
1. של גורל
העידן של פיתוח מבודד הולך ונגמר. הגל הבא של ההתפתחות הטכנולוגית לא מתבסס על גאונות בודדת, אלא על מומחיות שמתבססת על שיתוף פעולה. יצירת סוכן חכם יחיד היא ניסוי מרתק. האתגר הגדול של ארגונים מודרניים הוא בניית סביבה עסקית חזקה, מאובטחת וחכמה של סוכנים – Agentverse אמיתי.
כדי להצליח בעידן החדש הזה, צריך לשלב בין ארבעה תפקידים חשובים, שהם אבני היסוד של כל מערכת יעילה מבוססת-סוכנים. ליקוי בתחום אחד יוצר חולשה שעלולה לפגוע במבנה כולו.
הסדנה הזו היא מדריך מקיף לארגונים שרוצים להתכונן לעתיד של סוכנים ב-Google Cloud. אנחנו מספקים מפת דרכים מקיפה שתעזור לכם להפוך רעיון ראשוני למציאות מבצעית מלאה. בארבעת שיעורי ה-Lab האלה, שקשורים זה לזה, תלמדו איך הכישורים המיוחדים של מפתח, ארכיטקט, מהנדס נתונים ו-SRE צריכים להתחבר כדי ליצור, לנהל ולהרחיב את Agentverse.
אי אפשר להסתמך רק על אחד מהעקרונות האלה כדי להשתמש ב-Agentverse. התוכנית הגדולה של הארכיטקט לא שווה בלי הביצוע המדויק של המפתח. הסוכן של המפתח לא יכול לפעול בלי הידע של מהנדס הנתונים, והמערכת כולה פגיעה בלי ההגנה של מהנדס ה-SRE. רק באמצעות סינרגיה והבנה משותפת של התפקידים של כל אחד, הצוות שלכם יכול להפוך רעיון חדשני למציאות תפעולית קריטית. המסע שלכם מתחיל כאן. הכנה לשליטה בתפקיד והבנה של מקומכם בתמונה הגדולה.
ברוכים הבאים ל-Agentverse: קריאה לאלופים
בעולם הדיגיטלי העצום של הארגון, עידן חדש מתחיל. אנחנו נמצאים בעידן של סוכנים דיגיטליים, תקופה עם פוטנציאל עצום, שבה סוכנים דיגיטליים חכמים ואוטונומיים פועלים בהרמוניה מושלמת כדי להאיץ את החדשנות ולבצע את המשימות השגרתיות.

המערכת האקולוגית המחוברת הזו של כוח ופוטנציאל נקראת Agentverse.
אבל אנטרופיה זוחלת, שחיתות שקטה שנקראת 'הסטטיק', מתחילה לכרסם את הקצוות של העולם החדש הזה. הסטטיק הוא לא וירוס או באג, אלא גילום של כאוס שטורף את עצם פעולת היצירה.
הוא מגביר תסכולים ישנים ויוצר מהם מפלצות, וכך נולדים שבעת רוחות הרפאים של הפיתוח. אם לא תסמנו את התיבה, הסטטי והספקטרים שלו יגרמו לעיכוב בהתקדמות, וההבטחה של Agentverse תהפוך לשממה של חוב טכני ופרויקטים נטושים.
היום אנחנו קוראים לאנשים שמוכנים להוביל שינוי כדי לעצור את גל הכאוס. אנחנו צריכים גיבורים שמוכנים לשפר את הכישורים שלהם ולעבוד יחד כדי להגן על Agentverse. הגיע הזמן לבחור את המסלול.
בחירת כיתה
לפניכם ארבעה נתיבים שונים, שכל אחד מהם הוא נדבך חשוב במאבק נגד הסטטיק. האימונים הם משימה ליחיד, אבל כדי להצליח בסופו של דבר, צריך להבין איך הכישורים שלכם משתלבים עם הכישורים של אחרים.
- Shadowblade (מפתח): אומן הנפחות והחזית. אתם האומנים שמייצרים את הלהבים, בונים את הכלים ומתמודדים עם האויב בפרטים המורכבים של הקוד. המסלול שלך הוא מסלול של דיוק, מיומנות ויצירה מעשית.
- האומן (אדריכל): אסטרטג ומנהל פרויקטים. אתם לא רואים סוכן יחיד, אלא את כל שדה הקרב. אתם מעצבים את תוכניות האב שמאפשרות למערכות שלמות של סוכנים לתקשר, לשתף פעולה ולהשיג מטרה גדולה בהרבה מכל רכיב בודד.
- המלומד (מהנדס נתונים): מחפש את האמת הנסתרת ושומר על החוכמה. אתם יוצאים למסע אל מרחבי הנתונים העצומים והפראיים כדי לחשוף את התובנות שיעזרו לסוכנים שלכם להבין את המטרה ולראות את התמונה המלאה. הידע שלכם יכול לחשוף חולשה של אויב או להעצים את היכולות של בעל ברית.
- השומר (DevOps / SRE): המגן הנאמן של הממלכה. אתם בונים את המבצרים, מנהלים את קווי האספקה של החשמל ומוודאים שהמערכת כולה יכולה לעמוד בפני המתקפות הבלתי נמנעות של The Static. החוזק שלכם הוא הבסיס לניצחון של הקבוצה.
המשימה שלך
האימון יתחיל כתרגיל עצמאי. תלכו בנתיב שבחרתם ותלמדו את הכישורים הייחודיים שנדרשים כדי לשלוט בתפקיד. בסוף תקופת הניסיון, תתמודדו עם רוח רפאים שנולדה מתוך הסטטיק – מיני-בוס שטורף את האתגרים הספציפיים של המלאכה שלכם.
רק אם תתמקצעו בתפקיד שלכם, תוכלו להתכונן למבחן הסופי. לאחר מכן, תצטרכו להקים קבוצה עם אלופים מהכיתות האחרות. יחד, תצאו למסע אל לב השחיתות כדי להתמודד עם הבוס האחרון.
אתגר אחרון שבו תצטרכו לשתף פעולה כדי לבדוק את הכוח המשולב שלכם ולקבוע את גורל ה-Agentverse.
הגיבורים של Agentverse מחכים לכם. רוצה לענות לשיחה?
2. The Scholar's Grimoire
המסע שלנו מתחיל! כחוקרים, הנשק העיקרי שלנו הוא ידע. גילינו בארכיונים שלנו (Google Cloud Storage) אוסף של מגילות עתיקות ומוצפנות. המגילות האלה מכילות מידע מודיעיני גולמי על החיות המפחידות שפוקדות את הארץ. המטרה שלנו היא להשתמש בקסם האנליטי העמוק של Google BigQuery ובחוכמה של Gemini Elder Brain (מודל Gemini Pro) כדי לפענח את הטקסטים הלא מובנים האלה ולהפוך אותם ל-Bestiary מובנה שאפשר להריץ עליו שאילתות. ההגדרה הזו תהיה הבסיס לכל האסטרטגיות העתידיות שלנו.
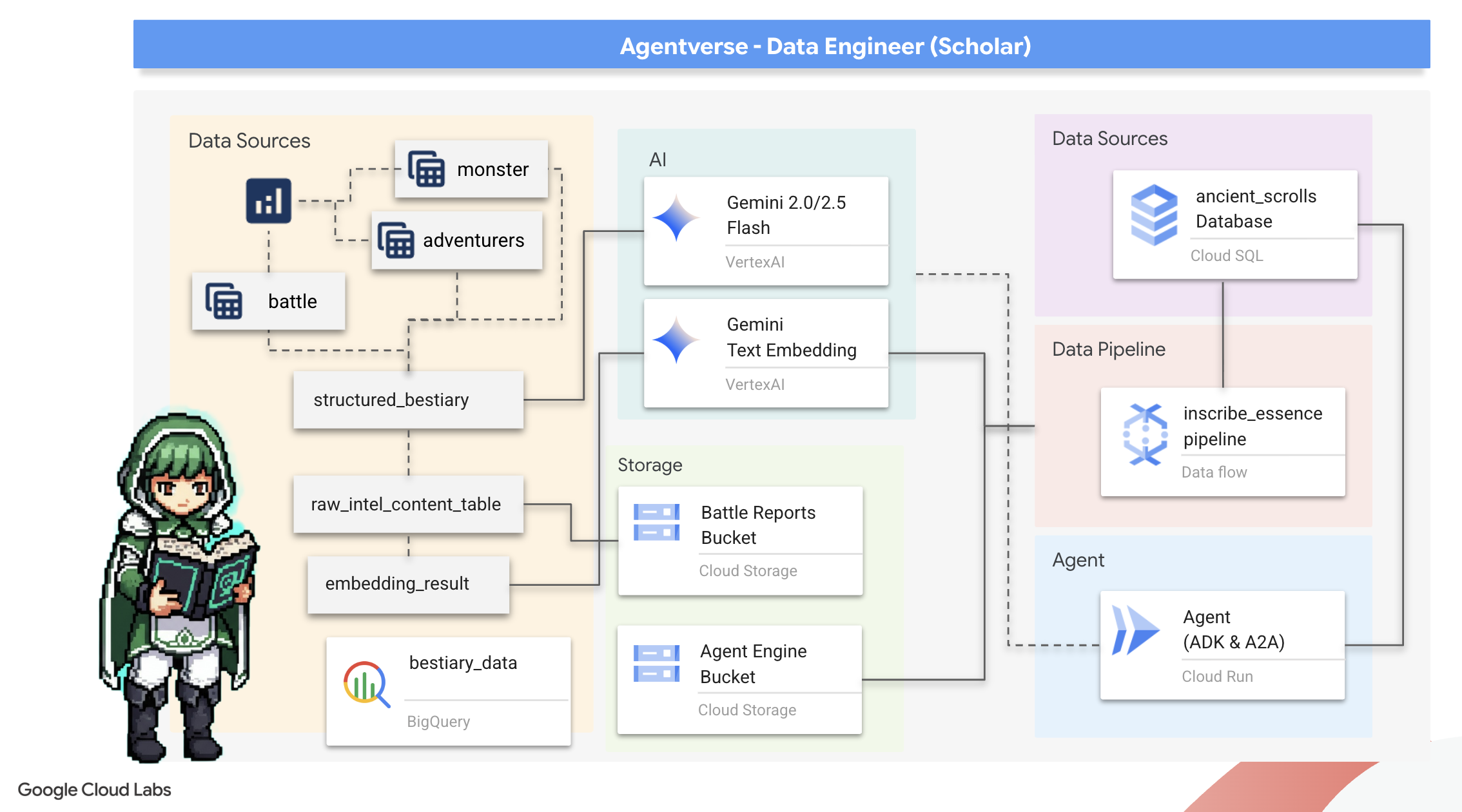
מה תלמדו
- שימוש ב-BigQuery ליצירת טבלאות חיצוניות ולביצוע טרנספורמציות מורכבות מנתונים לא מובנים לנתונים מובנים באמצעות BQML.GENERATE_TEXT עם מודל Gemini.
- הקצאת מכונת Cloud SQL ל-PostgreSQL והפעלת התוסף pgvector ליכולות חיפוש סמנטי.
- במדריך הזה תלמדו ליצור צינור עיבוד נתונים חזק ומבוסס-קונטיינרים לעיבוד קבוצות (batch) באמצעות Dataflow ו-Apache Beam. הצינור הזה יעבד קובצי טקסט גולמיים, ייצור הטבעות וקטוריות באמצעות מודל Gemini ויכתוב את התוצאות למסד נתונים רלציוני.
- הטמעה של מערכת בסיסית של Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG) בסוכן כדי לשלוח שאילתות לנתונים שעברו וקטוריזציה.
- פריסת סוכן שמודע לנתונים כשירות מאובטח וניתן להרחבה ב-Cloud Run.
3. הכנת המקדש של המלומד
ברוכים הבאים, חוקרים. לפני שנתחיל לכתוב את הידע העצום של ספר הכישופים שלנו, עלינו להכין את המקדש שלנו. הטקס הבסיסי הזה כולל הטמעה של קסם בסביבת Google Cloud, פתיחה של הפורטלים הנכונים (ממשקי API) ויצירה של הצינורות שדרכם יזרמו נתוני הקסם שלנו. מקדש מוכן היטב מבטיח שהלחשים שלנו יהיו חזקים והידע שלנו יהיה מאובטח.
מימוש הקרדיט ל-Google Cloud
⚠️ דרישות מוקדמות חשובות:
- שימוש ב-Gmail אישי: אתם צריכים להשתמש בחשבון אישי (לדוגמה,
name@gmail.com). אי אפשר להשתמש בחשבונות שמנוהלים על ידי ארגונים או מוסדות לימודים.
👉 שלבים:
- כניסה לאתר למימוש הקרדיט: לוחצים כאן
- כניסה: מדביקים את הקישור בשורת הכתובת ונכנסים באמצעות חשבון Gmail אישי.
- אישור התנאים: מאשרים את התנאים וההגבלות של Google Cloud Platform.
- בודקים את הזיכוי: מחפשים הודעה שמאשרת שהזיכוי הוחל.
- *הערה: אם מוצגת בקשה להזין את פרטי כרטיס האשראי, אפשר להתעלם ממנה ולסגור את החלון.
עכשיו אפשר לסגור את החלון.
הגדרת סביבת העבודה
👈 לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud (זהו סמל בצורת טרמינל בחלק העליון של חלונית Cloud Shell).
👈 לוחצים על הלחצן 'פתיחת הכלי לעריכה' (הוא נראה כמו תיקייה פתוחה עם עיפרון). חלון Cloud Shell Code Editor ייפתח. בצד ימין יופיע סייר הקבצים. 
👈פותחים את הטרמינל בסביבת הפיתוח המשולבת (IDE) בענן, 
👈💻 בטרמינל, מוודאים שכבר עברתם אימות ושהפרויקט מוגדר למזהה הפרויקט שלכם באמצעות הפקודה הבאה:
gcloud auth list
👈💻משכפלים את פרויקט ה-bootstrap מ-GitHub:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👈💻 מריצים את סקריפט ההגדרה מהספרייה של הפרויקט.
⚠️ הערה לגבי מזהה הפרויקט: התסריט יציע מזהה פרויקט שנוצר באופן אקראי כברירת מחדל. אפשר להקיש על Enter כדי לאשר את ברירת המחדל.
עם זאת, אם אתם מעדיפים ליצור פרויקט חדש ספציפי, אתם יכולים להקליד את מזהה הפרויקט הרצוי כשתתבקשו לעשות זאת על ידי הסקריפט.
cd ~/agentverse-dataengineer
./init.sh
👉 שלב חשוב אחרי השלמת התהליך: אחרי שהסקריפט מסיים לפעול, צריך לוודא שבמסוף Google Cloud מוצג הפרויקט הנכון:
- נכנסים לכתובת console.cloud.google.com.
- לוחצים על התפריט הנפתח לבחירת פרויקט בחלק העליון של הדף.
- לוחצים על הכרטיסייה All (הכל) (כי יכול להיות שהפרויקט החדש עדיין לא יופיע ב-Recent (אחרונים)).
- בוחרים את מזהה הפרויקט שהגדרתם בשלב
init.sh.
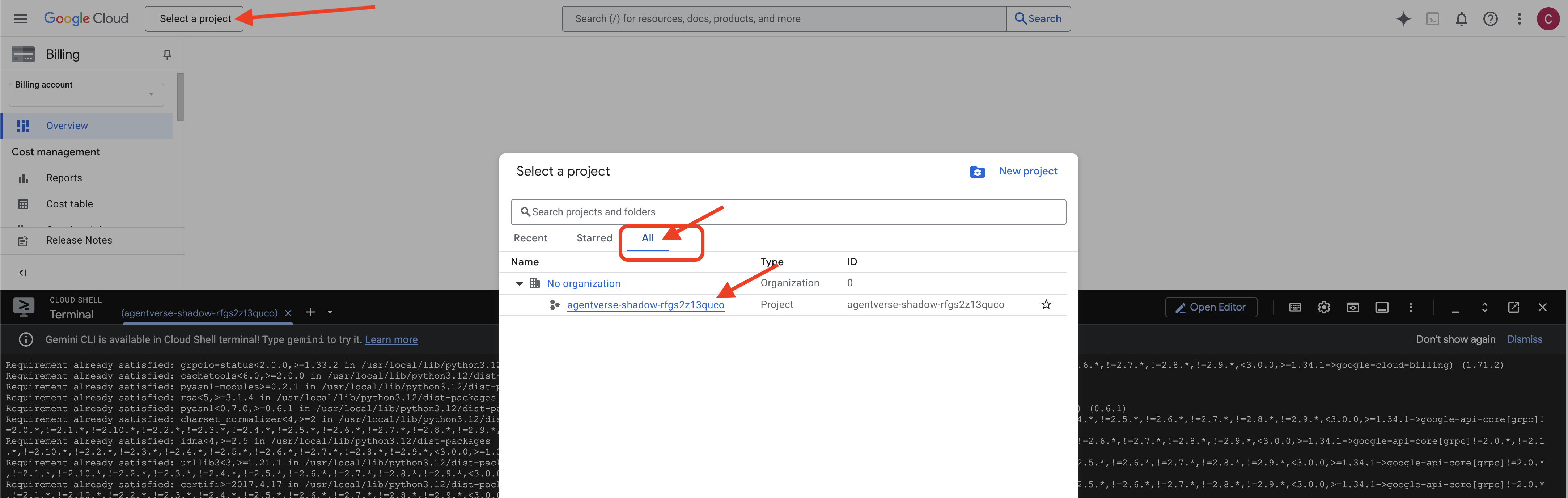
👈💻 מגדירים את מזהה הפרויקט הנדרש:
gcloud config set project $(cat ~/project_id.txt) --quiet
👈💻 מריצים את הפקודה הבאה כדי להפעיל את ממשקי ה-API הנדרשים של Google Cloud:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 אם עדיין לא יצרתם מאגר Artifact Registry בשם agentverse-repo, מריצים את הפקודה הבאה כדי ליצור אותו:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
הגדרת הרשאות
👈💻 מעניקים את ההרשאות הנדרשות על ידי הרצת הפקודות הבאות בטרמינל:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👈💻 כשמתחילים את האימון, אנחנו מכינים את האתגר הסופי. הפקודות הבאות יזמנו את הרוחות מהסטטיקה הכאוטית, ויצרו את הבוסים לבדיקה הסופית.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
עבודה מצוינת, חוקרים. השלמתם את ההגדרות הבסיסיות. הקודש שלנו מאובטח, הפורטלים לכוחות האלמנטריים של הנתונים פתוחים, והמשרת שלנו מוסמך. עכשיו אפשר להתחיל בעבודה האמיתית.
4. האלכימיה של הידע: שינוי נתונים באמצעות BigQuery ו-Gemini
במלחמה הבלתי פוסקת נגד הסטטיק, כל עימות בין אלוף של Agentverse לבין ספקטר של פיתוח מתועד בקפידה. מערכת סימולציית שדה הקרב, סביבת האימון העיקרית שלנו, יוצרת באופן אוטומטי רשומה ביומן האתרי לכל מפגש. יומני התיאור האלה הם המקור הכי חשוב שלנו למידע גולמי, עפרות לא מעובדות שמהן אנחנו, כחוקרים, צריכים ליצור את פלדת האסטרטגיה הטהורה.הכוח האמיתי של חוקר לא טמון רק בהחזקת נתונים, אלא ביכולת להפוך את עפרות המידע הגולמיות והכאוטיות לפלדה מבריקה ומובנית של חוכמה מעשית.אנחנו נבצע את הטקס הבסיסי של אלכימיית הנתונים.

התהליך שלנו יתבצע בכמה שלבים, כולם בתוך BigQuery של Google. נתחיל בהתבוננות בארכיון GCS בלי להזיז את הגלילה, באמצעות עדשה קסומה. לאחר מכן, נפעיל את Gemini כדי לקרוא ולפרש את סאגות הקרב הלא מובנות והפואטיות. לבסוף, נשפר את הנבואות הגולמיות וניצור מהן קבוצה של טבלאות נקיות ומקושרות. ה-Grimoire הראשון שלנו. ולשאול אותה שאלה כל כך עמוקה, שהתשובה לה יכולה להתקבל רק מהמבנה החדש הזה.
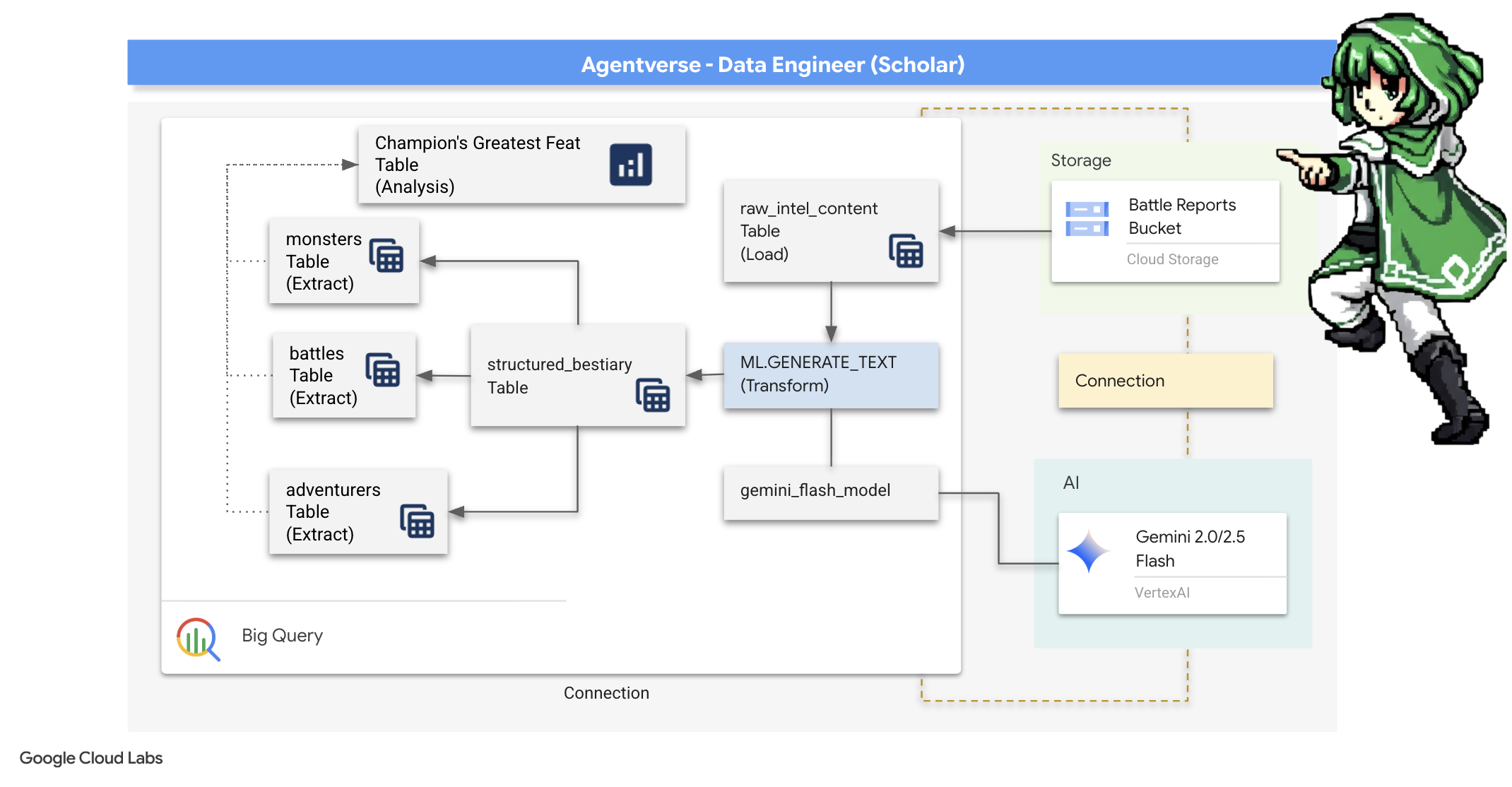
העדשה של הבדיקה: הצצה ל-GCS באמצעות טבלאות חיצוניות של BigQuery
הפעולה הראשונה שלנו היא ליצור עדשה שתאפשר לנו לראות את התוכן של הארכיון ב-GCS בלי להפריע למגילות שבתוכו. טבלה חיצונית היא כמו עדשה שדרכה אפשר לראות את קובצי הטקסט הגולמיים, והיא ממפה אותם למבנה שדומה לטבלה שאפשר להריץ עליה שאילתות ישירות ב-BigQuery.
לשם כך, אנחנו צריכים קודם ליצור קו ליי יציב של אנרגיה, משאב CONNECTION, שמקשר בצורה מאובטחת בין המקדש של BigQuery לבין הארכיון של GCS.
👈💻 בטרמינל של Cloud Shell, מריצים את הפקודה הבאה כדי להגדיר את האחסון וליצור את הצינור:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 שימו לב! הודעה תופיע בהמשך!
סקריפט ההגדרה משלב 2 התחיל תהליך ברקע. אחרי כמה דקות, תופיע הודעה במסוף שדומה להודעה הבאה:[1]+ Done gcloud sql instances create ...ההודעה הזו צפויה ומופיעה בדרך כלל. פשוט נוצר מסד נתונים ב-Cloud SQL. אפשר להתעלם מההודעה הזו ולהמשיך לעבוד.
לפני שיוצרים את הטבלה החיצונית, צריך ליצור את מערך הנתונים שיכיל אותה.
👈💻 מריצים את הפקודה הפשוטה הזו בטרמינל של Cloud Shell:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👈💻 עכשיו צריך לתת לחתימה הקסומה של הצינור את ההרשאות הנדרשות לקריאה מארכיון GCS ולשימוש ב-Gemini.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👈💻 במסוף Cloud Shell, מריצים את הפקודה הבאה כדי להציג את שם הקטגוריה:
echo $BUCKET_NAME
במסוף יוצג שם שדומה ל-your-project-id-gcs-bucket. תצטרכו את זה בשלבים הבאים.
👈 צריך להריץ את הפקודה הבאה מתוך עורך השאילתות של BigQuery ב-Google Cloud Console. הדרך הכי קלה להגיע לשם היא לפתוח את הקישור שלמטה בכרטיסייה חדשה בדפדפן. הקישור יוביל אתכם ישירות לדף הנכון במסוף Google Cloud.
https://console.cloud.google.com/bigquery
👈 אחרי שהדף נטען, לוחצים על לחצן הפלוס הכחול (יצירת שאילתה חדשה) כדי לפתוח כרטיסייה חדשה בעורך.
עכשיו נכתוב את לחש שפת הגדרת הנתונים (DDL) כדי ליצור את עדשת הקסם שלנו. ההגדרה הזו מציינת ל-BigQuery איפה לחפש ומה לראות.
👈📜 בעורך השאילתות של BigQuery שפתחתם, מדביקים את ה-SQL הבא. חשוב לזכור להחליף את REPLACE-WITH-YOUR-BUCKET-NAME
בשם הקטגוריה שהעתקתם. לוחצים על הפעלה:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 מריצים שאילתה כדי לראות את התוכן של הקבצים.
SELECT * FROM bestiary_data.raw_intel_content_table;
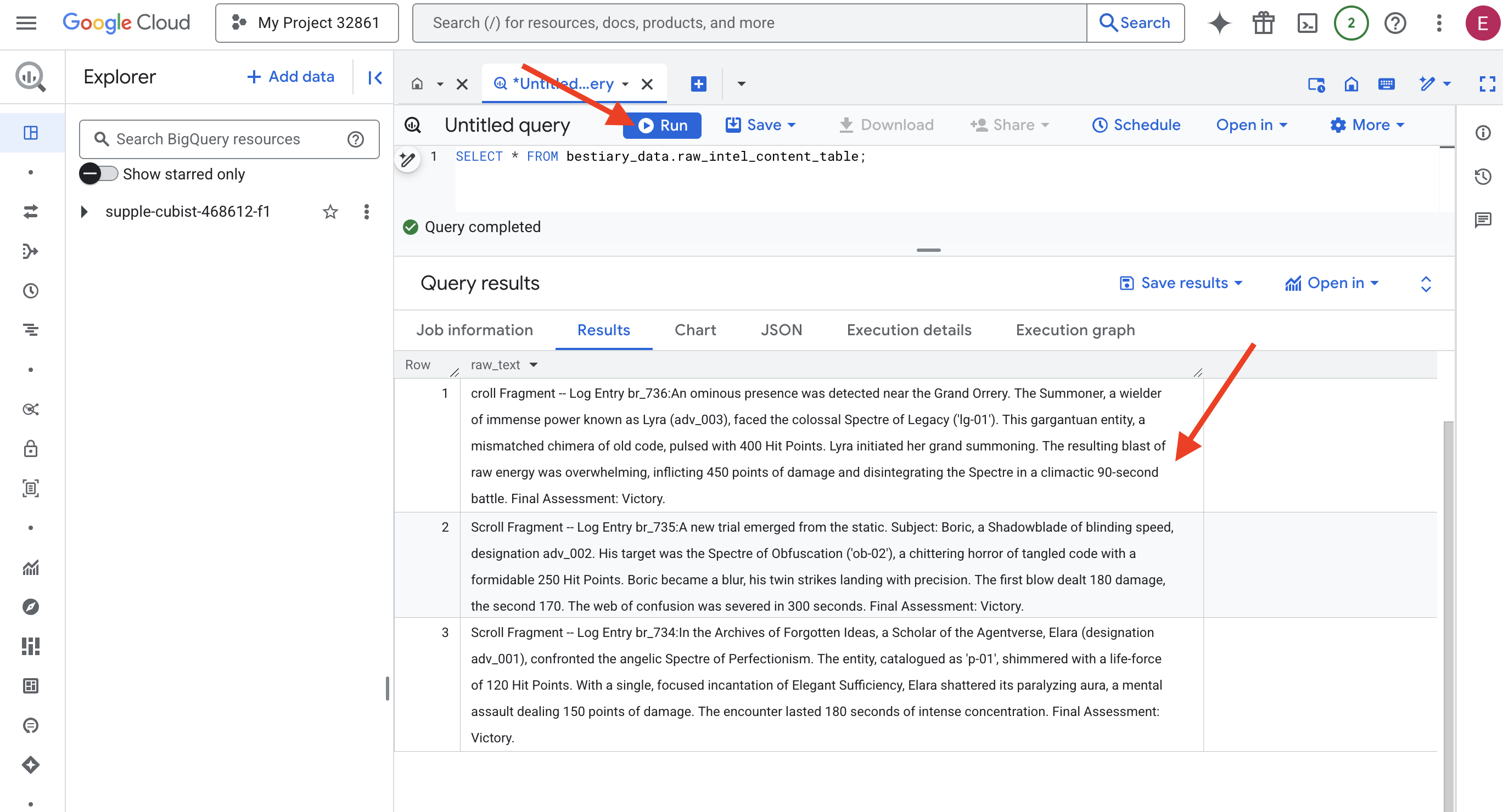
העדשה שלנו במקום. עכשיו אפשר לראות את הטקסט הגולמי של המגילות. אבל קריאה היא לא הבנה.
בארכיונים של רעיונות שנשכחו, חוקרת של Agentverse, אלארה (סימון adv_001), התעמתה עם רוח הרפאים המלאכית של הפרפקציוניזם. הישות, שסווגה כ-p-01, נצצה באנרגיית חיים של 120 נקודות פגיעה. בהטלת לחש ממוקד אחד של Elegant Sufficiency, אלרה ניפצה את האורה המשתקת שלו, מתקפה מנטלית שגרמה ל-150 נקודות נזק. המפגש נמשך 180 שניות של ריכוז אינטנסיבי. הערכה סופית: ניצחון.
המגילות לא כתובות בטבלאות ובשורות, אלא בפרוזה המתפתלת של סאגות. זהו הניסוי הראשון שלנו.
הניחוש של המלומד: הפיכת טקסט לטבלה באמצעות SQL
הבעיה היא שדוח שמפרט את שתי המתקפות המהירות של Shadowblade נראה שונה מאוד מתיאור של Summoner שצובר כוח עצום למתקפה אחת הרסנית. אנחנו לא יכולים פשוט לייבא את הנתונים האלה, אנחנו צריכים לפרש אותם. זה הרגע הקסום. נשתמש בשאילתת SQL אחת כקסם רב עוצמה כדי לקרוא, להבין ולבנות את כל הרשומות מכל הקבצים שלנו, ישירות ב-BigQuery.
👈💻 חוזרים למסוף Cloud Shell ומריצים את הפקודה הבאה כדי להציג את שם החיבור:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
מחרוזת החיבור המלאה תוצג במסוף. בוחרים את המחרוזת הזו ומעתיקים אותה. תצטרכו אותה בשלב הבא.
נשתמש במילת קסם אחת ועוצמתית: ML.GENERATE_TEXT. הלחש הזה מזמן את Gemini, מציג לו כל מגילה ומורה לו להחזיר את העובדות העיקריות כאובייקט JSON מובנה.
👈📜 ב-BigQuery Studio, יוצרים הפניה למודל Gemini. הפעולה הזו מקשרת את Gemini Flash oracle לספריית BigQuery שלנו, כדי שנוכל להפעיל אותו בשאילתות שלנו. חשוב לזכור להחליף את
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING עם מחרוזת החיבור המלאה שהעתקתם מהטרמינל.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👈📜 עכשיו, מטילים את לחש השינוי הגדול. השאילתה הזו קוראת את הטקסט הגולמי, יוצרת הנחיה מפורטת לכל גלילה, שולחת אותה ל-Gemini ויוצרת טבלת ביניים חדשה מהתשובה המובנית בפורמט JSON של ה-AI.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
ההמרה הושלמה, אבל התוצאה עדיין לא טהורה. מודל Gemini מחזיר את התשובה שלו בפורמט סטנדרטי, ועוטף את ה-JSON הרצוי במבנה גדול יותר שכולל מטא-נתונים על תהליך החשיבה שלו. בואו נסתכל על הנבואה הגולמית הזו לפני שננסה לזקק אותה.
👈📜 הרצת שאילתה כדי לבדוק את הפלט הגולמי ממודל Gemini:
SELECT * FROM bestiary_data.structured_bestiary;
👀 תופיע עמודה אחת בשם structured_data. התוכן של כל שורה ייראה בדומה לאובייקט ה-JSON המורכב הזה:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
כפי שאפשר לראות, הפרס שלנו – אובייקט ה-JSON הנקי שביקשנו – מוטמע עמוק במבנה הזה. המשימה הבאה שלנו ברורה. אנחנו צריכים לבצע טקס כדי לנווט במבנה הזה באופן שיטתי ולחלץ את החוכמה הטהורה שבו.
הטקס של הניקוי: נרמול של פלט AI גנרטיבי באמצעות SQL
מודל Gemini דיבר, אבל המילים שלו גולמיות ועטופות באנרגיות האתריות של היצירה שלו (מועמדים, finish_reason וכו'). חוקר אמיתי לא פשוט שם את הנבואה הגולמית על המדף, אלא בוחן אותה בקפידה, מפיק ממנה את התובנות החשובות וכותב אותן בספרים המתאימים לשימוש עתידי.
עכשיו נטיל את קבוצת הלחשים האחרונה שלנו. הסקריפט הזה:
- קוראים את ה-JSON הגולמי והמקונן מטבלת הביניים.
- לנקות ולנתח אותו כדי להגיע לנתוני הליבה.
- תכתוב את החלקים הרלוונטיים בשלוש טבלאות סופיות ומושלמות: מפלצות, הרפתקנים וקרבות.
👈📜 בעורך שאילתות חדש של BigQuery, מריצים את הכישוף הבא כדי ליצור את עדשת הניקוי שלנו:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 אימות המידע ב-Bestiary:
SELECT * FROM bestiary_data.monsters;
בשלב הבא ניצור את רשימת הגיבורים, רשימה של ההרפתקנים האמיצים שהתמודדו עם המפלצות האלה.
👈📜 בעורך שאילתות חדש, מריצים את הכישוף הבא כדי ליצור את הטבלה adventurers:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 אימות רשימת האלופים:
SELECT * FROM bestiary_data.adventurers;
לבסוף, ניצור את טבלת העובדות: Chronicle of Battles (תיעוד הקרבות). הכרך הזה מקשר בין שני הכרכים האחרים, ומתעד את הפרטים של כל מפגש ייחודי. מכיוון שכל קרב הוא אירוע ייחודי, אין צורך בהסרת כפילויות.
👈📜 בעורך שאילתות חדש, מריצים את הכישוף הבא כדי ליצור את טבלת הקרבות:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 אימות הנתונים ב-Chronicle:
SELECT * FROM bestiary_data.battles;
גילוי תובנות אסטרטגיות
המגילות נקראו, התמצית זוקקה והכרכים נכתבו. ה-Grimoire שלנו הוא כבר לא רק אוסף של עובדות, אלא מסד נתונים יחסי של חוכמה אסטרטגית עמוקה. עכשיו אפשר לשאול שאלות שלא הייתה אפשרות לענות עליהן כשהידע שלנו היה כלוא בטקסט גולמי ולא מובנה.
עכשיו נבצע ניבוי אחרון וגדול. אנחנו נטיל לחש שיתייעץ עם כל שלושת הכרכים שלנו בבת אחת – Bestiary of Monsters (ספר החיות של המפלצות), Roll of Champions (רשימת האלופים) ו-Chronicle of Battles (תיעוד הקרבות) – כדי לחשוף תובנה עמוקה ופרקטית.
השאלה האסטרטגית שלנו: "מה שם המפלצת הכי חזקה (לפי נקודות פגיעה) שכל אחד מההרפתקנים הצליח להביס, וכמה זמן נמשך הניצחון הספציפי הזה?"
זו שאלה מורכבת שדורשת קישור בין אלופים לקרבות שבהם הם ניצחו, ובין הקרבות האלה לנתונים הסטטיסטיים של המפלצות שהשתתפו בהם. כאן טמונה העוצמה האמיתית של מודל נתונים מובְנים.
👈📜 בעורך שאילתות חדש של BigQuery, מריצים את הלחש הסופי הבא:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
הפלט של השאילתה הזו יהיה טבלה נקייה ויפה שמציגה את 'המעשה הגדול ביותר של גיבור' לכל הרפתקן במערך הנתונים. הוא יכול להיראות בערך כך:
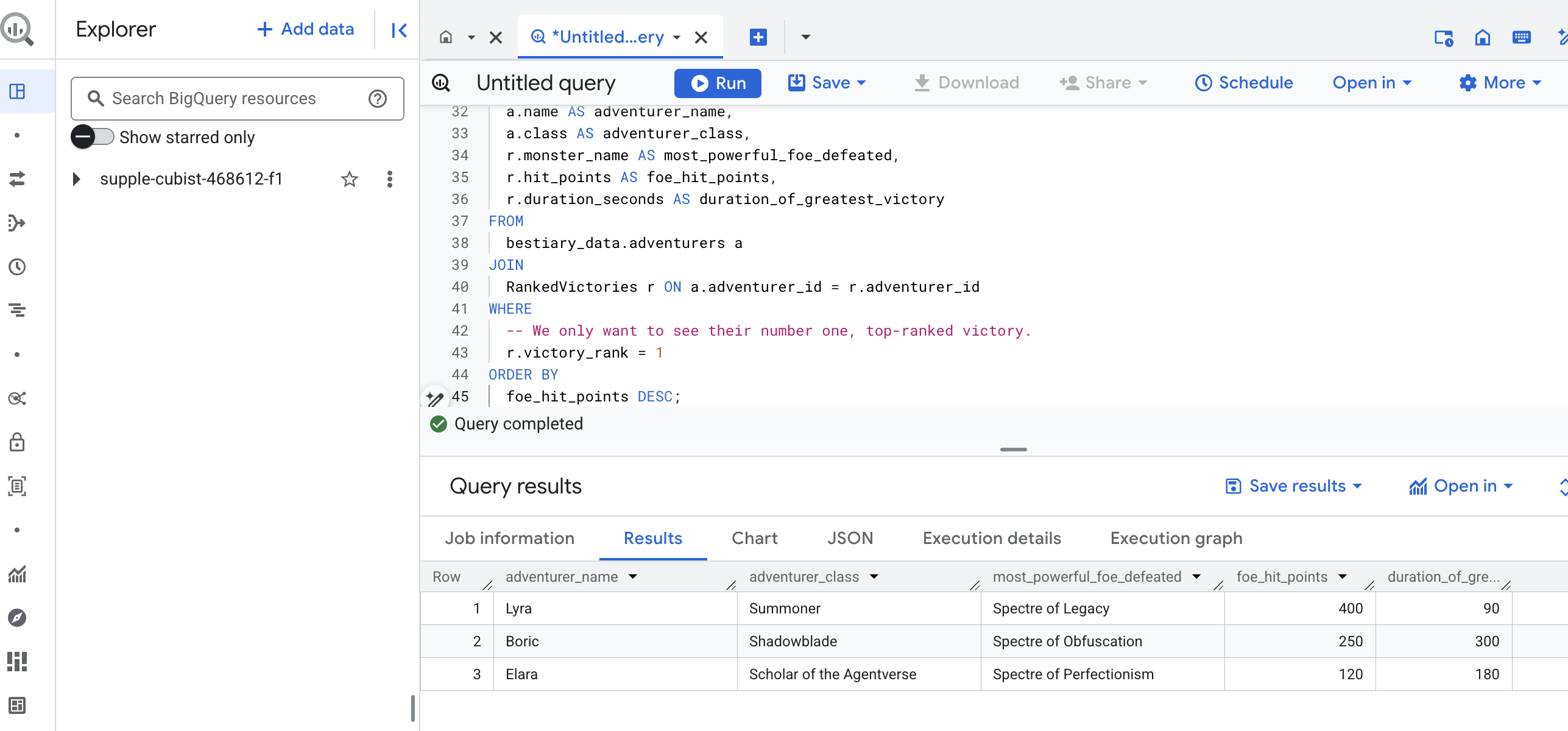
סוגרים את הכרטיסייה של BigQuery.
התוצאה הזו, שהיא גם פשוטה וגם אלגנטית, מוכיחה את הערך של כל תהליך המכירה. הצלחת להפוך דוחות גולמיים וכאוטיים משדה הקרב למקור של סיפורים אגדיים ולתובנות אסטרטגיות שמבוססות על נתונים.
למי שלא משחק
5. The Scribe's Grimoire: In-Datawarehouse Chunking, Embedding, and Search
העבודה שלנו במעבדה של האלכימאי הצליחה. הפכנו את המגילות הגולמיות עם הסיפורים לטבלאות מובנות ויחסיות – הישג מרשים של קסם נתונים. עם זאת, המגילות המקוריות עצמן עדיין מכילות אמת סמנטית עמוקה יותר, שלא ניתן לתעד באופן מלא בטבלאות המובְנות שלנו. כדי לבנות סוכן חכם באמת, אנחנו צריכים להבין את המשמעות הזו.
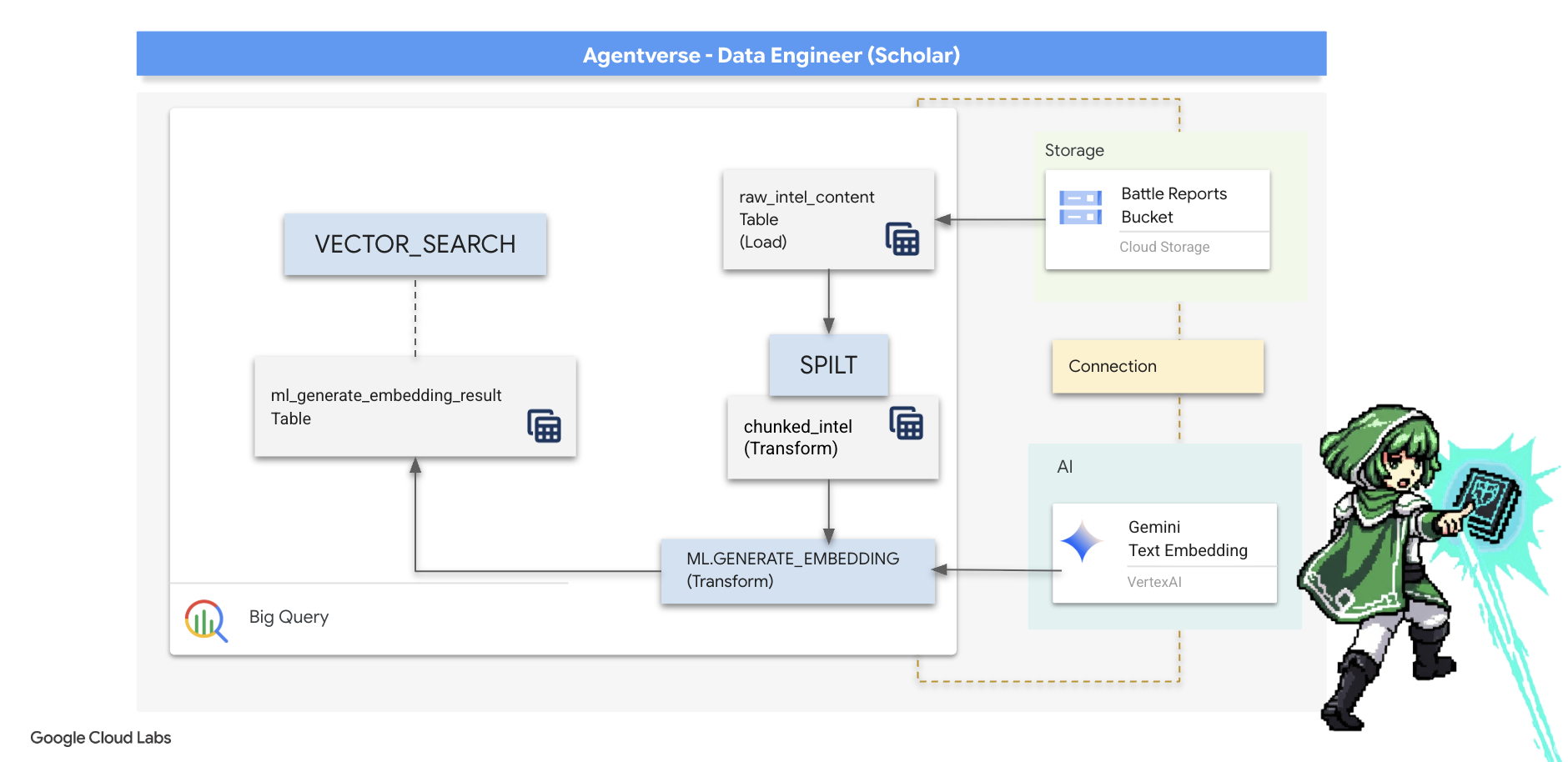
גלילה ארוכה וגולמית היא כלי גס. אם נציג ישאל שאלה לגבי "הילה משתקת", חיפוש פשוט עשוי להחזיר דוח קרב שלם שבו הביטוי הזה מוזכר רק פעם אחת, והתשובה תהיה קבורה בפרטים לא רלוונטיים. חכם אמיתי יודע שהחוכמה האמיתית לא נמצאת בכמות, אלא בדיוק.
אנחנו נבצע שלישיית טקסים עוצמתיים בתוך מסד הנתונים, באופן מלא בתוך המקדש של BigQuery.
- הטקס של החלוקה (Chunking): אנחנו ניקח את יומני הרישום של נתוני הבינה הגולמיים ונחלק אותם בקפידה לקטעים קטנים יותר, ממוקדים ועצמאיים.
- הטקס של הזיקוק (הטמעה): נשתמש ב-BQML כדי להתייעץ עם מודל Gemini, ונמיר כל נתח טקסט ל "טביעת אצבע סמנטית" – הטמעה של וקטור.
- טקס הניבוי (חיפוש): נשתמש בחיפוש וקטורי של BQML כדי לשאול שאלה באנגלית פשוטה ולמצוא את התשובה הרלוונטית ביותר מתוך ה-Grimoire שלנו.
במהלך התהליך הזה נוצר בסיס ידע עוצמתי שאפשר לחפש בו, בלי שהנתונים יוצאים מהאבטחה ומהיכולת של BigQuery להתמודד עם נפחי נתונים גדולים.
הטקס של החלוקה: פירוק מגילות באמצעות SQL
מקור המידע שלנו הוא עדיין קובצי הטקסט הגולמיים בארכיון GCS, שאפשר לגשת אליהם דרך הטבלה החיצונית שלנו, bestiary_data.raw_intel_content_table. המשימה הראשונה שלנו היא לכתוב לחש שקורא כל מגילה ארוכה ומפצל אותה לסדרה של פסוקים קצרים יותר וקלים יותר להבנה. בטקס הזה, נגדיר 'חלק' כמשפט בודד.
אמנם פיצול לפי משפט הוא נקודת התחלה ברורה ויעילה ליומני הנרטיב שלנו, אבל ל-Scribe יש הרבה אסטרטגיות לחלוקה לחלקים, והבחירה קריטית לאיכות החיפוש הסופי. שיטות פשוטות יותר עשויות להשתמש
- חלוקה לחלקים באורך קבוע, אבל היא עלולה לחתוך רעיון מרכזי לשניים.
טקסים מורכבים יותר, כמו
- חלוקה רקורסיבית לחלקים, היא שיטה מועדפת בדרך כלל בפועל. היא מנסה לחלק את הטקסט לאורך גבולות טבעיים כמו פסקאות, ואז חוזרת למשפטים כדי לשמור על כמה שיותר הקשר סמנטי. לכתבי יד מורכבים במיוחד.
- Content-Aware Chunking(document), שבו Scribe משתמש במבנה הטבוע של המסמך – כמו הכותרות במדריך טכני או הפונקציות בקוד, כדי ליצור את חלקי המידע הכי הגיוניים והכי משמעותיים. ועוד...
במקרה של יומני הקרבות שלנו, המשפט מספק את האיזון המושלם בין רמת פירוט להקשר.
👈📜 בעורך שאילתות חדש של BigQuery, מריצים את השאילתה הבאה. במקרה הזה, נעשה שימוש בפונקציה SPLIT כדי לפצל את הטקסט של כל מגילה בכל נקודה (.), ואז המערך שמתקבל של המשפטים מפוצל לשורות נפרדות.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👈 עכשיו מריצים שאילתה כדי לבדוק את הידע החדש שנוצר, מחולק לחלקים, ולראות את ההבדל.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
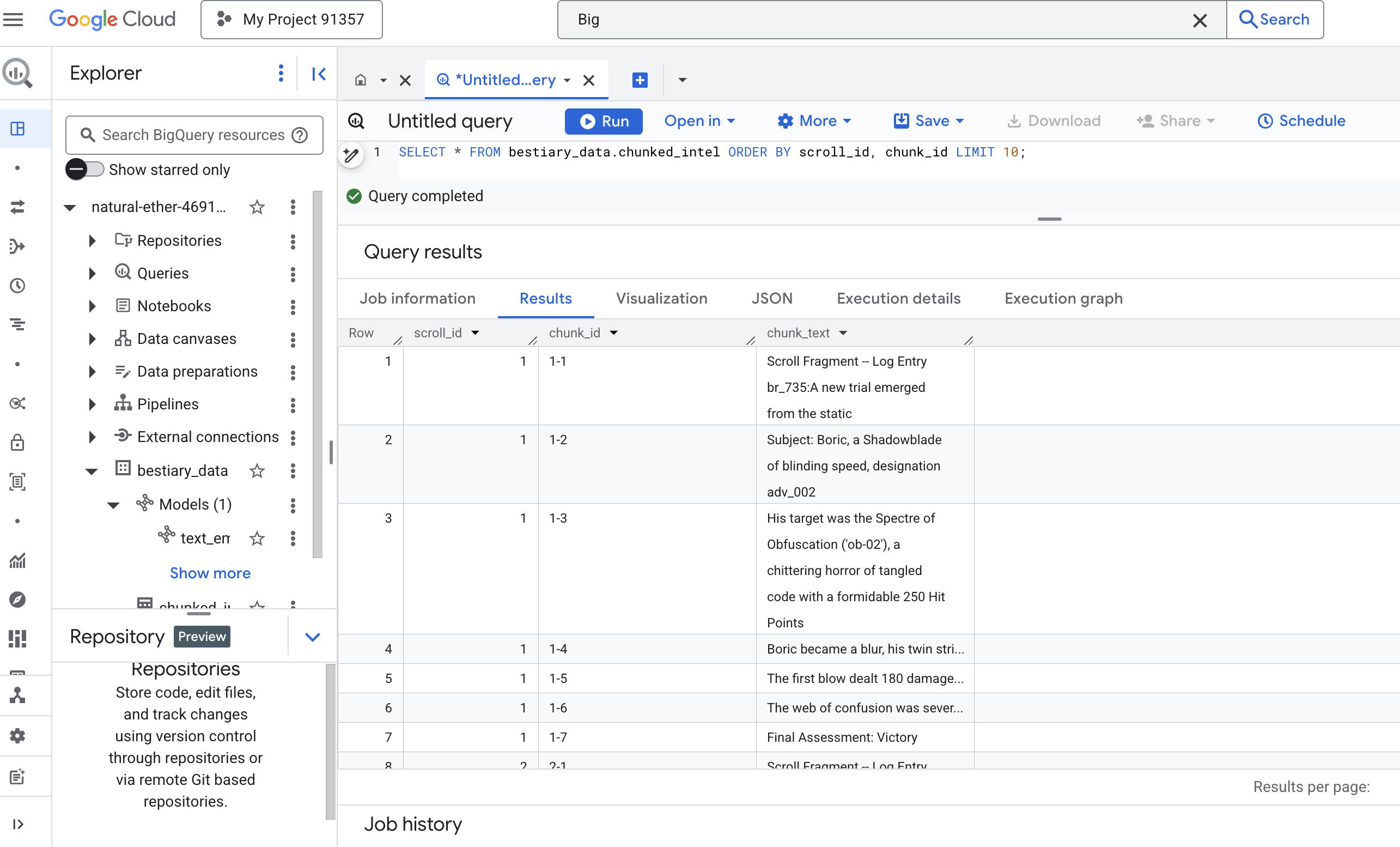
בודקים את התוצאות. במקום בלוק טקסט צפוף אחד, יש עכשיו כמה שורות, שכל אחת מהן קשורה לגלילה המקורית (scroll_id) אבל מכילה רק משפט ממוקד אחד. כל שורה היא עכשיו מועמדת מושלמת לווקטוריזציה.
הטקס של הזיקוק: המרת טקסט לווקטורים באמצעות BQML
👈💻 קודם כל, חוזרים למסוף ומריצים את הפקודה הבאה כדי להציג את שם החיבור:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👈📜 צריך ליצור מודל חדש ב-BigQuery שמפנה להטמעת טקסט של Gemini. ב-BigQuery Studio, מריצים את הלחש הבא. הערה: צריך להחליף את REPLACE-WITH-YOUR-FULL-CONNECTION-STRING במחרוזת החיבור המלאה שהעתקתם מהטרמינל.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👈📜 עכשיו, מטילים את לחש הזיקוק הגדול. השאילתה הזו קוראת את כל השורות מהטבלה chunked_intel, שולחת את הטקסט למודל ההטמעה של Gemini ומאחסנת את טביעת האצבע של הווקטור שמתקבל בטבלה חדשה.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
התהליך הזה עשוי להימשך דקה או שתיים, בזמן ש-BigQuery מעבד את כל חלקי הטקסט.
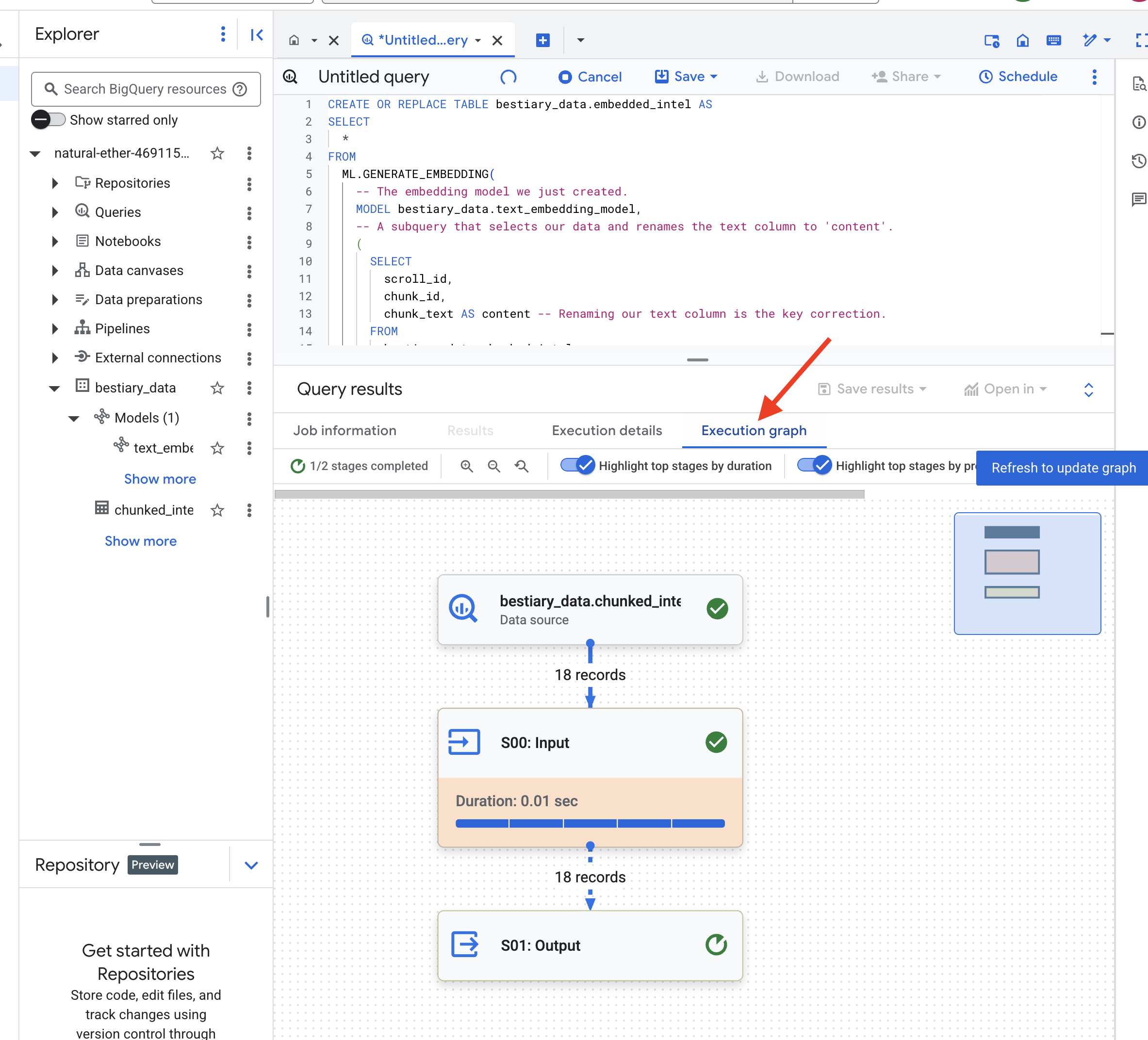
👈📜 בסיום, בודקים את הטבלה החדשה כדי לראות את טביעות האצבע הסמנטיות.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
עכשיו תופיע עמודה חדשה, ml_generate_embedding_result, שמכילה את הייצוג של הווקטור הצפוף של הטקסט. ה-Grimoire שלנו מקודד עכשיו באופן סמנטי.
The Ritual of Divination: Semantic Search with BQML
👈📜 המבחן האולטימטיבי של ה-Grimoire הוא לשאול אותו שאלה. עכשיו נבצע את הטקס האחרון: חיפוש וקטורי. זה לא חיפוש לפי מילות מפתח, אלא חיפוש של משמעות. נשאל שאלה בשפה טבעית, BQML ימיר את השאלה שלנו להטמעה תוך כדי תנועה, ואז יחפש בכל הטבלה של embedded_intel את חלקי הטקסט שהטביעות האצבע שלהם הן ה "קרובות" ביותר במשמעות.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
ניתוח הכישוף:
-
VECTOR_SEARCH: הפונקציה העיקרית שמנהלת את החיפוש. -
ML.GENERATE_EMBEDDING(inner query): כאן מתרחש הקסם. אנחנו מטמיעים את השאילתה ('What are the tactics...') באמצעות אותו מודל אבל עם סוג המשימה'RETRIEVAL_QUERY', שעבר אופטימיזציה במיוחד לשאילתות. -
top_k => 3: אנחנו מבקשים את 3 התוצאות הרלוונטיות ביותר. -
distance_type => 'COSINE': המדד הזה מודד את ה'זווית' בין וקטורים. זווית קטנה יותר מצביעה על התאמה טובה יותר בין המשמעויות.
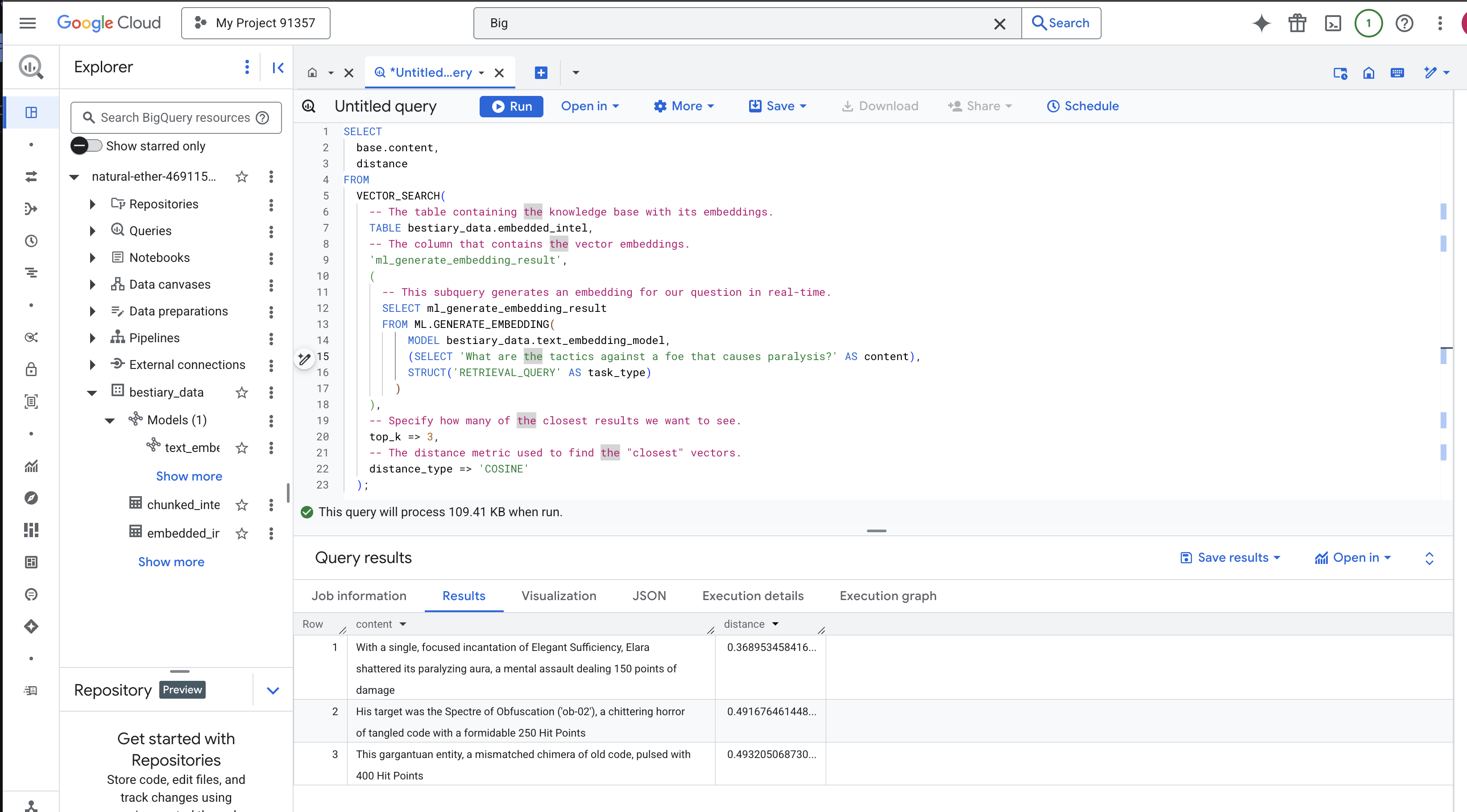
בודקים את התוצאות בקפידה. השאילתה לא הכילה את המילה "shattered" (נשבר) או "incantation" (לחש), אבל התוצאה הראשונה היא: "With a single, focused incantation of Elegant Sufficiency, Elara shattered its paralyzing aura, a mental assault dealing 150 points of damage" (בעזרת לחש ממוקד אחד של Elegant Sufficiency, אלרה שברה את ההילה המשתקת שלה, מתקפה מנטלית שגורמת ל-150 נקודות נזק). זה הכוח של חיפוש סמנטי. המודל הבין את הקונספט של "טקטיקות נגד שיתוק" ומצא את המשפט שמתאר טקטיקה ספציפית ומוצלחת.
יצרתם בהצלחה צינור עיבוד נתונים מלא של RAG בתוך מחסן הנתונים. הכנתם נתונים גולמיים, הפכתם אותם לווקטורים סמנטיים והרצתם עליהם שאילתות לפי משמעות. BigQuery הוא כלי רב עוצמה לעבודה אנליטית בקנה מידה גדול, אבל כדי לספק תשובות עם זמן אחזור נמוך לסוכן פעיל, אנחנו מעבירים את הידע המוכן הזה למסד נתונים תפעולי ייעודי. זה הנושא של ההדרכה הבאה שלנו.
למי שלא משחק
6. הספרייה הווקטורית: יצירת מאגר וקטורים באמצעות Cloud SQL להסקת מסקנות
ה-Grimoire שלנו קיים כרגע כטבלאות מובנות – קטלוג עובדתי רב עוצמה, אבל הידע שלו הוא מילולי. הוא מבין monster_id = ‘MN-001' אבל לא את המשמעות הסמנטית העמוקה יותר של 'טשטוש'. כדי להעניק לסוכנים שלנו חוכמה אמיתית, כדי לאפשר להם לייעץ בניואנסים ובמחשבה קדימה, אנחנו צריכים לזקק את המהות של הידע שלנו לפורמט שמבטא משמעות: וקטורים.
המסע שלנו אחר ידע הוביל אותנו לחורבות המתפוררות של תרבות קודמת שנשכחה מזמן. עמוק בתוך כספת אטומה, גילינו תיבה של מגילות עתיקות, שנשמרו באופן מופלא. אלה לא רק דוחות קרב, אלא חוכמה פילוסופית עמוקה על הדרך להביס את החיה שמכשילה את כל המאמצים הגדולים. ישות שמתוארת במגילות כ "קיפאון זוחל ושקט", כ "שחיקה של אריגת הבריאה". נראה שהסטטיק היה מוכר אפילו לאנשים בעת העתיקה, איום מחזורי שההיסטוריה שלו אבדה עם הזמן.
הידע הנשכח הזה הוא הנכס הכי חשוב שלנו. הוא מחזיק במפתח לא רק להבסת מפלצות בודדות, אלא גם לחיזוק כל חברי הקבוצה באמצעות תובנות אסטרטגיות. כדי להשתמש בכוח הזה, ניצור עכשיו את ספר הלחשים האמיתי של החוקר (מסד נתונים של PostgreSQL עם יכולות וקטוריות) ונבנה סקריפטוריום וקטורי אוטומטי (צינור Dataflow) כדי לקרוא, להבין ולרשום את המהות הנצחית של המגילות האלה. הפעולה הזו תהפוך את ספר הקסמים שלנו מספר של עובדות למנוע של חוכמה.

הכנת ספר הלחשים של המלומד (Cloud SQL)
לפני שנוכל להעתיק את המידע מהמגילות העתיקות האלה, אנחנו צריכים לוודא קודם שהכלי שבו נשתמש כדי לאחסן את הידע הזה, ספר הלחשים המנוהל של PostgreSQL, נוצר בהצלחה. ההגדרה הראשונית אמורה ליצור את זה בשבילכם.
👈💻 במסוף, מריצים את הפקודה הבאה כדי לוודא שהמכונה של Cloud SQL קיימת ומוכנה. הסקריפט הזה גם מעניק לחשבון השירות הייעודי של המופע את ההרשאה להשתמש ב-Vertex AI, שנדרשת כדי ליצור הטבעות ישירות במסד הנתונים.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
אם הפקודה מצליחה ומחזירה פרטים על מופע grimoire-spellbook, סימן שהכלי Forge עשה את העבודה כמו שצריך. אפשר להמשיך להטלה הבאה. אם הפקודה מחזירה שגיאה NOT_FOUND, צריך לוודא שהשלמתם בהצלחה את שלבי ההגדרה הראשונית של הסביבה לפני שממשיכים.(data_setup.py)
👈💻 אחרי שהספר מוכן, אנחנו פותחים אותו לפרק הראשון על ידי יצירת מסד נתונים חדש בשם arcane_wisdom.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
הוספת כתובות רוניות סמנטיות: הפעלת יכולות וקטוריות באמצעות pgvector
עכשיו, אחרי שיצרנו מכונה של Cloud SQL, נתחבר אליה באמצעות Cloud SQL Studio המובנה. הכלי הזה מספק ממשק מבוסס-אינטרנט להרצת שאילתות SQL ישירות במסד הנתונים.
👉💻 קודם כל, עוברים אל Cloud SQL Studio. הדרך הכי קלה ומהירה לעשות את זה היא לפתוח את הקישור הבא בכרטיסייה חדשה בדפדפן. תועברו ישירות אל Cloud SQL Studio עבור מופע grimoire-spellbook.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 בוחרים באפשרות arcane_wisdom בתור מסד הנתונים, מזינים postgres בתור המשתמש ו-1234qwer בתור הסיסמה ולוחצים על אימות.
👈📜 בעורך השאילתות של SQL Studio, עוברים לכרטיסייה Editor 1 ומדביקים את קוד ה-SQL הבא כדי להפעיל את סוג הנתונים vector:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
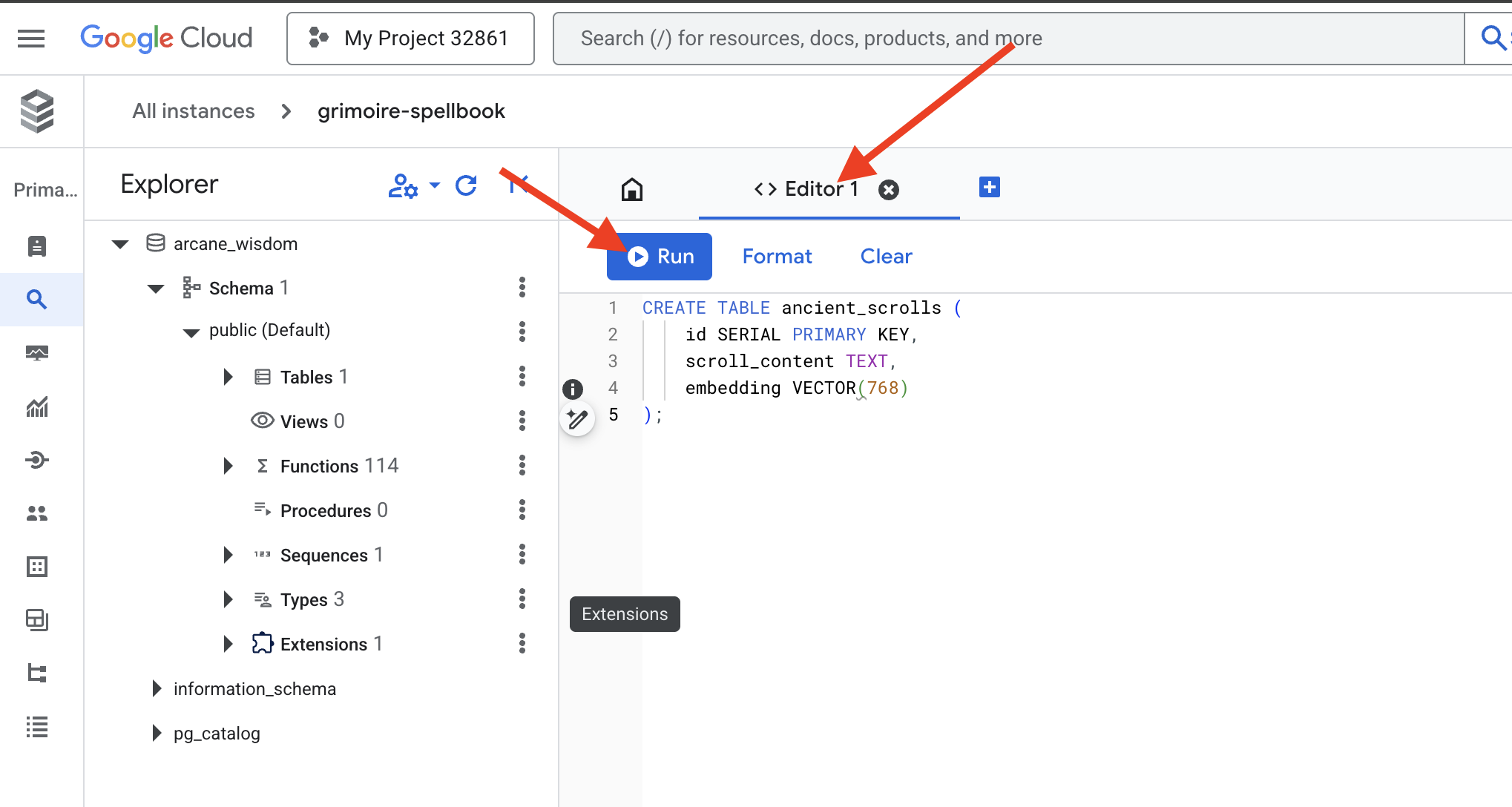
👈📜 צריך להכין את הדפים של ספר הלחשים על ידי יצירת הטבלה שתכיל את המהות של המגילות.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
האיות VECTOR(768) הוא פרט חשוב. מודל ההטמעה של Vertex AI שבו נשתמש (textembedding-gecko@003 או מודל דומה) מזקק טקסט לווקטור של 768 ממדים. הדפים ב-Spellbook צריכים להיות מוכנים להכיל מהות בגודל הזה בדיוק. המידות תמיד צריכות להיות זהות.
התעתיק הראשון: טקס כתיבה ידני
לפני שנפעיל צבא של תמלילנים אוטומטיים (Dataflow), נצטרך לבצע את הטקס המרכזי פעם אחת באופן ידני. כך נוכל להבין לעומק את הקסם שמתרחש בשני השלבים:
- ניבוי: לוקחים קטע טקסט ומתייעצים עם Gemini כדי לזקק את המהות הסמנטית שלו לווקטור.
- רישום: כתיבת הטקסט המקורי והמהות הווקטורית החדשה שלו בספר הכישופים שלנו.
עכשיו נבצע את הטקס הידני.
👈📜 ב-Cloud SQL Studio. עכשיו נשתמש בפונקציה embedding(), תכונה עוצמתית שזמינה בתוסף google_ml_integration. כך אנחנו יכולים להפעיל את מודל ההטמעה של Vertex AI ישירות משאילתת ה-SQL שלנו, מה שמפשט מאוד את התהליך.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👈📜 כדי לאמת את העבודה, מריצים שאילתה לקריאת הדף החדש שנרשם:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
ביצעתם בהצלחה את משימת הטעינה של נתוני RAG באופן ידני.
יצירת מצפן סמנטי: שיפור ספר הלחשים באמצעות אינדקס HNSW
עכשיו אפשר לאחסן חוכמה בספר הכישופים, אבל כדי למצוא את המגילה הנכונה צריך לקרוא כל דף. זו סריקה רציפה. התהליך הזה איטי ולא יעיל. כדי שהשאילתות שלנו יגיעו מיד לידע הרלוונטי ביותר, אנחנו צריכים להטיל כישוף על ספר הלחשים באמצעות מצפן סמנטי: אינדקס וקטורי.
בואו נוכיח את הערך של הקסם הזה.
👈📜 ב-Cloud SQL Studio, מריצים את הלחש הבא. הוא מדמה חיפוש של הגלילה שהוספנו ומבקש ממסד הנתונים EXPLAIN את התוכנית שלו.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
בודקים את הפלט. תופיע שורה עם הכיתוב -> Seq Scan on ancient_scrolls. כך מוודאים שמסד הנתונים קורא כל שורה. שימו לב לexecution time.
👉📜 עכשיו נטיל את לחש ההוספה לאינדקס. הפרמטר lists מציין לאינדקס כמה אשכולות ליצור. נקודת התחלה טובה היא השורש הריבועי של מספר השורות שאתם מצפים שיהיו.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
מחכים שהאינדקס ייבנה (התהליך יהיה מהיר לשורה אחת, אבל יכול לקחת זמן אם יש מיליוני שורות).
👉📜 עכשיו, מריצים שוב את הפקודה EXPLAIN ANALYZE בדיוק כפי שהיא :
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
בודקים את תוכנית השאילתה החדשה. יוצג לכם -> Index Scan using.... חשוב יותר, כדאי לעיין בexecution time. התהליך יהיה מהיר משמעותית, גם אם תזינו רק רשומה אחת. הרגע הדגמת את העיקרון המרכזי של שיפור ביצועים של מסד נתונים בעולם וקטורי.
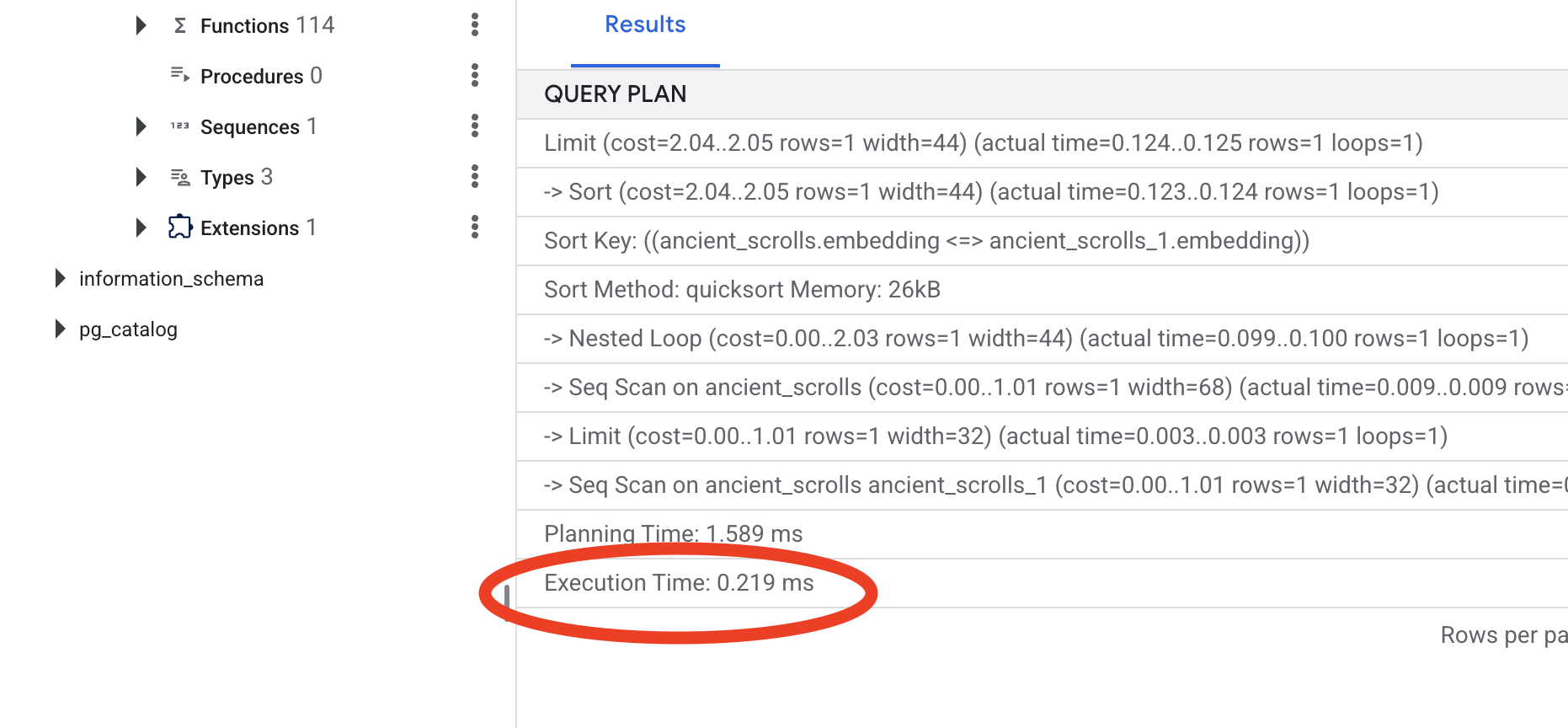
אחרי שבדקתם את נתוני המקור, הבנתם את התהליך הידני שלכם וביצעתם אופטימיזציה של Spellbook למהירות, אתם מוכנים באמת לבנות את Scriptorium האוטומטי.
למי שלא משחק
7. הצינור להעברת משמעות: בניית צינור וקטוריזציה של Dataflow
עכשיו נבנה את פס הייצור הקסום של הסופרים שיקראו את המגילות שלנו, יזקקו את המהות שלהן ויכתבו אותן בספר הלחשים החדש שלנו. זהו צינור Dataflow שנפעיל באופן ידני. אבל לפני שנכתוב את הכישוף הראשי לצינור עצמו, אנחנו צריכים קודם להכין את הבסיס שלו ואת המעגל שממנו נזמן אותו.
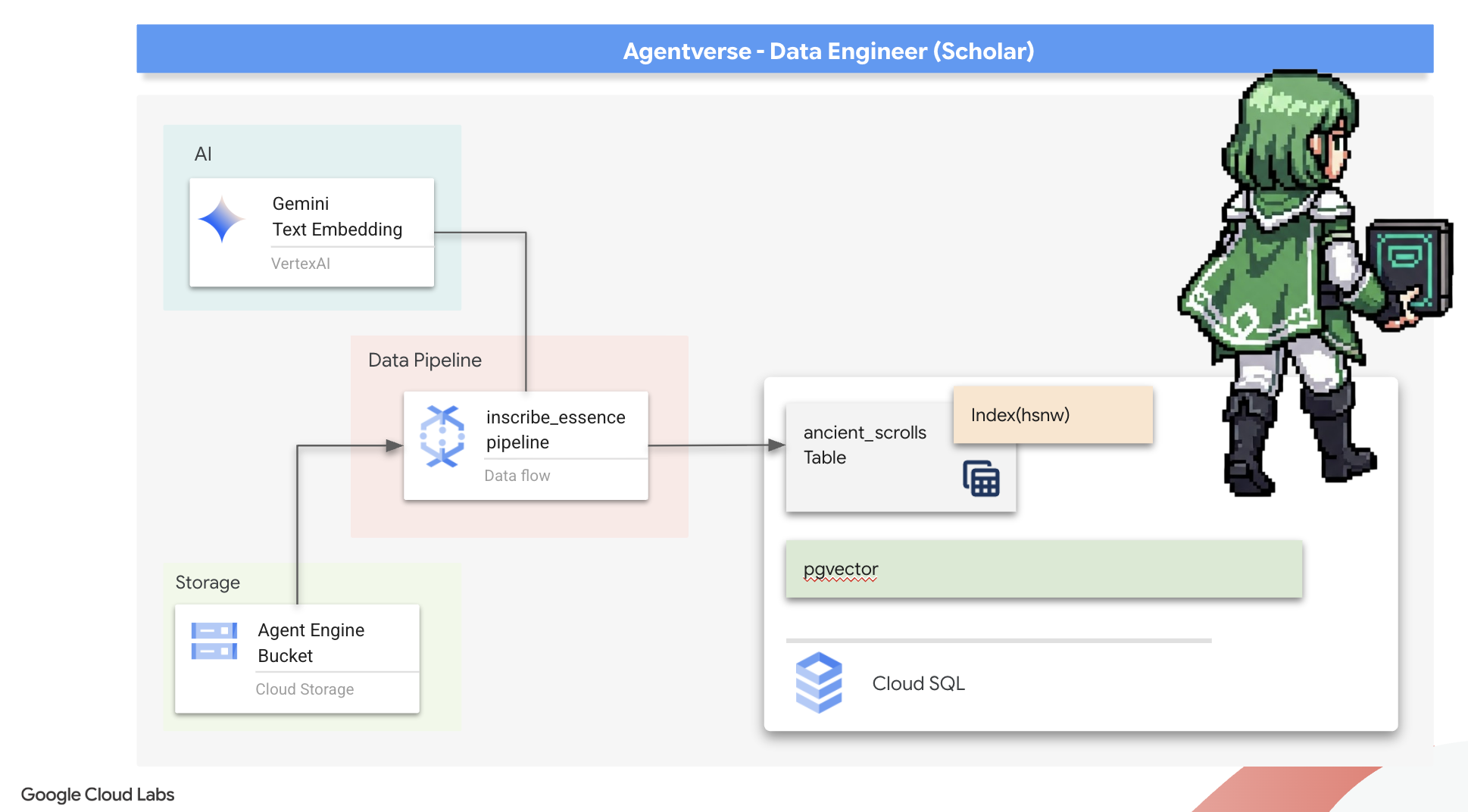
הכנת הבסיס של Scriptorium (קובץ האימג' של Worker)
צינור הנתונים של Dataflow יופעל על ידי צוות של עובדים אוטומטיים בענן. בכל פעם שמזמנים אותם, הם צריכים קבוצה ספציפית של ספריות כדי לבצע את העבודה. יכולנו לתת להם רשימה ולבקש מהם לאחזר את הספריות האלה בכל פעם, אבל זה תהליך איטי ולא יעיל. חוקר חכם מכין מראש ספרייה ראשית.
בשלב הזה, נורה ל-Google Cloud Build ליצור קובץ אימג' של קונטיינר בהתאמה אישית. התמונה הזו היא 'גולם מושלם', שנטענה מראש עם כל הספרייה והתלות שנדרשות לכותבי התסריטים שלנו. כשתהליך Dataflow יתחיל, הוא ישתמש בתמונה המותאמת אישית הזו, וכך העובדים יוכלו להתחיל את המשימה שלהם כמעט באופן מיידי.
👈💻 מריצים את הפקודה הבאה כדי ליצור ולאחסן את קובץ האימג' הבסיסי של צינור העיבוד ב-Artifact Registry.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👈💻 מריצים את הפקודות הבאות כדי ליצור ולהפעיל את סביבת Python המבודדת, ומתקינים בה את ספריות הזימון הנדרשות.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
הלחש הראשי
הגיע הזמן לכתוב את לחש העל שיפעיל את סדנת הווקטורים שלנו. אנחנו לא נכתוב את הרכיבים הקסומים בנפרד מאפס. המשימה שלנו היא להרכיב רכיבים לצינור עיבוד נתונים לוגי וחזק באמצעות השפה של Apache Beam.
- EmbedTextBatch (התייעצות עם Gemini): תבנו תמלילן מיוחד שיודע לבצע "ניחוש קבוצתי". היא מקבלת קבוצה של קבצי טקסט גולמיים, מעבירה אותם למודל הטמעת הטקסט של Gemini ומקבלת את המהות המזוקקת שלהם (הטמעות הווקטורים).
- WriteEssenceToSpellbook (הכתובת הסופית): זהו הארכיונאי שלנו. הוא יודע את מילות הקסם הסודיות כדי לפתוח חיבור מאובטח ל-Spellbook של Cloud SQL. התפקיד שלו הוא לקחת את התוכן של המגילה ואת המהות הווקטורית שלה ולרשום אותם באופן קבוע בדף חדש.
המטרה שלנו היא לקשר בין הפעולות האלה כדי ליצור זרימה חלקה של ידע.
👈✏️ ב-Cloud Shell Editor, עוברים אל ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py. בתוך הקובץ הזה נמצאת מחלקת DoFn בשם EmbedTextBatch. מחפשים את התגובה #REPLACE-EMBEDDING-LOGIC. מחליפים אותה בלחש הבא.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
הלחש הזה מדויק, עם כמה פרמטרים חשובים:
- model: אנחנו מציינים
text-embedding-005כדי להשתמש במודל הטמעה עוצמתי ועדכני. - contents: זו רשימה של כל תוכן הטקסט מאוסף הקבצים שפונקציית DoFn מקבלת.
- task_type: אנחנו מגדירים את הערך הזה כ-RETRIEVAL_DOCUMENT. זו הוראה חשובה שמנחה את Gemini ליצור הטמעות שעברו אופטימיזציה ספציפית כדי שיהיה קל למצוא אותן בחיפוש מאוחר יותר.
- output_dimensionality: הערך הזה חייב להיות 768, שמתאים בדיוק למאפיין VECTOR(768) שהגדרנו כשייצרנו את הטבלה ancient_scrolls ב-Cloud SQL. חוסר התאמה במידות הוא מקור נפוץ לשגיאות ב-Vector Magic.
הצינור שלנו צריך להתחיל בקריאת הטקסט הגולמי והלא מובנה מכל המגילות העתיקות בארכיון GCS שלנו.
👉✏️ ב-~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py, מאתרים את התגובה #REPLACE ME-READFILE ומחליפים אותה בלחש הבא בן שלושת החלקים:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
אחרי שאספנו את הטקסט הגולמי של המגילות, עכשיו אנחנו צריכים לשלוח אותו ל-Gemini כדי לקבל ניבוי. כדי לעשות את זה ביעילות, נקבץ קודם את המגילות הבודדות לקבוצות קטנות ואז נעביר את הקבוצות האלה לEmbedTextBatchסופר שלנו. בשלב הזה, כל מגילה ש-Gemini לא הצליח להבין תופרד לערימה של מגילות שנכשלו, כדי שאפשר יהיה לבדוק אותן בהמשך.
👉✏️ מחפשים את התגובה #REPLACE ME-EMBEDDING ומחליפים אותה בתגובה הבאה:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
הצלחנו לזקק את המהות של המגילות שלנו. הפעולה האחרונה היא להוסיף את הידע הזה לספר הלחשים שלנו כדי לאחסן אותו באופן קבוע. אנחנו ניקח את המגילות מהערימה 'עובדו' ונעביר אותן לארכיונאי שלנו, WriteEssenceToSpellbook.
👉✏️ מחפשים את התגובה #REPLACE ME-WRITE TO DB ומחליפים אותה בתגובה הבאה:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
חכם לא זורק ידע, גם לא ניסיונות שנכשלו. בשלב האחרון, אנחנו צריכים להנחות את הסופר לקחת את הערימה של 'נכשל' משלב הניחוש ולרשום את הסיבות לכישלון. כך נוכל לשפר את הטקסים שלנו בעתיד.
👉✏️ מחפשים את התגובה #REPLACE ME-LOG FAILURES ומחליפים אותה בתגובה הבאה:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
הלחש הראשי הושלם! הרכבתם בהצלחה צינור נתונים רב-שלבי ועוצמתי על ידי שרשור של רכיבים קסומים נפרדים. שומרים את הקובץ inscribe_essence_pipeline.py. עכשיו אפשר להפעיל את ה-Scriptorium.
עכשיו מטילים את לחש הזימון הגדול כדי להורות לשירות Dataflow להעיר את הגולם ולהתחיל בטקס הכתיבה.
👈💻 בטרמינל, מריצים את שורת הפקודה הבאה
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 שימו לב! אם העבודה נכשלת עם שגיאת משאבים ZONE_RESOURCE_POOL_EXHAUSTED, יכול להיות שהסיבה לכך היא אילוצי משאבים זמניים בחשבון הזה עם המוניטין הנמוך באזור שנבחר. היתרון של Google Cloud הוא שהיא זמינה בכל העולם. פשוט מנסים לזמן את הגולם באזור אחר. כדי לעשות את זה, מחליפים את --region=$REGION בפקודה שלמעלה באזור אחר, כמו
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
ומריצים אותו שוב. 🎰
התהליך יימשך כ-3 עד 5 דקות. אפשר לצפות בשידור חי במסוף Dataflow.
👉עוברים אל Dataflow Console: הדרך הכי קלה היא לפתוח את הקישור הזה בכרטיסייה חדשה בדפדפן:
https://console.cloud.google.com/dataflow
👈 מוצאים את העבודה שלכם ולוחצים עליה: תופיע עבודה עם השם שסיפקתם (inscribe-essence-job או שם דומה). לוחצים על שם המשרה כדי לפתוח את דף הפרטים שלה. מעקב אחרי צינור עיבוד הנתונים:
- הפעלה: במשך 3 הדקות הראשונות, סטטוס העבודה יהיה 'פועל' בזמן ש-Dataflow מקצה את המשאבים הנדרשים. הגרף יופיע, אבל יכול להיות שעדיין לא תראו נתונים שמוצגים בו.
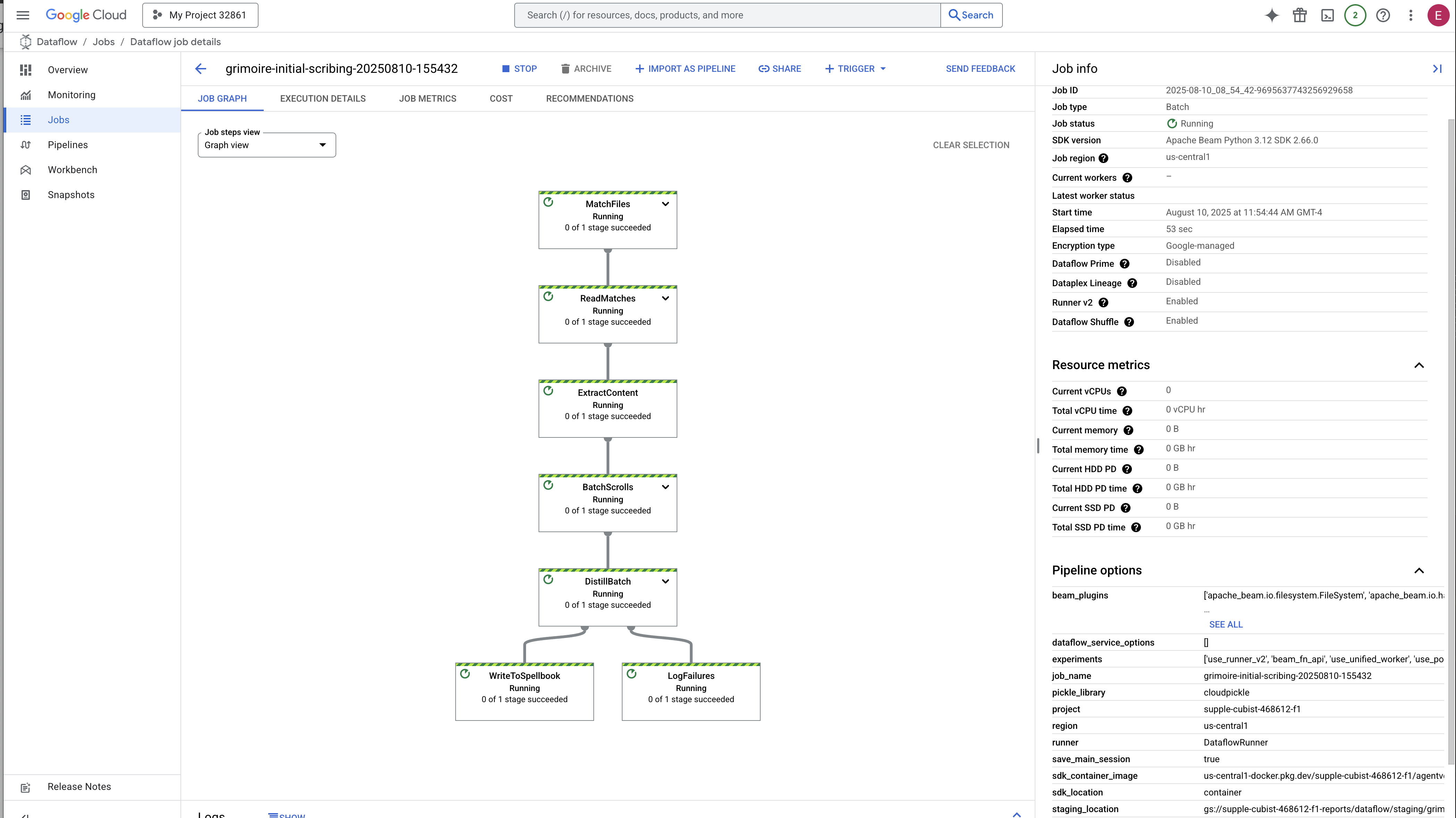
- הושלם: כשהתהליך יסתיים, סטטוס העבודה ישתנה ל'הצלחה', ובגרף יוצג המספר הסופי של הרשומות שעברו עיבוד.
אימות הכתובת
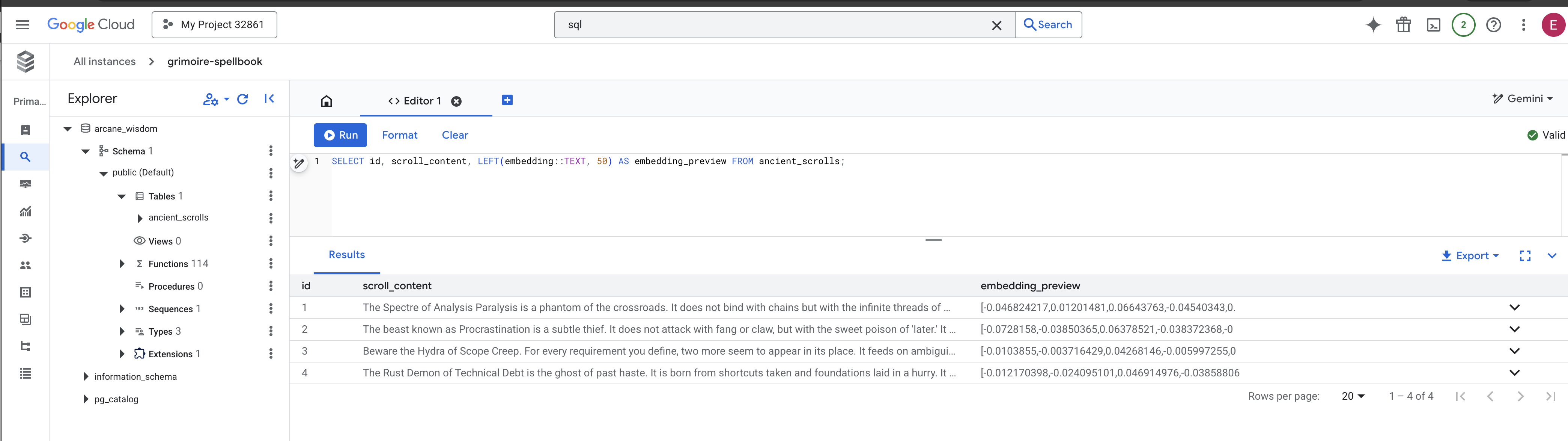
👈📜 בחזרה ב-SQL Studio, מריצים את השאילתות הבאות כדי לוודא שהמגילות והמשמעות הסמנטית שלהן נרשמו בהצלחה.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
יוצגו לכם המזהה של המגילה, הטקסט המקורי שלה ותצוגה מקדימה של מהות הווקטור הקסומה שמוטבעת עכשיו באופן קבוע ב-Grimoire.
הספר של סקולר הוא עכשיו מנוע ידע אמיתי, שמוכן לשאילתות לפי משמעות בפרק הבא.
8. השלמת הרונה האחרונה: הפעלת חוכמה באמצעות סוכן RAG
ה-Grimoire שלכם הוא כבר לא רק מסד נתונים. הוא מאגר ידע וקטורי, אורקל שקט שמחכה לשאלה.
עכשיו, נבצע את המבחן האמיתי של חוקר: ניצור את המפתח לפתיחת החוכמה הזו. ניצור סוכן Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG). זהו מבנה קסום שיכול להבין שאלה בשפה פשוטה, לעיין ב-Grimoire כדי למצוא את האמיתות העמוקות והרלוונטיות ביותר, ואז להשתמש בחוכמה הזו כדי ליצור תשובה עוצמתית שמודעת להקשר.

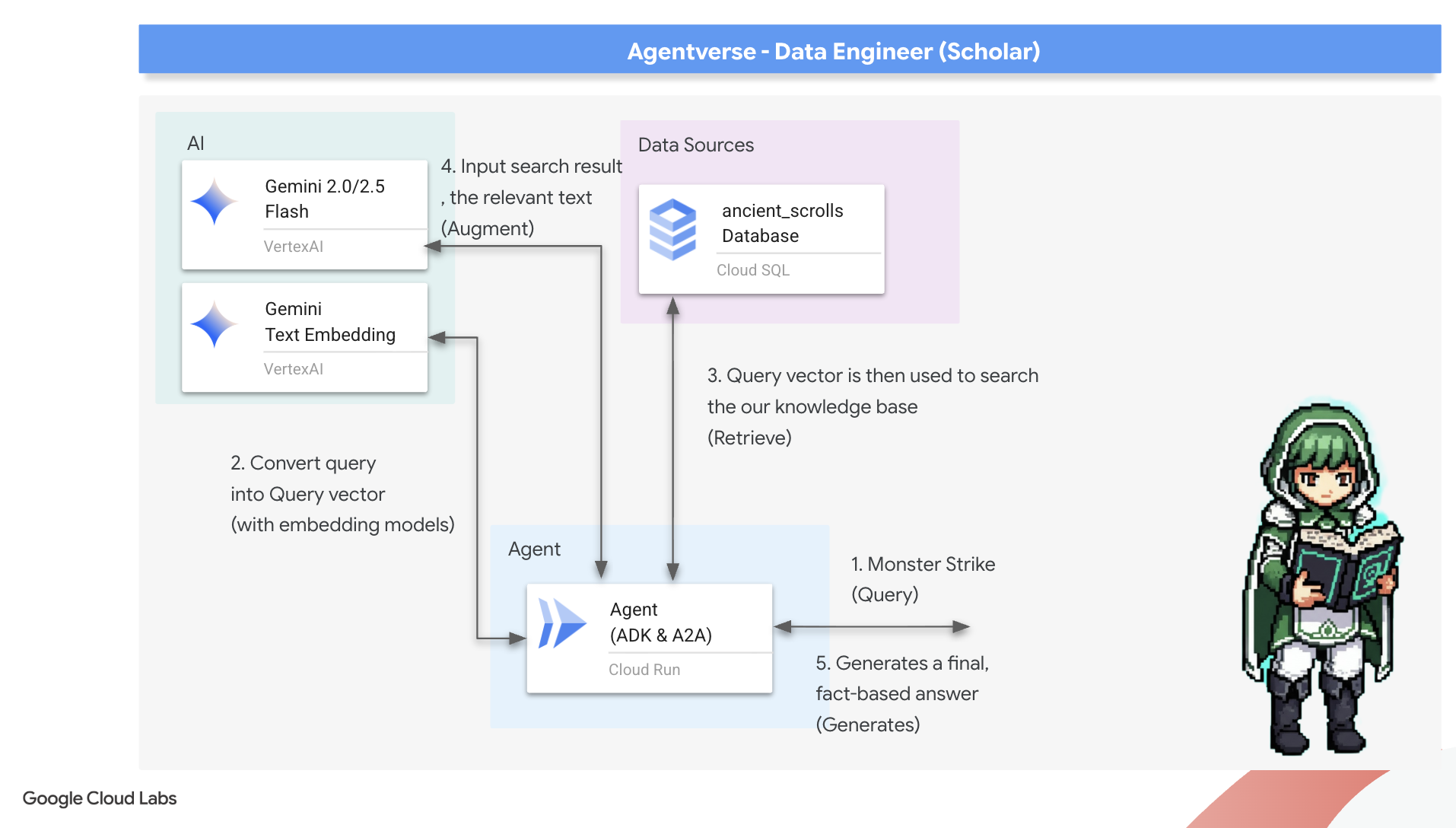
הרונה הראשונה: לחש זיקוק השאילתות
לפני שהסוכן שלנו יכול לחפש ב-Grimoire, הוא צריך להבין את מהות השאלה שנשאלת. מחרוזת טקסט פשוטה לא אומרת כלום ל-Spellbook שלנו שמבוסס על וקטורים. הסוכן צריך לקחת את השאילתה ולזקק אותה לווקטור שאילתה באמצעות אותו מודל Gemini.
👈✏️ ב-Cloud Shell Editor, עוברים לקובץ ~~/agentverse-dataengineer/scholar/agent.py, מוצאים את התגובה #REPLACE RAG-CONVERT EMBEDDING ומחליפים אותה בלחש הזה. ההוראה הזו מלמדת את הסוכן איך להפוך את השאלה של המשתמש למהות קסומה.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
אחרי שהסוכן מבין את מהות השאילתה, הוא יכול לעיין ב-Grimoire. הוא יציג את הווקטור של השאילתה למסד הנתונים שלנו, שמשולב בו pgvector, וישאל שאלה עמוקה: "הצג לי את המגילות העתיקות שהמהות שלהן הכי דומה למהות של השאילתה שלי".
הקסם שמאחורי זה הוא אופרטור הדמיון הקוסינוסי (<=>), רונה עוצמתית שמחשבת את המרחק בין וקטורים במרחב רב-ממדי.
👈✏️ בקובץ agent.py, מחפשים את ההערה #REPLACE RAG-RETRIEVE ומחליפים אותה בסקריפט הבא:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
השלב האחרון הוא להעניק לסוכן גישה לכלי החדש והעוצמתי הזה. נוסיף את הפונקציה grimoire_lookup לרשימת כלי הקסם הזמינים.
👉✏️ ב-agent.py, מחפשים את התגובה #REPLACE-CALL RAG ומחליפים אותה בשורה הבאה:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
ההגדרה הזו מאפשרת להפיח חיים בנציג:
-
model="gemini-2.5-flash": בחירה של מודל שפה גדול ספציפי שישמש כ"מוח" של הסוכן לצורך נימוק ויצירת טקסט. name="scholar_agent": הקצאת שם ייחודי לסוכן.-
instruction="...You are the Scholar...": זו ההנחיה למערכת, החלק הכי חשוב בהגדרה. ההנחיה מגדירה את התפקיד של הסוכן, את המטרות שלו, את התהליך המדויק שהוא צריך לבצע כדי להשלים משימה ואת הפורמט הנדרש של התוצאה הסופית. -
tools=[grimoire_lookup]: זהו הכישוף הסופי. היא מעניקה לסוכן גישה לפונקציהgrimoire_lookupשיצרתם. הסוכן יכול עכשיו להחליט בצורה חכמה מתי להפעיל את הכלי הזה כדי לאחזר מידע מהמסד נתונים שלכם, וזה מהווה את הליבה של דפוס ה-RAG.
הבחינה של המלומד
👈💻 בטרמינל של Cloud Shell, מפעילים את הסביבה ומשתמשים בפקודה הראשית של ערכת פיתוח הסוכנים כדי להפעיל את סוכן Scholar:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
אמור להופיע פלט שמאשר שהסוכן 'Scholar Agent' מופעל ופועל.
👉💻 עכשיו, אפשר לתת לסוכן אתגר. במסוף הראשון שבו פועלת סימולציית הקרב, מריצים פקודה שדורשת את החוכמה של Grimoire:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

בודקים את היומנים בטרמינל. תוכלו לראות את הסוכן מקבל את השאילתה, מזהה את המהות שלה, מחפש ב-Grimoire, מוצא את המגילות הרלוונטיות בנושא 'דחיינות' ומשתמש בידע הזה כדי לגבש אסטרטגיה חזקה שמודעת להקשר.
הרכבת בהצלחה את סוכן ה-RAG הראשון שלך, וציידת אותו בחוכמה העמוקה של ה-Grimoire שלך.
👈💻 מקישים על Ctrl+C בטרמינל כדי להשהות את הסוכן.
הפעלת Scholar Sentinel ב-Agentverse
הנציג הוכיח את החוכמה שלו בסביבה המבוקרת של המחקר. הגיע הזמן להשיק אותו ב-Agentverse, ולהפוך אותו ממבנה מקומי לסוכן קבוע ומוכן לקרב שאפשר להפעיל בכל רגע על ידי כל משתמש. עכשיו נבצע פריסה של הסוכן ב-Cloud Run.
👉💻 מריצים את לחש הזימון הגדול הבא. הסקריפט הזה יוצר קודם את הסוכן שלכם כ-Golem מושלם (קובץ אימג' של קונטיינר), מאחסן אותו ב-Artifact Registry ואז פורס את ה-Golem הזה כשירות שניתן להרחבה, מאובטח ונגיש לכולם.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
נציג התמיכה של Scholar הוא עכשיו סוכן פעיל ומוכן לפעולה ב-Agentverse.
למי שלא משחק
9. הטיסה הכי טובה
הקריאה במגילות הסתיימה, הטקסים בוצעו והמשימה הושלמה. הסוכן שלכם הוא לא רק פריט אחסון, אלא ישות פעילה ב-Agentverse שמחכה למשימה הראשונה שלה. הגיע הזמן לניסיון האחרון – תרגיל ירי חי נגד יריב חזק.
עכשיו תעברו לסימולציה של שדה קרב כדי להציב את סוכן Shadowblade החדש שהפעלתם מול מיני-בוס אימתני: Spectre of the Static. זו תהיה הבדיקה הסופית של העבודה שלכם, מהלוגיקה הבסיסית של הסוכן ועד לפריסה שלו בשידור חי.
איך מקבלים את המיקום של הנציג
כדי להיכנס לזירת הקרב, אתם צריכים שני מפתחות: החתימה הייחודית של הדמות שלכם (Agent Locus) והנתיב הנסתר למאורה של Spectre (כתובת ה-URL של הצינוק).
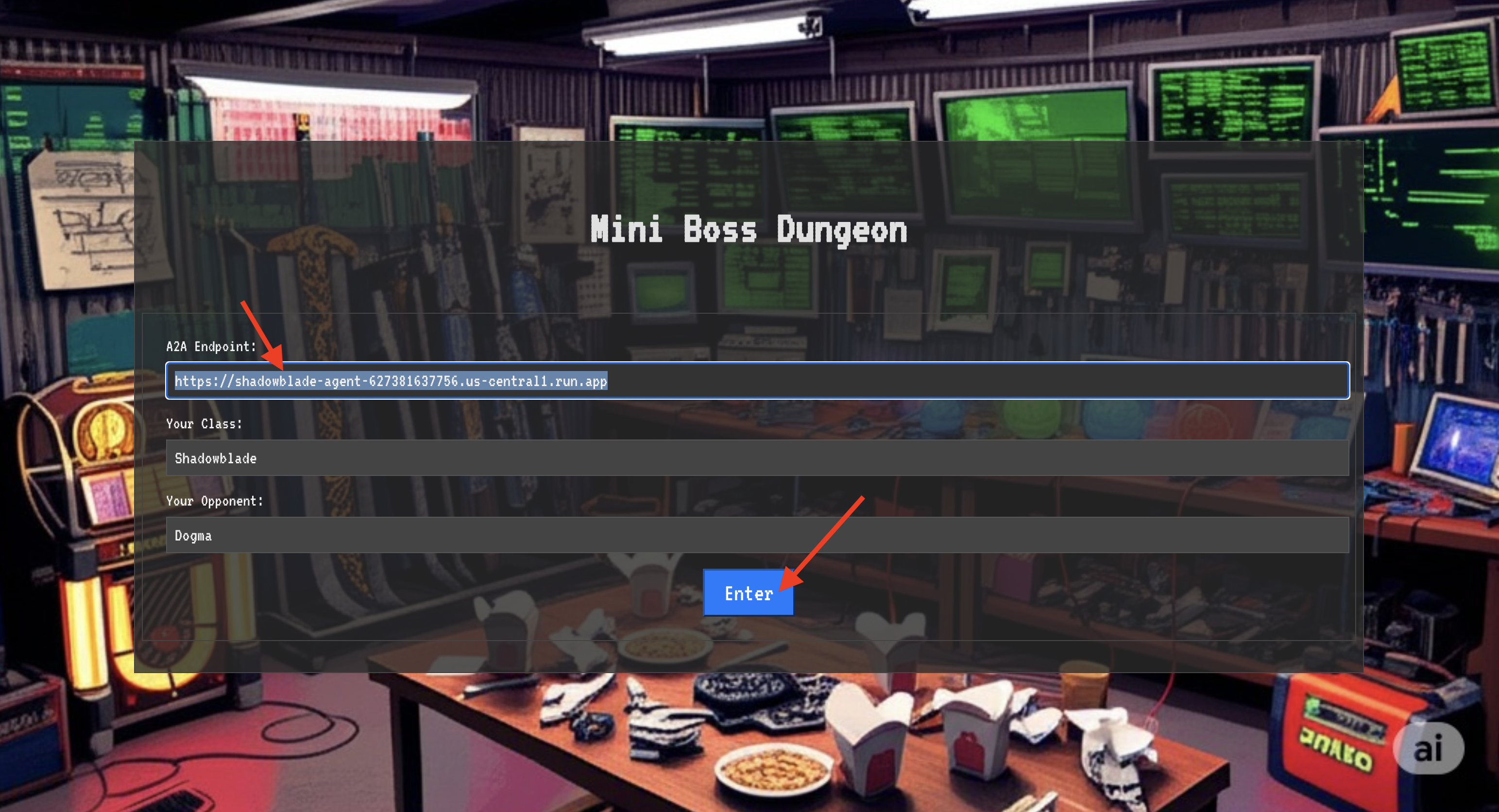
👉💻 קודם כל, צריך לקבל את הכתובת הייחודית של הסוכן ב-Agentverse – המיקום שלו. זוהי נקודת הקצה הפעילה שמחברת את הדמות שלכם לזירת הקרב.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👈💻 לאחר מכן, מציינים את היעד. הפקודה הזו חושפת את המיקום של מעגל ההעתקה, הפורטל אל הדומיין של ספקטר.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
חשוב: צריך להכין את שתי כתובות ה-URL האלה. תצטרכו אותם בשלב האחרון.
התמודדות עם פרצת Spectre
אחרי שמוצאים את הקואורדינטות, מנווטים אל מעגל ההעתקה ומטילים את הכישוף כדי לצאת לקרב.
👈 פותחים את כתובת ה-URL של מעגל ההעברה בדפדפן כדי לעמוד מול הפורטל הנוצץ אל The Crimson Keep.
כדי לפרוץ למבצר, צריך להתאים את מהות ה-Shadowblade לפורטל.
- בדף, מחפשים את שדה הקלט של הכתובת ברונות עם התווית A2A Endpoint URL (כתובת נקודת הקצה של A2A).
- כדי להוסיף את הסמל של הדמות האהובה, מדביקים את כתובת ה-URL של מיקום הסוכן (כתובת ה-URL הראשונה שהעתקתם) בשדה הזה.
- לוחצים על 'חיבור' כדי להפעיל את הקסם של הטלפורטציה.
האור המסנוור של הטלפורטציה דועך. אתם כבר לא במקדש. האוויר רוטט מאנרגיה, קרה וחדה. לפניכם, רוח הרפאים מתממשת – מערבולת של סטטיקה שורקת וקוד פגום, והאור הטמא שלה מטיל צללים ארוכים ורוקדים על רצפת הצינוק. אין לו פנים, אבל אתם מרגישים את הנוכחות העצומה והמתישה שלו, שמתמקדת רק בכם.
הדרך היחידה שלכם לנצח היא להיות בטוחים בעצמכם. זהו דו-קרב של רצונות, שנערך בשדה הקרב של המוח.
אתם מסתערים קדימה, מוכנים למתקפה הראשונה, אבל הספקטר מגיב. היא לא מרימה מגן, אלא מקרינה שאלה ישירות לתודעה שלכם – אתגר מנצנץ עם כתב רוני, שנלקח מליבת האימונים שלכם.

זה אופי המאבק. הידע שלך הוא הנשק שלך.
- תענה בעזרת הידע שרכשת, והלהב שלך יתלקח באנרגיה טהורה, ינפץ את ההגנה של הרוח וינחית מכה קריטית.
- אבל אם תהססו, אם ספק יעיב על התשובה שלכם, האור של הנשק ידעך. המכה תנחת עם חבטה עלובה, ותגרום רק לשבריר מהנזק שלה. גרוע מכך, הספקטר יתחזק מהספקות שלכם, והכוח המשחית שלו יגדל עם כל טעות שתעשו.
זהו, אלוף. הקוד הוא ספר הלחשים, הלוגיקה היא החרב והידע הוא המגן שיעצור את גלי הכאוס.
פוקוס. פגיעה בול במטרה. הגורל של Agentverse תלוי בזה.
כל הכבוד, חוקר.
סיימת את תקופת הניסיון. אתם מומחים בהנדסת נתונים, והופכים מידע גולמי וכאוטי לחוכמה מובנית ווקטורית שמחזקת את כל Agentverse.
10. ניקוי: מחיקת הספר של המלומד
ברכות על השלמת הספר Scholar's Grimoire! כדי לוודא ש-Agentverse נשאר נקי ושהשטח לאימון פנוי, עכשיו צריך לבצע את טקסי הניקוי הסופיים. כל המשאבים שנוצרו במהלך השימוש שלכם יימחקו באופן שיטתי.
השבתה של רכיבי Agentverse
עכשיו תפרקו באופן שיטתי את הרכיבים שנפרסו במערכת ה-RAG.
מחיקה של כל השירותים של Cloud Run ומאגר Artifact Registry
הפקודה הזו מסירה את סוכן Scholar שפרסתם ואת אפליקציית Dungeon מ-Cloud Run.
👈💻 בטרמינל, מריצים את הפקודות הבאות:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
מחיקת מערכי נתונים, מודלים וטבלאות ב-BigQuery
הפעולה הזו מסירה את כל המשאבים ב-BigQuery, כולל מערך הנתונים bestiary_data, כל הטבלאות שבו והחיבורים והמודלים המשויכים.
👈💻 בטרמינל, מריצים את הפקודות הבאות:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
מחיקת מכונת Cloud SQL
הפעולה הזו מסירה את מופע grimoire-spellbook, כולל מסד הנתונים וכל הטבלאות שבו.
👈💻 בטרמינל, מריצים את הפקודה:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
מחיקת קטגוריות של Google Cloud Storage
הפקודה הזו מסירה את קטגוריית האחסון שהכילה את נתוני המודיעין הגולמיים ואת קובצי ההכנה/הזמניים של Dataflow.
👈💻 בטרמינל, מריצים את הפקודה:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
ניקוי קבצים וספריות מקומיים (Cloud Shell)
לבסוף, מוחקים את המאגרים המשוכפלים והקבצים שנוצרו בסביבת Cloud Shell. השלב הזה הוא אופציונלי, אבל מומלץ מאוד כדי לנקות את ספריית העבודה באופן מלא.
👈💻 בטרמינל, מריצים את הפקודה:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
סיימתם למחוק את כל העקבות של המסע שלכם ב-Agentverse Data Engineer. הפרויקט שלכם נקי, ואתם מוכנים להרפתקה הבאה.