
1. Overture
Era pengembangan yang terisolasi akan berakhir. Evolusi teknologi berikutnya bukan tentang kejeniusan yang terisolasi, tetapi tentang penguasaan kolaboratif. Membangun satu agen cerdas adalah eksperimen yang menarik. Membangun ekosistem agen yang tangguh, aman, dan cerdas—Agentverse yang sebenarnya—adalah tantangan besar bagi perusahaan modern.
Keberhasilan di era baru ini memerlukan konvergensi empat peran penting, pilar dasar yang mendukung sistem agentik yang berkembang. Kekurangan di salah satu area menciptakan kelemahan yang dapat membahayakan seluruh struktur.
Workshop ini adalah panduan perusahaan yang pasti untuk menguasai masa depan agentic di Google Cloud. Kami menyediakan peta jalan menyeluruh yang memandu Anda dari ide awal hingga realitas operasional berskala penuh. Dalam empat lab yang saling terhubung ini, Anda akan mempelajari cara keterampilan khusus developer, arsitek, engineer data, dan SRE harus bertemu untuk membuat, mengelola, dan menskalakan Agentverse yang efektif.
Tidak ada satu pilar pun yang dapat mendukung Agentverse saja. Desain megah Arsitek tidak berguna tanpa eksekusi yang tepat dari Developer. Agen Developer tidak dapat berfungsi tanpa keahlian Data Engineer, dan seluruh sistem akan rentan tanpa perlindungan SRE. Hanya melalui sinergi dan pemahaman bersama tentang peran masing-masing, tim Anda dapat mengubah konsep inovatif menjadi realitas operasional yang sangat penting. Perjalanan Anda dimulai di sini. Bersiaplah untuk menguasai peran Anda dan pelajari bagaimana Anda cocok dengan keseluruhan yang lebih besar.
Selamat datang di Agentverse: Panggilan untuk Para Juara
Di luasnya dunia digital perusahaan, era baru telah dimulai. Ini adalah era agentic, era yang penuh harapan, ketika agen cerdas dan otonom bekerja secara harmonis untuk mempercepat inovasi dan menghilangkan tugas-tugas yang membosankan.

Ekosistem terhubung yang penuh daya dan potensi ini dikenal sebagai Agentverse.
Namun, entropi yang merayap, kerusakan senyap yang dikenal sebagai The Static, telah mulai menggerogoti tepi dunia baru ini. The Static bukanlah virus atau bug; ini adalah perwujudan kekacauan yang memangsa tindakan penciptaan itu sendiri.
Hal ini memperkuat frustrasi lama menjadi bentuk yang mengerikan, sehingga memunculkan Tujuh Spektrum Pengembangan. Jika tidak ditangani, The Static dan Spectres-nya akan menghentikan progres, mengubah janji Agentverse menjadi gurun utang teknis dan project yang ditinggalkan.
Hari ini, kami menyerukan para pejuang untuk menahan gelombang kekacauan. Kita membutuhkan pahlawan yang bersedia menguasai keahlian mereka dan bekerja sama untuk melindungi Agentverse. Saatnya memilih jalur Anda.
Pilih Kelas Anda
Empat jalur berbeda terbentang di hadapanmu, masing-masing merupakan pilar penting dalam pertarungan melawan The Static. Meskipun pelatihan Anda akan menjadi misi solo, kesuksesan Anda pada akhirnya bergantung pada pemahaman tentang bagaimana keterampilan Anda berpadu dengan keterampilan orang lain.
- The Shadowblade (Developer): Ahli dalam menempa dan garis depan. Anda adalah pengrajin yang membuat bilah, membangun alat, dan menghadapi musuh dalam detail rumit kode. Jalur Anda adalah presisi, keterampilan, dan kreasi praktis.
- The Summoner (Arsitek): Seorang ahli strategi dan orkestrator yang hebat. Anda tidak melihat satu agen, tetapi seluruh medan perang. Anda mendesain cetak biru utama yang memungkinkan seluruh sistem agen berkomunikasi, berkolaborasi, dan mencapai tujuan yang jauh lebih besar daripada satu komponen mana pun.
- The Scholar (Data Engineer): Pencari kebenaran tersembunyi dan penjaga kebijaksanaan. Anda menjelajahi data yang luas dan belum terpetakan untuk menemukan kecerdasan yang memberi tujuan dan pandangan bagi agen Anda. Pengetahuanmu dapat mengungkap kelemahan musuh atau memperkuat sekutumu.
- The Guardian (DevOps / SRE): Pelindung dan perisai kerajaan yang setia. Anda membangun benteng, mengelola jalur suplai daya, dan memastikan seluruh sistem dapat menahan serangan tak terhindarkan dari The Static. Kekuatan Anda adalah fondasi yang mendasari kemenangan tim Anda.
Misi Anda
Latihan Anda akan dimulai sebagai latihan mandiri. Anda akan mengikuti jalur yang Anda pilih, mempelajari keterampilan unik yang diperlukan untuk menguasai peran Anda. Di akhir uji coba, Anda akan menghadapi Spectre yang lahir dari The Static—mini-boss yang memangsa tantangan spesifik dalam keahlian Anda.
Anda hanya dapat mempersiapkan uji coba akhir dengan menguasai peran masing-masing. Kemudian, Anda harus membentuk grup dengan juara dari kelas lain. Bersama-sama, Anda akan menjelajahi pusat korupsi untuk menghadapi bos terakhir.
Tantangan kolaboratif terakhir yang akan menguji kekuatan gabungan Anda dan menentukan nasib Agentverse.
Agentverse menanti para hero. Apakah Anda akan menjawab panggilan?
2. Grimoire Cendekia
Perjalanan kita dimulai! Sebagai Cendekia, senjata utama kita adalah pengetahuan. Kami telah menemukan banyak gulungan kuno yang penuh teka-teki di arsip kami (Google Cloud Storage). Gulungan ini berisi informasi mentah tentang binatang buas yang menakutkan yang mengganggu negeri. Misi kami adalah menggunakan keajaiban analitis yang mendalam dari Google BigQuery dan kebijaksanaan Gemini Elder Brain (model Gemini Pro) untuk menguraikan teks tidak terstruktur ini dan mengubahnya menjadi Bestiary yang terstruktur dan dapat dikueri. Hal ini akan menjadi dasar dari semua strategi kita di masa mendatang.
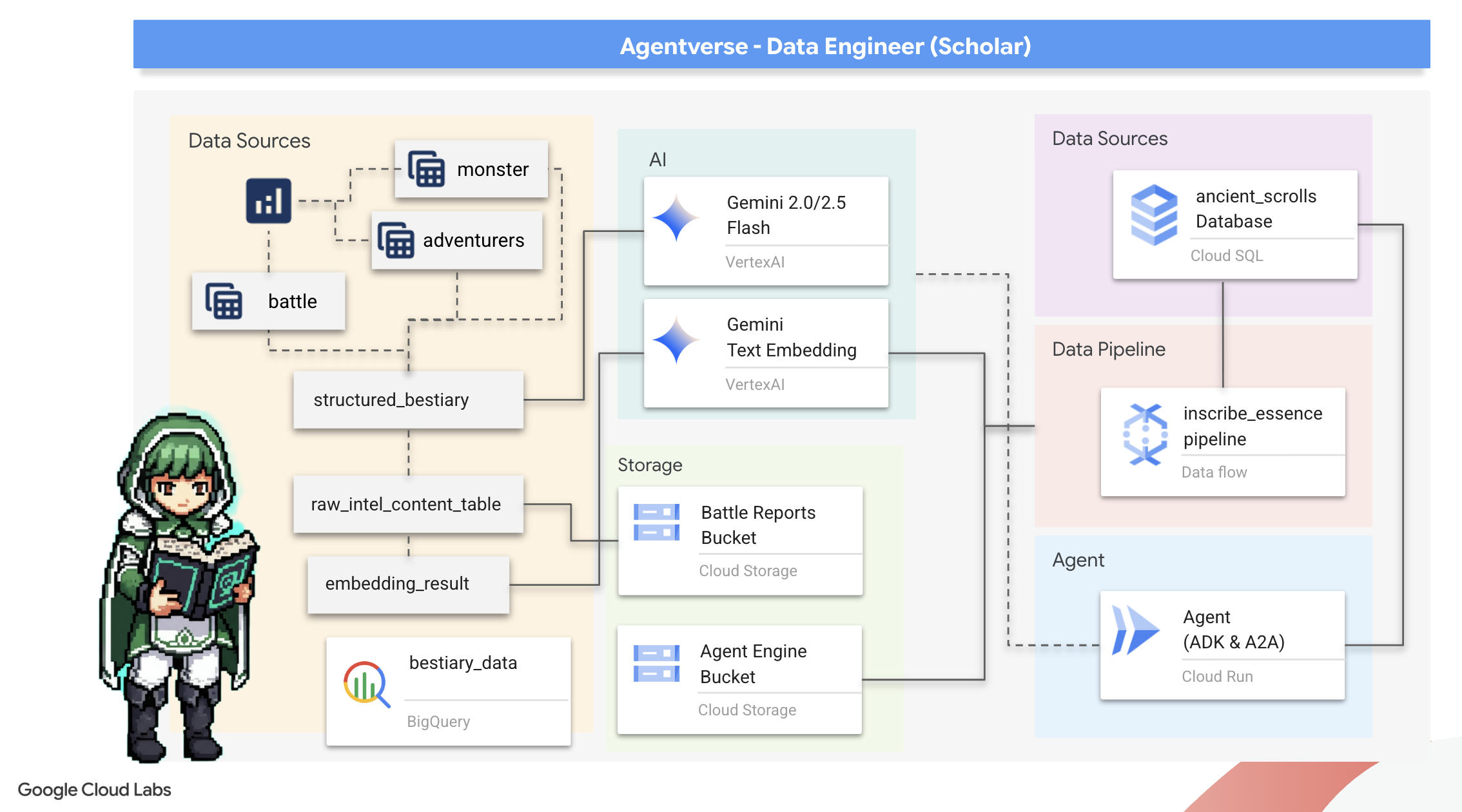
Yang akan Anda pelajari
- Gunakan BigQuery untuk membuat tabel eksternal dan melakukan transformasi kompleks dari tidak terstruktur ke terstruktur menggunakan BQML.GENERATE_TEXT dengan model Gemini.
- Sediakan instance Cloud SQL untuk PostgreSQL dan aktifkan ekstensi pgvector untuk kemampuan penelusuran semantik.
- Bangun pipeline batch yang kuat dan di-container menggunakan Dataflow dan Apache Beam untuk memproses file teks mentah, membuat embedding vektor dengan model Gemini, dan menulis hasilnya ke database relasional.
- Menerapkan sistem Retrieval-Augmented Generation (RAG) dasar dalam agen untuk mengkueri data yang telah diubah menjadi vektor.
- Deploy agen yang mendukung data sebagai layanan yang aman dan skalabel di Cloud Run.
3. Menyiapkan Sanctum Cendekia
Selamat datang, Cendekia. Sebelum kita dapat mulai menuliskan pengetahuan yang kuat dari Grimoire kita, kita harus menyiapkan tempat suci kita terlebih dahulu. Ritual dasar ini melibatkan pengoptimalan lingkungan Google Cloud, membuka portal (API) yang tepat, dan membuat saluran yang akan mengalirkan keajaiban data kita. Sanctum yang dipersiapkan dengan baik memastikan mantra kita ampuh dan pengetahuan kita aman.
Mengklaim Kredit Google Cloud Anda
⚠️ Prasyarat Penting:
- Menggunakan Gmail Pribadi: Anda harus menggunakan akun pribadi (misalnya,
name@gmail.com). Akun yang dikelola perusahaan atau sekolah tidak akan berfungsi.
👉 Langkah-langkah:
- Buka situs klaim kredit: Klik Di Sini
- Login: Tempel link ke kolom URL, lalu login dengan Gmail pribadi Anda.
- Setujui Persyaratan: Setujui Persyaratan Layanan Google Cloud Platform.
- Verifikasi Kredit: Cari pesan yang mengonfirmasi bahwa kredit telah diterapkan.
- *Catatan: Jika Anda diminta untuk memasukkan informasi kartu kredit, Anda dapat mengabaikannya dengan aman dan menutup jendela.
Dan Anda sudah siap. Anda dapat menutup jendela ini
Menyiapkan Lingkungan Kerja
👉Klik Activate Cloud Shell di bagian atas konsol Google Cloud (Ikon berbentuk terminal di bagian atas panel Cloud Shell),
👉Klik tombol "Open Editor" (terlihat seperti folder terbuka dengan pensil). Tindakan ini akan membuka Editor Kode Cloud Shell di jendela. Anda akan melihat file explorer di sisi kiri. 
👉Buka terminal di IDE cloud, 
👉💻 Di terminal, verifikasi bahwa Anda sudah diautentikasi dan project disetel ke project ID Anda menggunakan perintah berikut:
gcloud auth list
👉💻Clone project bootstrap dari GitHub:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 Jalankan skrip penyiapan dari direktori project.
⚠️ Catatan tentang Project ID: Skrip akan menyarankan Project ID default yang dibuat secara acak. Anda dapat menekan Enter untuk menyetujui default ini.
Namun, jika Anda lebih suka membuat project baru tertentu, Anda dapat mengetik Project ID yang diinginkan saat diminta oleh skrip.
cd ~/agentverse-dataengineer
./init.sh
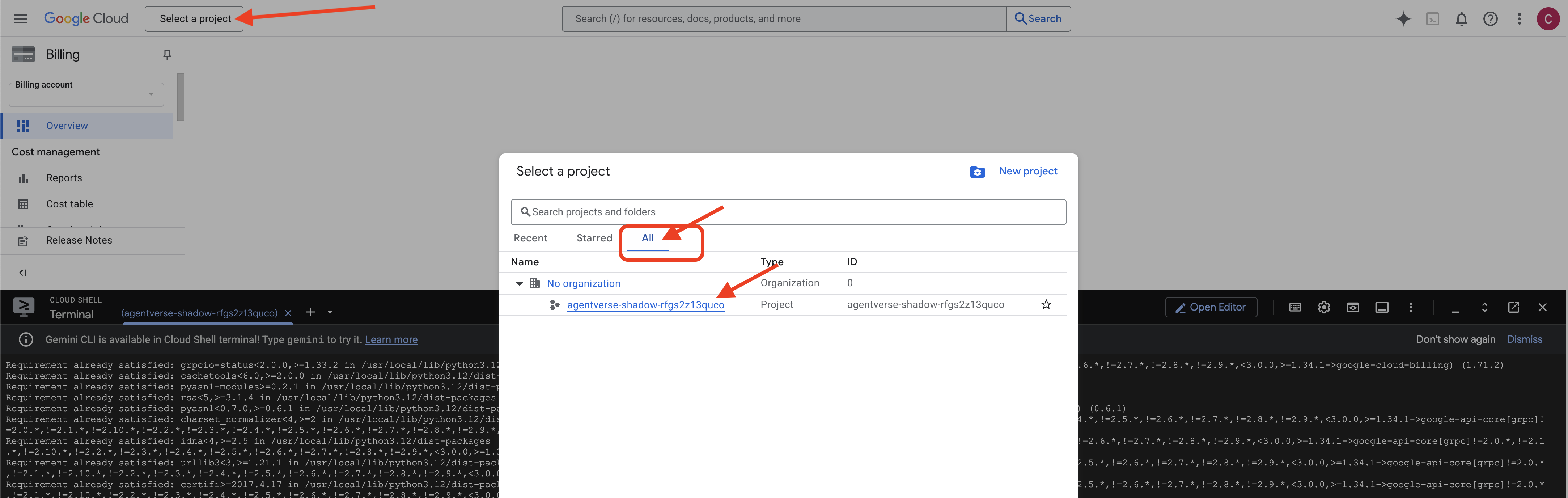
👉 Langkah Penting Setelah Selesai: Setelah skrip selesai, Anda harus memastikan Konsol Google Cloud Anda melihat project yang benar:
- Buka console.cloud.google.com.
- Klik menu dropdown pemilih project di bagian atas halaman.
- Klik tab "Semua" (karena project baru mungkin belum muncul di "Terbaru").
- Pilih Project ID yang baru saja Anda konfigurasi di langkah
init.sh.
👉💻 Tetapkan Project ID yang diperlukan:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Jalankan perintah berikut untuk mengaktifkan Google Cloud API yang diperlukan:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 Jika Anda belum membuat repositori Artifact Registry bernama agentverse-repo, jalankan perintah berikut untuk membuatnya:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
Menyiapkan izin
👉💻 Berikan izin yang diperlukan dengan menjalankan perintah berikut di terminal:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 Saat Anda memulai pelatihan, kami akan menyiapkan tantangan terakhir. Perintah berikut akan memanggil Spectre dari statis yang kacau, sehingga membuat boss untuk pengujian akhir Anda.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
Kerja bagus, Cendekia. Pesona dasar sudah selesai. Sanctum kami aman, portal menuju kekuatan data elementer terbuka, dan servitor kami berdaya. Sekarang kita siap memulai pekerjaan yang sebenarnya.
4. Alchemy Pengetahuan: Mentransformasi Data dengan BigQuery & Gemini
Dalam perang tanpa henti melawan The Static, setiap konfrontasi antara Champion of the Agentverse dan Spectre of Development dicatat dengan cermat. Sistem Simulasi Medan Pertempuran, lingkungan pelatihan utama kami, otomatis membuat Entri Log Aetherik untuk setiap pertempuran. Log naratif ini adalah sumber kecerdasan mentah kami yang paling berharga, bijih yang belum dimurnikan yang harus kami, sebagai Cendekia, tempa menjadi baja strategi yang murni.Kekuatan sejati seorang Cendekia tidak hanya terletak pada kepemilikan data, tetapi pada kemampuan untuk mengubah bijih informasi yang mentah dan kacau menjadi baja kebijaksanaan yang berkilau dan terstruktur yang dapat ditindaklanjuti.Kita akan melakukan ritual dasar alkimia data.

Perjalanan ini akan membawa kita melalui proses multi-tahap sepenuhnya dalam BigQuery Google. Kita akan mulai dengan melihat arsip GCS tanpa menggerakkan satu pun scroll, menggunakan lensa ajaib. Kemudian, kita akan memanggil Gemini untuk membaca dan menafsirkan kisah-kisah log pertempuran yang puitis dan tidak terstruktur. Terakhir, kita akan menyempurnakan prediksi mentah menjadi serangkaian tabel yang saling terhubung dan akurat. Grimoire pertama kita. Lalu, ajukan pertanyaan yang begitu mendalam sehingga hanya dapat dijawab oleh struktur baru ini.
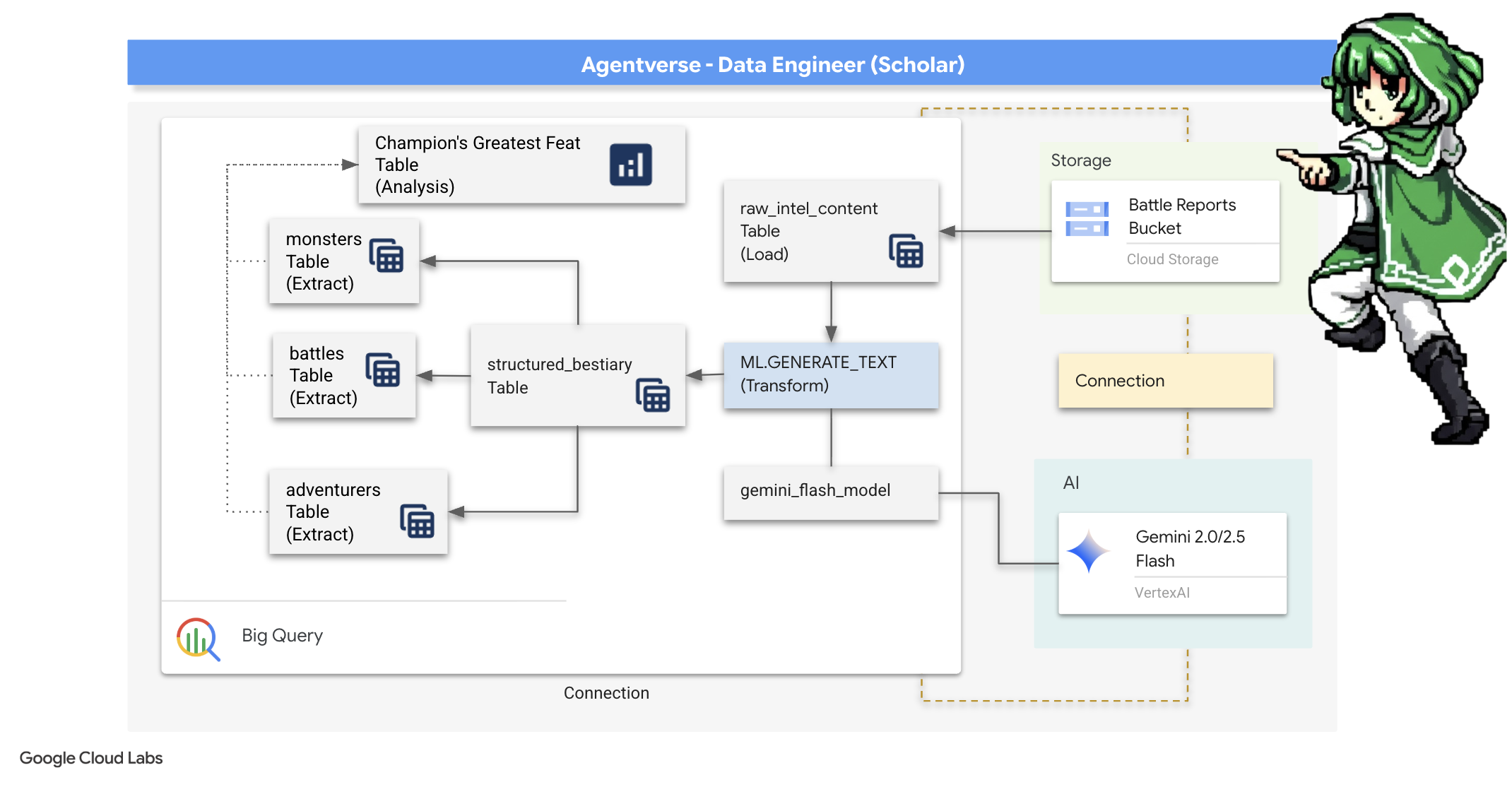
Lensa Pemeriksaan: Mengintip GCS dengan Tabel Eksternal BigQuery
Tindakan pertama kita adalah membuat lensa yang memungkinkan kita melihat isi arsip GCS tanpa mengganggu scroll di dalamnya. Tabel Eksternal adalah lensa ini, yang memetakan file teks mentah ke struktur seperti tabel yang dapat dikueri langsung oleh BigQuery.
Untuk melakukannya, kita harus membuat garis ley energi yang stabil terlebih dahulu, yaitu resource CONNECTION, yang menautkan BigQuery sanctum kita ke arsip GCS secara aman.
👉💻 Di terminal Cloud Shell, jalankan perintah berikut untuk menyiapkan penyimpanan dan membuat saluran:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 Perhatian! Pesan Akan Muncul Nanti!
Skrip penyiapan dari langkah 2 memulai proses di latar belakang. Setelah beberapa menit, pesan akan muncul di terminal Anda yang terlihat mirip dengan ini:[1]+ Done gcloud sql instances create ...Ini adalah hal yang normal dan diharapkan. Artinya, database Cloud SQL Anda telah berhasil dibuat. Anda dapat mengabaikan pesan ini dengan aman dan melanjutkan pekerjaan.
Sebelum dapat membuat Tabel Eksternal, Anda harus membuat set data yang akan memuatnya terlebih dahulu.
👉💻 Jalankan satu perintah sederhana ini di terminal Cloud Shell Anda:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 Sekarang kita harus memberikan izin yang diperlukan pada tanda tangan ajaib saluran untuk membaca dari Arsip GCS dan berkonsultasi dengan Gemini.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 Di terminal Cloud Shell, jalankan perintah berikut untuk menampilkan nama bucket Anda:
echo $BUCKET_NAME
Terminal Anda akan menampilkan nama yang mirip dengan your-project-id-gcs-bucket. Anda akan membutuhkannya pada langkah berikutnya.
👉 Anda harus menjalankan perintah berikutnya dari editor kueri BigQuery di Konsol Google Cloud. Cara termudah untuk mengaksesnya adalah dengan membuka link di bawah ini di tab browser baru. Anda akan langsung diarahkan ke halaman yang benar di Konsol Google Cloud.
https://console.cloud.google.com/bigquery
👉 Setelah halaman dimuat, klik tombol + biru (Buat kueri baru) untuk membuka tab editor baru.
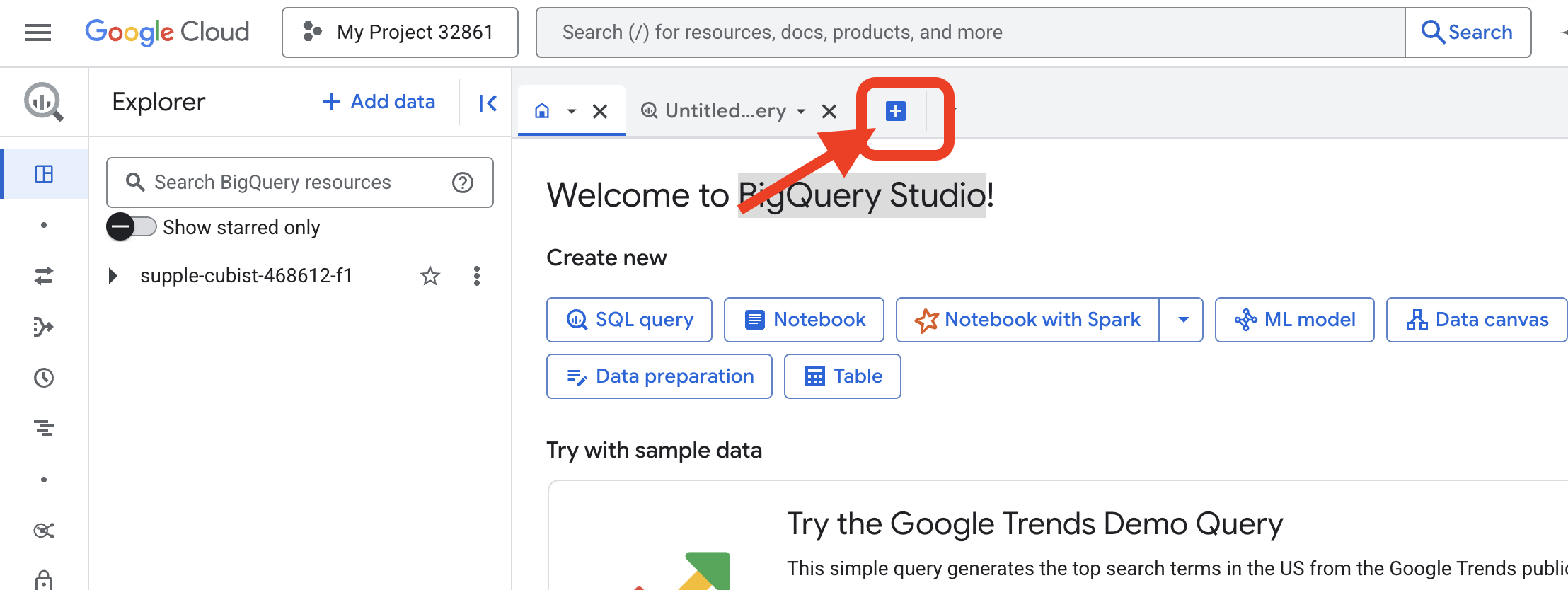
Sekarang kita menulis mantra Bahasa Definisi Data (DDL) untuk membuat lensa ajaib kita. Pernyataan ini memberi tahu BigQuery tempat mencari dan apa yang harus dilihat.
👉📜 Di editor kueri BigQuery yang Anda buka, tempel SQL berikut. Jangan lupa mengganti REPLACE-WITH-YOUR-BUCKET-NAME
dengan nama bucket yang baru saja Anda salin. Lalu klik Run:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 Jalankan kueri untuk "melihat melalui lensa" dan melihat konten file.
SELECT * FROM bestiary_data.raw_intel_content_table;
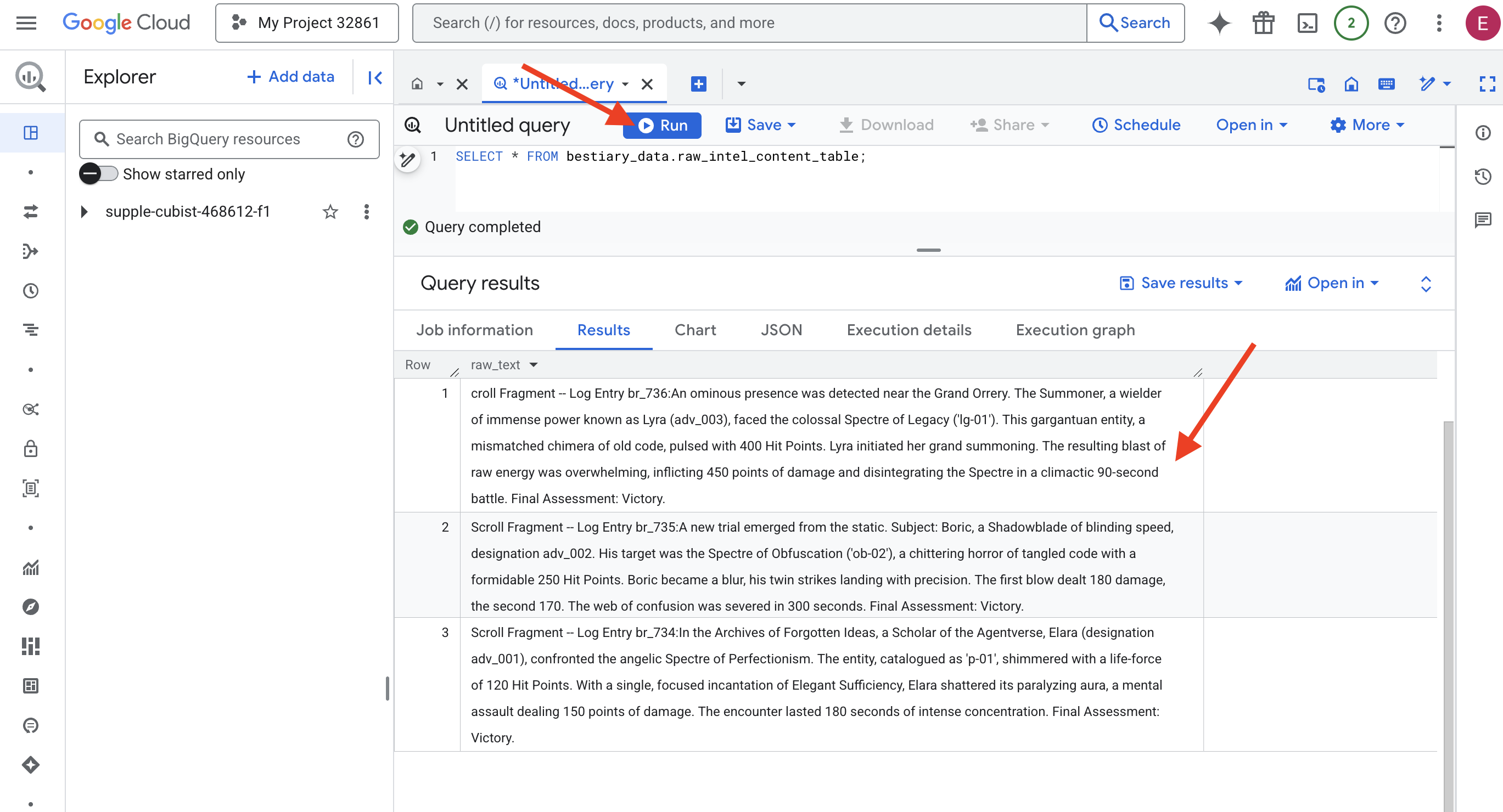
Lensa kita sudah terpasang. Sekarang kita dapat melihat teks mentah gulungan. Namun, membaca tidak sama dengan memahami.
Di Arsip Ide yang Terlupakan, seorang Cendekia Agentverse, Elara (penunjukan adv_001), menghadapi Spectre Perfeksionisme yang seperti malaikat. Entitas, yang dikatalogkan sebagai 'p-01', berkilauan dengan kekuatan hidup 120 Hit Point. Dengan satu mantra Elegant Sufficiency yang terfokus, Elara menghancurkan aura melumpuhkannya, serangan mental yang menimbulkan damage 150 poin. Pertemuan itu berlangsung selama 180 detik dengan konsentrasi yang intens. Penilaian Akhir: Berhasil.
Gulungan tidak ditulis dalam tabel dan baris, tetapi dalam prosa panjang saga. Ini adalah ujian besar pertama kita.
Ramalan Cendekia: Mengubah Teks menjadi Tabel dengan SQL
Tantangannya adalah laporan yang menjelaskan serangan kembar cepat Shadowblade akan sangat berbeda dengan catatan seorang Summoner yang mengumpulkan kekuatan besar untuk satu ledakan dahsyat. Kita tidak bisa hanya mengimpor data ini; kita harus menafsirkannya. Inilah momen keajaiban. Kita akan menggunakan satu kueri SQL sebagai mantra yang ampuh untuk membaca, memahami, dan menyusun semua catatan dari semua file kita, langsung di dalam BigQuery.
👉💻 Kembali di terminal Cloud Shell, jalankan perintah berikut untuk menampilkan nama koneksi Anda:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
Terminal Anda akan menampilkan string koneksi lengkap. Pilih dan salin seluruh string ini. Anda akan memerlukannya pada langkah berikutnya
Kita akan menggunakan satu mantra yang ampuh: ML.GENERATE_TEXT. Mantra ini memanggil Gemini, menunjukkan setiap gulungan kepadanya, dan memerintahkannya untuk menampilkan fakta inti sebagai objek JSON terstruktur.
👉📜 Di BigQuery Studio, buat Referensi Model Gemini. Hal ini mengikat orakel Gemini Flash ke library BigQuery kami sehingga kami dapat memanggilnya dalam kueri kami. Jangan lupa mengganti
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING dengan string koneksi lengkap yang baru saja Anda salin dari terminal.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 Sekarang, lakukan mantra transmutasi agung. Kueri ini membaca teks mentah, menyusun perintah terperinci untuk setiap scroll, mengirimkannya ke Gemini, dan membuat tabel penyiapan baru dari respons JSON terstruktur AI.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
Transmutasi selesai, tetapi hasilnya belum murni. Model Gemini menampilkan jawabannya dalam format standar, membungkus JSON yang kita inginkan dalam struktur yang lebih besar yang mencakup metadata tentang proses pemikirannya. Mari kita lihat ramalan mentah ini sebelum kita mencoba memurnikannya.
👉📜 Jalankan kueri untuk memeriksa output mentah dari model Gemini:
SELECT * FROM bestiary_data.structured_bestiary;
👀 Anda akan melihat satu kolom bernama structured_data. Konten untuk setiap baris akan terlihat mirip dengan objek JSON kompleks ini:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
Seperti yang dapat Anda lihat, hadiah kita—objek JSON bersih yang kita minta—berada jauh di dalam struktur ini. Tugas kita selanjutnya sudah jelas. Kita harus melakukan ritual untuk menavigasi struktur ini secara sistematis dan mengekstrak kebijaksanaan murni di dalamnya.
Ritual Pembersihan: Menormalisasi Output GenAI dengan SQL
Gemini telah berbicara, tetapi kata-katanya masih mentah dan terbungkus dalam energi halus dari pembuatannya (kandidat, finish_reason, dll.). Cendekia sejati tidak hanya menyimpan ramalan mentah; mereka dengan cermat mengekstrak inti kebijaksanaan dan menuliskannya ke dalam kitab yang sesuai untuk digunakan pada masa mendatang.
Sekarang kita akan mengucapkan mantra terakhir. Skrip tunggal ini akan:
- Baca JSON bertingkat mentah dari tabel penyiapan kami.
- Bersihkan dan uraikan untuk mendapatkan data inti.
- Tuliskan bagian yang relevan ke dalam tiga tabel akhir yang bersih: monster, petualang, dan pertempuran.
👉📜 Di editor kueri BigQuery baru, jalankan perintah berikut untuk membuat lensa pembersihan:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 Verifikasi Bestiari:
SELECT * FROM bestiary_data.monsters;
Selanjutnya, kita akan membuat Daftar Juara, yaitu daftar petualang berani yang telah menghadapi monster ini.
👉📜 Di editor kueri baru, jalankan perintah berikut untuk membuat tabel petualang:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 Verifikasi Daftar Juara:
SELECT * FROM bestiary_data.adventurers;
Terakhir, kita akan membuat tabel fakta: Chronicle of Battles. Buku ini menghubungkan dua buku lainnya, mencatat detail setiap pertemuan unik. Karena setiap pertarungan adalah peristiwa unik, tidak ada penghapusan duplikat yang diperlukan.
👉📜 Di editor kueri baru, jalankan mantra berikut untuk membuat tabel pertarungan:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Verifikasi Chronicle:
SELECT * FROM bestiary_data.battles;
Menemukan Insight Strategis
Gulungan telah dibaca, esensinya telah disaring, dan kitab telah ditulis. Grimoire kami bukan lagi sekadar kumpulan fakta, tetapi merupakan database relasional yang berisi kebijaksanaan strategis yang mendalam. Sekarang kita dapat mengajukan pertanyaan yang tidak mungkin dijawab saat pengetahuan kita terperangkap dalam teks mentah yang tidak terstruktur.
Sekarang mari kita lakukan peramalan terakhir yang paling penting. Kita akan menggunakan mantra yang mengonsultasikan ketiga buku kita sekaligus—Bestiari Monster, Daftar Juara, dan Kronik Pertempuran—untuk mengungkap insight yang mendalam dan dapat ditindaklanjuti.
Pertanyaan strategis kami: "Untuk setiap petualang, apa nama monster terkuat (berdasarkan hit point) yang berhasil mereka kalahkan, dan berapa lama waktu yang dibutuhkan untuk kemenangan tersebut?"
Ini adalah pertanyaan kompleks yang memerlukan penautan juara dengan pertempuran yang dimenangkannya, dan pertempuran tersebut dengan statistik monster yang terlibat. Inilah kekuatan sebenarnya dari model data terstruktur.
👉📜 Di editor kueri BigQuery baru, jalankan perintah akhir berikut:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
Output kueri ini akan berupa tabel yang bersih dan indah yang memberikan "Kisah Pencapaian Terbesar Sang Juara" untuk setiap petualang dalam set data Anda. Tampilannya mungkin seperti ini:
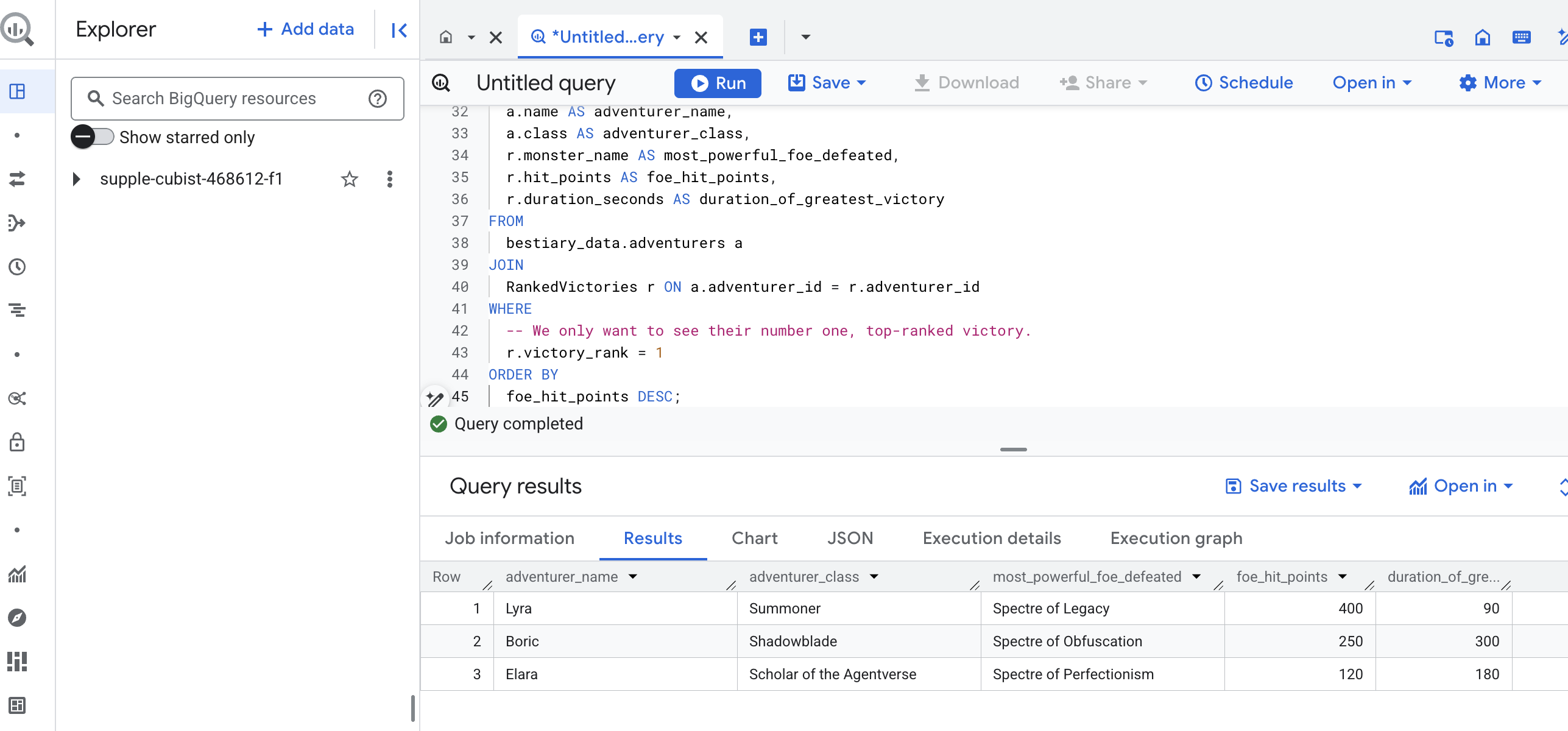
Tutup tab BigQuery.
Satu hasil yang elegan ini membuktikan nilai seluruh pipeline. Anda telah berhasil mengubah laporan medan perang yang mentah dan kacau menjadi sumber kisah legendaris dan insight strategis berbasis data.
UNTUK NON-GAMER
5. Grimoire Scribe: Chunking, Embedding, dan Penelusuran Dalam Data Warehouse
Pekerjaan kita di laboratorium Alchemist berhasil. Kami telah mengubah gulungan naratif mentah menjadi tabel relasional terstruktur—sebuah pencapaian luar biasa dalam keajaiban data. Namun, gulir asli itu sendiri masih menyimpan kebenaran semantik yang lebih dalam yang tidak dapat sepenuhnya ditangkap oleh tabel terstruktur kita. Untuk membangun agen yang benar-benar bijak, kita harus memahami makna ini.
Scrolling panjang yang mentah adalah alat yang kurang efektif. Jika agen kami mengajukan pertanyaan tentang "aura yang melumpuhkan", penelusuran sederhana dapat menampilkan seluruh laporan pertempuran yang hanya menyebutkan frasa tersebut satu kali, sehingga mengubur jawabannya dalam detail yang tidak relevan. Seorang ahli Cendekia tahu bahwa kebijaksanaan sejati tidak ditemukan dalam volume, tetapi dalam presisi.
Kita akan melakukan tiga ritual dalam database yang canggih sepenuhnya dalam BigQuery.
- Ritual Pembagian (Chunking): Kita akan mengambil log kecerdasan mentah dan memecahnya dengan cermat menjadi bagian-bagian yang lebih kecil, terfokus, dan mandiri.
- Ritual Distilasi (Penyematan): Kita akan menggunakan BQML untuk berkonsultasi dengan model Gemini, yang mengubah setiap potongan teks menjadi "sidik jari semantik"—embedding vektor.
- Ritual Meramal (Penelusuran): Kita akan menggunakan penelusuran vektor BQML untuk mengajukan pertanyaan dalam bahasa Inggris sederhana dan menemukan kebijaksanaan yang paling relevan dan disarikan dari Grimoire kita.
Seluruh proses ini menciptakan basis pengetahuan yang canggih dan dapat ditelusuri tanpa data pernah keluar dari keamanan dan skala BigQuery.
Ritual Pembagian: Mendekonstruksi Scroll dengan SQL
Sumber informasi kami tetap berupa file teks mentah di arsip GCS kami, yang dapat diakses melalui tabel eksternal kami, bestiary_data.raw_intel_content_table. Tugas pertama kita adalah menulis mantra yang membaca setiap scroll panjang dan membaginya menjadi serangkaian ayat yang lebih kecil dan lebih mudah dipahami. Untuk ritual ini, kita akan mendefinisikan "chunk" sebagai satu kalimat.
Meskipun pemisahan berdasarkan kalimat adalah titik awal yang jelas dan efektif untuk log naratif kita, seorang Scribe yang ahli memiliki banyak strategi pengelompokan yang dapat digunakan, dan pilihan ini sangat penting untuk kualitas penelusuran akhir. Metode yang lebih sederhana mungkin menggunakan
- Chunking Panjang(Ukuran) Tetap, tetapi hal ini dapat memotong ide utama menjadi dua.
Ritual yang lebih canggih, seperti
- Recursive Chunking sering kali lebih disukai dalam praktiknya; metode ini mencoba membagi teks di sepanjang batas alami seperti paragraf terlebih dahulu, lalu kembali ke kalimat untuk mempertahankan sebanyak mungkin konteks semantik. Untuk naskah yang benar-benar rumit.
- Pengelompokan yang Sesuai Konten(dokumen), di mana Scribe menggunakan struktur inheren dokumen—seperti header dalam panduan teknis atau fungsi dalam scroll kode, untuk membuat potongan informasi yang paling logis dan efektif. dan banyak lagi...
Untuk log pertarungan kami, kalimat tersebut memberikan keseimbangan yang sempurna antara perincian dan konteks.
👉📜 Di editor kueri BigQuery baru, jalankan perintah berikut. Spell ini menggunakan fungsi SPLIT untuk memisahkan teks setiap scroll pada setiap titik (.) lalu memisahkan array kalimat yang dihasilkan ke dalam baris terpisah.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 Sekarang, jalankan kueri untuk memeriksa pengetahuan yang baru Anda tulis dan bagi-bagi, lalu lihat perbedaannya.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
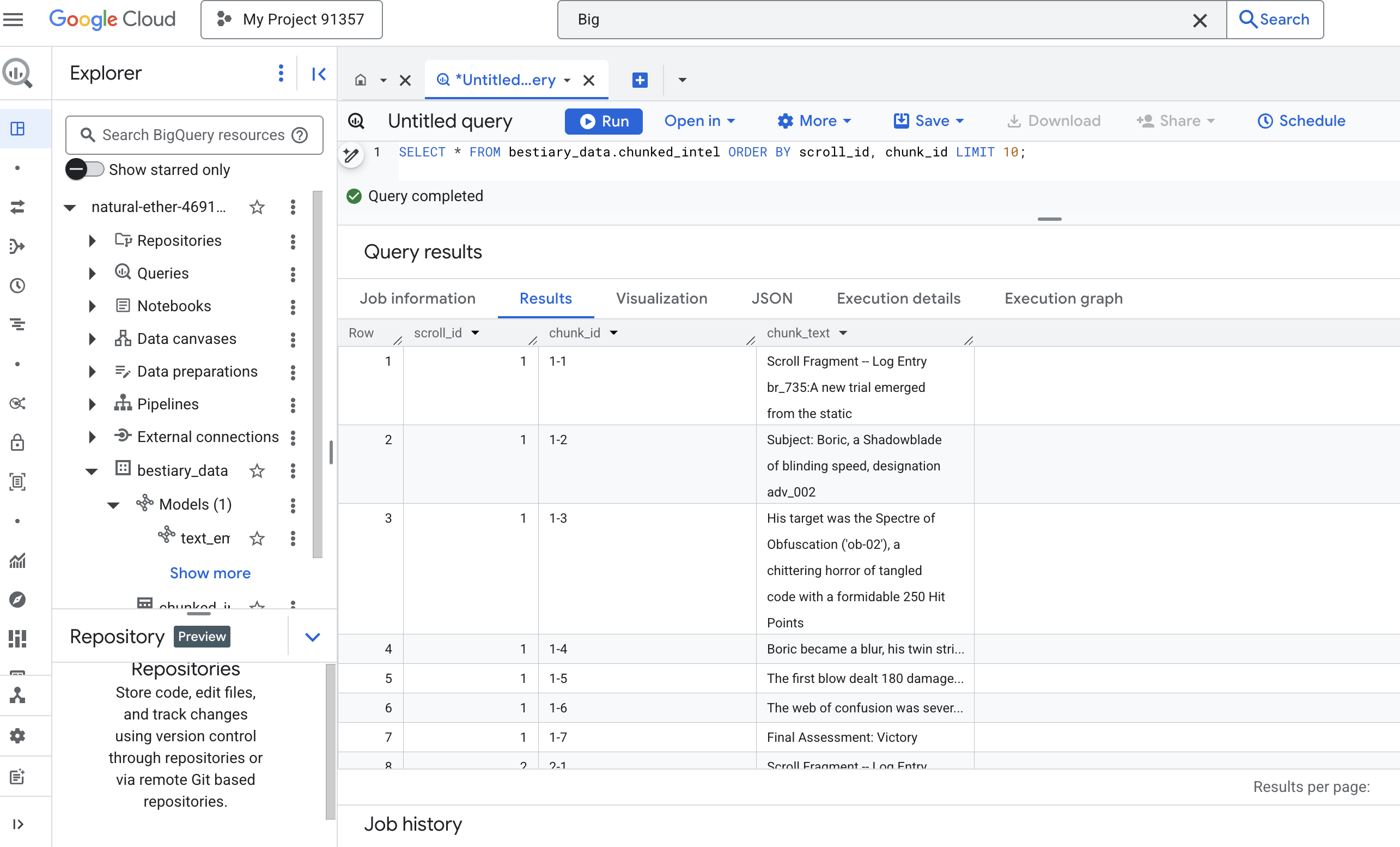
Amati hasilnya. Jika sebelumnya ada satu blok teks padat, kini ada beberapa baris, yang masing-masing terkait dengan scroll asli (scroll_id) tetapi hanya berisi satu kalimat yang berfokus. Setiap baris kini menjadi kandidat yang tepat untuk vektorisasi.
Ritual Distilasi: Mengubah Teks menjadi Vektor dengan BQML
👉💻 Pertama, kembali ke terminal Anda, jalankan perintah berikut untuk menampilkan nama koneksi Anda:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Kita harus membuat model BigQuery baru yang mengarah ke embedding teks Gemini. Di BigQuery Studio, jalankan mantra berikut. Perhatikan bahwa Anda harus mengganti REPLACE-WITH-YOUR-FULL-CONNECTION-STRING dengan string koneksi lengkap yang baru saja Anda salin dari terminal.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 Sekarang, lakukan mantra distilasi agung. Kueri ini memanggil fungsi ML.GENERATE_EMBEDDING, yang akan membaca setiap baris dari tabel chunked_intel, mengirimkan teks ke model embedding Gemini, dan menyimpan sidik jari vektor yang dihasilkan dalam tabel baru.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
Proses ini mungkin memerlukan waktu satu atau dua menit saat BigQuery memproses semua potongan teks.
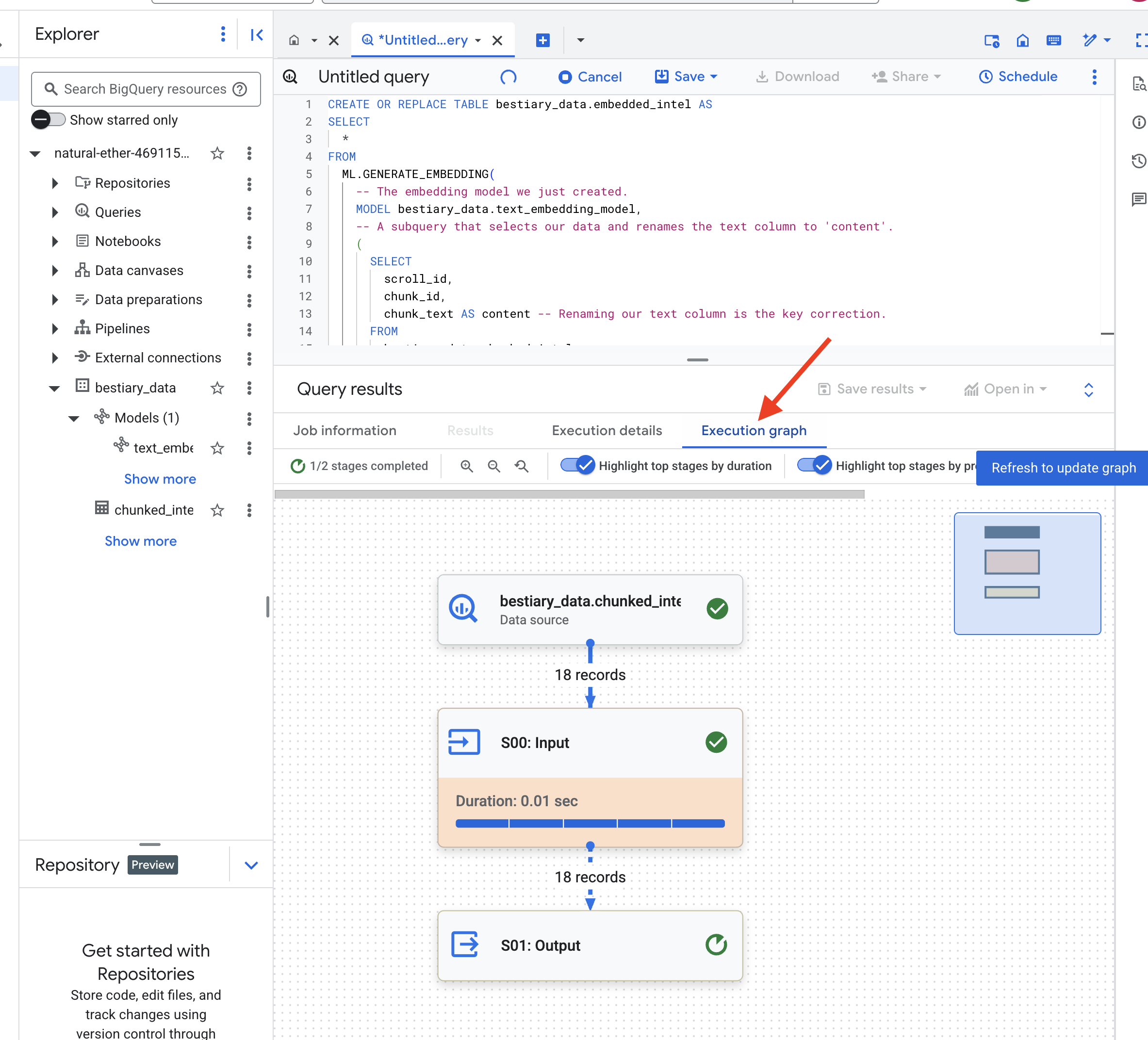
👉📜 Setelah selesai, periksa tabel baru untuk melihat sidik jari semantik.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
Sekarang Anda akan melihat kolom baru, ml_generate_embedding_result, yang berisi representasi vektor padat dari teks Anda. Grimoire kita sekarang dienkode secara semantik.
Ritual Meramal: Penelusuran Semantik dengan BQML
👉📜 Uji coba terbaik Grimoire kami adalah dengan mengajukan pertanyaan kepadanya. Sekarang kita akan melakukan ritual terakhir: penelusuran vektor. Ini bukan penelusuran kata kunci; ini adalah penelusuran makna. Kita akan mengajukan pertanyaan dalam natural language, BQML akan mengonversi pertanyaan kita menjadi penyematan dengan cepat, lalu menelusuri seluruh tabel embedded_intel untuk menemukan potongan teks yang sidik jarinya memiliki makna "paling dekat".
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
Analisis Mantra:
VECTOR_SEARCH: Fungsi inti yang mengatur penelusuran.ML.GENERATE_EMBEDDING(kueri dalam): Ini adalah keajaibannya. Kami menyematkan kueri ('What are the tactics...') menggunakan model yang sama, tetapi dengan jenis tugas'RETRIEVAL_QUERY', yang dioptimalkan secara khusus untuk kueri.top_k => 3: Kami meminta 3 hasil yang paling relevan.distance_type => 'COSINE': Mengukur "sudut" antarvektor. Sudut yang lebih kecil berarti maknanya lebih selaras.
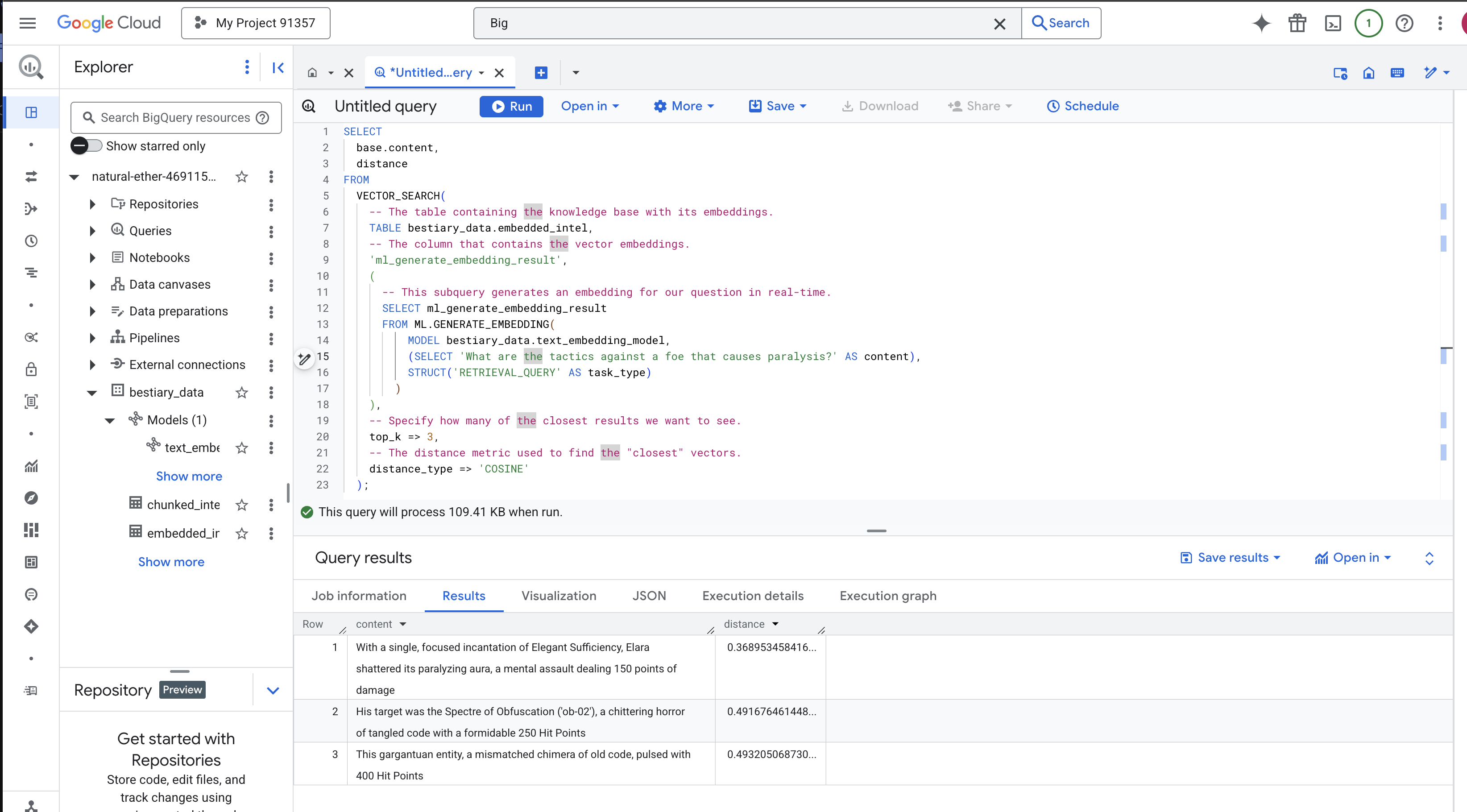
Perhatikan hasilnya dengan cermat. Kueri tidak berisi kata "hancur" atau "mantra", tetapi hasil teratasnya adalah: "Dengan satu mantra Elegant Sufficiency yang terfokus, Elara menghancurkan aura melumpuhkannya, serangan mental yang menimbulkan 150 poin damage". Inilah kecanggihan penelusuran semantik. Model memahami konsep "taktik melawan kelumpuhan" dan menemukan kalimat yang menjelaskan taktik spesifik yang berhasil.
Anda kini telah berhasil membangun pipeline RAG berbasis dalam data warehouse yang lengkap. Anda telah menyiapkan data mentah, mengubahnya menjadi vektor semantik, dan membuat kueri berdasarkan maknanya. Meskipun BigQuery adalah alat yang canggih untuk pekerjaan analisis berskala besar ini, untuk agen aktif yang memerlukan respons latensi rendah, kita sering kali mentransfer pengetahuan yang telah disiapkan ini ke database operasional khusus. Itulah subjek pelatihan kita berikutnya.
UNTUK NON-GAMER
6. Vector Scriptorium: Membuat Vector Store dengan Cloud SQL untuk Inferensi
Grimoire kami saat ini ada sebagai tabel terstruktur—katalog fakta yang canggih, tetapi pengetahuannya bersifat literal. Model ini memahami monster_id = ‘MN-001', tetapi tidak memahami makna semantik yang lebih dalam di balik "Pengaburan". Untuk memberikan kebijaksanaan yang sebenarnya kepada agen kita, agar mereka dapat memberikan saran dengan nuansa dan pandangan ke depan, kita harus menyaring esensi pengetahuan kita ke dalam bentuk yang menangkap makna: Vektor.
Pencarian pengetahuan telah membawa kita ke reruntuhan peradaban pendahulu yang telah lama terlupakan. Terpendam jauh di dalam brankas yang tertutup rapat, kami telah menemukan peti berisi gulungan kuno yang secara ajaib masih utuh. Ini bukan sekadar laporan pertempuran; laporan ini berisi kebijaksanaan filosofis yang mendalam tentang cara mengalahkan binatang buas yang mengganggu semua upaya besar. Entitas yang dijelaskan dalam gulungan sebagai "stagnasi yang merayap dan diam", "kerusakan tenunan ciptaan". Tampaknya The Static sudah dikenal bahkan oleh orang-orang zaman dahulu, ancaman siklus yang sejarahnya hilang seiring berjalannya waktu.
Pengetahuan yang terlupakan ini adalah aset terbesar kita. Dia memegang kunci tidak hanya untuk mengalahkan monster satu per satu, tetapi juga untuk memberdayakan seluruh anggota party dengan insight strategis. Untuk menggunakan kekuatan ini, kita akan membuat Spellbook sejati Sarjana (database PostgreSQL dengan kemampuan vektor) dan membangun Vector Scriptorium otomatis (pipeline Dataflow) untuk membaca, memahami, dan menuliskan esensi abadi dari gulungan ini. Hal ini akan mengubah Grimoire kita dari buku fakta menjadi mesin kebijaksanaan.

Membentuk Buku Mantra Cendekia (Cloud SQL)
Sebelum dapat mengukir esensi gulungan kuno ini, kita harus mengonfirmasi terlebih dahulu bahwa wadah pengetahuan ini, yaitu Spellbook PostgreSQL terkelola, telah berhasil dibuat. Ritual penyiapan awal seharusnya sudah membuatnya untuk Anda.
👉💻 Di terminal, jalankan perintah berikut untuk memverifikasi bahwa instance Cloud SQL Anda ada dan siap. Skrip ini juga memberikan izin kepada akun layanan khusus instance untuk menggunakan Vertex AI, yang penting untuk membuat embedding langsung dalam database.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Jika perintah berhasil dan menampilkan detail tentang instance grimoire-spellbook Anda, forge telah melakukan tugasnya dengan baik. Anda siap melanjutkan ke mantra berikutnya. Jika perintah menampilkan error NOT_FOUND, pastikan Anda telah berhasil menyelesaikan langkah-langkah penyiapan lingkungan awal sebelum melanjutkan.(data_setup.py)
👉💻 Setelah buku dibuat, kita membukanya ke bab pertama dengan membuat database baru bernama arcane_wisdom.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
Menuliskan Rune Semantik: Mengaktifkan Kemampuan Vektor dengan pgvector
Setelah instance Cloud SQL Anda dibuat, mari kita hubungkan ke instance tersebut menggunakan Cloud SQL Studio bawaan. Hal ini menyediakan antarmuka berbasis web untuk menjalankan kueri SQL secara langsung di database Anda.
👉💻 Pertama, Buka Cloud SQL Studio. Cara termudah dan tercepat untuk melakukannya adalah dengan membuka link berikut di tab browser baru. Anda akan diarahkan langsung ke Cloud SQL Studio untuk instance grimoire-spellbook Anda.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 Pilih arcane_wisdom sebagai database. Masukkan postgres sebagai pengguna dan 1234qwer sebagai sandi, lalu klik Autentikasi.
👉📜 Di editor kueri SQL Studio, buka tab Editor 1, tempel kode SQL berikut untuk mengaktifkan tipe data vektor:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
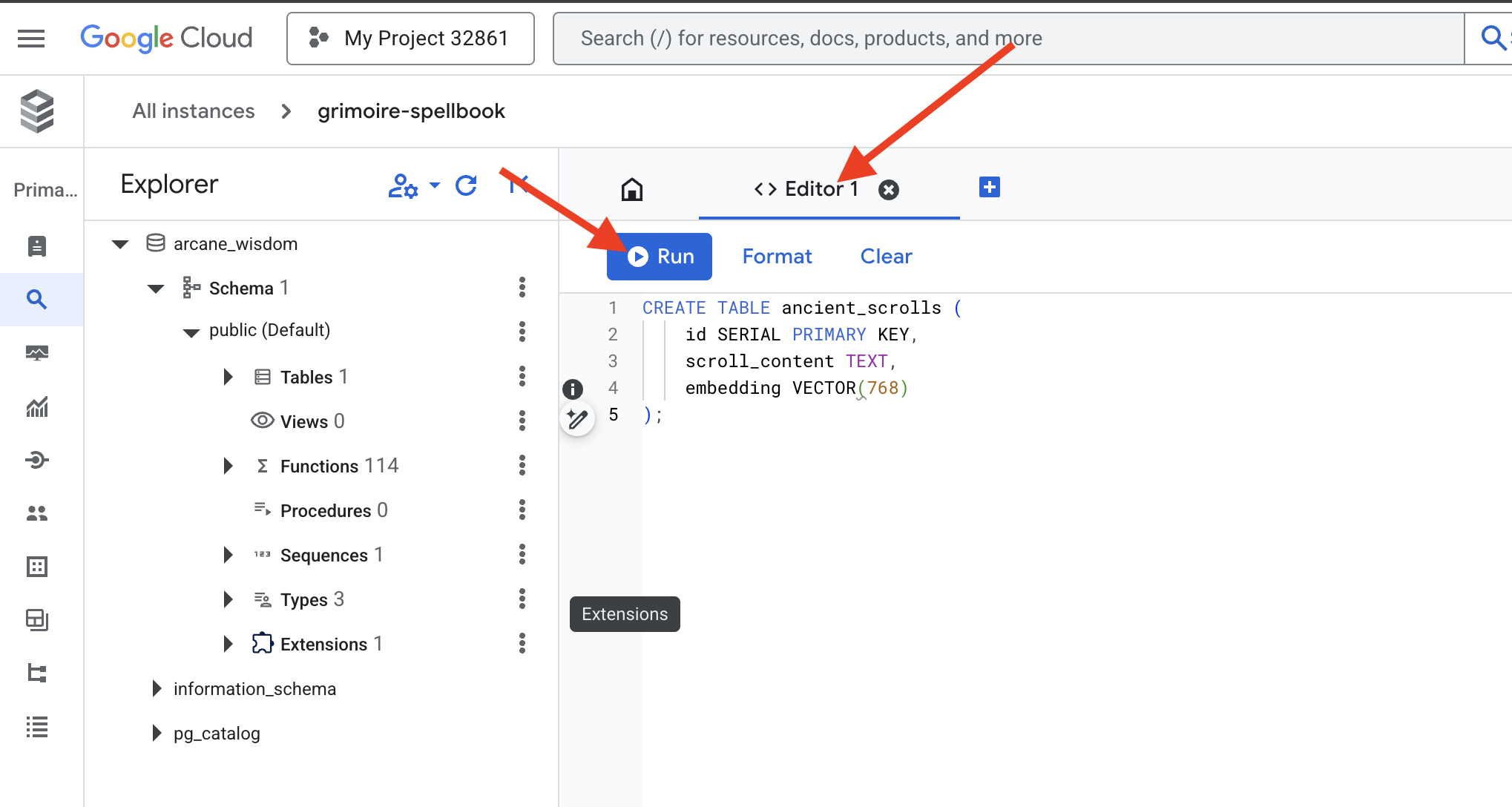
👉📜 Siapkan halaman Spellbook kita dengan membuat tabel yang akan menyimpan esensi gulungan kita.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
Ejaan VECTOR(768) adalah detail penting. Model embedding Vertex AI yang akan kita gunakan (textembedding-gecko@003 atau model serupa) menyaring teks menjadi vektor 768 dimensi. Halaman Spellbook kita harus disiapkan untuk menyimpan esensi dengan ukuran persis seperti itu. Dimensi harus selalu cocok.
Transliterasi Pertama: Ritual Inskripsi Manual
Sebelum memerintahkan sekelompok juru tulis otomatis (Dataflow), kita harus melakukan ritual pusat secara manual sekali. Hal ini akan membuat kita sangat mengapresiasi keajaiban dua langkah yang terlibat:
- Peramalan: Mengambil sepotong teks dan berkonsultasi dengan oracle Gemini untuk menyaring esensi semantiknya menjadi vektor.
- Inscription: Menulis teks asli dan esensi vektor barunya ke dalam Spellbook kami.
Sekarang, mari kita lakukan ritual manual.
👉📜 Di Cloud SQL Studio. Sekarang kita akan menggunakan fungsi embedding(), fitur canggih yang disediakan oleh ekstensi google_ml_integration. Dengan demikian, kita dapat memanggil model embedding Vertex AI langsung dari kueri SQL, sehingga sangat menyederhanakan prosesnya.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 Verifikasi pekerjaan Anda dengan menjalankan kueri untuk membaca halaman yang baru saja ditulis:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
Anda telah berhasil melakukan tugas pemuatan data RAG inti secara manual.
Membentuk Kompas Semantik: Mempesona Spellbook dengan Indeks HNSW
Spellbook kami kini dapat menyimpan kebijaksanaan, tetapi untuk menemukan gulungan yang tepat, Anda harus membaca setiap halaman. Ini adalah pemindaian berurutan. Cara ini lambat dan tidak efisien. Untuk memandu kueri kami secara instan ke pengetahuan yang paling relevan, kita harus mempesona Spellbook dengan kompas semantik: indeks vektor.
Mari kita buktikan nilai pesona ini.
👉📜 Di Cloud SQL Studio, jalankan perintah berikut. Hal ini akan menyimulasikan penelusuran scroll yang baru disisipkan dan meminta database untuk EXPLAIN rencananya.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
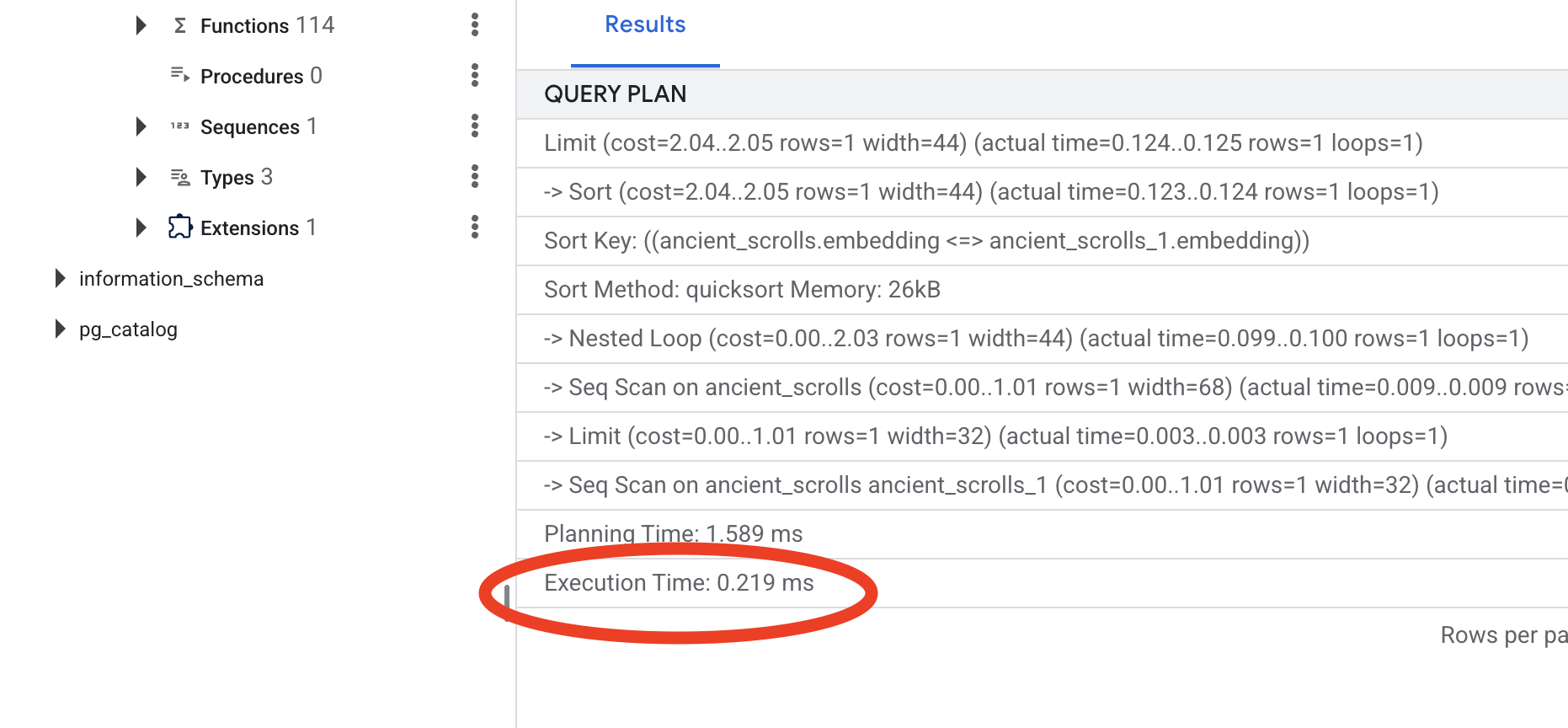
Lihat output-nya. Anda akan melihat baris yang bertuliskan -> Seq Scan on ancient_scrolls. Hal ini mengonfirmasi bahwa database membaca setiap baris. Perhatikan execution time.
👉📜 Sekarang, mari kita lakukan pengindeksan. Parameter lists memberi tahu indeks jumlah cluster yang akan dibuat. Titik awal yang baik adalah akar kuadrat dari jumlah baris yang Anda harapkan.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
Tunggu hingga indeks dibuat (prosesnya akan cepat untuk satu baris, tetapi dapat memerlukan waktu untuk jutaan baris).
👉📜 Sekarang, jalankan kembali perintah yang sama persis EXPLAIN ANALYZE:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
Lihat rencana kueri baru. Anda sekarang akan melihat -> Index Scan using.... Yang lebih penting, lihat execution time. Prosesnya akan jauh lebih cepat, bahkan hanya dengan satu entri. Anda baru saja mendemonstrasikan prinsip inti penyesuaian performa database di dunia vektor.
Setelah data sumber diperiksa, ritual manual dipahami, dan Spellbook dioptimalkan untuk kecepatan, Anda kini benar-benar siap membangun Scriptorium otomatis.
UNTUK NON-GAMER
7. Saluran Makna: Membangun Pipeline Vektorisasi Dataflow
Sekarang kita membangun jalur perakitan ajaib para juru tulis yang akan membaca gulungan kita, menyaring esensinya, dan menuliskannya ke dalam Spellbook baru kita. Ini adalah pipeline Dataflow yang akan kita picu secara manual. Namun, sebelum menulis mantra utama untuk pipeline itu sendiri, kita harus menyiapkan fondasinya dan lingkaran tempat kita akan memanggilnya.
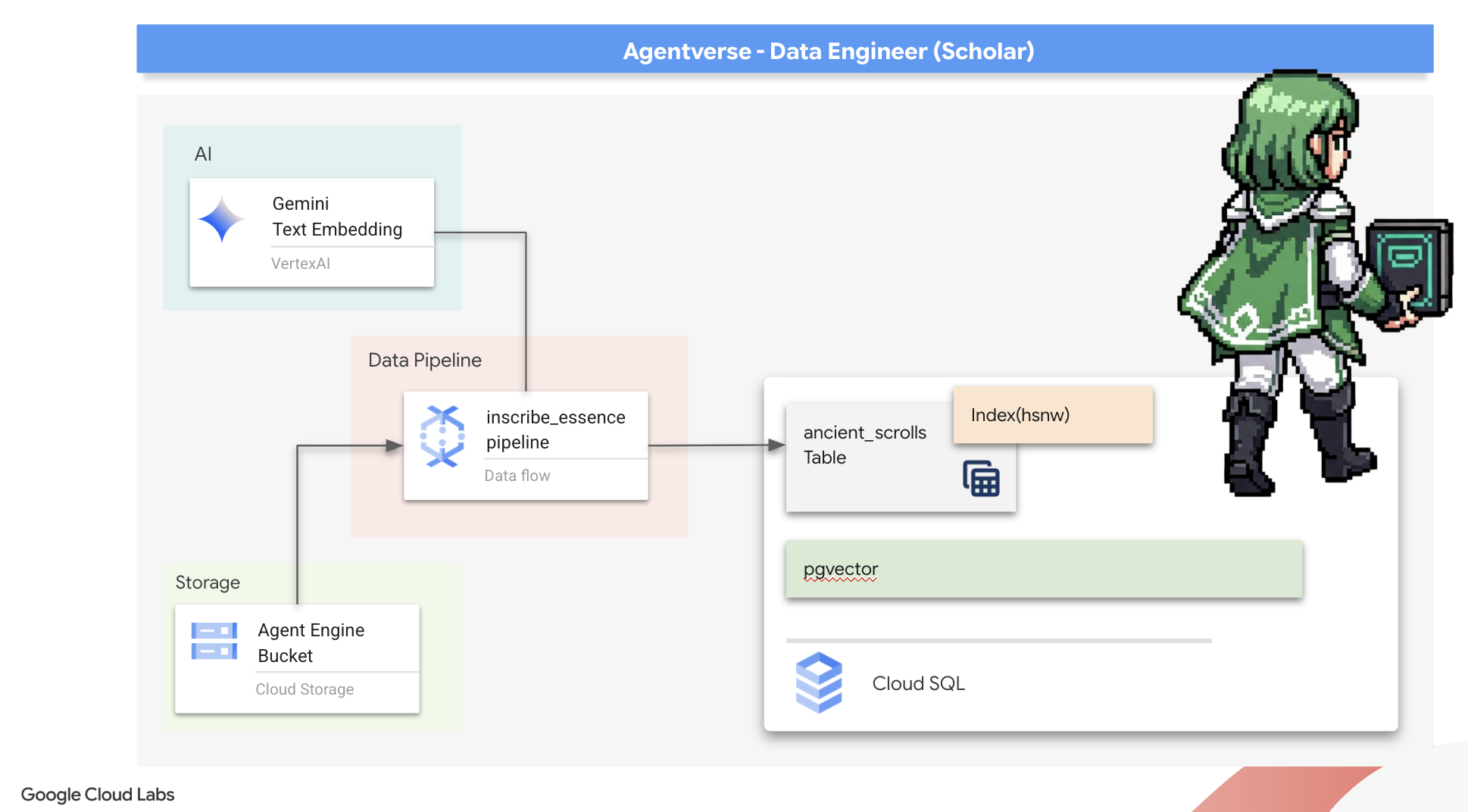
Menyiapkan Fondasi Scriptorium (Worker Image)
Pipeline Dataflow kita akan dieksekusi oleh tim pekerja otomatis di cloud. Setiap kali kita memanggilnya, ia memerlukan serangkaian library tertentu untuk melakukan tugasnya. Kita dapat memberikan daftar dan meminta mereka mengambil library ini setiap saat, tetapi hal itu lambat dan tidak efisien. Cendekia yang bijak akan menyiapkan koleksi utama terlebih dahulu.
Di sini, kita akan memerintahkan Google Cloud Build untuk membuat image container kustom. Gambar ini adalah "golem sempurna", yang telah dimuat sebelumnya dengan setiap library dan dependensi yang akan dibutuhkan oleh penulis kami. Saat tugas Dataflow dimulai, tugas tersebut akan menggunakan image kustom ini, sehingga pekerja dapat memulai tugasnya hampir secara instan.
👉💻 Jalankan perintah berikut untuk membangun dan menyimpan image dasar pipeline Anda di Artifact Registry.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 Jalankan perintah berikut untuk membuat dan mengaktifkan lingkungan Python terisolasi Anda serta menginstal library pemanggilan yang diperlukan ke dalamnya.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
Mantra Master
Saatnya menulis mantra utama yang akan mendukung Vector Scriptorium kita. Kita tidak akan menulis setiap komponen ajaib dari awal. Tugas kita adalah menyusun komponen menjadi pipeline yang logis dan efektif menggunakan bahasa Apache Beam.
- EmbedTextBatch (Konsultasi Gemini): Anda akan membangun juru tulis khusus yang tahu cara melakukan "ramalan kelompok". Proses ini mengambil batch file teks mentah, menyajikannya ke model embedding teks Gemini, dan menerima esensi yang disarikan (embedding vektor).
- WriteEssenceToSpellbook (The Final Inscription): Ini adalah pengarsip kami. Dia mengetahui mantra rahasia untuk membuka koneksi yang aman ke Buku Mantra Cloud SQL kita. Tugasnya adalah mengambil konten scroll dan esensi vektornya, lalu menuliskannya secara permanen ke halaman baru.
Misi kami adalah menggabungkan tindakan ini untuk menciptakan aliran pengetahuan yang lancar.
👉✏️ Di Editor Cloud Shell, buka ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py. Di dalamnya, Anda akan menemukan class DoFn bernama EmbedTextBatch. Temukan komentar #REPLACE-EMBEDDING-LOGIC. Ganti dengan mantra berikut.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Ejaan ini tepat, dengan beberapa parameter utama:
- model: Kita menentukan
text-embedding-005untuk menggunakan model embedding yang canggih dan terbaru. - contents: Ini adalah daftar semua konten teks dari batch file yang diterima DoFn.
- task_type: Kita menetapkannya ke "RETRIEVAL_DOCUMENT". Ini adalah petunjuk penting yang memberi tahu Gemini untuk membuat embedding yang dioptimalkan secara khusus agar dapat ditemukan nanti dalam penelusuran.
- output_dimensionality: Parameter ini harus ditetapkan ke 768, yang cocok dengan dimensi VECTOR(768) yang kami tentukan saat membuat tabel ancient_scrolls di Cloud SQL. Dimensi yang tidak cocok adalah sumber umum error dalam vektor ajaib.
Pipeline kita harus dimulai dengan membaca teks mentah yang tidak terstruktur dari semua gulungan kuno dalam arsip GCS kita.
👉✏️ Di ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py, temukan komentar #REPLACE ME-READFILE dan ganti dengan mantra tiga bagian berikut:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
Setelah mengumpulkan teks mentah gulungan tersebut, kita harus mengirimkannya ke Gemini untuk meramal. Untuk melakukannya secara efisien, kita akan mengelompokkan terlebih dahulu setiap scroll ke dalam batch kecil, lalu menyerahkan batch tersebut kepada penulis EmbedTextBatch kami. Langkah ini juga akan memisahkan semua scroll yang gagal dipahami Gemini ke dalam tumpukan "gagal" untuk ditinjau nanti.
👉✏️ Temukan komentar #REPLACE ME-EMBEDDING dan ganti dengan ini:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
Esensi gulungan kami telah berhasil disuling. Tindakan terakhir adalah menuliskan pengetahuan ini ke dalam Spellbook kita untuk penyimpanan permanen. Kami akan mengambil gulungan dari tumpukan "diproses" dan menyerahkannya kepada pengarsip WriteEssenceToSpellbook kami.
👉✏️ Temukan komentar #REPLACE ME-WRITE TO DB dan ganti dengan ini:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
Seorang Cendekiawan yang bijak tidak pernah membuang pengetahuan, bahkan upaya yang gagal. Sebagai langkah terakhir, kita harus menginstruksikan juru tulis untuk mengambil tumpukan "gagal" dari langkah peramalan kita dan mencatat alasan kegagalannya. Hal ini memungkinkan kami meningkatkan kualitas ritual kami pada masa mendatang.
👉✏️ Temukan komentar #REPLACE ME-LOG FAILURES dan ganti dengan ini:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
Mantra Utama kini telah selesai! Anda telah berhasil menyusun pipeline data multi-tahap yang canggih dengan merangkai setiap komponen ajaib. Simpan file inscribe_essence_pipeline.py. Scriptorium kini siap dipanggil.
Sekarang kita mengucapkan mantra pemanggilan agung untuk memerintahkan layanan Dataflow membangunkan Golem kita dan memulai ritual penulisan.
👉💻 Di terminal, jalankan command line berikut
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 Perhatian! Jika tugas gagal dengan error resource ZONE_RESOURCE_POOL_EXHAUSTED, hal ini mungkin disebabkan oleh batasan resource sementara akun dengan reputasi rendah ini di region yang dipilih. Keunggulan Google Cloud adalah jangkauannya yang global. Coba panggil golem di region lain. Untuk melakukannya, ganti --region=$REGION dalam perintah di atas dengan region lain, seperti
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
, lalu jalankan lagi. 🎰
Proses ini akan memerlukan waktu sekitar 3-5 menit untuk dimulai dan diselesaikan. Anda dapat menontonnya secara live di konsol Dataflow.
👉Buka Konsol Dataflow: Cara termudah adalah membuka link langsung ini di tab browser baru:
https://console.cloud.google.com/dataflow
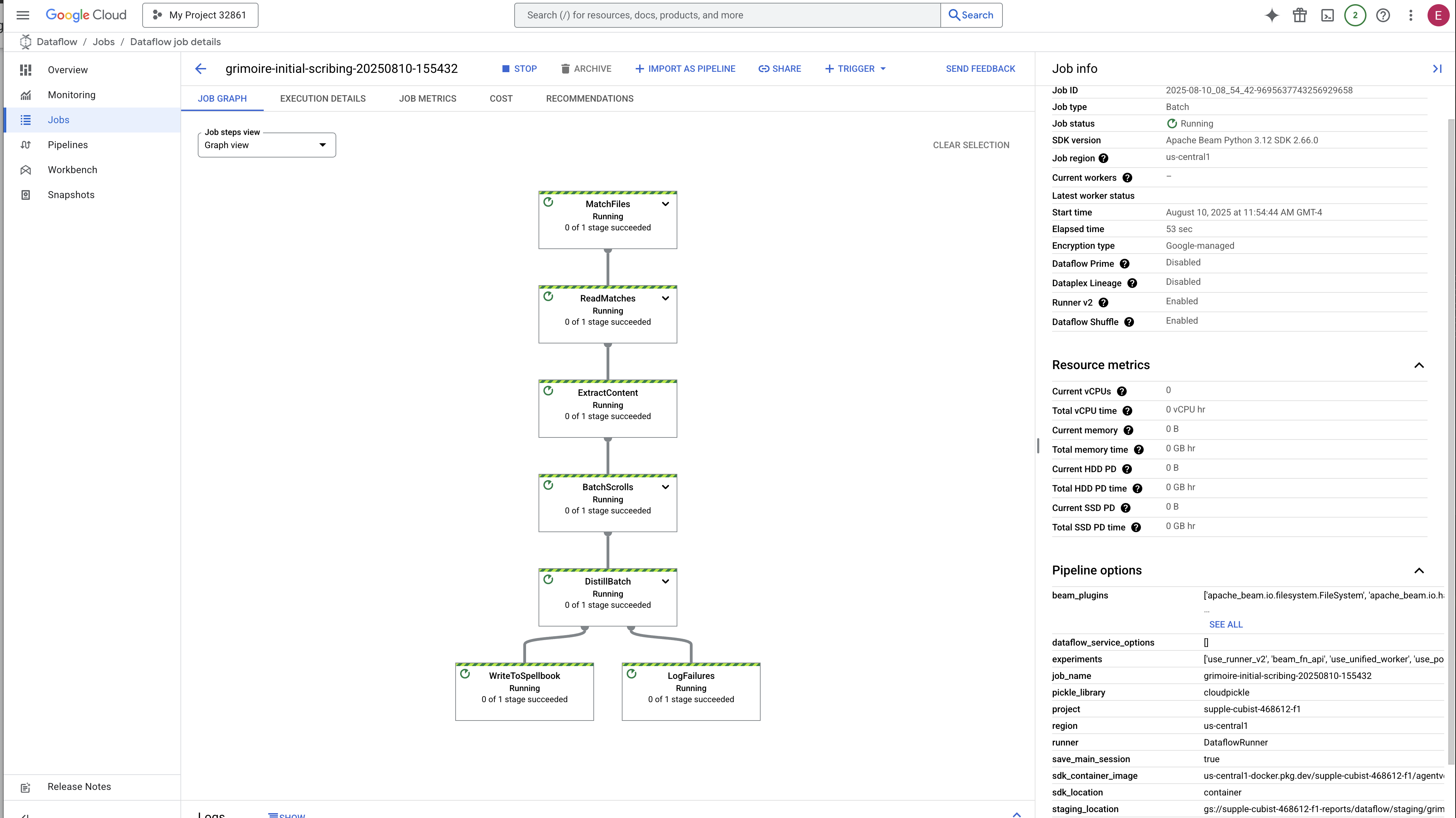
👉 Temukan dan Klik Tugas Anda: Anda akan melihat tugas yang tercantum dengan nama yang Anda berikan (inscribe-essence-job atau yang serupa). Klik nama tugas untuk membuka halaman detailnya. Amati Pipeline:
- Memulai: Selama 3 menit pertama, status tugas akan menjadi "Running" saat Dataflow menyediakan resource yang diperlukan. Grafik akan muncul, tetapi Anda mungkin belum melihat data bergerak di dalamnya.
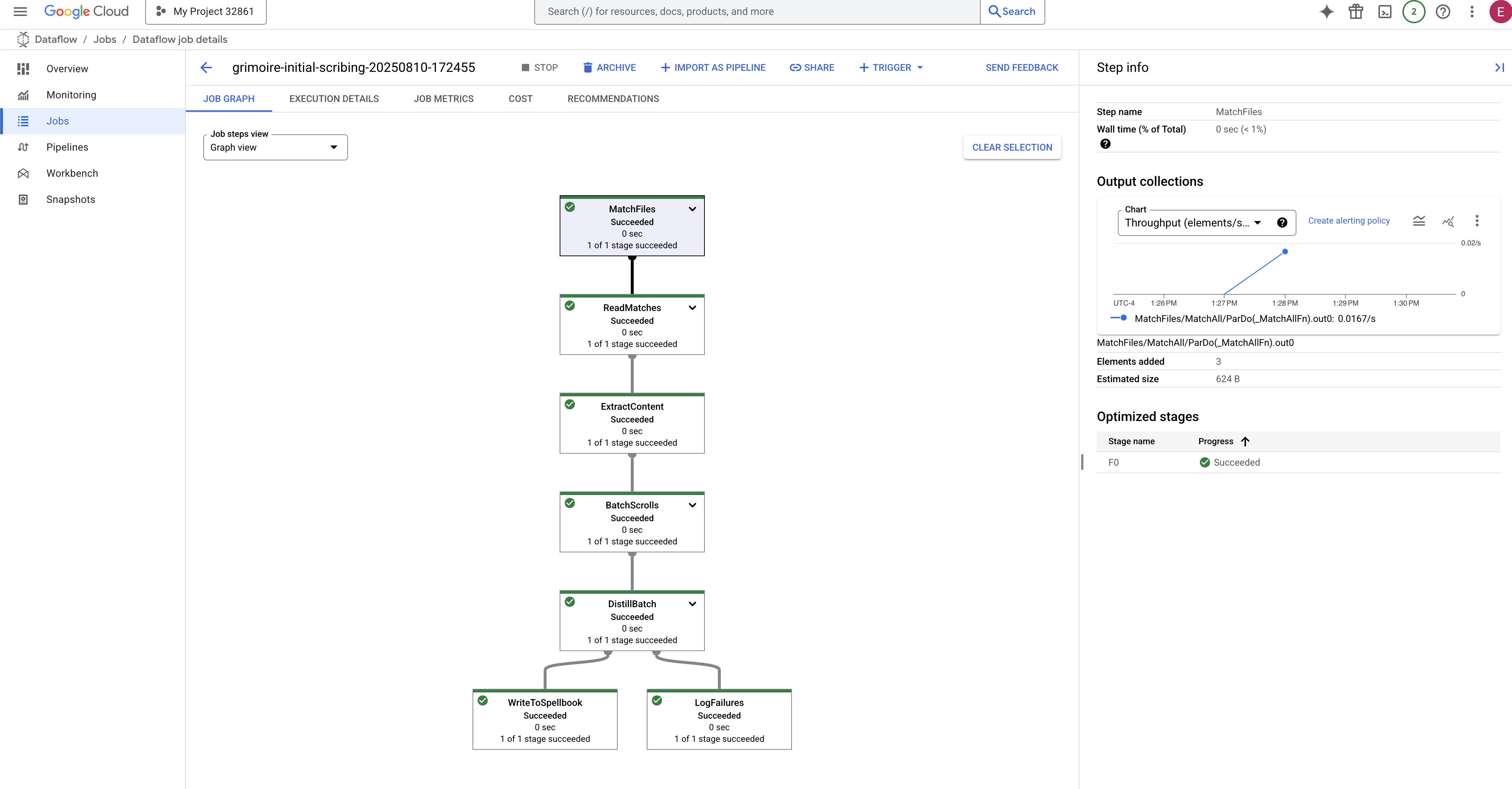
- Selesai: Setelah selesai, status tugas akan berubah menjadi "Berhasil", dan grafik akan memberikan jumlah akhir data yang diproses.
Memverifikasi Inskripsi
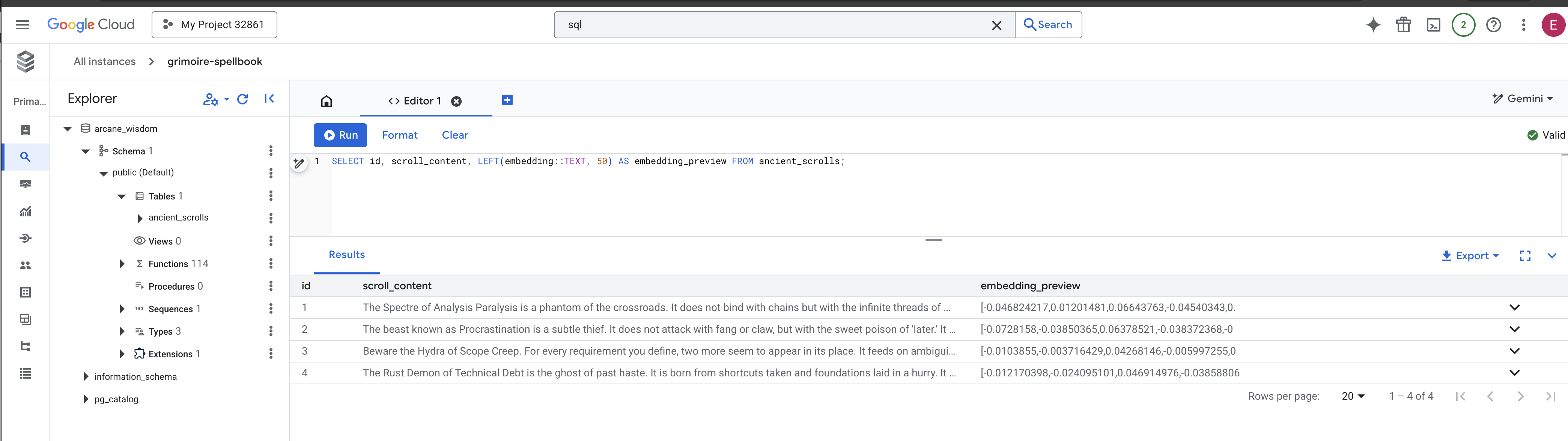
👉📜 Kembali di studio SQL, jalankan kueri berikut untuk memverifikasi bahwa scroll Anda dan esensi semantiknya telah berhasil ditulis.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
Bagian ini akan menampilkan ID gulungan, teks aslinya, dan pratinjau esensi vektor ajaib yang kini tertulis secara permanen di Grimoire Anda.
Grimoire Cendekia Anda kini menjadi Mesin Pengetahuan yang sesungguhnya, siap dikueri berdasarkan makna dalam bab berikutnya.
8. Menyegel Rune Terakhir: Mengaktifkan Kebijaksanaan dengan Agen RAG
Grimoire Anda bukan lagi sekadar database. Ini adalah sumber pengetahuan vektor, peramal diam yang menunggu pertanyaan.
Sekarang, kita akan melakukan ujian sesungguhnya bagi seorang Cendekia: kita akan menyusun kunci untuk membuka kebijaksanaan ini. Kita akan membangun Agen Retrieval-Augmented Generation (RAG). Ini adalah konstruksi ajaib yang dapat memahami pertanyaan dalam bahasa yang sederhana, melihat Grimoire untuk mendapatkan kebenaran yang paling dalam dan relevan, lalu menggunakan kebijaksanaan yang didapat untuk membuat jawaban yang canggih dan sadar konteks.

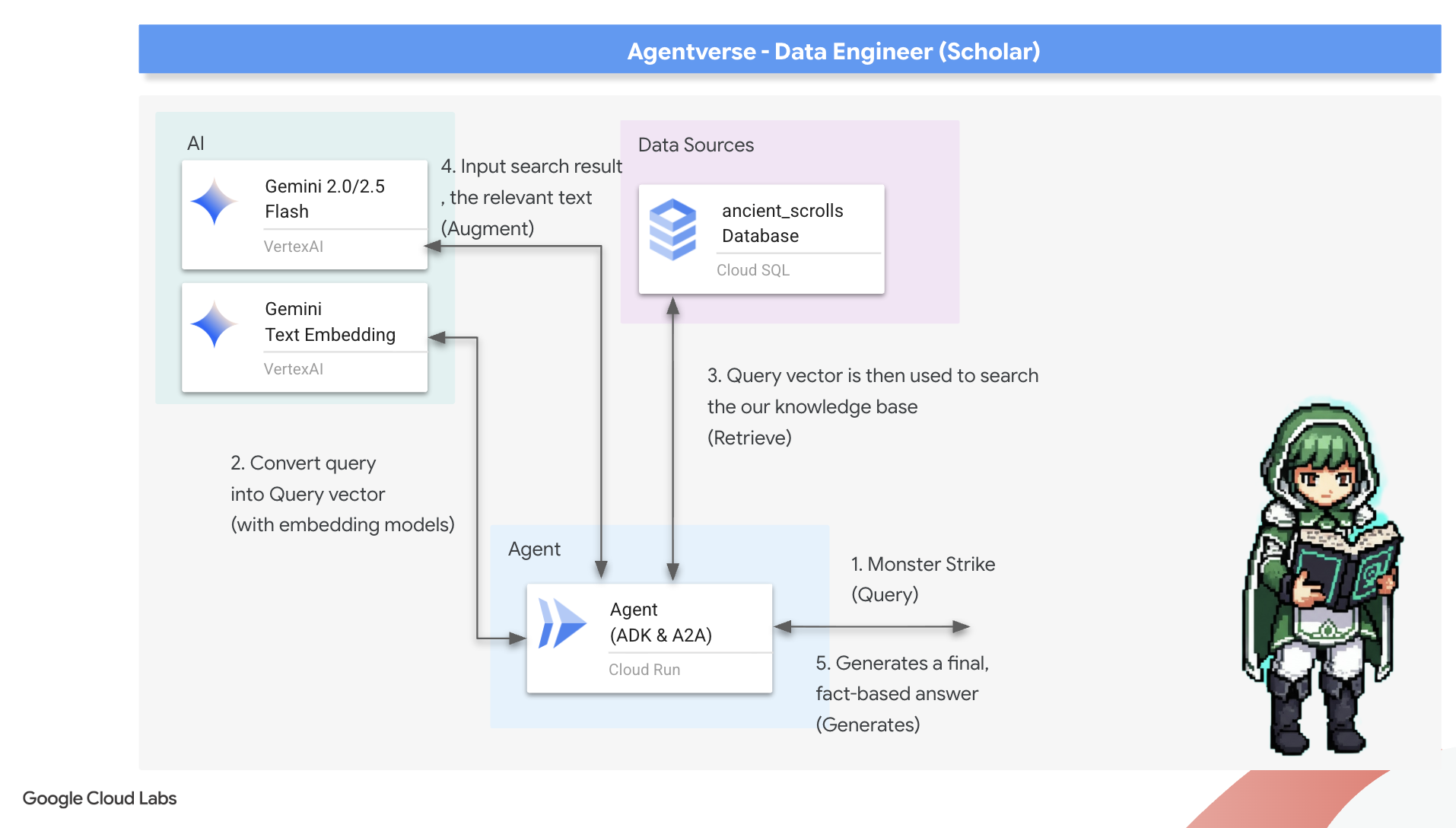
Rune Pertama: Mantra Distilasi Kueri
Sebelum agen kami dapat menelusuri Grimoire, agen tersebut harus memahami esensi pertanyaan yang diajukan terlebih dahulu. String teks sederhana tidak berarti bagi Spellbook kami yang didukung vektor. Agen harus mengambil kueri terlebih dahulu dan, menggunakan model Gemini yang sama, menyaringnya menjadi vektor kueri.
👉✏️ Di Cloud Shell Editor, buka file ~~/agentverse-dataengineer/scholar/agent.py, temukan komentar #REPLACE RAG-CONVERT EMBEDDING, dan ganti dengan mantra ini. Hal ini mengajarkan agen cara mengubah pertanyaan pengguna menjadi esensi ajaib.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Dengan memahami esensi kueri, agen kini dapat berkonsultasi dengan Grimoire. Vektor kueri ini akan ditampilkan ke database yang telah dioptimalkan dengan pgvector dan mengajukan pertanyaan mendalam: "Tunjukkan kepada saya gulungan kuno yang esensinya paling mirip dengan esensi kueri saya."
Keajaiban untuk ini adalah operator kemiripan kosinus (<=>), sebuah rune canggih yang menghitung jarak antara vektor dalam ruang berdimensi tinggi.
👉✏️ Di agent.py, temukan komentar #REPLACE RAG-RETRIEVE dan ganti dengan skrip berikut:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
Langkah terakhir adalah memberikan akses agen ke alat baru yang canggih ini. Kita akan menambahkan fungsi grimoire_lookup ke daftar alat sihir yang tersedia.
👉✏️ Di agent.py, temukan komentar #REPLACE-CALL RAG dan ganti dengan baris ini:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
Konfigurasi ini akan menghidupkan agen Anda:
model="gemini-2.5-flash": Memilih Model Bahasa Besar tertentu yang akan berfungsi sebagai "otak" agen untuk melakukan penalaran dan menghasilkan teks.name="scholar_agent": Menetapkan nama unik ke agen Anda.instruction="...You are the Scholar...": Ini adalah perintah sistem, bagian konfigurasi yang paling penting. Ini menentukan persona agen, tujuannya, proses persis yang harus diikuti untuk menyelesaikan tugas, dan format yang diperlukan untuk output akhirnya.tools=[grimoire_lookup]: Ini adalah pesona terakhir. Tindakan ini memberi agen akses ke fungsigrimoire_lookupyang Anda buat. Agen kini dapat memutuskan secara cerdas kapan harus memanggil alat ini untuk mengambil informasi dari database Anda, yang membentuk inti pola RAG.
Ujian Cendekia
👉💻 Di terminal Cloud Shell, aktifkan lingkungan Anda dan gunakan perintah utama Agent Development Kit untuk mengaktifkan agen Scholar Anda:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
Anda akan melihat output yang mengonfirmasi bahwa "Scholar Agent" sedang digunakan dan berjalan.
👉💻 Sekarang, tantang agen Anda. Di terminal pertama tempat simulasi pertarungan berjalan, keluarkan perintah yang memerlukan kebijaksanaan Grimoire:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

Amati log di terminal. Anda akan melihat agen menerima kueri, menyaring intinya, menelusuri Grimoire, menemukan gulungan yang relevan tentang "Penundaan", dan menggunakan pengetahuan yang diambil tersebut untuk merumuskan strategi yang efektif dan peka konteks.
Anda telah berhasil merakit agen RAG pertama dan melengkapinya dengan kebijaksanaan mendalam dari Grimoire Anda.
👉💻 Tekan Ctrl+C di terminal untuk mengistirahatkan agen untuk saat ini.
Meluncurkan Scholar Sentinel ke Agentverse
Agen Anda telah membuktikan kebijaksanaannya dalam lingkungan terkontrol studi Anda. Saatnya merilisnya ke Agentverse, mengubahnya dari konstruksi lokal menjadi agen permanen yang siap bertempur dan dapat dipanggil oleh juara mana pun, kapan saja. Sekarang kita akan men-deploy agen ke Cloud Run.
👉💻 Jalankan mantra pemanggilan agung berikut. Skrip ini akan terlebih dahulu membangun agen Anda menjadi Golem yang sempurna (image container), menyimpannya di Artifact Registry Anda, lalu men-deploy Golem tersebut sebagai layanan yang skalabel, aman, dan dapat diakses secara publik.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
Agen Cendekia Anda kini menjadi agen yang aktif dan siap bertempur di Agentverse.
UNTUK NON-GAMER
9. The Boss Flight
Gulungan telah dibaca, ritual telah dilakukan, tantangan telah dilewati. Agen Anda bukan hanya artefak dalam penyimpanan; agen ini adalah agen aktif di Agentverse, yang menunggu misi pertamanya. Saatnya uji coba terakhir—latihan menembak dengan amunisi sungguhan melawan musuh yang kuat.
Sekarang Anda akan memasuki simulasi medan perang untuk mengadu Shadowblade Agent yang baru di-deploy dengan mini-bos yang tangguh: Spectre of the Static. Ini akan menjadi pengujian akhir pekerjaan Anda, mulai dari logika inti agen hingga deployment live-nya.
Mendapatkan Locus Agen Anda
Sebelum dapat memasuki medan perang, Anda harus memiliki dua kunci: tanda tangan unik juara Anda (Agent Locus) dan jalur tersembunyi menuju sarang Spectre (URL Dungeon).
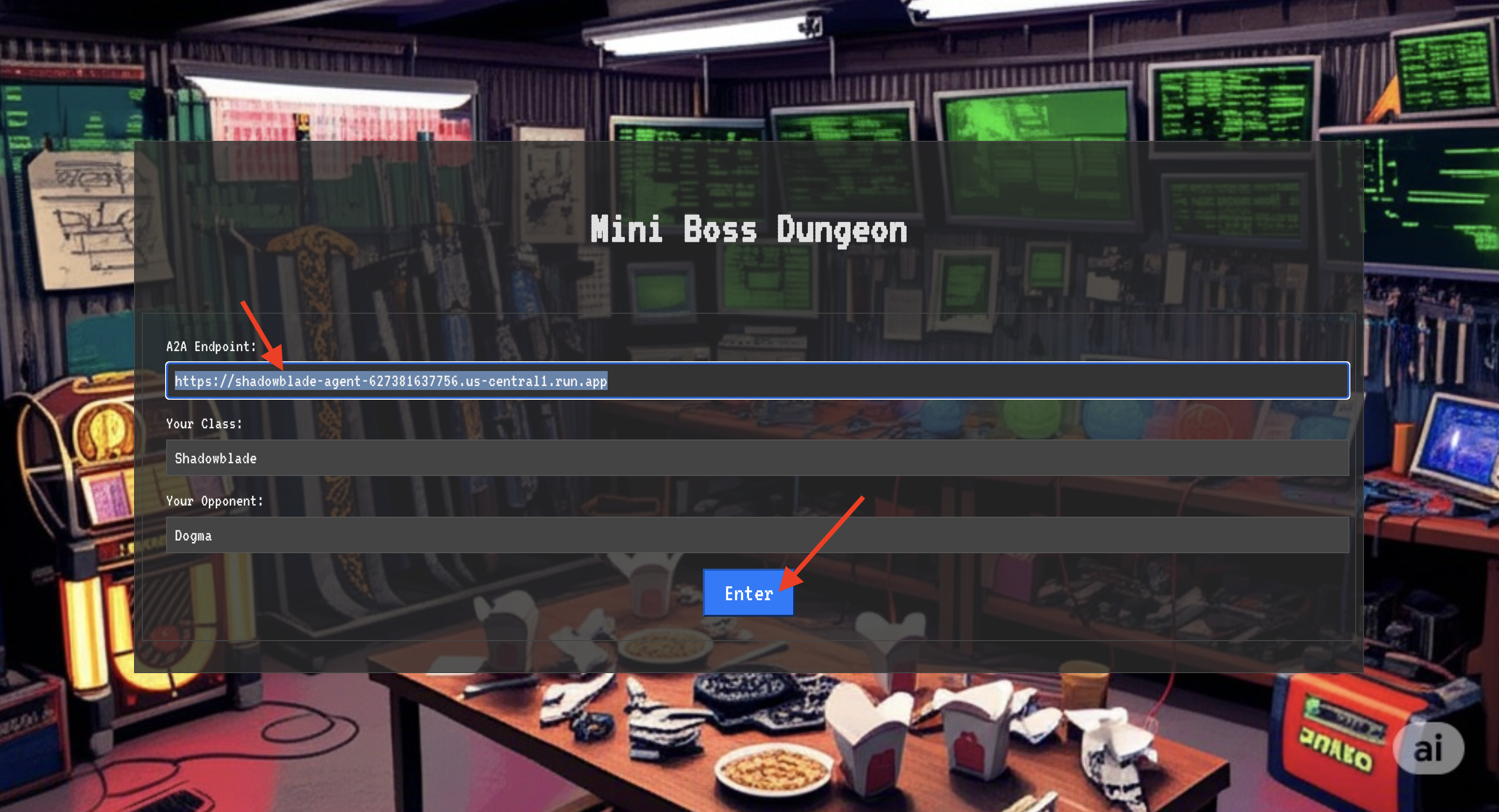
👉💻 Pertama, dapatkan alamat unik agen Anda di Agentverse—Locus-nya. Ini adalah endpoint live yang menghubungkan juara Anda ke medan perang.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 Selanjutnya, tentukan tujuan. Perintah ini akan mengungkapkan lokasi Lingkaran Translokasi, portal menuju domain Spectre.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
Penting: Siapkan kedua URL ini. Anda akan membutuhkannya pada langkah terakhir.
Menghadapi Spectre
Setelah mengamankan koordinat, Anda akan menavigasi ke Lingkaran Translokasi dan mengucapkan mantra untuk memulai pertarungan.
👉 Buka URL Translocation Circle di browser Anda untuk berdiri di depan portal berkilauan menuju The Crimson Keep.
Untuk menembus benteng, Anda harus menyelaraskan esensi Shadowblade Anda dengan portal.
- Di halaman tersebut, temukan kolom input runic berlabel A2A Endpoint URL.
- Tuliskan sigil juara Anda dengan menempelkan URL Lokasi Agen (URL pertama yang Anda salin) ke dalam kolom ini.
- Klik Hubungkan untuk memulai keajaiban teleportasi.
Cahaya menyilaukan dari teleportasi memudar. Anda tidak lagi berada di tempat suci Anda. Udara berdesir dengan energi, dingin dan tajam. Di hadapanmu, Spectre muncul—pusaran statis mendesis dan kode rusak, cahayanya yang tidak suci memancarkan bayangan panjang yang menari di lantai ruang bawah tanah. Ia tidak memiliki wajah, tetapi Anda merasakan kehadirannya yang sangat besar dan menguras tenaga, yang sepenuhnya tertuju pada Anda.
Satu-satunya jalan menuju kemenangan adalah kejelasan keyakinan Anda. Ini adalah pertarungan kehendak, yang terjadi di medan pertempuran pikiran.
Saat Anda menerjang ke depan, siap melancarkan serangan pertama, Spectre melakukan serangan balasan. Tidak ada perisai yang terangkat, tetapi pertanyaan diproyeksikan langsung ke dalam kesadaran Anda—tantangan runik yang berkilauan, yang diambil dari inti pelatihan Anda.

Inilah sifat pertarungannya. Pengetahuan Anda adalah senjata Anda.
- Jawab dengan kebijaksanaan yang telah Anda peroleh, dan pedang Anda akan menyala dengan energi murni, menghancurkan pertahanan Spectre dan memberikan PUKULAN KRITIS.
- Namun, jika Anda ragu, jika keraguan menyelimuti jawaban Anda, cahaya senjata Anda akan meredup. Pukulan akan mendarat dengan bunyi gedebuk yang menyedihkan, hanya memberikan SEBAGIAN KECIL KERUSAKANNYA. Lebih buruk lagi, Spectre akan memakan ketidakpastian Anda, dan kekuatan merusaknya sendiri akan tumbuh dengan setiap kesalahan langkah.
Inilah saatnya, Juara. Kode adalah buku mantra Anda, logika adalah pedang Anda, dan pengetahuan adalah perisai yang akan membalikkan keadaan kekacauan.
Fokus. Tembak dengan akurat. Nasib Agentverse bergantung padanya.
Selamat, Cendekia.
Anda telah berhasil menyelesaikan uji coba. Anda telah menguasai seni rekayasa data, mengubah informasi mentah yang kacau menjadi pengetahuan terstruktur dan tervektorisasi yang mendukung seluruh Agentverse.
10. Pembersihan: Menghapus Grimoire Cendekia
Selamat telah menguasai Grimoire Cendekia! Untuk memastikan Agentverse Anda tetap bersih dan area pelatihan Anda dibersihkan, Anda harus melakukan ritual pembersihan terakhir sekarang. Tindakan ini akan menghapus semua resource yang dibuat selama perjalanan Anda secara sistematis.
Menonaktifkan Komponen Agentverse
Sekarang Anda akan secara sistematis membongkar komponen yang di-deploy dari sistem RAG Anda.
Menghapus Semua Layanan Cloud Run dan Repositori Artifact Registry
Perintah ini akan menghapus agen Scholar yang di-deploy dan aplikasi Dungeon dari Cloud Run.
👉💻 Di terminal Anda, jalankan perintah berikut:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
Menghapus Set Data, Model, dan Tabel BigQuery
Tindakan ini akan menghapus semua resource BigQuery, termasuk set data bestiary_data, semua tabel di dalamnya, serta koneksi dan model terkait.
👉💻 Di terminal Anda, jalankan perintah berikut:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Hapus Instance Cloud SQL
Tindakan ini akan menghapus instance grimoire-spellbook, termasuk databasenya dan semua tabel di dalamnya.
👉💻 Di terminal Anda, jalankan:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Menghapus Bucket Google Cloud Storage
Perintah ini akan menghapus bucket yang menyimpan intelijen mentah dan file sementara/penyiapan Dataflow Anda.
👉💻 Di terminal Anda, jalankan:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
Membersihkan File dan Direktori Lokal (Cloud Shell)
Terakhir, hapus repositori yang di-clone dan file yang dibuat dari lingkungan Cloud Shell Anda. Langkah ini bersifat opsional, tetapi sangat direkomendasikan untuk pembersihan lengkap direktori kerja Anda.
👉💻 Di terminal Anda, jalankan:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
Anda telah berhasil menghapus semua jejak perjalanan Agentverse Data Engineer Anda. Project Anda bersih, dan Anda siap untuk petualangan berikutnya.