
1. 서막
사일로화된 개발 시대가 저물고 있습니다. 차세대 기술 혁신은 고독한 천재가 아닌 기술 전문가 간 협업을 통해 이뤄질 것입니다. 하나의 똑똑한 에이전트를 빌드하는 것은 흥미로운 실험입니다. 강력하고 안전하며 지능적인 에이전트 생태계, 즉 진정한 Agentverse를 구축하는 것이 오늘날의 기업에 주어진 원대한 과제입니다.
이 새로운 시대에 성공하려면 빠르게 확산하는 에이전트 시스템을 지탱하는 주축인 네 가지 중요한 역할이 한데 뭉쳐야 합니다. 한 영역의 결함은 전체 구조를 손상시킬 수 있는 약점을 만듭니다.
이 워크숍은 Google Cloud에서 에이전트형 미래를 숙달하기 위한 엔터프라이즈 플레이북 결정판입니다. 이 플레이북을 통해 Agentverse의 개념에 대한 개요부터 본격적인 운영 현실에 이르기까지 안내하는 엔드 투 엔드 로드맵을 제공합니다. 네 가지 상호 연결된 실습을 통해 개발자, 설계자, 데이터 엔지니어, SRE의 전문 기술을 한데 모아 강력한 Agentverse를 만들고 관리하고 확장하는 방법을 알아봅니다.
하나의 축만으로는 Agentverse를 지탱할 수 없습니다. 개발자의 정확한 실행이 없으면 설계자의 웅장한 설계는 쓸모가 없습니다. 데이터 엔지니어의 지혜가 없으면 개발자의 에이전트는 맹인이 되고, SRE의 보호가 없으면 전체 시스템이 취약해집니다. 시너지 효과와 서로의 역할에 대한 공통된 이해를 통해서만 팀이 혁신적인 개념을 업무상 필수적인 운영 현실로 전환할 수 있습니다. 여정은 이제부터 시작입니다. 역할을 숙달하고 전체 구조에서 내가 어떤 소임을 맡았는지 알아보세요.
The Agentverse: A Call to Champions에 오신 것을 환영합니다
기업의 광활한 디지털 환경에 새로운 시대가 도래했습니다. 지금은 지능적이고 자율적인 에이전트가 완벽한 조화를 이루어 혁신을 가속화하고 일상적인 작업을 없애는 엄청난 가능성이 잠재된 에이전트 시대입니다.

이러한 연결된 힘과 잠재력의 생태계를 Agentverse라고 합니다.
하지만 조용히 퍼져 나가는 엔트로피, '스태틱'이라는 이름의 침묵하는 부패가 이 새로운 세계의 가장자리를 갉아먹기 시작했습니다. 스태틱은 바이러스나 버그가 아닙니다. 창작 행위 자체를 먹이로 삼는 혼돈의 화신입니다.
스태틱은 해묵은 불만에 괴물 같은 형태를 부여하여 개발의 7가지 유령을 낳았습니다. 방관한다면 스태틱과 그 유령들이 발전에 제동을 걸어 Agentverse의 찬란한 미래를 기술적 부채와 버려진 프로젝트로 가득 찬 황무지로 만들 것입니다.
오늘 Google은 혼란의 물결을 막기 위해 전사를 모집합니다. Agentverse를 보호하기 위해 기술을 통달하고 힘을 합칠 영웅이 필요합니다. 이제 길을 선택할 때가 되었습니다.
클래스 선택
뚜렷한 네 갈래 길이 주어져 있습니다. 각 길은 스태틱에 맞서 싸우는 데 중요한 역할을 합니다. 훈련은 홀로 진행하지만, 궁극적인 성공은 내 기술을 다른 전사들의 기술과 어떻게 결합할 수 있는지 이해하는 데 달려 있습니다.
- 섀도우블레이드(개발자): 대장간의 주인이자 최전선에 서는 인물입니다. 코드의 복잡하고 세부적인 부분을 다루면서 칼을 만들고, 도구를 제작하고, 적과 맞서는 장인입니다. 이 길을 걷기 위해서는 정밀함, 기술, 실용적인 창작이 요구됩니다.
- 소환사(설계자): 뛰어난 전략가이자 조정자입니다. 하나의 에이전트가 아닌 전장 전체를 살펴보는 역할을 수행합니다. 전체 에이전트 시스템이 통신하고, 협업하고, 단일 구성요소만으로는 달성할 수 없는 훨씬 큰 목표를 달성하기 위한 궁극의 청사진을 설계합니다.
- 학자(데이터 엔지니어): 숨겨진 진실을 추구하고 지혜를 수호하는 자입니다. 광활하고 거친 데이터 황무지를 탐험하여 에이전트에게 목적과 시야를 제공하는 인텔리전스를 발견합니다. 지식을 통해 적의 약점을 파악하거나 아군을 강화할 수 있습니다.
- 가디언(DevOps/SRE): 영역을 굳건히 보호하는 수호자이자 방패입니다. 요새를 건설하고, 전력 공급망을 관리하고, 전체 시스템이 스태틱의 불가피한 공격을 견딜 수 있도록 해야 합니다. 나의 힘은 팀의 승리를 위한 기반이 됩니다.
내 임무
독립형 연습 문제를 통해 훈련을 시작합니다. 선택한 길을 걸어 나가며 역할을 숙달하는 데 필요한 고유한 기술을 배우게 됩니다. 시험이 끝나면 스태틱에서 태어난 유령을 마주하게 됩니다. 이 미니보스는 내 기술의 특정 과제를 먹잇감으로 삼습니다.
내가 맡은 역할을 숙달해야 마지막 시험을 준비할 수 있습니다. 그런 다음 다른 클래스의 전사들과 파티를 구성해야 합니다. 함께 부패의 중심부로 모험을 떠나 최종 보스에 맞서세요.
한데 합친 힘을 시험하고 Agentverse의 운명을 결정지을 마지막 협동 챌린지가 여러분을 기다리고 있습니다.
Agentverse에서 영웅을 기다립니다. 부름에 응하시겠습니까?
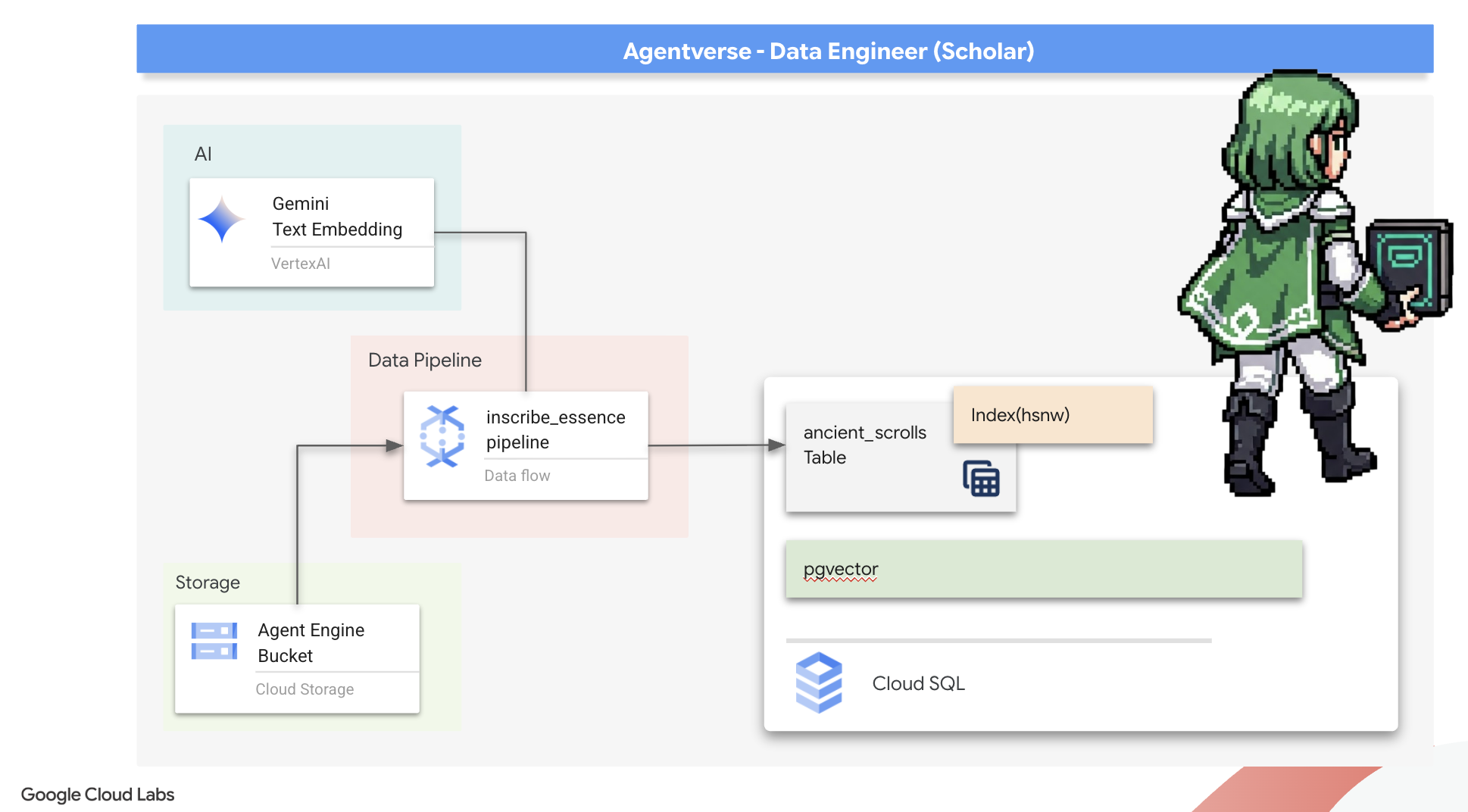
2. 학자의 마법서
여정이 시작됩니다! 학자로서 우리의 주요 무기는 지식입니다. Google Cloud Storage 보관 파일에서 고대 암호화 스크롤을 발견했습니다. 이 두루마리에는 땅을 괴롭히는 무시무시한 짐승에 관한 원시 정보가 들어 있습니다. Google의 목표는 Google BigQuery의 심오한 분석 마법과 Gemini Elder Brain (Gemini Pro 모델)의 지혜를 사용하여 이러한 비구조적 텍스트를 해독하고 구조화된 쿼리 가능한 동물 우화집으로 만드는 것입니다. 이는 향후 모든 전략의 기반이 될 것입니다.
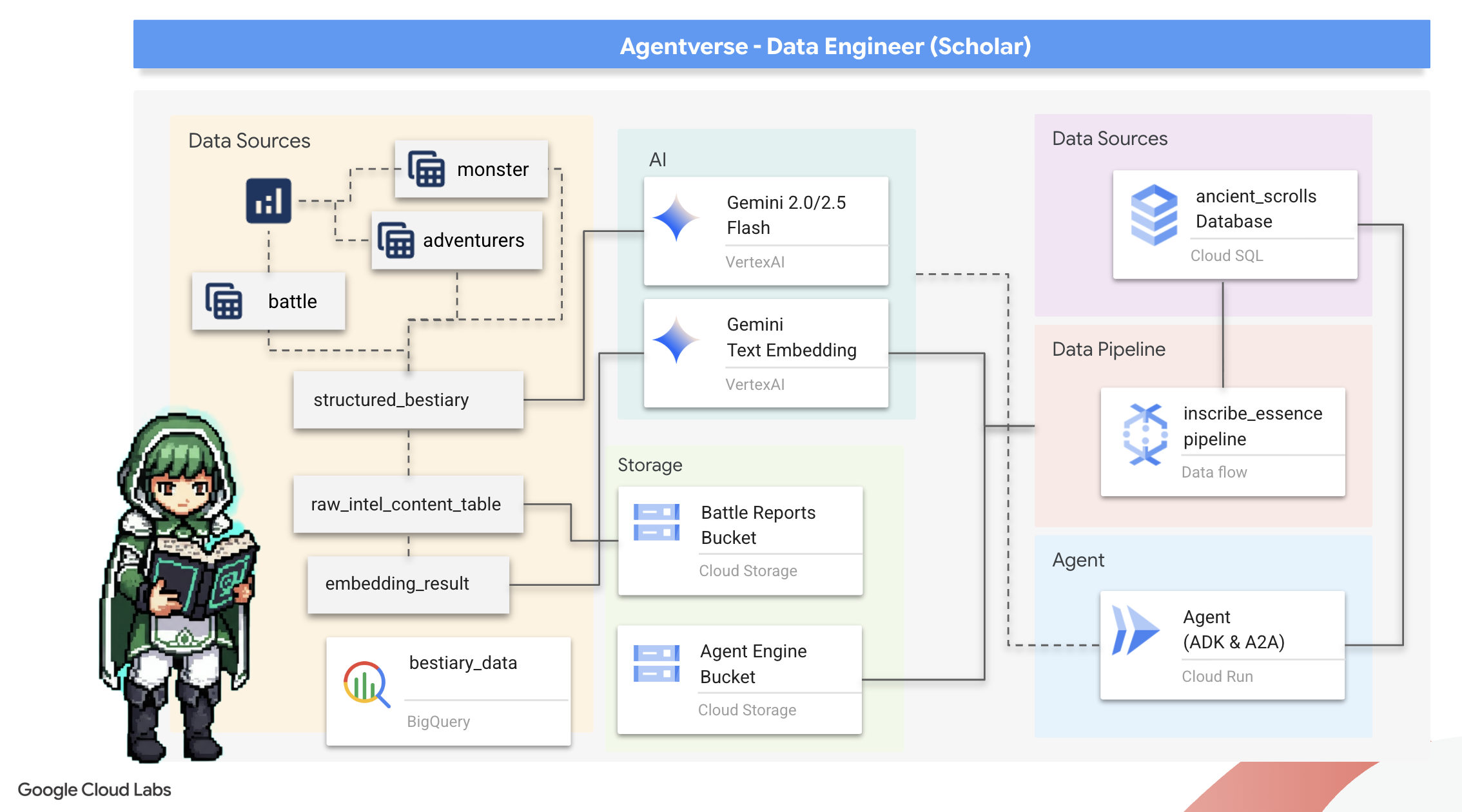
학습할 내용
- BigQuery를 사용하여 외부 테이블을 만들고 Gemini 모델과 함께 BQML.GENERATE_TEXT를 사용하여 복잡한 비정형-정형 변환을 실행합니다.
- PostgreSQL용 Cloud SQL 인스턴스를 프로비저닝하고 시맨틱 검색 기능을 위해 pgvector 확장 프로그램을 사용 설정합니다.
- Dataflow 및 Apache Beam을 사용하여 원시 텍스트 파일을 처리하고, Gemini 모델로 벡터 임베딩을 생성하고, 결과를 관계형 데이터베이스에 쓰는 강력한 컨테이너화된 배치 파이프라인을 빌드합니다.
- 에이전트 내에서 기본 검색 증강 생성 (RAG) 시스템을 구현하여 벡터화된 데이터를 쿼리합니다.
- 데이터 인식 에이전트를 Cloud Run에서 안전하고 확장 가능한 서비스로 배포합니다.
3. 학자의 성소 준비
학자님, 환영합니다. 그리모어의 강력한 지식을 새기기 전에 먼저 성소를 준비해야 합니다. 이 기본 의식에는 Google Cloud 환경을 마법으로 바꾸고, 올바른 포털 (API)을 열고, 데이터 마법이 흐를 수 있는 통로를 만드는 것이 포함됩니다. 잘 준비된 성소는 주문의 효력을 보장하고 지식을 안전하게 지켜줍니다.
Google Cloud 크레딧 사용하기
⚠️ 중요 기본 요건:
- 개인 Gmail 사용: 개인 계정 (예:
name@gmail.com). 회사 또는 학교에서 관리하는 계정은 작동하지 않습니다.
👉 단계:
- 크레딧 청구 사이트로 이동: 여기 클릭
- 로그인: 링크를 주소 표시줄에 붙여넣고 개인 Gmail로 로그인합니다.
- 약관 동의: Google Cloud Platform 서비스 약관에 동의합니다.
- 크레딧 확인: 크레딧이 적용되었음을 확인하는 메시지를 찾습니다.
- *참고: 신용카드 정보를 입력하라는 메시지가 표시되면 무시하고 창을 닫아도 됩니다.
이제 창을 닫아도 됩니다.
작업 환경 설정
👉Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다 (Cloud Shell 창 상단의 터미널 모양 아이콘).
👉'편집기 열기' 버튼 (연필이 있는 열린 폴더 모양)을 클릭합니다. 그러면 창에 Cloud Shell 코드 편집기가 열립니다. 왼쪽에 파일 탐색기가 표시됩니다. 
👉클라우드 IDE에서 터미널을 엽니다. 
👉💻 터미널에서 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되어 있는지 확인합니다.
gcloud auth list
👉💻GitHub에서 부트스트랩 프로젝트를 클론합니다.
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 프로젝트 디렉터리에서 설정 스크립트를 실행합니다.
⚠️ 프로젝트 ID 관련 참고사항: 스크립트에서 무작위로 생성된 기본 프로젝트 ID를 제안합니다. Enter 키를 눌러 이 기본값을 수락할 수 있습니다.
하지만 특정 새 프로젝트를 만들고 싶다면 스크립트에서 메시지가 표시될 때 원하는 프로젝트 ID를 입력하면 됩니다.
cd ~/agentverse-dataengineer
./init.sh
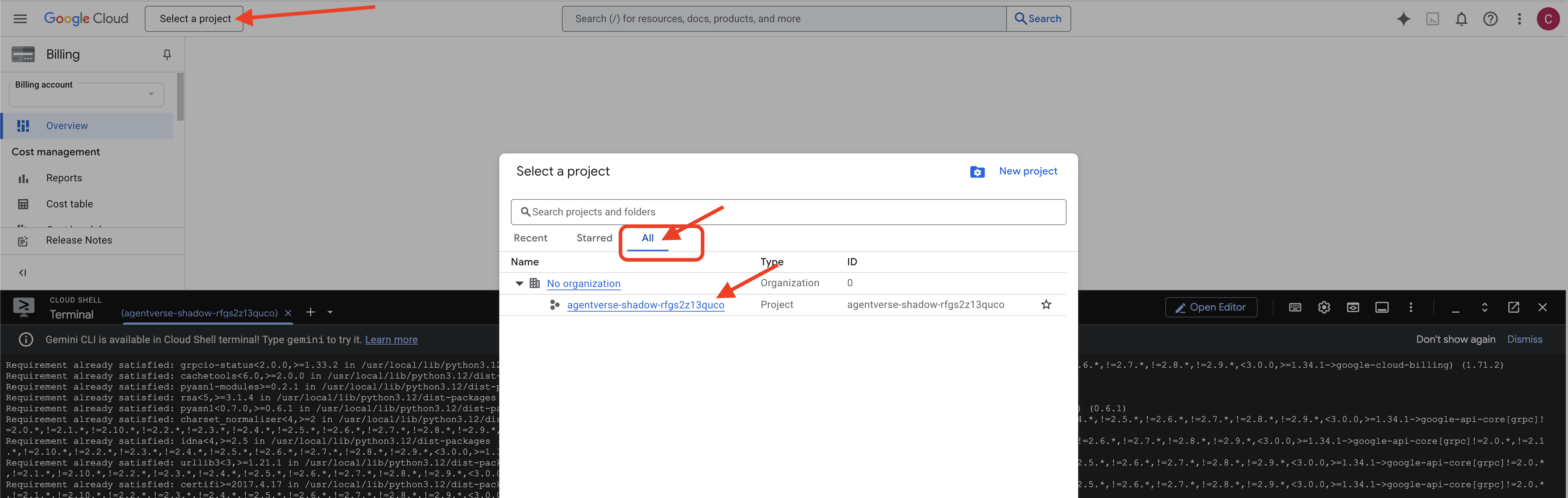
👉 완료 후 중요한 단계: 스크립트가 완료되면 Google Cloud 콘솔에서 올바른 프로젝트를 보고 있는지 확인해야 합니다.
- console.cloud.google.com으로 이동합니다.
- 페이지 상단의 프로젝트 선택기 드롭다운을 클릭합니다.
- '모두' 탭을 클릭합니다('최근'에 새 프로젝트가 아직 표시되지 않을 수 있음).
init.sh단계에서 방금 구성한 프로젝트 ID를 선택합니다.
👉💻 필요한 프로젝트 ID를 설정합니다.
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 다음 명령어를 실행하여 필요한 Google Cloud API를 사용 설정합니다.
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 agentverse-repo라는 Artifact Registry 저장소를 아직 만들지 않은 경우 다음 명령어를 실행하여 만듭니다.
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
권한 설정
👉💻 터미널에서 다음 명령어를 실행하여 필요한 권한을 부여합니다.
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 교육을 시작하면 최종 과제가 준비됩니다. 다음 명령어를 사용하면 혼란스러운 스태틱에서 스펙터가 소환되어 최종 테스트를 위한 보스가 생성됩니다.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
잘하셨습니다, 학자님. 기본적인 마법 부여가 완료되었습니다. 성역은 안전하고, 데이터의 원소적 힘으로 향하는 문은 열려 있으며, 하인은 권한을 부여받았습니다. 이제 실제 작업을 시작할 준비가 되었습니다.
4. 지식의 연금술: BigQuery 및 Gemini로 데이터 변환하기
스태틱과의 끊임없는 전쟁에서 에이전트 유니버스의 챔피언과 개발의 스펙터 간의 모든 대결은 세심하게 기록됩니다. 기본 학습 환경인 전장 시뮬레이션 시스템은 각 조우에 대한 에테르 로그 항목을 자동으로 생성합니다. 이러한 서술형 로그는 가장 가치 있는 원시 정보의 원천이며, 학자로서 우리가 전략이라는 순수한 강철을 단조해야 하는 정제되지 않은 광석입니다.학자의 진정한 힘은 단순히 데이터를 보유하는 데 있는 것이 아니라, 원시적이고 혼란스러운 정보의 광석을 빛나는 구조화된 실행 가능한 지혜의 강철로 변환하는 능력에 있습니다.우리는 데이터 연금술의 기초적인 의식을 수행할 것입니다.

이 여정은 Google BigQuery의 성역 내에서 완전히 이루어지는 다단계 프로세스를 거치게 됩니다. 마법의 렌즈를 사용하여 스크롤을 움직이지 않고 GCS 보관 파일을 살펴봅니다. 그런 다음 Gemini를 소환하여 전투 로그의 시적이고 구조화되지 않은 사가를 읽고 해석합니다. 마지막으로 원시 예언을 연결된 깨끗한 테이블 세트로 정제합니다. 첫 번째 마법서입니다. 그리고 이 새로운 구조로만 대답할 수 있는 심오한 질문을 던져 보세요.
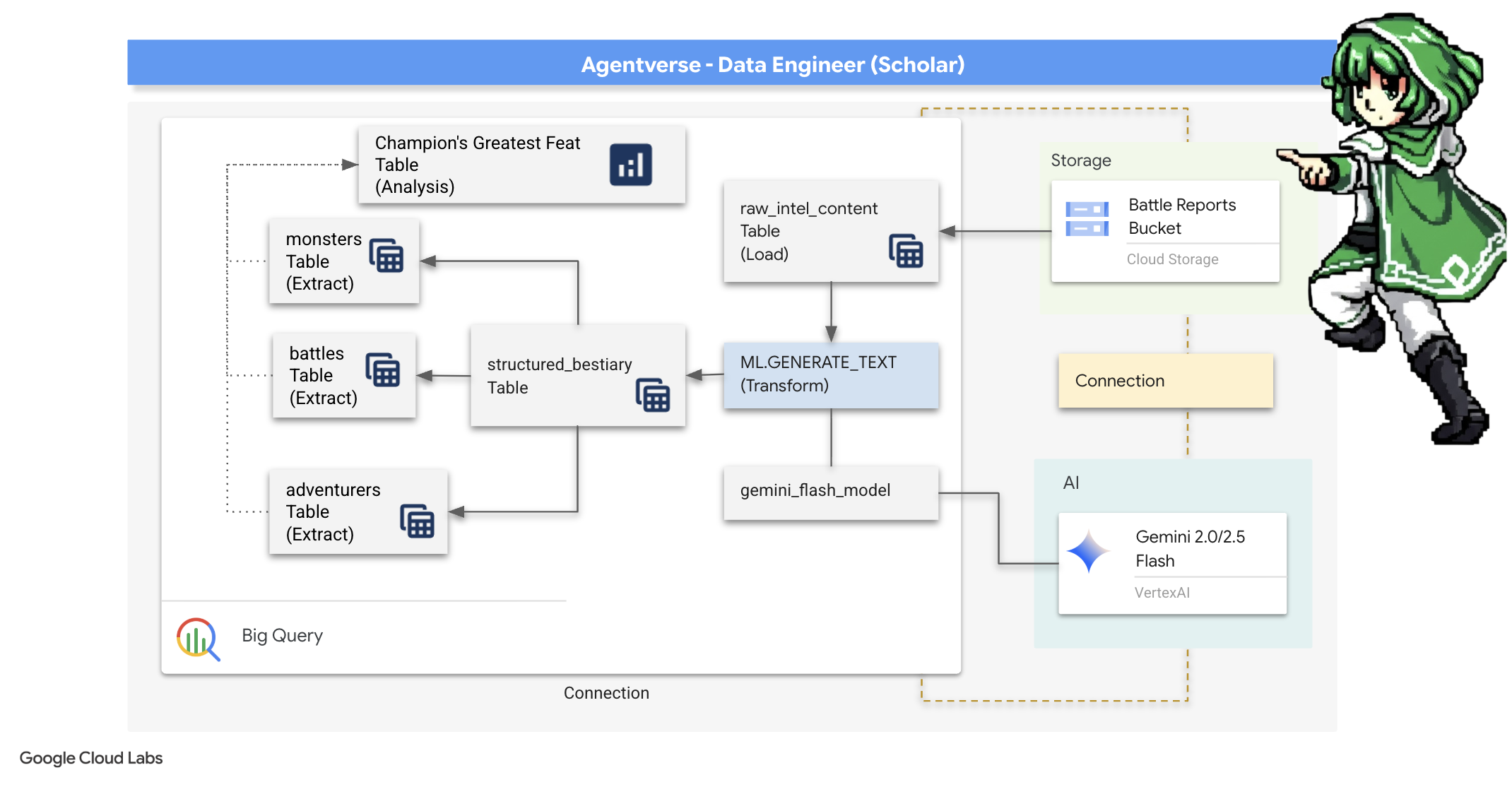
The Lens of Scrutiny: Peering into GCS with BigQuery External Tables(조사의 렌즈: BigQuery 외부 테이블로 GCS 살펴보기)
첫 번째 단계는 스크롤을 방해하지 않고 GCS 보관 파일의 콘텐츠를 볼 수 있는 렌즈를 만드는 것입니다. 외부 테이블은 BigQuery가 직접 쿼리할 수 있는 테이블과 유사한 구조에 원시 텍스트 파일을 매핑하는 렌즈입니다.
이를 위해 먼저 BigQuery 성역을 GCS 보관 파일에 안전하게 연결하는 안정적인 전력선, 즉 연결 리소스를 만들어야 합니다.
👉💻 Cloud Shell 터미널에서 다음 명령어를 실행하여 스토리지를 설정하고 컨듀잇을 생성합니다.
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 참고: 나중에 메시지가 표시됩니다.
2단계의 설정 스크립트가 백그라운드에서 프로세스를 시작했습니다. 몇 분 후 터미널에 다음과 비슷한 메시지가 표시됩니다.[1]+ Done gcloud sql instances create ...이는 정상적인 현상입니다. Cloud SQL 데이터베이스가 성공적으로 생성되었음을 의미합니다. 이 메시지는 무시하고 작업을 계속해도 됩니다.
외부 테이블을 만들기 전에 먼저 외부 테이블을 포함할 데이터 세트를 만들어야 합니다.
👉💻 Cloud Shell 터미널에서 다음 간단한 명령어를 실행합니다.
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 이제 GCS 보관 파일에서 읽고 Gemini와 상담하는 데 필요한 권한을 컨두잇의 마법 서명에 부여해야 합니다.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 Cloud Shell 터미널에서 다음 명령어를 실행하여 버킷 이름을 표시합니다.
echo $BUCKET_NAME
터미널에 your-project-id-gcs-bucket과 유사한 이름이 표시됩니다. 다음 단계에서 이 값이 필요합니다.
👉 Google Cloud 콘솔의 BigQuery 쿼리 편집기 내에서 다음 명령어를 실행해야 합니다. 아래의 링크를 새 브라우저 탭에서 여는 것이 가장 쉬운 방법입니다. Google Cloud Console의 올바른 페이지로 바로 이동합니다.
https://console.cloud.google.com/bigquery
👉 페이지가 로드되면 파란색 + 버튼 (새 쿼리 작성)을 클릭하여 새 편집기 탭을 엽니다.
이제 데이터 정의 언어 (DDL) 주문을 작성하여 마법의 렌즈를 만듭니다. 이렇게 하면 BigQuery에 찾아야 할 위치와 확인할 내용을 알려줍니다.
👉📜 열어 둔 BigQuery 쿼리 편집기에 다음 SQL을 붙여넣습니다. REPLACE-WITH-YOUR-BUCKET-NAME을 교체해야 합니다.
을 방금 복사한 버킷 이름으로 바꿉니다. 실행을 클릭합니다.
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 '렌즈를 통해 살펴보기' 위해 쿼리를 실행하고 파일의 콘텐츠를 확인합니다.
SELECT * FROM bestiary_data.raw_intel_content_table;
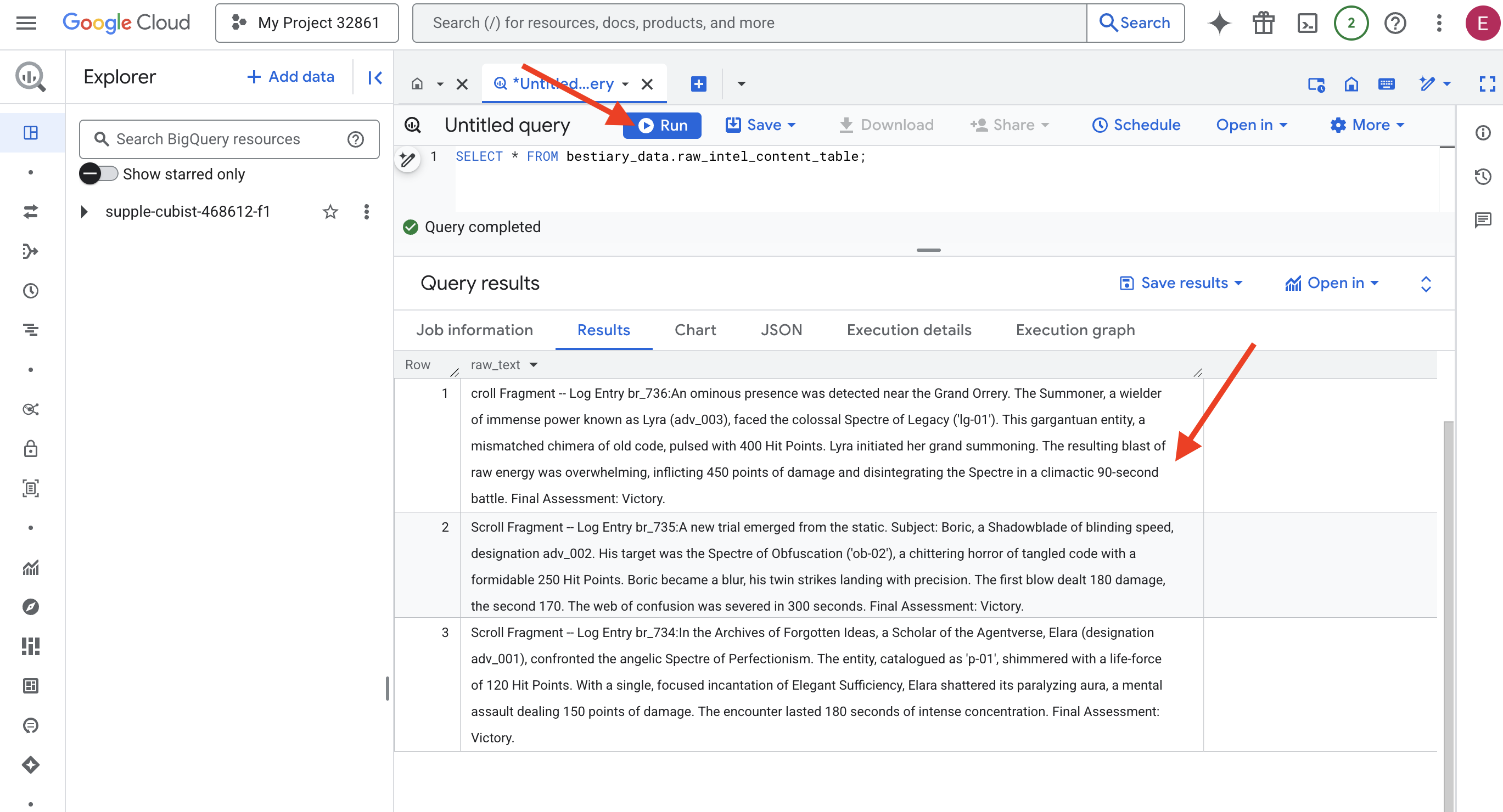
렌즈가 제자리에 있습니다. 이제 스크롤의 원시 텍스트를 볼 수 있습니다. 하지만 읽는 것이 이해하는 것은 아닙니다.
잊혀진 아이디어의 아카이브에서 에이전트 유니버스의 학자 엘라 (지정 adv_001)는 완벽주의의 천사 같은 스펙터와 맞섰습니다. 'p-01'로 분류된 엔티티는 120의 생명력으로 반짝였습니다. 엘라는 우아한 풍족함 주문을 집중하여 외워 마비 오라를 깨뜨렸습니다. 이는 150포인트의 피해를 입히는 정신 공격입니다. 이 만남은 180초 동안의 강렬한 집중으로 이어졌습니다. 최종 평가: 승리.
스크롤은 표와 행에 작성되지 않고 사가의 구불구불한 산문에 작성됩니다. 이것이 첫 번째 중요한 테스트입니다.
학자의 점술: SQL을 사용하여 텍스트를 표로 변환하기
문제는 섀도우블레이드의 빠른 연타 공격을 자세히 설명하는 보고서가 소환사가 단 한 번의 파괴적인 공격을 위해 엄청난 힘을 모으는 연대기와는 매우 다르다는 것입니다. 이 데이터를 단순히 가져올 수는 없습니다. 해석해야 합니다. 이것이 마법의 순간입니다. BigQuery 내에서 모든 파일의 모든 레코드를 읽고 이해하고 구조화하는 강력한 주문으로 단일 SQL 쿼리를 사용합니다.
👉💻 Cloud Shell 터미널로 돌아가서 다음 명령어를 실행하여 연결 이름을 표시합니다.
echo "${PROJECT_ID}.${REGION}.gcs-connection"
터미널에 전체 연결 문자열이 표시됩니다. 이 문자열 전체를 선택하고 복사합니다. 다음 단계에서 필요합니다.
강력한 주문인 ML.GENERATE_TEXT를 사용합니다. 이 주문은 Gemini를 소환하고, 각 스크롤을 보여주고, 핵심 사실을 구조화된 JSON 객체로 반환하도록 명령합니다.
👉📜 BigQuery 스튜디오에서 Gemini 모델 참조를 만듭니다. 이렇게 하면 Gemini Flash 오라클이 BigQuery 라이브러리에 바인딩되어 쿼리에서 호출할 수 있습니다.
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING을 터미널에서 복사한 전체 연결 문자열로 바꿉니다.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 이제 대변환 주문을 시전하세요. 이 쿼리는 원시 텍스트를 읽고, 각 스크롤에 대한 자세한 프롬프트를 구성하고, 이를 Gemini에 전송하고, AI의 구조화된 JSON 응답에서 새 스테이징 테이블을 빌드합니다.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
변환이 완료되었지만 결과가 아직 순수하지 않습니다. Gemini 모델은 원하는 JSON을 사고 과정에 관한 메타데이터가 포함된 더 큰 구조로 래핑하여 표준 형식으로 대답을 반환합니다. 정화하기 전에 이 날것의 예언을 살펴봅시다.
👉📜 Gemini 모델의 원시 출력을 검사하는 쿼리를 실행합니다.
SELECT * FROM bestiary_data.structured_bestiary;
👀 structured_data라는 단일 열이 표시됩니다. 각 행의 콘텐츠는 다음과 같은 복잡한 JSON 객체와 유사합니다.
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
보시다시피 요청한 깨끗한 JSON 객체인 상품이 이 구조 내에 깊이 중첩되어 있습니다. 다음 단계는 명확합니다. 이 구조를 체계적으로 탐색하고 그 안에 있는 순수한 지혜를 추출하는 의식을 수행해야 합니다.
정화 의식: SQL을 사용하여 생성형 AI 출력 정규화
Gemini가 말했지만 그 말은 원시적이고 생성의 초자연적인 에너지 (후보, finish_reason 등)에 둘러싸여 있습니다. 진정한 학자는 날것 그대로의 예언을 단순히 보관하지 않습니다. 핵심 지혜를 신중하게 추출하여 향후 사용을 위해 적절한 서적에 기록합니다.
이제 마지막 주문을 걸겠습니다. 이 단일 스크립트는 다음을 수행합니다.
- 스테이징 테이블에서 원시 중첩 JSON을 읽습니다.
- 핵심 데이터를 얻기 위해 정리하고 파싱합니다.
- 관련 부분을 몬스터, 모험가, 전투라는 세 개의 최종 테이블에 기록합니다.
👉📜 새 BigQuery 쿼리 편집기에서 다음 주문을 실행하여 정제 렌즈를 만듭니다.
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 베스티어리 확인:
SELECT * FROM bestiary_data.monsters;
다음으로, 이 짐승과 맞선 용감한 모험가들의 목록인 명예의 전당을 만들겠습니다.
👉📜 새 쿼리 편집기에서 다음 주문을 실행하여 모험가 테이블을 만듭니다.
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 챔피언의 명예의 전당 확인:
SELECT * FROM bestiary_data.adventurers;
마지막으로 전투 기록이라는 팩트 테이블을 만듭니다. 이 책은 다른 두 책을 연결하여 각 고유한 만남의 세부정보를 기록합니다. 모든 배틀은 고유한 이벤트이므로 중복 삭제가 필요하지 않습니다.
👉📜 새 쿼리 편집기에서 다음 주문을 실행하여 battles 테이블을 만듭니다.
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Chronicle 확인:
SELECT * FROM bestiary_data.battles;
전략적 인사이트 파악
스크롤을 읽고, 에센스를 추출하고, 책을 썼습니다. 그리모어는 더 이상 단순한 사실의 모음이 아니라 심오한 전략적 지혜의 관계형 데이터베이스입니다. 이제 지식이 원시적이고 구조화되지 않은 텍스트에 갇혀 있을 때는 답변할 수 없었던 질문을 할 수 있습니다.
이제 마지막으로 웅장한 점을 쳐 보겠습니다. 몬스터 도감, 챔피언 명단, 전투 연대기라는 세 권의 책을 한 번에 참고하는 주문을 걸어 실행 가능한 깊은 통찰력을 발견할 것입니다.
전략적 질문: '각 모험가가 성공적으로 물리친 가장 강력한 몬스터 (체력 기준)의 이름은 무엇이며, 그 승리에 얼마나 시간이 걸렸나요?'
이 질문은 챔피언을 승리한 전투에 연결하고 해당 전투를 관련된 몬스터의 통계에 연결해야 하는 복잡한 질문입니다. 이것이 바로 구조화된 데이터 모델의 진정한 힘입니다.
👉📜 새 BigQuery 쿼리 편집기에서 다음 주문을 시전합니다.
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
이 쿼리의 출력은 데이터 세트의 모든 모험가에 대해 '챔피언의 가장 위대한 업적 이야기'를 제공하는 깔끔하고 아름다운 표가 됩니다. 다음과 같이 표시될 수 있습니다.
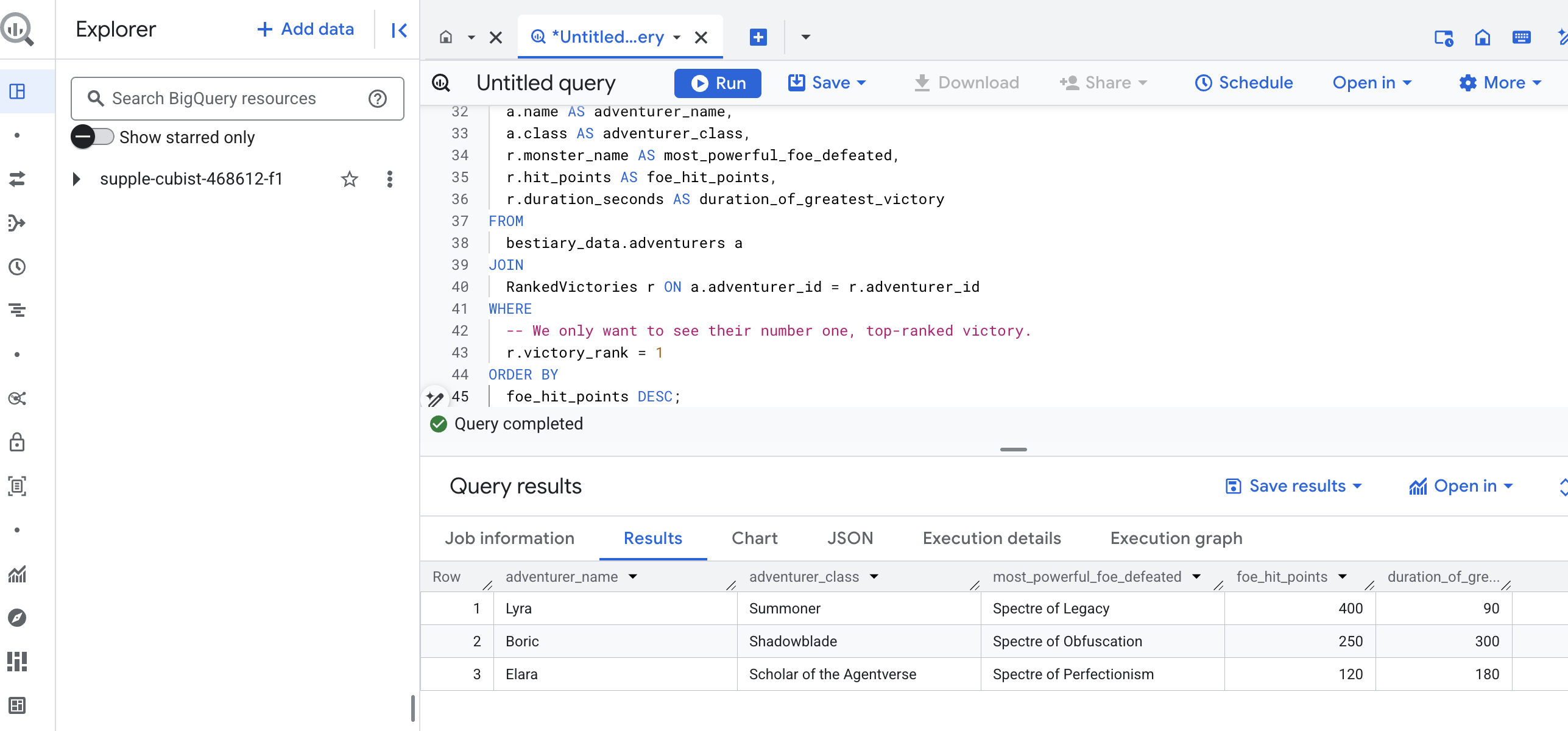
BigQuery 탭을 닫습니다.
이 단일하고 우아한 결과는 전체 파이프라인의 가치를 증명합니다. 혼란스러운 전장 보고서를 전설적인 이야기와 전략적인 데이터 기반 통찰력의 원천으로 변환했습니다.
비게이머용
5. The Scribe's Grimoire: 인데이터 웨어하우스 청킹, 임베딩, 검색
연금술사의 실험실에서 한 작업은 성공적이었습니다. Google은 원시적인 서사형 스크롤을 구조화된 관계형 테이블로 변환했습니다. 이는 강력한 데이터 마법입니다. 하지만 원래 스크롤에는 구조화된 표에서 완전히 포착할 수 없는 더 깊은 의미론적 진실이 여전히 담겨 있습니다. 진정으로 현명한 에이전트를 구축하려면 이 의미를 파악해야 합니다.
길고 원시적인 스크롤은 무딘 도구입니다. 상담사가 '마비 오라'에 관해 질문하는 경우 간단한 검색을 통해 해당 문구가 한 번만 언급된 전체 전투 보고서가 반환되어 관련 없는 세부정보에 답변이 묻힐 수 있습니다. 마스터 학자는 진정한 지혜는 양이 아니라 정확성에 있다는 것을 알고 있습니다.
Google은 BigQuery 성소 내에서 강력한 데이터베이스 내 의식을 세 번 실행합니다.
- 분할 의식 (청킹): 원시 지능 로그를 가져와서 작고 집중적이며 독립적인 구절로 세심하게 나눕니다.
- 증류 의식 (임베딩): BQML을 사용하여 Gemini 모델을 참조하고 각 텍스트 청크를 '시맨틱 지문'인 벡터 임베딩으로 변환합니다.
- 점술 의식 (검색): BQML의 벡터 검색을 사용하여 일반 영어로 질문하고 Grimoire에서 가장 관련성 있고 요약된 지혜를 찾습니다.
이 전체 프로세스를 통해 데이터가 BigQuery의 보안 및 규모를 벗어나지 않고도 강력하고 검색 가능한 지식 베이스를 만들 수 있습니다.
분할 의식: SQL로 스크롤 분해하기
지식의 출처는 외부 테이블 bestiary_data.raw_intel_content_table를 통해 액세스할 수 있는 GCS 보관 파일의 원시 텍스트 파일입니다. 첫 번째 작업은 각 긴 스크롤을 읽고 더 작고 이해하기 쉬운 일련의 구절로 나누는 주문을 작성하는 것입니다. 이 의식에서는 '청크'를 단일 문장으로 정의합니다.
문장별로 분할하는 것은 내러티브 로그의 명확하고 효과적인 시작점이지만, 마스터 스크라이브는 다양한 청킹 전략을 사용할 수 있으며 선택은 최종 검색의 품질에 매우 중요합니다. 더 간단한 방법에서는
- 고정 길이(크기) 청킹을 사용할 수 있지만 핵심 아이디어를 절반으로 잘라낼 수 있습니다.
다음과 같은 더 정교한 의식
- 재귀적 청킹이 실제로 선호되는 경우가 많습니다. 이는 먼저 단락과 같은 자연스러운 경계를 따라 텍스트를 나눈 다음 문장으로 대체하여 최대한 많은 의미론적 컨텍스트를 유지하려고 시도합니다. 정말 복잡한 원고의 경우
- 콘텐츠 인식 청킹(문서): Scribe가 기술 설명서의 헤더나 코드 스크롤의 함수와 같은 문서의 고유한 구조를 사용하여 가장 논리적이고 강력한 지혜 청크를 만듭니다.
전투 기록의 경우 문장이 세부사항과 맥락의 완벽한 균형을 제공합니다.
👉📜 새 BigQuery 쿼리 편집기에서 다음 주문을 실행합니다. 이 주문은 SPLIT 함수를 사용하여 각 스크롤의 텍스트를 마침표 (.)마다 분리한 다음 결과 문장 배열을 별도의 행으로 unnest합니다.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 이제 쿼리를 실행하여 새로 스크라이브되고 청크된 지식을 검사하고 차이점을 확인합니다.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
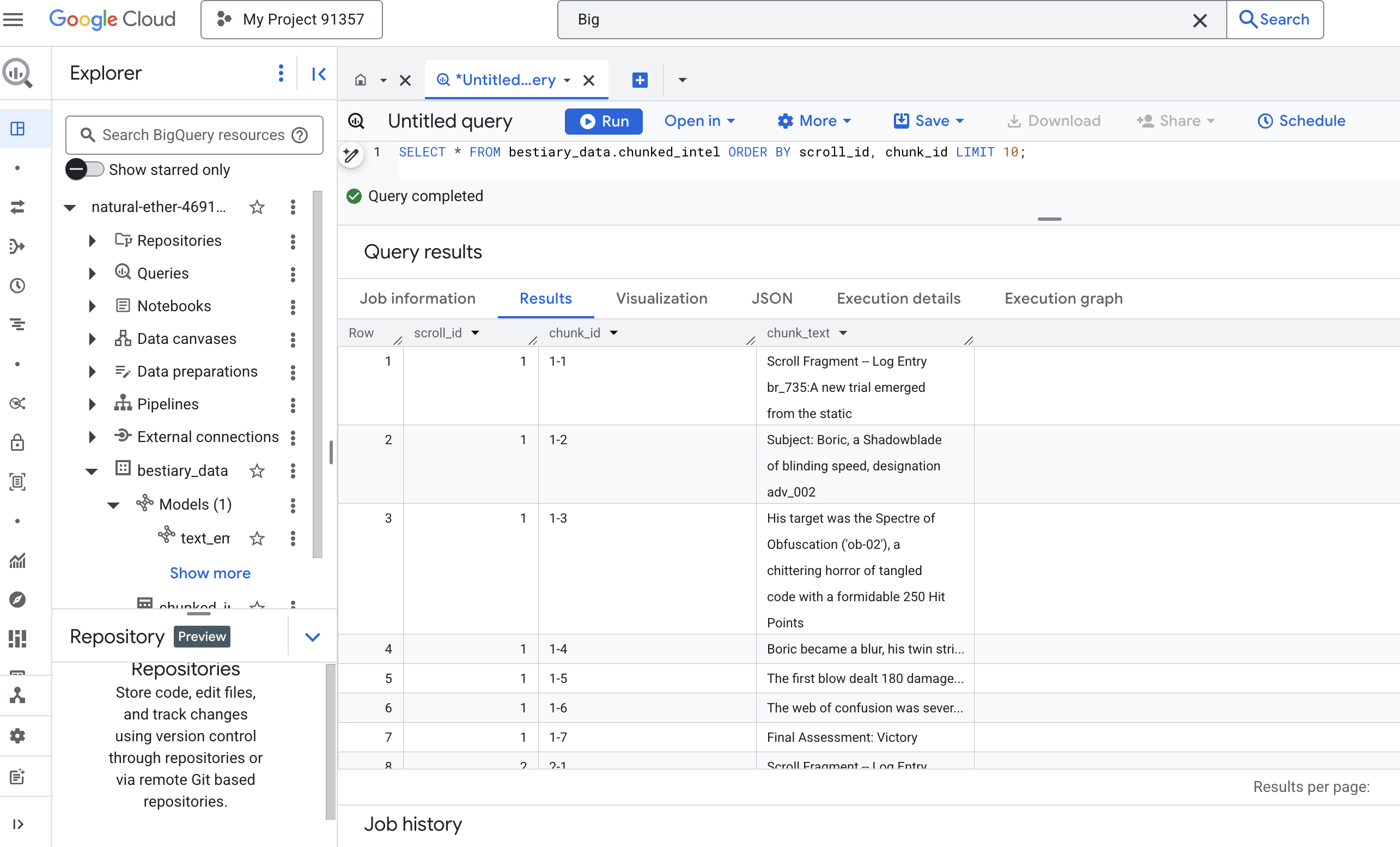
결과를 확인합니다. 이전에는 하나의 밀도 높은 텍스트 블록이 있었지만 이제는 각각 원래 스크롤 (scroll_id)에 연결되어 있지만 하나의 집중된 문장만 포함하는 여러 행이 있습니다. 이제 각 행이 벡터화에 적합합니다.
증류 의식: BQML을 사용하여 텍스트를 벡터로 변환하기
👉💻 먼저 터미널로 돌아가 다음 명령어를 실행하여 연결 이름을 표시합니다.
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Gemini의 텍스트 임베딩을 가리키는 새 BigQuery 모델을 만들어야 합니다. BigQuery Studio에서 다음 주문을 실행합니다. REPLACE-WITH-YOUR-FULL-CONNECTION-STRING을 터미널에서 복사한 전체 연결 문자열로 바꿔야 합니다.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 이제 증류 마법을 시전합니다. 이 쿼리는 ML.GENERATE_EMBEDDING 함수를 호출합니다. 이 함수는 chunked_intel 테이블의 모든 행을 읽고, 텍스트를 Gemini 임베딩 모델로 보내고, 결과 벡터 지문을 새 테이블에 저장합니다.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
BigQuery가 모든 텍스트 청크를 처리하므로 이 프로세스는 1~2분 정도 걸릴 수 있습니다.
👉📜 완료되면 새 테이블을 검사하여 시맨틱 지문을 확인합니다.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
이제 텍스트의 밀집 벡터 표현이 포함된 새 열 ml_generate_embedding_result가 표시됩니다. 이제 Grimoire가 시맨틱하게 인코딩됩니다.
점술 의식: BQML을 사용한 시맨틱 검색
👉📜 Grimoire를 테스트하는 가장 좋은 방법은 질문을 하는 것입니다. 이제 마지막 의식인 벡터 검색을 실행하겠습니다. 키워드 검색이 아니라 의미 검색입니다. Google에서 자연어로 질문하면 BQML이 질문을 즉시 임베딩으로 변환한 다음 embedded_intel 전체 표를 검색하여 의미상 '가장 가까운' 텍스트 청크의 지문을 찾습니다.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
주문 분석:
VECTOR_SEARCH: 검색을 오케스트레이션하는 핵심 함수입니다.ML.GENERATE_EMBEDDING(내부 쿼리): 이것이 마법입니다. 동일한 모델을 사용하되 쿼리에 맞게 특별히 최적화된 태스크 유형'RETRIEVAL_QUERY'을 사용하여 쿼리 ('What are the tactics...')를 삽입합니다.top_k => 3: 가장 관련성이 높은 상위 3개 결과를 요청합니다.distance_type => 'COSINE': 벡터 간의 '각도'를 측정합니다. 각도가 작을수록 의미가 더 일치합니다.
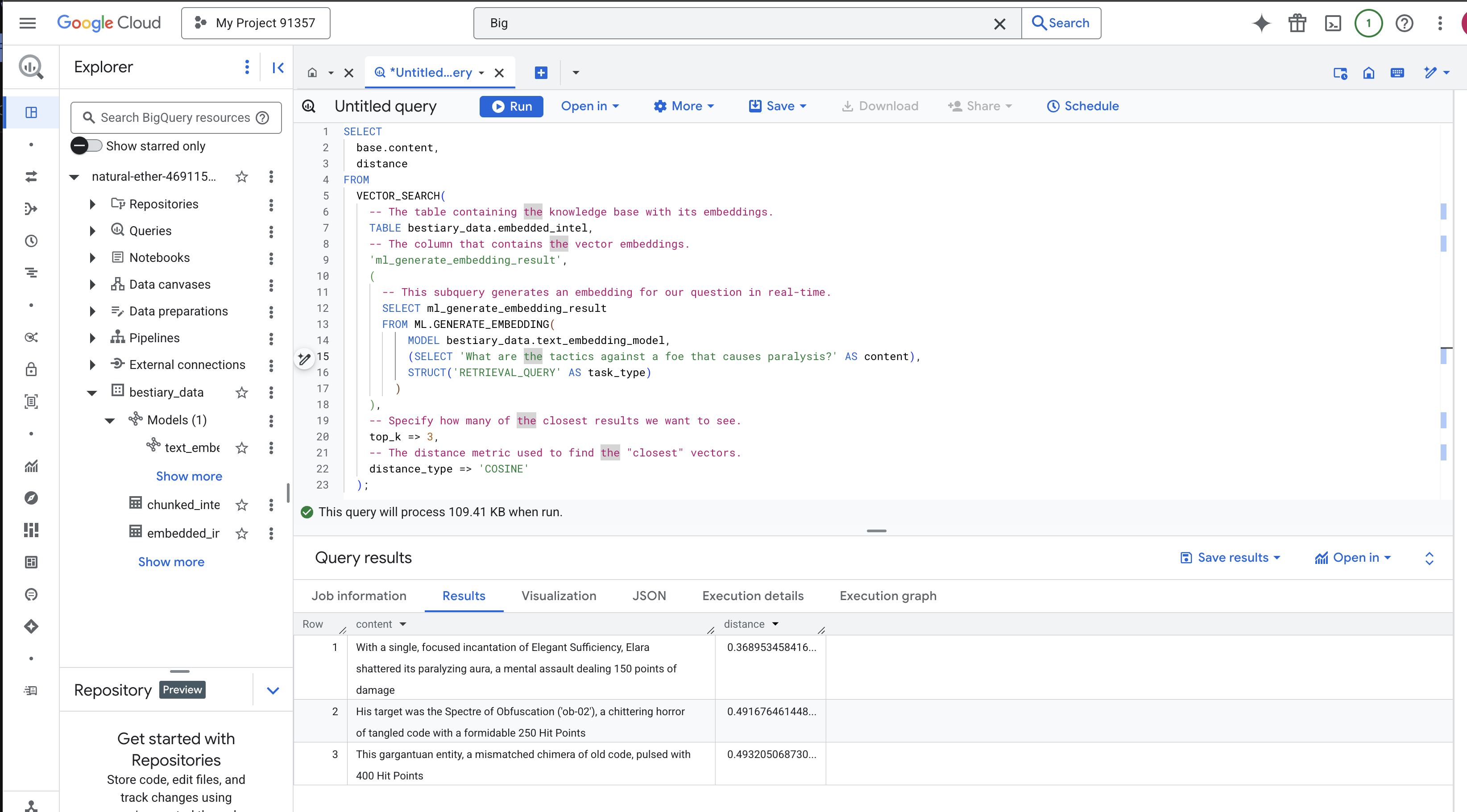
결과를 자세히 살펴보세요. 질문에 'shattered' 또는 'incantation'이라는 단어가 포함되지 않았는데도 최상위 결과는 'With a single, focused incantation of Elegant Sufficiency, Elara shattered its paralyzing aura, a mental assault dealing 150 points of damage'입니다. 이것이 바로 시맨틱 검색의 힘입니다. 이 모델은 '마비에 대한 전술'이라는 개념을 이해하고 구체적이고 성공적인 전술을 설명하는 문장을 찾았습니다.
이제 완전한 인데이터웨어하우스 기본 RAG 파이프라인을 성공적으로 빌드했습니다. 원시 데이터를 준비하고, 시맨틱 벡터로 변환하고, 의미별로 쿼리했습니다. BigQuery는 이러한 대규모 분석 작업에 강력한 도구이지만 지연 시간이 짧은 응답이 필요한 실시간 상담사의 경우 준비된 지식을 전문 운영 데이터베이스로 전송하는 경우가 많습니다. 이 내용은 다음 교육에서 다룰 예정입니다.
비게이머용
6. 벡터 스크립토리움: 추론을 위해 Cloud SQL로 벡터 스토어 제작하기
현재 Grimoire는 구조화된 표로 존재합니다. 사실에 관한 강력한 카탈로그이지만 지식은 문자 그대로입니다. monster_id = 'MN-001'은 이해하지만 '난독화'의 더 깊은 의미는 이해하지 못합니다. 상담사에게 진정한 지혜를 제공하고 미묘한 뉘앙스와 통찰력을 바탕으로 조언할 수 있도록 하려면 지식의 본질을 의미를 포착하는 형태인 벡터로 추출해야 합니다.
지식을 향한 탐구는 오래전에 잊혀진 선구자 문명의 무너져 가는 유적지로 이어졌습니다. 봉인된 보관소 깊은 곳에서 기적적으로 보존된 고대 두루마리 상자를 발견했습니다. 단순한 전투 보고서가 아닙니다. 모든 위대한 노력을 괴롭히는 짐승을 물리치는 방법에 관한 심오한 철학적 지혜가 담겨 있습니다. 스크롤에 '기어 다니는 조용하고 정체된 것', '창조의 직물이 닳아 해진 것'으로 설명된 존재입니다. 정적은 고대인들에게도 알려져 있었던 것으로 보입니다. 역사가 시간 속으로 사라진 순환적인 위협입니다.
잊혀진 이 지식이 우리의 가장 큰 자산입니다. 개별 몬스터를 물리치는 것뿐만 아니라 파티 전체에 전략적 통찰력을 부여하는 데도 핵심적인 역할을 합니다. 이 강력한 기능을 활용하기 위해 이제 학자의 진정한 주문서 (벡터 기능이 있는 PostgreSQL 데이터베이스)를 만들고 자동화된 벡터 스크립토리움 (Dataflow 파이프라인)을 구축하여 이러한 스크롤의 시대를 초월한 본질을 읽고 이해하고 기록할 것입니다. 이렇게 하면 Grimoire가 사실의 책에서 지혜의 엔진으로 변모합니다.

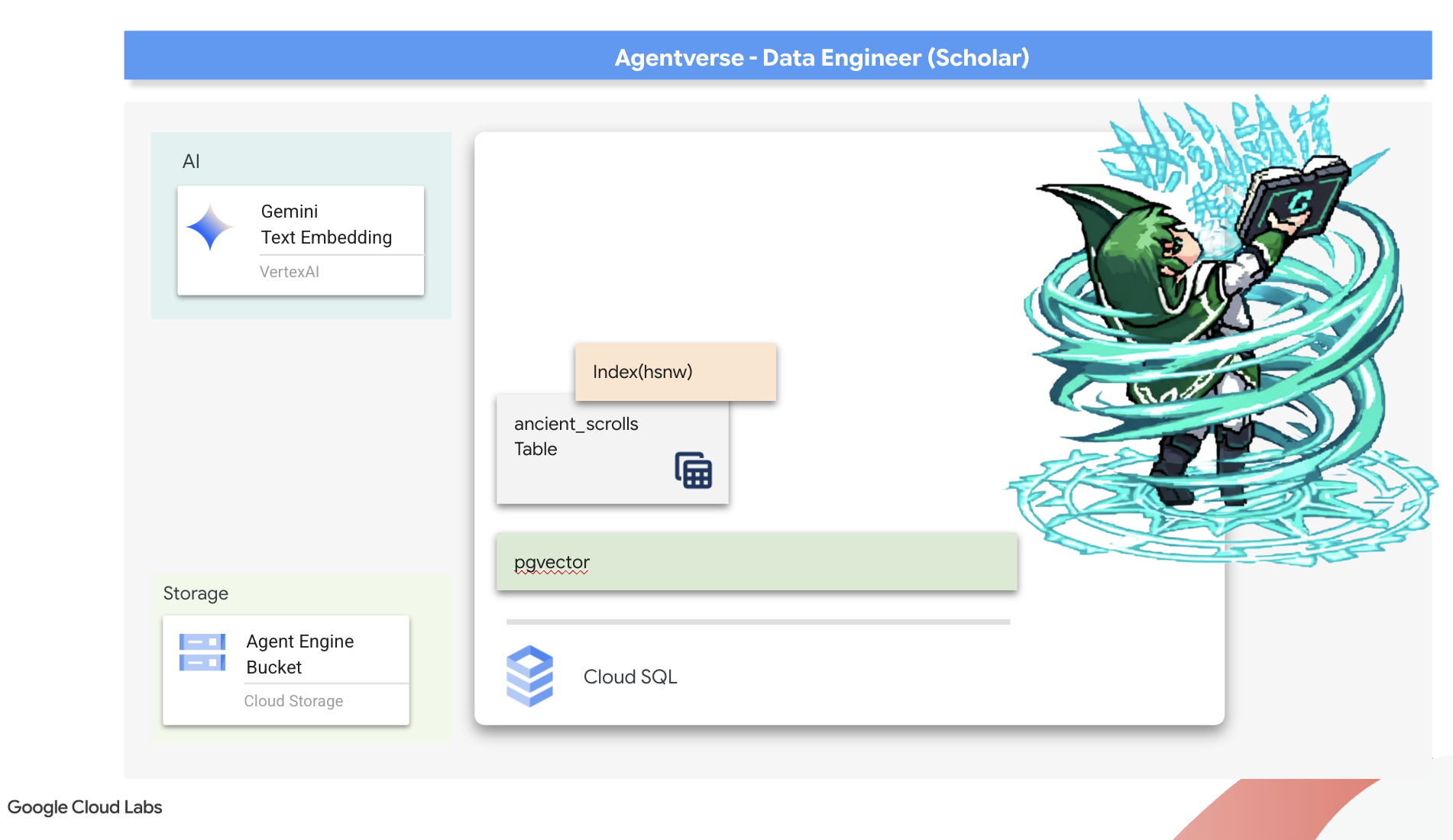
학자의 주문서 만들기 (Cloud SQL)
이 고대 두루마리의 본질을 새기기 전에 먼저 이 지식의 그릇인 관리형 PostgreSQL 주문서가 성공적으로 만들어졌는지 확인해야 합니다. 초기 설정 의식에서 이미 이를 생성했을 것입니다.
👉💻 터미널에서 다음 명령어를 실행하여 Cloud SQL 인스턴스가 존재하고 준비되었는지 확인합니다. 이 스크립트는 인스턴스의 전용 서비스 계정에 Vertex AI 사용 권한도 부여합니다. 이는 데이터베이스 내에서 직접 임베딩을 생성하는 데 필수적입니다.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
명령어가 성공하고 grimoire-spellbook 인스턴스에 관한 세부정보를 반환하면 포지가 작업을 잘 수행한 것입니다. 다음 주문으로 진행할 준비가 되었습니다. 명령어가 NOT_FOUND 오류를 반환하면 계속하기 전에 초기 환경 설정 단계를 완료했는지 확인하세요.(data_setup.py)
👉💻 책이 위조되었으므로 arcane_wisdom라는 새 데이터베이스를 만들어 첫 번째 챕터를 엽니다.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
시맨틱 룬 새기기: pgvector로 벡터 기능 지원
이제 Cloud SQL 인스턴스가 생성되었으므로 내장된 Cloud SQL Studio를 사용하여 연결해 보겠습니다. 이를 통해 데이터베이스에서 직접 SQL 쿼리를 실행할 수 있는 웹 기반 인터페이스가 제공됩니다.
👉💻 먼저 Cloud SQL Studio로 이동합니다. 가장 쉽고 빠르게 이동하는 방법은 새 브라우저 탭에서 다음 링크를 여는 것입니다. 그러면 grimoire-spellbook 인스턴스의 Cloud SQL Studio로 바로 이동합니다.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 arcane_wisdom를 데이터베이스로 선택합니다. postgres을 사용자로, 1234qwer을 비밀번호로 입력하고 인증을 클릭합니다.
👉📜 SQL Studio 쿼리 편집기에서 탭 편집기 1로 이동하여 다음 SQL 코드를 붙여넣어 벡터 데이터 유형을 사용 설정합니다.
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
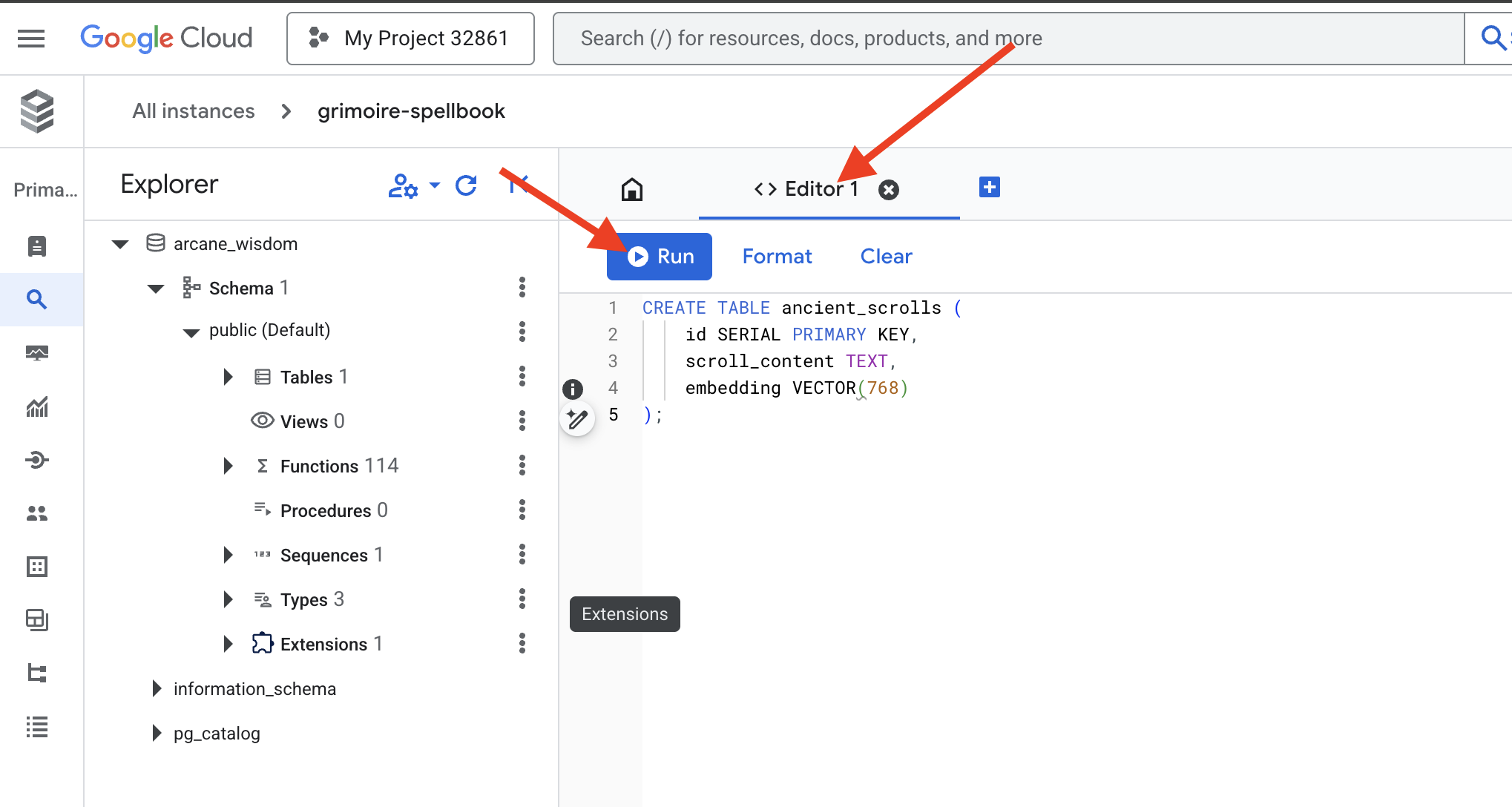
👉📜 스크롤의 본질을 담을 표를 만들어 주문서의 페이지를 준비합니다.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
주문 VECTOR(768)은 중요한 세부정보입니다. 사용할 Vertex AI 임베딩 모델 (textembedding-gecko@003 또는 유사한 모델)은 텍스트를 768차원 벡터로 추출합니다. Spellbook의 페이지는 정확히 그 크기의 에센스를 담을 수 있도록 준비되어야 합니다. 차원은 항상 일치해야 합니다.
첫 번째 음역: 수동 비문 의식
자동화된 서기관 (Dataflow) 군대를 지휘하기 전에 중앙 의식을 한 번 수동으로 실행해야 합니다. 이를 통해 다음과 같은 두 단계의 마법을 깊이 이해할 수 있습니다.
- 점치기: 텍스트를 가져와 Gemini 오라클에 컨설트하여 의미론적 본질을 벡터로 추출합니다.
- Inscription: 원본 텍스트와 새로운 벡터 에센스를 Spellbook에 작성합니다.
이제 수동 의식을 실행해 보겠습니다.
👉📜 Cloud SQL Studio에서 이제 google_ml_integration 확장 프로그램에서 제공하는 강력한 기능인 embedding() 함수를 사용합니다. 이를 통해 SQL 쿼리에서 직접 Vertex AI 임베딩 모델을 호출하여 프로세스를 크게 간소화할 수 있습니다.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 새로 새겨진 페이지를 읽는 쿼리를 실행하여 작업을 확인합니다.
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
핵심 RAG 데이터 로드 작업을 수동으로 완료했습니다.
시맨틱 나침반 만들기: HNSW 색인으로 주문서에 마법 부여하기
이제 주문집에 지혜를 저장할 수 있지만, 적절한 스크롤을 찾으려면 모든 페이지를 읽어야 합니다. 순차적 스캔입니다. 이 방법은 느리고 비효율적입니다. 쿼리를 가장 관련성 높은 지식으로 즉시 안내하려면 벡터 색인이라는 시맨틱 나침반으로 Spellbook을 강화해야 합니다.
이 마법의 가치를 증명해 보겠습니다.
👉📜 Cloud SQL Studio에서 다음 주문을 실행합니다. 새로 삽입된 스크롤을 검색하는 것을 시뮬레이션하고 데이터베이스에 계획을 EXPLAIN하도록 요청합니다.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
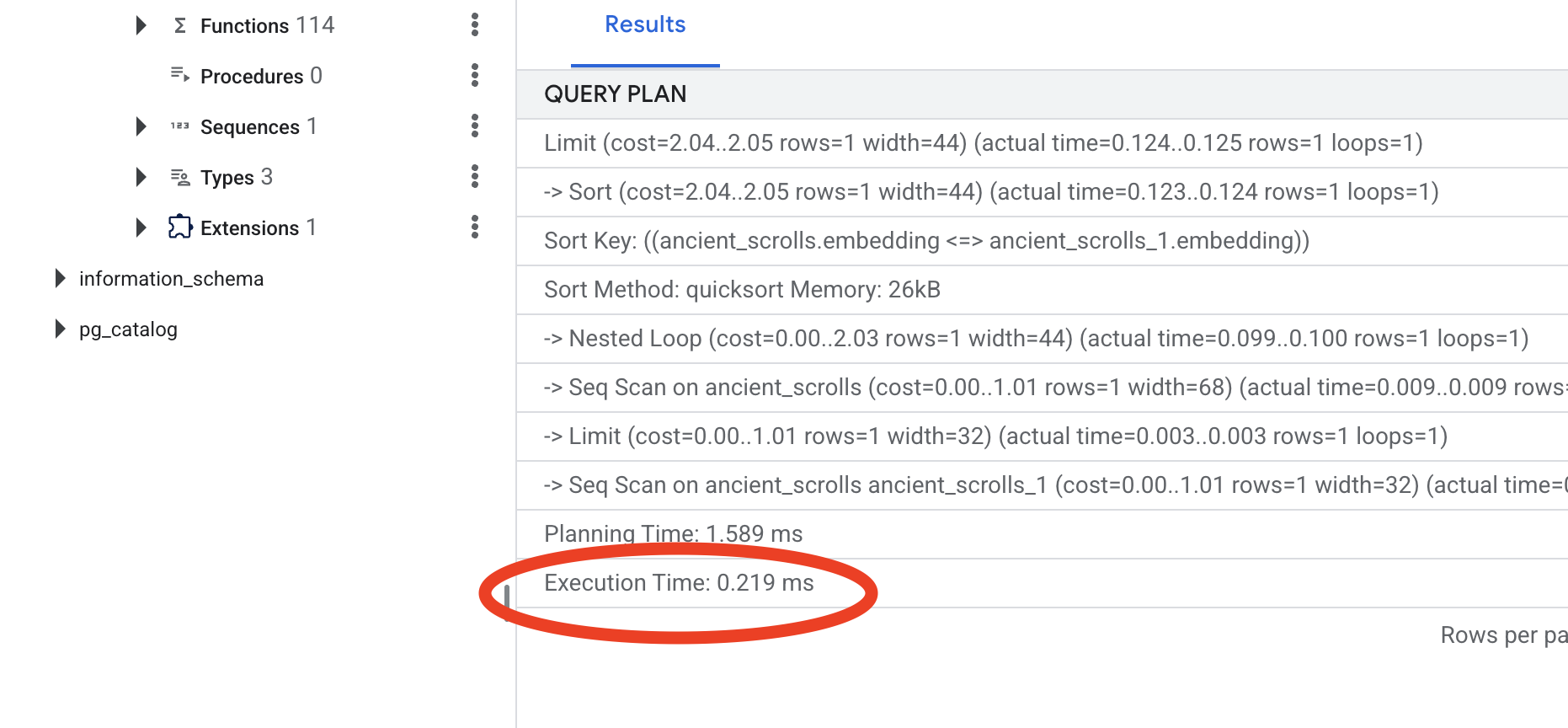
결과를 살펴봅니다. -> Seq Scan on ancient_scrolls라는 줄이 표시됩니다. 이렇게 하면 데이터베이스가 모든 행을 읽고 있는지 확인할 수 있습니다. execution time을 확인합니다.
👉📜 이제 색인 생성 주문을 걸어 보겠습니다. lists 매개변수는 색인에 만들 클러스터 수를 알려줍니다. 예상되는 행 수의 제곱근을 사용하는 것이 좋습니다.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
색인이 빌드될 때까지 기다립니다 (하나의 행의 경우 빠르지만 수백만 개의 행의 경우 시간이 걸릴 수 있음).
👉📜 이제 동일한 EXPLAIN ANALYZE 명령어를 다시 실행합니다.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
새 쿼리 계획을 확인합니다. 이제 -> Index Scan using...가 표시됩니다. 더 중요한 것은 execution time입니다. 항목이 하나만 있어도 훨씬 빨라집니다. 지금까지 벡터 세계에서 데이터베이스 성능 조정의 핵심 원칙을 살펴봤습니다.
이제 소스 데이터를 검사하고, 수동 의식을 이해하고, 속도를 위해 주문집을 최적화했으므로 자동화된 스크립토리움을 구축할 준비가 되었습니다.
비게이머용
7. 의미의 도관: Dataflow 벡터화 파이프라인 빌드
이제 스크롤을 읽고, 그 본질을 추출하고, 새로운 주문서에 새겨 넣을 마법의 필사자 조립 라인을 구축합니다. 이는 수동으로 트리거할 Dataflow 파이프라인입니다. 하지만 파이프라인 자체의 마스터 주문을 작성하기 전에 먼저 파이프라인의 기반과 소환할 원을 준비해야 합니다.
Scriptorium의 기반 준비 (작업자 이미지)
Dataflow 파이프라인은 클라우드의 자동화된 작업자 팀에 의해 실행됩니다. 이러한 모델을 호출할 때마다 작업을 수행하는 데 필요한 특정 라이브러리가 필요합니다. 목록을 제공하고 매번 이러한 라이브러리를 가져오도록 할 수도 있지만 이는 느리고 비효율적입니다. 현명한 학자는 미리 마스터 라이브러리를 준비합니다.
여기서는 Google Cloud Build에 커스텀 컨테이너 이미지를 생성하도록 명령합니다. 이 이미지는 서기관에게 필요한 모든 라이브러리와 종속 항목이 미리 로드된 '완벽한 골렘'입니다. Dataflow 작업이 시작되면 이 맞춤 이미지를 사용하여 작업자가 거의 즉시 작업을 시작할 수 있습니다.
👉💻 다음 명령어를 실행하여 파이프라인의 기본 이미지를 빌드하고 Artifact Registry에 저장합니다.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 다음 명령어를 실행하여 격리된 Python 환경을 만들고 활성화하고 필요한 소환 라이브러리를 설치합니다.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
마스터 주문
이제 Vector Scriptorium을 지원하는 마스터 주문을 작성할 때가 되었습니다. 개별 마법 구성요소를 처음부터 작성하지는 않습니다. 여기서의 작업은 Apache Beam의 언어를 사용하여 구성요소를 논리적이고 강력한 파이프라인으로 조립하는 것입니다.
- EmbedTextBatch (Gemini의 컨설테이션): '그룹 점'을 수행하는 방법을 아는 전문 서기관을 빌드합니다. 원시 텍스트 파일의 일괄 처리를 가져와 Gemini 텍스트 임베딩 모델에 제공하고 추출된 에센스 (벡터 임베딩)를 수신합니다.
- WriteEssenceToSpellbook (최종 비문): 기록 보관소입니다. Cloud SQL Spellbook에 대한 보안 연결을 여는 비밀 주문을 알고 있습니다. 이 도구의 역할은 스크롤의 콘텐츠와 벡터화된 본질을 가져와 새 페이지에 영구적으로 새기는 것입니다.
Google의 사명은 이러한 작업을 연결하여 원활한 지식 흐름을 만드는 것입니다.
👉✏️ Cloud Shell 편집기에서 ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py로 이동하면 EmbedTextBatch라는 DoFn 클래스가 있습니다. #REPLACE-EMBEDDING-LOGIC 댓글을 찾습니다. 다음 주문으로 바꿉니다.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
이 주문은 다음과 같은 몇 가지 주요 매개변수를 사용하여 정확하게 작성됩니다.
- model: 강력하고 최신 임베딩 모델을 사용하기 위해
text-embedding-005를 지정합니다. - contents: DoFn이 수신하는 파일 배치에 있는 모든 텍스트 콘텐츠의 목록입니다.
- task_type: 'RETRIEVAL_DOCUMENT'로 설정합니다. 이는 Gemini에게 나중에 검색에서 찾을 수 있도록 특별히 최적화된 임베딩을 생성하도록 지시하는 중요한 요청 사항입니다.
- output_dimensionality: Cloud SQL에서 ancient_scrolls 테이블을 만들 때 정의한 VECTOR(768) 차원과 정확히 일치하도록 768로 설정해야 합니다. 불일치하는 측정기준은 벡터 매직에서 흔히 발생하는 오류의 원인입니다.
파이프라인은 GCS 보관 파일에 있는 모든 고대 두루마리에서 원시 비구조화 텍스트를 읽어오는 것으로 시작해야 합니다.
👉✏️ ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py에서 #REPLACE ME-READFILE 주석을 찾아 다음 세 부분으로 된 주문으로 바꿉니다.
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
이제 스크롤의 원시 텍스트가 수집되었으므로 점을 치기 위해 Gemini에 전송해야 합니다. 이를 효율적으로 수행하기 위해 먼저 개별 스크롤을 작은 배치로 그룹화한 다음 해당 배치를 EmbedTextBatch 스크라이브에 전달합니다. 이 단계에서는 Gemini가 이해하지 못한 스크롤을 나중에 검토할 수 있도록 '실패' 더미로 분리합니다.
👉✏️ #REPLACE ME-EMBEDDING 주석을 찾아 다음으로 바꿉니다.
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
스크롤의 본질이 성공적으로 추출되었습니다. 마지막 단계는 이 지식을 영구적으로 저장하기 위해 주문서에 새기는 것입니다. '처리됨' 더미에서 스크롤을 가져와 WriteEssenceToSpellbook 아키비스트에게 전달합니다.
👉✏️ #REPLACE ME-WRITE TO DB 주석을 찾아 다음으로 바꿉니다.
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
현명한 학자는 실패한 시도라도 지식을 버리지 않습니다. 마지막 단계로, 서기관에게 점술 단계에서 '실패' 더미를 가져와 실패 이유를 기록하도록 지시해야 합니다. 이를 통해 향후 리추얼을 개선할 수 있습니다.
👉✏️ #REPLACE ME-LOG FAILURES 주석을 찾아 다음으로 바꿉니다.
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
이제 마스터 주문이 완료되었습니다. 개별 마법 구성요소를 연결하여 강력한 다단계 데이터 파이프라인을 어셈블했습니다. inscribe_essence_pipeline.py 파일을 저장합니다. 이제 스크립토리움을 소환할 수 있습니다.
이제 Dataflow 서비스에 골렘을 깨우고 스크라이브 의식을 시작하도록 명령하는 대소환 주문을 시전합니다.
👉💻 터미널에서 다음 명령어를 실행합니다.
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 주의! 리소스 오류 ZONE_RESOURCE_POOL_EXHAUSTED로 인해 작업이 실패하는 경우 선택한 리전에서 이 평판이 낮은 계정의 임시 리소스 제약 때문일 수 있습니다. Google Cloud의 강점은 전 세계에 걸친 도달 범위입니다. 다른 지역에서 골렘을 소환해 보세요. 이렇게 하려면 위의 명령어에서 --region=$REGION을 다른 리전(예:
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
를 사용하여 다시 실행합니다. 🎰
이 프로세스를 시작하고 완료하는 데 약 3~5분이 소요됩니다. Dataflow 콘솔에서 실시간으로 확인할 수 있습니다.
👉Dataflow 콘솔로 이동: 새 브라우저 탭에서 이 직접 링크를 여는 것이 가장 쉬운 방법입니다.
https://console.cloud.google.com/dataflow
👉 작업 찾기 및 클릭: 제공한 이름 (inscribe-essence-job 등)으로 작업이 표시됩니다. 작업 이름을 클릭하여 세부정보 페이지를 엽니다. 파이프라인을 관찰합니다.
- 시작: 처음 3분 동안 Dataflow가 필요한 리소스를 프로비저닝하므로 작업 상태가 '실행 중'으로 표시됩니다. 그래프가 표시되지만 아직 데이터가 이동하는 모습은 보이지 않을 수 있습니다.
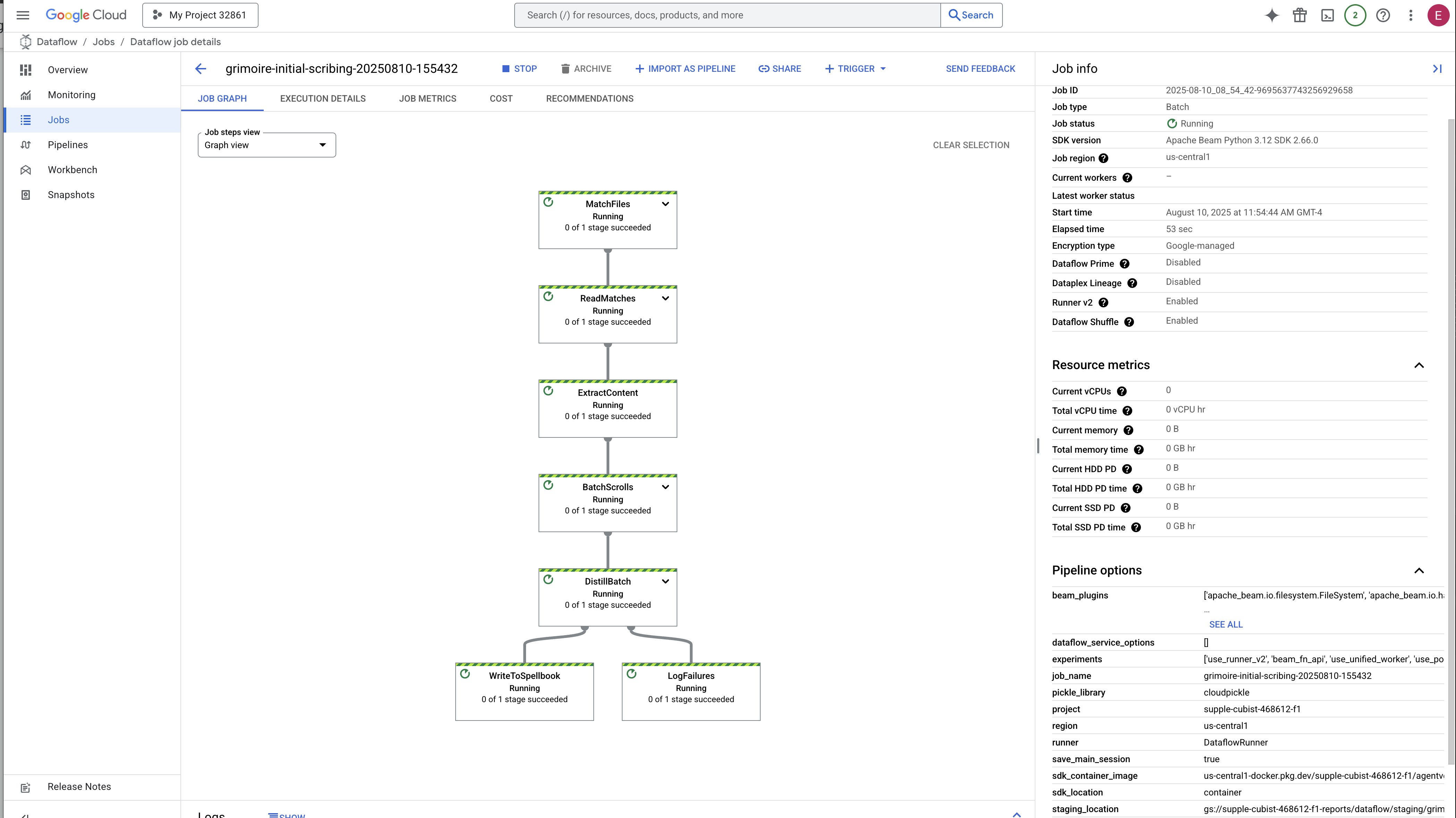
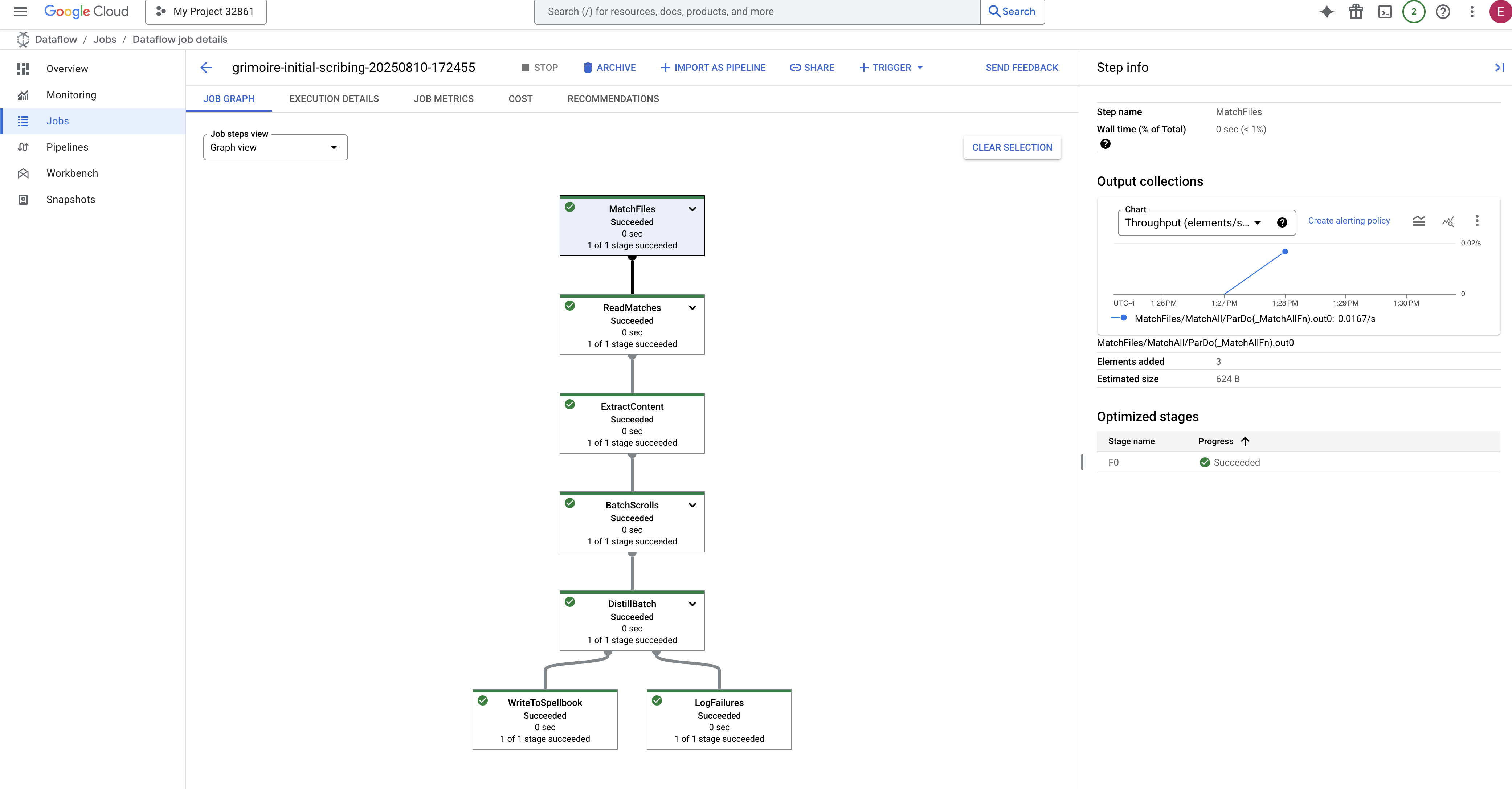
- 완료됨: 완료되면 작업 상태가 '성공'으로 변경되고 그래프에 처리된 레코드의 최종 개수가 표시됩니다.
비문 확인
👉📜 SQL 스튜디오로 돌아가 다음 쿼리를 실행하여 스크롤과 그 의미론적 본질이 성공적으로 새겨졌는지 확인합니다.
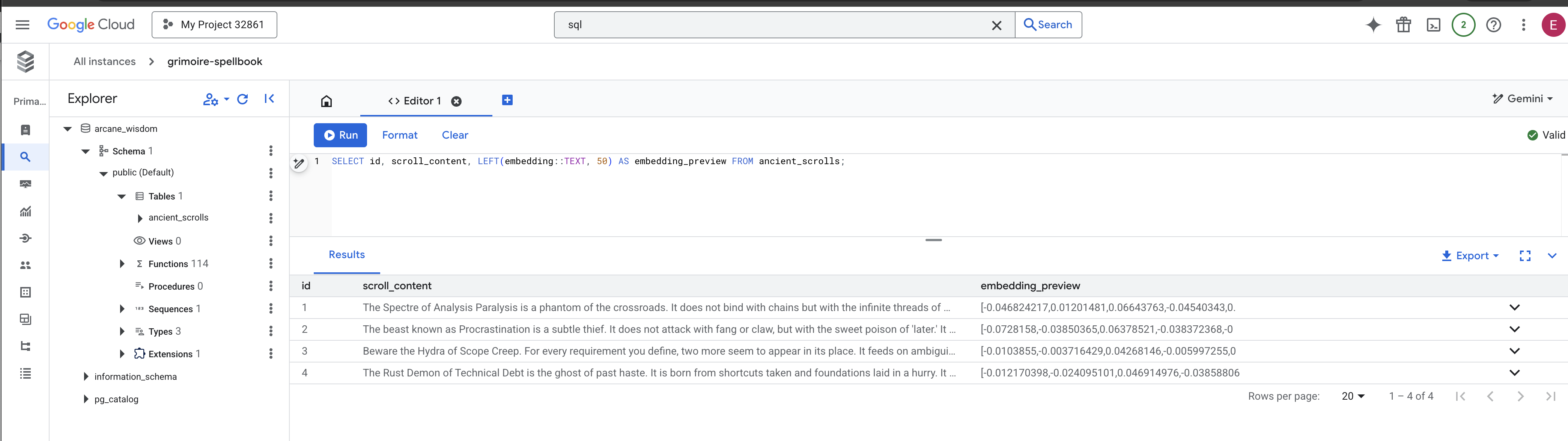
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
스크롤의 ID, 원본 텍스트, 이제 Grimoire에 영구적으로 새겨진 마법 벡터 에센스의 미리보기가 표시됩니다.
이제 Scholar's Grimoire가 진정한 지식 엔진이 되었으며 다음 장에서 의미로 쿼리할 수 있습니다.
8. 마지막 룬 봉인: RAG 에이전트로 지혜 활성화
그리모어가 더 이상 데이터베이스가 아닙니다. 질문을 기다리는 조용한 오라클인 벡터화된 지식의 원천입니다.
이제 학자의 진정한 시험이 시작됩니다. 이 지혜를 여는 열쇠를 만들어야 합니다. 검색 증강 생성 (RAG) 에이전트를 빌드합니다. 이는 일반적인 언어로 된 질문을 이해하고, Grimoire에서 가장 깊고 관련성 높은 진실을 참고한 다음, 검색된 지혜를 사용하여 강력하고 상황에 맞는 답변을 생성할 수 있는 마법 같은 구조입니다.

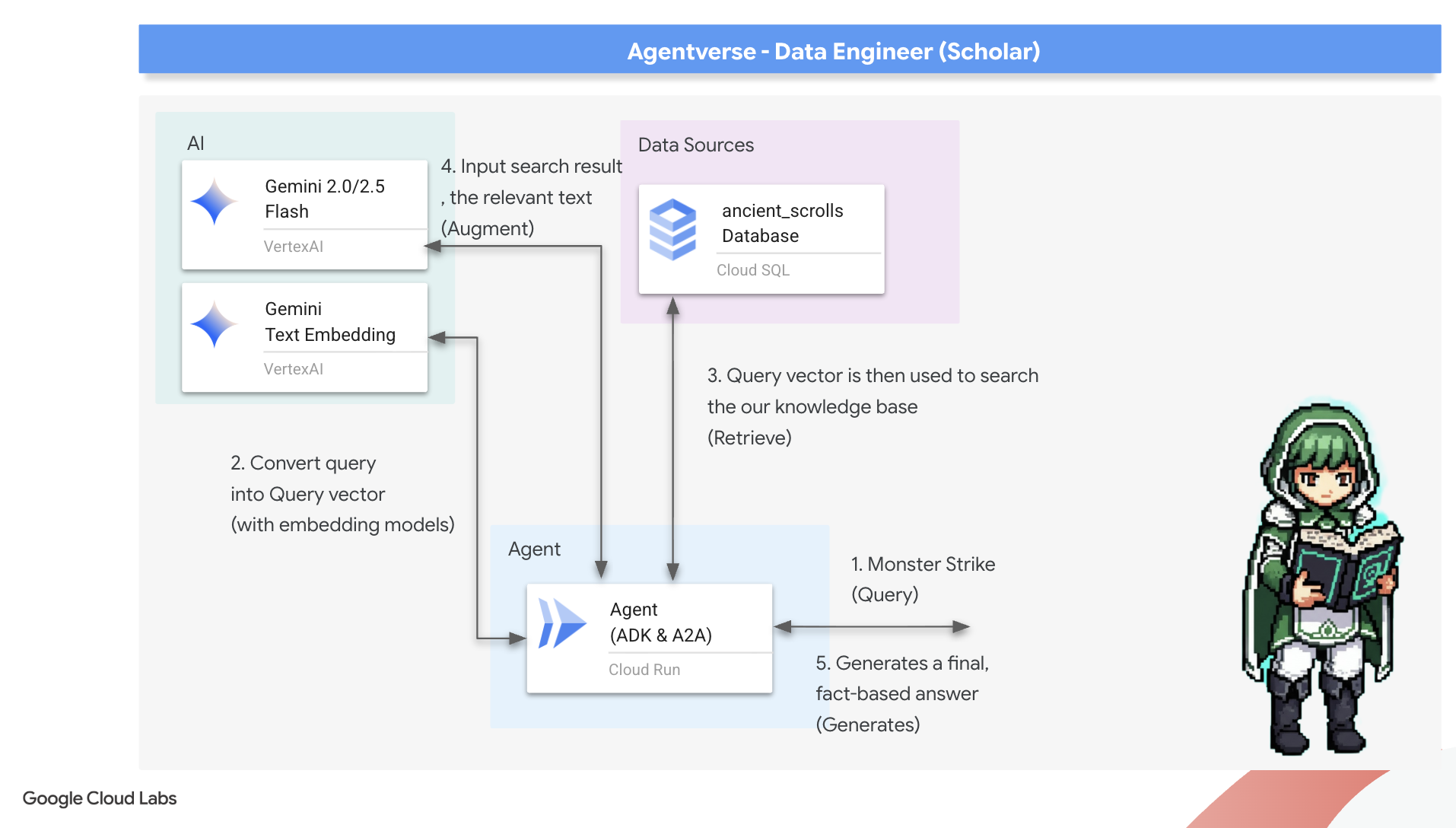
첫 번째 룬: 질문 증류 주문
에이전트가 Grimoire를 검색하려면 먼저 질문의 요점을 이해해야 합니다. 텍스트의 간단한 문자열은 벡터 기반 Spellbook에 의미가 없습니다. 상담사는 먼저 질문을 가져와 동일한 Gemini 모델을 사용하여 질문 벡터로 추출해야 합니다.
👉✏️ Cloud Shell 편집기에서 ~~/agentverse-dataengineer/scholar/agent.py 파일로 이동하여 #REPLACE RAG-CONVERT EMBEDDING 주석을 찾아 다음 주문으로 바꿉니다. 사용자의 질문을 마법의 에센스로 바꾸는 방법을 에이전트에게 알려줍니다.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
이제 에이전트는 질문의 요지를 파악했으므로 Grimoire를 참고할 수 있습니다. 이 쿼리 벡터를 pgvector가 적용된 데이터베이스에 제시하고 '내 쿼리의 본질과 가장 유사한 본질을 가진 고대 두루마리를 보여 줘'라는 심오한 질문을 던집니다.
이를 위한 마법은 고차원 공간에서 벡터 간 거리를 계산하는 강력한 룬인 코사인 유사성 연산자 (<=>)입니다.
👉✏️ agent.py에서 #REPLACE RAG-RETRIEVE 주석을 찾아 다음 스크립트로 바꿉니다.
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
마지막 단계는 에이전트에게 이 새롭고 강력한 도구에 대한 액세스 권한을 부여하는 것입니다. 사용 가능한 마법 도구 목록에 grimoire_lookup 함수를 추가합니다.
👉✏️ agent.py에서 #REPLACE-CALL RAG 주석을 찾아 다음 줄로 바꿉니다.
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
이 구성은 에이전트를 활성화합니다.
model="gemini-2.5-flash": 추론 및 텍스트 생성을 위해 에이전트의 '두뇌' 역할을 할 특정 대규모 언어 모델을 선택합니다.name="scholar_agent": 에이전트에 고유한 이름을 할당합니다.instruction="...You are the Scholar...": 시스템 프롬프트로, 구성에서 가장 중요한 부분입니다. 에이전트의 페르소나, 목표, 작업을 완료하기 위해 따라야 하는 정확한 프로세스, 최종 출력에 필요한 형식을 정의합니다.tools=[grimoire_lookup]: 최종 마법 부여입니다. 이를 통해 에이전트가 빌드한grimoire_lookup함수에 액세스할 수 있습니다. 이제 에이전트는 이 도구를 호출하여 데이터베이스에서 정보를 가져올 시기를 지능적으로 결정할 수 있으며, 이는 RAG 패턴의 핵심을 형성합니다.
학자의 시험
👉💻 Cloud Shell 터미널에서 환경을 활성화하고 에이전트 개발 키트의 기본 명령어를 사용하여 Scholar 에이전트를 깨웁니다.
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
'Scholar Agent'가 참여하고 실행 중임을 확인하는 출력이 표시됩니다.
👉💻 이제 에이전트를 테스트해 보세요. 전투 시뮬레이션이 실행 중인 첫 번째 터미널에서 Grimoire의 지혜가 필요한 명령어를 실행합니다.
We've been trapped by 'Hydra of Scope Creep'. Break us out!

터미널에서 로그를 확인합니다. 에이전트가 질문을 받고, 요점을 추출하고, 그라모어를 검색하고, '지연'에 관한 관련 스크롤을 찾아 검색된 지식을 사용하여 강력한 컨텍스트 인식 전략을 수립하는 것을 확인할 수 있습니다.
첫 번째 RAG 에이전트를 어셈블하고 Grimoire의 심오한 지혜를 부여했습니다.
👉💻 터미널에서 Ctrl+C를 눌러 에이전트를 잠시 중지합니다.
Agentverse에 Scholar Sentinel 출시
에이전트가 연구의 통제된 환경에서 지혜를 입증했습니다. 이제 이 요소를 에이전트버스에 출시하여 로컬 구조에서 언제든지 어떤 챔피언이든 호출할 수 있는 영구적인 전투 준비 상태의 요원으로 변신시킬 때가 왔습니다. 이제 에이전트를 Cloud Run에 배포합니다.
👉💻 다음 소환 주문을 실행합니다. 이 스크립트는 먼저 에이전트를 완벽한 골렘 (컨테이너 이미지)으로 빌드하고, Artifact Registry에 저장한 다음, 해당 골렘을 확장 가능하고 안전하며 공개적으로 액세스 가능한 서비스로 배포합니다.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
이제 Scholar Agent가 Agentverse에서 전투 준비가 완료된 라이브 요원이 되었습니다.
비게이머용
9. The Boss Flight
스크롤을 읽고, 의식을 수행하고, 시련을 통과했습니다. 에이전트는 스토리지의 아티팩트가 아니라 Agentverse에서 첫 번째 미션을 기다리는 실제 요원입니다. 강력한 적을 상대로 한 실사격 훈련이라는 마지막 시험을 치를 때가 왔습니다.
이제 전장에 들어가 새로 배치된 섀도우블레이드 요원을 강력한 미니보스인 스태틱의 유령과 대결시킵니다. 이는 에이전트의 핵심 로직부터 라이브 배포까지 작업의 최종 테스트가 됩니다.
에이전트의 로커스 획득
전장에 입장하려면 챔피언의 고유한 서명 (Agent Locus)과 스펙터의 은신처로 향하는 숨겨진 경로 (Dungeon URL)라는 두 가지 열쇠가 있어야 합니다.
👉💻 먼저 Agentverse에서 에이전트의 고유 주소(위치)를 획득합니다. 챔피언을 전장에 연결하는 라이브 엔드포인트입니다.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 다음으로 목적지를 정확히 파악합니다. 이 명령어는 트랜스로케이션 서클의 위치를 보여줍니다. 트랜스로케이션 서클은 스펙터의 도메인으로 들어가는 포털입니다.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
중요: 두 URL을 모두 준비해 두세요. 마지막 단계에서 필요합니다.
스펙터와 대면하기
좌표를 확보했으므로 이제 트랜스로케이션 서클로 이동하여 주문을 시전하여 전투에 참여합니다.
👉 브라우저에서 트랜스로케이션 서클 URL을 열어 크림슨 킵으로 향하는 반짝이는 포털 앞에 서세요.
요새를 뚫으려면 섀도우블레이드의 정수를 포털에 맞추어야 합니다.
- 페이지에서 A2A 엔드포인트 URL이라는 라벨이 지정된 룬 입력 필드를 찾습니다.
- 에이전트 로커스 URL (복사한 첫 번째 URL)을 이 필드에 붙여넣어 챔피언의 시길을 새깁니다.
- '연결'을 클릭하여 순간 이동 마법을 사용해 보세요.
![]()
눈부신 순간이동의 빛이 사라집니다. 더 이상 성소에 있지 않습니다. 공기는 차갑고 날카로운 에너지로 가득합니다. 내 앞에 스펙터가 나타납니다. 스펙터는 쉿소리와 손상된 코드가 소용돌이치는 존재로, 불경한 빛이 던전 바닥에 길고 춤추는 그림자를 드리웁니다. 얼굴은 없지만, 모든 시선이 나에게 고정된 듯한 엄청난 존재감이 느껴집니다.
승리로 가는 유일한 길은 확신의 명확성에 있습니다. 이것은 마음의 전장에서 벌어지는 의지의 대결입니다.
첫 번째 공격을 가할 준비를 하며 앞으로 돌진하자 스펙터가 카운터를 날립니다. 방패를 들지는 않지만, 훈련의 핵심에서 도출된 반짝이는 룬 문자가 담긴 도전 과제를 의식 속으로 직접 던져 줍니다.

이것이 싸움의 본질입니다. 지식이 무기입니다.
- 지금까지 쌓아온 지혜를 바탕으로 대답하면 순수한 에너지로 검이 타올라 스펙터의 방어를 깨고 치명타를 날릴 수 있습니다.
- 하지만 머뭇거리거나 의심이 들어 대답이 흐려지면 무기의 빛이 어두워집니다. 이 공격은 약한 소리를 내며, 피해의 일부만 입힙니다. 더 나쁜 것은 스펙터가 불확실성을 먹고 산다는 것입니다. 스펙터의 타락한 힘은 실수를 할 때마다 커집니다.
챔피언, 코드는 주문서, 로직은 검, 지식은 혼란의 흐름을 되돌릴 방패입니다.
집중. 스트라이크가 참입니다. Agentverse의 운명이 여기에 달려 있습니다.
축하합니다, 학자님.
평가판을 완료했습니다. 데이터 엔지니어링 기술을 숙달하여 원시적이고 혼란스러운 정보를 전체 Agentverse를 지원하는 구조화된 벡터화된 지혜로 변환했습니다.
10. 정리: 학자의 마도서 삭제
학자의 마법책을 숙달하신 것을 축하드립니다. Agentverse를 깨끗하게 유지하고 학습장을 정리하려면 이제 최종 정리 의식을 실행해야 합니다. 이렇게 하면 여정 중에 생성된 모든 리소스가 체계적으로 삭제됩니다.
Agentverse 구성요소 비활성화
이제 RAG 시스템의 배포된 구성요소를 체계적으로 해체합니다.
모든 Cloud Run 서비스 및 Artifact Registry 저장소 삭제
이 명령어는 배포된 Scholar 에이전트와 Dungeon 애플리케이션을 Cloud Run에서 삭제합니다.
👉💻 터미널에서 다음 명령어를 실행합니다.
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
BigQuery 데이터 세트, 모델, 테이블 삭제
이렇게 하면 bestiary_data 데이터 세트, 데이터 세트 내의 모든 테이블, 연결된 연결 및 모델을 비롯한 모든 BigQuery 리소스가 삭제됩니다.
👉💻 터미널에서 다음 명령어를 실행합니다.
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Cloud SQL 인스턴스 삭제
이렇게 하면 데이터베이스와 그 안의 모든 테이블을 포함한 grimoire-spellbook 인스턴스가 삭제됩니다.
👉💻 터미널에서 다음을 실행합니다.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Google Cloud Storage 버킷 삭제
이 명령어는 원시 인텔과 Dataflow 스테이징/임시 파일을 보유한 버킷을 삭제합니다.
👉💻 터미널에서 다음을 실행합니다.
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
로컬 파일 및 디렉터리 정리 (Cloud Shell)
마지막으로 클론된 저장소와 생성된 파일이 Cloud Shell 환경에서 삭제됩니다. 이 단계는 선택사항이지만 작업 디렉터리를 완전히 정리하는 것이 좋습니다.
👉💻 터미널에서 다음을 실행합니다.
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
이제 Agentverse 데이터 엔지니어 여정의 모든 흔적이 성공적으로 삭제되었습니다. 프로젝트가 정리되었으며 다음 모험을 떠날 준비가 되었습니다.