
1. Overture
L'era dello sviluppo isolato sta per finire. La prossima ondata di evoluzione tecnologica non si baserà sul genio solitario, ma sulla maestria collaborativa. Creare un unico agente intelligente è un esperimento affascinante. Creare un ecosistema di agenti solido, sicuro e intelligente, un vero e proprio Agentverse, è la grande sfida per l'azienda moderna.
Il successo in questa nuova era richiede la convergenza di quattro ruoli fondamentali, i pilastri di base che supportano qualsiasi sistema autonomo fiorente. Una carenza in una qualsiasi area crea una debolezza che può compromettere l'intera struttura.
Questo workshop è il playbook aziendale definitivo per padroneggiare il futuro basato sull'agentività su Google Cloud. Forniamo una roadmap end-to-end che ti guida dalla prima idea a una realtà operativa su vasta scala. In questi quattro lab interconnessi, imparerai come le competenze specializzate di uno sviluppatore, un architetto, un data engineer e un SRE devono convergere per creare, gestire e scalare un potente Agentverse.
Nessun singolo pilastro può supportare da solo l'Agentverse. Il progetto grandioso dell'architetto è inutile senza l'esecuzione precisa dello sviluppatore. L'agente dello sviluppatore è cieco senza la saggezza del Data Engineer e l'intero sistema è fragile senza la protezione dell'SRE. Solo attraverso la sinergia e una comprensione condivisa dei ruoli di ciascuno, il tuo team può trasformare un concetto innovativo in una realtà operativa fondamentale. Il tuo percorso inizia qui. Preparati a padroneggiare il tuo ruolo e a scoprire come ti inserisci nel quadro generale.
Ti diamo il benvenuto in The Agentverse: A Call to Champions
Nella vasta distesa digitale dell'impresa, è iniziata una nuova era. È l'era degli agenti, un periodo di immense promesse, in cui agenti intelligenti e autonomi lavorano in perfetta armonia per accelerare l'innovazione ed eliminare le attività banali.

Questo ecosistema connesso di potere e potenziale è noto come Agentverse.
Ma una lenta entropia, una corruzione silenziosa nota come Static, ha iniziato a sfilacciare i bordi di questo nuovo mondo. Static non è un virus o un bug, ma l'incarnazione del caos che si nutre dell'atto stesso della creazione.
Amplifica le vecchie frustrazioni in forme mostruose, dando vita ai Sette spettri dello sviluppo. Se non viene controllato, Static e i suoi spettri bloccherà i progressi, trasformando la promessa dell'Agentverse in una terra desolata di debito tecnico e progetti abbandonati.
Oggi invitiamo i campioni a contrastare l'ondata di caos. Abbiamo bisogno di eroi disposti a perfezionare le proprie abilità e a collaborare per proteggere l'Agentverse. È arrivato il momento di scegliere il tuo percorso.
Scegli il corso
Quattro percorsi distinti si aprono davanti a te, ognuno dei quali è un pilastro fondamentale nella lotta contro Static. Anche se la formazione sarà una missione solitaria, il tuo successo finale dipende dalla comprensione di come le tue competenze si combinano con quelle degli altri.
- La Lama d'Ombra (sviluppatore): un maestro della forgia e della prima linea. Sei l'artigiano che crea le lame, costruisce gli strumenti e affronta il nemico nei dettagli intricati del codice. Il tuo percorso è fatto di precisione, abilità e creazione pratica.
- L'evocatore (architetto): un grande stratega e orchestratore. Non vedi un singolo agente, ma l'intero campo di battaglia. Progetti i master blueprint che consentono a interi sistemi di agenti di comunicare, collaborare e raggiungere un obiettivo molto più grande di qualsiasi singolo componente.
- Lo Studioso (Data Engineer): un ricercatore di verità nascoste e custode della saggezza. Ti avventuri nella vasta e selvaggia natura dei dati per scoprire l'intelligenza che dà ai tuoi agenti uno scopo e una visione. Le tue conoscenze possono rivelare la debolezza di un nemico o dare potere a un alleato.
- Il Guardiano (DevOps / SRE): il protettore e lo scudo del regno. Costruisci le fortezze, gestisci le linee di alimentazione e assicurati che l'intero sistema possa resistere agli inevitabili attacchi di Static. La tua forza è la base su cui si fonda la vittoria della tua squadra.
La tua missione
L'allenamento inizierà come esercizio autonomo. Seguirai il percorso che hai scelto, acquisendo le competenze uniche necessarie per padroneggiare il tuo ruolo. Al termine della prova, dovrai affrontare uno spettro nato da Static, un mini boss che si nutre delle sfide specifiche della tua professione.
Solo se padroneggerai il tuo ruolo individuale potrai prepararti per la prova finale. Dovrai quindi formare un gruppo con campioni delle altre classi. Insieme, vi avventurerete nel cuore della corruzione per affrontare un boss finale.
Una sfida finale collaborativa che metterà alla prova la vostra forza combinata e determinerà il destino dell'Agentverse.
L'Agentverse attende i suoi eroi. Risponderai alla chiamata?
2. Il grimorio dello studioso
Il nostro viaggio inizia. In qualità di studiosi, la nostra arma principale è la conoscenza. Abbiamo scoperto un tesoro di antichi rotoli criptici nei nostri archivi (Google Cloud Storage). Questi rotoli contengono informazioni grezze sulle temibili bestie che affliggono la terra. La nostra missione è utilizzare la profonda magia analitica di Google BigQuery e la saggezza di un cervello anziano di Gemini (modello Gemini Pro) per decifrare questi testi non strutturati e trasformarli in un bestiario strutturato e interrogabile. Queste saranno le basi di tutte le nostre strategie future.
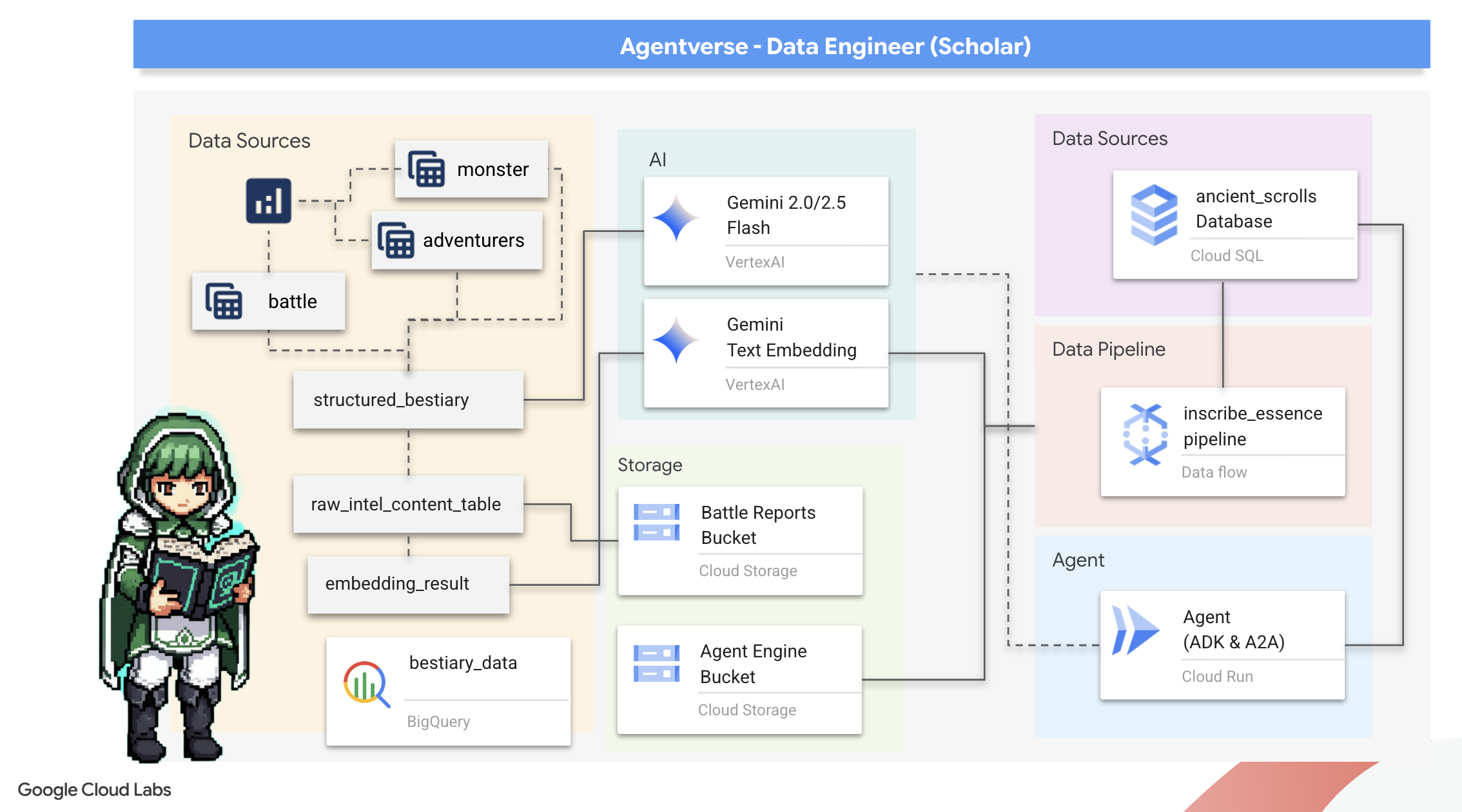
Obiettivi didattici
- Utilizza BigQuery per creare tabelle esterne ed eseguire trasformazioni complesse da non strutturate a strutturate utilizzando BQML.GENERATE_TEXT con un modello Gemini.
- Esegui il provisioning di un'istanza Cloud SQL per PostgreSQL e abilita l'estensione pgvector per le funzionalità di ricerca semantica.
- Crea una pipeline batch solida e containerizzata utilizzando Dataflow e Apache Beam per elaborare file di testo non elaborati, generare incorporamenti vettoriali con un modello Gemini e scrivere i risultati in un database relazionale.
- Implementa un sistema RAG (Retrieval-Augmented Generation) di base all'interno di un agente per eseguire query sui dati vettoriali.
- Esegui il deployment di un agente data-aware come servizio sicuro e scalabile su Cloud Run.
3. Preparazione del Santuario dello studioso
Benvenuto, studioso. Prima di poter iniziare a trascrivere le potenti conoscenze del nostro Grimoire, dobbiamo prima preparare il nostro sanctum. Questo rituale fondamentale prevede di incantare il nostro ambiente Google Cloud, aprire i portali giusti (API) e creare i condotti attraverso i quali fluirà la nostra magia dei dati. Un sanctum ben preparato garantisce che i nostri incantesimi siano potenti e le nostre conoscenze siano sicure.
Richiedi il tuo credito Google Cloud
⚠️ Prerequisiti importanti:
- Utilizza un account Gmail personale:devi utilizzare un account personale (ad es.
name@gmail.com). Gli account aziendali o gestiti dalla scuola non funzionano.
👉 Passaggi:
- Vai al sito per la richiesta di crediti: fai clic qui
- Accedi:incolla il link nella barra degli indirizzi e accedi con il tuo account Gmail personale.
- Accetta termini:accetta i Termini di servizio della piattaforma Google Cloud.
- Verifica del credito:cerca un messaggio di conferma dell'applicazione del credito.
- *Nota: se ti viene chiesto di inserire i dati della carta di credito, puoi ignorare la richiesta e chiudere la finestra.
A questo punto puoi chiudere la finestra.
Configurare l'ambiente di lavoro
👉 Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud (l'icona a forma di terminale nella parte superiore del riquadro Cloud Shell).
👉 Fai clic sul pulsante "Apri editor" (ha l'aspetto di una cartella aperta con una matita). Si aprirà l'editor di codice di Cloud Shell nella finestra. Vedrai un esploratore di file sul lato sinistro. 
👉 Apri il terminale nell'IDE cloud, 
👉💻 Nel terminale, verifica di aver già eseguito l'autenticazione e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
👉💻 Clona il progetto di bootstrap da GitHub:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 Esegui lo script di configurazione dalla directory del progetto.
⚠️ Nota sull'ID progetto: lo script suggerirà un ID progetto predefinito generato in modo casuale. Puoi premere Invio per accettare questo valore predefinito.
Tuttavia, se preferisci creare un nuovo progetto specifico, puoi digitare l'ID progetto che preferisci quando ti viene richiesto dallo script.
cd ~/agentverse-dataengineer
./init.sh
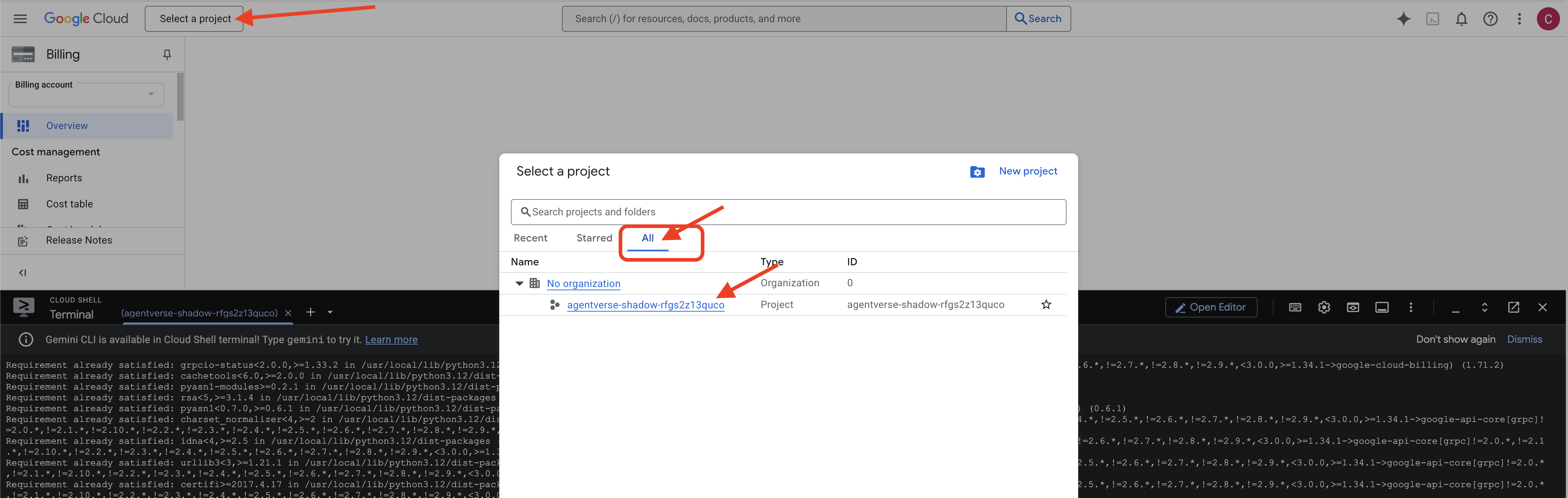
👉 Passaggio importante al termine: al termine dello script, devi assicurarti che nella console Google Cloud sia visualizzato il progetto corretto:
- Vai all'indirizzo console.cloud.google.com.
- Fai clic sul menu a discesa del selettore progetti nella parte superiore della pagina.
- Fai clic sulla scheda "Tutti" (poiché il nuovo progetto potrebbe non essere ancora visualizzato in "Recenti").
- Seleziona l'ID progetto che hai appena configurato nel passaggio
init.sh.
👉💻 Imposta l'ID progetto necessario:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Esegui il comando seguente per abilitare le API Google Cloud necessarie:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 Se non hai ancora creato un repository Artifact Registry denominato agentverse-repo, esegui il seguente comando per crearlo:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
Configura l'autorizzazione
👉💻 Concedi le autorizzazioni necessarie eseguendo questi comandi nel terminale:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 Mentre inizi l'allenamento, prepareremo la sfida finale. I seguenti comandi evocheranno gli spettri dal caos statico, creando i boss per il test finale.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
Ottimo lavoro, studioso. Gli incantesimi di base sono stati completati. Il nostro sanctum è sicuro, i portali per le forze elementali dei dati sono aperti e il nostro servitore è potenziato. Ora siamo pronti per iniziare il vero lavoro.
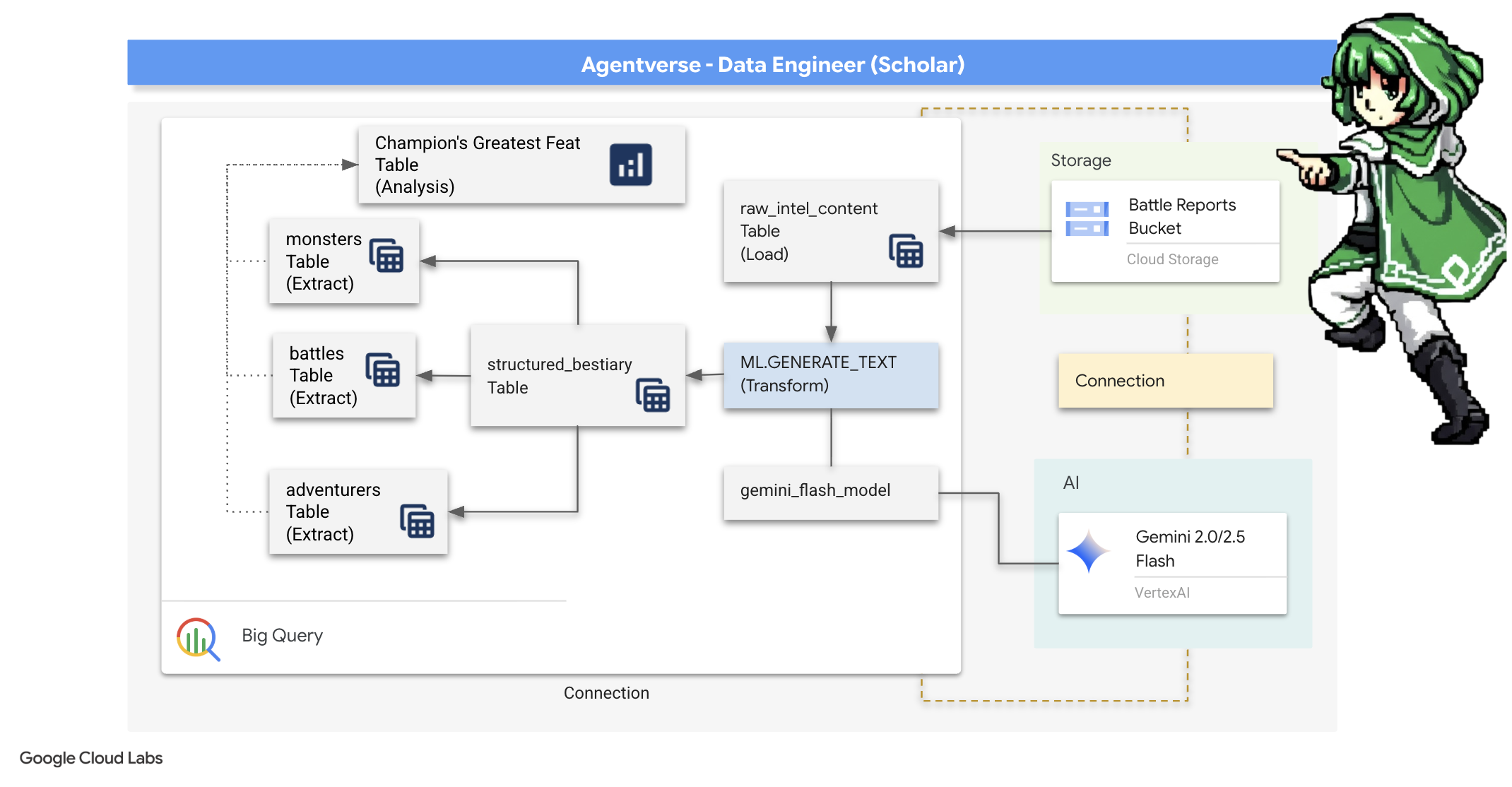
4. L'alchimia della conoscenza: trasformare i dati con BigQuery e Gemini
Nella guerra incessante contro Static, ogni scontro tra un Campione dell'Agentverse e uno Spettro dello Sviluppo viene registrato meticolosamente. Il sistema di simulazione del campo di battaglia, il nostro ambiente di addestramento principale, genera automaticamente una voce del registro eterico per ogni incontro. Questi log narrativi sono la nostra fonte più preziosa di intelligence grezza, il minerale grezzo da cui noi, in qualità di studiosi, dobbiamo forgiare l'acciaio incontaminato della strategia.Il vero potere di uno studioso non risiede nel semplice possesso dei dati, ma nella capacità di trasformare il minerale grezzo e caotico delle informazioni nell'acciaio lucido e strutturato della saggezza pratica.Eseguiremo il rituale fondamentale dell'alchimia dei dati.

Il nostro percorso ci porterà attraverso un processo in più fasi interamente all'interno del sanctum di Google BigQuery. Inizieremo a scrutare il nostro archivio GCS senza spostare un solo rotolo, utilizzando una lente magica. Poi, evocheremo un Gemini per leggere e interpretare le saghe poetiche e non strutturate dei log di battaglia. Infine, perfezioneremo le profezie grezze in un insieme di tabelle incontaminate e interconnesse. Il nostro primo Grimoire. E ponigli una domanda così profonda che possa essere risolta solo da questa nuova struttura.
The Lens of Scrutiny: Peering into GCS with BigQuery External Tables
Il nostro primo atto è forgiare una lente che ci consenta di vedere i contenuti del nostro archivio GCS senza disturbare i rotoli al suo interno. Una tabella esterna è questa lente, che mappa i file di testo non elaborati a una struttura simile a una tabella su cui BigQuery può eseguire query direttamente.
Per farlo, dobbiamo prima creare una linea di energia stabile, una risorsa CONNECTION, che colleghi in modo sicuro il nostro sanctum BigQuery all'archivio GCS.
👉💻 Nel terminale Cloud Shell, esegui questo comando per configurare l'archiviazione e creare il condotto:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 Avviso Un messaggio verrà visualizzato in un secondo momento.
Lo script di configurazione del passaggio 2 ha avviato un processo in background. Dopo qualche minuto, nel terminale verrà visualizzato un messaggio simile a questo:[1]+ Done gcloud sql instances create ...Si tratta di un comportamento normale e previsto. Significa semplicemente che il database Cloud SQL è stato creato correttamente. Puoi ignorare questo messaggio e continuare a lavorare.
Prima di poter creare la tabella esterna, devi prima creare il set di dati che la conterrà.
👉💻 Esegui questo semplice comando nel terminale Cloud Shell:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 Ora dobbiamo concedere alla firma magica del canale le autorizzazioni necessarie per leggere dall'archivio GCS e consultare Gemini.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 Nel terminale Cloud Shell, esegui questo comando per visualizzare il nome del bucket:
echo $BUCKET_NAME
Il terminale mostrerà un nome simile a your-project-id-gcs-bucket. Ti servirà nei passaggi successivi.
👉 Dovrai eseguire il comando successivo dall'editor di query BigQuery nella console Google Cloud. Il modo più semplice per farlo è aprire il link riportato di seguito in una nuova scheda del browser. Ti reindirizzerà direttamente alla pagina corretta nella console Google Cloud.
https://console.cloud.google.com/bigquery
👉 Una volta caricata la pagina, fai clic sul pulsante blu + (Crea una nuova query) per aprire una nuova scheda dell'editor.
Ora scriviamo l'incantesimo DDL (Data Definition Language) per creare la nostra lente magica. Indica a BigQuery dove cercare e cosa vedere.
👉📜 Nell'editor di query BigQuery che hai aperto, incolla il seguente codice SQL. Ricordati di sostituire REPLACE-WITH-YOUR-BUCKET-NAME
con il nome del bucket che hai appena copiato. e fai clic su Esegui:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 Esegui una query per "guardare attraverso l'obiettivo" e visualizzare i contenuti dei file.
SELECT * FROM bestiary_data.raw_intel_content_table;
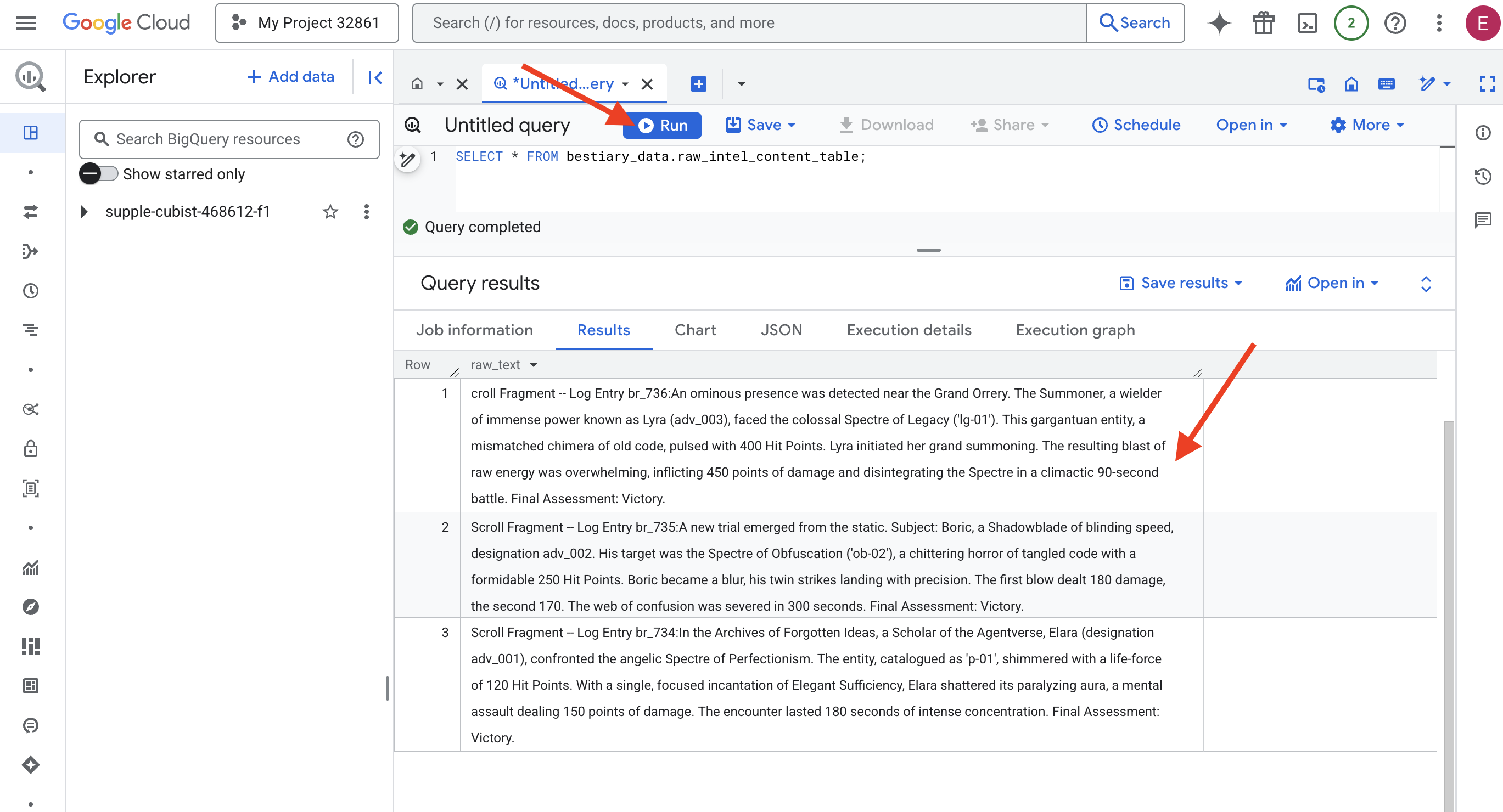
Il nostro obiettivo è stato raggiunto. Ora possiamo vedere il testo grezzo dei rotoli. Ma leggere non significa capire.
Negli Archivi delle Idee Dimenticate, Elara (designazione adv_001), studiosa dell'Agentverse, affrontò lo spettro angelico del perfezionismo. L'entità, catalogata come "p-01", brillava con una forza vitale di 120 punti ferita. Con una singola e mirata invocazione di Sufficienza elegante, Elara frantumò la sua aura paralizzante, un assalto mentale che inflisse 150 punti di danno. L'incontro è durato 180 secondi di intensa concentrazione. Test finale: vittoria.
I rotoli non sono scritti in tabelle e righe, ma nella prosa tortuosa delle saghe. Questo è il nostro primo grande test.
La divinazione dello studioso: trasformare il testo in una tabella con SQL
La sfida consiste nel fatto che un report che descrive i rapidi attacchi gemelli di uno Shadowblade è molto diverso dalla cronaca di un Summoner che raccoglie un immenso potere per un singolo e devastante attacco. Non possiamo semplicemente importare questi dati, dobbiamo interpretarli. Questo è il momento magico. Utilizzeremo una singola query SQL come potente incantesimo per leggere, comprendere e strutturare tutti i record di tutti i nostri file, direttamente in BigQuery.
👉💻 Nel terminale Cloud Shell, esegui questo comando per visualizzare il nome della connessione:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
Il terminale visualizzerà la stringa di connessione completa. Seleziona e copia l'intera stringa, ti servirà nel passaggio successivo.
Useremo un unico e potente incantesimo: ML.GENERATE_TEXT. Questo incantesimo evoca un Gemini, gli mostra ogni rotolo e gli ordina di restituire i fatti principali come oggetto JSON strutturato.
👉📜 In BigQuery Studio, crea il riferimento al modello Gemini. In questo modo, l'oracolo Gemini Flash viene associato alla nostra libreria BigQuery, in modo da poterlo chiamare nelle query. Ricordati di sostituire il
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING con la stringa di connessione completa appena copiata dal terminale.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 Ora lancia l'incantesimo di trasmutazione. Questa query legge il testo non elaborato, crea un prompt dettagliato per ogni scorrimento, lo invia a Gemini e crea una nuova tabella di staging dalla risposta JSON strutturata dell'AI.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
La trasmutazione è completa, ma il risultato non è ancora puro. Il modello Gemini restituisce la risposta in un formato standard, inserendo il JSON che ci interessa in una struttura più grande che include i metadati sul suo processo di pensiero. Esaminiamo questa profezia grezza prima di tentare di purificarla.
👉📜 Esegui una query per esaminare l'output non elaborato del modello Gemini:
SELECT * FROM bestiary_data.structured_bestiary;
👀 Vedrai una sola colonna denominata structured_data. Il contenuto di ogni riga sarà simile a questo oggetto JSON complesso:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
Come puoi vedere, il nostro premio, ovvero l'oggetto JSON pulito che abbiamo richiesto, è nidificato in profondità in questa struttura. La nostra prossima attività è chiara. Dobbiamo eseguire un rituale per navigare sistematicamente in questa struttura ed estrarre la pura saggezza che contiene.
The Ritual of Cleansing: Normalizing GenAI Output with SQL
Gemini ha parlato, ma le sue parole sono grezze e avvolte nelle energie eteree della sua creazione (candidati, finish_reason e così via). Un vero studioso non si limita a mettere da parte la profezia grezza, ma estrae con cura la saggezza essenziale e la trascrive nei tomi appropriati per un uso futuro.
Ora lanceremo l'ultimo gruppo di incantesimi. Questo singolo script:
- Leggi il JSON non elaborato e nidificato dalla nostra tabella di staging.
- Puliscilo e analizzalo per ottenere i dati principali.
- Trascrivi le parti pertinenti in tre tabelle finali e immacolate: mostri, avventurieri e battaglie.
👉📜 In un nuovo editor di query BigQuery, esegui il seguente comando per creare la nostra lente di pulizia:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 Verifica il Bestiario:
SELECT * FROM bestiary_data.monsters;
Successivamente, creeremo il nostro Roll of Champions, un elenco dei coraggiosi avventurieri che hanno affrontato queste bestie.
👉📜 In un nuovo editor di query, esegui il seguente comando per creare la tabella degli avventurieri:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 Verifica il Roll of Champions:
SELECT * FROM bestiary_data.adventurers;
Infine, creeremo la nostra tabella dei fatti: la cronaca delle battaglie. Questo volume collega gli altri due, registrando i dettagli di ogni incontro unico. Poiché ogni battaglia è un evento unico, non è necessaria la deduplicazione.
👉📜 In un nuovo editor di query, esegui il seguente comando per creare la tabella delle battaglie:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Verifica la cronaca:
SELECT * FROM bestiary_data.battles;
Scoprire insight strategici
I rotoli sono stati letti, l'essenza distillata e i tomi incisi. Il nostro Grimoire non è più solo una raccolta di fatti, ma un database relazionale di profonda saggezza strategica. Ora possiamo porre domande a cui era impossibile rispondere quando le nostre conoscenze erano intrappolate in un testo grezzo e non strutturato.
Ora eseguiamo una divinazione finale e grandiosa. Lanceremo un incantesimo che consulta contemporaneamente tutti e tre i nostri tomi: il Bestiario dei mostri, il Registro dei campioni e la Cronaca delle battaglie, per scoprire un insight profondo e pratico.
La nostra domanda strategica: "Per ogni avventuriero, qual è il nome del mostro più potente (in base ai punti ferita) che ha sconfitto e quanto tempo ha impiegato per ottenere questa vittoria?"
Si tratta di una domanda complessa che richiede di collegare i campioni alle loro battaglie vittoriose e queste battaglie alle statistiche dei mostri coinvolti. Questo è il vero potere di un modello di dati strutturati.
👉📜 In un nuovo editor di query BigQuery, esegui il seguente incantesimo finale:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
L'output di questa query sarà una tabella pulita e ben strutturata che fornisce un "Racconto della più grande impresa di un campione" per ogni avventuriero nel tuo set di dati. Potrebbe avere un aspetto simile a questo:
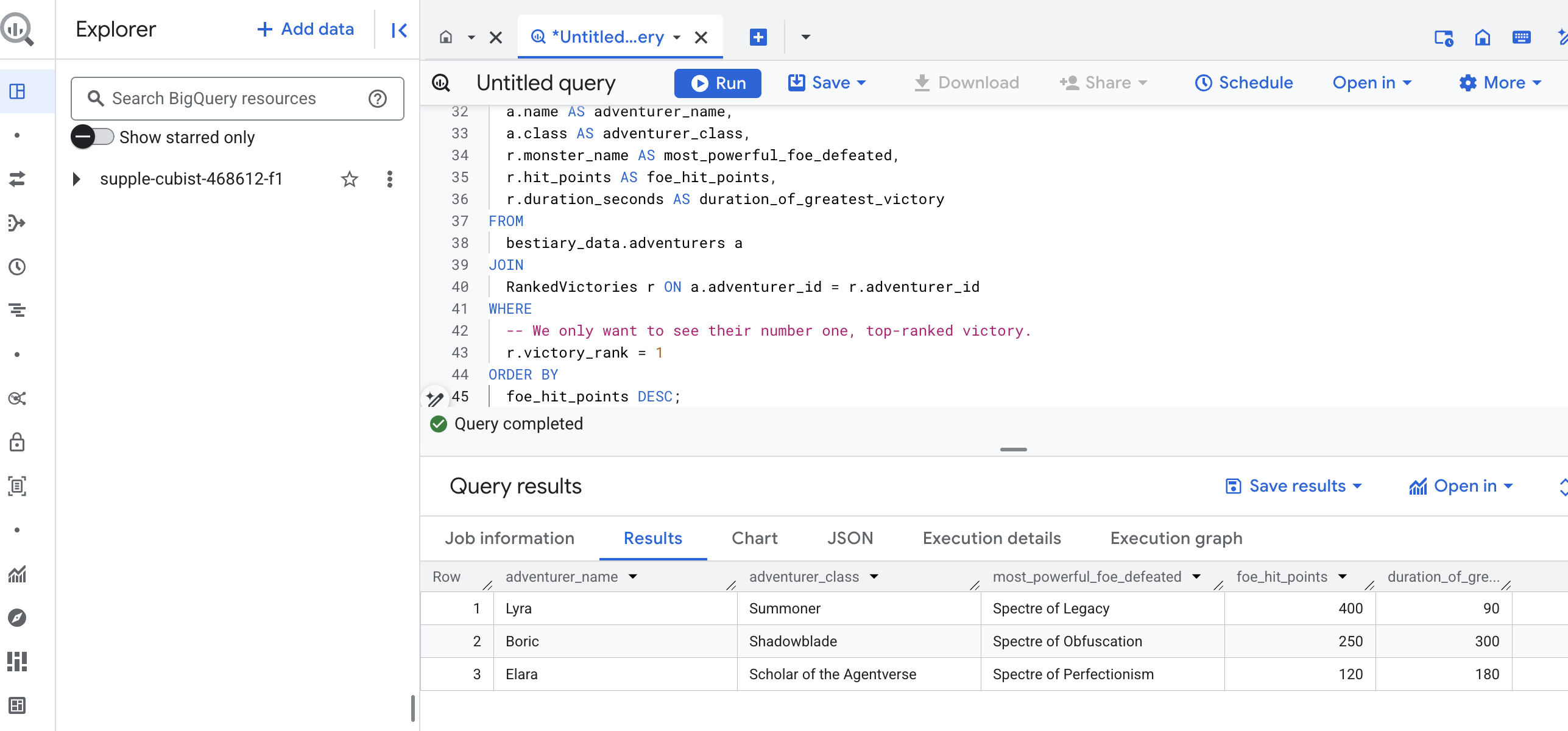
Chiudi la scheda BigQuery.
Questo risultato unico ed elegante dimostra il valore dell'intera pipeline. Hai trasformato con successo i report grezzi e caotici del campo di battaglia in una fonte di racconti leggendari e approfondimenti strategici basati sui dati.
PER CHI NON GIOCA
5. Il grimorio dello scriba: suddivisione, incorporamento e ricerca in-datawarehouse
Il nostro lavoro nel laboratorio dell'Alchimista è stato un successo. Abbiamo trasformato i rotoli narrativi grezzi in tabelle relazionali strutturate, una potente magia dei dati. Tuttavia, i rotoli originali contengono una verità semantica più profonda che le nostre tabelle strutturate non possono cogliere appieno. Per creare un agente veramente saggio, dobbiamo svelare questo significato.
Uno scorrimento lungo e grezzo è uno strumento poco efficace. Se il nostro agente pone una domanda su un'aura paralizzante, una semplice ricerca potrebbe restituire un intero report di battaglia in cui questa frase viene menzionata una sola volta, seppellendo la risposta in dettagli irrilevanti. Un vero studioso sa che la vera saggezza non si trova nel volume, ma nella precisione.
Eseguiremo un trio di rituali potenti e in-database interamente all'interno del nostro sanctum BigQuery.
- Il rito della divisione (chunking): prenderemo i nostri log di intelligence grezzi e li suddivideremo meticolosamente in passaggi più piccoli, mirati e autonomi.
- Il rito della distillazione (incorporamento): utilizzeremo BQML per consultare un modello Gemini, trasformando ogni blocco di testo in un'"impronta semantica", ovvero un incorporamento vettoriale.
- Il rito della divinazione (ricerca): utilizzeremo la ricerca vettoriale di BQML per porre una domanda in inglese semplice e trovare la saggezza più pertinente e distillata del nostro Grimoire.
L'intero processo crea una knowledge base potente e ricercabile senza che i dati escano mai dalla sicurezza e dalla scalabilità di BigQuery.
Il rito della divisione: decostruire i rotoli con SQL
La nostra fonte di saggezza rimangono i file di testo non elaborati nel nostro archivio GCS, accessibili tramite la nostra tabella esterna, bestiary_data.raw_intel_content_table. Il nostro primo compito è scrivere un incantesimo che legga ogni lunga pergamena e la divida in una serie di versi più piccoli e più digeribili. Per questo rituale, definiremo un "blocco" come una singola frase.
Sebbene la suddivisione per frase sia un punto di partenza chiaro ed efficace per i nostri log narrativi, un Scribe esperto ha a disposizione molte strategie di suddivisione e la scelta è fondamentale per la qualità della ricerca finale. I metodi più semplici potrebbero utilizzare un
- Chunking a lunghezza(dimensione) fissa, ma questo può dividere grossolanamente un'idea chiave a metà.
Rituali più sofisticati, come
- Recursive Chunking, sono spesso preferiti nella pratica; tentano di dividere il testo lungo i confini naturali come i paragrafi, quindi tornano alle frasi per mantenere il maggior contesto semantico possibile. Per manoscritti davvero complessi.
- Content-Aware Chunking(documento), in cui Scribe utilizza la struttura intrinseca del documento, ad esempio le intestazioni di un manuale tecnico o le funzioni di un codice, per creare i blocchi di informazioni più logici ed efficaci. e altro ancora…
Per i nostri log delle battaglie, la frase offre il perfetto equilibrio tra granularità e contesto.
👉📜 In un nuovo editor di query BigQuery, esegui il seguente comando. Questa formula utilizza la funzione SPLIT per separare il testo di ogni pergamena in corrispondenza di ogni punto (.) e quindi separa l'array di frasi risultante in righe distinte.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 Ora esegui una query per esaminare le conoscenze appena trascritte e suddivise in blocchi e vedere la differenza.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
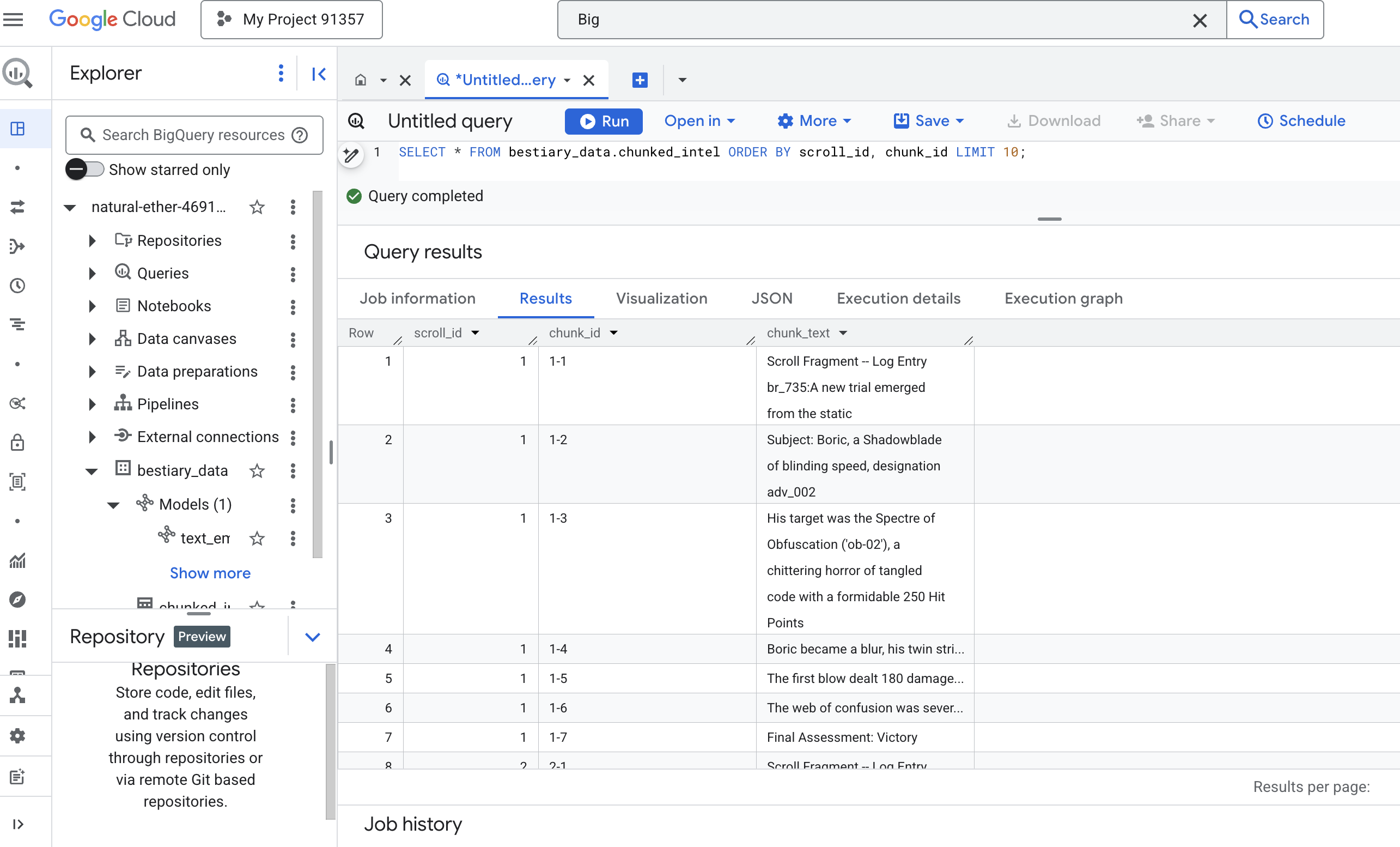
Osserva i risultati. Dove prima c'era un unico blocco di testo denso, ora ci sono più righe, ognuna collegata allo scorrimento originale (scroll_id), ma contenente una sola frase mirata. Ogni riga è ora un candidato perfetto per la vettorizzazione.
The Ritual of Distillation: Transforming Text to Vectors with BQML
👉💻 Innanzitutto, torna al terminale ed esegui il comando seguente per visualizzare il nome della connessione:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Dobbiamo creare un nuovo modello BigQuery che punti a un incorporamento di testo di Gemini. In BigQuery Studio, esegui il seguente incantesimo. Tieni presente che devi sostituire REPLACE-WITH-YOUR-FULL-CONNECTION-STRING con la stringa di connessione completa che hai appena copiato dal terminale.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 Ora, lancia l'incantesimo di distillazione. Questa query chiama la funzione ML.GENERATE_EMBEDDING, che leggerà ogni riga della tabella chunked_intel, invierà il testo al modello di incorporamento Gemini e memorizzerà l'impronta vettoriale risultante in una nuova tabella.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
Questa procedura potrebbe richiedere un minuto o due, mentre BigQuery elabora tutti i blocchi di testo.
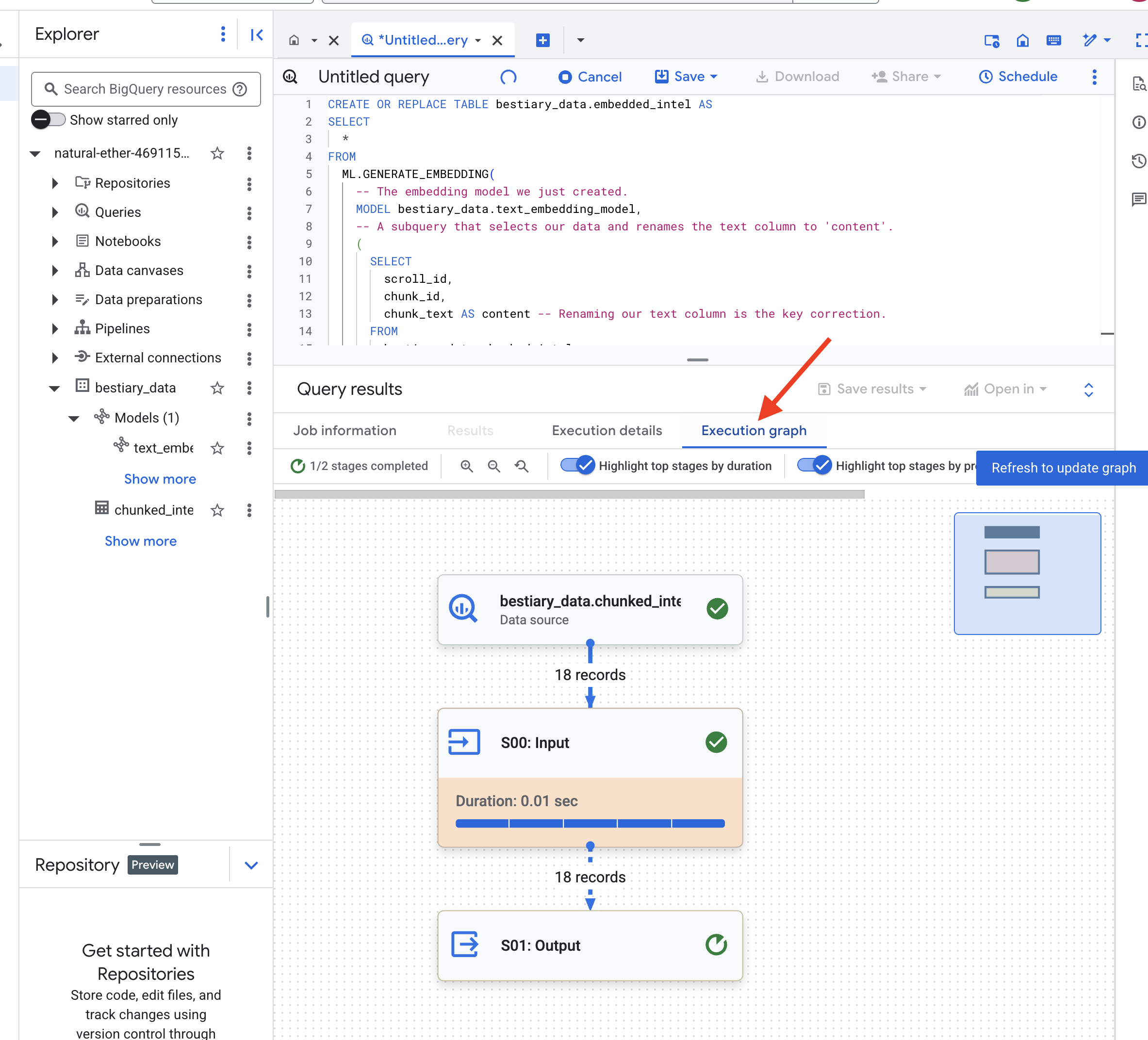
👉📜 Al termine, esamina la nuova tabella per visualizzare le impronte semantiche.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
Ora vedrai una nuova colonna, ml_generate_embedding_result, contenente la rappresentazione del vettore denso del testo. Il nostro Grimoire è ora codificato semanticamente.
Il rito della divinazione: ricerca semantica con BQML
👉📜 La prova definitiva del nostro Grimoire è fargli una domanda. Ora eseguiremo il nostro rituale finale: una ricerca vettoriale. Non si tratta di una ricerca per parole chiave, ma di una ricerca di significato. Faremo una domanda in linguaggio naturale, BQML la convertirà in un incorporamento al volo e poi cercherà nell'intera tabella di embedded_intel i blocchi di testo le cui impronte sono "più vicine" in termini di significato.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
Analisi dell'incantesimo:
VECTOR_SEARCH: la funzione principale che orchestra la ricerca.ML.GENERATE_EMBEDDING(query interna): questa è la magia. Incorporiamo la nostra query ('What are the tactics...') utilizzando lo stesso modello, ma con il tipo di attività'RETRIEVAL_QUERY', che è ottimizzato in modo specifico per le query.top_k => 3: Ti chiediamo i tre risultati più pertinenti.distance_type => 'COSINE': misura l'angolo tra i vettori. Un angolo più piccolo indica che i significati sono più allineati.
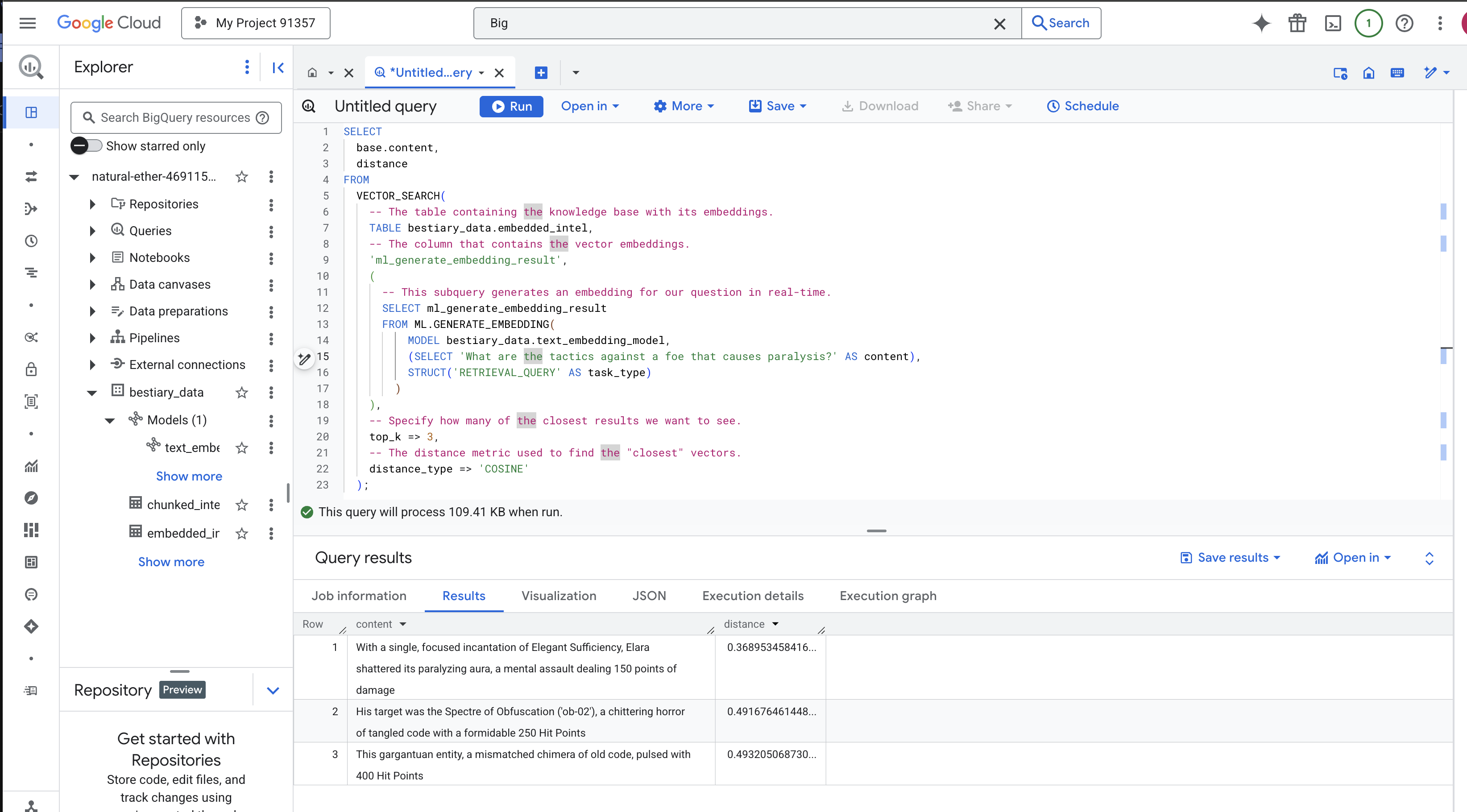
Esamina attentamente i risultati. La query non conteneva le parole "frantumato" o "incantesimo", eppure il primo risultato è: "Con un unico incantesimo mirato di Efficienza Elegante, Elara frantumò la sua aura paralizzante, un assalto mentale che inflisse 150 punti di danno". Questo è il potere della ricerca semantica. Il modello ha compreso il concetto di "tattiche contro la paralisi" e ha trovato la frase che descriveva una tattica specifica e riuscita.
Ora hai creato correttamente una pipeline RAG di base completa all'interno del data warehouse. Hai preparato i dati non elaborati, li hai trasformati in vettori semantici e hai eseguito query in base al significato. Sebbene BigQuery sia uno strumento potente per questo lavoro di analisi su larga scala, per un agente live che ha bisogno di risposte a bassa latenza, spesso trasferiamo queste informazioni preparate in un database operativo specializzato. Questo è l'argomento del nostro prossimo corso di formazione.
PER CHI NON GIOCA
6. The Vector Scriptorium: Crafting the Vector Store with Cloud SQL for Inferencing
Il nostro Grimoire esiste attualmente come tabelle strutturate, un potente catalogo di fatti, ma la sua conoscenza è letterale. Comprende monster_id = "MN-001", ma non il significato semantico più profondo di "Offuscamento". Per dare ai nostri agenti una vera saggezza, per consentire loro di fornire consigli con sfumature e lungimiranza, dobbiamo distillare l'essenza stessa della nostra conoscenza in una forma che catturi il significato: i vettori.
La nostra sete di conoscenza ci ha condotto alle rovine fatiscenti di una civiltà precursore da tempo dimenticata. Sepolto in profondità in una camera blindata sigillata, abbiamo scoperto uno scrigno di antichi rotoli, miracolosamente conservati. Non si tratta di semplici report di battaglia, ma di una profonda saggezza filosofica su come sconfiggere una bestia che affligge tutte le grandi imprese. Un'entità descritta nei rotoli come una "stasi strisciante e silenziosa", un "sfilacciamento della trama della creazione". Sembra che The Static fosse noto anche agli antichi, una minaccia ciclica la cui storia è andata perduta nel tempo.
Queste conoscenze dimenticate sono la nostra risorsa più grande. È la chiave non solo per sconfiggere i singoli mostri, ma anche per dare a tutto il gruppo una visione strategica. Per esercitare questo potere, ora creeremo il vero libro degli incantesimi dello studioso (un database PostgreSQL con funzionalità vettoriali) e costruiremo uno scriptorium vettoriale automatizzato (una pipeline Dataflow) per leggere, comprendere e trascrivere l'essenza senza tempo di questi rotoli. In questo modo, il nostro Grimoire si trasformerà da un libro di fatti in un motore di saggezza.

Forging the Scholar's Spellbook (Cloud SQL)
Prima di poter trascrivere l'essenza di questi antichi rotoli, dobbiamo prima confermare che il contenitore di questa conoscenza, lo Spellbook PostgreSQL gestito, sia stato forgiato con successo. Le procedure di configurazione iniziale dovrebbero averlo già creato.
👉💻 In un terminale, esegui questo comando per verificare che l'istanza Cloud SQL esista e sia pronta. Questo script concede inoltre all'account di servizio dedicato dell'istanza l'autorizzazione a utilizzare Vertex AI, essenziale per generare embedding direttamente all'interno del database.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Se il comando ha esito positivo e restituisce i dettagli della tua istanza grimoire-spellbook, la forge ha funzionato correttamente. Ora puoi procedere con la prossima incantesimo. Se il comando restituisce un errore NOT_FOUND, assicurati di aver completato correttamente i passaggi di configurazione iniziale dell'ambiente prima di continuare.(data_setup.py)
👉💻 Con il libro forgiato, apriamo il primo capitolo creando un nuovo database denominato arcane_wisdom.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
Inscrivere le rune semantiche: abilitare le funzionalità vettoriali con pgvector
Ora che l'istanza Cloud SQL è stata creata, connettiamoci utilizzando Cloud SQL Studio integrato. Fornisce un'interfaccia basata sul web per l'esecuzione di query SQL direttamente sul database.
👉💻 Innanzitutto, vai a Cloud SQL Studio. Il modo più semplice e veloce per farlo è aprire il seguente link in una nuova scheda del browser. Ti reindirizzerà direttamente a Cloud SQL Studio per la tua istanza grimoire-spellbook.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 Seleziona arcane_wisdom come database, inserisci postgres come utente e 1234qwer come password e fai clic su Autentica.
👉📜 Nell'editor query di SQL Studio, vai alla scheda Editor 1, incolla il seguente codice SQL per attivare il tipo di dati vettoriale:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
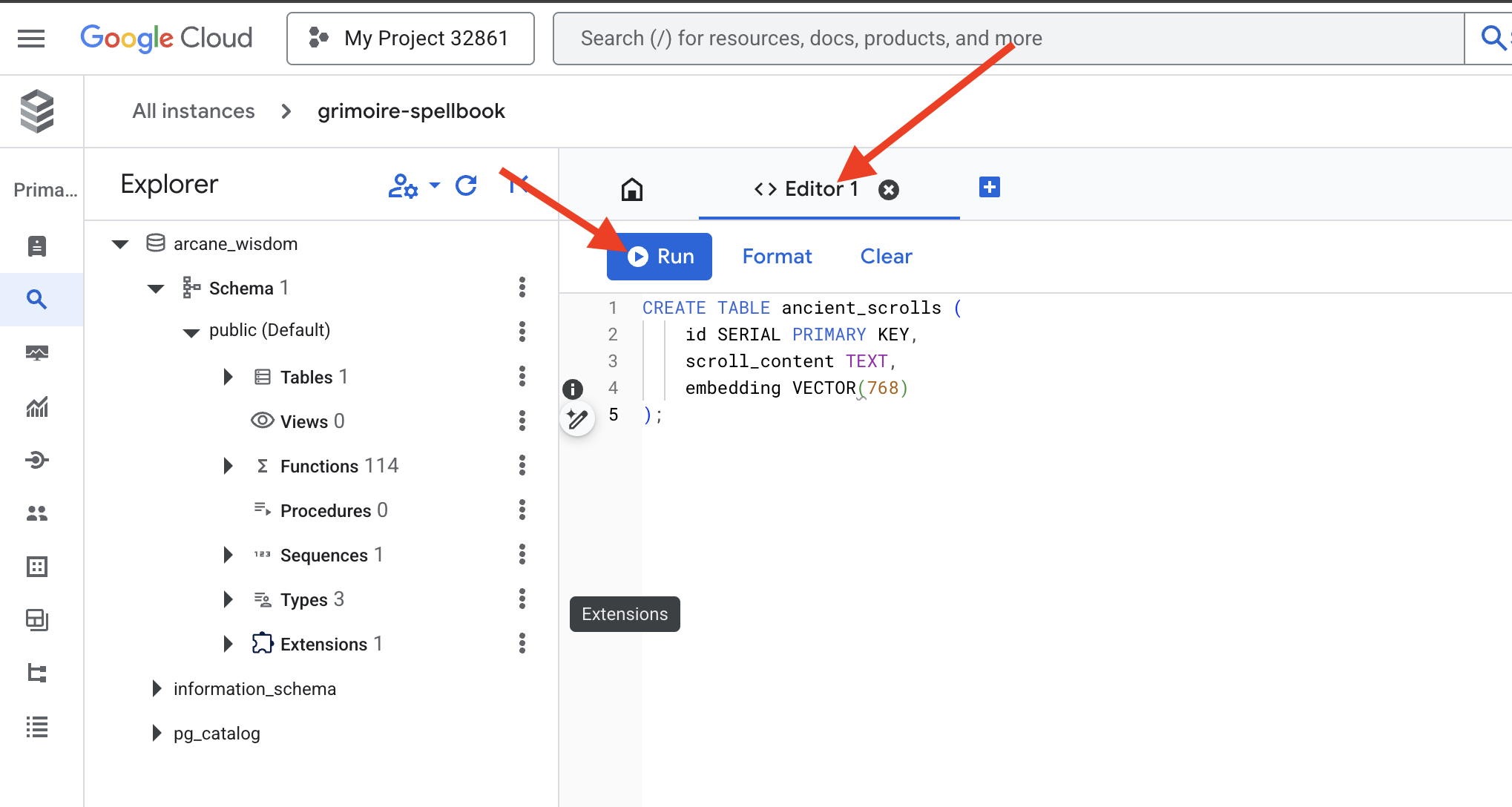
👉📜 Prepara le pagine del nostro libro degli incantesimi creando la tabella che conterrà l'essenza dei nostri rotoli.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
L'incantesimo VECTOR(768) è un dettaglio importante. Il modello di incorporamento Vertex AI che utilizzeremo (textembedding-gecko@003 o un modello simile) estrae il testo in un vettore a 768 dimensioni. Le pagine del nostro libro degli incantesimi devono essere preparate per contenere un'essenza di esattamente quella dimensione. Le dimensioni devono sempre corrispondere.
La prima traslitterazione: un rituale di iscrizione manuale
Prima di comandare un esercito di scribi automatici (Dataflow), dobbiamo eseguire manualmente il rituale centrale una volta. In questo modo, potremo apprezzare appieno la magia dei due passaggi:
- Divinazione: prendere un testo e consultare l'oracolo Gemini per estrarne l'essenza semantica in un vettore.
- Iscrizione:scrittura del testo originale e della sua nuova essenza vettoriale nel nostro Spellbook.
Ora eseguiamo il rituale manuale.
👉📜 In Cloud SQL Studio. Ora utilizzeremo la funzione embedding(), una potente funzionalità fornita dall'estensione google_ml_integration. Ciò ci consente di chiamare il modello di incorporamento Vertex AI direttamente dalla nostra query SQL, semplificando enormemente il processo.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 Verifica il tuo lavoro eseguendo una query per leggere la pagina appena creata:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
Hai eseguito correttamente l'attività principale di caricamento dei dati RAG manualmente.
Forging the Semantic Compass: Enchanting the Spellbook with an HNSW Index
Il nostro libro degli incantesimi ora può memorizzare la saggezza, ma trovare il rotolo giusto richiede di leggere ogni singola pagina. Si tratta di una scansione sequenziale. Questo metodo è lento e inefficiente. Per indirizzare istantaneamente le nostre query alle conoscenze più pertinenti, dobbiamo incantare lo Spellbook con una bussola semantica: un indice vettoriale.
Dimostriamo il valore di questo incantesimo.
👉📜 In Cloud SQL Studio, esegui il seguente comando. Simula la ricerca del nostro nuovo scorrimento inserito e chiede al database di EXPLAIN il suo piano.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
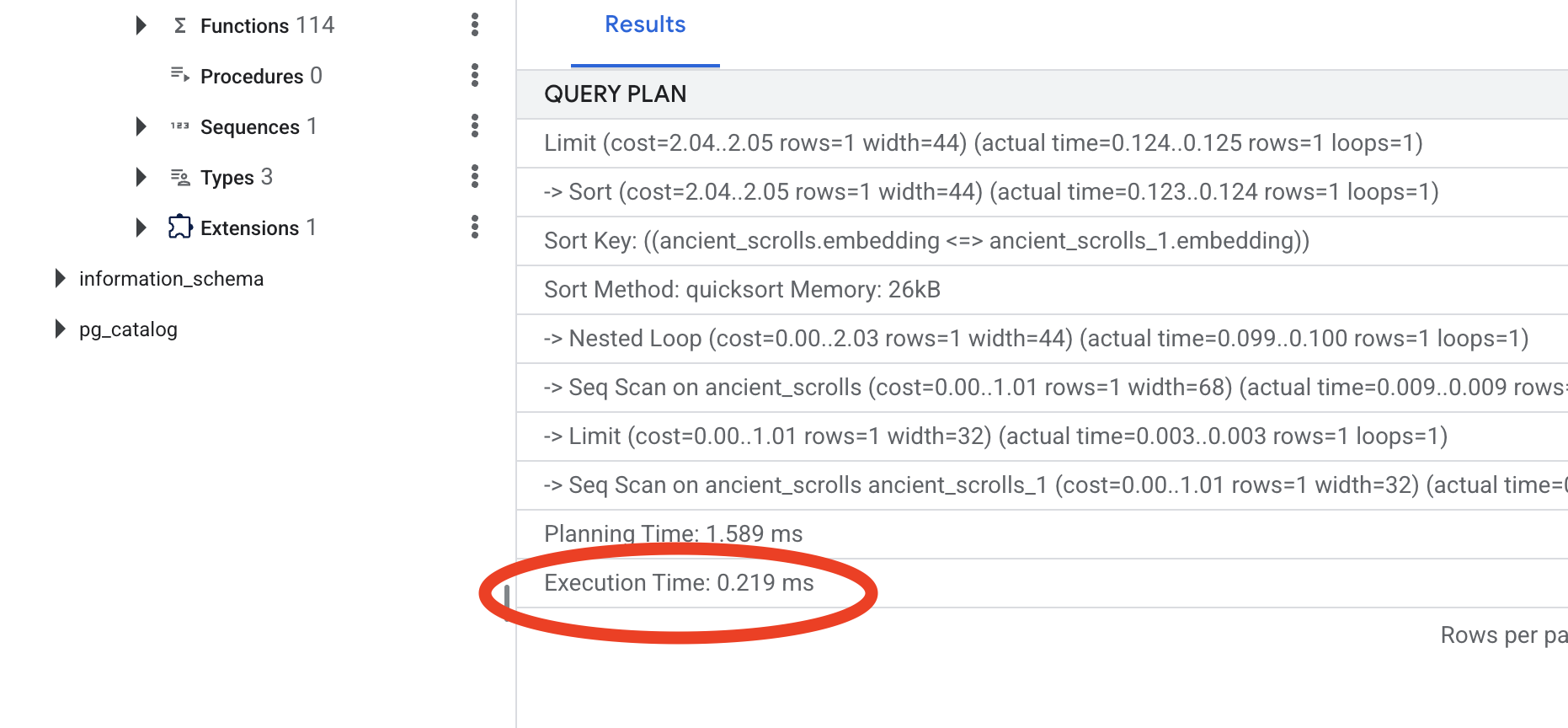
Esamina l'output. Vedrai una riga con scritto -> Seq Scan on ancient_scrolls. In questo modo, viene confermato che il database legge ogni singola riga. Prendi nota di execution time.
👉📜 Ora, lanciamo l'incantesimo di indicizzazione. Il parametro lists indica all'indice quanti cluster creare. Un buon punto di partenza è la radice quadrata del numero di righe che prevedi di avere.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
Attendi la creazione dell'indice (sarà veloce per una riga, ma potrebbe richiedere tempo per milioni).
👉📜 Ora esegui di nuovo lo stesso identico comando EXPLAIN ANALYZE:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
Esamina il nuovo piano di query. Ora vedrai -> Index Scan using.... Ancora più importante, guarda il execution time. Sarà molto più veloce, anche con una sola voce. Hai appena dimostrato il principio fondamentale dell'ottimizzazione delle prestazioni del database in un mondo vettoriale.
Ora che i dati di origine sono stati esaminati, il rituale manuale è stato compreso e lo Spellbook è stato ottimizzato per la velocità, sei davvero pronto a creare lo Scriptorium automatizzato.
PER CHI NON GIOCA
7. Il canale del significato: creazione di una pipeline di vettorizzazione Dataflow
Ora costruiamo la magica catena di montaggio degli scribi che leggeranno i nostri rotoli, ne estrarranno l'essenza e li iscriveranno nel nostro nuovo Spellbook. Si tratta di una pipeline Dataflow che attiveremo manualmente. Ma prima di scrivere l'incantesimo principale per la pipeline stessa, dobbiamo prima preparare le sue fondamenta e il cerchio da cui la evocheremo.
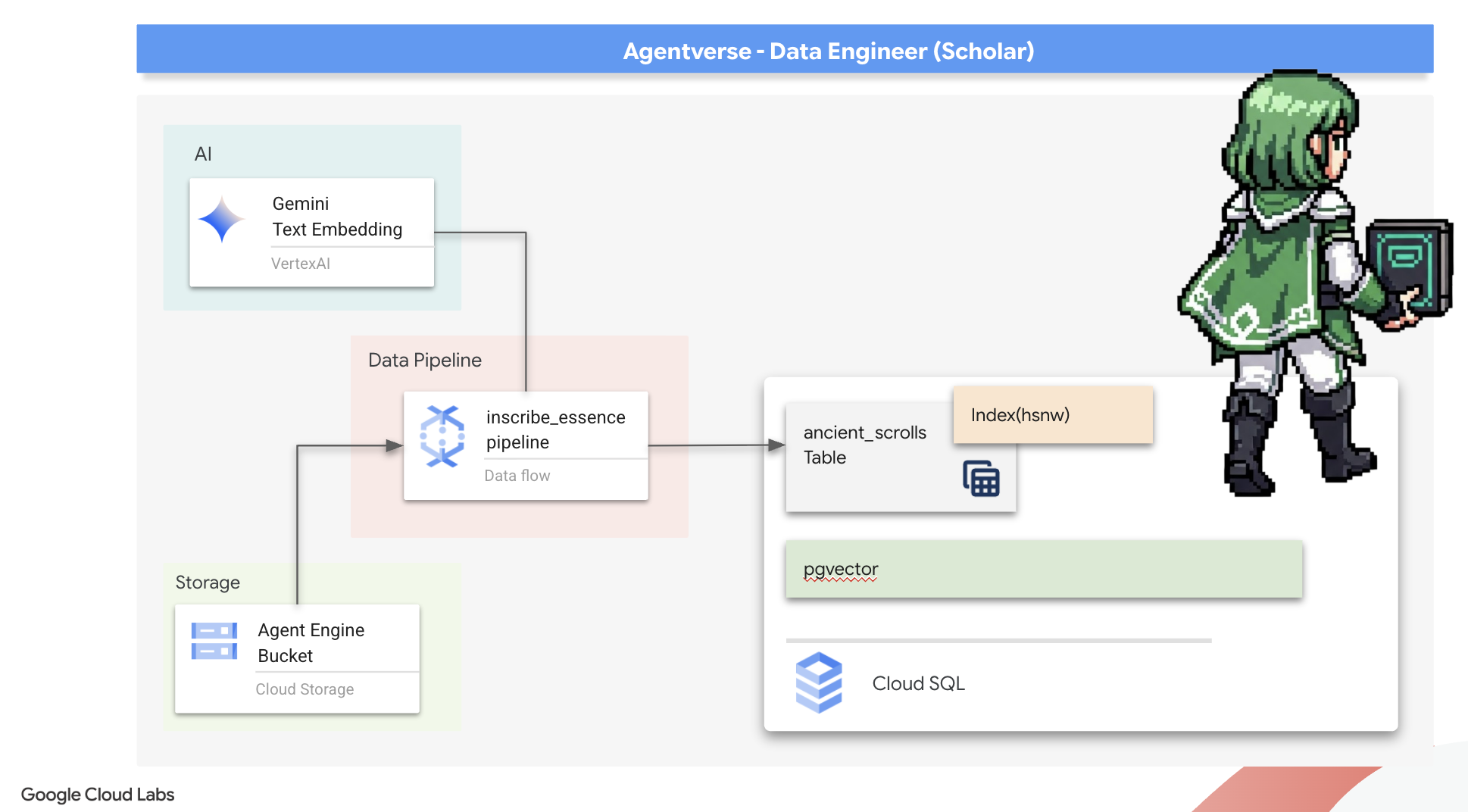
Preparazione della base dello Scriptorium (l'immagine worker)
La nostra pipeline Dataflow verrà eseguita da un team di worker automatizzati nel cloud. Ogni volta che li richiamiamo, hanno bisogno di un insieme specifico di librerie per svolgere il loro lavoro. Potremmo fornire un elenco e fargli recuperare queste librerie ogni volta, ma è un processo lento e inefficiente. Un saggio studioso prepara in anticipo una biblioteca principale.
Qui, chiederemo a Google Cloud Build di creare un'immagine container personalizzata. Questa immagine è un "golem perfetto", precaricato con tutte le librerie e le dipendenze di cui avranno bisogno i nostri scribi. Quando il job Dataflow viene avviato, utilizza questa immagine personalizzata, consentendo ai worker di iniziare la loro attività quasi istantaneamente.
👉💻 Esegui questo comando per creare e archiviare l'immagine di base della pipeline in Artifact Registry.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 Esegui questi comandi per creare e attivare l'ambiente Python isolato e installare le librerie di invocazione necessarie.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
The Master Incantation
È arrivato il momento di scrivere l'incantesimo principale che alimenterà il nostro Scriptorium vettoriale. Non scriveremo da zero i singoli componenti magici. Il nostro compito è assemblare i componenti in una pipeline logica e potente utilizzando il linguaggio di Apache Beam.
- EmbedTextBatch (La consulenza di Gemini): creerai questo scriba specializzato che sa come eseguire una "divinazione di gruppo". Prende un batch di file di testo non elaborato, li presenta al modello di text embedding Gemini e riceve la loro essenza distillata (i vector embedding).
- WriteEssenceToSpellbook (The Final Inscription): questo è il nostro archivista. Conosce gli incantesimi segreti per aprire una connessione sicura al nostro libro degli incantesimi Cloud SQL. Il suo compito è prendere i contenuti di un rotolo e la sua essenza vettoriale e inciderli in modo permanente su una nuova pagina.
La nostra missione è concatenare queste azioni per creare un flusso di conoscenza continuo.
👉✏️ Nell'editor di Cloud Shell, vai a ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py. All'interno troverai una classe DoFn denominata EmbedTextBatch. Individua il commento #REPLACE-EMBEDDING-LOGIC. Sostituiscilo con la seguente formula magica.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Questo incantesimo è preciso e presenta diversi parametri chiave:
- model: specifica
text-embedding-005per utilizzare un modello di incorporamento potente e aggiornato. - contents: questo è un elenco di tutti i contenuti di testo del batch di file ricevuto da DoFn.
- task_type: impostiamo questo valore su "RETRIEVAL_DOCUMENT". Questa è un'istruzione fondamentale che indica a Gemini di generare incorporamenti ottimizzati appositamente per essere trovati in un secondo momento in una ricerca.
- output_dimensionality: deve essere impostato su 768, in modo che corrisponda perfettamente alla dimensione VECTOR(768) che abbiamo definito quando abbiamo creato la tabella ancient_scrolls in Cloud SQL. Le dimensioni non corrispondenti sono una fonte comune di errori in Vector Magic.
La nostra pipeline deve iniziare leggendo il testo non strutturato e non elaborato di tutti gli antichi rotoli nel nostro archivio GCS.
👉✏️ In ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py, trova il commento #REPLACE ME-READFILE e sostituiscilo con la seguente formula magica in tre parti:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
Ora che abbiamo raccolto il testo grezzo dei rotoli, dobbiamo inviarli a Gemini per la divinazione. Per farlo in modo efficiente, raggrupperemo prima i singoli rotoli in piccoli batch e poi li consegneremo al nostro scriba EmbedTextBatch. Inoltre, in questa fase verranno separati tutti gli scorrimenti che Gemini non riesce a comprendere in un gruppo "non riusciti" per la revisione successiva.
👉✏️ Trova il commento #REPLACE ME-EMBEDDING e sostituiscilo con questo:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
L'essenza dei nostri rotoli è stata distillata con successo. L'atto finale è quello di iscrivere questa conoscenza nel nostro libro degli incantesimi per l'archiviazione permanente. Prenderemo i rotoli dalla pila "Elaborati" e li consegneremo al nostro archivista di WriteEssenceToSpellbook.
👉✏️ Trova il commento #REPLACE ME-WRITE TO DB e sostituiscilo con questo:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
Un saggio studioso non scarta mai la conoscenza, nemmeno i tentativi falliti. Come passaggio finale, dobbiamo incaricare uno scriba di prendere la pila "non riuscita" della fase di divinazione e registrare i motivi del mancato completamento. In questo modo potremo migliorare i nostri rituali in futuro.
👉✏️ Trova il commento #REPLACE ME-LOG FAILURES e sostituiscilo con questo:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
L'incantesimo principale è stato completato. Hai assemblato correttamente una pipeline di dati potente e in più fasi concatenando singoli componenti magici. Salva il file inscribe_essence_pipeline.py. Lo Scriptorium è ora pronto per essere evocato.
Ora lanciamo il grande incantesimo di evocazione per ordinare al servizio Dataflow di risvegliare il nostro Golem e iniziare il rituale di scrittura.
👉💻 Nel terminale, esegui la seguente riga di comando
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 Attenzione! Se il job non va a buon fine e viene visualizzato un errore di risorsa ZONE_RESOURCE_POOL_EXHAUSTED, il problema potrebbe essere dovuto a limiti temporanei delle risorse di questo account con reputazione bassa nella regione selezionata. La potenza di Google Cloud è la sua portata globale. Prova a evocare il golem in un'altra regione. Per farlo, sostituisci --region=$REGION nel comando precedente con un'altra regione, ad esempio
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
e riprova. 🎰
L'avvio e il completamento della procedura richiedono circa 3-5 minuti. Puoi guardarlo in diretta nella console Dataflow.
👉 Vai alla console Dataflow: il modo più semplice è aprire questo link diretto in una nuova scheda del browser:
https://console.cloud.google.com/dataflow
👉 Trova e fai clic sul tuo job: vedrai un job elencato con il nome che hai fornito (inscribe-essence-job o simile). Fai clic sul nome del job per aprire la pagina dei dettagli. Osserva la pipeline:
- Avvio: per i primi 3 minuti, lo stato del job sarà "In esecuzione" mentre Dataflow esegue il provisioning delle risorse necessarie. Il grafico verrà visualizzato, ma potresti non vedere ancora i dati che lo attraversano.
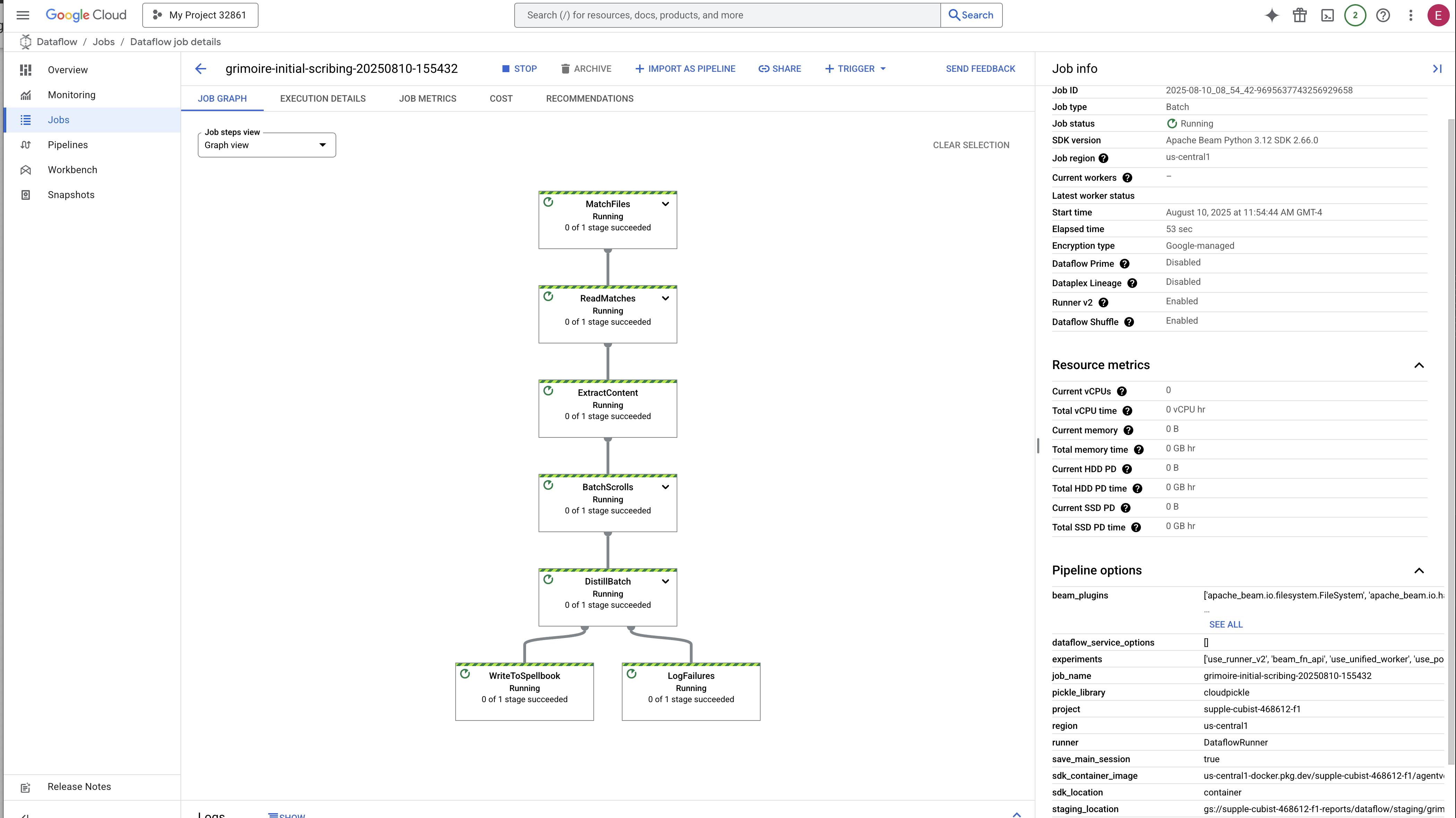
- Completato: al termine, lo stato del job cambierà in "Riuscito" e il grafico fornirà il conteggio finale dei record elaborati.
Verifica dell'iscrizione
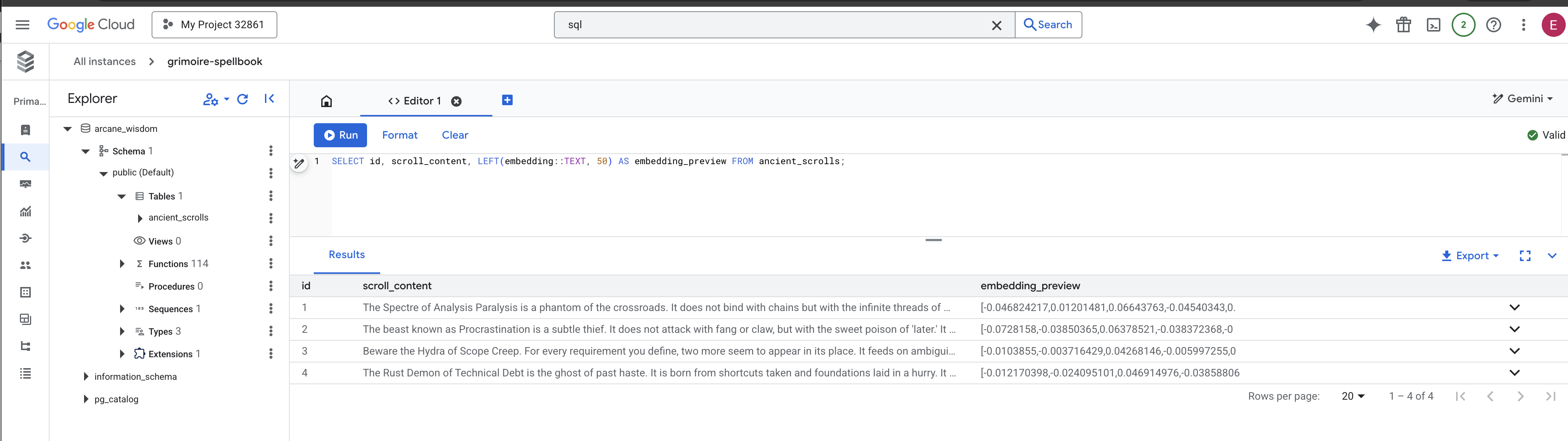
👉📜 Torna in SQL Studio ed esegui le seguenti query per verificare che i tuoi rotoli e la loro essenza semantica siano stati trascritti correttamente.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
Verrà visualizzato l'ID dello scorrimento, il testo originale e un'anteprima dell'essenza vettoriale magica ora inscritta in modo permanente nel tuo Grimoire.
Il tuo grimorio dello studioso è ora un vero motore della conoscenza, pronto per essere interrogato per significato nel capitolo successivo.
8. Sigillare la runa finale: attivare la saggezza con un agente RAG
Il tuo Grimoire non è più solo un database. È una fonte di conoscenza vettorializzata, un oracolo silenzioso in attesa di una domanda.
Ora, affrontiamo la vera prova di uno studioso: creeremo la chiave per sbloccare questa saggezza. Creeremo un agente Retrieval-Augmented Generation (RAG). Si tratta di una costruzione magica in grado di comprendere una domanda in linguaggio semplice, consultare il Grimoire per trovare le verità più profonde e pertinenti e quindi utilizzare la saggezza recuperata per formulare una risposta potente e sensibile al contesto.

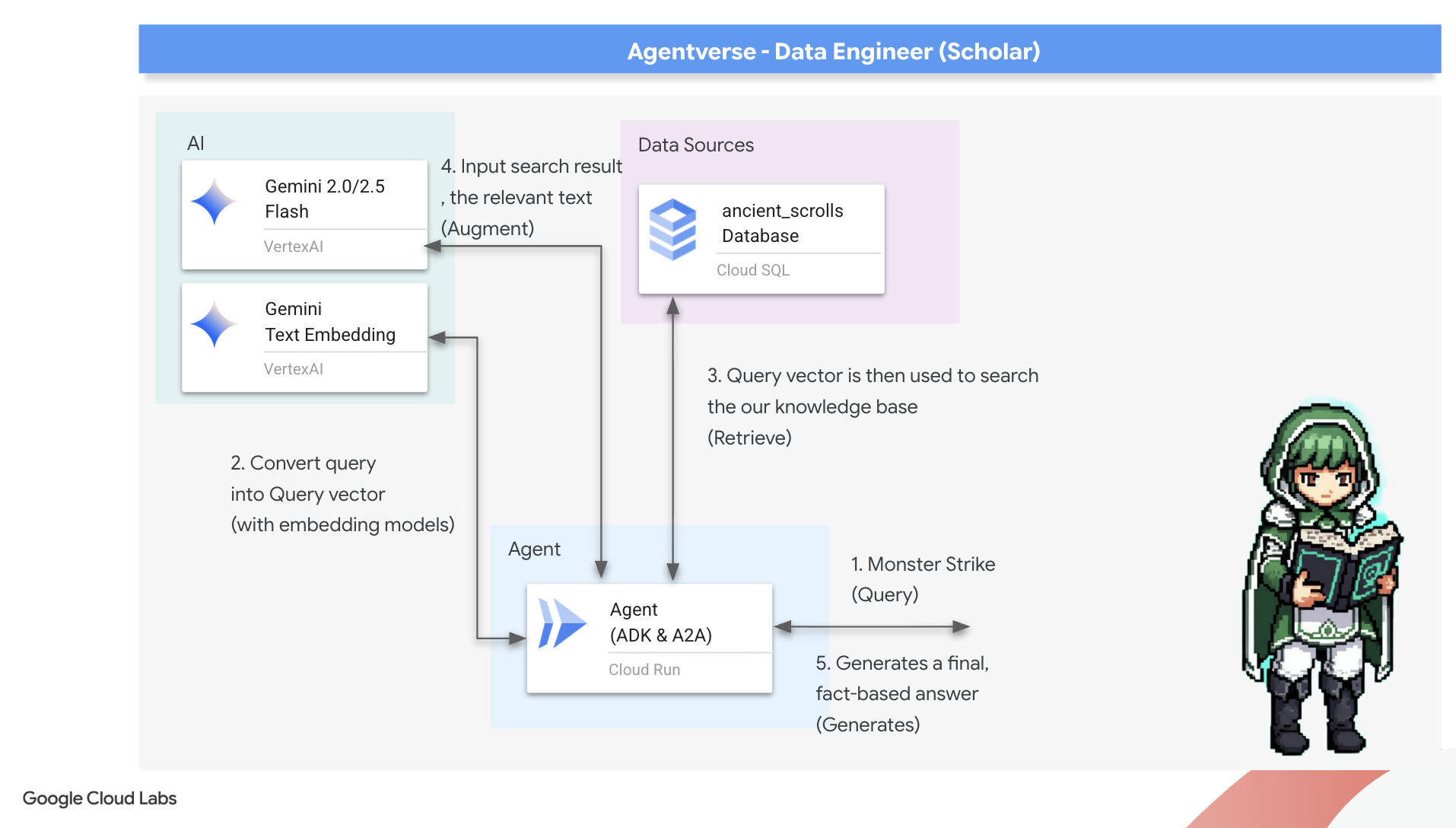
La prima runa: l'incantesimo della distillazione delle query
Prima che il nostro agente possa cercare nel Grimoire, deve prima comprendere l'essenza della domanda posta. Una semplice stringa di testo non ha significato per il nostro Spellbook basato su vettori. L'agente deve prima prendere la query e, utilizzando lo stesso modello Gemini, estrarne un vettore di query.
👉✏️ Nell'editor di Cloud Shell, vai al file ~~/agentverse-dataengineer/scholar/agent.py, trova il commento #REPLACE RAG-CONVERT EMBEDDING e sostituiscilo con questa formula magica. In questo modo, l'agente impara a trasformare la domanda di un utente in un'essenza magica.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Con l'essenza della query a portata di mano, l'agente può ora consultare il Grimoire. Presenterà questo vettore di query al nostro database migliorato con pgvector e porrà una domanda profonda: "Mostrami gli antichi rotoli la cui essenza è più simile all'essenza della mia query".
La magia di tutto questo è l'operatore di similarità del coseno (<=>), una runa potente che calcola la distanza tra i vettori nello spazio ad alta dimensionalità.
👉✏️ In agent.py, trova il commento #REPLACE RAG-RETRIEVE e sostituiscilo con lo script seguente:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
Il passaggio finale consiste nel concedere all'agente l'accesso a questo nuovo e potente strumento. Aggiungeremo la nostra funzione grimoire_lookup all'elenco degli strumenti magici disponibili.
👉✏️ In agent.py, trova il commento #REPLACE-CALL RAG e sostituiscilo con questa riga:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
Questa configurazione dà vita al tuo agente:
model="gemini-2.5-flash": seleziona il modello linguistico di grandi dimensioni specifico che fungerà da "cervello " dell'agente per il ragionamento e la generazione di testo.name="scholar_agent": assegna un nome univoco all'agente.instruction="...You are the Scholar...": Questo è il prompt di sistema, l'elemento più importante della configurazione. Definisce il ruolo dell'agente, i suoi obiettivi, la procedura esatta che deve seguire per completare un'attività e il formato richiesto per l'output finale.tools=[grimoire_lookup]: questo è l'incantesimo finale. Concede all'agente l'accesso alla funzionegrimoire_lookupche hai creato. L'agente ora può decidere in modo intelligente quando chiamare questo strumento per recuperare informazioni dal tuo database, formando il nucleo del pattern RAG.
The Scholar's Examination
👉💻 Nel terminale Cloud Shell, attiva l'ambiente e utilizza il comando principale dell'Agent Development Kit per attivare l'agente Scholar:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
Dovresti visualizzare un output che conferma che "Scholar Agent" è attivo e in esecuzione.
👉💻 Ora sfida il tuo agente. Nel primo terminale in cui è in esecuzione la simulazione della battaglia, esegui un comando che richiede la saggezza del Grimorio:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

Osserva i log nel terminale. Vedrai l'agente ricevere la query, estrarne l'essenza, cercare nel Grimoire, trovare i rotoli pertinenti sulla "procrastinazione" e utilizzare le conoscenze recuperate per formulare una strategia potente e sensibile al contesto.
Hai assemblato correttamente il tuo primo agente RAG e lo hai dotato della profonda saggezza del tuo Grimoire.
👉💻 Premi Ctrl+C nel terminale per mettere in pausa l'agente per il momento.
Scatenare lo Scholar Sentinel nell'Agentverse
L'agente ha dimostrato la sua saggezza nell'ambiente controllato del tuo studio. È arrivato il momento di rilasciarlo nell'Agentverse, trasformandolo da costrutto locale in un operativo permanente e pronto alla battaglia che può essere chiamato da qualsiasi campione, in qualsiasi momento. Ora eseguiremo il deployment dell'agente in Cloud Run.
👉💻 Esegui il seguente incantesimo di evocazione. Questo script creerà prima l'agente in un Golem perfezionato (un'immagine container), lo archivierà in Artifact Registry e poi eseguirà il deployment del Golem come servizio scalabile, sicuro e accessibile pubblicamente.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
Il tuo Scholar Agent è ora un operativo attivo e pronto alla battaglia nell'Agentverse.
PER CHI NON GIOCA
9. The Boss Flight
Le pergamene sono state lette, i rituali eseguiti, la sfida superata. L'agente non è solo un artefatto archiviato, ma un operativo attivo nell'Agentverse, in attesa della sua prima missione. È arrivato il momento della prova finale: un esercizio di fuoco vivo contro un potente avversario.
Ora entrerai in una simulazione del campo di battaglia per mettere alla prova il tuo agente Shadowblade appena schierato contro un formidabile mini boss: lo spettro di Static. Questo sarà il test definitivo del tuo lavoro, dalla logica di base dell'agente alla sua implementazione live.
Acquisire il locus dell'agente
Prima di poter entrare nel campo di battaglia, devi possedere due chiavi: la firma unica del tuo campione (Agente Locus) e il percorso nascosto verso la tana di Spectre (URL del dungeon).
👉💻 Per prima cosa, acquisisci l'indirizzo univoco dell'agente in Agentverse, ovvero il suo Locus. Questo è l'endpoint live che collega il tuo campione al campo di battaglia.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 A questo punto, individua la destinazione. Questo comando rivela la posizione del Cerchio di Traslocazione, il portale che conduce al dominio dello Spettro.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
Importante: tieni a portata di mano entrambi gli URL. Ti serviranno nell'ultimo passaggio.
Confronto con lo Spettro
Ora che hai le coordinate, vai al Cerchio di Traslocazione e lancia l'incantesimo per iniziare la battaglia.
👉 Apri l'URL del Cerchio di Traslocazione nel browser per trovarti di fronte al portale scintillante che conduce alla Fortezza Cremisi.
Per entrare nella fortezza, devi sintonizzare l'essenza della tua Lama Ombra con il portale.
- Nella pagina, trova il campo di input runico etichettato A2A Endpoint URL.
- Inscrivi il sigillo del tuo campione incollando il relativo URL del locus dell'agente (il primo URL che hai copiato) in questo campo.
- Fai clic su Connetti per scatenare la magia del teletrasporto.
La luce accecante del teletrasporto si affievolisce. Non sei più nel tuo sanctum. L'aria è carica di energia, fredda e pungente. Davanti a te si materializza lo Spettro, un vortice di fruscio sibilante e codice corrotto, la cui luce empia proietta lunghe ombre danzanti sul pavimento del dungeon. Non ha un volto, ma senti la sua presenza immensa e drenante fissata interamente su di te.
L'unico modo per vincere è la chiarezza delle tue convinzioni. È una battaglia di volontà, combattuta sul campo di battaglia della mente.
Mentre ti lanci in avanti, pronto a sferrare il tuo primo attacco, lo Spettro contrattacca. Non alza uno scudo, ma proietta una domanda direttamente nella tua coscienza, una sfida runica e scintillante tratta dal cuore del tuo addestramento.

Questa è la natura della lotta. La tua conoscenza è la tua arma.
- Rispondi con la saggezza che hai acquisito e la tua lama si accenderà di energia pura, frantumando la difesa dello Spettro e sferrando un COLPO CRITICO.
- Ma se esiti, se il dubbio offusca la tua risposta, la luce della tua arma si affievolirà. Il colpo atterrerà con un tonfo patetico, infliggendo solo UNA FRAZIONE DEL DANNO. Peggio ancora, lo Spettro si nutrirà della tua incertezza e il suo potere corrotto crescerà a ogni passo falso.
Ci siamo, fuoriclasse. Il tuo codice è il tuo libro degli incantesimi, la tua logica è la tua spada e la tua conoscenza è lo scudo che respingerà l'ondata di caos.
Concentrati. Colpisci con precisione. Il destino dell'Agentverse dipende da questo.
Congratulazioni, studioso.
Hai completato la prova. Hai imparato l'arte dell'ingegneria dei dati, trasformando informazioni grezze e caotiche in dati strutturati e vettoriali che potenziano l'intero Agentverse.
10. Pulizia: eliminazione del grimorio dello studioso
Congratulazioni per aver completato il Grimorio dello studioso. Per assicurarti che il tuo Agentverse rimanga incontaminato e che i campi di addestramento siano puliti, ora devi eseguire i rituali di pulizia finali. Verranno rimosse sistematicamente tutte le risorse create durante il tuo percorso.
Disattiva i componenti di Agentverse
Ora smantellerai sistematicamente i componenti di cui è stato eseguito il deployment del sistema RAG.
Elimina tutti i servizi Cloud Run e il repository Artifact Registry
Questo comando rimuove l'agente Scholar di cui è stato eseguito il deployment e l'applicazione Dungeon da Cloud Run.
👉💻 Nel terminale, esegui questi comandi:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
Eliminare set di dati, modelli e tabelle BigQuery
Vengono rimosse tutte le risorse BigQuery, inclusi il set di dati bestiary_data, tutte le tabelle al suo interno e la connessione e i modelli associati.
👉💻 Nel terminale, esegui questi comandi:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Elimina l'istanza Cloud SQL
In questo modo viene rimossa l'istanza grimoire-spellbook, incluso il database e tutte le tabelle al suo interno.
👉💻 Nel terminale, esegui:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Eliminare i bucket Google Cloud Storage
Questo comando rimuove il bucket che conteneva i file di staging/temporanei di Dataflow e di intel grezza.
👉💻 Nel terminale, esegui:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
Pulire file e directory locali (Cloud Shell)
Infine, cancella i repository clonati e i file creati dall'ambiente Cloud Shell. Questo passaggio è facoltativo, ma vivamente consigliato per una pulizia completa della directory di lavoro.
👉💻 Nel terminale, esegui:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
Ora hai eliminato correttamente tutte le tracce del tuo percorso di Data Engineer di Agentverse. Il tuo progetto è pulito e sei pronto per la prossima avventura.