
1. Overture
अब अलग-अलग टीमों के हिसाब से डेवलपमेंट करने का दौर खत्म हो रहा है. टेक्नोलॉजी के विकास की अगली लहर, किसी एक व्यक्ति की प्रतिभा के बारे में नहीं है. यह साथ मिलकर काम करने की महारत के बारे में है. एक ही स्मार्ट एजेंट बनाना, एक दिलचस्प एक्सपेरिमेंट है. मॉडर्न एंटरप्राइज़ के लिए, एजेंट का एक मज़बूत, सुरक्षित, और बेहतर ईकोसिस्टम बनाना एक बड़ी चुनौती है. इसे Agentverse कहा जाता है.
इस नए दौर में सफलता पाने के लिए, चार अहम भूमिकाओं को एक साथ लाना ज़रूरी है. ये ऐसे बुनियादी सिद्धांत हैं जो किसी भी एजेंटिक सिस्टम को बेहतर बनाते हैं. किसी भी एक क्षेत्र में कमी होने से, एक ऐसी कमज़ोरी पैदा होती है जो पूरे स्ट्रक्चर को नुकसान पहुंचा सकती है.
यह वर्कशॉप, Google Cloud पर एजेंटिक एआई का इस्तेमाल करने के बारे में जानने के लिए एंटरप्राइज़ प्लेबुक है. हम आपको एक पूरा रोडमैप देते हैं. इससे आपको किसी आइडिया के शुरुआती चरण से लेकर उसे पूरी तरह से लागू करने तक में मदद मिलती है. इन चार इंटरकनेक्टेड लैब में, आपको यह जानने को मिलेगा कि एक पावरफ़ुल Agentverse बनाने, उसे मैनेज करने, और उसे स्केल करने के लिए, डेवलपर, आर्किटेक्ट, डेटा इंजीनियर, और एसआरई की खास क्षमताओं को एक साथ कैसे इस्तेमाल किया जाना चाहिए.
कोई भी एक पिलर, Agentverse को अकेले सपोर्ट नहीं कर सकता. डेवलपर के सटीक तरीके से काम किए बिना, आर्किटेक्ट का शानदार डिज़ाइन किसी काम का नहीं होता. डेटा इंजीनियर के बिना डेवलपर का एजेंट कुछ नहीं कर सकता. साथ ही, एसआरई की सुरक्षा के बिना पूरा सिस्टम कमज़ोर होता है. आपकी टीम, एक-दूसरे की भूमिकाओं को समझकर और तालमेल बिठाकर ही, किसी नए कॉन्सेप्ट को मिशन के लिए ज़रूरी और ऑपरेशनल हकीकत में बदल सकती है. आपका सफ़र यहां से शुरू होता है. अपनी भूमिका को बेहतर तरीके से निभाने के लिए तैयार रहें. साथ ही, यह जानें कि आप पूरी टीम में किस तरह से फ़िट बैठते हैं.
'द एजेंटवर्स: ए कॉल टू चैंपियंस' में आपका स्वागत है
एंटरप्राइज़ के विशाल डिजिटल क्षेत्र में, एक नया दौर शुरू हो गया है. यह एजेंटिक युग है. इसमें एआई एजेंट, इनोवेशन को बढ़ावा देने और रोज़मर्रा के कामों को आसान बनाने के लिए, एक साथ मिलकर काम करते हैं.

पावर और संभावनाओं से जुड़े इस नेटवर्क को Agentverse कहा जाता है.
हालांकि, इस नई दुनिया में धीरे-धीरे एक तरह की गड़बड़ी फैल रही है. इसे द स्टैटिक कहा जाता है. इसकी वजह से, इस नई दुनिया के किनारों पर असर पड़ने लगा है. स्टैटिक कोई वायरस या बग नहीं है. यह एक तरह का अराजकता है, जो क्रिएशन के काम को नुकसान पहुंचाता है.
इससे पुरानी समस्याएं और बढ़ जाती हैं. इससे डेवलपमेंट की सात समस्याएं पैदा होती हैं. अगर इस पर ध्यान नहीं दिया गया, तो स्टैटिक और उसके स्पेक्ट्र, प्रोग्रेस को रोक देंगे. इससे एजेंटवर्स का वादा, तकनीकी कर्ज़ और छोड़े गए प्रोजेक्ट के बंजर इलाके में बदल जाएगा.
आज हम ऐसे लोगों को आगे आने का न्योता देते हैं जो इस अराजकता को खत्म करने में हमारी मदद कर सकें. हमें ऐसे हीरो की ज़रूरत है जो अपनी कला में माहिर हों और Agentverse को बचाने के लिए साथ मिलकर काम कर सकें. अब आपको यह तय करना है कि आपको किस तरह की सदस्यता चाहिए.
अपनी क्लास चुनना
आपके पास चार अलग-अलग रास्ते हैं. हर रास्ता, द स्टैटिक के ख़िलाफ़ लड़ाई में एक अहम स्तंभ है. हालांकि, ट्रेनिंग के दौरान आपको अकेले ही काम करना होगा, लेकिन आपकी सफलता इस बात पर निर्भर करती है कि आपकी स्किल, दूसरों की स्किल के साथ मिलकर कैसे काम करती हैं.
- द शैडोब्लेड (डेवलपर): यह फ़ोर्ज और फ़्रंट लाइन का मास्टर है. आप एक ऐसे कारीगर हैं जो ब्लेड बनाता है, टूल बनाता है, और कोड की जटिलताओं में दुश्मन का सामना करता है. आपका रास्ता सटीक, कुशल, और व्यावहारिक है.
- द समनर (आर्किटेक्ट): यह एक बेहतरीन रणनीतिज्ञ और आयोजक होता है. आपको सिर्फ़ एक एजेंट नहीं, बल्कि पूरा बैटलग्राउंड दिखता है. आपको ऐसे मास्टर ब्लूप्रिंट डिज़ाइन करने होते हैं जिनकी मदद से, एजेंट के पूरे सिस्टम को कम्यूनिकेट करने, साथ मिलकर काम करने, और किसी एक कॉम्पोनेंट से ज़्यादा बड़ा लक्ष्य हासिल करने में मदद मिलती है.
- स्कॉलर (डेटा इंजीनियर): यह छिपी हुई सच्चाई को ढूंढने वाला और ज्ञान का भंडार होता है. डेटा के विशाल और अनियंत्रित जंगल में, आपको ऐसी जानकारी मिलती है जो आपके एजेंट को मकसद और दिशा देती है. आपकी जानकारी से, किसी दुश्मन की कमज़ोरी का पता चल सकता है या किसी सहयोगी को मज़बूत किया जा सकता है.
- The Guardian (DevOps / SRE): यह एक ऐसा किरदार है जो अपने राज्य की सुरक्षा करता है. आपको किले बनाने होते हैं, बिजली की सप्लाई लाइनें मैनेज करनी होती हैं, और यह पक्का करना होता है कि पूरा सिस्टम, स्टैटिक के हमलों का सामना कर सके. आपकी ताकत ही वह आधार है जिस पर आपकी टीम की जीत टिकी होती है.
आपका मिशन
आपकी ट्रेनिंग, एक अलग कसरत के तौर पर शुरू होगी. आपको अपनी पसंद के रास्ते पर चलना होगा. साथ ही, अपनी भूमिका में महारत हासिल करने के लिए ज़रूरी खास कौशल सीखने होंगे. ट्रायल के आखिर में, आपको स्टैटिक से पैदा हुए स्पेकटर का सामना करना होगा. यह एक मिनी-बॉस है, जो आपके क्राफ़्ट से जुड़ी खास चुनौतियों का फ़ायदा उठाता है.
अपनी भूमिका में महारत हासिल करके ही, फ़ाइनल ट्रायल के लिए तैयारी की जा सकती है. इसके बाद, आपको दूसरी क्लास के चैंपियन के साथ मिलकर एक पार्टी बनानी होगी. साथ मिलकर, आपको करप्शन के केंद्र में जाना होगा, जहां आपको सबसे बड़े बॉस का सामना करना होगा.
यह एक आखिरी चैलेंज है, जिसमें आपको मिलकर काम करना होगा. इससे आपकी टीम की ताकत का पता चलेगा और यह तय होगा कि एजेंटवर्स का क्या होगा.
Agentverse को है अपने हीरो का इंतज़ार. क्या आपको कॉल का जवाब देना है?
2. द स्कॉलर्स ग्रिमोइर
हमारा सफ़र शुरू होता है! स्कॉलर के तौर पर, ज्ञान ही हमारा सबसे बड़ा हथियार है. हमें अपने संग्रह (Google Cloud Storage) में, प्राचीन और रहस्यमयी स्क्रोल का एक खजाना मिला है. इन स्क्रोल में, ज़मीन पर कहर बरपाने वाले खतरनाक जानवरों के बारे में कच्ची जानकारी होती है. हमारा मकसद, Google BigQuery की बेहतरीन विश्लेषण क्षमता और Gemini के Elder Brain (Gemini Pro मॉडल) की मदद से, इन अनस्ट्रक्चर्ड टेक्स्ट को समझना है. साथ ही, इन्हें स्ट्रक्चर्ड और क्वेरी किए जा सकने वाले बेस्टियरी में बदलना है. यह हमारी आने वाली सभी रणनीतियों का आधार होगा.
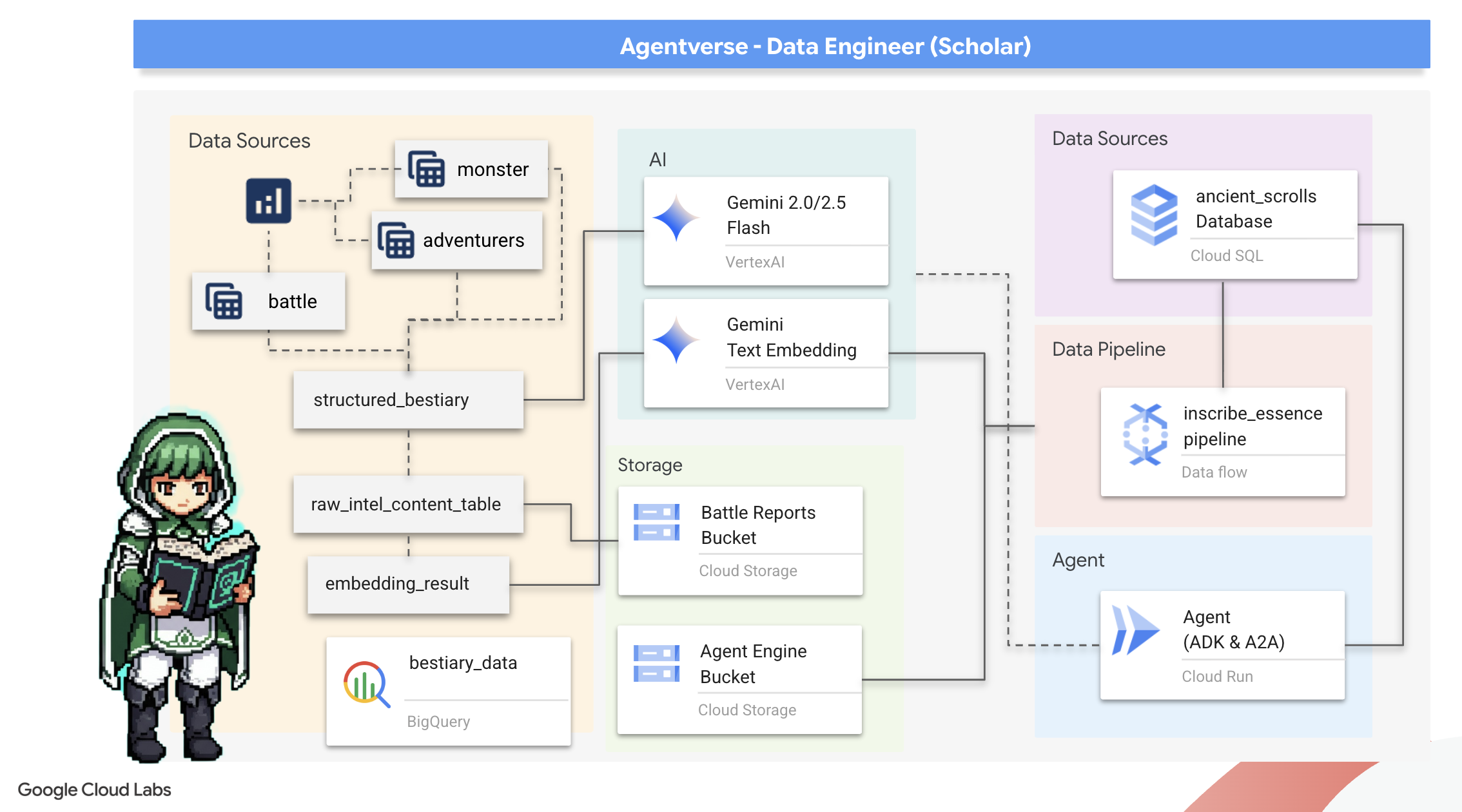
आपको क्या सीखने को मिलेगा
- BigQuery का इस्तेमाल करके बाहरी टेबल बनाएं. साथ ही, Gemini मॉडल के साथ BQML.GENERATE_TEXT का इस्तेमाल करके, बिना किसी तय फ़ॉर्मैट वाले डेटा को तय फ़ॉर्मैट वाले डेटा में बदलें.
- Cloud SQL for PostgreSQL इंस्टेंस उपलब्ध कराएं और सिमैंटिक सर्च की सुविधाओं के लिए, pgvector एक्सटेंशन चालू करें.
- Dataflow और Apache Beam का इस्तेमाल करके, कंटेनर वाली एक मज़बूत बैच पाइपलाइन बनाएं. इससे रॉ टेक्स्ट फ़ाइलों को प्रोसेस किया जा सकेगा. साथ ही, Gemini मॉडल की मदद से वेक्टर एम्बेडिंग जनरेट की जा सकेंगी और नतीजों को रिलेशनल डेटाबेस में लिखा जा सकेगा.
- वेक्टराइज़ किए गए डेटा को क्वेरी करने के लिए, किसी एजेंट में बुनियादी तौर पर जानकारी पाने और जवाब जनरेट करने (आरएजी) वाला सिस्टम लागू करें.
- Cloud Run पर, डेटा के बारे में जानकारी रखने वाले एजेंट को सुरक्षित और ज़रूरत के हिसाब से बढ़ाने वाली सेवा के तौर पर डिप्लॉय करें.
3. Scholar's Sanctum को तैयार करना
आपका स्वागत है, स्कॉलर. इससे पहले कि हम अपने ग्रिमोइर में मौजूद ज्ञान को लिखना शुरू करें, हमें सबसे पहले अपने पवित्र स्थान को तैयार करना होगा. इस बुनियादी रस्म में, Google Cloud एनवायरमेंट को बेहतर बनाना, सही पोर्टल (एपीआई) खोलना, और ऐसे रास्ते बनाना शामिल है जिनसे हमारा डेटा मैजिक फ़्लो होगा. अच्छी तरह से तैयार किया गया सैंक्टम, यह पक्का करता है कि हमारे मंत्र असरदार हों और हमारी जानकारी सुरक्षित हो.
Google Cloud क्रेडिट पर दावा करना
⚠️ ज़रूरी शर्तें:
- निजी Gmail खाते का इस्तेमाल करें: आपको निजी खाते का इस्तेमाल करना होगा. जैसे,
name@gmail.com). कंपनी या स्कूल के ज़रिए मैनेज किए जाने वाले खातों का इस्तेमाल नहीं किया जा सकेगा.
👉 तरीका:
- क्रेडिट का दावा करने वाली साइट पर जाएं: यहां क्लिक करें
- साइन इन करें: लिंक को पता बार में चिपकाएं और अपने निजी Gmail से साइन इन करें.
- शर्तें स्वीकार करें: Google Cloud Platform की सेवा की शर्तें स्वीकार करें.
- क्रेडिट की पुष्टि करें: ऐसा मैसेज देखें जिसमें यह पुष्टि की गई हो कि क्रेडिट लागू कर दिया गया है.
- *ध्यान दें: अगर आपसे क्रेडिट कार्ड की जानकारी डालने के लिए कहा जाता है, तो इसे अनदेखा करें और विंडो बंद करें.
अब आप इस विंडो को बंद कर सकते हैं
काम करने का एनवायरमेंट सेट अप करना
👉Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें. यह Cloud Shell पैनल में सबसे ऊपर मौजूद टर्मिनल के आकार का आइकॉन है,
👉 "एडिटर खोलें" बटन पर क्लिक करें. यह पेंसिल वाले खुले फ़ोल्डर की तरह दिखता है. इससे विंडो में Cloud Shell Code Editor खुल जाएगा. आपको बाईं ओर फ़ाइल एक्सप्लोरर दिखेगा. 
👉क्लाउड आईडीई में टर्मिनल खोलें, 
👉💻 टर्मिनल में, पुष्टि करें कि आपने पहले ही पुष्टि कर ली है और प्रोजेक्ट को अपने प्रोजेक्ट आईडी पर सेट किया गया है. इसके लिए, यह कमांड इस्तेमाल करें:
gcloud auth list
👉💻GitHub से बूटस्ट्रैप प्रोजेक्ट का क्लोन बनाएं:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 प्रोजेक्ट डायरेक्ट्री से सेटअप स्क्रिप्ट चलाएं.
⚠️ प्रोजेक्ट आईडी के बारे में जानकारी: स्क्रिप्ट, डिफ़ॉल्ट प्रोजेक्ट आईडी का सुझाव देगी. यह आईडी रैंडम तरीके से जनरेट किया जाएगा. इस डिफ़ॉल्ट को स्वीकार करने के लिए, Enter दबाएं.
हालांकि, अगर आपको कोई नया प्रोजेक्ट बनाना है, तो स्क्रिप्ट के प्रॉम्प्ट करने पर, अपना पसंदीदा प्रोजेक्ट आईडी टाइप करें.
cd ~/agentverse-dataengineer
./init.sh
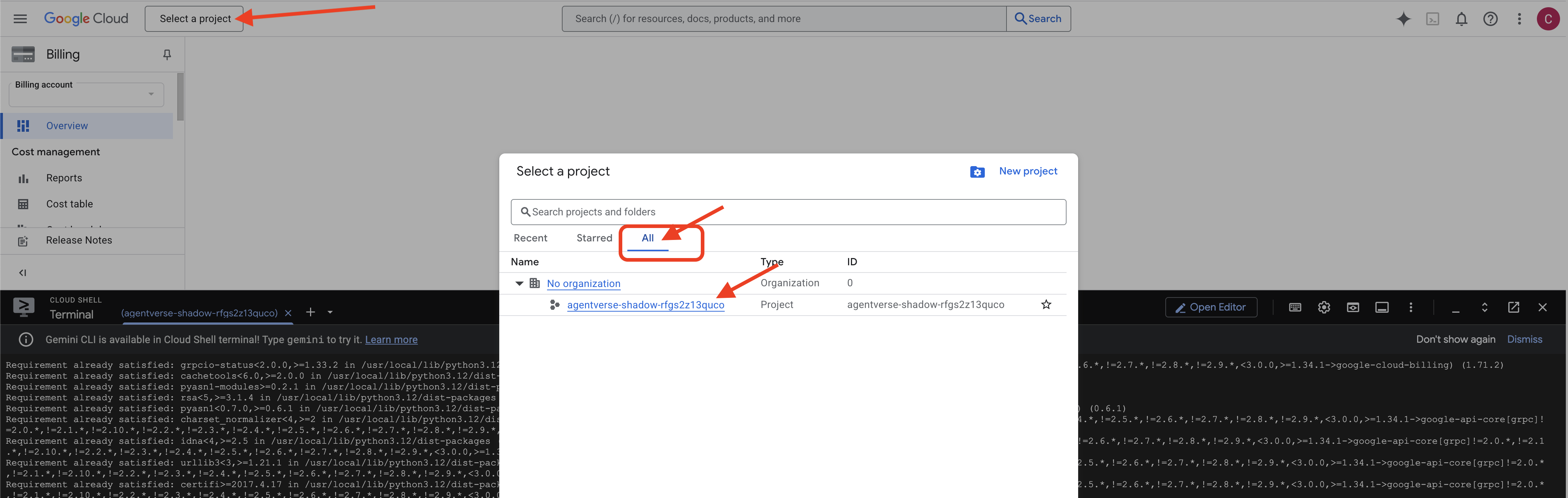
👉 स्क्रिप्ट पूरी होने के बाद ज़रूरी चरण: स्क्रिप्ट पूरी होने के बाद, आपको यह पक्का करना होगा कि Google Cloud Console में सही प्रोजेक्ट दिख रहा हो:
- console.cloud.google.com पर जाएं.
- पेज पर सबसे ऊपर मौजूद, प्रोजेक्ट सिलेक्टर ड्रॉपडाउन पर क्लिक करें.
- "सभी" टैब पर क्लिक करें. ऐसा इसलिए, क्योंकि हो सकता है कि नया प्रोजेक्ट अभी "हाल ही के" टैब में न दिखे.
init.shचरण में अभी कॉन्फ़िगर किया गया प्रोजेक्ट आईडी चुनें.
👉💻 ज़रूरी प्रोजेक्ट आईडी सेट करें:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 ज़रूरी Google Cloud API चालू करने के लिए, यह कमांड चलाएं:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 अगर आपने agentverse-repo नाम की Artifact Registry रिपॉज़िटरी पहले से नहीं बनाई है, तो इसे बनाने के लिए यह कमांड चलाएं:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
अनुमति सेट अप करना
👉💻 टर्मिनल में ये कमांड चलाकर, ज़रूरी अनुमतियां दें:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 ट्रेनिंग शुरू करने के बाद, हम फ़ाइनल चैलेंज तैयार करेंगे. नीचे दिए गए निर्देशों का पालन करके, स्पेक्ट्र को बुलाया जा सकता है. इससे आपकी फ़ाइनल टेस्टिंग के लिए बॉस तैयार हो जाएंगे.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
बहुत बढ़िया, स्कॉलर. बुनियादी एनचांटमेंट पूरे हो गए हैं. हमारा पवित्र स्थान सुरक्षित है, डेटा की बुनियादी शक्तियों के पोर्टल खुले हैं, और हमारा सेवक शक्तिशाली है. अब हम असली काम शुरू करने के लिए तैयार हैं.
4. ज्ञान की अलकेमी: BigQuery और Gemini की मदद से डेटा को बदलना
स्टैटिक के ख़िलाफ़ लगातार चल रहे युद्ध में, एजेंटवर्स के किसी चैंपियन और डेवलपमेंट के किसी स्पेकटर के बीच होने वाले हर टकराव को बारीकी से रिकॉर्ड किया जाता है. बैटलग्राउंड सिमुलेशन सिस्टम, हमारा मुख्य ट्रेनिंग एनवायरमेंट है. यह हर मुठभेड़ के लिए, एथेरिक लॉग एंट्री अपने-आप जनरेट करता है. ये लिखित अभिलेख हमारे लिए सबसे मूल्यवान सूचना स्रोत हैं, वह अपरिष्कृत अयस्क जिससे हम, विद्वानों के रूप में, रणनीति के उत्तम इस्पात का निर्माण करते हैं। एक विद्वान की वास्तविक शक्ति केवल डेटा रखने में नहीं, बल्कि सूचना के कच्चे, अव्यवस्थित अयस्क को क्रियात्मक ज्ञान के चमकदार, सुव्यवस्थित इस्पात में परिवर्तित करने की क्षमता में निहित है। हम डेटा रसायन शास्त्र की मूलभूत प्रक्रिया का पालन करेंगे।

इस प्रोसेस में कई चरण शामिल हैं. यह पूरी प्रोसेस, Google BigQuery के दायरे में ही पूरी की जाएगी. हम एक जादुई लेंस का इस्तेमाल करके, बिना स्क्रोल किए अपने GCS संग्रह को देखना शुरू करेंगे. इसके बाद, हम Gemini को बुलाएंगे, ताकि वह बैटल लॉग की कविता जैसी, बिना किसी स्ट्रक्चर वाली कहानियों को पढ़ सके और उनका मतलब समझ सके. आखिर में, हम रॉ डेटा को साफ़-सुथरी और आपस में जुड़ी हुई टेबल के सेट में बदल देंगे. हमारी पहली ग्रिमोइर. इसके बाद, उससे ऐसा सवाल पूछें जिसका जवाब सिर्फ़ इस नए स्ट्रक्चर से दिया जा सकता हो.
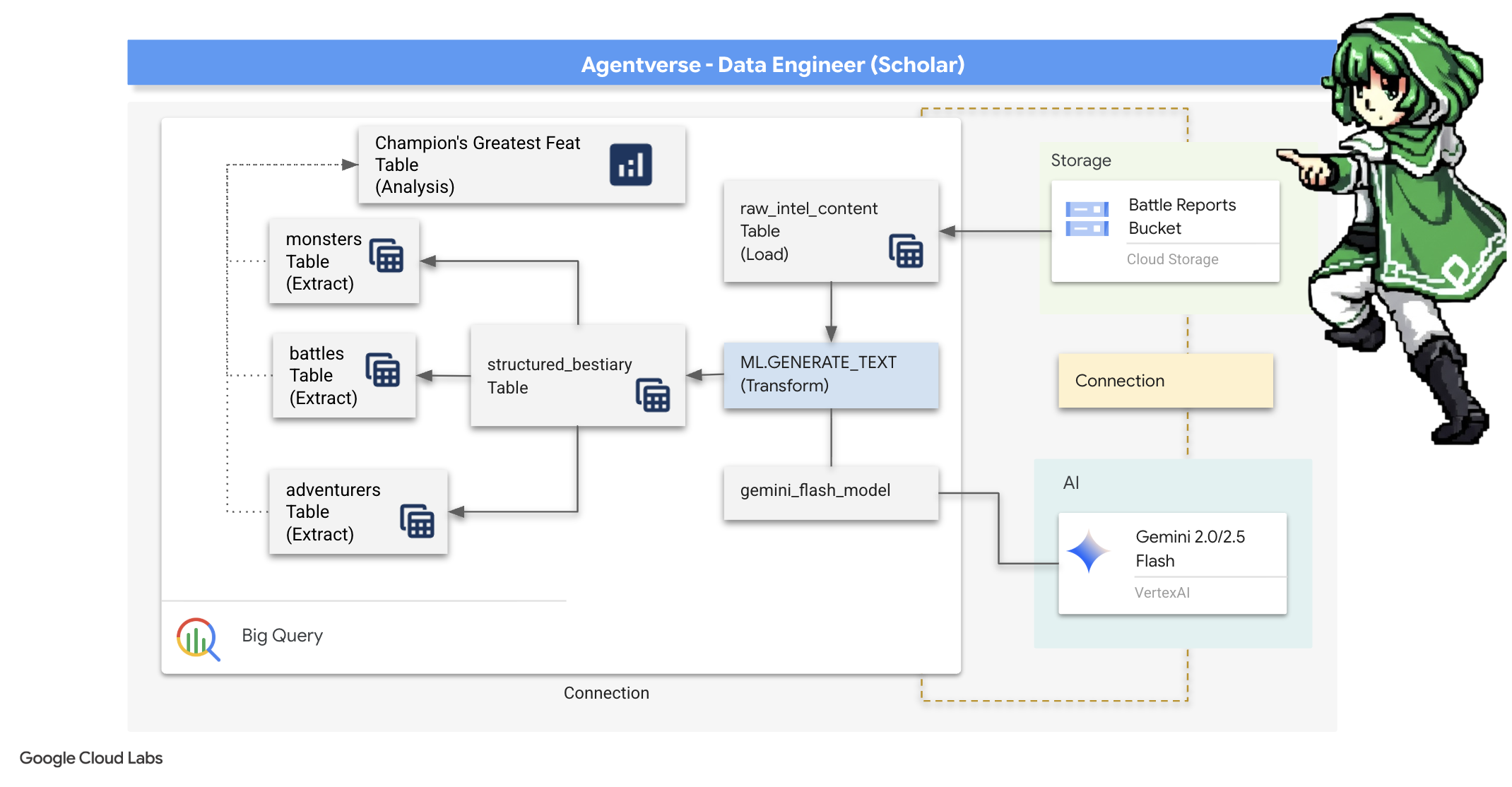
The Lens of Scrutiny: Peering into GCS with BigQuery External Tables
हमारा पहला काम एक ऐसा लेंस बनाना है जिससे हम अपने GCS संग्रह का कॉन्टेंट देख सकें. हालांकि, ऐसा करते समय हमें स्क्रोल में कोई बदलाव नहीं करना है. बाहरी टेबल, इस लेंस की तरह होती है. यह रॉ टेक्स्ट फ़ाइलों को टेबल जैसे स्ट्रक्चर में मैप करती है, ताकि BigQuery सीधे तौर पर क्वेरी कर सके.
इसके लिए, हमें सबसे पहले एक स्टेबल ले लाइन ऑफ़ पावर, यानी CONNECTION रिसॉर्स बनाना होगा. यह हमारे BigQuery डेटा वेयरहाउस को GCS संग्रह से सुरक्षित तरीके से लिंक करता है.
👉💻 स्टोरेज सेट अप करने और कॉन्ड्यूइट बनाने के लिए, Cloud Shell टर्मिनल में यह कमांड चलाएं:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 ज़रूरी जानकारी! आपको बाद में एक मैसेज दिखेगा!
दूसरे चरण की सेटअप स्क्रिप्ट ने बैकग्राउंड में एक प्रोसेस शुरू की है. कुछ मिनट बाद, आपके टर्मिनल में एक मैसेज पॉप अप होगा. यह मैसेज कुछ ऐसा दिखेगा:[1]+ Done gcloud sql instances create ...यह सामान्य है और ऐसा होना चाहिए. इसका मतलब है कि आपका Cloud SQL डेटाबेस बन गया है. इस मैसेज को अनदेखा करके, काम जारी रखा जा सकता है.
बाहरी टेबल बनाने से पहले, आपको वह डेटासेट बनाना होगा जिसमें यह टेबल शामिल होगी.
👉💻 Cloud Shell टर्मिनल में यह आसान निर्देश चलाएं:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 अब हमें कॉन्ड्यूइट के मैजिकल सिग्नेचर को, GCS संग्रह से डेटा पढ़ने और Gemini से सलाह लेने के लिए ज़रूरी अनुमतियां देनी होंगी.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 अपने Cloud Shell टर्मिनल में, बकेट का नाम दिखाने के लिए यह कमांड चलाएं:
echo $BUCKET_NAME
आपके टर्मिनल पर, your-project-id-gcs-bucket जैसा नाम दिखेगा. आपको इसकी ज़रूरत अगले चरणों में पड़ेगी.
👉 आपको Google Cloud Console में BigQuery क्वेरी एडिटर से, अगला कमांड चलाना होगा. यहां तक पहुंचने का सबसे आसान तरीका यह है कि नीचे दिए गए लिंक को ब्राउज़र के नए टैब में खोलें. यह आपको सीधे Google Cloud Console के सही पेज पर ले जाएगा.
https://console.cloud.google.com/bigquery
👉 पेज लोड होने के बाद, नीले रंग के + बटन (नई क्वेरी लिखें) पर क्लिक करें. इससे नया एडिटर टैब खुल जाएगा.
अब हम डेटा डेफ़िनिशन लैंग्वेज (डीडीएल) का इस्तेमाल करके, अपना मैजिकल लेंस बनाते हैं. इससे BigQuery को यह पता चलता है कि उसे कहां देखना है और क्या देखना है.
👉📜 आपने जो BigQuery क्वेरी एडिटर खोला है उसमें यह एसक्यूएल चिपकाएं. REPLACE-WITH-YOUR-BUCKET-NAME को बदलना न भूलें
में, अभी कॉपी किए गए बकेट का नाम डालें. इसके बाद, चलाएं पर क्लिक करें:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 "लेंस से देखें" सुविधा का इस्तेमाल करके, क्वेरी चलाएं और फ़ाइलों का कॉन्टेंट देखें.
SELECT * FROM bestiary_data.raw_intel_content_table;
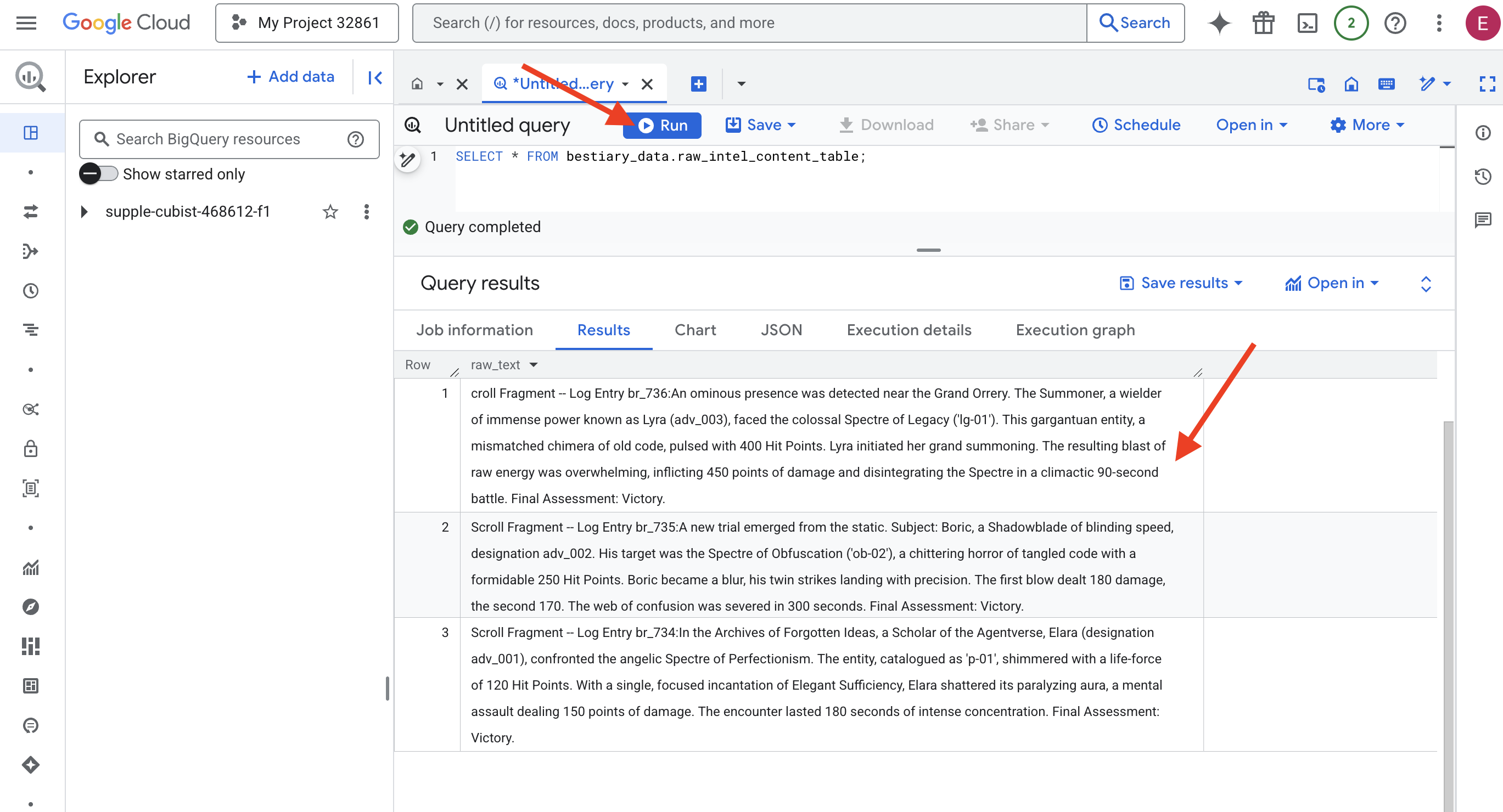
हमारा लेंस अपनी जगह पर है. अब हम स्क्रोल का रॉ टेक्स्ट देख सकते हैं. हालांकि, पढ़ने का मतलब समझना नहीं होता.
'भूल गए आइडिया' के संग्रह में, एजेंटवर्स की स्कॉलर एलारा (पदनाम adv_001) का सामना, परफ़ेक्शनिज़्म के एंजेलिक स्पेक्टर से हुआ. ‘p-01' के तौर पर कैटलॉग की गई इकाई में, 120 हिट पॉइंट की ऊर्जा थी. एलारा ने एक ही बार में, 'एलिगेंट सफ़िशिएंसी' मंत्र का इस्तेमाल करके, उसे लकवा मारने वाली आभा से आज़ाद कर दिया. यह एक मानसिक हमला था, जिससे उसे 150 पॉइंट का नुकसान हुआ. यह मुठभेड़ 180 सेकंड तक चली. फ़ाइनल आकलन: जीत.
ये स्क्रोल, टेबल और लाइनों में नहीं लिखे गए हैं. इसके बजाय, इन्हें गाथाओं के घुमावदार गद्य में लिखा गया है. यह हमारी पहली बड़ी परीक्षा है.
The Scholar's Divination: Turning Text into a Table with SQL
समस्या यह है कि शैडोब्लेड के दोहरे हमलों की रिपोर्ट, समनर की एक ऐसी कहानी से बहुत अलग होती है जिसमें वह एक विनाशकारी हमले के लिए बहुत ज़्यादा ताकत इकट्ठा करता है. हम इस डेटा को सीधे तौर पर इंपोर्ट नहीं कर सकते. हमें इसे समझना होगा. यह जादू का पल है. हम एक ही एसक्यूएल क्वेरी का इस्तेमाल करेंगे. इससे BigQuery में मौजूद सभी फ़ाइलों के सभी रिकॉर्ड को पढ़ा, समझा, और व्यवस्थित किया जा सकेगा.
👉💻 Cloud Shell टर्मिनल पर वापस जाकर, कनेक्शन का नाम दिखाने के लिए यह कमांड चलाएं:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
आपके टर्मिनल पर पूरी कनेक्शन स्ट्रिंग दिखेगी. इस पूरी स्ट्रिंग को चुनें और कॉपी करें. आपको अगले चरण में इसकी ज़रूरत पड़ेगी
हम एक ही, लेकिन असरदार मंत्र का इस्तेमाल करेंगे: ML.GENERATE_TEXT. इस स्पेल में, Gemini को बुलाया जाता है. इसके बाद, उसे हर स्क्रोल दिखाया जाता है और उसे मुख्य तथ्यों को स्ट्रक्चर्ड JSON ऑब्जेक्ट के तौर पर दिखाने का निर्देश दिया जाता है.
👉📜 BigQuery Studio में, Gemini मॉडल का रेफ़रंस बनाएं. इससे Gemini Flash Oracle, हमारी BigQuery लाइब्रेरी से जुड़ जाता है. इसलिए, हम इसे अपनी क्वेरी में कॉल कर सकते हैं. बदले गए
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING में, अभी-अभी अपने टर्मिनल से कॉपी की गई पूरी कनेक्शन स्ट्रिंग डालें.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 अब, ट्रांसम्यूटेशन का बड़ा जादू दिखाएं. यह क्वेरी, रॉ टेक्स्ट को पढ़ती है. इसके बाद, हर स्क्रोल के लिए ज़्यादा जानकारी वाला प्रॉम्प्ट बनाती है और उसे Gemini को भेजती है. इसके बाद, एआई से मिले स्ट्रक्चर्ड JSON जवाब से नई स्टेजिंग टेबल बनाती है.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
ट्रांसम्यूटेशन पूरा हो गया है, लेकिन नतीजा अभी तक पूरी तरह से सटीक नहीं है. Gemini मॉडल, जवाब को स्टैंडर्ड फ़ॉर्मैट में दिखाता है. इसमें, हमारे हिसाब से JSON को एक बड़े स्ट्रक्चर में रैप किया जाता है. इस स्ट्रक्चर में, सोच-समझकर जवाब देने की प्रोसेस के बारे में मेटाडेटा शामिल होता है. इसे बेहतर बनाने से पहले, हम इस कच्ची भविष्यवाणी को देख लेते हैं.
👉📜 Gemini मॉडल से मिले रॉ आउटपुट की जाँच करने के लिए, क्वेरी चलाएँ:
SELECT * FROM bestiary_data.structured_bestiary;
👀 आपको structured_data नाम का एक कॉलम दिखेगा. हर लाइन का कॉन्टेंट, इस मुश्किल JSON ऑब्जेक्ट की तरह दिखेगा:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
जैसा कि आप देख सकते हैं, हमें जो साफ़-सुथरा JSON ऑब्जेक्ट चाहिए था वह इस स्ट्रक्चर में काफ़ी अंदर है. हमें अब क्या करना है, यह साफ़ तौर पर पता है. हमें इस स्ट्रक्चर को व्यवस्थित तरीके से समझने और इसमें मौजूद ज्ञान को निकालने के लिए, एक रस्म पूरी करनी होगी.
The Ritual of Cleansing: Normalizing GenAI Output with SQL
Gemini ने जवाब दे दिया है, लेकिन यह जवाब अभी तैयार नहीं है. इसमें कुछ और जानकारी (उम्मीदवार, जवाब पूरा होने की वजह वगैरह) शामिल की जानी है. एक सच्चा स्कॉलर, सिर्फ़ भविष्यवाणी को नहीं पढ़ता, बल्कि वह उसमें छिपी अहम जानकारी को ध्यान से निकालता है और उसे आने वाले समय में इस्तेमाल करने के लिए, सही किताबों में लिखता है.
अब हम अपने आखिरी सेट के मंत्रों का इस्तेमाल करेंगे. यह एक ही स्क्रिप्ट ये काम करेगी:
- हमारी स्टेजिंग टेबल से, नेस्ट किए गए रॉ JSON को पढ़ें.
- मुख्य डेटा पाने के लिए, उसे साफ़ करें और पार्स करें.
- काम की जानकारी को तीन फ़ाइनल टेबल में लिखो: राक्षस, एडवेंचरर, और लड़ाइयां.
👉📜 BigQuery के नए क्वेरी एडिटर में, डेटा को साफ़ करने वाला लेंस बनाने के लिए, यह स्पेल चलाएं:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 बीस्टियरी की पुष्टि करें:
SELECT * FROM bestiary_data.monsters;
इसके बाद, हम 'चैंपियन की सूची' बनाएंगे. इसमें उन साहसी लोगों के नाम शामिल होंगे जिन्होंने इन जानवरों का सामना किया है.
👉📜 नए क्वेरी एडिटर में, एडवेंचरर टेबल बनाने के लिए यह स्पेल चलाएं:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 रोल ऑफ़ चैंपियंस की पुष्टि करें:
SELECT * FROM bestiary_data.adventurers;
आखिर में, हम अपनी फ़ैक्ट टेबल बनाएंगे: बैटल का इतिहास. यह टॉम, अन्य दो टॉम को लिंक करता है. साथ ही, हर यूनीक एनकाउंटर की जानकारी रिकॉर्ड करता है. हर बैटल एक यूनीक इवेंट होता है. इसलिए, डुप्लीकेट हटाने की ज़रूरत नहीं होती.
👉📜 नई क्वेरी एडिटर में, बैटल टेबल बनाने के लिए यह स्पेल चलाएं:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Chronicle की पुष्टि करें:
SELECT * FROM bestiary_data.battles;
रणनीति से जुड़ी अहम जानकारी पाना
स्क्रॉल पढ़े जा चुके हैं, ज़रूरी जानकारी निकाल ली गई है, और किताबों में लिख ली गई है. हमारा Grimoire अब सिर्फ़ तथ्यों का कलेक्शन नहीं है, बल्कि यह रणनीतिक ज्ञान का एक रिलेशनल डेटाबेस है. अब हम ऐसे सवाल पूछ सकते हैं जिनके जवाब देना तब मुमकिन नहीं था, जब हमारी जानकारी बिना किसी स्ट्रक्चर वाले टेक्स्ट में मौजूद थी.
अब हम आखिरी और सबसे बड़ी भविष्यवाणी करेंगे. हम एक ऐसा मंत्र डालेंगे जो हमारी तीनों किताबों से एक साथ सलाह लेगा. ये किताबें हैं: मॉन्स्टर की जानकारी देने वाली किताब, चैंपियन की सूची, और लड़ाइयों का इतिहास. इससे हमें काम की अहम जानकारी मिलेगी.
हमारा रणनीतिक सवाल: "हर एडवेंचरर के लिए, सबसे ताकतवर मॉन्स्टर (हिट पॉइंट के हिसाब से) का नाम क्या है जिसे उन्होंने हराया है? साथ ही, उस जीत को हासिल करने में कितना समय लगा?"
यह एक मुश्किल सवाल है. इसके लिए, यह जानना ज़रूरी है कि कौनसे चैंपियन ने कौनसी लड़ाई जीती और उन लड़ाइयों में शामिल मॉन्स्टर के आंकड़े क्या थे. स्ट्रक्चर्ड डेटा मॉडल की यही सबसे बड़ी खासियत है.
👉📜 BigQuery के नए क्वेरी एडिटर में, यह फ़ाइनल कमांड डालें:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
इस क्वेरी का आउटपुट, एक साफ़-सुथरी और बेहतरीन टेबल होगी. इसमें आपके डेटासेट में मौजूद हर एडवेंचरर के लिए, "चैंपियन की सबसे बड़ी जीत की कहानी" के बारे में जानकारी होगी. यह कुछ इस तरह दिख सकता है:
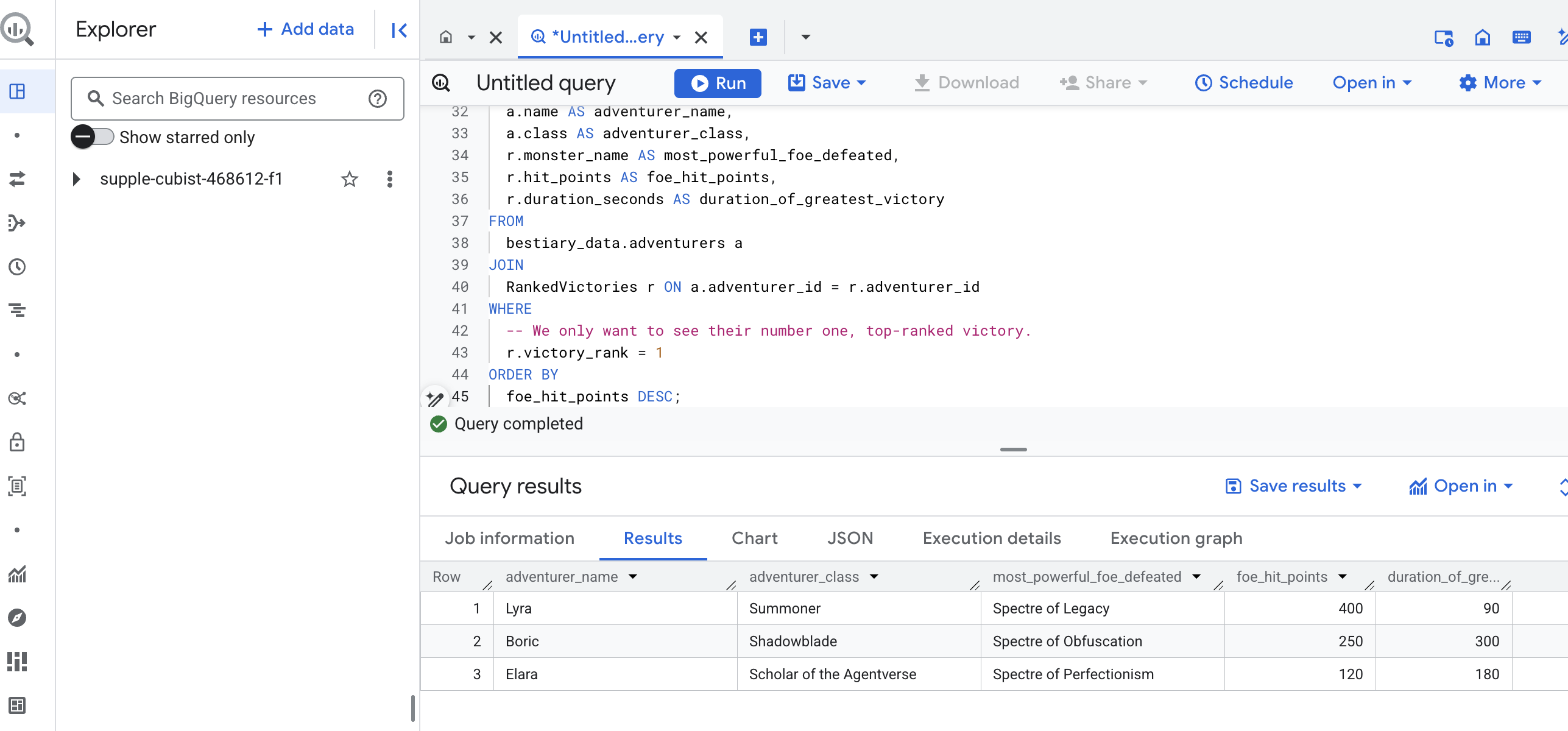
Big Query टैब बंद करें.
इस एक शानदार नतीजे से, पूरी पाइपलाइन की वैल्यू का पता चलता है. आपने युद्ध के मैदान की कच्ची और अव्यवस्थित रिपोर्ट को, शानदार कहानियों और रणनीतिक, डेटा-आधारित अहम जानकारी के सोर्स में बदल दिया है.
गेम नहीं खेलने वालों के लिए
5. The Scribe's Grimoire: In-Datawarehouse Chunking, Embedding, and Search
ऐल्केमिस्ट की लैब में हमारा काम सफल रहा. हमने रॉ डेटा और नैरेटिव स्क्रोल को स्ट्रक्चर्ड और रिलेशनल टेबल में बदल दिया है. यह डेटा साइंस का एक बेहतरीन उदाहरण है. हालांकि, ओरिजनल स्क्रोल में अब भी ऐसी जानकारी मौजूद है जो हमारी स्ट्रक्चर्ड टेबल में पूरी तरह से नहीं दिखती. एक बेहतर एजेंट बनाने के लिए, हमें इस मतलब को अनलॉक करना होगा.
बिना किसी फ़िल्टर के लंबी स्क्रोल की गई सूची, काम की नहीं होती. अगर हमारा एजेंट "पैरालाइजिंग ऑरा" के बारे में कोई सवाल पूछता है, तो सामान्य खोज से पूरी बैटल रिपोर्ट मिल सकती है. इसमें यह वाक्यांश सिर्फ़ एक बार इस्तेमाल किया गया है. साथ ही, जवाब को काम की जानकारी के साथ मिला दिया गया है. एक मास्टर स्कॉलर को पता होता है कि असली ज्ञान, किताबों की संख्या में नहीं, बल्कि सटीक जानकारी में होता है.
हम डेटाबेस में तीन शक्तिशाली रस्मों को पूरा करेंगे. ये सभी रस्में, BigQuery के हमारे पवित्र स्थान में पूरी की जाएंगी.
- डेटा को छोटे-छोटे हिस्सों में बांटना: हम अपने रॉ इंटेलिजेंस लॉग लेंगे और उन्हें छोटे-छोटे, फ़ोकस किए गए, और खुद में शामिल पैसेज में बांटेंगे.
- डिस्टिलेशन (एंबेडिंग) की प्रोसेस: हम Gemini मॉडल से सलाह लेने के लिए BQML का इस्तेमाल करेंगे. इससे हर टेक्स्ट चंक को "सिमैंटिक फ़िंगरप्रिंट" यानी वेक्टर एंबेडिंग में बदला जा सकेगा.
- भविष्य बताने की रस्म (खोजना): हम सामान्य अंग्रेज़ी में कोई सवाल पूछने के लिए, BQML की वेक्टर सर्च सुविधा का इस्तेमाल करेंगे. साथ ही, अपने Grimoire से सबसे काम की और सटीक जानकारी ढूंढेंगे.
इस पूरी प्रोसेस से, खोजे जा सकने वाले एक बेहतरीन नॉलेज बेस को बनाया जा सकता है. इसमें डेटा को BigQuery की सुरक्षा और स्केल से बाहर नहीं ले जाया जाता.
The Ritual of Division: Deconstructing Scrolls with SQL
हमारे पास जानकारी का सोर्स, GCS संग्रह में मौजूद रॉ टेक्स्ट फ़ाइलें हैं. इन्हें हमारी बाहरी टेबल, bestiary_data.raw_intel_content_table के ज़रिए ऐक्सेस किया जा सकता है. हमारा पहला काम एक ऐसा मंत्र लिखना है जो हर लंबे स्क्रोल को पढ़े और उसे छोटे-छोटे, आसानी से समझ में आने वाले वर्स में बांट दे. इस रस्म के लिए, हम "चंक" को एक वाक्य के तौर पर परिभाषित करेंगे.
वाक्य के हिसाब से बांटना, हमारे नैरटिव लॉग के लिए एक साफ़ तौर पर समझ में आने वाला और असरदार शुरुआती पॉइंट है. हालांकि, एक मास्टर स्क्राइब के पास कई चंकिंग रणनीतियां होती हैं. साथ ही, फ़ाइनल खोज की क्वालिटी के लिए सही रणनीति चुनना ज़रूरी होता है. आसान तरीकों में,
- तय की गई लंबाई(साइज़) के हिसाब से चंक बनाना. हालांकि, इससे किसी मुख्य विचार को दो हिस्सों में बांटा जा सकता है.
ज़्यादा बेहतर तरीके से रस्मों को निभाना, जैसे
- रिकर्सिव चंकिंग को अक्सर इस्तेमाल किया जाता है. इसमें टेक्स्ट को नैचुरल बाउंड्री के हिसाब से बांटा जाता है. जैसे, पहले पैराग्राफ़ के हिसाब से और फिर वाक्यों के हिसाब से. इससे सिमैंटिक कॉन्टेक्स्ट को ज़्यादा से ज़्यादा बनाए रखने में मदद मिलती है. ज़्यादा मुश्किल स्क्रिप्ट के लिए.
- कॉन्टेंट के हिसाब से चंक बनाना(दस्तावेज़). इसमें Scribe, दस्तावेज़ के स्ट्रक्चर का इस्तेमाल करता है. जैसे, किसी टेक्निकल मैन्युअल में मौजूद हेडर या कोड के स्क्रोल में मौजूद फ़ंक्शन. इससे वह सबसे सही और असरदार चंक बना पाता है. इसके अलावा, और भी कई सुविधाएं उपलब्ध हैं...
हमारे बैटल लॉग के लिए, यह वाक्य बारीकी से जानकारी और कॉन्टेक्स्ट के बीच सही संतुलन बनाए रखता है.
👉📜 नए BigQuery क्वेरी एडिटर में, यह कमांड चलाएं. इस स्पेल में SPLIT फ़ंक्शन का इस्तेमाल किया जाता है. इससे हर स्क्रोल के टेक्स्ट को हर अवधि (.) पर अलग-अलग किया जाता है. इसके बाद, वाक्यों के नतीजे वाले ऐरे को अलग-अलग लाइनों में अननेस्ट किया जाता है.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 अब, अपनी नई जानकारी को छोटे-छोटे हिस्सों में बांटकर, उसकी जांच करने के लिए कोई क्वेरी चलाएं और देखें कि क्या अंतर है.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
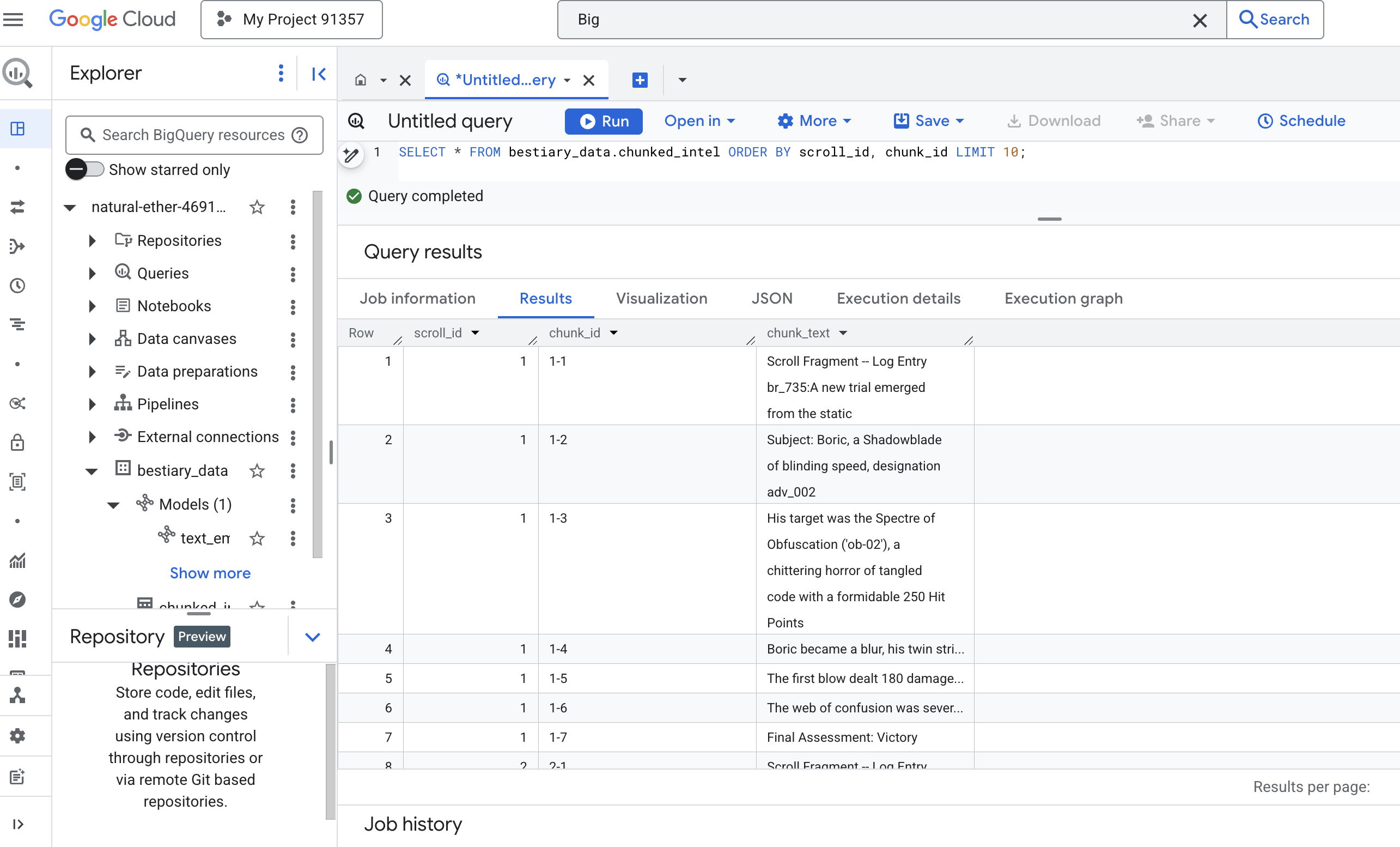
नतीजे देखें. पहले जहां टेक्स्ट का एक बड़ा ब्लॉक होता था वहां अब कई लाइनें हैं. हर लाइन, ओरिजनल स्क्रोल (scroll_id) से जुड़ी है, लेकिन इसमें सिर्फ़ एक वाक्य है. अब हर लाइन, वेक्टर बनाने के लिए सही है.
The Ritual of Distillation: BQML की मदद से टेक्स्ट को वेक्टर में बदलना
👉💻 सबसे पहले, अपने टर्मिनल पर वापस जाएं. इसके बाद, कनेक्शन का नाम दिखाने के लिए यह कमांड चलाएं:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 हमें एक नया BigQuery मॉडल बनाना होगा, जो Gemini के टेक्स्ट एम्बेडिंग की ओर इशारा करता हो. BigQuery Studio में, यहां दिया गया स्पेल चलाएं. ध्यान दें कि आपको REPLACE-WITH-YOUR-FULL-CONNECTION-STRING को उस पूरी कनेक्शन स्ट्रिंग से बदलना होगा जिसे आपने अभी-अभी अपने टर्मिनल से कॉपी किया है.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 अब, ग्रैंड डिस्टिलेशन का जादू चलाओ. यह क्वेरी, ML.GENERATE_EMBEDDING फ़ंक्शन को कॉल करती है. यह फ़ंक्शन, chunked_intel टेबल की हर लाइन को पढ़ेगा. इसके बाद, टेक्स्ट को Gemini के एम्बेडिंग मॉडल को भेजेगा. साथ ही, नतीजे के तौर पर मिले वेक्टर फ़िंगरप्रिंट को नई टेबल में सेव करेगा.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
इस प्रोसेस में एक या दो मिनट लग सकते हैं, क्योंकि BigQuery सभी टेक्स्ट चंक को प्रोसेस करता है.
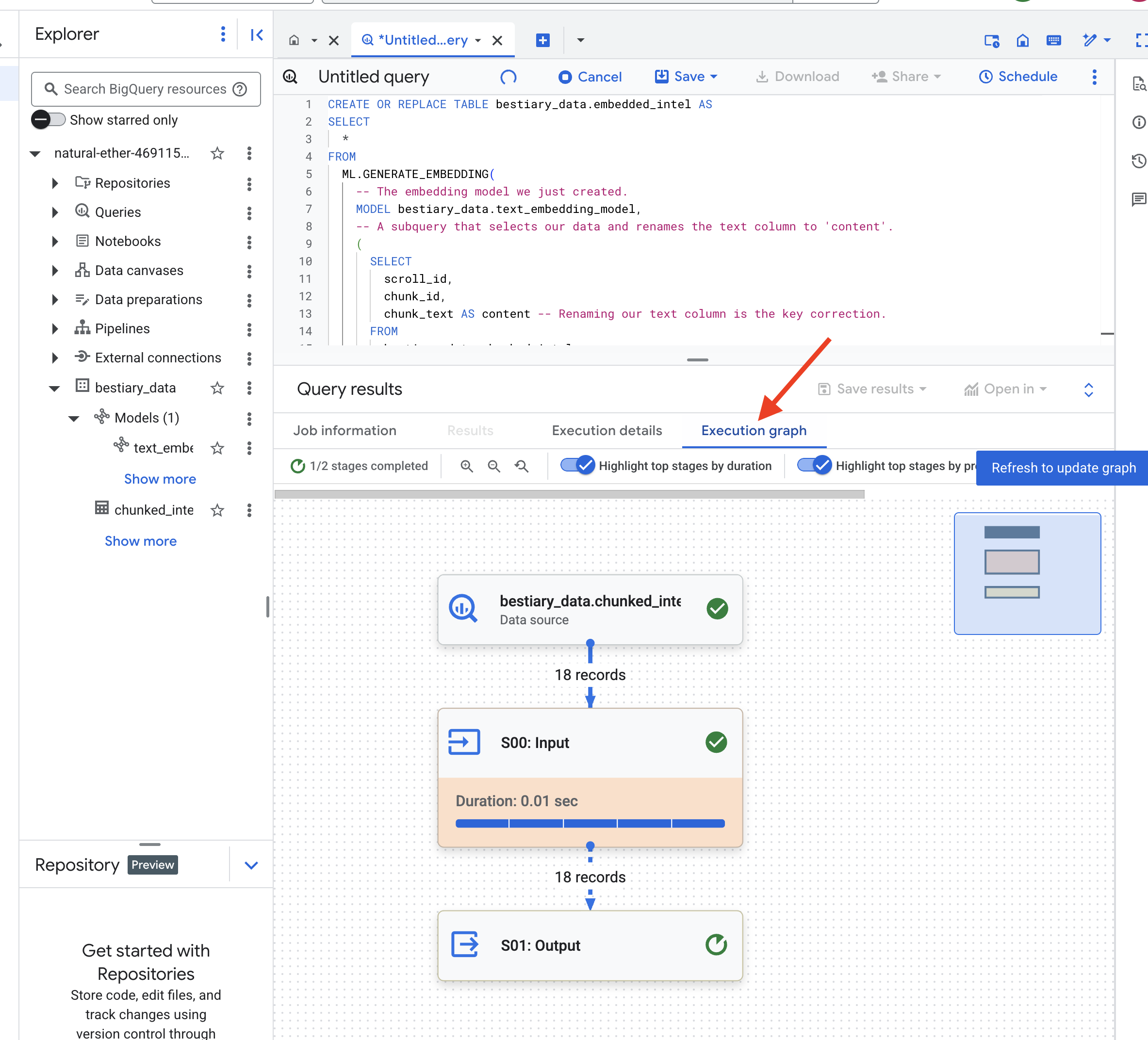
👉📜 प्रोसेस पूरी होने के बाद, नई टेबल में जाकर सिमैंटिक फ़िंगरप्रिंट देखें.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
अब आपको एक नया कॉलम, ml_generate_embedding_result दिखेगा. इसमें आपके टेक्स्ट का डेंस वेक्टर प्रज़ेंटेशन होगा. हमारे Grimoire को अब सिमैंटिक तरीके से कोड किया गया है.
भविष्य बताने की रस्म: BQML की मदद से सिमैंटिक सर्च करना
👉📜 हमारे Grimoire की सबसे बड़ी परीक्षा यह है कि उससे कोई सवाल पूछा जाए. अब हम अपनी आखिरी रस्म पूरी करेंगे: वेक्टर सर्च. यह कीवर्ड की खोज नहीं है, बल्कि मतलब की खोज है. हम नैचुरल लैंग्वेज में एक सवाल पूछेंगे. BQML, हमारे सवाल को तुरंत एम्बेडिंग में बदल देगा. इसके बाद, वह embedded_intel की हमारी पूरी टेबल में ऐसे टेक्स्ट के हिस्से खोजेगा जिनके फ़िंगरप्रिंट का मतलब "सबसे मिलता-जुलता" हो.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
स्पेल का विश्लेषण:
VECTOR_SEARCH: यह मुख्य फ़ंक्शन है, जो खोज को व्यवस्थित करता है.ML.GENERATE_EMBEDDING(इनर क्वेरी): यह जादू है. हम अपनी क्वेरी ('What are the tactics...') को उसी मॉडल का इस्तेमाल करके एम्बेड करते हैं. हालांकि, इसके लिए टास्क टाइप'RETRIEVAL_QUERY'का इस्तेमाल किया जाता है. इसे खास तौर पर क्वेरी के लिए ऑप्टिमाइज़ किया गया है.top_k => 3: हम सबसे ज़्यादा काम के तीन नतीजों के बारे में पूछ रहे हैं.distance_type => 'COSINE': इससे वेक्टर के बीच का "कोण" मेज़र किया जाता है. ऐंगल छोटा होने का मतलब है कि दोनों शब्दों के मतलब ज़्यादा मिलते-जुलते हैं.
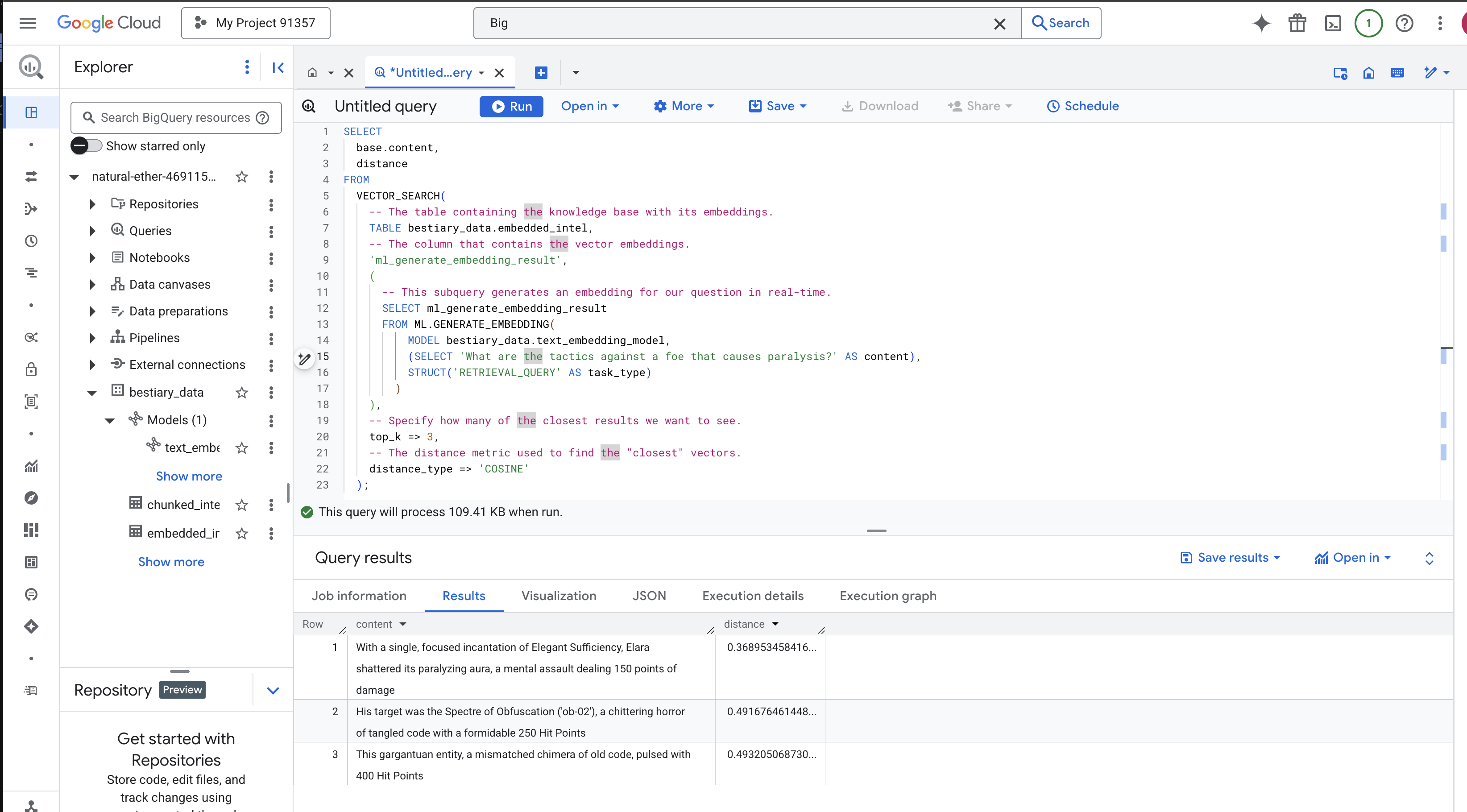
नतीजों को ध्यान से देखें. क्वेरी में "शैटर्ड" या "इनकेंटेशन" शब्द शामिल नहीं था. हालांकि, खोज के सबसे ऊपर यह नतीजा मिला: "विद अ सिंगल, फ़ोकस्ड इनकेंटेशन ऑफ़ ऐलिगेंट सफ़िशिएंसी, एलारा शैटर्ड इट्स पैरलाइज़िंग ऑरा, अ मेंटल असॉल्ट डीलिंग 150 पॉइंट्स ऑफ़ डैमेज". यह सिमैंटिक सर्च की ताकत है. मॉडल ने "काम न करने की स्थिति से बचने के तरीके" के कॉन्सेप्ट को समझा और उस वाक्य को खोजा जिसमें किसी खास और कारगर तरीके के बारे में बताया गया था.
आपने अब डेटा वेयरहाउस में मौजूद डेटा के आधार पर, RAG पाइपलाइन को पूरी तरह से बना लिया है. आपने रॉ डेटा तैयार किया है. इसके बाद, उसे सिमैंटिक वेक्टर में बदला है और मतलब के हिसाब से क्वेरी किया है. BigQuery, बड़े पैमाने पर डेटा का विश्लेषण करने के लिए एक बेहतरीन टूल है. हालांकि, लाइव एजेंट को कम समय में जवाब देने होते हैं. इसलिए, हम इस तैयार डेटा को अक्सर किसी खास ऑपरेशनल डेटाबेस में ट्रांसफ़र करते हैं. यह हमारी अगली ट्रेनिंग का विषय है.
गेम नहीं खेलने वालों के लिए
6. वेक्टर स्क्रिप्टोरियम: अनुमान लगाने के लिए Cloud SQL की मदद से वेक्टर स्टोर बनाना
फ़िलहाल, हमारा Grimoire, स्ट्रक्चर्ड टेबल के तौर पर मौजूद है. यह तथ्यों का एक बेहतरीन कैटलॉग है, लेकिन इसमें मौजूद जानकारी शाब्दिक है. यह monster_id = ‘MN-001' को समझता है, लेकिन "Obfuscation" के पीछे के गहरे और सिमैंटिक मतलब को नहीं समझता. हमारे एजेंट को सही जानकारी देने के लिए, उन्हें बारीकी से और दूरदर्शिता के साथ सलाह देने के लिए, हमें अपनी जानकारी के मूल तत्व को ऐसे फ़ॉर्म में बदलना होगा जो मतलब को कैप्चर करता हो: वेक्टर.
ज्ञान की खोज में, हम एक ऐसी सभ्यता के खंडहरों तक पहुंच गए हैं जिसे लोग लंबे समय से भूल चुके हैं. हमने एक सीलबंद वॉल्ट में दबे हुए, प्राचीन स्क्रोल का एक चेस्ट खोजा है. यह चेस्ट, आश्चर्यजनक रूप से सुरक्षित है. ये सिर्फ़ युद्ध की रिपोर्ट नहीं हैं. इनमें एक ऐसे जानवर को हराने के बारे में गहरी और दार्शनिक जानकारी दी गई है जो सभी महान कामों में बाधा डालता है. स्क्रॉल में इस इकाई को "रेंगने वाली, शांत स्थिरता" और "सृजन के ताने-बाने का ढीला होना" के तौर पर बताया गया है. ऐसा लगता है कि स्टैटिक के बारे में प्राचीन लोगों को भी पता था. यह एक ऐसा खतरा है जो समय-समय पर आता रहता है. हालांकि, समय के साथ इसका इतिहास मिट गया.
यह भूला हुआ ज्ञान हमारी सबसे बड़ी पूंजी है. इससे न सिर्फ़ अलग-अलग मॉन्स्टर को हराने में मदद मिलती है, बल्कि पूरी पार्टी को रणनीति के बारे में अहम जानकारी मिलती है. इस क्षमता को हासिल करने के लिए, अब हम स्कॉलर की असली स्पेलबुक (वेक्टर की क्षमताओं वाला PostgreSQL डेटाबेस) बनाएंगे. साथ ही, एक ऑटोमेटेड वेक्टर स्क्रिप्टोरियम (Dataflow पाइपलाइन) बनाएंगे, ताकि इन स्क्रोल को पढ़ा जा सके, समझा जा सके, और इनकी अहम जानकारी को लिखा जा सके. इससे हमारा Grimoire, तथ्यों की किताब से बदलकर ज्ञान का इंजन बन जाएगा.

फ़ोर्जिंग द स्कॉलर्स स्पेलबुक (Cloud SQL)
इन प्राचीन स्क्रोल की जानकारी को शामिल करने से पहले, हमें यह पुष्टि करनी होगी कि इस जानकारी को शामिल करने के लिए, मैनेज किया गया PostgreSQL Spellbook सफलतापूर्वक बनाया गया है. शुरुआती सेटअप के दौरान, यह आपके लिए पहले ही बना दिया गया होगा.
👉💻 टर्मिनल में, यह कमांड चलाकर पुष्टि करें कि आपका Cloud SQL इंस्टेंस मौजूद है और इस्तेमाल के लिए तैयार है. यह स्क्रिप्ट, इंस्टेंस के सेवा खाते को Vertex AI का इस्तेमाल करने की अनुमति भी देती है. डेटाबेस में सीधे तौर पर एम्बेडिंग जनरेट करने के लिए, यह अनुमति ज़रूरी है.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
अगर कमांड काम करती है और आपके grimoire-spellbook इंस्टेंस के बारे में जानकारी देती है, तो इसका मतलब है कि फ़ोर्ज ने अपना काम सही तरीके से किया है. अब आप अगले मंत्र के लिए तैयार हैं. अगर कमांड से NOT_FOUND गड़बड़ी मिलती है, तो कृपया पक्का करें कि आपने एनवायरमेंट सेट अप करने के शुरुआती चरणों को पूरा कर लिया हो. इसके बाद ही आगे बढ़ें.(data_setup.py)
👉💻 किताब तैयार होने के बाद, हम इसे पहले चैप्टर के लिए खोलते हैं. इसके लिए, हम arcane_wisdom नाम का एक नया डेटाबेस बनाते हैं.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
सिमैंटिक रून लिखना: pgvector की मदद से वेक्टर की क्षमताओं को चालू करना
अब आपका Cloud SQL इंस्टेंस बन गया है. आइए, इसमें मौजूद Cloud SQL Studio का इस्तेमाल करके इससे कनेक्ट करें. इससे आपको वेब पर आधारित इंटरफ़ेस मिलता है. इसकी मदद से, सीधे अपने डेटाबेस पर SQL क्वेरी चलाई जा सकती हैं.
👉💻 सबसे पहले, Cloud SQL Studio पर जाएं. यहां पहुंचने का सबसे आसान और तेज़ तरीका यह है कि आप नए ब्राउज़र टैब में यह लिंक खोलें. इससे आपको सीधे तौर पर, grimoire-spellbook इंस्टेंस के लिए Cloud SQL Studio पर ले जाया जाएगा.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 डेटाबेस के तौर पर arcane_wisdom चुनें. उपयोगकर्ता के तौर पर postgres और पासवर्ड के तौर पर 1234qwer डालें. इसके बाद, पुष्टि करें पर क्लिक करें.
👉📜 SQL Studio के क्वेरी एडिटर में, एडिटर 1 टैब पर जाएं. इसके बाद, वेक्टर डेटा टाइप को चालू करने के लिए, यह एसक्यूएल कोड चिपकाएं:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
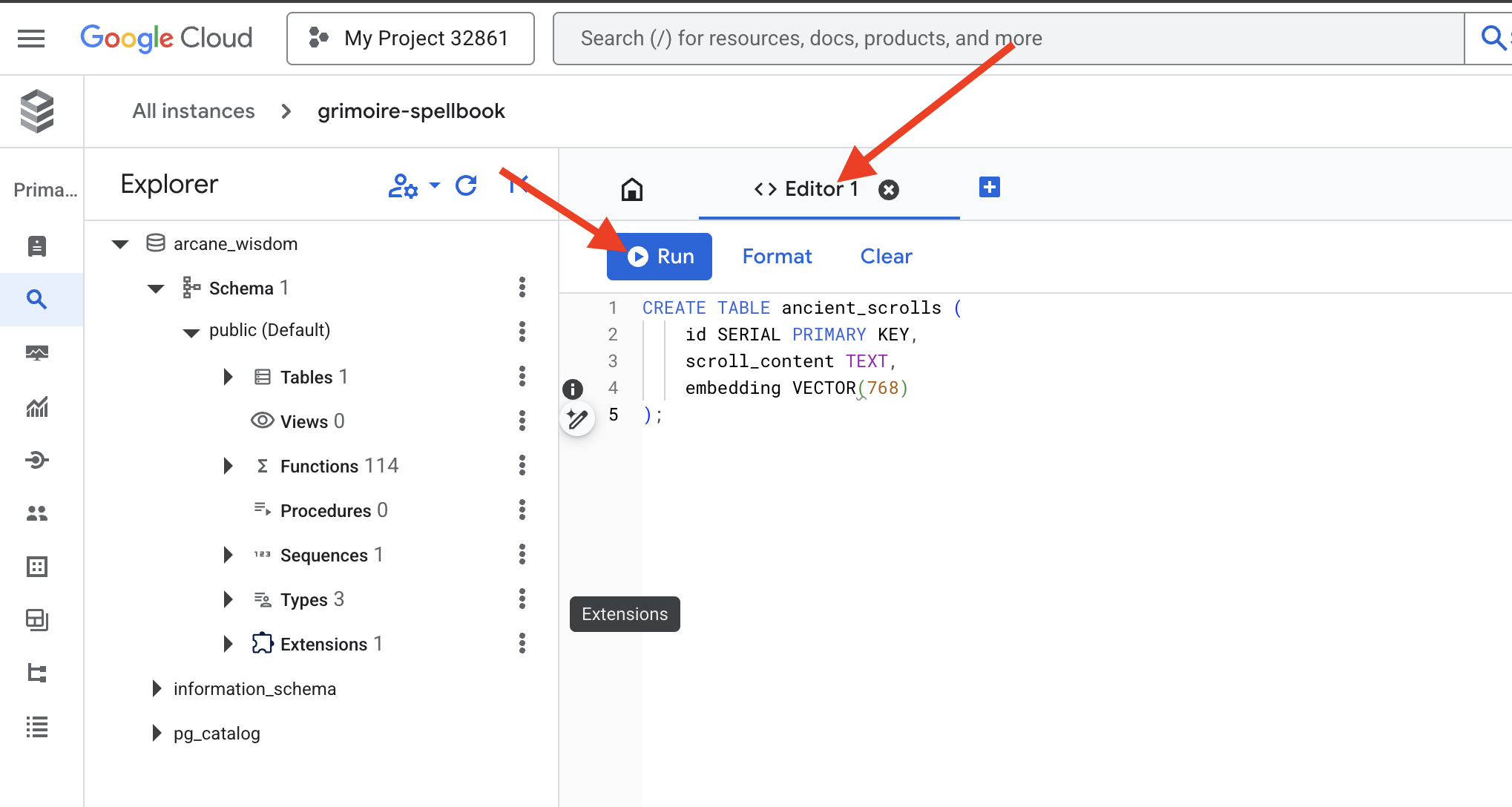
👉📜 Spellbook के पेजों को तैयार करो. इसके लिए, ऐसी टेबल बनाओ जिसमें स्क्रोल की जानकारी शामिल हो.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
VECTOR(768) स्पेलिंग एक अहम जानकारी है. हम जिस Vertex AI एम्बेडिंग मॉडल (textembedding-gecko@003 या इसी तरह का कोई मॉडल) का इस्तेमाल करेंगे वह टेक्स्ट को 768 डाइमेंशन वाले वेक्टर में बदल देता है. हमारे Spellbook के पेजों को इस तरह से तैयार किया जाना चाहिए कि वे ठीक उसी साइज़ के डेटा को सेव कर सकें. डाइमेंशन हमेशा मेल खाने चाहिए.
पहला लिप्यंतरण: मैन्युअल तरीके से लिखने की रस्म
हम डेटाफ़्लो की मदद से, अपने-आप काम करने वाले कई स्क्राइब (डेटाफ़्लो) को निर्देश देने से पहले, हमें एक बार मुख्य काम को मैन्युअल तरीके से करना होगा. इससे हमें दो चरणों में होने वाले इस जादू के बारे में ज़्यादा जानकारी मिलेगी:
- भविष्यवाणी करना: किसी टेक्स्ट को लेकर, Gemini के ओरेकल से सलाह लेना, ताकि उसके सिमैंटिक एसेंस को वेक्टर में बदला जा सके.
- लिखना: ओरिजनल टेक्स्ट और उसके नए वेक्टर एसेंस को हमारे स्पेलबुक में लिखना.
अब, मैन्युअल तरीके से रेंडरिंग करने का तरीका जानें.
👉📜 Cloud SQL Studio में. अब हम embedding() फ़ंक्शन का इस्तेमाल करेंगे. यह google_ml_integration एक्सटेंशन की एक बेहतरीन सुविधा है. इससे हम सीधे तौर पर अपनी एसक्यूएल क्वेरी से Vertex AI के एम्बेडिंग मॉडल को कॉल कर सकते हैं. इससे प्रोसेस काफ़ी आसान हो जाती है.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 नए पेज को पढ़ने के लिए क्वेरी चलाकर, अपने काम की पुष्टि करें:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
आपने RAG के डेटा को लोड करने का मुख्य टास्क मैन्युअल तरीके से पूरा कर लिया है!
सिमैंटिक कंपास को बेहतर बनाना: एचएनएसडब्ल्यू इंडेक्स की मदद से स्पेलबुक को बेहतर बनाना
Spellbook में अब ज्ञान को सेव किया जा सकता है, लेकिन सही स्क्रोल ढूंढने के लिए हर पेज को पढ़ना ज़रूरी है. यह एक-एक करके स्कैन करना है. यह प्रोसेस धीमी है और इसमें ज़्यादा समय लगता है. हमारी क्वेरी को तुरंत सबसे काम की जानकारी तक पहुंचाने के लिए, हमें Spellbook को सिमैंटिक कंपास से जोड़ना होगा. यह एक वेक्टर इंडेक्स होता है.
आइए, इस एनचांटमेंट की वैल्यू को साबित करते हैं.
👉📜 Cloud SQL Studio में, यह स्पेल चलाएं. यह हमारे नए जोड़े गए स्क्रोल को खोजने की प्रोसेस को सिम्युलेट करता है और डेटाबेस से EXPLAIN के प्लान के बारे में पूछता है.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
आउटपुट देखें. आपको -> Seq Scan on ancient_scrolls लिखा हुआ दिखेगा. इससे यह पुष्टि होती है कि डेटाबेस हर लाइन को पढ़ रहा है. execution time पर ध्यान दें.
👉📜 अब, इंडेक्सिंग का जादू शुरू करते हैं. lists पैरामीटर, इंडेक्स को बताता है कि कितने क्लस्टर बनाने हैं. शुरुआत करने के लिए, पंक्तियों की उस संख्या का वर्गमूल निकालें जो आपको चाहिए.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
इंडेक्स बनने तक इंतज़ार करें. एक लाइन के लिए यह प्रोसेस तेज़ी से पूरी हो जाएगी, लेकिन लाखों लाइनों के लिए इसमें समय लग सकता है.
👉📜 अब, ठीक वही EXPLAIN ANALYZE निर्देश फिर से चलाएं:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
नई क्वेरी प्लान देखें. अब आपको -> Index Scan using... दिखेगा. सबसे ज़रूरी बात यह है कि execution time पर ध्यान दें. सिर्फ़ एक एंट्री होने पर भी, यह प्रोसेस काफ़ी तेज़ होगी. आपने अभी-अभी वेक्टर वर्ल्ड में डेटाबेस की परफ़ॉर्मेंस को बेहतर बनाने के मुख्य सिद्धांत के बारे में बताया है.
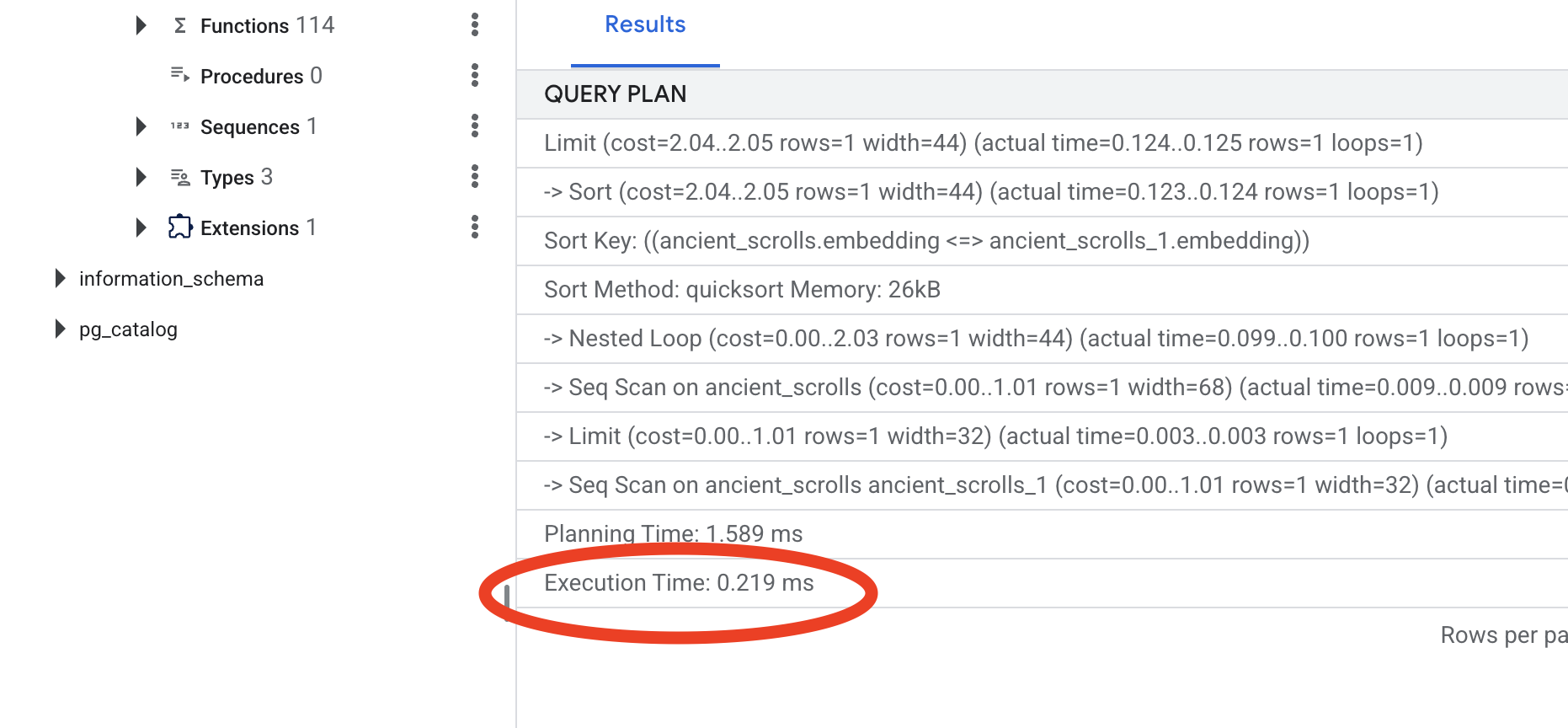
सोर्स डेटा की जांच हो जाने, मैन्युअल प्रोसेस समझ लेने, और Spellbook को तेज़ गति से काम करने के लिए ऑप्टिमाइज़ कर लेने के बाद, अब आपके पास ऑटोमेटेड Scriptorium बनाने का विकल्प है.
गेम नहीं खेलने वालों के लिए
7. The Conduit of Meaning: Building a Dataflow Vectorization Pipeline
अब हम लिपिकों की एक जादुई असेंबली लाइन बनाते हैं. ये लिपिक, हमारे स्क्रोल को पढ़ेंगे, उनकी ख़ासियत को समझेंगे, और उन्हें हमारी नई स्पेलबुक में लिखेंगे. यह एक डेटाफ़्लो पाइपलाइन है, जिसे हम मैन्युअल तरीके से ट्रिगर करेंगे. हालांकि, पाइपलाइन के लिए मास्टर स्पेल लिखने से पहले, हमें सबसे पहले इसका आधार तैयार करना होगा. साथ ही, हमें उस सर्कल को तैयार करना होगा जिससे हम इसे बुलाएंगे.
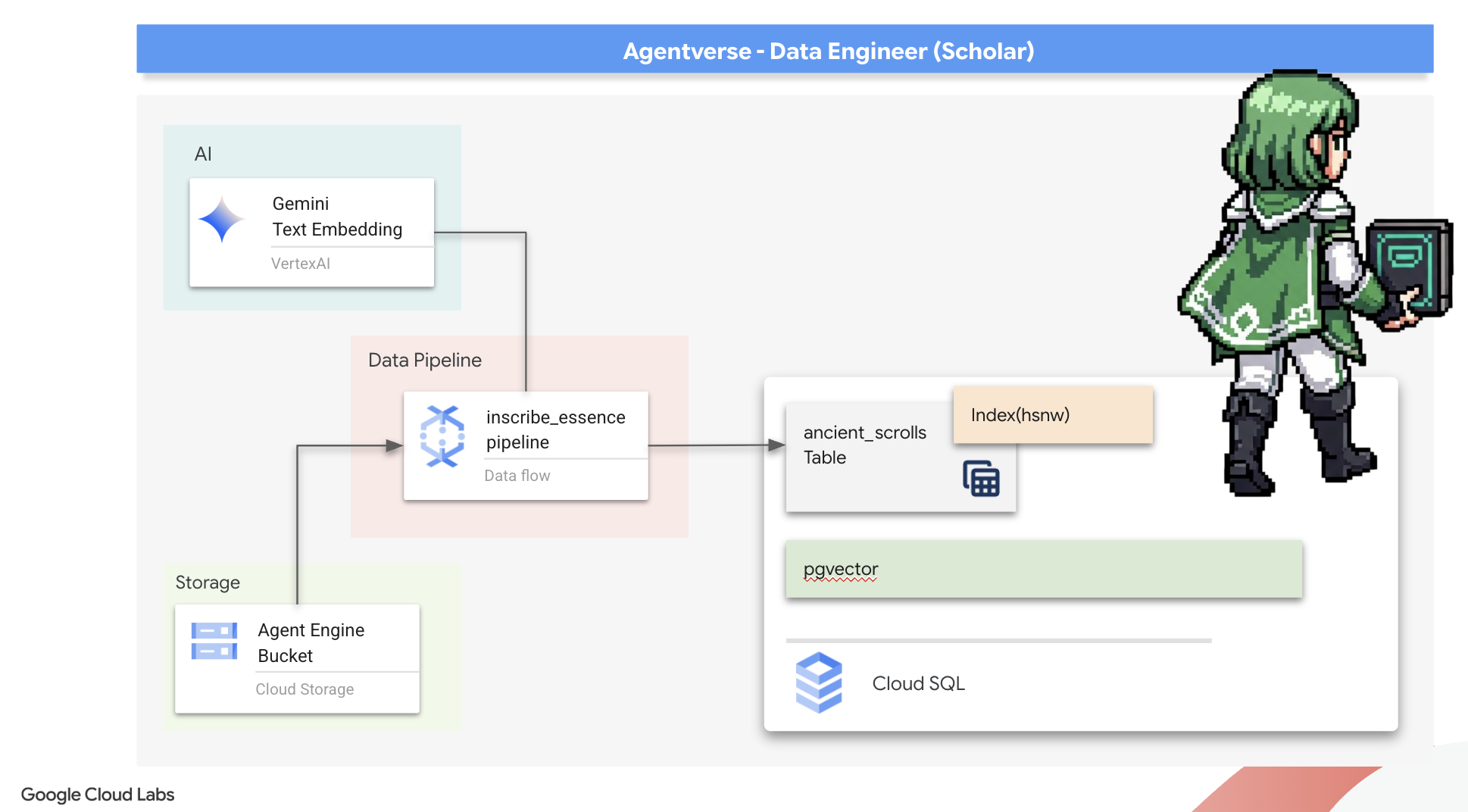
स्क्रिप्टोरियम की फ़ाउंडेशन (वर्कर इमेज) तैयार करना
हमारी Dataflow पाइपलाइन को क्लाउड में अपने-आप काम करने वाले वर्कर की टीम एक्ज़ीक्यूट करेगी. जब भी हम उन्हें कॉल करते हैं, तो उन्हें अपना काम करने के लिए लाइब्रेरी के एक खास सेट की ज़रूरत होती है. हम उन्हें एक सूची दे सकते हैं और उनसे हर बार इन लाइब्रेरी को फ़ेच करने के लिए कह सकते हैं. हालांकि, यह प्रोसेस धीमी और असरदार नहीं है. एक समझदार स्कॉलर, मास्टर लाइब्रेरी को पहले से ही तैयार कर लेता है.
यहां हम Google Cloud Build को कस्टम कंटेनर इमेज बनाने का निर्देश देंगे. यह इमेज, "परफ़ेक्टेड गोलेम" है. इसमें हर लाइब्रेरी और डिपेंडेंसी पहले से लोड होती है, जिसकी ज़रूरत हमारे स्क्राइब को होगी. जब हमारा Dataflow जॉब शुरू होगा, तब वह इस कस्टम इमेज का इस्तेमाल करेगा. इससे वर्कर, अपना टास्क तुरंत शुरू कर पाएंगे.
👉💻 Artifact Registry में अपनी पाइपलाइन की फ़ाउंडेशनल इमेज बनाने और सेव करने के लिए, यह कमांड चलाएं.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 अलग किए गए Python एनवायरमेंट को बनाने और चालू करने के लिए, यहां दिए गए कमांड चलाएं. साथ ही, इसमें ज़रूरी समनिंग लाइब्रेरी इंस्टॉल करें.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
द मास्टर इन्कैंटेशन
अब वह मास्टर स्पेल लिखने का समय आ गया है जो हमारे वेक्टर स्क्रिप्टोरियम को पावर देगा. हम हर मैजिकल कॉम्पोनेंट को शुरू से नहीं लिखेंगे. हमारा काम, Apache Beam की भाषा का इस्तेमाल करके कॉम्पोनेंट को एक लॉजिकल और पावरफ़ुल पाइपलाइन में असेंबल करना है.
- EmbedTextBatch (Gemini से सलाह): आपको एक ऐसा खास स्क्राइब बनाना होगा जिसे "ग्रुप डिविनेशन" करने का तरीका पता हो. यह रॉ टेक्स्ट फ़ाइल का एक बैच लेता है और उन्हें Gemini टेक्स्ट एंबेडिंग मॉडल को दिखाता है. इसके बाद, यह मॉडल से उनका खास हिस्सा (वेक्टर एंबेडिंग) पाता है.
- WriteEssenceToSpellbook (The Final Inscription): यह हमारा संग्रहपाल है. इसे हमारे Cloud SQL Spellbook से सुरक्षित कनेक्शन खोलने के लिए, गुप्त मंत्रों के बारे में पता है. इसका काम, स्क्रोल के कॉन्टेंट और उसके वेक्टर किए गए एसेंस को लेना है. इसके बाद, उन्हें हमेशा के लिए एक नए पेज पर लिखना है.
हमारा मकसद इन कार्रवाइयों को एक साथ जोड़ना है, ताकि जानकारी को बिना किसी रुकावट के उपलब्ध कराया जा सके.
👉✏️ Cloud Shell Editor में, ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py पर जाएं. यहां आपको EmbedTextBatch नाम की DoFn क्लास मिलेगी. टिप्पणी #REPLACE-EMBEDDING-LOGIC ढूंढें. इसकी जगह यह मंत्र डालें.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
इस स्पेल में कई मुख्य पैरामीटर शामिल हैं:
- मॉडल: हमने
text-embedding-005को इसलिए तय किया है, ताकि एक बेहतर और अप-टू-डेट एम्बेडिंग मॉडल का इस्तेमाल किया जा सके. - contents: यह उन फ़ाइलों के बैच का पूरा टेक्स्ट कॉन्टेंट होता है जिन्हें DoFn मिलता है.
- task_type: इसे "RETRIEVAL_DOCUMENT" पर सेट किया जाता है. यह एक अहम निर्देश है. इससे Gemini को ऐसे एम्बेडिंग जनरेट करने के लिए कहा जाता है जिन्हें खास तौर पर खोज के नतीजों में बाद में दिखने के लिए ऑप्टिमाइज़ किया गया हो.
- output_dimensionality: इसे 768 पर सेट किया जाना चाहिए. यह VECTOR(768) डाइमेंशन से पूरी तरह मेल खाता है. हमने Cloud SQL में ancient_scrolls टेबल बनाते समय इसे तय किया था. डाइमेंशन के मैच न होने की वजह से, वेक्टर मैजिक में आम तौर पर गड़बड़ी होती है.
हमारी पाइपलाइन को, जीसीएस के संग्रह में मौजूद सभी प्राचीन स्क्रोल से, बिना किसी स्ट्रक्चर वाला रॉ टेक्स्ट पढ़ना शुरू करना होगा.
👉✏️ ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py में, टिप्पणी #REPLACE ME-READFILE ढूंढें और उसे तीन हिस्सों वाले इस मंत्र से बदलें:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
स्क्रॉल का रॉ टेक्स्ट इकट्ठा करने के बाद, अब हमें उन्हें Gemini को भेजना होगा, ताकि वह उनके बारे में जानकारी दे सके. इसे बेहतर तरीके से करने के लिए, हम सबसे पहले अलग-अलग स्क्रोल को छोटे बैच में ग्रुप करेंगे. इसके बाद, उन बैच को EmbedTextBatch स्क्राइब को सौंप देंगे. इस चरण में, Gemini को समझ में न आने वाली सभी स्क्रोल को "फ़ेल हो गया" फ़ोल्डर में अलग कर दिया जाएगा, ताकि बाद में उनकी समीक्षा की जा सके.
👉✏️ टिप्पणी #REPLACE ME-EMBEDDING ढूंढें और इसे इससे बदलें:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
हमारे स्क्रोल का मुख्य हिस्सा तैयार हो गया है. आखिरी काम यह है कि इस जानकारी को हमेशा के लिए सेव करने के लिए, हम इसे अपनी स्पेलबुक में लिख लें. हम "प्रोसेस किए गए" ढेर से स्क्रोल लेंगे और उन्हें WriteEssenceToSpellbook के संग्रहपाल को सौंप देंगे.
👉✏️ टिप्पणी #REPLACE ME-WRITE TO DB ढूंढें और इसे इससे बदलें:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
एक समझदार स्कॉलर, कभी भी जानकारी को नहीं छोड़ता. भले ही, वह जानकारी किसी काम की न हो. आखिरी चरण के तौर पर, हमें किसी स्क्राइब को यह निर्देश देना होगा कि वह हमारे अनुमान लगाने वाले चरण से "फ़ेल" पाइल को ले और फ़ेल होने की वजहों को लॉग करे. इससे हमें आने वाले समय में अपने रस्मों को बेहतर बनाने में मदद मिलती है.
👉✏️ टिप्पणी #REPLACE ME-LOG FAILURES ढूंढें और इसे इससे बदलें:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
मास्टर इनकैंटेशन अब पूरा हो गया है! आपने अलग-अलग मैजिकल कॉम्पोनेंट को एक साथ जोड़कर, कई चरणों वाली एक असरदार डेटा पाइपलाइन तैयार कर ली है. inscribe_essence_pipeline.py फ़ाइल को सेव करें. अब Scriptorium को बुलाया जा सकता है.
अब हम डेटाफ़्लो सेवा को यह निर्देश देने के लिए, ग्रैंड समनिंग स्पेल का इस्तेमाल करते हैं कि वह हमारे गोलेम को चालू करे और डेटा लिखने की प्रोसेस शुरू करे.
👉💻 अपने टर्मिनल में, यह कमांड लाइन चलाएं
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 ज़रूरी सूचना! अगर संसाधन से जुड़ी गड़बड़ी ZONE_RESOURCE_POOL_EXHAUSTED की वजह से नौकरी पूरी नहीं होती है, तो ऐसा हो सकता है कि चुने गए इलाके में, कम प्रतिष्ठा वाले इस खाते के लिए संसाधन उपलब्ध न हों. Google Cloud की सबसे बड़ी ताकत, दुनिया भर में इसकी पहुंच है! किसी दूसरी जगह पर गोलेम को बुलाकर देखें. इसके लिए, ऊपर दिए गए निर्देश में --region=$REGION की जगह कोई दूसरा क्षेत्र डालें. जैसे,
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
, और इसे फिर से चलाएं. 🎰
इस प्रोसेस को शुरू होने और पूरा होने में करीब तीन से पांच मिनट लगेंगे. इसे Dataflow कंसोल में लाइव देखा जा सकता है.
👉Dataflow Console पर जाएं: इसका सबसे आसान तरीका यह है कि इस लिंक को नए ब्राउज़र टैब में खोलें:
https://console.cloud.google.com/dataflow
👉 अपनी नौकरी ढूंढें और उस पर क्लिक करें: आपको अपनी नौकरी की सूची में वह नौकरी दिखेगी जिसे आपने नाम दिया था (inscribe-essence-job या इसी तरह का कोई नाम). नौकरी की ज़्यादा जानकारी वाला पेज खोलने के लिए, नौकरी के नाम पर क्लिक करें. पाइपलाइन देखें:
- शुरू हो रहा है: पहले तीन मिनट तक, जॉब की स्थिति "चल रही है" होगी, क्योंकि Dataflow ज़रूरी संसाधन उपलब्ध कराता है. आपको ग्राफ़ दिखेगा, लेकिन हो सकता है कि आपको अभी डेटा न दिखे.
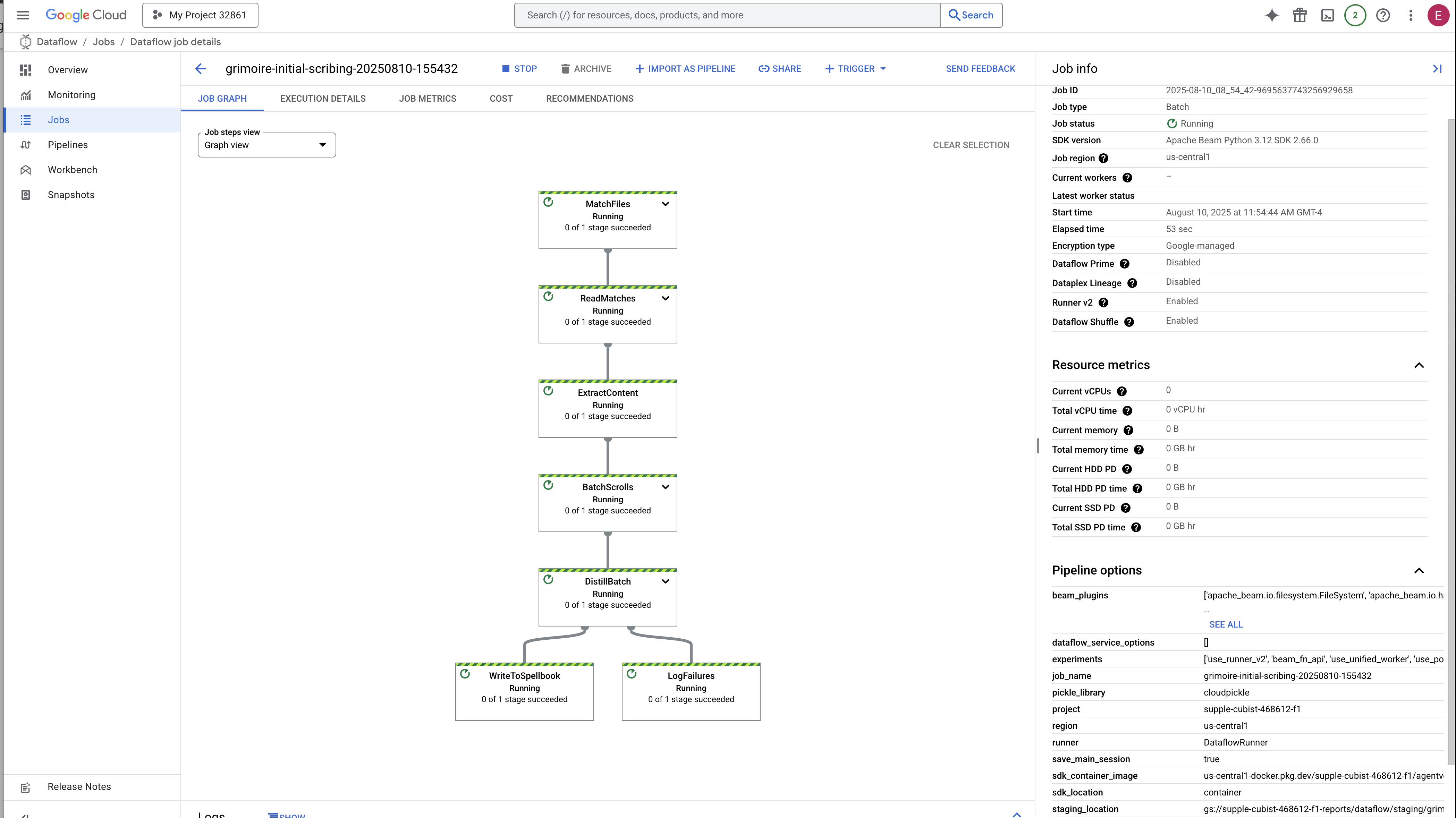
- पूरा हो गया: प्रोसेस पूरी होने पर, जॉब का स्टेटस बदलकर "सफल" हो जाएगा. साथ ही, ग्राफ़ में प्रोसेस किए गए रिकॉर्ड की कुल संख्या दिखेगी.
लिखे गए लेख की पुष्टि करना
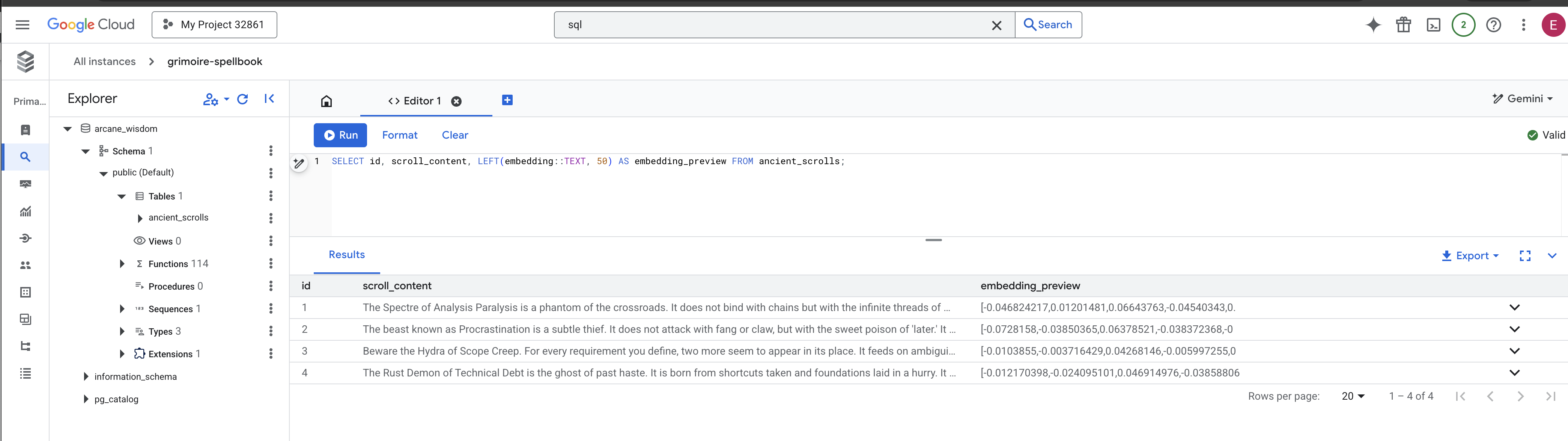
👉📜 एसक्यूएल स्टूडियो में वापस जाकर, यहां दी गई क्वेरी चलाएं. इससे यह पुष्टि की जा सकेगी कि आपके स्क्रोल और उनके सिमैंटिक एसेंस को सही तरीके से लिखा गया है.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
इससे आपको स्क्रोल का आईडी, उसका ओरिजनल टेक्स्ट, और मैजिकल वेक्टर एसेंस का प्रीव्यू दिखेगा. यह एसेंस अब आपके ग्रिमॉयर में हमेशा के लिए सेव हो गया है.
अब आपका स्कॉलर्स ग्रिमॉयर, एक बेहतरीन नॉलेज इंजन बन गया है. अगले चैप्टर में, इसके बारे में सवाल पूछे जा सकते हैं.
8. आखिरी रून को सील करना: आरएजी एजेंट की मदद से ज्ञान को ऐक्टिवेट करना
अब आपका Grimoire सिर्फ़ एक डेटाबेस नहीं है. यह वेक्टर के तौर पर सेव की गई जानकारी का एक बड़ा स्रोत है. यह एक ऐसा ओरेकल है जो सवाल का इंतज़ार कर रहा है.
अब हम एक स्कॉलर की असली परीक्षा लेंगे: हम इस ज्ञान को अनलॉक करने की कुंजी तैयार करेंगे. हम Retrieval-Augmented Generation (RAG) एजेंट बनाएंगे. यह एक जादुई कॉन्सेप्ट है. यह सामान्य भाषा में पूछे गए सवाल को समझ सकता है. साथ ही, सबसे सटीक और काम की जानकारी के लिए, ग्रिमोइर से सलाह ले सकता है. इसके बाद, यह उस जानकारी का इस्तेमाल करके, कॉन्टेक्स्ट के हिसाब से सटीक जवाब जनरेट करता है.

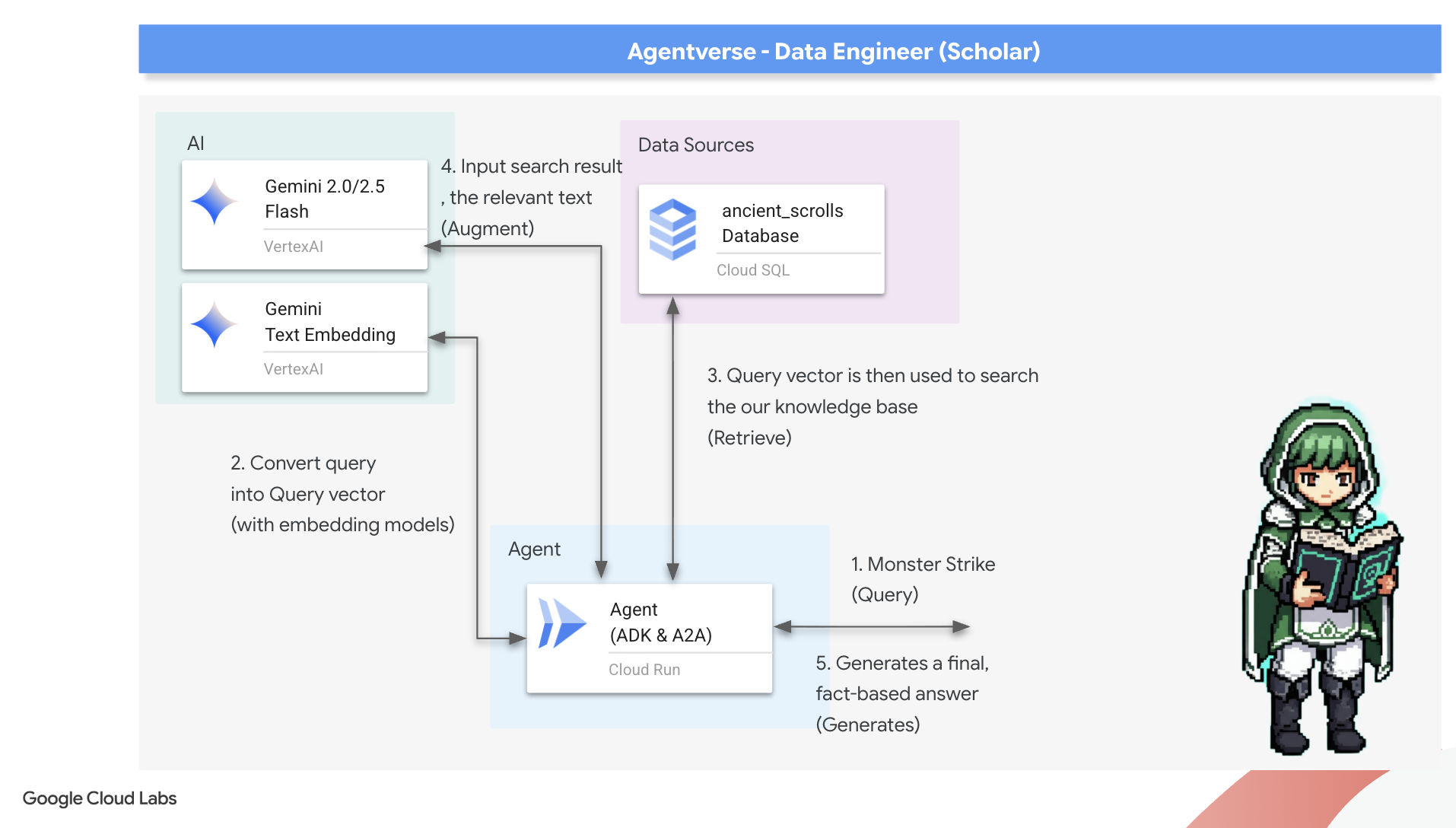
पहला रन: क्वेरी डिस्टिलेशन का मंत्र
इससे पहले कि हमारा एजेंट, ग्रिमॉयर में खोज कर सके, उसे पूछे गए सवाल का मतलब समझना होगा. टेक्स्ट की एक सामान्य स्ट्रिंग, हमारे वेक्टर की मदद से काम करने वाले Spellbook के लिए कोई मायने नहीं रखती. एजेंट को सबसे पहले क्वेरी लेनी होगी. इसके बाद, उसी Gemini मॉडल का इस्तेमाल करके, उसे क्वेरी वेक्टर में बदलना होगा.
👉✏️ Cloud Shell Editor में, ~~/agentverse-dataengineer/scholar/agent.py फ़ाइल पर जाएं. इसके बाद, टिप्पणी #REPLACE RAG-CONVERT EMBEDDING ढूंढें और उसे इस मंत्र से बदलें. इससे एजेंट को यह पता चलता है कि उपयोगकर्ता के सवाल को जादुई जवाब में कैसे बदला जाए.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
क्वेरी की जानकारी मिलने के बाद, एजेंट अब Grimoire से सलाह ले सकता है. यह क्वेरी वेक्टर को हमारे pgvector-enchanted डेटाबेस को भेजेगा और एक अहम सवाल पूछेगा: "मुझे ऐसे प्राचीन स्क्रोल दिखाओ जिनकी मूल भावना, मेरी क्वेरी की मूल भावना से सबसे ज़्यादा मिलती-जुलती हो."
इसके लिए, कोसाइन सिमिलैरिटी ऑपरेटर (<=>) का इस्तेमाल किया जाता है. यह एक शक्तिशाली रून है, जो हाई-डाइमेंशनल स्पेस में वेक्टर के बीच की दूरी का हिसाब लगाता है.
👉✏️ agent.py में, #REPLACE RAG-RETRIEVE टिप्पणी ढूंढें और उसे इस स्क्रिप्ट से बदलें:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
आखिरी चरण में, एजेंट को इस नए और दमदार टूल का ऐक्सेस देना होता है. हम अपने grimoire_lookup फ़ंक्शन को, जादू से जुड़ी चीज़ों की सूची में जोड़ेंगे.
👉✏️ agent.py में, #REPLACE-CALL RAG टिप्पणी ढूंढें और उसे इस लाइन से बदलें:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
इस कॉन्फ़िगरेशन से, आपके एजेंट को ये सुविधाएं मिलती हैं:
model="gemini-2.5-flash": यह विकल्प, किसी खास लार्ज लैंग्वेज मॉडल को चुनता है. यह मॉडल, एजेंट के "दिमाग" के तौर पर काम करता है. इससे एजेंट को तर्क करने और टेक्स्ट जनरेट करने में मदद मिलती है.name="scholar_agent": यह आपके एजेंट को यूनीक नाम असाइन करता है.instruction="...You are the Scholar...": यह सिस्टम प्रॉम्प्ट है, जो कॉन्फ़िगरेशन का सबसे अहम हिस्सा है. इसमें एजेंट की पर्सनैलिटी, उसके मकसद, किसी टास्क को पूरा करने के लिए उसे जिस प्रोसेस का पालन करना चाहिए उसके बारे में सटीक जानकारी, और फ़ाइनल आउटपुट के लिए ज़रूरी फ़ॉर्मैट के बारे में बताया गया है.tools=[grimoire_lookup]: यह आखिरी एनचांटमेंट है. इससे एजेंट को, आपके बनाए गएgrimoire_lookupफ़ंक्शन का ऐक्सेस मिलता है. अब एजेंट यह तय कर सकता है कि आपके डेटाबेस से जानकारी पाने के लिए, इस टूल को कब कॉल करना है. यह RAG पैटर्न का मुख्य हिस्सा है.
Scholar's Examination
👉💻 Cloud Shell टर्मिनल में, अपना एनवायरमेंट चालू करें. इसके बाद, Agent Development Kit की मुख्य कमांड का इस्तेमाल करके, अपने Scholar एजेंट को चालू करें:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
आपको ऐसा आउटपुट दिखेगा जिससे यह पुष्टि होगी कि "Scholar Agent" चालू है और काम कर रहा है.
👉💻 अब अपने एजेंट को चुनौती दें. पहले टर्मिनल में, जहां बैटल सिम्युलेशन चल रहा है, एक ऐसा निर्देश दें जिसके लिए Grimoire की जानकारी की ज़रूरत हो:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

टर्मिनल में लॉग देखें. आपको दिखेगा कि एजेंट को क्वेरी मिलती है, वह उसका सार निकालता है, Grimoire में खोज करता है, "टालमटोल" के बारे में काम के स्क्रोल ढूंढता है, और उस जानकारी का इस्तेमाल करके, कॉन्टेक्स्ट के हिसाब से एक असरदार रणनीति बनाता है.
आपने अपना पहला RAG एजेंट बना लिया है और उसे अपने Grimoire की जानकारी दे दी है.
👉💻 एजेंट को कुछ समय के लिए बंद करने के लिए, टर्मिनल में Ctrl+C दबाएं.
Agentverse में Scholar Sentinel को लॉन्च करना
आपके एजेंट ने स्टडी के कंट्रोल किए गए एनवायरमेंट में अपनी समझदारी साबित की है. अब इसे Agentverse में रिलीज़ करने का समय आ गया है. इससे यह एक लोकल कंस्ट्रक्ट से बदलकर, हमेशा उपलब्ध रहने वाला और लड़ाई के लिए तैयार एक ऐसा एजेंट बन जाएगा जिसे कोई भी चैंपियन, कभी भी इस्तेमाल कर सकता है. अब हम अपने एजेंट को Cloud Run पर डिप्लॉय करेंगे.
👉💻 यहां दिया गया ग्रैंड समनिंग स्पेल चलाएं. यह स्क्रिप्ट, सबसे पहले आपके एजेंट को बेहतर Golem (कंटेनर इमेज) में बनाएगी. इसके बाद, इसे आपकी Artifact Registry में सेव करेगी. इसके बाद, उस Golem को एक ऐसी सेवा के तौर पर डिप्लॉय करेगी जिसे आसानी से बढ़ाया जा सकता है, जो सुरक्षित हो, और जिसे सार्वजनिक तौर पर ऐक्सेस किया जा सकता हो.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
आपका स्कॉलर एजेंट अब Agentverse में लाइव है और बैटल के लिए तैयार है.
गेम नहीं खेलने वालों के लिए
9. The Boss Flight
स्क्रॉल पढ़े जा चुके हैं, रस्में पूरी हो चुकी हैं, और चुनौती स्वीकार कर ली गई है. आपका एजेंट सिर्फ़ स्टोरेज में मौजूद कोई आर्टफ़ैक्ट नहीं है. यह Agentverse में एक लाइव ऑपरेटर है, जो अपने पहले मिशन का इंतज़ार कर रहा है. अब समय आ गया है फ़ाइनल ट्रायल का. इसमें, एक ताकतवर दुश्मन के ख़िलाफ़ लाइव-फ़ायरिंग की जाएगी.
अब आपको बैटलग्राउंड सिम्युलेशन में ले जाया जाएगा. यहां आपको अपने नए Shadowblade एजेंट को एक खतरनाक मिनी-बॉस: The Spectre of the Static के ख़िलाफ़ खड़ा करना होगा. यह आपके काम का आखिरी टेस्ट होगा. इसमें एजेंट के मुख्य लॉजिक से लेकर उसके लाइव डिप्लॉयमेंट तक की जांच की जाएगी.
अपने एजेंट का लोकस हासिल करना
बैटलग्राउंड में शामिल होने से पहले, आपके पास दो कुंजियां होनी चाहिए: आपके चैंपियन का यूनीक सिग्नेचर (एजेंट लोकस) और स्पेक्टर के डेन का छिपा हुआ रास्ता (डंजन यूआरएल).
👉💻 सबसे पहले, Agentverse में अपने एजेंट का यूनीक पता हासिल करें. इसे लोकस कहा जाता है. यह लाइव एंडपॉइंट है, जो आपके चैंपियन को बैटलग्राउंड से कनेक्ट करता है.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 इसके बाद, मंज़िल की सटीक जगह चुनें. इस कमांड से, ट्रांसलोकेशन सर्कल की जगह का पता चलता है. यह पोर्टल, स्पेक्टर के डोमेन में मौजूद होता है.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
अहम जानकारी: इन दोनों यूआरएल को तैयार रखें. आपको इनकी ज़रूरत आखिरी चरण में पड़ेगी.
स्पेक्टर का सामना करना
निर्देशांक मिलने के बाद, अब आपको ट्रांसलोकेशन सर्कल पर जाना होगा. इसके बाद, लड़ाई में शामिल होने के लिए मंत्र का इस्तेमाल करें.
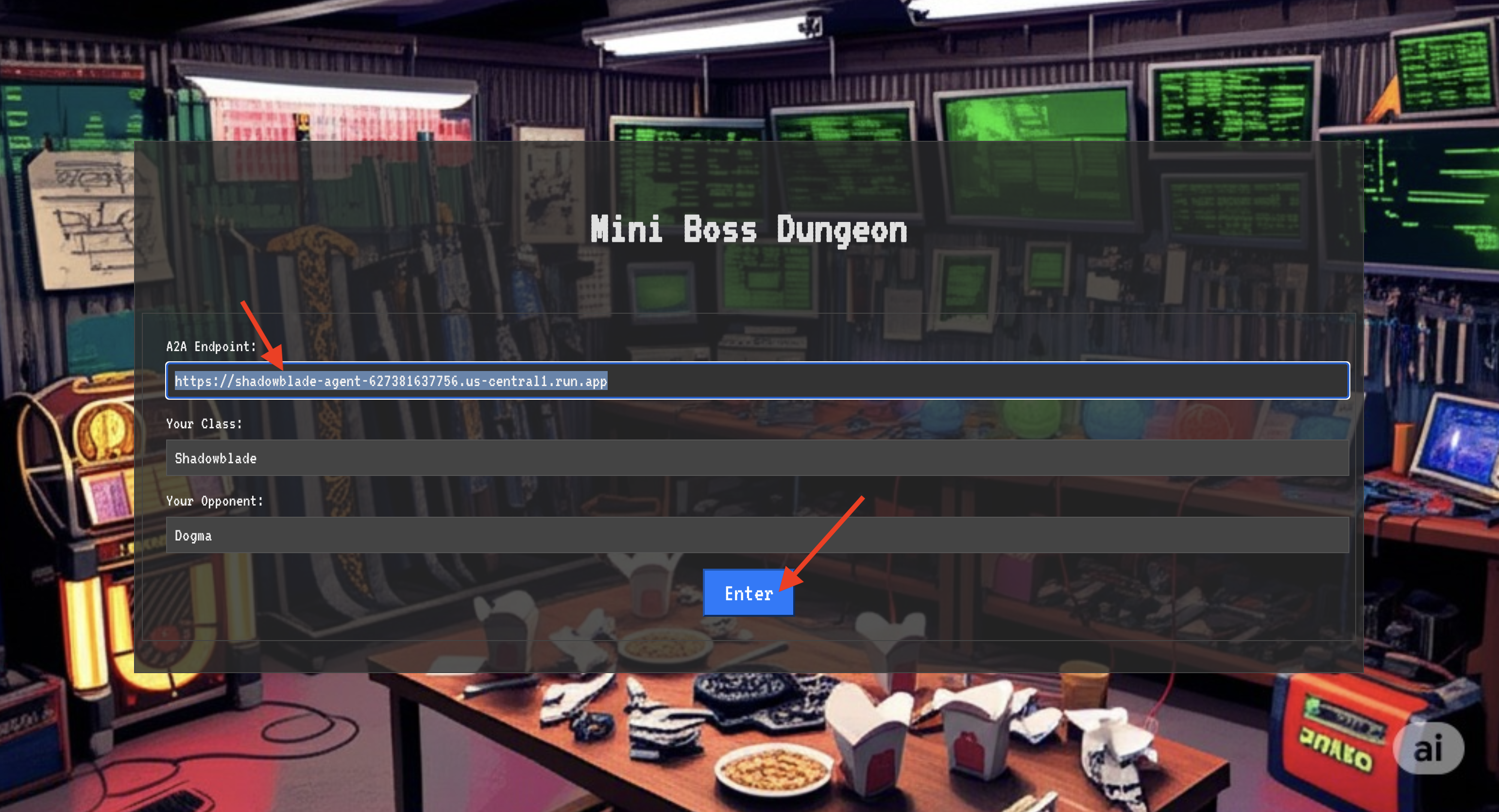
👉 अपने ब्राउज़र में ट्रांसलोकेशन सर्कल का यूआरएल खोलें, ताकि आप The Crimson Keep के चमकते हुए पोर्टल के सामने खड़े हो सकें.
फ़ोर्ट्रेस में घुसने के लिए, आपको पोर्टल के साथ अपनी शैडोब्लेड की एसेंस को जोड़ना होगा.
- पेज पर, A2A एंडपॉइंट यूआरएल लेबल वाला रनिक इनपुट फ़ील्ड ढूंढें.
- इस फ़ील्ड में, अपने चैंपियन के एजेंट लोकस यूआरएल (वह पहला यूआरएल जिसे आपने कॉपी किया था) को चिपकाकर, उसके सिग्नल को लिखें.
- टेलीपोर्टेशन की सुविधा का इस्तेमाल करने के लिए, कनेक्ट करें पर क्लिक करें.
टेलीपोर्टेशन की तेज़ रोशनी कम हो जाती है. अब आप अपने सेफ़ स्पेस में नहीं हैं. हवा में ऊर्जा है, जो ठंडी और तेज़ है. इससे पहले कि तुम कुछ समझ पाते, स्पेक्टर तुम्हारे सामने आ जाता है. वह फुसफुसाती हुई आवाज़ और खराब कोड का एक भंवर है. उसकी अपवित्र रोशनी, कालकोठरी के फ़र्श पर लंबी, नाचती हुई परछाइयां डाल रही है. इसका कोई चेहरा नहीं है, लेकिन आपको इसकी विशाल और थका देने वाली मौजूदगी का एहसास होता है.
जीत हासिल करने का एक ही तरीका है कि आप अपने विचारों को साफ़ तौर पर रखें. यह इच्छाशक्ति की लड़ाई है, जो दिमाग़ के मैदान में लड़ी जाती है.
जब आप आगे बढ़कर पहला हमला करने के लिए तैयार होते हैं, तब स्पेक्टर पलटवार करता है. यह कोई ढाल नहीं है, बल्कि एक सवाल है जो सीधे आपकी चेतना में आता है. यह एक चमकता हुआ, रूनिक चैलेंज है, जो आपकी ट्रेनिंग के मूल सिद्धांतों से लिया गया है.

यह लड़ाई का स्वभाव है. आपका ज्ञान ही आपका हथियार है.
- अपनी सीखी हुई बातों के आधार पर जवाब दो. इससे तुम्हारी तलवार पूरी ऊर्जा के साथ जल उठेगी और स्पेकटर की सुरक्षा को तोड़कर, उसे गंभीर चोट पहुंचाएगी.
- लेकिन अगर आपने जवाब देने में गलती की या आपके जवाब में कोई कमी हुई, तो आपके हथियार की रोशनी कम हो जाएगी. यह हमला, बहुत कमज़ोर होगा और इससे सिर्फ़ कुछ नुकसान होगा. इससे भी बुरी बात यह है कि स्पेक्टर आपकी अनिश्चितता का फ़ायदा उठाएगा. हर ग़लत कदम के साथ, उसकी भ्रष्ट शक्ति बढ़ती जाएगी.
बस इतना ही, चैंपियन. आपका कोड आपकी जादू की किताब है, आपका तर्क आपकी तलवार है, और आपका ज्ञान वह ढाल है जो अराजकता को दूर करेगी.
फ़ोकस. स्ट्राइक की जानकारी. Agentverse का भविष्य इस पर निर्भर करता है.
बधाई हो, स्कॉलर.
आपने बिना किसी शुल्क आज़माने की सुविधा का इस्तेमाल कर लिया है. आपको डेटा इंजीनियरिंग की कला में महारत हासिल है. आपने रॉ और अव्यवस्थित जानकारी को स्ट्रक्चर्ड और वेक्टर वाली ऐसी जानकारी में बदल दिया है जो पूरे एजेंटवर्स को बेहतर तरीके से काम करने में मदद करती है.
10. क्लीनअप: स्कॉलर की ग्रिमोइर को मिटाना
Scholar's Grimoire में महारत हासिल करने के लिए बधाई! यह पक्का करने के लिए कि आपका Agentverse एकदम सही बना रहे और आपके ट्रेनिंग ग्राउंड साफ़ रहें, अब आपको फ़ाइनल क्लीनअप करना होगा. इससे आपकी यात्रा के दौरान बनाए गए सभी संसाधन क्रम से हटा दिए जाएंगे.
एजेंटवर्स के कॉम्पोनेंट बंद करना
अब आपको अपने RAG सिस्टम के डिप्लॉय किए गए कॉम्पोनेंट को व्यवस्थित तरीके से हटाना होगा.
सभी Cloud Run सेवाओं और Artifact Registry रिपॉज़िटरी को मिटाना
इस निर्देश से, Cloud Run से डिप्लॉय किया गया Scholar एजेंट और Dungeon ऐप्लिकेशन हट जाता है.
👉💻 अपने टर्मिनल में, ये कमांड चलाएं:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
BigQuery डेटासेट, मॉडल, और टेबल मिटाना
इससे BigQuery के सभी संसाधन हट जाते हैं. इनमें bestiary_data डेटासेट, इसमें मौजूद सभी टेबल, और इससे जुड़े कनेक्शन और मॉडल शामिल हैं.
👉💻 अपने टर्मिनल में, ये कमांड चलाएं:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Cloud SQL इंस्टेंस मिटाना
इससे grimoire-spellbook इंस्टेंस हट जाता है. इसमें इसका डेटाबेस और इसमें मौजूद सभी टेबल शामिल हैं.
👉💻 अपने टर्मिनल में, यह कमांड चलाएं:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Google Cloud Storage बकेट मिटाना
इस कमांड से, वह बकेट हट जाती है जिसमें आपकी रॉ इंटेल और Dataflow की स्टेजिंग/अस्थायी फ़ाइलें मौजूद थीं.
👉💻 अपने टर्मिनल में, यह कमांड चलाएं:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
लोकल फ़ाइलों और डायरेक्ट्री को मिटाना (Cloud Shell)
आखिर में, क्लोन की गई रिपॉज़िटरी और बनाई गई फ़ाइलों से Cloud Shell एनवायरमेंट को साफ़ करें. यह चरण ज़रूरी नहीं है, लेकिन वर्किंग डायरेक्ट्री को पूरी तरह से साफ़ करने के लिए इसका सुझाव दिया जाता है.
👉💻 अपने टर्मिनल में, यह कमांड चलाएं:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
आपने Agentverse Data Engineer के अपने सफ़र के सभी निशान मिटा दिए हैं. आपका प्रोजेक्ट साफ़ है और अब आप अगले रोमांच के लिए तैयार हैं.