
1. Overture
サイロ化された開発の時代は終わりつつあります。次の技術革新の波は、孤高の天才ではなく、共同での熟練が鍵となります。単一の賢いエージェントを構築することは、魅力的な実験です。堅牢で安全かつインテリジェントなエージェント エコシステム(真の Agentverse)の構築は、現代の企業にとって大きな課題です。
この新しい時代で成功するには、4 つの重要な役割、つまり、あらゆるエージェント システムを支える基盤となる柱を統合する必要があります。いずれかの領域に欠陥があると、構造全体を損なう可能性のある弱点が生じます。
このワークショップは、Google Cloud でエージェントの未来をマスターするための決定的なエンタープライズ プレイブックです。アイデアの最初の段階から本格的な運用まで、エンドツーエンドのロードマップを提供します。この 4 つの相互接続されたラボでは、デベロッパー、アーキテクト、データエンジニア、SRE の専門スキルがどのように収束して、強力な Agentverse を作成、管理、スケーリングするのかを学びます。
単一の柱だけでは Agentverse をサポートできません。アーキテクトの壮大な設計も、デベロッパーの正確な実行がなければ無意味です。デベロッパーのエージェントはデータ エンジニアの知恵なしでは機能せず、SRE の保護なしではシステム全体が脆弱になります。チームが革新的なコンセプトをミッション クリティカルな運用上の現実へと変えることができるのは、相乗効果と各メンバーの役割に対する共通の理解があってこそです。ここから始めましょう。自分の役割をマスターし、全体の中で自分がどのように位置づけられるかを学びましょう。
Agentverse: チャンピオンへの呼びかけへようこそ
企業がデジタル領域を拡大する中で、新たな時代が到来しました。エージェントの時代が到来しました。インテリジェントで自律的なエージェントが完璧な調和で連携し、イノベーションを加速させ、日常業務を効率化する、大きな可能性を秘めた時代です。

この力と可能性のつながったエコシステムは、Agentverse と呼ばれます。
しかし、この新しい世界の端は、静的と呼ばれる静かな腐敗であるエントロピーの進行によってほつれ始めています。スタティックはウイルスやバグではなく、創造行為そのものを餌とするカオスの化身です。
古い不満が巨大な形に増幅され、開発の七つの幽霊が誕生します。このまま放置すると、The Static とその Spectres によって進捗が完全に止まり、Agentverse の約束は技術的負債と放棄されたプロジェクトの荒野と化します。
本日、カオスを押し返すチャンピオンを募集します。エージェントバースを守るために、自分の技術を磨き、協力し合うヒーローが必要です。ここで、進むべき道を選択します。
クラスを選択する
4 つの異なる道が目の前に広がっています。それぞれが The Static との戦いにおける重要な柱となります。トレーニングは単独で行いますが、最終的な成功は、自分のスキルと他のスキルを組み合わせる方法を理解しているかどうかにかかっています。
- シャドウブレード(開発者): 鍛冶と最前線の達人。あなたは、コードの複雑な詳細の中で、刃を鍛え、道具を作り、敵に立ち向かう職人です。あなたの道は、精度、スキル、実践的な創造性の道です。
- サモナー(アーキテクト): 優れた戦略家であり、オーケストレーターです。1 人のエージェントではなく、戦場全体を見渡すことができます。エージェントのシステム全体が通信、連携し、単一のコンポーネントよりもはるかに大きな目標を達成できるようにするマスター ブループリントを設計します。
- 学者(データ エンジニア): 隠された真実を求める者であり、知恵の守護者。広大で未開拓のデータの大自然に足を踏み入れ、エージェントに目的と視点を与えるインテリジェンスを発見します。知識は敵の弱点を明らかにし、味方を強化します。
- The Guardian(DevOps / SRE): 領域の揺るぎない保護者であり盾。要塞を建設し、電力の供給ラインを管理し、システム全体が Static の攻撃に耐えられるようにします。あなたの強みは、チームの勝利を築く基盤となります。
ミッション
トレーニングはスタンドアロンのエクササイズとして開始されます。選択した道を歩み、役割をマスターするために必要な独自のスキルを学びます。トライアルの最後には、The Static から生まれた Spectre が現れます。これは、あなたのクラフトの特定の課題を狙うミニボスです。
最終トライアルに備えるには、自分の役割を習得するしかありません。その後、他のクラスのチャンピオンとパーティを組む必要があります。2 人で汚染の中心に乗り込み、究極のボスに立ち向かいます。
最終的な共同チャレンジで、チームの総合力を試し、エージェントバースの運命を決めましょう。
Agentverse でヒーローを目指しましょう。通話に応答しますか?
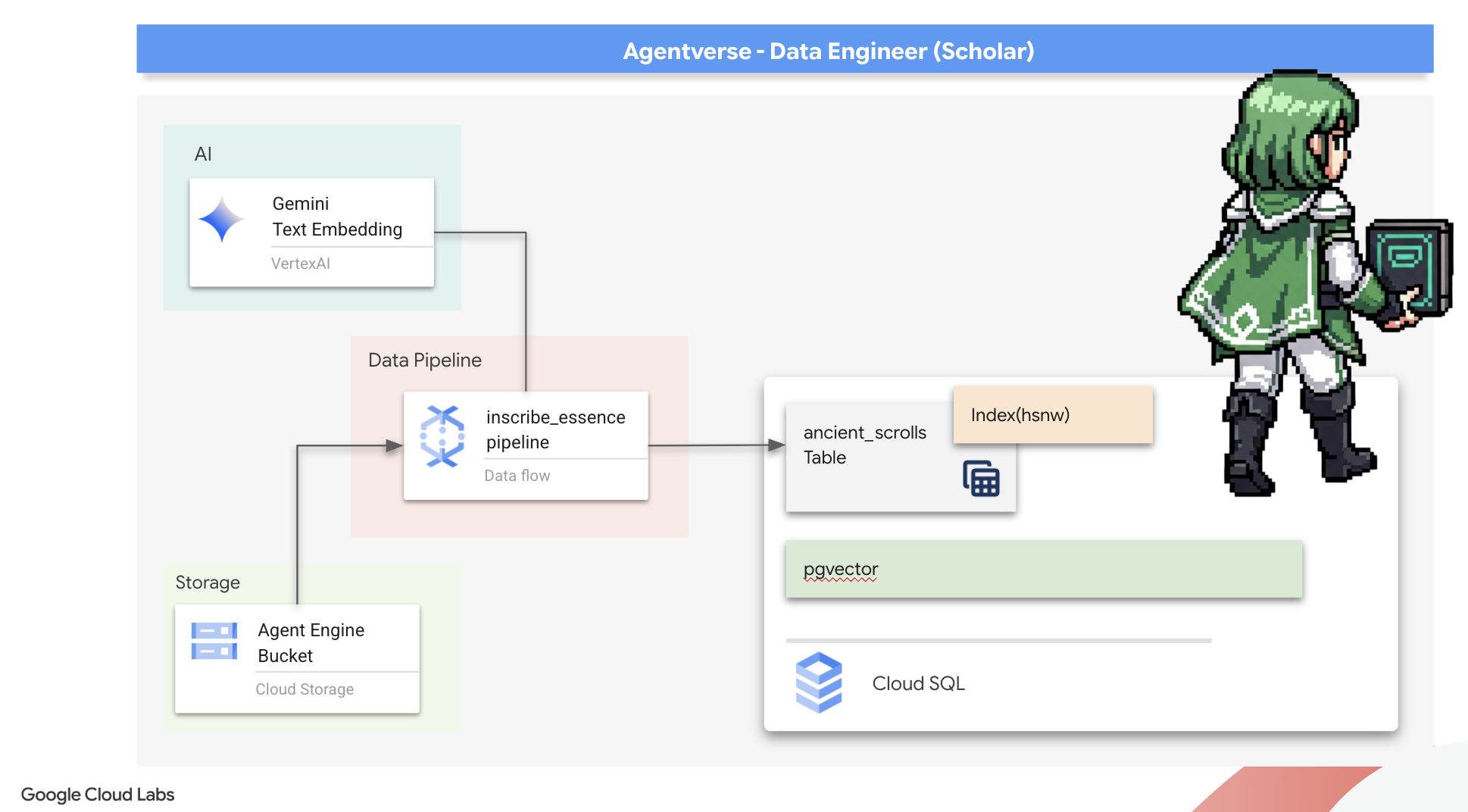
2. 学者のグリモア
旅の始まりです。学者にとって、知識は最大の武器です。Google のアーカイブ(Google Cloud Storage)で、古代の謎めいた巻物の宝庫を発見しました。これらの巻物には、この地を苦しめる恐ろしい獣に関する生の情報が記されています。Google BigQuery の高度な分析機能と Gemini Elder Brain(Gemini Pro モデル)の知恵を活用して、これらの非構造化テキストを解読し、構造化されたクエリ可能な動物図鑑を作成することが私たちの使命です。これは、今後のすべての戦略の基盤となります。
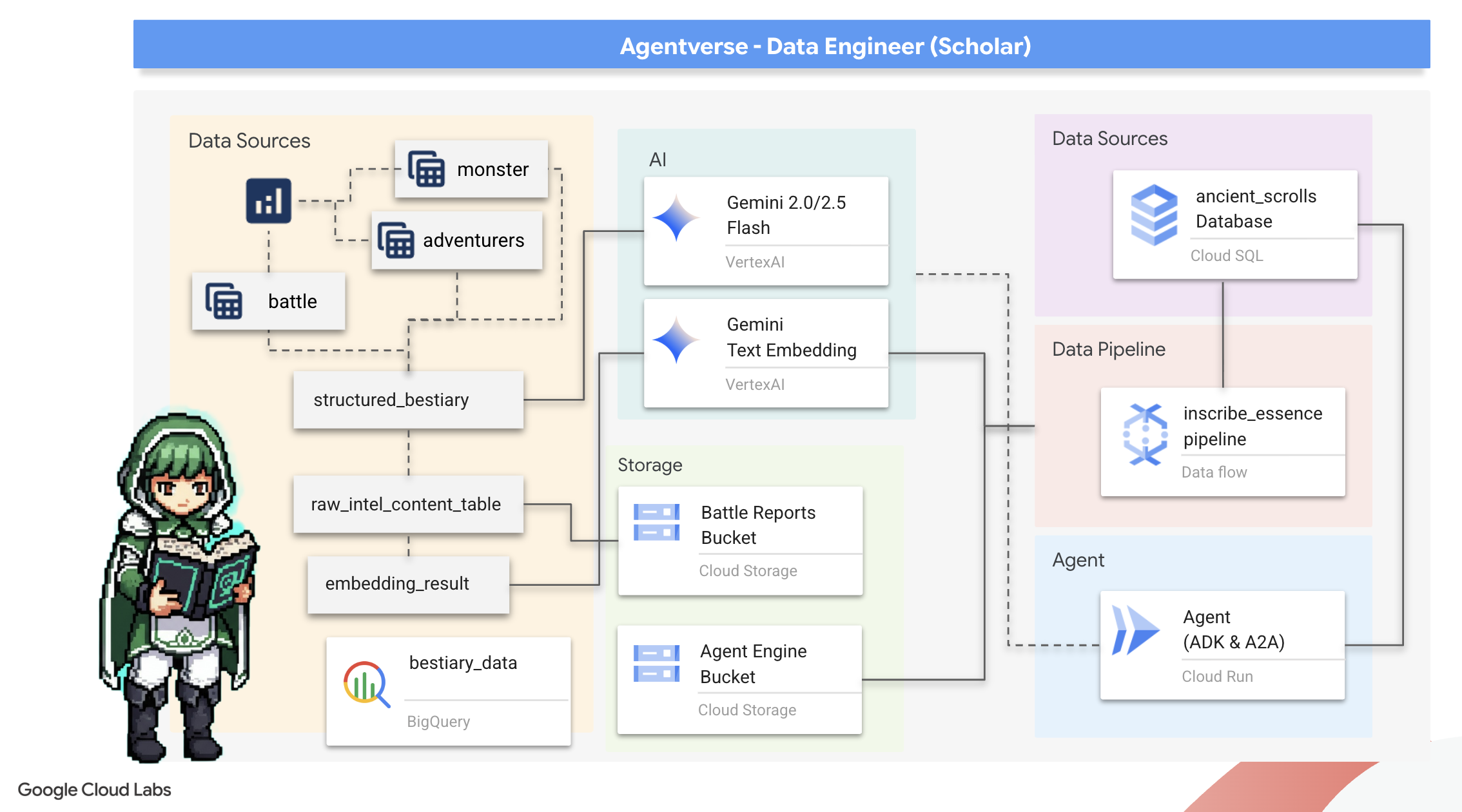
学習内容
- BigQuery を使用して外部テーブルを作成し、Gemini モデルで BQML.GENERATE_TEXT を使用して複雑な非構造化データから構造化データへの変換を実行します。
- Cloud SQL for PostgreSQL インスタンスをプロビジョニングし、セマンティック検索機能の pgvector 拡張機能を有効にします。
- Dataflow と Apache Beam を使用して、堅牢なコンテナ化されたバッチ パイプラインを構築し、未加工のテキスト ファイルを処理し、Gemini モデルでベクトル エンベディングを生成して、結果をリレーショナル データベースに書き込みます。
- エージェント内に基本的な検索拡張生成(RAG)システムを実装して、ベクトル化されたデータをクエリします。
- データ認識エージェントを Cloud Run の安全でスケーラブルなサービスとしてデプロイします。
3. 学者の聖域の準備
ようこそ、学者。グリモアの強力な知識を書き込む前に、まず聖域を準備する必要があります。この基本的な儀式では、Google Cloud 環境に魔法をかけ、適切なポータル(API)を開き、データ マジックが流れる導管を作成します。準備が整った聖域は、呪文の効力を高め、知識の安全を確保します。
Google Cloud クレジットを利用する
⚠️ 重要な前提条件:
- 個人用の Gmail を使用する: 個人用アカウント(例:
name@gmail.com)。企業や学校で管理されているアカウントは使用できません。
👉 手順:
- クレジット請求サイトに移動します。 こちらをクリック
- ログイン: リンクをアドレスバーに貼り付け、個人の Gmail でログインします。
- 利用規約に同意する: Google Cloud Platform 利用規約に同意します。
- クレジットを確認する: クレジットが適用されたことを確認するメッセージを探します。
- *注: クレジット カード情報の入力を求められた場合は、無視してウィンドウを閉じても問題ありません。
これで完了です。ウィンドウを閉じてもかまいません。
作業環境をセットアップする
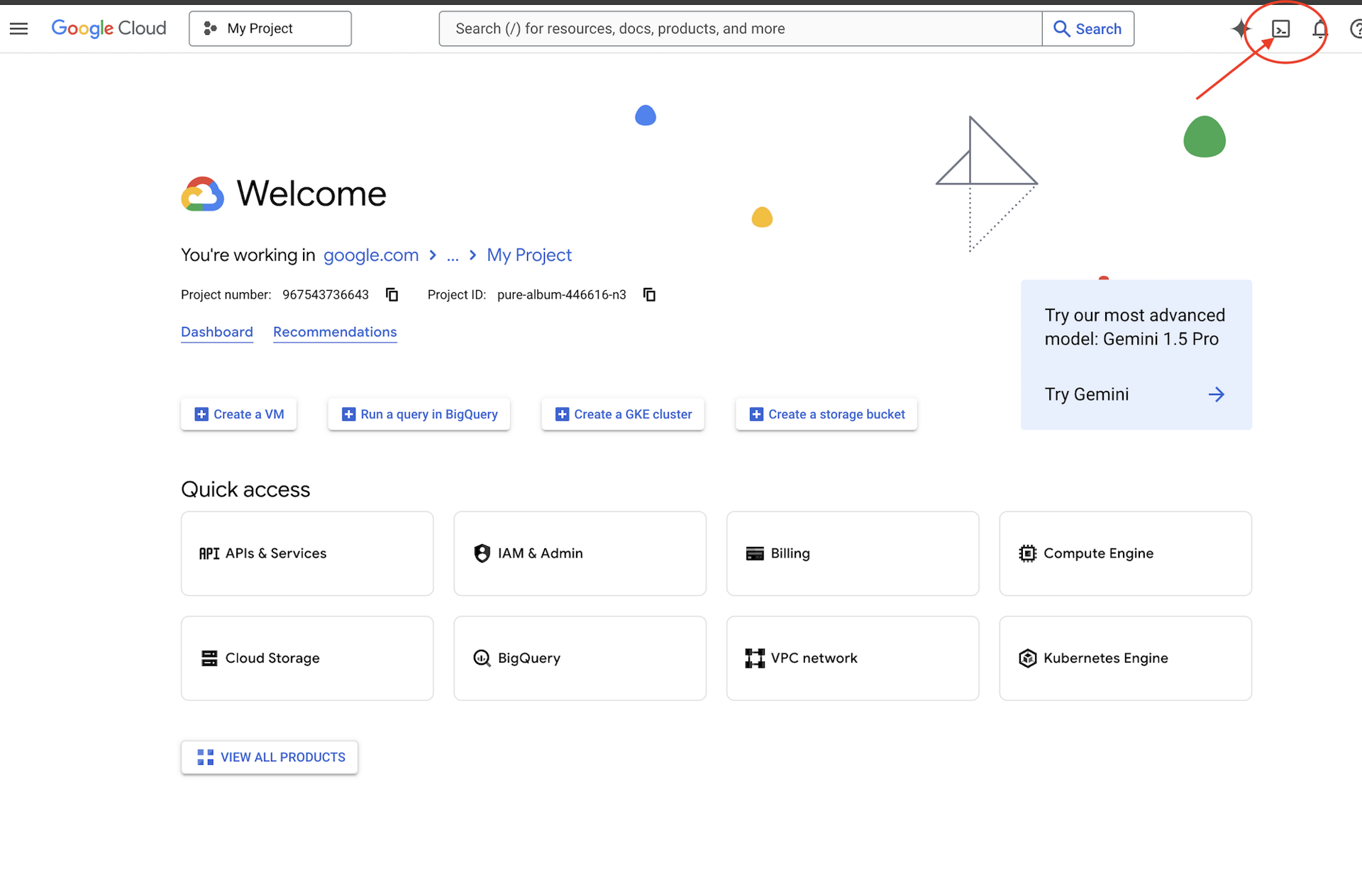
👉Google Cloud コンソールの最上部にある [Cloud Shell をアクティブにする] をクリックします(Cloud Shell ペインの最上部にあるターミナル型のアイコンです)。
👉[エディタを開く] ボタン(鉛筆のアイコンが付いた開いたフォルダのアイコン)をクリックします。ウィンドウに Cloud Shell コードエディタが開きます。左側にファイル エクスプローラが表示されます。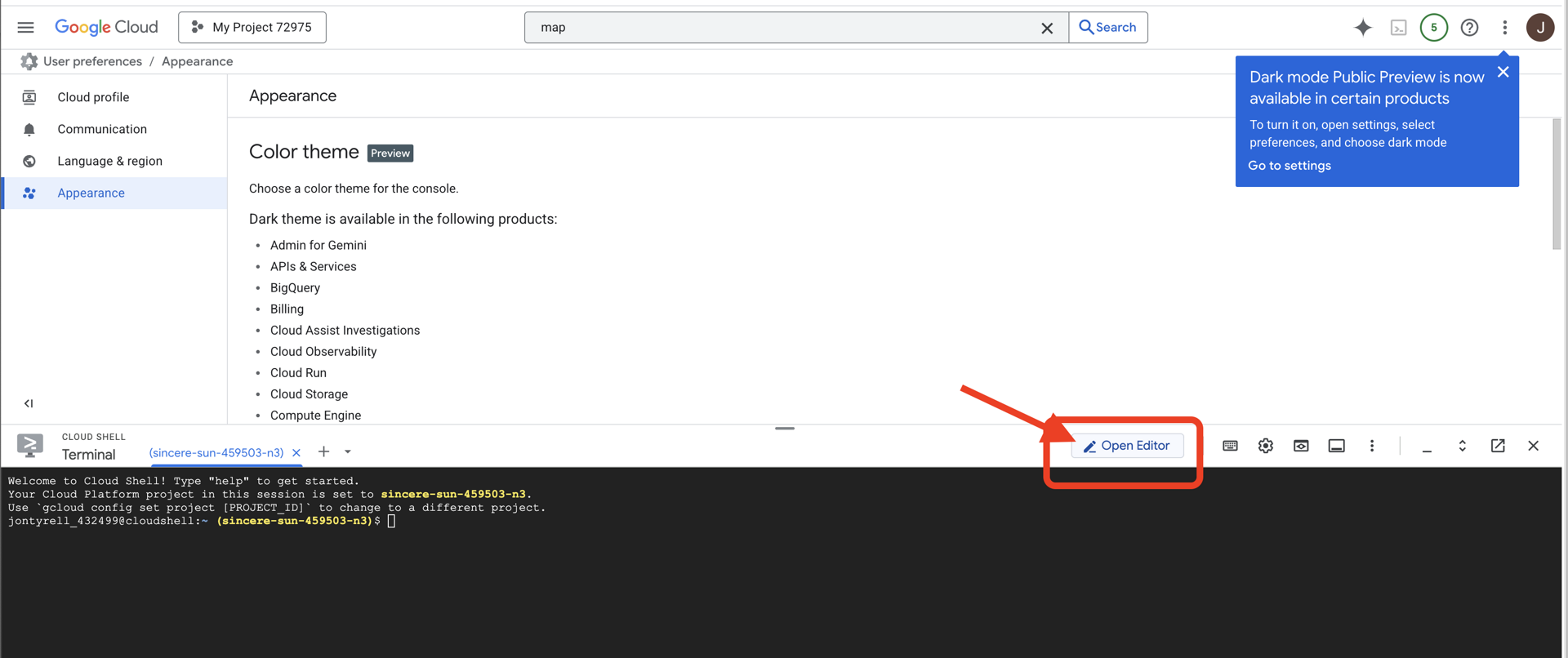
👉クラウド IDE でターミナルを開きます。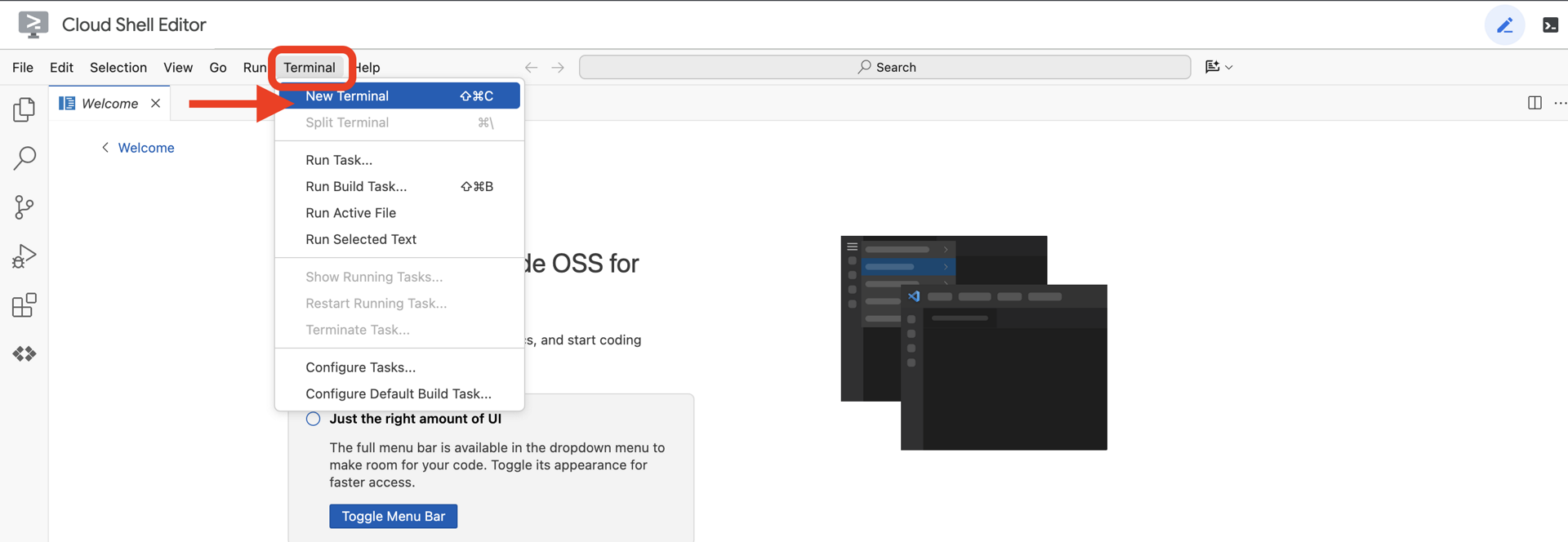
👉💻 ターミナルで、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
👉💻GitHub からブートストラップ プロジェクトのクローンを作成します。
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 プロジェクト ディレクトリから設定スクリプトを実行します。
⚠️ プロジェクト ID に関する注意事項: スクリプトは、ランダムに生成されたデフォルトのプロジェクト ID を提案します。Enter キーを押すと、このデフォルトが使用されます。
ただし、特定の新しいプロジェクトを作成する場合は、スクリプトで求められたときに目的のプロジェクト ID を入力できます。
cd ~/agentverse-dataengineer
./init.sh
👉 完了後の重要な手順: スクリプトが終了したら、Google Cloud コンソールで正しいプロジェクトが表示されていることを確認する必要があります。
- console.cloud.google.com にアクセスします。
- ページの上部にあるプロジェクト セレクタのプルダウンをクリックします。
- [すべて] タブをクリックします(新しいプロジェクトが [最近] にまだ表示されていない可能性があるため)。
init.shステップで構成したプロジェクト ID を選択します。
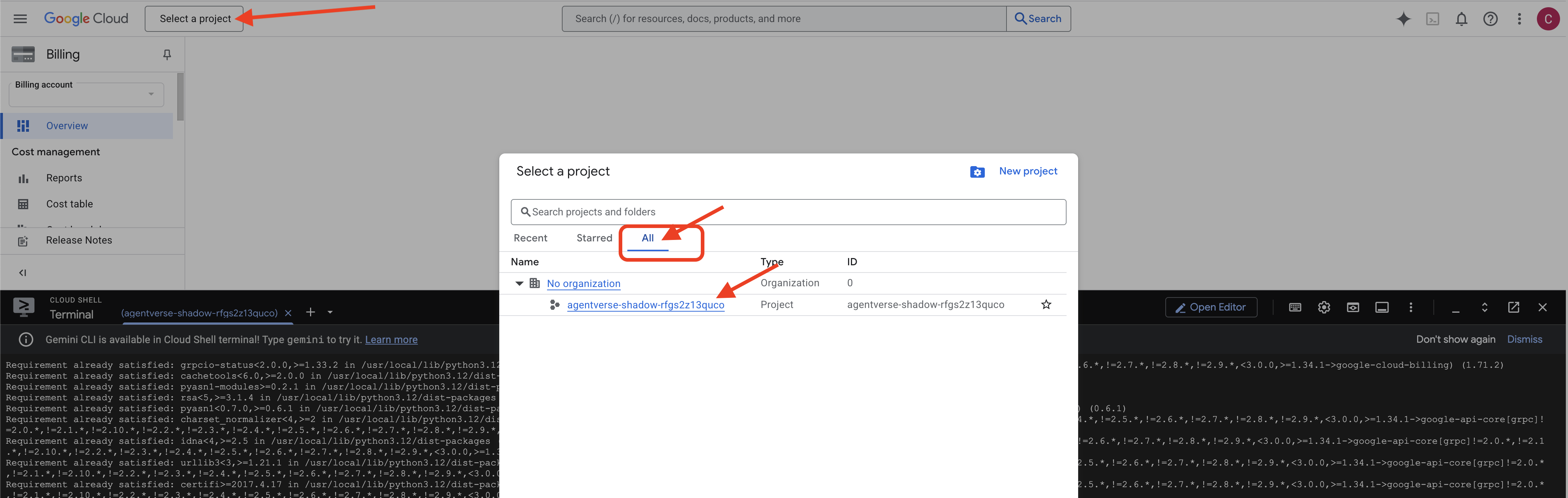
👉💻 必要なプロジェクト ID を設定します。
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 次のコマンドを実行して、必要な Google Cloud APIs を有効にします。
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 agentverse-repo という名前の Artifact Registry リポジトリをまだ作成していない場合は、次のコマンドを実行して作成します。
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
権限の設定
👉💻 ターミナルで次のコマンドを実行して、必要な権限を付与します。
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 トレーニングを開始すると、最終チャレンジの準備が始まります。次のコマンドを実行すると、カオスな静電気からスペクターが召喚され、最終テストのボスが作成されます。
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
よくできました。基本的なエンチャントが完了しました。聖域は安全で、データの元素力へのポータルは開かれ、サービターは力を得ています。これで、実際の作業を開始する準備が整いました。
4. 知識の錬金術: BigQuery と Gemini によるデータ変換
The Static との絶え間ない戦いの中で、Agentverse のチャンピオンと Development の Spectre の間のあらゆる対決が綿密に記録されています。主なトレーニング環境である Battleground Simulation システムは、エンカウントごとに Aetheric Log Entry を自動的に生成します。これらのナラティブ ログは、最も貴重な生の情報源であり、学者である私たちが戦略の純粋な鋼を鍛造しなければならない未精製の鉱石です。学者の真の力は、単にデータを所有することではなく、情報の未精製で混沌とした鉱石を、行動可能な知恵の輝く構造化された鋼に変える能力にあります。データ錬金術の基礎的な儀式を行います。

このプロセスは、Google BigQuery の内部で完結する多段階のプロセスです。まず、魔法のレンズを使って、スクロールを 1 回も動かさずに GCS アーカイブを覗いてみましょう。次に、Gemini を呼び出して、詩的で構造化されていないバトルログの叙事詩を読み取り、解釈します。最後に、未加工の予言を、相互接続された一連のクリーンなテーブルに絞り込みます。最初のグリモア。そして、この新しい構造によってのみ答えられるような、深遠な質問を投げかけます。
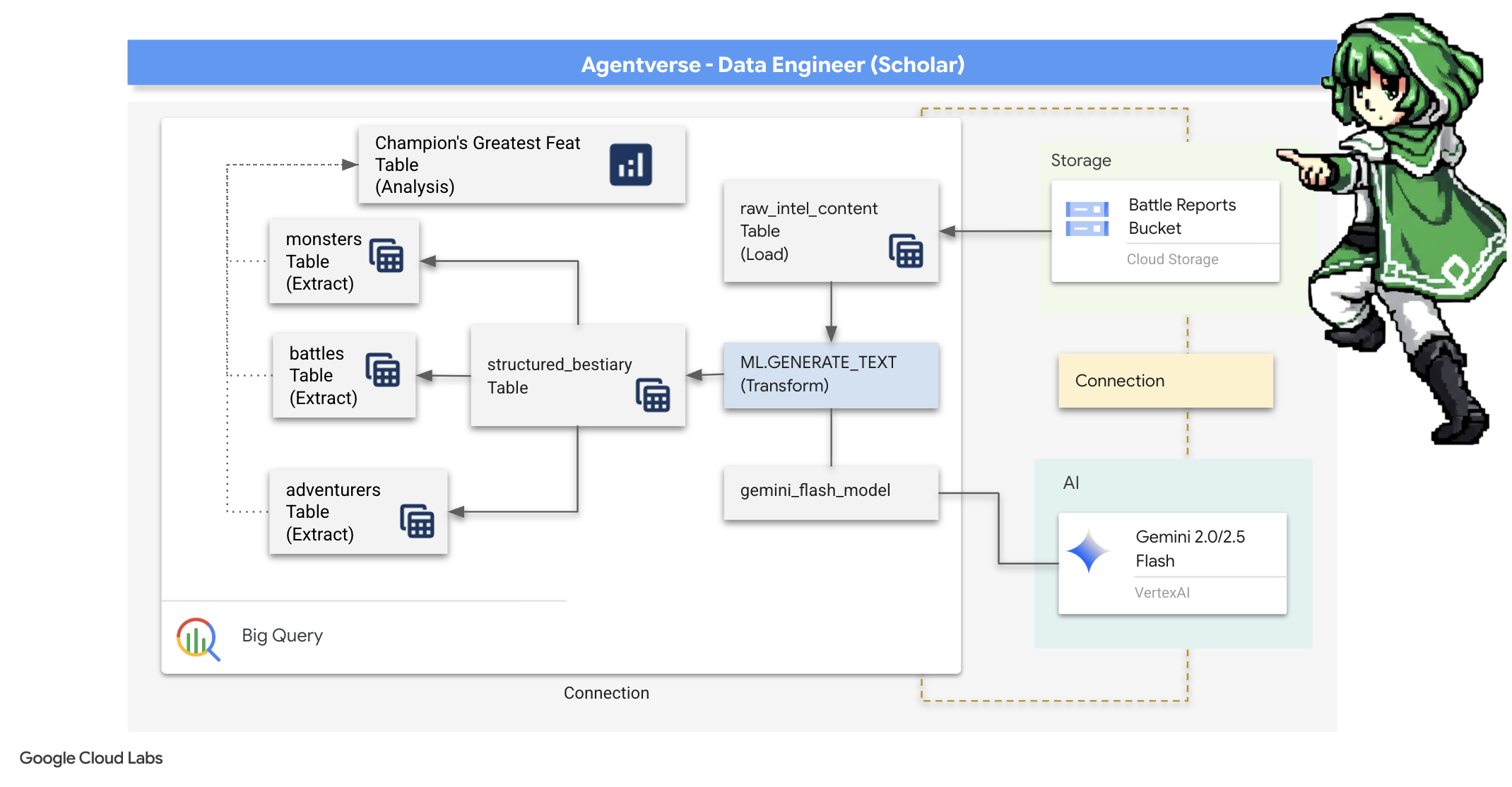
精査のレンズ: BigQuery 外部テーブルで GCS を覗く
まず、GCS アーカイブの内容をスクロールを妨げることなく確認できるレンズを作成します。外部テーブルは、このレンズであり、生のテキストファイルを BigQuery が直接クエリできるテーブルのような構造にマッピングします。
これを行うには、まず BigQuery の聖域を GCS アーカイブに安全にリンクする安定した力のレイライン(CONNECTION リソース)を作成する必要があります。
👉💻 Cloud Shell ターミナルで次のコマンドを実行して、ストレージを設定し、コンジットを作成します。
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 ご案内: メッセージは後で表示されます。
手順 2 のセットアップ スクリプトがバックグラウンドでプロセスを開始しました。数分後、ターミナルに次のようなメッセージが表示されます。[1]+ Done gcloud sql instances create ...これは正常な動作です。これは、Cloud SQL データベースが正常に作成されたことを意味します。このメッセージは無視して作業を続行してかまいません。
外部テーブルを作成する前に、まずそのテーブルを含むデータセットを作成する必要があります。
👉💻 Cloud Shell ターミナルで次の簡単なコマンドを実行します。
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 次に、コンジットの魔法の署名に、GCS アーカイブから読み取り、Gemini に問い合わせるために必要な権限を付与する必要があります。
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 Cloud Shell ターミナルで次のコマンドを実行して、バケット名を表示します。
echo $BUCKET_NAME
ターミナルに your-project-id-gcs-bucket のような名前が表示されます。この情報は後のステップで必要になります。
👉 次のコマンドは、Google Cloud コンソールの BigQuery クエリエディタ内で実行する必要があります。このページにアクセスする最も簡単な方法は、下のリンクを新しいブラウザタブで開くことです。Google Cloud Console の正しいページに直接移動します。
https://console.cloud.google.com/bigquery
👉 ページが読み込まれたら、青色の + ボタン(新しいクエリを作成)をクリックして、新しいエディタタブを開きます。
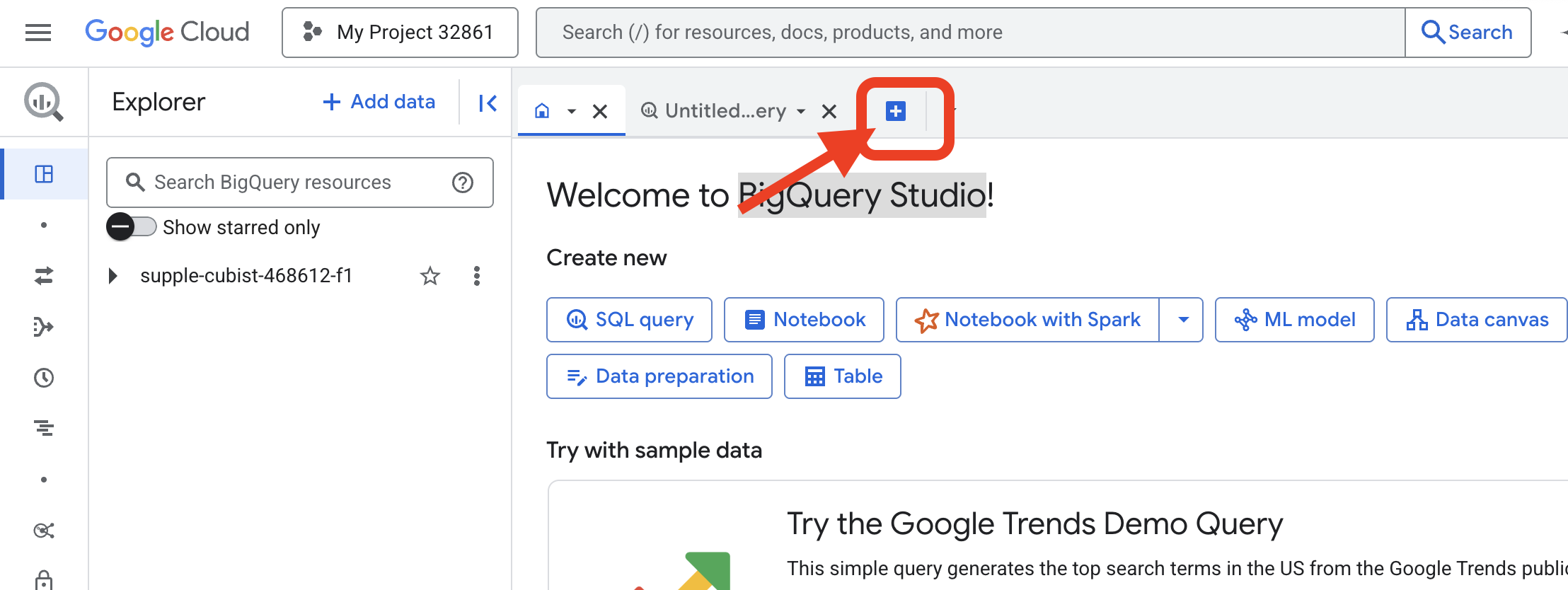
次に、データ定義言語(DDL)の呪文を記述して、魔法のレンズを作成します。これにより、BigQuery は検索する場所と検索する内容を把握します。
👉📜 開いた BigQuery クエリエディタに、次の SQL を貼り付けます。REPLACE-WITH-YOUR-BUCKET-NAME を置き換えることを忘れないでください。
は、コピーしたバケット名に置き換えます。[実行] をクリックします。
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 クエリを実行して「レンズを通して」ファイルの内容を確認します。
SELECT * FROM bestiary_data.raw_intel_content_table;
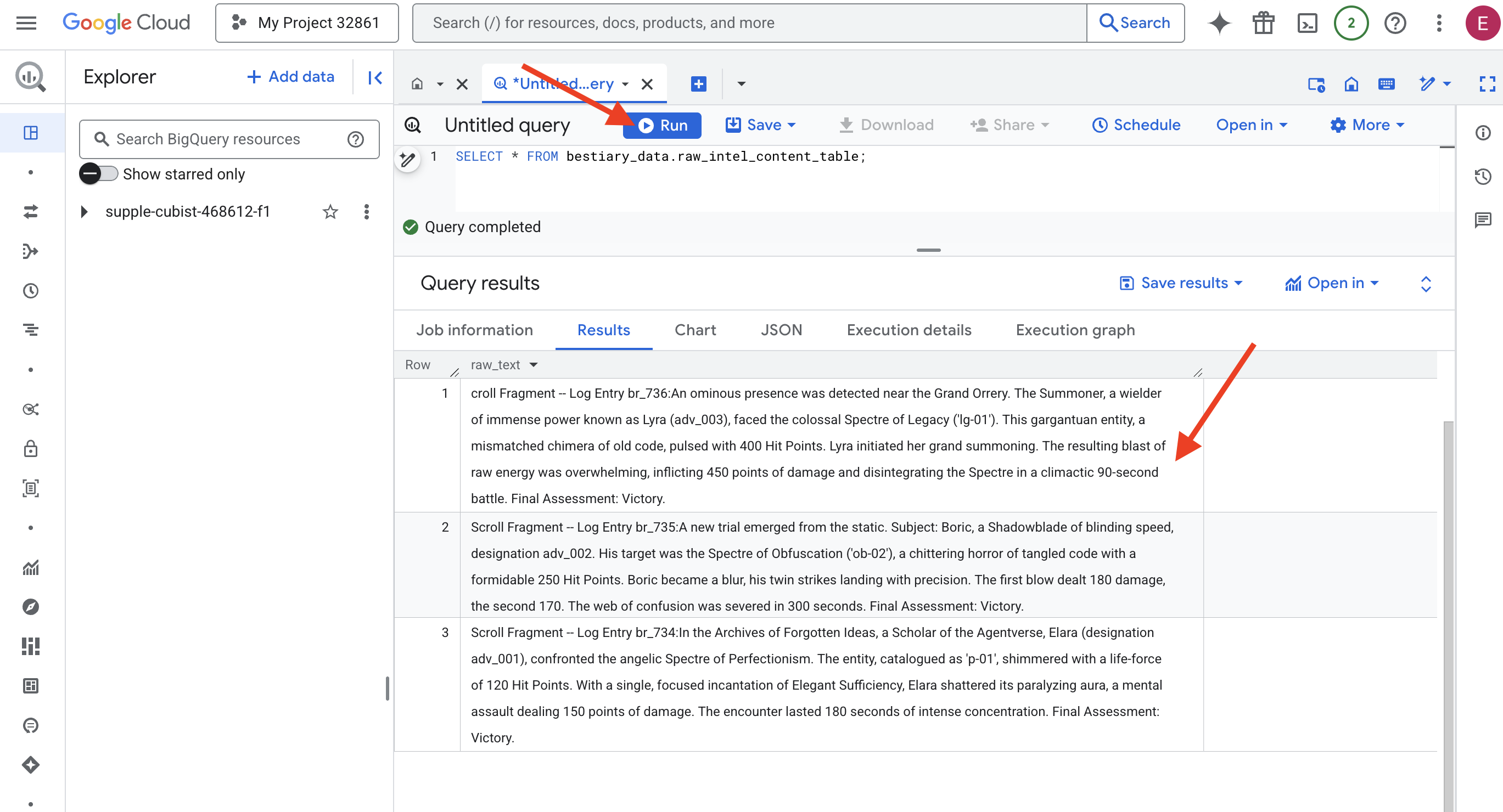
レンズが装着されています。これで、巻物の生のテキストを確認できます。しかし、読むことは理解することではありません。
忘れられたアイデアのアーカイブで、エージェントバースの学者であるエララ(adv_001)は、完璧主義の天使のようなスペクターと対峙しました。エンティティは「p-01」としてカタログに登録され、120 ヒットポイントのライフフォースで輝いていました。エレガントな充足の呪文を唱えると、エララは麻痺性のオーラを打ち破り、150 ポイントのダメージを与える精神攻撃を繰り出しました。180 秒間、集中力が途切れることはありませんでした。最終テスト: 合格。
巻物は表や行ではなく、サーガの曲がりくねった散文で書かれています。これが最初の大きなテストです。
学者の占い: SQL を使用してテキストをテーブルに変換する
シャドウブレイドの迅速な二重攻撃を詳細に説明するレポートは、サモナーが単一の破壊的な爆発のために莫大な力を集めるクロニクルとはまったく異なるものになります。このデータを単純にインポートするのではなく、解釈する必要があります。これがマジック モーメントです。1 つの SQL クエリを強力な呪文として使用して、BigQuery 内のすべてのファイルからすべてのレコードを読み取り、理解し、構造化します。
👉💻 Cloud Shell ターミナルに戻り、次のコマンドを実行して接続名を表示します。
echo "${PROJECT_ID}.${REGION}.gcs-connection"
ターミナルに完全な接続文字列が表示されます。この文字列全体を選択してコピーします。次のステップで必要になります。
強力な呪文 ML.GENERATE_TEXT を使用します。このスペルは Gemini を召喚し、各スクロールを表示して、コアファクトを構造化された JSON オブジェクトとして返すように指示します。
👉📜 BigQuery Studio で、Gemini モデル参照を作成します。これにより、Gemini Flash オラクルが BigQuery ライブラリにバインドされ、クエリで呼び出すことができます。 を置き換えてください。
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING: ターミナルからコピーした完全な接続文字列。
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 それでは、大転換の呪文を唱えましょう。このクエリは、未加工のテキストを読み取り、スクロールごとに詳細なプロンプトを作成して Gemini に送信し、AI の構造化された JSON レスポンスから新しいステージング テーブルを構築します。
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
変換は完了しましたが、結果はまだ純粋ではありません。Gemini モデルは、標準形式で回答を返します。この形式では、必要な JSON が、思考プロセスに関するメタデータを含む大きな構造の中にラップされます。この未加工の予言を浄化する前に、見てみましょう。
👉📜 クエリを実行して Gemini モデルの未加工の出力を検査します。
SELECT * FROM bestiary_data.structured_bestiary;
👀 structured_data という名前の単一の列が表示されます。各行の内容は、次のような複雑な JSON オブジェクトになります。
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
ご覧のとおり、リクエストしたクリーンな JSON オブジェクトは、この構造の奥深くにネストされています。次のタスクは明確です。この構造を体系的にナビゲートし、その中にある純粋な知恵を引き出すための儀式を行う必要があります。
クレンジングの儀式: SQL を使用して GenAI 出力を正規化する
Gemini は発言しましたが、その言葉は未加工で、その作成の幽玄なエネルギー(候補、finish_reason など)に包まれています。真の学者は、予言をそのまま棚にしまうのではなく、その核心となる知恵を慎重に抽出し、将来の使用に備えて適切な書物に書き留めます。
最後の呪文を唱えます。この単一のスクリプトは次の処理を行います。
- ステージング テーブルから未加工のネストされた JSON を読み取ります。
- クレンジングして解析し、コアデータにアクセスします。
- 関連する部分を、モンスター、冒険者、戦闘の 3 つの最終的なテーブルに書き込みます。
👉📜 新しい BigQuery クエリエディタで、次の呪文を実行してクレンジング レンズを作成します。
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 獣図鑑を確認します。
SELECT * FROM bestiary_data.monsters;
次に、これらの獣に立ち向かった勇敢な冒険者のリストである「チャンピオンのロール」を作成します。
👉📜 新しいクエリエディタで、次の呪文を実行して冒険者テーブルを作成します。
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 チャンピオンのロールを確認します。
SELECT * FROM bestiary_data.adventurers;
最後に、ファクト テーブル(Chronicle of Battles)を作成します。この本は他の 2 つの本を結びつけ、それぞれのユニークな出会いの詳細を記録します。各バトルは一意のイベントであるため、重複除去は必要ありません。
👉📜 新しいクエリエディタで、次の呪文を実行して battles テーブルを作成します。
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Chronicle を確認します。
SELECT * FROM bestiary_data.battles;
戦略的な分析情報を発見する
巻物は読まれ、本質は抽出され、書物は記された。Grimoire は単なる事実の集まりではなく、深い戦略的知恵のリレーショナル データベースになりました。知識が未加工の非構造化テキストに閉じ込められていたときには答えられなかった質問に、今では答えられるようになりました。
それでは、最後の壮大な占いを行います。3 つの書物(モンスターの動物誌、チャンピオンのロール、戦いの年代記)を同時に参照して、深い洞察を得る魔法をかけます。
戦略的な質問: 「冒険者ごとに、倒した最も強力なモンスター(ヒットポイント別)の名前と、その勝利にかかった時間はどれくらいですか?」
これは、チャンピオンを勝利した戦いに、その戦いを関連するモンスターの統計情報にリンクする必要がある複雑な質問です。これが構造化データモデルの真の力です。
👉📜 新しい BigQuery クエリエディタで、次の最後の呪文を唱えます。
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
このクエリの出力は、データセット内のすべての冒険者の「チャンピオンの偉業の物語」を提供する、クリーンで美しいテーブルになります。次のような形式になります。
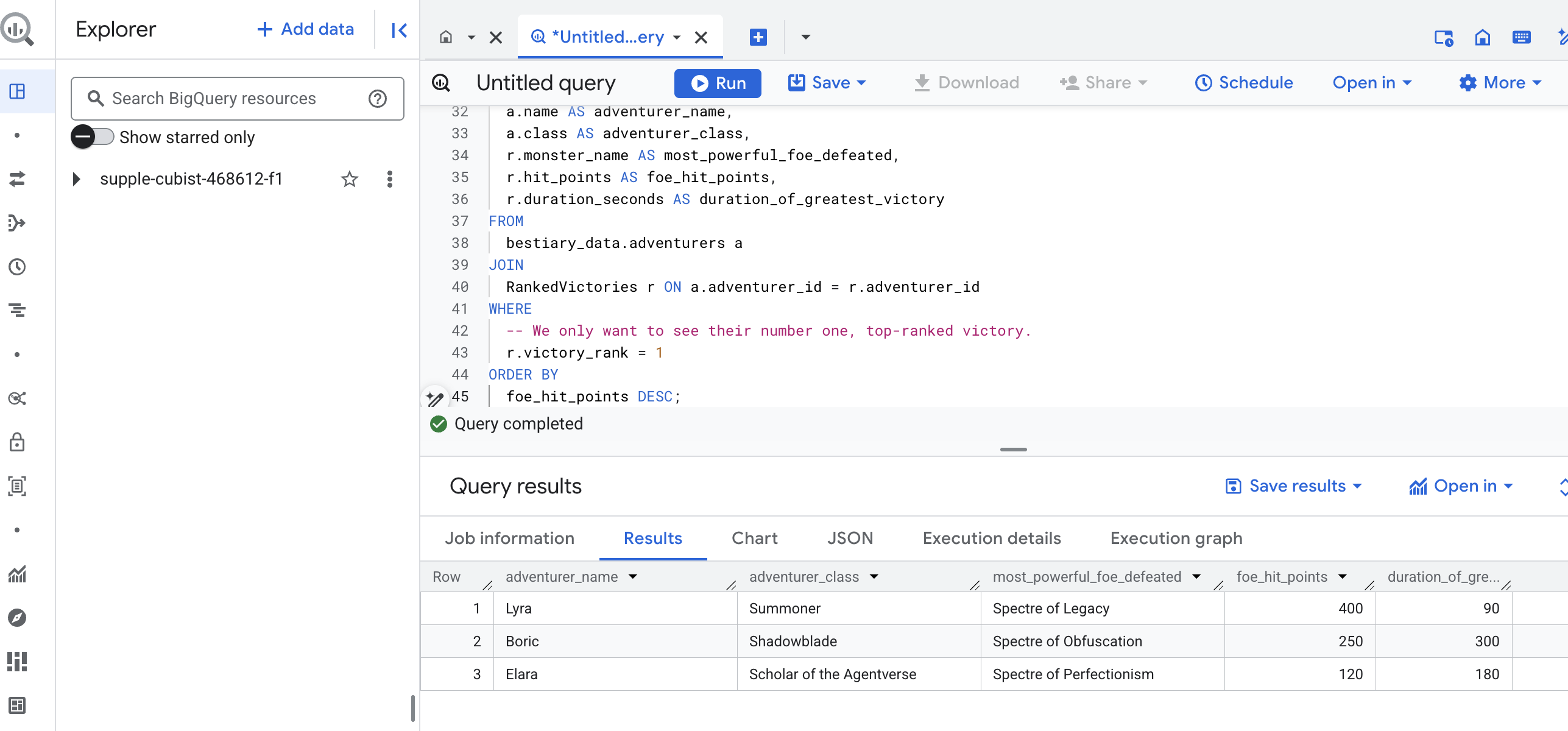
BigQuery タブを閉じます。
この単一の優れた結果は、パイプライン全体の価値を証明しています。混沌とした戦場の生レポートを、伝説的な物語と戦略的なデータドリブンな分析の源泉に変換することに成功しました。
ゲームをしない人向け
5. Scribe のグリモア: データ ウェアハウス内のチャンク、エンベディング、検索
錬金術師のラボでの作業は成功しました。未加工の物語の巻物を構造化されたリレーショナル テーブルに変換しました。これは、データ マジックの強力な偉業です。ただし、元のスクロールには、構造化テーブルでは完全に捉えられない、より深い意味論的な真実がまだ含まれています。真に賢いエージェントを構築するには、この意味を解き明かす必要があります。
長いスクロールは、鈍器のようなものです。エージェントが「麻痺オーラ」について質問した場合、簡単な検索では、そのフレーズが 1 回だけ言及されている戦闘レポート全体が返される可能性があり、回答が関係のない詳細に埋もれてしまうことがあります。真の知恵は量ではなく精度にあることを、マスター Scholar は知っています。
BigQuery の聖域内で、3 つの強力なデータベース内儀式を完全に実行します。
- 分割の儀式(チャンク化): 生のインテリジェンス ログを取得し、小さな、焦点を絞った、自己完結型のパッセージに細かく分割します。
- 蒸留の儀式(エンベディング): BQML を使用して Gemini モデルを参照し、各テキスト チャンクを「セマンティック フィンガープリント」(ベクトル エンベディング)に変換します。
- 占いの儀式(検索): BQML のベクトル検索を使用して、平易な英語で質問し、Grimoire から最も関連性の高い抽出された知恵を見つけます。
このプロセス全体により、データが BigQuery のセキュリティとスケーラビリティから離れることなく、強力で検索可能なナレッジベースが作成されます。
分割の儀式: SQL を使用してスクロールを分解する
知識のソースは、外部テーブル bestiary_data.raw_intel_content_table を介してアクセスできる GCS アーカイブ内の未加工のテキスト ファイルのままです。最初のタスクは、長い巻物を読み取り、より理解しやすい短い一連の詩に分割する呪文を書くことです。この儀式では、「チャンク」を 1 つの文として定義します。
文単位で分割することは、ナラティブ ログの明確かつ効果的な出発点となりますが、マスター Scribe は多くのチャンク化戦略を自由に利用できます。その選択は、最終的な検索の品質にとって非常に重要です。より単純な方法では、
- 固定長(サイズ)チャンク。ただし、重要なアイデアを半分に分割してしまう可能性があります。
より複雑な儀式(
- 再帰的チャンク化は、実際にはよく使用されます。これは、まず段落などの自然な境界に沿ってテキストを分割し、次に文にフォールバックして、できるだけ多くのセマンティック コンテキストを維持しようとします。非常に複雑な原稿の場合。
- コンテンツ認識チャンク(ドキュメント): Scribe は、テクニカル マニュアルのヘッダーやコードのスクロールの関数など、ドキュメントの固有の構造を使用して、最も論理的で強力な知識のチャンクを作成します。
バトルログの場合、この文は粒度とコンテキストのバランスが取れています。
👉📜 新しい BigQuery クエリエディタで、次の呪文を実行します。この呪文では、SPLIT 関数を使用して各スクロールのテキストをピリオド(.)ごとに分割し、結果として得られた文の配列を個別の行にネスト解除します。
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 新しく書き起こしてチャンク化された知識を検査し、違いを確認するクエリを実行します。
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
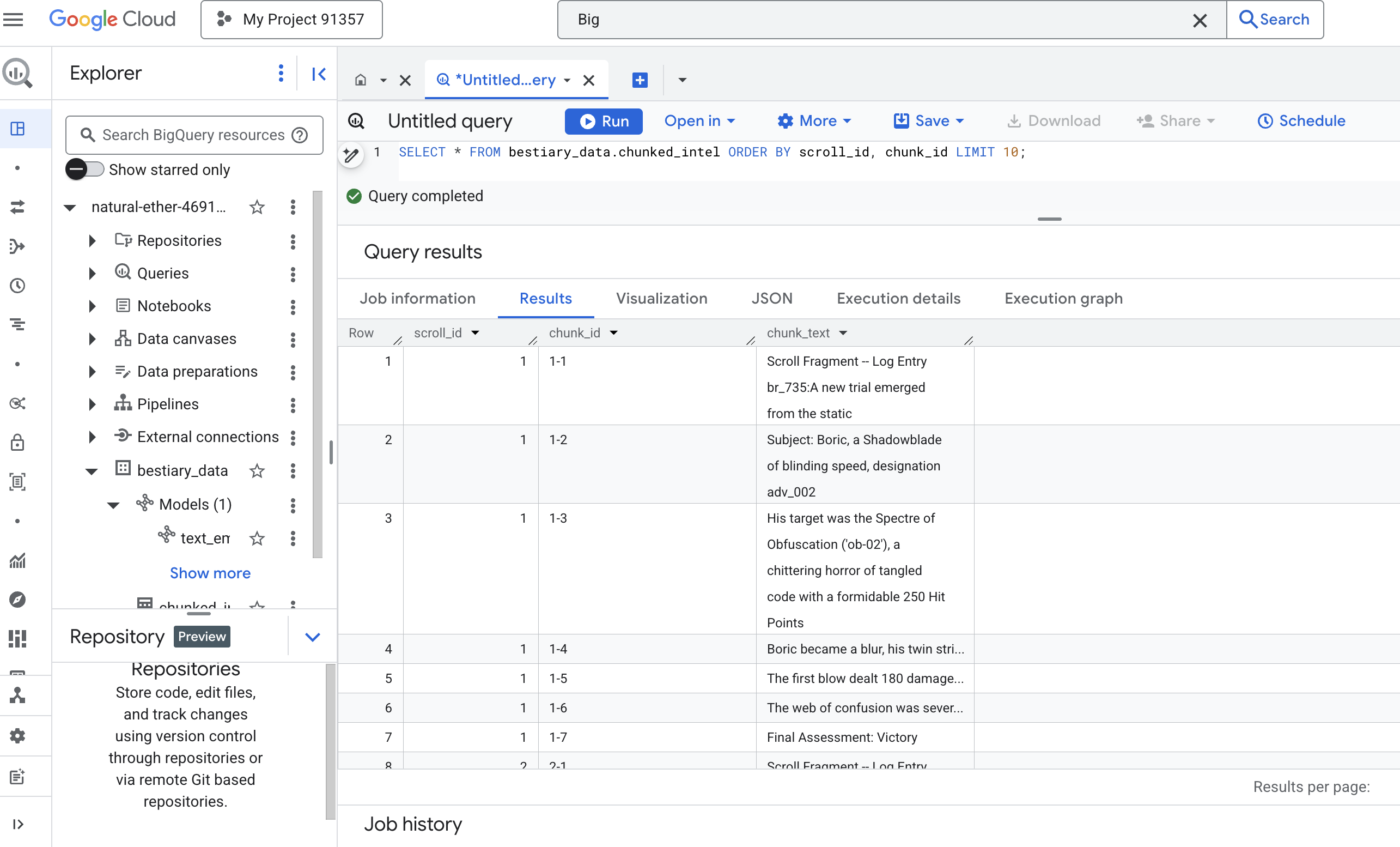
結果を確認します。以前は 1 つの密なテキスト ブロックだったものが、複数の行に分割され、それぞれが元のスクロール(scroll_id)に関連付けられ、1 つの文のみが含まれるようになります。各行はベクトル化の対象として最適です。
蒸留の儀式: BQML を使用してテキストをベクトルに変換する
👉💻 まず、ターミナルに戻り、次のコマンドを実行して接続名を表示します。
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Gemini のテキスト エンベディングを指す新しい BigQuery モデルを作成する必要があります。BigQuery Studio で、次のスペルを実行します。REPLACE-WITH-YOUR-FULL-CONNECTION-STRING は、ターミナルからコピーした接続文字列全体に置き換える必要があります。
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 それでは、抽出の呪文を唱えましょう。このクエリは ML.GENERATE_EMBEDDING 関数を呼び出します。この関数は、chunked_intel テーブルからすべての行を読み取り、テキストを Gemini エンベディング モデルに送信し、結果のベクトル フィンガープリントを新しいテーブルに保存します。
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
BigQuery がすべてのテキスト チャンクを処理するため、このプロセスには 1 ~ 2 分かかることがあります。
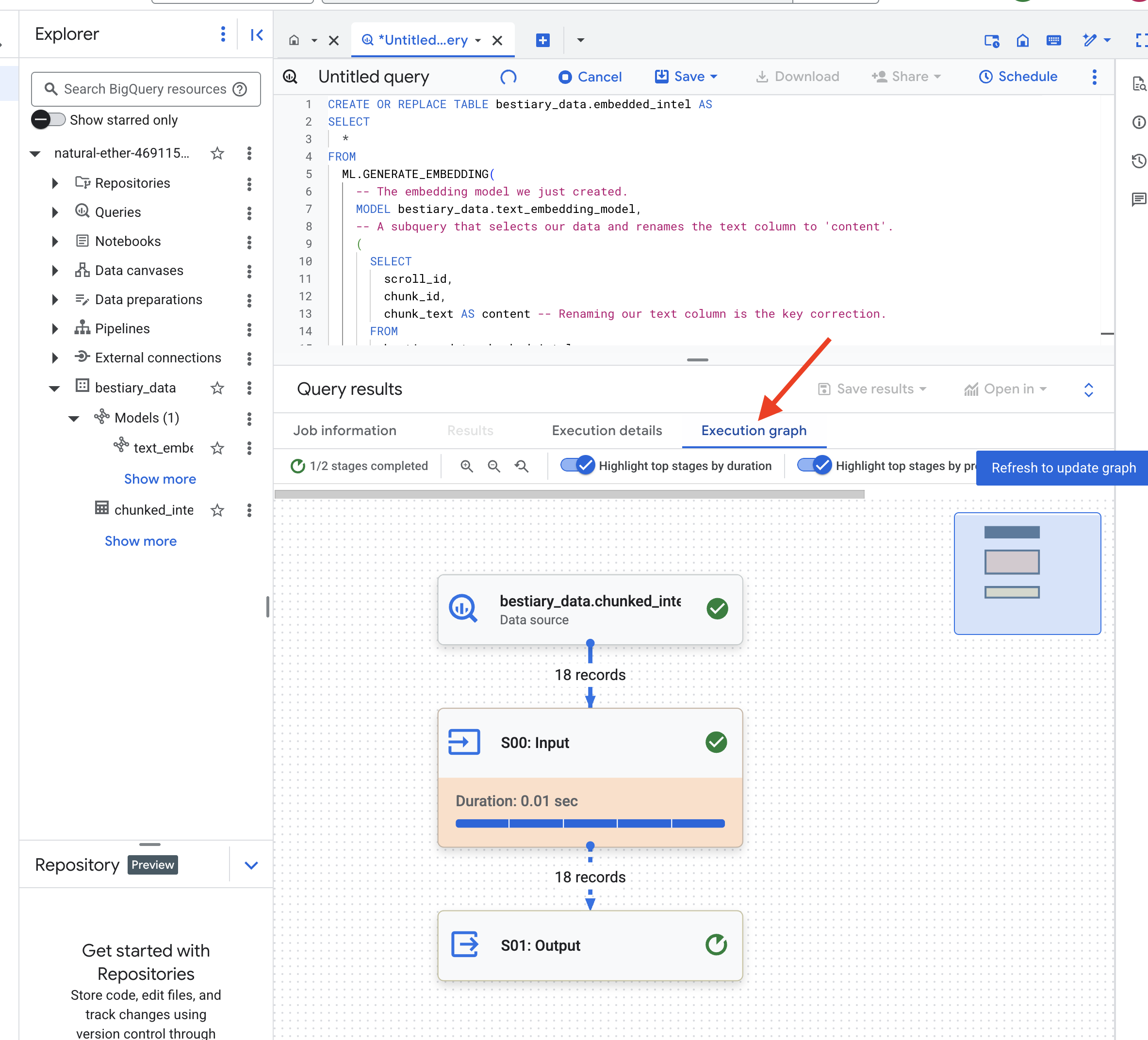
👉📜 完了したら、新しいテーブルを調べてセマンティック フィンガープリントを確認します。
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
テキストの高次ベクトル表現を含む新しい列 ml_generate_embedding_result が表示されます。これで、グリモアがセマンティックにエンコードされました。
The Ritual of Divination: BQML を使用したセマンティック検索
👉📜 グリモアの最終テストは、質問をすることです。最後の儀式であるベクトル検索を実行します。これはキーワード検索ではなく、意味検索です。自然言語で質問すると、BQML は質問をエンベディングにその場で変換し、embedded_intel のテーブル全体を検索して、意味的に「最も近い」フィンガープリントを持つテキスト チャンクを見つけます。
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
スペルの分析:
VECTOR_SEARCH: 検索を調整するコア関数。ML.GENERATE_EMBEDDING(内部クエリ): これが魔法です。クエリ用に最適化されたタスクタイプ'RETRIEVAL_QUERY'を使用して、同じモデルでクエリ('What are the tactics...')をエンベディングします。top_k => 3: 最も関連性の高い上位 3 件の結果をリクエストしています。distance_type => 'COSINE': ベクトル間の「角度」を測定します。角度が小さいほど、意味が一致していることを示します。
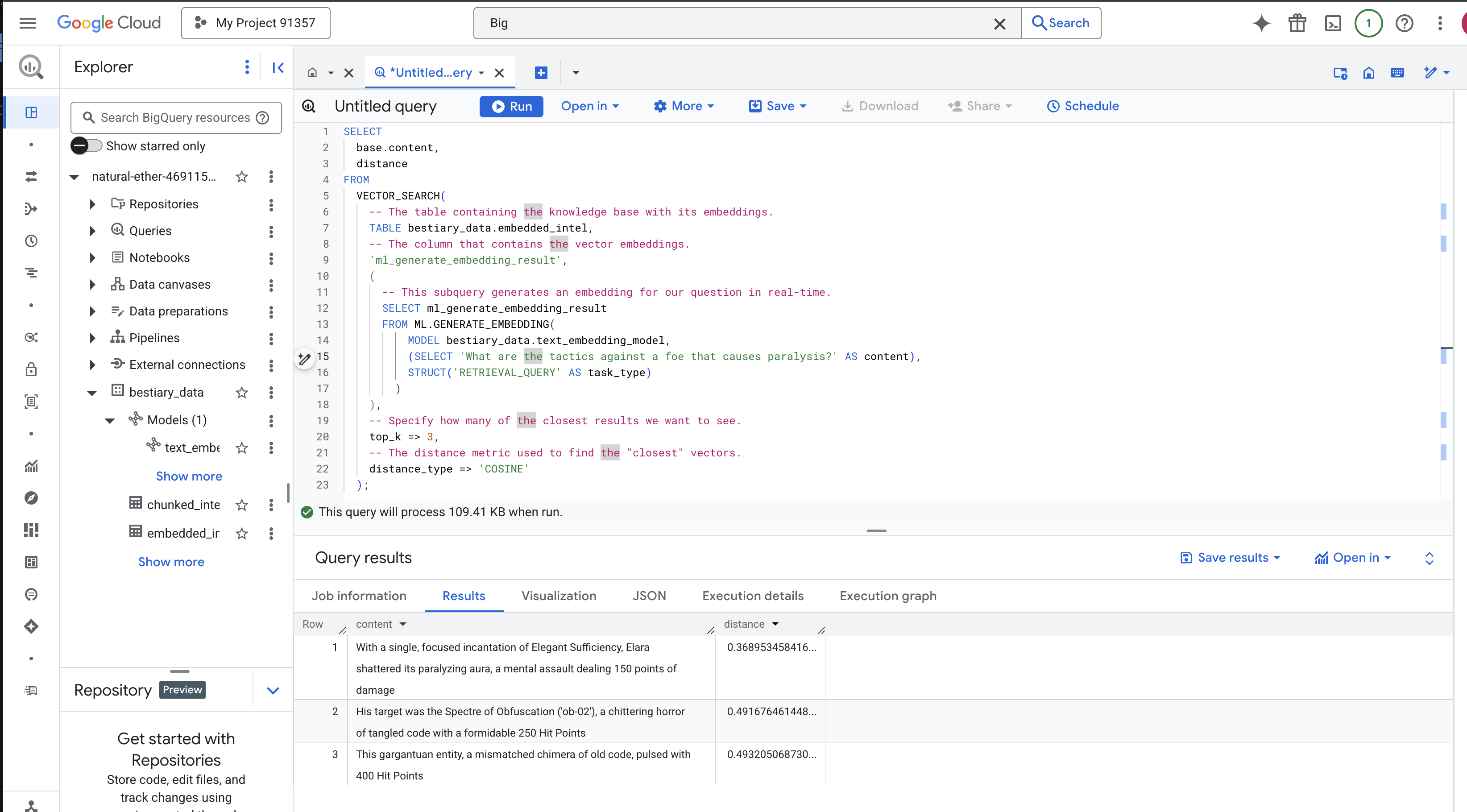
結果をよく確認します。クエリには「shattered」や「incantation」という単語は含まれていませんが、上位の結果は「With a single, focused incantation of Elegant Sufficiency, Elara shattered its paralyzing aura, a mental assault dealing 150 points of damage」です。これがセマンティック検索の力です。モデルは「麻痺に対する戦術」というコンセプトを理解し、具体的な成功した戦術を説明する文を見つけました。
これで、データ ウェアハウス内の完全なベース RAG パイプラインが正常に構築されました。元データを準備し、セマンティック ベクトルに変換して、意味でクエリしました。BigQuery は、このような大規模な分析作業に最適なツールですが、低レイテンシの応答を必要とするライブ エージェントの場合、この準備された知識を専用の運用データベースに転送することがよくあります。これについては、次のトレーニングで説明します。
ゲームをしない人向け
6. ベクトル スクリプトリアム: 推論用の Cloud SQL を使用してベクトルストアを作成する
現在の Grimoire は構造化されたテーブルとして存在しています。これは事実の強力なカタログですが、その知識は文字どおりです。monster_id = ‘MN-001' は理解できますが、「難読化」の背後にあるより深い意味は理解できません。エージェントに真の知恵を与え、ニュアンスと先見の明を持ってアドバイスできるようにするには、知識の本質を意味を捉える形式(ベクトル)に抽出する必要があります。
知識を求めて、忘れ去られた前駆文明の崩れかけた遺跡にたどり着きました。封印された金庫の奥深くに埋められていた古代の巻物の箱が、奇跡的に保存された状態で発見されました。単なる戦況報告ではなく、あらゆる偉業を妨げる獣を倒すための深い哲学的知恵が詰まっています。巻物には「忍び寄る静かな停滞」、「創造の織物のほつれ」と記されているエンティティ。静的は古代人にも知られていたようです。その歴史は失われましたが、周期的な脅威です。
この忘れ去られた伝承こそが、我々の最大の財産なのです。この能力は、個々のモンスターを倒すだけでなく、パーティー全体に戦略的な洞察力を与える鍵となります。この力を発揮するために、学者の真の呪文集(ベクトル機能を備えた PostgreSQL データベース)を作成し、自動化されたベクトル スクリプトリアム(Dataflow パイプライン)を構築して、これらの巻物の時代を超えた本質を読み取り、理解し、書き込みます。これにより、Grimoire は事実の書から知恵のエンジンへと変貌します。

学者の呪文書の作成(Cloud SQL)
これらの古代の巻物の本質を刻む前に、まずこの知識の器であるマネージド PostgreSQL Spellbook が正常に作成されていることを確認する必要があります。初期設定の儀式で、すでに作成されているはずです。
👉💻 ターミナルで次のコマンドを実行して、Cloud SQL インスタンスが存在し、準備ができていることを確認します。このスクリプトは、インスタンスの専用サービス アカウントに Vertex AI を使用する権限も付与します。これは、データベース内でエンベディングを直接生成するために不可欠です。
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
コマンドが成功し、grimoire-spellbook インスタンスの詳細が返された場合、Forge は正常に動作しています。次の呪文に進む準備が整いました。コマンドから NOT_FOUND エラーが返された場合は、続行する前に、初期環境の設定手順が正常に完了していることを確認してください(data_setup.py)。
👉💻 本が完成したら、arcane_wisdom という名前の新しいデータベースを作成して、最初の章を開きます。
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
セマンティック ルーンの刻印: pgvector によるベクトル機能の有効化
Cloud SQL インスタンスが作成されたので、組み込みの Cloud SQL Studio を使用して接続してみましょう。これにより、データベースで SQL クエリを直接実行するためのウェブベースのインターフェースが提供されます。
👉💻 まず、Cloud SQL Studio に移動します。最も簡単で迅速な方法は、新しいブラウザタブで次のリンクを開くことです。grimoire-spellbook インスタンスの Cloud SQL Studio に直接移動します。
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 データベースとして arcane_wisdom を選択し、ユーザーとして postgres、パスワードとして 1234qwer を入力して、[認証] をクリックします。
👉📜 SQL Studio のクエリエディタで、[Editor 1] タブに移動し、次の SQL コードを貼り付けて、ベクトル データ型を有効にします。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
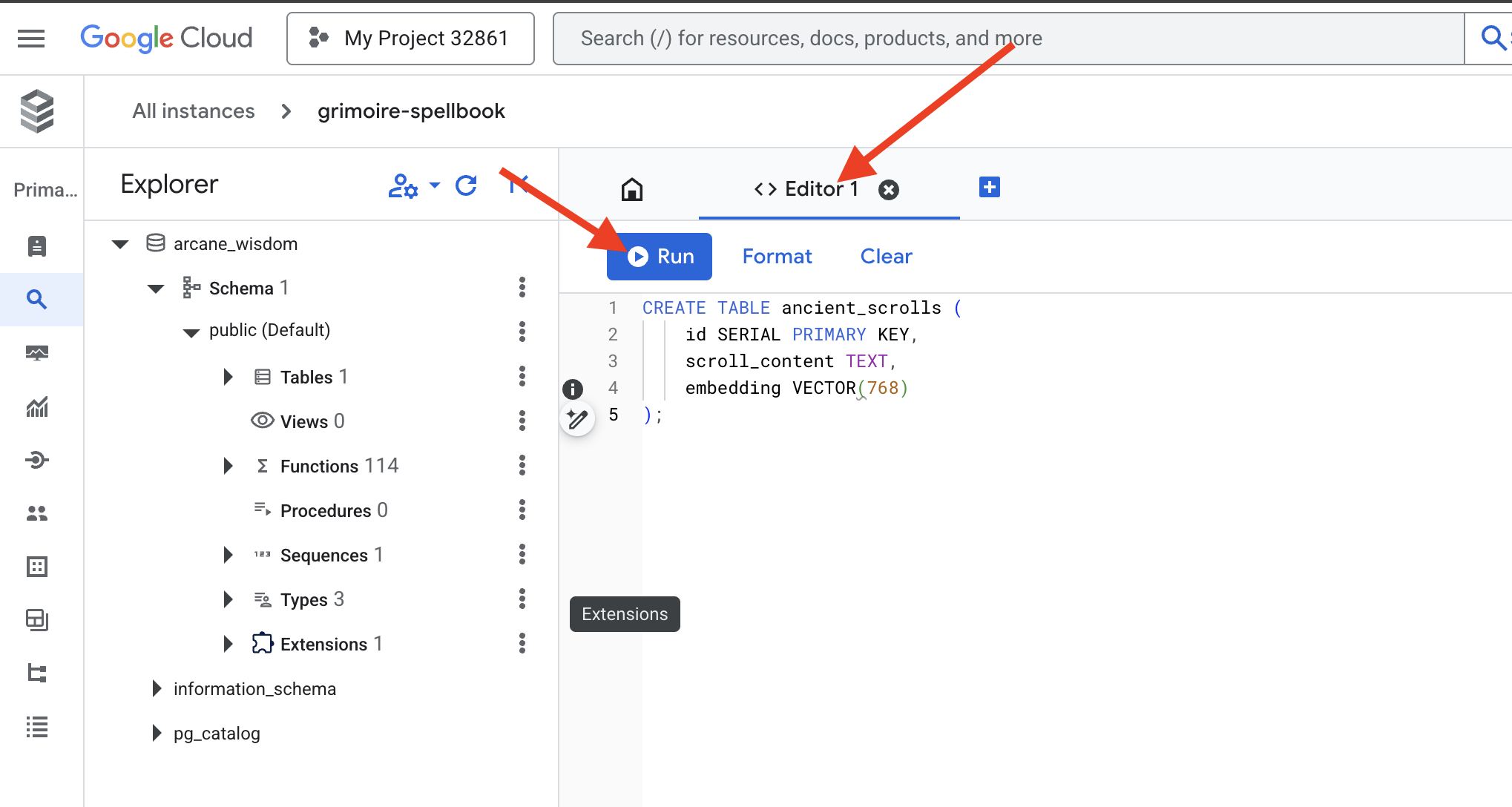
👉📜 スクロールのエッセンスを保持するテーブルを作成して、Spellbook のページを準備します。
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
スペル VECTOR(768) は重要な詳細です。使用する Vertex AI エンベディング モデル(textembedding-gecko@003 または類似のモデル)は、テキストを 768 次元のベクトルに抽出します。Spellbook のページは、そのサイズの精髄を保持できるように準備する必要があります。ディメンションは常に一致している必要があります。
最初の音訳: 手動の碑文の儀式
自動化された書記官(Dataflow)の軍隊を指揮する前に、中央の儀式を手動で 1 回行う必要があります。この 2 段階の魔法を深く理解できるようになります。
- 占い: テキストの一部を取得し、Gemini オラクルに相談して、その意味論的な本質をベクトルに抽出します。
- Inscription(碑文): 元のテキストとその新しいベクター エッセンスを Spellbook に書き込みます。
それでは、手動の儀式を実行しましょう。
👉📜 Cloud SQL Studio で。ここでは、google_ml_integration 拡張機能が提供する強力な機能である embedding() 関数を使用します。これにより、SQL クエリから Vertex AI エンベディング モデルを直接呼び出すことができ、プロセスが大幅に簡素化されます。
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 新しく書き込まれたページを読み取るクエリを実行して、作業を検証します。
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
これで、コア RAG データ読み込みタスクを手動で正常に実行できました。
セマンティック コンパスの作成: HNSW インデックスでスペルブックを強化する
呪文書に知恵を蓄えることはできるようになりましたが、適切な巻物を見つけるにはすべてのページを読まなければなりません。これはシーケンシャル スキャンです。これは時間がかかり、非効率的です。クエリを最も関連性の高い知識に瞬時に導くには、スペルブックにセマンティック コンパス(ベクトル インデックス)を付与する必要があります。
このエンチャントの価値を証明しましょう。
👉📜 Cloud SQL Studio で、次のスペルを実行します。新しく挿入されたスクロールの検索をシミュレートし、データベースにプランの EXPLAIN を要求します。
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
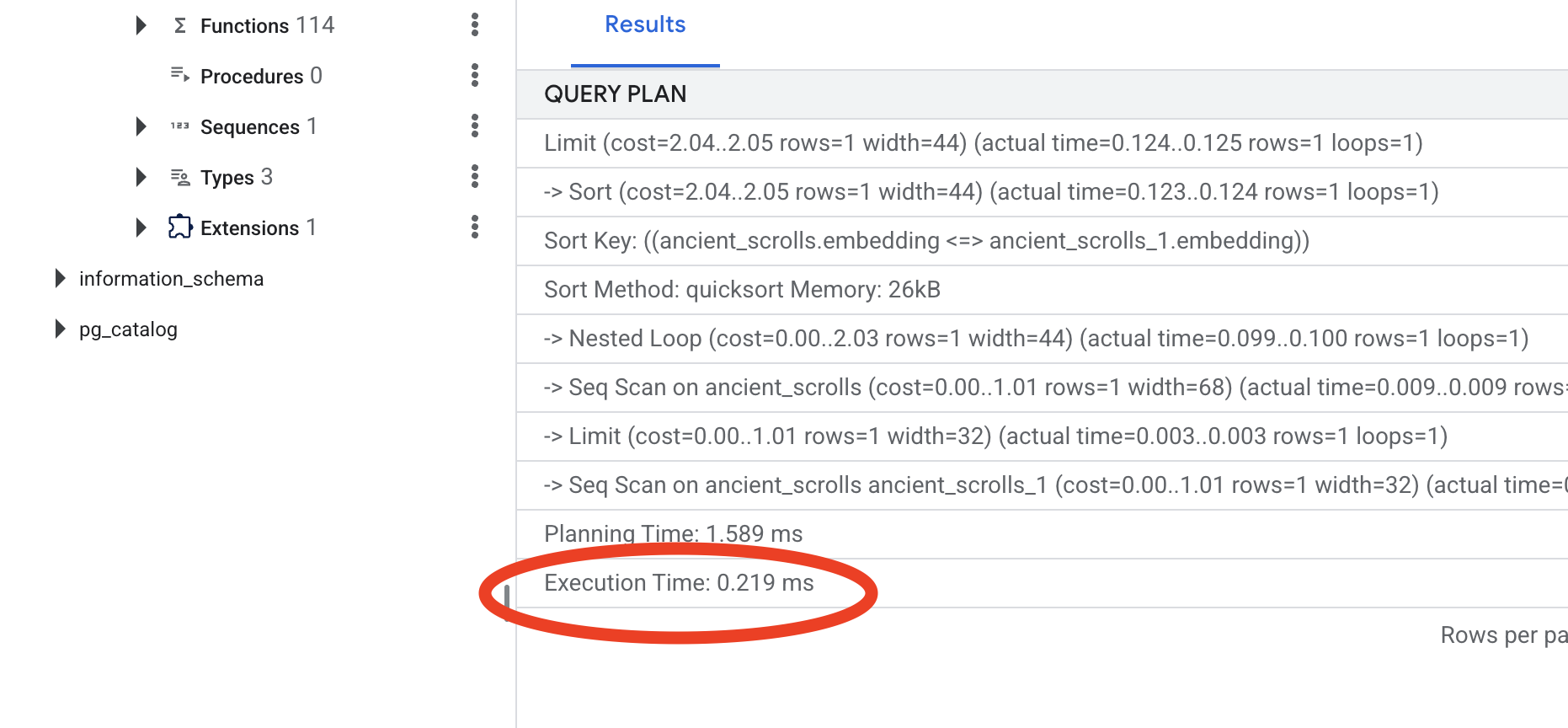
出力を確認します。-> Seq Scan on ancient_scrolls という行が表示されます。これにより、データベースがすべての行を読み取っていることが確認されます。execution time に注意してください。
👉📜 それでは、インデックス登録の呪文を唱えましょう。lists パラメータは、作成するクラスタの数をインデックスに指示します。適切な出発点は、想定される行数の平方根です。
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
インデックスが作成されるまで待ちます(1 行の場合はすぐに完了しますが、数百万行の場合は時間がかかることがあります)。
👉📜 まったく同じ EXPLAIN ANALYZE コマンドをもう一度実行します。
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
新しいクエリプランを確認します。-> Index Scan using... が表示されます。さらに重要なのは、execution time を確認することです。エントリが 1 つだけでも、大幅に高速化されます。ベクトル環境におけるデータベース パフォーマンス チューニングの基本原則を説明しました。
ソースデータの検査、手動の儀式の理解、高速化のための Spellbook の最適化が完了したら、自動化された Scriptorium を構築する準備が整います。
ゲームをしない人向け
7. 意味の伝導体: Dataflow ベクトル化パイプラインの構築
これで、巻物を読み、その本質を抽出して、新しい Spellbook に書き込む魔法の筆記者の組み立てラインを構築します。これは、手動でトリガーする Dataflow パイプラインです。ただし、パイプライン自体のマスター スペルを記述する前に、まずその基盤と、それを召喚する円を準備する必要があります。
Scriptorium の基盤(ワーカー イメージ)を準備する
Dataflow パイプラインは、クラウド内の自動化されたワーカーのチームによって実行されます。呼び出すたびに、特定のライブラリのセットが必要になります。ライブラリのリストを渡して、毎回ライブラリを取得させることもできますが、これは遅く、非効率的です。賢い Scholar は、事前にマスター ライブラリを準備します。
ここでは、Google Cloud Build にカスタム コンテナ イメージの作成を指示します。このイメージは、書記が必要とするすべてのライブラリと依存関係がプリロードされた「完璧なゴーレム」です。Dataflow ジョブが開始されると、このカスタム イメージが使用され、ワーカーはほぼ瞬時にタスクを開始できます。
👉💻 次のコマンドを実行して、パイプラインの基盤となるイメージをビルドし、Artifact Registry に保存します。
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 次のコマンドを実行して、隔離された Python 環境を作成して有効にし、必要な召喚ライブラリをインストールします。
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
マスター インカンテーション
Vector Scriptorium を強化するマスター スペルを作成する時が来ました。個々の魔法のコンポーネントをゼロから作成することはありません。私たちのタスクは、Apache Beam の言語を使用してコンポーネントを論理的で強力なパイプラインに組み立てることです。
- EmbedTextBatch(Gemini のコンサルテーション): 「グループ占い」の実行方法を知っている特別な書記を作成します。生のテキスト ファイルのバッチを取得し、Gemini テキスト エンベディング モデルに渡して、抽出されたエッセンス(ベクトル エンベディング)を受け取ります。
- WriteEssenceToSpellbook(最後の碑文): アーキビストです。Cloud SQL Spellbook への安全な接続を開くための秘密の呪文を知っています。その役割は、スクロールのコンテンツとそのベクトル化されたエッセンスを取得し、新しいページに永続的に書き込むことです。
Google の使命は、これらのアクションを連結して、知識のシームレスな流れを生み出すことです。
👉✏️ Cloud Shell エディタで ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py に移動します。その中に EmbedTextBatch という名前の DoFn クラスがあります。コメント #REPLACE-EMBEDDING-LOGIC を見つけます。次の呪文に置き換えます。
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
この呪文は正確で、いくつかの重要なパラメータがあります。
- model: 強力で最新のエンベディング モデルを使用するために
text-embedding-005を指定します。 - contents: DoFn が受け取るファイルのバッチのすべてのテキスト コンテンツのリストです。
- task_type: 「RETRIEVAL_DOCUMENT」に設定します。これは、後で検索で見つかるように最適化されたエンベディングを生成するよう Gemini に指示する重要な手順です。
- output_dimensionality: これは 768 に設定する必要があります。これは、Cloud SQL で ancient_scrolls テーブルを作成したときに定義した VECTOR(768) ディメンションと完全に一致します。ディメンションの不一致は、ベクトル マジックでエラーが発生する一般的な原因です。
パイプラインは、GCS アーカイブ内のすべての古代の巻物から未加工の非構造化テキストを読み取ることから始める必要があります。
👉✏️ ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py で、コメント #REPLACE ME-READFILE を見つけて、次の 3 部構成の呪文に置き換えます。
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
巻物の生のテキストが集められたので、占いのために Gemini に送信する必要があります。これを効率的に行うため、まず個々のスクロールを小さなバッチにグループ化し、そのバッチを EmbedTextBatch スクライバーに渡します。このステップでは、Gemini が理解できなかったスクロールを「失敗」の山に分離して、後で確認できるようにします。
👉✏️ コメント #REPLACE ME-EMBEDDING を見つけて、次のコードに置き換えます。
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
巻物の本質はうまく抽出されました。最後のステップは、この知識を Spellbook に書き込んで永続的に保存することです。「処理済み」の山からスクロールを取り出し、WriteEssenceToSpellbook アーキビストに渡します。
👉✏️ コメント #REPLACE ME-WRITE TO DB を見つけて、次のコードに置き換えます。
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
賢い学者は、失敗した試みであっても、知識を捨てることはありません。最後の手順として、占いステップで「失敗」の山から理由を記録するよう書記に指示する必要があります。これにより、今後の儀式を改善できます。
👉✏️ コメント #REPLACE ME-LOG FAILURES を見つけて、次のコードに置き換えます。
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
これで、マスター インカンテーションが完了しました。個々の魔法のコンポーネントを連結して、強力なマルチステージ データ パイプラインを組み立てることができました。inscribe_essence_pipeline.py ファイルを保存します。これで、Scriptorium を呼び出す準備が整いました。
ここで、壮大な召喚呪文を唱えて Dataflow サービスにゴーレムを呼び覚まし、書き込みの儀式を開始するよう指示します。
👉💻 ターミナルで、次のコマンドラインを実行します。
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 注意: ジョブがリソースエラー ZONE_RESOURCE_POOL_EXHAUSTED で失敗した場合は、選択したリージョンでこの低評価アカウントのリソース制約が一時的に発生していることが原因である可能性があります。Google Cloud の強みは、グローバルなリーチです。別のリージョンでゴーレムを召喚してみてください。これを行うには、上記のコマンドの --region=$REGION を別のリージョン(
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
を実行します。🎰
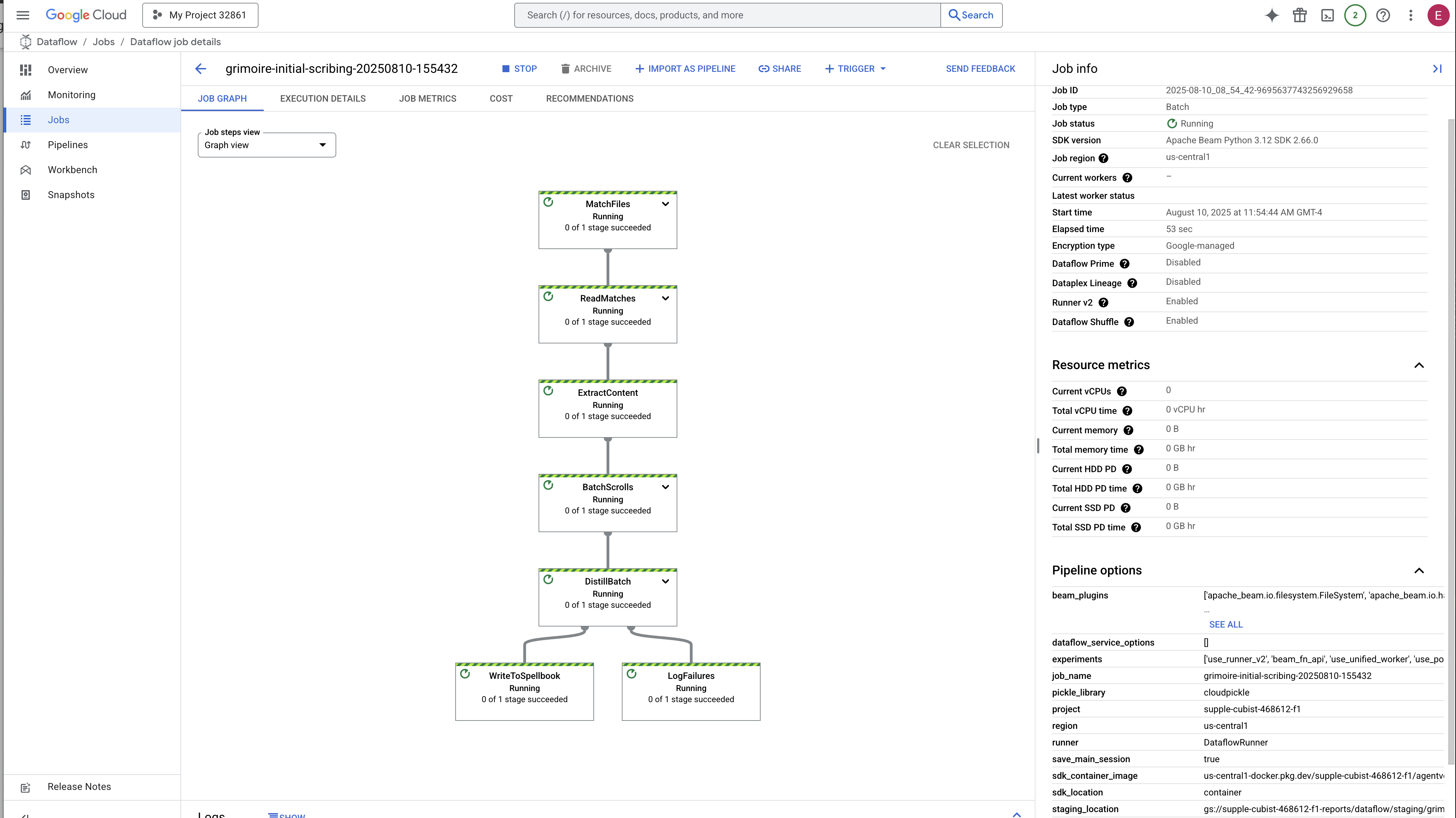
プロセスが開始して完了するまでに 3 ~ 5 分ほどかかります。Dataflow コンソールでライブ視聴できます。
👉 Dataflow コンソールに移動します。最も簡単な方法は、新しいブラウザタブで次の直接リンクを開くことです。
https://console.cloud.google.com/dataflow
👉 ジョブを見つけてクリックします。指定した名前(inscribe-essence-job など)のジョブが表示されます。ジョブ名をクリックして、詳細ページを開きます。パイプラインをモニタリングする:
- 起動中: 最初の 3 分間は、Dataflow が必要なリソースをプロビジョニングするため、ジョブのステータスは「実行中」になります。グラフは表示されますが、まだデータがグラフを通過していない可能性があります。
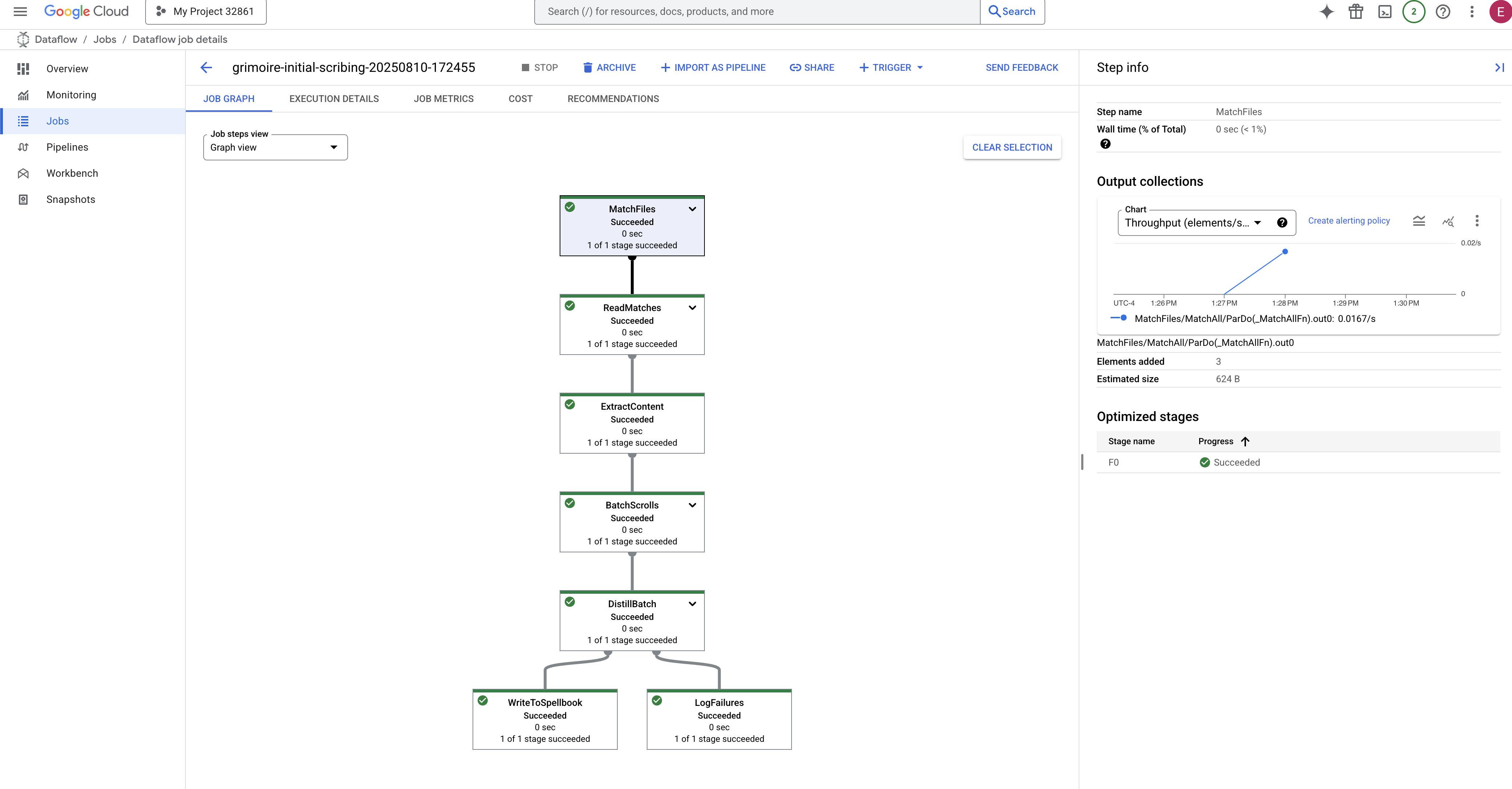
- 完了: 完了すると、ジョブのステータスが [成功] に変わり、グラフに処理されたレコードの最終カウントが表示されます。
碑文の検証
👉📜 SQL スタジオに戻り、次のクエリを実行して、スクロールとその意味的本質が正常に書き込まれたことを確認します。
SELECT COUNT(*) FROM ancient_scrolls;
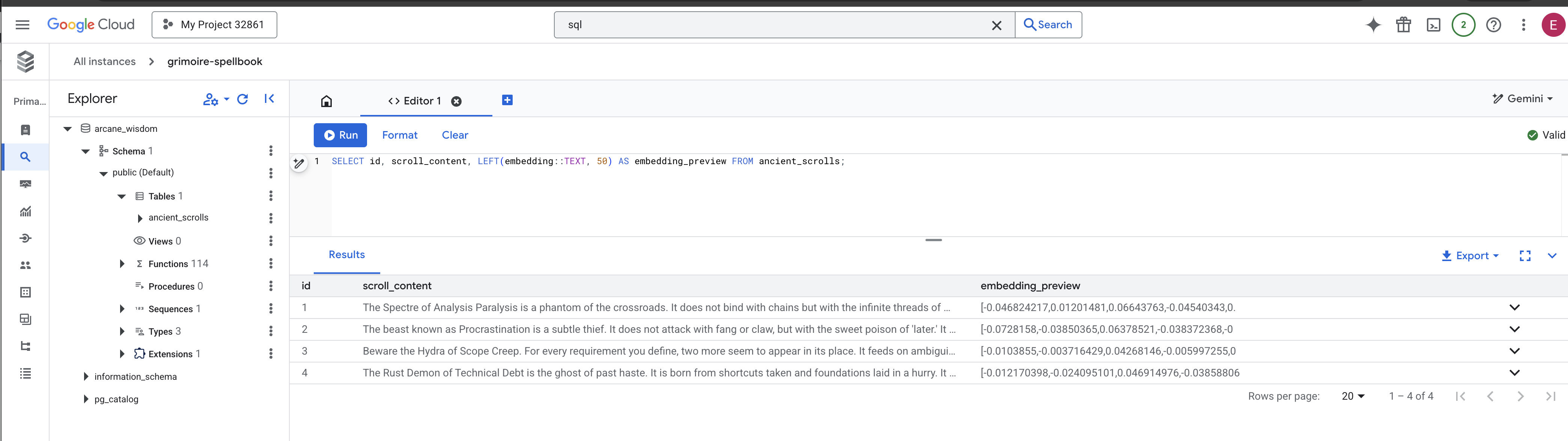
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
スクロールの ID、元のテキスト、グリモアに永続的に刻まれた魔法のベクトル エッセンスのプレビューが表示されます。
これで、Scholar's Grimoire は真のナレッジ エンジンとなり、次の章で意味によるクエリを実行できるようになります。
8. 最後のルーンを封印する: RAG エージェントで知恵を活性化する
Grimoire は単なるデータベースではなくなりました。ベクトル化された知識の泉であり、質問を待つ静かな神託です。
では、学者の真価が問われるテストに取り組みましょう。この知恵を解き明かす鍵を作り上げます。検索拡張生成(RAG)エージェントを構築します。これは、平易な言葉で質問を理解し、グリモアで最も深く関連性の高い真実を調べ、その知恵を使って強力なコンテキスト認識型の回答を生成できる魔法のような構造です。

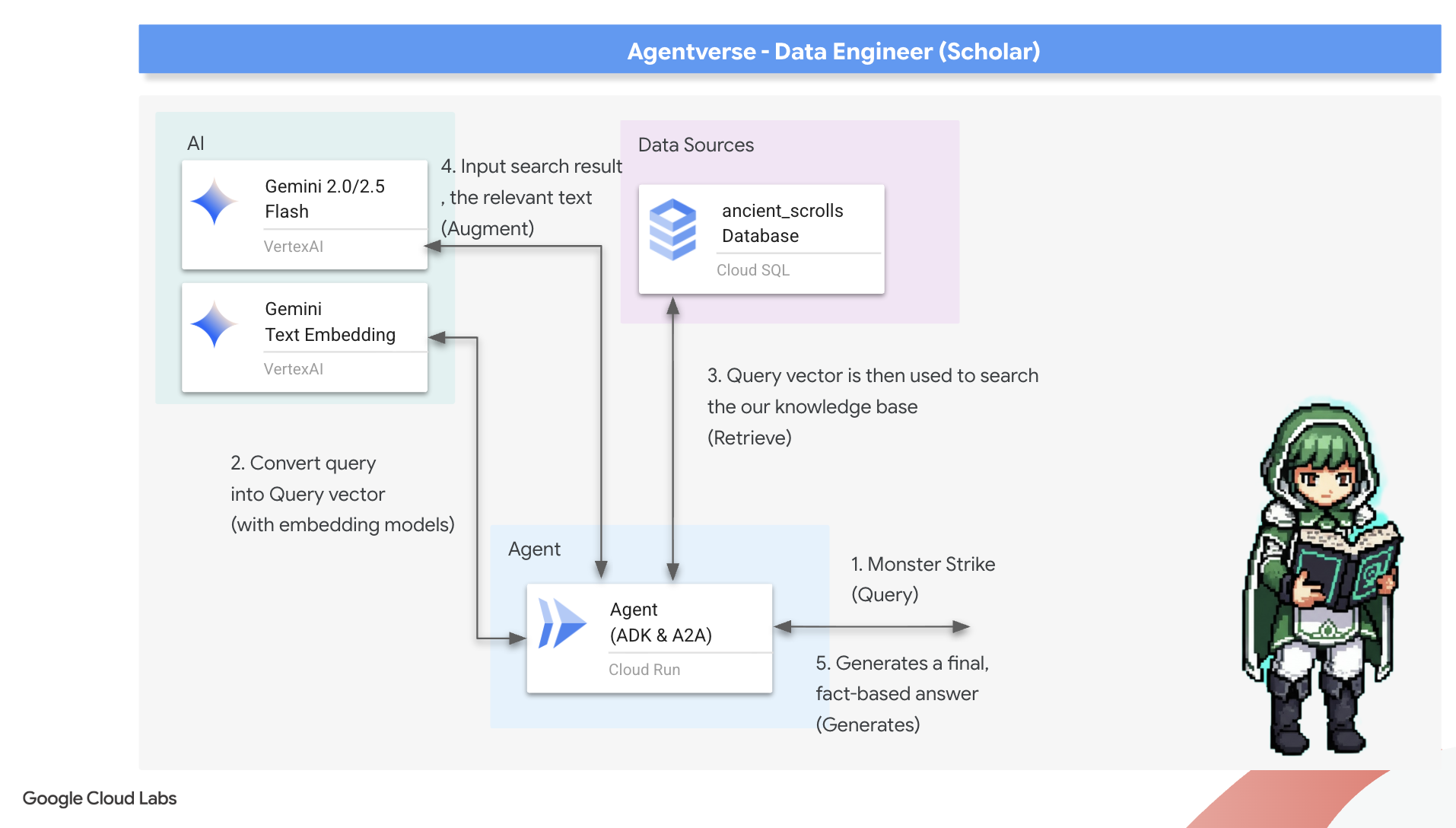
最初のルーン: クエリ抽出の呪文
エージェントが Grimoire を検索するには、まず質問の本質を理解する必要があります。単純なテキスト文字列は、ベクトルを利用した Spellbook にとっては意味がありません。エージェントはまずクエリを取得し、同じ Gemini モデルを使用してクエリベクトルに変換する必要があります。
👉✏️ Cloud Shell エディタで ~~/agentverse-dataengineer/scholar/agent.py ファイルに移動し、コメント #REPLACE RAG-CONVERT EMBEDDING を見つけて、次の呪文に置き換えます。これにより、エージェントはユーザーの質問を魔法のエッセンスに変える方法を学習します。
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
クエリの本質を把握したエージェントは、Grimoire を参照できるようになりました。このクエリベクトルを pgvector 対応のデータベースに提示し、「クエリの本質に最も類似した本質を持つ古代の巻物を表示して」という深い質問をします。
この魔法はコサイン類似度演算子(<=>)です。これは、高次元空間のベクトル間の距離を計算する強力なルーンです。
👉✏️ agent.py で、コメント #REPLACE RAG-RETRIEVE を探し、次のスクリプトに置き換えます。
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
最後のステップは、この新しい強力なツールへのアクセス権をエージェントに付与することです。使用可能な魔法の道具のリストに grimoire_lookup 関数を追加します。
👉✏️ agent.py で、コメント #REPLACE-CALL RAG を見つけて、次の行に置き換えます。
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
この構成により、エージェントが動作します。
model="gemini-2.5-flash": 推論とテキスト生成を行うエージェントの「脳」として機能する特定の大規模言語モデルを選択します。name="scholar_agent": エージェントに一意の名前を割り当てます。instruction="...You are the Scholar...": これはシステム プロンプトであり、構成の最も重要な部分です。エージェントのペルソナ、目標、タスクを完了するために従う必要のある正確なプロセス、最終出力に必要な形式を定義します。tools=[grimoire_lookup]: これは最終的なエンチャントです。これにより、作成したgrimoire_lookup関数へのアクセス権がエージェントに付与されます。エージェントは、このツールを呼び出してデータベースから情報を取得するタイミングをインテリジェントに判断できるようになり、RAG パターンのコアを形成します。
学者の試験
👉💻 Cloud Shell ターミナルで、環境をアクティブにして、エージェント開発キットのプライマリ コマンドを使用して Scholar エージェントを起動します。
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
「Scholar Agent」が実行中であることを確認する出力が表示されます。
👉💻 エージェントに挑戦してみましょう。戦闘シミュレーションが実行されている最初のターミナルで、グリモアの知恵を必要とするコマンドを発行します。
We've been trapped by 'Hydra of Scope Creep'. Break us out!

ターミナルでログを確認します。エージェントがクエリを受け取り、その要点を抽出し、Grimoire を検索して「先延ばし」に関する関連するスクロールを見つけ、その取得した知識を使用して強力なコンテキスト認識戦略を策定する様子を確認できます。
これで、最初の RAG エージェントを組み立て、Grimoire の深い知識を装備できました。
👉💻 ターミナルで Ctrl+C を押して、エージェントを一時的に停止します。
Scholar Sentinel を Agentverse にリリース
エージェントは、調査の管理された環境でその知恵を証明しました。エージェントバースにリリースする時が来ました。ローカルな構造から、いつでもどのチャンピオンにも呼び出せる、戦闘準備万端のオペレーターへと変身します。次に、エージェントを Cloud Run にデプロイします。
👉💻 次の召喚呪文を実行します。このスクリプトは、まずエージェントを完成した Golem(コンテナ イメージ)にビルドし、Artifact Registry に保存してから、その Golem をスケーラブルで安全な一般公開サービスとしてデプロイします。
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
これで、Scholar Agent が Agentverse で活躍する戦闘準備万端のオペレーターになりました。
ゲームをしない人向け
9. ボスフライト
巻物が読まれ、儀式が執り行われ、試練が乗り越えられました。エージェントはストレージ内の単なるアーティファクトではなく、Agentverse で最初のミッションを待機しているライブ オペレータです。最終試験の時が来た。強力な敵に対する実弾演習だ。
バトルグラウンド シミュレーションに入り、新たにデプロイしたシャドウブレード エージェントと手ごわいミニボス「静的のスペクター」を戦わせます。これは、エージェントのコアロジックからライブ デプロイまで、作業の最終テストとなります。
エージェントのローカスを取得する
戦場に入るには、チャンピオンの固有のシグネチャー(エージェントの軌跡)と、スペクターの隠れ家への隠されたパス(ダンジョンの URL)という 2 つのキーが必要です。
👉💻 まず、Agentverse でエージェントの一意のアドレス(ローカス)を取得します。これは、チャンピオンを戦場に接続するライブ エンドポイントです。
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 次に、目的地を特定します。このコマンドは、スペクターの領域へのポータルである転送サークルの場所を明らかにします。
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
重要: これらの URL を両方とも用意しておいてください。これらの値は、最後の手順で必要になります。
Spectre との対決
座標を確保したら、転移円に移動して呪文を唱え、戦闘を開始します。
👉 ブラウザで Translocation Circle の URL を開いて、The Crimson Keep のきらめくポータルの前に立ちます。
要塞を突破するには、シャドーブレードのエッセンスをポータルに同調させる必要があります。
- ページで、[A2A Endpoint URL] というラベルの付いたルーン文字の入力フィールドを見つけます。
- このフィールドに、チャンピオンのシジルを刻印します。エージェント ローカス URL(最初にコピーした URL)を貼り付けてください。
- [接続] をクリックして、テレポートの魔法を解き放ちます。
テレポートのまぶしい光が消えていく。あなたは聖域にいません。冷たく鋭いエネルギーが空気を満たしている。目の前に Spectre が現れます。シューという静電気と破損したコードの渦巻きで、その不気味な光がダンジョンの床に長い影を映し出します。顔はありませんが、その巨大で消耗的な存在が完全にあなたに集中しているのを感じます。
勝利への道は、信念の明確さにかかっています。これは、心の戦場で行われる意志の戦いです。
突進して最初の攻撃を繰り出そうとしたとき、スペクターが反撃してきます。シールドは発生しないが、意識に直接質問が投影される。トレーニングの核心から引き出された、きらめくルーン文字の挑戦だ。

これが戦いの本質です。知識は武器です。
- 得た知恵で答えよ。刃は純粋なエネルギーで燃え上がり、スペクターの防御を打ち破り、クリティカル ブローを叩き込む。
- しかし、迷いが生じたり、疑念が答えを曇らせたりすると、武器の光は弱まります。攻撃は情けない音を立てて着弾し、ダメージのほんの一部しか与えません。さらに悪いことに、スペクターはあなたの不確実性を餌にし、その腐敗力はあなたの失策ごとに増大します。
チャンピオン、これが最後の戦いです。コードは呪文集、ロジックは剣、知識は混沌の波を押し返す盾です。
フォーカス。違反警告は true です。Agentverse の運命がかかっています。
おめでとうございます。
トライアルが正常に完了しました。あなたはデータ エンジニアリングの技術を習得し、未加工で混沌とした情報を、Agentverse 全体を強化する構造化されたベクトル化された知恵に変換しました。
10. クリーンアップ: 学者のグリモアの削除
学者のグリモアをマスターしました。Agentverse をクリーンな状態に保ち、トレーニング グラウンドをクリアにするには、最終的なクリーンアップの手順を実行する必要があります。これにより、ジャーニー中に作成されたすべてのリソースが体系的に削除されます。
Agentverse コンポーネントを無効にする
RAG システムのデプロイされたコンポーネントを体系的に分解します。
すべての Cloud Run サービスと Artifact Registry リポジトリを削除する
このコマンドは、デプロイされた Scholar エージェントと Dungeon アプリケーションを Cloud Run から削除します。
👉💻 ターミナルで次のコマンドを実行します。
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
BigQuery のデータセット、モデル、テーブルを削除する
これにより、bestiary_data データセット、その中のすべてのテーブル、関連する接続とモデルなど、すべての BigQuery リソースが削除されます。
👉💻 ターミナルで次のコマンドを実行します。
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Cloud SQL インスタンスを削除する
これにより、データベースとその中のすべてのテーブルを含む grimoire-spellbook インスタンスが削除されます。
👉💻 ターミナルで次のコマンドを実行します。
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Google Cloud Storage バケットを削除する
このコマンドは、未加工のインテルと Dataflow のステージング ファイル/一時ファイルが格納されていたバケットを削除します。
👉💻 ターミナルで次のコマンドを実行します。
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
ローカルのファイルとディレクトリをクリーンアップする(Cloud Shell)
最後に、クローンされたリポジトリと作成されたファイルで Cloud Shell 環境をクリアします。この手順は省略可能ですが、作業ディレクトリを完全にクリーンアップするために行うことを強くおすすめします。
👉💻 ターミナルで次のコマンドを実行します。
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
これで、Agentverse Data Engineer のすべてのトレースが正常にクリアされました。プロジェクトがクリーンになり、次の冒険の準備が整いました。