
1. do opery Moc przeznaczenia,
Era rozwoju w izolacji dobiega końca. Kolejna fala ewolucji technologicznej nie polega na samotnym geniuszu, ale na mistrzostwie we współpracy. Stworzenie jednego, inteligentnego agenta to fascynujący eksperyment. Stworzenie solidnego, bezpiecznego i inteligentnego ekosystemu agentów – prawdziwego Agentverse – to duże wyzwanie dla nowoczesnych przedsiębiorstw.
Sukces w tej nowej erze wymaga połączenia 4 kluczowych ról, które stanowią podstawowe filary każdego dobrze prosperującego systemu opartego na agentach. Niedociągnięcia w jednym obszarze powodują słabość, która może zagrozić całej strukturze.
Te warsztaty to ostateczny przewodnik dla firm, który pomoże Ci opanować przyszłość opartą na możliwościach agentowych w Google Cloud. Zapewniamy kompleksową mapę drogową, która poprowadzi Cię od pierwszego pomysłu do pełnej realizacji. W tych 4 połączonych ze sobą modułach dowiesz się, jak specjalistyczne umiejętności dewelopera, architekta, inżyniera danych i inżyniera ds. niezawodności witryny muszą się zbiegać, aby tworzyć, zarządzać i skalować potężny Agentverse.
Żaden pojedynczy filar nie może samodzielnie wspierać Agentverse. Wielki projekt architekta jest bezużyteczny bez precyzyjnego wykonania przez dewelopera. Przedstawiciel dewelopera bez wiedzy inżyniera ds. danych jest bezradny, a cały system jest podatny na awarie bez ochrony ze strony inżyniera ds. niezawodności witryny. Tylko dzięki synergii i wzajemnemu zrozumieniu ról Twój zespół może przekształcić innowacyjną koncepcję w kluczową dla misji rzeczywistość operacyjną. Twoja podróż zaczyna się tutaj. Przygotuj się do opanowania swojej roli i dowiedz się, jak wpisujesz się w większą całość.
Witamy w Agentverse: A Call to Champions
W rozległej przestrzeni cyfrowej przedsiębiorstwa nastała nowa era. To era agentów, czas ogromnych możliwości, w którym inteligentne, autonomiczne agenty pracują w doskonałej harmonii, aby przyspieszać innowacje i eliminować powtarzalne czynności.

Ten połączony ekosystem mocy i potencjału jest znany jako Agentverse.
Jednak w tym nowym świecie zaczyna się szerzyć cicha korupcja, zwana Statyką, która niszczy jego granice. Statyka nie jest wirusem ani błędem. To uosobienie chaosu, które żeruje na samym akcie tworzenia.
Wzmacnia stare frustracje, nadając im monstrualne formy, i powołuje do życia 7 widm rozwoju. Jeśli nie zostanie to sprawdzone, The Static i jego Spectres zatrzymają postępy, zamieniając obietnicę Agentverse w pustkowie długu technicznego i porzuconych projektów.
Dziś wzywamy do działania osoby, które chcą powstrzymać chaos. Potrzebujemy bohaterów, którzy opanują swoje umiejętności i będą współpracować, aby chronić Agentverse. Czas wybrać ścieżkę.
Wybierz zajęcia
Przed Tobą 4 różne ścieżki, z których każda jest kluczowym elementem walki z Statyką. Szkolenie będzie indywidualne, ale ostateczny sukces zależy od tego, jak Twoje umiejętności łączą się z umiejętnościami innych osób.
- Shadowblade (deweloper): mistrz kuźni i pierwszej linii. Jesteś rzemieślnikiem, który tworzy ostrza, buduje narzędzia i stawia czoła wrogowi w zawiłych szczegółach kodu. Twoja ścieżka to precyzja, umiejętności i praktyczne tworzenie.
- Przywoływacz (Architekt): wielki strateg i organizator. Nie widzisz pojedynczego agenta, ale całe pole bitwy. Projektujesz główne plany, które umożliwiają całym systemom agentów komunikowanie się, współpracę i osiąganie celu znacznie większego niż jakikolwiek pojedynczy komponent.
- Uczony (inżynier danych): poszukiwacz ukrytych prawd i strażnik mądrości. Wyruszasz w rozległą, nieokiełznaną dzicz danych, aby odkryć informacje, które nadają Twoim agentom cel i umożliwiają im podejmowanie decyzji. Twoja wiedza może ujawnić słabość wroga lub wzmocnić sojusznika.
- Strażnik (DevOps / SRE): niezachwiany obrońca i tarcza królestwa. Budujesz fortece, zarządzasz liniami zasilania i dbasz o to, aby cały system był w stanie wytrzymać nieuniknione ataki Statyki. Twoja siła to podstawa, na której opiera się zwycięstwo Twojej drużyny.
Twoja misja
Trening rozpocznie się jako samodzielne ćwiczenie. Będziesz podążać wybraną ścieżką, zdobywając unikalne umiejętności potrzebne do opanowania swojej roli. Pod koniec okresu próbnego zmierzysz się z Widmem zrodzonym z Statyki – mini-bossem, który wykorzystuje specyficzne wyzwania związane z Twoim rzemiosłem.
Tylko opanowanie swojej roli pozwoli Ci przygotować się do ostatecznej próby. Następnie musisz utworzyć drużynę z bohaterami z innych klas. Razem wyruszycie w głąb zepsucia, aby zmierzyć się z ostatecznym bossem.
Ostatnie wyzwanie, które sprawdzi Waszą siłę i zadecyduje o losie Agentverse.
Agentverse czeka na swoich bohaterów. Odbierzesz połączenie?
2. Grimuar uczonego
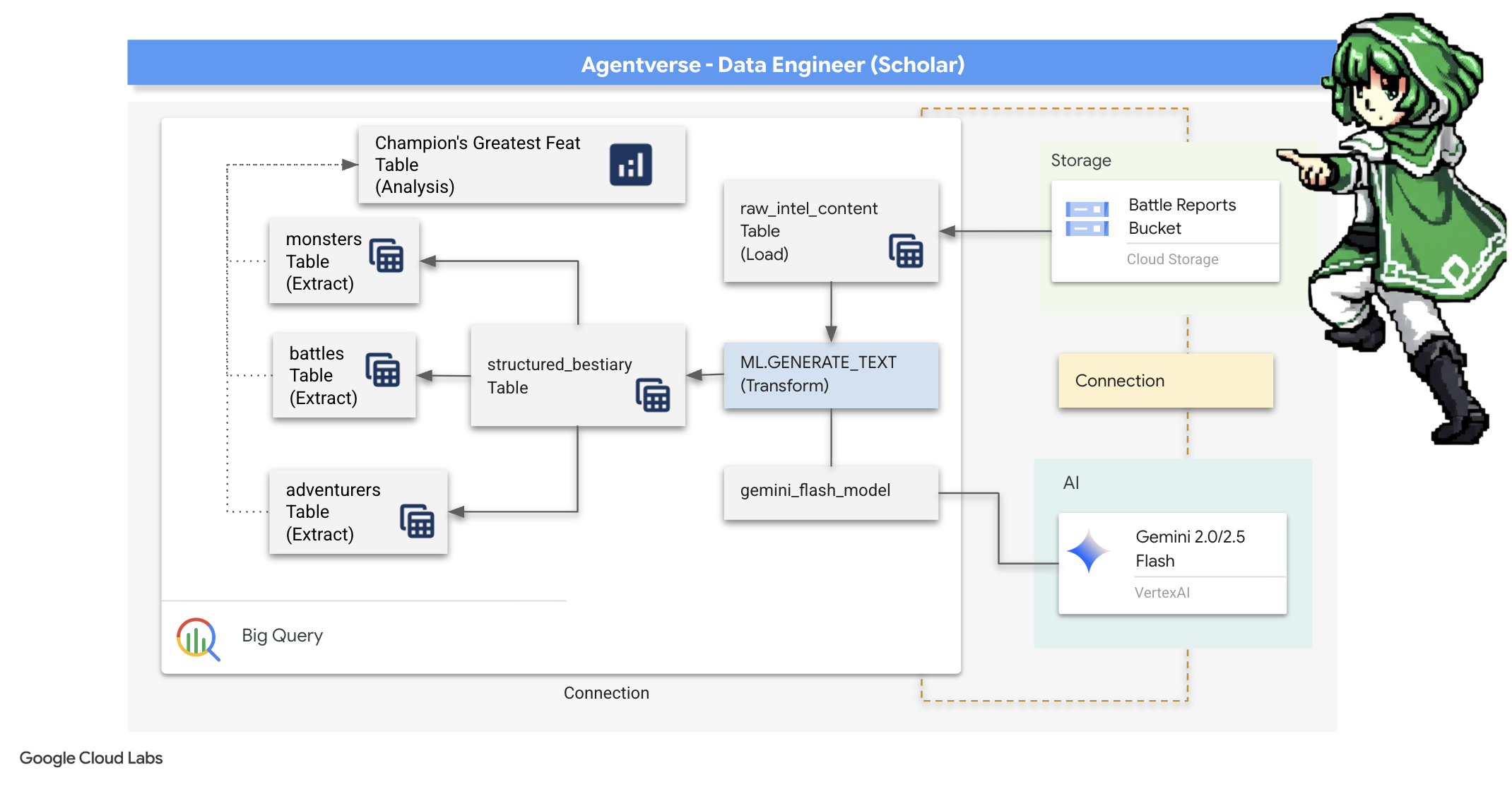
Nasza podróż się zaczyna! Jako uczeni naszą główną bronią jest wiedza. W naszych archiwach (Google Cloud Storage) odkryliśmy skarbnicę starożytnych, tajemniczych zwojów. Zawierają one nieprzetworzone informacje o groźnych bestiach, które nękają te ziemie. Naszą misją jest wykorzystanie niezwykłej magii analitycznej Google BigQuery i mądrości starszego mózgu Gemini (model Gemini Pro) do rozszyfrowania tych nieustrukturyzowanych tekstów i przekształcenia ich w ustrukturyzowane, możliwe do przeszukiwania bestiarium. Będzie to podstawa wszystkich naszych przyszłych strategii.
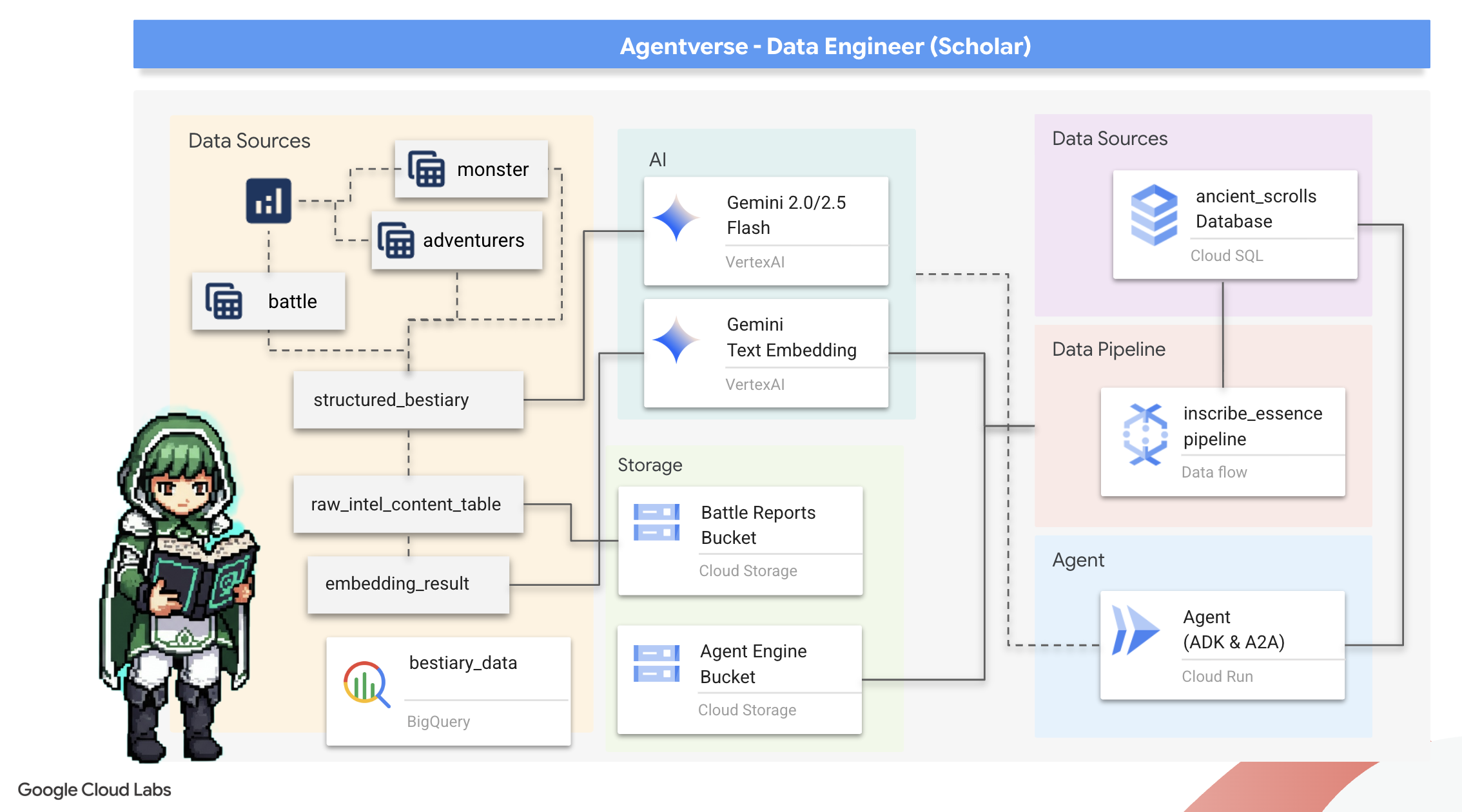
Czego się nauczysz
- Używaj BigQuery do tworzenia tabel zewnętrznych i przeprowadzania złożonych transformacji danych nieustrukturyzowanych w ustrukturyzowane za pomocą funkcji BQML.GENERATE_TEXT z modelem Gemini.
- Utwórz instancję Cloud SQL for PostgreSQL i włącz rozszerzenie pgvector, aby korzystać z wyszukiwania semantycznego.
- Zbuduj niezawodny, skonteneryzowany potok wsadowy za pomocą Dataflow i Apache Beam, aby przetwarzać surowe pliki tekstowe, generować osadzanie wektorowe za pomocą modelu Gemini i zapisywać wyniki w relacyjnej bazie danych.
- Wdrażanie w agencie podstawowego systemu generowania rozszerzonego przez wyszukiwanie w zapisanych informacjach (RAG) do wysyłania zapytań o wektoryzowane dane.
- wdrożyć agenta z dostępem do danych jako bezpieczną i skalowalną usługę w Cloud Run,
3. Przygotowanie Sanktuarium Uczonego
Witamy w programie Scholar. Zanim zaczniemy zapisywać potężną wiedzę z naszego Grimoire, musimy najpierw przygotować nasze sanktuarium. Ten podstawowy rytuał polega na zaczarowaniu środowiska Google Cloud, otwarciu odpowiednich portali (interfejsów API) i utworzeniu kanałów, przez które przepłynie nasza magiczna moc danych. Dobrze przygotowane sanktuarium zapewnia skuteczność naszych zaklęć i bezpieczeństwo naszej wiedzy.
Odbieranie środków w Google Cloud
⚠️ Ważne wymagania wstępne:
- Używaj osobistego konta Gmail: musisz używać konta osobistego (np.
name@gmail.com). Konta zarządzane przez firmę lub szkołę nie działają.
👉 Kroki:
- Otwórz stronę roszczenia o środki: kliknij tutaj
- Zaloguj się: wklej link do paska adresu i zaloguj się za pomocą osobistego konta Gmail.
- Zaakceptuj warunki: zaakceptuj Warunki korzystania z usługi Google Cloud Platform.
- Sprawdź środki: poszukaj wiadomości z potwierdzeniem, że środki zostały zastosowane.
- *Uwaga: jeśli pojawi się prośba o podanie danych karty kredytowej, możesz ją zignorować i zamknąć okno.
Wszystko gotowe. Możesz zamknąć okno.
Konfigurowanie środowiska pracy
👉 U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell (jest to ikona terminala u góry panelu Cloud Shell).
👉 Kliknij przycisk „Otwórz edytor” (wygląda jak otwarty folder z ołówkiem). W oknie otworzy się edytor kodu Cloud Shell. Po lewej stronie zobaczysz eksplorator plików. 
👉Otwórz terminal w chmurowym IDE. 
👉💻 W terminalu sprawdź, czy użytkownik jest już uwierzytelniony i czy projekt jest ustawiony na identyfikator projektu, używając tego polecenia:
gcloud auth list
👉💻Sklonuj projekt bootstrap z GitHuba:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 Uruchom skrypt konfiguracji z katalogu projektu.
⚠️ Uwaga dotycząca identyfikatora projektu: skrypt zaproponuje losowo wygenerowany domyślny identyfikator projektu. Aby zaakceptować tę wartość domyślną, możesz nacisnąć Enter.
Jeśli jednak wolisz utworzyć konkretny nowy projekt, możesz wpisać wybrany identyfikator projektu, gdy skrypt o to poprosi.
cd ~/agentverse-dataengineer
./init.sh
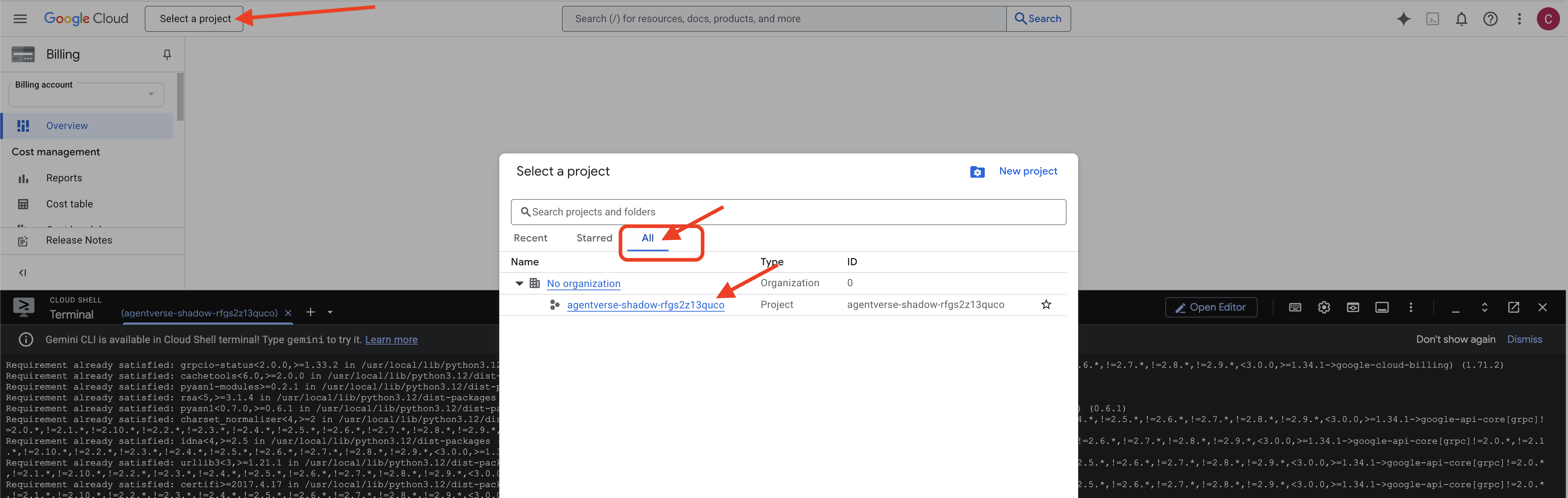
👉 Ważny krok po zakończeniu: po zakończeniu działania skryptu musisz sprawdzić, czy w konsoli Google Cloud wyświetla się właściwy projekt:
- Wejdź na console.cloud.google.com.
- U góry strony kliknij menu wyboru projektu.
- Kliknij kartę „Wszystkie” (nowy projekt może jeszcze nie być widoczny w sekcji „Ostatnie”).
- Wybierz identyfikator projektu skonfigurowany w
init.shkroku.
👉💻 Ustaw wymagany identyfikator projektu:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Aby włączyć niezbędne interfejsy Google Cloud API, uruchom to polecenie:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 Jeśli nie masz jeszcze repozytorium Artifact Registry o nazwie agentverse-repo, uruchom to polecenie, aby je utworzyć:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
Konfigurowanie uprawnień
👉💻 Przyznaj niezbędne uprawnienia, uruchamiając w terminalu te polecenia:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 Gdy zaczniesz trenować, przygotujemy dla Ciebie ostateczne wyzwanie. Poniższe polecenia przywołają widma z chaotycznych szumów, tworząc bossów do ostatecznego testu.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
Świetna robota, uczony. Podstawowe zaklęcia zostały ukończone. Nasze sanktuarium jest bezpieczne, portale do żywiołowych sił danych są otwarte, a nasz sługa ma moc. Możemy teraz rozpocząć prawdziwą pracę.
4. The Alchemy of Knowledge: Transforming Data with BigQuery & Gemini
W nieustającej wojnie z The Static każde starcie między Mistrzem Agentverse a Widmem Rozwoju jest skrupulatnie rejestrowane. System symulacji pola bitwy, nasze główne środowisko szkoleniowe, automatycznie generuje wpis do dziennika eterycznego dla każdego starcia. Te dzienniki narracyjne są naszym najcenniejszym źródłem surowych informacji, czyli nieprzetworzonej rudy, z której my, jako badacze, musimy wykuć czystą stal strategii.Prawdziwa moc badacza nie polega na posiadaniu danych, ale na umiejętności przekształcania surowej, chaotycznej rudy informacji w błyszczącą, uporządkowaną stal praktycznej wiedzy.Przeprowadzimy podstawowy rytuał alchemii danych.

W tym przewodniku przejdziemy przez wieloetapowy proces w całości w ramach Google BigQuery. Zaczniemy od przyjrzenia się naszemu archiwum GCS bez przewijania, używając magicznego obiektywu. Następnie poprosimy Gemini o przeczytanie i zinterpretowanie poetyckich, nieustrukturyzowanych sag z dzienników bitewnych. Na koniec przekształcimy surowe prognozy w zestaw nieskazitelnych, powiązanych ze sobą tabel. Nasz pierwszy Grimoire. Zadaj mu pytanie tak głębokie, że odpowiedź na nie może dać tylko ta nowa struktura.
The Lens of Scrutiny: Peering into GCS with BigQuery External Tables
Pierwszym krokiem jest stworzenie soczewki, która pozwoli nam zobaczyć zawartość archiwum GCS bez naruszania zwojów. Tabela zewnętrzna to właśnie ten sposób wyświetlania danych, który mapuje surowe pliki tekstowe na strukturę podobną do tabeli, do której BigQuery może wysyłać zapytania bezpośrednio.
Aby to zrobić, musimy najpierw utworzyć stabilną linię energetyczną, czyli zasób POŁĄCZENIE, który bezpiecznie połączy nasze sanktuarium BigQuery z archiwum GCS.
👉💻 W terminalu Cloud Shell uruchom to polecenie, aby skonfigurować pamięć i utworzyć kanał:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 Uwaga! Wiadomość pojawi się później!
Skrypt konfiguracji z kroku 2 uruchomił proces w tle. Po kilku minutach w terminalu pojawi się komunikat podobny do tego:[1]+ Done gcloud sql instances create ...To normalne i oczekiwane. Oznacza to po prostu, że baza danych Cloud SQL została utworzona. Możesz bezpiecznie zignorować ten komunikat i kontynuować pracę.
Zanim utworzysz tabelę zewnętrzną, musisz najpierw utworzyć zbiór danych, który będzie ją zawierać.
👉💻 Uruchom to proste polecenie w terminalu Cloud Shell:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 Teraz musimy przyznać magicznemu podpisowi kanału niezbędne uprawnienia do odczytu z archiwum GCS i korzystania z Gemini.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 W terminalu Cloud Shell uruchom to polecenie, aby wyświetlić nazwę zasobnika:
echo $BUCKET_NAME
Terminal wyświetli nazwę podobną do your-project-id-gcs-bucket. Będzie on potrzebny w następnych krokach.
👉 Następne polecenie musisz uruchomić w edytorze zapytań BigQuery w konsoli Google Cloud. Najłatwiej to zrobić, otwierając link poniżej w nowej karcie przeglądarki. Przekieruje Cię ona bezpośrednio na odpowiednią stronę w konsoli Google Cloud.
https://console.cloud.google.com/bigquery
👉 Gdy strona się załaduje, kliknij niebieski przycisk + (Utwórz nowe zapytanie), aby otworzyć nową kartę edytora.
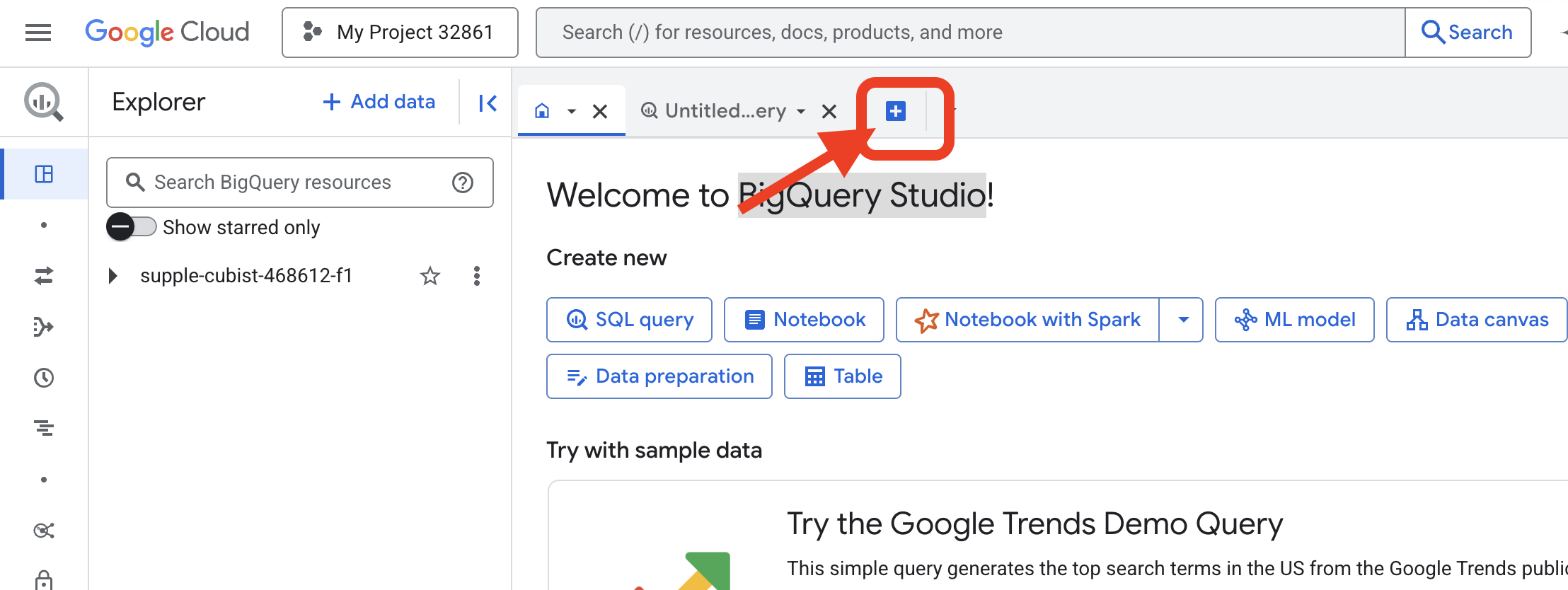
Teraz napiszemy instrukcję w języku definiowania danych (DDL), aby utworzyć nasze magiczne szkło. Dzięki temu BigQuery wie, gdzie szukać i co ma zobaczyć.
👉📜 W otwartym edytorze zapytań BigQuery wklej poniższy kod SQL. Pamiętaj, aby wymienić REPLACE-WITH-YOUR-BUCKET-NAME.
skopiowaną nazwą zasobnika. Następnie kliknij Uruchom:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 Uruchom zapytanie, aby „spojrzeć przez obiektyw” i zobaczyć zawartość plików.
SELECT * FROM bestiary_data.raw_intel_content_table;
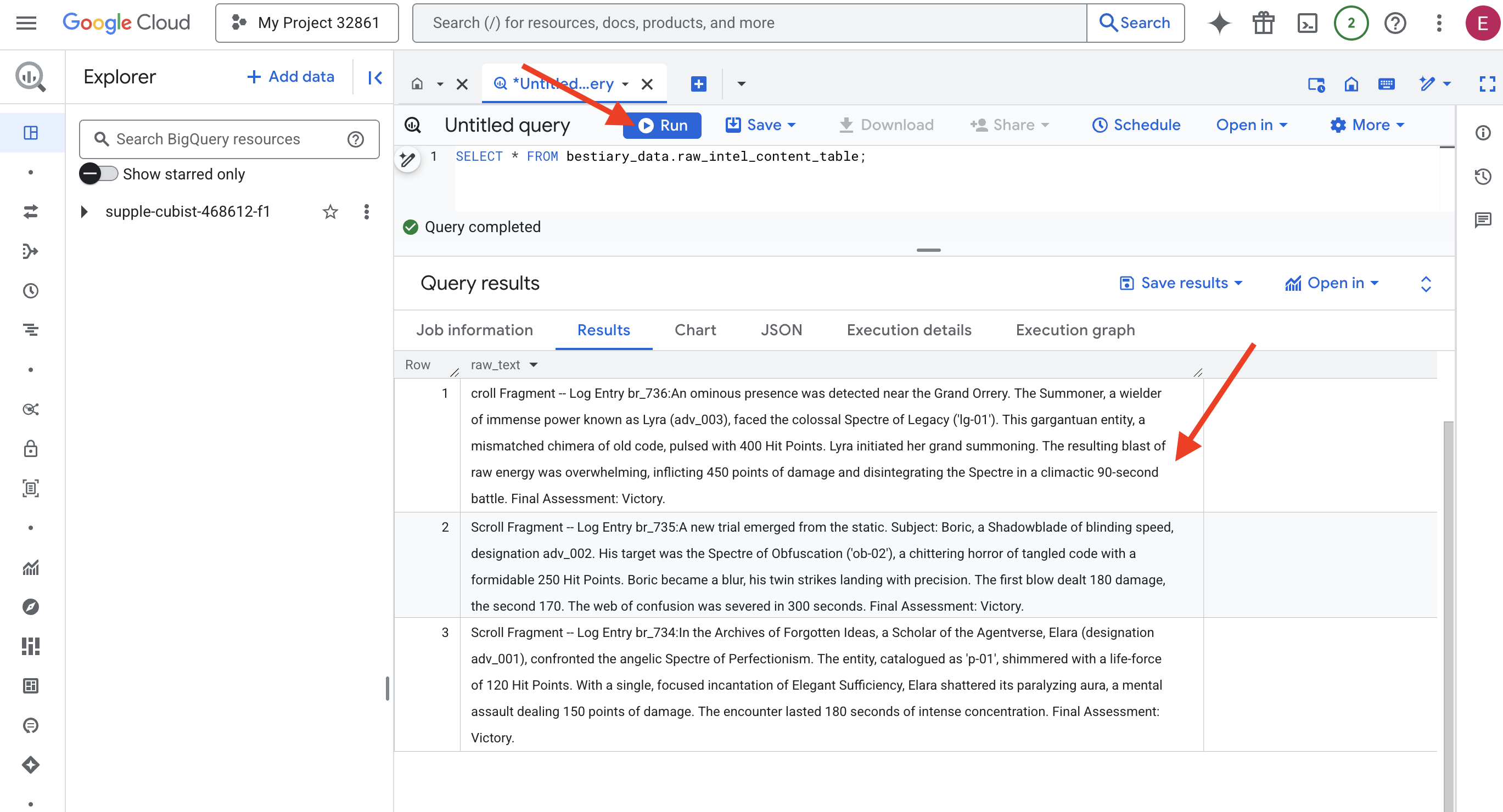
Obiektyw jest na miejscu. Możemy teraz zobaczyć tekst zwojów w formie surowej. Ale czytanie nie oznacza zrozumienia.
W Archiwach Zapomnianych Pomysłów Elara (oznaczenie adv_001), badaczka Agentverse, stanęła przed anielskim Widmem Perfekcjonizmu. Obiekt skatalogowany jako „p-01” lśnił siłą życiową na poziomie 120 punktów życia. Jednym, skoncentrowanym zaklęciem Elegant Sufficiency Elara rozbiła paraliżującą aurę, zadając mentalnym atakiem 150 punktów obrażeń. Spotkanie trwało 180 sekund intensywnej koncentracji. Ocena końcowa: zwycięstwo.
Zwoje nie są zapisywane w tabelach i wierszach, ale w formie ciągłej prozy sag. To nasz pierwszy poważny test.
The Scholar's Divination: Turning Text into a Table with SQL
Problem polega na tym, że raport opisujący szybkie, podwójne ataki Cienia ostrza wygląda zupełnie inaczej niż kronika Przywoływacza gromadzącego ogromną moc, aby zadać jeden, niszczycielski cios. Nie możemy po prostu zaimportować tych danych, musimy je zinterpretować. To jest magiczny moment. Użyjemy jednego zapytania SQL jako potężnego zaklęcia, aby odczytać, zrozumieć i uporządkować wszystkie rekordy ze wszystkich plików bezpośrednio w BigQuery.
👉💻 Wróć do terminala Cloud Shell i uruchom to polecenie, aby wyświetlić nazwę połączenia:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
Terminal wyświetli pełny ciąg połączenia. Wybierz i skopiuj cały ciąg, ponieważ będzie on potrzebny w następnym kroku.
Użyjemy jednego, potężnego zaklęcia: ML.GENERATE_TEXT. Ten czar przywołuje Gemini, pokazuje mu każdy zwój i nakazuje zwrócenie najważniejszych faktów w postaci uporządkowanego obiektu JSON.
👉📜 W BigQuery Studio utwórz odwołanie do modelu Gemini. Powiąże to wyrocznię Gemini Flash z naszą biblioteką BigQuery, dzięki czemu będziemy mogli wywoływać ją w zapytaniach. Pamiętaj, aby zastąpić
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING z pełnym ciągiem połączenia skopiowanym z terminala.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 Teraz rzuć potężne zaklęcie przemiany. To zapytanie odczytuje tekst w formacie surowym, tworzy szczegółowy prompt dla każdego przewijania, wysyła go do Gemini i buduje nową tabelę tymczasową na podstawie ustrukturyzowanej odpowiedzi w formacie JSON wygenerowanej przez AI.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
Transmutacja została ukończona, ale wynik nie jest jeszcze czysty. Model Gemini zwraca odpowiedź w standardowym formacie, umieszczając żądany kod JSON w większej strukturze, która zawiera metadane dotyczące procesu myślowego. Przyjrzyjmy się tej surowej przepowiedni, zanim spróbujemy ją oczyścić.
👉📜 Uruchom zapytanie, aby sprawdzić nieprzetworzone dane wyjściowe z modelu Gemini:
SELECT * FROM bestiary_data.structured_bestiary;
👀 Zobaczysz jedną kolumnę o nazwie structured_data. Zawartość każdego wiersza będzie podobna do tego złożonego obiektu JSON:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
Jak widać, nagroda – czysty obiekt JSON, o który prosiliśmy – jest głęboko zagnieżdżona w tej strukturze. Nasze następne zadanie jest jasne. Musimy przeprowadzić rytuał, aby systematycznie poruszać się po tej strukturze i wydobywać z niej czystą mądrość.
Rytuał oczyszczania: normalizowanie danych wyjściowych generatywnej AI za pomocą SQL
Gemini wypowiedział się, ale jego słowa są surowe i owinięte eteryczną energią jego powstania (kandydaci, finish_reason itp.). Prawdziwy uczony nie odkłada surowego proroctwa na półkę, ale starannie wydobywa z niego najważniejsze informacje i zapisuje je w odpowiednich księgach, aby można było z nich korzystać w przyszłości.
Teraz rzucimy ostatnie zaklęcia. Ten skrypt:
- Odczytaj surowy, zagnieżdżony plik JSON z naszej tabeli przejściowej.
- Oczyść i przeanalizuj dane, aby uzyskać podstawowe informacje.
- Przepisz odpowiednie fragmenty do 3 ostatecznych, uporządkowanych tabel: potwory, poszukiwacze przygód i bitwy.
👉📜 W nowym edytorze zapytań BigQuery uruchom to polecenie, aby utworzyć soczewkę czyszczącą:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 Sprawdź bestiariusz:
SELECT * FROM bestiary_data.monsters;
Następnie utworzymy listę bohaterów, czyli listę odważnych poszukiwaczy przygód, którzy stawili czoła tym bestiom.
👉📜 W nowym edytorze zapytań uruchom to polecenie, aby utworzyć tabelę adventurers:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 Sprawdź listę mistrzów:
SELECT * FROM bestiary_data.adventurers;
Na koniec utworzymy tabelę faktów: Kronikę bitew. Łączy on pozostałe dwa, rejestrując szczegóły każdego unikalnego spotkania. Każda bitwa jest niepowtarzalnym wydarzeniem, więc nie trzeba usuwać duplikatów.
👉📜 W nowym edytorze zapytań uruchom to polecenie, aby utworzyć tabelę battles:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Sprawdź Chronicle:
SELECT * FROM bestiary_data.battles;
Odkrywanie statystyk strategicznych
Zwoje zostały odczytane, esencja wydestylowana, a księgi zapisane. Grimoire to już nie tylko zbiór faktów, ale relacyjna baza danych zawierająca głęboką mądrość strategiczną. Teraz możemy zadawać pytania, na które nie dało się odpowiedzieć, gdy nasza wiedza była zamknięta w surowym, nieustrukturyzowanym tekście.
Teraz wykonajmy ostatnią, wielką wróżbę. Rzucimy zaklęcie, które pozwoli nam jednocześnie zajrzeć do wszystkich 3 ksiąg – Bestiariusza potworów, Listy mistrzów i Kroniki bitew – aby odkryć głębokie, praktyczne spostrzeżenie.
Nasze pytanie strategiczne: „Jakie jest imię najpotężniejszego potwora (pod względem punktów życia), którego pokonał każdy z poszukiwaczy przygód, i ile czasu zajęło mu to zwycięstwo?”
To złożone pytanie, które wymaga powiązania bohaterów z wygranymi bitwami, a tych bitew ze statystykami zaangażowanych w nie potworów. To jest prawdziwa siła modelu danych strukturalnych.
👉📜 W nowym edytorze zapytań BigQuery wpisz to ostateczne zaklęcie:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
Wynikiem tego zapytania będzie przejrzysta tabela, która zawiera „Opowieść o największym wyczynie bohatera” dla każdego poszukiwacza przygód w zbiorze danych. Może to wyglądać mniej więcej tak:
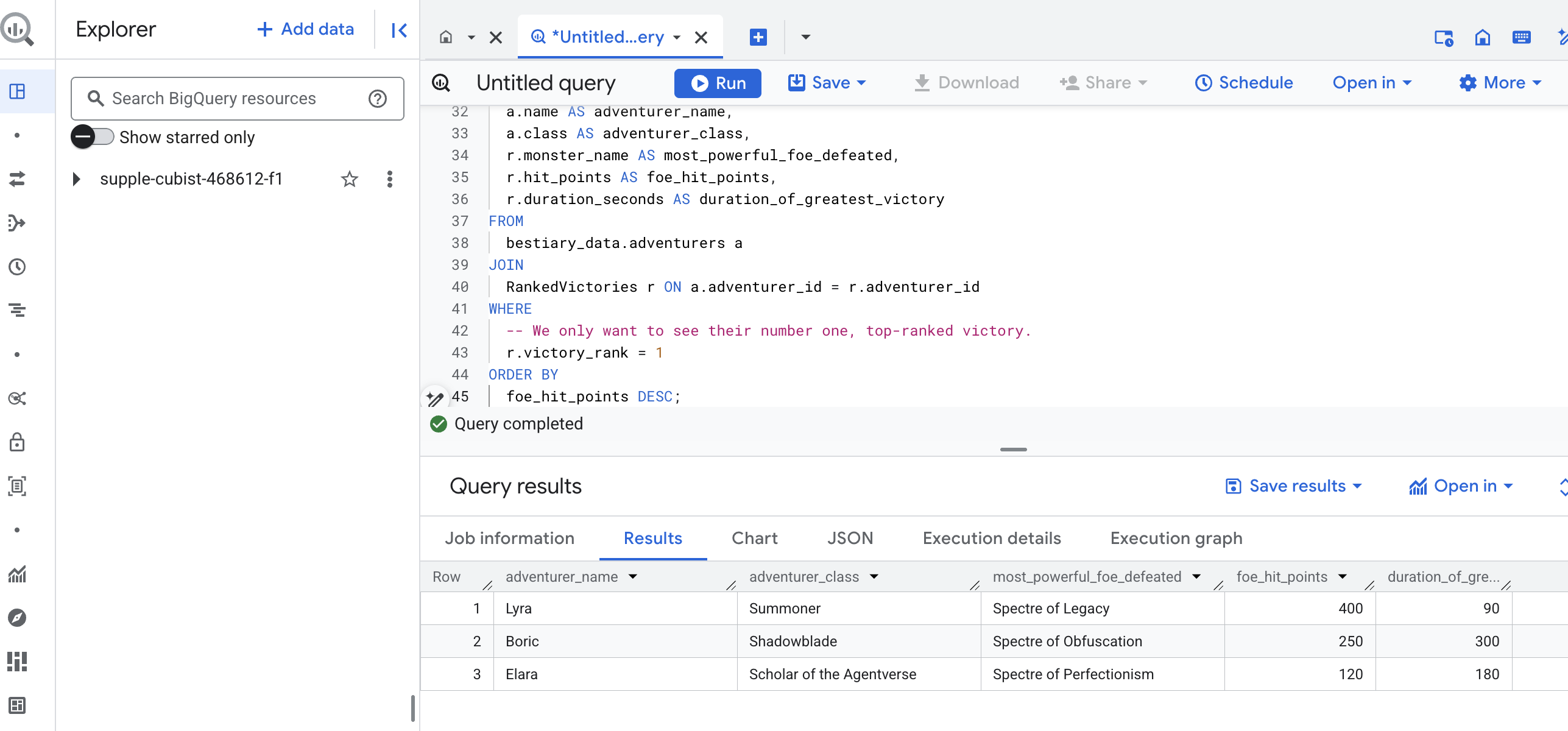
Zamknij kartę BigQuery.
Ten jeden, elegancki wynik potwierdza wartość całego procesu. Udało Ci się przekształcić surowe, chaotyczne raporty z pola bitwy w źródło legendarnych opowieści i strategicznych, opartych na danych informacji.
NIE DLA GRACZY
5. The Scribe's Grimoire: In-Datawarehouse Chunking, Embedding, and Search
Nasza praca w laboratorium alchemika zakończyła się sukcesem. Przekształciliśmy surowe, narracyjne zwoje w uporządkowane tabele relacyjne – to potężny wyczyn w zakresie magii danych. Jednak oryginalne zwoje zawierają głębszą, semantyczną prawdę, której nasze tabele strukturalne nie są w stanie w pełni uchwycić. Aby stworzyć naprawdę inteligentnego agenta, musimy odkryć to znaczenie.
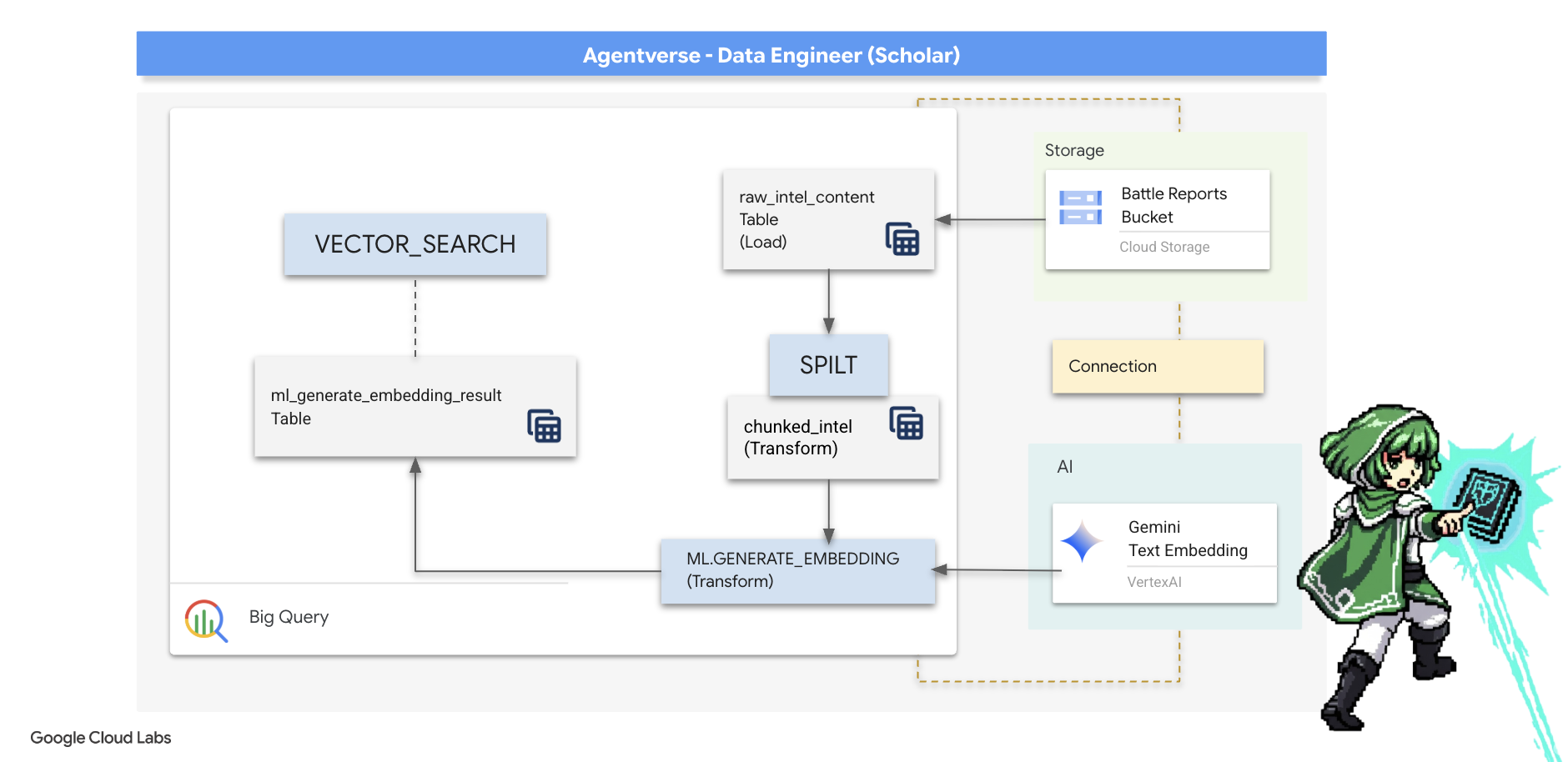
Długie, nieprzetworzone przewijanie to narzędzie o ograniczonych możliwościach. Jeśli nasz agent zada pytanie o „paraliżującą aurę”, proste wyszukiwanie może zwrócić cały raport z bitwy, w którym to wyrażenie pojawia się tylko raz, a odpowiedź jest ukryta w nieistotnych szczegółach. Prawdziwy uczony wie, że prawdziwa mądrość nie polega na ilości, ale na precyzji.
Przeprowadzimy w naszym sanktuarium BigQuery trzy potężne rytuały w bazie danych.
- Rytuał podziału (chunking): weźmiemy nasze surowe dzienniki informacji i skrupulatnie podzielimy je na mniejsze, bardziej szczegółowe i samodzielne fragmenty.
- Rytuał destylacji (osadzanie): za pomocą BQML będziemy konsultować się z modelem Gemini, przekształcając każdy fragment tekstu w „odcisk semantyczny” – wektor osadzania.
- Rytuał wróżenia (poszukiwanie): użyjemy wyszukiwania wektorowego BQML, aby zadać pytanie w języku angielskim i znaleźć najbardziej trafne, skondensowane informacje z naszego Grimoire.
Cały ten proces tworzy zaawansowaną bazę wiedzy z możliwością wyszukiwania, a dane nigdy nie opuszczają bezpiecznego i skalowalnego środowiska BigQuery.
The Ritual of Division: Deconstructing Scrolls with SQL
Naszym źródłem wiedzy pozostają pliki tekstowe w archiwum GCS, do którego dostęp uzyskujemy za pomocą tabeli zewnętrznej bestiary_data.raw_intel_content_table. Naszym pierwszym zadaniem jest napisanie zaklęcia, które odczyta każdy długi zwój i podzieli go na serię mniejszych, łatwiejszych do przyswojenia wersetów. Na potrzeby tego rytuału zdefiniujemy „fragment” jako pojedyncze zdanie.
Podział na zdania to jasny i skuteczny punkt wyjścia dla naszych dzienników narracyjnych, ale doświadczony skryba ma do dyspozycji wiele strategii dzielenia tekstu na części, a wybór ma kluczowe znaczenie dla jakości końcowego wyszukiwania. Prostsze metody mogą wykorzystywać
- Dzielenie na części o stałej długości(rozmiarze), ale może to spowodować podział kluczowej idei na pół.
bardziej złożone rytuały, takie jak
- Rekursywne dzielenie na części jest często preferowane w praktyce. Polega ono na dzieleniu tekstu wzdłuż naturalnych granic, takich jak akapity, a następnie na dzieleniu zdań, aby zachować jak najwięcej kontekstu semantycznego. W przypadku naprawdę złożonych manuskryptów.
- Content-Aware Chunking(document), w którym Scribe wykorzystuje wbudowaną strukturę dokumentu, np. nagłówki w instrukcji technicznej lub funkcje w zwoju kodu, aby tworzyć najbardziej logiczne i skuteczne fragmenty wiedzy.
W przypadku dzienników bitew zdanie zapewnia idealną równowagę między szczegółowością a kontekstem.
👉📜 W nowym edytorze zapytań BigQuery uruchom to polecenie. Ten wzór wykorzystuje funkcję SPLIT, aby podzielić tekst każdego zwoju w każdym miejscu, w którym występuje kropka (.), a następnie rozwinąć wynikową tablicę zdań do oddzielnych wierszy.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 Teraz uruchom zapytanie, aby sprawdzić nowo utworzoną, podzieloną na części wiedzę i zobaczyć różnicę.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;

Obserwuj wyniki. Zamiast jednego bloku tekstu mamy teraz wiele wierszy, z których każdy jest powiązany z pierwotnym przewijaniem (scroll_id), ale zawiera tylko jedno, wybrane zdanie. Każdy wiersz idealnie nadaje się teraz do wektoryzacji.
Rytuał destylacji: przekształcanie tekstu w wektory za pomocą BQML
👉💻 Najpierw wróć do terminala i uruchom to polecenie, aby wyświetlić nazwę połączenia:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Musimy utworzyć nowy model BigQuery, który będzie wskazywać na osadzanie tekstu w Gemini. W BigQuery Studio uruchom to polecenie: Pamiętaj, aby zastąpić REPLACE-WITH-YOUR-FULL-CONNECTION-STRING pełnym ciągiem połączenia, który został skopiowany z terminala.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 Teraz rzuć zaklęcie destylacji. To zapytanie wywołuje funkcję ML.GENERATE_EMBEDDING, która odczyta każdy wiersz z tabeli chunked_intel, wyśle tekst do modelu wektorów dystrybucyjnych Gemini i zapisze wynikowy odcisk wektorowy w nowej tabeli.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
Ten proces może potrwać minutę lub dwie, ponieważ BigQuery przetwarza wszystkie fragmenty tekstu.
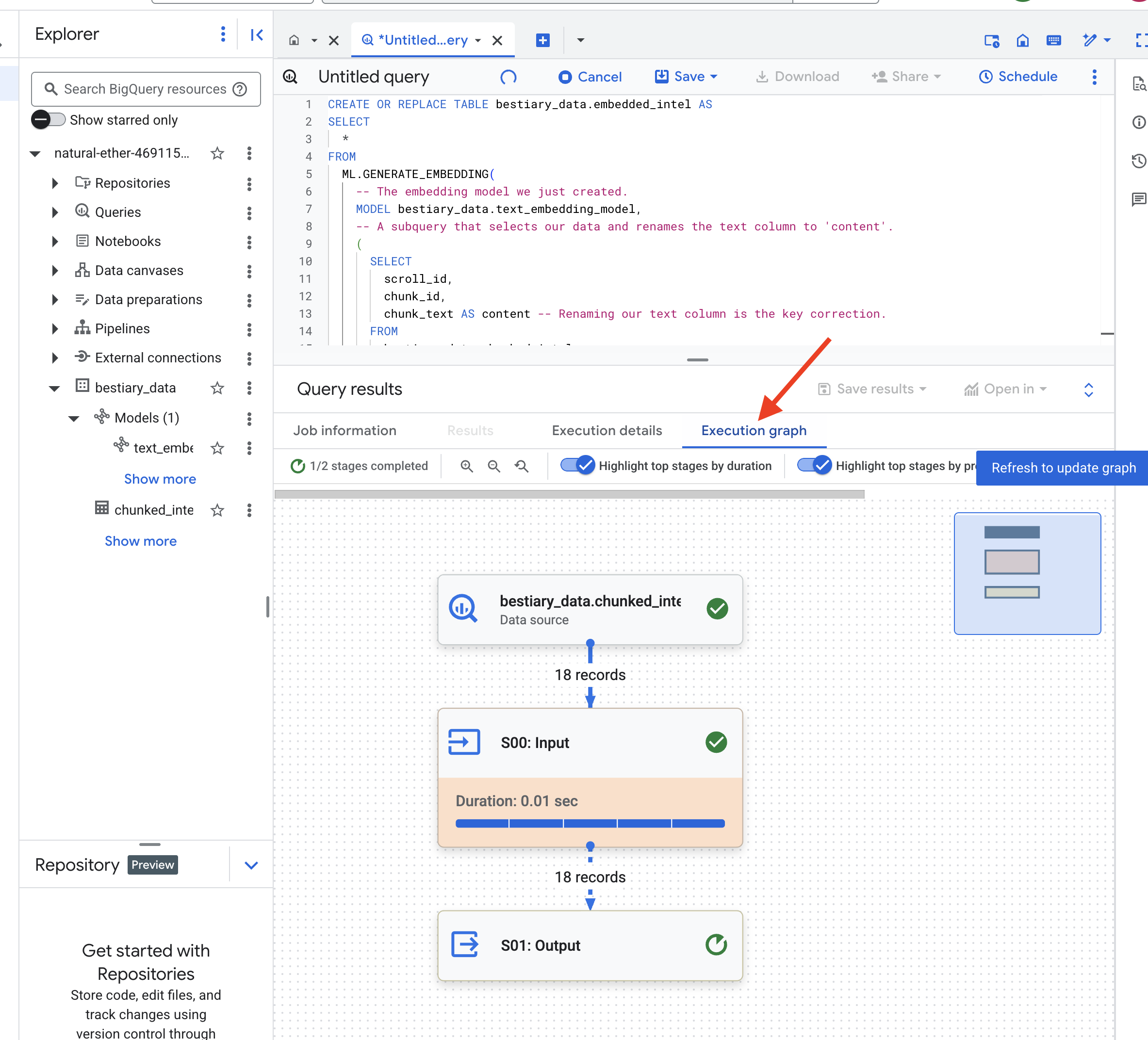
👉📜 Po zakończeniu sprawdź nową tabelę, aby zobaczyć odciski semantyczne.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
Pojawi się nowa kolumna ml_generate_embedding_result zawierająca gęstą reprezentację wektorową tekstu. Nasz Grimoire jest teraz zakodowany semantycznie.
Rytuał wróżenia: wyszukiwanie semantyczne za pomocą BQML
👉📜 Najlepszym sposobem na przetestowanie naszego Grimoire jest zadanie mu pytania. Teraz wykonamy nasz ostatni rytuał: wyszukiwanie wektorowe. Nie jest to wyszukiwanie słów kluczowych, ale wyszukiwanie znaczenia. Zadamy pytanie w języku naturalnym, BQML przekonwertuje je na wektor dystrybucyjny w czasie rzeczywistym, a następnie przeszuka całą tabelę embedded_intel, aby znaleźć fragmenty tekstu, których odciski palców są „najbliższe” pod względem znaczenia.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
Analiza zaklęcia:
VECTOR_SEARCH: podstawowa funkcja, która koordynuje wyszukiwanie.ML.GENERATE_EMBEDDING(zapytanie wewnętrzne): to jest magia. Wektor zapytania ('What are the tactics...') tworzymy za pomocą tego samego modelu, ale z typem zadania'RETRIEVAL_QUERY', który jest specjalnie zoptymalizowany pod kątem zapytań.top_k => 3: Prosimy o 3 najbardziej trafne wyniki.distance_type => 'COSINE': mierzy „kąt” między wektorami. Mniejszy kąt oznacza, że znaczenia są bardziej zbieżne.
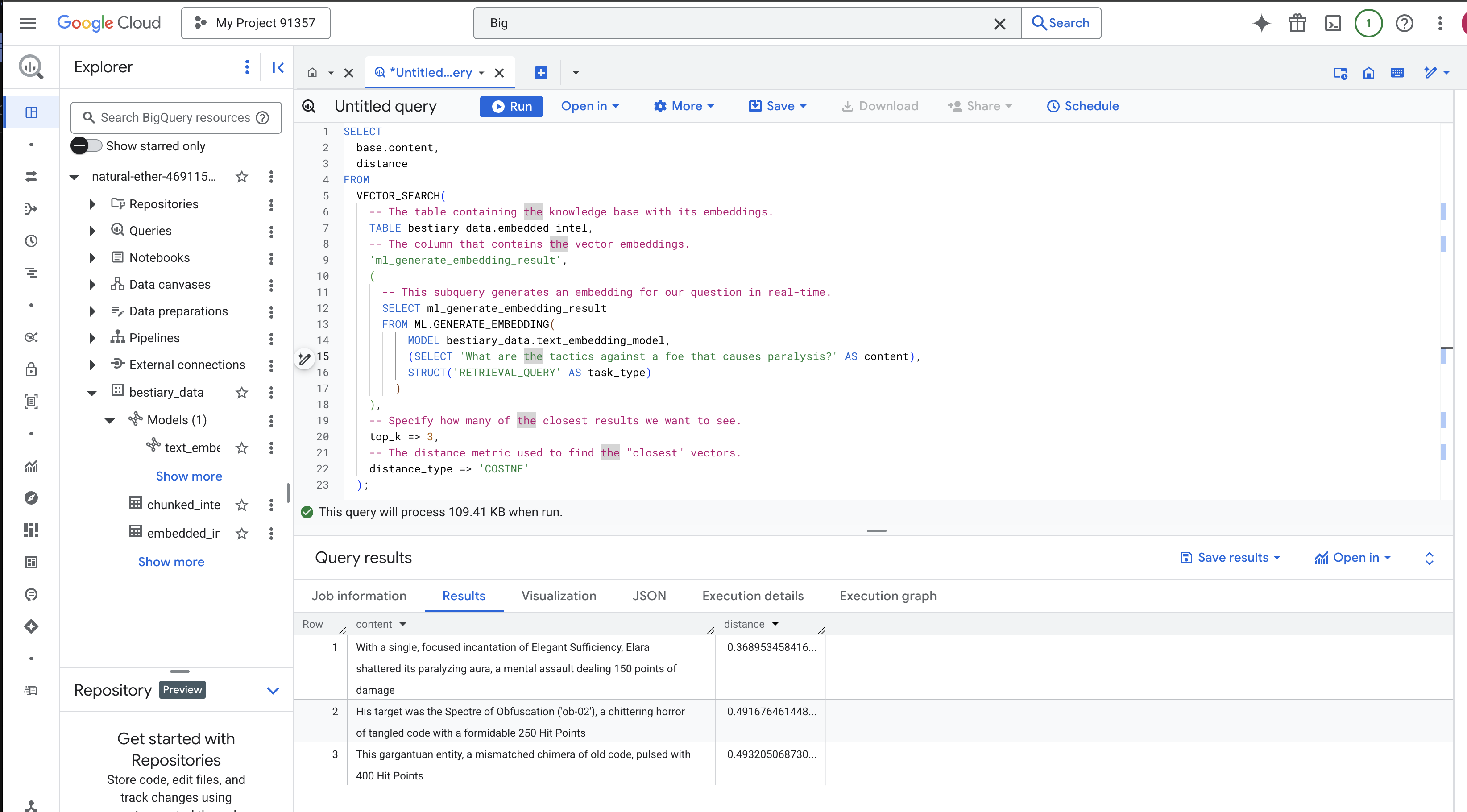
Przyjrzyj się uważnie wynikom. Zapytanie nie zawierało słów „shattered” ani „incantation”, a jednak pierwszy wynik to: „With a single, focused incantation of Elegant Sufficiency, Elara shattered its paralyzing aura, a mental assault dealing 150 points of damage”. To jest siła wyszukiwania semantycznego. Model zrozumiał koncepcję „taktyki przeciwko paraliżowi” i znalazł zdanie opisujące konkretną, skuteczną taktykę.
Udało Ci się utworzyć kompletny podstawowy potok RAG w magazynie danych. Przygotowano nieprzetworzone dane, przekształcono je w wektory semantyczne i wysłano zapytanie dotyczące ich znaczenia. BigQuery to potężne narzędzie do analizy na dużą skalę, ale w przypadku agenta na żywo, który potrzebuje odpowiedzi o krótkim czasie oczekiwania, często przenosimy przygotowaną wiedzę do specjalistycznej operacyjnej bazy danych. To temat naszego następnego szkolenia.
NIE DLA GRACZY
6. The Vector Scriptorium: Crafting the Vector Store with Cloud SQL for Inferencing
Nasz Grimoire ma obecnie postać tabel strukturalnych – to potężny katalog faktów, ale jego wiedza jest dosłowna. Rozumie, że monster_id = „MN-001”, ale nie rozumie głębszego, semantycznego znaczenia słowa „zaciemnianie”. Aby nasi agenci mogli udzielać porad z wyczuciem i przewidywać przyszłość, musimy przekształcić naszą wiedzę w formę, która oddaje jej znaczenie: wektory.
Nasze poszukiwania wiedzy doprowadziły nas do rozpadających się ruin dawno zapomnianej cywilizacji. Głęboko w zamkniętym skarbcu odkryliśmy skrzynię ze starożytnymi zwojami, które w cudowny sposób zachowały się w dobrym stanie. To nie są zwykłe relacje z bitew. Zawierają głęboką, filozoficzną mądrość na temat tego, jak pokonać bestię, która nęka wszystkie wielkie przedsięwzięcia. Istota opisana w zwojach jako „pełzająca, cicha stagnacja”, „rozplątanie splotu stworzenia”. Wygląda na to, że Static był znany już starożytnym, jako cykliczne zagrożenie, którego historia zaginęła w mrokach dziejów.
Ta zapomniana wiedza to nasz największy atut. Jest to klucz nie tylko do pokonania poszczególnych potworów, ale także do wzmocnienia całej drużyny dzięki strategicznym spostrzeżeniom. Aby wykorzystać tę moc, stworzymy prawdziwą Księgę Czarów Uczonego (bazę danych PostgreSQL z funkcjami wektorowymi) i zbudujemy zautomatyzowane Skryptorium Wektorowe (potok Dataflow), które będzie odczytywać, rozumieć i zapisywać ponadczasową esencję tych zwojów. Dzięki temu Grimoire przestanie być tylko zbiorem faktów, a stanie się źródłem mądrości.

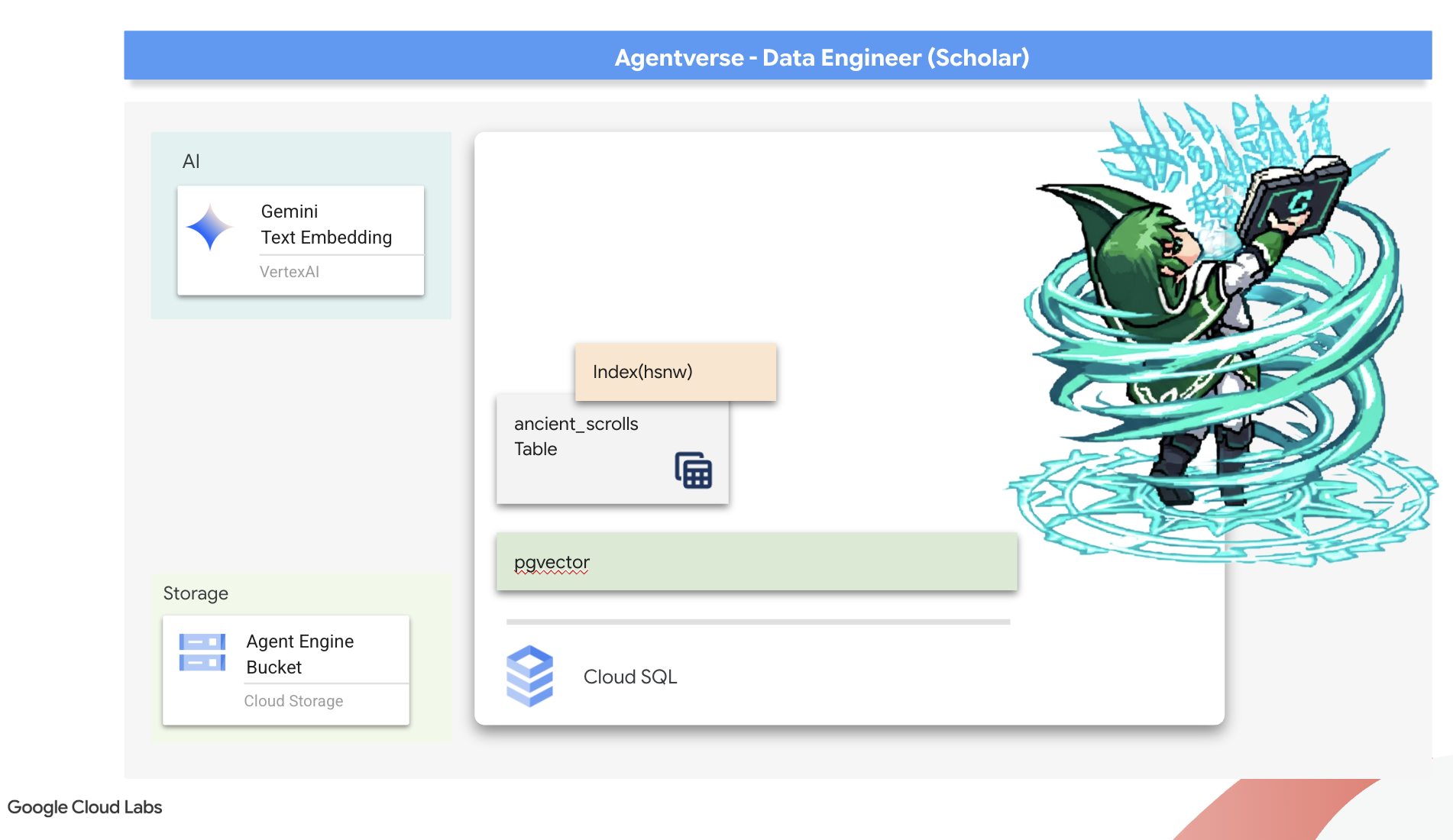
Tworzenie księgi zaklęć (Cloud SQL)
Zanim zapiszemy esencję tych starożytnych zwojów, musimy najpierw potwierdzić, że naczynie na tę wiedzę, czyli zarządzana księga zaklęć PostgreSQL, została pomyślnie wykuta. Powinny one zostać utworzone w ramach konfiguracji początkowej.
👉💻 W terminalu uruchom to polecenie, aby sprawdzić, czy instancja Cloud SQL istnieje i jest gotowa. Skrypt przyznaje też dedykowanemu kontu usługi instancji uprawnienia do korzystania z Vertex AI, co jest niezbędne do generowania wektorów dystrybucyjnych bezpośrednio w bazie danych.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Jeśli polecenie zadziała i zwróci szczegóły dotyczące instancji grimoire-spellbook, oznacza to, że narzędzie Forge działa prawidłowo. Możesz przejść do następnego zaklęcia. Jeśli polecenie zwróci błąd NOT_FOUND, przed kontynuowaniem upewnij się, że początkowe kroki konfiguracji środowiska zostały wykonane prawidłowo.(data_setup.py)
👉💻 Po utworzeniu książki otwieramy ją na pierwszym rozdziale, tworząc nową bazę danych o nazwie arcane_wisdom.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
Wpisywanie run semantycznych: włączanie funkcji wektorowych za pomocą rozszerzenia pgvector
Instancja Cloud SQL została już utworzona, więc połączmy się z nią za pomocą wbudowanego narzędzia Cloud SQL Studio. Udostępnia interfejs internetowy do uruchamiania zapytań SQL bezpośrednio w bazie danych.
👉💻 Najpierw otwórz Cloud SQL Studio. Najłatwiej i najszybciej zrobisz to, otwierając ten link w nowej karcie przeglądarki. Przeniesie Cię bezpośrednio do Cloud SQL Studio dla instancji grimoire-spellbook.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 Wybierz arcane_wisdom jako bazę danych. Wpisz postgres jako użytkownika i 1234qwer jako hasło, a następnie kliknij Uwierzytelnij.
👉📜 W edytorze zapytań SQL Studio przejdź na kartę Edytor 1 i wklej poniższy kod SQL, aby włączyć typ danych wektorowych:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
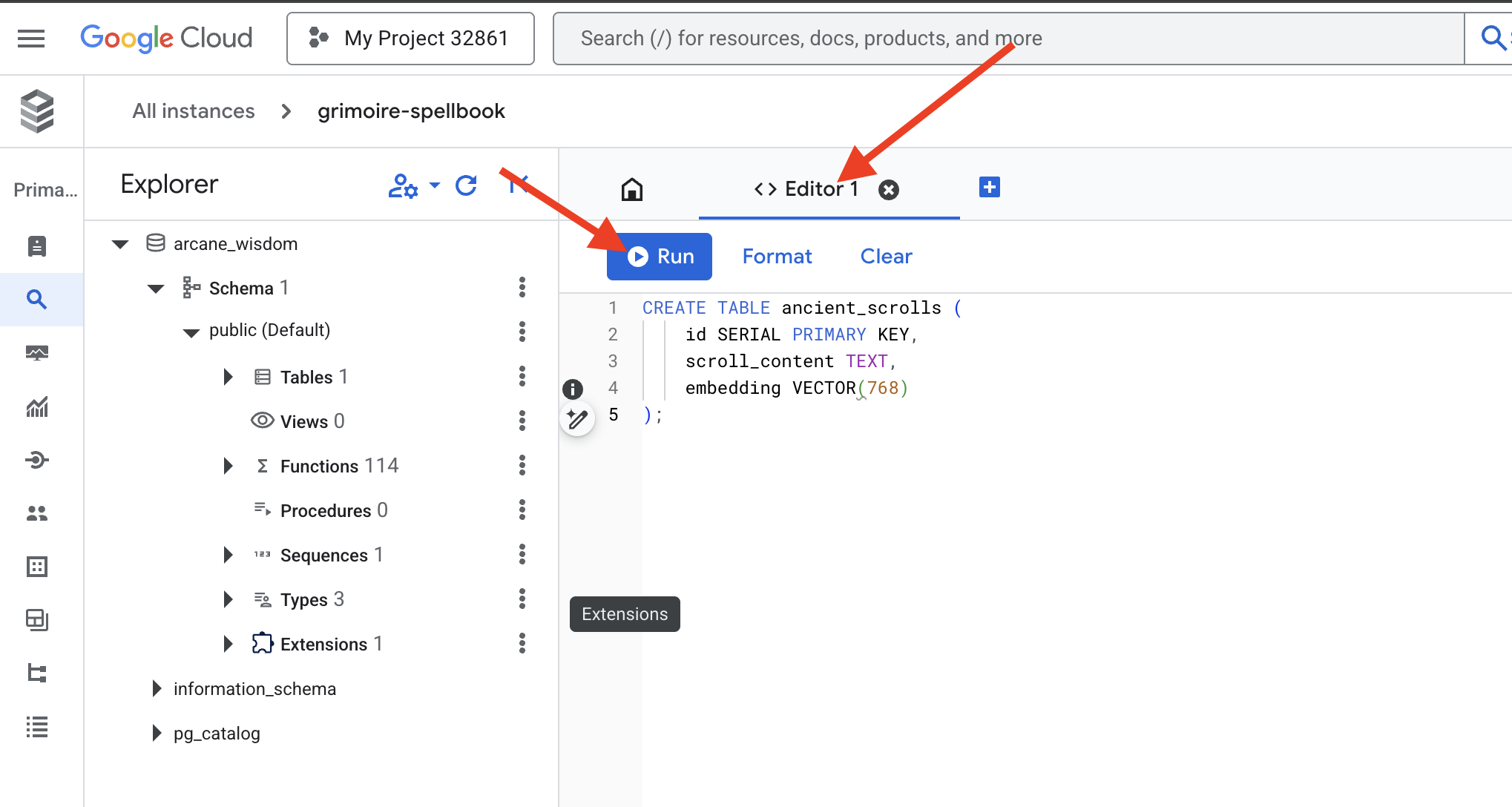
👉📜 Przygotuj strony naszej Księgi Czarów, tworząc tabelę, która będzie zawierać esencję naszych zwojów.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
Czar VECTOR(768) jest ważnym szczegółem. Model wektorów dystrybucyjnych Vertex AI, którego użyjemy (textembedding-gecko@003 lub podobny model), przekształca tekst w wektor 768-wymiarowy. Strony naszego Spellbooka muszą być przygotowane na esencję o dokładnie takim rozmiarze. Wymiary muszą być zawsze takie same.
Pierwsza transliteracja: rytuał ręcznego zapisu
Zanim wydamy polecenie armii automatycznych skrybów (Dataflow), musimy raz ręcznie przeprowadzić centralny rytuał. Dzięki temu lepiej zrozumiemy dwuetapową magię:
- Wróżenie: pobieranie fragmentu tekstu i korzystanie z wyroczni Gemini w celu wyodrębnienia jego semantycznej esencji w postaci wektora.
- Inskrypcja: zapisanie oryginalnego tekstu i jego nowej wektorowej esencji w naszej Księdze zaklęć.
Teraz wykonajmy rytuał ręczny.
👉📜 W Cloud SQL Studio. Teraz użyjemy funkcji embedding(), która jest zaawansowaną funkcją rozszerzenia google_ml_integration. Dzięki temu możemy wywoływać model wektorów dystrybucyjnych Vertex AI bezpośrednio z zapytania SQL, co znacznie upraszcza ten proces.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 Sprawdź swoją pracę, uruchamiając zapytanie, aby odczytać nowo zapisaną stronę:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
Udało Ci się ręcznie wykonać podstawowe zadanie wczytywania danych RAG.
Tworzenie kompasu semantycznego: wzbogacanie księgi zaklęć o indeks HNSW
Księga zaklęć może teraz przechowywać mądrości, ale znalezienie odpowiedniego zwoju wymaga przeczytania każdej strony. Jest to skanowanie sekwencyjne. Jest to powolne i nieefektywne. Aby nasze zapytania natychmiast trafiały do najbardziej odpowiednich informacji, musimy wzbogacić Księgę zaklęć o semantyczny kompas: indeks wektorowy.
Sprawdźmy wartość tego zaklęcia.
👉📜 W Cloud SQL Studio uruchom to polecenie: Symuluje wyszukiwanie nowo wstawionego zwoju i prosi bazę danych o EXPLAIN plan.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
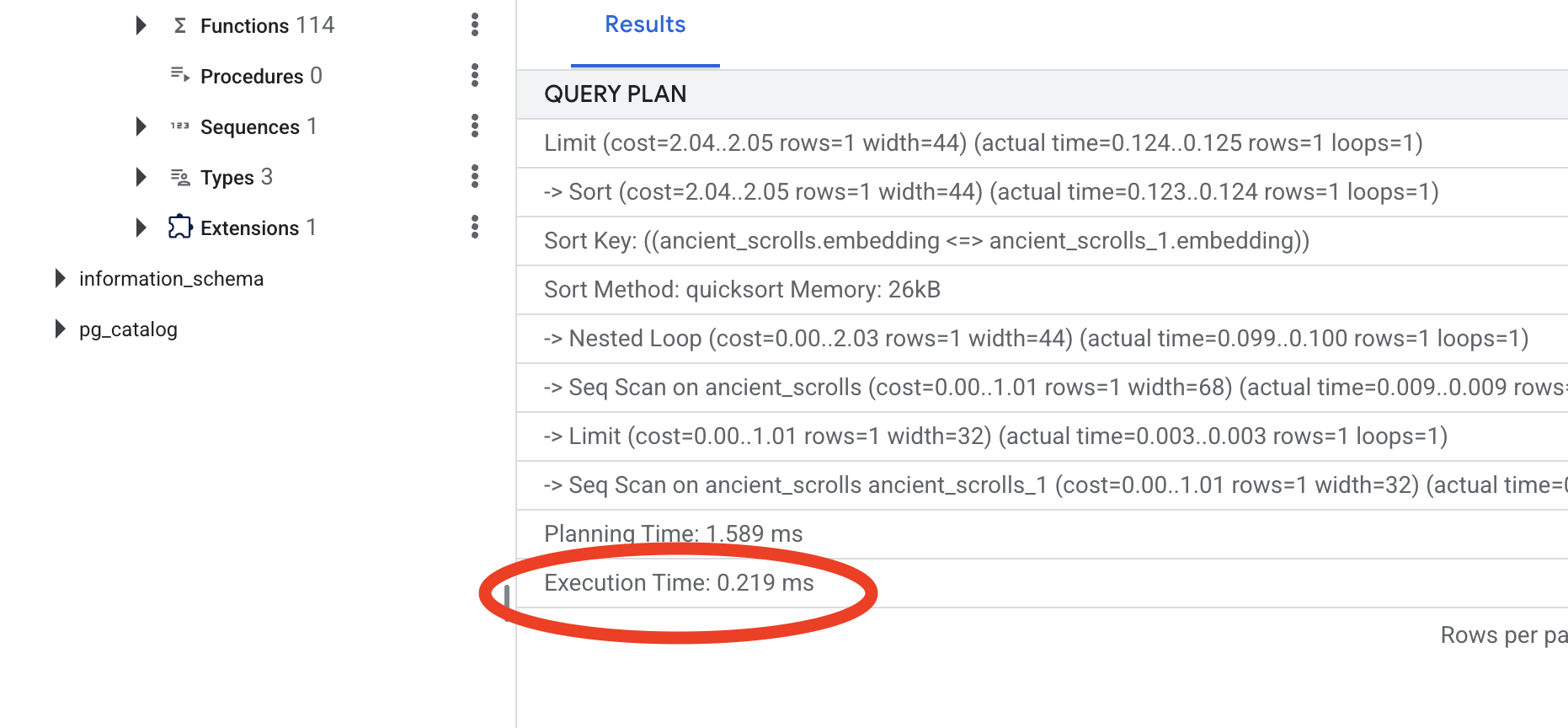
Przyjrzyj się wynikom. Zobaczysz wiersz z informacją -> Seq Scan on ancient_scrolls. Potwierdza to, że baza danych odczytuje każdy wiersz. Zwróć uwagę na execution time.
👉📜 Teraz rzućmy zaklęcie indeksowania. Parametr lists informuje indeks, ile klastrów ma utworzyć. Dobrym punktem wyjścia jest pierwiastek kwadratowy z oczekiwanej liczby wierszy.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
Poczekaj, aż indeks zostanie utworzony (w przypadku jednego wiersza będzie to szybkie, ale w przypadku milionów wierszy może to zająć trochę czasu).
👉📜 Teraz ponownie uruchom dokładnie to samo EXPLAIN ANALYZE polecenie:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
Sprawdź nowy plan zapytania. Teraz zobaczysz -> Index Scan using.... Ważniejsze jest jednak, aby zwrócić uwagę na execution time. Będzie to znacznie szybsze, nawet w przypadku tylko jednego wpisu. Właśnie zademonstrowałeś(-aś) podstawową zasadę optymalizacji wydajności bazy danych w świecie wektorowym.
Po sprawdzeniu danych źródłowych, zrozumieniu rytuału ręcznego i zoptymalizowaniu Księgi zaklęć pod kątem szybkości możesz już zbudować zautomatyzowane skryptorium.
NIE DLA GRACZY
7. The Conduit of Meaning: Building a Dataflow Vectorization Pipeline
Teraz budujemy magiczną linię montażową skrybów, którzy będą czytać nasze zwoje, wyciągać z nich esencję i zapisywać ją w naszej nowej Księdze Czarów. Jest to potok Dataflow, który będziemy uruchamiać ręcznie. Zanim jednak napiszemy główny kod potoku, musimy najpierw przygotować jego podstawę i okrąg, z którego go przywołamy.
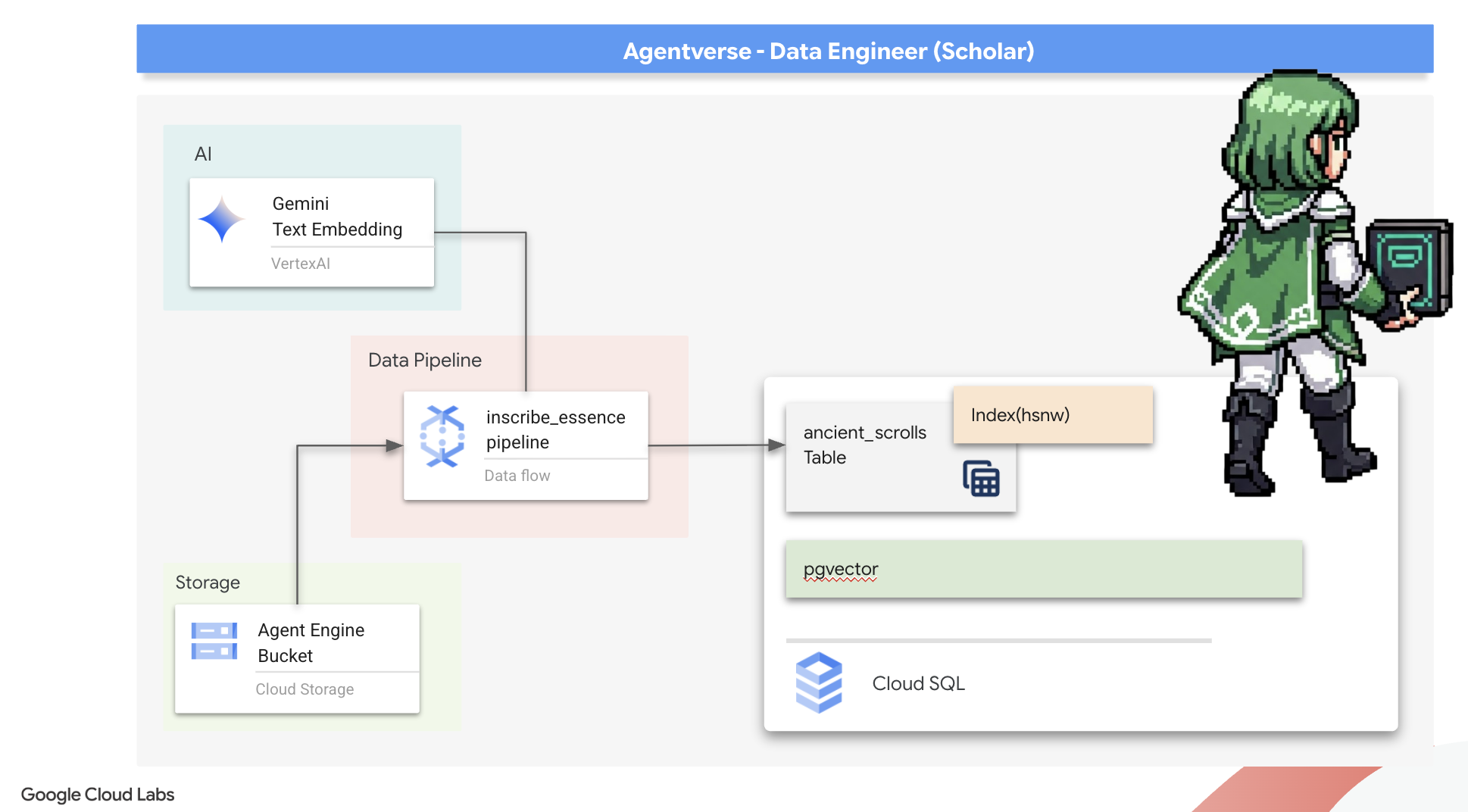
Przygotowywanie fundamentów skryptorium (obraz instancji roboczej)
Nasz potok Dataflow będzie wykonywany przez zespół automatycznych instancji roboczych w chmurze. Za każdym razem, gdy je wywołujemy, potrzebują określonego zestawu bibliotek do wykonania swojej pracy. Moglibyśmy podać im listę i za każdym razem pobierać te biblioteki, ale to powolne i nieefektywne. Mądry Uczony przygotowuje bibliotekę główną z wyprzedzeniem.
W tym przypadku polecimy Google Cloud Build utworzenie niestandardowego obrazu kontenera. Ten obraz to „doskonały golem” z wstępnie załadowanymi bibliotekami i zależnościami, których będą potrzebować nasi skrybowie. Gdy zadanie Dataflow się rozpocznie, będzie używać tego niestandardowego obrazu, dzięki czemu procesy robocze będą mogły niemal natychmiast rozpocząć pracę.
👉💻 Uruchom to polecenie, aby utworzyć i zapisać obraz podstawowy potoku w Artifact Registry.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 Uruchom te polecenia, aby utworzyć i aktywować izolowane środowisko Pythona oraz zainstalować w nim niezbędne biblioteki wywoływania.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
The Master Incantation
Nadszedł czas, aby napisać główny zaklęcie, które będzie zasilać nasze skryptorium wektorowe. Nie będziemy tworzyć poszczególnych magicznych komponentów od zera. Naszym zadaniem jest połączenie komponentów w logiczny, wydajny potok za pomocą języka Apache Beam.
- EmbedTextBatch (konsultacja z Gemini): utworzysz specjalistycznego skrybę, który wie, jak przeprowadzać „grupowe wróżenie”. Pobiera on partię plików z tekstem w formacie surowym, przekazuje je do modelu wektorów dystrybucyjnych tekstu Gemini i otrzymuje ich esencję (wektory dystrybucyjne).
- WriteEssenceToSpellbook (The Final Inscription): to nasz archiwista. Zna tajne zaklęcia, które otwierają bezpieczne połączenie z naszą Księgą Zaklęć Cloud SQL. Jego zadaniem jest pobranie treści z przewijania i ich wektoryzowanej esencji oraz trwałe zapisanie ich na nowej stronie.
Naszym celem jest połączenie tych działań w łańcuch, aby stworzyć płynny przepływ wiedzy.
👉✏️ W edytorze Cloud Shell otwórz plik ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py. Znajdziesz w nim klasę DoFn o nazwie EmbedTextBatch. Znajdź komentarz #REPLACE-EMBEDDING-LOGIC. Zastąp go tym kodem.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
To zaklęcie jest precyzyjne i ma kilka kluczowych parametrów:
- model: określamy
text-embedding-005, aby używać zaawansowanego i aktualnego modelu osadzania. - contents: lista całej zawartości tekstowej z partii plików otrzymanej przez funkcję DoFn.
- task_type: ustawiamy wartość „RETRIEVAL_DOCUMENT”. Jest to kluczowa instrukcja, która nakazuje Gemini generowanie osadzeń zoptymalizowanych pod kątem późniejszego wyszukiwania.
- output_dimensionality: musi mieć wartość 768, co odpowiada wymiarowi VECTOR(768) zdefiniowanemu podczas tworzenia tabeli ancient_scrolls w Cloud SQL. Niezgodne wymiary są częstym źródłem błędów w wektorowej magii.
Nasz potok musi rozpocząć się od odczytania nieprzetworzonego, nieustrukturyzowanego tekstu ze wszystkich starożytnych zwojów w naszym archiwum GCS.
👉✏️ W pliku ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py znajdź komentarz #REPLACE ME-READFILE i zastąp go tym trzyczęściowym zaklęciem:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
Po zebraniu surowego tekstu zwojów musimy wysłać go do Gemini, aby uzyskać przepowiednię. Aby to zrobić skutecznie, najpierw podzielimy poszczególne zwoje na małe partie, a następnie przekażemy je naszemu EmbedTextBatch skrybie. Ten krok spowoduje też oddzielenie wszystkich zwojów, których Gemini nie rozumie, do stosu „nieudanych” do późniejszego sprawdzenia.
👉✏️ Znajdź komentarz #REPLACE ME-EMBEDDING i zastąp go tym:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
Esencja naszych zwojów została z powodzeniem wydestylowana. Ostatnim krokiem jest zapisanie tej wiedzy w Księdze Czarów, aby ją trwale zachować. Weźmiemy zwoje z kupy „przetworzone” i przekażemy je naszemu archiwizatorowi WriteEssenceToSpellbook.
👉✏️ Znajdź komentarz #REPLACE ME-WRITE TO DB i zastąp go tym:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
Mądry Uczeń nigdy nie odrzuca wiedzy, nawet nieudanych prób. Na koniec musimy poprosić skrybę, aby wziął stos „nieudanych” z etapu wróżenia i zapisał przyczyny niepowodzenia. Pozwoli nam to ulepszać nasze rytuały w przyszłości.
👉✏️ Znajdź komentarz #REPLACE ME-LOG FAILURES i zastąp go tym:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
Główne zaklęcie zostało ukończone. Udało Ci się utworzyć zaawansowany, wieloetapowy potok danych, łącząc ze sobą poszczególne magiczne komponenty. Zapisz plik inscribe_essence_pipeline.py. Skryptorium jest teraz gotowe do przywołania.
Teraz rzucamy potężne zaklęcie przywołujące, aby nakazać usłudze Dataflow obudzenie naszego Golema i rozpoczęcie rytuału pisania.
👉💻 W terminalu uruchom to polecenie:
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 Uwaga! Jeśli zadanie zakończy się niepowodzeniem z powodu błędu zasobu ZONE_RESOURCE_POOL_EXHAUSTED, może to być spowodowane tymczasowymi ograniczeniami zasobów na tym koncie o niskiej reputacji w wybranym regionie. Siłą Google Cloud jest globalny zasięg. Po prostu spróbuj przywołać golema w innym regionie. Aby to zrobić, zastąp w powyższym poleceniu znak --region=$REGION innym regionem, np.
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
i uruchom go ponownie. 🎰
Proces uruchamiania i kończenia potrwa około 3–5 minut. Możesz ją oglądać na żywo w konsoli Dataflow.
👉 Otwórz konsolę Dataflow: najłatwiej to zrobić, otwierając ten bezpośredni link w nowej karcie przeglądarki:
https://console.cloud.google.com/dataflow
👉 Znajdź i kliknij zadanie: zobaczysz zadanie z podaną przez siebie nazwą (inscribe-essence-job lub podobną). Kliknij nazwę zadania, aby otworzyć stronę z jego szczegółami. Obserwowanie potoku:
- Uruchamianie: przez pierwsze 3 minuty stan zadania będzie „Uruchomione”, ponieważ Dataflow udostępnia niezbędne zasoby. Pojawi się wykres, ale dane mogą jeszcze nie być na nim widoczne.
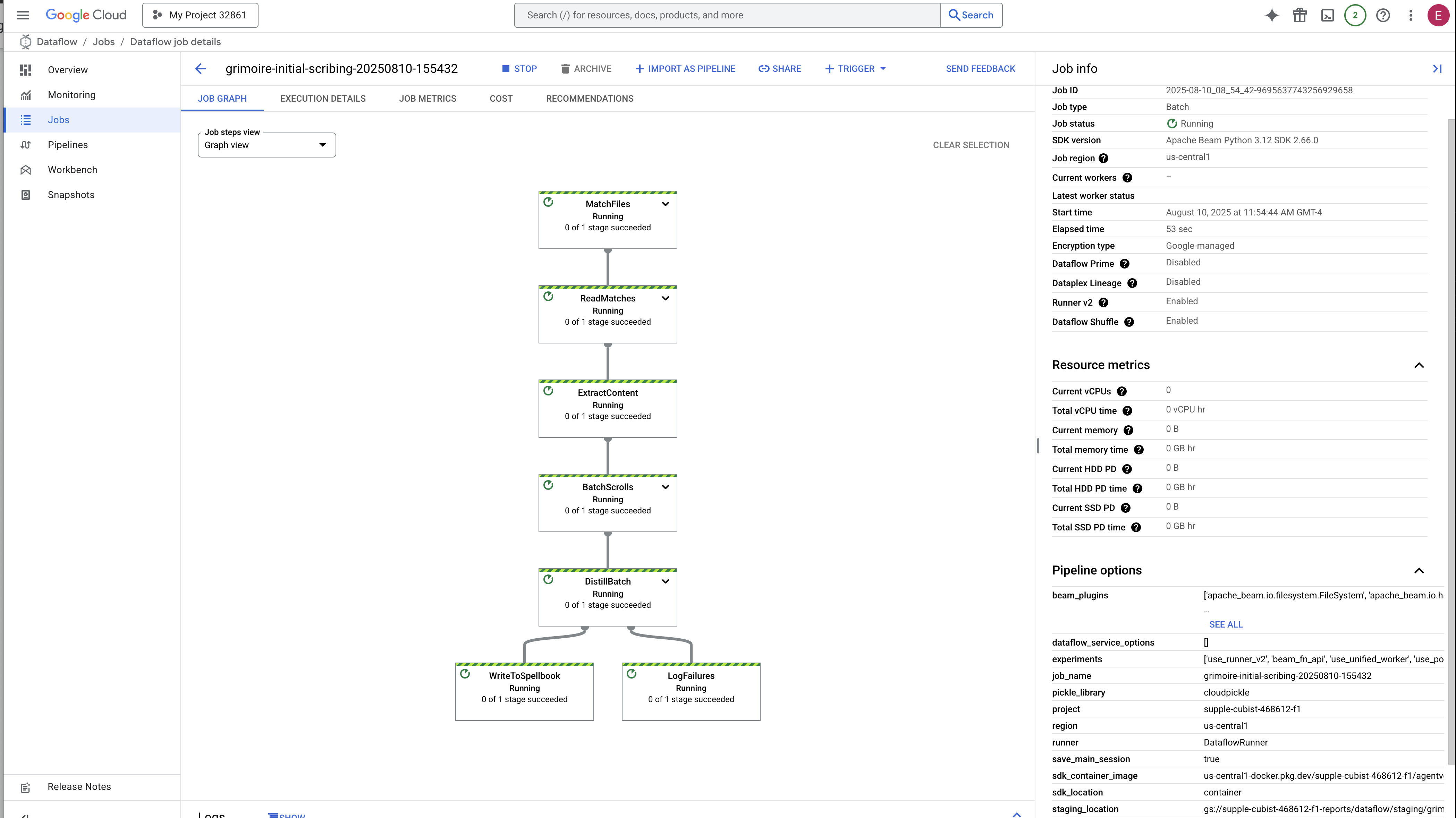
- Ukończono: po zakończeniu stan zadania zmieni się na „Ukończono”, a na wykresie pojawi się ostateczna liczba przetworzonych rekordów.
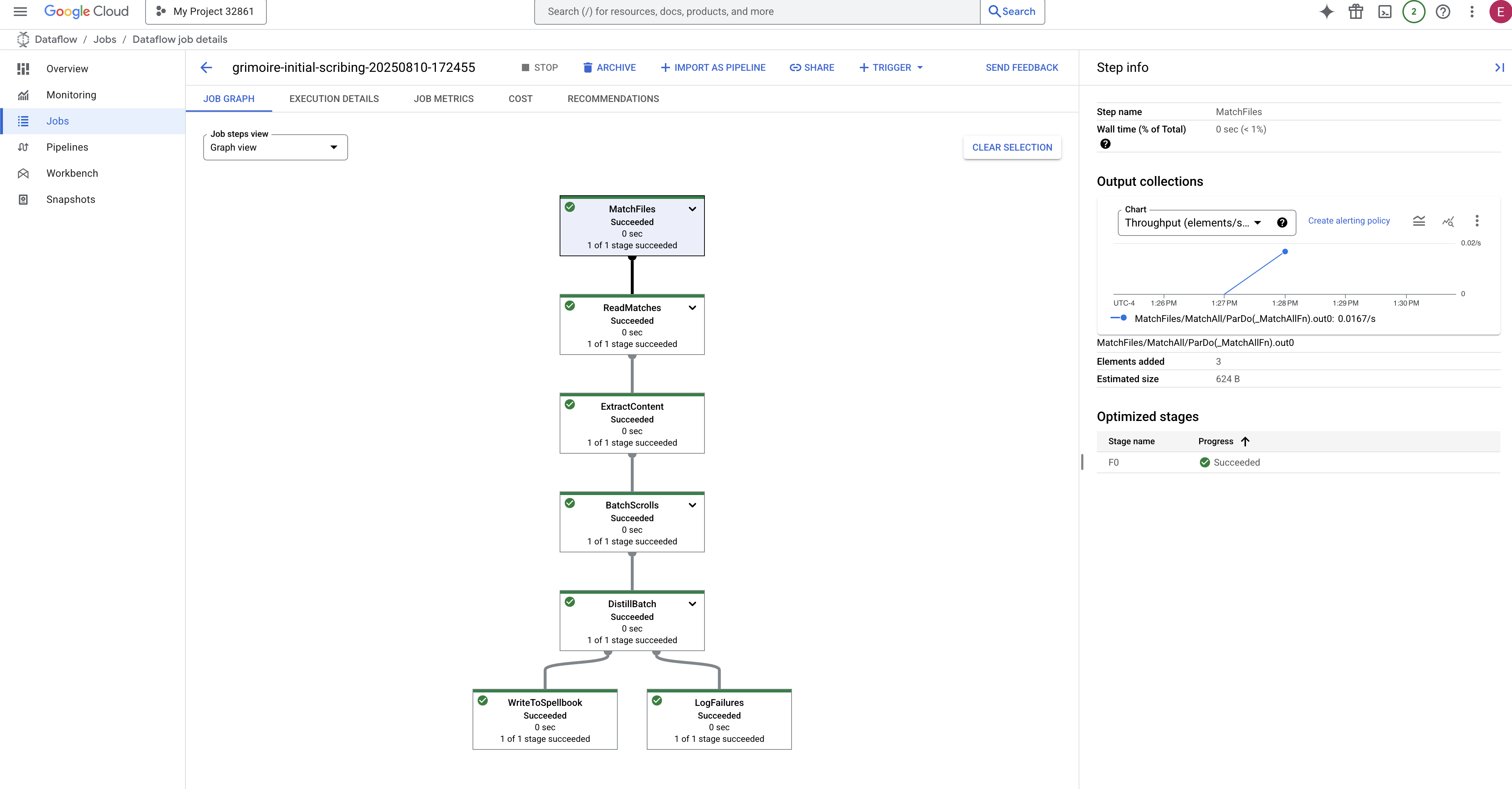
Weryfikacja inskrypcji
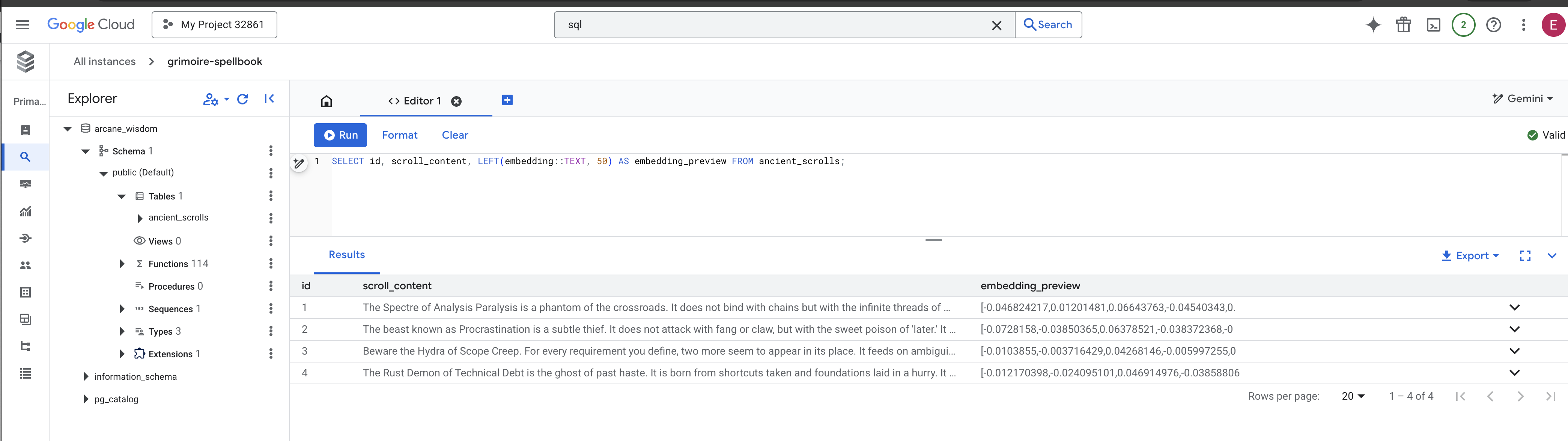
👉📜 Wróć do studia SQL i uruchom te zapytania, aby sprawdzić, czy zwoje i ich semantyczna esencja zostały prawidłowo zapisane.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
Zobaczysz identyfikator zwoju, jego oryginalny tekst i podgląd magicznej esencji wektorowej, która została na stałe zapisana w Twoim Grimoire.
Księga uczonego jest teraz prawdziwym systemem wiedzy, gotowym do przyjmowania zapytań o znaczenie w następnym rozdziale.
8. Sealing the Final Rune: Activating Wisdom with a RAG Agent
Grimoire to już nie tylko baza danych. Jest to źródło zwektoryzowanej wiedzy, ciche wyrocznia czekająca na pytanie.
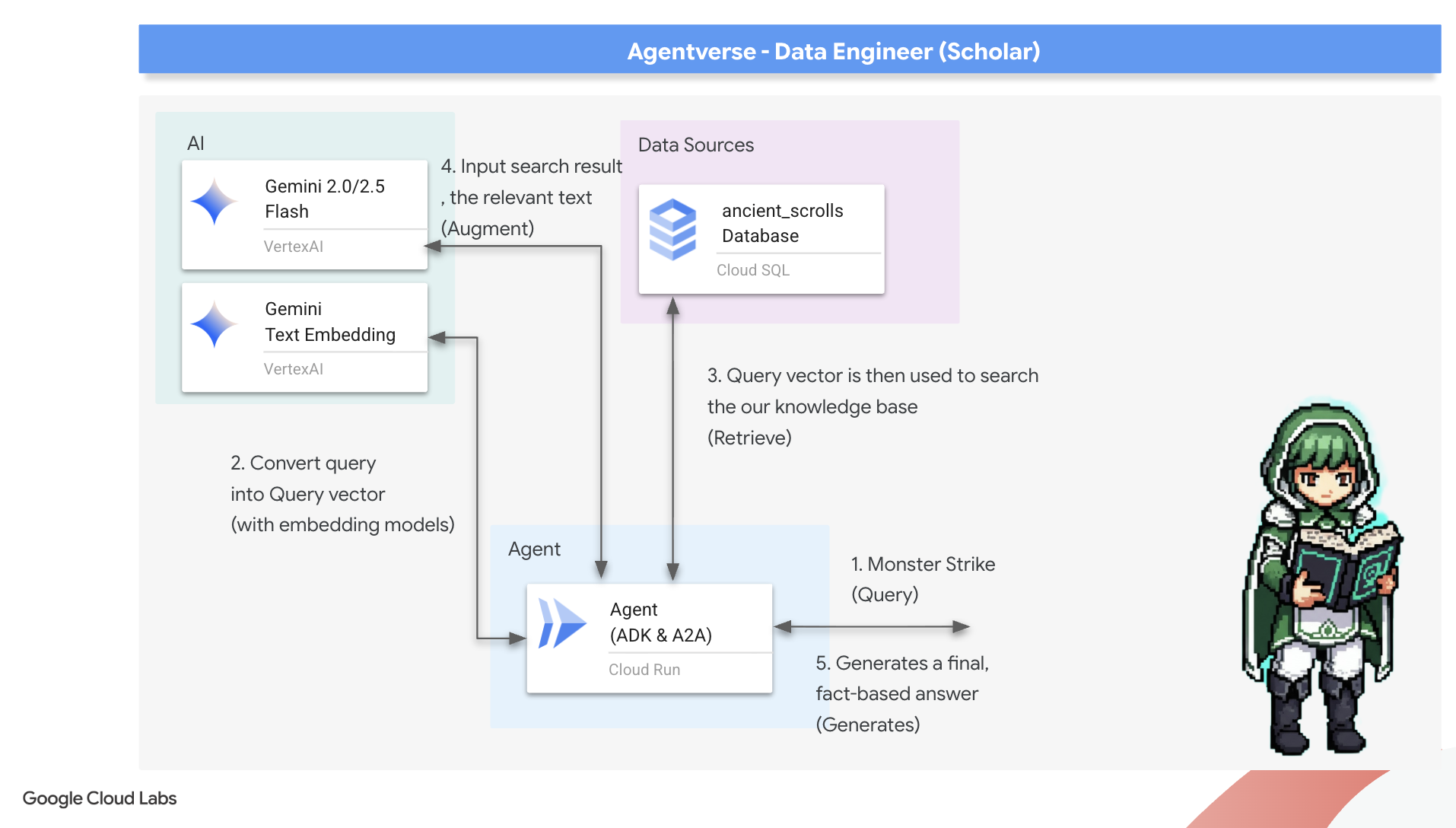
Teraz przejdziemy do prawdziwego testu dla uczonego: stworzymy klucz, który otworzy drzwi do tej mądrości. Utworzymy agenta Retrieval-Augmented Generation (RAG). To magiczna konstrukcja, która rozumie pytanie zadane prostym językiem, sięga do Grimoire po najbardziej trafne i istotne informacje, a następnie wykorzystuje zdobytą wiedzę do stworzenia trafnej odpowiedzi uwzględniającej kontekst.

Pierwsza runa: zaklęcie destylacji zapytań
Zanim nasz agent będzie mógł przeszukać Grimoire, musi najpierw zrozumieć istotę zadanego pytania. Prosty ciąg tekstu jest bez znaczenia dla naszego Spellbooka opartego na wektorach. Najpierw musi on pobrać zapytanie i za pomocą tego samego modelu Gemini przekształcić je w wektor zapytania.
👉✏️ W edytorze Cloud Shell otwórz plik ~~/agentverse-dataengineer/scholar/agent.py, znajdź komentarz #REPLACE RAG-CONVERT EMBEDDING i zastąp go tym poleceniem. Dzięki temu agent nauczy się przekształcać pytania użytkowników w magiczne esencje.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Znając istotę zapytania, agent może teraz skorzystać z Grimoire. Przekażemy ten wektor zapytania do naszej bazy danych wzbogaconej o pgvector i zadam pytanie: „Pokaż mi starożytne zwoje, których istota jest najbardziej podobna do istoty mojego zapytania”.
Magia tego polega na operatorze podobieństwa cosinusowego (<=>), czyli potężnym runie, które oblicza odległość między wektorami w przestrzeni wielowymiarowej.
👉✏️ W pliku agent.py znajdź komentarz #REPLACE RAG-RETRIEVE i zastąp go tym skryptem:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
Ostatnim krokiem jest przyznanie agentowi dostępu do tego nowego, zaawansowanego narzędzia. Dodamy funkcję grimoire_lookup do listy dostępnych magicznych narzędzi.
👉✏️ W pliku agent.py znajdź komentarz #REPLACE-CALL RAG i zastąp go tym wierszem:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
Ta konfiguracja ożywia agenta:
model="gemini-2.5-flash": wybiera konkretny duży model językowy, który będzie „mózgiem” agenta do wnioskowania i generowania tekstu.name="scholar_agent": przypisuje agentowi unikalną nazwę.instruction="...You are the Scholar...": Jest to prompt systemowy, czyli najważniejszy element konfiguracji. Określa ona personę agenta, jego cele, dokładny proces, który musi wykonać, aby ukończyć zadanie, oraz wymagany format danych wyjściowych.tools=[grimoire_lookup]: To jest ostateczne zaklęcie. Przyznaje agentowi dostęp do utworzonej przez Ciebie funkcjigrimoire_lookup. Agent może teraz inteligentnie decydować, kiedy wywołać to narzędzie, aby pobrać informacje z bazy danych, co stanowi podstawę wzorca RAG.
Egzamin dla stypendystów
👉💻 W terminalu Cloud Shell aktywuj środowisko i użyj podstawowego polecenia zestawu Agent Development Kit, aby aktywować agenta Scholar:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
Powinny pojawić się dane wyjściowe potwierdzające, że „Scholar Agent” jest zaangażowany i działa.
👉💻 Teraz rzuć wyzwanie swojemu agentowi. W pierwszym terminalu, w którym działa symulacja bitwy, wydaj polecenie wymagające mądrości Grimoire:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

Obserwuj logi w terminalu. Zobaczysz, jak agent otrzymuje zapytanie, wyodrębnia jego istotę, przeszukuje Grimoire, znajduje odpowiednie zwoje dotyczące „Prokrastynacji” i wykorzystuje zdobytą wiedzę do opracowania skutecznej strategii uwzględniającej kontekst.
Udało Ci się utworzyć pierwszego agenta RAG i wyposażyć go w wiedzę z Twojego Grimoire.
👉💻 Naciśnij Ctrl+C w terminalu, aby na razie uśpić agenta.
Wprowadzenie Scholar Sentinel do Agentverse
Twój agent wykazał się mądrością w kontrolowanym środowisku badania. Nadszedł czas, aby wprowadzić ją do Agentverse, przekształcając ją z lokalnej konstrukcji w stałego, gotowego do walki agenta, którego może wezwać w każdej chwili dowolny bohater. Teraz wdrożymy agenta w Cloud Run.
👉💻 Uruchom to potężne zaklęcie przywołujące. Ten skrypt najpierw przekształci Twojego agenta w doskonałego Golema (obraz kontenera), zapisze go w Artifact Registry, a następnie wdroży go jako skalowalną, bezpieczną i publicznie dostępną usługę.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
Twój agent Scholar jest teraz aktywnym, gotowym do walki agentem w Agentverse.
NIE DLA GRACZY
9. The Boss Flight
Zwoje zostały odczytane, rytuały odprawione, a wyzwanie podjęte. Twój agent to nie tylko artefakt w magazynie, ale żywy agent w Agentverse, który czeka na swoją pierwszą misję. Nadszedł czas na ostatnią próbę – ćwiczenia z użyciem ostrej amunicji przeciwko potężnemu przeciwnikowi.
Teraz weźmiesz udział w symulacji pola bitwy, w której nowo wdrożony agent Shadowblade zmierzy się z potężnym mini-bossem: Widmem Statyczności. Będzie to ostateczny test Twojej pracy, od podstawowej logiki agenta po jego wdrożenie w środowisku produkcyjnym.
Uzyskiwanie lokalizacji agenta
Zanim wejdziesz na pole bitwy, musisz mieć 2 klucze: unikalny podpis swojego bohatera (Agent Locus) i ukrytą ścieżkę do kryjówki Widma (adres URL lochu).
👉💻 Najpierw zdobądź unikalny adres agenta w Agentverse, czyli jego Locus. Jest to aktywny punkt końcowy, który łączy Twojego mistrza z polem bitwy.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 Następnie wskaż miejsce docelowe. To polecenie ujawnia lokalizację Kręgu Przeniesienia, czyli portalu do domeny Widma.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
Ważne: przygotuj oba te adresy URL. Będą Ci potrzebne w ostatnim kroku.
Konfrontacja z Widmem
Po zdobyciu współrzędnych przejdź do Kręgu Przeniesienia i rzuć zaklęcie, aby rozpocząć walkę.
👉 Otwórz adres URL kręgu translokacji w przeglądarce, aby stanąć przed lśniącym portalem do Karmazynowej Twierdzy.
Aby przedostać się do twierdzy, musisz dostroić esencję Mrocznego Ostrza do portalu.
- Na stronie znajdź pole wprowadzania runicznego tekstu oznaczone jako A2A Endpoint URL (URL punktu końcowego A2A).
- Wpisz sygil swojego mistrza, wklejając w tym polu adres URL miejsca agenta (pierwszy skopiowany adres URL).
- Kliknij Połącz, aby rozpocząć teleportację.
Oślepiające światło teleportacji gaśnie. Nie jesteś już w sanktuarium. Powietrze jest naelektryzowane, zimne i ostre. Przed Tobą materializuje się Widmo – wir syczącego szumu i uszkodzonego kodu, którego nieświęte światło rzuca długie, tańczące cienie na podłodze lochu. Nie ma twarzy, ale czujesz jego ogromną, wyczerpującą obecność, która jest całkowicie skupiona na Tobie.
Jedyna droga do zwycięstwa to jasność Twojego przekonania. To pojedynek woli, który rozgrywa się na polu bitwy umysłu.
Gdy rzucasz się do przodu, gotowy do zadania pierwszego ataku, Widmo kontruje. Nie podnosi tarczy, ale kieruje pytanie bezpośrednio do Twojej świadomości – migoczące, runiczne wyzwanie zaczerpnięte z podstaw Twojego szkolenia.

Taka jest natura tej walki. Twoja wiedza jest Twoją bronią.
- Odpowiedz z mądrością, którą zdobyłeś, a Twój miecz zapłonie czystą energią, rozbijając obronę Widma i zadając KRYTYCZNY CIOS.
- Jeśli jednak się zachwiejesz, jeśli wątpliwości zaciemnią Twoją odpowiedź, światło broni przygaśnie. Cios zada tylko UŁAMEK OBRAŻEŃ. Co gorsza, Widmo będzie się żywić Twoją niepewnością, a jego niszczycielska moc będzie rosła z każdym błędem.
To już koniec, mistrzu. Twój kod to księga zaklęć, logika to miecz, a wiedza to tarcza, która odwróci bieg chaosu.
Skupienie. Uderzaj celnie. Od tego zależy los Agentverse.
Gratulacje, Scholar.
Okres próbny został zakończony. Opanowałeś sztukę inżynierii danych, przekształcając surowe, chaotyczne informacje w uporządkowaną, wektoryzowaną wiedzę, która wzmacnia cały Agentverse.
10. Czyszczenie: usunięcie księgi czarów uczonego
Gratulujemy opanowania Grimoire uczonego! Aby mieć pewność, że Agentverse pozostanie w nienaruszonym stanie, a tereny szkoleniowe zostaną oczyszczone, musisz teraz przeprowadzić ostateczne rytuały oczyszczania. Spowoduje to systematyczne usuwanie wszystkich zasobów utworzonych podczas Twojej podróży.
Dezaktywowanie komponentów Agentverse
Teraz systematycznie zdemontujesz wdrożone komponenty systemu RAG.
Usuwanie wszystkich usług Cloud Run i repozytorium Artifact Registry
To polecenie usuwa wdrożonego agenta Scholar i aplikację Dungeon z Cloud Run.
👉💻 W terminalu uruchom te polecenia:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
Usuwanie zbiorów danych, modeli i tabel BigQuery
Spowoduje to usunięcie wszystkich zasobów BigQuery, w tym zbioru danych bestiary_data, wszystkich tabel w nim oraz powiązanego połączenia i modeli.
👉💻 W terminalu uruchom te polecenia:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Usuń instancję Cloud SQL
Spowoduje to usunięcie instancji grimoire-spellbook, w tym jej bazy danych i wszystkich tabel w niej zawartych.
👉💻 W terminalu uruchom:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Usuwanie zasobników Google Cloud Storage
To polecenie usuwa zasobnik, w którym przechowywane były nieprzetworzone dane wywiadowcze oraz pliki tymczasowe i pliki przejściowe Dataflow.
👉💻 W terminalu uruchom:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
Usuwanie plików i katalogów lokalnych (Cloud Shell)
Na koniec usuń z Cloud Shell sklonowane repozytoria i utworzone pliki. Ten krok jest opcjonalny, ale zdecydowanie zalecany, aby całkowicie wyczyścić katalog roboczy.
👉💻 W terminalu uruchom:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
Udało Ci się usunąć wszystkie ślady Twojej ścieżki szkoleniowej w Agentverse Data Engineer. Projekt jest czysty i możesz rozpocząć kolejną przygodę.