'armer de la sagesse profonde de votre Grimoire.
👉💻 Appuyez sur Ctrl+C dans le terminal pour mettre l'agent en veille pour le moment.
Découvrez Scholar Sentinel dans l'Agentverse
Votre agent a prouvé sa sagesse dans l'environnement contrôlé de votre étude. Il est temps de le libérer dans l'Agentverse, de le transformer d'une construction locale en un agent permanent et prêt au combat qui peut être appelé par n'importe quel champion, à tout moment. Nous allons maintenant déployer notre agent sur Cloud Run.
👉💻 Exécutez le sortilège d'invocation suivant. Ce script va d'abord compiler votre agent dans un Golem parfait (une image de conteneur), le stocker dans votre Artifact Registry, puis déployer ce Golem en tant que service évolutif, sécurisé et accessible au public.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
Votre agent Scholar est désormais un agent opérationnel prêt au combat dans l'Agentverse.
POUR LES NON-GAMERS
9. The Boss Flight
Les parchemins ont été lus, les rituels accomplis et le gant passé. Votre agent n'est pas qu'un artefact stocké. Il s'agit d'un agent opérationnel dans l'Agentverse, qui attend sa première mission. L'heure de l'épreuve finale a sonné : un exercice de tir réel contre un adversaire puissant.
Vous allez maintenant participer à une simulation de champ de bataille pour opposer votre agent Shadowblade nouvellement déployé à un mini-boss redoutable : le Spectre du statique. Il s'agit du test ultime de votre travail, de la logique de base de l'agent à son déploiement en direct.
Obtenir le locus de votre agent
Avant de pouvoir entrer sur le champ de bataille, vous devez posséder deux clés : la signature unique de votre champion (Agent Locus) et le chemin caché vers le repaire du Spectre (URL du donjon).
👉💻 Tout d'abord, obtenez l'adresse unique de votre agent dans l'Agentverse, son locus. Il s'agit du point de terminaison en direct qui connecte votre champion au champ de bataille.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 Ensuite, identifiez la destination. Cette commande révèle l'emplacement du cercle de translocation, le portail vers le domaine du Spectre.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
Important : Gardez ces deux URL à portée de main. Vous en aurez besoin lors de la dernière étape.
Affronter le Spectre
Maintenant que vous avez les coordonnées, vous allez vous rendre au cercle de translocation et lancer le sort pour partir au combat.
👉 Ouvrez l'URL du cercle de translocation dans votre navigateur pour vous tenir devant le portail scintillant menant à la Forteresse écarlate.
Pour franchir la forteresse, vous devez accorder l'essence de votre Lame d'ombre au portail.
- Sur la page, recherchez le champ de saisie runique intitulé URL du point de terminaison A2A.
- Inscrivez le sigil de votre champion en collant l'URL du locus de l'agent (la première URL que vous avez copiée) dans ce champ.
- Cliquez sur "Connecter" pour activer la téléportation.
La lumière aveuglante de la téléportation s'estompe. Vous n'êtes plus dans votre sanctuaire. L'air est froid et vif, et crépite d'énergie. Le Spectre se matérialise devant vous : un vortex de grésillements et de code corrompu, dont la lumière impie projette de longues ombres dansantes sur le sol du donjon. Il n'a pas de visage, mais vous sentez sa présence immense et épuisante fixée entièrement sur vous.
Votre seul chemin vers la victoire réside dans la clarté de votre conviction. Il s'agit d'un duel de volontés, qui se déroule sur le champ de bataille de l'esprit.
Alors que vous vous élancez vers l'avant, prêt à lancer votre première attaque, le Spectre contre. Il ne lève pas de bouclier, mais projette une question directement dans votre conscience : un défi runique et scintillant tiré du cœur de votre entraînement.

C'est la nature du combat. Votre savoir est votre arme.
- Répondez avec la sagesse que vous avez acquise, et votre lame s'embrasera d'une énergie pure, brisant la défense du Spectre et portant un COUP CRITIQUE.
- Mais si vous hésitez, si le doute obscurcit votre réponse, la lumière de votre arme s'éteindra. Le coup atterrira avec un bruit sourd pathétique, n'infligeant qu'UNE FRACTION DE SES DÉGÂTS. Pire encore, le Spectre se nourrira de votre incertitude, son propre pouvoir de corruption grandissant à chaque faux pas.
C'est le moment, Champion. Votre code est votre grimoire, votre logique est votre épée et vos connaissances sont le bouclier qui repoussera la vague de chaos.
Concentration. Tirez juste. Le sort de l'Agentverse en dépend.
Félicitations, Scholar.
Vous avez terminé la période d'essai. Vous avez maîtrisé les arts de l'ingénierie des données, en transformant des informations brutes et chaotiques en sagesse structurée et vectorisée qui permet à l'ensemble de l'Agentverse de fonctionner.
10. Nettoyage : purger le grimoire du Scholar
Félicitations, vous avez maîtrisé le Grimoire du Scholar ! Pour que votre Agentverse reste impeccable et que votre terrain d'entraînement soit dégagé, vous devez maintenant effectuer les rituels de nettoyage finaux. Toutes les ressources créées au cours de votre parcours seront systématiquement supprimées.
Désactiver les composants Agentverse
Vous allez maintenant démanteler systématiquement les composants déployés de votre système RAG.
Supprimer tous les services Cloud Run et le dépôt Artifact Registry
Cette commande supprime votre agent Scholar déployé et l'application Dungeon de Cloud Run.
👉💻 Dans votre terminal, exécutez les commandes suivantes :
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
Supprimer des ensembles de données, des modèles et des tables BigQuery
Cela supprime toutes les ressources BigQuery, y compris l'ensemble de données bestiary_data, toutes les tables qu'il contient, ainsi que la connexion et les modèles associés.
👉💻 Dans votre terminal, exécutez les commandes suivantes :
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Supprimer l'instance Cloud SQL
L'instance grimoire-spellbook est alors supprimée, y compris sa base de données et toutes les tables qu'elle contient.
👉 💻 Dans votre terminal, exécutez la commande suivante :
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Supprimer des buckets Google Cloud Storage
Cette commande supprime le bucket qui contenait vos fichiers bruts d'informations et de préproduction/temporaires Dataflow.
👉 💻 Dans votre terminal, exécutez la commande suivante :
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
Nettoyer les fichiers et répertoires locaux (Cloud Shell)
Enfin, supprimez les dépôts clonés et les fichiers créés de votre environnement Cloud Shell. Bien que facultative, cette étape est vivement recommandée pour nettoyer complètement votre répertoire de travail.
👉 💻 Dans votre terminal, exécutez la commande suivante :
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
Vous avez supprimé toutes les traces de votre parcours Data Engineer dans Agentverse. Votre projet est propre et vous êtes prêt pour votre prochaine aventure.